Knowledge-Refined Dual Context-Aware Network for Partially Relevant Video Retrieval
Retrieving partially relevant segments from untrimmed videos remains difficult due to two persistent challenges: the mismatch in information density between text and video segments, and limited attention mechanisms that overlook semantic focus and ev…
Authors: Junkai Yang, Qirui Wang, Yaoqing Jin
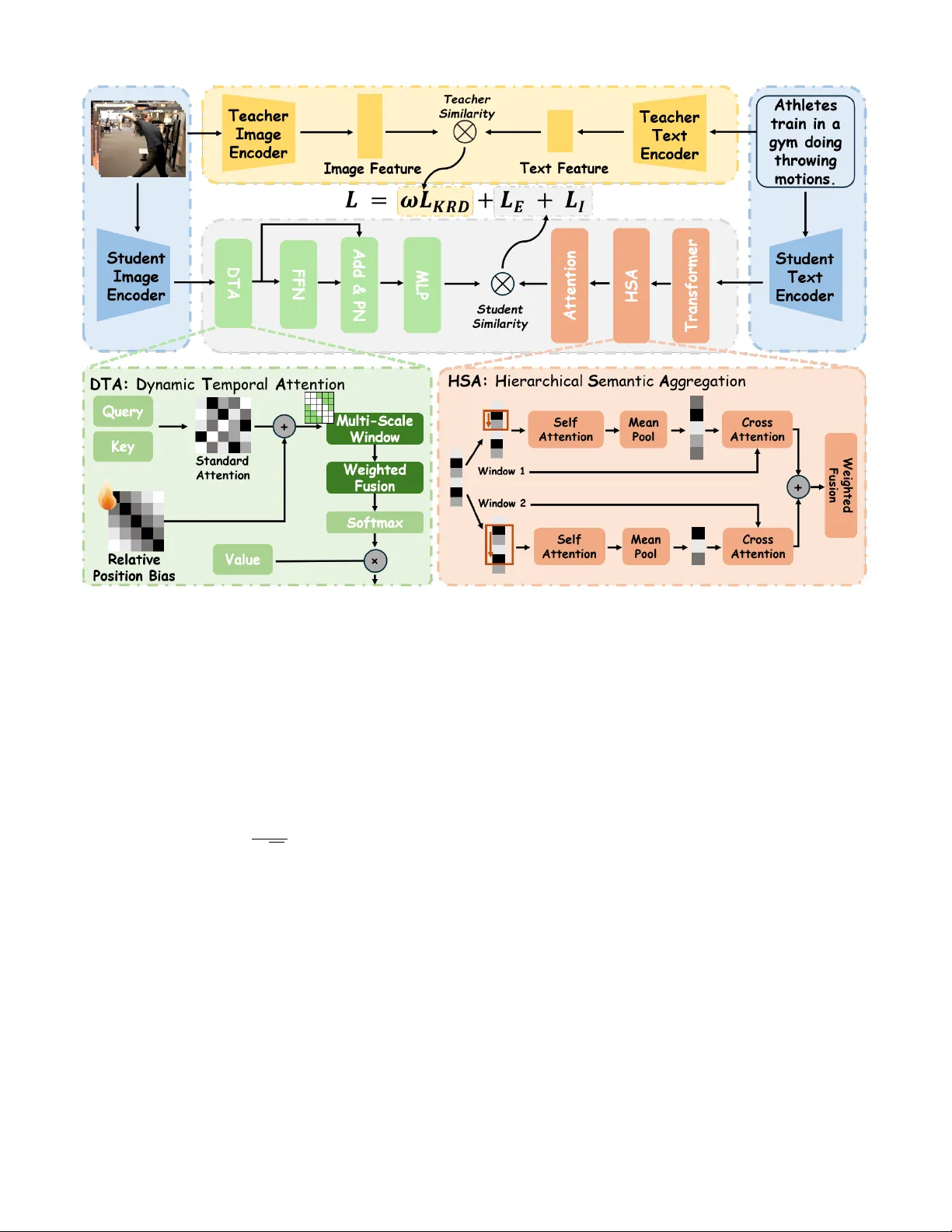
Kno wledge-Refined Dual Conte xt-A ware Netw ork for P artially Rele v ant V ideo Retrie v al Junkai Y ang 1 , † , Qirui W ang 1 , † , Y aoqing Jin 2 , † , Shuai Ma 1 , Minghan Xu 1 , Shanmin Pang 1 , ∗ 1 School of Software Engineering, Xi’an Jiaotong Uni versity 2 Faculty of Computer Science, Electrical Engineering and Information T echnology , Univ ersit ¨ at Stuttgart † These authors contributed equally to this w ork. ∗ Corresponding author . I . A B S T R AC T Retrieving partially relevant segments from untrimmed videos remains difficult due to tw o persistent challenges: the mismatch in information density between text and video segments, and limited attention mechanisms that overlook semantic focus and event correlations. W e present KDC-Net, a Knowledge-Refined Dual Context-A ware Network that tackles these issues from both textual and visual perspecti ves. On the text side, a Hierarchical Semantic Aggregation module captures and adapti vely fuses multi-scale phrase cues to enrich query semantics. On the video side, a Dynamic T emporal Attention mechanism employs relati ve positional encoding and adaptiv e temporal windo ws to highlight key ev ents with local temporal coherence. Additionally , a dynamic CLIP-based dis- tillation strategy , enhanced with temporal-continuity-aware re- finement, ensures segment-aw are and objective-aligned kno wl- edge transfer . Experiments on PR VR benchmarks show that KDC-Net consistently outperforms state-of-the-art methods, especially under low moment-to-video ratios. Index T erms —Relevant V ideo Retrieval, V ideo Analysis, Cross- model Matching I I . I N T RO D U C T I O N W ith the rapid rise of short-video platforms and video- centric social media [1], ef ficiently retrieving relev ant content from massiv e collections of untrimmed videos has become increasingly crucial. T o address this need, the task of Partially Relev ant V ideo Retriev al (PR VR) has emerged [2] [3] [4], aiming to localize segments within raw videos that partially match a given textual query . Unlike traditional text-to-video retriev al (T2VR) [5], which operates on pre-trimmed clips [6] [7], PR VR more faithfully reflects real-world scenarios and has gained considerable attention in recent years. Despite notable progress, existing approaches still face two fundamental challenges. First, on the textual side, most cur- rent models rely on T ransformer-based flattened self-attention, which lacks e xplicit modeling of the inherent local compo- sitional structure of natural language [8]. As a result, core semantic units—namely multi-word phrases—tend to be di- luted [9] [10], preventing the model from forming a properly hierarchical understanding of comple x queries. Second, on the Fig. 1. The Overview diagram illustrates the task objectives of PR VR, and also shows that the Knowledge Refined Distillation strategy we proposed can effecti vely optimize the distilled signals obtained from the teacher model. visual side, directly applying standard self-attention to frame sequences introduces a form of temporal agnosticism: permu- tation in variance prevents the model from inherently capturing ev ent-level temporal dependencies [11], while the global and uniform attention computation ignores the strong locality priors essential for segment retriev al. This not only leads to inefficient computation but also makes the model highly susceptible to noise from irrele vant frames. Furthermore, many state-of-the-art methods rely on kno wledge distillation from large pretrained vision-language models such as CLIP . Y et, standard distillation follows a blind imitation paradigm since CLIP is not tailored for video understanding [12], and its similarity distributions often contain noise and ambiguity [13]. A student model that imitates these signals uncritically wastes capacity trying to fit imperfect supervision, ultimately limiting its performance ceiling. T o address these challenges systematically , we propose the Knowledge-Refined Dual Context-A ware Network (KDC- Net), which introduces coordinated innovations across text representation, video modeling, and training methodology . T o resolve the lack of hierarchical textual information, we design the Hierarchical Semantic Aggregation (HSA) module. It explicitly extracts multi-scale textual phrases using sliding windows and applies self-attention within each phrase to capture local dependencies, producing high-quality phrase- lev el features. A learnable fusion mechanism then adaptiv ely integrates these multi-scale phrase representations back into the token sequence, yielding a dense, compositionally en- riched, and hierarchically structured query representation. T o address the sparsity of semantic focus in video mod- eling, we introduce the Dynamic T emporal Attention (DT A) mechanism. DT A injects learnable relati ve positional biases to capture temporal relationships more ef fectiv ely and employs dynamically generated multi-scale temporal windows to re- strict the attention field. This encourages the model to focus computational resources on temporally coherent key ev ents while suppressing irrelev ant noise, enabling rob ust modeling of both short-term motions and long-term dynamics. Finally , to overcome the limitations of con ventional distilla- tion, we propose a novel Kno wledge Refinement Distillation (KRD) strategy . Instead of directly using CLIP’ s similarity distribution as supervision, KRD acts as a critical ev alua- tor , Leveraging the prior that real events exhibit temporal continuity , we identify consecuti vely high-confidence or low- confidence regions in the teacher distribution via dynamic thresholding. High-confidence segments are amplified, lo w- confidence ones are suppressed, and the refined, cleaner distri- bution serves as the student’ s learning target. This refinement substantially improv es the quality and utility of the distillation signal, leading to more ef ficient and robust kno wledge transfer . In summary , our main contributions are as follows: • W e introduce the HSA module, which explicitly models and adaptiv ely fuses phrase-lev el semantics to produce richly structured textual representations. • W e dev elop the DT A mechanism, which injects relativ e positional priors and dynamic temporal windows into attention computation, enabling accurate and efficient modeling of multi-scale temporal dynamics. • W e propose the KRD strategy , which denoises and enhances teacher signals prior to distillation, enabling more robust and effecti ve knowledge transfer . Extensiv e experiments across multiple benchmarks demonstrate the superiority of our method. I I I . R E L A T E D W O R K A. P artially Relevant V ideo Retrieval PR VR aims to locate segments in untrimmed videos match- ing a textual query , demanding both cross-modal alignment and temporal localization. Recent methods hav e explored div erse strategies: MS-SL [2] integrates multi-level features, PEAN [14] uses hierarchical modeling, T -D3N [15] enhances textual semantics, and GMMFormer [3] models frame de- pendencies with Gaussian constraints. DL-DKD [16] le verage large-scale pretraining or distill knowledge from CLIP . How- ev er, these methods often rely on flat attention mechanisms that neglect the hierarchical semantics of text queries. Fur- thermore, their video modeling struggles to capture multi-scale temporal dynamics and is susceptible to noise from irrelev ant content. In contrast, our work addresses these gaps with a hierarchical text encoder and a dynamic temporal attention mechanism for video. B. Knowledge Distillation Knowledge distillation is widely used in cross-modal re- triev al to transfer the alignment capabilities of large vision- language models like CLIP to smaller student models [17] [18] [19]. For instance, T eachT ext applies knowledge distillation to text-video retriev al [20], GCKD [21] introduces the teacher model to generate cross-domain pseudo-similarity labels to al- leviate the distribution shift problem in cross-domain transfer, DL-DKD [16] uses a dual-branch framew ork. Howe ver , these approaches often emplo y blind imitation paradigm, treating the teacher’ s output as a perfect target. This overlooks inherent noise, especially when applying image-text models like CLIP to video, forcing the student to fit suboptimal signals. Our pro- posed Kno wledge Refinement Distillation (KRD) ov ercomes this by first refining the teacher’ s noisy signal using temporal continuity priors before guiding the student, enabling more robust knowledge transfer . I V . M E T H O D O L O G Y KDC-Net is designed to learn robust and fine-grained representations for both text and video to address the core challenges in PR VR. It consists of three key components: a Hierarchical Semantic Aggregation (HSA) module for text encoding, a Dynamic T emporal Attention (DT A) mechanism for video modeling, and a nov el Knowledge Refinement Dis- tillation (KRD) strategy for training. A. Hierar chical Semantic Aggr egation for T ext T o capture the compositional nature of language, we in- troduce the HSA module. Given word-lev el features Q = { q i } L i =1 , HSA first employs multi-scale sliding windo ws to generate a set of phrase-lev el features P ( m ) for each scale m ∈ M . Specifically , each phrase feature is extracted by applying Multi-Head Attention followed by av erage pooling within its corresponding window to model local context. Then, to enrich the original word features with hierarchical context, each word feature q i is updated via a two-stage aggregation. First, for each scale m , a scale-specific context vector a ( m ) i is computed by attending to all phrase features within that scale: a ( m ) i = X j softmax ( q i · p ( m ) j √ D ) p ( m ) j (1) where p ( m ) j ∈ P ( m ) . This allo ws each word to aggregate information from semantically rele vant phrases at a specific granularity . Second, these scale-specific vectors are fused using learnable importance weights β ( m ) to form the final enhanced representation: q ′ i = LayerNorm ( q i + X m ∈M β ( m ) a ( m ) i ) (2) Finally , pooling the enhanced word features { q ′ i } L i =1 to pro- duces the final query representation q ∈ R D . Fig. 2. Illustration of KDC-Net. It employs a distillation framew ork, the student model comprises two independent branches with no parameter sharing. B. Dynamic T emporal Attention for V ideo For a sequence of video frame features V = { v i } K i =1 ∈ R K × D , we propose the DT A mechanism to replace the standard self-attention in our video encoder . DT A injects two critical temporal priors into the attention calculation to effecti vely model temporal dynamics and suppress noise. The attention score between a query frame i and a key frame j is formulated as: score ( i, j ) = q ⊤ i k j √ d k + b i,j + m i,j (3) where the first term is the standard dot-product attention. The second term, b i,j , is a learnable relative position bias. It explicitly encodes temporal ordering by mapping the relativ e distance ( j − i ) to a learnable embedding, allowing the model to distinguish frames based on their temporal separation. The third term, m i,j , is a dynamic windo w mask that restricts attention to a local neighborhood around frame i , defined as: m i,j = ( 0 , if | j − i | ≤ U −∞ , otherwise (4) where U is the window radius. By emplo ying multiple windo w sizes, this mask focuses computation on temporally relev ant frames and adapts to dif ferent action scales. This design allows DT A to efficiently capture both short-term actions and long- term dependencies. Furthermore, to address the high temporal redundancy in video features, we introduce Purification Normalization (PN) as a lightweight substitute for standard LayerNorm. PN explicitly purifies features by identifying and removing redundant information. It computes a self-similarity matrix S from the input features x to model intra-sequence redundancy , then subtracts the redundancy-focused representation from the original features. The process is formulated as: x out = LayerNorm ( x − λ · ( S · x )) (5) where λ is a scale factor , and S = Softmax ( ˆ x · ˆ x ⊤ ) with ˆ x being the L2-normalized features. This allows the video encoder to produce more discriminativ e representations. C. Knowledge Refinement Distillation Giv en a query-video pair ( Q, V ) , we utilize CLIP’ s image and text encoders to extract modality-specific features. Specif- ically , each frame v i ∈ V is encoded into a visual embedding f t i , yielding the frame-level representation F t = { f t i } K i =1 ∈ R K × d , while the query Q is mapped to a global textual feature q t ∈ R 1 × d , where d is the shared embedding dimension. T o effecti vely transfer the semantic alignment capability of the teacher model into the student network, we focus on distilling the similarity distribution between the query and individual video frames. Formally , the semantic similarity distribution S t ∈ R K is computed as: S t = [cos( f t 1 , q t ) , cos( f t 2 , q t ) , ..., cos( f t K , q t )] (6) T o le verage the power of large pre-trained models like CLIP while avoiding the blind imitation pitfall of standard Knowledge Distillation, we propose a novel KRD strategy . Confidence thresholds are dynamically determined based on the current batch’ s prediction statistics. Specifically , given a teacher-generated score sequence S t = { s t 1 , s t 2 , ..., s t K } , we compute the mean µ s = 1 K P K i =1 s t i and standard deviation σ s = q 1 K P K i =1 ( s t i − µ s ) 2 . Using these statistics, we set adaptiv e thresholds as: τ hig h = µ s + σ s , τ low = µ s − σ s (7) which allo w flexible boundary adjustment to accommodate varying confidence distributions across video sequences. T o capture temporal continuity , we employ a sliding- window local decision strategy that models confidence cor- relations among adjacent frames. For each score s t i , a local window w i = [ s t i , s t i +1 , . . . , s t i + k ] with window size k is defined. If all values in w i exceed the high threshold τ hig h , the region is identified as high-confidence and enhanced; if all fall below the lo w threshold τ low , it is penalized. The adjusted score is computed as: ˜ s t i = s t i + I ( i ) · α, I ( i ) = 1 , if W i ≥ τ high − 1 , if W i ≤ τ low 0 , otherwise (8) where I ( i ) is the indicator function and α = µ s · σ s µ s + σ s modulates the adjustment strength by jointly considering the dispersion and mean of the confidence scores. A more concentrated distribution reduces α , lessening adjustment, while higher mean confidence increases it. The student model is then trained to match this refined distribution. The KRD loss is the KL-diver gence between the student’ s predicted similarity distribution and the refined teacher distribution: L K RD = K X i =1 K L log( σ ( s s i )) ∥ σ ˜ s t i (9) where σ is the softmax function. This refinement paradigm ensures a more robust and efficient knowledge transfer . D. Learning and Infer ence In the exploration branch of the student model, we jointly employ InfoNCE loss and T riplet Ranking loss to enhance the discriminativ e ability of the learned representations. The total loss for this branch is denoted as L E [16] [22] [23]. For the inheritance branch, we similarly adopt InfoNCE loss and Triplet Ranking loss to enhance consistency with the teacher model’ s representations, resulting in a loss term L I . In addition, we incorporate the kno wledge distillation loss L KRD , refined through the KRD module, to further strengthen knowledge transfer from the teacher . Following the dynamic distillation strategy proposed in DL-DKD, an exponentially decaying weight w is applied to gradually reduce the influence of the teacher as training progresses. The ov erall training objectiv e is formulated as: L = L E + L I + w · L KRD (10) During inference, only the student model is used for re- triev al. Given a video-text pair ( Q, V ) , we independently compute similarity scores using representations from the inheritance and exploration branches, denoted as S I ( Q, V ) and S E ( Q, V ) , respectiv ely . These scores are then fused via weighted aggregation to obtain the final similarity: Sim ( Q, V ) = δ · S E ( Q, V ) + (1 − δ ) · S I ( Q, V ) (11) where δ ∈ [0 , 1] is a tunable coefficient that adjusts the relativ e contribution of each branch. Given a textual query Q , all candidate videos V are ranked based on the computed similarity scores Sim ( Q, V ) . V . E X P E R I M E N T A. Datasets W e conduct experiments on two standard benchmarks: TVR and ActivityNet Captions. TVR [29] includes 21.8K untrimmed videos with moment-le vel annotations; we use 17.4K for training and 2.2K for ev aluation. Acti vityNet [31] Captions contains 20K annotated Y ouT ube videos. W e follow the standard split protocol from for fair comparison. B. Evaluation Metrics W e report retriev al performance using Recall@K (R@K, K ∈ { 1 , 5 , 10 , 100 } ) and SumR. R@K measures the proportion of correct results in the top-K, and SumR reflects overall retriev al quality . All metrics are reported as percentages, with higher values indicating better performance. C. Implementation Details For student model, we follow MS-SL [2] to encode queyr - video features, and uses the hidden dimension of 384. For CLIP teacher model, we adopt V ision T ransformer V iT -B/32, and encode queries and videos to 512 dimension features. On TVR, we trained for 100 epochs with an initial learning rate of 0.0002. On ActivityNet Captions, we used an initial learning rate of 0.00025 and trained for 50 epochs. All experiments are performed on a single NVIDIA R TX 4090 GPU. D. Comparison with the State-of-the-Art T able I present comparisons between KDC-Net and existing PR VR methods. On TVR, KDC-Net achiev es highest SumR of 184.9, outperforming DL-DKD by +5.0 points and GMM- Former by +8.3 points, while setting a best R@1 record of 15.4%. These results demonstrate the KDC-Net’ s strength in high-precision retrie val across div erse queries. On the more challenging Acti vityNet Captions, KDC-Net also achie ves the best SumR of 148.5 and consistently surpasses prior methods T ABLE I P E RF O R M AN C E C O M P A R I S ON O N A C T I VI T Y N ET C A P TI O N S , T V R A N D P ER F O R MA N C E O N D I FFE R E N T M /V I N T ERV A L S O F T V R ( O N L Y E X I S TI N G O P EN - S O UR C E M O D EL S ) . A L L M E T RI C S A R E R E P ORT E D A S P E R CE N TAG ES ( % ) . R @ K D E N OT ES R E C AL L AT R A NK K . Model ActivityNet Captions TVR TVR: M/V Intervals R@1 R@5 R@10 R@100 SumR R@1 R@5 R@10 R@100 SumR (0, 0.2] (0.2, 0.4] (0.4, 1] CE [24] 5.5 19.1 29.9 71.1 125.6 3.7 12.8 20.1 64.5 101.1 104.1 149.5 165.5 W2VV++ [25] 5.4 18.7 29.7 68.8 122.6 5.0 14.7 21.7 61.8 103.2 99.0 140.7 161.3 VSE++ [22] 4.9 17.7 28.2 67.1 117.9 7.5 19.9 27.7 66.0 121.1 119.1 109.8 133.5 DE [26] 5.6 18.8 29.4 67.8 121.7 7.6 20.1 28.1 67.6 123.4 123.2 139.7 161.3 DE++ [27] 5.3 18.4 29.2 68.0 121.0 8.8 21.9 30.2 67.4 128.3 124.7 131.4 149.0 RIVRL [28] 5.2 18.0 28.2 64.4 117.8 9.4 23.4 32.2 70.6 135.6 133.0 121.1 135.1 XML [29] 5.3 19.4 30.6 73.1 128.4 10.0 26.5 37.3 81.3 155.1 156.7 151.5 151.0 ReLoCLNet [23] 5.7 18.9 30.0 72.0 126.6 10.7 28.1 38.1 80.3 157.1 157.7 153.1 156.7 MS-SL [2] 7.1 22.5 34.7 75.8 140.1 13.5 32.1 43.4 83.4 172.4 169.6 163.4 175.8 PEAN [14] 7.4 23.0 35.5 75.9 141.8 13.5 32.8 44.1 83.9 174.2 / / / T -D3N [15] 7.3 23.8 36.0 76.6 145.1 13.8 33.8 45.0 83.9 176.5 / / / DL-DKD [16] 8.0 25.0 37.5 77.1 147.6 14.4 34.9 45.8 84.9 179.9 179.8 175.8 179.9 LH [30] 7.4 23.5 35.8 75.8 142.4 13.2 33.2 44.4 85.5 176.3 / / / GMMFormer [3] 8.3 24.9 36.7 76.1 146.0 13.9 33.3 44.5 84.9 176.6 176.2 172.8 177.4 BGM-Net [4] 7.2 23.8 36.0 76.9 143.9 14.1 34.7 45.9 85.2 179.9 / / / KDC-Net 8.1 25.3 38.0 77.5 148.8 15.4 36.3 47.6 85.6 184.9 184.4 178.5 183.9 T ABLE II A B LAT IO N S T U D IE S O F E AC H C O M P ON E N T O N T V R Modules Metrics HSA DT A KRD R@1 R@5 R@10 R@100 SumR 14.4 34.1 45.0 84.3 177.8 √ 14.2 34.5 45.7 84.6 179.0 √ √ 15.5 36.2 46.6 85.3 183.6 √ √ 14.9 35.4 46.1 85.4 181.8 √ 15.2 35.8 46.0 85.1 182.1 √ 15.0 35.0 45.4 85.1 180.6 √ √ 15.3 35.9 46.9 85.4 183.7 √ √ √ 15.4 36.3 47.6 85.6 184.9 on R@5 and R@10. Notably , it improv es over the PR VR base- line MS-SL by 6.0% in SumR, underscoring its effecti veness in complex video retriev al scenarios. T o enable finer-grained analysis, we follo w the comparison criteria proposed by MS-SL to divide the TVR dataset into three intervals based on the moment-to-video (M/V) ratio of each query , which measures the proportion of relev ant content within a video. Lower M/V values indicate shorter target segments amid more irrelevant content, thus posing greater retriev al challenges. This ev aluation helps assess robustness under varying query difficulties and content sparsity . Detailed results across three M/V intervals are shown in table I, where our method clearly outperforms the compared approaches. E. Ablation Study 1) Analysis on Components: W e conduct ablation studies to assess the impact of each component in KDC-Net, as summarized in table II. Removing any of the three modules results in a noticeable performance drop from the full model to the baseline, validating components’ contributions. Among them, HSA is essential for fine-grained cross-modal alignment, while DT A improves temporal relation modeling and reduces redundancy . KRD enhances teacher supervision and distilla- tion effecti veness. 2) Analysis on DT A: W e in vestigate the impact of key hyperparameters in DT A by varying the maximum relative position and window size as shown in fig. 3 (b). Results rev eal that performance improves when the two are configured in a balanced manner . Specifically , increasing either parameter leads to performance gains up to a point, after which the improv ement plateaus, reflecting a trade-of f between receptive field expansion and local attention precision. The best SumR score is achiev ed at a maximum relative position of 30 and window size of 20. Notably , the model performs best when their ratio is around 1.5, suggesting that a slightly broader relativ e position range than the attention windo w effectiv ely enhances spatial bias modeling. W e further study the impact of the scale parameter λ in the PN module, as shown in fig. 3 (c). Performance peaks at λ = 0 . 1 , indicating optimal feature separation. Notably , exceeding this value causes a sharper decline in performance compared to lower values, suggesting that over -regularization is more detrimental than under-re gularization. These findings validate the PN module’ s design in ef fectiv ely balancing discriminability and information preservation. 3) Analysis on KRD: W e conduct an ablation study on TVR to assess the impact of sliding window size in the KRD module, varying it from 2 to 6. As sho wn in fig. 3 (a), the best performance is achieved with a window size of 3. A smaller window limits inter-frame interaction, hindering effecti ve learning, while a larger window introduces noise from irrelev ant frames, degrading alignment quality . Windo w sizes of 3–5 yield consistently strong results, highlighting the importance of modeling fine-grained, localized frame intervals for effecti ve retriev al. 4) Analysis on P arameters and Branc hes: In order to in vestigate the parameter δ used in the Inference stage to balance the weights of exploration branch and inheritance branch, we conducted ablation experiments as shown in fig. 3 Fig. 3. Ablation studies: (a) KRD window size ablation; (b) DT A parameters ablation; (c) δ and λ parameters ablation. T ABLE III A B LAT IO N S T U D IE S O N E AC H B R AN C H Branch ActivityNet TVR Inheritance Exploration R@1 R@5 R@10 R@100 SumR R@1 R@5 R@10 R@100 SumR √ 6.2 20.5 33.5 73.9 134.1 12.7 32.1 42.4 83.9 171.1 √ 7.8 24.5 36.5 76.8 145.6 11.8 30.2 41.0 82.6 165.6 √ √ 8.1 25.3 38.0 77.5 148.8 15.4 36.3 47.6 85.6 184.9 (c). The results show that the best performance is achie ved when δ is 0.1. The experiments shown in table III demonstrate that the dual-branch learning strategy adopted by KDC-Net is effecti ve. Simply using the teacher signal from the inherited branch for learning or independently learning through the exploration branch alone cannot achieve higher results. V I . C O N C L U S I O N W e propose KDC-Net, a novel method for PR VR that achiev es new state-of-the-art results through three key in- nov ations: adapti ve hierarchical semantic modeling, dynamic temporal visual encoding, and dynamic refined knowledge distillation. Extensiv e experiments on TVR and ActivityNet Captions demonstrate consistent improvements ov er strong baselines, especially under low M/V ratio scenarios. The results of comprehensiv e comparison and ablation experiments hav e confirmed the ability of KDC-Net in bridging the seman- tic gap between complex text queries and untrimmed video content, laying a solid foundation for future PR VR research. R E F E R E N C E S [1] Hao Fei, Shengqiong W u, W ei Ji, and et al., “V ideo-of-thought: Step- by-step video reasoning from perception to cognition, ” arXiv preprint arXiv:2501.03230 , 2024. [2] Jianfeng Dong, Xianke Chen, Minsong Zhang, and et al., “Partially relev ant video retriev al, ” in A CM MM , 2022, pp. 246–257. [3] Y uting W ang, Jinpeng W ang, Bin Chen, and et al., “Gmmformer: Gaussian-mixture-model based transformer for ef ficient partially rele vant video retrie val, ” in AAAI , 2024, vol. 38, pp. 5767–5775. [4] Shukang Yin, Sirui Zhao, Hao W ang, and et al., “Exploiting instance- lev el relationships in weakly supervised text-to-video retriev al, ” A CM T rans. Multimedia Comput. Commun. Appl. , vol. 20, no. 10, pp. 1–21, 2024. [5] Zhiguo Chen, Xun Jiang, Xing Xu, and et al., “Joint searching and grounding: Multi-granularity video content retrieval, ” in ACM MM , 2023, pp. 975–983. [6] Cheol-Ho Cho, W onJun Moon, W oojin Jun, and et al., “ Ambiguity- restrained text-video representation learning for partially relev ant video retriev al, ” in AAAI , 2025, vol. 39, pp. 2500–2508. [7] Y abing W ang, Jianfeng Dong, T ianxiang Liang, and et al., “Cross-lingual cross-modal retrie val with noise-robust learning, ” in A CM MM , 2022, pp. 422–433. [8] Shijie W ang, Huahu Xu, Jue Gao, and et al., “Efficient attention in partially relevant video retriev al: A benchmarking study on accuracy- efficienc y trade-of fs, ” in ICCEA , 2025, pp. 01–04. [9] Y uting W ang, Jinpeng W ang, Bin Chen, and et al., “Gmmformer v2: An uncertainty-aware framework for partially relev ant video retrie val, ” arXiv:2405.13824 , 2024. [10] Qirui W ang, Qi Guo, Y iding Sun, Junkai Y ang, Dongxu Zhang, Shan- min Pang, and Qing Guo, “Personalq: Select, quantize, and serve personalized diffusion models for ef ficient inference, ” arXiv pr eprint arXiv:2603.22943 , 2026. [11] Junlong Ren, Gangjian Zhang, Y u Hu, and et al., “Exploiting inter- sample correlation and intra-sample redundancy for partially relev ant video retrie val, ” arXiv preprint , 2025. [12] Qun Zhang, Chao Y ang, Bin Jiang, and et al., “Multi-grained alignment with kno wledge distillation for partially relev ant video retriev al, ” ACM T ransactions on Multimedia Computing, Communications and Applica- tions , 2025. [13] Ioana Croitoru, Simion-Vlad Bogolin, Marius Leordeanu, and et al., “T eachtext: Crossmodal text-video retrie val through generalized distil- lation, ” Artificial Intelligence , vol. 338, pp. 104235, 2025. [14] Xun Jiang, Zhiguo Chen, Xing Xu, and et al., “Progressi ve event alignment network for partial relev ant video retriev al, ” in ICME , 2023, pp. 1973–1978. [15] Dingxin Cheng, Shuhan K ong, Bin Jiang, and et al., “Transferable dual multi-granularity semantic exca vating for partially relev ant video retriev al, ” Image V is. Comput. , vol. 149, pp. 105168, 2024. [16] Jianfeng Dong, Minsong Zhang, Zheng Zhang, and et al., “Dual learning with dynamic knowledge distillation for partially relevant video retriev al, ” in ICCV , 2023, pp. 11302–11312. [17] Geoffrey Hinton, Oriol V inyals, and Jef f Dean, “Distilling the kno wledge in a neural network, ” arXiv preprint , 2015. [18] GuangHao Meng, Sunan He, Jinpeng W ang, and et al., “Evdclip: Improving vision-language retrieval with entity visual descriptions from large language models, ” in AAAI , 2025, vol. 39, pp. 6126–6134. [19] Y i W ang, Kunchang Li, Xinhao Li, and et al., “Intern video2: Scaling foundation models for multimodal video understanding, ” in ECCV . 2024, pp. 396–416, Springer . [20] Alec Radford, Jong W ook Kim, Chris Hallacy , and et al., “Learning transferable visual models from natural language supervision, ” in ICML , 2021, pp. 8748–8763. [21] Bingjun Luo, Jinpeng W ang, Zewen W ang, and et al., “Graph-based cross-domain knowledge distillation for cross-dataset text-to-image per- son retrie val, ” in AAAI , 2025, vol. 39, pp. 568–576. [22] Fartash Faghri, David J Fleet, Jamie Ryan Kiros, and et al., “Vse++: Improving visual-semantic embeddings with hard negativ es, ” arXiv pr eprint arXiv:1707.05612 , 2017. [23] Hao Zhang, Aixin Sun, W ei Jing, and et al., “V ideo corpus moment retriev al with contrastiv e learning, ” in ACM SIGIR , 2021, pp. 685–695. [24] Y ang Liu, Samuel Albanie, Arsha Nagrani, and et al., “Use what you hav e: V ideo retrieval using representations from collaborativ e experts, ” arXiv pr eprint arXiv:1907.13487 , 2019. [25] Xirong Li, Chaoxi Xu, Gang Y ang, and et al., “W2vv++ fully deep learning for ad-hoc video search, ” in ACM MM , 2019, pp. 1786–1794. [26] Jianfeng Dong, Xirong Li, Chaoxi Xu, and et al., “Dual encoding for zero-example video retriev al, ” in CVPR , 2019, pp. 9346–9355. [27] Jianfeng Dong, Xirong Li, Chaoxi Xu, and et al., “Dual encoding for video retrie val by text, ” IEEE T rans. P attern Anal. Mach. Intell. , vol. 44, no. 8, pp. 4065–4080, 2021. [28] Jianfeng Dong, Y abing W ang, Xianke Chen, and et al., “Reading- strategy inspired visual representation learning for text-to-video re- triev al, ” IEEE T rans. Circuits Syst. V ideo T echnol. , vol. 32, no. 8, pp. 5680–5694, 2022. [29] Jie Lei, Licheng Y u, T amara L Berg, and et al., “Tvr: A large-scale dataset for video-subtitle moment retrie val, ” in ECCV , 2020, pp. 447– 463. [30] Sheng Fang, Tiantian Dang, Shuhui W ang, and et al., “Linguistic hallucination for text-based video retriev al, ” IEEE T rans. Cir cuits Syst. V ideo T echnol. , vol. 34, no. 10, pp. 9692–9705, 2024. [31] Ranjay Krishna, Kenji Hata, Frederic Ren, and et al., “Dense-captioning ev ents in videos, ” in ICCV , 2017, pp. 706–715.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment