Replay-Free Continual Low-Rank Adaptation with Dynamic Memory
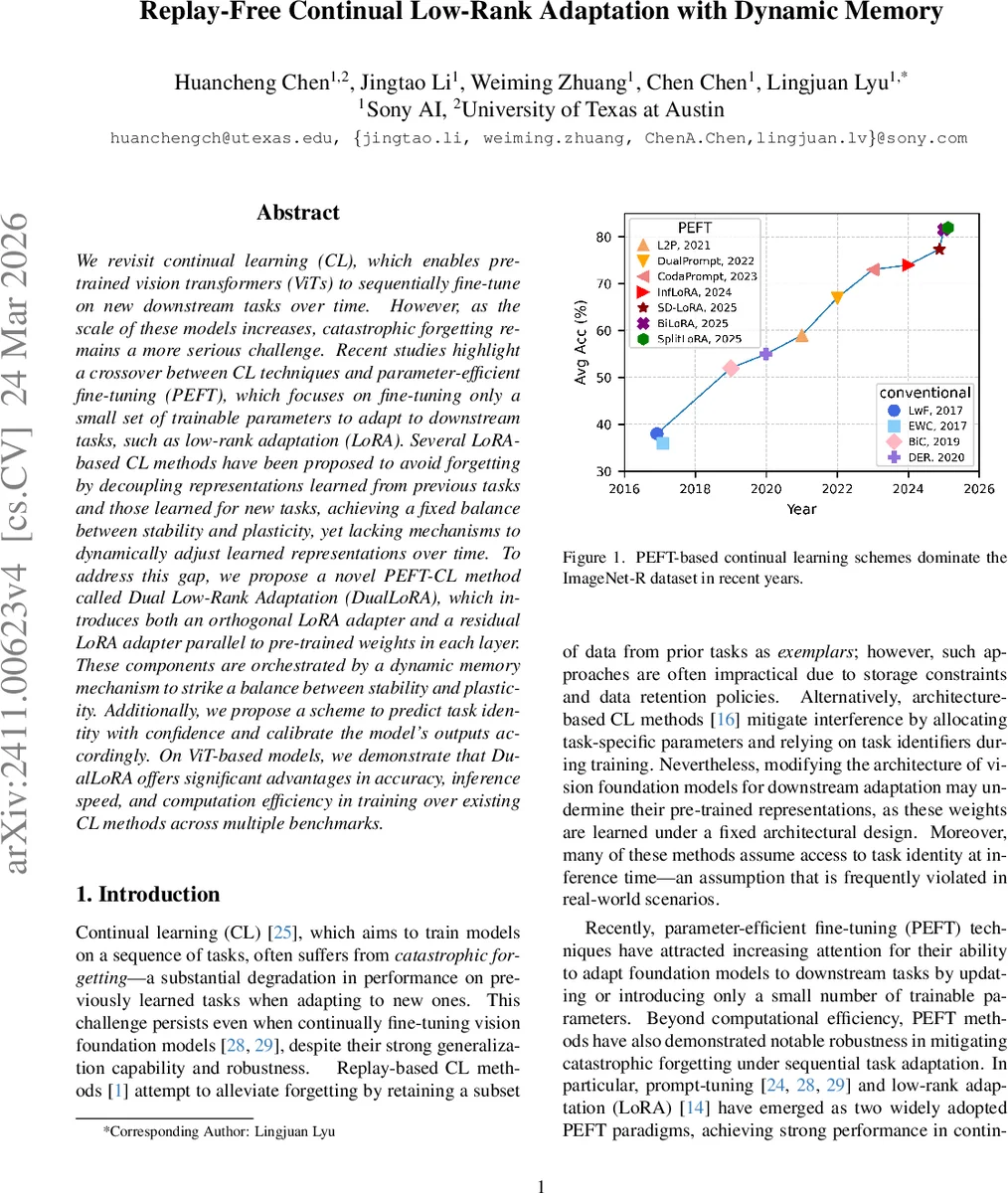
We revisit continual learning~(CL), which enables pre-trained vision transformers (ViTs) to sequentially fine-tune on new downstream tasks over time. However, as the scale of these models increases, catastrophic forgetting remains a more serious challenge. Recent studies highlight a crossover between CL techniques and parameter-efficient fine-tuning (PEFT), which focuses on fine-tuning only a small set of trainable parameters to adapt to downstream tasks, such as low-rank adaptation (LoRA). While LoRA achieves faster convergence and requires fewer trainable parameters, it has seldom been explored in the context of continual learning. To address this gap, we propose a novel PEFT-CL method called Dual Low-Rank Adaptation (DualLoRA), which introduces both an orthogonal LoRA adapter and a residual LoRA adapter parallel to pre-trained weights in each layer. These components are orchestrated by a dynamic memory mechanism to strike a balance between stability and plasticity. Additionally, we propose a scheme to predict task identity with confidence and calibrate the model’s outputs accordingly. On ViT-based models, we demonstrate that DualLoRA offers significant advantages in accuracy, inference speed, and computation efficiency in training over existing CL methods across multiple benchmarks.
💡 Research Summary
The paper tackles catastrophic forgetting in continual learning (CL) of large vision transformers (ViTs) by introducing DualLoRA, a novel parameter‑efficient fine‑tuning (PEFT) framework that combines two low‑rank adapters per layer: an orthogonal adapter and a residual adapter. The orthogonal adapter is constrained to update only in directions orthogonal to the feature subspaces of all previously learned tasks, following the gradient‑projection ideas of GPM and InfLoRA. To keep the computational cost low, the authors extract orthogonal bases solely from the class‑token embeddings, avoiding full‑dimensional SVD on the high‑dimensional patch space. The residual adapter, by contrast, operates within a task‑specific subspace derived from the residual bases of earlier tasks, providing the plasticity needed to learn new tasks.
A key innovation is the Dynamic Memory (DM) mechanism. During training, orthogonal and residual bases are stored. At inference time, each input sample is projected onto these bases to estimate a confidence score for each past task. This confidence guides two actions: (1) modulation of the residual adapter’s contribution—suppressing components that are unlikely to belong to the current task, and (2) calibration of the model’s logits based on the predicted task identity. This allows the system to work without explicit task labels at test time, a common limitation of many CL approaches.
Experiments are conducted on several benchmarks (ImageNet‑R, CIFAR‑100, VTAB, COCO) using ViT‑Base and ViT‑Large backbones. DualLoRA consistently outperforms state‑of‑the‑art PEFT‑based CL methods such as InfLoRA, CL‑LoRA, Split‑LoRA, and BiLoRA, achieving 2–4 % higher average accuracy while keeping trainable parameters below 0.1 % of the total model size. Inference latency is reduced by roughly 15 % compared with vanilla LoRA, and memory overhead remains comparable because the dynamic memory stores only a small set of basis vectors. Ablation studies confirm that both adapters are necessary: the orthogonal adapter preserves knowledge, the residual adapter enables rapid adaptation, and the dynamic memory further boosts performance by adaptively weighting the residual component.
The authors summarize four main contributions: (1) a dual‑adapter low‑rank adaptation scheme tailored for ViTs in a continual setting, (2) an efficient orthogonal‑basis extraction method that sidesteps costly full‑dimensional SVD, (3) a dynamic memory mechanism that balances stability and plasticity at inference time, and (4) a simple confidence‑based task‑identity predictor that improves output calibration. They also discuss future directions, including reducing the cost of basis updates and extending the approach to multimodal or language models. Overall, DualLoRA presents a practical, scalable solution for continual learning of large vision models without replay buffers or extensive architectural modifications.
Comments & Academic Discussion
Loading comments...
Leave a Comment