Can we automatize scientific discovery in the cognitive sciences?
The cognitive sciences aim to understand intelligence by formalizing underlying operations as computational models. Traditionally, this follows a cycle of discovery where researchers develop paradigms, collect data, and test predefined model classes.…
Authors: Akshay K. Jagadish, Milena Rmus, Kristin Witte
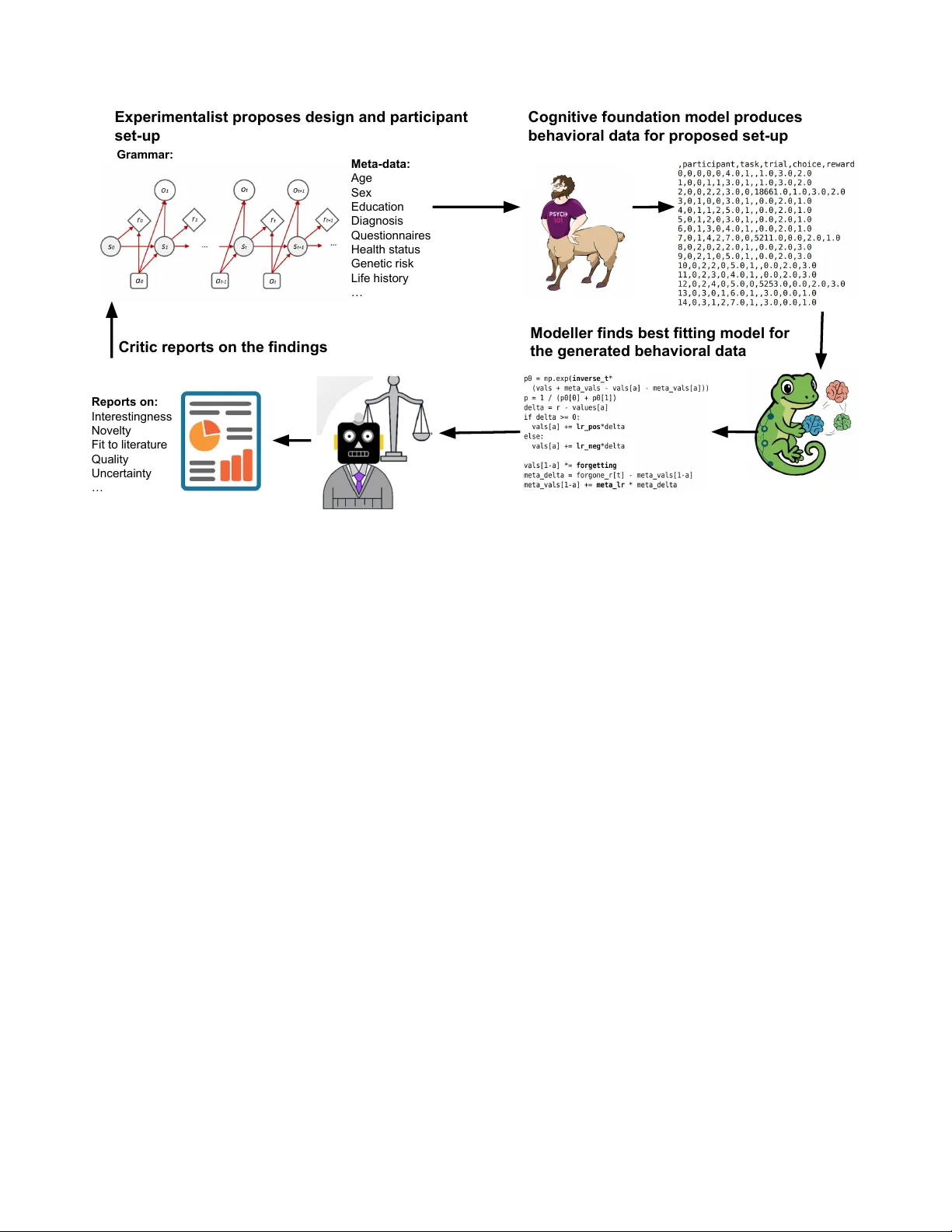
Can we automatize scientific discovery in the cognitive sciences? Akshay K. Ja gadish 1 , Milena Rmus 2 , Kristin Witte 2,3 , Marvin Mathony 2 , Marcel Binz 2 , and Eric Schulz 2,* 1 Princeton AI Lab, Princeton Univ ersity , New Jerse y , USA 2 Institute f or Human-Centered AI, Helmholtz Munich, Neuherberg, Ger many 3 Ludwig-Maximilians-University , Munich, 80539, Germany * eric.schulz@helmholtz-munich.de ABSTRA CT The cognitive sciences aim to understand intelligence by f or malizing underlying operations as computational models. T radition- ally , this follo ws a cycle of disco very where researchers de velop par adigms, collect data, and test predefined model classes. Howe v er , this manual pipeline is fundamentally constrained by the slow pace of human inter vention and a search space limited by researchers’ bac kground and intuition. Here, w e propose a paradigm shift toward a fully automated, in silico science of the mind that implements e v ery stage of the disco very cycle using Large Language Models (LLMs). In this frame work, e xperimental paradigms e xploring conceptually meaningful task structures are directly sampled from an LLM. High-fidelity behavior al data are then simulated using foundation models of cognition. The tedious step of handcrafting cognitive models is replaced by LLM-based program synthesis, which perf or ms a high-throughput search ov er a vast landscape of algor ithmic hypotheses . Finally , the discovery loop is closed by optimizing f or “interestingness”, a metr ic of conceptual yield ev aluated by an LLM-critic. By enabling a f ast and scalab le approach to theor y dev elopment, this automated loop functions as a high-throughput in-silico discov er y engine, surf acing inf ormative e xperiments and mechanisms for subsequent v alidation in real human populations. Introduction The cogniti ve sciences aim to understand intelligence using computational models 1 . These models formally ground theories about cognitive processes by specifying interpretable operations and dynamics underlying human reasoning, learning, and decision-making 2 . The standard model of discovery in the cogniti ve sciences typically follo ws a virtuous cycle of four stages 3 . First, researchers dev elop a paradigm to test a particular feature of human cognition. Second, a suf ficient volume of data is collected from human participants. Third, a predefined class of models is handcrafted and tested against the collected data, which corresponds to targeted hypothesis testing of the in v olved cogniti ve processes. Finally , the results of the experiment are revie wed by the scientific community , who then innovate on the paradigm, model class, and model comparisons in volv ed. While this process has led to general progress in our understanding of cognition, it remains constrained by se veral structural disadvantages. The primary constraint is the inherent slowness of a cycle that relies on human in volvement at every step, where the time elapsed between initial h ypothesis and final publication can span years and thus decouple the pace of theory dev elopment from the velocity of data acquisition. Furthermore, this manual pipeline restricts the space of hypothesis that gets explored, which is often restricted to familiar e xperimental designs and model classes rather than the vast landscape of all possible paradigms and algorithmic solutions. This reliance on researcher -driv en designs introduces subtle biases and limits the scalability of experimentation and theory de velopment. These limitations raise the question: can we remove the bottlenecks imposed by human interv ention and genuinely scale up scientific discovery in the cognitiv e sciences? 4 , 5 W e argue that we should seriously consider accelerating the discovery process by automating the steps in volv ed in the process 6 . W e are currently at a critical inflection point where models capable of automating each step of the standard discov ery cycle are becoming a vailable 7 . In the follo wing sections, we examine ho w the four constituent stages of this c ycle, i.e., proposing experiments, generating data, synthesizing models, and closing the loop through iterati ve refinement, can be implemented in silico. By enabling a new approach that is remarkably fast, scalable, and widely applicable, an automated science of the mind is no longer a distant fiction, but an imminent reality . Proposing e xperiments Automated disco very be gins by defining the space of possible experiments. If machine algorithms are to generate new paradigms rather than merely optimize existing ones, a formal language for describing experimental structures and ho w their constituent Experimentalist proposes design and participant set-up Grammar: Meta-data: Age Sex Education Diagnosis Questionnaires Health status Genetic risk Life history … Cognitive foundation model produces behavioral data for proposed set-up Modeller finds best fitting model for the generated behavioral data Reports on: Interestingness Novelty Fit to literature Quality Uncertainty … Critic reports on the findings Figure 1. An automated c ycle of scientific discovery in the cogniti ve sciences. An experimentalist proposes e xperiments, a cogniti ve foundation model generates beha vioral data. A modeller proposes and tests different computational models. Finally , a critic judges the “interestingness” of the results and parsed that signal back to the experimentalist for further optimization. components can be combined is required. A natural starting point are generative grammars o ver experiments 8 . For instance, a grammar ov er Markov Decision Processes (MDPs) 9 could provide an initial foundation. Because MDPs are formally defined by en vironmental states, transition dynamics, and reward structures, they can capture a vast class of decision-making tasks used in psychology and neuroscience, ranging from simple multi-armed bandits 10 to multi-step planning paradigms 11 . Y et, this approach immediately exposes a representational bottleneck: automated discovery is fundamentally constrained by the expressi vity of its underlying grammar . Ideally , the task language should be able to e xpress a broad range of existing cognitiv e experiments while allo wing flexible integration of new experiments with pre viously unexplored f actors. Building such a language remains a ke y scientific challenge. W e propose that a promising strategy in the future is to use an LLM itself as an intelligent experiment sampler . In this framework, an LLM directly proposes a set of experiments that are best positioned to elicit a specific type of behavior or test a specific hypothesis, and critically , it can further refine them based on feedback, adding or removing ke y experimental factors as needed. Generating data Once a task is specified, the cycle proceeds to the generation of synthetic beha vioral data. This is achiev ed using recent iterations of the Centaur model 12 , a foundation model of human cognition. These models can generate data for any cogniti ve experiment that can be e xpressed in language format. For example, MDP-like tasks can be described as a task in which the agent needs to choose between multiple options repeatedly to maximize rew ards. Once the agent made a choice, the reward of the chosen option gets generated, the choice and its outcome are appended to the trial history that is then re-submitted as a new prompt to generate the next choice, and so forth 13 . Unlike traditional cogniti ve models that require manual parameter tuning, foundation models, like Centaur , can generate de novo data that are often indistinguishable from human behavior . While the ability of these models to generalize to entirely nov el experimental structures remains a subject of ongoing debates, current evidence suggests the y can (at least to some extent) successfully extrapolate to tasks outside their initial training distrib ution 14 . In recent efforts, we aim to scale the underlying datasets for these models by an order of magnitude and integrate extensi ve subject-specific metadata. By incorporating demographics (e.g., age, gender , nationality) and questionnaire scores (e.g., psychiatric symptom scales), the data generation process can be conditioned on specific indi vidual differences. This allows the system to simulate not just a generic agent, but a targeted participant profile, for instance, simulating the behavior of a 30-year-old indi vidual with high scores in obsessive-compulsi ve traits performing a specific planning task. By parsing both the 2/ 5 proposed experiment and these subject-specific features into the generati ve engine, we can produce high-fidelity beha vioral data that reflects the high-dimensional complexity of real-world populations. This data can the be submitted to the next step of the cycle: model synthesis. Synthesizing models The third stage of the discov ery cycle, i.e. model synthesis and comparison, is traditionally labor-intensi ve. In the standard paradigm, researchers must manually specify a small set of candidate models, deri ve their likelihood functions, and fit them to empirical data using computationally demanding optimization routines. This process is not only slo w but also inherently biased to ward a narro w set of “cogniti vely plausible” functions that humans are familiar with and are capable of formalizing and testing. T o automate this stage, we must shift from carefully handcrafting to synthesizing models at scale, where the search space encompasses a vast landscape of algorithmic h ypotheses. Recent advances ha ve demonstrated that LLMs can act as creativ e agents in this symbolic space 15 . For instance, Rmus and Jagadish et al. 16 lev eraged LLMs’ abilities to generate hypotheses about cognitiv e processes, dev eloping a novel pipeline for Guided generation of Computational Cognitiv e Models (GeCCo) that can synthesize cognitiv e models as Python functions, and iterati vely refine them based on feedback on their predicti ve performance. Through this iterati ve feedback loop, the system uses these performance signals to refine its code, exploring the algorithmic space to arri ve at the best-fitting model while maintaining a record of all intermediate hypotheses. Other approaches to automated model discovery rely on ev olutionary algorithms 17 , which use mutation and crossover operators to ev olve complex architectures from simpler b uilding blocks, or on hybrid systems that couple evolutionary search with LLM-based program synthesis. One example is FunSearch 18 , which iterativ ely samples code variants for a target function, ex ecutes them to obtain an objectiv e score, and retains the best programs as seeds for further search. While such methods can be computationally expensi ve, they offer a path to ward discovering mechanisms that human intuition might overlook, transforming model synthesis into an objectiv e, high-throughput search over cogniti ve programs 19 . Closing the loop The final—and conceptually hardest—step is to close the loop: deciding ho w the outcome of one iteration should shape the next e xperiment, participant profiles and model search. In a fully autonomous pipeline, this requires specifying an objecti ve for the process of scientific discovery itself. Classical strategies from optimal experimental design and active learning may offer a principled starting point: we can propose tasks that maximize expected information gain, reduce posterior uncertainty ov er models, or target re gions of the task grammar where candidate explanations disagree most strongly . Y et these criteria are myopic. They re ward discriminability e ven when the resulting distinctions are scientifically unilluminating, and they often steer the system tow ard edge cases that are statistically informative b ut theoretically dull. T o move be yond this, the loop must optimize not only informati veness, but also inter estingness . Building on recent work on open-ended discov ery and self-improving search 20 , we can introduce a critic model that e valuates the outcome of each cycle and proposes what to do at the beginning of the next cycle, following an LLM-as-judge framework. In concrete terms, the critic scores a discovery tuple —the proposed e xperiment, the simulated participant profile(s), the generated data, and the space of models that best e xplains it—along dimensions such as no velty relati ve to the system’ s prior discov eries, compressibility or simplicity of the best e xplanation, the presence of qualitativ e signatures, and the extent to which the results suggest a transferable principle rather than a task-specific hack. Closing the c ycle, experiment generation is guided by an inter estingness signal that re wards discov eries with high conceptual yield. The system can then iterati vely bias its proposals toward configurations that produce sharp theoretical contrasts, uncover new behavioral phenomena, or force the in vention of ne w explanatory primiti ves 21 . Importantly , this does not eliminate the scientist. Instead, it acts as a high-throughput search in the hypothesis space: humans define the problem, the expressi veness of the task language, the structure of the output model family , ev aluation principles, the shape of the expected theory , and other constraints, while the automated loop surfaces a small set of unusually informati ve experiments and mechanisms. The highest-scoring discov eries can then be validated in vivo with human participants, keeping the process anchored to biological cognition while dramatically scaling up and accelerating the search for theory . Discussion Jorge Luis Bor ges imagined the Library of Babel : an infinite archi ve containing e very possible book, masterpieces and proofs alongside endless gibberish. An automated science of the mind risks building the cognitiv e analogue of that library: a vast enumerativ e engine that generates every possible task, e very possible dataset, ev ery possible model, most of it worthless. The goal here, ho wev er , is not to flood cognitiv e science with an ocean of synthetic “books”. It is to surface the rare volumes that 3/ 5 matter: experiments that carv e nature at its joints, models that compress behavior into e xplanatory principles, and predictions that surviv e contact with actual data. If automation succeeds, it should not remove the scientist from discovery , but rather act as an amplifier of our ability to search, to falsify , and to learn. This paper has outlined an end-to-end vision for such a system: an engine that proposes experiments, generates beha vioral data in silico, discov ers mechanistic models at scale, and closes the loop by steering search tow ard high-value discov eries. The promise is apparent, and so are the failure modes. A credible discussion must therefore be blunt about what can go wrong—because the central risk is not merely technical failure, but epistemic failure: producing persuasi ve-looking results that are scientifically hollow . The proposed cycle is only as strong as its weakest step. First, automated experimental design is bounded by the expressibility and interpretability of the task language. A task grammar determines what e xperiments can be proposed, and much of scientific innovation comes from stepping outside the currently explored space: in venting ne w paradigms, ne w measurements, or new representational framings. No search procedure can discov er what the representation forbids. This makes the experiment grammar itself a central scientific object: it must be able to cover multiple cogniti ve task domains, from sequential decision-making, memory , and categorization to reasoning, and social cognition, and it should be pressure-tested by systematically probing where it fails. Second, synthetic data generation is not guaranteed to be a faithful substitute for humans. Behavioral foundation models may rely on shortcuts, drift toward “a verage” subjects, or fail under genuine distribution shift. Even plausible-looking beha vior can be produced for the wrong reasons, yielding an illusion of mechanistic clarity . A pragmatic stance is to treat such models as accelerators for hypothesis generation rather than as ground truth: they should be continuously calibrated against benchmark effects, challenged with adv ersarial tasks designed to expose heuristics, and, where appropriate, complemented or replaced by smaller , local simulators tuned to specific task families. Third, model discov ery over programs is not smooth optimization. Instead, the optimization space is rugged: tiny edits to the code can break a model, distinct mechanisms can be beha viorally indistinguishable, and LLM-guided search can inherit strong priors and stylistic biases from their training data. There is no guarantee of finding a globally best mechanism, and ev aluation metrics can be gamed unless carefully designed. Nevertheles s, it is undeniable that this approach can explore far more candidates than was previously possible, and early results suggest that it can discover genuinely new mechanistic descriptions rather than simply rephrasing familiar ones under the right conditions. Finally , closing the loop with an “interestingness” signal is both enticing and dangerous. A critic could rew ard theatrical nov elty , drift to ward idiosyncratic edge cases, or be gamed by policies that learn to manufacture superficial weirdness. Interestingness should therefore not be a single scalar oracle. A safer design is multi-objectiv e: combine nov elty with robustness, parsimony , generalization across tasks and populations, and, crucially , unification, i.e., explaining multiple phenomena with shared mechanisms. Despite these risks, the upside of the proposal is large. Automating the loop could increase the throughput of discov ery by orders of magnitude, shifting human effort from enumerating possibilities to defining problem representations, the shape of the solutions, constraints, and decisi ve tests. The most immediate dividends may come from indi vidual differences: conditioning simulated participants on demographics and psychometrics naturally links cogniti ve modeling with computational psychiatry , enabling mechanistic accounts of heterogeneity rather than an “a verage mind. ” The current proposal can also e xpand beyond behavior by integrating neuroscience, requiring candidate mechanisms to predict both choices and neural signatures, and beyond te xt, by incorporating perception to support psychophysics and more ecological paradigms. More broadly , it offers a route to addressing the generalization crisis: by systematically searching for in variances across task variants and populations, we can turn generalization from a post-hoc hope into an explicit selection criterion for theories. In summary , we appear to be near an inflection point where the required components, i.e. structured experiment representa- tions, behavioral generators, scalable program search, and critic-guided exploration, are simultaneously becoming feasible. The challenge now is epistemic as much as technical: to build systems that produce fe wer books and more knowledge, and to de velop norms that k eep automated discov ery tethered to empirical v alidation. The Library of Babel contains e verything; science is the art of finding the fe w pages worth reading. An automated discov ery engine will be worth b uilding if it reliably elev ates those pages. Ackno wledg ements AJ is supported by the Natural and Artificial Mind (NAM) Fello wship, which is generously supported by the Scully Perestsman foundation. ES is funded by the Helmholtz Association, an ERC Starting Grant on "T o wards an Artificial Cogniti ve Science”, and a W ellcome Discovery A ward. 4/ 5 References 1. Busemeyer , J. R. & Diederich, A. Cognitive modeling (Sage, 2010). 2. Sun, R. The Cambridg e Handbook of Computational Psychology (Cambridge Univ ersity Press, Cambridge, 2008). 3. Klahr , D. & Dunbar, K. Dual space search during scientific reasoning. Cogn. Sci. 12 , 1–48, DOI: 10.1207/ s15516709cog1201_1 (1988). 4. King, R. D. et al. The automation of science. Science 324 , 85–89 (2009). 5. Lu, C. et al. The ai scientist: T ow ards fully automated open-ended scientific discovery . arXiv pr eprint (2024). 6. Musslick, S. et al. Automating the practice of science: Opportunities, challenges, and implications. Pr oc. Natl. Acad. Sci. 122 , e2401238121 (2025). 7. Binz, M. et al. Ho w should the advancement of large language models af fect the practice of science? Pr oc. Natl. Acad. Sci. 122 , e2401227121 (2025). 8. Musslick, S., Strittmatter, Y . & Dubova, M. Closed-loop scientific discovery in the behavioral sciences. PsyArXiv 10 (2024). 9. Miconi, T . Procedural generation of meta-reinforcement learning tasks. arXiv preprint arXiv:2302.05583 (2023). 10. W ilson, R. C., Geana, A., White, J. M., Ludvig, E. A. & Cohen, J. D. Humans use directed and random exploration to solve the e xplore–exploit dilemma. J. experimental psychology: Gen. 143 , 2074 (2014). 11. Daw , N. D., Gershman, S. J., Seymour , B., Dayan, P . & Dolan, R. J. Model-based influences on humans’ choices and striatal prediction errors. Neur on 69 , 1204–1215 (2011). 12. Binz, M. et al. A foundation model to predict and capture human cognition. Natur e 644 , 1002–1009 (2025). 13. Binz, M. & Schulz, E. Using cogniti ve psychology to understand gpt-3. Pr oc. Natl. Acad. Sci. 120 , e2218523120 (2023). 14. Binz, M. & Schulz, E. T urning large language models into cognitiv e models. arXiv pr eprint arXiv:2306.03917 (2023). 15. Austin, J. et al. Program synthesis with lar ge language models. arXiv pr eprint arXiv:2108.07732 (2021). 16. Rmus, M., Jagadish, A. K., Mathony , M., Ludwig, T . & Schulz, E. Generating computational cognitiv e models using large language models. In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Systems . 17. Noviko v , A. et al. Alphaev olve: A coding agent for scientific and algorithmic discovery . arXiv pr eprint (2025). 18. Romera-Paredes, B. et al. Mathematical discoveries from program search with large language models. Nature 625 , 468–475 (2024). 19. Castro, P . S. et al. Discovering symbolic cogniti ve models from human and animal behavior . In International Conference on Machine Learning , 6849–6890 (PMLR, 2025). 20. Zhang, J., Lehman, J., Stanley , K. & Clune, J. Omni: Open-endedness via models of human notions of interestingness. In The T welfth International Confer ence on Learning Repr esentations . 21. Y amada, Y . et al. The ai scientist-v2: W orkshop-level automated scientific discov ery via agentic tree search. arXiv pr eprint arXiv:2504.08066 (2025). 5/ 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment