SafePilot: A Framework for Assuring LLM-enabled Cyber-Physical Systems
Large Language Models (LLMs), deep learning architectures with typically over 10 billion parameters, have recently begun to be integrated into various cyber-physical systems (CPS) such as robotics, industrial automation, and autopilot systems. The ab…
Authors: Weizhe Xu, Mengyu Liu, Fanxin Kong
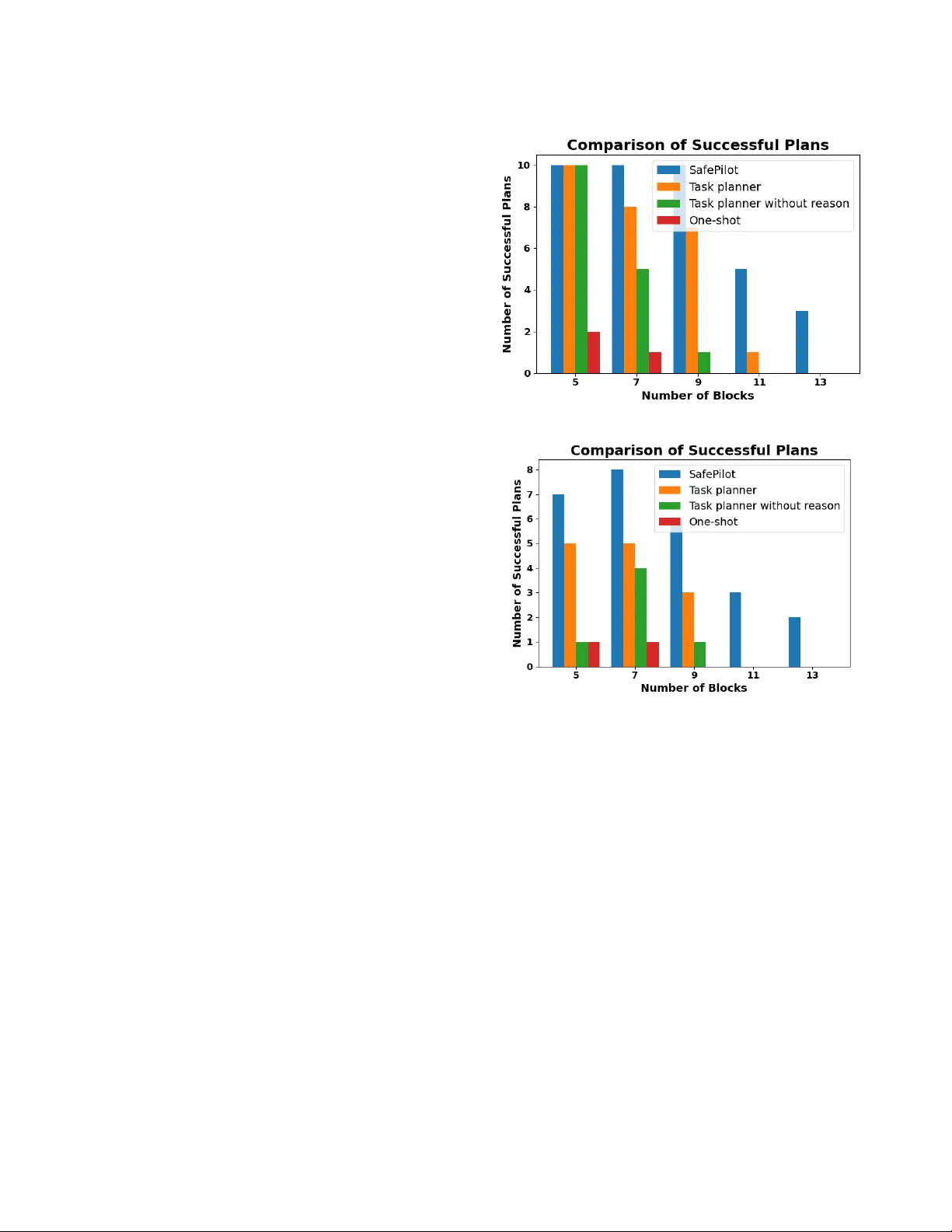
SafePilot: A Framew ork for Assuring LLM-enabled Cyber-P hysical Systems W eizhe Xu University of Notre Dame Notre Dame, IN, USA wxu3@nd.edu Mengyu Liu W ashington State University Richland, W A, USA mengyu.liu@wsu.edu Fanxin Kong University of Notre Dame Notre Dame, IN, USA f kong@nd.edu Abstract Large Language Models (LLMs), deep learning architectures with typically ov er 10 billion parameters, have recently begun to be inte- grated into various cyber-physical systems (CPS) such as robotics, industrial automation, and autopilot systems. The abstract knowl- edge and reasoning capabilities of LLMs are employed for tasks like planning and navigation. Howe ver , a signicant challenge arises from the tendency of LLMs to pr oduce "hallucinations"—outputs that are coherent yet factually incorrect or contextually unsuitable. This characteristic can lead to undesirable or unsafe actions in the CPS. Therefore, our resear ch focuses on assuring the LLM-enabled CPS by enhancing their critical properties. W e propose SafePi- lot, a novel hierarchical neuro-symbolic framework that provides end-to-end assurance for LLM-enabled CPS according to attribute- based and temporal specications. Given a task and its spe cication, SafePilot rst invokes a hierarchical planner with a discriminator that assesses task complexity . If the task is deemed manageable, it is passed directly to an LLM-base d task planner with built-in verication. Otherwise, the hierarchical planner applies a divide- and-conquer strategy , decomposing the task into sub-tasks, each of which is individually planned and later merged into a nal so- lution. The LLM-based task planner translates natural language constraints into formal specications and veries the LLM’s output against them. If violations are detected, it identies the aw , adjusts the prompt accordingly , and re-invokes the LLM. This iterative process continues until a valid plan is produce d or a predene d limit is reached. Our framework supports LLM-enabled CPS with both attribute-based and temporal constraints. Its eectiveness and adaptability are demonstrated through two illustrative case studies. Ke ywords large language models, cyber-physical systems, assurance, formal language, formal verication 1 Introduction Cyber-physical systems (CPS) [ 8 , 10 , 24 , 25 , 29 ] integrate comput- ing and networking components to contr ol the physical system and interact with the environment using sensors and actuators. Distin- guished by their autonomous and adaptive features, CPS show a remarkable advancement beyond traditional control systems. T o further enhance their intelligence and versatility , researchers have continuously explored new paradigms. In parallel, Large Language Models (LLMs), such as GPT -4 [ 31 ] and LLeMA [ 36 ] have achieved Conference’XX, XXX, XXX 2026. ACM ISBN 978-x-xxxx-xxxx-x/Y YY Y/MM https://doi.org/10.1145/nnnnnnn.nnnnnnn remarkable progress, demonstrating str ong abilities, such as per- ception, interaction, decision-making and reasoning [ 39 ]. Recent studies have begun to investigate the integration of LLMs into CPS to provide sophisticate d intelligence supp ort. In some scenarios, LLMs act as assistants in tasks such as data processing, contextual understanding, and information retrieval [ 6 , 14 ]. In other cases, LLMs serve as decision-makers, generating task plans and guiding CPS to accomplish specic objectives [ 9 , 17 , 22 , 28 , 33 ]. These LLM- enabled CPS that employ LLMs as decision-makers are the primary focus of this study . While LLMs signicantly enhance the intelligence of CPS by providing advanced reasoning capabilities, the probabilistic nature of LLMs conicts with the deterministic b ehavior expected in CPS. This conict introduces risks and instability , p otentially leading to severe consequences [ 7 ]. For instance, a r obot following an LLM- generated plan could collide with obstacles or miss the deadline. This issue, called hallucination, happens when the model generates responses that seem reasonable but are actually incorrect, mean- ingless, or made up. Hallucinations can arise from various sources and are often unavoidable, including the absence of sucient con- textual information and the inherent limitations in the reasoning capabilities of LLMs. This hallucination phenomenon in LLMs p oses signicant risks to LLM-enabled CPS, severely undermining their adoption and deployment in real-world applications. Therefore, assuring the reliability and safety of these LLM-enabled CPS has become an urgent and critical problem that must be addressed. Although various testing and assurance techniques have be en proposed for both neural networks and CPS, none of them can ef- fectively assure the reliability of LLM-enabled CPS. As for assuring neural networks [ 20 , 23 , 43 ], these approaches are inadequate for LLMs, due to the enormous numb er of parameters and the wide range of their applications. Furthermore, traditional verication and safety assurance approaches for CPS are inadequate for han- dling the adaptive and evolving natur e of LLMs. In addition, users seek to not only verify the outputs of LLMs but also guide their behavior to ensure accurate and reliable results. This paper aims to present a r obust and generalizable frame work specically designed for LLM-enabled CPS, which not only assures critical specications such as safety but also enhances the planning capabilities of LLMs. Howev er , de veloping a frame work to assure LLM-enabled CPS is challenging due to two key challenges. The rst challenge is to en- sure that LLMs do not violate critical spe cications, such as safety and temp oral constraints. Due to the aforementioned phenome- non of hallucination, LLMs are inherently susceptible to producing incorrect or misleading outputs that may violate these specica- tions. Moreover , the vast number of parameters in LLMs makes Conference’XX, 2026, XXX, XXX W eizhe Xu, Mengyu Liu, and Fanxin Kong direct verication of the models practically infeasible. Compound- ing the diculty , LLM-enable d CPS often involve natural language as the inputs and outputs, which fall outside the scope of tradi- tional verication tools that are not equippe d to assess compliance with specications and outputs expressed in natural language. The second challenge stems from the inherent limitations of LLM capa- bilities. Despite substantial advancements, LLMs still struggle with complex reasoning tasks, such as those requiring multiple goals and constraints satisfaction, which undermines their eectiveness in generating correct solutions for comple x planning problems. Sev- eral techniques, such as retrieval augmented generation (RA G) [ 40 ] and chain-of-thought pr ompting (Co T) [ 34 ], have be en pr oposed to partially mitigate these limitations in certain scenarios. How ever , they only address the problem at a supercial level. As task com- plexity continually increases, such techniques become inadequate, often failing to produce reliable or correct outcomes. T o address the above challenges, we propose our hierarchical neuro-symbolic framework, SafePilot, which aims to provide com- prehensive and general assurance for LLM-enabled CPS. Our frame- work takes as input a task description and corresponding speci- cations, such as safety and temporal spe cications, expressed in natural language under a predened format, and generates a plan that satises the given specication. Our system is compose d of several key components. The rst is hierarchical planner , which operates at a high level of abstraction. It does not generate detailed plans directly . Instead, it is responsible for decomposing and com- posing tasks and plans. It receives the initial task description and specications from the user and rst passes them through a dis- criminator to assess the diculty of the task for the LLM. If the task is determined to be too challenging, the hierarchical planner is activate d to address the problem using a divide-and-conquer strategy . Specically , it decomposes the original task into a series of sub-tasks, which are individually solved by other components. The resulting sub-plans are then comp osed into a nal plan by the hierarchical planner . The second is verier . It rst receives the specications expressed in natural language and leverages the LLM to translate them into formal formulas. The verier is then responsible for checking whether a given plan satises these formal formulas, that is, whether the plan adheres to the sp ecications. The third is task planner . It receives a task description from the hi- erarchical planner and uses the LLM to generate a step-by-step plan candidate. This candidate is passed to the verier for validation. If the plan fails to meet the spe cications, the system constructs a new prompt based on the verication feedback to guide the LLM in gen- erating a revised plan candidate . This iterative process continues until a plan satisfying the specications is produced or a predened iteration limit is reached. All sub-plans and the nal plan are sub- jected to verication by the verier to ensur e strict adherence to the given specications. Through this approach, our hierarchical neuro-symbolic framework, SafePilot, is capable of solving complex planning problems while ensuring strict compliance with given specications. In summary , our research makes sev eral key contributions: (1) W e propose SafePilot, a novel hierarchical neur o-symbolic frame- work that provides end-to-end assurance for LLM-enabled CPS. (2) W e address the critical assurance problem in LLM-enabled CPS by introducing a verication-guided planning mechanism. (3) W e enhance the capability of LLM-enabled CPS in solving complex tasks through a hierarchical planning strategy . (4) W e demonstrate that SafePilot is both general and eective through extensive case studies involving complex planning tasks. The remainder of the paper is organized as follows. Se ction 2 presents the related works. Section 3 giv es the preliminaries of this paper . Se ction 4 provides the details of system design. Section 5 evaluates our frame work using two case studies. Se ction 6 concludes the paper . 2 Related W orks In this section, we rst introduce applications of LLM-enabled CPS, then discuss certain LLM-enabled CPS where the LLM is responsible for reasoning and planning, and nally review works on verifying certain LLM-enabled CPS, comparing it with our own approach. LLM-enabled CPS. LLM-enabled CPS are applied across vari- ous elds, and the role of LLMs in these systems varies signicantly . In some LLM-enabled CPS, LLMs assist with tasks such as data pro- cessing and context grounding. They do not make sp ecic de cisions within the system but provide support to the system. Howe ver , this paper primarily focuses on applications where LLMs serve as the "brain" of the system [ 39 ], meaning that these systems leverage the reasoning and planning capabilities of LLMs. Researchers have leveraged LLMs in systems for reasoning and planning. Traditional planning methods [ 3 , 13 , 35 , 41 ] require hu- man experts to carefully design solutions for specic problems and implement algorithms using programming languages, such as C++ or Java. In contrast, LLMs possess versatility and ease of use, allowing them to generate plans for dierent problems by constructing prompts in natural language tailored to specic sce- narios. Jansen [ 18 ] demonstrates the capability of LLMs to gener- ate high-level instructions for robots based solely on natural lan- guage inputs. Dilu [ 38 ] presents the concept of integrating LLMs as decision-makers in autonomous vehicles, enabling them to generate sequences of actions. RT -2 [ 6 ] develops a multimodal LLM capable of processing images and user instructions as inputs to generate plans in an end-to-end approach. Similarly , PaLM-E [ 11 ] intr oduces embodied language models that integrate continuous real-world sensor data directly into the LLM, enhancing its ability to perceive and interpret envir onmental contexts. Despite these advancements, the reliability of LLM-enabled CPS has consistently been a concern. Due to the interaction between CPS and the physical world, reli- ability is a crucial aspect of their design and operation. Without guarantees of reliability , a CPS may enter an unsafe state or miss deadlines, potentially leading to signicant losses. Therefore, veri- fying LLM-enabled CPS is a necessary prerequisite b efore they can be deployed in real-world applications. How ever , due to the vast number of parameters in LLMs, v erifying an LLM directly is clearly an impractical task. Assuring LLM-enable d CPS. Some resear chers are focusing on assuring LLM-enabled CPS. Ahn et al. [ 2 ] propose a method to leverage LLMs for generating plans in robotic applications. At each timestep, they evaluate the usefulness and feasibility of all potential skills suggested by the LLM, executing the one with the highest score. Ho wever , their approach focuses only on the validity of each individual step, wher eas systems, such as robotics, typically requir e a plan consisting of multiple steps. Their method cannot ensure SafePilot: A Framework for Assuring LLM-enabled Cyber-P hysical Systems Conference’XX, 2026, XXX, XXX that the nal plan is both useful and feasible. Lin et al. [ 22 ] extend this approach by incorporating multi-step planning. Despite that, these methods do not provide formal guarantees, and their focus is limited to attribute-based constraints. Some researchers go further , using formal logic to assist in veri- fying LLM-enabled CPS. Jha, et al. [ 19 ] propose a counterexample guided synthesis framework for motion planning. Their metho d provides formal guarantees, while limited to attribute-based con- straints expressible through rst-order logic (FOL) [ 4 ]. Their ap- proach merely uses counterexamples to guide the LLM toward better outcomes, rather than providing detailed reasoning, this re- sults in only limited improvements in the LLM with each iteration. Y ang, et al. [ 42 ] propose a framework to reduce the ambiguity to enforce the temporal constraints for LLM-driven r obot agents. Even so, their approach has notable issues. First, their approach relies solely on Linear T emporal Logic (LTL) [ 5 ], a type of temp oral logic that can eectively express constraints such as deadlines or access sequences. However , many attribute-based constraints, such as the distance to obstacles, cannot be well-expressed in LTL. These con- straints are common safety constraints in systems, such as robotics or autonomous driving, and can be expressed by FOL. Second, their method veries each step of the plan as it is generated. If a step fails verication, the state reached by the previously veried steps is treated as the initial state. Then the LLM is queried to generate new plan steps from this initial state, with verication continuing until the target state is reached. This approach gradually pr ogresses toward the target state through v eried steps. However , it has sig- nicant drawbacks. For example, the veried steps generated by the LLM might guide the system to an initial state from which the target state cannot be reached, leading to the failur e of the entire plan. Existing methods [ 2 , 19 , 22 , 42 ] struggle to fully express attribute- based and temporal constraints in CPS. Our approach, however , supports both FOL and LTL, eectively capturing these constraints. Some methods verify individual steps, which may cause the o verall plan to violate constraints [ 2 ] or make it challenging to generate a complete plan [ 42 ]. Our method, on the other hand, considers the plan as a whole, prompting the LLM to generate the entire plan from scratch each time , thereby avoiding these issues. Compared to approaches [ 19 , 42 ] that use only countere xamples from failed verications to iteratively prompt the LLM, our method go es a step further by generating natural language-based reasoning from the verication process. This reasoning includes not only steps that adhere to constraints throughout the plan but also highlights the steps that violate constraints and explains the reasons for the violations. This approach eectively enhances the LLM’s success rate. LLMs in Complex CPS T asks. T o address more complex prob- lems, some approaches employ te chniques such as Chain-of- Thought (Co T) [ 34 ] prompting or Retrieval- A ugmented Generation (RAG) [ 40 ] to enhance the reasoning capabilities of LLMs, with the aim of pro- ducing more accurate and reliable results. Some appr oaches, such as [ 37 ], adopt a step-by-step execution of sub-tasks to handle a complete task. Howe ver , the sub-tasks are manually decomposed by the user b efore sending to the system, and the relationships among sub-tasks are organized using user-dened LTL formulas. This reliance on manual specication raises the barrier to use and limits the method’s general applicability . Furthermore, their ap- proach can only provide pr obabilistic guarantees. In contrast, our approach does not require manual decomposition of sub-tasks by the user and is capable of providing assurance of sp ecications, thereby improving both usability and reliability . In summary , existing approaches fall short in two key aspects: they are unable to simultaneously and eectively handle both safety (attribute-based) and temporal sp ecications, and the y lack the abil- ity to scale to complex planning problems. Our proposed framework addresses both challenges by supporting specications expressed in both FOL and LTL, ensuring comprehensive compliance, and by introducing a hierarchical planning strategy that enables the system to solve complex tasks through automated decomp osition and iterative renement. This allows our method to provide strong reliability guarantees while maintaining scalability and usability across diverse CPS. 3 Preliminaries In this se ction, we rst introduce the two types of formal logic used in this work and then present the problem statement. First-order Logic. First-order logic (FOL) is a formal system that extends propositional logic with the ability to quantify over individual elements within a domain. A typical rst-or der language consists of: A set of terms representing objects in the domain, which can be variables, constants, or function symb ols applied to other terms. A set of predicate symb ols that can be use d to expr ess proper- ties of, or relations among, the obje cts denoted by the terms. Logical connectives ( e.g., ∧ , ∨ , ¬ , → ) and quantiers (i.e., ∀ for “for all” and ∃ for “there exists”). A formula in rst-order logic can assert that certain predicates hold (or do not hold) for sp ecic combinations of terms. By us- ing quantiers, one can express statements ab out all objects in the domain or the existence of some objects satisfying particular properties. This expressive power makes FOL especially useful for specifying constraints in planning or synthesis problems, where the ability to quantify over objects and relations is often crucial. In our work, FOL is used to formally describe some safety-related constraints. Examples include avoiding collisions with obstacles, or ensuring that the robotic arm is not already holding a block b efore attempting to pick one up. Linear T emp oral Logic. Linear temporal logic (LTL) is a modal temporal logic designed to reason about the behavior of systems over time. In contrast to purely FOL, LTL formulas incorp orate tem- poral operators that capture how properties ev olve along a linear timeline (i.e., a single sequence of states). The key temporal opera- tors include: X 𝜑 (Next): 𝜑 must hold in the next state. G 𝜑 (Globally ): 𝜑 must hold in all future states. F 𝜑 (Eventually): 𝜑 must hold at some state in the future. 𝜑 U 𝜓 (Until): 𝜑 must hold continuously until 𝜓 eventually becomes true. LTL is widely used in the formal specication and verication of reactive systems, wher e it is crucial to ensure that certain temporal requirements hold throughout an execution. By leveraging LTL, one can succinctly capture constraints that must persist or eventually occur , making LTL a natural t for modeling and verifying temporal properties in planning tasks. In our work, LTL is used to formally describe the temporal-related constraints. Examples include visiting city A before visiting city D, or not visiting city B in y our travel. Conference’XX, 2026, XXX, XXX W eizhe Xu, Mengyu Liu, and Fanxin Kong Problem Statement. W e begin by introducing the key con- cepts and notations motivated by the elds of formal synthesis and planning. Formally , we dene our planning problem as a tuple ⟨S , A , T , 𝑠 0 , S 𝑔 , C ⟩ , where S is a nite, discrete set of states cap- turing the possible congurations of both the controllable agent and the environment. Depending on the domain, this can include observable variables of the agent itself ( e.g., positions, statuses) and any relevant aspects of the environment (e.g., obstacles, events). A is the set of symb olic actions that the controllable agent is able to perform. Each action 𝑎 ∈ A generally has preconditions (i.e., the requirements under which it can be executed) and eects (i.e., how it modies the state). T : S × A → S is the state transi- tion function describing how the environment evolves when an action 𝑎 is applied in a state 𝑠 . Specically , if action 𝑎 is feasible in state 𝑠 , then T ( 𝑠 , 𝑎 ) returns the resulting state. 𝑠 0 ∈ S is the initial world state from which planning begins. S 𝑔 ⊆ S is the set of goal states . Each goal state must satisfy a list of user-dened goal conditions (e.g., pr opositions) combined by logical operators such as and , or , and not . C represents additional specications that must hold throughout plan execution, encompassing b oth logical and temporal constraints. W e may view C as dening a subset S 𝐶 ⊆ S where every state in S 𝐶 satises these specications. A valid plan must ensure that all visited states lie in S 𝐶 . A solution to this planning problem is a symbolic plan 𝜋 = ⟨ 𝑎 1 , 𝑎 2 , . . . , 𝑎 𝑛 ⟩ , 𝑎 𝑖 ∈ A for all 𝑖 = 1 , . . . , 𝑛 − 1 . 𝑠 .𝑡 . 𝑠 𝑖 = T ( 𝑠 𝑖 − 1 , 𝑎 𝑖 ) for all 𝑖 = 1 , . . . , 𝑛 − 1 , 𝑠 𝑖 ∈ Pre ( 𝑎 𝑖 + 1 ) for all 𝑖 = 0 , . . . , 𝑛 − 1 , 𝑠 𝑖 ∈ S 𝐶 for all 𝑖 = 0 , . . . , 𝑛, 𝑠 𝑛 ∈ S 𝑔 . The feasibility conditions for 𝜋 are as follows: Thr oughout the execution of the actions 𝑎 1 , 𝑎 2 , . . . , 𝑎 𝑛 , the system transitions though the corresponding states 𝑠 1 , 𝑠 2 , . . . , 𝑠 𝑛 . Pre ( ·) represents the precon- ditions of an action. The preconditions of 𝑎 𝑖 + 1 must b e satised in the state resulting from applying 𝑎 𝑖 , for 𝑖 = 0 , . . . , 𝑛 − 1 . Every intermediate state 𝑠 𝑖 must belong to S 𝐶 , ensuring that all states satisfy the required specications C . The nal state, obtained after applying 𝑎 𝑛 , must lie in S 𝑔 , thus meeting all goal conditions. In other words, the plan must not only achieve the designated goals but also ensure that no specication constraints are violated at any stage. In this paper , we investigate methods to synthesize such a plan eciently , respecting both the logical and temporal requirements encapsulated in C . 4 System Design This section begins with an overview of the entire framework. W e then provide a detailed explanation of the LLM-driven task planning and verication process within our system. Finally , we present our hierarchical planning methods. 4.1 Overview Fig. 1 illustrates the framew ork of our proposed hierarchical neuro- symbolic LLM-enabled planner , SafePilot, which consists of three main components: the hierarchical planner , the task planner , and the verier , shown in blue, orange, and purple, respectively . The Figure 1: The overview of our hierarchical neuro-symbolic LLM-enabled planner . SafePilot receives the task description and spe cications in natural language from the user , and nally outputs a plan to the controllable agent. The plan not only satises the task’s goal but also follows the specications, including both temp oral and logical specications. It is worth noting that our method represents concrete tasks using a format similar to PDDL (Planning Domain Denition Lan- guage) [ 1 ], a standardized language commonly used in automated planning. Such structured representations not only facilitate LLM comprehension but also enable accurate and automate d processing by our verier . While we adopt a PDDL-like format for clarity and consistency , the approach is exible and can accommodate other structured representations depending on the implementation, such as JSON. Prior works [ 15 , 32 ] have explored the integration of LLMs with PDDL by prompting the LLM to generate complete PDDL les from natural language descriptions, which are then processed by conventional PDDL-based planners. However , these approaches often suer from the limited accuracy of LLM-generated PDDL, necessitating expert review and incurring signicant manual eort. In contrast, our approach requires users only to structure the prob- lem in a specic format, while allowing other components—such as action descriptions—to remain in natural language. This design choice signicantly lowers the barrier to use and enhances overall usability . The hierarchical planner operates at an abstract level. Rather than generating detailed plans on its own, it orchestrates the entire planning process by decomposing and composing tasks. Upon re- ceiving the initial task and specications, the hierarchical planner rst invokes a discriminator that gauges the complexity of the task for the LLM. If the task is deemed to o challenging, the hierarchi- cal planner steps in to manage the pr oblem via a strategy akin to dynamic programming, subdividing the original task into multiple sub-tasks. Each sub-task is then handed o to other components for resolution, and their respective sub-plans are comp osed into an overall plan. Otherwise, the hierar chical planner delegates the original task directly to the other components for pr ocessing. By initially evaluating the complexity of a given task, the system can determine whether decomposition is required, thereby preventing unnecessary time and computational overhead cause d by LLMs failing to solve overly complex problems. This divide-and-conquer strategy not only enhances eciency but also provides a system- atic method for eectively harnessing LLMs to address challenging tasks. Once the hierar chical planner sends a sub-task or the original one, the task planner generates a detailed, step-by-step plan candi- date. This candidate is then passed to the v erier for validation. If it SafePilot: A Framework for Assuring LLM-enabled Cyber-P hysical Systems Conference’XX, 2026, XXX, XXX fails any spe cication, the v erication feedback is used to construct a rened prompt for the LLM, prompting it to revise the plan. This iterative loop continues until a valid plan is found or a predened iteration limit is reached. The verier enforces compliance with the given temporal and logical sp ecications. It begins by translating the user-provided natural language specications into formal formulas using the LLM, ensuring that safety and temporal requirements are expressed pre- cisely . Whenever a candidate plan is propose d from the task planner , the verier checks it against these formal specications using for- mal verication. This check determines whether the plan is valid or violates any constraints. If a violation is detected, a reasoning prompt is generated based on the verication process to guide the LLM in producing a revised plan. Throughout this process, all sub-plans and the nal composed plan must pass verication, ensuring they rigorously adhere to the user-dened requirements. 4.2 LLM-driven T ask P lanning with V erications In this subsection, we introduce how the task planner and the verier operate. They r eceive either decomposed sub-tasks or the original task from the hierarchical planner , and leverage the LLM along with the verication tool to generate a plan that satises the given specications, which is then returned to the Hierarchical Planner . Figure 2: LLM-driven T ask P lanning with V erication. Here we use a sub-task received from hierarchical planner . Fig 2 illustrates the LLM-driven task planning with verication, comprising four primar y processes highlighte d in blue: context grounding, logic specication, and formal verication. For illustra- tion purp oses, here we use a sub-task received fr om the hierarchical planner as an example. The context grounding process, illustrated by yellow paths, is a shared pr ocedure between the task planner and the verier . It takes the original task or the sub-task and the natural language speci- cations as the input, and translates to tw o well-designed prompts through prompt engine ering [ 26 , 27 ] as the output. The rst prompt is to require the LLMs to translate natural language-based speci- cations C into formal specications expressed as logical formulas. The generated logical formulas are then reviewed by domain ex- perts, with the detailed process described later . The second one is to instruct the LLM to generate multi-step plans that achieve the target and satisfy these specications. From a symb olic perspective, the second pr ompt r epresents a set of all possible plans. If the prompt design is insucient, prev enting full grounding, may lead to fundamental err ors, corresponding to lead the LLMs to produce incorrect results. T ypically , we b egin with straightforward examples to help the LLM understand the context. This is a widely used method for constructing ee ctive prompts [ 2 , 19 , 22 ]. Subsequently , we guide the LLM to imitate this process in accomplishing the actual tasks. Here is an example of an initial prompt. Example of an Initial Prompt # T asks background. Y ou are a planner for drivers. There are several cities on the map and some paths between these cities, for example, A -B means there is one path between city A and city B. ... # Permitted actions. The driver is able to take a path multiple times and can visit a city multiple times. ... # Example problem. Here is an example problem and the corr ect result. Given the planning problem driver-0 ... # Example result. The solution for the problem driver-0 is: ST ART -PLAN 1. A -> B ... # Problem. Now please giv e me the result of the new planning problem driver-1 b elow , the solution’s format should b e the same as the example solution: Given the planning problem driver-1 (dene (problem driv er-1) ... As shown in the e xample above, w e rst provide the task back- ground, followed by the op erations the LLM is p ermitted to use. Next, we present a sample pr oblem along with the correct answer in the specied format. Finally , we provide the problem to be solved, instructing the LLM to respond in the same format as the sample problem. For the logic specication process, marked by green paths, it takes the logic formula 𝝋 output from the LLM as input, which after experts reviewing, is converted into an automaton (for temporal specications) as the output. Here we use the temporal specica- tions as an example. The output for logical specications, similar to that for temp oral spe cications, depends on the specic verication tool used, which will be explained in detail later . This is a process operating in the verier component. Specically , before the logic specication process runs, the LLM receives a prompt related to the specications and outputs a corresponding logic formula, such as LTL. Fig. 3 shows the process of the logic spe cication component, where 𝐴 and 𝐵 here indicate whether the driv er has visited cities 𝐴 and 𝐵 . As you can see, the LLM takes natural language-based specications C as input and outputs a logic formula 𝝋 . In the gure, we use an LTL formula for illustration. This logic formula 𝝋 Conference’XX, 2026, XXX, XXX W eizhe Xu, Mengyu Liu, and Fanxin Kong Figure 3: Illustration of Logic Specication. Here we use an LTL formula as an example of the logic formulas. is then review ed by a human expert. If it does not pass the review , the LLM is prompted to regenerate it until it is approved. After passing the human expert review , the logic formula 𝝋 is sent to a transducer , which automatically converts it into an automaton 𝐴 . This automaton 𝐴 is the nal output of the logic spe cication process. It is important to note that for the same tasks and constraints, the required automaton 𝐴 is identical, meaning the formal sp eci- cation component only needs to execute once. This consistency of the automaton across iterations minimizes manual eort. This automaton represents a set of plans that satisfy the specications. Upon completion of context grounding and logic specication, the LLM generates a candidate plan for the controllable agent, though its compliance with constraints is yet to be conrmed. The formal verication process, depicted in red paths, receives two inputs: the candidate plan and the automaton derived from the specications. This component can b e viewed as a function which outputs True or False according to the verication r esult. It utilizes formal verication to ols, such as Z3 Python API [ 30 ] or Spot Python [ 12 ], to ascertain whether the plan breaches the formal spec- ications. Z3 is designed as a high-performance SMT (Satisability Modulo Theories) solver , which extends FOL with additional the o- ries, making it highly versatile for various applications. It is widely used in elds like formal verication, automated reasoning, and constraint solving. Spot is an op en-source librar y and tool designed for the manipulation, verication, and optimization of automata and temp oral logic formulas. It is p opular in elds of formal verica- tion, particularly for handling LTL and other temporal logics, and is useful for creating, transforming, and verifying automata represen- tations of temporal logic sp ecications. Both of these tools provide comprehensive documentation to help users quickly get started. In SafePilot, Z3 Python API is emplo yed for FOL verication, while Spot Python API is used for LTL verication. If the plan satises the formal verication, it is then sent back to the hierarchical plan- ner component. If it fails, the verication process yields detailed feedback, which is then transformed into a r easoning pr ompt. Then the LLM could, based on its commonsense and reasoning capabil- ities, analyze the reasons, actively collect more information, and generate a more accurate and specication-compliant plan. Here is a simple example from the case study of the navigation problem. Reasoning Example D → B B → C is invalid. It violates the constraint: Y ou shouldn’t go to B until you go to A before. In this reasoning prompt, we rst identify which step in the plan is incorrect and then specify the corr esponding constraint that has be en violated. This detailed reasoning greatly contributes to improving the output of the LLM. This point will be demonstrated through experiments later . The LLM continuously renes its output until it either passes verication or reaches the predened iteration limit. It is important to note that our LLM-driven task planning with verications can only guarantee that the outputted plan meets the requirements. Howev er , it cannot guarantee that a plan will always b e outputted. If the iteration limit is exceeded, it will output a failure. 4.3 Hierarchical P lanning Hierarchical planning is a process that is carried out at the be- ginning by the hierarchical planner component. It b egins with a discriminator that evaluates whether a task is suitable for direct LLM-based planning. This prevents r epeated failed attempts and unnecessary computation. If the task is judged too dicult, it is decomposed into sub-tasks; otherwise, it is passed directly to the LLM-driven task planner with verication. The resulting sub-plans are later recomposed into the nal solution through a divide-and- conquer strategy . T o assess task diculty , directly scoring natural-language queries is unreliable due to their variability . Instead, we evaluate complexity from the LLM’s own perspective. By examining the average token- level output probabilities [ 21 ], we estimate the model’s condence in generating the intended answer . These probabilities are aggre- gated into a condence score and compared with a user-dene d threshold to determine whether decomposition is required. For tasks requiring decomposition, the de comp osition and composition module parses the goal into a Boolean logic tree (e.g., using AND/OR/NOT connectors). Each sub-goal be comes an independent sub-task, while shared components such as actions remain unchanged. Designing this process is non-trivial: (1) the task planner cannot guarantee a feasible plan for every sub-task, and (2) it may return dierent plans across iterations, altering the initial state for subsequent sub-tasks. Thus, we incorp orate a failure- resilient mechanism that supports backtracking. When planning for a sub-task fails, the system revisits and revises previous sub-plans to restore a new valid initial state for the sub-task. A user-dened retr y limit determines how many times this process may repeat. However , if the composed sub-plan ultimately fails to pass v erication, the sub-goals and their corresponding sub-plans can ser ve as concrete in-domain examples to guide the LLM in solving the original goal directly . This plays a role similar to RAG, while av oiding the need to prepare large datasets or perform similarity-based retrieval. For simplicity , Algorithm 1 illustrates the procedure for goals connected by the AND operator . Line 1–3 dene the inputs and a global failure counter 𝑓 indexed by initial and goal nodes. Line 4 performs AND-decomposition of the goal into a list of sub-goals SafePilot: A Framework for Assuring LLM-enabled Cyber-P hysical Systems Conference’XX, 2026, XXX, XXX Algorithm 1 Hierarchical T ask De composition and Composition 1: Input : Goal tree 𝐺 , initial state 𝑠 0 , max attempts 𝑡 2: Output : P lan 𝜋 and nal state 𝑠 , or ∅ 3: Global : Failure counter 𝑓 (keyed by initial and goal nodes) 4: G 𝑠𝑢𝑏 ← GetSubgoals ( 𝐺 ) ⊲ AND-decomposition 5: 𝑠 ← 𝑠 0 , 𝜋 total ← ∅ , 𝑘 ← 0 ⊲ idx, state, plan 6: St ack ← ∅ ⊲ Stores ( 𝑘 , 𝑠 , 𝜋 ) 7: while 0 ≤ 𝑘 < | G 𝑠𝑢𝑏 | do 8: 𝐺 𝑘 ← G 𝑠𝑢𝑏 [ 𝑘 ] ⊲ Process a sub-task 9: if 𝑓 [ ( 𝑠 , 𝐺 𝑘 ) ] ≥ 𝑡 then ⊲ T oo many failures on ( 𝑠 , 𝐺 𝑘 ) 10: if St ack = ∅ then 11: return ( 𝜋 total , ∅ ) ⊲ No more rollback 12: ( 𝑘 , 𝑠 , 𝜋 total ) ← St ack.pop ( ) ⊲ Rollback 13: continue 14: ( 𝜋 sub , 𝑠 ′ ) ← HierarchicalPlanner ( 𝐺 𝑘 , 𝑠 , 𝑡 ) 15: if 𝑠 ′ = ∅ then ⊲ Sub-task failed 16: 𝑓 [ ( 𝑠 , 𝐺 𝑘 ) ] ← 𝑓 [ ( 𝑠 , 𝐺 𝑘 ) ] + 1 17: continue 18: else ⊲ Sub-task success 19: St ack.push ( ( 𝑘 , 𝑠 , 𝜋 total ) ) ⊲ Record start point 20: 𝜋 total ← 𝜋 total ⊕ 𝜋 sub 21: 𝑓 [ ( 𝑠 , 𝐺 𝑘 ) ] ← 0 , 𝑠 ← 𝑠 ′ , 𝑘 ← 𝑘 + 1 ⊲ Reset counter 22: return ( 𝜋 total , 𝑠 ) G 𝑠𝑢𝑏 . Line 5-6 initialize the current state, the accumulated plan, the sub-goal index, and the stack (for rollback) The main loop (Lines 7–21) processes sub-goals sequentially . Lines 9-13 handle the case where a sub-goal 𝐺 𝑘 has failed too many times: the algorithm rolls back by popping from the stack and restoring a previous state and partial plan. If the stack is empty , the whole procedure fails. Line 14 recursively invokes the hierarchical planner on this sub-goal. Line 15-17 treat unsuccessful sub-task planning by incrementing the failure counter . Line 18-21 handle successful sub-task planning. The start point of the current sub-task is pushed onto the St ack to facilitate potential revision later . The sub-plan is concatenated into 𝜋 total , the failure counter for ( 𝑠 , 𝐺 𝑘 ) is reset, and the state is updated. The algorithm then proceeds to the next sub-goal. In line 4, the AND-decomposition may produce sub-goals that either have or do not have logical or sequential dependencies. When no dependencies exist, the sub-goals are solved independently , their sub-plans are concatenated, and the resulting plan is veried. If this verication fails, the generated sub-tasks and sub-plans ser ve as concrete examples to guide the LLM-based planner with verication to produce a corrected plan. When dependencies do exist, meaning that executing a later sub-task may aect the validity of an earlier one, the sub-plans cannot be composed directly . In this case, the sub-tasks and sub-plans again function as guiding examples for the LLM-based planner to synthesize a new valid overall plan. Through the hierarchical planning, we provide a feasible solution for enabling LLMs to tackle complex planning problems. The nal composed plan adher es to both the specications and the nal goal, thereby ensuring the overall safety of the LLM-enabled CPS. 5 Experiments In this section, we use two case studies to illustrate the eectiveness of our framework. The rst case involves a Blocksworld problem using FOL, which exemplies issues wher e constraints can be ex- pressed using FOL, such as a robot navigating a maze or avoiding obstacles. The second case employs LTL for a navigation problem, representing issues where constraints can be expressed using LTL, such as robotic motion planning with deadlines or event order constraints. Additionally , FOL is employed in this case to handle certain logical specications. In the experimental process, our framework is already e quipped to handle these issues. W e only need to construct the initial prompt based on the problem, and the framework can operate automatically to yield the nal result. W e conduct experiments using two LLMs, GPT -4o and GPT -3.5-turb o. It is important to note that our metho d can b e easily extended to other LLM-enabled CPS with dierent LLMs and tasks. Due to space limitations in the main text, we present only a portion of the prompts. 5.1 Blocksworld Problem 5.1.1 Background. In this case study , we address the Blo cksworld [ 16 ] problem, which is a classic planning pr oblem for robotic arms, with primary constraints based on various attributes, such as action preconditions. This problem involves a set of blocks, typically p osi- tioned on a at surface, and the goal is to rearrange these blocks from an initial state to a target state using a specied set of robotic arm actions, including pick up, put down, stack, and unstack. Each operation of the robotic arm is governed by corresponding logical constraints, which can be expressed using FOL. Figure 4: An example of a Blocksworld problem. The left side indicates the initial state, while the right side represents the goal state. 5.1.2 Motivating Example. W e provide an example to demonstrate the process and principles. The initial and goal state of this problem are shown in Fig. 4. If de composition is required, it can be p erformed by rst examining whether the statements connected by the AND operator in the goal have any logical dependencies. For example, in this case, the goal can be divide d into three sub-goals, each corresponding to a separate stack of blocks. However , treating these three statements as separate sub-goals may lead to multiple possible outcomes, as the target state doesn’t clearly specify which blocks should be on the table. This ambiguity can cause the composed goal to fail verication. In such cases, the sub-goals and their sub-plans can serve as concrete examples to guide the LLM in solving the original goal directly . For clarity of presentation, we use a relatively simple example here that does not require decomposition via the hierarchical planner . Therefore, we directly use the LLM-driven planner with v erica- tion to deal with the example. Initially , we establish the background Conference’XX, 2026, XXX, XXX W eizhe Xu, Mengyu Liu, and Fanxin Kong knowledge and request the LLM to generate the relevant FOL con- straints, expressed using the Z3 Python API. This information is then saved into a le as the 1 st prompt. For illustration purposes, only part of the prompt is shown in the experiment section. The LLM generates the corresponding FOL based on the rst prompt, ex- pressed using the Z3 Python API, and it is conrme d as correct by a human e xpert in the formal specication component. Subsequently , we construct the 2 nd prompt and store it in a le, shown b elow . Similar to the 1 st prompt, this 2 nd prompt begins by introducing the background knowledge and permitted actions. Then it provides an example problem along with the correct answ er . Finally , it presents the target problem and instructs the LLM to output the result in the same format as the example. The framework takes these two prompt les and initiates its execution. The framework initially outputs the FOL expressed in the form of the Z3 Python API. After verication by the user , the LLM begins generating the plan, resulting in the 2 nd output, as shown on the left. The framework uses the pr eviously generated FOL to verify the produced plan. It can be found that the result violates the specications, generates r easoning, and pr ovides this as the 3 rd prompt. In the 2 nd output, the plan attempts to stack block 5 on block 3 while block 2 is already on block 3, which violates the specication. The LLM generates the 3 rd output, which, after verication, me ets all sp ecications and is output as the nal correct result to the user or agents. This experiment illustrates that our approach can successfully extract the correct plan from an LLM while ensuring compliance with FOL constraints. 1 st Prompt Y ou are a motion planner who wants to use Z3 to verify your plan. Now we consider the Blocksworld planning problem. The objects in the problem domain include a nite number of cubical blo cks, and a table large enough to hold all of them. Each block is on a single other object (either another block or the table). For each block b, either b is clear or else there is a unique block a sitting on b. ... Pick-up: The block must be clear and on the table in state s1. The block must not be in the hand in state s1. The block must be in the hand in state s2. The blo ck must not be on the table in state s2 and must not b e clear . For all other blocks x, the state of the hand, table, and clear should remain the same between s1 and s2. For all blocks x, y , the state of the stacked should remain the same b etween s1 and s2. ... Above are the details of these operations. I will use Z3 to verify future plans. please help me complete the following code in which translate all the above four actions into rst order logic using the the formatting of Z3 Pyhton API. Please do not alter the code within the provided class State . I don’t need any explanation. Y our response should include all the code, starting with ’from z3 import *’ . Below is the incomplete code. I have already implemented the pick_up, stack functions for your reference ... 2nd Prompt ... (define (problem BW-rand-6) (:domain blocksworld-4ops) (:objects b1 b2 b3 b4 b5 b6) (:init (arm-empty) (on b1 b6) (on b2 b3) (on-table b3) (on b4 b1) (on-table b5) (on-table b6) (clear b2) (clear b4) (clear b5) ) (:goal (and (on b1 b2) (on b5 b3) (on b6 b4)))) 2nd Output 1. pick-up b5 2. stack b5 b3 3. unstack b1 b6 4. pick-up b6 5. stack b6 b4 6. unstack b2 b3 7. stack b2 b1 3rd Prompt 1. pick-up b5 2. stack b5 b3 is invalid. Step 2 violates the precondition of the action stack. 3rd Output 1. unstack b4 b1 2. put-down b4 3. unstack b1 b6 4. put-down b1 5. pick-up b6 6. stack b6 b4 7. unstack b2 b3 8. put-down b2 9. pick-up b5 10. stack b5 b3 11. pick-up b1 12. stack b1 b2 It is also possible to deploy SafePilot on a real testbe d. W e demonstrate this feature using a real 6 DOFs (Degree of Freedoms) robotic arm to perform the same Blocksworld problem in Fig. 4. The robotic arm is embedde d with a Raspberry Pi and can execute corresponding actions based on the plan generate d by the LLM for the Blocksworld problem. W e input the initial state of the blocks and the target state into SafePilot. The SafePilot generates a veri- ed plan and outputs it to the robotic arm. The robotic arm then executes the plan step by step, adhering to the specied constraints and achieving the target state for the blocks. Figure 5: Deploy SafePilot on a rob otic arm to solve a Blocksworld problem. The left image shows the initial state, the middle image shows the robotic arm executing the plan, and the right image shows the nal state. SafePilot: A Framework for Assuring LLM-enabled Cyber-P hysical Systems Conference’XX, 2026, XXX, XXX 5.1.3 antitative Experiments. W e analyze the p erformance of our framework and the baselines on 50 random Blocksworld prob- lems with dierent block numbers and dierent LLMs. W e select three typ es of baselines. The rst is a one-shot approach, which cancels the iterations in our LLM-driven task planner and directly veries the LLM’s rst generated plan as the nal result. The sec- ond is the LLM-driven task planner in our proposed framework but without reasoning, which removes the r easoning process after verication, providing only the generate d plan is invalid as the prompt for the next iteration with the LLM. This baseline is similar to the method in [ 19 ]. Since this method [ 19 ] only supports FOL, it is suitable for the Blocksworld case study . The third is the LLM- driven planner with verication in our proposed framew ork, which removes the hierarchical planner from SafePilot. Our experiment uses two LLMs: GPT -4o and GPT -3.5-turb o. In our selected prob- lems, the number of blocks is 5, 7, 9, 11, and 13, with ten problems for each quantity . The LLM-driven planner’s iteration limitation has been set to 20. The limitation 𝑡 of the number of failures for a single sub-task is set to 3. The r esults of quantitative experiments are sho wn in Fig. 6. First, the number of successful plans generated by SafePilot exceeds that of all other methods, especially as the number of blo cks increases, which indicates a higher level of task complexity . In such cases, other methods generally fail to produce correct plans, whereas SafePilot, through the use of the hierarchical planner , equips the LLM with the capability to eectively handle complex problems. As the number of blocks increases, the number of successful plans generated by our SafePilot also shows a noticeable decline. This is because our hierarchical planner p erforms decomposition base d on the goal, without altering the problem’s world space. As a re- sult, although the sub-task goals are signicantly simplied, the expanding world space reduces the likelihoo d of the LLM gener- ating correct plans. Second, the number of successful plans using task planner is noticeably higher than that of task planner without reasoning. This demonstrates the eectiveness of using reasoning to guide the LLMs in updating the plan. Third, compared to other methods, the success rate of the one-shot approach is very low . It is nearly impossible to generate a valid plan as the numb er of blocks increases. This demonstrates that iteratively prompting the LLM is very helpful in improving results. Given the probabilistic nature of LLMs, only one attempt may fail to yield correct results. This also demonstrates that the chosen Blockworlds problem is not trivial for the LLM. In addition, we can also observe that the overall number of successful plans of GPT -4o is signicantly higher than that of GPT -3.5-turbo, which is expecte d, as GPT -4o has more parameters and greater reasoning capability . W e also perform experiments to analyze the impact of iteration limits on the number of successful plans generated by the LLM. W e used SafePilot with GPT -4o to test the results for 50 Blocksworld problems with iteration numbers set to 10, 20, and 30. Among the 50 problems, the number of blocks was 5, 7, 9, 11, and 13, with ten problems for each quantity . The results are shown in Fig. 7. From the gure, we can observe that higher iteration limits lead to a greater number of successful plans. This eect is espe cially pronounced as the problems become more complex, i.e., as the number of blocks increases. This is because more complex problems require stronger (a) GPT -4o. (b) GPT -3.5-turbo. Figure 6: The p erformances of LLMs on Blocksworld prob- lem. Fig. 6a uses GPT -4o, while Fig. 6b uses GPT -3.5-turb o. The blue bars represent the SafePilot, and the orange bars represent the task planner which removes the hierarchical planner from SafePilot. The green bars represent the task planner without reason, which is similar to method [ 19 ]. The red bars represent the one-shot method. planning capabilities, and higher iteration limits enable SafePilot to exhibit enhanced planning capability . 5.2 Navigation Problem 5.2.1 Background. In this case study , we demonstrate the applica- bility of our approach in handling planning problems that involve timing-related constraints. W e address a navigation problem that requires the LLM to devise a plan for a driver while adhering to temporal constraints, which can be expressed by LTL. This is a classic navigation-related planning problem, with constraints that include both attribute-based factors, such as the presence of path- ways, and time-related constraints, such as the sequence of visits. Conference’XX, 2026, XXX, XXX W eizhe Xu, Mengyu Liu, and Fanxin Kong Figure 7: The performance of GPT -4o on Blocksworld prob- lem using SafePilot with dierent iteration limits. The blue, orange, green, and red bars represent iteration limits of 10, 20, and 30, respectively . This problem involves se veral cities, some of which are connected by roads. The driver aims to r each several target cities. The driver cannot traverse between cities without a dir ect path in a single step. W e task the LLM with producing a plan for the driver to reach the target cities without violating the requirements. 5.2.2 Motivating Example. W e present a detailed example to illus- trate the process and underlying principles. Similar to the Blocksworld problem, we use a relativ ely simple example here that does not re- quire decomposition via the hierarchical planner for clarity of pre- sentation. W e initially introduce the problem context and request the LLM to generate logic formulas representing the constraints. The temporal requirement in this illustrative example is "Y ou should have b een to C and D before you go to G". This requirement is asked to be specie d as an LTL formula. It will then be translated to an automaton expressed using the Spot Python API for further verication. The other attribute-base d requirements, such as the precondition for traveling from city A to city B, are specied as FOL constraints and expressed using the Z3 Python API, similar to the Blocksworld problem. This content is saved as the 1 st prompt. Subsequently , we provide an example with the correct outcome and instruct the LLM to solve a new problem following the same format. The content of the second prompt is also preser ved in a le, as shown in the 2 nd prompt below . The map of this problem is shown as Maps below . 2 nd Prompt Y ou are a planner for drivers. There are several cities on the map and some paths between these cities, for example, (road A B) means ther e is one path between city A and city B. All the paths will b e provided to you. The driver is able to take a path multiple times and can visit a city multiple times. The driver can only run one path in a step. ... Here is an example problem and the corr ect result. ... Now please give me the result of the new planning problem driver-1 below , the solution’s format should be the same as the example solution: Given the planning problem driver-1 (dene (problem driver-1) (:cities A B C D E F G) (:con- straints (Y ou should have been to C and D before you go to G)) (:init (road A B) (road A E) (road E D) (road B C) (road B F) (road F G) (reached A) ( at A) ) (:goal ( and (reached F) (reached G)) )) Maps 2 nd Output A → B B → C C → B B → F F → G 3 rd Prompt A → B B → C C → B B → F F → G is invalid. It violates the con- straint: Y ou should have been to C and D before you go to G. 3 rd Output A → B B → C C → B B → A A → E E → D D → E E → A A → B B → F F → G The framework then takes these tw o prompt les and initiates its execution. It rst produces the LTL formula as the 1 st output, which, upon user validation of its accuracy . The LTL formula for this scenario is expressed as: G ( ¬ 𝑔 U ( 𝑐 ∧ 𝑑 ) ) , where g, c, and d indicate the proposition that the driver has alr eady reached cities G, C, or D , respectively . This LTL formula format is supported by the verication tool Spot, which we use in our framework. This LTL formula is then been transferred to an automaton in the formal specication component. The LLM then b egins to generate plan candidates. W e receive the 2 nd output from the LLM as detailed abov e. After verication, our framework determines that the plan is invalid and provides reasoning as the 2 nd prompt. The plan is deemed invalid because it directly proceeded to city G without passing through city D at the fth step, thereby violating the temporal constraints. The framework r e-queries LLM using the 3 rd prompt and then gets the 3 rd output. This plan passes all verications within the framework and is output as the nal correct result to the user or agent. This experiment demonstrates that our method can obtain the correct plan from LLM while ensuring temporal constraints. 5.2.3 antitative Experiments. W e evaluate the performance of our framework and baseline methods on 50 randomly generated navigation problems, varying in specications. In these problems, the number of cities is 7, 9, 11, 13 and 15, with ten problems for each quantity . W e select the same three baseline methods used in the experiments from the Blo cksworld case study . The results are shown in Fig. 8. The success rate of SafePilot is signicantly higher than that of the three baselines. This demonstrates that our framework can eectively handle problems with temporal requirements. SafePilot: A Framework for Assuring LLM-enabled Cyber-P hysical Systems Conference’XX, 2026, XXX, XXX Figure 8: The performance of GPT -4o on Navigation problem. The blue, orange, and green bars represent the SafePilot, the task planner , the task planner without reason and one-shot methods, respectively . 6 Conclusion W e propose d SafePilot, a hierarchical neur o-symbolic framework for assuring LLM-enabled CPS. Users can customize their tasks inheriting the built-in classes. Moreover , we provide comprehensive experiments and examples of how to verify and guide LLM-enabled CPS to pr ovide corr ect results. In the future , w e will integrate more tasks into our framew ork and support additional types of formal logic. W e will further enhance the planning capabilities of the LLM to reduce the number of iterations by developing better reasoning and ne-tuning the LLM. Additionally , we will enhance the LLM’s ability to generate logic formulas. This will reduce the frequency of human expert revie ws for LLM-generated logic formulas, thereby minimizing human eort. References [1] Constructions Aeronautiques, Adele Howe, Craig Knoblo ck, ISI Drew McDermott, Ashwin Ram, Manuela V eloso, Daniel W eld, David Wilkins Sri, Anthony Barrett, Dave Christianson, et al . 1998. Pddl| the planning domain denition language . T echnical Report, Tech. Rep. (1998). [2] Michael Ahn, Anthony Brohan, Noah Brown, Y evgen Chebotar , Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, K eerthana Gopalakrishnan, Karol Haus- man, et al . 2022. Do as i can, not as i say: Grounding language in robotic aordances. arXiv preprint arXiv:2204.01691 (2022). [3] Luke Antonyshyn, Jeerson Silveira, Sidney Givigi, and Joshua Marshall. 2023. Multiple mobile robot task and motion planning: A survey . Comput. Surveys 55, 10 (2023), 1–35. [4] Jon Barwise. 1977. An introduction to rst-order logic. In Studies in Logic and the Foundations of Mathematics . V ol. 90. Elsevier , 5–46. [5] Andreas Bauer , Martin Leucker, and Christian Schallhart. 2010. Comparing LTL semantics for runtime verication. Journal of Logic and Computation 20, 3 (2010), 651–674. [6] Anthony Brohan, Noah Brown, Justice Carbajal, Y evgen Chebotar , Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, A vinava Dubey , Chelsea Finn, et al . 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818 (2023). [7] Y ufan Chen, Arjun Arunasalam, and Z Berkay Celik. 2023. Can large language models provide security & privacy advice? measuring the ability of llms to r efute misconceptions. In Proceedings of the 39th A nnual Computer Security A pplications Conference . 366–378. [8] Hongjun Choi, W en-Chuan Lee, Y ousra Aafer , Fan Fei, Zhan T u, Xiangyu Zhang, Dongyan Xu, and Xinyan Deng. 2018. Detecting attacks against robotic vehicles: A control invariant approach. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Se curity . 801–816. [9] Can Cui, Zichong Y ang, Y upeng Zhou, Yunsheng Ma, Juanwu Lu, and Ziran W ang. 2023. Large language models for autonomous driving: Real-world experiments. arXiv preprint arXiv:2312.09397 (2023). [10] György Dán and Henrik Sandberg. 2010. Stealth attacks and protection schemes for state estimators in power systems. In 2010 rst IEEE international conference on smart grid communications . IEEE, 214–219. [11] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdh- ery , Brian Ichter , Ayzaan W ahid, Jonathan T ompson, Quan Vuong, Tianhe Yu, et al . 2023. Palm-e: An embo died multimodal language model. arXiv preprint arXiv:2303.03378 (2023). [12] Alexandre Duret-Lutz, Etienne Renault, Maximilien Colange, F lorian Renkin, Alexandre Gbaguidi Aisse, Philipp Schlehuber-Caissier , Thomas Medioni, An- toine Martin, Jérôme Dubois, Clément Gillard, and Henrich Lauko. 2022. From Spot 2.0 to Spot 2.10: What’s New? . In Proceedings of the 34th International Confer- ence on Computer Aided V erication (CA V’22) (Lecture Notes in Computer Science, V ol. 13372) . Springer, 174–187. doi:10.1007/978- 3- 031- 13188- 2_9 [13] Kutluhan Erol. 1995. Hierarchical task network planning: formalization, analysis, and implementation . University of Maryland, College Park. [14] Daocheng Fu, Xin Li, Licheng W en, Min Dou, Pinlong Cai, Botian Shi, and Y u Qiao. 2024. Drive like a human: Rethinking autonomous driving with large language models. In Proceedings of the IEEE/CVF Winter Conference on A pplications of Computer Vision . 910–919. [15] Elliot Gestrin, Marco Kuhlmann, and Jendrik Seipp. 2024. Nl2plan: Robust llm- driven planning from minimal text descriptions. arXiv preprint (2024). [16] Naresh Gupta and Dana S Nau. 1992. On the complexity of blocks-world planning. A rticial intelligence 56, 2-3 (1992), 223–254. [17] T akashi Inagaki, Akari Kato, Koichi T akahashi, Haruka Ozaki, and Genki N Kanda. 2023. LLMs can generate robotic scripts from goal-oriented instructions in biological laboratory automation. arXiv preprint arXiv:2304.10267 (2023). [18] Peter A Jansen. 2020. Visually-grounded planning without vision: Language models infer detailed plans from high-level instructions. arXiv pr eprint arXiv:2009.14259 (2020). [19] Sumit Kumar Jha, Susmit Jha, Patrick Lincoln, Nathaniel D Bastian, Alvaro V elasquez, Rickard Ewetz, and Sandeep Neema. 2023. Neuro symbolic reasoning for planning: Counterexample guided inductive synthesis using large language models and satisability solving. arXiv preprint arXiv:2309.16436 (2023). [20] Guy Katz et al. 2017. Reluplex: An ecient SMT solver for verifying de ep neural networks. In CA V 2017 . Springer. [21] Joonghoon Kim, Saeran Park, Kiyoon Jeong, Sangmin Le e, Seung Hun Han, Jiyoon Lee, and Pilsung Kang. 2023. Which is b etter? exploring prompting strategy for llm-based metrics. arXiv preprint arXiv:2311.03754 (2023). [22] Kevin Lin, Christopher Agia, T oki Migimatsu, Marco Pav one, and Jeannette Bohg. 2023. T ext2motion: From natural language instructions to feasible plans. arXiv preprint arXiv:2303.12153 (2023). [23] Changliu Liu, T omer Arnon, Christopher Lazarus, Christopher Strong, Clark Barrett, Mykel J Kochenderfer , et al . 2021. Algorithms for verifying deep neural networks. Foundations and Trends ® in Optimization 4, 3-4 (2021), 244–404. [24] Mengyu Liu, Lin Zhang, W eizhe Xu, Shixiong Jiang, and Fanxin Kong. 2024. CPSim: Simulation T oolbox for Se curity Problems in Cyber-P hysical Systems. ACM Transactions on Design Automation of Electronic Systems 29, 5 (2024), 1–16. [25] Mengyu Liu et al. 2022. Fail-safe: Securing cyber-physical systems against hidden sensor attacks. In RTSS . IEEE. [26] Pengfei Liu et al. 2023. Pre-train, prompt, and predict: A systematic sur vey of prompting methods in natural language processing. Comput. Surveys 55, 9 (2023), 1–35. [27] Ggaliwango Mar vin, Nakayiza Hellen, Daudi Jjingo, and Joyce Nakatumba- Nabende. 2023. Prompt engineering in large language models. In International conference on data intelligence and cognitive informatics . Springer , 387–402. [28] Nathalia Nascimento, Paulo Alencar , and Donald Cowan. 2023. GPT -in-the- Loop: Adaptive Decision-Making for Multiagent Systems. arXiv preprint arXiv:2308.10435 (2023). [29] Fabio Pasqualetti, Florian Dörer, and Francesco Bullo. 2011. Cyber-physical attacks in power networks: Models, fundamental limitations and monitor de- sign. In 2011 50th IEEE Conference on Decision and Control and European Control Conference . IEEE, 2195–2201. [30] Microsoft Research. 2024. Z3 Prover . https://github.com/Z3Prover/z3. GitHub repository , accessed on 2024-11-12. [31] Katharine Sanderson. 2023. GPT-4 is here: what scientists think. Nature 615, 7954 (2023), 773. [32] T om Silver , V arun Hariprasad, Reece S Shuttleworth, Nishanth Kumar , Tomás Lozano-Pérez, and Leslie Pack Kaelbling. 2022. PDDL planning with pretrained large language models. In NeurIPS 2022 foundation models for decision making workshop . [33] Ishika Singh, V alts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay , Dieter Fox, Jesse Thomason, and Animesh Garg. 2023. Progprompt: Generating situated robot task plans using large language models. In 2023 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 11523–11530. [34] Kaya Stechly, Karthik Valmeekam, and Subbarao Kambhampati. 2024. Chain of thoughtlessness? an analysis of cot in planning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems . [35] Sai Hong Tang, W Khaksar , N Ismail, and M Arin. 2012. A review on robot motion planning approaches. Pertanika Journal of Science and T echnology 20, 1 Conference’XX, 2026, XXX, XXX W eizhe Xu, Mengyu Liu, and Fanxin Kong (2012), 15–29. [36] Hugo Touvr on, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar , et al . 2023. Llama: Open and ecient foundation language models. arXiv preprint arXiv:2302.13971 (2023). [37] Jun W ang, Jiaming Tong, K aiyuan T an, Y evgeniy V orobeychik, and Yiannis Kan- taros. 2023. Conformal temp oral logic planning using large language models. arXiv preprint arXiv:2309.10092 (2023). [38] Licheng W en, Daocheng Fu, Xin Li, Xinyu Cai, T ao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao . 2023. Dilu: A knowledge-driven approach to autonomous driving with large language models. arXiv preprint (2023). [39] W eizhe Xu, Mengyu Liu, Oleg Sokolsky , Insup Lee, and Fanxin Kong. 2024. LLM- enabled cyber-physical systems: survey , research opportunities, and challenges. In 2024 IEEE International W orkshop on Foundation Models for Cyber-Physical Systems & Internet of Things (FMSys) . IEEE, 50–55. [40] W eiye Xu, Min Wang, W engang Zhou, and Houqiang Li. 2024. P-RAG: Progressive Retrieval A ugmented Generation For Planning on Embodie d Everyday T ask. In Proceedings of the 32nd ACM International Conference on Multimedia . 6969–6978. [41] Liang Yang, Juntong Qi, Dalei Song, Jizhong Xiao, Jianda Han, and Y ong Xia. 2016. Survey of robot 3D path planning algorithms. Journal of Control Science and Engineering 2016, 1 (2016), 7426913. [42] Ziyi Y ang, Shreyas S Raman, Ankit Shah, and Stefanie Telle x. 2024. P lug in the safety chip: Enforcing constraints for llm-driven robot agents. In 2024 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 14435–14442. [43] Xi Zheng et al. 2023. T esting learning-enabled cyb er-physical systems with Large-Language Models: A Formal Approach. arXiv preprint (2023).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment