Gradient-Informed Bayesian and Interior Point Optimization for Efficient Inverse Design in Nanophotonics
Inverse design, particularly geometric shape optimization, provides a systematic approach for developing high-performance nanophotonic devices. While numerous optimization algorithms exist, previous global approaches exhibit slow convergence and conv…
Authors: Yannik Mahlau, Yannick Augenstein, Tyler W. Hughes
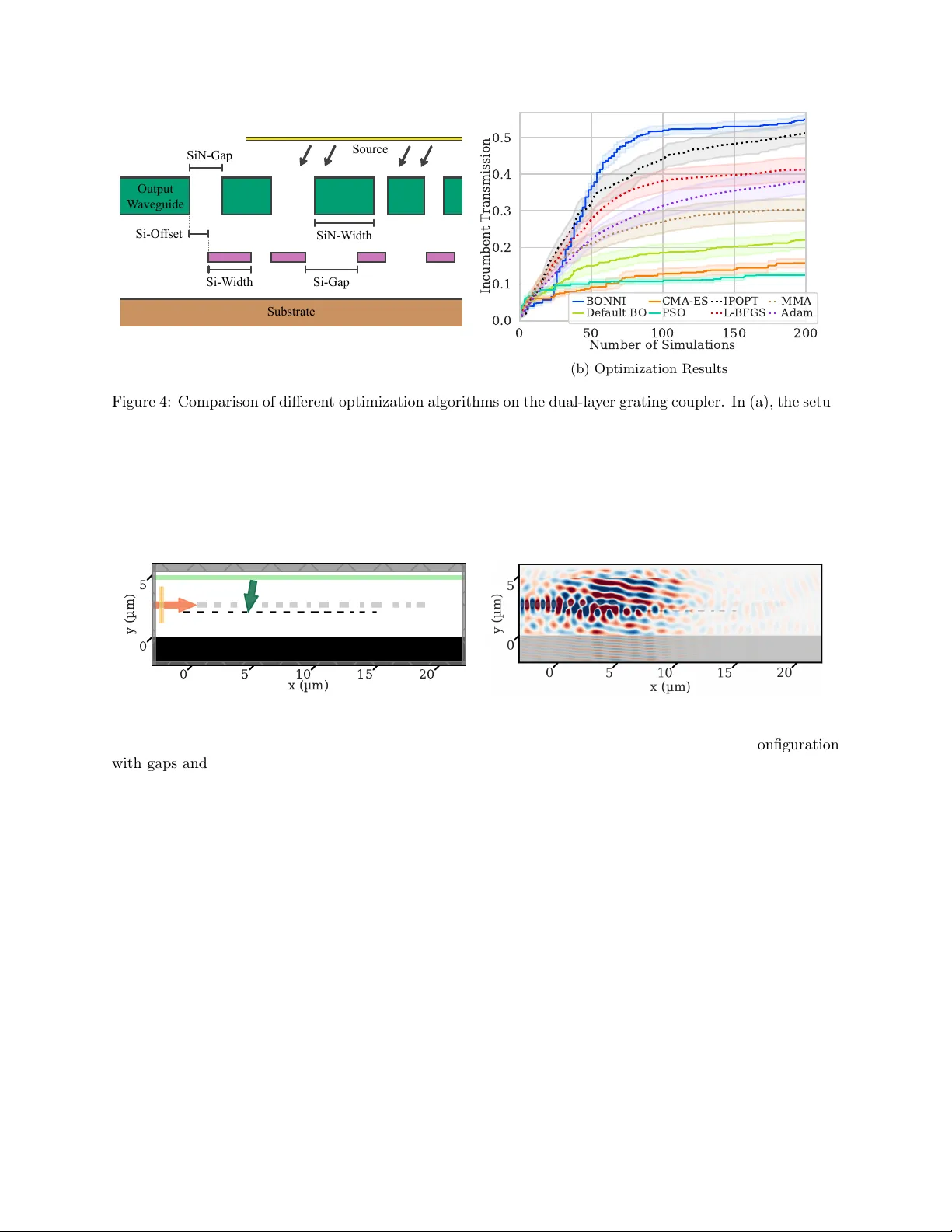
BONNI: Gradien t-Informed Ba y esian and In terior P oin t Optimization for Efficien t In v erse Design in Nanophotonics Y annik Mahlau* 1,4 , Y annic k Augenstein 4 , T yler W. Hughes 4 , Marius Lindauer 2,3 , and Bo do Rosenhahn 1,3 1 Institute of Information Pro cessing, Leibniz Universit y Hannov er, German y 2 Institute of Artificial Intelligence, Leibniz Universit y Hannov er, German y 3 L3S Research Cen ter, Hanno v er, German y 4 Flexcompute, W atertown, MA, USA *Email: mahlau@tn t.uni-hanno v er.de Abstract In verse design, particularly geometric shap e optimization, pro vides a systematic approach for dev el- oping high-p erformance nanophotonic devices. While numerous optimization algorithms exist, previous global approac hes exhibit slo w conv ergence and conv ersely local search strategies frequently b ecome trapp ed in lo cal optima. T o address the limitations inherent to both lo cal and global approaches, w e in tro duce BONNI: Ba yesian optimization through neural netw ork ensemble surrogates with interior point optimization. It augmen ts global optimization with an efficient incorp oration of gradien t information to determine optimal sampling p oints. This capability allows BONNI to circumv ent the lo cal optima found in many nanophotonic applications, while capitalizing on the efficiency of gradient-based optimization. W e demonstrate BONNI’s capabilities in the design of a distributed Bragg reflector as well as a dual-lay er grating coupler through an exhaustive comparison against other optimization algorithms commonly used in literature. Using BONNI, w e were able to design a 10-lay er distributed Bragg reflector with only 4.5% mean sp ectral error, compared to the previously rep orted results of 7.8% error with 16 lay ers. F urther designs of a broadband wa veguide tap er and photonic crystal wa veguide transition v alidate the capabilities of BONNI. In tro duction The design of comp onents for nanophotonic applications is challenging and often inv olv es lab or-in tensive man ual iterations. Man y optimal designs defy h uman intuition, and the high-dimensional, non-con vex parameter spaces in volv ed remain challenging even for automated optimization metho ds. In verse design automates the search for optimal design parameters through an optimization algorithm without human in- terv ention [1, 2]. It is categorized in to tw o primary subfields: top ology optimization and shap e optimization. T op ology optimization modifies material distribution directly across a discretized domain, often in volving thousands of v ariables. While this approac h offers significant geometric flexibility , it p oses challenges re- garding manufacturing v ariabilit y [3, 4] and the integration of strict fabrication constrain ts [5, 6, 7, 8, 9]. Consequen tly , we fo cus on shap e optimization, where the geometry is defined through explicit parameteri- zation with a small num b er of design v ariables. This problem is form ulated as finding the optimal design v ector x ∗ ∈ arg max x ∈X f ( x ) , where X ⊊ R d represen ts the feasible design space. Optimization strategies for solving this problem generally fall into tw o categories: global and gradien t- based metho ds. Global approaches, such as P article Swarm Optimization (PSO) [10] and Genetic Algorithms (GA) [11], rely on sto chastic sampling to explore the landscap e of f ( x ) . While robust, these metho ds suffer from the curse of dimensionalit y , as the sampling density required to locate solutions grows exp onen tially with the num b er of design parameters. Con versely , gradient-based (or lo cal) metho ds leverage the gradien t 1 ∇ f to guide the search direc tion. By utilizing the adjoint metho d [12], these gradients can be computed at a cost roughly equiv alent to one additional sim ulation. This makes gradien t-based schemes highly efficien t for high-dimensional problems. How ever, in non-con vex landscap es, they are susceptible to con vergence at lo cal optima, p oten tially failing to reach the global optimum x ∗ . In nanophotonic shap e optimization, the ob jectiv e landscap e is usually characterized by a multitude of lo cal optima [13]. F or example, in Distributed Bragg Reflectors (DBRs) [14, 15], the interference b et ween reflected and transmitted w av es depends cyclically on la yer thickness, creating an oscillatory ob jective function. F urthermore, the geometric constrain ts imp osed b y low-dimensional shap e parameterization often restrict the design space, increasing the num b er of lo cal optima even more. V arious optimization algorithms are emplo yed in nanophotonic inv erse design. This v ariety stems from a lack of comparative studies and the inherent difficult y of the applications [16, 17, 18]. A simple lo cal optimization algorithm is gradient descen t with the Adam optimizer [19], which adaptiv ely estimates the momen tum during optimization. The Adam optimizer is the standard c hoice for optimizing the parameters of neural netw orks due to its memory efficiency and capability of working with batc hed training data. Another common algorithm is L-BF GS, which is a quasi-Newton algorithm estimating the Hessian matrix using limited memory during optimization [20]. Alternativ ely , the Metho d of Mo ving Asymptotes (MMA) [21] generates a sequence of conv ex separable subproblems using rational function approximations, where the curv ature is con trolled by adjusting the p osition of v ertical asymptotes at each iteration. This approac h is p opular in in verse design due to the abilit y of incorp orating non-linear constraints as well as quic k conv ergence. Complemen ting these lo cal methods, a v ariet y of global optimization approaches are utilized in nanopho- tonics. PSO [10] is a p opulation-based algorithm, in which a swarm of candidate solutions iteratively explores the searc h space by adjusting their velocities according to their own b est-kno wn p ositions as well as the global optim um. Since PSO do es not include gradien t information, it can b e employ ed in applications where the gradien t is difficult or imp ossible to obtain. How ever, as a consequence, con vergence is also typically slow er than that of gradien t-based algorithms, esp ecially in high-dimensional applications. Another gradien t-free global optimization approach is the Cov ariance Matrix Adaptation Evolution Strategy (CMA-ES) [22]. It is a sto c hastic algorithm sampling candidate solutions from a multiv ariate normal distribution. During optimiza- tion, it adaptiv ely up dates the cov ariance matrix to learn the correlations and correct scaling of the ob jective landscap e. Bay esian optimization takes a more principled approach by learning a surrogate mo del of f using previous samples, which is used to determine the optimal next sampling p oint. Ba yesian optimization is a well-studied algorithm with prov able conv ergence guaran tees, where its application to high-dimensional applications is an emerging field [23, 24, 25]. F or example, T uRBO incorp orates lo cal probabilistic mo dels in to the optimization lo op b y maintaining a trust region [26]. Ho wev er, due to the need to sample the entire design space to build an effective surrogate mo del, gradient- free Ba yesian optimization does not scale well to applications with more than appro ximately 10 design parameters, which includes the ma jorit y of nanophotonic design tasks. One approach to alleviate the burden of many high-fidelity simulations, which are costly even using GPU-acceleration [27, 28], is using m ulti- fidelit y optimization strategies [29]. Even though this reduces simulation cost, balancing the simulation sp eed with accurate results can b e difficult. Therefore, we fo cus on high-fidelity simulations and prop ose BONNI, a global optimization approac h capable of efficiently incorporating gradient information in to the optimization process. BONNI combines Bay esian optimization, neural netw ork ensemble surrogate mo dels and Interior Poin t Optimization (IPOPT) [30]. While it is also p ossible to incorp orate gradient information in to standard Bay esian optimization, the computational complexity of Gaussian pro cess regression scales cubically in the num b er of observ ations. This issue is further comp ounded when gradient observ ations expand the effective dataset size by a factor of d + 1 , limiting its scalability in high-dimensional applications [31, 32]. In contrast, BONNI lev erages the expressivity of neural netw orks as function approximators for surrogate mo deling [33, 34, 35], which scales w ell to man y dimensions. Internally , BONNI learns the mapping from design parameters to a probability distribution ov er the figure of merit via the surrogate mo del. During optimization, the probability distribution is used to determine the next sampling p oin t b y computing the exp ected improv ement ov er the current b est design parameters. This process of learning a surrogate and determining the next sampling p oint is rep eated un til conv ergence to a global optimum or the computational 2 0.4 0.2 0.0 Fn. V alue 4 2 0 2 4 P arameter V alue 100 50 Acq. V alue Surrogate Prediction True Function Observations Next Query Acquisition Function Figure 1: Visualization of the components of BONNI. In the upp er plot, the surrogate ensemble is trained on four observ ations (red dots) and gradients (red arrows), giv en through ev aluations of the true function (dashed black line). The individual neural net work predictions in the ensemble are visualized through colored lines, forming a confidence measure of the surrogate model. In the b ottom plot, the exp ected improv ement acquisition v alue is displa yed, which is calculated based on mean and standard deviation of the ensemble predictions. The maxim um of the acquisition function (green dashed line) is used as the next sampling p oint for function ev aluation (green star). After including the newly sampled p oin t in the dataset of sampled p oin ts, this pro cess rep eats until conv ergence or computational budget is exhausted. budget is exhausted. The full optimization pip eline of BONNI is published op en-source 1 with a Python in terface to facilitate its adoption. W e demonstrate the capabilities of BONNI through t wo inv erse design applications. Our first application addresses the need for distributed Bragg reflectors for indium gallium nitride (InGaN) micro Light Emitting Dio des ( µ -LEDs). Subsequen tly , we also optimize a dual-lay er grating coupler for maximizing transmission efficiency at the interfaces of photonic in tegrated circuits. Additionally , w e pro vide further studies on the design of a broadband w av eguide tap er and photonic crystal wa veguide transition in the supplementary material. Metho ds In optimization applications, one aims to find a maximum x ∗ ∈ arg max x ∈X f ( x ) where f is a blac k b ox function lac king an analytical closed-form expression. The domain X ⊊ R d in our applications is a b ounded subset of Cartesian space with d dimensions, defined through a box constraint in every dimension. F or nanophotonic applications, the function f is ev aluated through a n umerical simulation, which is exp ensive. Ho wev er, despite the high computational cost of simulations, the gradient of f is av ailable through differ- en tiable simulation soft ware [27, 36]. With the adjoint m ethod [12], computing the gradient ∇ f requires appro ximately the same computational resources as the ev aluation of f itself. Ba y esian Optimization with Neural Netw ork Ensem bles Our optimization algorithm BONNI follows similar steps to standard Bay esian optimization with the addition of gradient information. BONNI trains a surrogate mo del on n previously observ ed triplets of input v ectors, function v alues and gradien ts x ( i ) , f ( x ( i ) ) , ∇ f ( x ( i ) ) with 1 ≤ i ≤ n . At the b eginning of optimization, if no previous observ ations are a v ailable, a fixed n umber of input v alues are randomly sampled and ev aluated. The goal of the surrogate mo del is to appro ximate the function f and its gradient. Sp ecifically , the surrogate mo del learns a mapping from input v alues x ∈ X to a probability distribution ov er function v alues f ( x ) . In gradient- free Bay esian optimization, Gaussian pro cesses are used for this task. How ever, while there hav e b een efforts to incorporate gradient information into the Gaussian pro cess surrogates of Bay esian optimization [31], the computational complexit y makes the usage in man y applications infeasible. Instead, we train an ensemble 1 The BONNI and IPOPT implementation can b e accessed at https://github.com/ymahlau/bonni . 3 Algorithm 1 BONNI Require: Domain X , Ob jectiv e f , Gradien t ∇ f 1: Initialize dataset D with random samples 2: while budget not exhausted do 3: 1. Surrogate T raining 4: T rain NN ensem ble { g ( · | θ ( j ) ) } m j =1 on D 5: Minimize loss eq. (1) and eq. (2) 6: 2. Acquisi tion Optimization 7: x next ← arg max x ∈X EI ( x ) using IPOPT 8: 3. Ev aluation and Up date 9: D ← D ∪ { ( x next , f ( x next ) , ∇ f ( x next ) } 10: end while 11: return x ∗ ∈ arg max ( x, · , · ) ∈D f ( x ) of neural net works [33, 37]. A neural netw ork ensem ble is a set of neural netw orks that ha ve the same arc hitecture, but different parameters. Since each netw ork in the ensemble yields a differen t output, w e can quan tify the predictive uncertaint y by measuring the v ariance among the mo del outputs. Other neural net work arc hitectures capable of capturing uncertaint y are Bay esian neural netw orks (BNNs) [38, 39], often implemen ted through drop out [40]. How ever, we c ho ose ensembles since they exhibit faster and more stable training and prediction qualities compared to BNNs [41]. Eac h net work in the ensemble consists of 4 fully connected lay ers with 256 hidden units, 8 normalization groups [42] and gelu activ ation function [43] in all but the last la yer. This architecture was c hosen to balance mo del capacity with training speed. T o train the neural netw orks in the ensemble, their outputs are optimized to fit function v alues and gradients at the previously sampled input p oints. W e use g ( x ( i ) | θ ( j ) ) with 1 ≤ j ≤ m to denote the prediction of the neural net work with parameters θ ( j ) in an ensem ble of size m for the sampling p oint of index i . The loss functions for fitting function v alues and gradien ts are L f = 1 nm n X i =1 m X j =1 f ( x ( i ) ) − g ( x ( i ) | θ ( j ) ) 2 , (1) L ∇ = 1 dnm n X i =1 m X j =1 ∇ f ( x ( i ) ) − ∂ g ( x ( i ) | θ ( j ) ) ∂ x ( i ) 2 2 , (2) where n is the n umber of training data p oin ts. The full loss is defined as L = L f + L ∇ , which is optimized using the Adam optimizer with decoupled weigh t decay regularization [19, 44] and a cosine learning rate sc hedule [45]. Although a weigh ting hyperparameter could balance the loss terms, we omit it. The high capacit y of the ensemble allo ws it to fit b oth targets with negligible error, rendering weigh ting unnecessary . Consequen tly , all net works in the ensem ble learn to closely matc h function v alues and gradients at the sampled p oin ts. While this tight fit to observ ations could in principle reduce diversit y b etw een ensemble mem b ers near sampled p oin ts, we find that the differen t random initializations [46] main tain sufficient predictiv e diversit y in unexplored regions to drive effective exploration. Within regions far from the sampled data, many different interpolations are plausible such that the v ariance b etw een the mo dels in the ensem ble is high. In contrast, close to s ampled data p oin ts, the mo dels are equally constrained, which leads to v ery similar predictions. Therefore, the v ariance b etw een predictions can b e used for uncertain ty estimation. In fig. 1, the differen t mo del predictions of a trained ensemble are visualized. Subsequen tly , the utility of a proposed sampling p oin t x is ev aluated based on the trained surrogate mo del. Given the surrogate’s probabilit y distribution o ver the function v alues f ( x ) , an acquisition function balances the exploration of regions with high uncertain ty and the exploitation of promising regions with low uncertain ty . In Bay esian optimization, a common choice of acquisition function is the Exp ected Improv ement (EI) [47, 48], which we also use for BONNI. The EI is defined as the exp ected increase in function v alue o ver 4 0 50 100 150 200 Simulations 0.4 0.3 0.2 0.1 Incumbent V alue B ONNI Default B O PSO CMA-ES IPOPT MMA L-BFGS Adam (a) 10d 0 50 100 150 200 Simulations 0.4 0.3 0.2 0.1 (b) 50d 0 50 100 150 200 Simulations 0.4 0.3 0.2 0.1 (c) 100d Figure 2: Comparison of differen t optimization algorithms on the Rastrigin function in (a) 10, (b) 50 and (c) 100 dimensions. F or all three exp eriments, function v alues are rescaled to the in terv al [ − 1 , 0] . The algorithms with dotted lines are local gradient-based algorithms while the solid lines visualize global algorithms. W e ev aluate the incum b ent, whic h is the b est v alue found giv en a n umber of sim ulations. All optimizations w ere p erformed ov er 100 random initial configurations. The dark lines represent the mean and the shaded regions the standard error o ver these 100 individual runs. all previous samples through the new sample. This is expressed as EI ( x | f ( ˆ x )) = E [max( f ( x ) − f ( ˆ x ) , 0)] = σ ( x ) h µ ( x ) − f ( ˆ x ) σ ( x ) , (3) where ˆ x ∈ arg max 1 ≤ i ≤ n f ( x ( i ) ) is the currently b est sampled p oin t. The function h is defined as h ( z ) = ϕ ( z ) + z Φ( z ) with ϕ and Φ b eing the PDF and CDF of a standard normal distribution, resp ectiv ely . In our implemen tation, we use the logarithmic EI [49], which is a n umerically stable v ariant of EI. W e note that the EI acquisition function assumes a Gaussian predictive distribution, whereas the ensemble provides only empirical mean and v ariance estimates. F or mo derately sized ensembles, this approximation may in tro duce bias. How ever, we find it to be effective in practice for guiding the optimization, consistent with prior work on ensemble-based Bay esian optimization [37]. As a next step, the optimal next sampling p oint is determined by lo cating the maximum of EI ov er the input domain X . This is an optimization problem of similar complexity to the original problem of optimizing the function f . Ho wev er, the ev aluation of the surrogate g is orders of magnitude faster than the original function f , such that this optimization b ecomes feasible. W e use the IPOPT [30] algorithm to p erform this optimization, whic h we describ e in more detail in the supplementary material. While w e choose IPOPT due to its strong optimization capabilities for this step, in general any optimization algorithm could b e used. After determining the new sampling p oin t x ( n +1) ∈ arg max x ∈X EI ( x | f ( ˆ x )) , the exp ensive function f ( x ( n +1) ) and its gradien t ∇ f ( x ( n +1) ) are ev aluated. Once this new triplet is added to the set of previous observ ations, the optimization con tinues by rep eating the same pro cess un til the time or computational budget is exhausted. This pro cess is summarized in algorithm 1. Moreov er, in fig. 1, the connection b etw een the surrogate mo del, the acquisition function and the next sampling p oint is visualized for a single iteration in the BONNI optimization lo op. Syn thetic V alidation T o v alidate the functionalit y of BONNI, we test it in a computationally inexpensive b enchmark function. The Rastrigin function with d dimensions is defined as f Rastrigin = − 10 d − d X t =1 x 2 t − 10 cos (2 π x t ) (4) on the domain [ − 5 . 12 , 5 . 12] d . This function contains many lo cal optima with a single global optimum of v alue zero. W e rescale the function such that the function v alues are in the range [ − 1 , 0] for b etter comparison across different num b ers of dimensions. 5 0 500 1000 1500 2000 Number of Simulations 0.30 0.25 0.20 0.15 0.10 0.05 Incumbent Spectral Error B ONNI Default B O CMA-ES PSO IPOPT L-BFGS MMA Adam (a) Optimization Results 500 600 700 800 W avelength (nm) 0.00 0.25 0.50 0.75 1.00 Transmission Design T arget (b) T ransmission Sp ectrum 150.9 nm 100.1 nm 53.8 nm 279.1 nm 58.8 nm 92.2 nm 163.4 nm 92.6 nm 167.5 nm 394.2 nm TiO2 SiO2 (c) La yer Heights Figure 3: Optimization results for the DBR. In (a), the optimization results of the differen t algorithms are visualized. The algorithms with dotted lines are lo cal gradient-based algorithms while the solid lines visualize global algorithms. W e ev aluate the incum b ent, which is the b est v alue found giv en a n umber of sim ulations. All optimizations w ere p erformed ov er 10 random initial configurations. The dark lines represent the mean and the shaded regions the standard error ov er these 10 individual runs. In (b), the sp ectrum of the b est design found by BONNI is display ed (blue) and compared to the target sp ectrum, which is a step function around 620 nm (red). In (c), the lay er heigh ts for this design of silicon dioxide (blue) and titanium dio xide (red) are visualized. In fig. 2, the optimization results for the 10-, 50- and 100-dimensional Rastrigin function are display ed. These dimensionalities represen t typical nanophotonic s hape optimization applications. In all three v ariants, BONNI achiev es the best results, v alidating the adv antage of com bining global optimization with gradient information. Notably , the second b est results are achiev ed b y IPOPT, indicating its efficacy as a standalone optimizer. In contrast, gradient-free global optimization fails to conv erge to comp etitive solutions for the 50- and 100-dimensional optimization problems. Only in the 10-dimensional example do es Bay esian optimization ac hieve results comparable to IPOPT within the simulation budget. Results W e next apply BONNI to real nanophotonic design tasks. T o ensure a rigorous comparison, we use the n umber of simulations as a metric of computational cos t. Because the adjoin t metho d requires an addi- tional simulation to compute gradients, gradient-based algorithms are limited to half the iteration count of deriv ative-free metho ds to reflect the same computational budget. In all our optimizations, we plot the b est result found given a num b er of simulations in an incumbent plot. This reflects practical design constraints, where the goal is the best results within a sp ecific computational bu dget. F or statistically relev ant results, we run optimizations multiple times and rep ort mean and standard error. Due to the computational cost of sim- ulations, the real design tasks are p erformed ov er 10 random initial configurations, compared to 100 for the syn thetic b enc hmark. While this limits statistical pow er, the consisten t ranking of algorithms across seeds and the magnitude of performance differences supp ort the conclusions drawn. T o facilitate repro ducibility , w e also publish the full co de for the simulation setup online. The p erformance of an optimization algorithm dep ends on the choice of hyperparameters. While hy- p erparameter optimization can increase p erformance [50, 51], it is prohibitively exp ensiv e for nanophotonic applications. T o reflect a realistic setting with our b enc hmarks, we do not p erform sp ecific hyperparameter optimization and instead use the default parameters of the resp ectiv e frameworks. W e report the detailed h yp erparameters in the supplemen tary material. W e note that BONNI incurs additional computational o verhead p er iteration for surrogate training and acquisition function optimization. In our exp erimen ts, this o verhead amounts to approximately 5 seconds p er iteration. F or applications inv olving full wa ve sim ulations taking min utes to hours, this ov erhead is negligible; for inexp ensiv e simulations suc h as the T ransfer Matrix Metho d (TMM), the ov erhead b ecomes a larger fraction of total run time. 6 Distributed Bragg Reflector The fabrication of classical aluminum gallium indium phosphide (AlGaInP) µ -LEDs is difficult to scale to sizes below 20 µ m due to their strong decrease in efficiency at this scale. Therefore, InGaN is a preferred tec hnology for red light µ -LEDs, which has a higher efficiency at micrometer sizes [52, 53]. Additionally , InGaN µ -LEDs are less complex to fabricate and hav e b etter thermal stability . How ev er, due to the Quantum- Confined Stark Effect (QCSE), red InGaN µ -LEDs change color under v arying current. Specifically , a blue shift o ccurs, degrading color accuracy significantly [54]. While recent adv ances in manufacturing tec hniques for reducing the quantum-mec hanical stress of InGaN are able to alleviate the QCSE [55], blue shift remains an issue. DBRs ha ve b een prop osed as a p ossible solution for filtering the undesired shorter w av elengths of the visible sp ectrum [56]. They are structures of alternating la yers with high- and low-refractiv e index materials. By adjusting the heigh ts of the different lay ers, DBRs can con trol transmission and reflection at different w av elengths [57]. While a larger num b er of la yer pairs allo ws more fine-grained control o ver the transmission sp ectrum, it also increases fabrication cost. Even though typical DBR designs require more than 10 lay ers to ac hieve high efficiencies [58, 59], we show that it is p ossible to design a DBR filter with only five lay er pairs using BONNI. In this exp eriment, we use titanium dio xide and silicon dioxide for a high and lo w refractive index, resp ectively . F or simulation, we use the tmm Python library [60]. W e note that TMM simulations are computationally inexp ensiv e compared to full-wa ve metho ds, making this b enchmark primarily a test of optimization quality rather than sample efficiency under expensive ev aluations. The refractiv e indices of titanium dioxide and silicon dioxide are set to 2 . 5 and 1 . 46 resp ectively , with a background refractive index of 1. The target sp ectrum is an idealized step profile with zero transmission b elo w 620nm and full transmission ab ov e this threshold. W e use the av erage error b et ween the design and the target sp ectrum as the ob jective function to minimize, computed at 100 equally spaced wa velength bins b etw een 500 and 800nm. The ob jective function is defined as f DBR ( x ) = − 1 | Λ | X λ ∈ Λ 1 λ> ˆ λ − T ( x, λ ) , (5) where 1 c is the iden tity function for condition c , ˆ λ is the cutoff wa velength at 620nm and T ( x, λ ) denotes the transmission of the DBR with lay er heights x at wa v elength λ . In fig. 3, the optimization results are visualized. BONNI achiev es the best results, surpassing lo cal optimization algorithms after just a few hundred simulations. All of the lo cal optimization algorithms quic kly stagnate in a lo cal optim um since the design application has a lot of lo cal optima. Among the lo cal optimization algorithms, IPOPT yields the b est results. Standard gradient-free Ba yesian optimization is also able to surpass the lo cal optimizers, but only muc h later than BONNI. The b est design found by BONNI ac hieves a mean sp ectral error of 4 . 5% , corresp onding to a p eak suppression of -19.9 dB b elo w 620 nm and a verage transmission of 97% ab o ve 620 nm. Compared to previously rep orted mean sp ectral error of 7 . 8% with custom-designed 16 la yers [56], BONNI is able to achiev e b etter results with few er lay ers. Dual-La y er Grating Coupler A p ersisten t challenge in photonic integrated circuits is the in terface b etw een c hip and macroscopic optical fib ers [61, 62]. While edge coupling achiev es high transmission efficiency , it requires precise alignmen t and is inheren tly restricted to the die dicing stage [63, 64]. Therefore, near vertical grating couplers hav e b ecome a common solution for wafer-scale pro cess control [65]. Since single-lay er grating couplers ha ve transmission losses of m ultiple decibels and enhancemen ts suc h as reflectors add fabrication costs, dual-lay er grating couplers hav e b ecome an emerging technology [66, 67]. Gradien t-based design of grating couplers is notoriously difficult as the optimization landscap e contains man y lo cal optima due to the inheren t resonances. Figure 4a displays the parameterization and sim ulation scene of the grating coupler. The simulation setup includes a source with wa v elength 1 . 55 µ m and a 10 -degree angle to preven t reflections. Constructed on a silicon substrate with silicon oxide cladding of thickness 2 µ m, the lo wer grating lay er consists of silicon with thickness 90 nm. In contrast, the upp er lay er consists of silicon nitride of thic kness 400 nm, with a distance of 300 nm to the low er lay er. The widths and gaps of the 7 Substrat e Output W aveguide Source SiN - Gap SiN - W idth Si - Of fset Si - W idth Si - Gap (a) P arameterization and Simulation Scene 0 50 100 150 200 Number of Simulations 0.0 0.1 0.2 0.3 0.4 0.5 Incumbent Transmission B ONNI Default B O CMA-ES PSO IPOPT L-BFGS MMA Adam (b) Optimization Results Figure 4: Comparison of differen t optimization algorithms on the dual-la yer grating coupler. In (a), the setup of the grating coupler is sho wn. A source (yello w) at the top emits a Gaussian b eam onto the t wo grating la yers of silicon Nitride (green) and silicon (pink). T ransmission is measured at the output w a veguide on the right side. The tw o grating lay ers are placed on top of a silicon substrate (brown). In (b), the sim ulation results are displa yed. W e ev aluate the incum b ent, which is the b est design found given a num b er of simulations. All optimizations were performed on 10 random initial configurations and we rep ort mean (solid line) as well as standard error (shaded area). The algorithms with dotted lines are lo cal gradient-based algorithms while the solid lines visualize global algorithms. x (µm) y (µm) 0 5 10 15 20 0 5 (a) Grating design (b) E y -field distribution Figure 5: Analysis of the b est grating coupler design pro duced by BONNI. In (a), the design configuration with gaps and widths of gratings is shown. In (b), the simulation result of the design is visualized. silicon and silicon nitride gratings are the adjustable parameters for optimization. A dditionally , we include parameters for a lateral offset for each of the la yers. With 15 gratings and 15 gaps in b oth lay ers, the total n umber of parameters for this application is 62. F or this b enchmark, the figure of merit is the transmission at a wa v elength of 1 . 55 µ m. In fig. 4b, the results of optimizations are sho wn. BONNI achiev es the highest transmission efficiency of -2.2 dB with a mean of -2.6 ± 0.3 dB across seeds, follow ed by IPOPT at -2.9 ± 0.7 dB. The gradient-based lo cal optimization algorithms, namely L-BFGS, Adam and MMA, only conv erge to a w orse lo cal optimum. Ho wev er, they p erform b etter than the gradient-free global optimization algorithms, namely default BO, CMA-ES and PSO, whic h only find sub optimal solutions with less than 20% transmission. In fig. 5, the b est design found by BONNI is visualized. Discussion Our optimization study demonstrates that BONNI consistently yields sup erior designs compared to the other ev aluated optimization algorithms. It clearly outp erforms the alternative global optimization approaches PSO, CMA-ES, and gradient-free Bay esian Optimization across all b enc hmarks. The main dra wback of 8 BONNI is the training time required for the ensemble surrogate, particularly in the absence of GPU accel- eration. BONNI requires ab out five seconds to determine the optimal next sampling p oin t when using GPU acceleration. Without GPU acceleration, the computation time is about five times higher, though sp ecific n umbers dep end on the hardw are setup and algorithm hyperparameters. While this ov erhead is negligible when the underlying simulations are time-consuming, it b ecomes more pronounced during short sim ulations. Ho wev er, even in scenarios inv olving rapid function ev aluations like TMM simulations for the distributed Bragg reflectors, the p erformance gap b etw een BONNI and comp eting algorithms is substantial; the sup erior solution quality justifies the additional computational time b etw een samples. Remark ably , IPOPT consistently achiev ed the best p erformance among all gradien t-based algorithms and rank ed second ov erall, trailing only BONNI in nearly all scenarios. This indicates that IPOPT is a capable optimization approac h, despite being rarely utilized in the curren t nanophotonic literature [68, 69, 70]. Consequen tly , we recommend IPOPT o ver other standard gradien t-based approac hes as a lo cal optimization algorithm. The selection b etw een lo cal and global optimization strategies remains problem-dependent. In high- dimensional parameter spaces with thousands of design v ariables, lo cal optimization typically outp erforms global metho ds, as it can rapidly con verge to a local optimum. In con trast, global approaches fail to sufficien tly explore high-dimensional parameter spaces due to the curse of dimensionalit y . Similarly , in smo oth optimization landscap es with few lo cal optima, lo cal metho ds are generally more efficien t. How ev er, most shap e optimization applications are characterized by up to 75 design parameters with highly complex, m ulti-mo dal landscap es. In these contexts, global optimization yields sup erior results than lo cal optimization, pro vided there is a sufficient sampling budget. As a practical guideline, we recommend BONNI for design problems featuring a difficult optimization landscap e and few er than approximately 75 parameters, where gradien t descent is prone to entrapmen t in sub optimal lo cal minima. In very high-dimensional settings, suc h as top ology optimization where train- ing BONNI’s surrogate b ecomes computationally prohibitive, IPOPT or direct gradient metho ds remain the pragmatic c hoice. F urthermore, in low-dimensional applications with smo oth optimization landscapes, IPOPT offers comparable solution quality with low er algorithmic complexit y . Finally , our results emphasize the critical role of gradient information in shap e optimization, as shown by the consistently higher p er- formance of gradient-based algorithms ov er gradient-free alternativ es in the 62-dimensional grating coupler b enc hmark. F rom an application p ersp ectiv e, our exp eriments suggest that substantial p erformance gains are attain- able in many photonics design applications by selecting the appropriate optimization algorithm. In the design of b oth distributed Bragg reflectors and grating couplers, BONNI demonstrated the p otential to generate sup erior structures. F urthermore, the strong performance of IPOPT, which is rarely used in the photonics literature, highlights a lack of rigorous comparative studies in the field of inv erse design. Conclusion W e addressed the limitations of previous optimization strategies in nanophotonic in verse design by in tro- ducing the BONNI algorithm: Bay esian optimization with neural net work ensemble surrogates and in terior p oin t optimization. Through tw o design tasks, w e demonstrated that BONNI is the sup erior choice for applications that hav e many local optima and are difficult to optimize through gradien t descent. In both the distributed Bragg reflector and the dual-la yer grating coupler, BONNI ac hieved b etter results than the other algorithms tested. Using BONNI, we w ere able to design a distributed Bragg reflector with higher p erformance using fewer lay ers than previous results. Moreov er, for constrained computational budgets, IPOPT prov es to b e a highly efficien t standalone optimizer, particularly when the num b er of lo cal optima is mo derate or when simulation cost is low. F uture work will explore the application of BONNI to mixed-v ariable domains. A capability of BONNI is its native supp ort for mixed-v ariable optimization problems con taining b oth differentiable and non- differen tiable contin uous parameters. This is achiev ed b y masking the gradient loss for parameters where gradien ts are una v ailable, while still lev eraging gradient information for the remaining parameters. T o the b est of our knowledge, BONNI is unique among Bay esian optimization methods in offering this capability . While b oth applications presented here are fully differentiable, this mixed-v ariable supp ort holds significant 9 p oten tial for applications suc h as radio-frequency an tenna design, where material choices or discrete struc- tural features co exist with contin uously tunable geometric parameters. Demonstrating this capability on mixed-v ariable photonic design problems is a primary direction for future work. A c kno wledgemen ts The authors thank Luk as Berg and Jari Luca Glüß for their help reviewing the manuscript. This work w as supp orted by the F ederal Ministry of Education and Research (BMBF), Germany , under the AI service center KISSKI (grant no. 01IS22093C), the Deutsche F orsc hungsgemeinsc haft (DFG) under German y’s Excellence Strategy within the Clusters of Excellence Pho enixD (EXC2122) and Quan tum F rontiers-2 (EXC2123) , the Europ ean Union under gran t agreement no. 101136006 – XTREME. Additionally , this work was funded b y the Deutsche F orsc hungsgemeinsc haft (DF G, German Researc h F oundation) – 517733257. Supp orting information The following files are av ailable free of charge. • Supplemen tary Information: F urther exp erimen ts, analysis and a detailed list of the hyperparameters used in our optimizations. References 1. S. Molesky; Z. Lin; A. Y. Piggott; W. Jin; J. V uck ov ić; A. W. R odriguez. Inv erse design in nanopho- tonics. In: Natur e Photonics 2018 , 12, 659–670. 2. J. Noh; T. Badlo e; C. Lee; J. Y un; S. So; J. Rho. In verse design meets nanophotonics: F rom computa- tional optimization to artificial neural netw ork. In: Intel ligent Nanote chnolo gy 2023 , 3–32. 3. Y. Augenstein; C. Ro ckstuhl. Inv erse design of nanophotonic devices with structural in tegrity. In: ACS photonics 2020 , 7, 2190–2196. 4. S. Raza; M. Hammo o d; N. A. Jaeger; L. Chrostowski. F abrication-aw are inv erse design with shap e optimization for photonic in tegrated circuits. In: Optics L etters 2024 , 50, 117–120. 5. A. Y. Piggott; J. Pet ykiewicz; L. Su; J. V učk ović. F abrication-constrained nanophotonic inv erse design. In: Scientific r ep orts 2017 , 7, 1786. 6. M. Chen; J. Jiang; J. A. F an. Design space reparameterization enforces hard geometric constraints in in verse-designed nanophotonic devices. In: ACS Photonics 2020 , 7, 3141–3151. 7. M. F. Sch ub ert; A. K. Cheung; I. A. Williamson; A. Spyra; D. H. Alexander. Inv erse design of photonic devices with strict foundry fabrication constraints. In: ACS Photonics 2022 , 9, 2327–2336. 8. F. Sch ub ert; Y. Mahlau; K. Bethmann; F. Hartmann; R. Caspary; M. Munderloh; J. Ostermann; B. Rosenhahn. Quantized in verse design for photonic integrated circuits. In: A CS ome ga 2025 , 10, 5080– 5086. 9. T. Dai; Y. Shao; C. Mao; Y. W u; S. Azzouz; Y. Zhou; J. A. F an. Shaping freeform nanophotonic devices with geometric neural parameterization. In: npj Computational Materials 2025 , 11, 259. 10. J. Kennedy; R. Eb erhart. Particle swarm optimization. In: Pr o c e e dings of ICNN’95-international c on- fer enc e on neur al networks . 4 . ieee. 1995, 1942–1948. 11. S. Kato ch; S. S. Chauhan; V. Kumar. A review on genetic algorithm: past, present, and future. In: Multime dia to ols and applic ations 2021 , 80, 8091–8126. 12. L. S. Pon tryagin. Mathematic al the ory of optimal pr o c esses . Routledge, 2018. doi : 10.1201/9780203749319 . 13. R. Marzban; A. Adibi; R. P estourie. In verse design in nanophotonics via representation learning. In: A dvanc e d Optic al Materials 2026 , 14, e02062. 10 14. S. W ang. Principles of distributed feedback and distributed Bragg-reflector lasers. In: IEEE Journal of Quantum Ele ctr onics 1974 , 10, 413–427. 15. M. F. Sc hubert; J.-Q. Xi; J. K. Kim; E. F. Sc hubert. Distributed Bragg reflector consisting of high-and lo w-refractive-index thin film lay ers made of the same material. In: Applie d physics letters 2007 , 90. 16. P .-I. Schneider; X. Garcia Santiago; V. Soltwisc h; M. Hammerschmidt; S. Burger; C. Ro c kstuhl. Bench- marking fiv e global optimization approac hes for nano-optical shap e optimization and parameter recon- struction. In: ACS Photonics 2019 , 6, 2726–2733. 17. C. Lee; J. Rho. Benchmarking Optimization Metho ds Enabling Efficient Designs for Diverse Nanopho- tonic Applications. In: A dvanc e d Optic al Materials 2025 , 13, 2500195. doi : https : / / doi . org / 10 . 1002/adom.202500195 . 18. Y. Mahlau; M. Sc hier; C. Reinders; F. Sch ub ert; M. Bügling; B. Rosenhahn. Multi-Agent Reinforcement Learning for Inv erse Design in Photonic In tegrated Circuits. In: R einfor c ement L e arning Journal 2025 , 6, 1794–1815. 19. D. P . Kingma. Adam: A metho d for sto c hastic optimization. In: arXiv pr eprint arXiv:1412.6980 2014 . 20. D. C. Liu; J. No cedal. On the limited memory BFGS metho d for large scale optimization. In: Mathe- matic al pr o gr amming 1989 , 45, 503–528. 21. K. Sv anberg. The metho d of mo ving asymptotes—a new metho d for structural optimization. In: Inter- national journal for numeric al metho ds in engine ering 1987 , 24, 359–373. 22. N. Hansen; A. Ostermeier. Adapting arbitrary normal mutation distributions in evolution strategies: The co v ariance matrix adaptation. In: Pr o c e e dings of IEEE international c onfer enc e on evolutionary c omputation . IEEE. 1996, 312–317. 23. C. Hv arfner; E. O. Hellsten; L. Nardi. V anilla Bay esian Optimization Performs Great in High Dimen- sions. In: F orty-first International Confer enc e on Machine L e arning . 2024. 24. L. Papenmeier; M. Poloczek; L. Nardi. Understanding High-Dimensional Bay esian Optimization. In: F orty-se c ond International Confer enc e on Machine L e arning . 2025. 25. C. Doumont; D. F an; N. Maus; J. R. Gardner; H. Moss; G. Pleiss. W e Still Don’t Understand High- Dimensional Bay esian Optimization. In: arXiv pr eprint arXiv:2512.00170 2025 . 26. D. Eriksson; M. P earce; J. Gardner; R. D. T urner; M. Poloczek. Scalable global optimization via lo cal Ba yesian optimization. In: A dvanc es in neur al information pr o c essing systems 2019 , 32. 27. Flexcompute. Tidy3D: har dwar e-ac c eler ate d ele ctr omagnetic solver for fast simulations at sc ale . 2022. 28. Y. Mahlau; F. Sch ub ert; K. Bethmann; R. Caspary; A. C. Lesina; M. Munderloh; J. Ostermann; B. Rosenhahn. A flexible framework for large-scale FDTD simulations: op en-source inv erse design for 3D nanostructures. In: Photonic and Phononic Pr op erties of Engine er e d Nanostructur es XV . 13377 . SPIE. 2025, 40–52. 29. L. Lu; R. Pestourie; S. G. Johnson; G. Romano. Multifidelity deep neural op erators for efficient learning of partial differen tial equations with application to fast inv erse design of nanoscale heat transp ort. In: Physic al R eview R ese ar ch 2022 , 4, 023210. 30. A. Wäch ter; L. T. Biegler. On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. In: Mathematic al pr o gr amming 2006 , 106, 25–57. 31. X. Garcia-San tiago; S. Burger; C. Rockstuhl; P .-I. Sc hneider. Ba yesian optimization with improv ed scalabilit y and deriv ative information for efficien t design of nanophotonic structures. In: Journal of Lightwave T e chnolo gy 2021 , 39, 167–177. 32. D. Eriksson; K. Dong; E. Lee; D. Bindel; A. G. Wilson. Scaling Gaussian Pro cess Regression with Deriv atives. In: A dvanc es in Neur al Information Pr o c essing Systems . Ed. by S. Bengio; H. W allach; H. Laro c helle; K. Grauman; N. Cesa-Bianchi; R. Garnett. 31 . Curran Asso ciates, Inc., 2018. 33. J. Sno ek; O. Ripp el; K. Swersky; R. Kiros; N. Satish; N. Sundaram; M. Pat wary; M. Prabhat; R. Adams. Scalable Ba yesian Optimization Using Deep Neural Netw orks. In: Pr o c e e dings of the 32nd International Confer enc e on Machine L e arning . 37 . Pro ceedings of Machine Learning Research. PMLR, 2015, 2171– 2180. 11 34. M. Chen; R. Lup oiu; C. Mao; D.-H. Huang; J. Jiang; P . L alanne; J. A. F an. High sp eed simulation and freeform optimization of nanophotonic devices with ph ysics-augmented deep learning. In: ACS Photonics 2022 , 9, 3110–3123. 35. Y. Augenstein; T. Repan; C. Ro c kstuhl. Neural op erator-based surrogate solver for free-form electro- magnetic inv erse design. In: ACS Photonics 2023 , 10, 1547–1557. 36. Y. Mahlau; F. Sch ub ert; L. Berg; B. Rosenhahn. FDTD X: High-P erformance Op en-Source FDTD Sim ulation with Automatic Differentiation. In: Journal of Op en Sour c e Softwar e 2026 , 11, 8912. doi : 10.21105/joss.08912 . 37. B. Lakshminaray anan; A. Pritzel; C. Blundell. Simple and Scalable Predictiv e Uncertain ty Estimation using Deep Ensembles. In: A dvanc es in Neur al Information Pr o c essing Systems . Ed. b y I. Guy on; U. V. Luxburg; S. Bengio; H. W allach; R. F ergus; S. Vishw anathan; R. Garnett. 30 . Curran Asso ciates, Inc., 2017. 38. E. Goan; C. F o okes. “ Ba yesian neural netw orks: An in tro duction and survey”. In: Case Studies in Applie d Bayesian Data Scienc e: CIRM Je an-Morlet Chair, F al l 2018 . Springer, 2020, 45–87. 39. G. Makrygiorgos; J. H. S. Ip; A. Mesbah. T ow ards Scalable Bay esian Optimization via Gradien t- Informed Bay esian Neural Netw orks. In: arXiv pr eprint arXiv:2504.10076 2025 . 40. Y. Gal; Z. Ghahramani. Drop out as a bay esian approximation: Represen ting mo del uncertaint y in deep learning. In: international c onfer enc e on machine le arning . PMLR. 2016, 1050–1059. 41. F. K. Gustafsson; M. Danelljan; T. B. Schon. Ev aluating Scalable Bay esian Deep Learning Metho ds for Robust Computer Vision. In: 2020 IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition W orkshops (CVPR W) . 2020, 1289–1298. doi : 10.1109/CVPRW50498.2020.00167 . 42. Y. W u; K. He. Group normalization. In: Pr o c e e dings of the Eur op e an c onfer enc e on c omputer vision (ECCV) . 2018, 3–19. 43. D. Hendrycks. Gaussian Error Linear Units (Gelus). In: arXiv pr eprint arXiv:1606.08415 2016 . 44. I. Loshchilo v; F. Hutter. Decoupled W eight Decay Regularization. In: International Confer enc e on L e arning R epr esentations . 2019. 45. I. Loshchilo v; F. Hutter. SGDR: Stochastic Gradient Descent with W arm Restarts. In: International Confer enc e on L e arning R epr esentations . 2017. 46. K. He; X. Zhang; S. Ren; J. Sun. Delving deep into rectifiers: Surpassing human-lev el p erformance on imagenet classification. In: Pr o c e e dings of the IEEE international c onfer enc e on c omputer vision . 2015, 1026–1034. 47. J. Mo ckus. The application of Bay esian metho ds for seeking the extremum. In: T owar ds glob al opti- mization 1998 , 2, 117. 48. D. R. Jones; M. Schonlau; W. J. W elch. Efficient global optimization of exp ensiv e black-box functions. In: Journal of Glob al optimization 1998 , 13, 455–492. 49. S. Ament; S. Daulton; D. Eriksson; M. Balandat; E. Bakshy. Unexp ected impro vemen ts to exp ected impro vemen t for ba yesian optimization. In: A dvanc es in Neur al Information Pr o c essing Systems 2023 , 36, 20577–20612. 50. M. Lindauer; M. F eurer; K. Eggensp erger; A. Biedenk app; F. Hutter. T ow ards Assessing the Impact of Ba yesian Optimization’s Own Hyp erparameters. In: IJCAI 2019 DSO W orkshop . Ed. b y P . De Causmaec ker; M. Lom bardi; Y. Zhang. 2019. 51. J. Mo osbauer; M. Binder; L. Schneider; F. Pfisterer; M. Beck er; M. Lang; L. K otthoff; B. Bischl. Au- tomated Benchmark-Driv en Design and Explanation of Hyp erparameter Optimizers. In: IEEE T r ans- actions on Evolutionary Computation 2022 , 26, 1336–1350. 52. Z. Zh uang; D. Iida; K. Ohk aw a. InGaN-based red light-emitting dio des: from traditional to micro-LEDs. In: Jap anese Journal of Applie d Physics 2021 , 61, SA0809. 53. P . Li; J. Ewing; M. S. W ong; Y. Y ao; H. Li; S. Gandrothula; J. M. Smith; M. Iza; S. Nak amura; S. P . DenBaars. Adv ances in InGaN-based RGB micro-light-emitting dio des for AR applications: Status and p erspective. In: APL Materials 2024 , 12, 080901. issn : 2166-532X. doi : 10.1063/5.0222618 . 12 54. R.-H. Horng; C.-X. Y e; P .-W. Chen; D. Iida; K. Ohk aw a; Y.-R. W u; D.-S. W uu. Study on the effect of size on InGaN red micro-LEDs. In: Scientific r ep orts 2022 , 12, 1324. 55. Y.-S. Cheng; Y. D. Chen; D.-Y. Lin; M. Zhou; C.-C. Cheng; Y. F u; H. Y ang; C.-F. Lin. High-Efficiency and Stable Emission W a velength Red InGaN Light-Emitting Dio des with Porous Distributed Bragg Reflectors on Si Substrates. In: ACS Applie d Optic al Materials 2024 , 2, 2241–2247. 56. W.-C. Miao; Y.-H. Hong; F.-H. Hsiao; J.-D. Chen; H. Chiang; C.-L. Lin; C.-C. Lin; S.-C. Chen; H.-C. Kuo. Mo dified distributed Bragg reflectors for color stabilit y in InGaN red micro-LEDs. In: Nanoma- terials 2023 , 13, 661. 57. C. Sheppard. Appro ximate calculation of the reflection co efficien t from a stratified medium. In: Pur e and Applie d Optics: Journal of the Eur op e an Optic al So ciety Part A 1995 , 4, 665. 58. I. Y. Ab e; A. Mazzeo; A. S. F erlauto; M. I. Alay o; E. G. Melo. In verse design of distributed bragg reflector targeting a sharp reflectivit y sp ectrum. In: Photonics and Nanostructur es - F undamentals and Applic ations 2023 , 57, 101183. issn : 1569-4410. doi : https://doi.org/10.1016/j.photonics.2023. 101183 . 59. H.-J. Lee; J.-Y. Park; L.-K. Kw ac; J. Lee. Improv ement of Near-Infrared Light-Emitting Dio des’ Optical Efficiency Using a Broadband Distributed Bragg Reflector with an AlAs Buffer. In: Nanomaterials 2024 , 14. issn : 2079-4991. doi : 10.3390/nano14040349 . 60. S. J. Byrnes. Multila yer optical calculations. In: arXiv pr eprint arXiv:1603.02720 2016 . 61. W. Tian; Y. W ang; H. Dang; H. Hou; Y. Xi. Photonic Integrated Circuits: Research A dv ances and Challenges in Interconnection and Pac k aging T echnologies. In: Photonics 2025 , 12. issn : 2304-6732. doi : 10.3390/photonics12080821 . 62. G. Son; S. Han; J. Park; K. Kw on; K. Y u. High-efficiency broadband light coupling b etw een optical fib ers and photonic in tegrated circuits. In: Nanophotonics 2018 , 7, 1845–1864. doi : doi : 10. 1515 /nanoph - 2018- 0075 . 63. X. Mu; S. W u; L. Cheng; H. F u. Edge Couplers in Silicon Photonic In tegrated Circuits: A Review. In: Applie d Scienc es 2020 , 10. issn : 2076-3417. doi : 10.3390/app10041538 . 64. H.-S. Jang; H. Heo; S. Kim; H. Hwang; H. Lee; M.-K. Seo; H. K won; S.-W. Han; H. Jung. F abrication of a 3D mo de size conv erter for efficient edge coupling in photonic integrated circuits. In: Opt. Expr ess 2025 , 33, 6909–6917. doi : 10.1364/OE.541701 . 65. R. Marchetti; C. Laca v a; L. Carroll; K. Gradk owski; P . Minzioni. Coupling strategies for silicon pho- tonics integrated chips. In: Photon. R es. 2019 , 7, 201–239. doi : 10.1364/PRJ.7.000201 . 66. M. Dai; L. Ma; Y. Xu; M. Lu; X. Liu; Y. Chen. Highly efficient and p erfectly vertical c hip-to-fib er dual-la yer grating coupler. In: Opt. Expr ess 2015 , 23, 1691–1698. doi : 10.1364/OE.23.001691 . 67. V. Vitali; C. Lacav a; T. Domínguez Bucio; F. Y. Gardes; P . Petropoulos. Highly efficient dual-level grating couplers for silicon nitride photonics. In: Scientific R ep orts 2022 , 12, 15436. issn : 2045-2322. doi : 10.1038/s41598- 022- 19352- 9 . 68. S. Ro jas-Labanda; O. Sigm und; M. Stolpe. A short n umerical study on the optimization methods influence on top ology optimization. In: Structur al and Multidisciplinary Optimization 2017 , 56, 1603– 1612. 69. G. Angeris; J. V učk ović; S. Bo yd. Heuristic metho ds and p erformance bounds for photonic design. In: Optics Expr ess 2021 , 29, 2827–2854. 70. K. E. Swartz; D. A. White; D. A. T ortorelli; K. A. Jame s. T op ology optimization of 3D photonic crystals with complete bandgaps. In: Optics Expr ess 2021 , 29, 22170–22191. 71. N. Hansen; yoshihik oueno; ARF1; S. Cakmak; G. Kadleco v á; G. A. Lóp ez; K. Nozaw a; L. Rolshov en; Y. Akimoto; brieglhostis; D. Bro c khoff. CMA-ES/pycma: r4.4.1 . V ersion r4.4.1. No v. 2025. doi : 10 . 5281/zenodo.17765087 . 72. L. J. V. Miranda. PySwarms, a research-toolkit for Particle Swarm Optimization in Python. In: Journal of Op en Sour c e Softwar e 2018 , 3. doi : 10.21105/joss.00433 . 13 73. H. W. Kuhn; A. W. T uck er. Nonlinear programming. In: Pr o c e e dings of the Se c ond Berkeley Symp osium on Mathematic al Statistics and Pr ob ability, 1950 . Univ. California Press, Berkeley-Los Angeles, Calif., 1951, 481–492. 74. W. Karush. Minima of functions of several v ariables with inequalities as side constrain ts. In: M. Sc. Dissertation. Dept. of Mathematics, Univ. of Chic ago 1939 . 75. J. No cedal; S. J. W right. Numeric al Optimization . 2nd. Springer Series in Op erations Research and Financial Engineering. Springer, 2006. isbn : 978-0-387-30303-1. doi : 10.1007/978- 0- 387- 40065- 5 . 76. R. Fletcher; S. Leyffer. Nonlinear programming without a p enalt y function. In: Mathematic al Pr o gr am- ming 2002 , 91, 239–269. 77. A. Wäch ter; L. T. Biegler. Line Search Filter Metho ds for Nonlinear Programming: Motiv ation and Global Con vergence. In: SIAM Journal on Optimization 2005 , 16, 1–31. doi : 10.1137/S1052623403426556 . 78. T. Baba. Slow ligh t in photonic crystals. In: Natur e photonics 2008 , 2, 465–473. 79. C. L. Pan uski; I. Christen; M. Mink ov; C. J. Brab ec; S. T ra jtenberg-Mills; A. D. Griffiths; J. J. McK- endry; G. L. Leake; D. J. Coleman; C. T ran, et al. A full degree-of-freedom spatiotemp oral light mo d- ulator. In: Natur e Photonics 2022 , 16, 834–842. 80. K. Hirotani; R. Shiratori; T. Baba. Si photonic crystal slow-ligh t wa veguides optimized through infor- matics technology . In: Optics L etters 2021 , 46, 4422–4425. 81. R. Shiratori; M. Nak ata; K. Hay ashi; T. Baba. P article swarm optimization of silicon photonic crystal w av eguide transition. In: Optics letters 2021 , 46, 1904–1907. 82. Y. T erada; K. Miyasak a; K. K ondo; N. Ishikura; T. T amura; T. Baba. Optimized optical coupling to silica-clad photonic crystal w av eguides. In: Optics letters 2017 , 42, 4695–4698. 14 BONNI Hyp erparameters The prop osed BONNI algorithm utilizes a neural net work ensem ble surrogate and in terior p oin t optimization for the acquisition function. The sp ecific hyperparameters used for the ensemble training and the internal optimization lo op are detailed in T able 1. F or the distributed Bragg reflector, we p erformed 1000 iterations of BONNI starting with 50 random samples. F or the dual-level grating coupler, 100 iterations with 10 random samples w ere used. BONNI trains an ensemble of m ulti-lay er p erceptrons, where the input is transformed b y a normalized embedding mapping the parameter range as embedding ( x ) = ( z , cos ( z ) , sin ( z )) where z = ( x − x min ) / ( x max − x min ) . Additionally , the target v alues are normalized to a mean of zero and a standard deviation of one. F or acquisition function optimization, we run IPOPT multiple times from differen t starting points. The starting points are selected by ev aluating the acquisition function on a num b er of random p oints and choosing the b est as a starting p oint. Comp onen t P arameter V alue Ensem ble Ensem ble Size ( m ) 100 Net work Architecture 4-La yer MLP , 256 hidden c hannels A ctiv ation F unction GeLU [43] Group Normalization [42] 8 Groups Initialization He Normal [46] Em b edding Channels 3 T raining Optimizer A dam W [19, 44] Learning Rate p eak 1e-3 to 1e-9 Sc heduler Cosine Annealing [45] Ep ochs p er Iteration 1000 Batc h Size All sampled p oints so far A cquisition Inner Opt. Max Iter 200 Num parallel runs 10 Random start samples 100 T able 1: Hyp erparameters for the BONNI Algorithm. Baseline Algorithm Configurations T o ensure fair comparison, w e utilized standard op en-source implementations for baseline algorithms. Unless otherwise noted, default parameters provided by the resp ectiv e frameworks were used. The default Bay esian optimization, IPOPT, L-BF GS and MMA algorithms do not hav e sp ecific hyperparameters. F or the Adam optimizer, we used a fixed learning rate of 0.01 without weigh t regularization. F or the CMA-ES algorithm, w e used σ 0 = 0 . 2 as a h yp erparameter in the PyCMA framework [71]. F or PSO, we used c 1 = 0 . 5 , c 2 = 0 . 3 and w = 0 . 9 with 20 particles in the PySwarms framework [72]. Exp erimen t Details The distributed Bragg reflector consists of 5 lay er pairs of titanium dio xide and silicon dioxide. F or titanium dio xide, w e used a refractive index of 2 . 5 and for silicon dioxide 1 . 46 . The titanium dioxide lay ers heights w ere restricted b et ween 26 . 6 and 240 nm. The silicon dioxide lay er heights were restricted b et ween 45 . 5 and 410 nm. F or the dual-lay er grating coupler, we restrict b oth the silicon gap and the grating width to the range b et ween 0 . 1 and 1 µ m. F or the silicon nitride lay er, we restrict the gap widths b etw een 0 . 3 and 1 µ m, while the widths are restricted b etw een 0 . 2 and 1 µ m. 15 In terior P oin t Optimization W e use IPOPT [30] for optimizing the acquisition function to determine the optimal next sampling p oint. IPOPT is well suited for this inner optimization b ecause the exp ected impro vemen t surface is smo oth and differen tiable through the neural netw ork ensem ble, and the design domain X is defined b y simple b ox constrain ts, a setting where IPOPT’s barrier method is particularly efficient. IPOPT is an algorithm that solv es general nonlinear optimization problems of the form max x ∈ R d f ( x ) s.t. x ≥ 0 . (6) An y form of b ox constrain ts defining X can b e con verted in to the form of eq. (6) using slack v ariables. Moreo ver, it is also p ossible to incorp orate nonlinear constrain ts of the form c ( x ) = 0 , but these are not required for our applications. Instead of solving the original optimization problem, IPOPT solv es a series of simpler barrier problems giv en by max x ∈ R d φ µ ( x ) := f ( x ) + µ d X t =1 ln( x t ) , (7) where x t denotes the en try of index t in the d -dimensional vector x . The parameter µ represen ts the barrier strength and is annealed to zero during optimization using an adaptive sc heduling based on the Karush-Kuhn- T uck er conditions [73, 74] for eq. (6). T o solv e the barrier problems, IPOPT emplo ys a v ariant of damp ed Newton’s metho d utilizing a line-search approac h [75]. Sp ecifically , to determine the search direction, the primal-dual formulation of eq. (7) is linearized and solved iterativ ely [76]. This approach has b een prov en to globally con verge under specific assumptions [77]. T o accelerate con vergence, IPOPT also employs several enhancemen ts to the scheme describ ed ab ov e. F or details, we refer to the original pap er [30]. Although we emplo y IPOPT primarily for acquisition function optimization, it has the p oten tial to b e a p otent standalone optimizer, despite its scarcit y in nanophotonic generative design literature. A dditional Exp erimen ts W e perform additional exp eriments to test the limits of BONNI in more applications. Both the follo wing broadband w av eguide tap er and photonic crystal wa v eguide tap er fav or lo cal gradien t-based optimization. The broadband wa veguide tap er application has a simple optimization landscap e with few lo cal optima. The photonic crystal wa veguide taper has 90 dimensions, which makes global optimization difficult. Moreo ver, w e analyze the effect of the neural netw ork architecture on the optimization results in the distributed Bragg reflector application. Broadband W a v eguide T ap er A simple application with few parameters is the design of a broadband wa veguide tap er. Its purp ose is ac hieving optimal coupling b etw een the mo des of a small and large wa veguide of widths 450 nm and 4 . 5 µ m. P arameterized through a list of 30 anchor p oin ts represen ting the distance from the center line, the design shap e is derived by fitting a cubic spline through them. The w av eguide consists of silicon surrounded by silicon dio xide, with a w av eguide height of 220 nm. T o optimize for worst-case broadband transmission, the figure of merit f is defined as f ( x ) = min λ T ( x, λ ) , (8) where λ is the w av elength in the range b et ween 1 and 1 . 5 µ m and T is the transmission for the giv en w av elength and design parameters x represented as a vector of 30 anc hor p oin ts. Figure 6a presents the quan titative results of the different optimization algorithms. IPOPT conv erges to a go od solution very quickly , while L-BF GS and MMA fail to find a go o d solution. Giv en enough time, 16 0 50 100 150 200 Number of Simulations 0.70 0.72 0.74 0.76 0.78 0.80 0.82 Transmission B ONNI Default B O CMA-ES PSO IPOPT Adam MMA L-BFGS (a) Optimization results (b) Energy distribution in optimized design Figure 6: Optimization results for the broadband w av eguide taper In (a), the p erformance of differen t optimization algorithms for this application is visualized. All optimizations w ere p erformed on 5 random initial configurations and we rep ort mean (b old line) as w ell as standard error (shaded area). The algorithms with dotted lines are lo cal gradien t-based algorithms while the solid lines visualize global algorithms. In (b), the b est design found by BONNI with its energy distribution is shown. BONNI and default gradient descen t ev entually matc h the p erformance of IPOPT. The con vergence sp eed of gradien t descent could b e improv ed by tuning the learning rate, though this may also lead to divergence or premature con vergence to a lo cal optimum. In contrast, IPOPT and BONNI do not rely on learning rate tuning. After the full simulation budget, BONNI has the b est p erformance on av erage, though differences are small. Similar to the b enchmark in the previous section, b oth PSO and CMA-ES do not find a go od solution. A comparison b etw een BONNI and default BO shows the adv antage of gradient information in the optimization pro cess. The default BO conv erges more slowly to an optimal solution compared to BONNI and do es not reach it within the simulation budget. Figure 6b visualizes the b est design found by BONNI. Photonic Crystal W a veguide T ransition Photonic crystal wa veguides are structures that con trol the flow of light using a p erio dic arrangement of materials with differen t refractiv e indices. By introducing a line defect into this crystal lattice, they confine ligh t within a sp ecific path, prev enting it from escaping in to the surrounding lattice due to the photonic bandgap effect. Their main use cases are slow light [78] and high qualit y factor for light mo dulation [79]. W e optimize the transition b etw een a silicon strip wa veguide and a photonic crystal wa veguide. The photonic crystal structure has a lattice constan t of 394 nm and a hole radius of 96 nm, while the strip w av eguide has a width of 1.002 µ m and a height of 210 nm. This is similar to previously rep orted setups [80, 81]. In the baseline configuration, the first ten holes in the transition area are tap ered, whic h increases transmission [82]. During optimization, the p osition and radius of the first ten holes in the first three rows are treated as design v ariables for optimization. With 30 holes being optimized, this results in 90 degrees of freedom for the optimization. Specifically , the p ositions of the holes are constrained to a maxim um shift of 96 nm in each of the x and y directions. F or the hole size, the radius can b e optimized b etw een 40 and 150 nm. The figure of merit for this b enchmark is the transmission of the TE-mo de at wa velength 1 . 55 µ m. Figure 7a displays the results of the optimizations. In this b enc hmark, local optimization algorithms p erform best due to the high dimensionality of the design space, which makes global optimization difficult. F rom the lo cal optimization algorithms, IPOPT demonstrates the b est results, follow ed by Adam, L-BFGS and MMA. BONNI yields the highest transmission among the global optimization algorithms, follow ed b y standard BO. F ollo wing the same trend from the previous sections, CMA-ES and PSO hav e inferior p erformance compared to the other algorithms. In fig. 7b, the b est design found b y IPOPT for the photonic crystal wa veguide transition is shown. 17 0 50 100 150 200 Number of Simulations 0.2 0.4 0.6 0.8 1.0 Transmission IPOPT Adam L-BFGS MMA B ONNI Default B O PSO CMA-ES (a) Optimization results (b) Photonic crystal design Figure 7: Optimization results for the photonic crystal w av eguide transition. In (a), the simulation results are displa yed. All optimizations were p erformed on 5 random initial configurations and w e rep ort mean (solid line) as well as standard error (shaded area). The algorithms with dotted lines are lo cal gradient-based algorithms while the solid lines visualize global algorithms. In (b), the optimal design found by IPOPT is visualized with its E y -distribution in sim ulation. The p osition and radii of the first ten holes in the first three rows (red circles) can b e optimized. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment