Human-in-the-Loop Pareto Optimization: Trade-off Characterization for Assist-as-Needed Training and Performance Evaluation
During human motor skill training and physical rehabilitation, there is an inherent trade-off between task difficulty and user performance. Characterizing this trade-off is crucial for evaluating user performance, designing assist-as-needed (AAN) pro…
Authors: Harun Tolasa, Volkan Patoglu
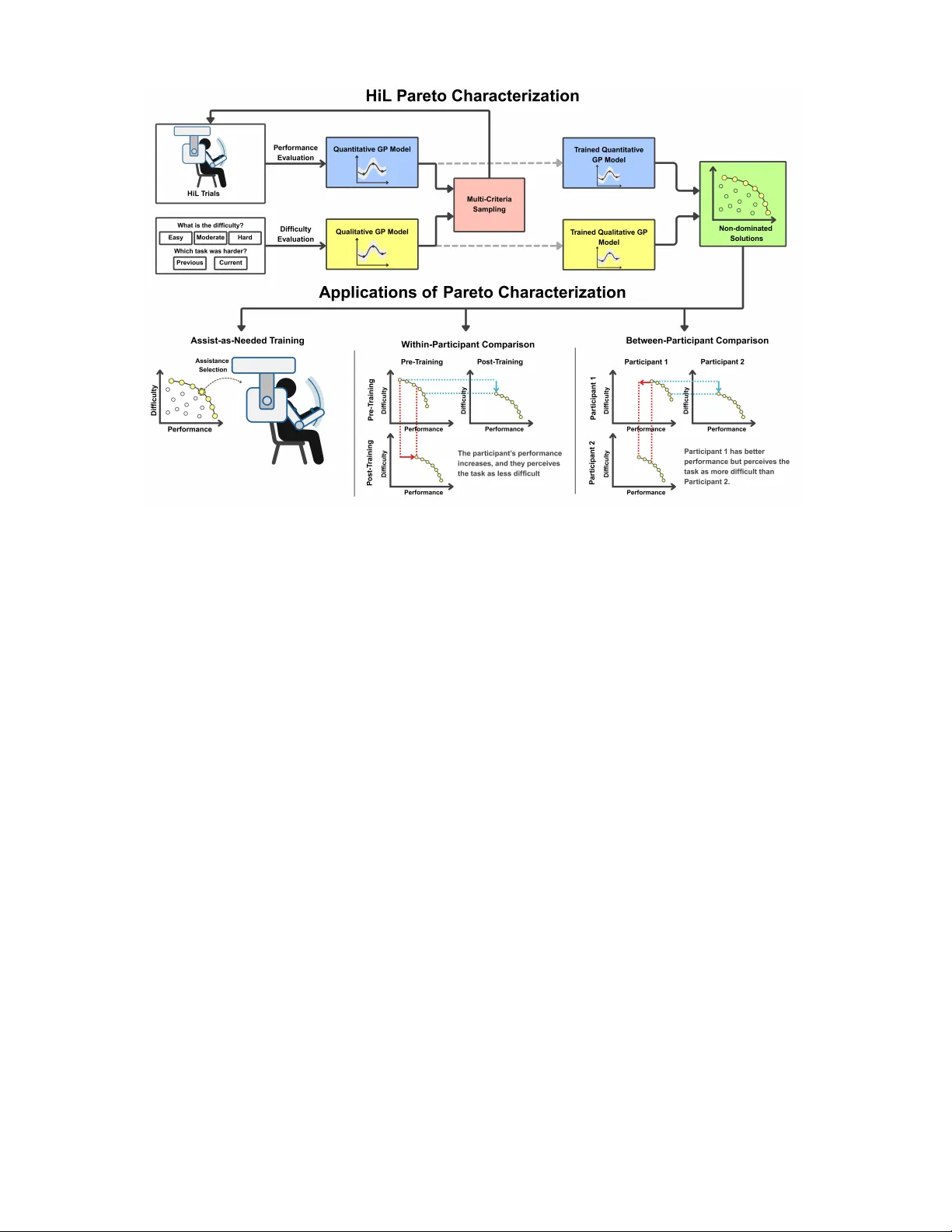
1 Human-in-the-Loop P areto Optimization: T rade-of f Characterization for Assist-as-Needed T raining and Performance Ev aluation Harun T olasa, Student Member , IEEE V olkan P atoglu, Member , IEEE Abstract —During human motor skill training and ph ysical re- habilitation, ther e is an inherent trade-off between task difficulty and user performance. Characterizing this trade-off is crucial for evaluating user performance, designing assist-as-needed (AAN) protocols, and assessing the efficacy of training protocols. In this study , we propose a novel human-in-the-loop (HiL) P areto optimization approach to characterize the trade-off between task performance and the perceived challenge level of motor learning or rehabilitation tasks. W e adapt Bayesian multi-criteria optimization to systematically and efficiently perform HiL Pareto characterizations. Our HiL optimization employs a hybrid model that measures perf ormance with a quantitative metric, while the percei ved challenge level is captured with a qualitative metric derived from prefer ence-based user feedback. W e demonstrate the feasibility of the proposed HiL Par eto characterization through a user study . Furthermore, we present the utility of the framework thr ough three use cases in the context of a manual skill training task administered to healthy individuals with haptic feedback. First, we demonstrate how the characterized trade- off can be used to design a sample AAN training protocol for a motor learning task and to evaluate the group-le vel efficacy of the proposed AAN protocol relative to a baseline adaptive assistance pr otocol. Second, we demonstrate that individual-level comparisons of the trade-offs characterized befor e and after the training session enable fair e valuation of training progress under different assistance levels. This ev aluation method is mor e general than standard performance evaluations, as it can pro vide insights even when users cannot perform the task without assistance. Third, we show that the characterized trade-offs also enable fair performance comparisons among different users, as they captur e the best possible performance of each user under all feasible assistance levels. Index T erms —Par eto optimization, Bayesian multi-criteria op- timization, human-in-the-loop optimization, qualitative perfor - mance, assist-as-needed paradigms, interaction control, f orce- feedback devices, motor learning, robot-assisted rehabilitation. I . I N T R O D U CT I O N Physical human-robot interaction (pHRI) is commonly used for training tasks, such as human motor skill training or robot-assisted physical rehabilitation. In such applications, the efficac y of the training, typically measured by performance ev aluations administered after the training without any assis- tance, is of utmost importance. Haptic assistance is provided only during the training sessions, when the user is coupled to a force-feedback robot, to ensure that the execution of the H. T olasa and V . Patoglu are with the F aculty of Engineering and Natural Sciences at Sabanci University , Istanbul, Turkiye. { harun.tolasa, volkan.patoglu } @sabanciuniv.edu . This work has been par- tially supported by TUBIT AK Grants 120N523 and 23A G003. task can be completed with sufficient success. For instance, consider a stroke patient going through physical rehabilitation, for whom task ex ecution may not be feasible without a proper lev el of assistance. For such a patient, some lev el of assistance is necessary for task completion. On the other hand, too much assistance during training is known to be detrimental, as users may learn to rely on the existence of this support and slack [1], [2]. T oo much assistance may also cause the task to be per - ceiv ed as not sufficiently challenging by the patient, resulting in a lack of engagement. As a consequence of excessiv e assistance, users may not learn how to successfully execute the task when no assistance is av ailable. Accordingly , there exists an inherent trade-off between the lev el of assistance provided and the lev el of challenge perceived by the user for any giv en motor control/rehabilitation task. This trade-off has been widely acknowledged in the litera- ture, and it has been established that an optimal assistance le vel consists of the least assistance that allows a user to execute a task with a sufficient lev el of success. Controllers that aim to provide such assistance are commonly referred to as assist-as- needed (AAN) controllers. AAN controllers aim to keep the assistance lev el at a proper level to maximally challenge but not to overwhelm users with task difficulty or demotiv ate them with continual failures. The literature on AAN control mostly focuses on the design of interaction controllers that can administer assistance forces safely and naturally , without ov erriding users’ intent. In par- ticular , path-following controllers, such as velocity field con- trollers [3] and controllers with guaranteed coupled stability properties, such as passi ve velocity field controllers [4], hav e been proposed and adopted in many related works [5]–[9]. Although these studies on interaction control are indispensable for the safe and natural deli very of force feedback, these control approaches necessitate the proper assistance lev el to be provided as an input, typically by a domain expert. In AAN controllers, the proper lev el of assistance is com- monly decided empirically or heuristically , based on thresholds imposed on the measured/estimated performance of the user . Most methods utilize sensor inputs or biosignals [10]–[14], such as EMG and EEG, to adjust the level of assistance to promote voluntary participation based on some pre-determined thresholds. Adaptiv e controllers that utilize the dynamic model of the user and the de vice to minimize a cost function [15] or rely on statistical estimates of psychophysical thresholds [16] hav e also been proposed. Reinforcement learning algorithms hav e been used to dev elop AAN controllers that do not depend 2 Fig. 1. Proposed HiL Pareto characterization scheme and its application to AAN training, within- and between-participant performance evaluations. on user- or device-specific parameters [17]. Furthermore, in addition to quantitativ e measures, more qualitative aspects, such as the psychological states of the user, hav e been es- timated by neural networks to adjust assistance le vels [18], [19]. Interested readers are referred to the revie w articles [20], [21] for recent implementations of AAN control techniques for lower - and upper-extremity rehabilitation. While these studies are quite promising, the characterization of the underlying trade-of f between the performance v ersus the perceiv ed task difficulty and the determination of a customized lev el of assistance to be provided to a user are still open chal- lenges, commonly delegated to a domain expert. The problem is challenging as each individual is unique; furthermore, user preferences and perceptions undergo continuous changes as learning/recov ery takes place with training. For instance, the perceiv ed challenge lev el of a task under a certain level of assistance is likely to decrease as a user gets better at the task. User-dependent metrics that are not easy to quantify , such as moti vation and comfort level, may directly affect the percei ved challenge level. Hence, determining the ideal assistance le vel necessitates personalization, possibly through a characterization of the underlying trade-off between the perceiv ed challenge level and the performance for each user . Characterization of the trade-off between the percei ved challenge lev el and the task performance can guide training by helping designers to establish a proper le vel of assistance for AAN controllers. Moreover , such characterizations can be performed at different stages of the training, such that changes in user preferences/performance can be captured as learning takes place and the assistance can be adjusted accordingly . Furthermore, such trade-off characterizations can serve as a novel means for e valuating performance at a group- or individual-le v el. While typical ev aluations of manual skill training or physical rehabilitation are performed when no assistance is provided, as this represents the real-life use case, such e valuations cannot capture improvements in performance during the early phases of training/rehabilitation. For instance, if a task is excessi vely hard for a patient, then it may not be possible for the patient to execute it successfully without a proper lev el of assistance. In such cases, ev aluations with no assistance will not capture any improv ement with training, as the patient’ s success rate will remain low . On the other hand, a comparison of the characterized trade-offs between the perceiv ed challenge level versus the performance of a user , or a group of users, at dif ferent stages of training provides a feasible alternati ve: the time e valuation of the trade-off provides a rigorous means to fairly assess the progress, under all feasible assistance le vels. In addition, such trade-of f characterizations also enable comparisons among v arious users or groups of users. It is important to emphasize that ensuring the rigor and fairness of such performance comparisons under assistance necessitates the characterization of the trade-of f via Pareto optimization, since multiple variables, such as assistance and the perceived challenge le vels, need to be considered simultaneously . In this study , we propose a human-in-the-loop (HiL) P areto optimization approach to characterize the trade-off (i.e., Pareto optimal results forming a set of non-dominated solutions) between the user’ s performance and the percei ved challenge lev el for a motor learning task. During the optimization, the user performance is measured by a quantitativ e metric, while the perceiv ed challenge lev el is captured by a qualitativ e metric gathered through preference-based qualitati v e feedback, as depicted in Figure 1. A multi-criteria Bayesian optimization technique is utilized for HiL Pareto optimization of this hybrid model with quantitativ e and qualitati ve metrics. The sample- 3 efficienc y of the underlying Bayesian optimization is a crucial aspect, as it enables the trade-of f to be characterized system- atically and efficiently by focusing on the relev ant portion of the search space and without inducing fatigue to participants. Once the trade-off is characterized via HiL Pareto opti- mization, first, we demonstrate how this trade-off can be used to guide the training sessions with Pareto optimal assistance lev els. In particular , we sho w ho w a subset of optimal solutions can be selected from the set of non-dominated solutions to guide AAN training sessions. Second, we show that the trade- off ev olves in time as learning takes place, and P areto-front curves capturing the trade-off can be used to fairly ev aluate both the individual- and group-lev el progress. Third, we show that the characterized trade-offs can also be used for fair performance comparisons among differ ent users , by capturing the best possible performance of each user under all feasible assistance le vels. Contributions The main contribution of this study is a novel HiL Pareto op- timization frame work with hybrid (quantitativ e and qualitati v e) performance measures, as depicted in the first ro w of Figure 1. W e not only formulate the HiL trade-off characterization framew ork but also show its feasibility through a user study by demonstrating that the proposed HiL Pareto optimization can be used to systematically and efficiently characterize the trade-off between the performance and the percei ved challenge lev el of a motor skill learning task. Our second contrib ution is the demonstration of the useful- ness of the HiL trade-off characterization through three use cases, as depicted in the second row of Figure 1. Within the context of a case study inv olving a manual skill training task administered to healthy individuals with haptic feedback, we demonstrate that - the non-dominated solutions characterizing the trade-of f between the performance and the perceiv ed challenge lev el can be used to design AAN controllers, - the comparisons of the trade-off curves characterized at different stages of training can be used to establish a nov el and rigorous means of individual- and group-lev el performance e valuation across assistance le vels, and - the trade-off curves of different users can be used for fair comparisons among v arious users, as they capture the best possible performance of each user under all feasible assistance le vels. I I . R E L A T E D W O R K Bayesian optimization is a sample-efficient deri vati ve-free global optimization approach [22] that has been employed in sev eral studies in volving HiL optimization. For instance, HiL applications of these algorithms ha ve been used to optimize wearable robotic assistive devices, where the ev aluation of optimization metrics is costly , or the number of experiments is constrained by human in volv ement [23]–[26]. HiL Bayesian optimization studies focus on the optimization of a single-criterion cost function. These techniques are mostly based on quantitative metrics, such as metabolic cost [23]– [26]. Recently , qualitativ e metrics, such as perceived realism, hav e been captured by probabilistic latent functions and used to implement HiL Bayesian optimizations [27]–[31]. Bayesian optimization approaches have been extended to solve multi-criteria optimization problems [32]–[37]. One means to address a multi-criteria optimization problem is to use a weighted sum of the cost functions to form a single aggregate cost function. Such scalarization approaches enable the original multi-objective problem to be formulated as a single-criterion optimization problem. Scalarization ap- proaches hav e also been applied to the Bayesian optimization setting, either by utilizing an aggregate cost function [32] or a scalarized acquisition function for parameter sampling [33], [34]. Howe ver , in all scalarization methods, since the relative weights of cost functions need to be pre-determined, the design preferences among the objectiv es must be assigned a priori, before gaining suf ficient kno wledge of the trade-of f inv olved. On the other hand, for multi-criteria optimization prob- lems, Pareto optimization methods compute a set of non- dominated solutions that correspond to optimal designs for different design preferences among the optimization metrics, and all such non-dominated solutions constitute the Pareto- front [38]–[40]. Unlike the single-shot scalarization-based optimization methods, Pareto methods fully characterize the trade-off among multiple objectiv es. Once the Pareto-front solutions are computed, the designer can study these solutions to get an insight into the underlying trade-offs and make an informed decision to finalize the design by selecting a subset of optimal solutions from the Pareto set. Pareto-optimization approaches have also been applied in the Bayesian optimization setting [35]–[37]. Existing tech- niques can be loosely classified as hyper-v olume improve- ment approaches [36], information-theoretic methods [37], and wrapper methods via single-objective acquisition func- tions [35]. In hyper -volume improvement approaches, the ex- pected improv ement acquisition function is extended for multi- objectiv es to produce an ef fecti ve sampling strategy [36], while the information-theoretic methods derive a single acquisition function to maximize information gain for all objectives [37]. Information-theoretic methods hav e also been extended to work with multiple qualitati ve metrics [41]. Finally , the wrap- per methods utilize a multi-criteria optimizer to compute a surrogate Pareto-front characterizing the trade-off between the acquisition functions and sample parameters with the highest volumetric variance [35]. The previous studies of the authors focus on single-criterion HiL Bayesian optimization with qualitati ve metrics to improv e perceiv ed realism of haptic rendering [30], [42] and to explore visual-haptic cue integration during multi-modal haptic ren- dering under conflicting cues [31]. This study extends these works to HiL P areto optimization for the characterization of the underlying trade-off between users’ performance and perceiv ed challenge le vel of motor learning tasks. The under- lying concepts, mathematical formulations, and optimization approaches used to solve Pareto optimization problems are distinct from those of single-criterion optimization [38]; hence, the extension from single-criterion HiL optimization to HiL Pareto optimization is substantial. 4 Application of Pareto optimization approaches in a HiL setting has only recently been pursued. In addition to this study , a multi-objective HiL optimization problem has recently been addressed in [43] as a case study , utilizing a genetic algorithm-based solver to adjust the assistance profiles of an ankle exoskeleton by simultaneously minimizing two quanti- tativ e metrics capturing gait deviations. Our study considers hybrid (both quantitati ve and qualitative) metrics, relies on a sample-efficient Bayesian Pareto optimization approach, and applies the framework in a human motor skill learning setting. Specifically , our study extends the Bayesian Pareto optimization approach in [35] to hybrid models and applies it in the HiL context for a human motor skill learning task. Our study not only applies HiL Pareto optimization in a motor skill learning setting with hybrid metrics, but also demonstrates its usefulness for the ev aluation of individual- and group-lev el performance and for the design of AAN controllers. Finally , the comparison of Pareto solutions to enable fair comparisons of performance among v arious designs is new to the motor skill learning context, while the idea has been successfully applied to comparisons of exoskeleton perfor- mance of musculoskeletal simulations [44] and comparisons of interaction controller performance in the context of pHRI [45]. I I I . H U M A N - I N - T H E - L O O P P A R E TO O P T I M I Z AT I O N The goal of HiL Pareto optimization is to characterize the inherent trade-off between task difficulty and performance. In general, these two metrics are in direct conflict with each other; hence, a multi-objectiv e optimization needs to be performed to consider them simultaneously . While it is easier to measure task performance directly through quantitati ve metrics, the task difficulty is much harder to capture, as it depends on many aspects, including b ut not limited to the sensorimotor skills, as well as engagement, (physical/mental) fatigue, and comfort le vel of the user . Along these lines, we measure the task performance ( GP num ) quan- titativ ely based on users’ scores, as detailed in Section III-B, while we capture the perceiv ed challenge lev el ( GP q ual ) of the users by directly acquiring their qualitati ve feedback, by querying for their ordinal classifications and pair-wise prefer- ences, as detailed in Section III-C. Gi ven these two metrics, the follo wing max-max optimization problem is solved over the design variable of assistance percentage, subject to the physical/mental constraints imposed by the user: max assistance % ∈ [0 , 100] GP num : task performance GP q ual : perceiv ed task difficulty subject to: physical and mental constraints of the user While performing HiL Pareto optimization, it is important to determine the trade-off among multiple conflicting objectiv e functions, while also minimizing the total resource cost of the experiments. Among v arious approaches, multi-criteria Bayesian optimization techniques hold promise for use in HiL applications due to their inherent sample efficienc y [46], as the central idea of all Bayesian optimization approaches is to minimize the number of observ ations while rapidly conv erging to the optimal solution(s). Accordingly , Bayesian optimiza- tion provides a class of sample-efficient global optimization methods, where a probabilistic model conditioned on pre vious observations is used to determine the future e valuations. The statistical modeling in multi-criteria Bayesian opti- mization techniques is typically handled by one Gaussian process (GP) model for each objecti ve to ensure the tractability of the problem, while the selection of the acquisition function to capture the trade-off between multiple objectiv es results in various alternativ e techniques [32]–[34]. W e utilize a customized version of the wrapper method, called Uncertainty-aware Searc h framework for optimizing Multiple Objectives (USeMO), which is based on single- objectiv e acquisition functions [35]. USeMO utilizes a multi- criteria sampling strategy that allo ws one to leverage acqui- sition functions from single-objectiv e Bayesian optimization to solve the multi-objecti ve Bayesian optimization problem, as detailed in Section III-D. W e hav e preferred USeMO as its application to optimizations with hybrid (qualitative and quantitative) metrics is more accessible. Please note that USeMO is a sample optimization approach appropriate for HiL P areto optimization, and alternative methods, such as [36], [37], may also be adapted for HiL Pareto optimization. A. An Overview of HiL Multi-Criteria Bayesian Optimization The multi-criteria Bayesian optimization approach, summa- rized in Algorithm 1, relies on two GP regression models: one based on quantitativ e performance scores as detailed in Section III-B, and another one based on qualitativ e feedback collected from the participants as detailed in Section III-C. Both GP regression models possess their corresponding ac- quisition functions. During the initial iterations, parameters are selected via the Sobol sequence to ensure search-space exploration. For the rest of the iterations, new solutions are computed via the sampling strategy proposed in [35] and further detailed in Section III-D. Algorithm 1 HiL Bayesian Pareto Optimization Initiate A : Feasible parameter space, GP num : Quantitativ e GP re- gression model, GP qual : Qualitative GP regression model, N : # of iterations, N 0 : # of space-filling iterations 1: Assign acquisition function α num to GP num 2: Assign acquisition function α qual to GP qual 3: Create a sampling set x with size N 0 using Sobol sequence 4: for n = 1 to N do 5: if n ≤ N 0 then 6: Select x n from set x 7: else 8: Compute surrogate Pareto set: 9: x p ← arg max x ∈ A ( α num , α qual ) 10: Select parameter: 11: x n ← arg max x ∈ x p ( σ qual · σ num ) 12: Append x n to set x 13: Use x n in the task trial 14: Get the performance score s n 15: Append s n to s and re-calculate y 16: Get user’ s qualitativ e feedback q n 17: Append q n to set q 18: Update GP num using x and standardized score set y 19: Update GP qual using x and qualitativ e feedback set q 20: Compute Pareto front using the mean predictions of the GP models 21: Plot the Pareto front and list the non-dominated solutions 5 In particular, the sampling strategy utilizes a multi-criteria optimizer to compute a surrogate Pareto front characterizing the trade-off between the conflicting acquisition functions. Then, from the set of non-dominated solutions on the surrogate Pareto front, a parameter with the highest volumetric variance is selected for the next sampling. At the end of the trade-off characterization session, Algorithm 1 utilizes a multi-criteria optimizer to compute the non-dominated solutions forming the Pareto front of the expected performance scores and expected perceiv ed challenge lev el. Once the Pareto set is computed, it can be used for ev aluations, or promising non-dominated solutions can be selected as in Section III-F to design AAN training protocols. B. Quantitative Gaussian Pr ocess Regr ession Model A GP regression model, GP num , is designed to learn the relationship between the level of assistance and the partici- pant’ s performance. The maximum applicable assistance level during a task is represented by one, while zero represents the case without assistance. Let A = { x ⊂ R d : 0 ≤ x i ≤ 1 } be the feasible parameter space and x i be the assistance lev el. Let x = { x 1 , x 2 , .., x n } be a set consisting of n assistance levels used in previous task trials. Then, let s = { s 1 , s 2 , .., s n } be a set consisting of n observed performance scores corresponding to x , and let y = { y 1 , y 2 , .., y n } be the statistically standardized version of s . The dataset used to train the numerical GP regression model is represented with D N = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ..., ( x n , y n ) } . Finally , let f N ( x ) be the black-box function representing the relationship between the assistance le vel and the standardized performance scores. T o model the deviation of the score measurements, we assume that the standardized performance scores are affected by a Gaussian white noise with v ariance σ 2 w , and observe their noisy version y . Then, the prior black- box function f N for the performance scores can be modeled as f N ( x ) ∼ G P (0 , K N + σ 2 w I ) (1) with K N ∈ R n × n , k N i,j = k N ( x i , x j ) , is a kernel function used for the correlation. The performance scores for an unknown assistance level can be predicted via Bayesian inference. Let x ∗ be any arbitrary assistance le vel, and let f N ∗ | D N be the corresponding performance score estimation based on previously acquired performance scores. Then, the Bayesian inference indicates f N ∗ | D N ∼ G P ( µ N ∗ | D N , σ 2 N ∗ | D N ) (2) µ N ∗ | D N = k N ∗ , 1: n ( K N + σ 2 w I ) − 1 y (3) σ 2 N ∗ | D N = k N ∗ , ∗ − k N ∗ , 1: n ( K N + σ 2 w I ) − 1 k N 1: n, ∗ (4) C. Qualitative Gaussian Pr ocess Regr ession Model A second GP regression model, GP q ual , is designed to learn the relationship between the assistance level and the perceiv ed challenge of the task as percei ved by the participant. During the Pareto characterization session, after each task trial, the participant classifies the perceiv ed challenge level of the task trial by selecting one of the following categories: easy , moderate , and hard . Then, excluding initialization, the participant compares the perceived challenge level of the task trial with that of the previous iteration. Based on the modeled probabilities of the responses, the qualitativ e GP regression model is updated. The range of assistance lev el is represented by A = { x ⊂ R d : 0 ≤ x i ≤ 1 } , as in the quantitati ve GP regression model. Let f Q ( x ) be the latent function representing the participant’ s perceiv ed challenge le vel of the task. The prior distribution of f Q ( x ) is modeled with a normal GP distribution. f Q ( x ) ∼ G P (0 , K Q ) (5) where K Q ∈ R n × n , k Q i,j = k Q ( x i , x j ) is the noiseless kernel matrix of the qualitativ e GP regression model. It is worth noting that the kernel functions used in both models need not be identical. Let q be the set of qualitative feedback provided by the participant, where q consists of both ordinal classifications q o = { q o 1 , q o 1 , ..., q o n } and pairwise preferences q p = { q p 2 , q p 3 , ..., q p n } . The dataset including ordinal classifica- tions is defined as D O = { ( x 1 , q o 1 ) , ( x 2 , q o 2 ) , ..., ( x n , q on ) } , and the dataset including pairwise comparisons is defined as D P = { ( x 1 , x 2 , q p 1 ) , ( x 2 , x 3 , q p 2 ) , ..., ( x n − 1 , x n , q p n ) } . Then, the dataset consisting of all qualitative feedback can be defined as D Q = D O ∪ D P . The probability of the latent function based on the provided feedback is calculated from the proportionality P ( f Q | D Q ) ∝ P ( D Q | f Q ) P ( f Q ) , where P ( f Q ) is the prior unbiased prob- ability of the regression model and P ( D Q | f Q ) is the proba- bility of the qualitativ e feedback of the participant is correct based on the giv en latent function. Ordinal classifications and pairwise comparisons are mod- eled as in [28]–[31], [47], as follows: Let O = { o 1 , o 2 , o 3 } be the finite set of three ordinal classifications representing the perceiv ed challenge level from “easy” to “hard”. Let t be the set of ordered thresholds used to distinguish ordinal classifications t = { t o 0 , t o 1 , t o 2 , t o 3 } and −∞ = t o 0 < t o 1 < t o 2 < t o 3 = ∞ . Then, the probability for the participant to correctly classify a parameter x i with the ordinal class o th j is modeled as P ( q o i = o j | f Q ) = Φ t o j − f Q ( x i )) c o − Φ t oj − 1 − f Q ( x i ) c o (6) where Φ represents the cumulati ve distribution function of the Gaussian distribution and c o > 0 is used to capture the classification noise. The probability of the participant correctly identifying the harder one between two task trials is giv en by P ( q p i = ( x i ≻ x i − 1 ) | f Q ) = Φ ( f Q ( x i ) ) − f Q ( x i − 1 ) ) c p (7) where c p > 0 captures the noise in pair-wise preferences. Under the assumption of the independence of provided qualitativ e feedback, P ( D Q | f Q ) = P ( D O | f Q ) P ( D P | f Q ) is calculated as P ( D Q | f Q ) = n Y i =1 P ( q o i | f Q ) n Y i =2 P ( q p i | f Q ) . (8) 6 The posterior distribution of the regression model is com- puted by the Laplace approximation [48]. Utilizing this com- monly adopted method for posterior approximation, it becomes possible to make predictions for Bayesian optimization and extend the probabilistic deri vations to capture qualitati ve feed- back from humans [28], [29], [31], [49]. The perceived challenge lev el estimate for the participant f Q ∗ | D Q for any arbitrary assistance level x ∗ can be computed using the posterior model as follo ws: f Q ∗ | D Q ∼ GP ( µ ∗| D Q , σ 2 ∗| D Q ) (9) µ ∗| D Q = k Q ∗ , 1: n K − 1 Q ˆ f Q (10) σ 2 ∗| D Q = k Q ∗∗ − k Q ∗ , 1: n ( W − 1 + K Q ) − 1 k Q 1: n, ∗ (11) where K is the noiseless covariance matrix calculated with RBF kernel, W is the negati ve Hessian matrix W ij = − ∂ 2 log ( P ( D Q | f ( x )) ∂ f ( x i ) ∂ f ( x j ) and ˆ f is the latent function that maximizes the log-likelihood ˆ f = ar gmax f ( x ) ( log ( P ( D Q | f Q ) P ( f Q ))) . D. Sampling Strate gy for HiL P ar eto Characterization Let α num be the acquisition function of GP num and let α q ual be the acquisition function of GP q ual . Given these acquisition functions, first, a computationally cheap Pareto optimization problem is solved to find the parameter set x p lying on the surrogate Pareto front. Next, a parameter is selected among x p based on the maximum volumetric uncertainty , where the volumetric uncertainty is calculated by multiplying the standard deviations as follows: x p = argmax x ∈ A ( α num , α q ual ) (12) x n = argmax x ∈ x p ( σ ( x ) | D N n − 1 × σ ( x ) | D Q n − 1 ) . (13) E. Acquisition Function and Hyper-P arameter Selection Acquisition functions and hyperparameters of the HiL op- timization utilized in this study are empirically determined, based on e xpertise gained through pilot experiments. T en trials were observ ed to be sufficient for HiL P areto characterizations. In particular , a radial basis function (RBF) kernel, k i,j = exp( − θ || x i − x j || 2 2 ) , is used for modeling both GP num and GP q ual . The kernel hyperparameters θ N for GP num and θ Q for GP q ual are both selected as 5 . The observation noise hyper-parameter σ 2 w of GP num is selected as 0 . 1 . The hyperparameters c p and c o , capturing the pairwise preference and ordinal classification noise, are selected as 0 . 5 and 1 , respectiv ely . The ordinal classification thresholds are selected as t = {−∞ , − 0 . 5 , 0 . 5 , ∞} . For the parameter sampling strategy , two upper confidence bound (UCB) acquisition functions are used. T o sample an assistance level x n for n th trial, α num and α q ual are used as α num ( x ∗ ) n = µ ∗| D N n − 1 + λ N σ ∗| D N n − 1 (14) α q ual ( x ∗ ) n = µ ∗| D Q n − 1 + λ Q σ ∗| D Q n − 1 (15) where λ N and λ Q are the hyper -parameters of GP num and GP q ual , respecti vely , and x ∗ is an any arbitrary feasible assistance lev el. In these equations, λ N is selected as 2 , while λ Q is selected as 1 . Once the human-subject experiments were completed, we compared the empirically selected GP hyperparameters with the MLE-optimized values determined from the data and ver- ified that the Pareto-optimal assistance levels obtained under both parameter sets remain close to each other . F . Sample Design Selection for P areto-based AAN T r aining All Pareto solutions characterizing the trade-off between the user performance and the perceiv ed challenge are optimal. W ithout additional preference information, all Pareto opti- mal solutions are mathematically equal. The Pareto selection process imposes additional preferences on the set of Pareto optimal solutions to select a subset among them. Pareto optimization methods allow the designer to impose additional constraints after the computation of the non-dominated so- lutions and inspection of the trade-off in volv ed among the conflicting objectives. Unlike scalarization approaches, where the preferences need to be assigned a priori, the ability to impose additional constraints on the set of optimal solutions corresponding to different preferences in a multi-shot manner is among the most beneficial aspects of Pareto approaches. The trade-off between performance and task dif ficulty char- acterized via HiL Pareto optimization can provide insights to guide the design of AAN algorithms. T o demonstrate how such protocols can be designed by the characterized trade-of f, we propose and test the efficacy of a sample AAN training protocol. By imposing new constraints on the Pareto-front based on domain expertise, we form the AAN training protocol as shown in Figure 2, so that the controller keeps the task moderately challenging while allowing the user to achieve an acceptable le vel of performance. Perce � ved Challenge Level E a s y T ask Performance M o d e r a t e H a r d S e l e ct e d N o n - D o m i n a t e d S o l u t i o n s 4 0 % o f m a x s c o r e 8 0 % o f m a x s c o r e Fig. 2. Selection of non-dominated solutions from the Pareto-front by introducing design constraints after characterizing the trade-off In particular , to facilitate a design selection among all non- dominated solutions, we introduce personalized thresholds to the set of non-dominated solutions to keep the percei ved challenge lev el and quantitativ e performance sufficiently high, as decided by the domain expert. In the sample protocol, the performance range is limited to 40–80% of the capacity of the individual, while the challenge range is limited to 40– 80% of the percei ved challenge lev el of the indi vidual. All 7 solutions in this range ha ve been selected to be included in the training session, to induce diversity in the training ex ercises. The proposed AAN training method emphasizes the importance of customization of the assistance based on individual performance characterizations. It is important to note that the resulting AAN training protocol based on HiL Pareto characterization is merely a sample design selected by the domain expert that utilizes a set of non-dominated solutions for div ersity-focused personalized AAN training. The Pareto selection process is not unique, and alternativ e training methods may be devised from the same set of Pareto solutions. While each of these protocols is equally valid from a multi-criteria design perspectiv e, their training efficac y is likely to v ary significantly . T o examine how the selected threshold affects the set of assistance le vels used during AAN training, we ev aluated alternativ e thresholds on the Pareto solutions after the human- subject experiments were completed. The analysis re veals that threshold ranges of 30–70%, 40–80% and 50–90% yield mean assistance lev els of 30 . 6 ± 22 . 3 %, 39 . 3 ± 22 . 6 %, and 52 . 3 ± 17 . 8 %, respecti vely . As expected, shifting the thresholds to cover higher performance yields increased assistance lev els. Giv en different preferences yield different AAN strategies with varying training outcomes, more sophisticated designs, such as an adapti ve protocol for selecting the appropriate threshold ranges to be imposed on Pareto solutions to adjust the assistance le vels based on instantaneous user performance on the fly , may perform better than the sample AAN protocol in terms of training ef ficacy . The sample AAN protocol is preferred due to its simplicity , as the main goal of this study is to illustrate the feasibility of such designs based on HiL Pareto characterizations. I V . H U M A N S U B J E C T E X P E R I M E N T This section presents the application of the proposed HiL Pareto optimization approach to a manual skill training task with haptic feedback, administered to healthy volunteers. It demonstrates that HiL Pareto optimization can be used to (i) efficiently and systematically characterize the trade-off between the task performance and the perceiv ed challenge lev el, (ii) design AAN training protocols, and (iii) establish a novel and rigorous means of performance e valuation under assistance, within and between participants and groups. A. P articipants 34 participants, with an average age of 23.6 ± 3.6 years participated in the experiment. The participants performed a motor learning task using a force-feedback joystick with their dominant hand. All participants signed the informed consent form approv ed by the Institutional Revie w Board of Sabanci Univ ersity (Protocol No: FENS-2025-18). Participants with any known sensory-motor disability or significant prior experience with haptic de vices are e xcluded from the study . Similarly , ceiling pre-training performance of 80% under less than 40% assistance was used as an exclusion criterion to av oid saturation during training. Ac- cordingly , participants completed warm-up and pre-ev aluation sessions to verify that the task is suf ficiently challenging; two participants who achiev ed ceiling-level performance were excluded from the study before the group assignments. Eligible participants were assigned to experimental groups using a Latin square method to achiev e balanced group allocations. Participants were blinded to group identity and protocol dif- ferences throughout the experiment. All assigned participants completed the full protocol without technical failures or with- drawal, resulting in no attrition or missing data. B. T ask and Apparatus The motor learning task consists of a two-dimensional balancing of a virtual inv erted pendulum on a cart, displayed on an LCD screen, as shown in Figure 3(a). A single-axis force-feedback joystick, called HandsOn-SEA, presented in Figure 3(b), renders the dynamics of the cart and pendulum model, so that users feel as if they are moving the cart while operating the joystick. Assistance forces are also provided through this interface. T wo monsters, separated by a constant distance, provide continuous disturbances. The external distur - bances are generated using a stochastic process with identical parameters across participants and trials. The task fails if the pendulum rotates more than ± 50 ◦ or the cart touches the monsters. The objectiv e of the game is to survi ve for 25 s, with raw scores corresponding to the survi val time and normalized scores di vided by 25 s. Pendulum Balancing T ask HandsOn-SEA Haptic Interface (a) (b) Fig. 3. (a) A participant holding a force-feedback joystick (HandsOn-SEA) while interacting with the pendulum game, (b) HandsOn-SEA haptic interface The balancing task is intentionally designed to be challeng- ing to a void performance saturation; howe ver , due to the high sensitivity of the task dynamics, brief lapses of attention can easily lead to failures. Accordingly , participants are provided with three chances per trial, and a best-of-three score is used as a more robust and optimistic performance metric to reduce noise and avoid under-e valuating participant performance due to such momentary distractions. Interaction and assistance forces are rendered through HandsOn-SEA, a custom-b uilt single-axis haptic interface with series elastic actuation (SEA) [50]. HandsOn-SEA features a coreless DC motor equipped with an encoder to actuate its sector pulley through a capstan-driv e to impose desired mo- tions. A cross-fle xure pi vot, formed by crossing two symmetric leaf springs, acts as the compliant element located between the rigid sector pulley and the handle structures. A Hall- effect sensor constrained to move between the neodymium 8 W arm-Up 5-10 � terat � ons ~10 m � n Pr e- Evaluat � on 3 � terat � ons ~2 m � n Par eto Character � zat � on I 10 � terat � ons ~7 m � n T ra � n � ng 20 � terat � ons ~18 m � n Post- Evaluat � on 3 � terat � ons ~2 m � n Par eto Character � zat � on II 10 � terat � ons ~7 m � n Fig. 4. Experimental procedure block magnets embedded in the sector pulley measures the deflections of the compliant element, thereby enabling esti- mation of the interaction force. HandsOn-SEA can provide 15 N continuous force output at its handle with a force control bandwidth of 12 Hz, within a workspace of ± 55 ◦ . HandsOn- SEA works under velocity-sourced impedance control [51]– [54], implemented in real-time at 1 kHz, utilizing a TI C2000 microcontroller . The microcontroller communicates with the host computer , displaying the game via serial communication. T o determine assistance forces, an LQR controller is imple- mented to determine the appropriate cart positions to stabilize the pendulum and to mo ve the cart to the middle of the monsters. Along with the cart and pendulum dynamics, a virtual spring is rendered between the stabilizing controller- determined ideal position and the current position of the cart by HandsOn-SEA to provide assistance forces to participants. The assistance is adjusted through the stiffness of the coupling spring; the lar ger the spring constant, the larger the assistance. C. Experimental Conditions The training efficacy of the proposed AAN training method based on Pareto optimization (test group) is compared with a control group based on a commonly employed performance- based adaptiv e assistance controller . Each group had an equal number of participants. The follo wing protocols are compared: i) T est Gr oup – P areto Appr oach: As detailed in Sec- tion III-F, the AAN training method based on Pareto optimization relies on HiL characterizations of the trade- off between the task performance and the percei ved change level. Pareto-based approach naturally results in a div erse set of assistance levels. After a trade-off is characterized, thresholds are introduced to select the subset of non-dominated solutions that span from 40% to 80% of the performance and the perceiv ed challenge lev el of individual users. Non-dominated solutions in this subset are used in the AAN training session by selecting the assistance lev els in a randomized order for each trial. If the number of non-dominated solutions is less than the number of trials, then the random selection process is restarted from the original non-dominated solution subset, after all solutions in the subset are used. On av erage, 32 . 9 ± 24 . 0 non-dominated solutions were located within the 40–80% thresholds. ii) Contr ol Gr oup – Adaptive Assistance: The control group is trained with a commonly used adaptiv e assistance controller . A performance-based adaptiv e assistance con- troller is implemented using an adaptiv e staircase ap- proach, as in [11], [55], [56]. The adapti ve approach is an online local search method that seeks a single assistance lev el for a participant during trials. The assistance level of the control group is initialized at 50% and employs a two-up-one-do wn variation. In this adapti ve approach, the assistance decreases by 10% after e very two consecutiv e successful trials or increases by 10% after each failure. D. Experimental Pr ocedur e The experiment consists of 6 sessions, as in Figure 4: warm- up, pre-ev aluation, pre-training HiL characterization, training, post-ev aluation, and post-training HiL characterization. The experimental procedure was administered identically for the control and the test groups, except for the assistance levels provided to each group during the training session. The warm-up session includes a tutorial to help participants become familiar with the rules and mechanics of the game. Participants play the game with several le vels of assistance. The warm-up session is concluded when a participant displays a clear understanding of the rules and can play the game without unpremeditated failure. Pre- and post-e valuations measure the performance of the participants under no assistance. A comparison of pre- versus post-ev aluation sessions provides a measure of participants’ progress after the training sessions. HiL Pareto characterization sessions are used to learn the trade-off between a participant’ s quantitativ e performance and the perceived challenge le vel of the game. For this purpose, two GP regression models are trained in each HiL session. During each iteration of the HiL learning, the participant plays the game with an assistance lev el determined by the optimization algorithm. Once the game ends, the best score of the participant is used to train a quantitative GP model. After each game, two questions are asked to the participant to determine the perceived dif ficulty of the game. First, the participant is asked to rate the challenge level of the game by selecting one option from “hard”, “moderate”, or “easy”, resulting in an ordinal classification. Next, (except for the first trial), the participant is asked to compare the challenge lev el of the last game with respect to the previous one in a pair- wise manner . The answers to these queries are used to train a qualitative GP regression model. Finally , utilizing a multi- criteria sampling strategy , the HiL optimization algorithm updates the assistance lev el provided for the next iteration. E. Hypotheses The human subject experiments aim to test the validity of the follo wing hypotheses: H 1 The trade-off between the performance and the perceived challenge le vel of a task can be characterized by utilizing a HiL Pareto optimization approach. H 2 Comparisons of the trade-off curves characterized at the different stages of training pro vide a rigorous means of ev aluating training performance within and between participants, across feasible assistance lev els. H 3 The non-dominated solutions characterizing the trade-of f between the performance and the percei ved challenge can be used to design an AAN training protocol. 9 P a r t i c i p a n t 1 P a r t i c i p a n t 2 A s sistance Level Assis tan c e Le v e l A s sistance Level Assist a n c e Le v e l T a s k Perfor m anc e T a s k Per f or m an c e T a sk P er f orman c e T a s k Pe rfo r m an c e Fig. 5. In the top rows, the orange and blue lines show the mean of the surrogate function for the perceived challenge and the task performance, respectiv ely , while the shading depicts their standard deviation. The bottom rows present the Pareto solutions with dark red dots, while the dominated solutions in the feasible set are shown with orange dots. The Pareto solutions inside the red squares are used during the training of the participants in the test group. V . R E S U LT S A N D D I S C U S S I O N In this section, we elaborate on each hypothesis presented in Section IV -E in the vie w of the experimental evidence. W e also demonstrate how the HiL Pareto optimization approach can be used to assess group-lev el progress under all feasible assistance le vels. A. Hypothesis 1 Figure 5 presents the GP regression models and the Pareto fronts, before and after the training, for two sample par- ticipants with high and intermediate performance. The data collected during the experiments are av ailable for download from our laboratory website 1 . In the top rows, the orange lines show the mean of the surrogate function for the perceived challenge level, while the orange shading depicts its standard deviation. Similarly , the blue lines represent the mean predic- tion for the game scores, while the blue shading depicts their standard deviation. The bottom rows present the Pareto plots characterized during pre- and post-training sessions, shown in the left and right columns. In the Pareto plots, the black points represent Pareto solu- tions, while the orange points depict all feasible solutions for the problem. Pareto solutions cover a non-trivial (and possibly disconnected, as in Figure 6) subset of the set of all feasible solutions, as they capture the non-dominated solutions of the trade-off between the expectations of the percei ved challenge lev el and the task performance (game score). For ease of vi- sualization, the Pareto plots are divided into three regions; the red, yello w , and green shades represent the percei ved challenge lev els of hard, moderate, and easy , respectively . Finally , the red squares indicate the Pareto solutions used during the training of the participants in the test group, according to the Pareto selection criteria detailed in Section III-F. As hypothesized in H 1 , Figure 5 provides e vidence that the trade-off between the performance and the percei ved challenge lev el of a task can be characterized via HiL Pareto optimization 1 http://hmi.sabanciuniv .edu/HiL Pareto Experiment Data.zip with hybrid performance measures. Thanks to the sample- efficienc y inherited from the underlying Bayesian optimiza- tion approach [35], HiL Pareto characterization con ver ged in 6 . 3 ± 1 . 8 min; hence, it can easily be performed before the training sessions without inducing fatigue to the participants. The top rows in Figure 5 verify that the Bayesian multi- criteria optimization technique samples from the regions of surrogate functions that conflict with each other . The ef ficiency of the sampling strategy in locating the conflicting regions and the uniformity of samples in these regions are key aspects of the efficienc y of the Pareto optimization technique that make its use adequate for HiL optimization. The bottom ro ws in Figure 5 characterize the trade-off between the performance and the perceived challenge lev el of the task. In particular , in the sample Pareto plots, both participants can achiev e their best scores when their perceiv ed challenge lev el is low , and their performance decreases as their perceiv ed challenge le vel increases. Furthermore, the trade-off curves also enable the ev aluation of whether the task is too challenging or too easy for the participant, by checking their performance under high and low assistance levels, respectively . If such a case is detected, it may be preferable to change the task to better cater to the abilities of the participant. Overall, the experimental results provide strong evidence that the trade-off between the performance and the perceiv ed challenge le vel of a task can be characterized by utilizing a HiL Pareto optimization approach. Consequently , the results support the first hypothesis H 1 . B. Hypothesis 2 The proposed Pareto approach emphasizes the customiza- tion of training sessions based on individual performances. Accordingly , this section focuses on individual-level results. In the bottom ro ws of Figure 5, the changes between the pre- and post-training trade-off characterization plots capture the progression of the participants under assistance. For Par- ticipants 1 and 2, the shifts in the Pareto plots explicitly indicate that participants not only perceiv e the game as less 10 challenging after the training, but also their scores improve significantly . Accordingly , their post-training Pareto curves hav e shifted tow ards the right and downwards, compared to their pre-training P areto curves. For instance, for Participant 2, the perceived lev el of challenge for the most difficult trial has reduced from hard to moderate, indicating that the task became easier to perform as learning took place. The positive progress in the performance can also be observed by the shrinkage of the Pareto front tow ards the right side, which captures the region for higher game scores. This shift indicates the game scores for the most difficult perceiv ed challenge level hav e increased from 0.30 to 0.55 for Participant 2. These improvements can also be observed in the GP re- gression models, before and after the training. For instance, one can observe by inspecting the surrogate function for the perceiv ed challenge le vel and game scores of Participant 2 that the performance and challenge le vel saturate around 70% assistance before the training, while this saturation shifts to 45% assistance after the training. Hence, only the assistance lev els from 0% to 40% belong to the post-training solutions. Comparison of the pre- and post-training surrogate functions is especially useful to understand Pareto plots that consist of multiple disconnected sections. Figure 6 presents the results for a lo w-performing Participant 3, whose Pareto plots are harder to interpret, b ut the surrogate functions for the percei ved challenge level and the game scores can help understand the results. While the worst performance of Participant 3 did not significantly improv e from pre- to post-training, the shifts in the surrogate functions of this participant indicate that Partic- ipant 3 requires less assistance to achiev e a similar lev el of performance to the pre-training case. In particular, the increase in performance and the decrease in challenge level shifts from 70% assistance in the pre-training characterization results to 50% assistance in the post-training results. Accordingly , the trade-off characterization captures improvements in the performance that cannot be captured by simply observing the participants’ performance without any assistance. Finally , utilizing the HiL Pareto optimization, the trade-off curves of differ ent participants can also be compared with P a r t i c i p a n t 3 T as k P er formanc e A s sistance Level Assista nc e Le ve l T a s k P er fo r man c e Fig. 6. Results for a sample participant with low performance. The presen- tation follo ws the same format as in Figure 5. each other . For instance, the post-training Pareto front of Participant 2 is slightly better than the pre-training Pareto front of Participant 1, indicating that Participant 2 reaches a more advanced stage after the training, compared to the pre-training performance of Participant 1. Note that rigorous comparisons of dif ferent participants with each other , in general, is a very challenging task; a fair comparison of different participants is possible by considering the non-dominated solutions of the P areto optimization, as they capture the best possible performances for each challenge lev el [44], [45]. Overall, the results support that comparisons of the trade- off curves characterized at the different stages of training can provide a rigorous means of e valuating training performance, as hypothesized in H 2 . C. Hypothesis 3 T o assess the overall improv ement of the participants after the training session, we compare the unassisted game scores of the participants before and after the training sessions, as depicted by violin plots in Figure 7. Furthermore, a two-way mixed-design ANO V A is conducted to examine the effects of training phase (pre- vs. post-) and group (test vs. control) on the task performance. Prior to the analysis, assumptions for ANO V A were tested and verified as follows: The Shapiro- W ilk test confirms that the residuals were normally distributed (p = .420). Lev ene’ s test indicates the homogeneity of vari- ances for both the pre- (p = .406) and post-training phases (p = .955), supporting the assumption of equal variance across the groups. p < 0.001 1.0 0.8 0.6 0.4 0.2 0.0 Pre-T ra � n � ng Control Group T est Group Control Group T est Group Post-T ra � n � ng Normal � zed Scores Fig. 7. V iolin plots of the unassisted pre- and post-training performance There is a significant main ef fect of training phase (f(1,32) = 37.88, p < .001, partial η 2 = 0.542), indicating a statistically significant improv ement in performance from pre- to post-training across all participants. The main effect of the group is not significant (f(1,32) = 0.13, p = .725, partial η 2 = 0.004), suggesting that overall performance did not dif fer between the test and control groups. Furthermore, the interaction between the group and the training phase is not significant (f(1,32) = 0.08, p = .784, partial η 2 = 0.002), indicating that both groups showed similar impro vements from pre- to post-training. 11 C o n t r o l G r o u p ( a ) T e s t G r o u p ( b ) ( c ) P e r c e � v e d C h a l l e n g e T a s k P e r f o r m a n c e T a s k P e r f o r m a n c e A s s � s t a n c e l e v e l P e r c e � v e d C h a l l e n g e P r e - t r a � n � n g P o s t - t r a � n � n g P r e - t r a � n � n g P o s t - t r a � n � n g O v e r l a p p � n g p o � n t s I m p r o v e m e n t � n p e r c e � v e d c h a l l e n g e I m p r o v e m e n t � n t a s k p e r f o r m a n c e P r e - p o s t c h a n g e � n p r e d � c t e d p e r f o r m a n c e T e s t G r o u p C o n t r o l G r o u p Fig. 8. Comparison of aggregate Pareto solutions of control (a) and test (b) groups during pre- and post-training. In these figures, a shift of the Pareto front from left to right indicates improvement in task performance, while a shift from top to bottom indicates the task being perceived as less challenging. (c) Percent improvement of the av ailable performance of the control and test groups. Since no statistically significant differences are observed under no-assistance conditions, within the power and scope of the statistical analysis, there is no evidence that one protocol outperforms the other . T ogether with the successful implementation of the Pareto-based protocol, these results support hypothesis H 3 . Consequently , the results demonstrate that training based on non-dominated solutions can yield AAN protocols. D. Comparison of Gr oup P erformance under Assistance As discussed in Section I, typical ev aluations of manual skill training are performed when no assistance is provided, as in Section V -C, since this represents the real-life use case. On the other hand, such ev aluations cannot capture performance improv ements during the early phases of training or under assistance. One of the important insights pro vided by the proposed HiL Pareto optimization framework is that trade-offs characterized at different stages of training provide a rigorous means to fairly assess the progress of individuals, under all feasible assistance levels, as discussed in Section V -B. In this section, we demonstrate how performance analyses can be performed at a gr oup-level . In particular , we study the av erage improv ements of the control and test groups through their aggregate GP models. The goal of such analyses is not necessarily to sho w that one group is superior to the other , b ut to gain further insights into the performance of both training protocols under all feasible assistance le vels. T o estimate group-lev el performance, we first aggregate trained GP models by statistically av eraging them among the participants and use these aggregate GP models to de- riv e aggregate Pareto curves for each group during pre- and post-training characterizations. Figures 8(a) and (b) present aggregate Pareto plots for the control and test groups, re- spectiv ely . These comparisons across assistance lev els and pre/post-training characterization instances are rigorous and fair , as the Pareto solutions capture the best achiev able perfor - mance predicted for each group under all feasible assistance conditions at each characterization instance. The shifts of the aggregate Pareto curves from pre- to post-training in these figures indicate observable improv ements in the av erage task performance of both groups, together with minor improve- ments in their average perception of task difficulty . Next, we in vestig ate the dif ference in pre- and post-training performance predicted by the aggregate GP models of the two groups. Figure 8(c) presents, for each assistance le vel, the mean change in GP-predicted performance together with 95% confidence intervals obtained via non-parametric bootstrap- ping. For each bootstrap replicate, participants are resampled with replacement, the aggregate GP model is ev aluated at each assistance level, and the group-lev el mean change is recomputed. A total of 5000 bootstrap samples are used, and percentile-based confidence intervals are reported. Figure 8(c) shows that both groups possess wide confi- dence intervals at each assistance lev el, reflecting substan- tial inter-participant variability in GP-predicted performance improv ements. Gi ven the confidence intervals for the two groups largely overlap, it can be concluded that the overall performance improv ement is broadly similar for both training protocols across assistance le vels. As a descriptive trend, the test (Pareto-based) group achieves slightly higher mean performance gains, especially within the 40%-90% assistance lev el range. While these differences are not statistically robust for this particular human-subject experiment, similar analyses may lead to stronger trends for other experiments, providing valuable insights to the designers for making informed deci- sions while further optimizing the training protocol. T o hav e a better understanding of the assistance levels selected by the AAN protocols for an identical group of participants, Figure 9 presents the assistance le vel provided to Ada pt � ve as s � sta nc e p ro v � d ed to t he co ntr ol gr ou p Pro spe ct � ve a ss � st anc e to be pr ov � de d to the co nt rol g rou p � f th ey we re � n th e tes t (Pa re to) g rou p Ite rat � on Ass � st anc e Lev el Fig. 9. Assistance provided to participants in the control group (adaptive assistance) versus the pr ospective assistance that would hav e been provided to these participants in the control group if they were in the test gr oup (Pareto approach). Lines show the av erage assistance levels provided to participants, while shaded areas indicate one standard deviation. 12 the control group in comparison to the pr ospective assistance level that would hav e been provided to the same control group, if these participants were placed in the test group. Since the assistance le vels used in the Pareto-based training protocol are independent of the participant’ s instantaneous performance, they can be determined solely from their corresponding Pareto solutions. Consequently , the prospectiv e assistance le vels to be provided to the participants if they were in the test group are determined based on their pre-training HiL characterization. Figure 9 indicates that the adapti ve staircase method pro- vided mean assistance lev els around 60% to the control group, while the Pareto-based approach would have selected prospectiv e assistance levels closer to 40% on av erage for the same set of indi viduals in the control group. The difference between the mean assistance levels of the two approaches provides a possible explanation for larger performance change trends observ ed for the Pareto-based group between 40%-90% assistance levels in Figure 8(c). Training under lower mean assistance for the Pareto-based training protocol may hav e exposed participants to conditions demanding greater active control more frequently , and this could have contributed to the observed trend between 40%-90% assistance le vels. Since the confidence intervals for both the assistance le vel distributions in Figure 9 and the performance changes in Figure 8 have substantial o verlap, the assistance experienced by the two groups is quite similar at the group-lev el, and the observed trends need to be interpreted with caution. Overall, the analysis in this subsection does not provide evidence of significant differences between the two tested training protocols across assistance levels for this particular human-subject experiment. On the other hand, the proposed analysis method, based on comparing aggregate Pareto plots and GP models captured during pre- and post-training, pro- vides a rigorous method to fairly compare the performance of the control and test groups across all assistance lev els, thereby enabling the designer to capture potential differences among training protocols to gain useful insights. V I . C O N C L U S I O N This study demonstrates the feasibility of HiL Pareto opti- mization, its potential to help with the design of new AAN controllers, and its novel use for individual and group-level performance ev aluations and comparisons. Human subject experiments with qualitative and quantitati ve cost functions are provided to demonstrate the use of two different forms of feedback in HiL Pareto optimization. While the simplest models are used to promote ease of presentation, the proposed HiL Pareto optimization approach is generic and can be easily extended to Pareto solutions for any number and type of cost functions. Similarly , while this study has been conducted for the single decision variable of the assistance level, the proposed Pareto optimization method trivially extends to a larger number of decision variables. Furthermore, while we ha ve utilized USeMO as an efficient optimizer , similar results may be achie ved by utilizing other sample-efficient Pareto optimization approaches. A. Limitations of the Study While our results sho w that the Pareto-based training pro- tocol performs comparably with a commonly used adaptive method, the number of participants in this study is sufficient to detect medium effect sizes. As a result, smaller differ - ences between training strategies may have gone undetected. Similarly , group-lev el comparisons based on GP estimates provide only weak trends for our study , as the confidence regions of groups largely overlap. Further experiments with a larger number of participants, multiple training sessions, and long-term retention ev aluations may of fer deeper insights into performance dif ferences not captured in this feasibility study . Additionally , our current experiment ev aluates the effecti ve- ness of Pareto-based AAN training using a simple protocol to facilitate the presentation of the underlying Pareto-based design concept. The design of an effecti v e training protocol is an in v olved process that needs consideration of multiple aspects, such as scheduling of breaks and repetitions, that go beyond the determination of the proper lev el of assistance. Overall, it is important to re-emphasize that our focus in this feasibility study is to demonstrate that the characterized trade-off can help with the design of promising and effecti ve AAN protocols by providing insights. Designs of more so- phisticated AAN protocols and claims of improv ed training efficac y require further optimizations, such as sensitivity and robustness analyses, which are beyond the scope of this study . B. Ongoing W orks The determination and ev aluation of more sophisticated AAN approaches are parts of our ongoing work. Exploring and v alidating these approaches through systematic experi- mentation will help us better understand ho w to optimize AAN training using the HiL Pareto optimization framework. Since the task dif ficulty-user performance trade-of f also ex- ists in the rehabilitation context, the proposed HiL Pareto opti- mization approach is directly applicable to these applications. Figure 10 provides a snapshot of our ongoing studies, in which HiL Pareto optimization is applied to stroke patients with the AssistOn-Arm six DoF upper extremity e xoskeleton [57]–[59]. For the utilization of the proposed framework in rehabilita- tion applications, the perceiv ed challenge lev el cost function and the underlying HiL Pareto optimization method do not require any changes, while the rehabilitation task to be per- formed and the quantitativ e performance metric are modified with more clinically relev ant ones. HiL Pareto optimization can still be performed o ver the design v ariable of the assistance lev el pro vided to the user , capturing the force-feedback applied to the patient within a virtual tunnel around the nominal path of the rehabilitation ex ercise. The multi-DoF nature of the exosk eleton becomes relev ant only when the required assistance lev el in task space is mapped to the joint space of the robot for the appropriate actuator torques. As in the case of motor skill training, the number of design v ariables can be easily extended to include other relev ant v ariables, such as the diameter of the virtual tunnel utilized during rehabilitation. Overall, our results indicate that the proposed HiL Pareto optimization approach holds promise for applications in both manual skill training and robot-assisted rehabilitation. 13 A C K N O W L E D G E M E N T This work has been partially supported by TUBIT AK Grants 120N523 and 23A G003. R E F E R E N C E S [1] Y . Li, V . Patoglu, and M. K. O’Malley , “Negativ e efficac y of fixed gain error reducing shared control for training in virtual environments, ” ACM T ransactions on Applied P er ception , v ol. 6, no. 1, pp. 1–21, 2009. [2] A. Erdogan and V . Patoglu, “Slacking prevention during assistive contour following tasks with guaranteed coupled stability , ” in IEEE/RSJ Int. Conf. on Intelligent Robots and Systems , 2012, pp. 1587–1594. [3] J. Moreno-V alenzuela, “V elocity field control of robot manipulators by using only position measurements, ” Journal of the F ranklin Institute , vol. 344, no. 8, pp. 1021–1038, 2007. [4] P . Y . Li and R. Horowitz, “Passiv e velocity field control of mechanical manipulators, ” IEEE T rans. on Robotics and Automation , vol. 15, no. 4, pp. 751–763, 1999. [5] R. Colombo, I. Sterpi, A. Mazzone, C. Delconte, and F . Pisano, “Dev elopment of a progressive task regulation algorithm for robot-aided rehabilitation, ” in Int. Conf. of the IEEE Engineering in Medicine and Biology Society , 2011, pp. 3123–3126. [6] A. Erdogan and V . Patoglu, “Online Generation of V elocity Fields for Passi ve Contour Follo wing, ” in IEEE W orld Haptics Confer ence , 2011, pp. 245–250. [7] U. Keller , G. Rauter, and R. Riener , “Assist-as-needed path control for the P ASCAL rehabilitation robot, ” in IEEE Int. Conf. on Rehabilitation Robotics , 2013, pp. 1–7. [8] H. J. Asl, M. Y amashita, T . Narikiyo, and M. Kawanishi, “Field- Based Assist-as-Needed Control Schemes for Rehabilitation Robots, ” IEEE/ASME Tr ans. on Mechatr onics , vol. 25, no. 4, pp. 2100–2111, 2020. [9] J. Lopes, C. Pinheiro, J. Figueiredo, L. Reis, and C. Santos, “Assist- as-needed Impedance Control Strategy for a W earable Ankle Robotic Orthosis, ” in IEEE Int. Conf. on Autonomous Robot Systems and Competitions , 2020, pp. 10–15. [10] H. Krebs, J. Palazzolo, L. Dipietro, M. Ferraro, J. Krol, K. Ranneklei v , B. V olpe, and N. Hogan, “Rehabilitation Robotics: Performance-Based Progressiv e Robot-Assisted Therapy, ” Autonomous Robots , vol. 15, pp. 7–20, 2003. [11] Y . Li, J. C. Huegel, V . Patoglu, and M. K. O’Malley , “Progressi ve shared control for training in virtual en vironments, ” in W orld Haptics , 2009, pp. 332–337. [12] M. Sarac, E. Ko yas, A. Erdogan, M. Cetin, and V . Patoglu, “Brain Computer Interface based robotic rehabilitation with online modification of task speed, ” in IEEE Int. Conf. on Rehabilitation Robotics , 2013, pp. 1–7. [13] O. Ozdenizci, M. Y alcın, A. Erdogan, V . Patoglu, M. Grosse-W entrup, and M. Cetin, “Electroencephalographic identifiers of motor adaptation learning, ” Journal of Neural Engineering , vol. 14, no. 4, p. 046027, 2017. Fig. 10. A snapshot during HiL Pareto characterization and AAN training with the AssistOn-Arm upper-extremity exoskeleton [14] R. Y ang, Z. Shen, Y . L yu, Y . Zhuang, L. Li, and R. Song, “V oluntary Assist-as-Needed Controller for an Ankle Power-Assist Rehabilitation Robot, ” IEEE T rans. on Biomedical Engineering , vol. 70, no. 6, pp. 1795–1803, 2023. [15] J. L. Emken, J. E. Bobrow , and D. J. Reinkensmeyer , “Robotic move- ment training as an optimization problem: designing a controller that assists only as needed, ” Int. Conf. on Rehabilitation Robotics , pp. 307– 312, 2005. [16] V . Squeri, A. Basteris, and V . Sanguineti, “ Adaptive regulation of assistance ‘as needed’ in robot-assisted motor skill learning and neuro- rehabilitation, ” in IEEE Int. Conf. on Rehabilitation Robotics , 2011, pp. 1–6. [17] S. Pareek, H. J. Nisar , and T . K esav adas, “AR3n: A Reinforcement Learning-Based Assist-as-Needed Controller for Robotic Rehabilita- tion, ” IEEE Robotics & Automation Magazine , pp. 2–10, 2023. [18] B. Zhong, W . Niu, E. Broadbent, A. McDaid, T . M. C. Lee, and M. Zhang, “Bringing Psychological Strategies to Robot-Assisted Phys- iotherapy for Enhanced T reatment Efficacy , ” F r ontiers in Neur oscience , vol. 13, 2019. [19] A. Koenig, X. Omlin, L. Zimmerli, M. Sapa, C. Krewer , M. Bolliger , F . Mueller , and R. Riener , “Psychological state estimation from physi- ological recordings during robot-assisted gait rehabilitation, ” Journal of Rehabilitation Resear ch and Development , vol. 48, pp. 367–385, 2011. [20] R. Baud, A. Manzoori, A. Ijspeert, and M. Bouri, “Review of Control Strategies for Lower-limb Exoskeletons to Assist Gait, ” Journal of Neur oEngineering and Rehabilitation , vol. 18, no. 119, 2021. [21] D. Mahfouz, O. Shehata, E. Morgan, and F . Arrichiello, “A Compre- hensiv e Revie w of Control Challenges and Methods in End-Effector Upper-Limb Rehabilitation Robots, ” Robotics , vol. 13, no. 12, p. 181, 2024. [22] E. Brochu, V . M. Cora, and N. de Freitas, “A T utorial on Bayesian Optimization of Expensive Cost Functions, with Application to Activ e User Modeling and Hierarchical Reinforcement Learning, ” CoRR , 2010. [Online]. A vailable: https://arxiv .or g/abs/1012.2599 [23] W . Felt, J. C. Selinger , J. M. Donelan, and C. D. Remy , “Body-in-the- loop: Optimizing device parameters using measures of instantaneous energetic cost, ” PLOS One , vol. 10, no. 8, pp. 1–21, 2015. [24] J. R. Koller , D. H. Gates, D. P . Ferris, and D. C. Remy , “Body-in-the- Loop Optimization of Assistiv e Robotic Devices: A V alidation Study, ” in Robotics: Science and Systems , 2015. [25] Y . Ding, I. Galiana, A. Asbeck, S. de Rossi, J. Bae, T . Santos, V . de Araujo, S. Lee, K. Holt, and C. W alsh, “Biomechanical and physiological ev aluation of multi-joint assistance with soft exosuits, ” IEEE T r ans. on Neural Systems and Rehab. Eng. , vol. 25, no. 2, pp. 119–130, 2016. [26] J. Zhang, P . Fiers, K. A. Witte, R. W . Jackson, K. L. Poggensee, C. G. Atkeson, and S. H. Collins, “Human-in-the-loop optimization of exoskeleton assistance during walking, ” Science Robotics , vol. 356, no. 6344, pp. 1280–1284, 2017. [27] D. Sadigh, A. Dragan, S. Sastry , and S. Seshia, “Active Preference- Based Learning of Re ward Functions, ” in Robotics: Science and Systems , vol. 13, 2017. [28] K. Li, M. Tucker , E. Biyik, E. Novoseller , J. Burdick, Y . Sui, D. Sadigh, Y . Y ue, and A. Ames, “R OIAL: Region of interest active learning for characterizing exoskeleton gait preference landscapes, ” in IEEE Int. Conf. on Robotics and Automation , 2021, pp. 3212–3218. [29] E. Biyik, N. Huynh, M. Kochenderfer , and D. Sadigh, “ Active Preference-Based Gaussian Process Regression for Rew ard Learning, ” in Robotics: Science and Systems , 2020. [30] B. Catkin and V . Patoglu, “https://ieee xplore.ieee.org/document/10102327 Preference-Based Human-in-the-Loop Optimization for Percei ved Realism of Haptic Rendering, ” IEEE Tr ansactions on Haptics , vol. 16, no. 4, pp. 470–476, 2023. [31] H. T olasa, B. Catkin, and V . Patoglu, “Human-in-the-Loop Optimization of Perceiv ed Realism of Multi-Modal Haptic Rendering under Conflict- ing Sensory Cues, ” IEEE T rans. on Haptics , vol. 18, no. 2, pp. 295–311, 2025. [32] A. Mathern, O. Steinholtz, A. Sj ¨ oberg, M. ¨ Onnheim, K. Ek, R. Rem- pling, E. Gustavsson, and M. Jirstrand, “Multi-objective constrained Bayesian optimization for structural design, ” Structural and Multidis- ciplinary Optimization , vol. 63, 2021. [33] S. Suzuki, S. T ak eno, T . T amura, K. Shitara, and M. Karasuyama, “Multi-objectiv e Bayesian Optimization using Pareto-frontier Entropy , ” in Int. Conf. on Machine Learning , vol. 119, 2020, pp. 9279–9288. [34] B. Paria, K. Kandasamy , and B. P ´ oczos, “A Flexible Framew ork for Multi-Objectiv e Bayesian Optimization using Random Scalarizations, ” 14 in Uncertainty in Artificial Intelligence Conf. , v ol. 115, 2020, pp. 766– 776. [35] S. Belakaria, A. Deshwal, N. K. Jayakodi, and J. R. Doppa, “Uncertainty-aware search framework for multi-objectiv e Bayesian op- timization, ” in AAAI Conf. on Artificial Intelligence , vol. 34, no. 06, 2020, pp. 10 044–10 052, An extended version is available online at https://arxiv .org/abs/2204.05944. [36] M. Emmerich, J. W . Klinkenberg, and N. Bohrweg, “The computation of the expected improvement in dominated hypervolume of Pareto front approximations, ” Leiden Uni versity , The Netherlands, T echnical Report LIA CS-TR9-2008, 2008. [37] D. Hernandez-Lobato, J. Hernandez-Lobato, A. Shah, and R. Adams, “Predictiv e Entropy Search for Multi-objectiv e Bayesian Optimization, ” in Int. Conf. on Machine Learning , vol. 48, 2016, pp. 1492–1501. [38] P . Y . Papalambros and D. J. W ilde, Principles of optimal design: modeling and computation . Cambridge Univ ersity Press, 2000. [39] R. T . Marler and J. S. Arora, “The weighted sum method for multi- objectiv e optimization: New insights, ” Structural and Multidisciplinary Optimization , v ol. 41, no. 6, pp. 853–862, 2010. [40] R. Unal, G. Kiziltas, and V . Patoglu, “A multi-criteria design optimiza- tion frame work for haptic interfaces, ” in IEEE Haptics Symposium , 2008, pp. 231–238. [41] R. Astudillo, K. Li, M. T ucker , C. X. Cheng, A. D. Ames, and Y . Y ue, “Preferential Multi-Objectiv e Bayesian Optimization, ” CoRR , 2024. [Online]. A v ailable: https://arxiv .org/abs/2406.14699 [42] H. T olasa, G. Gemalmaz, and V . Patoglu, “Acti ve Learning of Fractional- Order V iscoelastic Model Parameters for Realistic Haptic Rendering, ” CoRR , 2025. [Online]. A v ailable: https://arxiv .or g/abs/2512.00667 [43] X. Zhang, A. Fredriksen, S. Palmcrantz, and E. M. Gutierrez-Fare wik, “Biplanar Ankle Assistance for Dropfoot Gait Post-Stroke with Multi- Objectiv e Human-In-the-Loop Optimization: A Case Study, ” in Int. Conf. on Rehabilitation Robotics , 2025, pp. 1132–1138. [44] A. K. Bonab and V . Patoglu, “Musculoskeletal Simulation-Based Multi- criteria Optimization Framework for Exoskeleton Design, ” IEEE T r ans. on Neural Systems and Rehabilitation Engineering , 2026, Early Access. [Online]. A vailable: https://ieeexplore.ieee.org/document/11367100 [45] Y . A ydin, O. T okatli, V . Patoglu, and C. Basdogan, “A Computational Multicriteria Optimization Approach to Controller Design for Physical Human-Robot Interaction, ” IEEE Tr ans. on Robotics , vol. 36, no. 6, pp. 1791–1804, 2020. [46] R. Garnett, Bayesian Optimization . Cambridge: Cambridge Univ ersity Press, 2023. [47] W . Chu and Z. Ghahramani, “Preference learning with Gaussian pro- cesses, ” in Int. Conf. on Machine Learning , 2005, pp. 137–144. [48] C. E. Rasmussen and C. Williams, Gaussian Pr ocesses for Machine Learning . MIT Press, 2005. [49] M. Tuck er , M. Cheng, E. Novoseller , R. Cheng, Y . Y ue, J. W . Bur- dick, and A. D. Ames, “Human Preference-Based Learning for High- dimensional Optimization of Exoskeleton W alking Gaits, ” in IEEE Int. Conf. on Robotics and Systems , 2020, pp. 3423–3430. [50] A. Otaran, O. T okatli, and V . Patoglu, “Physical Human-Robot Interac- tion Using HandsOn-SEA: An Educational Robotic Platform W ith Series Elastic Actuation, ” IEEE T rans. on Haptics , vol. 14, no. 4, pp. 922–929, 2021. [51] F . E. T osun and V . Patoglu, “Necessary and Sufficient Conditions for the Passi vity of Impedance Rendering With V elocity-Sourced Series Elastic Actuation, ” IEEE Tr ans. on Robotics , vol. 36, no. 3, pp. 757–772, 2020. [52] C. U. Kenanoglu and V . Patoglu, “Passive Realizations of Series Elastic Actuation: Effects of Plant and Controller Dynamics on Haptic Render- ing Performance, ” IEEE Tr ans. on Haptics , vol. 17, no. 4, pp. 882–899, 2024. [53] C. U. Kenanoglu and V . Patoglu, “Effect of Inherent Damping of the Series Elastic Element on Rendering Performance and Passivity of Interaction Control, ” ASME Journal of Dynamic Systems, Measurement, and Contr ol , vol. 147, no. 5, p. 051008, 2025. [54] C. U. Kenanoglu and V . Patoglu, “Effect of Reduced-Order Modelling on Passivity and Rendering Performance Analysis of Series Elastic Actuation, ” IEEE Robotics and Automation Letters , vol. 10, no. 6, pp. 5745–5752, 2025. [55] J. Anguera, J. Boccanfuso, J. Rintoul, O. Claflin, F . Faraji, J. Janowich, E. Kong, Y . Larraburo, C. Rolle, E. Johnston, and A. Gazzaley , “V ideo game training enhances cognitiv e control in older adults, ” Nature , vol. 501, pp. 97–101, 09 2013. [56] R. Gray , “Transfer of Training from V irtual to Real Baseball Batting, ” F r ontiers in Psychology , vol. 8, 2017. [57] H. Argunsah, B. Y alcin, M. A. Ergin, G. Coruhlu, M. Y alcin, V . Patoglu, and Z. G ¨ uven, “Advancing Precision Rehabilitation Through a Sensor - Based 6-DoF Robotic Exoskeleton: Clinical V alidation and Ergonomic Assessment, ” Sensors , v ol. 26, no. 1, 2026. [58] M. Ergin and V . Patoglu, “AssistOn-SE: A Self-Aligning Shoulder- Elbow Exoskeleton, ” in IEEE Int. Conf. on Robotics and Automation , 2012, pp. 2479–2485. [59] M. Y alcin and V . Patoglu, “Kinematics and Design of AssistOn-SE: A Self-Adjusting Shoulder-Elbo w Exoskeleton, ” in IEEE Int. Conf. on Biomedical Robotics and Biomechatr onics , 2012, pp. 1579–1585. Harun T olasa received his B.Sc. degree in me- chanical engineering from Bilkent Univ ersity (2021) and his M.Sc. in mechatronics engineering from Sabanci University (2024). Currently , he is pursuing his Ph.D. degree at Sabanci Univ ersity . His research interests include activ e learning, human-in-the-loop optimization, and haptic rendering. V olkan Patoglu is a full professor in mechatron- ics engineering at Sabanci Uni versity . He receiv ed his Ph.D. degree in mechanical engineering from the University of Michigan, Ann Arbor (2005) and worked as a post-doctoral researcher at Rice Univ er- sity (2006). His research is in the area of physical human-machine interaction, in particular , design and control of force feedback robotic systems with ap- plications to rehabilitation. His research extends to cognitiv e robotics. He has served as an associate ed- itor for IEEE Transactions on Haptics (2013–2017), IEEE Transactions on Neural Systems and Rehabilitation Engineering (2018– 2023), and IEEE Robotics and Automation Letters (2019–2024).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment