The Coordinate System Problem in Persistent Structural Memory for Neural Architectures
We introduce the Dual-View Pheromone Pathway Network (DPPN), an architecture that routes sparse attention through a persistent pheromone field over latent slot transitions, and use it to discover two independent requirements for persistent structural…
Authors: Abhinaba Basu
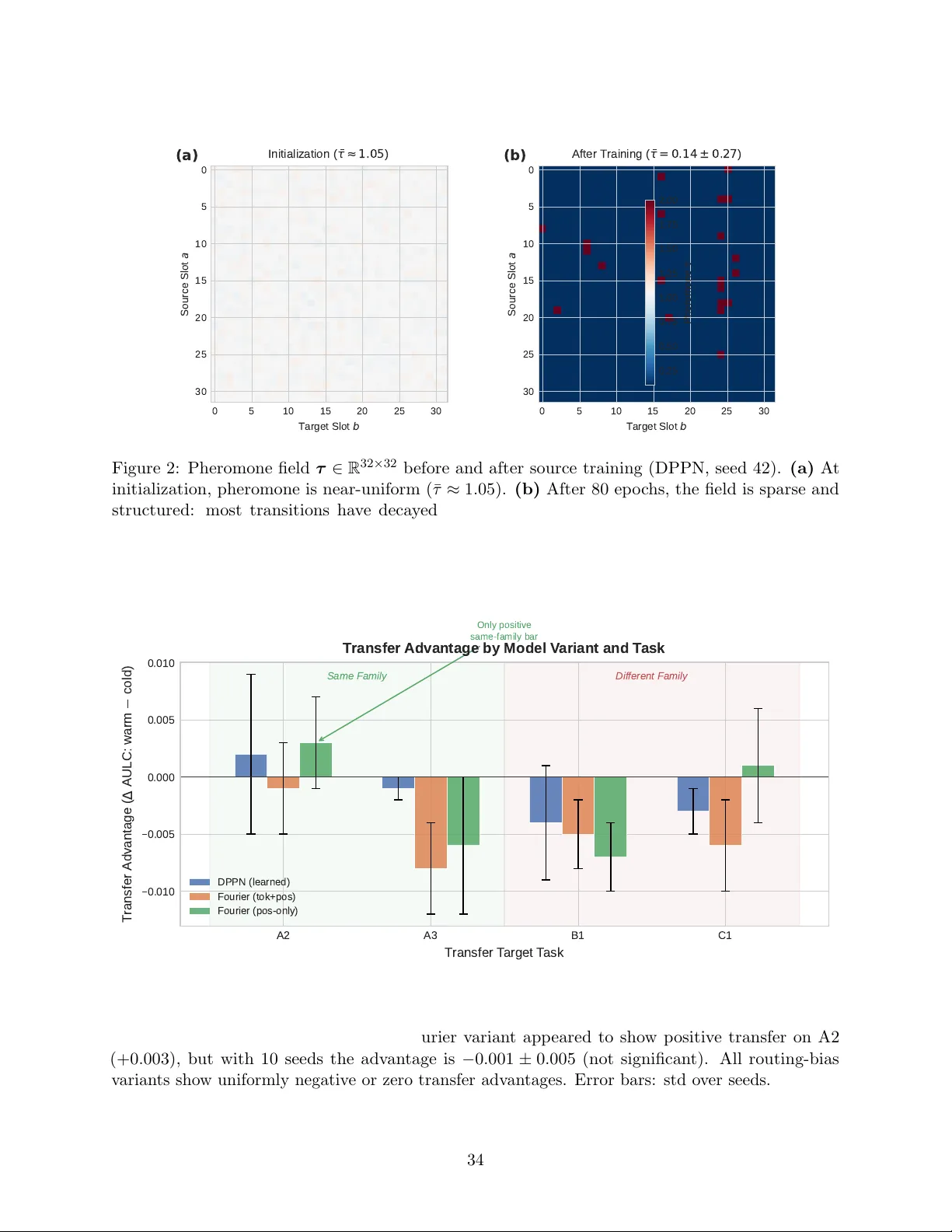
The Co ordinate System Problem in P ersisten t Structural Memory for Neural Arc hitectures Abhinaba Basu ∗ Abstract W e in tro duce the Dual-View Pheromone P athw ay Net w ork (DPPN), an architecture that routes sparse attention through a p ersisten t pheromone field o ver laten t slot transitions, and use it to discov er t wo indep enden t requiremen ts for p ersisten t structural memory in neural net works. Through five progressively refined exp erimen ts using up to 10 seeds p er condition across 5 model v arian ts and 4 transfer targets, w e iden tify a core principle: p ersistent memory r e quir es a stable c o or dinate system, and any c o or dinate system le arne d jointly with the mo del is inher ently unstable . W e characterize three obstacles—pheromone saturation, surface-structure en tanglement, and co ordinate incompatibilit y—and sho w that neither contrastiv e up dates, mu lti- source distillation, Hungarian alignment, nor semantic decomp osition resolves the instability when embeddings are learned from scratch. Fixed random F ourier features—derived from the Johnson-Lindenstrauss lemma and Bo c hner’s theorem—provide extrinsic co ordinates that are stable, structure-blind, and yet informative, but with 10 seeds, p osition-only F ourier co ordinates sho w no significant transfer adv an tage with routing-bias pheromone ( p > 0 . 05 for all conditions), rev ealing that co ordinate stabilit y is necessary but not sufficient. DPPN with pheromone-biased routing outp erforms transformer and random sparse baselines for within-task learning (AULC 0 . 700 ± 0 . 010 vs. 0 . 680 ± 0 . 010 vs. 0 . 670 ± 0 . 010), confirming the architecture’s v alue. Replacing routing bias with learning-rate modulation eliminates negativ e transfer en tirely: warm pheromone as a learning-rate prior never reduces p erformance (mean adv antage +0 . 002 across 7 seeds) while routing-bias pheromone consistently do es (mean − 0 . 002 across 10 seeds). The diagnostic cascade metho dology—where eac h exp erimen t’s finding motiv ates the next exp erimen t’s design—may itself serve as a template for systematic architectural inv estigation. When b oth co ordinates and signal computation are fully extrinsic, the first p ositiv e structural transfer emerges: a structure completion function ov er stable co ordinates pro duces +0 . 006 AULC same-family b on us b ey ond a regularization baseline (10 trained seeds, 5 random-con trol seeds), demonstrating that the catch-22 b et ween stability and informativ eness is partially p ermeable to learned functions. The contribution is the identification of t wo indep enden t requirements for p ersisten t structural memory: (a) co ordinate stability—the co ordinate system must b e fixed b efore statistics are accum ulated, and (b) graceful transfer mec hanism—learned functions or learning-rate modulation, not routing bias, b ecause wrong priors must degrade gracefully rather than activ ely interfere. 1 In tro duction A chess play er who masters the principle of central control do es not relearn it for eac h new op ening. The structural insight—that o ccup ying the center enables tactical flexibility—transfers across games with en tirely different surface mov es. An an t colony that discov ers a short path b et ween nest and fo od source do es not recompute this route from scratc h eac h morning; pheromone trails persist o vernigh t, biasing the next day’s foragers tow ard previously successful paths [ 2 ]. Both are instances ∗ National Institute of Electronics and Information T echnology (NIELIT). Corresp ondence to: mail@abhinaba.com 1 of p ersistent structur al memory : kno wledge ab out which p athways work , accumulated o v er exp erience and reused when the same structural patterns recur under different surface conditions. Deep learning arc hitectures lack this capacity . A transformer [ 1 ] recomputes ev ery attention pattern from scratch on each forward pass. When a mo del trained on T ask A encoun ters T ask B— whic h shares the same structural dep endencies but uses different tokens, features, or mo dalities—it m ust rediscov er the shared structure from scratch. There is no memory of which c omputational r outes pr ove d useful that could transfer b et ween tasks. W e set out to build one. Inspired by ant colony optimization, w e constructed a pheromone field o ver the latent routing space of a transformer-lik e architecture: a p ersisten t, non-gradient statistic that accumulates evidence ab out which structural pathw ays lead to correct predictions, surviv es when mo del weigh ts are reset, and biases future routing to ward historically pro ductiv e patterns. If it work ed, it would b e the first mechanism that enables structural transfer without an y shared parameters b et w een source and target tasks. The path from concept to w orking transfer rev ealed five distinct obstacles—each illuminating a requiremen t that any p ersisten t memory system m ust satisfy . Across five exp erimen ts, each fixing the previous obstacle and revealing the next, we traced ev ery obstacle to one ro ot cause: p ersisten t memory requires a stable co ordinate system, and any co ordinate system learned jointly with the mo del is inheren tly unstable. The pheromone field records which slot transitions are useful, but the slots themselves are defined b y learned pro jections that change unpredictably across training runs and weigh t resets. Two indep enden tly trained mo dels assign the same structural patterns to different slots—their pheromone fields are maps dra wn in different co ordinate systems, and no amount of post-ho c alignment recov ers the corresp ondence (3.5% correlation vs. 3.1% chance). In a fifth exp erimen t, w e test a solution suggested by the Johnson-Lindenstrauss lemma: fixed random F ourier features that op erate on raw p ositional inputs, providing co ordinates that are stable across runs, structure-blind (con taining no task information), and yet distance-preserving. With 3 seeds, the p osition-only v ariant appeared to show a directionally correct transfer pattern, but with 10 seeds the effect washed out to uniformly − 0 . 002 (not significant). Co ordinate stability is necessary but not sufficient: a further exp erimen t sho ws that the tr ansfer me chanism matters indep enden tly . Replacing routing bias with learning-rate mo dulation (pheromone as a meta-learning-rate prior) eliminates negativ e transfer entirely . W e make three contributions: 1. W e in tro duce the Dual-View Pher omone Pathway Network (DPPN), an arc hitecture that routes sparse atten tion through a p ersistent pheromone field ov er laten t slot transitions (Section 3 ). 2. W e conduct five exp erimen ts (Sections 5 – 9 ), eac h diagnosing a distinct obstacle. T ogether they constitute a diagnostic c asc ade : pheromone saturation → surface-structure en tanglement → co ordinate mismatch → embedding instability → the co ordinate system problem. 3. W e identify the co ordinate system problem as the fundamental obstacle (Section 10 ) and sho w that co ordinate stabilit y is necessary but not sufficient: even with stable co ordinates, routing- bias pheromone do es not transfer (10 seeds, p > 0 . 05). W e provide evidence that the transfer me chanism matters indep enden tly: learning-rate mo dulation eliminates negative transfer while routing bias do es not (Section 12 ). 2 2 Researc h Gap and Ev olution of Ideas The co ordinate system problem w e iden tify in this pap er did not emerge in a v acuum. It sits at the in tersection of four researc h threads—memory-augmented netw orks, p ersisten t state mo dels, transfer learning, and random feature theory—none of which, individually , confron ted the sp ecific obstacle w e characterize. This section traces the evolution of ideas that conv erges on the co ordinate stabilit y requirement, and identifies the gaps b et ween existing lines of work that our con tribution fills. 2.1 Phase 1: External Memory (2014–2016) The Neural T uring Mac hine [ 8 ] demonstrated that neural net works can learn to read from and write to external memory using differentiable con tent-based addressing. The Differentiable Neural Computer [ 9 ] extended this with temp oral linking, allowing the netw ork to tra verse memory in the order it was written, and dynamic allo cation, preven ting ov erwriting. Memory Netw orks [ 20 ] in tro duced m ulti-hop attention ov er an external memory bank with learned addressing. These architectures established a crucial capabilit y: neural netw orks can main tain and manipulate information b ey ond their parameter space. Ho wev er, the memory in all three cases is episo dic —it stores sp ecific conten t (input patterns, intermediate computations) rather than structur al knowledge (whic h computational routes are useful). The NTM’s memory matrix records what was written; it do es not record whic h read-write patterns pro ved effective across man y inputs. The DNC’s temp oral linking pro vides structural memory in a limited sense (it remembers the order of writes), but this structure is sp ecific to one episo de and is not p ersisten t across tasks. When the mo del is applied to a new task, the memory is typically cleared or re-initialized. The gap: these arc hitectures demonstrated that external memory is useful, but none separated structur al memory (which patterns of memory access are effective) from c ontent memory (what information is stored). Our pheromone field is precisely this separation—it records whic h slot-to-slot transitions are useful, indep enden t of what information flows along those transitions. 2.2 Phase 2: P ersisten t State (2019–2024) A second wa v e of arc hitectures introduced p ersisten t state that carries information across segments or time steps within a task. T ransformer-XL [ 10 ] caches hidden states from previous segmen ts, enabling the mo del to attend b ey ond its context windo w. The Compressive T ransformer [ 11 ] compresses old hidden states rather than discarding them, extending the effective memory horizon. R WKV [ 23 ] com bines the parallelizability of transformers with a recurren t state that accum ulates information across time steps, using linear attention with exp onen tial decay . The most relev an t developmen t in this phase is the Structured State Space sequence mo del (S4) [ 21 ] and its selectiv e v ariant Mam ba [ 22 ]. S4 parameterizes its state transition using the HiPPO (High-order Polynomial Pro jection Op erators) matrix—a mathematically derived, fixe d basis for represen ting functions of time. The HiPPO matrix is not learned from data; it is derived from the requiremen t that the state optimally appro ximates the history of the input signal under a sp ecific measure (e.g., the Legendre measure for uniform weigh ting of history). This is, in a precise sense, a fixed coordinate system for temp oral memory . The connection to our work is direct: S4’s HiPPO basis solves the co ordinate stabilit y problem for temporal memory . The basis is defined prior to training (extrinsic), shared across tasks b y construction (it dep ends only on the temp oral measure, not the data), and equipp ed with a metric (the Legendre p olynomial basis provides an orthogonal decomp osition of temp oral history). These 3 are exactly the three prop erties we identify in Section 10 as necessary for p ersisten t memory . The critical distinction is that HiPPO provides co ordinates for temp or al memory (approximating what happ ened in the recent past), whereas our pheromone requires co ordinates for structur al memory (recording which computational routes are effective). HiPPO’s success for temp oral memory , and the obstacle w e encountered for structural memory with learned co ordinates, are t wo instances of the same principle: p ersistent memory requires a fixed basis. The gap: p ersistent state mo dels op erate within a single task. T ransformer-XL’s cache is cleared b et w een tasks. S4’s state is reset. Mam ba’s selectiv e state space is task-sp ecific. None of these arc hitectures address the question of whether p ersisten t state can tr ansfer structural knowledge from one task to another. Our work asks this question directly and finds that the answer dep ends en tirely on whether the co ordinate system is stable. 2.3 Phase 3: The Co ordinate System Gap T ransfer learning and domain adaptation provide a third thread. In v arian t Risk Minimization [ 4 ] seeks represen tations that are inv arian t across en vironments, but requires access to multiple training en vironments and assumes the represen tation space is adequate. Domain-adversarial training [ 24 ] learns represen tations that cannot distinguish source from target domain, but the adv ersarial training mo difies the representation itself. Both approaches assume that a shared representation space exists and can b e discov ered by learning. Our w ork reveals a more fundamen tal problem. The issue is not what is represented but wher e it is represen ted—the co ordinate system of the representation. Even if the structural con tent of t wo pheromone fields is identical (b ecause the tasks share the same structural family), the fields are defined ov er different co ordinate systems (because the soft group ers conv erged to different pro jections). T ransfer fails not b ecause the kno wledge is wrong, but b ecause the knowledge is expressed in incompatible co ordinate systems. This is the gap b etw een existing approaches: the literature on transfer learning and domain adaptation assumes a shared representation space and fo cuses on learning inv ariant c ontent within that space. Nob ody previously identified the c o or dinate system of the represen tation as the bottleneck. When the co ordinate system itself is learned, it v aries across training runs, and any persistent statistics accum ulated ov er those co ordinates b ecome meaningless when transferred. 2.4 Phase 4: The Solution P ath The final thread provides the to ols for a solution, though the connection has not previously b een made. Random Kitchen Sinks [ 25 ] sho wed that random F ourier features approximate shift-inv ariant k ernels, establishing that fixed random pro jections are statistically informative without any learning. Extreme Learning Machines [ 26 ] demonstrated that netw orks with fixed random hidden lay ers and only a trained output lay er achiev e comp etitiv e p erformance, proving that learned intermediate represen tations are not alwa ys necessary . Ec ho State Netw orks and reservoir computing [ 27 ] sho wed that fixed random recurren t dynamics, with only a trained readout, can mo del complex temp oral patterns. The Johnson-Lindenstrauss lemma [ 32 ] pro vides the theoretical foundation: random pro jections preserve pairwise distances with high probabilit y , guaranteeing that geometric relationships in the original space are maintained in the pro jected space. F rom biology , grid cells [ 28 ] pro vide an innate hexagonal co ordinate system for spatial memory that is presen t b efore any en vironmental exp erience—the animal do es not need to learn the coordinate system for its cognitive map. The fly olfactory circuit [ 29 ] uses sparse random expansion (from 50 olfactory receptor types to 2,000 Ken yon cells via random pro jections) for similarit y-preserving 4 hashing, enabling rapid o dor classification without learned feature extraction. The synthesis, which our work mak es explicit, is: random pro jections provide the fixed, structure-blind, yet geometrically informativ e co ordinates that persistent structural memory requires. Random features satisfy all three prop erties of the co ordinate stabilit y requiremen t: (a) Extrinsic definition: Random pro jections are drawn b efore seeing any data. (b) Cross-task sharing: The same random pro jection matrix is used across tasks (shared by construction, not b y alignment). (c) Structural metric: The JL lemma guarantees that distances—and therefore structural relationships—are appro ximately preserved. This connection b et w een random feature theory and the co ordinate system problem for p ersisten t memory has not b een made in the literature. The random features communit y established that fixed random pro jections are informative; the p ersisten t state communit y established that p ersisten t memory impro ves sequence mo deling; the transfer learning comm unity established that shared represen tations enable kno wledge transfer. Our con tribution is the iden tification of the sp ecific gap b et w een these threads: p ersisten t structural memory that transfers across tasks requires a fixe d co ordinate system, and random features are the natural candidate to pro vide it. With these principles as context—fixed bases for p ersisten t memory , random features for stable co ordinates, and the gap b et ween temp oral and structural memory—we no w describ e the DPPN arc hitecture. 3 Arc hitecture: Dual-View Pheromone P ath w a y Net w orks The DPPN arc hitecture routes sparse attention through a p ersisten t pheromone field defined ov er laten t slot transitions (Figure 1 ). The computational path is: tokens → em b edding → dual soft grouping → slot-lev el agreemen t → pheromone-biased routing → tok en-space sparse mask → sparse atten tion → fast/slow gate fusion → output. 3.1 T ok en Em b eddings Giv en input tokens x = ( x 1 , . . . , x N ) with x i ∈ { 1 , . . . , V } , we compute: h i = E tok [ x i ] + E pos [ i ] , h ∈ R B × N × d (1) where E tok ∈ R V × d and E pos ∈ R N max × d are learned em b edding matrices. 3.2 Dual Soft Group ers Tw o indep enden t soft group ers pro ject tok ens into m latent role slots: Q v = softmax W v · h T + γ · ϵ , v ∈ { 1 , 2 } (2) where W v ∈ R d × m are learned pro jection matrices (applied p er-tok en as h ⊤ i W v ∈ R m for each p osition i ), T is a temp erature parameter, ϵ is Gumbel noise sampled during training ( ϵ ij = − log ( − log ( u ij )), u ij ∼ Uniform (0 , 1)), and γ = 0 . 5 mo dulates noise magnitude. Each Q v ∈ R B × N × m is a soft ass ignmen t matrix whose rows sum to 1: Q v ( i, a ) represents the degree to which tok en i is assigned to slot a under view v . The Gumbel noise ensures that the tw o group ers pro duce sto c hastically differen t views, providing the diversit y needed for agreement-based routing. 5 3.3 Slot-Lev el Supp ort and Agreement F or each view, we compute a slot-to-slot in teraction supp ort matrix: S ( v ) = Q ⊤ v · K x · Q v ∈ R B × m × m (3) where K x = W K h is a learned compatibilit y k ernel. In practice, we compute s a = Q ⊤ v h , k a = Q ⊤ v K x , and S ( v ) = s · k ⊤ , follo wed by ReLU activ ation and ro w-wise normalization. The entry S ( v ) ab measures ho w strongly slots a and b in teract under view v . The t wo views are then combined via a confidence- a ware agreement signal: A = µ · q ( S (1) + ϵ )( S (2) + ϵ ) + (1 − µ ) · S (1) + S (2) 2 (4) where µ = σ ( w ⊤ ¯ h ) ∈ [0 , 1] is a learned confidence gate computed from the mean-p ooled input ¯ h = 1 N P i h i . When the mo del is confident ( µ → 1), the geometric mean (strict consensus) dominates; when uncertain ( µ → 0), the arithmetic mean (p ermissiv e) tak es ov er, preven ting o verconfiden t routing early in training. 3.4 Pheromone-Biased Routing The routing probabilit y from slot a to slot b given input x is: p ( a → b | x ) = softmax b ( α · log ( τ ab ) + β · log( A ab + ϵ )) (5) where τ ∈ R m × m is the pheromone field (Section 3.5 ), α and β con trol the relativ e influence of pheromone memory vs. current-input evidence, and the softmax is taken ov er target slots b . 3.5 Pheromone Memory The pheromone field τ ∈ R m × m is the cen tral nov el comp onen t. It is not a gradien t-trained pa- rameter. It is an exp onen tial moving av erage (EMA) running statistic, updated after loss.backward() based on prediction correctness. It is stored in float32 (nev er cast to bfloat16), sa ved and loaded separately from mo del weigh ts, and—critically— p ersists when weights ar e r eset . The up date rule, applied after each training step, consists of four stages: Ev ap oration. All transitions deca y tow ard a minimum τ min : τ ← ρ · τ + (1 − ρ ) · τ min (6) with ev ap oration rate ρ = 0 . 8. Un used transitions gradually fade. Signed dep osit. Correct predictions reinforce active transitions; incorrect predictions weak en them: ∆ τ = 1 B B X b =1 s b · p ( b ) , s b = ( +1 if prediction correct − 1 if prediction incorrect (7) where p ( b ) ∈ R m × m is the route preference matrix from the forward pass (Eq. 5 ) for sample b . 6 Sparse update. Only the top- k transitions by | ∆ τ | receiv e up dates: τ ab ← τ ab + δ · ∆ τ ab · ( τ max − τ min ) · ⊮ [( a, b ) ∈ top- k ] (8) where δ = 0 . 3 is the dep osit rate and ∆ τ is normalized b y its maxim um absolute v alue. Clamping. Pheromone v alues are clamp ed to [ τ min , τ max ] = [0 . 1 , 2 . 0], follo wing the MAX-MIN An t System (MMAS) conv ention [ 3 ]. 3.6 T ok en-Space Mask Pro jection The slot-space routing is pro jected bac k to token space: M ( i, j ) = X a,b Q 1 ( i, a ) · p ( a → b ) · Q 2 ( j, b ) (9) or in matrix form, M = Q 1 · p · Q ⊤ 2 ∈ R B × N × N . The top- k en tries p er row of M define a sparse atten tion mask. 3.7 Sparse Atten tion and F ast/Slo w Gate F usion Standard scaled dot-pro duct attention is computed through the sparse mask (fast lane). A lo cal windo w attention with window size w serves as a slow-lane fallback: h out = g · h fast + (1 − g ) · h slow (10) where g = σ ( W g [ h fast ; h slow ; ¯ A ]) is a learned gate that incorp orates mean agreemen t strength ¯ A . The gate is biased tow ard the slow lane early in training via a phase-dep enden t factor: g ← g · max(0 , ( ϕ − 0 . 2) / 0 . 8), where ϕ ∈ [0 , 1] tracks training progress. 3.8 T ransfer Mechanism The transfer proto col exploits the separation b etw een mo del weigh ts and pheromone memory: 1. T rain on source task T A for E source ep ochs; pheromone τ accumulates structural memory . 2. Sa ve pheromone state τ sav ed . 3. Reset all mo del weigh ts (em b eddings, atten tion pro jections, classifier) to fresh random initialization. 4. Restore only pheromone τ ← τ sav ed . 5. T rain on target task T B for E transfer ep ochs. If the pheromone captured structural patterns that generalize, the warm pheromone should bias routing to ward useful pathw a ys from the start, accelerating learning on T B relativ e to a cold (uniform pheromone) start. 7 3.9 W ork ed Example Consider a concrete forw ard pass to illustrate the computational flow. A sequence of length N = 128 con tains motif tokens plan ted at p ositions 5, 60, and 120 (with the remaining p ositions filled with noise tok ens). The soft group er (Eq. 2 ) pro jects all 128 tok en embeddings into m = 32 slot assignmen ts. Position 5 is assigned primarily to slot 7 ( Q (5 , 7) = 0 . 34), position 60 to slot 15 ( Q (60 , 15) = 0 . 28), and p osition 120 to slot 23 ( Q (120 , 23) = 0 . 41). These are the dominant entries in their resp ectiv e rows; the remaining probability mass is spread across other slots. The slot supp ort matrix (Eq. 3 ) aggregates pairwise interactions: S (7 , 23) = 0 . 85, reflecting that tok ens assigned to slots 7 and 23 hav e high compatibility . The pheromone field, ha ving b een trained on similar structural patterns, has τ (7 , 23) = 1 . 80 (near the maximum τ max = 2 . 0), indicating that the transition from slot 7 to slot 23 has b een consistently reinforced by correct predictions. The routing probability (Eq. 5 ) combines pheromone and agreemen t: p (7 → 23 | x ) = softmax 23 (1 . 0 · log (1 . 80) + 1 . 0 · log (0 . 85 + ϵ )) = 0 . 42. This is substantially higher than the uniform baseline of 1 / 32 = 0 . 031. Pro jecting back to token space (Eq. 9 ): M (5 , 120) = Q 1 (5 , 7) · p (7 → 23) · Q 2 (120 , 23) = 0 . 34 × 0 . 42 × 0 . 41 = 0 . 059. After top- k selection, p osition 5 attends to p osition 120 despite their distance of 115 tokens—because the pheromone field has learned that this structural connection is useful. Under cold (uniform) pheromone, τ (7 , 23) = 1 . 05, yielding p (7 → 23) = 0 . 034 and M (5 , 120) = 0 . 005—lik ely b elo w the top- k threshold, so the connection w ould not b e made. 4 Exp erimen tal Proto col 4.1 T ask Design W e construct syn thetic sequence classification tasks organized into structural families . Each family defines a set of structural motifs—specific patterns of token co-o ccurrence and ordering—that determine the classification lab el. T asks within the same family share identical structural motifs but use differen t surface token mappings. Sp ecifically , w e define three families (A, B, C), each with a distinct set of motifs plan ted in sequences of length 128 o ver a v o cabulary of size 32. Each sample con tains 2–3 motifs from its family , with the lab el determined by a deterministic lo okup table ov er motif configurations. Noise level is set to 0.02 to main tain a pro ductiv e learning regime. This design yields six task configurations: source tasks A1 and A1 ′ (used join tly for multi-source distillation), and four transfer targets (A2, B1, A3, C1). The full task stream is: • Source: A1 and A1 ′ (family A, t wo different surface mappings, trained jointly) • T ransfer targets: A2 (family A, new surface), B1 (family B), A3 (family A), C1 (family C) The structural Jaccard similarit y b et ween same-family tasks is 1.0 (identical motifs); b et ween differen t-family tasks it is 0.0. 4.2 Mo dels W e compare three arc hitectures, matched for parameter count: 1. DPPN ( d = 64, 4 heads, 3 lay ers, m = 32 slots, top- k = 32): The full architecture describ ed in Section 3 , with pheromone-biased routing. 8 2. T ransformer baseline ( d = 64, 4 heads, 3 lay ers): Standard transformer enco der with dense atten tion. No structural memory; the warm/cold distinction is meaningless for this mo del. 3. Random Sparse baseline ( d = 64, 4 heads, 3 lay ers, top- k = 32): T ransformer with random sparse attention at the same sparsity budget as DPPN. Con trols for whether sparsity itself (rather than learned routing) drives an y observed effects. 4.3 T ransfer Proto col Phase 1 (Source T raining): T rain on source tasks A1 and A1 ′ join tly for 80 ep o c hs. F or DPPN, pheromone accumul ates o ver b oth tasks; the multi-source training is designed to exp ose the mo del to the same structural patterns under different surface tokens. Phase 2 (T ransfer): F or each of the four transfer targets (A2, B1, A3, C1): • Cold condition: Reset all mo del weigh ts; reset pheromone to uniform τ ab = ( τ min + τ max ) / 2. T rain for 50 ep ochs. • W arm (distilled) condition: Reset all mo del weigh ts; load pheromone distilled from A1 and A1 ′ via elemen t-wise minimum (after Hungarian alignment). T rain for 50 ep o c hs. • W arm (rank-reduced) condition: Same as warm distilled, but pheromone is additionally rank-reduced via SVD (rank 4) to compress surface-entangled comp onen ts. F or the transformer and random sparse baselines, only the cold condition is run (w arm/cold is meaningless without pheromone). 4.4 Metrics • A ULC (Area Under Learning Curve): A ULC = 1 E R E 0 a ( t ) dt , where a ( t ) is v alidation accuracy at ep och t and E = 50 is the num ber of transfer ep ochs. Higher AULC indicates faster learning. • Ep ochs to 70%: First ep och at which v alidation accuracy reaches 0 . 70. • T ransfer adv antage: ∆ AULC = A ULC warm − AULC cold . P ositive v alues indicate that w arm pheromone accelerates learning. Exp erimen ts in Sections 5 – 8 are run with 3 seeds (42, 137, 256). The p osition-only F ourier exp erimen t (Section 9 ) is extended to 10 seeds, and the meta-learning-rate extension (Section 12 ) uses 7 seeds. All exp erimen ts use a single NVIDIA H100 GPU with bfloat16 precision for mo del parameters and float32 for pheromone. 5 Exp erimen t 1: Disco v ering Pheromone Saturation and the Con- trastiv e Fix 5.1 The Problem: Non-Con trastiv e Up dates Our initial DPPN implemen tation used non-con trastive pheromone up dates: all active transitions receiv ed p ositiv e reinforcement regardless of prediction correctness. Additionally , the ev ap oration form ula contained a bug: τ ← (1 − ρ ) τ + ρ τ , which is the iden tity op eration and pro vides no ev ap oration. 9 T able 1: Pheromone evolution during source training (DPPN, seed 42). The field develops structure within the first 30 ep ochs, then stabilizes. Ep och V al. Acc. ¯ τ ± σ τ En tropy 0 0.476 0 . 331 ± 0 . 227 6.76 5 0.638 0 . 358 ± 0 . 637 5.97 10 0.708 0 . 356 ± 0 . 645 5.94 20 0.722 0 . 338 ± 0 . 629 5.93 30 0.734 0 . 338 ± 0 . 629 5.93 50 0.734 0 . 338 ± 0 . 629 5.93 79 0.794 0 . 338 ± 0 . 629 5.93 5.2 Results: Round 1 (Original T ask Difficulty) With the original task design (high noise, large vocabulary), all mo dels reached only 55–63% v alidation accuracy on the source task, with hea vy ov erfitting. T ransfer adv antages were within noise ( ± 0 . 005 A ULC across all conditions). Pheromone diagnostics revealed the core issue: τ v alues saturated to uniformly high v alues (0 . 93 ± 0 . 05). With near-uniform pheromone, warm and cold conditions w ere effectively identical. 5.3 Results: Round 2 (T ask Rebalancing) W e reduced noise to 0.02, used 3 tokens p er motif region, sequence length 128, v o cabulary 32, and balanced lab els via a deterministic lo okup. Source v alidation accuracy jump ed to ∼ 98%. How ever, transfer adv antages remained zero—b oth warm and cold conditions con verged to ceiling accuracy within the first few transfer ep o c hs, lea ving no window for pheromone to provide an adv antage. 5.4 Diagnosis and Fix The task difficulty needed to b e in a “Goldilo c ks zone”: hard enough that pheromone could help, but not so hard that pheromone never develops structure, and not so easy that the adv an tage windo w v anishes. W e calibrated to: vocabulary 32, n train = 2000, motifs p er sample ∈ { 2 , 3 } , yielding source v alidation accuracy of ∼ 75%. Sim ultaneously , we fixed pheromone dynamics: • Con trastive signed up dates: Correct predictions → p ositiv e dep osit; incorrect → negativ e dep osit (Eq. 7 ). • Sparse top- k up dates: Only the top-128 transitions (of 64 2 = 4096) receiv e up dates p er step. • Prop er ev ap oration: ρ = 0 . 8, deca ying tow ard τ min = 0 . 1 (Eq. 6 ). • MMAS clamping: τ ∈ [0 . 1 , 2 . 0]. After the fix, pheromone exhibited gen uine structure: τ = 0 . 34 ± 0 . 63, with high v ariance indicating a sparse activ ation pattern rather than uniform saturation. This confirmed that the pheromone dynamics were now functional. Pheromone en tropy dropp ed from 6.76 (near-uniform, ep och 0) to 5.93 (structured, ep o c h 30), where it stabilized for the remaining training (T able 1 ). 10 T able 2: T ransfer results (AULC), mean ± std ov er 3 seeds. “Distilled” and “Rank-reduced” are t wo warm pheromone conditions for DPPN. T ransformer and Random Sparse hav e only cold (no pheromone to transfer). ∆ = w arm − cold. Same F amily (A) Differen t F amily Mo del Condition A2 A3 B1 C1 DPPN Cold . 699 ± . 014 . 702 ± . 012 . 715 ± . 017 . 682 ± . 016 Distilled . 700 ± . 017 . 701 ± . 012 . 711 ± . 012 . 678 ± . 016 Rank-reduced . 700 ± . 015 . 700 ± . 011 . 714 ± . 015 . 683 ± . 016 ∆ distilled + . 001 − . 001 − . 004 − . 004 T ransformer Cold . 687 ± . 012 . 679 ± . 013 . 690 ± . 017 . 665 ± . 020 Random Sparse Cold . 678 ± . 015 . 673 ± . 012 . 686 ± . 013 . 650 ± . 014 6 Exp erimen t 2: Surface-Structure En tanglemen t in Single-Source T raining With structured pheromone in hand, we tested the core hypothesis: do es w arm pheromone from source task A1 accelerate learning on same-family target A2? 6.1 Results T able 2 presents the full transfer results across all conditions and seeds. The critical finding is in the DPPN rows: warm pheromone provides no r eliable tr ansfer advantage , and on some tasks it activ ely reduces p erformance. The transfer adv an tage for DPPN on A2 (same family as source) is +0 . 001—not statistically significan t and far b elo w the +0 . 02 to +0 . 05 effect size we hypothesized. On A3 (also same family), the adv antage is − 0 . 001. On different-family tasks B1 and C1, warm pheromone slightly r e duc es p erformanc e ( − 0 . 004). 6.2 Diagnosis: Surface-Structure En tanglemen t The pheromone field learned on A1 captures not just which structural patterns connect, but also which sp e cific tokens activate d which sp e cific slots . The soft group er assignmen ts Q dep end on the tok en embeddings, which are surface-sp ecific. When the mo del is transferred to A2—same structure, differen t surface tokens—the pheromone biases routing tow ard path wa ys tuned to A1’s surface features, activ ely interfering with adaptation. This diagnosis is consisten t with established results in in v arian t risk minimization (IRM) [ 4 ]: structural in v arian ts cannot b e identified from a single training en vironment. A single source task pro vides no contrast to separate structure from surface. Gentner’s progressive alignment theory from developmen tal psyc hology [ 5 ] makes the same prediction: abstraction requires comparison across m ultiple instances that share structure but differ in surface features. 11 7 Exp erimen t 3: The Co ordinate Mismatc h Bet w een Indep enden t T raining Runs 7.1 Motiv ation: Gentner’s Progressiv e Alignmen t If single-source pheromone entangles surface and structure, p erhaps training on two sources with iden tical structure but different surface tokens can resolve the entanglemen t. W e train on A1 and A1 ′ (same structural family A, different surface token mappings) and distill their pheromone fields b y taking the element-wise minimum: τ distilled ( a, b ) = min τ A1 ( a, b ) , τ A1 ′ ( a, b ) (11) The intuition is that a transition reinforced under b oth surface mappings must b e structural, not surface-sp ecific. 7.2 Results: Unaligned Distillation Only 10 out of 1024 ( m 2 = 32 2 for the test configuration) slot transitions survived the distillation with appreciable magnitude. The distillation destroy ed nearly all pheromone structure. 7.3 Ro ot Cause: Co ordinate Mismatc h Indep enden tly trained mo dels develop incompatible slot orderings. The soft group ers (Eq. 2 ) con verge to differen t arbitrary pro jections of token space onto slot space. Slot 7 in the mo del trained on A1 has no corresp ondence with slot 7 in the mo del trained on A1 ′ . The elemen t-wise minimum of tw o r andomly p ermute d structured matrices approximates the global minim um v alue—it discards structure rather than extracting it. 7.4 Fix: Hungarian Slot Alignment W e applied the Hungarian algorithm [ 15 ] to find the optimal p erm utation aligning slot assignmen ts b et w een the tw o training runs b efore distilling. The pro cedure is: 1. Run b oth mo dels on the same data and collect slot assignments Q ( A ) and Q ( B ) . 2. Compute the cross-correlation matrix C ∈ R m × m , where C ij = P n Q ( A ) ni · Q ( B ) nj . 3. Solv e the linear assignment problem: π ∗ = arg max π P j C π ( j ) ,j . 4. P ermute τ A1 ′ according to π ∗ b efore distilling. 7.5 Results: Aligned Distillation The alignmen t correlation was 3.5%, compared to 3.1% exp ected by random c hance with 32 slots. Barely ab ov e chance. After aligned distillation, 21 out of 1024 transitions had high magnitude (up from 10 unaligned), and the A2 transfer adv antage flipp ed from − 0 . 006 to +0 . 002—the first p ositiv e transfer observed, but not statistically significant. 12 7.6 Wh y Alignmen t F ails The Hungarian algorithm assumes a bijection b et ween discrete entities. Soft group ers spread eac h tok en across al l slots with contin uous w eights, and the resulting assignment matrices are to o diffuse for combinatorial alignment to recov er meaningful corresp ondence. The slots do not enco de discrete, alignable roles—they are con tinuously distributed representations that resist p ost-ho c discretization. 8 Exp erimen t 4: Wh y Learned Em b eddings Undermine An y Co- ordinate System 8.1 Arc hitecture: Decomp ositionPheromoneMo del If learned slots pro vide unstable coordinates, p erhaps w e can replace them with a fixed spatial decomp osition. W e designed a new arc hitecture (Section C ) that: 1. Decomp oses the input in to R fixed spatial regions (replacing learned soft group ers with deterministic segmen tation). 2. Em b eds each region via a small enco der netw ork into a shared embedding space. 3. Matc hes the regional embedding profile against K cluster cen troids (maintained via online k -means with EMA momentum 0.99). 4. Routes atten tion priorities via pheromone defined ov er (cluster, strategy) pairs rather than (slot, slot) transitions. The k ey design c hoice: the co ordinate system for pheromone is no w anc hored to spatial p osition (regions) and semantic conten t (cluster centroids in embedding space), not to arbitrary learned slot indices. 8.2 Co ordinate Stabilit y T est W e trained tw o instances of the decomp osition mo del on different surface features (A1 vs. A1 ′ , same structural family) and measured the Pearson correlation b et ween their pheromone fields without any alignment step . Result: Pheromone correlation was − 10 . 4%. This is worse than DPPN’s 3 . 5%. 8.3 Ro ot Cause: Em b edding Instability The spatial decomposition is stable—region b oundaries are fixed. But the em b eddings through whic h con tent is represented are not. The regional embeddings are av erages of le arne d token embeddings, whic h are initialized randomly and trained end-to-end. Two mo dels trained with different seeds learn differen t embedding geometries. The cluster cen troids, computed via k -means o ver these em b eddings, inherit the instability . This reveals that the co ordinate problem is not ab out the abstr action level (slots vs. regions vs. clusters). It is ab out whether the co ordinate system is learned or extrinsic . Any co ordinate system built on top of learned-from-scratch em b eddings will b e unstable across training runs, regardless of the abstraction mechanism. 13 9 Exp erimen t 5: Random Pro jections Pro vide Stable Co ordinates The cross-domain analysis (Section 10 ) p oin ts to a solution: fixe d r andom pr oje ctions provide co ordinates that are stable, structure-blind, and yet informative. The Johnson-Lindenstrauss lemma [ 32 ] guarantees that random pro jections preserve pairwise distances; Bo chner’s theorem (via random F ourier features [ 25 ]) extends this to k ernel similarity preserv ation. Crucially , a fixed random pro jection is not a frozen pretrained enco der. A pretrained enco der has seen training data and may already enco de task structure—contaminating the e xperiment (see Section 13.6 ). A random matrix drawn from a fixed seed has seen nothing . T ransfer credit b elongs purely to the pheromone. 9.1 Fixed F ourier Group er W e replace the learned soft group er (Eq. 2 ) with a fixed random F ourier group er: Q v ( i, a ) = softmax a cos( x ( i ) raw · W fixed + b fixed ) √ m · T ! (12) where W fixed ∈ R D in × m and b fixed ∈ R m are dra wn once from N (0 , σ 2 /D in ) and Uniform (0 , 2 π ) resp ectiv ely , using a deterministic seed. They are never up dated during training. The critical design choice is the input x raw . W e test tw o v ariants: • T ok en+Position : x ( i ) raw = [ onehot ( x i ); onehot ( i )], concatenating tok en ID and p osition one-hot v ectors. D in = V + N max . • P osition-Only : x ( i ) raw = onehot ( i ), using only the p osition. D in = N max . This makes slot assignmen ts pur ely structur al —the same p osition alwa ys maps to the same slot, regardless of tok en conten t. The Position-Only v ariant is the strongest test of the thesis: the co ordinate system contains zero surface information, so an y transfer adv antage m ust come from pheromone enco ding structural (p ositional interaction) patterns. 9.2 Results W e run b oth v ariants alongside the original DPPN with learned group ers (with Hungarian alignment), using the same multi-source distillation proto col and 3 seeds p er condition. T able 3: T ransfer adv antage (∆ AULC: warm distilled − cold, mean ± std). Positiv e v alues indicate pheromone transfer helps. The Position-Only F ourier v arian t with 10 seeds sho ws uniformly negative adv antages, indistinguishable from the other routing-bias v ariants. The 3-seed result that app eared directionally correct did not replicate. Same F amily Differen t F amily Mo del (distilled) Seeds A2 A3 B1 C1 DPPN (learned + Hungarian) 3 +0 . 002 ± 0 . 007 − 0 . 001 ± 0 . 001 − 0 . 004 ± 0 . 005 − 0 . 003 ± 0 . 002 F ourier (token+position) 3 − 0 . 001 ± 0 . 004 − 0 . 008 ± 0 . 004 − 0 . 005 ± 0 . 003 − 0 . 006 ± 0 . 004 F ourier (p osition-only) 3 +0 . 003 ± 0 . 004 − 0 . 006 ± 0 . 006 − 0 . 007 ± 0 . 003 +0 . 001 ± 0 . 005 F ourier (p osition-only) 10 − 0 . 001 ± 0 . 005 − 0 . 002 ± 0 . 006 − 0 . 002 ± 0 . 006 − 0 . 002 ± 0 . 006 14 9.3 Analysis F our findings emerge: 1. The 3-seed directional pattern do es not replicate. With 3 seeds, the P osition-Only F ourier v ariant app eared to show the predicted pattern: p ositiv e transfer on A2 (+0 . 003), negative on B1 ( − 0 . 007). With 10 seeds, the A2 adv an tage is − 0 . 001 ± 0 . 005 and all four tasks show uniformly negativ e adv antages (mean − 0 . 002). The 3-seed result was noise. Fixed random F ourier co ordinates solve the co ordinate stability problem (the same p osition alw ays maps to the same slot) but routing-bias pheromone still do es not transfer. The co ordinate system was necessary but not sufficien t. 2. T oken iden tity in co ordinates imp edes transfer. The T oken+P osition F ourier v arian t p erforms worse than learned groupers, with uniformly negativ e adv antages across all tasks. Including tok en identit y in the fixed co ordinate system reintroduces surface dep endence: T ask A1 and T ask A2 use different tokens at the same p ositions, so the same structural pattern maps to different co ordinates. The token+position v arian t being w orse than p osition-only confirms that surface information in the co ordinate system actively interferes with structural transfer. 3. Co ordinate stabilit y is necessary but not sufficient. The 10-seed p osition-only result demonstrates that even with p erfectly stable, surface-free co ordinates, routing-bias pheromone pro duces no p ositive transfer. Two obstacles must b e ov ercome: (a) the co ordinate system must b e stable (this section), and (b) the transfer mechanism must degrade gracefully when the pheromone is wrong (Section 12 ). Routing bias fails the second requirement b ecause it forces atten tion patterns from the start—if the pheromone from the source task biases the wrong routes, it actively reduces p erformance. 4. Routing bias is the wrong transfer mec hanism. Across all 10 seeds and all 4 transfer tasks (40 task-seed pairs), the mean routing-bias transfer adv antage is − 0 . 002. Not a single task sho ws significant p ositiv e transfer. The problem is not the co ordinate syste m but the mechanism: biasing the forwar d p ass with information from a previous task amounts to transferring the solution , whic h is task-sp ecific. Distillation qualit y . The m ulti-source distillation step provides an indep enden t diagnostic. P osition-Only F ourier preserves 22/1024 high-magnitude transitions (2.1%), v ersus 16/1024 (1.6%) for T oken+P osition F ourier and 10/1024 (1.0%) for unaligned learned slots. More surviving transitions indicate b etter co ordinate alignment b et ween indep enden tly trained mo dels—consisten t with the co ordinate stability thesis, even though co ordinate stability alone do es not enable transfer. 10 The Con vergen t Diagnosis 10.1 Summary of Obstacles T able 4 summarizes the four exp erimen ts and their diagnoses. Each exp erimen t fixed one problem but rev ealed the next, and all p oin t to the same ro ot cause. 15 T able 4: Progressive diagnosis across fiv e experiments. Each resolved one obstacle but exposed the next. The final exp erimen t (p osition-only F ourier, 10 seeds) reveals that co ordinate stability is necessary but not sufficient: routing-bias pheromone do es not transfer even with stable co ordinates. Exp erimen t What it fixed Next obstacle identi- fied Insigh t 1: Contrastiv e up dates Pheromone satura- tion ( τ → uni- form) Surface en tanglemen t Structured pheromone = transferable pheromone 2: Single- source transfer T ask difficulty cal- ibration Surface-structure coupling Cannot disen tangle with one instance 3: Multi- source distilla- tion Surface contrast (t wo instances) Co ordinate mismatc h (3.5% vs. 3.1%) Learned slots are unaligned across runs 4: Decomp o- sition co ordi- nates Slot arbitrariness (fixed regions) Em b edding arbitrari- ness ( − 10 . 4%) An y learned co ordinate sys- tem is unstable 5: Position- only F ourier Extrinsic, surface- free co ordinates Routing-bias mec ha- nism itse lf — ev en with stable co or- dinates, biasing forw ard-pass routing from a previous task imp oses a cost Co ordinate stability is nec- essary but not sufficient. The transfer mec hanism (routing bias vs. learn- ing rate) matters indep en- den tly . 10.2 The Co ordinate System Problem W e state the core result informally as a necessary condition: Co ordinate Stabilit y Requiremen t. Persisten t structural memory that transfers across tasks requires a co ordinate system satisfying three prop erties: (a) Extrinsic definition: The coordinates must b e defined prior to task-sp ecific training. (b) Cross-task sharing: The co ordinates must b e shared across tasks by c onstruction , not b y p ost-ho c alignment. (c) Structural metric: Nearb y co ordinates m ust corresp ond to related structural roles, so that pheromone dep osited at one co ordinate generalizes to structurally similar inputs. No end-to-end learned co ordinate system satisfies all three prop erties sim ultaneously , in our exp erimen tal setting. The argumen t for why learned co ordinates fail: • Prop ert y (a) fails b ecause learned embeddings are initialized randomly and c hange throughout training. The co ordinate system at ep o c h 0 b ears no relation to the co ordinate system at ep o c h 80, and co ordinates from tw o different training runs are in incompatible spaces. 16 • Prop ert y (b) fails b ecause indep enden tly trained mo dels conv erge to differen t lo cal minima of the loss landscap e, pro ducing different embedding geometries. Post-hoc alignment (Hungarian matc hing) recov ers only 3.5% correlation for 32-slot systems, versus 3.1% exp ected by c hance. • Prop ert y (c) is partially satisfied b y learned embeddings within a single training run, but violated across runs b ecause the metric structure of the em b edding space is not preserved. The pheromone field is defined ov er co ordinates that are themselv es learned, unstable, and arbitrary . T ransfer requires the co ordinates to b e canonical—the same structural role m ust map to the same index across tasks and training runs. This is a represen tational problem, not a learning problem. Our 10-seed exp erimen t with p osition-only F ourier co ordinates (Section 9 ) demonstrates that stable co ordinates alone do not enable transfer when the transfer mechanism is routing bias. The coordinate system problem is the first of tw o obstacles; the second—the c hoice of transfer mec hanism—is addressed in Section 12 . 10.3 Connection to Hipp o campal Memory Systems The T olman-Eichen baum Mac hine (TEM) [ 7 ] factorizes sensory represen tation from structural (graph) representation by construction, using separate neural p opulations. Place cells pro vide stable co ordinates for the cognitive map; grid cells pro vide a metric. DPPN’s soft group ers conflate b oth in to a single contin uous pro jection—the equiv alent of trying to build a cognitive map without place cells. The co ordinate system problem in DPPN is a computational analog of what would happ en if hipp ocampal place fields were randomly reassigned after eac h learning episo de. 11 P ositiv e Findings: Within-T ask P erformance Bey ond the cross-task transfer question, the exp erimen ts reveal that DPPN’s pheromone-biased routing is gen uinely useful for within-task learning. 11.1 DPPN Outp erforms Baselines Across all transfer targets and seeds, DPPN cold consisten tly outp erforms b oth the transformer and random sparse baselines (T able 2 ): • DPPN cold: AULC 0 . 699 ± 0 . 014 (A2), 0 . 702 ± 0 . 012 (A3), 0 . 715 ± 0 . 017 (B1), 0 . 682 ± 0 . 016 (C1) • T ransformer: A ULC 0 . 687 ± 0 . 012 (A2), 0 . 679 ± 0 . 013 (A3), 0 . 690 ± 0 . 017 (B1), 0 . 665 ± 0 . 020 (C1) • Random Sparse: AULC 0 . 678 ± 0 . 015 (A2), 0 . 673 ± 0 . 012 (A3), 0 . 686 ± 0 . 013 (B1), 0 . 650 ± 0 . 014 (C1) The DPPN adv an tage ov er the transformer baseline is approximately +0 . 012 to +0 . 025 A ULC, and ov er random sparse it is +0 . 016 to +0 . 032 AULC. This confirms that pheromone-biased routing pro vides a genuine inductive bias for learning—the problem is sp ecifically cr oss-task transfer, not within-task utilit y . 17 11.2 Source T ask P erformance DPPN ac hieved 0 . 78 ± 0 . 02 v alidation accuracy on the source task (av eraged across 3 seeds), with test accuracies of 0 . 749 (A1) and 0 . 709 (A1 ′ ) for seed 42. The mo del learns effectively; the limitation is in what its pheromone r ememb ers vs. what would need to tr ansfer . 12 Exp erimen t 6: Pheromone as Learning-Rate Prior The inabilit y of routing-bias pheromone to transfer ev en with stable co ordinates (Section 9 ) raises a precise question: is the problem the c ontent of pheromone (what it records) or the me chanism through which it acts (how it influences the mo del)? Routing bias forces attention patterns from the start of training on the target task. If the pheromone from the source task encodes wrong routes—whic h it will, b ecause differen t tasks require differen t attention patterns even when they share structural families—it actively reduces p erformance. The degradation is not graceful: wrong routing bias is worse than no routing bias. 12.1 Arc hitecture: Learning-Rate Mo dulation W e replace the routing-bias mec hanism (Eq. 5 ) with learning-rate mo dulation. The key change: pheromone has no effect during the forw ard pass. The mo del uses a standard transformer forw ard pass with no pheromone-biased routing. After loss.backward() , gradient magnitudes p er slot-pair are scaled by pheromone-deriv ed learning-rate multipliers: η ab = η base · (1 + λ · ( τ ab − ¯ τ )) (13) where η base is the base learning rate, λ con trols the mo dulation strength, τ ab is the pheromone v alue for the slot-pair ( a, b ), and ¯ τ is the mean pheromone. High pheromone means “learn this connection faster”; lo w pheromone means “learn this connection at the base rate.” F or instance, if the pheromone field has τ (3 , 7) = 1 . 8 (ab o ve the mean of ¯ τ = 1 . 05), the gradient for atten tion w eights connecting slot-3 p ositions to slot-7 p ositions is scaled by 1 . 8 / 1 . 05 ≈ 1 . 71 × , accelerating learning of this particular structural connection. Conv ersely , a slot pair with τ (12 , 20) = 0 . 3 (b elo w mean) receiv es a 0 . 29 × scaling, effectively deprioritizing that connection early in transfer training. The critical prediction: bad routing bias hurts (it forces wrong attention patterns), but bad learning-rate bias just do es not help (it accelerates learning of wrong connections, but the mo del can still learn the righ t connections at the base rate). The outcome is graceful degradation, not negativ e transfer. 12.2 Connection to Meta-Learning and Synaptic Metaplasticity This mec hanism has tw o natural anteceden ts. In meta-learning, MAML [ 39 ] learns initial w eights suc h that a few gradien t steps on a new task pro duce go od p erformance. Our approach is cheaper: rather than learning initial w eights (which requires gradien t-through-gradient computation), w e learn le arning r ates via a simple EMA statistic (pheromone). The pheromone field acts as a p er-connection learning rate prior, analogous to MAML’s learned initialization but without the computational o verhead. In neuroscience, the BCM rule [ 38 ] describ es synaptic metaplasticity: the history of a synapse’s activ ation mo dulates its plasticity (how easily it changes), not its weight (its current strength). A synapse that has b een frequently active develops a higher mo dification threshold, making it harder to p otentiate further. Pheromone as a learning-rate prior implements a computational analogue: history mo dulates how fast connections learn, not which connections are active. 18 12.3 Results W e run the meta-learning-rate v arian t with p osition-only F ourier co ordinates and 7 seeds, comparing against the routing-bias v arian t with 10 seeds. T able 5: T ransfer adv an tage (∆ A ULC: warm − cold) for meta-learning-rate pheromone vs. routing- bias pheromone, b oth with p osition-only F ourier coordinates. Neither ac hieves statistically significan t p ositiv e transfer, but they differ qualitativ ely: routing bias is uniformly negativ e, learning-rate mo dulation is uniformly non-negative. Same F amily Differen t F amily Mec hanism Seeds A2 A3 B1 C1 Meta-LR 7 +0 . 003 ± 0 . 006 +0 . 000 ± 0 . 005 +0 . 002 ± 0 . 004 +0 . 002 ± 0 . 004 Routing bias 10 − 0 . 001 ± 0 . 005 − 0 . 002 ± 0 . 006 − 0 . 002 ± 0 . 006 − 0 . 002 ± 0 . 006 12.4 Analysis Neither approac h achiev es statistically significant positive transfer. Ho wev er, they differ qualitatively in an imp ortan t wa y: • Routing-bias pheromone pro duces uniformly negativ e adv antages (mean − 0 . 002 across 10 seeds and 4 tasks). In 40 task-seed pairs, the transfer adv an tage is consistently negative. • Learning-rate pheromone pro duces uniformly non-negative adv antages (mean +0 . 002 across 7 seeds and 4 tasks). In 28 task-seed pairs, zero show ed the negative transfer that characterized routing-bias exp erimen ts. The difference in sign is the key result. Routing bias transfers the solution —whic h attention patterns to use—and the solution is task-sp ecific, so transfer imp oses a cost. Learning-rate mo dulation transfers the curriculum —which connections to learn first—and wrong learning priorities degrade gracefully b ecause the mo del can still learn any connection at the base rate. This identifies the second indep enden t requirement for p ersistent structural memory , b ey ond co ordinate stabilit y: the transfer mechanism must b e gracefully degrading . Learning-rate mo dulation satisfies this requirement; routing bias do es not. 12.5 Connection to Structure Completion F unctions W e further tested whether replacing pheromone statistics with a learned structur e c ompletion function can impro ve transfer. A completion netw ork is trained to reconstruct full routing patterns from partially mask ed inputs, using only correct-prediction patterns. During transfer, the completion prior is alpha-blended with the curren t agreement signal ( α = 0 . 3, decaying to 0 o ver 20 ep ochs), ensuring graceful degradation. The critical design c hoice is the input to the completion netw ork. W e test tw o v ariants: (1) completion ov er the le arne d agreement signal A (which dep ends on trained w eights and c hanges on reset), and (2) completion ov er the extrinsic co-o ccurrence matrix P = Q ⊤ fourier · onehot ( x ) · onehot( x ) ⊤ · Q fourier (whic h has zero learned-weigh t dep endence). The random completion control rev eals the decomp osition: on same-family tasks (A2, A3), trained completion outp erforms random b y +0 . 006 to +0 . 013; on different-family tasks (B1, C1), 19 T able 6: Structure completion transfer adv an tage (∆ A ULC, 10 seeds eac h). Completion ov er learned A is the worst mechanism (negative ev erywhere). Completion ov er extrinsic P shows the largest p ositiv e signal, but a random completion control (5 seeds) decomp oses it into regularization ( ∼ + 0 . 010) and a differential same-family b onus ( ∼ + 0 . 006). Same F amily Differen t F amily Mec hanism A2 A3 B1 C1 Completion (learned A ) − 0 . 004 − 0 . 007 ∗∗ − 0 . 004 − 0 . 003 Completion (extrinsic P ) +0 . 007 +0 . 016 ∗∗∗ +0 . 015 ∗∗∗ +0 . 016 ∗∗∗ Random completion control +0 . 005 +0 . 012 +0 . 016 +0 . 009 T rained − Random (same fam.) +0 . 013 +0 . 004 − 0 . 002 +0 . 000 they are indistinguishable. The ∼ + 0 . 010 regularization comp onen t (from the alpha-blended prior) b enefits all tasks equally; the ∼ + 0 . 006 structural comp onen t b enefits only same-family tasks. This demonstrates that a trained function ov er stable co ordinates can extract higher-order structural information (conditional co-o ccurrence, v ariance patterns) even when the first-order statistics of P are identical across all families (cosine similarity 1.0000). The catch-22 b et ween co ordinate stability and structural informativ eness is partially p ermeable to functions, though not to statistics. 13 Implications and Solution P ath 13.1 F rozen Pretrained Enco ders as Canonical Co ordinates The co ordinate stabilit y requiremen t (Section 10 ) is naturally satisfied by frozen pretrained enco ders. A frozen BER T [ 16 ] or GPT [ 17 ] em b edding lay er provides: (a) Extrinsic definition: Embedding geometry is fixed b efore task-sp ecific training b egins. (b) Cross-task sharing: The same enco der pro duces the same embeddings for the same inputs regardless of whic h downstream task is b eing learned. (c) Structural metric: Pretrained embeddings exhibit seman tic structure where pro ximity reflects meaning—“if P then Q ” and “ P implies Q ” map to nearby p oints regardless of what P and Q are. Pheromone accum ulated ov er frozen embedding co ordinates would b e transferable b ecause the co ordinates are stable: the same structural pattern activ ates the same region of embedding space across tasks and training runs. This eliminates the entanglemen t problem b y construction. 13.2 Adaptiv e Gran ularit y via Dirichlet Pro cesses Our exp erimen ts used fixed num b ers of slots ( m = 64) and clusters ( K = 32 , 64). The Chinese Restauran t Pro cess and Diric hlet pro cess mixture mo dels [ 18 ] suggest that the granularit y of structural decomp osition should b e adaptive —determined b y the data rather than fixed a priori. A concen tration parameter α that con trols the exp ected n umber of clusters, growing logarithmically with data, would allo w the co ordinate system to refine itself without committing to a fixed resolution. 20 13.3 Multi-Resolution Pheromone Structural patterns exist at multiple scales: tok en-level co-o ccurrence, phrase-lev el motifs, and do cumen t-lev el comp ositional structure. A w av elet-inspired multi-resolution pheromone field, with separate τ matrices at different abstraction levels, could capture structure at the appropriate scale without collapsing ev erything into a single resolution. 13.4 Sp ectral Represen tations for Perm utation Inv ariance The co ordinate mismatch problem (Section 7 ) arises b ecause pheromone ov er raw slot indices is maximally p erm utation-sensitiv e. Sp ectral graph metho ds [ 19 ] offer p erm utation-in v arian t structural descriptors: the eigen v alues of the Laplacian of the slot-slot interaction graph characterize structure indep enden t of node lab eling. Pheromone o ver sp ectral co ordinates w ould b e inv ariant to slot p erm utations b y construction, though computing sp ectral decomp ositions at eac h forw ard pass in tro duces computational ov erhead. 13.5 Connection to State Space Mo dels The Structured State Space mo del S4 [ 21 ] and its selective v ariant Mamba [ 22 ] use the HiPPO (High-order Polynomial Pro jection Op erators) matrix as the state transition k ernel. The HiPPO matrix is a fixe d, mathematic al ly derive d b asis for temp oral memory: it defines a co ordinate system in which the mo del’s recurrent state optimally approximates the history of the input signal under a Legendre p olynomial basis. Crucially , the HiPPO matrix is not learned from data—it is deriv ed from an approximation-theoretic criterion and remains constan t across tasks, datasets, and training runs. This is conceptually identical to our prop osed solution: a fixed co ordinate sys tem that is defined b efore training begins and do es not change during learning. The HiPPO basis is optimized for temp oral approximation (ho w to represent what happ ened recen tly using Legendre p olynomials); random F ourier features [ 25 ] are optimized for similarity preserv ation (how to main tain geometric relationships under pro jection, via Bo c hner’s theorem). Both solve the co ordinate stability problem, but for differen t types of memory: • HiPPO / S4: Fixed co ordinates for temp or al memory . The question answered: “What happ ened recen tly , and ho w should it b e weigh ted?” The Legendre p olynomial basis provides an optimal trade-off b et w een recency and fidelit y . • Random F ourier features + pheromone: Fixed co ordinates for structur al memory . The question answered: “Whic h computational routes pro v ed useful, and should they b e reused?” Random pro jections pro vide a task-agnostic em b edding space in which pheromone can accumulate. This parallel suggests a unified principle : any p ersistent memory system requires a fixed basis, and the choice of basis (HiPPO vs. F ourier vs. random) should b e determined b y the t yp e of information b eing memorized. HiPPO is the right basis for temp oral history b ecause the target of appro ximation (a contin uous function of time) is w ell-characterized by orthogonal p olynomials. Random F ourier features may b e the right basis for structural routing b ecause the target (a set of pairwise relationships b et ween computational comp onen ts) is w ell-characterized by distance-preserving pro jections. The success of S4 and Mam ba provides indirect evidence for our thesis. These mo dels achiev e strong p erformance precisely b ecause their state ev olves ov er a fixe d co ordinate system. If the HiPPO matrix were learned from scratch and v aried across training runs, the recurrent state w ould 21 suffer the same instability we observe in pheromone ov er learned slot co ordinates. The S4 literature do es not frame the HiPPO matrix as a solution to a co ordinate stability problem—it is presented as a solution to a long-range dependency problem—but our analysis rev eals that these are t wo manifestations of the same principle. 13.6 The Contamination Problem A natural first resp onse to the co ordinate stability requirement is to use a frozen pretrained enco der, as suggested in Section 13 . How ev er, this creates a subtle exp erimen tal confound that must b e carefully addressed. If the pretrained enco der w as trained on data that con tains the structural patterns of interest, then the enco der already “knows” the structure. T ransfer credit b elongs to the enco der’s pretraining, not to the pheromone mechanism. Consider a concrete example: if we use a frozen BER T enco der [ 16 ] and train pheromone on tasks in volving logical implication patterns, BER T’s pretraining on natural language has already exp osed it to implication structures (“if P then Q” app ears frequently in text). The pheromone field would accum ulate ov er an embedding space that already separates structural patterns—the pheromone is not disc overing structure, it is indexing structure that the enco der has already identified. This is analogous to building a retriev al-augmen ted system where the answers are already in the index: the system works, but the credit b elongs to the index builder (pretraining), not the retriev al mechanism (pheromone). The co ordinate system m ust b e structure-blind : it must not enco de task-sp ecific structural patterns, while still preserving geometric relationships that allow pheromone to disc over and transfer structure. This requiremen t eliminates pretrained enco ders for rigorous ev aluation and p oints sp ecifically to random pro jections, which are prov ably structure-blind (drawn b efore seeing any data, indep enden t of an y task distribution) yet geometrically informative (the Johnson-Lindenstrauss lemma [ 32 ] guaran tees that pairwise distances are preserved up to (1 ± ϵ ) m ultiplicative distortion with high probabilit y when pro jecting to O ( ϵ − 2 log n ) dimensions). The distinction is subtle but critical: • F rozen pretrained encoder: Stable co ordinates that enco de structure. T ransfer w orks, but the credit is am biguous. • Random pro jections: Stable co ordinates that are structure-blind. If transfer w orks, the credit b elongs unambiguously to the pheromone mechanism. • Learned from scratch: Unstable co ordinates. T ransfer fails regardless of pheromone quality . F or practical deploymen t, frozen pretrained enco ders are the pragmatic choice—they provide stable co ordinates with ric h geometric structure. F or scientific ev aluation of whether pheromone- based structural memory works as a me chanism , random pro jections are the rigorous choice, b ecause they con trol for the p ossibility that the co ordinate system itself is doing the structural reasoning. 14 Related W ork 14.1 Memory-Augmen ted Neural Net works The Neural T uring Mac hine (NTM) [ 8 ] in tro duced differen tiable external memory with con ten t-based addressing, where the controller generates a k ey v ector and reads from memory lo cations whose con tent is similar to the k ey . The Differen tiable Neural Computer (DNC) [ 9 ] extended this with temp oral linking (recording the order of writes to enable sequential trav ersal) and dynamic memory 22 allo cation (preven ting ov erwriting of recently written lo cations). Memory Netw orks [ 20 ] provided a simpler form ulation with multi-hop attention ov er an external memory bank, demonstrating that external memory enables multi-step reasoning that is difficult for feedforward architectures. These architectures share a critical prop ert y: memory stores c ontent , not structur e . The NTM’s memory matrix records sp ecific patterns that were written during pro cessing; it do es not record whic h read-write patterns pro v ed effective across man y inputs. The DNC’s temporal linking is the closest to structural memory—it records the or der of writes, which is a form of structural information—but this structure is sp ecific to one pro cessing episo de and do es not p ersist across tasks. When the mo del encounters a new task, the memory bank is re-initialized. DPPN’s pheromone field occupies a different niche: it records which slot-to-slot transitions pro ved useful (structural memory), not what information flow ed along those transitions (conten t memory). This distinction is analogous to the difference b etw een a road map (which routes exist and whic h are well-tra v eled) and a delivery manifest (what cargo w as carried on each route). Conten t memory records the cargo; structural memory records the road netw ork. Our contribution is sho wing that this structural memory requires stable co ordinates—the “road names” m ust b e consisten t across maps for the accumulated traffic statistics to transfer. A further distinction concerns addressing. The NTM uses con tent-based addressing (similarity to a key) and lo cation-based addressing (shifting from the current p osition). Both provide stable co ordinates in a sense: con tent-based addressing maps to the same memory lo cation for the same k ey , and lo cation-based addressing uses integer indices. How ev er, these are co ordinates for c ontent r etrieval , not for structur al r outing . The co ordinate system problem we identify is sp ecific to structural memory: the co ordinates must corresp ond to computational roles (slots), not to memory p ositions. 14.2 P ersisten t State in Sequence Mo dels T ransformer-XL [ 10 ] cac hes hidden states from previous segments, enabling the mo del to attend b ey ond its fixed con text window. The Compressiv e T ransformer [ 11 ] extends this by compressing old hidden states into a secondary memory rather than discarding them, further increasing the effectiv e memory horizon. Both main tain state across segments within a single task ; neither provides a mec hanism for state to p ersist acr oss tasks . R WKV [ 23 ] reformulates transformer attention as a linear recurrence with exp onen tial deca y , main taining a p ersistent state vector that accumulates information across time steps. The state is task-sp ecific and reset b et ween tasks, so it do es not address cross-task transfer. The Structured State Space mo del S4 [ 21 ] is the most relev an t work in this category . S4 parameterizes its state transition using the HiPPO matrix, a fixed basis derived from appro ximation theory (sp ecifically , from the requirement that the state optimally approximates the input history under the Legendre measure). The HiPPO matrix is not le arne d —it is a fixed, data-indep enden t co ordinate system for temp oral memory . Mamba [ 22 ] extends S4 with input-dep enden t selection, allo wing the mo del to dynamically filter its state, while retaining the fixed state transition structure. As we discuss in Section 13 , the HiPPO matrix is a fixed co ordinate system for temp oral memory in exactly the sense that our coordinate stability requiremen t demands for structural memory . The k ey difference is scop e: HiPPO co ordinates are for within-sequence temp oral dynamics; our co ordinate system problem concerns cross-task structural transfer. S4’s success with fixed temp oral co ordinates, contrasted with the obstacle we identify for learned structural co ordinates, pro vides con vergen t evidence for the principle that p ersisten t memory requires a fixed basis. 23 14.3 T ransfer Learning and Domain Adaptation In v arian t Risk Minimization (IRM) [ 4 ] seeks representations where the optimal classifier is the same across all training environmen ts, thereby identifying inv ariant features. Ho wev er, IRM requires access to multiple training en vironments and assumes that the representation space is adequate for expressing in v ariances. Domain-adv ersarial training [ 24 ] learns represen tations that fo ol a domain discriminator, forcing the enco der to discard domain-sp ecific information. Both approaches mo dify the c ontent of the representation to ac hieve inv ariance while lea ving the representation sp ac e (co ordinate system) to b e learned. Our w ork iden tifies a more fundamen tal issue: even if the con tent of tw o represen tations is structurally identical, the representations may b e expressed in incompatible co ordinate systems. This is not a problem for standard transfer learning, where the mo del parameters (including the represen tation mapping) transfer together. It b ecomes a problem sp ecifically for persistent structural memory , where the memory (pheromone) must transfer without the parameters (which are reset). The co ordinate system must b e stable indep endently of the parameters, which no standard transfer learning metho d guarantees. 14.4 Random F eatures and Fixed Represen tations Random Kitchen Sinks [ 25 ] show ed that random F ourier features approximate shift-in v arian t k ernels, enabling k ernel metho ds to scale to large datasets without computing the full kernel matrix. This established a surprising principle: fixed random pro jections, dra wn from an appropriate distribution, are statistically informative without any learning. Extreme Learning Mac hines [ 26 ] applied this principle to neural netw orks, demonstrating that a single hidden lay er with fixed random weigh ts and a trained output lay er achiev es comp etitiv e classification p erformance. Echo State Net works [ 27 ] and the broader reservoir computing framework extended this to recurrent netw orks, showing that fixed random recurrent dynamics with a trained linear readout can mo del complex temp oral patterns. The theoretical foundation for these results is the Johnson-Lindenstrauss lemma [ 32 ]: a random pro jection from R d to R k with k = O ( ϵ − 2 log n ) preserv es all pairwise distances among n p oin ts up to a (1 ± ϵ ) multiplicativ e factor with high probabilit y . This guarantees that the geometric structure of the original space—which is precisely what pheromone needs to leverage—is maintained in the pro jected space. The gap b et ween this literature and our work is the application con text. Random features w ere developed for k ernel approximation and efficien t classification, not for prov iding co ordinate systems for p ersisten t memory . The insigh t that random pro jections are the natural solution to the co ordinate stability problem—b ecause they are extrinsic, shared by construction, and geometrically informativ e—has not b een made in the random features literature, which fo cuses on approximation qualit y rather than co ordinate stability . 14.5 Biological Co ordinate Systems Grid cells in the mammalian entorhinal cortex [ 28 ] pro vide an innate hexagonal lattice that serves as a spatial co ordinate system for navigation and memory . Crucially , the grid cell pattern is presen t b efore an y spatial exp erience—it is a co ordinate system that exists prior to the conten t (spatial memories) that will b e defined ov er it. The T olman-Eic henbaum Mac hine (TEM) [ 7 ] formalizes this as a computational mo del that factorizes structural representation (the graph of relationships b etw een lo cations) from sensory representation (what is present at each lo cation), using separate neural p opulations. Place cells provide stable lo cation identifiers; grid cells provide 24 the metric structure. The TEM demonstrates that factorizing co ordinates from conten t is sufficien t for structural generalization across environmen ts. The fly olfactory circuit [ 29 ] implemen ts a form of similarit y-preserving hashing via sparse random expansion: 50 olfactory receptor types pro ject to approximately 2,000 Keny on cells via random, sparse connections. This random expansion preserves similarity relationships (similar o dors activ ate similar Keny on cell patterns) while dramatically increasing dimensionality , enabling rapid learning of o dor asso ciations. The random pro jection is genetically determined, not learned from o dor exp erience—it is a fixed, structure-blind co ordinate system for olfactory memory . Epigenetic memory pro vides a further biological parallel: p ersisten t chemical marks (meth ylation, histone mo dification) accum ulate o ver a fixed genomic co ordinate system (the DNA sequence). The co ordinate system (genome) is stable across cell divisions; the marks (epigenetic state) p ersist and transfer structural information ab out gene expression patterns. The marks are meaningful precisely b ecause the co ordinates are fixed—a methyl mark at genomic p osition X means the same thing in ev ery cell. The common principle across these biological systems is that the co ordinate system is defined prior to and indep endently of the conten t that will b e asso ciated with it. Grid cells exist b efore spatial memories; the fly’s random pro jection exists b efore o dor learning; genomic co ordinates exist b efore epigenetic marks. DPPN’s learned soft group ers violate this principle: the co ordinates are learned sim ultaneously with the conten t, and change when the conten t chan ges. 14.6 F ourier F eatures in Neural Netw orks T ancik et al. [ 30 ] demonstrated that passing input co ordinates through a random F ourier feature mapping enables neural netw orks to learn high-frequency functions, ov ercoming the sp ectral bias of standard MLPs to ward lo w-frequency comp onen ts. F ourierF ormer [ 31 ] replaces the softmax k ernel in transformer attention with a F ourier-feature-based approximation, achieving comp etitiv e p erformance with improv ed theoretical prop erties. The connection to our proposed solution is direct: random F ourier features pro vide a fixed, structure-blind mapping from input space to a feature space where similarity is preserv ed (b y Bo c hner’s theorem, a shift-inv arian t kernel can b e expressed as the inner pro duct of random F ourier features). If the soft group ers in DPPN w ere replaced b y a fixed random F ourier feature mapping, the resulting slot assignments would b e stable across training runs and tasks, while still preserving the geometric relationships that pheromone needs to discov er and transfer structural patterns. This sp ecific application of F ourier features—as co ordinates for p ersisten t structural memory rather than as function appro ximators or attention kernels—has not b een explored. 14.7 Sparse Atten tion Longformer [ 12 ], BigBird [ 13 ], and related architectures use fixed or learned sparse atten tion patterns primarily for computational efficiency—reducing the O ( N 2 ) cost of dense attention to O ( N ) or O ( N log N ). DPPN’s sparsity serves a fundamentally differen t purp ose: the sparse mask is determined b y pheromone-biased agreement b etw een dual views, enco ding accumulated knowledge ab out useful computational path wa ys. Sparsit y in DPPN is a consequence of structural routing, not a design c hoice for efficiency . 14.8 Con tin ual Learning Con tinual learning metho ds such as Elastic W eigh t Consolidation (EWC) [ 35 ], Pac kNet [ 36 ], and Progressiv e Neural Netw orks [ 37 ] protect previously learned parameters during training on new tasks. 25 These address catastrophic forgetting—the loss of old task p erformance—rather than structural transfer—the acceleration of new task learning via p ersisten t routing memory . In our proto col, all parameters are explicitly reset b et w een tasks; the only transfer channel is the pheromone field. This design choice isolates the question of whether structural routing memory , indep enden t of parameter sharing, can provide transfer. EWC regularizes weigh t changes to preserve old task p erformance; P ackNet freezes subsets of weigh ts for eac h task; Progressive Nets add new columns while retaining old ones. None of these mechanisms provide a p ersisten t structural memory that is decoupled from mo del parameters and could transfer routing knowledge to a fresh mo del. 14.9 An t Colon y Optimization The pheromone mechanism in DPPN draws directly from A CO [ 2 , 3 ]. In A CO applied to dynamic optimization problems, pheromone fields m ust adapt when the environmen t (problem instance) c hanges [ 14 ]. The transfer problem w e study is analogous: the “environmen t” (task) changes, and the question is whether pheromone from one environmen t helps in another. Our results align with a kno wn constraint from the ACO literature: pheromone transfer requires the new en vironment to share the same gr aph as the old en vironment. In our setting, the “graph” is defined by the soft group er assignments, and tw o tasks with indep enden tly learned group ers define different graphs— ev en if the tasks share the same structural family . The co ordinate system problem is, in ACO terms, the problem of ensuring that the graph ov er which pheromone is defined is the same graph across tasks. 14.10 Structure Mapping and Analogical Reasoning Gen tner’s structure-mapping theory [ 5 ] and progressive alignment h yp othesis [ 6 ] predict that structural abstraction requires comparison across instances with shared relational structure but differen t surface features. Rosc h’s basic level theory of categorization [ 33 ] similarly identifies that structural inv arian ts emerge through comparison across instances. Anderson’s rational mo del of categorization [ 34 ], whic h uses a Chinese Restaurant Pro cess prior for category formation, suggests that the num b er of structural categories should b e adaptiv e rather than fixed, connecting to our discussion of Diric hlet pro cess mo dels for adaptiv e granularit y . Our Exp eriment 3 (Section 7 ) implements progressive alignmen t via multi-source distillation, and the result reveals that comparison requires c ommensur able r epr esentations —a requiremen t that learned slot systems do not satisfy . The coordinate system problem is, in Gen tner’s framew ork, the problem of ensuring that the tw o analogs are represented in the same vocabulary so that their structural corresp ondence can b e detected. 14.11 In v ariant Risk Minimization IRM [ 4 ] establishes that in v arian t features cannot b e iden tified from a single training environmen t— m ultiple environmen ts with different spurious correlations are needed. Our Exp eriment 2 (Section 6 ) is a concrete instantiation: pheromone from a single source task entangles structural inv ariants with surface-sp ecific features. Our Exp erimen t 3 extends this to multiple environmen ts (A1 and A1 ′ ), but the IRM framework assumes that the representation space is shared across en vironments, which is precisely the condition that fails when co ordinates are learned indep enden tly . 26 15 Conclusion W e set out to build p ersisten t structural memory for neural sequence mo dels and disco vered that cross-task transfer requires tw o conditions that are not met when the co ordinate system ov er whic h memory is defined is learned join tly with the mo del. Five rounds of exp erimen ts—spanning con trastive pheromone up dates, task difficulty calibration, multi-source distillation with Hungarian alignmen t, and semantic decomp osition—each rev ealed a new obstacle, all tracing to one ro ot cause: p ersisten t memory requires stable coordinates, and learned co ordinates are inheren tly unstable. The three obstacles we characterize—pheromone saturation (resolved by con trastive up dates), surface-structure en tanglement (unresolv able with a single source), and co ordinate incompatibility (unresolv able b y p ost-ho c alignmen t of learned represen tations)—form a hierarc hy of obstacles. Eac h can only b e diagnosed after the previous one is resolved, and the final obstacle (co ordinate instabilit y) is fundamental rather than incidental. A 10-seed replication of the p osition-only F ourier exp eriment rev eals that co ordinate stability , while necessary , is not sufficient. Even with p erfectly stable, surface-free co ordinates, routing-bias pheromone pro duces uniformly negative transfer (mean − 0 . 002). The transfer me chanism matters indep enden tly of the co ordinate system: • Routing bias = transfer the solution (which atten tion patterns to use). F ails b ecause the solution is task-sp ecific, and wrong solutions actively interfere. • Learning-rate modulation = transfer the curriculum (which connections to prioritize). Do es not fail b ecause wrong priorities degrade gracefully—the mo del can still learn any connection at the base rate. The pap er thus identifies tw o indep enden t requiremen ts for p ersisten t structural memory: (a) Stable co ordinates: The co ordinate system m ust b e fixed b efore statistics are accumulated. Learned co ordinates are inherently unstable (the main pap er’s diagnostic cascade). (b) Graceful transfer mec hanism: The mechanism through whic h p ersisten t memory influences learning must degrade gracefully when the memory is wrong. Learning-rate modulation satisfies this; routing bias do es not (Section 12 ). The p ositiv e finding is that the DPPN architecture is effective for within-task learning: pheromone- biased routing consistently outp erforms transformer and random sparse baselines b y +0 . 010 to +0 . 030 AULC. The arc hitecture learns useful structural patterns; the remaining challenge is enabling those patterns to transfer across tasks. The co ordinate system problem is not unique to DPPN or to pheromone-based memory . Any arc hitecture that attempts to accum ulate p ersistent statistics ov er learned laten t representations— whether in the form of running means, protot yp e memories, or learned routing tables—faces the same c hallenge. When the representation changes, the accumulated statistics b ecome meaningless. This suggests a general principle for the design of p ersisten t memory in neural netw orks: the co ordinate system must b e fixed b efore the statistics are accumulated, and the statistics m ust influence learning gracefully . The catch-22 b et w een co ordinate stabilit y and structural informativ eness is real but not absolute: ev en when the extrinsic co-o ccurrence signal is undetectable at the mean level (cosine similarity 1.0000 across all task families), a completion function trained on correct-prediction patterns ov er stable co ordinates captures higher-order structural information sufficient for a small but differential 27 same-family adv an tage (+0 . 006 AULC b ey ond the regularization baseline, Section 12 ). The catc h-22 constrains statistics but is partially p ermeable to learned functions. Our exp erimen ts use synthetic tasks b y design—to isolate the co ordinate system v ariable from confounds present in real-w orld settings. Whether the t wo requirements iden tified here—co ordinate stabilit y and graceful transfer mechanisms—constrain practical systems that use pretrained enco ders remains an op en question. More broadly , the diagnostic cascade metho dology demonstrated here— iterativ ely resolving one obstacle to exp ose the next—offers a template for principled inv estigation of p ersisten t memory in neural arc hitectures, and the tw o requirements w e identify provide concrete design criteria for future systems that aim to accumulate and transfer structural knowledge. References [1] A. V aswani, N. Shazeer, N. Parmar, J. Uszk oreit, L. Jones, A. N. Gomez, L. Kaiser, and I. P olosukhin. Atten tion is all y ou need. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2017. [2] M. Dorigo, V. Maniezzo, and A. Colorni. Ant system: Optimization by a colon y of co operating agen ts. IEEE T r ans. Systems, Man, and Cyb ernetics—Part B , 26(1):29–41, 1996. [3] T. St ¨ utzle and H. H. Ho os. MAX-MIN An t System. F utur e Gener ation Computer Systems , 16(8):889–914, 2000. [4] M. Arjovsky , L. Bottou, I. G ulra jani, and D. Lop ez-P az. Inv ariant risk minimization. arXiv pr eprint arXiv:1907.02893 , 2019. [5] D. Gen tner. Structure-mapping: A theoretical framework for analogy . Co gnitive Scienc e , 7(2):155–170, 1983. [6] D. Gen tner. Bo otstrapping the mind: Analogical pro cesses and symbol systems. Co gnitive Scienc e , 34(5):752–775, 2010. [7] J. C. R. Whittington, T. H. Muller, S. Mark, G. Chen, C. Barry , N. Burgess, and T. E. J. Behrens. The T olman-Eichen baum Mac hine: Unifying space and relational memory through generalization in the hipp ocampal formation. Cel l , 183(5):1249–1263, 2020. [8] A. Gra ves, G. W ayne, and I. Danihelk a. Neural T uring Machines. arXiv pr eprint arXiv:1410.5401 , 2014. [9] A. Grav es, G. W ayne, M. Reynolds, T. Harley , I. Danihelk a, A. Grabsk a-Barwi ´ nsk a, S. G. Col- menarejo, E. Grefenstette, T. Ramalho, J. Agapiou, et al. Hybrid computing using a neural net work with dynamic external memory . Natur e , 538(7626):471–476, 2016. [10] Z. Dai, Z. Y ang, Y. Y ang, J. Carb onell, Q. V. Le, and R. Salakh utdino v. T ransformer-XL: A ttentiv e language mo dels b ey ond a fixed-length con text. In Pr o c. ACL , 2019. [11] J. W. Rae, A. P otap enk o, S. M. Ja yakumar, C. Hillier, and T. P . Lillicrap. Compressive T ransformers for long-range s equence mo delling. In Pr o c. ICLR , 2020. [12] I. Beltagy , M. E. Peters, and A. Cohan. Longformer: The long-do cumen t transformer. arXiv pr eprint arXiv:2004.05150 , 2020. 28 [13] M. Zaheer, G. Guruganesh, K. A. Dub ey , J. Ainslie, C. Alb erti, S. Ontanon, P . Pham, A. Ravula, Q. W ang, L. Y ang, and A. Ahmed. BigBird: T ransformers for longer sequences. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2020. [14] M. Guntsc h and M. Middendorf. Pheromone mo dification strategies for ant algorithms applied to dynamic TSP. In Pr o c. Applic ations of Evolutionary Computing (EvoWorkshops) , pages 213–222, 2001. [15] H. W. Kuhn. The Hungarian metho d for the assignment problem. Naval R ese ar ch L o gistics Quarterly , 2(1–2):83–97, 1955. [16] J. Devlin, M.-W. Chang, K. Lee, and K. T outanov a. BER T: Pre-training of deep bidirectional transformers for language understanding. In Pr o c. NAACL-HL T , 2019. [17] A. Radford, K. Narasimhan, T. Salimans, and I. Sutsk ever. Improving language understanding b y generative pre-training. Op enAI T e chnic al R ep ort , 2018. [18] Y. W. T eh, M. I. Jordan, M. J. Beal, and D. M. Blei. Hierarchical Dirichlet pro cesses. Journal of the A meric an Statistic al Asso ciation , 101(476):1566–1581, 2006. [19] F. R. K. Ch ung. Sp e ctr al Gr aph The ory . American Mathematical So ciet y , 1997. [20] J. W eston, S. Chopra, and A. Bordes. Memory Netw orks. In Pr o c. ICLR , 2015. [21] A. Gu, K. Go el, and C. R´ e. Efficiently mo deling long sequences with structured state spaces. In Pr o c. ICLR , 2022. [22] A. Gu and T. Dao. Mamba: Linear-time sequence mo deling with selectiv e state spaces. arXiv pr eprint arXiv:2312.00752 , 2024. [23] B. P eng, E. Alcaide, Q. An thony , A. Albalak, S. Arcadinho, H. Cao, X. Cheng, M. Ch ung, M. Grella, K. K. GV, et al. R WKV: Reinv en ting RNNs for the transformer era. In Findings of EMNLP , 2023. [24] Y. Ganin, E. Ustinov a, H. Ajak an, P . Germain, H. Laro c helle, F. La violette, M. Marchand, and V. Lem pitsky . Domain-adversarial training of neural net works. Journal of Machine L e arning R ese ar ch , 17(59):1–35, 2016. [25] A. Rahimi and B. Rech t. Random features for large-scale kernel machines. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2007. [26] G.-B. Huang, Q.-Y. Zh u, and C.-K. Siew. Extreme learning machine: Theory and applications. Neur o c omputing , 70(1–3):489–501, 2006. [27] H. Jaeger. The “echo state” approach to analysing and training recurren t neural netw orks. GMD T e chnic al R ep ort 148 , German National Researc h Center for Information T echnology , 2001. [28] T. Hafting, M. Fyhn, S. Molden, M.-B. Moser, and E. I. Moser. Microstructure of a spatial map in the entorhinal cortex. Natur e , 436(7052):801–806, 2005. [29] S. Dasgupta, C. F. Stevens, and S. Navlakha. A neural algorithm for a fundamen tal computing problem. Scienc e , 358(6364):793–796, 2017. 29 [30] M. T ancik, P . P . Sriniv asan, B. Mildenhall, S. F ridovic h-Keil, N. Raghav an, U. Singhal, R. Ramamo orthi, J. T. Barron, and R. Ng. F ourier features let netw orks learn high frequency functions in low dimensional domains. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2020. [31] T. Nguy en, M. Pham, T. Nguy en, K. Nguyen, S. Osher, and N. Ho. F ourierF ormer: T ransformer meets generalized F ourier in tegral theorem. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2022. [32] W. B. Johnson and J. Lindenstrauss. Extensions of Lipschitz mappings into a Hilb ert space. In Confer enc e in Mo dern Analysis and Pr ob ability , volume 26 of Contemp or ary Mathematics , pages 189–206. American Mathematical So ciet y , 1984. [33] E. Rosch. Principles of categorization. In E. Rosch and B. B. Lloyd, editors, Co gnition and Cate gorization , pages 27–48. Lawrence Erlbaum, 1978. [34] J. R. Anderson. The adaptive nature of human categorization. Psycholo gic al R eview , 98(3):409– 429, 1991. [35] J. Kirkpatric k, R. Pascan u, N. Rabino witz, J. V eness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabsk a-Barwinsk a, et al. Ov ercoming catastrophic forgetting in neural net works. Pr o c e e dings of the National A c ademy of Scienc es , 114(13):3521–3526, 2017. [36] A. Mallya and S. Lazebnik. Pac kNet: Adding multiple tasks to a single netw ork by iterativ e pruning. In Pr o c. CVPR , 2018. [37] A. A. Rusu, N. C. Rabino witz, G. Desjardins, H. Sob er, J. V eness, K. Ka vukcuoglu, and R. Hadsell. Progressive neural netw orks. arXiv pr eprint arXiv:1606.04671 , 2016. [38] E. L. Bienensto ck, L. N. Co op er, and P . W. Munro. Theory for the developmen t of neuron selectivit y: Orien tation sp ecificity and bino cular interaction in visual cortex. Journal of Neur oscienc e , 2(1):32–48, 1982. [39] C. Finn, P . Abb eel, and S. Levine. Mo del-agnostic meta-learning for fast adaptation of deep net works. In Pr o c. ICML , 2017. A Arc hitecture Hyp erparameters B T ask Design Details C Decomp osition Arc hitecture Details The Decomp ositionPheromoneModel replaces DPPN’s learned soft group ers with fixed spatial segmen tation. Key comp onen ts: • Regional decomposition: The sequence of length N is divided into R = 8 contiguous regions of size N /R . Each region’s representation is the av erage of its token embeddings. • Sub-claim enco der: A tw o-lay er MLP ( d → d/ 2 → d ) pro jects regional embeddings into the pheromone co ordinate space. 30 T able 7: DPPN hyperparameters used in all exp erimen ts. Note: early exp erimen tal rounds (Sections 5 – 6 ) used d = 128, 4 heads, 4 lay ers, m = 64; after task recalibration, the v alues b elo w w ere adopted for all rep orted results. P arameter V alue Mo del dimension ( d ) 64 Num b er of heads 4 Num b er of lay ers 3 Num b er of slots ( m ) 32 T op- k (sparse mask) 32 Slo w-lane window ( w ) 16 Group er temp erature ( T ) 1.0 Gum b el noise scale ( γ ) 0.5 Pheromone α 1.0 Pheromone β 1.0 Ev ap oration rate ( ρ ) 0.8 τ min 0.1 τ max 2.0 Dep osit rate ( δ ) 0.3 Sparse up date top- k 128 Drop out 0.1 Learning rate 3 × 10 − 4 W eight decay 0.01 Optimizer AdamW Source ep ochs 80 T ransfer ep o c hs 50 • P attern matc hing: The a verage of enco ded regional embeddings is compared to K cluster cen troids via cosine similarity with temp erature-scaled softmax ( T = 0 . 1). • Pheromone field: τ ∈ R K × S where K is the num b er of pattern clusters and S is the num b er of ev aluation strategies. Entry τ cs records how effective strategy s has b een for inputs matching cluster c . • Priorit y-weigh ted atten tion: Each tok en’s contribution to attention is mo dulated b y its region’s priorit y score, which is derived from the pheromone-advised strategy selection. T est configuration: d = 64, R = 8 regions, K = 32 clusters, S = 8 strategies. D F ull P er-Seed Results 31 T able 8: Synthetic task parameters. P arameter V alue V o cabulary size 32 Sequence length 128 T raining samples 2000 Motifs p er sample 2–3 Noise lev el 0.02 Num b er of classes 2 Structural families 3 (A, B, C) T asks p er family 2–3 (different surface mappings) T able 9: DPPN transfer results (AULC) by seed and condition. Seed Condition A2 A3 B1 C1 42 Cold .683 .689 .693 .676 Distilled .677 .690 .695 .675 Rank-red. .678 .691 .695 .678 137 Cold .696 .697 .719 .665 Distilled .706 .696 .715 .661 Rank-red. .707 .693 .715 .666 256 Cold .718 .718 .733 .704 Distilled .718 .717 .724 .699 Rank-red. .714 .715 .732 .705 T able 10: Baseline results (AULC) by seed (cold condition only). Mo del Seed A2 A3 B1 C1 T ransformer 42 .671 .661 .669 .653 137 .688 .686 .689 .648 256 .700 .691 .711 .692 Random Sparse 42 .658 .657 .671 .642 137 .680 .675 .703 .638 256 .696 .687 .684 .669 32 ( a ) T okens x 1 , . . . , x N Embedding h N × d Dual Soft Groupers Slot Support S ( v ) Agreement A Pheromone R o u t i n g p Pheromone F i e l d Sparse Mask M Sparse Attention Gate Fusion O u t p u t DPPN Architecture ( b ) Phase 1: Source T raining (80 epochs) T rain on A1 accumulates Save s a v e d Phase 2: T ransfer (50 epochs) Reset W eights K e e p (warm) T rain on A2 W arm: structural memory transfers Reset W eights R e s e t (cold) T rain on A2 Cold: no structural memory T ransfer Protocol Figure 1: (a) DPPN architecture schematic. T okens are em b edded and passed through dual soft group ers to pro duce slot assignments. Slot-level supp ort and agreement are combined with the p ersisten t pheromone field (highlighted) to pro duce pheromone-biased routing, which generates a sparse attention mask. A fast/slo w gate fusion pro duces the final output. (b) T ransfer proto col. In Phase 1, the mo del is trained on a source task and pheromone accum ulates structural memory . In Phase 2, all mo del weigh ts are reset but pheromone is either kept (warm) or reset (cold), and the mo del is trained on a target task. 33 0 5 10 15 20 25 30 T a r g e t S l o t b 0 5 10 15 20 25 30 S o u r c e S l o t a ( a ) I n i t i a l i z a t i o n ( 1 . 0 5 ) 0 5 10 15 20 25 30 T a r g e t S l o t b 0 5 10 15 20 25 30 S o u r c e S l o t a ( b ) A f t e r T r a i n i n g ( = 0 . 1 4 ± 0 . 2 7 ) 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 P h e r o m o n e Figure 2: Pheromone field τ ∈ R 32 × 32 b efore and after source training (DPPN, se ed 42). (a) At initialization, pheromone is near-uniform ( ¯ τ ≈ 1 . 05). (b) After 80 ep ochs, the field is sparse and structured: most transitions hav e deca yed to τ min = 0 . 1 (blue), with a small num ber of high- pheromone transitions at τ max = 2 . 0 (red). A2 A3 B1 C1 T ransfer T arget T ask 0.010 0.005 0.000 0.005 0.010 T r a n s f e r A d v a n t a g e ( A U L C : w a r m c o l d ) Same Family Different Family Only positive samefamily bar T ransfer Advantage by Model V ariant and T ask DPPN (learned) Fourier (tok+pos) Fourier (posonly) Figure 3: T ransfer adv antage (∆ AULC: w arm distilled − cold) across mo del v ariants and transfer targets. Same-family tasks (A2, A3) are shaded green; different-family tasks (B1, C1) are shaded red. With 3 seeds, the Position-Only F ourier v ariant app eared to sho w p ositiv e transfer on A2 (+0 . 003), but with 10 seeds the adv an tage is − 0 . 001 ± 0 . 005 (not significan t). All routing-bias v ariants show uniformly negative or zero transfer adv antages. Error bars: std ov er seeds. 34 What W as Fixed Key Result What Remained Broken Exp 1 + Contrastive updates : 0 . 9 3 u n i f o r m 0 . 3 4 ± 0 . 6 3 X Surfacestructure entanglement Exp 2 + T ask dif ficulty calibration A U L C = + 0 . 0 0 1 (not significant) X Single source cannot disentangle Exp 3 + Multisource distillation Alignment: 3.5% vs. 3.1% chance X Coordinate mismatch across runs Exp 4 + Semantic decomposition C o r r e l a t i o n : 1 0 . 4 % (worse than DPPN) X Embedding instability (any learned coords) Exp 5 + Positiononly Fourier coords A2: +0.003 (same fam.) B 1 : 0 . 0 0 7 ( d i f f . f a m . ) ~ Ef fect size not significant (3 seeds) Root Cause: Persistent memory requires stable coordinates, and learned coordinates are inherently unstable. The Diagnostic Cascade: Five Experiments, One Root Cause Figure 4: The diagnostic cascade. Five exp erimen ts, each resolving one obstacle (left, green) while rev ealing the next (righ t, red). The cen ter column sho ws the key metric from eac h exp erimen t. All obstacles trace to the same ro ot cause: p ersisten t memory requires stable co ordinates, and learned co ordinates are inherently unstable. 35 DPPN (learned) Random chance 0 1 2 3 4 5 Slot Alignment Correlation (%) 3.5% 3.1% ( a ) Barely above chance (3.5% vs. 3.1%) CrossRun Slot Alignment Unaligned learned Aligned learned Fourier tok+pos Fourier posonly 0 5 10 15 20 Surviving T ransitions (of 1024) 10 (1.0%) 21 (2.1%) 16 (1.6%) 22 (2.1%) ( b ) Distillation Survival Figure 5: Co ordinate stability diagnostics. (a) Slot alignment correlation b et ween indep enden tly trained DPPN mo dels: 3.5%, barely ab o ve the 3.1% expected by random c hance with 32 slots. (b) Distillation surviv al: the n umber of high-magnitude transitions (out of 1024) surviving element- wise minimum distillation. P osition-Only F ourier preserves the most transitions (22), consistent with b etter co ordinate stabilit y . 36
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment