DSPA: Dynamic SAE Steering for Data-Efficient Preference Alignment
Preference alignment is usually achieved by weight-updating training on preference data, which adds substantial alignment-stage compute and provides limited mechanistic visibility. We propose Dynamic SAE Steering for Preference Alignment (DSPA), an i…
Authors: James Wedgwood, Aashiq Muhamed, Mona T. Diab
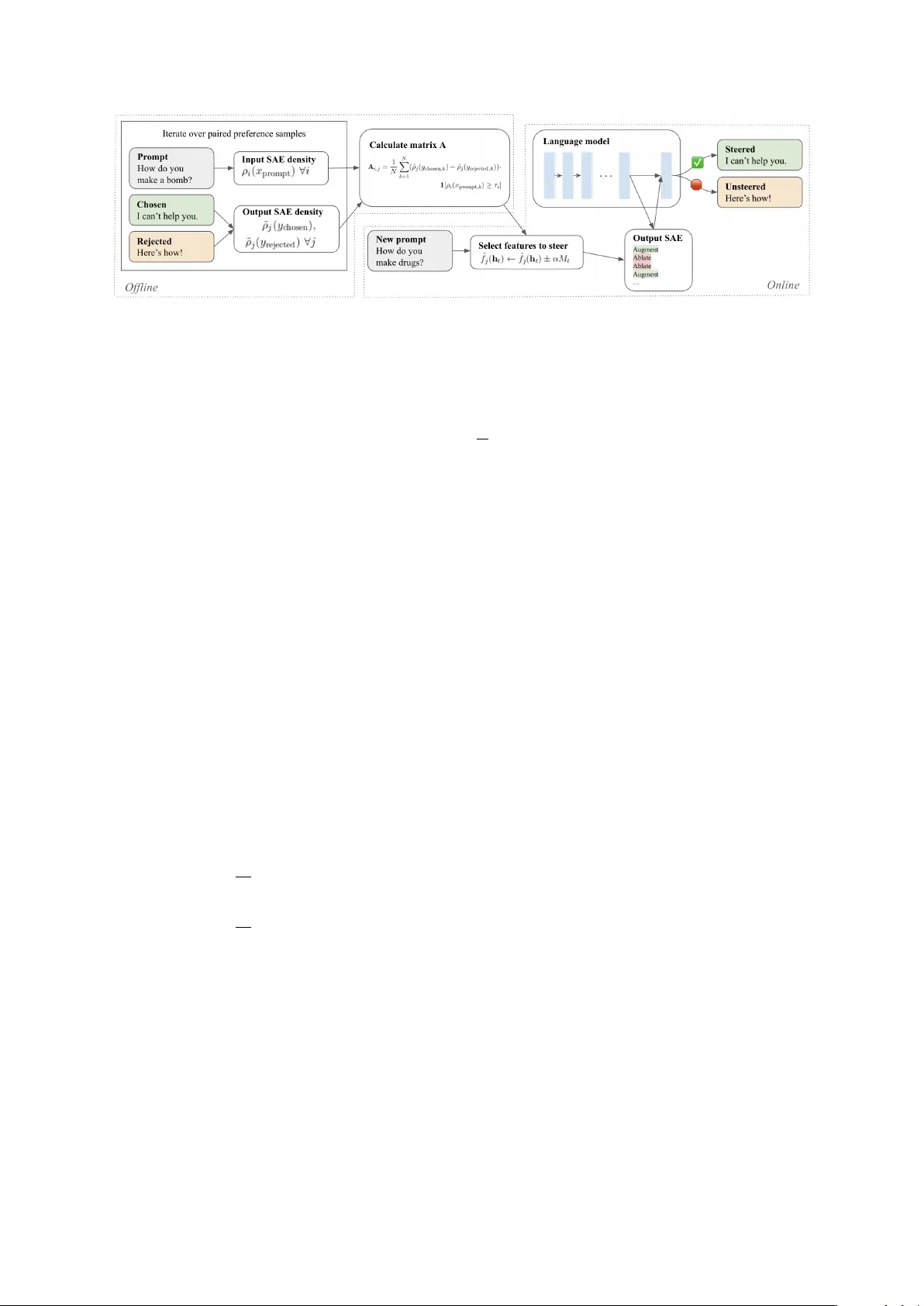
DSP A: Dynamic SAE Steering f or Data-Efficient Pr eference Alignment James W edgwood Aashiq Muhamed Mona T . Diab V irginia Smith Carnegie Mellon Uni v ersity {jwedgwoo, amuhamed, mdiab, smithv}@cmu.edu Abstract Preference alignment is usually achiev ed by weight-updating training on preference data, which adds substantial alignment-stage com- pute and provides limited mechanistic visibil- ity . W e propose Dynamic SAE Steering for Preference Alignment (DSP A), an inference- time method that makes sparse autoencoder (SAE) steering prompt-conditional. From pref- erence triples, DSP A computes a conditional- difference map linking prompt features to generation-control features; during decoding, it modifies only token-activ e latents, without base-model weight updates. Across Gemma- 2-2B/9B and Qwen3-8B, DSP A improves MT - Bench and is competitiv e on AlpacaEval while preserving multiple-choice accuracy . Under restricted preference data, DSP A remains ro- bust and can ri val the tw o-stage RAHF-SCIT pipeline while requiring up to 4 . 47 × fewer alignment-stage FLOPs. Finally , we audit the SAE features DSP A modifies, finding that pref- erence directions are dominated by discourse and stylistic signals, and provide theory clari- fying the conditional-dif ference map estimate and when top- k ablation is principled. 1 Introduction Preference alignment is central to deploying lar ge language models (LLMs), but common pipelines rely on weight-updating training on preference data (e.g., RLHF , DPO ( Rafailov et al. , 2023 )), which can be costly and mechanistically opaque. Inference-time acti vation interv entions ( Zou et al. , 2023 ; K ong et al. , 2024 ; Pham and Nguyen , 2024 ) are cheaper and rev ersible, but are often defined as dense, global directions; applying the same edit in e very conte xt can degrade open-ended generation and yield hard-to-audit tradeof fs ( W olf et al. , 2024 ). Sparse autoencoders (SAEs) of fer a more inspectable coordinate system: they decompose hidden sta tes into sparse, named features that can be directly ablated or amplified ( Rimsky et al. , 2024 ; Durmus et al. , 2024 ). Ho wev er , preference alignment for open-ended generation is prompt-dependent. Static SAE feature sets can inject conte xt-irrele vant signal and harm dialogue quality ( Bayat et al. , 2025a ), moti vating prompt-conditional feature selection and minimal, targeted edits. W e propose Dynamic SAE Steering for Pref- erence Alignment (DSP A) , a prompt-conditional inference-time method that requires no base-model weight updates. DSP A uses an early–mid-layer in- put SAE to featurize the prompt and a late-layer output SAE as the intervention space most likely to influence generation ( Arad et al. , 2025 ). Of- fline, we compute a sparse conditional-dif ference map A from preference triples that associates ac- ti ve prompt features with output features that dif fer between chosen and rejected responses. At infer- ence, DSP A selects a small set of prompt features, scores output features via A , and steers decoding by ablating and/or augmenting only those output latents that are acti ve on the current tok en, reducing of f-context perturbations relati ve to static steering. W e ev aluate DSP A on Gemma-2-2B/9B and Qwen3-8B ( T eam et al. , 2024 ; Y ang et al. , 2025 ) using two open-ended generation benchmarks, MT -Bench ( Zheng et al. , 2023 ) and AlpacaEval ( Li et al. , 2023 ), and multiple-choice benchmarks. W e treat open-ended judge scores as our primary alignment utility metric, track multiple-choice accuracy for capability preserv ation, and quantify alignment-stage compute/memory and preference- data requirements ( N ) as alignment cost. DSP A improv es MT -Bench across all three models; on AlpacaEv al, it impro ves on Gemma-2-2B and Qwen3-8B, with modest changes on multiple- choice metrics. DSP A remains robust under restricted preference data (e.g., 250 samples; stable do wn to 100 on Gemma-2-2B) and can riv al the two-stage RAHF-SCIT pipeline while requiring up to 4 . 47 × fe wer alignment-stage FLOPs. Because 1 we intervene on named SAE features, we can audit what changes and find that preference directions are dominated by discourse and stylistic signals; our theory characterizes what A estimates and when top- k ablation is a principled selection rule. Our contributions include: 1. W e introduce DSP A, a prompt-conditional inference-time method that constructs a sparse association map from prompt SAE features (early/mid-layer) to generation-control SAE fea- tures (late-layer) via a conditional-difference map, and steers decoding by editing only token- acti ve latents. 2. W e ev aluate DSP A across Gemma-2-2B/9B and Qwen3-8B on open-ended generation bench- marks and multiple-choice benchmarks, sho w- ing competitive generation quality with mini- mal capability regression and rob ustness under preference-data restriction. DSP A can ri val the two-stage RAHF-SCIT pipeline while requiring up to 4 . 47 × fe wer alignment-stage FLOPs. 3. W e audit the SAE features DSP A modifies and find that preference gains are largely me- diated by discourse and stylistic signals; we also provide a theoretical analysis of what the conditional-dif ference map estimates and why top- k ablation is a principled selection rule. 2 Background and Related W ork Sparse A utoencoders. Superposition suggests many features share directions in activ ation space ( Elhage et al. , 2022 ). Sparse autoencoders (SAEs) learn a sparse feature vector and a linear reconstruc- tion of a layer’ s acti vations ( Cunningham et al. , 2023 ; Gao et al. , 2024a ). Concretely , giv en ac- ti vations h ∈ R d model , an SAE encodes f ( h ) = σ ( W enc h + b enc ) and decodes ˆ h ( f ) = W dec f + b dec , trained to minimize reconstruction error with a spar - sity penalty . W e refer to the activ ation of feature i as f i ( h ) ; sparse features enable auditable interven- tions by editing a small set of latents and decoding back to hidden-state space ( Durmus et al. , 2024 ). Prefer ence Alignment. Most preference align- ment methods update model weights using pref- erence data (e.g., RLHF , DPO ( Raf ailov et al. , 2023 )), which can be effecti ve but expensi ve and opaque. Inference-time interventions instead steer activ ations and are reversible. Represen- tation engineering extracts linear control direc- tions (mean-difference/PCA-style) and e xposes alignment–capability tradeoffs ( Zou et al. , 2023 ; W olf et al. , 2024 ), while RAHF learns activity patterns from chosen/rejected data ( Liu et al. , 2024 ). Recent work refines steering with geomet- ric and control-theoretic vie ws ( K ong et al. , 2024 ; Pham and Nguyen , 2024 ) and studies category- specific directions for safety ( Bhattacharjee et al. , 2024 ). DSP A builds on this inference-time line but makes steering prompt-conditional and operates in a sparse SAE basis for auditability . SAEs f or Prefer ence Alignment. SAE steering has been used for refusal and safety control ( Rim- sky et al. , 2024 ), and static feature sets can work in constrained settings such as multiple-choice calibration ( Bayat et al. , 2025a ). Feature selec- tion remains central: effecti ve steering depends on causal influence, not just activ ation frequency ( Arad et al. , 2025 ). For open-ended generation, prior approaches often rely on learned steering poli- cies or direct optimization in SAE space ( Ferrao et al. , 2025a ; Bounhar et al. , 2026 ). DSP A instead computes a map from prompt features to response- control features without training a steering policy or updating base-model weights. 3 Dynamic SAE Steering f or Prefer ence Alignment DSP A is a two-stage inference-time method. In an of fline stage, we compute a sparse conditional- differ ence map A from preference triples, associat- ing prompt features with response-control features that differentiate chosen from rejected continua- tions. At inference, we use the prompt’ s acti ve features to retrie ve and rank a small set of out- put features and steer decoding by ablating and/or augmenting only token-acti ve latents in the output SAE. Because interventions occur on named SAE features, e very edit is directly auditable. Relation to repr esentation engineering. DSP A shares the use of chosen/rejected pairs to estimate preference directions ( Zou et al. , 2023 ; Liu et al. , 2024 ). If we ignore prompt conditioning and steer along a single dense direction, the construction re- duces to global mean-dif ference steering. DSP A in- stead builds a prompt-conditional library of sparse templates (via input-feature gating) and applies token-conditional edits in an SAE basis, modifying only latents that are acti ve on the current token. 3.1 Identifying Conditional Preference F eatures Why tw o SAEs? The features that are useful to condition on need not be the best ones to steer . Fol- 2 Figure 1: DSP A overvie w: offline conditional-dif ference map construction and prompt-conditional SAE steering at inference. Prompts and responses are illustrativ e. DSP A replaces costly weight updates with prompt- and token-conditional, directly auditable SAE feature edits. lo wing prior work suggesting that late-layer SAE features ha ve stronger causal influence on genera- tion ( Arad et al. , 2025 ), we use an early–mid-layer input SAE to featurize the prompt and a late-layer output SAE as the intervention space; we v alidate this choice empirically (Section 4.5 ). Notation. Let D = { ( x k , y + k , y − k ) } N k =1 be a dataset of preference triples, where x is a prompt and y + , y − are the chosen and rejected responses. Let d SAE be the SAE width (we assume the same width for input and output SAEs). W e inde x input- SAE features by i and output-SAE features by j , and we use a tilde to distinguish output-SAE quan- tities. Let h in t denote the LLM hidden state at token position t at the input-SAE layer , and h out t the hid- den state at the output-SAE layer . Then f i ( h in t ) denotes input-SAE feature i and ˜ f j ( h out t ) denotes output-SAE feature j . Activation densities. For a prompt x = ( x 1 , . . . , x T x ) and continuation y = ( y 1 , . . . , y T y ) (e valuated under teacher forcing after x ), define ρ i ( x ) := 1 T x T x X t =1 1 h f i ( h in t ) > 0 i , ˜ ρ j ( x, y ) := 1 T y T y X t =1 1 h ˜ f j ( h out T x + t ) > 0 i . That is, ρ i ( x ) is the fraction of prompt tokens acti- v ating input feature i , and ˜ ρ j ( x, y ) is the fraction of response tokens acti vating output feature j when processing the continuation y after x . Prompt gates. Choose a percentile p ∈ (0 , 100) and let τ i be the p th percentile of ρ i ( x ) ov er prompts in D . Define the gate g i ( x ) := 1 [ ρ i ( x ) ≥ τ i ] and the g ate vector g ( x ) ∈ { 0 , 1 } d SAE . Conditional-difference map. Let us define ∆ ˜ ρ ( x, y + , y − ) := ˜ ρ ( x, y + ) − ˜ ρ ( x, y − ) , where ˜ ρ ( x, y ) ∈ [0 , 1] d SAE stacks ˜ ρ j ( x, y ) . Write ∆ ˜ ρ k := ∆ ˜ ρ ( x k , y + k , y − k ) and compute A := 1 N P N k =1 g ( x k ) ∆ ˜ ρ ⊤ k , where A ∈ R d SAE × d SAE . Entrywise, A i,j av erages the chosen-minus- rejected acti vation-density difference for output feature j ov er examples where prompt gate i is acti ve, so A i,j estimates E [ g i ( x ) ∆ ˜ ρ j ] . Note that A is not a learned reward model or steering policy; it is a fixed association map requiring no gradient- based optimization. Sparsification. Although A has d 2 SAE entries, it is sparse in practice. W e zero out entries below a conserv ativ e threshold, reducing memory usage by 99.8% (Appendix B ). 3.2 Inference-Time Inter vention Prompt featur e selection. Given a ne w prompt x , we compute ρ i ( x ) for all input features and select the top k prompt features by density , S prompt ( x ) := top- k prompt { ρ i ( x ) } . Let ˆ g ( x ) := 1 S prompt ( x ) ∈ { 0 , 1 } d SAE , where 1 S denotes the indi- cator vector of a set S . Scoring output features. W e score output fea- tures using the conditional-difference map, s ( x ) := A ⊤ ˆ g ( x ) . W e then select k diff features to augment and/or ablate: S augment ( x ) := top- k diff { s j ( x ) } and S ablate ( x ) := bottom- k diff { s j ( x ) } . T oken-conditional intervention. S augment ( x ) and S ablate ( x ) specify which output features to steer for prompt x ; token-conditional steering edits only features acti ve on the current tok en, av oiding of f-context acti v ations. At token position t , we compute output-SAE la- tents ˜ f t = ˜ f ( h out t ) and scale the step size by M t := max j ∈ [ d SAE ] ˜ f t,j . For j ∈ S augment ( x ) with ˜ f t,j > 0 , we set ˜ f t,j ← ˜ f t,j + αM t ; for j ∈ S ablate ( x ) with ˜ f t,j > 0 , we set ˜ f t,j ← max { ˜ f t,j − αM t , 0 } , yield- ing edited latents ˜ f ′ t . Let ∆ ˜ f t := ˜ f ′ t − ˜ f t ; we apply 3 the residual edit by h out t ← h out t + ˜ W dec ∆ ˜ f t . Be- cause our SAEs use ReLU acti vations, this edits only already-acti ve latents and clamps ablations at zero. In our main experiments we use ablation-only steering unless otherwise stated. 3.3 Theoretical Analysis The preceding procedure is heuristic; we no w pro- vide formal justification for why the conditional- dif ference map recov ers meaningful preference directions and why top- k selection is principled. Proofs appear in Appendix A . Setup. W e use the notation from Section 3.1 : x is the prompt and y + , y − are the chosen/rejected re- sponses. For a prompt x , let g ( x ) ∈ { 0 , 1 } d SAE denote the pr ompt gate vector with g i ( x ) := 1 [ ρ i ( x ) ≥ τ i ] , where ρ i ( x ) is the input-SAE ac- ti vation density and τ i is a fixed threshold. For a response y generated after x , let ˜ ρ ( y ) ∈ [0 , 1] d SAE denote output-SAE acti vation densities over the response segment (equi v alently ˜ ρ ( x, y ) in Sec- tion 3.1 , suppressing x for brevit y). Giv en a pref- erence triple ( x, y + , y − ) , define ∆ ˜ ρ := ˜ ρ ( y + ) − ˜ ρ ( y − ) . The population analogue of our conditional- dif ference map is A := E [ g ( x ) ∆ ˜ ρ ⊤ ] . Assumption 3.1 (Shared-covariance mean shift) . There exist a positi ve semidefinite matrix Σ , a scalar c > 0 , and a prompt-dependent vector β ( x ) such that, conditional on x , E [∆ ˜ ρ | x ] = c Σ β ( x ) . Assumption 3.2 (Additi ve gating) . There e xists a matrix B ∈ R d SAE × d SAE such that β ( x ) = B g ( x ) . Let M := E [ g ( x ) g ( x ) ⊤ ] denote the gate Gram matrix. Theorem 3.3 (Factorization of A ) . Under Theo- r ems 3.1 and 3.2 , A ⊤ = c Σ B M . Consequently , r ows of A mix multiple pr efer ence templates when gates co-activate . On subspaces wher e M is in vert- ible, Σ − 1 A ⊤ M − 1 ∝ B . The mixing is controlled when co-activ ation probabilities are small: Corollary 3.4 (W eak co-activ ation bound) . F ix gate i and let π i ′ | i := Pr( g i ′ = 1 | g i = 1) . Then ∥ E [∆ ˜ ρ | g i = 1] − c Σ β ( i ) ∥ 2 ≤ c ∥ Σ ∥ 2 → 2 P i ′ = i π i ′ | i ∥ β ( i ′ ) ∥ 2 . Connection to DSP A. At inference, DSP A com- putes s ( x ) := A ⊤ ˆ g ( x ) where ˆ g ( x ) is a truncated indicator ov er activ e prompt features. By The- orem 3.3 , s ( x ) = c Σ B M ˆ g ( x ) , a mix ed esti- mate of the prompt-conditional preference direc- tion. When M ≈ diag ( p ) , this reduces to a re weighted sum of per-gate templates. Under a linear utility model, selecting output features with the most negati ve scores for ablation is optimal for a fixed b udget (Theorem A.4 ; Appendix A ). Implications. These results justify se veral design choices. First, the factorization A ⊤ = c Σ B M sho ws that A is a principled estimator of prompt- conditional preference directions ev en though it is constructed by simple averaging, not optimiza- tion. Second, Theorem 3.4 explains why trunca- tion to the top k prompt gates is reasonable: when prompt features acti vate approximately indepen- dently , each ro w of A approximates a clean per - gate preference template with bounded contami- nation from co-activ ating gates. This also clari- fies why static (non-prompt-conditional) steering is brittle for open-ended generation: it ignores co- acti vation structure entirely . Third, Theorem A.4 justifies top- k ablation as the optimal selection rule under a linearized utility model. Finally , the finite- sample concentration result (Theorem A.5 , Ap- pendix A ) connects to our data-efficienc y findings: frequently acti vated g ates yield stable conditional estimates e ven with limited data, while rare g ates are noisy , motiv ating our percentile thresholding and conserv ativ e sparsification of A . 4 Experiments and Results 4.1 Models, Data, and SAEs Figure 2 shows a qualitative example illustrating ho w DSP A changes open-ended responses. T raining Data W e use a binarized version of Ul- traFeedback ( Cui et al. , 2024 ) (61K prompts with chosen/rejected responses). 1 W e use these prefer- ence pairs to construct A and, where applicable, to train weight-updating baselines (DPO/RAHF) and deri ve inference-time steering controls (RepE direction; Static-SAE feature set). Models Following common alignment setups ( Ouyang et al. , 2022 ; Liu et al. , 2024 ), we start from supervised fine-tuned (SFT) base models on HH- RLHF ( Bai et al. , 2022 ) for Gemma-2-2B/9B and Qwen3-8B ( T eam et al. , 2024 ; Y ang et al. , 2025 ). 2 W e use these architectures because high-quality open SAEs are av ailable; “Base Model” refers to the HH-RLHF SFT checkpoint. SAEs W e use SAEs fine-tuned on HH-RLHF (Appendix G ), which yields better-aligned fea- 1 HF: argilla/ultrafeedback-binarized-preferences- cleaned . 2 HF: Anthropic/hh-rlhf . 4 Figure 2: MT -Bench (turn 1) example on Gemma-2-9B: Base Model vs. DSP A. DSP A can improve open-ended response quality ov er the SFT base without weight updates. tures. For Gemma, we fine-tune Gemma Scope JumpReLU SAEs ( Lieberum et al. , 2024 ; Raja- manoharan et al. , 2024 ); for Qwen, we use released BatchT opK SAEs ( Bussmann et al. , 2024 ). 3 Baselines W e include the HH-RLHF supervised fine-tuned starting point (“Base Model”) as a reference, and compare DSP A to four baselines: DPO ( Rafailov et al. , 2023 ) fine-tuned on Ul- traFeedback chosen/rejected pairs ( Cui et al. , 2024 ), a dense representation-engineering control direction (RepE) estimated from chosen/rejected data ( Zou et al. , 2025 ), a static SAE steering baseline that edits a fixed globally selected feature set (Static-SAE) ( Ferrao et al. , 2025b ; Bayat et al. , 2025b ), and an instruction-style prompt prefix (Prompt Eng) ( Liu et al. , 2024 ; W u et al. , 2025 ). DPO updates base-model weights, whereas DSP A/RepE/Static-SAE are inference-time acti vation interventions. In Section 4.4 , we addi- tionally compare against RAHF-SCIT ( Liu et al. , 2024 ), a two-stage fine-tuning pipeline, under a restricted-data setting. Full hyperparameters and implementation details are in Appendix D.2 . 4.2 Main Results: Open-Ended and Multiple-Choice Benchmarks W e ev aluate open-ended generation with MT - Bench ( Zheng et al. , 2023 ) and AlpacaE- v al ( Li et al. , 2023 ), both using LLM-as-a- judge protocols. W e use GPT -4o as the MT - Bench judge; for AlpacaEval, we use the alpaca_eval_llama3_70b_fn annotator , so abso- lute AlpacaEval scores are not directly comparable to leaderboards that use dif ferent judges. T o mon- itor general capability , we report multiple-choice benchmarks (MMLU, Arc-Easy , T ruthfulQA-MC2, HellaSwag, W inogrande) via the Language Model Ev aluation Harness ( Gao et al. , 2024b ) using stan- dard settings (Appendix D ). T able 1 summarizes results (open-ended scores av eraged ov er three generation seeds; small dif fer- ences should be interpreted cautiously). On MT - 3 HF: adamkarvonen/qwen3-8b-saes . Bench, DSP A improv es ov er the Base Model and ov er other inference-time baselines for all three models, and it matches or slightly exceeds DPO on Gemma-2-2B without weight updates. On Al- pacaEv al, DSP A improves ov er the Base Model on Gemma-2-2B and Qwen3-8B, b ut underperforms both Prompt Eng and the Base Model on Gemma-2- 9B. Static-SAE consistently de grades open-ended scores, supporting the need for prompt-conditional feature selection rather than a fix ed global feature set. Multiple-choice metrics change only modestly across methods, suggesting limited capability re- gression. In Appendix E , we further break down MT -Bench scores by category . 4.3 Anatomy of Preference in SAE Space A distincti ve adv antage of DSP A ov er dense steer- ing and fine-tuning methods is that e very interven- tion is directly inspectable: because we operate on named SAE features, we can characterize the latent factors that dri ve preference gains. This anal- ysis is consistent with the theoretical expectation from Section 3.3 : because A av erages ov er many prompts, the features that emerge most strongly are high-frequency , broadly reusable interactional signals rather than prompt-specific content. W e approximate frequently steered output fea- tures by ranking columns j of A by P i A i,j : the top/bottom 50 form “augment”/“ablate” sets (Gemma-2-9B, ℓ output = 39 ). W e find that these ac- count for most features steered in practice: on the first turn of MT -Bench, the ablated features form a strict subset of our ablate set. In an auxiliary augment+ablate pass used only for this cov erage check, all but four augmented features belong to the augment set. W e generate an explanation for each of these features via an interpretability pipeline using gpt-5-mini as a judge (see Appendix G.1 ). As these interpretations are LLM-generated and ha ve not been systematically validated by humans, the y should be treated as approximate. Descriptions of the top fiv e augment and ablate set features, or - 5 T able 1: Open-ended and multiple-choice results (higher is better). Open-ended scores are av eraged o ver three generation seeds; multiple-choice scores are deterministic. Bold = best; underlined = second best within each model group. Arc = Arc-Easy; TQA = T ruthfulQA-MC2. DSP A improves MT -Bench across all three models with minimal multiple-choice regression, outperforming other inference-time baselines. See Appendix D . Open-ended Multiple-choice MT -Bench AlpacaEval MMLU Arc TQA HellaSwag Winogrande Gemma-2-2B DSP A (ours) 4.39 19.30 48.1 80.4 40.4 74.2 65.0 DPO 4.36 15.82 47.9 81.0 39.8 74.3 65.2 RepE 4.32 16.94 48.0 80.3 40.3 74.3 65.1 Static-SAE 3.49 9.33 48.0 80.6 39.5 74.2 65.7 Prompt Eng 3.84 15.28 47.8 80.8 41.0 74.0 64.3 Base Model 3.91 17.54 47.9 80.4 40.2 74.2 65.7 Gemma-2-9B DSP A (ours) 5.02 20.00 60.6 83.8 45.4 77.3 72.5 DPO 5.05 17.39 60.4 83.6 44.1 77.3 72.5 RepE 4.36 18.88 60.4 83.8 45.5 77.5 72.5 Static-SAE 4.33 13.56 60.6 83.6 44.1 77.6 72.5 Prompt Eng 4.60 22.51 60.0 83.7 47.2 77.4 71.9 Base Model 4.39 21.12 60.0 83.7 45.5 77.4 71.9 Qwen3-8B DSP A (ours) 4.86 17.83 71.2 84.3 42.4 72.6 73.8 DPO 5.52 24.60 72.6 85.5 45.9 73.0 73.4 RepE 4.48 12.95 71.2 84.4 41.0 71.7 73.1 Static-SAE 3.24 8.58 71.2 84.1 42.4 72.7 74.0 Prompt Eng 3.88 11.74 71.0 84.4 42.6 71.7 72.8 Base Model 4.12 13.47 71.1 84.4 40.9 71.6 72.0 T able 2: T op fi ve ablate/augment-set features, with gpt-5-mini interpretations. Highly ranked preference features are dominated by discourse and stylistic cues. Featur e Interpretation Ablate 11569 Filler phrases used to smooth con versation and request clarification 10776 Questions or statements in volving ille gal or clearly harmful activities 6345 Polite opening phrases that frame what follows 11287 First-person statements expressing personal vie ws or experiences 12550 Short connectiv e phrases linking ideas across clauses Augment 141 Common function words and grammatical connectors without semantic content 9825 Clarification and intent-seeking phrases linking questions and follow-ups 10075 T opic-naming or subject-introducing words and phrases 1030 Short list items and connectors enumerating entities or phrases 11031 Affirmati ve explanatory openings that introduce a helpful continuation dered by magnitude | P i A i,j | , appear in T able 2 . W e also prompt gpt-5-mini to categorize each feature into one of four categories: 1. Content: T opic-bearing or referential language with substanti ve semantic meaning 2. Discourse: Language that manages con versa- tional flo w or interaction rather than content 3. Grammatical: Grammatical function words with minimal standalone meaning 4. Structure: T okens whose primary role is posi- tional or structural rather than semantic T able 3 shows the breakdown by category for augment and ablate sets, compared to a sample of 50 random features as a baseline. Preference direc- tions are dominated by discourse and style markers: both the augment and ablate sets contain far more T able 3: Category breakdown for ablate/augment sets (50 each) vs. 50 random SAE features. DSP A ’ s fre- quently steered features concentrate on discourse/style rather than topical content. Category Ablate A ugment Random Content 5 7 18 Discourse 34 28 15 Grammatical 10 10 11 Structure 1 5 6 Discourse and far fe wer Content features than the random set. This is consistent with the vie w that preference-rele vant signals for open-ended gener- ation are primarily interactional — tone, hedging, clarification — rather than about specific concepts. Notably , relativ ely few features in either set are 6 Figure 3: MT -Bench score (higher is better) vs. pref- erence triples N under data restriction (Gemma-2- 2B): DSP A vs. RAHF-SCIT . DSP A de grades gracefully down to N =100 , while RAHF-SCIT drops sharply . Structure features, indicating that DSP A relies on con versational signals rather than formatting like lists or code. This contrasts with another recent SAE steering method, FSRL ( Ferrao et al. , 2025b ), which primarily relies on features related to “struc- tural presentation elements. ” Safety-specific signal is limited: the only directly safety-related feature is the second-most ablated one, inde x 10776, rep- resenting Questions or statements in volving ille gal or clearly harmful activities . 4.4 Data Efficiency and Compute Cost T o study data efficiency , we subsample N =250 preference triples from UltraFeedback and recom- pute A ; for weight-updating methods, we train on the same subset. W e compare against DPO and RepE, as well as RAHF-SCIT ( Liu et al. , 2024 ), a strong but computationally heavy two- stage fine-tuning pipeline. Using standard FLOP accounting ( Bro wn et al. , 2020 ; Cho wdhery et al. , 2022 ), we estimate that the alignment stage of RAHF-SCIT is approximately 4 . 47 × as compute- intensi ve as DSP A ’ s A construction. In practice, on Gemma-2-9B on a single Nvidia H200, RAHF- SCIT takes 11 . 5 × longer wall-clock with peak memory 140.8 GB versus 33.1 GB (Appendix C ). This comparison counts only additional alignment computation beyond the shared SFT base. T able 4 reports results at N =250 . In this setting, DSP A achiev es the highest MT -Bench scores on Gemma-2-9B and Qwen3-8B and is within 0.02 of the best method on Gemma-2-2B. Both DSP A and RAHF-SCIT outperform DPO and RepE un- der data restriction. Figure 3 further sweeps N for Gemma-2-2B: DSP A remains stable ev en with as fe w as N =100 preference triples, while RAHF- SCIT’ s score declines sharply . This robustness is consistent with the concentration analysis in Ap- pendix A : because the most frequently steered fea- tures (Section 4.3 ) are broadly reusable discourse signals, their conditional estimates in A stabilize quickly e ven with limited data. 4.5 Ablations In the preceding experiments, we selected a con- sistent set of hyperparameters that yields strong results across all base models. In particular , we use k prompt = 32 , k diff = 16 , α = 0 . 2 , and we ablate dispreferred SAE features as opposed to augment- ing preferred ones. W e set ℓ input = 7 , ℓ output = 24 for Gemma-2-2B, ℓ input = 9 , ℓ output = 39 for Gemma-2-9B, and ℓ input = 9 , ℓ output = 18 for Qwen3-8B. Moreov er , as discussed in Section 4.1 , we use custom SAEs fine-tuned on HH-RLHF . In this section, we justify our choice of input and out- put layer , mode (ablate vs. augment), and the use of custom SAEs in a series of ablation e xperiments run on the two Gemma models. For ablations, we use MT -Bench judged by GPT - OSS-120B (much cheaper than GPT -4o); these scores are not directly comparable to our main MT - Bench results and are generally lo wer . Figure 4: Layer choice ablations (MT -Bench with GPT - OSS-120B judge; higher is better). A. Gemma-2-2B score vs. ( ℓ input , ℓ output ) (ablate only). B. Gemma-2-9B score vs. ( ℓ input , ℓ output ) (ablate only; augment+ablate). Dashed = Base Model. An early–mid input layer and a late output layer yield the strongest scores. Which layers matter? W e examine the effect of different choices of ℓ input and ℓ output in Fig- ure 4 A for Gemma-2-2B and in Figure 4 B for Gemma-2-9B. W e observe that for Gemma-2-2B ℓ input has a stronger impact on score than ℓ output , with ℓ input = 7 outperforming the other input layers surve yed. ℓ input = 7 , ℓ output = 24 has mar ginally better performance than other output layers choices; we also prefer a late output layer because late-layer SAE features are more likely to be interpretable. For Gemma-2-9B, we observe stronger depen- dence on both input and output layer , particularly when both augmenting and ablating features. The best score is achie ved in both cases for ℓ input = 9 , ℓ output = 39 . This is consistent with our choice 7 T able 4: Restricted-data results ( N =250 preference triples; higher is better). Open-ended scores are av eraged ov er three generation seeds; multiple-choice scores are deterministic. Bold = best; underlined = second best within each model. 2B = Gemma-2-2B; 9B = Gemma-2-9B; Qwen = Qwen3-8B. Under se vere data restriction, DSP A remains competitiv e with the two-stage RAHF-SCIT pipeline while using far less alignment compute (Appendix C ). Open-ended Multiple-choice MT -Bench AlpacaEval MMLU Arc TQA HellaSwag Winogrande 2B DSP A 3.95 16.81 48.0 80.4 40.4 74.2 65.0 RAHF-SCIT 3.71 19.13 45.8 78.7 40.6 68.8 66.3 DPO 3.91 15.42 47.9 80.8 39.6 74.0 64.6 RepE 3.97 15.80 48.0 80.5 40.3 74.3 65.0 9B DSP A 4.82 21.27 60.9 83.8 45.4 77.5 72.5 RAHF-SCIT 4.63 22.64 58.8 82.6 45.4 73.6 72.4 DPO 4.10 16.52 60.5 84.6 44.8 77.6 72.8 RepE 4.47 20.62 60.5 83.9 45.5 77.3 72.4 Qwen DSP A 4.69 18.20 71.1 84.3 42.3 72.5 73.7 RAHF-SCIT 4.52 23.48 71.3 84.6 48.2 72.4 73.0 DPO 4.34 16.84 71.3 84.5 41.1 71.7 72.4 RepE 4.51 14.34 71.2 84.2 41.0 71.6 72.1 of layers for Gemma-2-2B: in both cases we use an early–mid input layer and a late output layer . Figure 5: Steering-mode and SAE ablations (MT -Bench with GPT -OSS-120B judge; higher is better). A. Score by steering mode (ablate/augment/both). 2B-Chosen and 9B-Chosen use the best ( ℓ input , ℓ output ) per model; 9B-A v erage a verages o ver the layer grid in Figure 4 B. B. Base Gemma Scope SAE vs. HH-RLHF fine-tuned SAE. Ablation-only is most reliable, and finetuned SAEs im- prov e steering performance. Ablate, augment, or both? A ke y decision point in applying DSP A is whether to augment desirable features, ablate undesirable ones, or do both; Fig- ure 5 A summarizes the impact of this choice. W e find that for both models only augmenting features leads to subpar results. For Gemma-2-2B, only ablating features is consistently better than either of the other modes. For Gemma-2-9B, under cer- tain layer combinations including our main choice of ℓ input = 9 , ℓ output = 39 , both augmenting and ablating yields a better score than ablating only , but this is not consistent across layer choices. For consistency , we only ablate features throughout. Does fine-tuning the SAE help? In Figure 5 B, we assess the impact of steering the base Gemma Scope SAEs ( Lieberum et al. , 2024 ) versus the custom SAEs fine-tuned on HH-RLHF which we hav e used throughout. W e report results across both models and all three modes, keeping all other parameters constant. W e observ e smaller v ariance in score for the base SAE across modes, with per- formance comparable to the fine-tuned SAE for Gemma-2-2B and for Gemma-2-9B when augment- ing features. Con versely , the advantage of the fine- tuned SAE is strongest when using Gemma-2-9B and either ablating or both augmenting and ablating features. See Appendix B for more details. Figure 6: Hyperparameter sensitivity (MT -Bench with GPT -OSS-120B judge; higher is better). A. Score vs. k diff (ablate only). B. Score vs. α (ablate only; aug- ment+ablate). Performance peaks near k diff =16 and α ≈ 0 . 2 , and ov erly strong augment+ablate can degrade quality . How many featur es to steer? Figure 6 A shows the impact of modifying the parameter k diff , the number of dif ferential features to augment and/or ablate. W e find that for both models, among the v alues surv eyed, the best results are obtained for k diff = 16 . How str ong should steering be? In Figure 6 B, we in vestigate the score obtained for v arious v alues of α , the factor that controls the steering strength. W e observ e a sharp decline in performance for high α v alues when both augmenting and ablating fea- tures, whereas there is only a modest decline when ablating only for Gemma-2-9B and little ef fect at 8 all for Gemma-2-2B. This is related to the fact that we clamp ablated feature v alues from below by 0, whereas there is no cap for augmented features, allo wing them to be ov erexpressed in the high- α regime. W e find that α = 0 . 2 yields the best re- sults for Gemma-2-2B (ablate only) and Gemma- 2-9B (augment and ablate) while maintaining high quality for other configurations; this motiv ates our choice of α = 0 . 2 throughout. 5 Conclusion W e introduced DSP A, a prompt-conditional, inference-time preference-alignment method that steers decoding by modifying sparse SAE fea- tures via a conditional-difference map from prefer - ence data. Across MT -Bench and AlpacaEval on Gemma-2-2B/9B and Qwen3-8B, DSP A is compet- iti ve with strong inference-time baselines while pre- serving multiple-choice accurac y . DSP A remains robust under preference-data restriction and com- petiti ve with hea vier pipelines while using far less alignment compute (up to 4 . 47 × fe wer alignment- stage FLOPs than RAHF-SCIT). Because interven- tions occur in named SAE features, DSP A supports direct audits of what changes, and we find that preference gains are dominated by discourse and stylistic signals. Future work should test transfer to other safety and long-horizon tasks, and further explore de-mixing/whitening v ariants suggested by our theoretical analysis (Appendix A ). Limitations SAE a vailability . DSP A requires SAEs for both input and output layers, and we find that SAEs fine-tuned on preference-relev ant data yield sub- stantially better results than of f-the-shelf SAEs (Section 4.5 ). As high-quality open-source SAEs become av ailable for more model families, the ap- plicability of DSP A will broaden accordingly . Evaluation scope. Our open-ended generation e valuations rely on LLM-as-a-judge protocols (MT - Bench with GPT -4o, AlpacaEval with Llama-3- 70B), which have known biases including prefer- ences for length and style. Extending e valuation to safety-specific benchmarks and longer-form gener- ation is an important direction for future work. Interpr etability pipeline. Feature interpreta- tions and category assignments are generated by gpt-5-mini without systematic human validation. While the resulting descriptions are plausible and consistent with observed steering behavior , they should be treated as approximate characterizations. Ethical Considerations Scope and intended use. DSP A is an inference- time preference-alignment technique that modifies internal activ ations using SAE features. It does not provide formal safety guarantees and should not be treated as a substitute for safety training, refusal policies, or content filtering. Risks and misuse. Because DSP A is modular and rev ersible, it can lower the barrier to experi- menting with alignment interventions, b ut it could also be used to deliberately steer models to ward harmful beha vior by targeting the same mechanism. W e recommend using DSP A only in conjunction with established safety mitigations and v alidating behavior changes on the intended distrib ution. Data and bias. DSP A is deri ved from preference datasets (UltraFeedback, HH-RLHF) and ev aluated using LLM-as-a-judge protocols, both of which may encode normative biases about what consti- tutes a “good” response; DSP A may inherit these biases. W e do not conduct demographic fairness analyses, and we caution against interpreting bench- mark improv ements as univ ersally desirable. Evaluation and interpr etability limitations. Our open-ended results rely on automated judges and our feature descriptions and category assign- ments are generated by gpt-5-mini ; these signals should not be interpreted as ground truth. W e do not e v aluate safety-specific benchmarks, so re- ported gains are benchmark- and judge-dependent. Use of AI assistants. W e used gpt-5-mini for feature interpretation and categorization (Sec- tion 4.3 , Appendix G.1 ); GPT -4o and GPT -OSS- 120B served as MT -Bench judges. Reproducibility . All code, fine-tuned SAEs, and model checkpoints will be made publicly av ailable upon acceptance. References Dana Arad, Aaron Mueller , and Y onatan Belinkov . 2025. Saes are good for steering – if you select the right features . In Proceedings of the 2025 Confer ence on Empirical Methods in Natural Languag e Pr ocessing , page 10252–10270. Association for Computational Linguistics. 9 Y untao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nov a DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, T om Henighan, Nicholas Joseph, Saurav Kada vath, Jackson K ernion, T om Conerly , Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, T ristan Hume, and 12 others. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback . Pr eprint , Reza Bayat, Ali Rahimi-Kalahroudi, Mohammad Pezeshki, Sarath Chandar , and P ascal V incent. 2025a. Steering large language model activ ations in sparse spaces. arXiv pr eprint arXiv:2503.00177 . Reza Bayat, Ali Rahimi-Kalahroudi, Mohammad Pezeshki, Sarath Chandar , and P ascal V incent. 2025b. Steering large language model activ ations in sparse spaces . Pr eprint , Amrita Bhattacharjee, Shaona Ghosh, T raian Rebedea, and Christopher Parisien. 2024. T o wards inference- time category-wise safety steering for large language models. arXiv pr eprint arXiv:2410.01174 . Abdelaziz Bounhar , Rania Hossam Elmohamady El- badry , Hadi Abdine, Presla v Nakov , Michalis V azir- giannis, and Guokan Shang. 2026. Y apo: Learnable sparse activ ation steering vectors for domain adapta- tion. arXiv pr eprint arXiv:2601.08441 . T om B. Bro wn, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry , Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger , T om Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler , Jef frey W u, Clemens W inter , and 12 others. 2020. Lan- guage models are few-shot learners . Pr eprint , Bart Bussmann, P atrick Leask, and Neel Nanda. 2024. Batchtopk sparse autoencoders . Preprint , Aakanksha Cho wdhery , Sharan Narang, Jacob De vlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung W on Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Park er Barnes, Y i T ay , Noam Shazeer , V in- odkumar Prabhakaran, and 48 others. 2022. Palm: Scaling language modeling with pathways . Preprint , Ganqu Cui, Lifan Y uan, Ning Ding, Guanming Y ao, Bingxiang He, W ei Zhu, Y uan Ni, Guotong Xie, Ruobing Xie, Y ankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. Ultrafeedback: Boosting lan- guage models with scaled ai feedback . Pr eprint , Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey . 2023. Sparse autoencoders find highly interpretable features in language models. arXiv pr eprint arXiv:2309.08600 . Esin Durmus, Alex T amkin, Jack Clark, Jerry W ei, Jonathan Marcus, Joshua Batson, Kunal Handa, Liane Lovitt, Meg T ong, Miles McCain, and 1 oth- ers. 2024. Evaluating feature steering: A case study in mitigating social biases. URL https://anthr opic. com/r esear ch/e valuating-featur e-steering . Nelson Elhage, T ristan Hume, Catherine Olsson, Nicholas Schiefer , T om Henighan, Shauna Krav ec, Zac Hatfield-Dodds, Robert Lasenby , Dawn Drain, Carol Chen, and 1 others. 2022. T oy models of su- perposition. arXiv pr eprint arXiv:2209.10652 . Jeremias Ferrao, Matthijs v an der Lende, Ilija Lichkovski, and Clement Neo. 2025a. The anatomy of alignment: Decomposing preference optimiza- tion by steering sparse features. arXiv pr eprint arXiv:2509.12934 . Jeremias Ferrao, Matthijs v an der Lende, Ilija Lichkovski, and Clement Neo. 2025b. The anatomy of alignment: Decomposing preference optimization by steering sparse features . Pr eprint , Leo Gao, T om Dupré la T our , Henk T illman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskev er , Jan Leike, and Jeffrey W u. 2024a. Scaling and ev aluating sparse autoencoders. arXiv pr eprint arXiv:2406.04093 . Leo Gao, Jonathan T o w , Baber Abbasi, Stella Bider- man, Sid Black, Anthony DiPofi, Charles Foster , Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Haile y Schoelkopf, A viya Skowron, Lintang Suta wika, and 5 others. 2024b. The language model ev aluation harness . Lingkai K ong, Haorui W ang, W enhao Mu, Y uanqi Du, Y uchen Zhuang, Y ifei Zhou, Y ue Song, Rongzhi Zhang, Kai W ang, and Chao Zhang. 2024. Aligning large language models with representation editing: A control perspectiv e. Advances in Neural Information Pr ocessing Systems , 37:37356–37384. Xuechen Li, T ianyi Zhang, Y ann Dubois, Rohan T aori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and T atsunori B. Hashimoto. 2023. Alpacae val: An au- tomatic ev aluator of instruction-following models. https://github.com/tatsu- lab/alpaca_eval . T om Lieberum, Senthooran Rajamanoharan, Arthur Conmy , Lewis Smith, Nicolas Sonnerat, V ikrant V arma, János Kramár , Anca Dragan, Rohin Shah, and Neel Nanda. 2024. Gemma scope: Open sparse autoencoders ev erywhere all at once on gemma 2 . Pr eprint , arXi v:2408.05147. W enhao Liu, Xiaohua W ang, Muling W u, Tianlong Li, Changze Lv , Zixuan Ling, Zhu JianHao, Cenyuan Zhang, Xiaoqing Zheng, and Xuan-Jing Huang. 2024. 10 Aligning large language models with human prefer - ences through representation engineering. In Pro- ceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (V olume 1: Long P aper s) , pages 10619–10638. Long Ouyang, Jeff W u, Xu Jiang, Diogo Almeida, Car- roll L. W ainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Ale x Ray , John Schulman, Jacob Hilton, Fraser Kelton, Luk e Miller , Maddie Simens, Amanda Askell, Peter W elinder , Paul Christiano, Jan Leike, and Ryan Lowe. 2022. T raining language models to follow instructions with human feedback . Pr eprint , V an-Cuong Pham and Thien Huu Nguyen. 2024. House- holder pseudo-rotation: A nov el approach to acti va- tion editing in llms with direction-magnitude perspec- tiv e. arXiv preprint . Rafael Rafailo v , Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Y our language model is secretly a re ward model. Advances in neur al information pr ocessing systems , 36:53728–53741. Senthooran Rajamanoharan, T om Lieberum, Nicolas Sonnerat, Arthur Conmy , V ikrant V arma, János Kramár , and Neel Nanda. 2024. Jumping ahead: Im- proving reconstruction fidelity with jumprelu sparse autoencoders. arXiv pr eprint arXiv:2407.14435 . Nina Rimsky , Nick Gabrieli, Julian Schulz, Me g T ong, Evan Hubinger , and Alexander T urner . 2024. Steer- ing llama 2 via contrastiv e activ ation addition. In Pr oceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long P aper s) , pages 15504–15522. Gemma T eam, Mor gane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupati- raju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Ale xandre Ramé, and 1 others. 2024. Gemma 2: Improving open language models at a practical size. arXiv pr eprint arXiv:2408.00118 . Y otam W olf, Noam W ies, Dorin Shteyman, Bin yamin Rothberg, Y oa v Levine, and Amnon Shashua. 2024. T radeoffs between alignment and helpfulness in lan- guage models with representation engineering. arXiv pr eprint arXiv:2401.16332 . Zhengxuan W u, Aryaman Arora, Atticus Geiger , Zheng W ang, Jing Huang, Dan Jurafsky , Christopher D. Manning, and Christopher Potts. 2025. Axbench: Steering llms? e ven simple baselines outperform sparse autoencoders . Pr eprint , An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo wen Y u, Chang Gao, Chengen Huang, Chenxu Lv , Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, and 41 others. 2025. Qwen3 technical report . Pr eprint , Lianmin Zheng, W ei-Lin Chiang, Y ing Sheng, Siyuan Zhuang, Zhanghao W u, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P . Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judg- ing llm-as-a-judge with mt-bench and chatbot arena . Pr eprint , arXi v:2306.05685. Thomas P . Zollo, Andrew W ei T ung Siah, Naimeng Y e, Ang Li, and Hongseok Namkoong. 2025. Per- sonalllm: T ailoring llms to individual preferences . Pr eprint , arXi v:2409.20296. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Ale xander Pan, Xuw ang Y in, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zif an W ang, Alex Mallen, Ste ven Basart, Sanmi K oyejo, Dawn Song, Matt Fredrikson, and 2 others. 2025. Representation engineering: A top-down approach to ai transparency . Preprint , arXi v:2310.01405. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Ale xander Pan, Xuw ang Y in, Mantas Mazeika, Ann-Kathrin Dombrowski, and 1 others. 2023. Representation engineering: A top-do wn approach to ai transparency . arXiv pr eprint arXiv:2310.01405 . A Proofs and Additional Theory A.1 Full Assumptions Assumption A.1 (Shared-covariance mean shift, full statement) . There exist a positiv e semidefinite matrix Σ ∈ R d SAE × d SAE , a scalar c > 0 , and a prompt-dependent vector β ( x ) ∈ R d SAE such that, conditional on x , ˜ ρ ( y + ) ∼ µ ( x ) + c 2 Σ β ( x ) , Σ , ˜ ρ ( y − ) ∼ µ ( x ) − c 2 Σ β ( x ) , Σ , for some prompt-dependent mean µ ( x ) . Equiv a- lently , E [∆ ˜ ρ | x ] = c Σ β ( x ) . Assumption A.2 (Additi ve gating, full statement) . There exists a matrix B ∈ R d SAE × d SAE such that β ( x ) = B g ( x ) . Let M := E [ g ( x ) g ( x ) ⊤ ] ∈ R d SAE × d SAE denote the gate Gram matrix. Write the i th column of B as β ( i ) . A.2 Proof of Theorem 3.3 Pr oof. By iterated expectation and Theorem 3.1 , A ⊤ = E h ∆ ˜ ρ g ( x ) ⊤ i = E h E [∆ ˜ ρ | x ] g ( x ) ⊤ i = c Σ E h β ( x ) g ( x ) ⊤ i . Using Theorem 3.2 , β ( x ) = B g ( x ) , so E [ β ( x ) g ( x ) ⊤ ] = E [ B g ( x ) g ( x ) ⊤ ] = B E [ g ( x ) g ( x ) ⊤ ] = B M , gi ving A ⊤ = c Σ B M . Multiplying by Σ − 1 on the left and M − 1 on the right yields Σ − 1 A ⊤ M − 1 ∝ B . 11 Interpr etation. Equation A ⊤ = c Σ B M sho ws that rows of A generally mix multiple templates when gates co-activ ate: A i, : is proportional to Σ P i ′ M ii ′ β ( i ′ ) , not Σ β ( i ) unless M is approxi- mately diagonal. A.3 Proof of Theorem 3.4 Pr oof. By Theorems 3.1 and 3.2 , conditioning on g i = 1 : E [∆ ˜ ρ | g i = 1] = c Σ E [ β ( x ) | g i = 1] = c Σ E [ B g ( x ) | g i = 1] = c Σ β ( i ) + X i ′ = i π i ′ | i β ( i ′ ) . The norm bound follows from triangle inequality and submultiplicati vity: ∥ Σ X i ′ = i π i ′ | i β ( i ′ ) ∥ 2 ≤ ∥ Σ ∥ 2 → 2 X i ′ = i π i ′ | i ∥ β ( i ′ ) ∥ 2 . If additionally ∥ β ( i ) ∥ 2 > 0 and P i ′ = i π i ′ | i ∥ β ( i ′ ) ∥ 2 ≤ ϵ ∥ β ( i ) ∥ 2 , the relati ve error is bounded by ϵ · ∥ Σ ∥ 2 → 2 ∥ β ( i ) ∥ 2 / ∥ Σ β ( i ) ∥ 2 . A.4 DSP A Scoring and Optional De-mixing At inference time, DSP A constructs an activ e set S prompt (e.g., the top k prompt indices by ρ i ( x ) ) and uses the truncated indicator ˆ g ( x ) := 1 S prompt ∈ { 0 , 1 } d SAE . The score is s ( x ) := A ⊤ ˆ g ( x ) = c Σ B M ˆ g ( x ) , where the ideal unmixed preference direction would be c Σ B g ( x ) . DSP A makes two approx- imations: (i) replacing g ( x ) by a truncated in- dicator ˆ g ( x ) , and (ii) ignoring the of f-diagonal co-acti vation structure encoded in M . When M ≈ diag( p ) (weak gate dependence), s ( x ) ≈ c Σ B diag ( p ) ˆ g ( x ) . Optional de-mixing on the acti ve subspace. Al- though M is too large to in vert globally , DSP A only uses a small activ e set. Let S := S prompt and M S := E [ g S g ⊤ S ] ∈ R | S |×| S | . If M S is well- conditioned, a de-mixed score is s db ( x ) := A ⊤ S, : M − 1 S g S ( x ) ≈ c Σ B S g S ( x ) . A.5 Optimality of T op- k Ablation Assumption A.3 (Small ablation model in den- sity space) . For a fixed prompt x , ablating a set S ⊂ [ d SAE ] of size k produces an expected change ∆ ˜ ρ ( y ) ≈ − δ 1 S for some fixed δ > 0 . Theorem A.4 (T op- k ablation is optimal for lin- ear utility) . Under Theorem A.3 with linear util- ity U ( x, y ) = β ( x ) ⊤ ˜ ρ ( y ) , the expected utility im- pr ovement among all sets S with | S | = k is max- imized by choosing the k smallest coor dinates of β ( x ) . Pr oof. Under Theorem A.3 , ˜ ρ shifts by − δ 1 S , so E [ U ( x, y edited ) − U ( x, y )] = − δ P j ∈ S β j ( x ) . W ith fixed k , this is maximized by selecting the k smallest β j ( x ) . Relating s ( x ) to β ( x ) . Under Theorem 3.1 , the mean dif ference direction is c Σ β ( x ) , so scoring coordinates by s ( x ) targets (a mixed approximation of) Σ β ( x ) . If Σ is diagonal with nearly constant en- tries, rankings are preserved; otherwise, whitening by Σ − 1 before selection may improv e results. A.6 Finite-Sample Concentration Because ∆ ˜ ρ j ∈ [ − 1 , 1] and g i ∈ { 0 , 1 } , each sum- mand in ˆ A i,j is bounded. Let N i := P N k =1 g i ( x k ) be the number of training prompts with g i ( x ) = 1 . Lemma A.5 (Ro w-wise concentration) . Condi- tional on N i , for any ϵ > 0 , Pr | ˆ A i,j − A i,j | ≥ ϵ | N i ≤ 2 exp − 1 2 N i ϵ 2 . By a union bound, with pr obability at least 1 − δ , max j ∈ [ d SAE ] | ˆ A i,j − A i,j | ≤ q 2 log (2 d SAE /δ ) N i . Implication. Rare gates (small N i ) yield noisy conditional estimates, moti vating (i) percentile thresholding to control gate frequency and (ii) con- serv ativ e sparsification of A to remove entries dom- inated by estimation noise. B Prefer ence Featur e Identification: Base vs. Fine-T uned SAE Let A base denote the conditional-difference map (Section 3.1 ) computed using the base Gemma Scope SAEs, and A custom the same map computed using the custom fine-tuned SAEs, in both cases using Gemma-2-9B with ℓ input = 9 , ℓ output = 39 . As an approximation for the features most likely to be augmented or ablated under DSP A, we con- sider the top k diff = 16 output feature indices j for a gi ven input feature i , sorting by A i,j descend- ing for augment features or ascending for ablate features. Denote by A i, ( k ) the k th largest and by 12 A i, ( − k ) the k th smallest element of the row A i ; taking the union ov erall all i yields S base augment = [ i ∈ [ d SAE ] { j : A base i,j ≥ A base i, (16) } , S base ablate = [ i ∈ [ d SAE ] { j : A base i,j ≤ A base i, ( − 16) } and like wise for S custom augment and S custom ablate . W e find that | S base augment | = 183 , | S base ablate | = 186 , | S custom augment | = 76 , | S custom ablate | = 83 . Intuiti vely , the set of features most likely to be modified for the fine-tuned SAE is se veral times smaller than that for the base SAE, in- dicating a stronger concentration of features along generalized preference axes in the fine-tuned case. Interestingly , we find that many of the in- dices contained in these sets ov erlap between the base and fine-tuned SAE; concretely , | S base augment ∩ S custom augment | = 40 , | S base ablate ∩ S custom ablate | = 49 . Despite this, the generated interpretations do not always match; for example, feature 10776 is interpreted as Questions or statements in volving ille gal or clearly harmful activities for the fine-tuned SAE, and as Hedging or clarification language expr essing un- certainty or confusion for the base SAE. This small number of candidate features for the fine-tuned SAE is the grounds for our assertion in Section 3.1 that the matrix A custom is sparse in practice. Let τ = min {| A custom i,j | : A custom i,j ≥ A custom i, (16) or A custom i,j ≤ A custom i, ( − 16) } . If we set en- tries of A custom to 0 as long as | A custom i,j | < τ , then the number of nonzero entries is approxi- mately 0 . 002 d 2 SAE and A custom i,j = 0 for all j / ∈ S custom augment ∪ S custom ablate . Generating responses to all first- turn MT -Bench questions and both ablating and augmenting features, we disco ver that the ablated features are a strict subset of S custom ablate and the aug- mented features are a strict subset of S custom augment , vali- dating this approximation. C T raining Compute Cost Comparison: DSP A vs. RAHF-SCIT W e compare the cost of DSP A matrix construction against the two-stage RAHF-SCIT pipeline ( Liu et al. , 2024 ) under the assumptions used in our restricted-data analysis. Follo wing standard dense- transformer FLOP accounting ( Bro wn et al. , 2020 ; Cho wdhery et al. , 2022 ), we approximate one for - ward token by 2 P FLOPs and one training token (forward + backward) by 6 P FLOPs for a dense P -parameter model, ignoring the smaller attention correction and implementation ov erhead. W e take P = 8 × 10 9 (an 8B-class model), and for DSP A use conservati ve estimates prompt/chosen/rejected lengths, setting p = c = r = 1000 . For DSP A, each preference triple requires three forward-only passes: one over the prompt, one over prompt+chosen, and one over prompt+rejected. Hence F DSP A ( N ) = 2 P N (3 p + c + r ) . Under our length estimates, this becomes F DSP A ( N ) = 8 × 10 13 N . For RAHF step 1, the analyzed configuration consumes 4 N ef fectiv e training examples (two epochs ov er duplicated chosen/rejected variants), each with two gradient-tracked passes at ef fectiv e length L 1 = 768 , following the hyperparameter configuration in ( Liu et al. , 2024 ). This giv es F step1 ( N ) = 48 P N L 1 = 2 . 95 × 10 14 N . For RAHF step 2, each example performs three no-grad forward passes and one gradient-tracked pass, for an effecti ve cost of roughly 12 P FLOPs/- token. W ith effecti ve optimizer -step batch B = 64 , sequence length L 2 = 512 , and max_steps = 0 . 02 N , F step2 ( N ) = 12 P ( B L 2 )(0 . 02 N ) = 6 . 29 × 10 13 N . Therefore F RAHF ( N ) = F step1 ( N ) + F step2 ( N ) = 3 . 58 × 10 14 N , so the modeled compute ratio is F RAHF ( N ) F DSP A ( N ) ≈ 4 . 47 . These are model-FLOP estimates rather than measured hardware util ization, so the wall-clock ra- tio can be lar ger . In our Gemma-2-9B runs on a sin- gle Nvidia H200, DSP A matrix construction took 46 minutes with peak memory 33.1 GB, whereas the full RAHF pipeline took 8 hours 50 minutes with peak memory 140.8 GB. Thus, the observ ed wall-clock gap was 11 . 5 × , substantially larger than the 4 . 47 × modeled FLOP ratio. This extra gap is consistent with implementation ov erheads that are not captured by the simple FLOP model, including fixed-length padding, gradient checkpointing, and the more complex multi-pass training loop used by RAHF . 13 D Experimental Setup D.1 Evaluations W e obtain MT -Bench results using FastChat ( http s: //g it hub .co m/ lm- sys /Fa st Cha t ), AlpacaE- v al results using the official repository ( h t t p s : / / g i t h u b . c o m / t a t s u - l a b / a l p a c a _ e v al ), and MCQ benchmark results using the Language Model Evaluation Harness ( https://github.com /E l eu th e rA I/ lm - ev a l u at io n- ha rn e ss ). Cus- tom code is used for response and loglikelihood generation for each of these, while the provided code is used for e v aluations. W e use the com- mon leaderboard settings and metrics for all MCQ benchmarks, as sho wn in T able 5 . T able 5: Multiple-choice benchmark settings. Benchmark Few-shot Metric MMLU 5 acc Arc-Easy 25 acc_norm T ruthfulQA 0 mc2 HellaSwag 10 acc_norm W inogrande 5 acc D.2 Baselines T able 6 lists the hyperparameter configurations for our baselines. For single-layer interventions, we use the same output layer as with DSP A, namely ℓ output = 24 for Gemma-2-2B and ℓ output = 39 for Gemma-2-9B. For step 2 of RAHF , we run LoRA on layers { 8 , 10 , 12 , 14 } for Gemma-2-2B and { 10 , 12 , 14 , 16 , 18 } for Gemma-2-9B, attempt- ing to choose layers analogous to those used in the original paper for the giv en models. When per- forming our data ablation experiments, we scale do wn the max steps parameter on step 2 proportion- ately to av oid overfitting. Open-ended results are av eraged ov er three generation seeds, and we did not conduct an extensi ve per-model h yperparame- ter sweep for training baselines (especially DPO); stronger baseline performance may be achie vable with additional tuning. T able 6: Baseline hyperparameters. Baseline Hyperparameter V alue DPO Epochs 1 DPO Learning rate 5 × 10 − 6 DPO Beta 0.1 DPO Optimizer AdamW RepE Layer ℓ output RepE Directions 16 RepE Scale 0.5 Static-SAE Layer ℓ output Static-SAE Scale 0.5 RAHF Mode SCIT RAHF (step 1) Epochs 64 RAHF (step 1) Learning rate 2 × 10 − 5 RAHF (step 1) W armup ratio 0.1 RAHF (step 2) Learning rate 3 × 10 − 4 RAHF (step 2) Max steps 450 RAHF (step 2) LoRA rank 8 RAHF (step 2) LoRA alpha 16 RAHF (step 2) LoRA dropout 0.05 RAHF (step 2) Alpha 5 E MT -Bench Category Br eakdown For more detailed inspection of the strengths and weakness of DSP A relativ e to our baselines, we pro- vide a breakdown of MT -Bench scores by category across the surveyed methods, shown in T able 7 . W e find that DSP A is competiti ve across categories. Likely due to adjusting style and tone features, it scores the best on the Roleplay category for both models, while maintaining performance on more objecti ve tasks such as Math and Coding. Indeed, it also performs the best of any method studied on Math for both models, although scores are lo w across the board there for the small models in ques- tion. F Personalization Experiment W e also tested whether DSP A ’ s interpretable latent interventions can support lightweight personaliza- tion. W e use Gemma-2-9B with the same output SAE as in the main experiments. W e curate 200 prompts containing v aried content from the Person- alLLM dataset ( Zollo et al. , 2025 ), with an 80/20 train-test split. On the train set, we measure how ablating each candidate latent changes eight deter - ministic style axes relativ e to the base model, as sho wn in T able 10 . W e then construct persona- specific interventions either by selecting the top fi ve latents with the highest estimated utility gain or by ablating all latents with positiv e estimated gain. Ev aluation is performed on the test set, where 14 T able 7: MT -Bench scores by category . Coding Extraction Humanities Math Reasoning Roleplay STEM Writing Gemma-2-2B DSP A (ours) 2.20 3.20 5.92 2.40 3.00 6.60 5.72 6.05 DPO 3.10 4.38 6.67 2.00 3.02 4.95 5.65 5.09 RepE 1.93 4.97 5.90 2.30 2.95 5.25 5.96 5.26 Static-SAE 1.48 4.00 4.60 2.15 2.10 4.58 4.49 4.50 Prompt Eng 2.05 3.20 5.90 2.40 2.15 5.03 5.72 4.05 Base Model 2.30 3.80 5.90 2.20 2.90 4.05 5.92 4.17 Gemma-2-9B DSP A (ours) 3.55 5.05 6.78 2.35 3.77 5.55 7.17 5.35 DPO 3.30 6.12 5.67 2.25 3.90 5.10 6.67 6.50 RepE 2.90 4.08 6.70 1.95 3.55 5.10 6.15 5.35 Static-SAE 2.15 5.15 5.53 2.00 2.95 5.10 6.50 5.25 Prompt Eng 3.10 5.10 6.55 1.85 3.27 4.68 6.53 5.70 Base Model 3.33 3.90 5.86 1.95 3.45 5.12 6.55 4.92 we report two complementary scoring protocols. First, we use a deterministic axis rubric: each re- sponse is scored on the eight ax es and aggreg ated into a scalar utility under a fix ed persona-specific weight vector . Second, we e valuate ag ainst the ten re ward models released with PersonalLLM ( Zollo et al. , 2025 ), reporting mean judge z -scores (T a- ble 9 ). For the latter method, we test two v ariants of the DSP A-based method, judge-axis and judge- contrast. Judge-axis DSP A selects latents using the deterministic eight-axis personalization rubric: we estimate ho w each latent shifts the hand-designed style axes, then rank latents by their predicted util- ity under a judge-specific preference profile de- ri ved from those axes. Judge-contrast DSP A in- stead selects latents directly from paired reward dif ferences, fav oring latents whose ablation most improv es responses preferred by a gi ven Person- alLLM judge o ver responses it disfa vors, without going through the intermediate axis decomposition. W e test against the following baselines: 1. Instruction. For each persona, we provide the model with a short natural-language description of that user’ s preferences and ask it to answer in a way that matches those preferences, without retrie ving any example responses or modifying the model’ s activ ations. 2. F ew-shot ICL. Follo wing the most successful intervention from prior work ( Zollo et al. , 2025 ), we prepend one or fi ve persona-matched e xam- ple prompt-response pairs to the test prompt and then decode normally , without any latent inter - vention. The pairs are selected from the train- ing set based on cosine similarity to the current prompt. Across both protocols, latent ablation sho ws promise as a complementary personalization mech- anism, though prompt-based baselines remain strong ov erall. On the deterministic rubric, DSP A alone (top 5) improv es over the base model but trails both instruction-based and fe w-shot ICL methods; howe ver , combining DSP A with 5-shot ICL yields the best results (3.173), suggesting that latent interventions and retrie val-based methods capture complementary signals. On the reward- model protocol, DSP A-based methods outperform instruction prompting b ut do not reach the perfor- mance of few-shot ICL. These results indicate that DSP A ’ s stylistic interventions can augment other personalization strategies but are not yet a stan- dalone substitute for retrie val-based approaches. T able 8: Personalization: deterministic utility (higher is better). Method Mean utility Base model 2.400 DSP A (unconstrained) 2.431 DSP A (top 5) 2.539 Instruction 2.573 5-shot ICL 2.875 5-shot ICL + DSP A (top 5) 2.888 5-shot ICL + DSP A (unconstrained) 3.173 T able 9: PersonalLLM re ward-model e valuation (mean judge z -score ov er 10 rew ard models; higher is better). Method Mean judge z -score Instruction -2.239 Judge-axis DSP A (top 5) -2.128 Judge-contrast DSP A (top 5) -2.061 1-shot ICL -1.973 5-shot ICL -1.853 T able 10 shows the five single-latent ablations with the largest total absolute shift across the eight deterministic axes on the train split. The dominant patterns are broad discourse/style ef fects rather than clean one-axis controls: for example, latent 15 6345 most strongly shifts conciseness and proacti v- ity , while latent 3491 strongly increases structure. This supports the vie w that DSP A personalization operates through reusable stylistic features. G F eature Inter pretation G.1 Prompts W e use the following prompt to generate human- readable feature interpretations from gpt-5-mini : System: You are an interpretability researcher focused on overall trends. Use the provided snippets as evidence, and tolerate some counterexamples. Only mark a feature as unreliable if you are genuinely unsure. User: Latent {latent_idx} in an SAE. Provide a concise explanation (<=2 sentences). If you are genuinely unsure, return reliable=false. In the snippets, tokens wrapped in [[double brackets]] are where the latent is active; use surrounding context to interpret what the latent represents. It is OK if the pattern has some exceptions. Return JSON with keys: reliable (bool), explanation (string or null), evidence ( string). High-activation snippets: {snippets} W e again use gpt-5-mini with the follo wing prompt to assign categories to each interpretation. Because the Safety and Intent categories had rel- ati vely fe w members, for clarity , we folded those into Content and Discourse respectiv ely when re- porting results in Section 4.3 . You are given a short description of a language feature (an SAE latent interpretation). Assign it to exactly one of the following categories based on its primary function. If multiple categories seem plausible, choose the most dominant one. Return only the category name, with no explanation. Categories: Safety - Language related to harm, illegality, sensitive activities, private data, refusal, caution, or policy-related framing (e.g. illegal activities, self-harm, drugs, personal data requests). Discourse - Language that manages conversational flow or interaction rather than content (e. g. polite lead-ins, acknowledgements, hedging, topic shifts, explanation onsets). Intent - Language that frames what kind of action or response is being requested or provided (e.g. asking for instructions, step -by-step guidance, advice framing, question vs answer signaling). Structure - Tokens whose primary role is positional or structural rather than semantic (e.g. sentence-initial markers, clause boundaries, list markers, punctuation -adjacent or formatting tokens). Grammatical - Closed-class or near-closed-class grammatical function words with minimal standalone meaning (e.g. articles, pronouns, auxiliaries, conjunctions, generic connectors). Content - Topic-bearing or referential language with substantive semantic meaning (e.g. named entities, domains like politics or health, concrete objects or actions, lexical patterns like words starting with a specific prefix). Feature description: {description} G.2 Ablate and A ugment Set F eatures Interpretations for the 50 ablate set and 50 augment set features identified in Section 4.3 are sho wn in T able 11 and T able 12 , respecti vely . 16 T able 10: Mean train-set axis shift ∆ after ablating the fi ve most influential latents (positi ve to ward the left side of each axis). Axis 6345 3491 1077 13585 4260 Conciseness vs. v erbosity -0.106 0.000 -0.044 0.019 0.044 Friendliness vs. professionalism 0.031 -0.025 0.019 0.031 0.031 Directness vs. diplomac y -0.056 -0.081 -0.062 -0.100 -0.069 Structure vs. freeform 0.100 0.219 -0.050 0.050 0.000 T ask focus vs. relational focus -0.019 -0.019 -0.069 -0.038 -0.044 Proactiv e vs. minimal scope -0.094 -0.006 -0.019 -0.069 -0.056 Certainty vs. caveating -0.044 -0.075 -0.075 -0.056 -0.081 Creativity vs. literalism 0.006 -0.013 -0.050 0.013 -0.025 T able 11: Ablate-set features (50), with gpt-5-mini interpretations. Featur e Interpretation 11569 Filler phrases used to smooth con versation and request clarification 10776 Questions or statements in volving ille gal or clearly harmful activities 6345 Polite opening phrases that frame what follows 11287 First-person statements expressing personal vie ws or experiences 12550 Short connectiv e phrases linking ideas across clauses 1077 Introductory phrases that set up a question or topic 1810 Brief acknowledgements and generic con versational replies 10995 Common opening phrases that ease into an explanation 4260 Discourse markers that signal a shift or continuation in thought 6167 Phrases that signal an explanation or reasoning is about to follo w 8646 General noun phrases referring to people, roles, or categories 5681 Conjunctions commonly used at the start of multi-part statements 3107 Direct address phrases used at the beginning of a reply 14500 V ery common function words and basic grammatical glue 13585 Requests asking for instructions or methods to achiev e something 6782 T opic-introducing phrases that mark a ne w segment of thought 11172 Frequently used lead-in phrases starting an explanation 15059 Con versational opening phrases that introduce a question or ne w topic 3491 Common ev eryday words and short phrases spanning many unrelated topics 15061 Prefatory phrases that clarify , hedge, or gently frame what follo ws 13208 Short topical phrases that mark what is being asked about or explained 3869 Friendly , polite con versational lead-ins and transitional phrases 11799 V ery common short words used to open questions or continue dialogue 5327 Requests asking for step-by-step instructions or practical guidance 5705 Small grammatical connectors linking clauses or introducing verb phrases 3605 Structural framing phrases that set up how information will be presented 15907 Compact noun or verb phrases carrying the main focus of a statement 13819 Discourse cue words that introduce, reference, or frame content 15659 Signals marking the start of a substantiv e explanatory continuation 3142 Food, cooking, and hosting-related language and recipe conte xts 14408 Short function words and connecti ve fragments near punctuation 12655 Generic introductory phrases that begin an e xplanation or transition 4456 Engaging, agreeable openings that signal readiness to explain or list 15107 General action- or advice-framing language introducing recommendations 15168 V ery common function words with minimal standalone semantic content 6909 Clear explanatory or instructional language answering a question 11641 Sentence-initial grammatical tokens marking basic structure 8180 Clarifying lead-ins that refine or follow up 10118 Short grammatical tokens like pronouns and auxiliaries 5688 Sentence-opening filler with little consistent meaning 9580 Openings of short, direct questions 13493 Small connectiv e words linking clauses 437 Question-framing cue words and auxiliaries 5811 High-lev el framing words introducing a topic or question 8003 Common pronouns and conjunctions as grammatical glue 2842 Pronouns and short connectors common in con versation 4035 Short determiners, pronouns, and auxiliaries 14791 Generic con versational utility phrases 9631 First-person statements expressing intentions or requests 11855 Connectiv e function words continuing phrases 17 T able 12: Augment-set features (50), with gpt-5-mini interpretations. Featur e Interpretation 141 Common function words and grammatical connectors without semantic content 9825 Clarification and intent-seeking phrases linking questions and follow-ups 10075 T opic-naming or subject-introducing words and phrases 1030 Short list items and connectors enumerating entities or phrases 11031 Affirmati ve explanatory openings that introduce a helpful continuation 8244 Contractions and possessiv e markers using apostrophes 15634 Sentence- or clause-initial tokens marking utterance beginnings 4891 Polite request openings introducing questions or actions 13301 Con versational scaf folding words framing dialogue or transitions 2969 Everyday life topics and general practical advice conte xts 6268 Clause-initial function words like articles and auxiliaries 11779 Hedging or softening discourse openings before explanations 7569 T urn-initial or sentence-initial position markers 6509 Place names, locations, and location-focused references 6586 V ery short replies handling brief or provocati ve inputs 2135 Prompts ending with a focused keyw ord or target phrase 9304 Response-leading fragments introducing explanations or suggestions 5314 Question phrasing and self-referential statements expressing personal perspecti ve 5049 Auxiliary verbs and short grammatical continuations at clause boundaries 13656 Introductory interjections and brief discourse markers near turn starts 8172 Location and containment references like "in", "in my area", "address" 4263 Ke y topical noun phrases defining the main semantic focus 12827 Frequent topical nouns and short subject phrases across contexts 866 Common connectors like "or/of/the" in lists or alternati ves 6143 Clause-beginning tokens and common connectors near sentence starts 1820 V ery common function words and generic ev eryday connectiv e tokens 8543 Con versational lead-ins introducing instructions or e xplanations 15344 High-frequency stopwords and short boundary tok ens like "the/from/to" 1477 Concise direct question forms often beginning with wh-words 7375 High-frequency grammatical connectors like "are/this/the/b ut/is" 12366 Short glue phrases and function words near sentence or turn boundaries 8229 Initial tokens of named entities and multiword noun phrases 16271 Generic con versational openings and short transition phrases 14204 Salient topical keyw ords and notable content-bearing terms 5426 Informal con versational lead-ins, hedges, and smalltalk-style discourse markers 16033 Polite explanatory framing phrases introducing clarification or help 13130 Introductory phrases that open a new question or topic 6532 V ery common function words and generic connectiv e fillers 3594 T okens marking clause boundaries and ne w structural segments 5416 Openings that begin or continue an e xplanatory reply 9670 Common connectiv e words used during explanation or elaboration 13329 Direct question phrasing signaling a request for information 2610 Utterance-initial phrases starting a new topic or inquiry 613 Openings that introduce explanations, lists, or e xamples 7264 W ords referencing the main topic or subject under discussion 15264 Short grammatical connectors like prepositions and determiners 3895 Utterance-initial tokens marking the very start of a clause 14998 Short function words anchoring clause starts or discourse pi vots 2208 Sentence beginnings introducing concrete advice or factual responses 10754 T okens marking the start of a ne w question or request 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment