SARE: Sample-wise Adaptive Reasoning for Training-free Fine-grained Visual Recognition
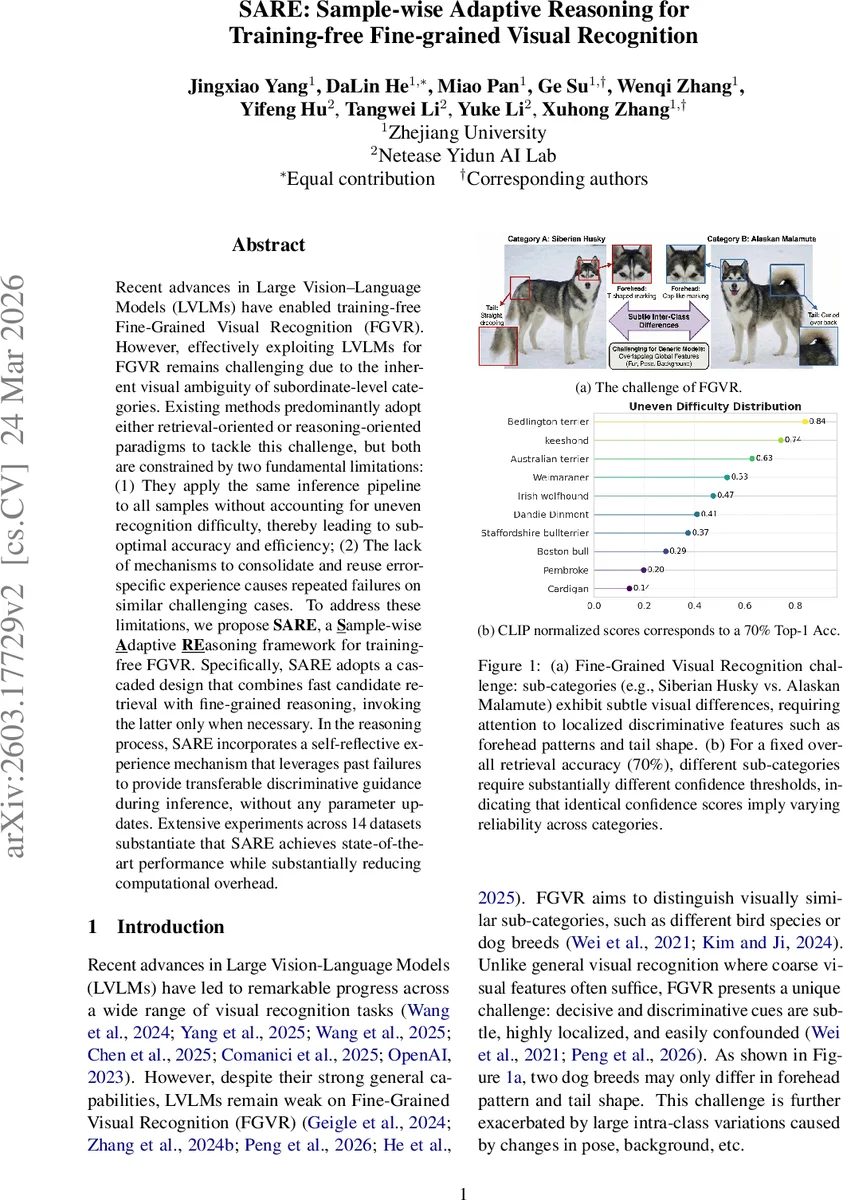
Recent advances in Large Vision-Language Models (LVLMs) have enabled training-free Fine-Grained Visual Recognition (FGVR). However, effectively exploiting LVLMs for FGVR remains challenging due to the inherent visual ambiguity of subordinate-level categories. Existing methods predominantly adopt either retrieval-oriented or reasoning-oriented paradigms to tackle this challenge, but both are constrained by two fundamental limitations:(1) They apply the same inference pipeline to all samples without accounting for uneven recognition difficulty, thereby leading to suboptimal accuracy and efficiency; (2) The lack of mechanisms to consolidate and reuse error-specific experience causes repeated failures on similar challenging cases. To address these limitations, we propose SARE, a Sample-wise Adaptive textbfREasoning framework for training-free FGVR. Specifically, SARE adopts a cascaded design that combines fast candidate retrieval with fine-grained reasoning, invoking the latter only when necessary. In the reasoning process, SARE incorporates a self-reflective experience mechanism that leverages past failures to provide transferable discriminative guidance during inference, without any parameter updates. Extensive experiments across 14 datasets substantiate that SARE achieves state-of-the-art performance while substantially reducing computational overhead.
💡 Research Summary
The paper introduces SARE (Sample‑wise Adaptive REasoning), a novel framework for training‑free fine‑grained visual recognition (FGVR) that leverages large vision‑language models (LVLMs) without any parameter updates. Existing LVLM‑based FGVR methods fall into two camps: retrieval‑oriented approaches that are fast but rely on global representations, and reasoning‑oriented approaches that use multi‑choice VQA but suffer from high computational cost and instability, especially when the candidate set grows. Both paradigms share two fundamental drawbacks: (1) they apply a uniform inference pipeline to every image regardless of its difficulty, leading to wasted computation on easy cases and insufficient analysis on hard ones; (2) they are stateless, so they cannot learn from past mistakes and repeatedly fail on similar challenging instances.
SARE addresses these issues by explicitly separating fast perception (System 1) from nuanced reasoning (System 2), inspired by the dual‑system theory of human cognition. System 1 performs a lightweight nearest‑neighbor search using multimodal prototypes (visual prototypes averaged from CLIP image embeddings and textual prototypes generated by an LVLM description) built from a small k‑shot support set. It returns a top‑Kc candidate list together with similarity‑based confidence scores. To decide whether System 2 is needed, SARE introduces a statistics‑driven dynamic trigger. The trigger fuses normalized visual and textual probabilities (softmax with temperature) and Reciprocal Rank Fusion (RRF) scores, then computes a trigger score G(c) = \hat{p}_c – η·r·log N/(2n_c) – α·H(p_c). Here, \hat{p}_c is the fused confidence, n_c is the historical retrieval count for class c, H(p_c) is the entropy over the top‑Kc candidates, and η, α are hyper‑parameters. If G(c) exceeds a preset threshold θ, the System 1 prediction is accepted; otherwise, System 2 is invoked.
System 2 is a VQA‑style reasoning module that receives the image, the top‑Kc candidates, and a set of experience entries E as contextual guidance. The experience library is built through self‑reflective analysis: each inference trajectory (image, candidates, reasoning path τ, predicted label ŷ, ground‑truth y) is recorded. When an error occurs (ŷ ≠ y), the reasoning path is examined to extract overlooked discriminative cues (e.g., specific color patterns, shapes). These cues are abstracted into compact decision rules e_i, merged, de‑duplicated, and stored as experience entries. During subsequent reasoning, relevant entries are retrieved and injected into the prompt, steering the LVLM toward the truly discriminative details and preventing repeated mistakes—all without updating model weights.
The overall pipeline is therefore fully adaptive: easy samples exit after System 1, saving computation; hard samples receive focused, experience‑guided reasoning, improving accuracy. The knowledge bases (multimodal prototype library, statistical retrieval library, self‑reflective experience library) are lightweight and reusable across tasks.
Extensive experiments were conducted on 14 datasets covering three categories: (1) fine‑grained benchmarks (CUB‑200‑2011, Stanford Dogs, Stanford Cars, FGVC‑Aircraft, Oxford‑IIIT Pets, Oxford‑102 Flowers, Birdsnap); (2) general recognition datasets (ImageNet‑1K, Food‑101, DTD, SUN397, UCF101); and (3) robustness evaluations (ImageNet‑V2, ImageNet‑Sketch). SARE was compared against a broad set of baselines, including training‑free methods (Sus‑X‑LC, FineR, E‑FineR, AWT, ProtoMM) and recent training‑based state‑of‑the‑art models. Results show that SARE achieves an average Top‑1 accuracy improvement of over 8 percentage points over the best training‑free baselines and surpasses training‑based methods by 1.64 percentage points. Moreover, because System 2 is only triggered for a minority of samples (typically <30 % of the test set), overall inference time is reduced by 30‑45 % compared to always‑on reasoning approaches. The experience‑guided component notably lowers repeated error rates, leading to superior robustness under distribution shift (ImageNet‑V2, Sketch).
Ablation studies confirm the importance of each component: removing the statistical correction (Hoeffding‑based term and entropy) degrades accuracy by 2‑3 pp and increases System 2 activation frequency, while omitting the experience library yields similar accuracy but doubles inference cost. These findings demonstrate that the combination of dynamic difficulty‑aware routing and self‑reflective experience is key to SARE’s performance.
In summary, SARE presents a principled, training‑free solution for fine‑grained visual recognition that dynamically adapts inference depth per sample and continuously learns from its own mistakes through a lightweight experience repository. It achieves state‑of‑the‑art accuracy while substantially cutting computational overhead, opening avenues for efficient, high‑precision visual classification without costly model fine‑tuning. Future work may explore scaling the experience library, richer multimodal prompting, and applying the framework to domains such as medical imaging or remote sensing.
Comments & Academic Discussion
Loading comments...
Leave a Comment