mmWave-Diffusion:A Novel Framework for Respiration Sensing Using Observation-Anchored Conditional Diffusion Model
Millimeter-wave (mmWave) radar enables contactless respiratory sensing,yet fine-grained monitoring is often degraded by nonstationary interference from body micromotions.To achieve micromotion interference removal,we propose mmWave-Diffusion,an obser…
Authors: Yong Wang, Qifan Shen, Bao Zhang
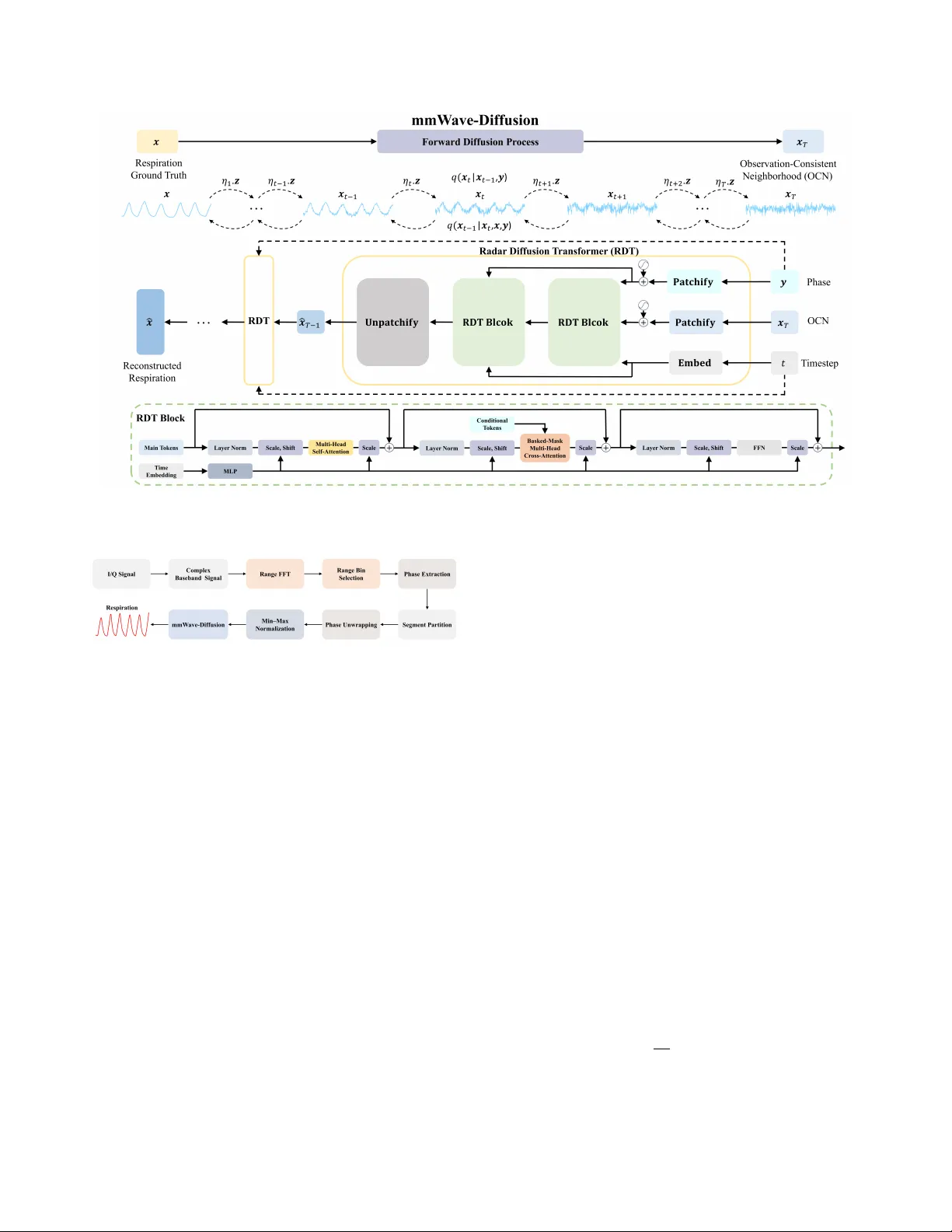
MMW A VE-DIFFUSION: A NO VEL FRAMEWORK FOR RESPIRA TION SENSING USING OBSER V A TION-ANCHORED CONDITIONAL DIFFUSION MODEL Y ong W ang ∗ , 1 , Qifan Shen ∗ , 1 ,Bao Zhang 1 ,Zijun Huang 1 ,Chengbo Zhu 1 , Shuai Y ao 1 ,Qisong W u † , 1 , 2 1 K ey Laboratory of Underw ater Acoustic Signal Processing of Ministry of Education, Southeast Uni versity , Nanjing, 211189, China 2 Purple Mountain Laboratories, Nanjing, 211111, China ABSTRA CT Millimeter-w av e (mmW a ve) radar enables contactless respiratory sensing, yet fine-grained monitoring is often degraded by non- stationary interference from body micromotions. T o achie ve mi- cromotion interference removal, we propose mmW a ve-Dif fusion, an observation-anchored conditional diffusion framew ork that di- rectly models the residual between radar phase observations and the respiratory ground truth, and initializes sampling within an observation-consistent neighborhood rather than from Gaussian noise—thereby aligning the generative process with the measure- ment physics and reducing inference ov erhead. The accompanying Radar Dif fusion T ransformer (RDT) is explicitly conditioned on phase observations, enforces strict one-to-one temporal alignment via patch-le vel dual positional encodings, and injects local physical priors through banded-mask multi-head cross-attention, enabling robust denoising and interference remo val in just 20 reverse steps. Evaluated on 13.25 hours of synchronized radar–respiration data, mmW a ve-Dif fusion achiev es state-of-the-art waveform reconstruc- tion and respiratory-rate estimation with strong generalization. Code repository: https://github .com/goodluckyongw/mmW ave-Dif fusion. Index T erms — Respiration monitoring, mmW ave radar , condi- tional diffusion model, T ransformer 1. INTRODUCTION Continuous, unobtrusiv e monitoring of respiratory patterns is criti- cal for chronic disease management, sleep assessment, and home- based care [1, 2]. Owing to its contactless operation and pri vacy- preserving nature, millimeter-wav e (mmW av e) radar is a promising sensing modality for this purpose [3]. Howe ver , in real-world en- vironments, fine-grained monitoring remains challenging: body mi- cromotions induce nonstationary artifacts that perturb radar-phase measurements and obscure subtle respiratory dynamics [4, 5]. In radar -based respiratory monitoring, early approaches relied on con ventional signal-processing techniques (e.g., filtering and mode decomposition) [6]. Howev er, the stationarity or indepen- dence assumptions underlying these methods render them highly sensitiv e to time-v arying interference in radar returns, often limit- ing performance to coarse respiratory-rate estimation and precluding high-fidelity wav eform reconstruction [1, 7]. Recently , deep learning ∗ The authors contributed equally . † Corresponding author . This work was supported by the National Natural Science Foundation of China under Grants No. 12374421, and 62293552, in part by Open fund of the Science and T echnology on Underwater T est and Control Laboratory (No. 2024-CXPT -GF-JJ-043), and supported by the Fundamental Research Funds for the Central Univ ersities under Grant No. 2242025F20003. models (e.g., CNNs and Transformers) hav e sought to learn direct mappings from noisy radar phase or I/Q signals to clean respiration wa veforms [3, 8]. Despite their high capacity , such “black-box” regressors are prone to overfitting en vironment-specific noise and may yield physiologically implausible outputs. Generati ve alter- nativ es, such as V ariational Autoencoders (V AEs), have also been explored [2, 9]; howe ver , the variational objective’ s simplified pos- terior assumptions (typically Gaussian) constrain expressi veness, prev enting faithful capture of complex, multimodal distributions. Diffusion models hav e recently emerged as a powerful genera- tiv e paradigm, advancing image synthesis and time-series forecast- ing [10, 11]. Their stepwise denoising mechanism enables modeling of complex, nonstationary , non-Gaussian degradations [12, 13], which naturally aligns with the challenges of radar -based respira- tory monitoring. Motivated by this insight, we propose mmW av e- Diffusion, an observation-anchored conditional dif fusion frame work for fine-grained radar respiratory sensing. T o effecti vely remove micromotion-induced interference, the forward process progres- siv ely injects perturbations along the residual between the observed radar phase and the target respiration signal; in the rev erse pro- cess, the model conditions explicitly on the phase observations and initializes the sampling trajectory within an Observation-Consistent Neighborhood (OCN). As denoising proceeds, micromotion artifacts are progressively suppressed, yielding a high-fidelity respiratory wa veform. This observation anchoring avoids the lengthy noise- start sampling of standard diffusion while preserving consistency with the measurement physics. T o instantiate the framework, we design the Radar Diffusion T ransformer (RDT), inspired by DiT [14]. RDT processes the main sequence (initialized from OCN to define the re verse denoising trajectory toward the clean waveform) and the conditional radar - phase sequence in parallel. Both streams are tokenized into non- ov erlapping patches and assigned independent positional encodings, enforcing strict one-to-one temporal correspondence. T o encode locality , RDT employs banded-mask multi-head cross-attention, injecting the prior that radar echoes correlate primarily with tem- porally proximate respiration and thereby suppressing long-range mismatches and spurious associations. These design choices inte- grate radar observations throughout mmW ave-Dif fusion’ s generati ve process, enabling targeted removal of micromotion interference and reconstruction of fine-grained respiratory wa veforms. 2. METHOD This section details the mmW ave-Dif fusion framew ork (Fig. 1) and presents the end-to-end pipeline from radar observ ations to respira- tory wa veform reconstruction. Fig. 1 : Overvie w of mmW a ve-Dif fusion with the Radar Diffusion T ransformer (RDT) architecture. Fig. 2 : Signal processing pipeline. 2.1. Signal Processing Pipeline Fig. 2 summarizes the end-to-end pipeline from raw radar I/Q to the reconstructed respiratory waveform. Raw I/Q streams acquired by the mmW a ve radar form a complex baseband signal. W e first apply a range Fast Fourier Transform (FFT) to obtain a 1-D range profile; with Moving T ar get Indication (MTI) and a Constant False Alarm Rate (CF AR) detector, we automatically select the range bin corresponding to the subject’ s chest [15, 16], and extract the phase sequence from this bin. Next, using a sliding window of w seconds with a hop of s seconds, the phase sequence is partitioned into seg- ments of length l . Each segment undergoes phase unwrapping and min–max normalization to [0 , 1] , yielding y ∈ R 1 × l . The respira- tory ground truth is segmented and normalized identically to obtain x ∈ R 1 × l . Feeding y into mmW av e-Diffusion produces the recon- structed respiratory wa veform ˆ x ∈ R 1 × l . 2.2. mmW ave-Diffusion For micromotion-robust radar respiratory sensing, we propose mmW a ve-Dif fusion. As illustrated in Fig. 1, the forward process starts from the respiratory ground truth x and advances along the residual path z = y − x : this residual, which encodes micromotion- induced wa veform distortions, is progressively injected, driving the state toward a Gaussian with mean y . Conv ersely , the re verse diffusion process initializes within an OCN of y and explicitly con- ditioned on y at each step; together with the accompanying RDT , the observation constrains the generativ e trajectory , enabling itera- tiv e denoising and remov al of micromotion interference, ultimately reconstructing a fine-grained respiratory wa veform. Forward Process: Unlike standard diffusion, whose forward process injects observation-agnostic Gaussian noise, mmW av e- Diffusion progressi vely injects the residual z encoding micromotion- induced interference, thereby constructing a T -step Markov chain that maps the respiratory ground truth x to the radar observa- tion y . This process is go verned by a monotonically increasing noise schedule { η t } T t =1 satisfying η 1 → 0 and η T → 1 , where t ∈ { 1 , 2 , . . . , T } index es the timesteps. The one-step transition kernel as follo ws: q ( x t | x t − 1 , y ) = N x t ; x t − 1 + α t z , κ 2 α t I , (1) where α t = η t − η t − 1 for t > 1 and α 1 = η 1 , κ is a noise hyper- parameter , and the chain is initialized at x 0 = x . From Eq. (1), the marginal distrib ution at any timestep t admits a closed form: q ( x t | x , y ) = N x t ; x + η t z , κ 2 η t I . (2) Eq. (2) sho ws that the mean of x t transitions smoothly from x to y as η t increases, thereby completing the degradation from the respiratory signal to the radar observation. W e explicitly inject a micromotion-encoded residual in the forward process, thereby preserving radar-measurement consistenc y throughout. Reverse Process: T o effectiv ely exploit the observ ations for guiding micromotion remov al, we initialize the re verse diffusion within an OCN of y , x T = y + κ √ η T ϵ , ϵ ∼ N ( 0 , I ) , (3) rather than initializing from pure Gaussian noise as in standard dif fu- sion, and then iterativ ely denoises to recov er the respiration ˆ x . The rev erse transition kernel p θ ( x t − 1 | x t , y ) is learned with the RDT network parameterized by θ , by minimizing the K ullback–Leibler (KL) di ver gence to the true posterior q ( x t − 1 | x t , x , y ) [17, 18]. Us- ing Eqs. (1)–(2), the true posterior admits the closed form: q ( x t − 1 | x t , x , y ) = N x t − 1 ; η t − 1 η t x t + α t η t x , κ 2 η t − 1 η t α t I . (4) Accordingly , we parameterize p θ as a Gaussian whose v ariance is fixed to match the true posterior , κ 2 η t − 1 η t α t I , and whose mean is µ θ ( x t , y , t ) = η t − 1 η t x t + α t η t RDT θ ( x t , y , t ) , (5) where the denoiser RDT θ ( · ) predicts the clean respiratory signal from the noisy state x t conditioned on y , progressively removing micromotion interference. Following prior w ork [19], the training objectiv e reduces to a Mean Squared Error (MSE) loss: L t = E t, x , y RDT θ ( x t , y , t ) − x 2 , (6) which enables RDT to denoise across noise levels and reconstruct a fine-grained respiratory wa veform. RDT : As the core denoiser of mmW av e-Diffusion, RDT operates along the reverse trajectory , initialized at the OCN state x T , and conditions on the radar-phase sequence y at each timestep. T o enhance denoising against micromotion interference, RDT uses dual patch-lev el positional encodings for the OCN-initialized main sequence x t and the conditional sequence y to enforce strict one-to-one temporal correspondence and mitigate positional con- founds, and applies a banded-mask multi-head cross-attention that limits cross-sequence interactions to a local temporal window , e x- plicitly encoding the locality prior that radar returns correlate pri- marily with temporally proximate respiration and suppressing long- range mismatches and spurious associations. In addition, we adopt timestep respacing [20] to sample a sparse subset of the T -step dif- fusion chain, substantially reducing inference cost. As sho wn in Fig. 1, we first partition x t and y into non- ov erlapping patches and add learnable positional encodings to each, producing N tokens per stream. This facilitates extraction of fine-grained temporal representations and strengthens positional alignment. In addition, the timestep t is mapped by an embedding layer . The resulting main tokens, conditional tokens, and timestep embedding serve as three input streams to L stacked RDT blocks. W ithin each block, the main-token stream first undergoes timestep-modulated normalization [14], followed by multi-head self-attention [21, 22] to model intra-sequence temporal dependen- cies. W e then employ a banded-mask multi-head cross-attention to fuse the conditional tok ens with the main stream. This mask hard-codes a locality prior by permitting interactions only within a temporal window , thereby suppressing long-range mismatches and spurious associations. The banded mask is defined elementwise as M ij = ( 0 , | i − j | ≤ u, −∞ , otherwise , (7) where i, j ∈ { 1 , . . . , N } index the main and conditional to- ken sequences, respectively; u is the local window radius; and M = [ M ij ] N i,j =1 ∈ R N × N is the mask matrix. F or a single head, cross-attention is computed as A ttention( Q , K , V ) = softmax QK ′ / √ d + M V , (8) where Q ∈ R N × d is the Query from the main tokens, K , V ∈ R N × d are the Ke y and V alue from the conditional tokens, d is the T able 1 : Performance of mmW ave-Dif fusion vs. Baselines Method W aveform Reconstruction Frequency Estimation CS ↑ MSE ↓ MAE ↓ RMSE ↓ SD ↓ MoRe-Fi [2] 0.754 0.104 1.336 1.835 1.822 MM-FGRM [3] 0.793 0.090 0.704 1.225 1.221 MM-MuRe [9] 0.760 0.100 1.949 2.336 1.416 LSTM [11] 0.798 0.151 1.058 1.339 1.211 U-Net [12] 0.701 0.135 0.865 1.240 1.193 Transformer [14] 0.752 0.108 1.107 1.428 1.240 BPF [26] 0.651 0.254 7.102 8.655 5.270 mmW ave-Diffusion 0.811 0.079 0.631 1.175 1.035 hidden dimension, ( · ) ′ denotes matrix transpose, and softmax( · ) is the softmax function. The cross-attention output is subsequently passed through a timestep-modulated Feed-Forw ard Network (FFN), whose output serves as the input to the next block. The final block’ s output is in verse-patched to ˆ x t − 1 ; iterating the step along the sam- pling path ultimately reconstructs the fine-grained wa veform ˆ x . 3. EXPERIMENT 3.1. Experimental Setup T o ev aluate mmW av e-Diffusion, we collected a synchronized radar–respiration dataset in an office en vironment using a 60 GHz IWR6843 FMCW radar with a DCA1000 board [23]; ground-truth respiration was recorded by a GDX-RB belt [24]. W e recorded 12 healthy subjects for 1 hour each, and written informed consent was obtained from all subjects. During acquisition, each subject sat approximately 1.2 m in front of the radar and breathed naturally . Ke y radar settings were: sweep bandwidth = 2 GHz; sample rate = 10 Msps; ADC samples = 512; frame periodicity = 50 ms; ramp duration = 51.2 µ s. A participant-wise split is adopted, with data from 8 subjects used for training and 4 for testing [2]. All results are reported on the test set to assess the cross-subject generalization of mmW av e-Diffusion. Signals are segmented with a 20 s sliding window and a 1 s step, yielding samples of 400 points. Respiratory monitoring performance is assessed along two dimensions: wav e- form reconstruction (Mean Squared Error (MSE), Cosine Similarity (CS)) and frequency estimation (Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), Standard Deviation (SD)). mmW a ve-Dif fusion was implemented in PyT orch on NVIDIA A100 T ensor Core GPUs. W e trained for 100 epochs using AdamW with an initial learning rate of 0.01 and employed ReduceLROn- Plateau for learning rate scheduling [25]. Key configuration details are: forward diffusion steps T = 1000 ; re verse process in 20 steps; a noise schedule { η t } T t =1 following Y ue et al. [17] with η 1 = 0 . 001 and η T = 0 . 999 ; noise hyperparameter κ = 0 . 7 ; L = 2 RDT blocks; each input sequence partitioned into N = 20 tokens; local window radius u = 1 ; and hidden dimension d = 256 . 3.2. Perf ormance Analysis T o v alidate the effecti veness of mmW a ve-Dif fusion, we system- atically compare it against three categories of baselines across fiv e metrics: advanced radar -based respiration monitoring meth- ods (MoRe-Fi [2], MM-FGRM [3], MM-MURE [9]); variants that adopt our diffusion paradigm while replacing the RDT denoiser with LSTM [11], U-Net [12], or T ransformer [14] backbones; and a classical Band-P ass Filter (BPF) baseline [26]. As sho wn in T able 1, mmW a ve-Dif fusion achie ves the best performance on all metrics: for wav eform reconstruction, CS/MSE are 0.811/0.079; for (a) Smartphone use (b) Con versation (c) Leg shaking (d) Page turning Fig. 3 : W a veform reconstruction under di verse body micromotions. respiratory-rate estimation, MAE/RMSE/SD are 0.631/1.175/1.035 Breaths Per Minute (BPM). These results substantiate the effecti ve- ness of the observation-anchored dif fusion framew ork and highlight the strength of RDT in capturing fine-grained respiratory patterns. W e further present qualitati ve evidence of mmW av e-Diffusion’ s micromotion-interference suppression. As shown in Fig. 3, typi- cal of fice micromotions (smartphone use, con versation, leg shak- ing, page turning) induce pronounced distortions in radar phase, markedly deviating from the near-sinusoidal respiratory ground truth. W ithin an observation-anchored diffusion paradigm, mmW ave- Diffusion conditions on observ ations throughout forward and rev erse steps to guide micromotion-interference remov al; together with the tailored RDT denoiser, artifacts are progressiv ely suppressed and physiological structure restored. Consequently , the reconstructed wa veforms closely match the ground truth in periodicity , morphol- ogy , and amplitude, demonstrating the robustness of our method. 3.3. Ablation Study W e quantify the contribution of each RDT component through sys- tematic ablations (T able 2). Configurations are as follows: V ariant1 remov es multi-head self-attention; V ariant2 removes the condi- tional phase tokens; V ariant3 replaces banded-mask multi-head cross-attention with direct concatenation of the conditional and main tokens at the RDT input; V ariant4 retains cross-attention but removes the banded mask. All variants underperform the full model, attesting to the substanti ve role of each component. V ari- ant1 exhibits the largest degradation (CS/MAE = 0.753/1.274), indicating that high-fidelity reconstruction requires jointly learn- ing a strong generati ve prior and explicitly modeling the intrinsic temporal dependencies of respiration. V ariant2 likewise incurs a substantial degradation (0.758/1.062), underscoring that explicit phase conditioning reinforces physical alignment and strengthens conditional guidance. V ariant4 (0.790/0.804) outperforms V ari- ant3 (0.762/0.957) yet remains below the full model (0.811/0.631), showing that cross-attention effecti vely le verages conditional ob- servations and that the banded mask enforces locality , mitigating spurious long-range correspondences and suppressing noise. 3.4. Distance Robustness Giv en that sensing distance is a principal determinant of Signal- to-Noise Ratio (SNR) in radar-based respiration monitoring, we T able 2 : Radar Diffusion T ransformer vs. Its V ariants. Method W aveform Reconstruction Frequency Estimation CS ↑ MSE ↓ MAE ↓ RMSE ↓ SD ↓ V ariant1 0.753 0.118 1.274 1.599 1.435 V ariant2 0.758 0.102 1.062 1.573 1.418 V ariant3 0.762 0.098 0.957 1.376 1.261 V ariant4 0.790 0.096 0.804 1.337 1.328 RDT 0.811 0.079 0.631 1.175 1.035 (a) Cosine similarity (b) Mean absolute error Fig. 4 : mmW av e-Diffusion performance across sensing distances. (Red dots: the mean values; Orange solid lines: the medians.) collected five additional synchronous datasets spanning 0.6–3.0 m (15-minute sessions) to ev aluate mmW ave-Dif fusion across sensing ranges. As summarized by the box plots in Fig. 4, reconstruction accuracy declines approximately monotonically with increasing distance, consistent with propagation physics (greater range attenu- ates the echo and lowers SNR). Importantly , performance does not exhibit catastrophic degradation at 3.0 m: CS = 0.723 and MAE = 0.823 BPM. These results indicate that the proposed mmW a ve- Diffusion framew ork enables reliable respiratory monitoring under varying SNR conditions in real-w orld en vironments. 4. CONCLUSION This paper proposes mmW av e-Diffusion, an observ ation-anchored conditional diffusion framework for fine-grained mmW a ve radar respiratory monitoring under micromotion interference, effecti vely removing micromotion artifacts. Specifically , the forward process explicitly injects the residual carrying interference information along the path between the radar observ ation and the respiratory ground truth; the rev erse process initializes within an observ ation-consistent neighborhood and explicitly conditions on the observation at each step to fully exploit it to constrain and guide the reconstruction. The accompanying Radar Diffusion T ransformer (RDT) encodes physical constraints—temporal correspondence and local match- ing—as structural priors through patch-level positional alignment and banded-mask multi-head cross-attention, thereby propagating the observations throughout the denoising trajectory and enabling the tar geted remo val of micromotion-induced interference. Ex- perimental results demonstrate that mmW a ve-Dif fusion achieves state-of-the-art performance across multiple metrics for wa veform reconstruction and respiratory-rate estimation. Ablation studies corroborate the necessity of each RDT component, and ev aluations across sensing distances (0.6–3.0 m) demonstrate robustness under varying SNR conditions. Overall, mmW av e-Diffusion sets a new benchmark for radar-based respiration monitoring and advances an effecti ve paradigm for the deep integration of physical priors with conditional diffusion. 5. REFERENCES [1] Jianyang W ang, Dongheng Zhang, Binbin Zhang, Jinbo Chen, Y ang Hu, and Y an Chen, “RF-GymCare: Introducing respira- tory prior for RF sensing in gym en vironments, ” Pr oceedings of the ACM on Interactive, Mobile, W ear able and Ubiquitous T ec hnologies , vol. 8, no. 3, pp. 1–28, 2024. [2] T ianyue Zheng, Zhe Chen, Shujie Zhang, Chao Cai, and Jun Luo, “MoRe-Fi: Motion-robust and fine-grained respiration monitoring via deep-learning UWB radar , ” in Pr oceedings of the 19th A CM Conference on Embedded Networked Sensor Systems , 2021, pp. 111–124. [3] Shuxuan W ang, Chong Han, Jian Guo, and Lijuan Sun, “MM- FGRM: Fine-grained respiratory monitoring using MIMO mil- limeter wa ve radar , ” IEEE T ransactions on Instrumentation and Measur ement , vol. 73, pp. 1–13, 2024. [4] Xingshuai Qiao, Y aobin Su, Xiuping Li, and T ao Shan, “Millimeter-w av e radar vital signs measurement with random body mov ement using missing data model, ” IEEE T ransac- tions on Instrumentation and Measur ement , vol. 74, pp. 1–14, 2025. [5] Y ong W ang, Dongyu Liu, Chendong Xu, Bao Zhang, Y i Lu, Kuiying Y in, Shuai Y ao, and Qisong W u, “GA WNet: A gated attention wav elet network for respiratory monitoring via millimeter-w av e radar , ” IEEE Signal Pr ocessing Letters , vol. 32, pp. 3695–3699, 2025. [6] Bo Zhang, Boyu Jiang, Rong Zheng, Xiaoping Zhang, Jun Li, and Qiang Xu, “Pi-V iMo: Physiology-inspired robust vital sign monitoring using mmW av e radars, ” ACM Tr ansactions on Internet of Things , vol. 4, no. 2, pp. 1–27, 2023. [7] Y ong W ang, Chendong Xu, Bao Zhang, Zijun Huang, Dongyu Liu, Shuai Y ao, Kuiying Y in, Qisong W u, and Chaochao W ang, “Fine-grained contactless human respiratory measure- ment using millimeter-w av e radar, ” IEEE T ransactions on In- strumentation and Measur ement , vol. 75, pp. 1–15, 2026. [8] Y ingxiao W u, Haocheng Ni, Changlin Mao, and Jianping Han, “Contactless reconstruction of ECG and respiration signals with mmW av e radar based on RSSRnet, ” IEEE Sensors Jour- nal , vol. 24, no. 5, pp. 6358–6368, 2024. [9] Chandler Bauder , Abdel-Kareem Moadi, V ijaysrini vas Ra- jagopal, T ianhao W u, Jian Liu, and Aly E. Fath y , “MM- MURE: mmW ave-based multi-subject respiration monitoring via end-to-end deep learning, ” IEEE Journal of Electr omag- netics, RF and Micr owaves in Medicine and Biology , vol. 9, no. 1, pp. 49–61, 2025. [10] Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang, “Diffusion-4k: Ultra-high-resolution image syn- thesis with latent dif fusion models, ” in 2025 IEEE/CVF Con- fer ence on Computer V ision and P attern Recognition (CVPR) , 2025, pp. 23464–23473. [11] Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland V ollgraf, “ Autore gressiv e denoising diffusion models for mul- tiv ariate probabilistic time series forecasting, ” in International Confer ence on Machine Learning . PMLR, 2021, pp. 8857– 8868. [12] Jonathan Ho, Ajay Jain, and Pieter Abbeel, “Denoising dif- fusion probabilistic models, ” Advances in Neural Information Pr ocessing Systems , vol. 33, pp. 6840–6851, 2020. [13] Prafulla Dhariwal and Alexander Nichol, “Diffusion models beat gans on image synthesis, ” Advances in Neural Information Pr ocessing Systems , vol. 34, pp. 8780–8794, 2021. [14] W illiam Peebles and Saining Xie, “Scalable diffusion models with Transformers, ” in 2023 IEEE/CVF International Confer- ence on Computer V ision (ICCV) , 2023, pp. 4172–4182. [15] Pape Sanoussy Diao, Thierry Alves, Benoit Poussot, and Syl- vain Azarian, “ A revie w of radar detection fundamentals, ” IEEE Aer ospace and Electr onic Systems Magazine , vol. 39, no. 9, pp. 4–24, 2024. [16] Salman Liaquat, Nor Muzlifah Mahyuddin, and Ijaz Haider Naqvi, “ An end-to-end modular framework for radar signal processing: A simulation-based tutorial, ” IEEE Aer ospace and Electr onic Systems Magazine , vol. 39, no. 9, pp. 98–118, 2024. [17] Zongsheng Y ue, Jianyi W ang, and Chen Change Loy , “Effi- cient diffusion model for image restoration by residual shift- ing, ” IEEE T ransactions on P attern Analysis and Machine In- telligence , v ol. 47, no. 1, pp. 116–130, 2025. [18] Jiawei Liu, Qiang W ang, Huijie Fan, Y inong W ang, Y andong T ang, and Liangqiong Qu, “Residual denoising dif fusion mod- els, ” in 2024 IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2024, pp. 2773–2783. [19] Qifan Shen, Xinwei Luo, and Long Chen, “ A deep learn- ing based iterati ve denoising algorithm for multiple frequency lines recov ery , ” Engineering Applications of Artificial Intelli- gence , v ol. 159, pp. 111601, 2025. [20] Jiaming Song, Chenlin Meng, and Stefano Ermon, “Denoising diffusion implicit models, ” arXiv pr eprint arXiv:2010.02502 , 2020. [21] Y ijun W ang, Y ong W ang, Chendong Xu, Shuai Y ao, and Qisong W u, “SelaFD:seamless adaptation of vision T rans- former fine-tuning for radar -based human acti vity recognition, ” in 2025 IEEE International Conference on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , 2025, pp. 1–5. [22] Y ong W ang, Cheng Lu, Hailun Lian, Y an Zhao, Bj ¨ orn W . Schuller , Y uan Zong, and W enming Zheng, “Speech Swin- T ransformer: Exploring a hierarchical Transformer with shifted windows for speech emotion recognition, ” in 2024 IEEE International Confer ence on Acoustics, Speech and Sig- nal Pr ocessing (ICASSP) , 2024, pp. 11646–11650. [23] Guangyu Lei, W ei Cheng, Xipeng Y in, and Y uqing Wu, “The dataset of multi-target vital signs monitored by FMCW radar , ” Data in Brief , vol. 57, pp. 111027, 2024. [24] Gianfranco Mauro, Maria De Carlos Diez, Julius Ott, Lorenzo Servadei, Manuel P . Cuellar , and Diego P . Morales-Santos, “Few-shot user-adaptable radar -based breath signal sensing, ” Sensors , v ol. 23, no. 2, 2023. [25] Y ong W ang, Chendong Xu, W eirui Na, Dongyu Liu, Jiuqi Y an, Shuai Y ao, and Qisong W u, “Hierarchical T ransformer with auxiliary learning for subject-independent respiration emotion recognition, ” IEEE Sensors Journal , vol. 25, no. 16, pp. 31290–31301, 2025. [26] Shekh M M Islam, Naoyuki Motoyama, Sergio Pacheco, and V ictor M. Lubecke, “Non-contact vital signs monitoring for multiple subjects using a millimeter wav e FMCW automotiv e radar , ” in 2020 IEEE/MTT -S International Microwave Sympo- sium (IMS) , 2020, pp. 783–786.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment