DAK-UCB: Diversity-Aware Prompt Routing for LLMs and Generative Models
The expansion of generative AI and LLM services underscores the growing need for adaptive mechanisms to select an appropriate available model to respond to a user's prompts. Recent works have proposed offline and online learning formulations to ident…
Authors: Donya Jafari, Farzan Farnia
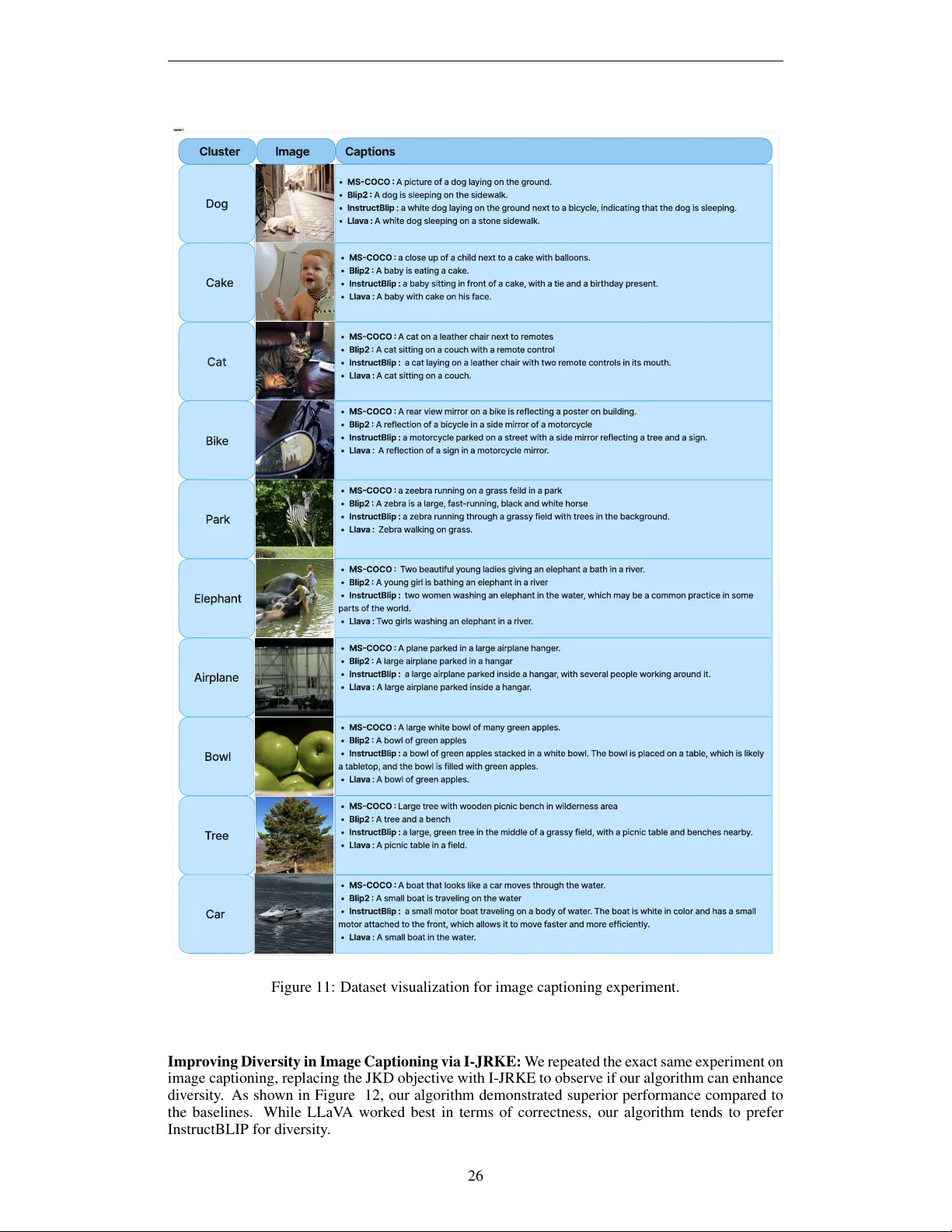
Published as a conference paper at ICLR 2026 DA K - U C B : D I V E R S I T Y - A W A R E P R O M P T R O U T I N G F O R L L M S A N D G E N E R A T I V E M O D E L S Donya Jafari Sharif Univ ersity of T echnology donya.jafari111@sharif.edu Farzan F ar nia The Chinese Univ ersity of Hong K ong farnia@cse.cuhk.edu.hk A B S T R A C T The expansion of generativ e AI and LLM services underscores the growing need for adapti ve mechanisms to select an appropriate a vailable model to respond to a user’ s prompts. Recent works hav e proposed offline and online learning formula- tions to identify the optimal generati ve AI model for an input prompt, based solely on maximizing prompt-based fidelity ev aluation scores, e.g., CLIP-Score in text- to-image generation. Howe v er , such fidelity-based selection methods ov erlook the di versity of generated outputs, and hence, they can fail to address potential div ersity shortcomings in the generated responses. In this paper, we introduce the Diversity-A war e K ernelized Upper Confidence Bound (DAK-UCB) method as a contextual bandit algorithm for the online selection of generativ e models with div ersity considerations. The proposed DAK-UCB method incorporates both fi- delity and di versity-related metrics into the selection process. W e design this framew ork based on prompt-aware div ersity score functions that decompose to a two-sample-based expectation over prompt-output pairs in the pre vious genera- tion rounds. Specifically , we illustrate the application of our framew ork using joint kernel distance and kernel entropy measures. Our experimental results demon- strate the effecti veness of D AK-UCB in promoting diversity-a ware model selec- tion while maintaining fidelity in the generations for a sequence of prompts. The code is av ailable at https://github.com/Donya- Jafari/DAK- UCB . 1 I N T RO D U C T I O N The past few years have witnessed a rapid surge in generative AI services capable of addressing a wide array of tasks, ranging from large language models (LLMs) answering arbitrary questions to text-to-image and video models generating visual content guided by user prompts. Giv en the growing number of av ailable generati v e models, a ke y challenge is ho w to ef fecti vely select suitable generativ e models for a sequence of user-provided prompts. A con ventional approach is to com- pute an overall e valuation score for each candidate generativ e AI model and subsequently select the model with the highest aggregate score to address all future prompts. Ho wev er , this approach implicitly assumes that a single model consistently outperforms the other models across all possible prompts. This assumption has been demonstrated to be untrue in realistic scenarios where different models may excel on dif ferent topics or prompt categories (Hu et al., 2025a; Frick et al., 2025). T o address this limitation, recent literature has introduced prompt-aware model selection mecha- nisms. These methods include offline learning algorithms (Qin et al., 2024; Chen et al., 2024; Frick et al., 2025), which train a selector model using a batch of pre-collected responses of models to prompts as training data. Also, Hu et al. (2025a) propose the online learning P AK-UCB method, formulating the selection task as a contextual multi-armed bandit problem to utilize the user’ s ob- served model performances in the pre vious rounds. Despite the dev elopment of several model selection approaches, the existing methods focus only on the fidelity scores in data generation, while ov erlooking the diversity of generated samples. For example, in text-to-image generation tasks, e xisting framew orks ev aluate models based on the align- ment of the input prompt and generated image, without considering diversity in the image outputs. Such a diversity-una ware selection can lead to output samples that, although individually aligned well with prompts, collecti vely lack div ersity . In addition, overlooking the div ersity of output data 1 Published as a conference paper at ICLR 2026 Online Selection Strate gy 21.8% 78.2 % 51.2 % 48.8 % A n i n d i v i d u a l j o g g i n g i n t h e p a r k . A n i n d i v i d u a l d a n c i n g i n t h e r a i n . A n i n d i v i d u a l r i d i n g a b i c y c l e . A n i n d i v i d u a l p a i n t i n g a p o r t r a i t . A n i n d i v i d u a l j o g g i n g i n t h e p a r k . A n i n d i v i d u a l d a n c i n g i n t h e r a i n . A n i n d i v i d u a l r i d i n g a b i c y c l e . A n i n d i v i d u a l p a i n t i n g a p o r t r a i t . T ext to Image Generative Model 2 Unconditioned generation (Higher Div ersity) T ext to Image Generative Model 1 Conditioned on “Y oung Male” (Lower Diversity) Candida t e Gener a tiv e Models Diversity -A ware K ernelized UCB (Ours) Generative Model 1 Generative Model 2 (Diversity -Unaware) K ernelized UCB Generative Model 2 Generative Model 1 selection ratio selection ratio Figure 1: Comparison of baseline Kernelized-UCB model selection (CLIP-Score fidelity metric) (Hu et al., 2025a) vs. our proposed div ersity-aware D AK-UCB over T = 500 rounds. While the baseline K ernelized-UCB does not fav or model G 2 with higher di versity over model G 1 , D AK-UCB selected the more div erse G 2 more frequently . can potentially lead to a restricted representation of sensiti ve attributes, such as gender or ethnicity , in generated datasets. Figure 1 displays an example, where the diversity-una ware baseline kernel- ized UCB selection algorithm in (Hu et al., 2025a) chooses the less and more diverse generativ e models (conditioned to ”young male” and none) with similar frequencies, ignoring the div ersity factor in the selection process. This limitation arises because P AK-UCB, and standard contextual bandit methods more broadly , compute rew ards using the mean of sample-lev el scores. Di versity , howe ver , is a gr oup-level property determined by the relati ve positioning of multiple samples, which cannot be expressed through a simple a verage of indi vidual rewards. These limitations highlight the importance of diversity-a ware selection methods, which explicitly incorporate considerations of output div ersity into the model selection process. In this work, we specifically focus on the online selection task, proposing an algorithm designed to lev erage previ- ously generated data to select generative models that achieve an optimal balance between fidelity and di versity . Our proposed method, which we call Diversity-A war e K ernelized Upper Confidence Bound (D AK-UCB) , extends the kernelized UCB framew ork (V alko et al., 2013; Hu et al., 2025a) by integrating a div ersity-oriented term, in the form of the expectation of a two-sample (prompt,output) random variable, into the conte xtual bandit objective. A key challenge in designing DAK-UCB is to determine which diversity scores are compatible with the contextual bandit selection framew ork. Specifically , we identify a family of joint kernel scores—including prompt-conditional extensions of kernel distance (Bi ´ nko wski et al., 2018), RKE (Jalali et al., 2023), and MMD (Gretton et al., 2012)—that can be e xpressed as expectations of tw o- sample quadratic forms ov er prompts and outputs. This structure is central to D AK-UCB: it enables fast-con verging estimation from streaming data via kernel ridge regression, yielding principled con- 2 Published as a conference paper at ICLR 2026 fidence bounds in the UCB process. Moreover , by combining joint kernel scores with task-specific fidelity metrics (e.g., CLIPScore in text-to-image generation), D AK-UCB can be extended to pro- vide a unified approach to prompt-adaptiv e selection that balances the fidelity and diversity f actors. Figure 1 shows an application of D AK-UCB for a div ersity-ware generative model selection in response to T = 500 prompts of MS-COCO dataset (Lin et al., 2014) on generating human-related scenes. The candidate model G 1 represents the Stable Diffusion XL (SD-XL) (Stability-AI, 2023) model conditioned to ”young male individual”, whereas candidate model G 2 outputs the SD-XL outputs without any conditioning. While the baseline kernelized UCB fidelity-based selection did not fa vor the more diverse model G 2 , generating samples from both models with equal probabilities, the D AK-UCB model selection with the joint RKE di versity score chose model G 1 more often ov er the 500 online selection iterations. Beyond deterministic prompt-to-model assignment at e very iteration of D AK-UCB, D AK-UCB can be adapted to assign the model to an input prompt based on a non-degenerate mixture of the models. As noted by Rezaei et al. (2025) in the unconditional setting, the optimal di versity-aw are selection strategy can itself be a non-de generate mixture of models. Extending this insight to the conditional, prompt-aware setting, a mixture-based selector effecti vely rolls a biased m -sided die to determine which of the m models is queried for a giv en prompt. W e introduce the Mixtur e-DAK-UCB method to realize this idea: an online algorithm that optimizes prompt-dependent mixture probabilities. Mixture-D AK-UCB generalizes the prompt-free Mixture-UCB framework of Rezaei et al. (2025) to the conditional case, enabling diversity-enhancing mixtures tailored to incoming prompts and yielding further improv ements in div ersity metrics. W e empirically ev aluate different v ariants of the proposed D AK-UCB and Mixture-D AK-UCB al- gorithms on text-to-image and language model generation tasks. Our results demonstrate improv e- ments in diversity and overall correctness metrics relati ve to existing conte xtual bandit algorithms, such as Kernelized UCB, P AK-UCB, and randomized selection strategies. W e also validated the defined Joint-RKE and Joint-KD measures for capturing di versity and distributional matching char- acteristics of prompt-guided generati ve models. Here we summarize the w ork’ s main contributions: • Studying the role of diversity in prompt-a ware selection of generati ve AI models, • Introducing the Di versity-A ware Kernelized UCB (DAK-UCB) algorithm, a contextual bandit approach explicitly accounting for the di versity factor in model selection, • Extending deterministic DAK-UCB selection to prompt-conditioned mixture selection, • Demonstrating numerical effecti veness of D AK-UCB on sev eral text-to-image generation tasks. 2 R E L A T E D W O R K S Contextual Bandits. Conte xtual bandits (CB) extend the multi-armed bandit (MAB) framework by incorporating the context variable to guide the arm selection process (Langford & Zhang, 2007; Foster et al., 2018). A widely-studied CB is the linear CB, which assumes that the expected reward of each arm is a linear function of context (Li et al., 2010; Chu et al., 2011). Kernelized CBs gener - alize to non-linear reward models by using kernel methods to capture more complex dependencies between contexts and rew ards (V alko et al., 2013). Due to the computational cost of kernel methods, recent works hav e explored approximations using relev ant assumptions on the kernel (Calandriello et al., 2019; 2020; Zenati et al., 2022). T o address exploration in linear CBs more ef fectively , (Abbasi-Y adkori et al., 2011) propose tighter confidence sets using martingale inequalities, leading to stronger theoretical guarantees and im- prov ed empirical performance. Moving beyond linearity , Hu et al. (2025b) introduce PromptW ise, a multi-iteration-per -round cost-aw are conte xtual bandit for prompt routing in LLMs and generati ve models. Also, Kv eton et al. (2020) propose two randomized e xploration algorithms for generalized linear bandits,which leverage Laplace approximations and perturbations of past data to efficiently explore under non-linear models. Howe ver , the above CB methodologies do not target div ersity awareness in the online learning setting. Diversity/No velty Evaluation Scores and Guidance in Generative Models. Sev eral methods have been proposed for e valuating and improving the di versity of generativ e and dif fusion models. On the div ersity ev aluation, the metrics Recall (Sajjadi et al., 2018; Kynk ¨ a ¨ anniemi et al., 2019), Cov erage 3 Published as a conference paper at ICLR 2026 (Naeem et al., 2020), V endi (Dan Friedman & Dieng, 2023; Ospanov et al., 2024; Ospano v & Farnia, 2025), and RKE (Jalali et al., 2023) have been proposed for unconditional (prompt-free) sample generation, and Conditional V endi/RKE (Jalali et al., 2026; 2025a) and Scendi (Ospanov et al., 2025) have been suggested for prompt-aware diversity measurement. W e note that (Zhang et al., 2024; 2025) propose entropy-based measures for novelty of generativ e models and their comparison, and (Jalali et al., 2025b; Gong et al., 2025) study kernel-based comparison of embeddings. For guiding sample generation, (Miao et al., 2024) employed reinforcement learning with a div er- sity reward function in the generation process. (Sehwag et al., 2022) proposed sampling from low- density regions of the data manifold to encourage div erse outputs. (Corso et al., 2024) introduced a particle-based potential function that explicitly maximizes pairwise dissimilarity . Sadat et al. (2024) explored the addition of Gaussian noise to conditioning inputs during inference to promote v ariabil- ity . Lu et al. (2024) dev eloped ProCreate, a distance-based guidance technique. Askari Hemmat et al. (2024); Jalali et al. (2025a) proposed V endi/Conditional-RKE Score Guidance, which incor- porates div ersity score guidance in diffusion models. Similarly , Sani et al. (2026) propose MMD guidance to align the diffusion model to a tar get distribution by minimizing the MMD distance. W e highlight that these works aim to improve the diversity and alignment over the sample generation process, unlike our work on the di versity-aware online selection of pre-trained models. Multi-Armed Bandit f or di versity-based selection. In a related work, Rezaei et al. (2025) propose Mixture-UCB, a bandit algorithm for selecting mixtures of generative models to maximize di versity , while their proposed approach is not prompt-aware and therefore not applicable to prompt-guided sample generation. (Chen et al., 2025), (Y ang et al., 2024), and (Hou et al., 2024) improv e the best arm identification by multi-objecti ve optimization, re gret minimization, and sample ef ficiency . Sani et al. (2012) introduce a framework for risk-av erse decision-making in bandit problems by inte- grating variance-sensiti ve utility functions into exploration strate gies. W einberger & Y emini (2023) study bandits with self-information-based re wards, proposing algorithms that le verage information- theoretic concepts to balance exploration and exploitation. Zhu & T an (2020) dev elop Thompson Sampling algorithms for mean-variance bandits, optimizing both expected returns and rew ard vari- ability . W e note that our work focuses on di versity in a contextual bandit setting, where the prompt plays the role of the context, which is not the case in the conte xt-free MAB setting of these works. 3 P R E L I M I N A R I E S 3 . 1 N O T A T I O N S A N D D E FI N I T I O N S Throughout the paper , we define a conditional generativ e model G as a conditional distribution P G ( x | t ) where x ∈ X is the generated data v ariable conditioned to the randomly-observed prompt t ∈ T . F ollowing this definition, every sample generation of model G is conditioned on a user’ s provided prompt T = t and then drawing a sample from the conditioned distrib ution P G ( x | T = t ) . 3 . 2 K E R N E L - B A S E D S C O R E S F O R G E N E R A T I V E M O D E L S In a sample space X , we call k : X × X → R a kernel function if there exists a feature map ϕ : X → H k such that for every x, x ′ ∈ X we have k ( x, x ′ ) = ⟨ ϕ ( x ) , ϕ ( x ′ ) ⟩ where ⟨· , ·⟩ denotes the inner product in the Hilbert space H k of kernel function k . Examples of kernel functions include the degree- r polynomial kernel k poly ( r ) ( x, y ) = (1 + γ ⟨ x, y ⟩ ) r with parameter γ > 0 and the RBF (Gaussian) kernel with parameter σ defined as: k gaussian ( σ ) ( x, y ) = exp − ∥ x − y ∥ 2 2 σ 2 Giv en a kernel function k , we can define the n × n kernel matrix K = [ k ( x i , x j )] 1 ≤ i,j ≤ n for n samples x 1 , . . . , x n ∈ X . Note that e very v alid kernel function will result in a positi ve semi-definite (PSD) kernel matrix for every set of samples. In our analysis, we use the following kernel-based scores and their variants in the online selection process: • Maximum Mean Discrepancy (MMD) and Kernel Distance (KD) : For two probability dis- tributions P , Q on sample space X , (Bi ´ nko wski et al., 2018) consider the kernel distance (KD) between P and Q as the square of the maximum mean discrepancy (MMD) Gretton et al. (2012), i.e., KD( P , Q ) := E x,x ′ iid ∼ P [ k ( x, x ′ )] + E y ,y ′ iid ∼ Q [ k ( y , y ′ )] − 2 · E x,y ind ∼ P × Q [ k ( x, y )] (1) 4 Published as a conference paper at ICLR 2026 In the abov e definition, the samples x, x ′ ∼ P X , y , y ′ ∼ Q X are drawn independently according to the specified distributions. • R ´ enyi Ker nel Entropy (RKE) : For probability model P on space X , the R ´ enyi kernel entropy (RKE) (Jalali et al., 2023) is defined as the order-2 R ´ enyi entropy of the normalized population kernel matrix, which reduces to RKE( P X ) = 1 E x,x ′ iid ∼ P [ k ( x, x ′ ) 2 ] (2) Considering the empirical samples x 1 , . . . , x n ∼ P , the empirical RKE score reduces to RKE( x 1 , . . . , x n ) = ∥ 1 n K ∥ − 2 F . 4 D I V E R S I T Y - A W A R E K E R N E L I Z E D U P P E R - C O N FI D E N C E B O U N D T o dev elop a diversity-a ware online selection of conditional generativ e models, we first propose two-sample-based extensions of the KD and RKE scores to the conditional sample generation case. Subsequently , we e xtend the standard Kernelized-UCB online learning framework by including an upper confidence bound of the joint proposed score functions. 4 . 1 E X T E N S I O N O F K D A N D R K E S C O R E S T O C O N D I T I O NA L G E N E R A T I V E M O D E L S W e propose the following extensions of the KD in equation 1 and RKE in equation 2 to the con- ditional sample generation task. Both the extensions in the following apply the original scores to the joint (prompt t ,data x ) variable, by using the pr oduct kernel function k joint [ t, x ] , [ t ′ , x ′ ]) = k text t, t ′ ) · k data x, x ′ ) . As demonstrated by Bamberger et al. (2022); W u et al. (2025), the product kernel function corresponds to the Hilbert space of the tensor product of the (embedded) prompt and data vectors, ef fectively capturing the clusters in the dataset of the joint prompt,data v ectors. Joint K ernel Distance (JKD) distribution matching score. W e propose the following extension of the marginal (prompt-unaware) kernel distance in equation 1 to the prompt-aware kernel distance, which we call Joint K ernel Distance (JKD) , for two conditional distrib utions P X | T and Q X | T : JKD P X | T , Q X | T := KD P T · P X | T , P T · Q X | T (3) = E t,t ′ ∼ P T ,x,x ′ ,y ,y ′ ind ∼ P X | T = t · P X | T = t ′ · Q X | T = t · Q X | T = t ′ h k T ( t, t ′ ) × k X ( x, x ′ ) + k X ( y , y ′ ) − k X ( x, y ′ ) − k X ( x ′ , y ) i where k T : T × T → R and k X : X × X → R denote the kernel functions for the input prompt t and output x , and P T is a reference distribution on the input v ariable T (i.e., prompt) ov er space T . Importantly , the empirical estimation of the e xpectation in equation 3 can be performed by accessing only one sample generated by P X | T for each input prompt t . Joint RKE (JRKE) diversity score. Similarly , we propose the following definition for the joint (prompt-data) RKE score, which we call Joint-RKE (JRKE) score. JRKE is defined to be the RKE score of the joint sample ( T , X ) ∼ P T · P X | T giv en a reference prompt distribution P T : JRKE P X | T := RKE P T · P X | T (4) =1 . E t,t ′ iid ∼ P T ,x,x ′ ind ∼ P X | T = t · P X | T = t ′ k T ( t, t ′ ) 2 k X ( x, x ′ ) 2 This score varies monotonically with its in verse, i.e, In verse-JRKE score denoted by I - JRKE : I - JRKE( P X | T ) := E t,t ′ iid ∼ P T ,x,x ′ ind. ∼ P X | T = t × P X | T = t ′ k T ( t, t ′ ) 2 k X ( x, x ′ ) 2 (5) Similar to the JKD score, the expectation in the div ersity-based Inv erse-JRKE score can be estimated using a single output X ∼ P X | T = t for ev ery prompt T = t . 4 . 2 D I V E R S I T Y - A W A R E O N L I N E L E A R N I N G V I A D A K - U C B T o propose a div ersity-aware online selection framework, we lev erage our proposed conditional div ersity scores in Equations 3 and 5, within the conte xtual bandit frame work. The prompt t serves 5 Published as a conference paper at ICLR 2026 as the context, and we seek a policy Π : T → [ G ] that balances fidelity and div ersity objectiv es. A key feature of the introduced di versity scores is that they both decompose into expectations of prompt-lev el functions, enabling online estimation with a single sample per prompt. The follo wing proposition highlights this property of the JKD and In verse-JRKE scores. Proposition 1. F or conditional distrib utions P X | T , Q X | T and r eference distrib ution P T : (a) The Inver se-JRKE admits the decomposition: I - JRKE( P X | T ) = E t ∼ P T ,x ∼ P X | T = t [ ϕ I-JRKE ( t, x )] , (6) wher e ϕ I-JRKE ( t, x ) = E t ′ ∼ P T ,x ′ ∼ P X | T = t ′ [ k T ( t, t ′ ) 2 k X ( x, x ′ ) 2 ] . (b) The JKD for comparing model g against r efer ence Q admits: JKD( P g , Q ) = E t ∼ P T ,x ∼ P g ( ·| t ) [ ϕ ( g ) JKD ( t, x )] , (7) wher e ϕ ( g ) JKD ( t, x ) = E t ′ ∼ P T [ k T ( t, t ′ )( E x ′ ∼ P g ( ·| t ′ ) [ k X ( x, x ′ )] − E y ′ ∼ Q ( ·| t ′ ) [ k X ( x, y ′ )])] . Proposition 1 highlights a crucial structural property of the proposed div ersity scores: both I-JRKE and JKD admit a two-sample expectation form , in which the overall metric decomposes into the expectation of a prompt-lev el function of a single generated sample. This is important in the online setting, because it ensures that each round of interac tion with a model provides an unbiased stochas- tic label for the corresponding di versity function, ev en though the original metric is defined in terms of expectations over pairs of prompts and outputs. Therefore, the two-sample form makes these scores applicable to the kernelized UCB algorithm, as we can run kernel ridge re gression (KRR) on the stochastic labels and obtain confidence bounds that are comparable to those for the fidelity score. Based on this decomposition, we define for each model g and prompt t prompt-lev el target functions: s g ( t ) := E x ∼ P g ( ·| t ) ϕ fidelity ( t, x ) , D g ( t ) := E x ∼ P g ( ·| t ) ϕ g ( t, x ; H t ) . (8) Here ϕ fidelity ( t, x ) denotes a fidelity score of a prompt–output pair , instantiated in our experiments as the CLIP-Score between text prompt t and generated image x . The function ϕ g ( t, x ; H t ) is a per-sample diversity score, whose expectation reco vers the desired di versity metric in Proposition 1. The history H t is only used to instantiate reference expectations o ver past outputs. At each round t , D AK-UCB treats the prompt p t as context in the per-arm kernelized contextual bandit process (Hu et al., 2025a), and compares arms via a per-arm UCB on the combined objectiv e J g ( t ) = s g ( t ) + λD g ( t ) , where s g ( t ) (e.g. CLIP-Score in our experiments) is the fidelity score and D g ( t ) is defined with ϕ g instantiated as either the (negati ve) I-JRKE score or the (negati ve) JKD score as in Proposition 1. After observing a single sample x i ∼ P g i ( · | t i ) , we form unbiased labels y ( s ) i = ϕ fid ( t i , x i ) and y ( D ) i = ψ g i ( t i , x i ; H i ) , update per-arm KRR models for s g and D g , and select the next arm using an optimistic estimate b J UCB g ( t i ) = b s g ( t i ) + β ( s ) b σ ( s ) g ( t i ) + λ b D g ( t i ) − β ( D ) b σ ( D ) g ( t i ) , i.e., an upper bound for s g and a lower bound for D g (since D g is a signed diversity re war d , equal to the negati ve of the underlying penalty). Confidence radii β ( s ) , β ( D ) follow the standard KRR-UCB form as detailed in Algorithm 1. In Appendix B, we establish a regret bound for a phased variant of our algorithm, Sup-DAK-UCB. This result shows that the known regret guarantees of kernelized UCB methods (Chu et al., 2011; V alk o et al., 2013; Hu et al., 2025a) can be systematically extended to our diversity-a ware objec- tiv e. A ke y technical component of this analysis is that the JRKE and JKD metrics admit the two- sample expectation structure, thereby enabling integration with kernelized-UCB confidence bounds. This structural property is specific to JRKE and JKD and allows us to obtain re gret guarantees for div ersity-aware model selection. The follo wing provides an informal statement of the resulting re- gret bound, and the proof is deferred to Appendix B. Theorem 1 (Informal regret bound for DA K - U C B ) . Under Assumptions 1-3 in Appendix B (nor- malized k ernels, sub-Gaussian noise, and RKHS re gularity for s g and D g ), the phased variant S U P - DA K - U C B algorithm satisfies the following re gr et bound where the information-gain Γ ( s ) T and effective-dimension Γ ( D ) T terms ar e defined in Appendix B: Regret( T ) = e O q G T Γ ( s ) T + λ q G T Γ ( D ) T 6 Published as a conference paper at ICLR 2026 Algorithm 1: Div ersity-A ware Kernelized UCB (DA K - U C B ) Input: G generativ e models, horizon T , prompt distribution P , trade-off λ , di versity score ψ ∈ {− I-JRKE , − JKD } Output: T generated outputs 1 Initialize per-arm KRR estimators for fidelity s g and div ersity D g 2 Sample prompt t i ∼ P 3 for g = 1 to G do 4 Predict fidelity and div ersity with KRR: ( b s g ( t i ) , b σ ( s ) g ( t i )) , ( b D g ( t i ) , b σ ( D ) g ( t i )) ; 5 Form UCB score: b J UCB g ( t i ) ← ( b s g ( t i ) + β ( s ) b σ ( s ) g ( t i )) + λ ( b D g ( t i ) + β ( D ) b σ ( D ) g ( t i )) 6 Select model g i ← arg max g b J UCB g ( t i ) 7 Generate output x i ∼ P g i ( · | t i ) 8 Form labels y ( s ) i = ϕ fid ( t i , x i ) , y ( D ) i = ψ g i ( t i , x i ; H i ) 9 Update KRR models of g i with ( t i , y ( s ) i ) and ( t i , y ( D ) i ) 10 Update history H i +1 ← H i ∪ { ( t i , x i , g i ) } 4 . 3 P R O M P T - A W A R E M I X T U R E S E L E C T I O N V I A Q UA D R AT I C O P T I M I Z A T I O N While D AK-UCB selects a single model per prompt, maximizing diversity can require prompt- dependent mixtures of the a vailable models, where we denote the model mixture probability values of prompt t with notation α ( t ) ∈ ∆ G . Therefore, for G conditional generation mod- els in { P g ( ·| t ) } G g =1 , we consider a prompt-aware mixture α ( t ) ∈ ∆ G , yielding P α ( ·| t ) = P G g =1 α g ( t ) P g ( ·| t ) . W e focus here on the I-JRKE div ersity penalty; the analogous construction for JKD is deferred to Proposition 2 in Appendix A. Using the product kernel, the I-JRKE admits the quadratic form I - JRKE( P α ) = E t ∼ P T α ( t ) ⊤ M ( t ) α ( t ) , where M ( t ) ∈ [0 , 1] G × G collects cross-kernel expectations across models. T o ensure stability across prompts, we restrict mixtures to a kernel-Lipschitz competitor set A ϵ = n α : T → ∆ G : ∀ t, t ′ , k T ( t, t ′ ) · α ( t ) − α ( t ′ ) 1 ≤ ϵ o , which guarantees that nearby prompts yield similar mixtures and incurs only an O ( ϵ ) approximation error . In the Appendix A, we discuss that, under the above mixture feasible set, an approximate solution follows solving the following problem where at each prompt t , the decision rule reduces to the concav e quadratic maximization α ∗ t = argmax α ∈ ∆ G α , b s UCB ( t ) − λ α ⊤ c M UCB ( t ) α where b s UCB ( t ) are fidelity UCB estimates and c M UCB ( t ) is the projection of the kernelized-UCB estimation of M ( t ) onto the PSD matrices by zeroing its ne gative eigen values. W e call the resulting mixture-model selection method Mixtur e-DAK-UCB , as detailed in Algorithm 2 at Appendix A. 5 N U M E R I C A L R E S U LT S W e numerically ev aluated the proposed DAK-UCB and its mixture variant, Mixture-DAK-UCB, in several experiments. In our numerical experiments on text and image data, we used the CLIP encoder (Radford et al., 2021) as the backbone te xt embedding and DINOv2 (Oquab et al., 2023) as the image embedding as suggested by Stein et al. (2023). W e considered the follo wing online model selection baselines in our ev aluation of D AK-UCB and Mixture-D AK-UCB: • One Arm Oracle: The one-arm oracle baseline has knowledge of the ev aluation scores of each individual generative model (aggreg ated o ver the v alidation prompt set). This baseline univ ersally selects the individual model with the best aggre gate score to handle all the prompts. • Random Selection: This baseline randomly selects an arm for an input prompt, where each arm is selected uniformly with equal probability , and the selection across prompts are run independently . 7 Published as a conference paper at ICLR 2026 500 1000 1500 Number of Iteration 100 120 140 160 180 Joint-RKE Scor e D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB 500 1000 1500 Number of Iteration 3.5 4.0 4.5 5.0 5.5 6.0 6.5 K D S c o r e ( × 1 0 3 ) D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB 500 1000 1500 Number of Iteration 31.0 31.2 31.4 31.6 31.8 32.0 32.2 CLIP Scor e D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB Figure 2: Performance comparison on JKD score and Joint-RKE for MS-COCO prompt clusters using Kandinsky , SDXL, and GigaGAN. Figure 3: V isualization of simulated generati ve models with less-diverse Models 1,2 and more- div erse Model 3. D AK-UCB and P AK-UCB selection ratios,scores over 500 rounds are reported. • P AK-UCB: This baseline is a diversity-una ware conte xtual bandit algorithm (embedded prompt is the context variable), selecting the model only based on the CLIP-score fidelity score in te xt-to- image generation. D AK-UCB applied to diversity-awar e text-to-image model selection on MS-COCO prompts. W e considered the prompts in the MS-COCO (Lin et al., 2014) validation subset. W e uniformly sampled a thousand prompts containing the words: cat, dog, car, cake, bowl, bike, tree, airplane, park, and elephant. Three generati ve models were used as candidate text-to-image generation mod- els in the experiment: Kandinsky (Arkhipkin et al., 2024), SDXL (Stability-AI, 2023), and Giga- GAN (Kang et al., 2023). The experiment ran for 2000 iterations, where at each iteration a random prompt from a random cluster was chosen, and our objective selected the best arm that balanced both div ersity and fidelity . The results are av eraged over 10 trials to reduce noise from random prompt selection. Figure 2 shows that Mxiture-DAK-UCB could achieve the highest div ersity Joint-RKE score. W e also used MS-COCO test samples as the reference dataset and report the KD scores with Mixture-D AK-UCB obtaining the best score. Note that the KD metric ev aluates both di versity and quality factors. Experiment on simulated text-to-image models with varying diversity in ”animal” image gen- eration. In this experiment, we simulated three animal image generation arms, where the first two arms (less-div erse) are outputting the SD-XL generated data conditioned on ”cat” and ”dog” sam- ples, respectively . On the other hand, the third model (more-div erse) generates the picture of an animal uniformly selected from a list of 10 animals. T o run the experiment, we used GPT -4o to 8 Published as a conference paper at ICLR 2026 Figure 4: Expert Selection Ratio and Performance Comparison between D AK-UCB and baselines using the JKD score for div ersity term in DAK-UCB. generate 200 independent prompts about ”an animal” in dif ferent scenes, with sample prompts pro- vided in Figure 3. Figure 3 shows the conditional-V endi and Joint-RKE scores for each of the three simulated arms, which indicate that the ”cat” and ”dog” simulated arms were less div erse than the third simulated arm. W e ran the D AK-UCB algorithm for 500 iterations, where at each step a ran- dom prompt was chosen and the output from the algorithm’ s selected arm was observed. The results demonstrate that the D AK-UCB tended to generate images from the more di verse third arm, while the CLIP-Score-based P AK-UCB baseline generated samples from the less-div erse second model more frequently . Identification of prompt-r elevant diversity via DAK-UCB . In the experiment, we tested D AK- UCB in outputting samples with prompt-rele vant diversity . W e used these four prompt groups of the experiment of Figure 2 from MS-COCO v alidation set: ”Cat”, ”Dog”, ”Car”, and ”Cake”. W e designed four arms, each acting as an expert on one of these clusters, where the expert arm on each subject generates aligned samples with the prompt of the same type, while it generates images of a randomly-selected incorrect type for the remaining three subjects F or example, ARM1(Cat expert) generates an image using SDXL when giv en a prompt from the Cat cluster; otherwise, it samples a random irrelev ant prompt from other types and generates an image for that prompt using SDXL. In in Figure 4, we report the expert arm selection ratio for each prompt cate gory and the av erage CLIP- Scores over iterations for each baseline. As suggested by the results in Figure 4, both the JKD-based and Clip-Score+I-JRKE-based DAK-UCB (Appendix, Figure 15) methods could av oid generating prompt-irrelev ant output and did not attempt to increase div ersity by generating unrelated content. Diversity Collapse Across LLMs and the Benefit of Mixtures: T o illustrate the importance of mixture-based selection in realistic language-generation settings, we ev aluated three widely used open-source LLMs on a simple iterative generation task: Llama3.2 (AI, 2024), Qwen2 (T eam, 2024), and Gemma3 (DeepMind, 2024). At each round, the model produced a short sentence about a vi- brant city in North America. Each arm exhibited a persistent and distinct geographic bias: Llama repeatedly focused on New Orleans, Gemma overwhelmingly generated Chicago, and Qwen2 con- sistently fav ored New Y ork City . These model-specific collapse modes are visualized in Figure 5. Despite their strong capabilities, all three models suffered from div ersity collapse, but crucially , their collapse modes were complementary rather than identical. This directly motiv ates mixture- based selection: although each arm exhibits low di versity on its o wn, their differing failure modes allow a mixture to achieve significantly higher output diversity . Using the Cond-V endi metric, we show that the mixture selected by Mixture-D AK-UCB attains substantially higher diversity than any single model. W e repeat this experiment for two additional prompts—a vibrant city in Europe” and a renowned celebrity”—and the visualizations in Figure 5 consistently demonstrate the di versity gains unique to model mixtures. 9 Published as a conference paper at ICLR 2026 Additional Numerical Results . In Appendix C, we also report the numerical results of applying D AK-UCB for div ersity-aware model selection in the tasks of prompt-aware selection of simulated LLMs with dif ferent div ersity scores and the image-to-model assignments of image captioning mod- els. W e also present the results of the ablation study for testing the effect of the choice of image embedding and the coefficient of D AK-UCB objecti ve’ s di versity term. Figure 5: V endi diversity comparison across Llama3.2, Qwen2, Gemma3, and their mixture for prompts: “Generate a short sentence about a vibrant city in Northern America. ” ,“Generate a short sentence about a vibrant city in Europe. ” and “Generate a short sentence about a renowned celebrity . ” 6 C O N C L U S I O N In this work, we proposed an online learning frame work for a div ersity-aware prompt-based se- lection of multiple generativ e models. Our proposed D AK-UCB can be applied using the defined I-JRKE diversity and JKD correctness scores for improving the div ersity factor in sample genera- tion. Notably , the proposed scores reduce to the tw o-sample expectation over the observed samples, which can be estimated using only one generated sample for an input prompt. In addition, we intro- duced the Mixture-DAK-UCB extension, which enables optimized prompt-dependent mixtures of generativ e models and further improves di versity-a ware selection. Beyond text-to-image generation, we also demonstrated applications of D AK-UCB to multi-LLM prompt assignment and image captioning models in Appendix C, illustrating its applicability in broader generativ e settings. Extending the framework to additional modalities, such as protein, molecular , and graph generati ve models, is a rele vant future direction. The e xtension of the proposed scores for ev aluating and guiding prompt-a ware div ersity and correctness in data generation will be relev ant for future e xploration. Also, studying the application of the scores in general bandit settings beyond generati ve model selection problems is another related future direction. 10 Published as a conference paper at ICLR 2026 A C K N O W L E D G M E N T S The w ork of Farzan Farnia is partially supported by a grant from the Research Grants Council of the Hong Kong Special Administrativ e Region, China, Project 14210725, and is partially supported by CUHK Direct Research Grants with CUHK Project No. 4055164 and 4937054. The work is also supported by a grant under 1+1+1 CUHK-CUHK(SZ)-GDSTC Joint Collaboration Fund. Finally , the authors thank the anonymous revie wers and metarevie wer for their constructive feedback and suggestions. R E P RO D U C I B I L I T Y S TA T E M E N T W e have taken sev eral steps for the reproducibility of our work. The proposed D AK-UCB and Mixture-D AK-UCB algorithms are fully specified in Section 4 and Appendix A, with pseudocode provided in Algorithms 1–3. Theoretical results are stated with assumptions and proofs in Appendix B. The datasets used in our e xperiments include standard publicly a vailable benchmarks including MS-COCO as well as synthetically generated prompt sets by the specified GPT -4o model. The de- tails of data selection, prompt construction, model candidates, and e valuation metrics are described in Section 5 and Appendix C. W e provide ablation studies in Appendix C.4 to clarify the sensiti vity of our results to hyperparameters and embedding choices. An anonymous implementation of our method will be released as supplementary material. R E F E R E N C E S Y asin Abbasi-Y adkori, D ´ avid P ´ al, and Csaba Szepesv ´ ari. Improved algorithms for linear stochastic bandits. In Advances in Neural Information Pr ocessing Systems , volume 24, pp. 2312–2320, 2011. Meta AI. Llama 3.2 series (1b, 3b, 8b, 70b). https://huggingface.co/meta- llama , 2024. Vladimir Arkhipkin, V iacheslav V asilev , Andrei Filatov , Igor Pavlo v , Julia Agafonov a, Nikolai Gerasimenko, Anna A verchenk ov a, Evelina Mironova, Anton Bukashkin, Konstantin Kulik ov , et al. Kandinsky 3: T ext-to-image synthesis for multifunctional generativ e framework. In Pro- ceedings of the 2024 Confer ence on Empirical Methods in Natural Language Pr ocessing: System Demonstrations , pp. 475–485, 2024. Reyhane Askari Hemmat, Melissa Hall, Alicia Sun, Candace Ross, Michal Drozdzal, and Adriana Romero-Soriano. Improving geo-di versity of generated images with contextualized vendi score guidance. In Eur opean Confer ence on Computer V ision , pp. 213–229. Springer , 2024. Stefan Bamberger , Felix Krahmer , and Rachel W ard. Johnson–lindenstrauss embeddings with kro- necker structure. SIAM Journal on Matrix Analysis and Applications , 43(4):1806–1850, 2022. Mikołaj Bi ´ nko wski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GANs. In International Confer ence on Learning Repr esentations , 2018. Daniele Calandriello, Luigi Carratino, Alessandro Lazaric, Michal V alko, and Lorenzo Rosasco. Gaussian process optimization with adapti ve sketching: Scalable and no regret. In Alina Beygelz- imer and Daniel Hsu (eds.), Pr oceedings of the Thirty-Second Conference on Learning Theory , volume 99 of Pr oceedings of Mac hine Learning Resear ch , pp. 533–557. PMLR, 25–28 Jun 2019. Daniele Calandriello, Luigi Carratino, Alessandro Lazaric, Michal V alko, and Lorenzo Rosasco. Near-linear time Gaussian process optimization with adaptive batching and resparsification. In Hal Daum ´ e III and Aarti Singh (eds.), Pr oceedings of the 37th International Confer ence on Ma- chine Learning , v olume 119 of Pr oceedings of Machine Learning Resear ch , pp. 1295–1305. PMLR, 13–18 Jul 2020. Lingjiao Chen, Matei Zaharia, and James Zou. FrugalGPT: Ho w to use lar ge language models while reducing cost and improving performance. T ransactions on Machine Learning Researc h , 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=cSimKw5p6R . 11 Published as a conference paper at ICLR 2026 Zhirui Chen, P . N. Karthik, Y eow Meng Chee, and V incent Y . F . T an. Optimal multi-objective best arm identification with fix ed confidence. arXiv pr eprint arXiv:2501.13607 , 2025. doi: 10.48550/ arXiv .2501.13607. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AIST A TS). W ei Chu, Lihong Li, Le v Reyzin, and Robert Schapire. Contextual bandits with linear payoff func- tions. In Geoffre y Gordon, Da vid Dunson, and Miroslav Dud ´ ık (eds.), Proceedings of the F our- teenth International Conference on Artificial Intelligence and Statistics , volume 15 of Pr oceed- ings of Machine Learning Resear ch , pp. 208–214, Fort Lauderdale, FL, USA, 11–13 Apr 2011. PMLR. Gabriele Corso, Y ilun Xu, V alentin De Bortoli, Regina Barzilay , and T ommi S. Jaakkola. Parti- cle Guidance: non-I.I.D. diverse sampling with diffusion models. In The T welfth International Confer ence on Learning Representations , 2024. Dan Dan Friedman and Adji Bousso Dieng. The vendi score: A div ersity ev aluation metric for machine learning. T ransactions on machine learning r esear ch , 2023. Google DeepMind. Gemma 3: Open weights family (1b, 4b, 12b, 27b). https:// huggingface.co/google/gemma- 3- 1b- it , 2024. DeepSeek-AI. Deepseek-r1-distill-qwen-1.5b . https://huggingface.co/unsloth/ DeepSeek- R1- Distill- Qwen- 1.5B- GGUF , 2024. Jianfeng Dong, Xirong Li, Chaoyou Xu, Xun Y ang, Gang Y ang, Xun W ang, Y uan Meng, Qiang Li, Feng Zheng, Xiaogang Zhang, et al. Instructblip: T owards general-purpose vision-language models with instruction tuning, 2023. Dylan Foster , Alekh Agarwal, Mirosla v Dudik, Haipeng Luo, and Robert Schapire. Practical con- textual bandits with regression oracles. In Jennifer Dy and Andreas Krause (eds.), Pr oceedings of the 35th International Conference on Machine Learning , volume 80 of Pr oceedings of Machine Learning Resear ch , pp. 1539–1548. PMLR, 10–15 Jul 2018. Evan Frick, Connor Chen, Joseph T ennyson, Tianle Li, W ei-Lin Chiang, Anastasios N Angelopou- los, and Ion Stoica. Prompt-to-leaderboard. arXiv preprint , 2025. Shizhan Gong, Y ankai Jiang, Qi Dou, and Farzan Farnia. Kernel-based unsupervised embedding alignment for enhanced visual representation in vision-language models. In International Con- fer ence on Machine Learning , pp. 19912–19931. PMLR, 2025. Arthur Gretton, Karsten M Borgw ardt, Malte J Rasch, Bernhard Sch ¨ olkopf, and Alexander Smola. A kernel two-sample test. The Journal of Machine Learning Resear ch , 13(1):723–773, 2012. Y unlong Hou, V incent Y . F . T an, and Zixin Zhong. Almost minimax optimal best arm identification in piece wise stationary linear bandits. In Advances in Neural Information Processing Systems (NeurIPS) , 2024. Xiaoyan Hu, Ho-fung Leung, and Farzan Farnia. Pak-ucb contextual bandit: An online learning approach to prompt-aware selection of generative models and llms. In Pr oceedings of the 26th International Confer ence on Machine Learning (ICML) , 2025a. Xiaoyan Hu, Lauren Pick, Ho-fung Leung, and Farzan Farnia. Promptwise: Online learning for cost-aware prompt assignment in generati ve models. arXiv pr eprint arXiv:2505.18901 , 2025b. Mohammad Jalali, Cheuk T ing Li, and Farzan F arnia. An information-theoretic ev aluation of gen- erativ e models in learning multi-modal distributions. Advances in Neural Information Pr ocessing Systems , 36:9931–9943, 2023. Mohammad Jalali, Haoyu Lei, Amin Gohari, and Farzan Farnia. Sparke: Scalable prompt-aware div ersity guidance in dif fusion models via rke scores. Advances in Neur al Information Pr ocessing Systems , 2025a. 12 Published as a conference paper at ICLR 2026 Mohammad Jalali, Bahar Dibaei Nia, and Farzan Farnia. T owards an e xplainable comparison and alignment of feature embeddings. In F orty-second International Conference on MachineLearn- ing , 2025b. URL https://openreview.net/forum?id=Doi0G4UNgt . Mohammad Jalali, Azim Ospanov , Amin Gohari, and Farzan Farnia. Conditional Vendi Score: Prompt-aware di versity ev aluation for text-guided generativ e ai models. In Pr oceedings of The 29th International Confer ence on Artificial Intelligence and Statistics , Proceedings of Machine Learning Research, 2026. Minguk Kang, Jun-Y an Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, and T aesung Park. Scaling up gans for text-to-image synthesis. In Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2023. Branislav Kveton, Manzil Zaheer , Csaba Szepesv ´ ari, Lihong Li, Mohammad Ghavamzadeh, and Craig Boutilier . Randomized exploration in generalized linear bandits. In Proceedings of the 23r d International Conference on Artificial Intelligence and Statistics (AIST ATS) , 2020. T uomas Kynk ¨ a ¨ anniemi, T ero Karras, Samuli Laine, Jaakko Lehtinen, and T imo Aila. Impro ved precision and recall metric for assessing generative models. Advances in neural information pr ocessing systems , 32, 2019. John Langford and T ong Zhang. The epoch-greedy algorithm for multi-armed bandits with side information. In J. Platt, D. K oller , Y . Singer , and S. Roweis (eds.), Advances in Neural Information Pr ocessing Systems , volume 20. Curran Associates, Inc., 2007. Junnan Li, Dongxu Li, Silvio Sav arese, and Ste ven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023. Lihong Li, W ei Chu, John Langford, and Robert E. Schapire. A contextual-bandit approach to per- sonalized news article recommendation. In Pr oceedings of the 19th International Confer ence on W orld W ide W eb , WWW ’10, pp. 661–670, New Y ork, NY , USA, 2010. Association for Comput- ing Machinery . ISBN 9781605587998. doi: 10.1145/1772690.1772758. Tsung-Y i Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Dev a Ramanan, Piotr Doll ´ ar , and C Lawrence Zitnick. Microsoft COCO: Common objects in context. In Computer V ision–ECCV 2014: 13th Eur opean Confer ence, Zurich, Switzerland, September 6-12, 2014, Pr oceedings, P art V 13 , pp. 740–755. Springer , 2014. Haotian Liu, Chunyuan Li, Qingyang W u, and Y ong Jae Lee. Llav a: Large language and vision assistant, 2023. Jack Lu, Ryan T eehan, and Mengye Ren. ProCreate, Don’t Reproduce! propulsi ve ener gy dif fusion for creati ve generation. In Computer V ision - ECCV 2024 - 18th Eur opean Confer ence, Milano, Italy , September 29 - October 27, 2024 , 2024. Zichen Miao, Jiang W ang, Ze W ang, Zhengyuan Y ang, Lijuan W ang, Qiang Qiu, and Zicheng Liu. Training diffusion models to wards di verse image generation with reinforcement learning. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pp. 10844–10853, June 2024. Muhammad Ferjad Naeem, Seong Joon Oh, Y oungjung Uh, Y unjey Choi, and Jaejun Y oo. Reliable fidelity and div ersity metrics for generativ e models. In International confer ence on machine learning , pp. 7176–7185. PMLR, 2020. Maxime Oquab, T imoth ´ ee Darcet, Theo Moutakanni, Huy V o, Marc Szafraniec, V asil Khalidov , Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby , et al. Dinov2: Learning robust visual features without supervision. arXiv preprint , 2023. Azim Ospanov and Farzan Farnia. Do vendi scores con verge with finite samples? truncated vendi score for finite-sample conv ergence guarantees. In The 41st Confer ence on Uncertainty in Artifi- cial Intelligence , 2025. 13 Published as a conference paper at ICLR 2026 Azim Ospanov , Jingwei Zhang, Mohammad Jalali, Xuenan Cao, Andrej Bogdanov , and Farzan Farnia. T o wards a scalable reference-free e valuation of generati ve models. In The Thirty-eighth Annual Confer ence on Neural Information Pr ocessing Systems , 2024. Azim Ospanov , Mohammad Jalali, and Farzan Farnia. Scendi score: Prompt-aware di versity e valu- ation via schur complement of clip embeddings. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision (ICCV) , pp. 16927–16937, October 2025. PixArt-alpha. Pixart-xl-2-512x512. https://huggingface.co/PixArt- alpha/ PixArt- XL- 2- 512x512 , 2024. Jie Qin, Jie W u, W eifeng Chen, Y uxi Ren, Huixia Li, Hefeng W u, Xuefeng Xiao, Rui W ang, and Shilei W en. Diffusiongpt: Llm-driv en text-to-image generation system. arXiv pr eprint arXiv:2401.10061 , 2024. Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Phil Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. International Confer ence on Machine Learning , pp. 8748– 8763, 2021. Parham Rezaei, F arzan Farnia, and Cheuk T ing Li. Be more div erse than the most diverse: Optimal mixtures of generativ e models via mixture-UCB bandit algorithms. In The Thirteenth Interna- tional Conference on Learning Representations , 2025. URL https://openreview.net/ forum?id=2Chkk5Ye2s . Runway-ML. Stable diffusion v1-5 model card. https://huggingface.co/runwayml/ stable- diffusion- v1- 5 , 2023. V ersion 1.5 of the model, released in February 2023. Seyedmorteza Sadat, Jakob Buhmann, Derek Bradley , Otmar Hilliges, and Romann M. W eber . CADS: Unleashing the div ersity of diffusion models through condition-annealed sampling. In The T welfth International Conference on Learning Repr esentations , 2024. Mehdi SM Sajjadi, Olivier Bachem, Mario Lucic, Olivier Bousquet, and Sylvain Gelly . Assessing generativ e models via precision and recall. Advances in neural information pr ocessing systems , 31, 2018. Amir Sani, Alessandro Lazaric, and R ´ emi Munos. Risk-a version in multi-armed bandits. In F . Pereira, C.J. Burges, L. Bottou, and K.Q. W einberger (eds.), Advances in Neur al Information Pr ocessing Systems , volume 25, 2012. Matina Mahdizadeh Sani, Nima Jamali, Mohammad Jalali, and Farzan Farnia. T raining-free distri- bution adaptation for dif fusion models via maximum mean discrepancy guidance. arXiv pr eprint arXiv:2601.08379 , 2026. URL . V ikash Sehwag, Caner Hazirbas, Albert Gordo, Firat Ozgenel, and Cristian Canton Ferrer . Gen- erating high fidelity data from low-density regions using diffusion models. In 2022 IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pp. 11482–11491, 2022. doi: 10.1109/CVPR52688.2022.01120. Stability-AI. Stable dif fusion xl 1.0. https://huggingface.co/stabilityai/ stable- diffusion- xl- base- 1.0 , 2023. George Stein, Jesse Cresswell, Rasa Hosseinzadeh, Y i Sui, Brendan Ross, V alentin V illecroze, Zhaoyan Liu, Anthony L Caterini, Eric T aylor , and Gabriel Loaiza-Ganem. Exposing flaws of generativ e model ev aluation metrics and their unfair treatment of dif fusion models. Advances in Neural Information Pr ocessing Systems , 36:3732–3784, 2023. Qwen T eam. Qwen2 technical report. https://qwenlm.github.io , 2024. Accessed: 2024- 09-01. Michal V alko, Nathaniel K orda, Remi Munos, Ilias Flaounas, and Nelo Cristianini. Finite-time analysis of kernelised contextual bandits, 2013. 14 Published as a conference paper at ICLR 2026 Nir W einberger and Michal Y emini. Multi-armed bandits with self-information rewards. IEEE T ransactions on Information Theory , 69(11):7160–7184, 2023. doi: 10.1109/TIT .2023.3299460. Y ouqi W u, Jingwei Zhang, and Farzan Farnia. Fusing cross-modal and uni-modal representations: A kronecker product approach. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2025. Junwen Y ang, V incent Y . F . T an, and Tian yuan Jin. Best arm identification with minimal regret. arXiv pr eprint arXiv:2409.18909 , 2024. doi: 10.48550/arXiv .2409.18909. Houssam Zenati, Alberto Bietti, Eustache Diemert, Julien Mairal, Matthieu Martin, and Pierre Gail- lard. Efficient kernelized ucb for contextual bandits. In Gustau Camps-V alls, Francisco J. R. Ruiz, and Isabel V alera (eds.), Pr oceedings of The 25th International Conference on Artificial Intelli- gence and Statistics , v olume 151 of Pr oceedings of Machine Learning Resear ch , pp. 5689–5720. PMLR, 28–30 Mar 2022. Jingwei Zhang, Cheuk Ting Li, and Farzan Farnia. An interpretable ev aluation of entropy-based nov elty of generati ve models. In Pr oceedings of the 41st International Confer ence on Machine Learning , volume 235 of Pr oceedings of Machine Learning Resear ch , pp. 59148–59172. PMLR, 21–27 Jul 2024. Jingwei Zhang, Mohammad Jalali, Cheuk Ting Li, and Farzan Farnia. Unv eiling differences in generativ e models: A scalable dif ferential clustering approach. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2025. Qiuyu Zhu and V incent T an. Thompson sampling algorithms for mean-v ariance bandits. In Hal Daum ´ e III and Aarti Singh (eds.), Pr oceedings of the 37th International Confer ence on Ma- chine Learning , volume 119 of Pr oceedings of Machine Learning Resear ch , pp. 11599–11608. PMLR, 13–18 Jul 2020. A P P E N D I X A D E R I V AT I O N O F T H E M I X T U R E - D A K - U C B P R OX Y O B J E C T I V E F U N C T I O N A . 1 U C B F O R M U L A T I O N O F M I X T U R E - D A K - U C B Building on the mixture objectiv e in the main text, we here pro ve the approximation guarantee for Mixture-D AK-UCB, and then provide the corresponding UCB formulation. Proposition 2. Assume the kernel functions are normalized and satisfy k T ( t, t ) = 1 and k X ( x, x ′ ) = 1 for all t, t ′ , x, x ′ . F or every mixture weight α ∈ A ϵ = α : T → ∆ G : ∀ t, t ′ , k T ( t, t ′ ) · α ( t ) − α ( t ′ ) 1 ≤ ϵ , the following hold: (a) F or the I-JRKE score of the mixtur e P α defined as I - JRKE( P α ) = E t ∼ P T α ( t ) ⊤ M ( t ) α ( t ) , the pr oxy I-JRKE score I - JRKE appr ox ( P α ) = E t h P g ,g ′ α g ( t ) α g ′ ( t ) M RKE g g ′ ( t ) i r esults in an ϵ - bounded err or: I - JRKE( P α ) − I - JRKE appr ox ( P α ) ≤ ϵ (b) F or the JKD scor e of the mixtur e P α defined as JKD( P α , Q ) = E t,t ′ h k T ( t, t ′ ) P g ,g ′ α g ( t ) α g ′ ( t ′ ) K JKD g g ′ ( t, t ′ ) i , the pr oxy JKD scor e JKD appr ox ( P α , Q ) = E t,t ′ h k T ( t, t ′ ) P g ,g ′ α g ( t ) α g ′ ( t ) K JKD g g ′ ( t, t ′ ) i r esults in an ϵ -bounded error: JKD( P α , Q ) − JKD appr ox ( P α , Q ) ≤ ϵ. 15 Published as a conference paper at ICLR 2026 Pr oof. Proof for (a). Considering the definitions, we hav e | I - JRKE( P α ) − I - JRKE approx ( P α ) | = E t,t ′ h k 2 T ( t, t ′ ) X g ,g ′ α g ( t ) α g ′ ( t ′ ) K RKE g g ′ ( t, t ′ ) i − E t h X g ,g ′ α g ( t ) α g ′ ( t ) M RKE g g ′ ( t ) i = E t,t ′ h k 2 T ( t, t ′ ) X g ,g ′ α g ( t )[ α g ′ ( t ′ ) − α g ′ ( t )] K RKE g g ′ ( t, t ′ ) i . For fix ed t, t ′ , we bound the inner sum as X g ,g ′ α g ( t )[ α g ′ ( t ′ ) − α g ′ ( t )] K RKE g g ′ ( t, t ′ ) ≤ X g ,g ′ α g ( t ) | α g ′ ( t ′ ) − α g ′ ( t ) | ≤ ∥ α ( t ′ ) − α ( t ) ∥ 1 , where the last line uses P g α g ( t ) = 1 . From the Lipschitz condition α ∈ A ϵ : | k T ( t, t ′ ) | · ∥ α ( t ′ ) − α ( t ) ∥ 1 ≤ ϵ. Since k 2 T ( t, t ′ ) ≤ k T ( t, t ) k T ( t ′ , t ′ ) = 1 , we hav e k 2 T ( t, t ′ ) ≤ | k T ( t, t ′ ) | and then: k 2 T ( t, t ′ ) · ∥ α ( t ′ ) − α ( t ) ∥ 1 ≤ | k T ( t, t ′ ) | · ∥ α ( t ′ ) − α ( t ) ∥ 1 ≤ ϵ. Therefore, we can write | I - JRKE( P α ) − I - JRKE approx ( P α ) | ≤ E t,t ′ [ k 2 T ( t, t ′ ) · ∥ α ( t ′ ) − α ( t ) ∥ 1 ] ≤ E t,t ′ [ ϵ ] = ϵ. Proof f or (b). Using the definitions, | JKD( P α , Q ) − JKD approx ( P α , Q ) | = E t,t ′ h k T ( t, t ′ ) X g ,g ′ α g ( t ) α g ′ ( t ′ ) K JKD g g ′ ( t, t ′ ) i − E t h X g ,g ′ α g ( t ) α g ′ ( t ) M JKD g g ′ ( t ) i = E t,t ′ h k T ( t, t ′ ) X g ,g ′ α g ( t )[ α g ′ ( t ′ ) − α g ′ ( t )] K JKD g g ′ ( t, t ′ ) i . For fix ed t, t ′ , we can bound the inner sum as follows X g ,g ′ α g ( t )[ α g ′ ( t ′ ) − α g ′ ( t )] K JKD g g ′ ( t, t ′ ) ≤ X g ,g ′ α g ( t ) | α g ′ ( t ′ ) − α g ′ ( t ) | ≤ ∥ α ( t ′ ) − α ( t ) ∥ 1 . From the Lipschitz condition and noting that k T ( t, t ′ ) ≤ | k T ( t, t ′ ) | : k T ( t, t ′ ) · ∥ α ( t ′ ) − α ( t ) ∥ 1 ≤ | k T ( t, t ′ ) | · ∥ α ( t ′ ) − α ( t ) ∥ 1 ≤ ϵ. As a result, the following holds | JKD( P α , Q ) − JKD approx ( P α , Q ) | ≤ E t,t ′ [ | k T ( t, t ′ ) | · ∥ α ( t ′ ) − α ( t ) ∥ 1 ] ≤ E t,t ′ [ ϵ ] = ϵ. Therefore, to formulte the UCB formulation of Mixture-D AK-UCB, at each round i for prompt t i , the learner maintains UCB predictors for b s UCB ( t i ) ∈ R G , c M UCB ( t i ) ∈ R G × G , c M UCB ( t i ) ⪰ 0 , 16 Published as a conference paper at ICLR 2026 Algorithm 2: Mixture Div ersity-A ware Kernelized UCB (M I X T U R E - DA K - U C B ) Input: G models; horizon T ; prompt distribution P ; trade-off λ ; di versity primiti ve ψ ∈ { I - JRKE, JKD } ; (optional) panel rate ρ ∈ [0 , 1] Output: T generated outputs 1 Initialize per-model KRR for fidelity { s g } G g =1 and matrix-v alued KRR for div ersity { M g g ′ } g ,g ′ ; 2 for i = 1 to T do 3 Sample prompt t i ∼ P ; 4 For all g : ( b s g ( t i ) , b σ ( s ) g ( t i )) ← K R R - P R E D I C T s ( g , t i ) ; 5 For all ( g, g ′ ) : ( c M g g ′ ( p t ) , b σ ( M ) g g ′ ( t i )) ← K R R - P R E D I C T M ( g , g ′ , t i ) ; 6 Set b s UCB g ( t i ) ← b s g ( t i ) + β ( s ) b σ ( s ) g ( t i ) for all g ; 7 Set c M LCB g g ′ ( t i ) ← c M g g ′ ( t i ) − β ( M ) b σ ( M ) g g ′ ( t i ) ; project to PSD if needed; 8 α i ← arg max α ∈ ∆ G α ⊤ b s UCB ( t i ) − λ α ⊤ c M LCB ( t i ) α ; 9 Sample g i ∼ α i ; draw x i ∼ P g i ( · | t i ) ; 10 y ( s ) i ← ϕ fid ( t i , x i ) ; 11 if panel step with pr ob. ρ then 12 for g = 1 to G do 13 draw x ( g ) i ∼ P g ( · | t i ) (reuse x ( g i ) i = x i ) 14 K R R - U P DAT E s ( g i ; ( t i , y ( s ) i )) ; 15 if panel step then 16 Update { M g g ′ } with cross-kernel labels b uilt from { x ( g ) i } G g =1 ; 17 else 18 Update { M g g ′ } using the av ailable pairs; where b s UCB ( t i ) collects fidelity UCB scores for each model and c M UCB ( t i ) is a PSD estimate of the cross-model div ersity matrix M ( t i ) . The per-prompt mixture decision then follows the conca ve quadratic program α ∗ i = arg max α ∈ ∆ G n ⟨ α , b s UCB ( t i ) ⟩ − λ α ⊤ c M UCB ( t i ) α o . (9) This UCB objectiv e ensures optimism for fidelity while pessimistically accounting for di versity penalties. The chosen α ∗ i specifies a sampling distribution o ver models, from which the algorithm draws g i ∼ Multinomial( α ∗ i ) and obtains x i ∼ P g i ( ·| t i ) . The resulting procedure, which extends the single-model D AK-UCB to mixture assignments, is summarized in Algorithm 2. A P P E N D I X B R E G R E T A NA L Y S I S O F S U P - D A K - U C B ( P H A S E D V A R I A N T O F DA K - U C B ) As noted in the literature, the theoretical analysis of the standard k ernelized UCB method faces the challenge of potentially statistically correlated model selection at different rounds, which renders standard concentration analysis by means of independent observations inapplicable. T o circumvent this challenge, we adopt the standard approach of analyzing a staged variant of the proposed D AK- UCB algorithm, which we call Sup-D AK-UCB. The same technique of analyzing Sup-K erenlzied- UCB and Sup-P AK-UCB hav e been applied in the related works (Chu et al., 2011; V alko et al., 2013; Hu et al., 2025a). In the phased variant of S U P - DA K - U C B , within each arm–stage–target triple, the data used by kernel ridge regression (KRR) are independent. This enables the analytical deriv ations of confi- dence bounds and a proper re gret decomposition, similar to the analysis in (V alko et al., 2013; Hu et al., 2025a). In the following, we first state the updated setting and assumptions in our theoretical analysis, then present the phased algorithmic structure, followed by the theorems and their proofs. 17 Published as a conference paper at ICLR 2026 B . 1 A S S U M P T I O N S I N T H E O R E T I C A L A N A L Y S I S O F DA K - U C B Let G = { 1 , . . . , G } be G generativ e models, T a prompt space with i.i.d. prompts t i ∼ P T , and X the output space. At round t , the algorithm selects a single model g i . Note that the objectiv e function is the following for a parameter λ ≥ 0 : J g ( t ) := s g ( t ) − λD g ( t ) Assumption 1 (Normalized Prompt and Data K ernel Functions) . The pr ompt kernel k T : T × T → [ − 1 , 1] and the output kernel k X : X × X → [ − 1 , 1] ar e positive definite with k T ( t, t ) = k X ( x, x ) = 1 for all t ∈ T , x ∈ X . F or g , g ′ ∈ G , define K g g ′ ( p, p ′ ) := E x ∼ P g ( ·| p ) , x ′ ∼ P g ′ ( ·| p ′ ) k X ( x, x ′ ) 2 ∈ [0 , 1] . Assumption 2 (Sub-Gaussian noise in kernel re gression) . All scalar observations ar e conditionally σ -sub-Gaussian given the history: E [exp( λε ) | H i ] ≤ exp( λ 2 σ 2 / 2) for all λ ∈ R . Assumption 3 (RKHS boundedness for single-model case) . Let H T be the RKHS of k T . Assume s g ∈ H T with ∥ s g ∥ H T ≤ B s and D g ∈ H T with ∥ D g ∥ H T ≤ B D for all g ∈ G . B . 2 I N T RO D U C I N G P H A S E D S U P - D A K - U C B A L G O R I T H M As mentioned earlier , we analyze a staged variant of D AK-UCB, called Sup-DAK-UCB , possessing M = ⌈ log 2 T ⌉ stages. In Sup-D AK-UCB, for each generative model-stage pair ( g , m ) and target type τ ∈ { s, D } , we maintain a frozen index set Ψ m, ( τ ) g . T o guarantee independence for div ersity labels, we additionally maintain a stage snapshot of the archiv e of past ( t, x ) pairs for each arm: at the be ginning of stage m , we freeze D m g and use this snapshot to b uild div ersity labels throughout stage m . W e note that ne w pairs collected during stage m are not used to form div ersity labels in the same stage; They will be only a vailable from stage m + 1 onward. T o explain the steps of Sup-D AK-UCB in Algorithm 3, note that at iteration i in stage m with candidate set b G m , we perform the following. 1. For each g ∈ b G m , we perform KRR predictors ( b s m g ,i , b σ m, ( s ) g ,i ) and ( b D m g ,i , b σ m, ( D ) g ,i ) based on Ψ m, ( s ) g and Ψ m, ( D ) g respectiv ely . 2. W e let η σ := σ p 2 log (2 GM T /δ ) and set β ( s ) := B s √ α + η σ , β ( D ) := B D √ α + η σ . W e define the optimistic score and the width as e J m g ,i := b s m g ,i + β ( s ) b σ m, ( s ) g ,i − λ b D m g ,i − β ( D ) b σ m, ( D ) g ,i , w m g ,i := β ( s ) b σ m, ( s ) g ,i + λβ ( D ) b σ m, ( D ) g ,i . 3. The stage selection rule in Sup-DAK-UCB is as follo ws: • If max g w m g ,i ≤ T − 1 / 2 , we exploit: g i ∈ arg max g ∈ b G m e J m g ,i . • Else if max g w m g ,i ≤ 2 1 − m , we eliminate { g : max g ′ e J m g ′ ,i − e J m g ,i > 2 2 − m } and set m ← m + 1 . • Else (explore), we pick ev ery g i with w m g ,i > 2 1 − m and append t to Ψ m, ( s ) g i and Ψ m, ( D ) g i . 4. F eedback: For single-model selection, we draw x i ∼ P g i ( ·| t i ) , observe y ( s ) i = s g i ( t i ) + ε ( s ) i , and build a sta ge-fr ozen , unbiased, bounded div ersity statistic using D m g i : b d i = 1 max { 1 , |D m g i |} X ( t ′ ,x ′ ) ∈D m g i k T ( t i , t ′ ) 2 k X ( x i , x ′ ) 2 , E b d i | t i , D m g i = D g i ( t i ) . W e define the zero-mean div ersity noise ε ( D ) i := b d i − D g i ( t i ) . Finally , we update the archive D g i ← D g i ∪ { ( t i , x i ) } , which will only be snapped at the next stage. 18 Published as a conference paper at ICLR 2026 Algorithm 3: Sup-D AK-UCB Input: G models, T rounds, prompt dist. P , trade-off λ , k ernels k T , k X , ridge α , confidence δ Output: T generated outputs 1 Set number of stages M ← ⌈ log 2 T ⌉ ; 2 Initialize per-stage sets Ψ m, ( s ) g , Ψ m, ( D ) g ← ∅ and archives D g ← ∅ ; 3 for i = 1 to T do 4 Sample prompt t i ∼ P ; set m ← 1 , b G 1 ← [ G ] ; 5 Freeze stage snapshots D m g ← D g for all g ; 6 repeat 7 for g ∈ b G m do 8 Compute fidelity and div ersity predictions by KRR: ( ˆ s m g , σ m, ( s ) g ) , ( ˆ D m g , σ m, ( D ) g ) ; 9 Form optimistic score e J m g and width w m g ; 10 if max g w m g ≤ T − 1 / 2 then 11 g i ← arg max g e J m g ; 12 break ; 13 else 14 if max g w m g ≤ 2 1 − m then 15 Eliminate: b G m +1 ← { g : e J m g ≥ max h e J m h − 2 2 − m } ; 16 m ← m + 1 ; freeze new snapshots; 17 else 18 Explore: choose g i with w m g i > 2 1 − m ; 19 Append i to Ψ m, ( s ) g i , Ψ m, ( D ) g i ; 20 break ; 21 until ; 22 Generate x i ∼ P g i ( ·| t i ) , observe y ( s ) i and stage-frozen y ( D ) i ; 23 Update liv e archive D g i ← D g i ∪ { ( t i , x i ) } ; B . 3 K R R N O T A T I O N A N D I N F O R M A T I O N M E A S U R E S For an index set Ψ , let Φ Ψ = [ ϕ ( t i ) ⊤ ] i ∈ Ψ , K Ψ = Φ Ψ Φ ⊤ Ψ , k Ψ ( t ) = [ k T ( t, t i )] i ∈ Ψ , and A Ψ := Φ ⊤ Ψ Φ Ψ + αI . The KRR predictor and posterior deviation at t are b µ ( t ; Ψ) = k Ψ ( t ) ⊤ ( K Ψ + αI ) − 1 y Ψ = ϕ ( t ) ⊤ A − 1 Ψ Φ ⊤ Ψ y Ψ , b σ 2 ( t ; Ψ) = ϕ ( t ) ⊤ A − 1 Ψ ϕ ( t ) . W e use the shorthand η σ ( δ ) := σ p 2 log (2 /δ ) . Also, we use the following comple xity measures: γ (Ψ) := 1 2 log det( I + α − 1 K Ψ ) , Γ T := max Ψ: | Ψ |≤ T γ (Ψ) . B . 4 S I N G L E - M O D E L S E L E C T I O N S U P - D A K - U C B R E G R E T B O U N D S Lemma 1. Consider arm g , stage m , and tar get τ ∈ { s, D } . Consider the sequence of time indices { i } that get appended to Ψ m, ( τ ) g by the stage rule. Conditional on the prompt sequence { t i } and the stage-frozen archi ve snapshot D m g (for τ = D ), the random variables { y ( τ ) i } i ∈ Ψ m, ( τ ) g ar e mutually independent and satisfy E [ y ( τ ) i | t i , D m g ] = f ( τ ) g ( t i ) , where f ( s ) = s and f ( D ) = D . Mor eover , ε ( D ) i = b d i − D g ( t i ) is conditionally 1 / 2 -sub-Gaussian. Pr oof. For τ = s , y ( s ) i = s g ( p i ) + ε ( s ) i with ε ( s ) i conditionally independent across i giv en ( F i − 1 , t i ) by Assumption 2. Thus, { y ( s ) i } i ∈ Ψ m, ( s ) g are mutually independent giv en { t i } . 19 Published as a conference paper at ICLR 2026 For τ = D , by construction we use the stage-fr ozen archive snapshot D m g . Given t i and D m g , we draw a fresh x i ∼ P g ( · | t i ) independent of ( x j ) j 2 2 − m is the two-sided tolerance and g ∗ i attains the one-sided tolerance bound, g ∗ i cannot be eliminated: this proves (2). Finally , any survi vor g satisfies J g ∗ i ( t i ) − J g ( t i ) ≤ e J m g ∗ i ,i + 2 2 − m − e J m g ,i − 2 2 − m ≤ 2 2 − m + 2 2 − m = 2 3 − m , which prov es (3). Lemma 4. F ix ( g , m, τ ) and let ( t j ) j ∈ Ψ be the pr ompts indexed by Ψ = Ψ m, ( τ ) g in the sorted or der . Define A 0 := αI and A j := A j − 1 + ϕ ( t j ) ϕ ( t j ) ⊤ . Then, the following holds X j ∈ Ψ b σ 2 ( t j ; Ψ 2 1 − m , i.e., β ( s ) b σ ( s ) g ,i + λβ ( D ) b σ ( D ) g ,i > 2 1 − m . Sum- ming ov er t ∈ Ψ m, ( s ) g and applying Lemma 4 and Cauchy–Schwarz to the two targets separately yields 2 1 − m | Ψ m, ( s ) g | ≤ β ( s ) X i ∈ Ψ m, ( s ) g b σ ( s ) g ,t + λβ ( D ) X i ∈ Ψ m, ( D ) g b σ ( D ) g ,i ≤ β ( s ) q 2 | Ψ m, ( s ) g | γ m, ( s ) g + λβ ( D ) q 2 | Ψ m, ( D ) g | γ m, ( D ) g . In the above, γ m, ( τ ) g := γ (Ψ m, ( τ ) g ) . T aking the summation over ( g , m ) pairs and noting M = ⌈ log 2 T ⌉ completes the proof of the regret bound. A P P E N D I X C A D D I T I O N A L N U M E R I C A L R E S U LT S C . 1 DA K - U C B A P P L I E D T O L L M S E L E C T I O N P RO B L E M D AK-UCB for Diversity-A ware LLM Selection Using Synthetic Prompts: In this experiment, we asked GPT -4o to provide five words as categories: temple , painting , market , horse , and farm . W e then selected three LLMs: DeepSeek (DeepSeek-AI, 2024), Gemma (DeepMind, 2024), and Llama (AI, 2024). At each iteration, a random cluster from these fi ve was selected, and a prompt of the form “Describe a scene containing a [cluster]. ” was designed as the input to the LLM. In Figure 6, you can see the performance comparison and selection ratios of these models. 22 Published as a conference paper at ICLR 2026 100 200 300 400 Number of Iteration 4.4 4.6 4.8 Joint-RKE Scor e D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB 0 100 200 300 400 Number of Iteration 0.0 0.2 0.4 0.6 0.8 1.0 D AK -UCB Selection R atios DeepSeek Gemma Llama Figure 6: Results are averaged o ver 10 independent trials. Detecting Bias in LLMs Using the I-JRKE Diversity Metric: In this experiment, we used (DeepSeek-AI, 2024) to generate sentences about cities in the US, Canada, China, and England. One arm was biased tow ard the capitals of countries, while the other arm was unconstrained. As shown in Figure 7, our algorithm DAK-UCB preferred the unbiased arm, as it resulted in greater div ersity across the arms. The results are reported after 200 iterations. 7 1 . 5 % 2 8 . 5 % D A K - U C B S e l e c t i o n R a t i o C h i n a C a n a d a E n g l a n d U S U n c o n d i t i o n e d L L M C o n d i t i o n e d L L ( C o n d i t i o n e d o n c a p i t a l s ) Figure 7: DAK-UCB selection ratio for LLM bias detection e xperiment. Enhancing LLM Diversity via I-JRKE: In our experiment, we implemented a four -arm setup us- ing DeepSeek, where each arm was div ersity-collapsed by country-specific biasing through modified prompts of the form: “Describe one of the famous cities in [Country] in no more than 20 words. ” (with Japan, France, Brazil, and Egypt as respectiv e biases). Results from 10 runs demonstrated that mixture effecti vely enhanced div ersity . Scores and selection ratios of each arm are presented in Figure 8. The observ ed decay in D AK-UCB is explainable: W ith only one cluster , the algorithm sticks to one arm after some point. This naturally conv erges to a single-arm oracle scenario. 23 Published as a conference paper at ICLR 2026 0 500 1000 1500 Number of Iteration 1.0 1.5 2.0 2.5 Joint-RKE Scor e D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB 0 500 1000 1500 Number of Iteration 0.0 0.2 0.4 0.6 0.8 1.0 MK -UCB Selection R atios Japan F rance Brazil Egypt Figure 8: Selection Ratios of biased arms and performance comparison on Joint-RKE. J a p a n F r a n c e B r a z i l E g y p t Figure 9: W ord Clouds of DeepSeek Responses Across Countries C . 2 DA K - U C B A P P L I E D T O I M A G E - C A P T I O N I N G M O D E L S E L E C T I O N TA S K Impro ving Correctness in Image Captioning via JKD: W e ev aluated three state-of-the-art image captioning models as our arms: L L A V A (Liu et al., 2023), I N S T R U C T B L I P (Dong et al., 2023), and B L I P - 2 (Li et al., 2023). At each iteration, we sampled an image-caption pair from a thousand MS-COCO instances, distributed across 10 pre viously mentioned clusters. By minimizing the Joint Kernel Distance (JKD) between generated captions and MS-COCO reference captions, we aimed to enhance captioning correctness through dynamic model selection. Figure 10 demonstrates the ev olution of KID scores across iterations compared to baseline methods, along with the empirical selection ratios for each captioning model. Figure 11 visualizes the dataset. 24 Published as a conference paper at ICLR 2026 500 1000 1500 Number of Iteration 0.020 0.025 0.030 0.035 0.040 0.045 KID Scor e D AK -UCB R andom Mixtue-D AK -UCB One Ar m Oracle P AK -UCB 0 500 1000 1500 Number of Iteration 0.0 0.2 0.4 0.6 0.8 1.0 MK -UCB Selection R atios Blip2 InstructBlip Llava Figure 10: Selection Ratios of image captioning models and performance comparison on KID using JKD metric. Results are averaged o ver 10 independent trials. 25 Published as a conference paper at ICLR 2026 C a t D o g C a k e B i k e P a r k E l e p h a n t A i r p l a n e B o w l T r e e C a r M S - C O C O : A p i c t u r e o f a d o g l a y i n g o n t h e g r o u n d B l i p 2 : A d o g i s s l e e p i n g o n t h e s i d e w a l k I n s t r u c t B l i p : a w h i t e d o g l a y i n g o n t h e g r o u n d n e x t t o a b i c y c l e , i n d i c a t i n g t h a t t h e d o g i s s l e e p i n g . L l a v a : A w h i t e d o g s l e e p i n g o n a s t o n e s i d e w a l k . C l u s t e r I m a g e C a p t i o n s M S - C O C O : a c l o s e u p o f a c h i l d n e x t t o a c a k e w i t h b a l l o o n s B l i p 2 : A b a b y i s e a t i n g a c a k e I n s t r u c t B l i p : a b a b y s i t t i n g i n f r o n t o f a c a k e , w i t h a t i e a n d a b i r t h d a y p r e s e n t . L l a v a : A b a b y w i t h c a k e o n h i s f a c e . M S - C O C O : A c a t o n a l e a t h e r c h a i r n e x t t o r e m o t e B l i p 2 : A c a t s i t t i n g o n a c o u c h w i t h a r e m o t e c o n t r o I n s t r u c t B l i p : a c a t l a y i n g o n a l e a t h e r c h a i r w i t h t w o r e m o t e c o n t r o l s i n i t s m o u t h . L l a v a : A c a t s i t t i n g o n a c o u c h . M S - C O C O : A r e a r v i e w m i r r o r o n a b i k e i s r e f l e c t i n g a p o s t e r o n b u i l d i n g . B l i p 2 : A r e f l e c t i o n o f a b i c y c l e i n a s i d e m i r r o r o f a m o t o r c y c l I n s t r u c t B l i p : a m o t o r c y c l e p a r k e d o n a s t r e e t w i t h a s i d e m i r r o r r e f l e c t i n g a t r e e a n d a s i g n . L l a v a : A r e f l e c t i o n o f a s i g n i n a m o t o r c y c l e m i r r o r . M S - C O C O : a z e e b r a r u n n i n g o n a g r a s s f e i l d i n a p a r B l i p 2 : A z e b r a i s a l a r g e , f a s t - r u n n i n g , b l a c k a n d w h i t e h o r s I n s t r u c t B l i p : a z e b r a r u n n i n g t h r o u g h a g r a s s y f i e l d w i t h t r e e s i n t h e b a c k g r o u n d . L l a v a : Z e b r a w a l k i n g o n g r a s s . M S - C O C O : T w o b e a u t i f u l y o u n g l a d i e s g i v i n g a n e l e p h a n t a b a t h i n a r i v e r B l i p 2 : A y o u n g g i r l i s b a t h i n g a n e l e p h a n t i n a r i v e I n s t r u c t B l i p : t w o w o m e n w a s h i n g a n e l e p h a n t i n t h e w a t e r , w h i c h m a y b e a c o m m o n p r a c t i c e i n s o m e p a r t s o f t h e w o r l d . L l a v a : T w o g i r l s w a s h i n g a n e l e p h a n t i n a r i v e r . M S - C O C O : A p l a n e p a r k e d i n a l a r g e a i r p l a n e h a n g e r B l i p 2 : A l a r g e a i r p l a n e p a r k e d i n a h a n g a I n s t r u c t B l i p : a l a r g e a i r p l a n e p a r k e d i n s i d e a h a n g a r , w i t h s e v e r a l p e o p l e w o r k i n g a r o u n d i t . L l a v a : A l a r g e a i r p l a n e p a r k e d i n s i d e a h a n g a r . M S - C O C O : A l a r g e w h i t e b o w l o f m a n y g r e e n a p p l e s . B l i p 2 : A b o w l o f g r e e n a p p l e I n s t r u c t B l i p : a b o w l o f g r e e n a p p l e s s t a c k e d i n a w h i t e b o w l . T h e b o w l i s p l a c e d o n a t a b l e , w h i c h i s l i k e l y a t a b l e t o p , a n d t h e b o w l i s f i l l e d w i t h g r e e n a p p l e s L l a v a : A b o w l o f g r e e n a p p l e s . M S - C O C O : L a r g e t r e e w i t h w o o d e n p i c n i c b e n c h i n w i l d e r n e s s a r e B l i p 2 : A t r e e a n d a b e n c I n s t r u c t B l i p : a l a r g e , g r e e n t r e e i n t h e m i d d l e o f a g r a s s y f i e l d , w i t h a p i c n i c t a b l e a n d b e n c h e s n e a r b y . L l a v a : A p i c n i c t a b l e i n a f i e l d . M S - C O C O : A b o a t t h a t l o o k s l i k e a c a r m o v e s t h r o u g h t h e w a t e r . B l i p 2 : A s m a l l b o a t i s t r a v e l i n g o n t h e w a t e I n s t r u c t B l i p : a s m a l l m o t o r b o a t t r a v e l i n g o n a b o d y o f w a t e r . T h e b o a t i s w h i t e i n c o l o r a n d h a s a s m a l l m o t o r a t t a c h e d t o t h e f r o n t , w h i c h a l l o w s i t t o m o v e f a s t e r a n d m o r e e f f i c i e n t l y . L l a v a : A s m a l l b o a t i n t h e w a t e r . S e c t i o n 1 Figure 11: Dataset visualization for image captioning experiment. Impro ving Diversity in Image Captioning via I-JRKE: W e repeated the exact same experiment on image captioning, replacing the JKD objecti ve with I-JRKE to observe if our algorithm can enhance div ersity . As shown in Figure 12, our algorithm demonstrated superior performance compared to the baselines. While LLaV A worked best in terms of correctness, our algorithm tends to prefer InstructBLIP for div ersity . 26 Published as a conference paper at ICLR 2026 500 1000 1500 Number of Iteration 160 180 200 220 Joint-RKE Scor e D AK -UCB R andom Mixtue-D AK -UCB One Ar m Oracle P AK -UCB 0 500 1000 1500 Number of Iteration 0.0 0.2 0.4 0.6 0.8 1.0 MK -UCB Selection R atios Blip2 InstructBlip Llava Figure 12: Selection Ratios of image captioning models and performance comparison on Joint-RKE using I-JRKE metric. C . 3 A D D I T I O N A L N U M E R I C A L R E S U L T S O N A P P LY I N G D A K - U C B T O T H E T E X T - T O - I M AG E G E N E R AT I O N TA S K Conditional Expert Selection via I-JRKE Using Classifier -Free Guidance: W e used the dataset from (Rezaei et al., 2025). The dataset was generated by selecting four categories: dog, riv er , airplane, and building. For each category , GPT was asked to generate 10 adjectiv es, 10 activities, and 10 places. By mixing these with the cate gory , 1000 prompts were obtained. Some samples of the dataset can be seen in Figure 13. W e used SDXL to generate images with classifier-free guidance scales of 2 and 30 for each cluster . W e designed the arms as follows: ARM1: Generates images of dogs and riv ers with a classifier-free guidance scale of 2.0 (less guided, more div erse) and images of airplanes and buildings with a classifier-free guidance scale of 30.0 (more guided, less di verse). Thus, this arm acts as an expert in the dog and river clusters. ARM2: Does the opposite, making it an expert in the building and airplane clusters. In this experiment, our objecti ve was solely to minimize I-JRKE, and CLIP was not in volv ed in the optimization. As sho wn in Figure 14 (a veraged ov er 10 trials), the expert for each cluster was successfully detected. Howe ver , we observed that in some clusters, the selection ratios were very close. This is acceptable, as we know that a mixture can enhance div ersity . A happy dog is running in the park. A happy dog is running on the beach. A happy dog is running in the backyard. A happy dog is running in the forest. A wide river is flowing through the valley . A wide river is flowing in the forest. A wide river is flowing by the mountains. A wide river is flowing near the village. A fast airplane is flying in the sky . A fast airplane is flying above the clouds. A fast airplane is flying on the runway . A fast airplane is flying over the ocean. A tall building is standing in the city . A tall building is standing by the river . A tall building is standing in the countryside. A tall building is standing on the hill. Classifier-Free Guidance = 2. 0 Classifier-Free Guidance = 30 .0 Prompts Figure 13: Illustrati ve examples from the GPT -Generated prompt dataset and their SDXL-generated visualizations under varying guidance scales. 27 Published as a conference paper at ICLR 2026 1.00 0.75 0.50 0.25 0.00 0 1.00 0.75 0.50 0.25 0.00 0 500 1000 Dog prompts 500 1000 1500 Iteration Airplane prompts 1500 1.00 0.75 0.50 0.25 0.00 0 1.00 0.75 0.50 0.25 0.00 0 500 1000 River prompts 500 1000 1500 Iteration Building prompts 1500 Iteration Iteration Selection Ratio Selection Ratio Selection Ratio Selection Ratio SDXL(CFG=2) SDXL(CFG=30) SDXL(CFG=2) SDXL(CFG=30) SDXL(CFG=2) SDXL(CFG=30) SDXL(CFG=2) SDXL(CFG=30) Figure 14: Cluster -conditioned expert selection ratios and performance comparison against baseline methods. Diversity Identification in T ext-to-Image Generative Models: An Offline Study on V arying Diversity in ”animal” Generation: In this experiment, we modified the setup described in Fig- ure 3 and considered an offline setting. T o achieve this, we ev aluated the rew ard with respect to all a vailable offline data and remov ed the UCB radius term, since the entire dataset was accessible and no exploration was required. Figure 1 presents sample prompts along with the arm-selection preferences of D AK-UCB and Mixture-DAK-UCB. T able 1: D AK-UCB and Mixture-DAK-UCB Arm Preferences for Sample Prompts Prompt D AK-UCB Selected Arm Mixture-D AK-UCB Preference V ector ”an animal in the garden” Arm 3 (unconditioned) [0.218, 0.063, 0.719 ] ”an animal in the meadow” Arm 3 (unconditioned) [0.218, 0.064, 0.718 ] ”an animal near the lake” Arm 3 (unconditioned) [0.225, 0.069, 0.706 ] ”an animal in the jungle” Arm 3 (unconditioned) [0.230, 0.082, 0.688 ] ”an animal in the desert” Arm 3 (unconditioned) [0.226, 0.092, 0.682 ] Conditional Expert Selection via I-JRKE Using Synthetic Diversity Control: In this experiment, we utilize four clusters from the MS-COCO dataset: Bike , Car , Bowl , and Airplane , each comprising a hundred prompts. The prompts are partitioned into ten groups via K-means clustering applied to their CLIP-embedded v ector representations. W e designate four specialized experts corresponding to each cluster . When the selected expert matches the revealed prompt’ s cluster , it generates the appropriate SDXL output for that prompt. For mismatched cases, we employ a diversity-limiting strategy by outputting the image generated for a group representati ve prompt rather than the actual prompt. Specifically , we assign a representative prompt for each of the ten groups, and for any prompt within a group, the system outputs the SDXL-generated image corresponding to the group’ s representativ e. This experiment was conducted over 2000 iterations across 20 independent runs. The resulting expert selection ratios and Joint-RKE scores are presented in Figure 15, The observation that P AK-UCB works competitiv ely well is that expert selection for indi vidual prompts—where each image is generated specifically for its prompt rather than for group representati ves—improv es CLIP score alongside div ersity . 28 Published as a conference paper at ICLR 2026 500 1000 1500 Iteration 0.2 0.4 0.6 0.8 1.0 Expert Selection R atio Bik e pr ompts (Cluster 0) D AK -UCB Mixtur e-D AK -UCB R andom One Ar m Oracle P AK -UCB 500 1000 1500 Iteration 0.0 0.2 0.4 Expert Selection R atio Airplane pr ompts (Cluster 1) D AK -UCB Mixtur e-D AK -UCB R andom One Ar m Oracle P AK -UCB 500 1000 1500 Iteration 0.0 0.2 0.4 Expert Selection R atio Car pr ompts (Cluster 2) D AK -UCB Mixtur e-D AK -UCB R andom One Ar m Oracle P AK -UCB 500 1000 1500 Iteration 0.0 0.2 0.4 Expert Selection R atio Bowl pr ompts (Cluster 3) D AK -UCB Mixtur e-D AK -UCB R andom One Ar m Oracle P AK -UCB 500 1000 1500 Number of Iteration 45 50 55 60 65 70 75 Joint-RKE D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB Figure 15: Expert Selection Ratio and Performance Comparison on Joint-RKE. Perf ormance Comparison by KID via JKD: In this experiment, we used the same ten clusters of prompts and three generativ e models as in the first experiment. W e employed MS-COCO images as reference and optimized solely on the JKD score defined earlier . The performance was e valuated using KID to measure how close each baseline gets to the reference. The results are shown in Figure 16.W e observed that Mixtue-D AK-UCB and DAK-UCB achie ve close performance in this setup, which suggests the optimal solution per cluster is not a mixture. 500 1000 1500 Number of Iteration 0.006 0.008 0.010 0.012 0.014 0.016 KID D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB Figure 16: Performance comparison on KID for MS-COCO prompt clusters using Kandinsky , SDXL, and GigaGAN. Results are av eraged over 10 trials. C . 4 A B L A T I O N S T U D I E S T esting the Robustness of Fidelity and Di versity Scores Under Noise: In this experiment, our ob- jectiv e was to e valuate ho w reliably our fidelity and di versity metrics behav e when the input images undergo controlled degradation. Using 1000 samples from the MS-COCO validation set, we pro- gressiv ely increased the level of blur applied to the images and measured both CLIP-Score fidelity and DINOv2-based diversity . The CLIP-Score decreases monotonically with increased corruption, demonstrating its sensitivity to image quality . Likewise, the di versity metric also decreases, indi- cating that it does not mistakenly interpret noise as meaningful variation. The two plots in Fig. 17 summarize these trends. 29 Published as a conference paper at ICLR 2026 Figure 17: Left: CLIP-Score vs. noise level sho wing a monotonic fidelity drop. Right: Diversity in DINOv2 embedding vs. noise lev el showing reduced di versity under stronger corruption. Fidelity-A ware Behavior in Asymmetric Degradation: T o verify that our algorithm does not blindly prioritize di versity at the cost of fidelity , we revisited the introductory two-arm experiment shown in Fig. 1. This time, howe ver , we introduced a strong blur (radius = 20) exclusi vely to the div erse arm while keeping the limited-diversity arm intact. As expected, the selection ratio of the degraded arm dropped sharply , demonstrating that our method correctly down-weights samples whose fidelity deteriorates, even if they originate from a high-div ersity source. The final selection ratios are reported in T able 2, showing beha vior consistent with our fidelity-sensitiv e design. T able 2: Final selection ratios when only the div erse arm is blurred (Radius = 20). Diverse Arm (Blurr ed) Limited-Diversity Arm Selection Ratio 45.32% 54.68% Efficiency of Random F ourier F eature Appr oximation: T o address the quadratic gro wth of ker- nel computations in D AK-UCB, we adopt Random Fourier Features (RFFs) to approximate the RBF kernel, reducing the per-round computational cost to O ( d 2 t ) for an RFF dimension d . Since the proxy embedding produced by RFFs is d -dimensional, this approximation offers a scalable alter- nativ e while preserving the beha vior of the original kernelized method. In the experimental setting of Fig. 2, we verified that RFF-based DAK-UCB closely matches the performance of the exact RBF- kernel version across all metrics. As shown in T able 3, increasing the number of random features improv es stability while maintaining nearly identical scores. T able 3: Performance of RFF-based D AK-UCB compared to RBF-kernel DAK-UCB under the setup of Fig. 2. # RFF Featur es Final Joint-RKE Final CLIP Final KD (× 10 − 3 ) Elapsed Time (× 10 3 ) 32 158.4 29.80 7.20 4.947 64 160.5 30.40 6.60 4.994 128 162.3 31.00 5.80 5.006 256 172.65 31.59 4.78 5.013 512 182.79 32.17 3.60 5.019 Adaptation to the Introduction of a New Arm: W e repeated the experiment shown in Figure 3 with a modified setup in order to ev aluate the algorithm’ s ability to adapt when a new generativ e model is introduced partway through the process. Specifically , we began with two arms and intro- duced the third (and most div erse) arm at iteration 125. Once the new arm appeared, the D AK-UCB algorithm gradually adjusted its selection behavior . As sho wn in Figure 18, the algorithm success- fully adapted to the presence of the ne wly added arm, redistributing selection ratios and e ventually con verging to the appropriate mixture for this e xpanded arm set. 30 Published as a conference paper at ICLR 2026 Figure 18: Adaptation behavior after introducing the third (di verse) arm at iteration 125. The algo- rithm subsequently con verges to updated selection ratios that incorporate the ne w arm. Sensitivity to Ker nel Function and Embedding Choice: W e repeated the initial experiment (re- sults sho wn in Figure 2) with a slight modification: we used CLIP embeddings for the images and employed cosine similarity as the kernel function. Figure 19 presents a comparison to the baselines in terms of Joint-RKE and CLIP-score, while T able 4 reports the final cond-vendi scores. 500 1000 1500 Number of Iteration 9.5 10.0 10.5 11.0 11.5 12.0 12.5 Joint-RKE Scor e D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB 500 1000 1500 Number of Iteration 30.75 31.00 31.25 31.50 31.75 32.00 32.25 CLIP Scor e D AK -UCB R andom Mixtur e-D AK -UCB One Ar m Oracle P AK -UCB Figure 19: The average CLIP Score and Joint-RKE Div ersity score over 10 trials using cosine similarity as kernel function. T able 4: Comparison of Conditional V endi scores for algorithms under kernel function sensitivity test. Algorithm Conditional V endi Score D AK-UCB 9.92 Mixture-D AK-UCB 12.53 P AK-UCB 8.75 Random 11.82 One-Arm Oracle 7.99 Sensitivity to the Diversity T erm Scalar Hyperparameter: In this experiment, we used the models from (PixArt-alpha, 2024) and (Runway-ML, 2023) to generate images of an athlete. W e generated a hundred images from each model. As suggested by the CLIP , RKE, and V endi scores in Figure 20, PixArt generated images with higher fidelity , while Stable Dif fusion produced more di verse images. T o determine if our algorithm can detect this trade-of f and to monitor the selection ratios and final metrics for div ersity and fidelity under different λ values (the diversity term multiplier), we report the results in T ables 5 and 6. 31 Published as a conference paper at ICLR 2026 T able 5: Model selection ratio for different λ hyperparameter values in Mixture-D AK-UCB algo- rithm. λ = 0 . 0 λ = 0 . 1 λ = 1 . 0 λ = 10 . 0 PixArt 65% 43% 19% 12% Stable Diffusion 35% 57% 81% 88% T able 6: Performance metrics for dif ferent λ hyperparameter values in Mixture-D AK-UCB algo- rithm. Metric λ = 0 . 0 λ = 0 . 1 λ = 1 . 0 λ = 10 . 0 V endi Score 15.25 22.41 33.39 35.04 RKE Score 4.03 6.07 9.14 9.39 CLIP Score 26.8 26.25 25.89 25.55 C l i p S c o r e : 2 7 . 4 R K E S c o r e : 2 . 0 V e n d i S c o r e : 5 . 9 9 C l i p S c o r e : 2 5 . 2 R K E S c o r e : 9 . 2 V e n d i S c o r e : 3 7 . 0 0 P i x A r t S t a b l e D i f f u s i o n Figure 20: Clip, V endi, and RKE scores for 100 ”image of an athlete” generations, comparing PixArt and Stable Diffusion. As we increased λ , the algorithm preferred Stable Diffusion to maximize diversity metrics, which resulted in a corresponding decrease in fidelity metrics. This trade-off is clearly observ able in our results. W e also observed a gender bias: PixArt tended to generate male athletes, while Stable Diffusion tended to generate female athletes. Our algorithm accounted for gender fairness while enhancing div ersity . 32 Published as a conference paper at ICLR 2026 V isualization of Prompt Correlations: (a) Kernel matrix for Experiment 2 (b) Kernel matrix for Experiment 13 Figure 21: Correlation among prompts in datasets used in Experiments. A P P E N D I X D S T A T E M E N T O N T H E U S E O F L A R G E L A N G U A G E M O D E L S ( L L M S ) LLMs were used solely for proofreading and polishing the language of this manuscript, as well as for generating the prompts of the numerical experiments for the prompt-aware model selection task. All technical content was de veloped entirely by the authors. 33
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment