Comparative analysis of dual-form networks for live land monitoring using multi-modal satellite image time series
Multi-modal Satellite Image Time Series (SITS) analysis faces significant computational challenges for live land monitoring applications. While Transformer architectures excel at capturing temporal dependencies and fusing multi-modal data, their quad…
Authors: Iris Dumeur, Jérémy Anger, Gabriele Facciolo
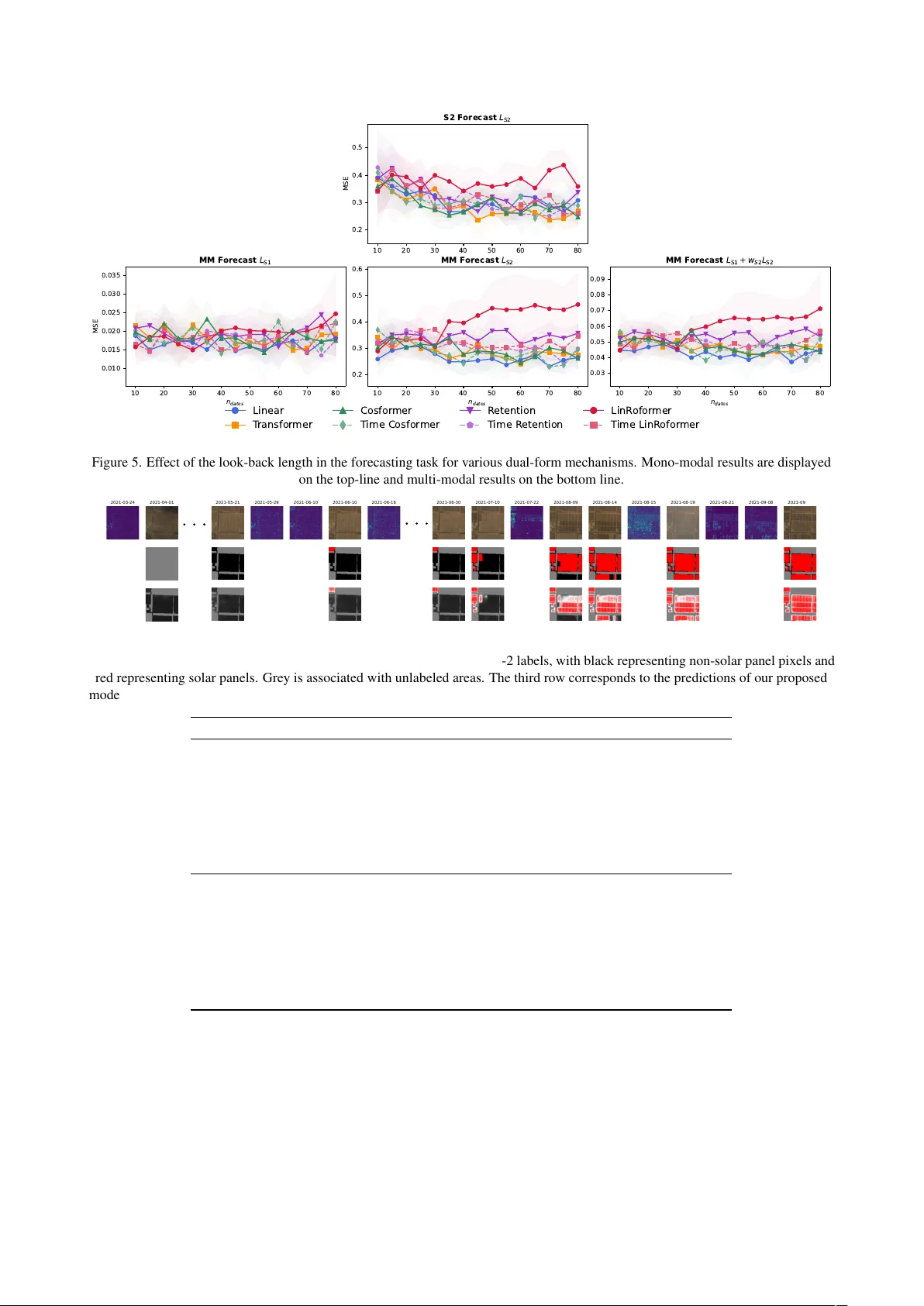
Comparative analysis of dual-f orm networks f or live land monitoring using multi-modal satellite image time series Iris Dumeur 1,2 , J ´ er ´ emy Anger 1,2 , Gabriele Facciolo 2,3 1 Kayrros SAS 2 Univ ersit ´ e Paris-Saclay , ENS Paris-Saclay , CNRS, Centre Borelli, 91190, Gif-sur-Yv ette, France 3 Institut Univ ersitaire de France Keyw ords: Dual-form architecture, Linear Attention, Retention, Satellite Image Time Series, Multi-modal, Land Monitoring. Abstract Multi-modal Satellite Image T ime Series (SITS) analysis f aces significant computational challenges for li ve land monitoring ap- plications. While T ransformer architectures excel at capturing temporal dependencies and fusing multi-modal data, their quadratic computational complexity and the need to reprocess entire sequences for each ne w acquisition limit their deployment for regular , large-area monitoring. This paper studies v arious dual-form attention mechanisms for efficient multi-modal SITS analysis, that enable parallel training while supporting recurrent inference for incremental processing. W e compare linear attention and reten- tion mechanisms within a multi-modal spectro-temporal encoder . T o address SITS-specific challenges of temporal irregularity and unalignment, we de velop temporal adaptations of dual-form mechanisms that compute token distances based on actual acquisition dates rather than sequence indices. Our approach is e v aluated on two tasks using Sentinel-1 and Sentinel-2 data: multi-modal SITS forecasting as a proxy task, and real-world solar panel construction monitoring. Experimental results demonstrate that dual-form mechanisms achie ve performance comparable to standard Transformers while enabling ef ficient recurrent inference. The multi- modal frame work consistently outperforms mono-modal approaches across both tasks, demonstrating the effecti veness of dual mechanisms for sensor fusion. The results presented in this work open new opportunities for operational land monitoring systems requiring regular updates o ver lar ge geographic areas. 1. Introduction Decades of Earth observation programs, from Landsat to Sen- tinel, ha ve produced frequent and consistent records of land sur- faces. Organized as multi-modal Satellite Image T ime Series (SITS), these data support a wide range of land monitoring applications (Miller et al., 2024). Howe ver , exploiting multi- modal SITS also presents unique challenges due to satellite ac- quisition constraints. T ime series frequently exhibit irregular temporal sampling due to cloud co verage, and v arying acquis- ition scenarios. Moreov er , due to orbit patterns, observ ations are often temporally unaligned, as SITS may hav e various ac- quisition dates. Despite these challenges, many time-critical ap- plications, such as deforestation, crop health or economic activ- ity monitoring require regular and timely predictions. Ideally , each new satellite acquisition should immediately trigger up- dated predictions for the observed area, enabling rapid decision- making for en vironmental management and policy implement- ation. Thus, in this work we study auto-regressi v e methods that can handle SITS specificities, perform effectiv e multi-sensor data fusion, capture long-range temporal dependencies, en- able parallel sequence processing during training, and maintain computational efficienc y for real-time inference. Follo wing the success of fully attentional architectures such as the Transformer (V aswani et al., 2017) in Natural Language Processing (NLP), these architectures ha ve been widely adap- ted for SITS analysis (Rußwurm and K ¨ orner , 2020, Garnot et al., 2020, Dumeur et al., 2024). Based on scaled dot-product attention, these architectures enable ef ficient parallel train- ing compared to earlier recurrent neural network approaches. Moreov er , through their positional encoding mechanisms, they can handle SITS temporal irre gularity and unalignment. Fur- thermore, T ransformers hav e demonstrated superior perform- ance in handling long temporal dependencies and fusing multi- modal data (T eam, 2025). Nevertheless, for regular and up-to- date land monitoring tasks, a major limitation remains: ana- lyzing a nov el satellite image with T ransformers requires re- processing the entire time series, resulting in computationally expensi ve inference that pre vents the regular monitoring o ver large areas. This constraint is increased by the T ransformer’ s quadratic computational complexity with respect to sequence length. Furthermore, in Natural Language Processing, linear/kernel at- tention mechanisms (Katharopoulos et al., 2020, Qin et al., 2022) as well as retention mechanisms (Sun et al., 2023a) ha ve emerged as alternati v es to T ransformer attention. These mech- anisms offer tw o complementary advantages: they preserv e the parallelizable training characteristics of T ransformers while en- abling recurrent inference, where ne w inputs can be processed incrementally without recomputing the entire sequence. As in (Sun et al., 2023a) we refer to these methods as dual-form , as they allow parallel training and are recurrent at inference. In practice, this is achieved by replacing the softmax in trans- former attention. Specifically , the first kernel-based attention network, the Linear Transformer (Katharopoulos et al., 2020), simply replaced softmax with a separable similarity function. Subsequently , with the CosFormer , (Qin et al., 2022) demon- strated that performances in NLP tasks could be improv ed by integrating cosine-based reweighting based on tok en distances. In the retention mechanism proposed in Retentiv e Neural Net- works (Sun et al., 2023a), the reweighting mechanism is in- spired by Rotary Positional Encoding (RoPE) (Su et al., 2024). These architectures exclusiv ely support the causal form of at- tention (relying only on past and current tokens), which is the only formulation that allows recurrent processing where future tokens are una v ailable. Despite their potential, these mechan- isms have mostly been applied to NLP tasks and hav e not yet been e xplored for SITS analysis, let alone for multi-modal time series. Consequently , this study aims to fill this knowledge gap by comparing various kernel-based attention mechanisms: the Lin- ear T ransformer (Katharopoulos et al., 2020), CosFormer (Qin et al., 2022), the RoPE Linear Transformer (Su et al., 2024), and Retention (Sun et al., 2023a). Due to SITS specificities, we also propose modifications of these existing architectures to address SITS temporal irregularity unalignment. W e ev aluate these dual form mechanisms using Sentinel-1 (S1) and Sentinel-2 (S2) SITS on two supervised tasks. First, due to the scarcity of la- bels for multi-temporal and multi-modal remote sensing tasks, we conduct experiments on a forecasting task that serves as a proxy task requiring no manual labels. Second, we ev aluate the various dual form mechanisms on a real-world application: solar panel construction site monitoring. In summary , the con- tributions of this paper are as follo ws: • A unified formulation of dual form mechanisms for SITS analysis; • A novel multi-modal spectro-spatio-temporal architecture that enables parallel training and efficient inference for land monitoring applications; • And comprehensive experimental results demonstrating that dual form mechanisms are ef fecti ve for multi-modal SITS analysis across both forecasting and multi-temporal segmentation tasks. 2. Dual-form neural networks In this paper , we explore both linear attention and reten- tion mechanisms for efficient auto-regressi ve multi-modal SITS analysis. Both mechanisms refer to a type of sequence ana- lysis, where, giv en an input sequence X = [ x 1 , . . . x T ] , com- posed of T vectors x i ∈ R (1 ,d ) , each output vector o i corres- ponds to a weighted sum of the v alue vectors ( v j = x j W V ∈ R (1 ,d V ) ) 1 ≤ i ≤ T , o i = i X j =1 a i,j v j . (1) While retention and linear attention dif fer in the similarity score a i,j used, the y both exhibit parallel and recurrent formulations that are suitable for f ast training and efficient inference, respect- iv ely . This section first revie ws the similarity scores a i,j for both attention and retention mechanisms before detailing their dual formulations. 2.1 Similarity scores 2.1.1 Linear attention In causal attention, the similarity scores a i,j correspond to s ( q i , k j ) P i j =1 s ( q i , k j ) , where s is the simil- arity function and q i = x i W Q ∈ R (1 ,d K ) and k j = x j W K ∈ R (1 ,d K ) correspond to the query and ke y vectors, respectively , thus the output vectors write as o i = P i j =1 s ( q i , k j ) v j P i j =1 s ( q i , k j ) . (2) A crucial component of attention is the similarity function s ( · , · ) employed. For instance, the T ransformer architecture (V aswani et al., 2017) uses the e xponential of the scaled dot product to compute similarity between pairs of query and key v ectors s ( q i , k j ) = exp q i · k T j √ d K . (3) In contrast, linear attention mechanisms re write attention through the lens of kernel methods (Tsai et al., 2019). The core idea introduced by (Katharopoulos et al., 2020) is to employ a separable similarity kernel s ( q i , k j ) = ϕ ( q i ) · ϕ ( k j ) T , (4) where ϕ corresponds to the feature map function, thus allowing both parallel and recurrent forms of causal attention (see Sec- tion 2.2). As shown in T able 1, existing linear attention mech- anisms differ in the ϕ function employed. A positive function ψ is used to map the ke y and query vector to R + (1 ,d K ) . First, the linear T ransformer (Katharopoulos et al., 2020) achiev es impressiv e results in NLP by simply using ϕ linear ( u ) = 1 + elu ( u ) . More recent architectures, such as CosFormer (Qin et al., 2022), propose integrating a reweighting mechanism that strengthens the influence of nearby tokens in the attention while decreasing the importance of distant elements. More spe- cifically , CosFormer employs cosine-based re weighting with cos π 2 × i − j M , where M is the maximum sequence length and the cosine values range between 0 and 1. Precisely , to match the general notation of linear attention: ϕ cosformer ( u i ) = [cos( π i 2 M ) ψ ( u i ) , sin( π i 2 M ) ψ ( u i )] (5) s cosformer ( q i , k j ) = ϕ cosformer ( q i ) ϕ cosformer ( k j ) T (6) s cosformer ( q i , k j ) = cos( π i 2 M ) ψ ( q i ) cos( π j 2 M ) ψ ( k j ) T + (7) sin( π i 2 M ) ψ ( q i ) sin( π j 2 M ) ψ ( k j ) T . (8) While this separable reweighting mechanism achiev es great res- ults in NLP , it exhibits potential dra wbacks. First, it requires knowledge of a maximum allo wed sequence length M during inference. Second, it cannot model periodic events, as the weights decrease with the distance between tokens. An altern- ativ e to cosine-based reweighting is the use of Rotary Positional Encoding (RoPE) (Su et al., 2024). In this mechanism, the query q i and key vector k j are projected by rotary matrices R θ ,i and R θ ,j , respectively . Thus, we consider ϕ RoPE ( u i ) = ψ ( u i ) R θ ,i . As detailed in Appendix A, pairs of features for query and key are rotated by an angle i × θ k that is propor- tional to the position i of the token in the sequence. Since R θ ,i R T θ ,j = R θ , ( i − j ) , RoPE enables the integration of relat- iv e position encoding within the attention mechanism. While RoPE does not rely on a sequence length M , it may produce negati v e attention scores within the sequence. In the remainder of this manuscript we refer to the application of RoPE with a linear attention mechanism as LinRoFormer . 2.1.2 Retention scores At the core of the Retentiv e neural network is the retention mechanism, which shares similarit- ies with LinRoFormer by integrating relativ e distances between tokens as rotations of the features a i,j = γ i − j h ( ψ ( q i ) R θ ,i )( ψ ( k ) j R θ ,j ) T . (9) Attention mechanism Similarity function s ( q i , k j ) T ransformer (V aswani et al., 2017) exp( q i · k j / √ d K ) Linear T ransformer (Katharopoulos et al., 2020) (1 + elu ( q i )) · (1 + elu ( k j )) T CosFormer (Qin et al., 2022) cos( π 2 × i − j M ) ψ ( q i ) · ψ ( k j ) T RoPE Linear transformer (Su et al., 2024) ( ψ ( q n ) R i θ )( ψ ( k m ) R j θ ) T T able 1. Considered attention mechanisms in this study and corresponding similarity functions. Nev ertheless, two important differences should be highlighted. First, a decay term γ h ∈ [0 , 1] is inte grated, which v aries for each retention head (the counterpart of attention heads) and is expected to stabilize the RoPE inte gration (similar to xPOS en- coding (Sun et al., 2023b)). Second, in contrast to attention scores where P m a n,m = 1 , no normalization of the scores is performed in retention. 2.2 Dual f ormulations All previously described mechanisms have the ability to process a sequence X into a sequence O = [ o 1 , . . . , o N ] in either: • Parallel form: O = σ ( M ) V , where all tokens ( v i = x i W V ) are processed in parallel to output all tar get tokens o i and σ may be a scaling operation or the identity func- tion. • Recurrent form: o n = r ( h n − 1 , x n ) , where the output o n is computed using a hidden state h n − 1 and the current token x n . Both linear attention and retention implement a multi-head mechanism, where specifically query , ke y and value vec- tors are split along the channel dimension to produce n head triplets ( q h , k h , v h ) with q h , k h ∈ R (1 ,d K /n head ) and v h ∈ R (1 ,d V /n head ) . While the final output of the linear attention mechanisms is o = [ o 1 ; . . . o h . . . ; o n heads ] ∈ R (1 ,d v ) , the multi- head retention mechanism, normalizes the output of each heads with a group Norm o norm = GroupNorm h ([ o 1 ; . . . o h . . . ; o n heads ]) (10) o = swish ( x W G ⊙ o norm ) W O , (11) with W G , W O learnable matrices both in R ( d model ,d model ) . T o sim- plify notation, parallel and recurrent forms are detailed on one single head. Parallel f ormulation. First, all mechanisms can be written under the same parallel formulation M = L ⊙ ϕ ( Q ) ϕ ( K ) T , (12) where L corresponds to a lower triangular matrix and ⊙ the Hadamard product. While L corresponds to a causal masking matrix with l i,j = 1 for linear attention, it encodes decay in- formation in retention with l i,j = γ i − j . In addition, in contrast to the retention mechanism, the attention mechanism performs a row-wise normalization operation noted as σ ( · ) . This formu- lation allows fast training, as all outputs can be computed in a single pass. Recurrent formulation. The recurrent forms of attention and retention also differ slightly due to the normalization process in attention. Therefore, linear attention requires to store two hid- den states T attn n for the accumulation, and d n for the normaliz- ation: T attn n ∈ R ( d K ,d v ) with T attn n +1 = T att n + ϕ ( k n +1 ) T v n +1 d n ∈ R d K with d n +1 = d n + ϕ ( k n +1 ) . Using these two hidden states, the output of the attention for the image n + 1 can be written as o attn n +1 = ϕ ( q n +1 ) h T attn n + ϕ ( k n +1 ) T v n +1 i ⊘ ( ϕ ( q n +1 ) [ d n + ϕ ( k n +1 )]) , (13) with ⊘ corresponding to scalar division and ( ϕ ( q n +1 ) [ d n + ϕ ( k n +1 )]) a scalar corresponding to the attention normalization. In contrast, retention only stores the hidden state T n , which is multiplied by a decay factor γ ∈ [0 , 1] at each time step T ret n +1 = γ T ret n + ϕ ( k n +1 ) T v n +1 (14) and o ret n +1 = ϕ ( q n +1 )[ γ T ret n + ϕ ( k n +1 ) T v n +1 ] . (15) These dual formulations appear promising for SITS analysis, offering both embarrassingly parallel learning on historical se- quences and recurrent inference with constant memory for pro- cessing new acquisitions. Howe ver , these architectures were initially developed for natural language processing (NLP) tasks. Although they offer performance comparable to that of causal transformers in NLP applications, their adaptation to multi- modal satellite image time series remains an open question, which this study examines. 3. Method This section first details the proposed multi-modal SITS en- coder that encapsulates the various dual-form mechanisms, then describes the two supervised tasks inv estigated in this study . Fi- nally , the datasets used for the experiments are defined. 3.1 Architectur e 3.1.1 Backbone overview The core of this paper is the comparison of v arious auto-regressiv e mechanisms for multi- modal SITS analysis. T o establish the comparison of various auto-regressi ve mechanisms on tasks that require liv e predic- tions, we design a nov el architecture focused on the encoding of multi-modal data with temporal information. The proposed multi-modal spectro-spatio-temporal encoder (MMSSTE) is in- spired by (Dumeur et al., 2024, Garnot and Landrieu, 2021), and is illustrated in Fig. 1. It is composed of three main blocks: • A modality-specific spectral-spatial downsampling en- coder (SSE), which processes each image of the SITS in- dependently . Given an image X t ∈ R ( C,H,W ) , the SSE Figure 1. Overvie w of the proposed multi-modal spectro-spatio temporal architecture, composed of: a modality specific spectro-spatial encoder (noted g S 1 resp. g S 2 ), a temporal fusion encoder , an upsampling operation with pixel shuf fle (P .S) and a task specific decoder layer . outputs a feature map X ′ ( t, · , · , · ) ∈ R ( d model ,H/ 2 ,W / 2) . W e de- note g S 1 and g S 2 the encoders for Sentinel-1 and Sentinel- 2 respectiv ely . • A multi-modal temporal fusion layer which processes in- dependently the ( H / 2) × ( W / 2) sequences X ′ ( · , · ,h,w ) ∈ R ( T ,d model ) using one of the multi-head attention mechan- isms. • A spatial up-sampling (P .S) layer which up-samples each of the T processed acquisitions independently to Y ( t, · , · , · ) ∈ R ( d model ,H,W ) using a pix el shuffle operator (Shi et al., 2016). A task-specific decoder that projects Y t into the T predicted targets Z t ∈ R ( K,H,W ) is used in the two considered super- vised training tasks. In this study , various dual-form mechan- isms are utilized to capture the synergies between modalities as well as extract complex temporal patterns. Other parts of the architecture (the SSE, spatial up-sampling, and task-specific de- coder) remain the same. More specifically , the SSE employed is a U-Net with four down-sampling blocks and only three up- sampling layers, which results in a spatial do wn-sampling op- eration. Then, positional encoded acquisition dates information ( PE ( τ t i )) i ≤ T 1 and their corresponding modality specific tok ens ( m t i ) i ≤ T are concatenated to their corresponding sequence token ( X ′ ( t i , · ,h,w ) ) i ≤ T , before being processed by the multi- modal multi temporal encoder . Precisely , the multi-modal fu- sion layers is composed of n layers layers. Each layer is com- posed of an attention (resp. retention) mechanism followed by feed-forward layers. The following hyper -parameters are used: n layers = 3 , n heads = 4 , d K = 64 , and d model = 64 . After the attention mechanism, the spatial up-sampling is performed with a pixel shuf fle operation (Shi et al., 2016). 3.1.2 T emporal fusion layers Existing dual-form mechan- isms, previously described in Section 2, were originally de- veloped for NLP and, to the best of our knowledge, hav e nev er been applied to SITS. Consequently , they mostly rely on token indices in the sequence and do not address SITS temporal irreg- ularity and unalignment. Therefore, in this paper we propose variations of the dual-form mechanisms that compute distances between tokens based on actual temporal information. Spe- cifically , modified versions of CosFormer , LinRoFormer , and the Retention neural network are proposed and are respecti vely 1 W e emplo y the absolute positional encoding as proposed in the original T ransformer (V aswani et al., 2017). Figure 2. Multi-modal forecasting framew ork. named Time CosF ormer , Time LinRoF ormer , and Time Reten- tion. In these proposed architectures, for a pair of tokens x i , x j , in- stead of computing the distance between token indices i − j , we employ t i − t j , which represents the distance in days between acquisitions. For Time CosFormer , we employ M = 700 , meaning that we consider that the maximum considered tem- poral distance between any two acquisitions in our tasks is 700 days. As the feature map function, we always employ ψ ( x ) = elu ( x ) + 1 , even if the original CosFormer (Qin et al., 2022) uses ψ ( x ) = ReLU ( x ) and original retention (Sun et al., 2023a) ψ ( x ) = x , as it appears to av oid head collapsing and stabilizing training. Finally , the training stability of LinRo- Former (resp. Time LinRoFormer) and Retention (resp. Time Retention) was improved by scaling ϕ RoPE ( u ) /d K , where d K is the number of features per head. 3.2 Supervised training tasks The in vestigated kernel-based linear attention mechanisms are compared on both a SITS forecasting task and a multi-temporal segmentation task. The forecasting task corresponds to a proxy task, which allo ws assessment of the model’ s ability to extract complex temporal understanding of the SITS. In contrast, the multi-temporal segmentation task corresponds to a realistic re- mote sensing application. In this section, we describe how the outputs of the MMSSTE backbone are used depending on the task. 3.2.1 Multi-modal forecasting task In the forecasting task, giv en the latent representation at time-step t denoted Y t , the decoder predicts b X t +1 . As shown in Fig. 2, a forecaster model f θ is placed on top of the output of the MMSSTE and processes independently the pix el-lev el representation of the multi-modal time series at step t denoted Y ( t, · ,h,w ) ∈ R d model (where h, w is the location of the pixel). In other words, the forecaster only processes the channel dimension and does not capture temporal nor spatial relationships. The same forecaster is used to reconstruct either S1 or S2 data. Modality-specific linear heads denoted π S 1 (resp. π S 2 ) are em- ployed on top of the forecaster to enforce the correct number of channels of the reconstruction. Along with the latent repres- entation of the pixel-le v el time series at time-step t to predict X ( t +1 , · ,h,w ) , auxiliary variables are employed. More specific- ally , we integrate: • W eather AgERA5 (Boogaard et al., 2020) time series of the n w days preceding date t + 1 denoted W t +1 ∈ R ( n w ,d w ) , where d w is the number of AgERA5 variables. • A learnable modality-specific token named m S 1 (resp. m S 2 ). • Angle variables a S 1 for S1 data containing an encoding of azimuth and incidence angles. For S2 forecasting, a S 2 is just a learnable placeholder . • The distance in days between the previous acquisition t and the one to predict denoted δ ( t,t +1) . The encoding of the auxiliary variables W t +1 and a S 1 t is de- tailed in Appendix B. T o incorporate relativ e distance between predictions, we integrate rotary positional encoding (RoPE) (Su et al., 2024). The RoPE performs rotations of the features of the latent representation Y ( t, · ,h,w ) by an angle proportional to the temporal distance δ ( t,t +1) . It relies on a rotary matrix R θ ,δ t,t +1 ∈ R ( d model ,d model ) RoPE ( Y ( t, · ,h,w ) , δ t,t +1 ) = R θ ,δ t,t +1 · Y ( t, · ,h,w ) . (16) Then, once the rotary positional encoding is applied, the result- ing encoded representation is concatenated with auxiliary vari- ables and processed by an MLP as Z S 1 t +1 = MLP [ RoPE ( Y t , δ t,t +1 ); m S 1 ; f w ( W t +1 ); f θ ( a t +1 )] . (17) The training loss corresponds to a weighted sum of the Mean Square Error (MSE) losses on each S1 and S2 data L = MSE S 1 + w S 2 MSE S 2 . (18) The loss is only applied on time steps t ∈ [ n after , T ] . In all our experiments, we set n after = 6 and w S 2 = 0 . 1 . V alidity and cloud masks are provided to the reconstruction loss to allo w the model to learn to ignore clouds and out-of-swath regions. 3.2.2 Multi-temporal segmentation task In the multi- temporal segmentation task, multiple labels are provided for each time series. At some time steps, labels Z t are pro vided. T o perform this real-world application scenario, a linear clas- sification layer is placed on top of the MMSSTE to project the output of each representation into the correct number of classes. The model is trained using Focal Loss. While the model out- puts predictions for all time steps, the loss is computed only on time steps with av ailable labels. 3.3 Datasets T o support the comparison of attention mechanisms, we collect one dataset for each task. Both datasets comprise of Sentinel-1 (SAR) and Sentinel-2 (optical) time series. For S1, IW GRD D V products are selected and processed with thermal noise remov al and gamma radiometric calibration, and geocoded to 10m resolution using the GLO-30 digital ele vation model. Con- secutiv e slices are assembled, and the amplitudes are sav ed with linear encoding. The validity masks are defined as the in- swath areas. For S2, bottom-of-atmosphere L2A products are used, selecting the 10m and 20m (upsampled to 10m) bands. Products with a cloud co ver lar ger than 20% are e xcluded from the dataset. Besides the in-swath areas, the validity masks for S2 also excludes regions classified as cloud or shadow by the CloudSEN12 cloud detector (A ybar et al., 2022). Multi-modal SITS f orecasting dataset. The forecasting dataset is composed of multi-modal SITS and exhibit signi- ficant temporal and geographical div ersity . P atches of size 512 × 512 pixels at 10m resolution hav e been selected through- out the world in v arious eco-regions and urban and sub-urban areas. In total, 640 sites were sampled. For each site, 15 consec- utiv e months of S1 and S2 data is do wnloaded, within the range 2019–2021. The resulting training set contains 444 samples, and 96 additional sites for the validation and for the test set each. For the weather data, AgERA5 (Boogaard et al., 2020) time series of n w = 10 past days are e xtracted for each satellite ac- quisition, with the follo wing v ariables ( d w = 8 ): precipitation flux, solar radiation flux, vapour pressure, 2m dewpoint temper- ature, and 10m wind speed; each using the 24h mean statistic, and 2m temperature with min/max/mean statistic. Multi-modal solar panel segmentation dataset. This super- vised segmentation dataset relies on human annotations. 650 solar panel projects were labeled over their duration using S2 imagery , totaling about 13000 annotated masks. Masks are composed of three re gions: un-constructed, installed solar panel, and out-of-site regions. T o complement the S2 acquis- itions, S1 is downloaded b ut not labeled. The resulting multi- modal dataset is split into 8 folds to perform k-fold training. For a giv en experiment the training is composed of fi ve folds, one in validation and to w on tests. 4. Experiments and Results The proposed model takes SITS of spatial dimension (128 × 128) as input. Both multi-modal tasks are compared with their S2 mono-modal versions. For training efficiency , S1 and S2 SITS lengths are limited to 16 acquisitions each during train- ing and v alidation. For the forecasting task, models are trained for 1400 epochs on a single NVIDIA A100 GPU with a batch size of 4 and a learning rate of 0.001. Four training runs are performed on different training set splits, resulting in testing on different test sets. For the solar panel detection task, mod- els are trained for 600 epochs on a single NVIDIA V100 GPU with a batch size of 2, a learning rate of 0.006, and focal loss parameters ( β = 0 . 58 , γ = 2 . 0 ). Using the solar panel data- sets k-fold split, two different experiments with dif ferent train- ing, validation and test split are performed. Mean and standard deviation of the results are reported for both tasks. W e first present results on the forecasting task, which serves as a proxy task for comple x temporal feature extraction, before detailing results obtained on a real-world application (solar panel detec- tion). 4.1 Multi-modal f orecasting W e first assess the v arious dual-form mechanisms on a forecast- ing task with n dates = 16 for each modality (consistent with the training and v alidation framework) and with n dates = 8 . In this first experiment, images are not selected consecutiv ely; thus, time series may exhibit significant temporal gaps within the in- put sequences. The reconstruction errors for both mono-modal and multi-modal framew orks are sho wn in Fig. 4. In the framework consistent with training conditions ( n dates = 16 ), for both multi-modal and mono-modal frame works, the av- erage MSE v alues are close. When the number of dates within the SITS is small, we observe stronger disparities in the res- ults compared to the training frame work with n dates = 16 . As expected, shorter input SITS (Satellite Image T ime Series) res- ult in more challenging predictions. Within the mono-modal 2020-04-14 2020-04-24 2020-04-29 2020-05-04 2020-05-21 2020-09-26 2020-09-26 2020-09-27 2020-09-28 2020-10-01 2020-10-02 2020-10-03 2020-10-13 2020-10-14 2020-10-15 2020-10-28 2020-10-31 2020-11-01 2020-11-02 2020-11-02 Figure 3. V isualization of the reconstruction in the multi-modal forecasting task using the Time CosFormer mechanism. The top row corresponds to the input and target SITS. The ( n − 1) th images are used by the model to predict the n th one. The bottom row corresponds to the reconstruction by our model. 0.2 0.3 0.4 0.5 0.6 0.7 0.8 MSE L S 2 , n d a t e s = 8 , S 2 L S 2 , n d a t e s = 1 6 , S 2 0.04 0.05 0.06 0.07 0.08 MSE L S 1 + w S 2 L S 2 , n d a t e s = 8 , S 1 + S 2 L S 1 + w S 2 L S 2 , n d a t e s = 1 6 , S 1 + S 2 Linear Transformer CosF ormer Time CosF ormer LinRoformer Time LinRoformer Retention Time Retention Figure 4. Boxplot showing the MSE on the forecasting task for various temporal fusion encoders. T op row represents result obtained in the mono-modal S2 forecasting framew ork, bottom row corresponds to the multi-modal reconstruction loss. On the boxplot a line is drawn at the median v alue. framew ork ( n dates = 8 ), dual mechanisms that integrate tem- poral information, specifically the Time CosFormer , T ime Re- tention, and T ime LinRoF ormer , consistently outperform their original counterparts. Furthermore, in mono-modal forecasting, linear mechanisms incorporating a reweighting scheme often slightly outperform both the original T ransformer and standard linear attention. Surprisingly , in the multi-modal configuration, linear attention outperforms all other mechanisms. W e hypothesize that be- cause the reweighting mechanism is based solely on the rel- ativ e temporal distance between acquisitions, it fails to account for the fact that tokens within the sequence belong to different modalities. In other words, when processing a token at timestep t i , the most relev ant information may not reside in the pre vi- ous acquisition, b ut rather in the closest acquisition of the same modality . Lastly , importantly , for both mono-modal and multi-modal tasks, the dual mechanisms appear to hav e similar performance to T ransformer attention while exhibiting a recurrent form. W e ha ve also confirmed the quality of the forecasting task by qualitativ ely looking at the reconstructions. As sho wn in Fig. 3, we observ e that the model is able to extract and summarize suf- ficient past information in the representation Y t to allow the forecaster to forecast Y t +1 . 4.2 Look-back length effect W e study in Fig. 5 the performance of v arious dual-form mech- anisms on either mono-modal (S2) or multi-modal forecasting tasks as a function of the look-back length. Specifically , for each SITS in the test dataset, we select consecuti ve n dates ac- quisitions and ensure that experiments with higher n dates val- ues include images from experiments with smaller n dates val- ues. If n dates is larger than the maximum length of S1 or S2, we set n dates = min( n S 1 , n S 2 ) , corresponding to the minimum between the S1 and S2 lengths. First, for most models, the S2 MSE in either mono-modal or multi-modal forecasting de- creases with an increase in n dates . The noise contained in S1 data prev ents us from observing such a clear trend in L S 1 in Fig. 5. Then, in the multi-modal task, apart from the LinRo- Former and Retention, we observe that most dual-form mech- anisms exhibit an improvement in L S 2 with an increase in look- back length. This illustrates interesting generalization capab- ilities, while these mechanisms have been trained with SITS of a maximum length of 16, they can be used at inference on much longer sequences. Although LinRoFormer and Retention achiev e good results under settings similar to training condi- tions (see Section 4.1), they have the highest S2 reconstruction errors in the multi-modal setting. This suggests that reweight- ing in dual-form mechanisms based on RoPE may generalize better if they rely on temporal acquisition dates. Second, we observe that other mechanisms (T ime Retention, Time LinRo- Former , Linear Transformer , CosFormer and T ime CosFormer) achiev e results comparable to the transformer with causal atten- tion (orange curve). Consequently , for the forecasting task, the similarity function in a causal T ransformer can be replaced with other dual-form mechanisms (kernel-based attention or reten- tion) without performance degradation. In terms of dual-form mechanism comparison, for those that integrate a cosine re- weigthing mechanism (CosFormer and Time CosF ormer), we observe that they appear to slightly impro ve the multi-modal re- construction results compared to T ime Retention and Time Lin- RoFormer . Lastly , consistent with our previous experiments, we observe that linear attention outperforms other dual mech- anisms in the multi-modal forecasting task. This highlights the limitations of e xisting dual mechanisms that incorporate tem- poral re-weighting when applied to multi-modal data. 4.3 Multi-temporal solar panel detection Fig. 6 illustrates the input, labels and prediction in our multi- temporal solar panel segmentation tasks. W e compare in T able 2 the multi-temporal segmentation results obtained for solar panel detection mechanisms. W e observe that all models trained with multi-modal data slightly achie ve superior performance compared to their mono- modal versions, demonstrating the ability of these mechanisms to perform multi-modal fusion. In addition, for this task we also observe dual-form mechanisms matching transformer at- tention performance on both mono-modal and multi-modal set- tings. Among dual-form mechanisms, there are no major differ - ences (performance gaps are often between 1-2 % in F1 score or mIoU). Nonetheless, LinRoFormer is the lo west-performing model on both tasks, with a gap of 4% in mIoU in both mono-modal 10 20 30 40 50 60 70 80 0.2 0.3 0.4 0.5 MSE S 2 F o r e c a s t L S 2 10 20 30 40 50 60 70 80 n d a t e s 0.010 0.015 0.020 0.025 0.030 0.035 MSE M M F o r e c a s t L S 1 10 20 30 40 50 60 70 80 n d a t e s 0.2 0.3 0.4 0.5 0.6 M M F o r e c a s t L S 2 10 20 30 40 50 60 70 80 n d a t e s 0.03 0.04 0.05 0.06 0.07 0.08 0.09 M M F o r e c a s t L S 1 + w S 2 L S 2 Linear T ransfor mer Cosfor mer T ime Cosfor mer R etention T ime R etention LinR ofor mer T ime LinR ofor mer Figure 5. Effect of the look-back length in the forecasting task for v arious dual-form mechanisms. Mono-modal results are displayed on the top-line and multi-modal results on the bottom line. 2021-03-24 2021-04-01 2021-05-21 2021-05-29 2021-06-10 2021-06-10 2021-06-16 2021-06-30 2021-07-10 2021-07-22 2021-08-09 2021-08-14 2021-08-15 2021-08-19 2021-08-21 2021-09-08 2021-09-08 Figure 6. Multi-temporal solar panel segmentation with S2 and S1 SITS performed with the T ime CosF ormer . The top ro w corresponds to the input SITS. The second ro w corresponds to the Sentinel-2 labels, with black representing non-solar panel pix els and red representing solar panels. Grey is associated with unlabeled areas. The third ro w corresponds to the predictions of our proposed model after the sigmoid function. The colormap matches the label scheme (1 is associated with red, 0.5 with white, and 0 with black). V ariant Model Mod Accuracy F1 Score IoU - T ransformer (non-causal) S2 0 . 92 ± 0 . 01 0 . 84 ± 0 . 02 0 . 73 ± 0 . 03 - T ransformer (causal) S2 0 . 92 ± 0 . 01 0 . 85 ± 0 . 01 0 . 74 ± 0 . 02 - Linear S2 0 . 92 ± 0 . 01 0 . 85 ± 0 . 03 0 . 73 ± 0 . 04 - CosFormer S2 0 . 92 ± 0 . 01 0 . 85 ± 0 . 02 0 . 75 ± 0 . 04 T ime CosFormer S2 0 . 92 ± 0 . 01 0 . 85 ± 0 . 02 0 . 74 ± 0 . 03 - LinRoFormer S2 0 . 91 ± 0 . 01 0 . 83 ± 0 . 02 0 . 71 ± 0 . 02 T ime LinRoFormer S2 0 . 91 ± 0 . 02 0 . 84 ± 0 . 04 0 . 72 ± 0 . 07 - Retention S2 0 . 92 ± 0 . 01 0 . 85 ± 0 . 02 0 . 74 ± 0 . 04 T ime Retention S2 0 . 92 ± 0 . 01 0 . 84 ± 0 . 03 0 . 72 ± 0 . 05 - T ransformer (non-causal) S1+S2 0 . 92 ± 0 . 01 0 . 85 ± 0 . 02 0 . 74 ± 0 . 03 - T ransformer (causal) S1+S2 0 . 93 ± 0 . 01 0 . 86 ± 0 . 02 0 . 76 ± 0 . 03 - Linear S1+S2 0 . 92 ± 0 . 00 0 . 85 ± 0 . 01 0 . 75 ± 0 . 01 - CosFormer S1+S2 0 . 93 ± 0 . 01 0 . 86 ± 0 . 03 0 . 76 ± 0 . 05 T ime CosFormer S1+S2 0 . 93 ± 0 . 01 0 . 86 ± 0 . 01 0 . 75 ± 0 . 02 - LinRoFormer S1+S2 0 . 91 ± 0 . 01 0 . 83 ± 0 . 02 0 . 72 ± 0 . 03 T ime LinRoFormer S1+S2 0 . 93 ± 0 . 01 0 . 86 ± 0 . 02 0 . 76 ± 0 . 03 - Retention S1+S2 0 . 93 ± 0 . 01 0 . 86 ± 0 . 02 0 . 76 ± 0 . 03 T ime Retention S1+S2 0 . 93 ± 0 . 01 0 . 86 ± 0 . 02 0 . 76 ± 0 . 03 T able 2. Multi-temporal solar panel segmentation metrics: mean and standard de viation across two dif ferent experiments. The T ime variant indicates modified re weighting mechanisms that account for acquisition dates. and multi-modal settings compared to the best models. Still, its temporal version, T ime LinRoFormer , outperforms it. This highlights the need to adapt existing mechanisms, to incorpor - ate SITS specificities. Based on our previous e xperiments on look-back length influence, we hypothesize that this perform- ance drop may be e xplained by different SITS lengths between training and testing. 5. Conclusion In this study , we have compared different dual-form mechan- isms for multi-modal satellite image time series analysis. First, results obtained on both the supervised forecasting task and the multi-temporal segmentation task demonstrate the ability of these mechanisms to fuse multi-modal data. In particular , these mechanisms often match the performance of original causal at- tention (V aswani et al., 2017) while of fering a recurrent formu- lation better suited for efficient inference. This result is prom- ising as it opens ne w opportunities for regular and up-to-date land monitoring applications. Second, we hav e studied the ef- fect of the look-back length in both mono-modal and multi- modal tasks. For mono-modal forecasting, the results suggest that integrating temporal information via a temporal layer re- weighting mechanism can slightly reduce forecasting error . Our experiments indicate that simple reweighting schemes, such as the CosF ormer or our proposed T ime CosF ormer , achie ve ex- cellent performance compared to more complex mechanisms like the LinRoF ormer or Retention. Howev er , in the multi- modal setting, simple linear attention outperforms these re- weighted dual mechanisms. Furthermore, future w orks could extend our comparativ e ana- lysis with other dual-form mechanisms such as State Space Models with Mamba 2 (Dao and Gu, 2024) as well as meas- uring performances depending on the size of the recurrent state. Moreov er , due to the scarcity of labeled data for numerous re- mote sensing applications, an important research direction is the de velopment of self-supervised learning approaches for our proposed dual-form architecture. In this context, our proposed forecasting task could serve as an interesting starting point, as it is closely related to masked autoencoder strate gies that ha ve prov en ef fectiv e for pretraining SITS (Dumeur et al., 2025, Dumeur et al., 2024, Y uan et al., 2022). Acknowledgments This work was financed by the Agence Innov ation D ´ efense (AID), within the framework of the Dual Innovation Support Scheme (RAPID - R ´ egime d’APpui ` a l’Innovation Duale), for the project ’DETEVENT’ (Agreement No. 2024 29 0970). This work was granted access to the HPC resources of IDRIS under the allocations 2025-AD011016513 and 2025- AD011012453R4 made by GENCI. Sentinel-1 and Sentinel-2 data is from Copernicus. This paper contains modified Coper- nicus Sentinel data. References A ybar , C., Ysuhuaylas, L., Loja, J., Gonzales, K., Herrera, F ., Bautista, L., Y ali, R., Flores, A., Diaz, L., Cuenca, N. et al., 2022. CloudSEN12, a global dataset for semantic understand- ing of cloud and cloud shadow in Sentinel-2. Scientific data , 9(1), 782. Boogaard, H., Schubert, J., De Wit, A., Lazebnik, J., Hutjes, R., V an der Grijn, G. et al., 2020. Agrometeorological indicat- ors from 1979 to present deri ved from reanalysis. Copernicus climate change service (C3S) climate data stor e (CDS) , 10. Dao, T ., Gu, A., 2024. Transformers are ssms: Generalized models and ef ficient algorithms through structured state space duality . arXiv preprint . Dumeur , I., V alero, S., Inglada, J., 2024. Self-Supervised Spatio-T emporal Representation Learning of Satellite Im- age T ime Series. IEEE J ournal of Selected T opics in Applied Earth Observations and Remote Sensing , 1-18. http://dx.doi.org/10.1109/JST ARS.2024.3358066. Dumeur , I., V alero, S., Inglada, J., 2025. Pa ving the W ay T o- ward Foundation Models for Irregular and Unaligned Satellite Image Time Series. IEEE T ransactions on Geoscience and Re- mote Sensing , 63, 1-21. Garnot, V . S. F ., Landrieu, L., 2021. P anoptic segmentation of satellite image time series with conv olutional temporal attention networks. 2021 IEEE/CVF International Conference on Com- puter V ision (ICCV) , 4852–4861. Garnot, V . S. F ., Landrieu, L., Giordano, S., Chehata, N., 2020. Satellite image time series classification with pixel-set encoders and temporal self-attention. Pr oceedings of the IEEE/CVF Con- fer ence on Computer V ision and P attern Recognition , 12325– 12334. Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F ., 2020. T ransformers are rnns: Fast autoregressiv e transformers with linear attention. H. D. III, A. Singh (eds), Pr oceedings of the 37th International Confer ence on Mac hine Learning , Proceed- ings of Machine Learning Research, 119, PMLR, 5156–5165. Miller , L., Pelletier, C., W ebb, G. I., 2024. Deep learning for satellite image time-series analysis: A revie w . IEEE Geoscience and Remote Sensing Magazine , 12(3), 81–124. Qin, Z., Sun, W ., Deng, H., Li, D., W ei, Y ., Lv , B., Y an, J., K ong, L., Zhong, Y ., 2022. cosformer: Rethinking softmax in attention. arXiv pr eprint arXiv:2202.08791 . Rußwurm, M., K ¨ orner , M., 2020. Self-Attention for Ra w Op- tical Satellite T ime Series Classification. ISPRS Journal of Pho- togrammetry and Remote Sensing , 169, 421-435. Shi, W ., Caballero, J., Husz ´ ar , F ., T otz, J., Aitken, A. P ., Bishop, R., Rueckert, D., W ang, Z., 2016. Real-time single image and video super-resolution using an efficient sub-pixel conv olu- tional neural network. Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , 1874–1883. Su, J., Ahmed, M., Lu, Y ., Pan, S., Bo, W ., Liu, Y ., 2024. Ro- former: Enhanced transformer with rotary position embedding. Neur ocomputing , 568, 127063. Sun, Y ., Dong, L., Huang, S., Ma, S., Xia, Y ., Xue, J., W ang, J., W ei, F ., 2023a. Retentive network: A successor to transformer for large language models. arXiv pr eprint arXiv:2307.08621 . Sun, Y ., Dong, L., Patra, B., Ma, S., Huang, S., Ben- haim, A., Chaudhary , V ., Song, X., W ei, F ., 2023b . A length-extrapolatable transformer . A. Rogers, J. Boyd-Graber, N. Okazaki (eds), Pr oceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , Association for Computational Linguistics, T oronto, Canada, 14590–14604. T eam, C., 2025. Chameleon: Mixed-Modal Early-Fusion Foundation Models. arXiv pr eprint arXiv:2405.09818 . Tsai, Y .-H. H., Bai, S., Y amada, M., Morency , L.-P ., Salakhutdinov , R., 2019. T ransformer dissection: An unified understanding for transformer’s attention via the lens of ker- nel. K. Inui, J. Jiang, V . Ng, X. W an (eds), Pr oceedings of the 2019 Confer ence on Empirical Methods in Natural Languag e Pr ocessing and the 9th International Joint Conference on Nat- ural Languag e Pr ocessing (EMNLP-IJCNLP) , Association for Computational Linguistics, Hong K ong, China, 4344–4353. V aswani, A., Shazeer , N., P armar , N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., Polosukhin, I., 2017. Attention is all you need. I. Guyon, U. V . Luxb urg, S. Bengio, H. W al- lach, R. Fer gus, S. V ishwanathan, R. Garnett (eds), Advances in Neural Information Pr ocessing Systems , 30, Curran Associ- ates, Inc. Y uan, Y ., Lei, L., Qingshan, L., Hang, R., Zhou, Z.-G., 2022. SITS-Former: A pre-trained spatio-spectral-temporal repres- entation model for Sentinel-2 time series classification. Inter - national J ournal of Applied Earth Observation and Geoinform- ation , 106, 102651. A. R OPE The rotary matrix (Su et al., 2024), detailed in Eq. (19) operates d/ 2 θ i rotations with θ i = 1 10000 2( i − 1) /d with i ∈ [1 , ..d/ 2] . R t = cos( tθ 1 ) − sin( tθ 1 ) · · · 0 0 sin( tθ 1 ) cos( tθ 1 ) · · · 0 0 . . . . . . . . . . . . . . . 0 0 · · · cos( tθ d/ 2 ) − sin( tθ d/ 2 ) 0 0 · · · sin( tθ d/ 2 ) cos( tθ d/ 2 ) (19) First,LinRoFormer applies a rotary matrix (noted R t ∈ R d k ,d k ) on each query and key vectors, which will integrate relative po- sitional encoding on the attention mechanism. f ( q , t ) = q 1 cos( tθ 1 ) − q 2 sin( tθ 1 ) q 2 cos( tθ 1 ) + q 1 sin( tθ 1 ) . . . q d − 1 cos( tθ d/ 2 ) − q d sin( tθ d/ 2 ) q d cos( tθ d/ 2 ) + q d − 1 sin ( tθ d/ 2 ) (20) B. A uxiliary variables encoding B.1 AgERA5 variable The forecaster takes as input a vector w ′ t +1 which corresponds to the encoding of the weather v ariables. In order to allow the model to learn relev ant temoporal pattern, we use a cross- attention mechanism with learnable queries Q α ∈ R ( n q ,d K w ) and the input AgERA5 time series noted W t +1 . As indicated in Eq. (21), on each attention head, the input time series are projected to Keys and V alues matrix using W K w ∈ R ( n w ,d K w ) , W V w ∈ R ( n w ,d w ) . The resulting weather vector correspond to a reshaped version of the projected time series W ′ t ∈ R ( n q ,d w ) noted w ′ t ∈ R ( n q × d w ) . W ′ t = Softmax Q α · ( W t · W K w ) T d K V W V w (21) B.2 S1 angles When predicting a S1 acquisition, the forecaster takes as input the angle vector noted a S 1 . As detailed in Eq. (22), this vector is an encoding of the azimuth ϕ and incidence angle θ of the S1 acquisition to predict. a S 1 t = Linear ([cos( ϕ t ); sin( ϕ t ); cos( θ t ) sin( θ t )]) (22) B.3 Retention implementation T o create a more consistent comparison to retention as im- plemented in the RetNet, we have operated sev eral modific- ations. The queries and keys vectors are first encoded with ϕ ( . ) = 1 + elu ( . ) and scaled 1 d k to ensure more stability in the training.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment