CALVO: Improve Serving Efficiency for LLM Inferences with Intense Network Demands
Distributed prefix caching has become a core technique for efficient LLM serving. However, for long-context requests with high cache hit ratios, retrieving reusable KVCache blocks from remote servers has emerged as a new performance bottleneck. Such …
Authors: Weiye Wang, Chen Chen, Junxue Zhang
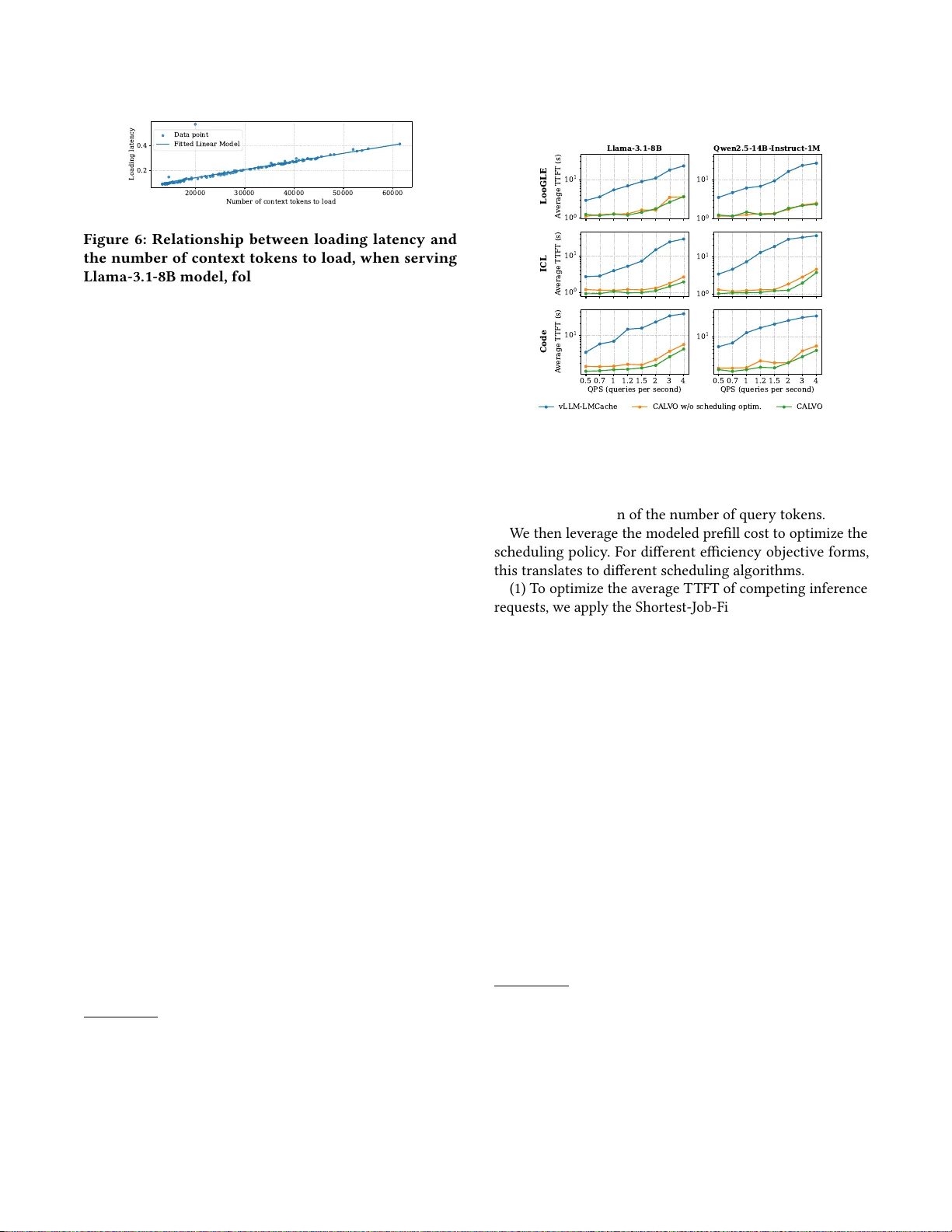
CALV O: Impro ve Serving Eiciency for LLM Inferences with Intense Netw ork Demands W eiye W ang Shanghai Jiao T ong University Chen Chen ∗ Shanghai Jiao T ong University Junxue Zhang University of Science and T echnology of China Zhusheng W ang Huawei Hui Y uan Huawei Zixuan Guan Huawei Xiaolong Zheng Huawei Qizhen W eng Institute of Articial Intelligence (T ele AI), China T elecom Yin Chen Institute of Articial Intelligence (T ele AI), China T elecom Minyi Guo Shanghai Jiao T ong University Abstract Distributed prex caching has become a core technique for ef- cient LLM serving. Howev er , for long-context requests with high cache hit ratios, retrieving reusable K V Cache blocks from remote servers has emerged as a new performance b ot- tleneck. Such network-intensive LLM infer ence is expe cted to be come increasingly common as agentic AI workloads continue to grow . Howev er , existing LLM inference engines remain largely compute-centric: they treat KV Cache loading as a subordinate phase to GP U execution and often fail to account for its delay explicitly during scheduling. W e present CALVO , an LLM ser ving engine that treats KVCache loading as a rst-class concern. CALV O decouples KVCache loading and GP U computation into indep endently managed, asynchronously progressing stages, enabling bet- ter utilization of network, PCIe, and computation resources. In addition, CALV O incorporates K V Cache loading delay as an explicit component of per-request ser vice cost, leading to more accurate scheduling de cisions. Experiments on a real testbed with diverse long-context workloads show that CALV O substantially improves the eciency of network- intensive LLM inference, achieving up to 61.67% higher SLO attainment than the baseline. 1 Introduction Large language models (LLMs) have demonstrated versatile capabilities on various real-world tasks like chatbot conversa- tion and code generation [ 9 , 25 , 27 ]. Given the surging user demands, LLM service providers nee d to eciently serve ∗ Chen Chen is the corresponding author . L2: DRAM L1: VRAM LLM Inference System Controlling Thread L3 L2 L2 L1 L3: Distributed KV Pool Compute Execution W orkflow Loading Loading V ia Network V ia PCIe FIFO Queue Control Figure 1: W orkow in a typical LLM infer ence engine (e .g., vLLM) when integrated with a distributed KV- Cache pooling frame work (e .g., LMCache). the incoming inference requests, for which Time-to-First- T oken (T TFT) is a key eciency metric. In particular , con- fronting the trend of increasing input context length (e.g., for document QA and project-level co de completion), pre- x caching [ 22 ] is prevalently adopted to optimize T TFT , which, by reusing previously-generated KVCache upon pre- x match, leverages storage resour ces for less computation. T o host large-volume KVCache in production platforms, distributed caching is often adopte d with the LLM inference engine, rendering it a common demand to conduct inter-node KVCache reuse. A s reported by existing works [ 22 ], a single node often fails to provide sucient memory capacity to attain high cache hit ratio. T o enlarge the available caching space, KVCache storage frameworks such as Mooncake [ 22 ] and LMCache [ 19 ] combine the DRAM spaces on distributed servers into a shared caching pool. As shown in Fig. 1, b e- fore the GP U computation of each inference starts, the LLM engine needs to load the reusable prex cache from r emote 1 W ang et al., W eiye W ang, Chen Chen, Junxue Zhang, Zhusheng W ang, Hui Y uan, Zixuan Guan, Xiaolong Zheng, Qizhen W eng, Yin Chen, and Minyi Guo memory (L3)—rst to its local CP U memory (L2) and then to its GP U HBM (L1). While inter-node KVCache reuse can improve the cache hit ratio and reduce redundant computation [ 22 ], it how- ever introduces non-negligible communication overhead. Our empirical measurements show that, when ser ving a long-context Lo oGLE dataset [ 13 ] with a distributed KV - Cache pool (with 400 Gbps links), the KVCache loading time may account for over 90% of the T TFT time. W e call such in- ference workloads— which rely heavily on prex caching and have a communication time comparable to computation —as network-intensive LLM inferences . With the wide adoption of KVCache pool and the high prompt similarity in popular LLM applications [ 15 ], network-intensiv e LLM inferences would be increasingly prevalent in pr oduction clusters. Howev er , when serving network-intensive LLM infer ences, existing LLM service engines [ 12 , 28 ]—designed for conven- tional computation-intensive inference workloads—often fail to attain high eciency . Those frameworks are designed to be compute-centric , treating cross-node K V Cache loading as a subordinate step controlled by the LLM compute scheduler . This design choice leads to two problems. First, the central- ized, compute-centric ser ving control incurs low utilization of both compute and network resources. Before an infer- ence completes all its stages (i.e., L3-to-L2 loading, L2-to-L1 loading, and GP U computing), no other inferences can si- multaneously utilize the temporally idled resources in any stage, causing substantial resource idling. Second, compute- centric scheduling control often leads to suboptimal service order . When determining the inference service order under contention, existing frameworks rely on simple heuristics like FIFO [ 12 ] or only consider the computation amount [ 6 ], totally ignoring the K V Cache loading delay which is actually a signicant part of the overall service cost, and this would compromise the overall T TFT performance. In this paper , we design CALV O , an optimized LLM engine for ecient serving of network-intensive LLM inferences, guided by the design philosophy to treat cross-node K V Cache loading as a rst-class citizen alongside computation . T o be concrete, ther e are two key techniques in CALV O . First, regarding cross-stage service coordination, CALV O decouples control across KV Cache loading and computation, so as to fully pipeline the inference serving path. A key chal- lenge is that loading can proceed only after the destination space at the higher storage le vel has been allocated. T o ad- dress this challenge, CALV O manages each K V Cache loading stage with an independent dispatcher-executor pair , and lets lower-lev el dispatchers proactively trigger space allocation at higher levels, so that loading at dierent stages can overlap as soon as data dependencies are satised. Second, regarding inter-inference scheduling order , CALV O incorporates the K V Cache loading delay of an inference as part of its ov erall service cost, which is more accurate and can help to optimize the scheduling performance. With sys- tem proling, we depict the ser vice cost as a binar y linear function which joins the factors of K V Cache loading and computation. That cost is then used for w orking out the best scheduling order—respectively for minimizing the av erage T TFT and for maximizing SLO attainment. CALV O is implemented atop vLLM [ 12 ], a mainstream LLM serving engine (together with LMCache [ 19 ], a popular KVCache access interlayer ). W e further verify the eective- ness of CALV O by conducting a compr ehensive evaluation with diverse benchmarks. The results show that, when ser v- ing network-intensive LLM infer ences, CALV O attains sig- nicantly higher eciency the status-quo practice, with an improvement of up to 61.67% in SLO attainment of T TFT . 2 Background and Motivation 2.1 LLM Inference: The Basics LLM inference: execution procedures and ser vice objec- tives. Large language models (LLMs) [ 4 , 7 , 26 ] have nowa- days been widely adopted in various elds like nance [ 14 ], arts [ 20 ] and science [ 23 ]. Applying LLM te chniques re- quires LLM inference , which contains two phases: prell and decode [ 30 ]. The prell phase processes the entire input prompt and constructs the intermediate attention keys and values (known as the KVCache ), which is commonly deemed computation-intensive. T o LLM service providers, ecient ser ving competing inference requests from diverse users is crucial. Sp ecically , a key ser vice quality metric is the time gap between the request arrival and the generation of the rst token, namely Time- T o- First- T oken (T TFT), which critically aects user experience. In this paper , we primarily consider accelerating the prell phase 1 , and focus on optimizing the T TFT p erformance. Prex caching: a common te chnique to save computa- tion cost. Mainstream LLM today now supports context window of 128K -2M tokens, enabling more long-context tasks like long-document QA [ 13 ]. Howev er , increased con- text size also introduces substantial computation demands, yielding a quadratic complexity in prelling computation [ 11 ]. T o mitigate this, production-grade LLM systems widely adopt prex caching, which stores the K V Cache for previously processed text prexes [ 1 , 18 ]. By reusing KV Cache across requests sharing the same prex, the LLM service system can avoid e xpensive re-computation during the prell phase , yielding a much better T TFT p erformance. For e xample, as illustrated later in Fig. 2, compared with performing pure 1 With the wide adoption of PD disaggregation [ 30 ] as well as the emergence of prell-only workloads [ 6 ], it is increasingly common to independently optimize the T TFT performance for the prell phase. 2 CALV O: Improve Serving Eiciency for LLM Inferences with Intense Network Demands T able 1: Statistics of representative long-context datasets. “ A vg. Context” denotes the average number of tokens in the provided context, and “ A vg. Quer y” denotes the average token length of the user query . Num. Reqs A vg. Context A vg. Quer y LooGLE 120 28 . 1 𝐾 28 ICL 120 28 . 3 𝐾 61 Code 100 38 . 3 𝐾 209 computation using vLLM, remotely loading the KVCache by vLLM-LMCache can reduce the T TFT by over 88%. 2.2 Network-Intensive LLM Inference Prevalence of distributed KVCache storage. With the ever-expanding long-context processing demands, the KV - Cache storage consumption keeps bo oming at a high rate, rendering the KVCache storage space on a single node eas- ily used up. For instance , when serving inference with the Llama-3.1-8B model, the K V Cache for merely 10M tokens would consume a storage space of over 1TB. T o accommo- date the large-volume KVCache content with relatively high speed (SSD, HDD or cloud storage platforms like S3 is of- ten too slow), modern LLM ser vice providers [ 22 ] often join the idled memor y on dierent servers into a distributed K V - Cache po ol [ 19 , 22 , 29 ], which is then plugged to the LLM inference engine [12, 28]. As previously shown in Fig. 1, there are three storage lay- ers for the KVCache content: L1—the GP U VRAM (HBM), L2—the local CP U DRAM, and L3—the remote CP U DRAM. When a LLM request arriv es, it will wait for being scheduled in a FIFO queue. Once a request is scheduled into a com- putation iteration, before the computation starts, the LLM engine needs to load the reusable KV Cache content to GP U VRAM. Specically , the engine rst searches for the longest reusable prex in the K V Cache pool; the spotted K V Cache prex (usually on remote host) would be loaded rst from L3 to L2 and then from L2 to L1. The inference computation will b e triggered once all the K V Cache ne eded by the cur- rent execution batch is done. After computation, the main control thread will go back to fetch a set of waiting requests to execute in the next iteration. KVCache loading: an emerging bottleneck for LLM in- ference. In typical LLM applications, an LLM inference in- put is composed of two parts: a static application-context and a dynamic user-query . The KVCache content of the shared context is usually reusable across dierent requests, with run- time computation only needed for processing the user query . In particular , with the in-depth adoption of LLM techniques, the static contexts in many applications are increasingly com- plex and lengthy . As shown later in T ab . 1, scenarios such as 4K 8K 16K 32K 48K 64K 96K T oken Length of Context 0 2 4 6 T TFT (s) vLLM-Compute vLLM-LMCache-Load vLLM-LMCache-Compute Figure 2: Breakdown of T TFT when a Llama-3.1-8B model serves requests with varying context-token length (to load from a remote server) yet xed query- token length. From the gure we learn that K V Cache reusing can eectively reduce T TFT , yet K V Cache load- ing now becomes a major bottleneck. long document Q A and project-lev el code completion task involve extremely long contexts (e.g., an average of 28.1K tokens in LooGLE [ 13 ]), whereas the corresponding user queries are relatively short ( e.g., only 28 tokens on average). This highlights an increasingly common pattern in the era of agentic AI era [15, 23]: long context, short quer y . Since KVCache r eusing essentially trades storage for com- putation eciency , a larger context-to-query ratio (i.e., a higher cache hit ratio) would shift the bottleneck from KV - Cache processing ( computation) to KVCache loading (com- munication). Fig. 2 shows the T TFT breakdown when serv- ing a single request with varying context lengths yet a xed query length (1000); the KVCache is loaded from a remote server following the setup in §4.1. It clearly demonstrates that, while KVCache reusing can help to reduce the ov erall T TFT , the ratio of K V Cache loading in T TFT keeps increas- ing, becoming an remarkable performance b ottleneck. For such LLM workloads with a high cache reuse ratio, since network transmission time is a key building block of their K V Cache loading delay , we call them as network- intensive LLM inference . As LLM applications be come more complex, it can b e expected that network-intensive LLM inference would be a mainstream LLM workload type in the future. Therefore, in this paper w e fo cus on eciency (T TFT) optimizations of network-intensive LLM inferences. 2.3 Ineciencies of Existing Practices While network-intensive LLM inferences are increasingly popular , existing LLM ser ving engines [ 12 , 28 ] still follow the legacy design for conventional computation-dominate LLM workloads. Our study shows that their compute-centric de- sign renders themselves high inecient for network-intensive inferences, and there are tw o reasons for that. 2.3.1 Low resource utilization due to centralized, compute- centric control of the entire ser ving workf low . Dierent K V - Cache processing stages in Fig. 1 require dierent resour ce 3 W ang et al., W eiye W ang, Chen Chen, Junxue Zhang, Zhusheng W ang, Hui Y uan, Zixuan Guan, Xiaolong Zheng, Qizhen W eng, Yin Chen, and Minyi Guo vLLM-LMCache CAL V O 0 10000 20000 30000 40000 50000 60000 70000 T oken Loading R ate (T oken/s) 160 180 200 220 240 Compute R ate (T oken/s) Load Compute Figure 3: Per-stage pro- cessing throughput in vLLM-LMCache is suboptimal (the throughput of our later proposed CALV O system is shown for comparison). R1 First (R1->R2) R2 First (R2->R1) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Timestamp (Second) R1 Load R1 Compute R2 Load R2 Compute Figure 4: Given two network-intensive requests, FIFO or compute-based SJF may prolong the average T TFT . types: network bandwidth for L3 → L2, PCIe bandwidth for L2 → L1, and GP U processors for computation. Howev er , the current LLM engines exemplied by vLLM adopts a central- ized ( single-threaded) contr ol ov er the entire workow: each stage (including the computation stage) is triggered passively as instructed by the main thread. Such a centralize d control is reasonable for conventional LLM workloads wher e there is no runtime KVCache loading, but no longer so for the emerging network-intensive LLM inferences: for which a centralized control is straightfor ward. when the K V Cache blocks of one inference request step to the next stage, the idled resources cannot be immediately used to serve other pending requests, leading to poor resource utilization. Our measurements conrm this ineciency . Specically , we ser ve the LooGLE dataset [ 13 ] over the Llama-3.1-8B model, with a workload intensity of 1.2 queries per second. W e measure per-stage processing throughput as the peak average throughput within any 20-second interval. In Fig. 3 we compare such per-stage processing throughput under vLLM-LMCache with that under our optimized CALV O en- gine (elaborated later in §3.1). The comparison results clearly demonstrate the resource utilization of current LLM serving frameworks is far from optimal. 2.3.2 Low scheduling quality due to blindness to KV Cache loading costs. On production LLM service backends, a mas- sive numb er of LLM inference submitted from dierent users may compete for the limited resources; under such resource contention, the scheduling order critically aects the over- all performance—in terms of the average T TFT value or the overall SLO attainment (in cases where a maximum al- lowable T TFT is associated for each request [ 17 ]). While KVCache loading has become a main p erformance bottle- neck for network-intensive LLM inference, existing LLM engines are blind to such costs in scheduling. Such blindness compromises the LLM scheduling quality . User Request Context Query Scheduler Priority Estimator Cache Hit Query API Executor L3 L2 Dispatcher - Allocate L2 space - Dispatch task L2 L1 Dispatcher - Allocate L1 space - Dispatch task L3 L2 Executor L2 L1 Executor Compute Executor Compute Context Manager CAL VO Component vLLM Component Request Flow Execution Flow Priority Queue Autonomous Execution (1) (2) (3) (4) (5) (7) (6) (8) Batch L3 Loading Concurrent load CUDA streams CAL VO Module Figure 5: W orkow of CALV O . T o illustrate the impact, we pr ole the loading and com- putation time of requests from the loogle dataset [ 31 ] with vLLM-LMCache. Consider two sampled requests: R1 ( arriv- ing earlier )—requiring 0.361 s to load and 0.019 s to compute , and R2—requiring 0.199 s to load and 0.025 s to compute. A scheduler that enforces naive FIFO or enforces SJF based on only the computation time [ 6 ] would prioritize R1, resulting in an average T TFT of 0.49 s. In contrast, another scheduler applying SJF with awareness to the KVCache loading time (prioritizing R2) can reduce the average T TFT to 0.41 s. Summary . In summary , the compute-centric nature of ex- isting LLM engines hurts the serving eciency of network- intensive LLM inferences; to improve, w e need to optimize existing LLM service engines in both inter-stage ser vice co- ordination and inter-request queue management. 3 Solution In this section, w e present CALV O , an optimized LLM engine that—by treating cross-network K V Cache loading as a rst- class citizen (stage) e qually important to prell-computation — can eciently serve network-intensive LLM infer ences. As shown in Fig. 5, CALV O is built atop vLLM; its workow is driven by a priority estimator and multiple loading dis- patcher/executors. By adding the autonomous dispatcher- s/executors, CALVO enhances the resource utilization in each stage; meanwhile, under the new priority estimator , CALVO improves the ov erall scheduling performance with aware- ness to the KVCache loading costs. Next we elaborate the optimizations respectively on the two aspects. 3.1 Inter-stage W orkow Optimization Recall that our previous study sho ws that, in existing LLM engines, the centralized control of the K V Cache processing workow (across all the stages of L3 → L2 loading, L2 → L1 loading, and GP U computation) compromises the overall resource utilization. T o maximize the resource utilization on each stage under the dataow dep endency , our insight is to equally grant each stage with the autonomy to act 4 CALV O: Improve Serving Eiciency for LLM Inferences with Intense Network Demands 20000 30000 40000 50000 60000 Number of context tokens to load 0.2 0.4 Loading latency Data point Fitted Linear Model Figure 6: Relationship b etween loading latency and the number of context tokens to load, when serving Llama-3.1-8B model, following the setup in §4.1. independently—similar to the classical dynamic sche duling mechanism in computer architecture design [24]. T o that end, in CALV O we let each KVCache loading stage managed by an independent dispatcher-executor pair . As de- picted in Fig. 5, for each loading stage, each dispatcher keeps driving its executor to conduct KVCache loading as long as (1) some lower-lev el K V Cache blocks of the highest-priority request ar e ready to pick up , and (2) the destination storage spaces of those KVCache blocks are allocate d . For the compute stage, when all K V -cache blocks required by a request nally become resident in L1 space, it immediately launches the prelling process, avoiding the compute wastage caused by waiting for loading completion in the critical path. Meanwhile, for smooth cross-stage negotiation, each time a stage completes loading a K V Cache block, it would issue a signal to the upper-level stage executor , so as to enable ne- grained loading overlapping. In particular , to let K V Cache loading be conducted autonomously , L1 space allocation should not be triggered by the compute stage in a reactive manner , which would block KVCache preloading; instead, in CALV O we let the low er-level stage dispatcher proactiv ely 2 trigger space allocation at the higher storage level. Similarly , when the L3 → L2 dispatcher issues a data transfer task to its executor , it will at the same time submit a GP U memory allo- cation request to the L2 → L1 dispatcher , so as to proactiv ely reserve GP U space for pipelined L2 → L1 loading. 3.2 Inter-request Scheduling Optimization T o optimize the overall scheduling performance, a prerequi- site is to precisely predict the ser vice cost of each LLM in- ference request; based on the discussion in §2.3.2, in CALV O we incorp orate the K V Cache loading delay as an indepen- dent component of the overall cost when ser ving a netw ork- intensive LLM inference. Specically , with oine system proling, we t out a binary linear function as the perfor- mance model, which respectively captures (1) 𝑇 load —loading latency as a function of the number of context tokens (which 2 While such proactive space allocation may take additional GPU memor y space, since the prell phase is computation-bound, trading additional memory consumption for faster execution is usually acceptable. In the extreme case where the available space in GPU memory in not enough, this method simply degrades to the reactive allocation method. 1 0 0 1 0 1 A verage T TFT (s) LooGLE Llama-3.1-8B 1 0 0 1 0 1 Qwen2.5-14B -Instruct-1M 1 0 0 1 0 1 A verage T TFT (s) ICL 1 0 0 1 0 1 0.5 0.7 1 1.2 1.5 2 3 4 QPS (queries per second) 1 0 1 A verage T TFT (s) Code 0.5 0.7 1 1.2 1.5 2 3 4 QPS (queries per second) 1 0 1 vLLM-LMCache CAL V O w/o scheduling optim. CAL V O Figure 7: Performance on A verage T TFT Latency . is linear as measured by Fig. 6), and (2) 𝑇 comp —computation latency as a function of the number of query tokens. W e then leverage the modeled prell cost to optimize the scheduling policy . For dierent eciency obje ctive forms, this translates to dierent scheduling algorithms. (1) T o optimize the average T TFT of competing inference requests, we apply the Shortest-Job-First (SJF) principle with the estimated prell cost, which is known to be optimal [ 5 ]. (2) T o optimize the o verall SLO attainment (in cases where each request is associated as a T TFT deadline at submission time), we apply the Least-Slack- Time-First (LSTF) principle, which is optimal for SLO attainment ratio [ 16 ]. For each incoming request, LSTF computes its slack time by LST = DDL − 𝑇 load − 𝑇 comp . The computed per-request LST serves as the priority of the corresponding request—with a smaller LST value indicating a higher urgency . 4 Evaluation 4.1 Experimental Setup Implementation. W e implement 3 CALV O on top of vLLM (v0.9.1) [ 12 ] and LMCache (v0.3.1) [ 19 ] with 3.3K lines of code, and we use Mooncake Store [ 22 ] as the L3 KVCache storage backend; all those frameworks are repr esentative in production environments. T o enable direct communication between loading dispatchers and loading executors without 3 For fair comparison, we identied and optimized tw o performance issues in vLLM-LMCache, which are orthogonal to our contributions. First, to ensure LMCache fully utilize loading bandwidth, we use Mo oncake ’s batch_get_- into interface for L3 → L2 transfers, and w e issue multiple L2 → L1 load kernels on dierent CUD A streams to better utilize PCIe bandwidth. Second, we restrict vLLM-LMCache to prell only one request at a time, preventing incorrect batching decisions by vLLM default scheduler . 5 W ang et al., W eiye W ang, Chen Chen, Junxue Zhang, Zhusheng W ang, Hui Y uan, Zixuan Guan, Xiaolong Zheng, Qizhen W eng, Yin Chen, and Minyi Guo 50 100 SLO A ttainment (%) LooGLE Llama-3.1-8B Qwen2.5-14B -Instruct-1M 50 100 SLO A ttainment (%) ICL 0.5 0.7 1 1.2 1.5 2 QPS (queries per second) 50 100 SLO A ttainment (%) Code 0.5 0.7 1 1.2 1.5 2 QPS (queries per second) vLLM-LMCache CAL V O w/o scheduling optim. CAL V O Figure 8: Performance on T TFT SLO Attainment. interrupting the main computation loop of vLLM, we use the ZeroMQ library [ 10 ] to implement inter-process communi- cation between worker process and scheduler process. T o make the vLLM scheduler agnostic to KV -cache loading, we override the add_request() function of the vLLM scheduler to intercept inference requests, prev enting them from being enqueued in vLLM’s FIFO computation scheduler queue. Hardware platform. The evaluation is conducted on one GP U node equipped with an 80 GB GP U and 128 GB CP U DRAM. The r emote CP U DRAM p ool consists of a CP U node with 512 GB DRAM; the tw o nodes are interconnected via RDMA with a 400 Gbps bandwidth link, all representative in modern GP U clusters. W orkloads. W e utilize two popular open-source LLMs with long context capabilities: Llama-3.1-8B-Instruct [ 2 ] and Qwen2.5-14B-Instruct-1M [ 25 ]. Meanwhile, we construct the test suite by sampling conte xts and corresponding queries from the three long context datasets: LooGLE [ 13 ] includes long documents from diverse sources such as arXiv , Wikipedia; ICL [ 31 ] features many-shot In-Context Learning tasks from diverse domains such as classication, summarization, r ea- soning, and translation; Code [ 3 ] covers varying coding tasks for LLM, and we use its project level code completion tasks for our evaluation. The statistics of these datasets are de- scribed in T ab. 1. Besides, since request arrival intervals are not available in these datasets, we simulate them following the Poisson distribution with dierent query intensities. 4.2 End-to-end Performance A verage T TFT . W e rst evaluate the end-to-end perfor- mance of CALVO under diverse QPS rates. As shown in Fig. 7, FIFO SJF -PT SJF P olicy 8 10 A verage T TFT (s) Figure 9: Comparison of dierent scheduling poli- cies in A verage T TFT . FIFO EDF LSTF P olicy 40% 60% 80% SLO A ttainment (%) Figure 10: Comparison of dierent scheduling poli- cies in SLO Attainment. regarding the average T TFT performance, CALV O substan- tially outperforms the default baseline (vLLM-LMCache) as well as its variant without scheduling optimization ( Use FIFO scheduling policy). For example , for the ICL dataset, when QPS is 1.2, CALVO can reduce the average T TFT by over 81.3%. Moreover , by comparing CALV O with its FIFO variant, we learn that scheduling optimization in CALVO is indee d indispensable for optimizing the overall performance e- ciency . SLO Attainment. T o che ck SLO attainment performance, we further assign each request with a T TFT SLO, by scal- ing its T TFT measured under interference-free conditions with a factor uniformly sample d from { 2 × , 4 × , 8 ×} , which is similar to prior works [ 8 , 21 ]. The results in Fig. 8 conrm the performance superiority of CALV O : in each case, the SLO attainment under CALV O is consistently better than the baselines. Specically , when the QPS is 1.2, the SLO attain- ment of CALV O is 61.67% higher than the vLLM-LMCache baseline. 4.3 Micro-benchmark Analysis Superiority of binary cost modeling. In infer ence sched- uling, another choice of cost modeling is to simply use the prell token numb er (we call the resultant scheduling method as SJF-PT ). W e thus compare CALV O (with the SJF policy integrated) against SJF-PT in Fig. 9, where each inference request is assigned a cache hit ratio randomly sampled from 25%, 50%, 75% and 100%. Fig. 9 suggests that, when not using the binary linear function for cost modeling, the estimated scheduling priority would be highly inaccurate, rendering the T TFT even worse than FIFO . Superiority of LSTF. W e also compar e CALV O (with the LSTF policy integrate d) with the Earliest Deadline First (EDF) policy , the latter not relying on the request service cost. As shown in Fig. 10, with the concrete knowledge of inference service cost, LSTF can make higher-quality scheduling de- cisions than the static EDF policy ( 73% versus 58% ). This conrms the need to leverage the information of KV Cache loading cost in scheduling. 6 CALV O: Improve Serving Eiciency for LLM Inferences with Intense Network Demands 25 50 100 Cache Hit R atio of Context (%) 0 10 20 A verage T TFT vLLM-LMCache CAL V O Figure 11: A verage T TFT under diverse cache hit rates. Sensitivity study on cache hit ratio. W e manually set the cache hit ratio respectively to 25%, 50%, 75% and 100%, and Fig. 11 shows the resultant CALV O performance. Accor ding to Fig. 11, the average T TFT performance is monotonously improving under CALVO as the cache hit ratio increases, suggesting that it is highly desirable to apply CALVO in the coming agentic AI era with high K V Cache reusing ratio [ 22 ]. 5 Conclusion and Future W ork In this paper , we design CALV O , an optimized LLM engine for ecient ser ving of network-intensive LLM inference. CALV O treats cross-server KVCache loading as a rst-class stage to serve, granting autonomy to each stage for higher resource utilization, and also incorporating K V Cache load- ing delay as indep endent cost factor for better scheduling decisions. Evaluations on long-context datasets show that CALV O can eectively enhance the serving eciency of network-intensive LLM infer ences in average T TFT and SLO attainment. In the future, we plan to extend CALVO to accelerate agentic AI workows, which requires the correlated KV - Cache loading tasks be scheduled in a coordinated manner . Meanwhile, we also plan to apply the network-as-a-rst- class-citizen philosophy into production inference system like Mooncake, so as to enhance the request routing perfor- mance as well as to mitigate the network collisions. References [1] Shubham Agarwal, Sai Sundaresan, Subrata Mitra, Debabrata Maha- patra, Archit Gupta, Rounak Sharma, Nirmal Joshua Kapu, T ong Yu, and Shiv Saini. 2025. Cache-Craft: Managing Chunk-Caches for Ef- cient Retrieval-A ugmented Generation. arXiv . doi:10.48550/arXiv . 2502.15734 [2] Meta AI. [n. d.]. Introducing Llama 3.1: Our Most Capable Models to Date. https://ai.meta.com/blog/meta-llama-3-1/. [3] Egor Bogomolov , Aleksandra Eliseeva, Timur Galimzyanov , Evgeniy Glukhov , Anton Shapkin, Maria Tigina, Y aroslav Golubev , Alexander Kovrigin, Arie van Deursen, Maliheh Izadi, and Timofey Bryksin. 2024. Long Code Arena: A Set of Benchmarks for Long-Context Code Models. arXiv:2406.11612 [cs] doi:10.48550/arXiv .2406.11612 [4] T om Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry , Amanda Askell, et al . 2020. Language mo dels are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901. [5] L. L. Cheng. 1985. A Proof of the Optimality of the Shortest-Job-First Policy for Monotone Processors. Op erations Research 33, 5 (1985), 1035–1040. doi:10.1287/opre.33.5.1035 [6] Kuntai Du, Bow en W ang, Chen Zhang, Yiming Cheng, Qing Lan, Hejian Sang, Yihua Cheng, Jiayi Y ao, Xiaoxuan Liu, Yifan Qiao, Ion Stoica, and Junchen Jiang. 2025. PrellOnly: An Inference Engine for Prell-only W orkloads in Large Language Model Applications. In Proceedings of the ACM SIGOPS 31st Symposium on Op erating Systems Principles . ACM, Lotte Hotel W orld Seoul Republic of Korea, 399–414. doi:10.1145/3731569.3764834 [7] Luciano Floridi and Massimo Chiriatti. 2020. GPT -3: Its nature, scope, limits, and consequences. Minds and Machines 30 (2020), 681–694. [8] Diandian Gu, Yihao Zhao, Yinmin Zhong, Yifan Xiong, Zhenhua Han, Peng Cheng, Fan Y ang, Gang Huang, Xin Jin, and Xuanzhe Liu. 2023. ElasticFlow: An Elastic Serverless Training Platform for Distributed Deep Learning. In Proceedings of the 28th A CM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2 . ACM, V ancouver BC Canada, 266–280. doi:10.1145/ 3575693.3575721 [9] Qiuhan Gu. 2023. Llm-based code generation metho d for golang com- piler testing. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symp osium on the Foundations of Software Engineering . 2201–2203. [10] iMatix Corporation. [n. d.]. ZeroMQ . https://zeromq.org. [11] Huiqiang Jiang, Y ucheng Li, Chengruidong Zhang, Qianhui Wu, Xu- fang Luo, Surin Ahn, Zhenhua Han, Amir H. Ab di, Dongsheng Li, Chin-Y ew Lin, Yuqing Y ang, and Lili Qiu. 2024. MInference 1.0: Accel- erating Pre-lling for Long-Context LLMs via Dynamic Sparse Atten- tion. In A nnual Conference on Neural Information Processing Systems 2024, NeurIPS 2024 . [12] W oosuk K won, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Ecient Memory Management for Large Language Model Ser v- ing with PagedAttention. In Proceedings of the 29th Symposium on Op- erating Systems Principles (SOSP ’23) . Association for Computing Ma- chinery , New Y ork, NY, USA, 611–626. doi:10.1145/3600006.3613165 [13] Jiaqi Li, Mengmeng W ang, Zilong Zheng, and Muhan Zhang. 2024. LooGLE: Can Long-Context Language Models Understand Long Con- texts? . In Proceedings of the 62nd A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Pap ers) , Lun- W ei Ku, Andre Martins, and Vivek Srikumar (Eds.). A ssociation for Computational Linguistics, Bangkok, Thailand, 16304–16333. doi:10.18653/v1/2024. acl- long.859 [14] Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. 2023. Large language models in nance: A survey . In Proceedings of the fourth A CM international conference on AI in nance . 374–382. [15] Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Y uqing Y ang, Fan Y ang, Chen Chen, and Lili Qiu. 2024. Parrot: Ecient Ser ving of LLM-based Applications with Semantic V ariable. In USENIX OSDI . [16] C. L. Liu and J. W . Layland. 1973. Scheduling Algorithms for Multi- programming in a Hard-Real- Time Environment. J. ACM 20, 1 (1973), 46–61. doi:10.1145/321738.321743 [17] Jiachen Liu, Zhiyu Wu, Jae- W on Chung, Fan Lai, Myungjin Lee, and Mosharaf Chowdhury . 2024. Andes: Dening and Enhancing Quality- of-Experience in LLM-Based T ext Streaming Services. [18] Y uhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray , Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Y ao, Shan Lu, Ganesh Anantha- narayanan, Michael Maire, Henry Homann, Ari Holtzman, and Junchen Jiang. 2024. CacheGen: KV Cache Compression and Stream- ing for Fast Large Language Model Serving. In Proceedings of the A CM SIGCOMM 2024 Conference . A CM, Sydney NSW A ustralia, 38–56. doi:10.1145/3651890.3672274 [19] LMCache. [n. d.]. LMCache. https://lmcache .ai/. [20] Christos Makridis. 2025. The Impact of Generative Articial Intelli- gence on Artists. A vailable at SSRN (2025). 7 W ang et al., W eiye W ang, Chen Chen, Junxue Zhang, Zhusheng W ang, Hui Y uan, Zixuan Guan, Xiaolong Zheng, Qizhen W eng, Yin Chen, and Minyi Guo [21] Deepak Narayanan, Keshav Santhanam, and Amar Phanishayee. 2023. Heterogeneity-A ware Cluster Scheduling Policies for Deep Learning W orkloads. In ASPLOS 23 . [22] Ruoyu Qin, Zheming Li, W eiran He , Jialei Cui, Feng Ren, Mingxing Zhang, Y ongwei Wu, W eimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation — A K V Cache-centric Architecture for Serving LLM Chatb ot. In 23rd USENIX Conference on File and Storage T echnologies (FAST 25) . USENIX Association, Santa Clara, CA, 155–170. [23] Shuo Ren, Pu Jian, Zhenjiang Ren, Chunlin Leng, Can Xie, and Jiajun Zhang. 2025. T owards Scientic Intelligence: A Sur vey of LLM-based Scientic Agents. arXiv preprint arXiv:2503.24047 (2025). [24] John Paul Shen and Mikko H. Lipasti. 1995. The Microarchitecture of Superscalar Processors. Proc. IEEE 83, 12 (1995), 1603–1623. doi:10. 1109/5.476077 [25] Qwen T eam. 2025. Qwen2.5-1M: Deploy Y our O wn Qwen with Context Length up to 1M T okens. https://qwenlm.github .io/blog/qwen2.5-1m/. [26] Hugo T ouvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozièr e, Naman Goyal, Eric Hambro, Faisal Azhar , et al . 2023. Llama: Open and ecient foundation language models. arXiv preprint arXiv:2302.13971 (2023). [27] Junchao Wu, Shu Y ang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, and Der ek Fai W ong. 2025. A survey on LLM-generated text detection: Necessity , methods, and future directions. Computational Linguistics (2025), 1–66. [28] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Je Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: E- cient Execution of Structured Language Model Programs. In Advances in Neural Information Processing Systems , A. Globerson, L. Mackey , D. Belgrave, A. Fan, U. Paquet, J. T omczak, and C. Zhang (Eds.), V ol. 37. Curran Associates, Inc., 62557–62583. [29] Zhiqiang Xie. [n. d.]. SGLang HiCache: Fast Hierarchical KV Caching with Y our Fav orite Storage Backends | LMSYS Org. https://lmsys.org/blog/2025-09-10-sglang-hicache. [30] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prell and Decoding for Goodput-optimized Large Language Model Serving. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) . USENIX Association, Santa Clara, CA, 193–210. [31] Kaijian Zou, Muhammad Khalifa, and Lu W ang. 2025. On Many- Shot In-Context Learning for Long-Context Evaluation. In Proce e d- ings of the 63rd Annual Me eting of the Association for Computational Linguistics (V olume 1: Long Papers) , W anxiang Che, Joyce Nab ende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Associ- ation for Computational Linguistics, Vienna, Austria, 25605–25639. doi:10.18653/v1/2025.acl- long.1245 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment