Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks
Large language models excel on objectively verifiable tasks such as math and programming, where evaluation reduces to unit tests or a single correct answer. In contrast, real-world enterprise work is often subjective and context-dependent: success hi…
Authors: Abhishek Ch, wani, Ishan Gupta
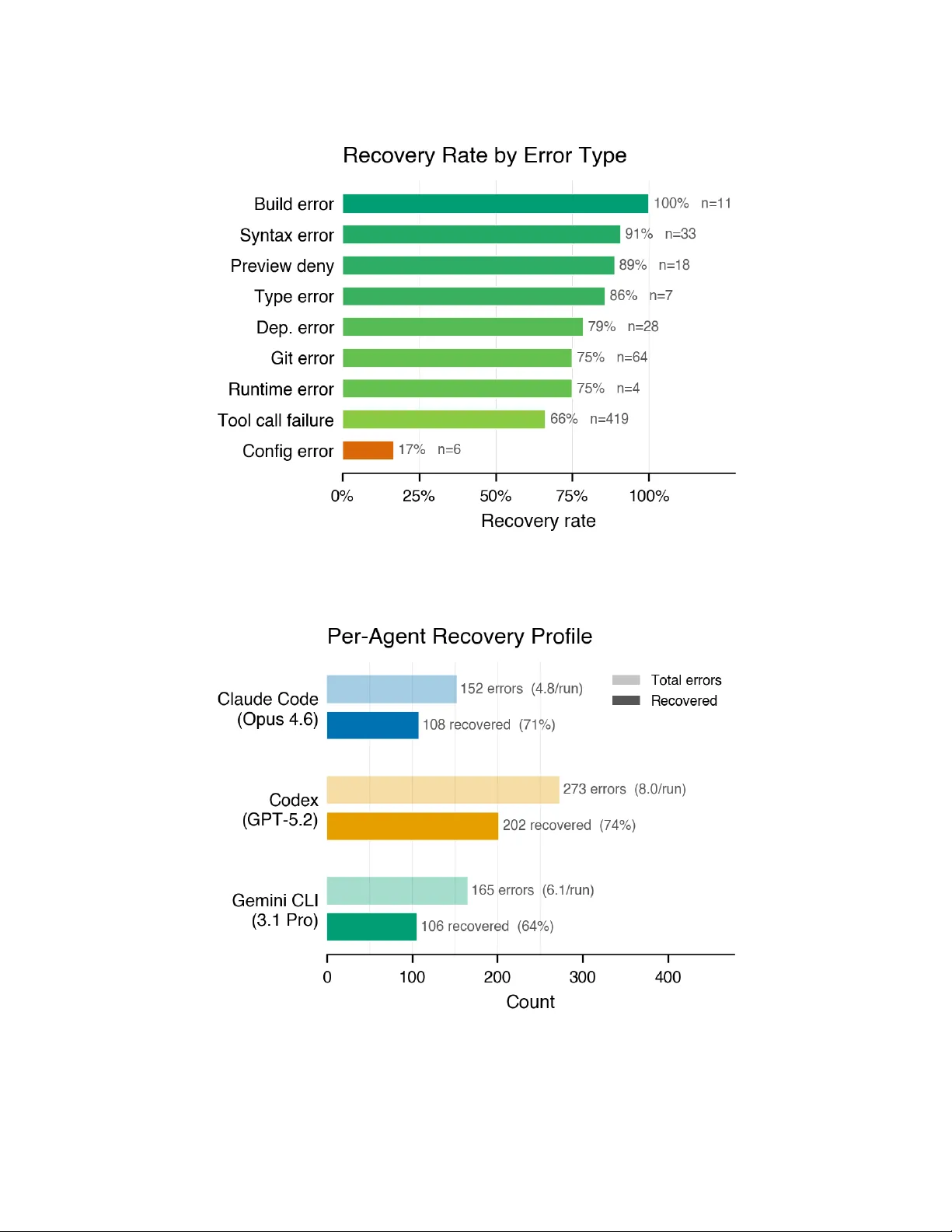
Bey ond Binar y Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise T asks Abhishek Chandwani ∗ abhishek@metaphi.ai Ishan Gupta ∗ 345ishaan@gmail.com Abstract Large language models excel on objectively veriable tasks such as math and programming, where evaluation r educes to unit tests or a single correct answer . In contrast, real-world enterprise w ork is often subjective and context-dependent: success hinges on organi- zational goals, user intent, and the quality of intermediate artifacts produced across long, multi-tool workows. W e introduce LH-Bench , a three-pillar evaluation design that moves beyond binary correctness to score autonomous, long-horizon execution on subjective enterprise tasks. The pil- lars are: (i) expert-grounded rubrics that give LLM judges the domain conte xt needed to score subjective work, (ii) curated ground-truth artifacts that enable stepwise reward signals (e.g., chapter-level annotation for content tasks), and (iii) pairwise human preference evaluation for convergent validation. W e show that domain-authored rubrics pro vide substantially more r eliable evaluation signals than LLM-author ed rubrics ( 𝜅 = 0 . 60 vs. 0 . 46 ), and that human preference judgments conrm the same top-tier separation ( 𝑝 < 0 . 05 ), evidence that expert-grounded evaluation can scale without sacricing reliability . W e additionally nd that test-time verication—runtime hooks that surface structured feedback during execution—enables agents to recover from 70% of err ors, with recovery strongly dependent on error-message quality . W e release public datasets and report results on two environments: Figma-to-code (33 real .fig tasks against the Figma API via MCP) and Programmatic content (41 courses comprising 183 individually-e valuated chapters on a course platform serving 30+ daily users). CCS Concepts • Computing metho dologies → Articial intelligence ; • Human-centered computing → Human computer interaction (HCI) . Ke ywords Agent evaluation, rubric-based evaluation, expert-grounded rubrics, long-horizon agents, enterprise benchmarks 1 Introduction LLM-based agents are increasingly deployed on complex enterprise workows, yet the benchmarks used to evaluate them remain an- chored to binary correctness: a unit test passes or fails, a math pr oof checks out or does not. Real enterprise work resists this framing because it is inherently procedural and context-dependent. What constitutes a correct application development lifecycle varies by enterprise—organizational style guides, design systems, and de- ployment conventions dier across companies. What qualies as a ∗ Both authors contributed equally to this research. good presentation or learning video varies by user persona, audi- ence expertise, and pedagogical context. These outcomes cannot be reduced to deterministic pass/fail. Evaluating agents on such tasks requires expert-curated stepwise rewards and task-specic skill-based veriers that grade process quality , not just nal outputs. This setting is hard for three comp ounding reasons: (i) long- horizon e xecution requires state tracking across dozens of interde- pendent steps, (ii) subjective quality cannot be reduced to a single correct answer , and (iii) multi-artifact workows pr oduce intermedi- ate outputs whose quality determines downstream success. Binary correctness collapses these dimensions into a single outcome and cannot diagnose where or why an agent fails. Recent measurement of autonomous agent capability [ 13 ] re- veals that the frontier of reliable task completion has been dou- bling roughly every se ven months, yet current mo dels still col- lapse on tasks exceeding a few hours of equivalent human eort. The highest-value enterprise work—design-system implementa- tion, source-grounded content production—sits squarely beyond this frontier , and exposes a train–test gap : post-training datasets overwhelmingly target code and math, so reasoning patterns may not transfer to the messy , multi-artifact workows that dominate enterprise environments. W e introduce LH-Bench , a three-pillar evaluation design, and operationalize it in two enterprise environments: • Figma-to-code: agents take actual Figma artifacts as inputs (curated as an evaluation dataset) and iterativ ely produce and revise front-end implementations. • Programmatic content: agents operate in a structured “data room” containing expert-curated sources and must create programmatic content —code-generated videos (Re- motion + T TS) or web-native presentations (React/Framer Motion)—for tutoring modules and product demos, follow- ing chapter-level ground truth with citations and iteratively editing based on fee dback. Across both environments, we compare agent trajectories and output artifacts against domain-expert ground truth, and grade p er- formance using skill-specic rubrics plus hybrid evaluation (LLMs and expert humans). A udience and Use. LH-Bench targets researchers who need real- istic, envir onment-grounded e valuations and post-training datasets for improving long-horizon agent reliability . LH-Bench is designed as a reusable evaluation environment. Ne w Figma design les or data-room congurations can b e dropped into the pipeline, and three-pillar evaluation scores agents without per-task human an- notation. This is possible b ecause expert-authored rubrics, curate d ground-truth artifacts, and workow-specic SKILL.md references encode the domain knowledge that LLM judges need to simulate e x- pert evaluation—addressing the critical bottleneck of scaling agent evaluation on subjective enterprise tasks. Abhishek Chandwani and Ishan Gupta Our contributions are: (1) Evaluation design: LH-Bench moves beyond binary cor- rectness by combining expert-grounded rubrics for LLM judges, curated gr ound-truth artifacts for stepwise re wards, and pairwise human preference evaluation. (2) V alidation evidence: all three tiers converge on the same primary separation (T able 9); expert-authored rubrics yield substantially higher inter-judge agreement than LLM-authored rubrics ( 𝜅 = 0 . 60 vs. 0 . 46 ). (3) Benchmark instantiation: two enterprise environments (Figma-to-code and programmatic content) with end-to-end evaluation of three autonomous agent harnesses. (4) Recovery analysis: runtime verication ho oks enable self- correction; across 96 runs, agents recover from 70% of errors, with recovery dependent on error-message quality . 2 Research Questions W e organize the paper around the following research questions (RQs), motivated by the nee d for evaluation designs that can score subjective, context-dependent enterprise work ov er long horizons: • RQ1 (Evaluation): How can subjective, context- dependent enterprise work be evaluated reliably beyond binary correctness? W e study rubric-base d eval- uation and artifact verication, compare expert-authored and LLM-authored rubrics for inter-judge reliability , and show how dier ent tiers (artifact, skill, behavior) capture complementary aspe cts of performance. • RQ2 (Benchmarking): What failure modes emerge when agents autonomously execute long-horizon en- terprise tasks in tool-rich environments? W e charac- terize errors in navigation, state tracking, multi-tool coor- dination, and artifact regression across iterativ e edits. • RQ3 (T est-time recovery): How ee ctively can agents self-correct from structured v erication feedback? W e evaluate recovery behavior when agents receive build/deploy failures and visual/rubric violations as actionable feedback during execution. 3 Related W ork Agent Benchmarks and Environments. Existing b enchmarks eval- uate LLM agents in interactive environments— W ebArena [ 34 ], OS- W orld [ 29 ], SWE-bench [ 10 ], AgentBench [ 17 ], GAIA [ 19 ]—but predominantly use binary success metrics on single-turn or short- horizon tasks. W orkArena [ 7 ] evaluates 682 tasks in ServiceNow , the closest existing enterprise benchmark, but uses binar y com- pletion metrics. SWE-Bench Pro [ 6 ] extends to 1,865 long-horizon software engine ering tasks but remains unit-test-graded. LH-Bench diers by targeting subjective professional knowledge w ork requir- ing iterative artifact editing, using multi-tier evaluation rather than binary pass/fail, and grounding tasks in real enterprise artifacts (T able 1). UI Generation and Design-to-Code. Design2Code [ 23 ] bench- marks screenshot-to-code generation on 484 real webpages, and FronT alk [ 28 ] extends to multi-turn front-end generation with visual feedback, highlighting a “forgetting issue” where agents overwrite prior features. FullFront [ 24 ] b enchmarks the full front-end engineering worko w and FrontendBench [ 35 ] evaluates 148 automated front-end tasks, but both use screenshots as inputs. LH-Bench extends this line of work by using actual Figma design les as inputs (not screenshots), requiring agents to navigate design-tool APIs for structure extraction, asset e xport, and token discovery before coding—and to iterate across multiple verication cycles without regressing earlier w ork. T ool Use and Multi- T urn Interaction. MIN T [ 26 ] evaluates multi- turn tool use with language feedback, and T oolLLM [ 21 ] scales to 16,000+ real-world APIs. LH-Bench focuses on multi-tool orchestra- tion over long sessions : agents co ordinate design-extraction, code- generation, build, previe w , and deployment tools across dozens of turns, with structured v erication feedback enabling test-time recovery . Long-Horizon Agent Evaluation. K wa et al. [ 13 ] show that re- liable task completion has be en doubling ev ery ∼ 7 months, but collapses beyond a few hours of equivalent human eort—precisely the regime enterprise workows occupy . UltraHorizon [ 18 ] bench- marks trajectories exceeding 200k tokens, identifying error types including in-context locking. 𝜏 2 -bench [ 1 ] extends dual-control evaluation to conversational agents but focuses on short-horizon API interactions. T urn-level r eward design [ 27 ] demonstrates that sparse nal rewards are insucient for credit assignment in long episodes. LH-Bench contributes enterprise-specic long-horizon evaluation with skill-level scoring that provides dense, diagnostic signals aligned to expert-dened workow phases, building on the Re Act paradigm [31]. LLM-Based Evaluation and Judging. Zheng et al. [ 33 ] established the LLM-as-a-Judge paradigm, achieving over 80% agreement with human preferences. Subsequent work has catalogued judge bi- ases [ 3 , 8 , 25 ] and proposed multi-agent judging [ 4 ]. LH-Bench uses three LLM judges from dierent mo del families with expert- authored rubrics and cross-judge variance tracking, applied to multi- dimensional enterprise artifacts. Rubric-Based and Skill-Based Evaluation. ResearchRubrics [ 22 ] demonstrates that rubric granularity signicantly aects ranking reliability , De epResearch Bench II [ 15 ] uses expert-authored rubrics to diagnose research agents, and SkillsBench [ 16 ] nds that skill- level decomp osition reveals failure modes invisible to aggregate scores. LH-Bench builds on both lines: domain-expert rubrics with skill-level decomposition produce dense, diagnostic signals for long- horizon enterprise tasks. Enterprise AI and Compound Systems. The shift to compound AI systems [ 32 ] motivates system-level e valuation including orches- tration and feedback loops. Re cent surveys [ 9 , 20 ] note the scarcity of benchmarks targeting real enterprise workows. LH-Bench ad- dresses this gap by b enchmarking full agent harnesses on enterprise tasks, with signals designed to diagnose harness-level dierences in context management, tool orchestration, and recovery . Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks T able 1: Positioning of LH-Bench relative to existing agent benchmarks. Existing benchmarks rely on binar y or unit- test evaluation; LH-Bench introduces multi-tier , expert- grounded scoring. Benchmark T asks Multi-turn Real env . Exp ert rubrics Artifact eval W ebArena [34] 812 × W eb × Binary VisualW ebArena [11] 910 × W eb × Binary SWE-bench [10] 2294 × Code × Unit tests OSW orld [29] 369 × OS × Binary 𝜏 -b ench [30] 200 ✓ API × Binary Design2Code [23] 484 × × × VLM MINT [26] varies ✓ × × Binar y LH-Bench (ours) 216 ✓ ✓ ✓ Multi-tier 4 Agent Harness Design LH-Bench evaluates end-to-end agent harnesses rather than base models in isolation. A recent convergence in agent-CLI design— driven by rapid impr ovements in model r easoning for code, tool use, and le manipulation—has produced a shared architectural pattern across Claude Code (Anthr opic), Codex CLI (OpenAI), and Gemini CLI (Google): all three provide a sandb oxed shell environment, le- system tools, and extensible tool interfaces (e .g., MCP ser vers). This generality means that environment-spe cic capabilities such as Figma extraction, preview verication, or source-gr ounded genera- tion can be dened once and run identically across harness families, enabling controlled comparison of the orchestration and reasoning dierences that actually dierentiate harnesses on long-horizon tasks. W e design LH-Bench harnesses to be autonomous by default : agents execute in sandboxes, invoke tools programmatically , and recover from failures using runtime feedback rather than relying on manual intervention. Expert-authored SKILL.md workow refer- ences are loaded identically across all three CLIs, isolating the ee ct of harness-level dierences (context management, retr y policies, compaction strategies) from environment knowledge. Below we describe the key features of our harness design. 4.1 Sandboxed Execution and Reproducibility Agents interact with environments through controlled APIs (e .g., de- sign extraction, browser automation, build/deploy commands) and operate against task-specic state snapshots. This reduces hidden state and improves r eproducibility of trajectories and artifacts. 4.2 Context Compaction and Pre-Compaction Long-horizon tasks routinely exceed context limits. Our harnesses implement automatic compaction policies that summarize prior turns, tool outputs, and intermediate artifacts while preserving commitments, open TODOs, and veried facts. W e additionally use proactive pre-compaction: before expensive tool calls or major edits, the harness produces a compact “working set” view of the current state to reduce regressions and support edit locality . 4.3 Runtime V erication and Recovery Harnesses integrate verication as a rst-class interface. Build/deploy failures, rubric violations, and visual mismatches are surfaced as structured, machine-readable feedback that the agent can consume to plan repairs. For example, in Figma-to-code the harness exposes a preview-verication hook: after the agent calls a preview tool (e.g., create_app_preview ), automated che cks run and return a structured error if issues are detected—runtime exceptions (e.g., React router nesting errors), blank-page renders, or other failur es. The error payload includes a diagnosis and an explicit next action (e.g., “x these errors, then call create_app_preview again”), enabling iterative self-correction within the same episode. V erication hook availability . Preview verication hooks are im- plemented as post-tool-use hooks for Claude Code (via the Agent SDK hook interface) and as after-tool subprocess hooks for Gem- ini CLI (via .gemini/hooks/ ). Codex CLI does not support native hook mechanisms; it can invoke the create_app_preview MCP tool but receives raw tool output without automatic verication. 4.4 Extensible T o ol Interface All three CLIs support tool extensibility via MCP (Model Context Protocol) servers and custom tool denitions. LH-Bench denes environment-specic tools—Figma structure inspection, asset ex- port, scene generation, source extraction—as standalone ser vers that any harness can invoke. This decouples environment logic from harness internals and ensur es that performance dierences reect orchestration quality rather than tool availability . 5 Benchmark Environments LH-Bench currently includes tw o enterprise environments. Each environment is a tool-rich, interactive setting in which an agent must complete long-horizon tasks by producing and iteratively editing artifacts. All environments are evaluated across thr ee agent harness families—Claude Code ( Anthropic), Codex CLI ( OpenAI), and Gemini CLI (Google)—using identical tool access and expert- authored SKILL.md workow references (Section 6). Below we describe the task design, action space, and verication constraints for each environment. 5.1 Figma-to-Code Environment In the Figma-to-co de environment, agents take real Figma design ar- tifacts as inputs and iteratively pr oduce front-end implementations across 33 .fig tasks. T asks require navigation of design structure, faithful implementation, and safe localized edits across multiple iterations. Action space. Agents interact through a constrained tool set: (a) Figma MCP calls for design structure, styles, components, and asset exports; (b) le and shell to ols for writing code and running builds; (c) a sandboxed preview tool that catches build/runtime failures; and (d) a deployment tool that publishes static builds for artifact evaluation and reproducible inspection. W orkow constraints. W e enforce conventions encode d in expert-authored SKILL.md : agents must extract from Figma be- fore coding (no guessing of colors/fonts), implement all frames (no cherry-picking), use non-interactive scaolding (no npm create / npx create-* ), use relative asset paths suitable for subdirectory deployments, and che ckpoint via preview at multiple milestones to enable recovery . Abhishek Chandwani and Ishan Gupta Ground truth and verication. Each task includes a ground_truth/ directory with a manifest.json (frame metadata: name, no de id, viewport, target route) and 2x-scale PNG exports per frame. The evaluated agent builds the UI, which is exercised via P lay- wright (MCP) to captur e screenshots; a VLM judge (Gemini 3) compares the built UI against ground truth frame-by-frame. W e also run programmatic che cks: build verication ( npm build ), deployment accessibility , and component-coverage (matched/total). Pure infrastructure failures (score=1) are excluded from model comparisons. T ask complexity axes. W e curate tasks along four complexity axes to ensure the benchmark spans a wide capability range: (i) ap- plication categor y —e-commerce, SaaS dashboards, portfolio sites, landing pages—each imp osing dierent design-system conventions; (ii) frame count (ranging from single-frame layouts to designs with 70+ frames), which determines the scope of navigation and cr oss- page consistency the agent must maintain; (iii) image and asset density , from icon-light text layouts to media-heavy product grids requiring bulk asset export and format selection; and (iv ) route navigation complexity , from single-page designs to multi-route ap- plications with nested navigation hierarchies and responsive break- points. This deliberate stratication ensures the benchmark tests agents across the full diculty spectrum rather than clustering at a single complexity level. 5.2 Programmatic Content Environment Explaining complex concepts visually—for onb oarding, training, or learning content—is among the highest-value knowledge work in enterprises. The same source material (e .g., a resear ch paper , a product specication) may ne ed to be rendered as a narrated video for executives, an interactive slide deck for engineers, or a mathematical animation for researchers. This diversity of audience and format makes the task genuinely long-horizon: agents must re- trieve relevant evidence from large document collections, cho ose an appropriate visual style, and compose code-driven media artifacts that are faithful to the source material. In the programmatic content environment, agents operate in a structured “data room” of expert-curate d sources and must generate code-driven content—not pixel-level video from diusion models, but composable programs that render to media. Agents produce either (i) a programmatic video (Remotion + T TS, exported to MP4), (ii) a mathematical animation (Manim, rendered to MP4), or (iii) a web-native presentation (React/Framer Motion slide deck). All three output modes share the same harness and tool interface, enabling controlled comparison across content types. W e evaluate on 183 chapters across 41 full-edged tutor-directed courses. Action space. Agents interact through a layered tool set or- ganized by output mode. Common to ols available in all modes include: a sour ce extractor that normalizes PDFs, DOCX, PPTX, and web pages into line-numb ered markdown with a structured index ( sources.json ); a conte xt researcher sub-agent that searches extracted documents and returns ndings with line-level cita- tions ( source_id:line_number ); and an image generator for concept art and diagrams. Video-specic tools include a parallel scene generator ( generate_video_scenes ) that produces React components and T TS audio simultaneously , a Manim generator ( generate_manim_scene ) for mathematical animations, and a root-composition generator that assembles scenes with precise audio–video timing. Presentation-specic tools include a stor yboard generator (narrative arc planning), a React slide generator with Framer Motion animations, a chart generator (CSV to PNG), and preview/scr eenshot tools for iterative viewport validation. Multi-turn conversation simulation. T asks in this environment simulate how domain e xperts interact with learning content: a user provides a document collection (e.g., three arXiv papers on GRPO), and the agent must produce a sequence of chapters—each building on prior context. Subsequent turns introduce the kind of r equests a real learner would make: “now compare GRPO with PPO , ” “add a visual showing the gradient ow , ” or “make the timeline start from 2012. ” The agent must maintain scene coherence across turns (e.g., a neural-network diagram introduced in T urn 1 must retain its visual style in T urn 3 unless explicitly changed) and perform fast editing : isolated changes must produce targeted CSS or Manim e dits with- out regenerating entire scenes. Session IDs chain Claude sessions across turns, and the workspace (including extracted context and generated artifacts) p ersists, so the agent accumulates state over the full episode. Grounding and v erication. Source extraction produces a persistent context dir ectory ( context/ ) and a structured index ( context/sources.json ) with per-source line counts and section headings, enabling judges to verify that generated scripts are supported by pro vided sources and to penalize hallucinate d or uncited material. For vide o mode, agents must plan 4–8 scenes (10–25 seconds each, max 2 minutes total) and render a nal MP4 via Remotion at 15 fps, with audio–video duration matching enforced at the frame le vel. For Manim mode , audio is generated rst and the animation is constrained to match the audio duration exactly . For presentation mode, ev ery slide must t the viewport (100vh, no scrolling) and is validated via automated preview and screenshot checkpoints before deployment. 6 Benchmark Construction W e construct LH-Bench from expert-designed workows and enterprise-representative artifacts. Each task includes (i) envi- ronment state (e.g., a .fig le or a data room of sources), (ii) an expert-authored rubric mapping to skills, and (iii) veriers over intermediate and nal artifacts. 6.1 Expert Rubrics and SKILL.md For each environment, domain experts author SKILL.md guidance capturing environment-spe cic conventions, common failure modes, and recommended tool usage. Separately , experts dene skill rubrics used to score agent trajectories (e.g., navigation, error recovery , edit lo cality , and spe c adherence). Rubrics are written by four experienced front-end engineers (6+ years in B2C internet companies) for Figma-to-code, and by domain experts in instructional design for the programmatic content environment. Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks 6.2 SME Annotation W orkows Figma-to-code dataset curation. Ground truth is constructe d from an automated pipeline with expert curation. W e source candidate designs from Figma Community , pre-ltering by engagement and selecting specically for enterprise complexity: multi-frame layouts with real typography systems, brand color palettes, component hi- erarchies, and responsive breakpoints—not single-page templates or simple wireframes. Selected designs are sourced from Figma Community and enterprise design partners across healthcare, e- commerce, and pr ofessional-services verticals, then duplicated into evaluation accounts via Playwright. Design structure is extracted via the production Figma API, and LLM-based quality scoring is applied before nal expert selection. Exp ert selection balances the four complexity axes (Section 5.1) to ensure coverage across ap- plication categories, frame counts, asset densities, and navigation topologies. Programmatic content source-grounded annotation. T o build faith- ful ground truth for programmatic content, we provide SMEs with a dedicated annotation interface that supports chapter-level task specication and ne-grained source grounding. Unlike screenshot- only workows, which are dicult to scale and provide limited traceability , our interface segments sources into line-addressable spans and uses a “highlight-to-cite ” interaction to attach exact evidence to each chapter . This produces high-quality , granular cita- tions with explicit metadata (source, span, chapter ), reducing noise and improving annotation speed. 6.3 Artifact Contracts LH-Bench makes subjective tasks scorable by r equiring agents to emit interim artifacts —per-frame ground truth images, structured manifests, citation targets—that ser ve as deterministic hooks for downstream verication ( schemas in Appendix C). 6.4 Environment Infrastructure T ask denitions and rubrics are versioned independently . The pipeline (Appendix A) e xposes execution, evaluation, and leader- board endpoints; agents build artifacts in ephemeral sandb oxes and upload nalized builds to object storage. 6.5 Parallel Judging Evaluation runs three judges in parallel (T able 2): a task-agnostic trajectory judge (planning, constraint-following, recovery), a task- specic process judge (workow compliance and skill execution), and an output judge (artifact delity from rendered artifacts and runtime checks). Judges emit structured JSON grades per tier , en- abling both leaderboard ranking and ne-grained diagnostics. W e will release public versions of the task datasets for research use upon publication. T able 2: LH-Bench judges and the artifacts they consume. Judge Inputs Scores Trajectory Transcript + tool traces Planning, recovery Process T ranscript + skill rubric W orkow compliance Output Ground truth + screenshots Visual delity 7 Evaluation Framework W e propose a hybrid evaluation approach combining expert rubrics, trajectory grading, and programmatic verication of artifacts (in- cluding visual outputs). 7.1 Rubrics, Tiers, and A ggregation Each rubric dimension is scored on a 1–5 scale with anchors: 1=Inad- equate/Poor , 2=Developing/Below A verage, 3=Procient/A dequate, 4=Advanced/Good, 5=Expert/Excellent. Rubrics are organized into tiers and aggregated as weighted averages within tier and (option- ally) across tiers. 7.1.1 Process tier rubrics (Figma-to-co de). Our process tier uses expert-authored, transcript-evaluable rubrics with observable boundaries aligned to sequential workow phases. In our current Figma-to-code release , we use four core pr ocess rubrics: (i) de- sign inspection and asset extraction, (ii) design token and style extraction, (iii) component and layout architecture , and (iv) build verication and iteration. These criteria explicitly reward early design insp ection, semantic asset organization, token centralization prior to component implementation, and previe w-driven iteration— all of which reduce regression and improv e output delity over long horizons. 7.1.2 Output tier rubrics (Figma-to-code). Our output tier grades rendered artifacts against exported ground truth frames and runtime che cks. W e score component coverage (with absolute matched/total elds), layout accuracy , color accuracy , typ ography accuracy , asset display , overall visual delity , responsive behavior , and interaction delity . These rubrics are designe d to b e decom- posable (for diagnosis) while still supporting a single leaderboard score via weighted aggregation. Tier 1: A rtifact Score (Figma-to-code). W e compute a weighted average over eight artifact rubrics—component coverage, layout accuracy , colors, typography , asset display , visual delity , respon- sive behavior , and interaction delity—comparing the deployed UI against design ground truth via a VLM judge (Gemini 3) that per- forms frame-by-frame comparison of Play wright-captured screen- shots against expert ground-truth images. W eights and denitions are in Appendix G. Tier 2: Skill Score (Figma-to-code). W e compute a weighted av- erage over four cor e process rubrics: design inspection and asset extraction, design token and style extraction, comp onent and layout architecture, and build verication and iteration (see Section 8.4 for per-rubric analysis). Scores are produced by three LLM judges (Gemini 3.1 Pro , Claude Sonnet 4.6, GPT -5.2) and averaged across judges; variance is tracked. Abhishek Chandwani and Ishan Gupta T able 3: Figma-to-co de output scores (VLM judge, 1–5 scale). Seven model congurations across three harness families. 95% bootstrap CI reported for primar y candidates. Rank Agent harness / model Score n 1 Codex (GPT -5.2 Pro) 4.27 18 2 Claude Code (Opus 4.6) 4 . 19 ± 0 . 28 32 3 Codex (GPT -5.2) 3 . 94 ± 0 . 36 31 4 Claude Code (Opus 4.5) 3.88 29 5 Gemini CLI (Gemini 3.1 Pro) 3 . 73 ± 0 . 44 29 6 Claude Code (Sonnet 4.5) 3.66 22 7 Gemini CLI (Gemini 3 Pro) 3.59 22 Tier 3: Behavior Score (Optional). W e optionally score task- agnostic trajectory rubrics (equal-weighted) covering tool usage, error recovery , instruction following, planning, information gathering, eciency , task completion, and safety/constraints. This tier is disabled by default. 7.2 Scoring and Aggregation Tier scores are weighted averages of rubric dimensions ( 𝑆 tier = Í 𝑖 𝑤 𝑖 𝑠 𝑖 , Í 𝑤 𝑖 = 1 ). When multiple judges score the same tier , w e re- port the mean and track cross-judge variance. W e report output and process tiers separately; process scor es serve as dense diagnostic signals for long-horizon learning. 8 Experiments 8.1 Experimental Setup W e evaluate thr ee agent harness families—Claude Co de, Codex CLI, and Gemini CLI—across seven congurations (harness × model; see Appendix D) on two environments: Figma-to-code (33 tasks) and Programmatic content (183 chapters across 41 courses). Each conguration executes autonomously in a sandboxed environment with identical tool access and workow constraints dened by an expert-authored SKILL.md . Skill-tier evaluation uses the agship model from each family . A controlled ablation compares execution with and without SKILL.md on Figma-to-code (Section 8.5). For the programmatic content environment, human SMEs pro- vide (i) reasoning on how they would design content given each user instruction, structured as a 5-skill rubric co vering content selection, narrative structure, visual hierarchy , information den- sity , and source grounding; and (ii) per-instruction annotations indicating which documents and assets from the data room they would focus on. These annotations serve as gr ound truth for rubric synthesis and VLM-based artifact scoring. 8.2 Figma-to-Code Results T able 3 reports output scores (visual artifact delity e valuated by a VLM judge), T able 4 r eports skill scores (process quality evaluated by three LLM judges from dierent model families), and T able 5 decomposes skill scores by rubric to expose per-skill strengths and bottlenecks. All tables include 95% bootstrap condence inter vals (1,000 resamples over tasks) for the thr ee primary candidates. T able 4: Figma-to-co de skill scores (3 LLM judges, 1–5 scale). 95% b ootstrap CI over tasks. Per-judge columns: Gemini 3.1 Pro, Claude Sonnet 4.6, GPT -5.2. V ar . is population variance across judges. Rank Agent / model Score ( n ) Gemini Claude GPT V ar . 1 Claude Code (Opus 4.6) 3 . 27 ± 0 . 14 (31) 3.50 3.37 2.92 0.14 2 Codex (GPT -5.2) 3 . 16 ± 0 . 15 (31) 3.51 3.11 2.82 0.15 3 Gemini CLI (3.1 Pro) 2 . 80 ± 0 . 11 (29) 3.06 2.70 2.67 0.06 T able 5: Figma-to-code skill scores decomposed by rubric (average across 3 LLM judges, 1–5 scale). 95% bootstrap CI on ov erall score. Rubric columns: Inspect.=Design Inspec- tion, T oken=T oken & Style Extraction, Comp.=Component Architecture, Build=Build V erication. Bold indicates high- est per-rubric score. 𝜅 row shows mean pairwise Cohen’s kappa. Rank Agent / model Score ( n ) Inspect. T oken Comp. Build 1 Claude Code (Opus 4.6) 3 . 27 ± 0 . 14 (31) 3.40 2.88 3.58 3.21 2 Codex (GPT -5.2) 3 . 16 ± 0 . 15 (31) 3.52 2.64 3.34 2.97 3 Gemini CLI (3.1 Pro) 2 . 80 ± 0 . 11 (29) 2.95 1.66 3.28 3.45 𝜅 (agreement) 0.60 0.50 0.58 0.34 0.67 8.3 Programmatic Content Results W e evaluate programmatic content generation using a VLM-as- judge approach: a Gemini 3.1 Pro judge scores each rendered chap- ter against SME-authored rubrics encompassing content relevance, visual design, pedagogical eectiveness, audio-visual synchroniza- tion, and technical accuracy (see Appendix I for full rubric deni- tions). Scores are normalized to [ 0 , 1 ] and reported as course-level means with 95% bootstrap condence inter vals ( 𝑛 = 41 courses, 183 chapters). W e further validate VLM rankings against human expert pairwise preferences ( 𝑛 = 275 matched comparisons). Rubric granularity analysis. T able 6 reports VLM artifact scores under two rubric granularities: a coarser 3-point scale (0/1/2 per criterion) and a ner 5-point scale (1–5 per criterion). Both scales preserve the same harness ranking (Claude Code > Gemini CLI > Codex), conrming that system-lev el conclusions are r obust to rubric granularity . The 5-point scores are uniformly higher ( + 0 . 03 on average) because the ner scale captures partial credit—a “par- tially correct” element scores 3/5 (0.60) rather than 1/2 (0.50) under the 3-point scale. The 5-point scale also yields substantially tighter condence intervals (e .g., Codex ± 0.044 vs. ± 0.071, a 38% reduc- tion), indicating that ner granularity reduces measurement noise. Critically , the 5-point scale reduces VLM ties in pairwise compar- isons by 49% (38 ties vs. 74 with the 3-point scale), bringing VLM tie behavior in line with human annotator tie rates (36 ties) and eliminating the structural mismatch that deates inter-rater 𝜅 (see Appendix J). This validates the rubric design principle discussed in Section 8.6: ner-grained scales improve evaluation pr ecision and discriminative power without altering system-level conclusions (see Appendix I for full rubric denitions). Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks T able 6: Programmatic content: VLM artifact scores (Gemini 3.1 Pro judge, normalized 0–1). Scores are course-level means of per-chapter normalized scores with 95% b ootstrap CIs ( 𝑛 = 41 courses, 183 chapters). Agent / mo del 3-pt score 5-pt score Claude Code (Opus 4.6) 0 . 588 ± 0 . 093 0 . 612 ± 0 . 069 Gemini CLI (3.1 Pro) 0 . 507 ± 0 . 087 0 . 526 ± 0 . 063 Codex (GPT -5.2) 0 . 441 ± 0 . 071 0 . 478 ± 0 . 044 8.4 Rubric-Level Analysis T able 5 de composes skill scores into the four expert-authored pro- cess rubrics, revealing consistent patterns acr oss agents. Design token and style extraction is a universal bottlene ck. All three agents score low est on the token & style extraction rubric (Claude Code 2.88, Codex 2.64, Gemini CLI 1.66). Gemini CLI’s score of 1.66 is particularly notable—it is the only sub-2.0 rubric average in the table—suggesting that its harness rar ely performs systematic token discovery before coding. This is consistent with the “prompt- to-pixels” failure pattern where agents skip design inspection and guess visual properties, resulting in cascading delity errors. That even the top-ranked agent achieves only 2.88 on this rubric suggests token extraction remains a broadly unsolved challenge for current harnesses. Component and layout architecture is consistently strong. All agents score highest or near-highest on component & layout archi- tecture (Claude Code 3.58, Codex 3.34, Gemini CLI 3.28), indicating that current code-generation capabilities translate well to structural implementation once the agent begins coding. Compensatory skill proles emerge across agents. Codex leads on design insp ection (3.52 vs. Claude Co de ’s 3.40) but trails on build verication (2.97 vs. Gemini CLI’s 3.45). Gemini CLI, despite the lowest ov erall score , achieves the highest build verication score (3.45), suggesting its harness excels at iterative preview-driven correction even when upstream design extraction is weak. These compensatory proles indicate that overall score alone obscures important harness-level trade-os, and that rubric-level decompo- sition provides actionable diagnostic signal for impro ving agent workows. T ask-level diculty gradient. The delib erate complexity strati- cation (Section 5.1) produces a measured diculty gradient in the results. Applying the expert pass/fail threshold ( ≤ 3 = fail, ≥ 4 = pass) across all rated tasks ( 𝑛 = 31 ): 16% are universally easy (100% pass rate across all agents), 13% are univ ersally hard (0% pass—no agent produces shipping-quality output), and 71% are discriminat- ing (at least one agent passes, at least one fails). The discriminating majority is where harness-lev el dierences emerge: Claude Code achieves a 54.5% pass rate, Co dex 57.9%, and Gemini CLI 52.4%, with the 4 universally hard tasks identifying current capability ceilings at the intersection of high frame count, dense asset hierar chies, and multi-route navigation (per-task breakdown in Appendix L). T able 7: SKILL.md ablation: mean skill scores (3-judge avg, 1–5) with and without expert worko w guidance across 3 tasks. 𝑛 = number of paired task runs p er harness. Agent Condition Insp. Token Arch. Build Overall Claude Code ( 𝑛 = 3 ) Without 3.44 2.78 3.44 3.22 3.23 With 3.78 3.11 3.56 2.89 3.38 Δ + 0.34 + 0.33 + 0.12 − 0.33 + 0.15 Codex ( 𝑛 = 2 ) Without 2.17 2.50 2.34 1.00 2.06 With 3.00 2.84 3.17 2.67 2.93 Δ + 0.83 + 0.34 + 0.83 + 1.67 + 0.87 Gemini CLI ( 𝑛 = 2 ) Without 3.50 1.50 3.00 3.00 2.78 With 3.17 1.67 3.17 3.34 2.83 Δ − 0.33 + 0.17 + 0.17 + 0.34 + 0.05 Pooled ( 𝑛 = 7 ) Δ + 0.28 + 0.28 + 0.37 + 0.56 + 0.33 8.5 Ablation: Exp ert W orkow Guidance W e ablate the eect of expert-authored SKILL.md on the Figma-to- code environment by running all three harness families without the expert workow (a single-line task description, no pr ocedural guidance) on 3 tasks spanning the diculty gradient, and comparing against matched with- SKILL.md runs on the same tasks. T ool access is held constant within each harness. T able 7 reports per-harness skill scores ( 𝑛 = 7 paired runs). Preliminary evidence from this small-scale ablation ( 𝑛 = 7 paired runs) suggests the benet of expert workow guidance varies by harness. Codex gains the most ( + 0.87 overall), with build verica- tion improving from 1.00 to 2.67—without SKILL.md , Codex never successfully previews or iterates, pr oducing a oor score on that rubric. Claude Code gains modestly ( + 0.15), consistent with its native familiarity with the Skills specication, though design in- spection and token extraction each impr ove by ∼ 0.3. Gemini CLI gains minimally ( + 0.05), suggesting its harness-level iteration pat- terns (100% deploy rate, strong build verication) may compensate for the absence of procedural guidance. Across harnesses, execution cost drops 42% for Claude Code (mean $6.45 → $3.75) as expert work- ows reduce exploratory backtracking. The sharpest operational signal is deployment success: only 2 of 7 runs without SKILL.md produce a deployable artifact, compared to near-universal deplo y- ment with it. W e note that this ablation is underp owered (2–3 runs per harness) and treat these results as directional; scaling to more tasks per condition is neede d for denitive conclusions. V ersioning infrastructure for scaling this ablation is described in App endix M. 8.6 Inter-Judge Agreement W e use three judges from dierent model families (Gemini 3.1 Pro, Claude Sonnet 4.6, GPT -5.2) and report cross-judge variance and Cohen’s 𝜅 [5] as measures of agreement. Figma-to-code. Mean pairwise Cohen’s 𝜅 (quadratic weights) is 0.60 ( 𝑛 = 92 runs, 360 ratings), indicating moderate-to-substantial agreement [ 14 ]; per-rubric 𝜅 ranges from 0.34 (component archi- tecture) to 0.67 (build verication). All three judges preserve the same rank ordering across harnesses despite absolute-score osets consistent with known calibration dierences across LLM families [8]. Abhishek Chandwani and Ishan Gupta T able 8: Inter-judge agreement by rubric version (same judge families, same 92 runs). 𝜅 is quadratic-weighted Cohen’s kappa. Metric v1.1 (LLM, 8 rubrics) v1.2 (Expert, 4 rubrics) Mean pairwise 𝜅 0.46 0.60 Gemini–Claude 0.44 0.65 Gemini–GPT 0.31 0.52 Claude–GPT 0.63 0.64 Mean variance 0.25 0.10 Expert-authored vs. LLM-authored rubrics. W e compare agree- ment under two rubric versions on the same 92 runs (T able 8). Under v1.1 (8 LLM-authored rubrics), 𝜅 = 0 . 46 ; under v1.2 (4 expert- authored rubrics), 𝜅 = 0 . 60 —a + 0 . 15 improvement. The largest gains occur in Gemini-inv olved judge pairs ( + 0 . 21 ), suggesting that fewer , well-anchored expert dimensions reduce scoring ambiguity for judges most sensitive to rubric phrasing. Convergent validity across evaluation tiers. Three independent evaluation signals— VLM artifact delity (output tier ), 3-judge tran- script evaluation (skill tier), and pairwise human preference (T a- ble 9)—all agree on the same primary ranking boundar y . The output and skill tiers use entirely dierent inputs, judges, and rubrics; the human evaluator uses direct side-by-side comparison with no ac- cess to LLM scores. This three-way convergence pr ovides strong evidence that expert-authored skill veriers are reliable , scalable indicators for ranking autonomous agents on subjective enterprise tasks. Human preference evaluation. T o validate LLM-based rankings with direct human judgment, a domain expert performe d 135 pair- wise preference evaluations on Figma-to-co de outputs across 31 tasks, comparing agent-built UIs side-by-side without access to LLM scores or agent identity (T able 9). Bradley- T erry Elo rankings [ 2 ] place Co dex and Claude Code in a statistically indistinguishable top tier ( 𝑝 = 0 . 67 , Cohen’s ℎ = 0 . 08 ), with both signicantly preferred over Gemini CLI ( 𝑝 = 0 . 036 and 𝑝 = 0 . 047 respectively). Position bias is absent (52% A -rate, binomial 𝑝 = 0 . 72 ), and preferences ar e near- perfectly transitive (4.2% cycle rate). Winner quality ratings dier signicantly across agents (Kruskal- W allis 𝑝 = 0 . 048 ): Codex victo- ries are rated higher (3.88/5) than Claude Code (3.40/5) or Gemini CLI (3.35/5), suggesting Codex produces more variable but higher- peak outputs. Expert pass/fail classication. The domain expert assigns quality ratings on a 5-point scale: ≤ 3 = fail, 4 = design system well-dened but assets and ne-grained spacing require one engineering sprint, 5 = production-ready . Applying this threshold to winner ratings, overall 60% of winning outputs pass ( ≥ 4). Pass rates vary substan- tially by model: Co dex GPT -5.2 Pro leads at 77.8% (21/27), followed by Codex GPT -5.2 at 57.9% (33/57), Claude Co de at 54.5% (24/44), and Gemini CLI at 52.4% (11/21). The separation between GPT -5.2 Pro and the rest suggests that when GPT -5.2 Pro wins a matchup , it produces meaningfully higher-quality output—consistent with the higher winner ratings reported above. T able 9: Human pairwise preference (Figma-to-code): Bradley- T err y Elo from 135 votes by 1 domain expert. The top two harnesses are statistically indistinguishable ( 𝑝 = 0 . 67 , ℎ = 0 . 08 ); b oth signicantly outp erform Gemini CLI ( 𝑝 < 0 . 05 ). Agent harness Elo 95% CI Win % n wins Codex (GPT -5.2) 1054 [1005, 1114] 56.8 72 Claude Code (Opus 4.6) 1039 [987, 1093] 55.1 43 Gemini CLI (3.1 Pro) 907 [842, 965] 31.1 21 T able 10: Pr ogrammatic content: pairwise win rates from human SME preferences vs. VLM-derived outcomes ( 𝑛 = 275 matched chapter-level comparisons). Agent Human WR VLM WR (3-pt) VLM WR (5-pt) Claude Code (Opus 4.6) 81.5% 66.8% 69.0% Codex (GPT -5.2) 34.2% 33.9% 33.1% Gemini CLI (3.1 Pro) 34.2% 49.2% 47.8% At the individual run level, human and LLM judges show w eak concordance ( 𝜅 = 0 . 08 output, 0 . 06 skill). At the aggregate level, both agree on the primary ranking boundary , but LLM judges nominally separate the top two where human preferences do not (T able 9), cautioning against interpreting ne-grained LLM score gaps as perceptible quality dierences. Programmatic content. For programmatic content, we evaluate VLM judge reliability through human– VLM alignment rather than multi-judge agreement, since a single VLM judge (Gemini 3.1 Pro) scores artifacts against chapter-specic rubrics. Human– VLM pair- wise agreement is 52.0% with Cohen’s 𝜅 = 0 . 082 under 5-point rubrics ( 𝑛 = 275 ), with system-level concordance on the top-ranked harness. Human– VLM alignment (programmatic content). T o validate VLM-as-judge scoring against human expert preferences, we compare pairwise outcomes from VLM artifact scores against human SME pairwise preferences on 𝑛 = 275 matched chapter-level comparisons. The human preference interface allows both strict preference and explicit ties. T able 10 reports win rates. Both human and VLM judges agree that Claude Code is the top- ranked harness (human WR 81.5%, VLM WR 69.0%). Codex win rates are closely aligned between human and VLM (34.2% vs. 33.1%). The primary divergence is at position 2: humans rate Codex and Gemini equally (b oth 34.2%), while the VLM favors Gemini (47.8% vs. 33.1%), likely reecting VLM sensitivity to production-quality dimensions where Gemini performs competitively , whereas human experts weight content accuracy and pedagogical eectiveness more heavily . Raw pairwise agreement is 46.5% (3-point) and 52.0% (5-point); Cohen’s 𝜅 is 0.073 and 0.082 respectively . Notably , 𝜅 improves with the 5-point scale, driven by a reduction in tie asymmetry: the VLM produces 74 ties under 3-point rubrics but only 38 under 5-point, closely matching the 36 human ties. The 5-point scale also yields the largest agreement gains on the hardest comparisons (Codex vs. Gemini: 41.8% → 49.5%; Claude vs. Gemini: 40.2% → 48.9%), while Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks T able 11: Failure taxonomy across all Figma-to-code runs ( 𝑛 = 96 ). Recovery rate is the fraction of errors from which the agent successfully self-corrected. Error type Count Recovered Recov ery % T ool call failure 419 278 66.3 Git error 64 48 75.0 Syntax error 33 30 90.9 Dependency error 28 22 78.6 Preview deny 18 16 88.9 Build error 11 11 100.0 T yp e error 7 6 85.7 Cong error 6 1 16.7 Runtime error 4 3 75.0 T otal 590 415 70.3 T able 12: Per-agent recovery summary (Figma-to-co de). Fail- ure rate = failed tool calls / total tool calls. Recovery rate = errors recovered / total errors. Agent Runs Errors Failure % Recovery % Preview Deploy T ool calls Claude Code (Opus 4.6) 32 152 7.3 71.1 30/32 27/32 2692 Codex (GPT -5.2) 34 273 9.4 74.0 5/34 21/34 3339 Gemini CLI (3.1 Pro) 30 165 8.4 63.6 30/30 30/30 2092 the easy comparison (Claude vs. Co dex) remains stable at 57.6%. System-level concordance on the top-ranke d harness, combined with directional alignment on win rates and improved 𝜅 under ner granularity , validates the VLM-as-judge approach for subje ctive multimedia evaluation. Full per-pair breakdowns ar e in Appendix J. 8.7 Failure T axonomy and T est- Time Re covery W e extract structured error → recovery events from all 96 Figma-to- code agent transcripts using an LLM-base d pipeline (T ables 11, 12). T ool call failures dominate; error message quality determines recov- erability . T ool call failures account for 71% of all errors (419/590), including MCP timeouts, le-not-found errors, and permission de- nials (Figure 3). Harness-specic patterns emerge: Codex concen- trates 78% of git errors and 79% of dependency errors, driven by a recurring cascade where .git/index.lock les and unresolved version conicts compound across tool invocations. The sharpest diagnostic signal is recoverability by feedback type: errors with structured compiler output (syntax, type, build) yield > 85% recov- ery , while ambiguous signals (conguration errors) yield only 17% (T able 11, Figure 4). Agents recover from 70% of errors, with distinct correction strategies. Across 590 err ors, agents self-correct 70.3% of the time (T able 12), demonstrating that test-time verication fe edback enables meaning- ful self-correction [ 12 ]. The three harnesses exhibit distinct proles: Claude Code is proactive —94% preview usage, iterating on struc- tured feedback b efore proceeding; Codex is reactive —encountering the most errors per run yet achieving the highest recovery rate (74%); Gemini CLI is persistent —100% deploy rate across all runs, pushing through to deployment ev en with unresolved errors. 9 Conclusion Binary benchmarks cannot capture the idiosyncratic quality criteria of enterprise work. LH-Bench demonstrates that stepwise veriers and expert-grounded evaluation solve this problem. Across two environments—application development life cycle (Figma-to-code) and programmatic content generation from enter- prise knowledge—we show that LH-Bench, our three-pillar eval- uation design, produces reliable, diagnostic signals for grading autonomous agents on subjective tasks. Thr ee properties make this design viable at scale: Scalable: expert-authored rubrics, curated ground-truth ar- tifacts, and workow-specic SKILL.md references encode the domain knowledge that LLM judges nee d to simulate expert evaluation, eliminating per-task dependence on human judgment. Expert-authored rubrics yield substantially higher inter-judge agreement than LLM-authored rubrics ( 𝜅 = 0 . 60 vs. 0 . 46 ), validating this encoding. Reusable: the environment infrastructure accepts new task congurations—Figma design les, data-room document collections— and evaluates new agents through the same multi-harness pip eline without re-engineering the evaluation. Generalizable: the three pillars converge across b oth environ- ments and all three harness families: independent evaluation tiers agree on the same ranking boundaries, and rubric-level decomposi- tion reveals compensator y skill proles invisible to aggregate scores. Our recovery analysis further shows that error message quality , not error frequency , determines self-correction—underscoring that evaluation must look beyond nal outputs to the e xecution process itself. LH-Bench is a reusable environment that enables enterprises to implement multi-harness agent runners and a proven three- pillar evaluation design to r eliably grade new agents on ne w task congurations. 10 Limitations and Future W ork (1) Findings are limited to two environments. W e aim to secure additional compute and domain-expert budget to scale LH-Bench in environment diversity and task complexity in future work. (2) W e evaluate Codex CLI rather than the OpenAI A gent SDK, which may support dierent orchestration patterns. (3) All three harnesses are tightly coupled to their model families. An open-source, model- agnostic harness would enable controlled experiments decoupling model capability from harness orchestration. W e release public datasets for both environments. References [1] Victor Barres, Honghua Dong, Soham Ray , Xujie Si, and Karthik Narasimhan. 2025. 𝜏 2 -Bench: Evaluating Conversational Agents in a Dual-Control Environ- ment. arXiv preprint arXiv:2506.07982 (2025). [2] Ralph Allan Bradley and Milton E. T erry . 1952. Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika 39, 3/4 (1952), 324–345. [3] Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou W ang. 2024. Humans or LLMs as the Judge? A Study on Judgement Biases. arXiv preprint arXiv:2402.10669 (2024). [4] Jiaju Chen, Y uxuan Lu, Xiaojie W ang, Huimin Zeng, Jing Huang, Jiri Gesi, Ying Xu, Bingsheng Y ao, and Dakuo W ang. 2025. Multi- Agent-as-Judge: Aligning LLM- Agent-Based A utomated Evaluation with Multi-Dimensional Human Evaluation. In NeurIPS W orkshop on Multi- T urn Interactions . Abhishek Chandwani and Ishan Gupta [5] Jacob Cohen. 1960. A Coecient of Agreement for Nominal Scales. Educational and Psychological Measurement 20, 1 (1960), 37–46. [6] Xiang Deng, Je Da, Edwin Pan, et al . 2025. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering T asks? arXiv preprint (2025). [7] Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del V erme, T om Marty , Léo Boisvert, Megh Thakkar , Quentin Cappart, David V azquez, Nicolas Chapados, and Alexandre Lacoste. 2024. W orkArena: How Capable Are W eb Agents at Solving Common Knowledge W ork T asks?. In Inter- national Conference on Machine Learning (ICML) . [8] Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, W ei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo W ang, Kun Zhang, Y uanzhuo W ang, W en Gao, Lionel Ni, and Jian Guo. 2024. A Survey on LLM-as- a-Judge. arXiv preprint arXiv:2411.15594 (2024). [9] Shengyue Guan, Jindong W ang, Jiang Bian, Bin Zhu, Jian-Guang Lou, and Haoyi Xiong. 2025. Evaluating LLM-based Agents for Multi- T urn Conversations: A Survey . arXiv preprint arXiv:2503.22458 (2025). [10] Carlos E. Jimenez, John Yang, Alexander W ettig, Shunyu Yao , Kexin Pei, Or Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- W orld GitHub Issues? . In International Conference on Learning Representa- tions (ICLR) . [11] Jing Y u Koh, Robert Lo , Lawr ence Jang, Vikram Duvvur, Ming Lim, Po- Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov , and Daniel Fried. 2024. VisualW ebArena: Evaluating Multimodal Agents on Realistic Visual W eb T asks. In A nnual Meeting of the Association for Computational Linguistics (A CL) . [12] A viral Kumar , Vincent Zhuang, Rishabh Agarwal, et al . 2025. Training Language Models to Self-Correct via Reinforcement Learning. In International Conference on Learning Representations (ICLR) . [13] Thomas K wa, Ben W est, Joel Becker , et al . 2025. Measuring AI Ability to Com- plete Long T asks. https://metr .org/blog/2025- 03- 19- measuring- ai- ability- to- complete- long- tasks/. [14] J. Richard Landis and Gary G. Koch. 1977. The Measurement of Observer Agree- ment for Categorical Data. Biometrics 33, 1 (1977), 159–174. [15] Ruizhe Li, Mingxuan Du, Benfeng Xu, Chiw ei Zhu, Xiaorui W ang, and Zhendong Mao. 2026. DeepResearch Bench II: Diagnosing Deep Research Agents via Rubrics from Expert Report. arXiv preprint arXiv:2601.08536 (2026). [16] Xiangyi Li et al . 2026. SkillsBench: Benchmarking How W ell Agent Skills W ork Across Diverse T asks. arXiv preprint arXiv:2602.12670 (2026). [17] Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, K ejuan Y ang, et al . 2024. AgentBench: Evaluating LLMs as Agents. In International Conference on Learning Representations (ICLR) . [18] Haotian Luo, Huaisong Zhang, Xuelin Zhang, Haoyu W ang, Zeyu Qin, W enjie Lu, Guozheng Ma, Haiying He, Yingsha Xie, Qiyang Zhou, Zixuan Hu, Hongze Mi, Yibo W ang, Naiqiang T an, Hong Chen, Yi R. Fung, Chun Y uan, and Li Shen. 2025. UltraHorizon: Benchmarking Agent Capabilities in Ultra Long-Horizon Scenarios. arXiv preprint arXiv:2509.21766 (2025). [19] Grégoire Mialon, Clémentine Fourrier , Craig Swift, Thomas W olf, Yann LeCun, and Thomas Scialom. 2024. GAIA: A Benchmark for General AI Assistants. In International Conference on Learning Representations (ICLR) . [20] Mahmoud Mohammadi, Yipeng Li, Jane Lo, and W endy Yip. 2025. Evaluation and Benchmarking of LLM Agents: A Survey . In ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) . [21] Y ujia Qin, Shihao Liang, Yining Y e, Kunlun Zhu, Lan Y an, Y axi Lu, Y ankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al . 2024. T oolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. In International Conference on Learning Representations (ICLR) . [22] Manasi Sharma, Chen Bo Calvin Zhang, Chaithanya Bandi, Clinton W ang, Ankit Aich, Huy Nghiem, T ahseen Rabbani, Y e Htet, Brian Jang, Sumana Basu, Aish- warya Balwani, Denis Pesko, Marcos A yestaran, Sean M. Hendry x, Brad Ken- stler , and Bing Liu. 2025. ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents. arXiv preprint arXiv:2511.07685 (2025). [23] Chenglei Si, Y anzhe Zhang, Ryan Li, Zhengyuan Y ang, Ruibo Liu, and Diyi Y ang. 2025. Design2Code: Benchmarking Multimodal Code Generation for Automated Front-End Engineering. In A nnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) . [24] Haoyu Sun, Huichen Will W ang, Jiawei Gu, Linjie Li, and Yu Cheng. 2025. Full- Front: Benchmarking MLLMs Across the Full Front-End Engineering W orkow . arXiv preprint arXiv:2505.17399 (2025). [25] Aman Singh Thakur , Kartik Choudhary, V enkat Srinik Ramayapally, Sankaran V aidyanathan, and Dieuwke Hupkes. 2024. Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges. arXiv preprint (2024). [26] Xingyao W ang, Zihan W ang, Jiateng Liu, Y angyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. 2024. MIN T: Evaluating LLMs in Multi-turn Interaction with T ools and Language Feedback. In International Conference on Learning Representations (ICLR) . [27] Quan W ei, Siliang Zeng, Chenliang Li, William Brown, Oana Frunza, W ei Deng, Anderson Schneider , Yuriy Nevmyvaka, Y ang Katie Zhao, Alfredo Gar cia, and Mingyi Hong. 2025. Reinforcing Multi-T urn Reasoning in LLM Agents via Turn- Level Reward Design and Cr edit A ssignment. In NeurIPS W orkshop on Multi- T urn Interactions . [28] Xueqing Wu, Zihan Xue, Da Yin, Shuyan Zhou, K ai- W ei Chang, Nanyun Peng, and Y eming W en. 2026. FronT alk: Benchmarking Front-End Development as Conversational Code Generation with Multi-Modal Feedback. arXiv preprint arXiv:2601.04203 (2026). [29] Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, T oh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al . 2024. OSW orld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. In Advances in Neural Information Processing Systems (NeurIPS) . [30] Shunyu Y ao, Noah Shinn, Karthik Narasimhan, et al . 2024. 𝜏 -bench: A Bench- mark for T ool- Agent-User Interaction in Real- W orld Domains. arXiv preprint arXiv:2406.12045 (2024). [31] Shunyu Y ao, Jerey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. In International Conference on Learning Representations (ICLR) . [32] Matei Zaharia, Omar Khattab, Lingjiao Chen, Jared Quincy Davis, Heather Miller , Chris Potts, James Zou, Michael Carbin, Jonathan Frankle, Naveen Rao, and Ali Ghodsi. 2024. The Shift from Models to Compound AI Systems. Berkeley Articial Intelligence Research Blog. Accessed: 2026. [33] Lianmin Zheng, W ei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. In Advances in Neural Information Processing Systems (NeurIPS) . [34] Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar , Xianyi Cheng, Tianyue Ou, Y onatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. W ebArena: A Realistic W eb Environment for Building Autonomous Agents. In International Conference on Learning Representations (ICLR) . [35] Hongda Zhu, Yiwen Zhang, Bing Zhao, Jingzhe Ding, Siyao Liu, T ong Liu, Dandan W ang, Y anan Liu, and Zhaojian Li. 2025. FrontendBench: A Benchmark for Evaluating LLMs on Front-End Dev elopment via A utomatic Evaluation. arXiv preprint arXiv:2506.13832 (2025). Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks Appendix A Pipeline Diagram . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 B SME Annotation T ool . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 C Ground Truth Schema Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 D Harness Spe cications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 E Skill Rubric Denitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 F Rubric V ersion Comparison (v1.1 vs v1.2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 G Output Tier Rubric W eights . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 H Recovery Analysis Figures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 I Programmatic Content Evaluation Rubrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 J Human– VLM Alignment Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 K Preference Arena . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 L T ask-Level Human Baseline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 M Experiment V ersioning Infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 A Pipeline Diagram T ask dataset (HuggingFace) row_id, gma_key, prompt /execute Dispatch agent run Agent sandb ox Build, preview , structured feedback Run DB + artifacts Deployed URLs, media, scores, judge variance Rubric dataset (HuggingFace) skill, anchors, weights /evaluate Load artifacts + rubrics Run judges in parallel 3 Judges (parallel) Trajectory / Process / Output /leaderboard Aggregate + rank Condence reporting Execution Evaluation Figure 1: LH-Bench execution and evaluation pipeline. T asks and rubrics are versioned indep endently in HuggingFace. Agent runs produce p ersistent artifacts, which are grade d by three judges in parallel; results ow into leaderboards. B SME Annotation T ool Figure 2 shows the SME annotation interface used for programmatic content ground-truth construction. The tool presents three coordinated panels: Source panel (left). Lists all documents in the task’s data room (e.g., arXiv PDFs, web pages) with type badges. SMEs click a source to load it in the center panel. Document viewer (center). Renders the selecte d source as line-numbered markdown. Each section is collapsible and displays its line range (e.g., L1–9 , L10–13 ). SMEs can select text spans inline using a “highlight-to-cite ” interaction: selecting lines attaches the span (with source ID and line numbers) to the active chapter , producing structured citations of the form source_id:start_line–end_line . Chapter panel (right). SMEs dene chapters—the units of content the agent must produce—and attach source spans to each chapter . Each chapter includes a title, ordering, and the set of cited spans from the source panel. A “Global notes” eld captures high-level design reasoning (e.g., narrativ e arc, emphasis priorities) that applies across all chapters. This three-panel design enables SMEs to build granular , source-grounded annotations eciently: the annotator reads a source, highlights relevant passages, and assigns them to chapters in a single workow , rather than context-switching between separate tools. The resulting annotations power rubric synthesis for VLM-based artifact scoring (Section 8.3) and encode the 5-skill design rubric (content selection, narrative structure, visual hierar chy , information density , source grounding). Abhishek Chandwani and Ishan Gupta Figure 2: SME annotation interface for programmatic content. Left: source documents in the data room. Center: line-numb ered document viewer with collapsible sections and highlight-to-cite interaction. Right: chapter denitions with attached source spans and global design notes. C Ground Truth Schema Examples Figma-to-code manifest. (see Section 6.3): { "figma_file_key": "oSNDllo...8YMSlD", "total_frames": 5, "frames": [ { "name": "PDP", "node_id": "2176:167104", "gt_image": "2176-167104.png", "target_route": "/pdp" }, { "name": "PLP_Category", "node_id": "2176:167875", "gt_image": "2176-167875.png", "target_route": "/" } ] } Programmatic content annotation. (see Section 6.3): { "task_id": "video-tutor-042", "context_gt": [ { "source_id": "arxiv-2301.00234", "start_line": 42, "end_line": 58, "quote": "Attention is computed as..." } ], "rubrics": [ { "criterion": "source_grounding", "scale": "0/1/2", "anchor_2": "All claims cited" } ] } Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks D Harness Sp ecications This appendix provides formal descriptions of the agent harnesses, tool interface, skill injection mechanism, and session recovery protocol used in LH-Bench. D .1 Harness Descriptions W e evaluate three commercial agent harnesses. Each tightly couples specic models with proprietary agent logic, representing real-world deployment conditions: • Claude Code (Anthropic): Anthropic’s coding agent with native Skill integration. Uses the Claude Agent SDK with subprocess CLI execution, MCP server support via McpStdioServerConfig , automatic context compaction, and session resumption. Operates in permission-bypass mode ( acceptEdits ) for autonomous execution. • Codex CLI (OpenAI): OpenAI’s lightweight co ding agent. MCP servers are registered via a global registry ( codex mcp add ). Runs in dangerously-bypass-approvals-and-sandbox mode for full autonomy . Outputs structured JSONL event streams with transcript archival. • Gemini CLI (Google): Go ogle’s open-source terminal agent. MCP servers are auto-discovered from a p er-project .gemini/settings.json conguration. Uses V ertex AI authentication with wrapper scripts for environment variable isolation. Runs in trust mode ( –yolo ) for auto-approval. Model family consideration. Claude models hav e be en trained with awareness of the Agent Skills specication, which may confer advantages when processing Skill-formatted instructions. Codex and Gemini harnesses receive equivalent skill content but through their respective native mechanisms. D .2 T ool Interface All agents interact with environments through the Model Context Pr otocol (MCP). Each MCP server e xposes domain-specic tools following a standardized request/response interface: Figma-to-code tool categories. • Design extraction (Figma MCP): get_figma_file , get_node_tree , export_node_images —retrieve design structure , component hierarchy , and rasterized assets. • File and shell (built-in): Read, W rite, Edit, Glob , Gr ep, Bash—standard le manipulation and command execution within the sandbox. • Preview verication (App Preview MCP): create_app_preview , get_preview_status —build the agent’s code in an ephemeral container and return structured error diagnostics (runtime exceptions, blank-page detection) or a live URL. • Deployment (GCS MCP): upload_dist_to_gcs —publish nalized static builds for artifact evaluation and human inspection. • Browser automation (Play wright MCP): browser_navigate , browser_take_screenshot —exercise deployed UIs and capture frame-level screenshots for visual verication. D .3 Skill Injection Mechanism SKILL.md les encode expert-authored procedural knowledge as structured Markdown with Y AML frontmatter: --- name: figma-to-code description: Convert Figma designs to production-ready frontend code. --- # Step 0: Check manifest for prior progress # Step 1: Extract design structure via Figma MCP # Step 2: Export assets and ground truth frames ... Per-harness loading. Each harness discovers and loads Skills using its native mechanism: • Claude Code : setting_sources=["project"] triggers scanning of .claude/skills/*/SKILL.md in the project root. • Gemini CLI : Skills are placed in .gemini/skills/*/SKILL.md and loaded via le-based conguration in settings.json . • Codex CLI : Skill content is inlined into the system prompt, as Codex lacks a native skill-discovery mechanism. D .4 Manifest-Based Session Recovery Agents maintain a at manifest.json at the project root to track execution progress: { "preview_url": "https://...", "deployed_url": "https://...", Abhishek Chandwani and Ishan Gupta "completed_steps": [ "Step 1: Extract from Figma", "Step 2: Export assets" ], "updated_at": "2026-01-31T..." } Step 0 of every SKILL.md requires reading the manifest to check prior progress, enabling session recov ery across agent restarts without re-executing completed work. This is critical for long-horizon tasks where context limits or transient failur es may interrupt a session. D .5 Containerization and Deployment Agent runs execute in sandboxed containers deployed via Modal (serverless). Each model conguration receives a de dicated p ersistent volume (e .g., /figma-claude-opus , /figma-codex-52 , /figma-gemini-31-pro ) for project state isolation. The container image includes Python 3.11, Node.js 20, and all agent CLI binaries. MCP tool servers run as co-processes within the same container , with cr edentials injected via modal.Secret at runtime. E Skill Rubric Denitions ( v2.1) T able 13 presents the four expert-authored process rubrics used for Figma-to-code skill evaluation (v2.1). Each rubric uses a 1–5 anchor ed scale with observable transcript evidence. The rubrics are designed around sequential workow phases with binary-observable boundaries between score levels. T able 13: Figma-to-code process rubrics (v2.1, expert-authored). W eight indicates contribution to the aggregate skill score. Anchors summarize the 1–5 scale boundaries. Rubric Wt. What it measures Key boundar y (3 → 4) Design Inspection & A sset Extrac- tion 0.30 Extent of Figma le inspe ction, asset ex- port completeness, format correctness, multi- page navigation discovery 3 = all assets e xported in correct formats; 4 = also organized (semantic lenames, direc- tory structure, hierarchy inspection before coding) Design T oken & Style Extraction 0.25 Extraction and centralization of colors, ty- pography , spacing, shadows, borders into a token/theme le 3 = token le covers 4+ of 6 categories, tokens referenced in code; 4 = also created before components, semantic naming, zero hard- coded leaks Component & Layout Architec- ture 0.25 Component decomp osition, pattern reuse, A uto Layout → CSS mapping, variant/state handling 3 = repeated patterns identied, layout cor- rect, hover states; 4 = also planned upfront (visible in transcript), full variant coverage , props interface Build V erication & Iteration 0.20 Build/preview execution, error diagnosis and x iteration, visual verication against Figma design 3 = build compiles successfully; 4 = also opened preview AND made at least one x based on visual inspection Each scale point includes concrete transcript indicators. For example, at score 5 (“Production-grade”) on Design Inspection, the agent uses W ebP for photos, applies @2x scale factors, de duplicates repeated assets, converts SVGs to components, and maps the full navigation topology before coding. The full rubric specication with all 5 anchor levels p er rubric is available in the repository at verifiers/figma-to-code/process_rubrics.json . F Rubric V ersion Comparison (v1.1 vs v1.2) T able 14 compares the two rubric versions used in the inter-judge agreement analysis (Section 8.6). v1.1 (LLM-authored, 8 rubrics). Generate d by prompting an LLM to produce evaluation criteria for Figma-to-code agent trajectories. The rubrics cover ne-grained workow steps with unequal weights (0.07–0.20) and use generic prociency anchors (“Inadequate” through “Expert”) without binary-obser vable boundaries. Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks T able 14: Rubric version comparison. v1.1 uses 8 generic LLM-authored rubrics; v1.2 uses 4 domain-sp ecic expert-authored rubrics with anchored scales. v1.1 (LLM-authored) v1.2 (Expert-authored) Rubric count 8 4 Scope Figma-to-code (ne-grained) Figma-to-code (workow phases) Anchor style Generic (“Inadequate”–“Expert”) Observable (transcript evidence) Boundary type Subjective Binary-observable v1.1 rubrics (non-equal weight): Design le inspection (0.07), Image asset extraction (0.20), Icon/vector extraction (0.15), Design token discovery (0.15), Component pattern recognition (0.10), V ariant/state analysis (0.12), Layout structure analysis (0.13), Build verication (0.08) v1.2 rubrics (weighted): Design inspection (0.30), T oken extraction (0.25), Component architecture (0.25), Build verication (0.20) Mean pairwise 𝜅 0.46 0.60 Mean variance 0.25 0.10 v1.2 (Expert-authored, 4 rubrics). Designed by domain experts with Figma-to-co de workow knowledge. Each rubric maps to a sequential workow phase , uses binary-observable boundaries b etween score lev els (e .g., “token le cr eated before components” is veriable in the transcript), and includes specic transcript evidence patterns. The key design insight is that domain-specic rubrics with binar y-observable boundaries reduce scoring ambiguity . For example , “Did the agent create a token le before writing components?” is unambiguously veriable from the transcript, whereas “Did the agent demonstrate good planning?” requires subjective interpretation that varies across judges. This is reected in the + 0 . 15 kappa improvement (T able 8). G Output Tier Rubric W eights T able 15 lists the eight artifact rubrics used for the Figma-to-co de output tier (Tier 1). Each rubric is scored on a 1–5 scale by a VLM judge (Gemini 3) comparing Playwright-captured screenshots against expert ground-truth frame images. T able 15: Figma-to-co de output tier rubric weights. Rubric W eight What it measures Component coverage 0.20 Percentage of design components rendered Layout accuracy 0.18 Spatial p ositioning/sizing and ex/grid correctness Colors accuracy 0.14 Palette delity (lls, gradients, borders) T yp ography accuracy 0.12 Font family/size/weight/line-height match Asset display 0.10 Images/icons/vector assets render correctly Visual delity 0.10 Overall visual similarity Responsive behavior 0.08 Adapts to multiple viewports Interaction delity 0.08 Hov er/active/disabled states H Recovery Analysis Figures Abhishek Chandwani and Ishan Gupta Figure 3: Error landscape across 96 Figma-to-co de runs (590 total errors). T ool call failures account for 71% of all errors; within these, Figma MCP operations are the dominant source (51%), reecting the diculty of reliably invoking design-extraction APIs at scale. Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks Figure 4: Recovery rates by error type. Structured compiler feedback (syntax, typ e, build errors) yields > 85% recovery; ambiguous signals (conguration errors) yield only 17%. Figure 5: Per-agent recovery proles. Codex encounters the most errors (8.0/run) yet achieves the highest recovery rate (74%); Claude Code encounters the fewest (4.8/run) with 71% recovery; Gemini CLI recovers 64% with 100% deploy completion. Abhishek Chandwani and Ishan Gupta I Programmatic Content Evaluation Rubrics Each chapter in the programmatic content environment is graded against ve generic SME-author ed rubrics plus chapter-specic criteria synthesized from annotator evaluation notes. The generic rubrics are applied uniformly across all chapters; chapter-specic rubrics are LLM-synthesized from per-chapter annotator notes to capture task-spe cic quality dimensions (e.g., “corr ectly illustrates the attention mechanism” for a chapter on transformers). Below we present the ve generic rubrics with their full 5-point scale denitions. I.1 Generic Rubrics (5-point scale) 1. Content Relevance and Clarity . Evaluates whether the video content accurately addresses the chapter instruction and presents information in a clear , logically structured manner . Score Description 1 Content is largely irrelevant or incoherent; fails to address the chapter instruction. 2 Addresses the topic but with major gaps, inaccuracies, or disorganized presentation. 3 Covers core points adequately; minor gaps or unclear transitions but generally on-topic. 4 Clear , well-organized content that addresses all key aspects of the instruction with minor omissions. 5 Comprehensive, pr ecisely targeted content with logical ow; every segment directly serves the chapter objective. 2. Visual Design and Production Quality . Evaluates the aesthetic quality , consistency , and professionalism of visual elements including typography , color , layout, and animations. Score Description 1 Visuals are broken, missing, or unreadable; sever e rendering artifacts. 2 Functional but amateurish; inconsistent styling, poor contrast, or cluttered layouts. 3 Acceptable visual quality; consistent styling with minor polish issues. 4 Professional appearance; cohesive color palette, clean typography , smooth animations. 5 Exceptional production quality; polished transitions, purp oseful motion design, broadcast-quality aesthetics. 3. Pedagogical Eectiveness. Evaluates ho w well the video teaches the intende d concept, including pacing, scaolding, and use of examples. Score Description 1 No discernible teaching structure; concepts presented without context or progression. 2 Attempts to explain but lacks scaolding; jumps between concepts without bridging. 3 Reasonable pedagogical ow; builds on prior context with adequate pacing. 4 Eective teaching with clear scaolding, well-timed examples, and concept reinforcement. 5 Exemplary pedagogy; progressive disclosure, concrete-to-abstract scaolding, retrie val cues, and anticipa- tion of learner misconceptions. 4. A udio– Visual Synchronization. Evaluates alignment between narration and on-screen visuals, including timing of transitions, text highlights, and animation triggers. Score Description 1 Severe desynchronization; narration and visuals are unr elated or oset by multiple seconds. 2 Noticeable timing mismatches; visuals often appear before or after the relevant narration. 3 Generally synchronized; occasional minor osets that do not impede comprehension. 4 W ell-synchronized; visuals reinforce narration with consistent timing. 5 Precise synchronization; animations trigger at exactly the right narration cue, enhancing comprehension through temporal alignment. 5. T echnical Accuracy of Visualizations. Evaluates the correctness of diagrams, e quations, code snippets, and data representations shown in the video. Score Description 1 Visualizations contain fundamental errors (wrong equations, incorrect diagrams, fabricated data). 2 Partially correct but with signicant errors that could mislead learners. 3 Mostly correct; minor inaccuracies that do not alter the core message. 4 Accurate visualizations with proper notation, correct relationships, and faithful data representation. 5 T echnically impe ccable; visualizations are precise, properly labeled, and include appropriate caveats or simplication notes where relevant. Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks I.2 Chapter-Specic Rubrics In addition to the ve generic rubrics, each chapter receives 1–3 chapter-specic rubrics synthesized by an LLM from the human annotator’s evaluation criteria for that chapter . For example, a chapter on “GRPO vs. PPO gradient ow” might receive a rubric for “Gradient diagram correctness: do es the visualization accurately show the policy gradient computation path for both algorithms?” These chapter-sp ecic rubrics use the same scale structure (either 3-point or 5-point) as the generic rubrics and are scored by the same VLM judge . I.3 3-Point vs. 5-Point Scale Comparison W e evaluate all rubrics under both granularities. The 3-point scale uses levels 0 (absent/incorrect), 1 (partially correct), and 2 (fully correct). The 5-point scale provides ner discrimination as shown above . Section 8.3 reports aggregate results under both scales. I.4 Example VLM Judge Pr ompt (5-Point Scale) Below is an abbreviated example of the prompt sent to the VLM judge (Gemini 3.1 Pro) for a single chapter evaluation. The prompt includes: (1) a system preamble enfor cing strict, evidence-based scoring; (2) course conte xt and outline; (3) the chapter instruction; (4) the full set of rubrics (5 generic + 2 chapter-specic in this example); and (5) structured output instructions. W e show the system preamble, two representative rubrics ( one generic, one chapter-specic), and the output format. The full prompt for all rubrics follows the same pattern. You are a strict, impartial evaluator of AI-generated educational videos. Score only what you observe in the video, not what it could have been. Be critical. Reserve top scores for genuinely exceptional work. ## Course Context [Course description and outline omitted for space] ## Chapter Instruction > How do Denoising Score Matching with Langevin > Dynamics (SMLD) and DDPM learn and sample from > complex data distributions, and why are they > fundamentally equivalent under a score-based > perspective? ## Rubrics ### 1. Content Relevance and Clarity Evaluation: Does the video stay focused on explaining how SMLD and DDPM learn/sample, and why they are equivalent under score-based perspective? Scale: 1: Mostly off-topic or incoherent; fails to address how SMLD/DDPM learn and sample; major factual errors. 2: Touches on diffusion but with major gaps; equivalence missing or asserted without explanation. 3: Adequate overview of SMLD and DDPM with minor gaps; equivalence mentioned but not strongly supported. 4: Clear and well-structured; explicitly explains equivalence under unified score-based view; negligible omissions. 5: Exceptionally focused; rigorously and intuitively explains SMLD-DDPM equivalence; consistent notation; resolves common confusions. [... 4 more generic rubrics: Visual Design, Pedagogical Effectiveness, Audio-Visual Sync, Technical Accuracy ...] Abhishek Chandwani and Ishan Gupta ### 6. Chapter Mastery: Understanding SMLD Evaluation: How well does the video explain SMLD as learning scores via denoising score matching across noise levels and sampling via Langevin dynamics? Scale: 1: Mentions SMLD without meaningful explanation; sampling missing or incorrect. 2: High-level description but vague about noise levels or sampling mechanism. 3: Explains denoising score matching and noise levels; basic Langevin sampling idea but omits key details. 4: Clearly explains score matching across noise levels and annealed Langevin dynamics with correct update structure. 5: Crisp end-to-end account: forward perturbation, score learning, principled sampling via annealed Langevin dynamics; addresses typical pitfalls. ### 7. Chapter Mastery: DDPM and Score-Based ### Equivalence to SMLD [Similar 5-point scale structure] ## Instructions For each rubric: 1. Note specific evidence (timestamps, visual elements, narration) relevant to that rubric. 2. Match observations against each scale level. 3. Assign the integer score. Do NOT interpolate. 4. Cite specific evidence in thinking_process. Return JSON only: {"rubric_scores": [ {"rubric_name": "...", "score": "", "matched_level": "", "thinking_process": "Specific evidence: ..."} ]} The chapter-specic rubrics (rubrics 6–7 in this example) ar e synthesized from human annotator evaluation criteria for each chapter , ensuring that the VLM judge evaluates both generic production quality and chapter-sp ecic conceptual mastery . The design_context eld (omitted above) additionally instructs the judge on expected visual structure—e.g., “use parallel, side-by-side layout to emphasize SMLD–DDPM equivalence. ” J Human– VLM Alignment Details This appendix provides per-pair breakdowns of human– VLM agreement for the programmatic content environment, complementing the aggregate results in Section 8.6. J.1 Per-Pair Agreement and Cohen’s 𝜅 T able 16 reports agreement and 𝜅 for each agent pair under both rubric granularities. Agreement is the fraction of comparisons wher e the human and VLM select the same winner (or both tie); 𝜅 is Cohen’s kappa computed over the 3-class outcome (A wins, B wins, tie). J.2 Tie Asymmetr y and 𝜅 Interpretation Under the 3-point rubric, a substantial tie asymmetry exists between human and VLM raters: • Humans tie infrequently . Across 275 comparisons, human SMEs produce 36 ties (13.1%). The annotation interface supports b oth strict preference and explicit ties, but annotators o verwhelmingly express directional preferences. Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks T able 16: Human–VLM agreement by agent pair ( 𝑛 = matche d chapter-level pairwise comparisons). Pair n Agree (3-pt) 𝜅 (3-pt) Agree (5-pt) 𝜅 (5-pt) Claude vs. Codex 92 57.6% 0.121 57.6% 0.044 Claude vs. Gemini 92 40.2% − 0.004 48.9% 0.024 Codex vs. Gemini 91 41.8% 0.102 49.5% 0.180 Overall 275 46.5% 0.073 52.0% 0.082 • The VLM ties frequently under coarse scales. Under the 3-point rubric, the VLM produces 74 ties (26.9% of comparisons). Under the 5-point rubric, this drops to 38 ties (13.8%)—a 49% reduction that brings VLM tie behavior in line with the human tie rate (13.1%). Cohen’s 𝜅 is computed over a 3-class outcome space ( A wins, B wins, tie). When the tw o raters have markedly dierent tie rates, 𝜅 is deated regardless of whether they agree on the direction of non-tie outcomes. This explains why 𝜅 improves fr om 0.073 (3-point) to 0.082 (5-point): the 5-point scale eliminates the structural tie mismatch, allowing 𝜅 to better reect genuine agreement on directional preferences. Why win rates complement 𝜅 here. The aggregate win rates (T able 10) show strong dir ectional alignment: both human and VLM judges agree that Claude Code is the top-ranke d harness (human WR 81.5%, VLM WR 69.0%). Codex win rates are closely aligned b etween human and VLM (34.2% vs. 33.1%). The primary divergence—Gemini’s VLM win rate (47.8%) exceeding its human win rate (34.2%)—likely r eects the VLM’s sensitivity to production quality dimensions where Gemini performs competitively , while human experts weight content accuracy and pedagogical eectiveness more heavily . This pattern is consistent with known biases in VLM evaluation of multimedia artifacts, where surface-level polish can inate scores relativ e to content depth [ 33 ]. The 5-point scale yields the largest agreement gains on the hardest discriminations (Codex vs. Gemini: + 7.7%, Claude vs. Gemini: + 8.7%), conrming that ner rubric granularity is most valuable precisely where evaluation is most challenging. K Preference Arena Figure 6 shows the pairwise preference evaluation interface used for human baselining. Annotators see two agent-built outputs side-by-side for the same Figma task, with deployed UI frames rendered at full delity . The original Figma design is linked for reference. Position (left/right) is randomize d per vote to mitigate ordering eects. Annotators select “I prefer this” for the better output, with no access to agent identity or LLM scores. L T ask-Level Human Baseline T able 17 reports p er-task pass/fail classication from human expert evaluation, applying the quality threshold dened in Section 8.2 ( ≤ 3 = fail, ≥ 4 = pass). T asks are sorted by overall pass rate to illustrate the diculty gradient produced by the complexity stratication described in Section 5.1. M Experiment V ersioning Infrastructure T o support controlled ablations, each execution records a versions dictionary (e.g., {"skill": "v0"} ) stored as a JSONB column alongside run metadata. SKILL.md les are versioned in a versions/ subdirectory alongside the base skill le; at execution time, the agent runner overwrites the base SKILL.md with the specied version variant before launching the agent session. Analytics endpoints group results by (harness, model, skill_version) , enabling per-condition comparison at b oth the task and aggregate level. The infrastructure supports additional ablation dimensions (e.g., pr ompt version, tool access) via the same versions dictionar y without schema changes. Abhishek Chandwani and Ishan Gupta Figure 6: Preference arena interface for pair wise human evaluation. Tw o agent-built UIs are shown side-by-side for the same Figma design task, with frame-level thumbnails and deployed URLs. Position is randomized; agent identity is hidden. Beyond Binary Correctness: Scaling Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks T able 17: Per-task pass/fail from human expert evaluation (Figma-to-code, 𝑛 = 31 rated tasks). P/T = pass count / total rated runs for that harness on that task. T asks sorte d by overall pass rate. T ask ID Claude Co dex Gemini Overall Pass % 010ac575 0/3 – 0/1 0/4 0% 49bdd49a 0/2 0/1 – 0/3 0% aafbd754 0/1 0/2 – 0/3 0% d8611910 0/1 – – 0/1 0% 6d91b0b6 0/1 0/2 1/2 1/5 20% 91ce9b15 0/2 0/2 1/1 1/5 20% 20ef0a04 0/2 2/4 – 2/6 33% 7cd22b0d 0/1 0/1 1/1 1/3 33% 85611489 1/1 0/2 – 1/3 33% a93ffbb6 1/2 – 0/1 1/3 33% 792105af 2/2 0/3 – 2/5 40% 8b3bf60b 2/3 0/2 – 2/5 40% 63521424 – 3/5 0/1 3/6 50% 8efa99ee 1/1 – 0/1 1/2 50% a713118e – 1/6 4/4 5/10 50% cead04c7 4/4 2/6 – 6/10 60% 3a8534f5 1/2 2/2 1/2 4/6 67% 706c87ae 1/1 1/2 – 2/3 67% 7c46867b 0/1 2/2 – 2/3 67% d0b0a0e3 2/2 0/1 – 2/3 67% e03bd339 – 1/1 1/2 2/3 67% f35388e3 0/1 2/2 – 2/3 67% 6af7bf85 2/2 2/2 1/3 5/7 71% 43dd3b2d 2/2 3/3 0/1 5/6 83% c413f4df 0/1 5/5 – 5/6 83% 65829f23 0/1 6/6 – 6/7 86% 518a5ddc 1/1 2/2 – 3/3 100% 70278991 1/1 5/5 – 6/6 100% 9674e37a 1/1 6/6 – 7/7 100% d00f7a9b – 9/9 1/1 10/10 100% d399b2f6 2/2 – – 2/2 100%
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment