PrismWF: A Multi-Granularity Patch-Based Transformer for Robust Website Fingerprinting Attack
Tor is a low-latency anonymous communication network that protects user privacy by encrypting website traffic. However, recent website fingerprinting (WF) attacks have shown that encrypted traffic can still leak users' visited websites by exploiting …
Authors: Yuhao Pan, Wenchao Xu, Fushuo Huo
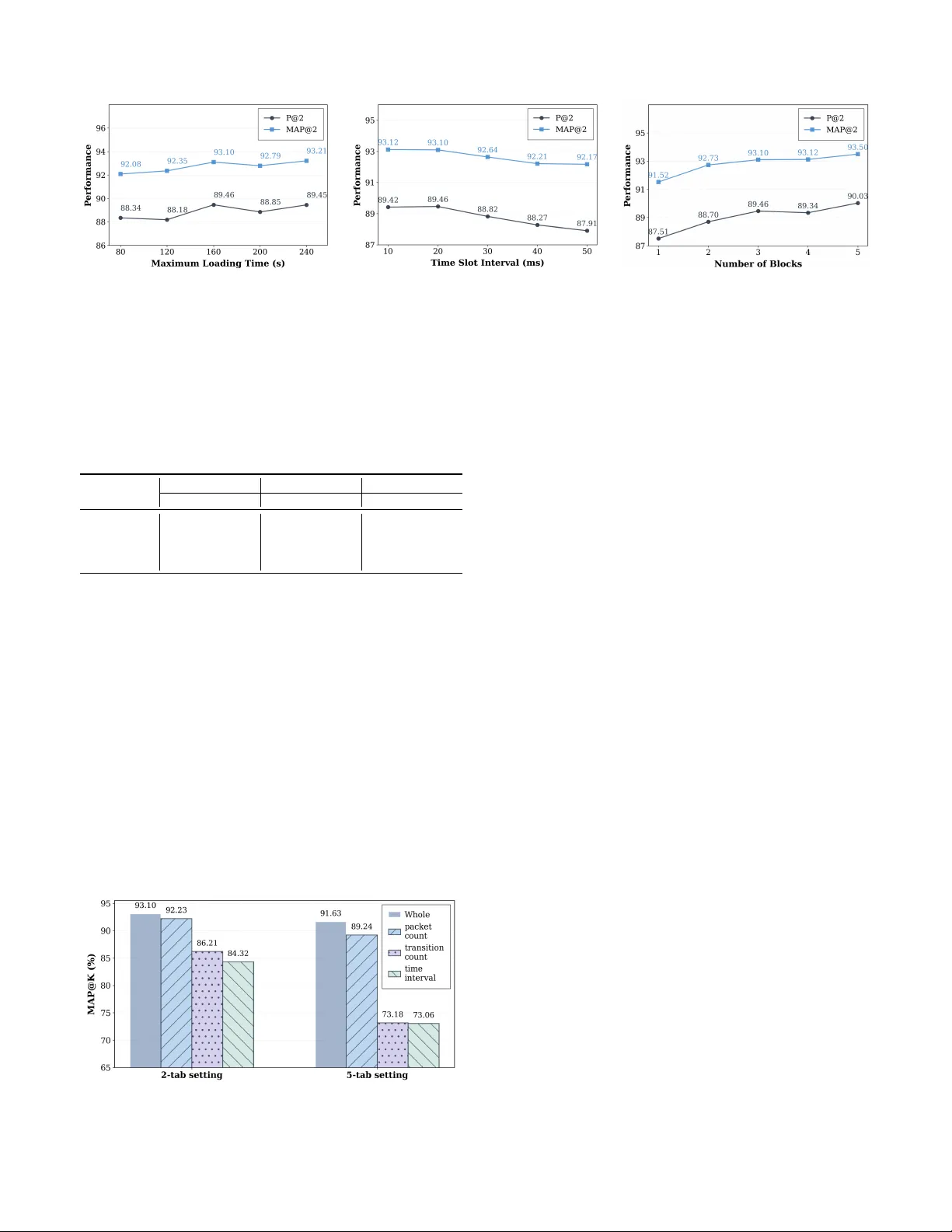
1 PrismWF: A Multi-Granularity P atch-Based T ransformer for Rob ust W ebsite Fingerprinting Attack Y uhao Pan ID , W enchao Xu ID , Member , IEEE , Fushuo Huo ID , Haozhao W ang ID , Member , IEEE , Xiucheng W ang ID , Graduate Student Member , IEEE, Nan Cheng ID , Senior Member , IEEE Abstract —T or is a low-latency anonymous communication network that protects user privacy by encrypting website traffic. Howev er , recent website fingerprinting (WF) attacks have shown that encrypted traffic can still leak users’ visited websites by exploiting statistical features such as pack et size, direction, and inter -arrival time. Most existing WF attacks formulate the prob- lem as a single-tab classification task, which significantly limits their effectiveness in realistic browsing scenarios where users access multiple websites concurrently , resulting in mixed traffic traces. T o this end, we propose PrismWF , a multi-granularity patch-based T ransformer f or multi-tab WF attack. Specifically , we design a rob ust traffic feature repr esentation for raw web traffic traces and extract multi-granularity features using con vo- lutional ker nels with differ ent r eceptive fields. T o effectively inte- grate inf ormation acr oss temporal scales, the proposed model re- fines features through three hierarchical interaction mechanisms: inter -granularity detail supplementation from fine to coarse granularities, intra-granularity patch interaction with dedicated router tokens, and router -guided dual-level intra- and cross- granularity fusion. This design aligns with the cognitive logic of global coarse-grained reconnaissance and local fine-grained querying, enabling effective modeling of mixed traffic patterns in WF attack scenarios. Extensive experiments on various datasets and WF defenses demonstrate that our method achie ves state- of-the-art performance compar ed to existing baselines. Index T erms —T or , W ebsite Fingerprint, Multi-tab Attack, Multi-Granularity . I . I N T R O D U C T I O N In recent years, the rapid growth of the Internet has inten- sified concerns ov er user priv acy during web browsing. T o mitigate these risks, anonymous communication systems have been widely deplo yed to conceal users’ identities and bro wsing behaviors. Among them, the T or network is one of the most widely used low-latency anonymity systems, serving millions of users worldwide [1], [2]. T or achieves anon ymity by routing Y uhao Pan and W enchao Xu are with the Division of Integrativ e Systems and Design, Hong Kong Univ ersity of Science and T echnology , Hong Kong, China (e-mail: ypanca@connect.ust.hk, wenchaoxu@ust.hk). W enchao Xu is the corr esponding author . Xiucheng W ang and Nan Cheng are with the State Ke y Labora- tory of ISN and School of T elecommunications Engineering, Xidian Univ ersity , Xi’an 710071, China (e-mail: xcwang 1@stu.xidian.edu.cn, dr .nan.cheng@ieee.org). Fushuo Huo is with the School of Cyber Science and Engineering, Southeast Univ ersity , Nanjing, China (e-mail: fushuohuo@seu.edu.cn). Haozhao W ang is with the School of Computer Science and T echnology , Huazhong Uni versity of Science and T echnology , W uhan, 430068, China (email: hz wang@hust.edu.cn). encrypted traffic through a multi-hop overlay network of relay nodes, such that no single relay can associate a user with their destination. While this design provides strong anonymity guarantees against network-lev el adversaries, it also gives rise to distincti ve traf fic patterns that can be e xploited by website fingerprinting attacks. Although T or provides strong anonymity guarantees at the network layer , the encrypted traf fic between the T or client and the entry node remains observable to a local adversary . By analyzing observable traf fic characteristics, such as packet sizes, packet directions, and inter -packet timing patterns, a local adversary can still infer sensitiv e information about users’ web activities. Early website fingerprinting (WF) attacks primarily relied on expert knowledge to manually design discriminativ e traf fic features, which were then fed into tra- ditional machine learning classifiers (e.g., random forests, support vector machines, and k -nearest neighbors) for website identification [3]–[5]. With the rapid advancement of deep learning (DL) [6], subsequent studies have proposed end- to-end neural network–based models that automatically learn discriminativ e representations directly from raw traf fic traces, significantly improving attack performance [7]–[9]. Moreover , as various mechanisms for defense against WF hav e been proposed, robust attack models (e.g., Deep Fingerprinting [10] and Robust Fingerprinting [11]) hav e been dev eloped to main- tain ef fecti veness under defended traffic conditions. These models are designed to mitigate performance degradation caused by traffic obfuscation and defense strategies, enabling more resilient WF attacks. Despite their effecti veness, existing single-tab WF attack methods still suffer from notable limitations. Most prior approaches are dev eloped under the core assumption that users access only one website at a time, where traffic from different domains is not interlea ved. Howe ver , in realistic browsing scenarios, users frequently visit multiple websites concurrently , resulting in mix ed traf fic traces with interleav ed packets from different websites. As a result, single-tab attack models are inherently limited and often struggle to achieve reliable performance under such traf fic mixing conditions. T o address this g ap, a number of multi-tab WF attack methods hav e been proposed to identify multiple coexisting websites from a single mixed traffic trace. Nev ertheless, existing multi- tab approaches still exhibit critical limitations that hinder their practical deployment and effecti v eness. On the one hand, some methods lack robust traf fic representation design and 2 directly le verage raw traf fic traces as input, which renders them incapable of accurately modeling the complex interleaving patterns of multi-tab traffic [12], [13]. On the other hand, other approaches adopt general DL architectures without adequately considering the mixed traffic traces of multi-tab bro wsing, leading to suboptimal performance. Furthermore, a subset of multi-tab WF attacks requires a priori knowledge of the exact number of concurrent websites present in the traffic trace, which is an unrealistic assumption in practical attack scenarios, undermining the methods’ real-w orld applicability [12], [14]. Motiv ated by these limitations, we propose PrismWF , a multi-granularity patch-based transformer tailored to the mixed characteristics of unidentified WF traf fic, which ex- plicitly models cross-temporal information interactions for robust multi-tab WF attacks. Concretely , we first transform raw website traf fic traces into a more rob ust representation that captures essential traf fic characteristics. Based on this representation, multi-granularity traffic features are extracted via parallel con volutional branches, yielding both coarse- grained global features and fine-grained local features. T o model the intrinsic information flow of website traffic, we design a traffic-a ware interaction mechanism that enables structured information exchange across granularities. Coarse- grained features capture broader contextual patterns of traffic segments, while fine-grained features preserve detailed tem- poral variations, allo wing complementary information to be effecti v ely integrated across scales. In addition, we introduce granularity-specific routers to aggregate semantic information within each granularity , and concatenate router representations from all granularities for final website identification. This de- sign substantially mitigates information loss caused by traffic mixing in multi-tab browsing scenarios, leading to improved robustness and accuracy in WF attacks. Extensiv e experiments demonstrate that PrismWF consis- tently achiev es state-of-the-art performance under multi-tab WF settings. Moreover , PrismWF remains robust under vari- ous WF defenses, maintains stable performance as the number of concurrently opened tabs increases, and generalizes well to more realistic mixed-tab scenarios where the number of visited websites is unknown a priori. The main contributions of this paper are summarized as follows: 1) W e propose PrismWF , a robust multi-tab WF attack model explicitly designed to address traffic mixing caused by concurrent multi-tab browsing. 2) W e introduce a nov el transformer-based architecture built upon Multi-Granularity Attention Blocks, which jointly model inter-granularity and intra-granularity traf- fic patterns across fine-to-coarse temporal scales. A dedicated router mechanism is further introduced to aggregate cross-granularity traffic cues, ef fectiv ely miti- gating performance degradation caused by traffic mixing in multi-tab scenarios. 3) W e conduct extensiv e experiments on large-scale public datasets under closed-world, open-world, and mixed-tab settings, and e valuate PrismWF against multiple state- of-the-art WF defense mechanisms. The experimental results show that PrismWF consistently achieves state- of-the-art performance in multi-tab WF attacks and demonstrates strong robustness under realistic deploy- ment conditions. The remainder of the paper is organized as follo ws. W e first introduce the related work in Section II and the threat model in Section III. W e present concrete design of PrismWF in Section IV from robust trace representation, website feature extraction, multi-granularity attention block, and website iden- tification. Next, we conduct a comprehensiv e ev aluation on the performance of PrismWF in Section V. W e discuss rele vant issues in Section VI and conclude this paper in Section VII. I I . R E L A T E D W O R K A. WF Attac k Single-tab WF attacks. Early WF attacks primarily relied on e xpert prior knowledge to transform raw traffic traces into hand-crafted features, followed by traditional machine learning techniques for website identification [4], [15]–[17]. W ang et al. [3] extracted a lar ge set of statistical features and improv ed k -NN classification through a weighted distance metric. Panchenko et al. [4] proposed CUMUL, which uses cumulativ e packet size features to represent traffic traces and employs an SVM classifier . T o improve rob ustness against noise and traffic perturbations, Hayes et al. [5] introduced the k -fingerprinting approach, which maps hand-crafted fea- tures into fingerprint representations via random forests and performs website identification using k -NN. W ith the strong capability of DL models for end-to-end feature learning, Rimmer et al. [7] first introduced the A WF framew ork, enabling WF attacks without manual feature en- gineering. Building upon this direction, Sirinam et al. [10] proposed DF , which adopts a deeper and more e xpressi ve CNN architecture. The DF model achiev es nearly 98% classification accuracy in the closed-world setting and maintains around 90% accuracy e ven under the WTF-P AD defense. Bhat et al. [8] presented V ar-CNN, a dual-branch residual conv olutional network. The two branches independently model packet di- rection sequences and temporal traffic v ariations, and their features are fused to improve WF performance, particularly under limited training data. T o further enhance portability and practical applicability , Sirinam et al. [9] explored an n -shot learning frame work based on triplet loss. By performing metric learning in the feature space, this approach pulls traffic traces from the same website closer together while pushing those from dif ferent websites farther apart, enabling more fle xible and transferable WF . Recently , Shen et al. [11] proposed the T raf fic Aggregation Matrix (T AM) traf fic representation, which aggregates uplink and downlink packets within fixed time slots to construct a robust traffic representation, enabling robust WF attacks. Deng et al. [18] proposed an early-stage WF attack based on spatio-temporal distribution analysis. By aligning features extracted from early traf fic and adopting supervised contrastiv e learning, their method enables accurate website identification at the early stage of page loading. Multi-tab WF attacks. Most existing WF methods rely on a single-tab assumption, where users are presumed to access only one website at a time. This assumption does not hold in practice, as multi-tab browsing generates mixed traffic 3 W eb s i t e A W eb s i t e C W eb s i t e B I d e al s i t u a t i o n R ea l i s t i c si t u at i o n Ti m e Fig. 1. Illustration of Traf fic Mixing Caused by Concurrent Multi-T ab Browsing. traces that substantially degrade the effecti veness of single-tab models. T o bridge this gap, researchers hav e started exploring multi-tab WF attacks, which aim to identify multiple website labels from a single mixed traf fic trace. In the field of multi-tab WF attacks, Guan et al. [12] proposed B APM, one of the first deep-learning-based end- to-end multi-tab WF attack models. BAPM performs block- lev el modeling on mix ed traffic traces to learn tab-aware representations and employs a self-attention mechanism to adaptiv ely fuse information across traffic blocks. Jin et al. [13] introduced a T ransformer -based WF attack model inspired by the DETR-style encoder–decoder architecture [19]. Their method adopts the feature extraction module from DF [10] as a backbone to preprocess ra w traf fic traces into feature sequences. A Transformer encoder is then used to capture global traffic context, while tab-aware query vectors in the decoder interact with encoded features to enable multi-tab website identification. Deng et al. [20], [21] proposed ARES, which first transforms multi-tab website traffic into the MT AF feature representation. Subsequently , multi-head attention is employed to capture global traffic dependencies, together with a T op- K sparse attention mechanism that focuses on traffic patterns most relev ant to tar get labels. More recently , Deng et al. [22] proposed CountMamba, which employs a causal CNN to extract traffic features and lev erages a Mamba state space model for multi-tab website fingerprinting attacks. B. WF Defense T o defend against WF attacks in T or, researchers have proposed to obfuscate traf fic traces by delaying real packets and injecting dummy packets, thereby effecti vely degrading the performance of WF attack models [23], [24]. Existing defenses can be broadly categorized into regularization-based WF defenses and adversarial example(AE)–based WF de- fenses. Regularization-based WF Defenses. Early WF defenses obfuscate traf fic fingerprints by enforcing fixed-time-interv al transmissions with uniform packet sizes. BuFLO [25] adopts a strict constant sending interval, pads all packets to a uniform size, and extends transmissions to a predefined maximum duration—effecti v ely eliminating timing and size-based dis- criminativ e features. T amara w [26] improv es upon BuFLO by supporting asymmetric constant rates for upstream and do wn- stream traf fic, which better matches the inherent asymmetry of web communications and reduces overhead. Despite this optimization, both approaches incur non-trivial bandwidth and latency ov erhead, se verely limiting their practical deployment in real-world scenarios. T o improve deployability , Ju ´ arez et al. [27] propose WTF-P AD, an adaptiv e padding defense that lev erages statistical models of traffic bursts to obfuscate web- site fingerprints without enforcing constant-rate transmission. Gong et al. propose FR ONT , a zero-delay and lightweight WF defense that injects dummy packets during idle periods. The padding interv als are randomly sampled from a Rayleigh distribution to obfuscate timing patterns. AE-based WF Defenses. Recently , AE-based techniques have been integrated into WF defenses, by injecting dummy packets to balance defensiv e efficacy and bandwidth ov erhead without additional latency . Mockingbird [28] employs a targeted strat- egy that iterati vely perturbs traf fic traces to ward a selected target to reduce distinguishability . Sadeghzadeh et al. [29] introduce A W A, constructing perturbations based on pairwise website relationships with two v ariants: NU A W A, which de- riv es sample-specific perturbations, and UA W A, which learns a univ ersal noise-dri ven perturbation for cross-website reuse. More recently , ALER T [30] utilizes a generator to produce targeted adversarial traffic, not only weakening adversarially trained attack models but also achieving state-of-the-art de- fense performance. Ho we ver , as these methods often suffer from degraded effecti veness in model transfer scenarios, we focus on ev aluating WF attacks under regularization-based defense settings. C. WF T race Repr esentation WF attacks identify target websites solely through traf fic analysis based on packet-le vel metadata, such as packet di- rection and timestamps. Early WF attack methods, including A WF [7] and DF [10], primarily relied on packet direc- tion sequences (i.e., +1 for outgoing packets and − 1 for incoming packets). Subsequent work, such as Tik-T ok [31], incorporated temporal information by jointly modeling packet directions and timestamps, leading to improved classifica- tion performance. Building on this line of research, Shen et al. [11] argued that transforming raw traffic traces into coarse- grained temporal representations can yield more rob ust attack performance, and proposed the T AM representation— which segments traffic into fixed-length time windows to form a 2 × N matrix ( N = ⌈ T /d ⌉ , with T as maximum page loading time and d as windo w size)—for recording incoming and outgoing packet counts. Follo wing this paradigm, a variety of window-based and statistical representations hav e been explored. For example, LASERBEAK [32] employed multi- dimensional statistical feature vectors, WFCA T [33] captured temporal characteristics using logarithmically binned inter- arriv al time (IA T) histograms, and ARES [21] proposed the MT AF representation, which extracts window-le vel features to jointly model cell-le vel and burst-le vel traffic patterns. I I I . T H R E AT M O D E L As illustrated in Fig. 2, users achieve anonymous web browsing via the T or network, where traf fic is routed through 4 E n t r y M i d d l e E xi t W e b s i t e s U s e r T or n e t w or k A d ve r s ar y Fig. 2. Illustration of T or network. a circuit of three randomly selected relay nodes—this multi- hop mechanism prevents destination websites from directly identifying users during access. In the WF threat model, the adversary is assumed to be positioned between the user and the T or entry node. Due to end-to-end encryption, the adversary cannot decrypt packet payloads and can only lev erage traffic metadata (e.g., packet timing, size, and direction) to infer the user’ s visited websites, formulating WF attacks as a traffic classification task. Following prior WF studies [9], [10], [13], [22], the adversary is restricted to passi ve observ ation, with no ability to modify , inject, or drop network packets. In a typical WF attack pipeline, the adversary first collects encrypted traffic traces by visiting a set of monitored websites via the T or network to construct a labeled training dataset. A WF attack model is then trained to associate encrypted traffic patterns with website identities. During deployment, the adversary passively observes the target user’ s encrypted traf fic and uses the trained model to infer visited websites. This study considers a more realistic and challenging WF attack scenario where users access multiple websites con- currently . Such concurrent access causes traf fic mixing in aggregated traces, significantly degrading traditional single-tab WF attack performance. W e further consider a practical mixed- tab setting, where the adversary has no prior knowledge of the number of concurrently accessed websites in collected traces. W e also account for WF defense mechanisms: giv en the high cost of customized defenses, users typically rely on publicly av ailable alternati ves in practice. WF attacks are commonly ev aluated under two standard settings [7], [10], [20], [22], [33]: the closed-world and open- world scenarios. Given the vast number of websites on the Internet, attackers typically monitor only a subset of websites of specific interest. In the closed-world scenario, the attack task is formulated as classifying traffic traces exclusi vely into the predefined set of monitored websites. In the more realistic open-world scenario, users may also visit a large number of websites outside the monitored set, referred to as unmonitored websites. T o distinguish between monitored and unmonitored traffic, prior work typically aggregates all unmonitored websites into an additional class, constructing a practical open-world ev aluation setting. I V . M E T H O D O L O G Y In this section, we first introduce the overall architecture of PrismWF and then detail each component. The pipeline of PrismWF is presented in Algorithm 2. A. Overall Arc hitectur e of PrismWF As illustrated in Fig. 3, PrismWF first transforms raw website traffic into a rob ust trace representation by partitioning each trace into fixed-length time slots and extracting an M - dimensional feature matrix that captures both pack et-level statistics and temporal interval characteristics. A multi-branch CNN feature extractor then models traffic patterns at different temporal granularities, where branches with distinct kernel sizes generate patch tokens covering coarse-grained contextual patterns and fine-grained local details. T o refine these multi- granularity representations, we introduce a traffic-a ware Multi- Granularity Attention Block with a dedicated router token for each granularity . Each block incorporates three complementary mechanisms: inter-granularity interaction for information e x- change across temporal scales, intra-granularity interaction for patch-lev el semantic aggregation, and inter-granularity router interaction for fusing semantic summaries across granularities. Finally , router tokens from all granularities are concatenated into a unified representation and fed into a linear classifier for multi-tab website identification. B. Rob ust T r ace Repr esentation Extracting effecti ve traf fic representations from interleav ed website traces is critical for downstream WF attack models, as raw traffic is often contaminated by packets from concur- rent websites and obfuscation mechanisms. In such settings, website-specific identity features are hard to isolate due to se- vere temporal noise and traffic interleaving. Existing represen- tations based on global traf fic statistics tend to ov erlook fine- grained temporal structures, making them vulnerable to WF defenses. Moreover , representations that rely solely on packet direction sequences fail to capture time-slot-lev el temporal dynamics, thereby limiting their ability to identify the injection timestamps of newly opened websites in multi-tab scenarios. T o address these challenges, we adopt a fix ed-size time-slot strategy that abstracts raw packet e vents into structured local temporal segments. Specifically , the time axis of each traf fic trace is partitioned into equal-length intervals with duration ∆ t , enabling localized modeling of traffic dynamics. Let a raw traffic trace collected from the T or network be denoted as x = { f 1 , f 2 , . . . , f N } , (1) where each packet event f i = ⟨ d i , t i ⟩ consists of a packet direction d i and its corresponding timestamp t i . Here, d i ∈ { +1 , − 1 } indicates outgoing ( +1 ) or incoming ( − 1 ) packets. Accordingly , the traffic trace can be represented as a matrix x ∈ R 2 × N , where the first ro w encodes packet directions and the second ro w records timestamp information. Giv en a predefined maximum page loading time T , the total number of time slots is computed as L = T ∆ t . For each time interv al, we extract a six-dimensional feature vector to characterize the traffic pattern within that slot. These features consist of tw o categories: packet-lev el statistics (4 dimensions) and time-interval features (2 dimensions). Specif- ically , the pack et-lev el statistics include (i) the numbers of incoming and outgoing packets, and (ii) the counts of direction 5 O r igina l T r a c e R obust T r a c e R e pr e se nta ti on Multi-Branch CNN Feature Extractor Router Concat Projection I de ntif ic a t i on M ulti - G r a n ul a r it y A tte ntio n B loc k × N R oute r toke n P a tc h toke n I nte r - gr a nu l a r i t y inte r a c ti o n In t ra- g r a n ul a r i t y r oute r - l e ve l inte r a c ti on In t ra- g r a n ul a r i t y p a t c h - l e v e l inte r a c ti on I nte r - gr a nu l a r i t y r oute r inte r a c ti on Fig. 3. Overview of the PrismWF . transitions from outgoing to incoming and from incoming to outgoing packets. The time-interval features capture the temporal gaps between consecutiv e outgoing-to-incoming and incoming-to-outgoing packet transitions within each time slot. By aggreg ating these features across all time intervals, we construct a unified traf fic feature matrix: M = ϕ ( x ) ∈ R 6 × L , (2) where ϕ ( · ) denotes the traffic feature construction function. In practice, the actual number of intervals is truncated to L if it exceeds the predefined value, or padded with zeros if it is insufficient to reach L . The detailed robust trace feature construction steps are presented in Algorithm 1. C. Multi-Granularity F eature Extraction W ebsite traffic traces are long temporal sequences con- taining patterns at multiple time scales. T o capture traf fic characteristics at dif ferent temporal resolutions, we employ G parallel CNN branches with distinct kernel sizes to e xtract multi-granularity features from the robust traffic representation M . Each branch focuses on a specific temporal granularity and projects the extracted features into a shared embedding space. For the i -th branch with kernel size k i , a CNN feature extractor is applied to obtain: F i = CNN i ( M ) ∈ R d × N i , (3) where d denotes the unified embedding dimension and N i represents the number of patch tokens produced at the cor- responding granularity . Each CNN i consists of three stacked con volutional blocks, inspiring by the design of the DF feature extractor . Each Con vBlock includes two 1D con volutional layers with batch normalization and ReLU activ ation, follo wed by a max-pooling layer for temporal downsampling and a dropout layer for regularization. Due to the use of dif ferent kernel sizes and pooling operations, each branch produces a Algorithm 1 Robust T race Feature Construction M = ϕ ( x ) Input: Traf fic trace x ; max loading time T ; time slot size ∆ t Output: Feature matrix M ∈ R 6 × L 1: L ← T ∆ t ▷ T otal time slots 2: M ← 0 6 × L 3: f or j = 1 to L do 4: I j ← { i | ( j − 1)∆ t ≤ t i < j ∆ t } ▷ Pack et indices in j -th slot 5: if I j = ∅ then 6: continue 7: end if 8: Extract ordered subsequence { ( t k , d k ) } n k =1 from { ( t i , d i ) } i ∈I j , where n ← |I j | 9: c + ← P n k =1 I ( d k = +1) , c − ← P n k =1 I ( d k = − 1) 10: n + − ← 0 , n − + ← 0 , s + − ← 0 , s − + ← 0 11: for k = 1 to n − 1 do 12: if d k = +1 ∧ d k +1 = − 1 then 13: n + − ← n + − + 1 , s + − ← s + − + ( t k +1 − t k ) 14: else if d k = − 1 ∧ d k +1 = +1 then 15: n − + ← n − + + 1 , s − + ← s − + + ( t k +1 − t k ) 16: end if 17: end f or 18: s + − ← I ( n + − > 0) · s + − n + − 19: s − + ← I ( n − + > 0) · s − + n − + 20: M [: , j ] ← [ c + , c − , n + − , n − + , s + − , s − + ] ⊤ 21: end f or 22: retur n M feature sequence of length N i , corresponding to a specific temporal granularity . The final Con vBlock in each branch outputs d -dimensional features, thus ensuring all branches generate tokens in the pre-defined unified embedding space. W e then transpose the feature matrix to obtain the patch token sequence for each 6 granularity: u i = F ⊤ i ∈ R N i × d . (4) This design enables seamless interaction among tokens from different granularities in subsequent attention layers, while N i varies across branches due to the different downsampling rates induced by distinct k ernel sizes. D. Multi-Granularity Attention Block After obtaining the multi-granularity representations of website traffic features, we further refine these features us- ing the proposed Multi-Granularity Attention Block, which is designed to enable structured information interaction across temporal scales. The model stacks B identical blocks, each consisting of three attention-based interaction lay- ers that jointly support intra-granularity feature modeling and inter-granularity semantic aggre gation. Specifically , intra- granularity interactions capture temporal dependencies within each granularity , while inter-granularity interactions fuse com- plementary semantic information across different granularities. Through this hierarchical, attention-driv en refinement process, the model progressi vely enhances the discriminability of traf fic representations, facilitating more accurate WF attack. The detailed design of each interaction layer is described belo w . Router T oken Injection. T o obtain compact and compara- ble representations across dif ferent temporal granularities, we introduce a learnable r outer token for each granularity le vel. The router token serves as a granularity-lev el semantic proxy that summarizes patch-lev el features into a fixed-dimensional representation, which is amenable to downstream projection and classification. Specifically , for the i -th granularity , a router token is defined as v i ∈ R 1 × d . (5) The router token is appended to the corresponding patch token sequence, ˜ u i = [ u i ; v i ] ∈ R ( N i +1) × d , (6) enabling the router token to interact with patch tokens within the same granularity and progressively aggregate granularity- specific semantic information. As a result, the router tokens yield compact granularity-wise representations that are con- catenated for final classifier prediction, while enabling cross- granularity information interaction via a shared projection space. Inter -granularity Interaction. T o enable effecti ve informa- tion exchange across dif ferent temporal granularities, we adopt a coarse-to-fine interaction paradigm where coarse-grained representations query and retriev e complementary information from finer-grained representations. This design is moti v ated by the inherent characteristics of website traffic traces, where traffic mixing frequently arises. Traf fic segments from dif- ferent websites may dominate different portions of a traf- fic sequence or become temporally interleav ed, resulting in mixed traffic patterns. Coarse-grained tokens provide a global and robust contextual perspective, while fine-grained tokens preserve detailed temporal variations. Our inter-granularity interaction mechanism lev erages this duality to guide fine- grained feature retriev al under macroscopic coarse-grained context, thereby mitigating the impact of traffic mixing. During inter-granularity interaction, only patch tok ens participate in cross-granularity information exchange, while router tokens are excluded. Let u ( b − 1) i ∈ R N i × d denote the patch token sequence of the i -th granularity at the ( b − 1) -th Multi-Granularity Attention Block. For two adjacent granularities, we employ a local coarse-to-fine cross-attention mechanism to realize information interaction. Specifically , each coarse-grained patch token is aligned with a corresponding temporal region in the fine-grained sequence, so that fine-grained features can be selectively queried from the relev ant time span. Assume the coarse-grained sequence contains N c patch tokens and the corresponding fine-grained sequence contains N f patch tokens. For the n -th coarse-grained patch token (with zero- based indexing) acting as the query , we compute the center index of its corresponding region in the fine-grained sequence as c n = ( n + 0 . 5) N f N c , (7) where offset +0 . 5 aligns the coarse-grained token with the temporal center (rather than left boundary) of its correspond- ing fine-grained re gion, enabling more accurate coarse-to-fine feature matching. W e then perform multi-head cross-attention (MHCA), which follows the standard attention formulation with queries and key–v alue pairs drawn from dif ferent tok en sequences. Specifically , coarse-grained patch tokens act as queries, while fine-grained patch tokens serve as ke ys and values within a local temporal window to preserve alignment and suppress irrelev ant interference. Let u f ∈ R N f × d denote the fine- grained patch token sequence. For the n -th coarse-grained patch tok en, we select a local subset of fine-grained patch tokens centered at c n , with the windo w size controlled by the hyper-parameter w , which specifies the maximum number of fine-grained tokens attended by each coarse-grained token: u ( c n ,w ) f = u f [ k ] k ∈ max 0 , c n − w 2 , min N f − 1 , c n + w 2 . (8) W ithin this local window , MHCA is applied to update the coarse-grained representations: u ′ c = MHCA u c , u ( c n ,w ) f , u ( c n ,w ) f , (9) where u c denotes the coarse-grained patch token sequence. This coarse-to-fine local cross-attention enables coarse-grained representations to selecti vely aggregate informativ e fine- grained temporal details while suppressing interference from unrelated or mixed traffic se gments, which is critical for robust multi-tab WF attacks. Intra-granularity Interaction. Within each temporal gran- ularity , we design an intra-granularity interaction module to model local temporal dependencies among patch tokens and global semantic conte xt summarized by the router token. T o this end, a hybrid attention mechanism with two comple- mentary branches is adopted: patch-le vel local interaction and router-le vel global aggregation. 7 (1) P atc h-level local interaction. Patch tokens exchange information via local multi-head self-attention to capture short- range temporal dependencies within the same granularity . Giv en the patch token sequence u ′ i ∈ R N i × d of the i - th granularity , the locally refined patch representations are computed as u loc i = MHA local ( u ′ i , u ′ i , u ′ i ) . (10) where MHA local ( · ) denotes multi-head self-attention restricted to a local temporal neighborhood to preserve temporal coher- ence while suppressing interference from distant segments. (2) Router-le vel global interaction. In parallel, the router token acts as a granularity-lev el semantic aggregator that summarizes global information within the same granularity . By attending to all locally refined patch tokens, the router token captures holistic traffic semantics that complement patch- lev el representations. The aggregated router representation is obtained via multi-head cross-attention: v glob i = MHCA v ′ i , u loc i , u loc i , (11) where v ′ i ∈ R 1 × d denotes the router token of the i -th granularity . T ogether , these two interaction branches enable ef fectiv e intra-granularity feature refinement by integrating fine-grained local temporal structures with global semantic context. Finally , the updated intra-granularity token sequence ˜ u ′′ i = [ u loc i ; v glob i ] serves as the input to subsequent interaction modules. Inter -granularity Router Interaction. T o enable global in- formation exchange across different granularities within each Multi-Granularity Attention Block, we perform global atten- tion among router tokens from all granularities. This design allows each router token to aggre gate complementary global semantic information captured at other temporal scales. Specif- ically , the router token of the i -th granularity is extracted from the corresponding token sequence ˜ u ′′ i , which consists of N i patch tokens followed by one router token: r ′′ i = ˜ u ′′ i [ N i + 1] ∈ R 1 × d , (12) where the ( N i + 1) -th position corresponds to the router token under 1-based indexing. All router tokens are concatenated to form a router -lev el sequence R = [ r ′′ 1 ; r ′′ 2 ; . . . ; r ′′ G ] ∈ R G × d , (13) which is updated via global multi-head self-attention: R ′ = MHA global ( R , R , R ) . (14) The updated router tokens R ′ are then redistributed to their corresponding granularities and written back to the token sequences for the ne xt block: ˜ u ( b ) i = ReplaceRouter( ˜ u ′′ i , R ′ [ i ]) , (15) where ReplaceRouter( · ) replaces the router token in ˜ u ′′ i with R ′ [ i ] while keeping all patch tokens unchanged. Algorithm 2 Pipeline of PrismWF for WF Attack Input: Raw traf fic trace x ; slot size ∆ t ; maximum loading time T ; branch kernels { k i } G i =1 ; number of attention blocks B ; local attention windows ( w intra , w inter ) ; (training only) website label y (single-/multi-tab) Output: Predicted website labels ˆ y 1: 1) Robust T race Representation 2: M ← ϕ ( x ; ∆ t, T ) ▷ M ∈ R M × L : slot-based traf fic features 3: 2) Multi-Granularity Featur e Extraction 4: f or i = 1 to G do 5: U i ← BranchCNN i ( M ; k i ) ▷ patch tokens U i ∈ R N i × d 6: r i ← InitRouter( d ) ▷ router token r i ∈ R 1 × d 7: ˜ U i ← [ U i ; r i ] ▷ append router tok en 8: end f or 9: 3) Stacked Multi-Granularity Attention Blocks 10: f or b = 1 to B do 11: Inter -Granularity Interaction (coarse → fine) 12: { ˜ U i } G i =1 ← InterGran ularityIn teraction( { ˜ U i } G i =1 , w inter ) 13: Intra-Granularity Interaction (patch-local + router -global) 14: { ˜ U i } G i =1 ← IntraGran ularityIn teraction( { ˜ U i } G i =1 , w intra ) 15: Inter -Granularity Router Interaction (router fu- sion) 16: { ˜ U i } G i =1 ← RouterInteract( { ˜ U i } G i =1 ) 17: end f or 18: 4) W ebsite Identification 19: z ← ConcatRouters( { ˜ U i } G i =1 ) 20: ˆ y ← f ( z ) ▷ website prediction (single-/multi-tab) 21: if training then 22: L ← L ( ˆ y , y ) 23: update model parameters by minimizing L 24: end if 25: retur n ˆ y E. W ebsite Identification After refining traffic representations across multiple tempo- ral granularities via the router mechanism, we perform website identification by aggregating global semantic information. Specifically , the final router tokens from all granularities are concatenated to form a unified global traffic representation z ∈ R Gd , where each router token summarizes granularity- specific semantics produced by the last Multi-Granularity Attention Block. The global representation z is then fed into the website identification classifier f , which applies a linear projection to produce classification logits o ov er C website categories. Depending on the task setting, the model supports both single-tab and multi-tab website fingerprinting. F or model optimization, we adopt task-specific loss functions: L = ( CE( o , y ) , single-tab setting , BCEWithLogits( o , y ) , multi-tab setting , (16) where y is a one-hot label in the single-tab case and y ∈ { 0 , 1 } C is a multi-hot label vector for the multi-tab case. Accordingly , cross-entropy (CE) loss is utilized for single- 8 tab case, while binary cross-entropy (BCE) with logits is employed for the multi-tab. V . E X P E R I M E N T S In this section, we conduct extensiv e experiments on large- scale datasets to e valuate the proposed PrismWF . W e first describe the experimental setup in Section V -A, including datasets, ev aluation metrics, baselines, and implementation details. Section V -B e valuates PrismWF under both closed- world and open-world multi-tab WF scenarios. W e further in vestigate the impact of the mixed-tab setting in Section V -C and assess the robustness of PrismWF against representativ e WF defenses in Section V -D. Finally , we conduct ablation studies in Section V -E to validate the effecti veness of each key component. A. Experimental Setup 1) Multi-tab Datasets: W e perform multi-tab WF attacks on the multi-tab datasets [20], [21], which model realistic multi- tab browsing behavior and include sub-datasets with different numbers of concurrently opened tabs (2-tab, 3-tab, 4-tab, and 5-tab). In each sub-dataset, each traffic trace contains mixed traffic generated by the corresponding number of bro wser tabs. ARES pro vides both closed-world and open-world ev aluation scenarios. In the closed-world setting, each sub-dataset con- tains traffic traces from 100 monitored website classes, with ov er 58,000 instances. In the open-world setting, unmonitored traffic is additionally included while the number of monitored classes remains 100, resulting in 64,000 traffic instances per sub-dataset. 2) Multi-tab evaluation metrics: For the multi-tab WF task, we follow prior work [20]–[22] and adopt Precision@K (P@K) and Mean A v erage Precision@K (MAP@K) to e valu- ate classification performance [34]. Let y denote the ground- truth multi-tab vector associated with a traffic instance x , where y i = 1 if x contains traffic from the i -th website and y i = 0 otherwise. Let ˆ y denote the predicted confidence scores produced by the model ov er all monitored website labels. Both P@K and MAP@K are computed based on the top- K website labels ranked by prediction confidence. P@K measures the precision among the top- K predicted website labels for each instance, defined as P@K( x ) = 1 K X i ∈ r K ( ˆ y ) y i , (17) where r K ( ˆ y ) denotes the set of website labels with the top- K highest predicted confidence scores. MAP@K e xtends P@K by further e valuating the ranking quality of predicted labels within the top- K results. Specifically , it quantifies whether true website labels tend to rank higher than non-relev ant ones by av eraging the precision values at different cutof f positions: MAP@K( x ) = 1 K K X i =1 P@i( x ) . (18) The final MAP@K score is obtained by averaging over all testing instances. 3) Baselines: In this work, we adopt DF [10], A WF [7], V ar-CNN [8], T ikT ok [31], Holmes [18], RF [11], B APM [12], TMWF [13], ARES [20], [21] and CountMamba [22] as baseline methods for both single-tab and multi-tab WF ev aluation. For traditional single-tab attack methods adapted for deployment in multi-tab scenarios, we follow the experi- mental setup of prior w ork and modify the classification head’ s output layer by removing the softmax activ ation and retaining the raw logit outputs [20]–[22]. Subsequently , we employ the binary cross-entropy loss with logits (BCEW ithLogitsLoss) as the loss function to train these models, thereby facilitating their deployment in multi-tab classification tasks. T ABLE I P A R A M E T E R S E T T I N G S F O R P R I S M W F . Model Part Details V alue Multi-Branch CNN Embedding Dimension 256 Branch Number 4 Kernel Sizes [15, 11, 7, 5] Con vBlocks per Branch 3 Multi-Granularity Block Block Number 3 Attention Head Number 8 Intra-Granularity W indow 5 Inter-Granularity Windo w 3 FFN Dimension 1024 Classification Head Router Fusion Dimension 256 × 4 4) Implementation detail: W e train the PrismWF model in an en vironment with Python 3.10.19 and PyT orch 2.1.2, with the implementation consisting of ov er 2,000 lines of code. All experiments are conducted on NVIDIA A800-SXM4-80GB GPUs. For single-tab WF tasks, each model is trained for 50 epochs, while for multi-tab tasks, all models are trained for 80 epochs. More detailed deployment configurations of PrismWF are provided in T able I. B. Multi-T ab Attack P erformance In this section, we e valuate the performance of WF attack models in multi-tab scenarios under both closed-world and open-world settings. For baseline methods originally designed for single-tab WF (e.g., A WF , DF , Tik-T ok, V ar-CNN, and RF), we adopt the same multi-tab adaptation strategy described in Section V -A3, follo wing the standard practice of prior multi- tab WF attacks. For representati ve multi-tab WF methods (B APM, TMWF , ARES, and CountMamba), we directly use their publicly released codes for training and testing without modifications. 1) Closed-world scenario: Experimental results demon- strate that the proposed PrismWF consistently outperforms all baseline methods across both P@k and MAP@k e val- uation metrics, achieving a new state of the art, as shown in T able II. T raditional single-tab attack methods, including A WF , DF , T ik-T ok, V ar-CNN, and RF , exhibit significantly inferior performance compared to recent representati ve multi- tab approaches such as TMWF , CountMamba, ARES, and PrismWF . Among these multi-tab baselines, B APM sho ws 9 T ABLE II C O M PAR I S O N W I T H E X I S T I N G M E T H O D S U N D E R M U LTI - TA B B RO W S I N G : C L O S E D - W O R L D A N D O P E N - W O R L D S C E NA R I O S . Scenario # of tabs Metrics A WF DF T ik-T ok V ar-CNN RF B APM TMWF CountMamba ARES PrismWF Closed-world 2-tab P@2 15.66 63.01 70.47 72.94 64.66 57.22 78.24 87.33 87.78 89.46 MAP@2 17.93 72.64 78.87 81.16 73.13 66.38 83.20 91.89 92.00 93.10 3-tab P@3 11.67 45.62 53.51 56.32 47.24 43.09 67.02 81.52 84.56 87.01 MAP@3 13.93 58.57 65.91 69.93 59.44 53.52 73.87 87.76 90.09 91.48 4-tab P@4 11.49 43.15 49.60 40.35 44.25 41.23 65.97 81.26 85.59 88.38 MAP@4 13.64 55.32 61.87 55.62 56.69 51.04 72.52 87.41 90.49 92.34 5-tab P@5 10.84 35.48 41.34 38.75 34.60 34.67 64.00 73.89 83.27 87.54 MAP@5 12.24 46.90 52.94 51.25 44.63 42.88 70.83 81.46 88.38 91.63 Open-world 2-tab P@2 17.59 60.77 69.04 70.46 62.63 55.65 73.98 85.02 86.17 87.83 MAP@2 20.32 70.21 77.23 79.27 71.64 64.71 79.97 90.09 90.91 91.97 3-tab P@3 12.13 45.56 53.35 57.89 47.32 42.07 66.47 81.17 83.69 86.03 MAP@3 14.62 58.43 66.18 71.61 60.41 52.50 73.58 87.86 89.45 91.36 4-tab P@4 11.90 42.19 49.02 40.32 43.25 40.20 67.08 79.98 85.04 88.11 MAP@4 14.35 54.62 61.20 53.41 56.14 50.39 73.54 86.40 90.01 92.08 5-tab P@5 11.96 36.74 42.74 39.39 36.93 35.65 64.21 75.60 84.11 88.52 MAP@5 14.04 48.47 54.99 52.03 47.79 44.38 71.06 83.09 89.11 92.33 relativ ely limited effecti veness compared to the stronger recent methods. Specifically , under the 2-tab setting, PrismWF achiev es a P@2 score of 89.46%, outperforming BAPM, TMWF , Count- Mamba, and ARES by 32.24%, 11.22%, 2.13%, and 1.68%, respectiv ely . In terms of MAP@2, PrismWF attains 93.10%, exceeding the same baselines by 26.72%, 9.90%, 1.21%, and 1.10%, respectiv ely . Under the more challenging 5-tab setting, the performance of existing multi-tab baselines (including B APM, TMWF , CountMamba, and ARES) degrades substan- tially compared to their 2-tab results. In contrast, PrismWF maintains stable and superior performance, highlighting its robustness to sev ere traffic mixing. This adv antage stems from the carefully designed traffic-a ware attention mechanism, which enables effecti ve information querying from coarse- grained traf fic patches to fine-grained patches across multiple temporal granularities. As a result, PrismWF achie ves a P@5 of 87.54% and a MAP@5 of 91.63%, surpassing B APM by 52.87% and 48.75%, TMWF by 23.54% and 20.80%, CountMamba by 13.65% and 10.17%, and ARES by 4.27% and 3.25%. These results clearly demonstrate that PrismWF is significantly more ef fectiv e at identifying mixed traffic traces under multi-tab bro wsing scenarios. 2) Open-world scenario: Consistent with prior work [10], [13], [20], [22], all unmonitored websites are grouped into a single class—introducing an additional label compared to the closed-world setting and substantially increasing classifi- cation difficulty , especially under multi-tab traffic mixing. This setting reflects a more realistic, challenging threat model, as attackers must handle unknown background traffic. As shown in T able II, PrismWF consistently outperforms all baselines across multi-tab configurations in the open-world setting. In the 2-tab scenario, it achieves a P@2 of 87.83% and a MAP@2 of 91.97%, demonstrating strong discrimination between monitored and unmonitored traf fic under mild mix- ing. Notably , PrismWF maintains stable performance as the number of concurrent tabs increases: in the challenging 5-tab setting, it attains a P@5 of 88.52% and a MAP@5 of 92.33%, indicating robust performance under heavy traffic interleaving. Its advantages over representative multi-tab baselines become more pronounced with se vere mixing—in the 5-tab open-world scenario, PrismWF outperforms BAPM by 52.87% in P@5 and 47.95% in MAP@5, TMWF by 24.31% in P@5 and 21.27% in MAP@5, CountMamba by 12.92% in P@5 and 9.24% in MAP@5, and ARES by 4.41% in P@5 and 3.22% in MAP@5. This trend suggests that the proposed multi- granularity representation and router-based semantic aggre- gation effecti vely isolate website-specific fingerprint patterns from unmonitored background traf fic and interleav ed multi- tab flows. Ov erall, these results demonstrate PrismWF’ s strong generalization to open-world settings and superior robustness under the combined challenges of unknown websites and sev ere multi-tab traf fic mixing. C. Multi-T ab Attac k P erformance under V arying Numbers of T abs T o better reflect realistic WF attack scenarios, we ev aluate the cross-tab generalization capability of different WF attack models under mixed-tab training and arbitrary-tab testing. In this setting, the number of concurrently opened tabs in captured traf fic is unkno wn a priori ; we refer to it as the mixed-tab setting . Unlike prior ev aluations that train and test models under fixed tab-count settings [22], this setup more closely aligns with practical multi-tab browsing beha viors. Specifically , we randomly sample 30% of traffic traces from each of the 2-tab, 3-tab, 4-tab, and 5-tab datasets and merge them into a unified mixed-tab training set. Models trained on this heterogeneous dataset are then ev aluated on test sets with dif ferent fixed numbers of tabs, enabling a comprehensi v e 10 T ABLE III P E R F O R M A N C E U N D E R M I X E D - TA B T R A I N I N G A N D D I FF E R E N T T E S T I N G TA B S E T T I N G S ( % ) . Method 2-tab (T est) 3-tab (T est) 4-tab (T est) 5-tab (T est) P@2 MAP@2 P@3 MAP@3 P@4 MAP@4 P@5 MAP@5 TMWF 60.50 70.09 48.30 61.64 44.99 58.01 38.56 50.93 CountMamba 78.00 86.35 67.54 80.63 63.86 77.91 54.63 69.50 ARES 80.93 88.08 72.67 83.81 71.11 82.69 63.99 77.05 PrismWF 82.01 88.81 75.77 85.90 74.59 85.32 68.12 79.87 assessment of multi-tab WF performance under realistic and varying traffic mixing. As sho wn in T able III, the proposed PrismWF consistently achiev es state-of-the-art performance across all testing tab set- tings. On the 2-tab test set, PrismWF attains a P@2 of 82.01% and a MAP@2 of 88.81%, outperforming CountMamba by 4.01% and 2.46%, and surpassing ARES by 1.08% and 0.73%, respectiv ely . More importantly , PrismWF maintains strong performance advantages under heavier traffic mixing. On the most challenging 5-tab test set, PrismWF achiev es a P@5 of 68.12% and a MAP@5 of 79.87%, e xceeding CountMamba by 13.49% and 10.37%, and outperforming ARES by 4.13% and 2.82%, respectively . W e observe a consistent decline in P@K and MAP@K as the number of concurrent tabs increases, as expected: identifying all target websites grows more difficult with stronger temporal interleaving and feature mixing in traffic traces. Nev ertheless, PrismWF exhibits superior robust- ness and stability compared to existing methods, pro ving that its multi-granularity representation learning and router -based interaction mechanisms ef fectiv ely handle sev ere traf fic mixing under heterogeneous multi-tab conditions. D. Multi-T ab Attack against WF Defenses In this section, we select three representativ e WF defense mechanisms (WTF-P AD [27], Front [35], and RegulaT or [36]) to ev aluate their ef fectiv eness against WF attacks in multi- tab browsing scenarios. T amara w [26] is excluded due to its prohibiti vely high bandwidth ov erhead and latency for practical deployment. WTF-P AD adaptively injects dummy packets into raw traffic traces to perturb original website traffic, disrupting salient statistical features e xploited by finger- printing attacks. Front targets information leakage in the initial phase of website access and adopts a Rayleigh-distribution- based random dummy packet padding strategy to obfuscate front-end traf fic patterns. RegulaT or combines pack et delay manipulation with dummy packet injection to ef fecti vely blur burst-le vel statistical characteristics of website traffic. W e ev aluate multi-tab WF attacks under these defenses in two representativ e settings: a 2-tab scenario and a more challenging 5-tab scenario. As sho wn in T able IV and V, PrismWF consistently achie ves state-of-the-art performance across all six dataset–defense combinations. In the 2-tab setting, T able IV summarizes the performance of different multi-tab WF attacks under three representative defense mechanisms. Overall, the proposed PrismWF con- sistently achiev es the best performance across all defenses in terms of both P@2 and MAP@2. Under the WTF-P AD defense, PrismWF attains a P@2 of 84.72% and a MAP@2 of 89.70%, outperforming ARES by 2.01% in P@2 and 1.92% in MAP@2, and surpassing CountMamba by 5.64% and 4.34%, respecti vely . Compared with TMWF , PrismWF exhibits substantial improv ements of 24.54% in P@2 and 22.71% in MAP@2, demonstrating superior discriminative capability under moderate packet padding. Among the three defenses, Front is relati vely weaker , under which all multi- tab WF attacks achie ve their highest accuracy . Ne vertheless, PrismWF still delivers the best performance under Front, achieving 86.76% P@2 and 91.22% MAP@2, consistently outperforming all baseline methods. RegulaT or provides the strongest defense among the three by manipulating packet delays and injecting dummy packets at the burst le vel, which significantly disrupts coarse-grained traf fic patterns. Despite this challenge, PrismWF remains the most effecti ve method, achieving a P@2 of 72.18% and a MAP@2 of 78.29%. In contrast, CountMamba suf fers a dramatic performance col- lapse under RegulaT or , with both P@2 and MAP@2 reduced to approximately 2.7%, likely due to its reliance on causal CNNs and state-space models that are sensitiv e to burst-le v el perturbations. T ABLE IV C O M PAR I S O N O F W F AT TAC K S O N T H R E E R E P R E S E N TA T I V E D E F E N S E S I N T H E 2 - TAB S E T T I N G . WTF-P AD Front RegulaT or Attack P@2 MAP@2 P@2 MAP@2 P@2 MAP@2 TMWF 60.18 66.99 64.73 72.92 41.49 48.08 CountMamba 79.08 85.36 83.97 89.29 2.69 2.70 ARES 82.71 87.78 85.53 90.39 71.09 77.53 PrismWF 84.72 89.70 86.76 91.22 72.18 78.29 In the 5-tab setting, we observ e that all attack metrics (i.e., P@5 and MAP@5) decrease compared to those in the 2-tab setting. This degradation can be attributed to more intricate traffic mixing and interleaving dynamics, which substantially increase the difficulty of multi-tab WF attack. Despite this elev ated comple xity , the proposed PrismWF model maintains relativ ely stable performance across all three representativ e defense mechanisms. More importantly , PrismWF exhibits more pronounced advantages over competing baselines in the 5-tab setting than in the 2-tab setting. As shown in T able V, PrismWF achiev es the highest P@5 and MAP@5 values under all defense scenarios, with P@5 scores of 77.94% (WTF- P AD), 83.92% (Front), and 53.49% (RegulaT or). Compared with the second-best baseline (ARES), PrismWF improves P@5 by 4.05%, 5.92%, and 0.87% under the three WF 11 (a) Maximum Loading Time (b) T ime Slot Interval (c) Number of Blocks Fig. 4. Ablation study of different hyperparameter settings on WF attack performance. defenses, respectively . These results clearly demonstrate the superior rob ustness of PrismWF in complex multi-tab brows- ing en vironments. T ABLE V C O M PAR I S O N O F W F AT TAC K S O N T H R E E R E P R E S E N TA T I V E D E F E N S E S I N T H E 5 - TAB S E T T I N G . WTF-P AD Front RegulaT or Attack P@5 MAP@5 P@5 MAP@5 P@5 MAP@5 TMWF 42.45 49.66 39.50 47.12 19.16 22.01 CountMamba 59.86 69.00 65.48 74.58 5.69 5.77 ARES 73.89 80.69 78.00 84.20 52.62 58.93 PrismWF 77.94 83.99 83.92 88.90 53.49 59.67 E. Ablation Study In this section, we conduct systematic ablation studies on the proposed model to e v aluate the contributions of each core component to the overall WF attack performance, and further in vestigate the sensitivity of key hyperparameters. 1) Design of T race F eatur e Representation: The proposed trace feature representation comprises six channels, con- structed by integrating three types of traffic statistical features. Each traffic statistic is further split into incoming and outgoing packet streams, resulting in a total of 3 × 2 = 6 feature channels. For ablation experiments, we isolate each type of traffic statistic (i.e., its corresponding incoming and outgoing channels) individually , along with the full fused feature set, yielding four distinct experimental configurations to quantify the contrib ution of each feature component. Fig. 5. Ablation study on different trace feature representations. As shown in Fig. 5, the fused (Whole) feature set achiev es the best attack performance across both 2-tab and 5-tab settings, with MAP@2 reaching 93.10% and 91.63% re- spectiv ely . Among single-feature settings, packet count yields the highest performance, confirming its status as the most discriminativ e feature for WF attacks—a finding consistent with prior work [10], [11]. Although the time interv al feature exhibits relatively low performance when used in isolation, it provides complementary temporal information that is critical for enhancing the accurac y of the fused feature input. 2) Impact of Maximum Loading T ime: W e analyze the impact of the maximum loading time used in robust trace construction. The maximum loading time determines how much traf fic is retained from each trace and thus directly affects the completeness of temporal information av ailable for WF attack. As shown in Fig. 4a, we ev aluate four different maximum loading times: 80 s, 120 s, 160 s, and 240 s, while keeping all other settings unchanged. The results show that perfor- mance improv es significantly when increasing the loading time from 80 s to 160 s, indicating that longer observation windows provide more discriminative traf fic patterns. Specif- ically , PrismWF achie ves a P@2 of 89.46% and a MAP@2 of 93.10% at 160 s. Further increasing the loading time to 240 s brings only marginal gains (P@2 = 89.45%, MAP@2 = 93.21%), suggesting diminishing returns. Therefore, we adopt 160 s as the default maximum loading time, which offers a fa vorable trade-off between attack effecti v eness and practical inference ef ficiency . 3) Impact of T ime Slot Interval: W e next explore the effect of time slot interval on trace discretization, a key parameter that controls the temporal resolution of robust trace represen- tations and dictates the input sequence length of the model. As sho wn in Fig. 4b, we v ary the time slot interv al from 10 ms to 50 ms under a fixed maximum loading time of 160 s. A smaller interval results in finer -grained temporal features b ut longer input sequences, whereas a larger interv al leads to coarser representations with reduced sequence length. Experimental results demonstrate a consistent decline in at- tack performance as the interval increases. In particular , the optimal performance is observed at 20 ms, where PrismWF attains a P@2 of 89.46% and a MAP@2 of 93.10%. When the interv al exceeds 30 ms, both P@2 and MAP@2 drop noticeably , suggesting that overly coarse temporal aggregation erodes the model’ s capability to capture fine-grained traffic dynamics. Based on this trade-off analysis, we set the default 12 time slot interv al to 20 ms, which ef fectiv ely balances temporal resolution, attack performance, and computational efficienc y . 4) Impact of Number of Blocks: W e in vestigate the influ- ence of the number of stacked Multi-Granularity Attention Blocks on WF attack performance. Specifically , we v ary the number of blocks from 1 to 5 while keeping all other settings unchanged. As sho wn in Fig. 4c, performance consistently improv es as more blocks are stacked, indicating that deeper multi-granularity interaction enables more ef fectiv e refinement of traf fic representations. W ith only one block, the model achiev es the lo west performance, with P@2 = 87.51% and MAP@2 = 91.52%. As the number of blocks increases, both metrics steadily improv e, reaching the best performance at 5 blocks (P@2 = 90.03%, MAP@2 = 93.50%). These results show that stacking multiple Multi-Granularity Atten- tion Blocks impro ves the model’ s ability to capture com- plex temporal dependencies and cross-granularity interactions. Howe v er , more blocks also introduce higher computational cost. Therefore, the number of blocks should be chosen by balancing performance gains and computational efficienc y . 5) Sensitivity Analysis of Model Arc hitectur e: The core component of PrismWF is the Multi-Granularity Attention Block , which integrates three complementary interaction mech- anisms for multi-tab WF attacks. T o quantify the contribution of each component, we conduct ablation studies by selecti vely removing individual modules under the most challenging set- ting, i.e., the 5-tab scenario with representati ve WF defenses. Specifically , we ev aluate three variants: (i) removing router interaction (RI), (ii) removing fine-to-coarse cross-granularity interaction (GI), and (iii) replacing the multi-granularity design with a single-granularity CNN equipped only with intra- granularity attention. These variants are compared against the full PrismWF model to assess the effecti veness of each architectural component. T ABLE VI S E N S I T I V I T Y A N A L Y S I S O F M O D E L A R C H I T E C T U R E . WTF-P AD Fr ont RegulaT or Attack P@5 MAP@5 P@5 MAP@5 P@5 MAP@5 PrismWF (w/o RI + GI) 69.24 79.13 76.49 84.66 43.26 50.10 PrismWF (w/o RI) 75.80 83.17 80.60 87.08 50.89 59.18 PrismWF (Single-G) 73.89 82.02 79.41 86.66 48.89 57.49 PrismWF (Full) 77.94 83.99 83.92 88.90 53.49 59.67 As sho wn in T able VI, the full PrismWF model con- sistently achie ves the best performance across all WF de- fenses. In particular , PrismWF attains P@5/MAP@5 scores of 77.94%/83.99% under WTF-P AD, 83.92%/88.90% under Front, and 53.49%/59.67% under RegulaT or , demonstrating the ef fectiv eness of the proposed architecture under dif ferent WF defenses. Removing router interaction leads to noticeable degradation under all defenses. For example, under RegulaT or , PrismWF (w/o RI) achie ves a P@5 of 50.89%, which is 2.60% lower than the full model, indicating that router -le vel interaction provides consistent performance gains by aggregat- ing global semantic information across temporal scales. The largest drop occurs when both router interaction and cross- granularity interaction are removed. PrismWF (w/o RI + GI) suffers P@5 reductions of 8.70%, 7.43%, and 10.23% under WTF-P AD, Front, and RegulaT or , respectiv ely , suggesting that multi-granularity feature extraction alone is insufficient under se vere traffic mixing and defense-induced obfuscation. The single-granularity variant also exhibits inferior perfor- mance relati ve to the full model. Under RegulaT or , PrismWF (Single-G) achieves a P@5 of 48.89%, which is 4.60% lower than the full model, further confirming the importance of multi-granularity modeling. Overall, these results highlight that router interaction and cross-granularity interaction play complementary and indispensable roles. Router interaction facilitates global semantic fusion across temporal scales, while cross-granularity interaction enables ef fectiv e fine-to-coarse information alignment. T ogether with multi-branch CNNs for extracting temporal features at different resolutions, the pro- posed architecture significantly enhances robustness against complex traffic mixing and strong WF defenses. V I . D I S C U S S I O N In this section, we discuss the limitations of the proposed method and outline promising directions for future work. Multi-T ab WF Attacks for Large-Scale Monitoring. In this work, we consider a moderate-scale setting with approximately 100 monitored websites. Scaling multi-tab WF attacks to much larger monitored sets (e.g., hundreds or thousands of websites) remains a challenging problem. As the number of target websites increases, traffic patterns become more di verse and label ambiguity becomes more sev ere, which may degrade classification performance. A potential future direction is to incorporate structured relationships among websites (e.g., user browsing preferences or co-visitation patterns), which may further enhance scalability and robustness in large-scale multi- tab scenarios [37], [38]. Designing WF defenses tailored f or multi-tab scenarios. Most existing WF defense mechanisms are designed under the single-tab assumption [27], [35], [36], [39]. Their effecti ve- ness may de grade in multi-tab settings, where traf fic mixing and interlea ving introduce more complex temporal dynamics. Giv en that multi-tab browsing represents a more realistic and challenging threat model, it is important to design WF defenses that explicitly account for concurrent website access. Future work may explore defense mechanisms that le verage inter-tab traffic interactions or dynamically adapt padding and scheduling strategies based on multi-tab traffic characteristics. Evaluation in Real-W orld Defense Deployments. Consistent with prior works [10], [11], [22], [40], this paper e valuates the proposed method using simulated defense mechanisms. Howe v er , simulated en vironments often overlook practical fac- tors such as deployment costs, network latency , and dynamic traffic v ariations in real-w orld scenarios—factors that may lead to discrepancies between simulated and real-world defense performance. In future work, we will deplo y representati ve WF defenses in real-world en vironments and ev aluate both at- tack effecti veness and defense cost under realistic operational settings. V I I . C O N C L U S I O N In this paper , we propose PrismWF , a high-performance multi-tab WF attack method tailored for traffic mixing scenar- 13 ios in realistic multi-tab browsing en vironments. Specifically , PrismWF first constructs a robust traf fic feature representation, then lev erages a multi-branch CNN to extract traffic features at different granularities, and finally employs a multi-granularity attention block—custom-designed to capture the inherent char - acteristics of real-world multi-tab mixed traf fic—to refine fea- ture representations, thereby enabling ef fecti ve website iden- tification. Extensive experiments demonstrate that PrismWF achiev es state-of-the-art performance with remarkable stabil- ity across three challenging scenarios: closed-world settings, open-world settings, and en vironments with representativ e WF defense mechanisms deployed. For future work, we plan to extend the proposed method to support large-scale monitored website sets and to explore dedicated defense mechanisms targeting multi-tab WF attacks. R E F E R E N C E S [1] R. Dingledine, N. Mathewson, and P . Syverson, “T or: The { Second- Generation } onion router, ” in 13th USENIX Security Symposium (USENIX Security 04) , 2004. [2] A. Mani, T . W ilson-Brown, R. Jansen, A. Johnson, and M. Sherr, “Understanding tor usage with priv acy-preserving measurement, ” in Pr oceedings of the Internet Measurement Confer ence 2018 , 2018, pp. 175–187. [3] T . W ang, X. Cai, R. Nithyanand, R. Johnson, and I. Goldberg, “Effecti ve attacks and provable defenses for website fingerprinting, ” in 23r d USENIX Security Symposium (USENIX Security 14) , 2014, pp. 143– 157. [4] A. Panchenko, F . Lanze, J. Pennekamp, T . Engel, A. Zinnen, M. Henze, and K. W ehrle, “W ebsite fingerprinting at internet scale. ” in NDSS , vol. 1, 2016, p. 23477. [5] J. Hayes and G. Danezis, “k-fingerprinting: A robust scalable web- site fingerprinting technique, ” in 25th USENIX Security Symposium (USENIX Security 16) , 2016, pp. 1187–1203. [6] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , 2016, pp. 770–778. [7] V . Rimmer, D. Preuveneers, M. Juarez, T . V an Goethem, and W . Joosen, “ Automated website fingerprinting through deep learning, ” arXiv pr eprint arXiv:1708.06376 , 2017. [8] S. Bhat, D. Lu, A. Kwon, and S. Dev adas, “V ar-cnn: A data-efficient website fingerprinting attack based on deep learning, ” arXiv preprint arXiv:1802.10215 , 2018. [9] P . Sirinam, N. Mathews, M. S. Rahman, and M. Wright, “T riplet fingerprinting: More practical and portable website fingerprinting with n-shot learning, ” in Proceedings of the 2019 ACM SIGSAC Confer ence on Computer and Communications Security , 2019, pp. 1131–1148. [10] P . Sirinam, M. Imani, M. Juarez, and M. Wright, “Deep fingerprinting: Undermining website fingerprinting defenses with deep learning, ” in Pr oceedings of the 2018 A CM SIGSAC confer ence on computer and communications security , 2018, pp. 1928–1943. [11] M. Shen, K. Ji, Z. Gao, Q. Li, L. Zhu, and K. Xu, “Subverting website fingerprinting defenses with robust traf fic representation, ” in 32nd USENIX Security Symposium (USENIX Security 23) , 2023, pp. 607–624. [12] Z. Guan, G. Xiong, G. Gou, Z. Li, M. Cui, and C. Liu, “Bapm: block attention profiling model for multi-tab website fingerprinting attacks on tor , ” in Pr oceedings of the 37th Annual Computer Security Applications Confer ence , 2021, pp. 248–259. [13] Z. Jin, T . Lu, S. Luo, and J. Shang, “Transformer-based model for multi- tab website fingerprinting attack, ” in Pr oceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security , 2023, pp. 1050–1064. [14] Y . Xu, T . W ang, Q. Li, Q. Gong, Y . Chen, and Y . Jiang, “ A multi- tab website fingerprinting attack, ” in Pr oceedings of the 34th Annual Computer Security Applications Conference , 2018, pp. 327–341. [15] A. Panchenko, L. Niessen, A. Zinnen, and T . Engel, “W ebsite finger- printing in onion routing based anonymization netw orks, ” in Pr oceedings of the 10th annual ACM workshop on Privacy in the electr onic society , 2011, pp. 103–114. [16] X. Cai, X. C. Zhang, B. Joshi, and R. Johnson, “T ouching from a distance: W ebsite fingerprinting attacks and defenses, ” in Proceedings of the 2012 ACM confer ence on Computer and communications security , 2012, pp. 605–616. [17] T . W ang and I. Goldberg, “Improved website fingerprinting on tor, ” in Pr oceedings of the 12th ACM workshop on W orkshop on privacy in the electr onic society , 2013, pp. 201–212. [18] X. Deng, Q. Li, and K. Xu, “Robust and reliable early-stage website fingerprinting attacks via spatial-temporal distribution analysis, ” in Pr o- ceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , 2024, pp. 1997–2011. [19] N. Carion, F . Massa, G. Synnaev e, N. Usunier , A. Kirillov , and S. Zagoruyko, “End-to-end object detection with transformers, ” in Eur opean confer ence on computer vision . Springer , 2020, pp. 213– 229. [20] X. Deng, Q. Y in, Z. Liu, X. Zhao, Q. Li, M. Xu, K. Xu, and J. W u, “Robust multi-tab website fingerprinting attacks in the wild, ” in 2023 IEEE symposium on security and privacy (SP) . IEEE, 2023, pp. 1005– 1022. [21] X. Deng, X. Zhao, Q. Y in, Z. Liu, Q. Li, M. Xu, K. Xu, and J. W u, “T owards robust multi-tab website fingerprinting, ” IEEE T ransactions on Networking , 2026. [22] X. Deng, R. Zhao, Y . W ang, M. Zhan, Z. Xue, and Y . W ang, “Count- mamba: A generalized website fingerprinting attack via coarse-grained representation and fine-grained prediction, ” in 2025 IEEE Symposium on Security and Privacy (SP) . IEEE, 2025, pp. 1419–1437. [23] N. Mathews, J. K. Holland, S. E. Oh, M. S. Rahman, N. Hopper, and M. Wright, “Sok: A critical evaluation of efficient website fingerprinting defenses, ” in 2023 IEEE Symposium on Security and Privacy (SP) . IEEE, 2023, pp. 969–986. [24] Y . Cui, G. W ang, K. V u, K. W ei, K. Shen, Z. Jiang, X. Han, N. W ang, Z. Lu, and Y . Liu, “ A comprehensive surve y of website fingerprinting attacks and defenses in tor: Advances and open challenges, ” arXiv pr eprint arXiv:2510.11804 , 2025. [25] K. P . Dyer , S. E. Coull, T . Ristenpart, and T . Shrimpton, “Peek-a-boo, i still see you: Why efficient traf fic analysis countermeasures f ail, ” in 2012 IEEE symposium on security and privacy . IEEE, 2012, pp. 332–346. [26] X. Cai, R. Nithyanand, T . W ang, R. Johnson, and I. Goldberg, “ A systematic approach to developing and ev aluating website fingerprinting defenses, ” in Pr oceedings of the 2014 ACM SIGSA C confer ence on computer and communications security , 2014, pp. 227–238. [27] M. Juarez, M. Imani, M. Perry , C. Diaz, and M. Wright, “T oward an efficient website fingerprinting defense, ” in European Symposium on Resear ch in Computer Security . Springer , 2016, pp. 27–46. [28] M. S. Rahman, M. Imani, N. Mathews, and M. Wright, “Mockingbird: Defending against deep-learning-based website fingerprinting attacks with adversarial traces, ” IEEE T ransactions on Information F orensics and Security , vol. 16, pp. 1594–1609, 2020. [29] A. M. Sadeghzadeh, B. T ajali, and R. Jalili, “ A wa: Adversarial website adaptation, ” IEEE T ransactions on Information F orensics and Security , vol. 16, pp. 3109–3122, 2021. [30] L. Qiao, B. Wu, H. Li, C. Gao, W . Y uan, and X. Luo, “Trace-agnostic and adversarial training-resilient website fingerprinting defense, ” in IEEE INFOCOM 2024-IEEE Confer ence on Computer Communications . IEEE, 2024, pp. 211–220. [31] M. S. Rahman, P . Sirinam, N. Mathe ws, K. G. Gangadhara, and M. Wright, “T ik-tok: The utility of packet timing in website finger- printing attacks, ” arXiv preprint , 2019. [32] N. Mathews, J. K. Holland, N. Hopper, and M. Wright, “Laserbeak: Evolving website fingerprinting attacks with attention and multi-channel feature representation, ” IEEE T ransactions on Information F orensics and Security , 2024. [33] J. Gong, W . Cai, S. Liang, Z. Guan, T . W ang, and E.-C. Chang, “Wfcat: Augmenting website fingerprinting with channel-wise attention on timing features, ” IEEE T ransactions on Dependable and Secure Computing , 2025. [34] J. Liu, W .-C. Chang, Y . W u, and Y . Y ang, “Deep learning for extreme multi-label text classification, ” in Pr oceedings of the 40th international ACM SIGIR confer ence on r esearc h and development in information r etrieval , 2017, pp. 115–124. [35] J. Gong and T . W ang, “Zero-delay lightweight defenses against website fingerprinting, ” in 29th USENIX Security Symposium (USENIX Security 20) , 2020, pp. 717–734. [36] J. K. Holland and N. Hopper, “Regulator: A straightforward website fingerprinting defense, ” arXiv preprint , 2020. [37] Z.-M. Chen, X.-S. W ei, P . W ang, and Y . Guo, “Multi-label image recognition with graph con volutional networks, ” in Proceedings of the 14 IEEE/CVF confer ence on computer vision and pattern reco gnition , 2019, pp. 5177–5186. [38] T . Ridnik, E. Ben-Baruch, N. Zamir , A. Noy , I. Friedman, M. Protter , and L. Zelnik-Manor, “ Asymmetric loss for multi-label classification, ” in Pr oceedings of the IEEE/CVF international conference on computer vision , 2021, pp. 82–91. [39] M. Shen, K. Ji, J. W u, Q. Li, X. Kong, K. Xu, and L. Zhu, “Real- time website fingerprinting defense via traf fic cluster anon ymization, ” in 2024 IEEE Symposium on Security and Privacy (SP) . IEEE, 2024, pp. 3238–3256. [40] M. Shen, J. W u, J. Ai, Q. Li, C. Ren, K. Xu, and L. Zhu, “Swallow: A transfer -robust website fingerprinting attack via consistent feature learning, ” in Pr oceedings of the 2025 A CM SIGSA C Conference on Computer and Communications Security , 2025, pp. 1574–1588.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment