Physics-Aware, Shannon-Optimal Compression via Arithmetic Coding for Distributional Fidelity
Assessing whether two datasets are distributionally consistent is central to modern scientific analysis, particularly as generative artificial intelligence produces synthetic data whose fidelity must be validated against real observations in increasi…
Authors: Cristiano Fanelli
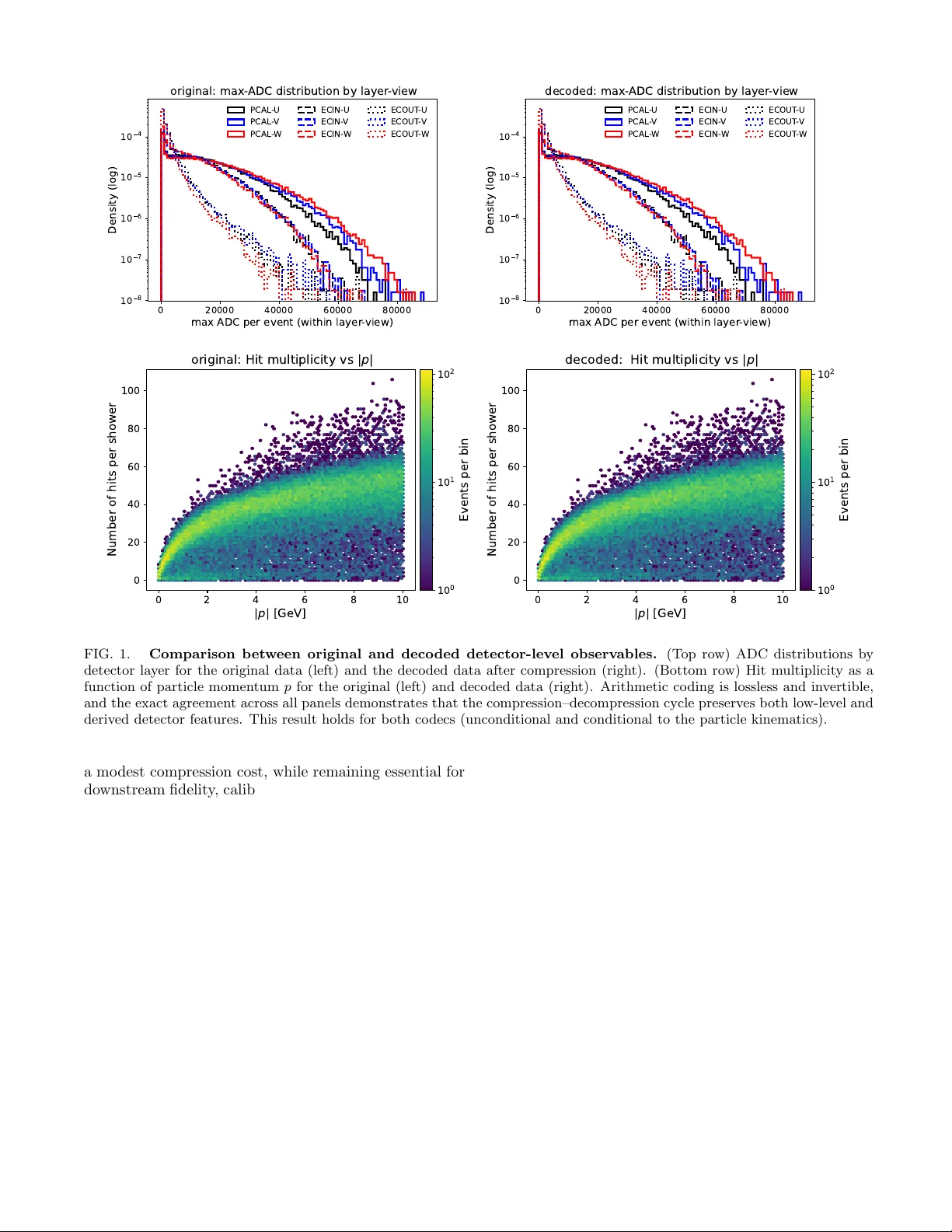
Ph ysics-Aw are, Shannon-Optimal Compression via Arithmetic Co ding for Distributional Fidelit y Cristiano F anelli 1 , ∗ 1 Scho ol of Computing, Data Scienc es, and Physics, Wil liam & Mary, Wil liamsbur g, V A, USA (Dated: F ebruary 27, 2026) Assessing whether tw o datasets are distributional ly c onsistent has b ecome a cen tral theme in mo d- ern scien tific analysis, particularly as generative artificial in telligence is increasingly used to pro duce syn thetic datasets whose fidelity m ust b e rigorously v alidated against the original data on which they are trained, a task made more c hallenging b y the con tinued growth in data v olume and prob- lem dimensionalit y . In this work, we propose the use of arithmetic coding to provide a lossless and in vertible compression of datasets under a physics-informed probabilistic representation. Datasets that share the same underlying ph ysical correlations admit comparable optimal descriptions, while discrepancies in those correlations—arising from miscalibration, mismodeling, or bias—manifest as an irreducible excess in co de length. This excess co delength defines an operational fidelity metric, quan tified directly in bits through differences in ac hiev able compression length relative to a ph ysics- inspired reference distribution. W e demonstrate that this metric is global, interpretable, additiv e across components, and asymptotically optimal in the Shannon sense. Moreov er, w e sho w that dif- ferences in codelength correspond to differences in expected negative log-likelihoo d ev aluated under the same physics-informed reference mo del. As a byproduct, we also demonstrate that our com- pression approach ac hieves a higher compression ratio than traditional general-purp ose algorithms suc h as gzip . Our results establish lossless, ph ysics-aw are compression based on arithmetic co ding not as an end in itself, but as a measuremen t instrumen t for testing the fidelit y betw een datasets. I. INTR ODUCTION Assessing whether t wo datasets are described b y the same underlying probability distribution is a founda- tional problem across man y disciplines [ 1 – 5 ]. In the con text of generative artificial intelligence, this question arises naturally when ev aluating how faithfully synthetic data produced by generative mo dels reproduce the dis- tribution of the original data [ 6 – 9 ]. In the ph ysical sci- ences, closely related c hallenges app ear in comparisons b et w een Monte Carlo simulations and data collected un- der v arying exp erimental conditions, as well as in detec- tor calibration, data v alidation, and the assessmen t of the fidelit y of approximate or generativ e sim ulation tech- niques [ 10 – 15 ]. As mo dern experiments generate increas- ingly large, high-dimensional, and multimodal datasets, traditional approac hes to distributional comparison face gro wing limitations. Methods based on handcrafted test statistics, lo w-dimensional summaries, or explicitly pa- rameterized lik eliho ods often rely on design choices that b ecome difficult to justify or interpret as dimensional- it y and complexity increase, and whose b eha vior may b e dominated by mo deling assumptions rather than by in- trinsic prop erties of the data. A wide range of statistical tools hav e b een developed to address distributional consistency , including div ergence- based measures, k ernel-based distances, embedding- space metrics, and classical goo dness-of-fit tests. While p o w erful in sp ecific settings, these approaches generally require the explicit choice of a test statistic, kernel, fea- ∗ cfanelli@wm.edu ture space, or approximate lik eliho o d, introducing as- sumptions that are external to the data representation itself. In high-dimensional and multimodal regimes, such c hoices can strongly influence sensitivity and interpreta- tion [ 16 ]. Divergence-based measures, such as the Kull- bac k–Leibler and Jensen–Shannon divergences, provide principled information-theoretic notions of distributional discrepancy and admit well-defined axiomatic and geo- metric interpretations [ 3 , 17 , 18 ]. Ho wev er, these diver- gences are not directly observ able from finite samples and t ypically require explicit density mo dels, parametric as- sumptions, or v ariational approximations to b e estimated in practice [ 16 , 19 ]. Sample-based distances, including k ernel methods suc h as the Maximum Mean Discrepancy or optimal- transp ort–based metrics, a v oid explicit density estima- tion but depend on externally sp ecified structures—such as kernel bandwidths or cost functions—that are not uniquely determined b y the physical represen tation of the data [ 4 , 20 ]. Embedding-based fidelity metrics assess consistency in a learned feature space rather than at the lev el of the original data distribution [ 4 , 16 ], while classi- cal go o dness-of-fit tests—including binned and unbinned lik eliho o d-based tests—rely on selected observ ables or binning schemes and, in the large-sample limit, may reject the n ull hypothesis for arbitrarily small pertur- bations, quan tifying statistical detectability rather than practical distributional fidelity [ 1 , 21 – 23 ]. In this work, we use lossless c ompr ession as an op era- tional probe of distributional fidelity . Rather than in tro- ducing an auxiliary distance, classifier, or feature space, w e interpret the exc ess c o delength b etw een datasets as a representation-conditional statistic that directly quan- tifies distributional mismatc h. F or a fixed, ph ysics- 2 informed probabilistic representation, lossless compres- sion provides a canonical and intrinsic realization of dis- tributional comparison. Arithmetic coding (AC) [ 24 , 25 ] plays a central role in this framework. As a lossless compression technique, AC pro vides a constructive realization of Shannon-optimal enco ding for a given probabilit y assignmen t. W e em- plo y a physics-awar e arithmetic codec whose probabilis- tic structure reflects known features of the physical pro- cesses underlying the detector resp onse. Giv en a prob- abilistic mo del q ( x ), arithmetic co ding produces a bi- nary description whose length approaches − log 2 q ( x ), up to finite-precision effects, establishing a direct and arc hitecture-indep enden t mapping b et ween probabilit y and achiev able co delength. In this work, A C is used not as a pro duction co dec, but as a r efer enc e instrument that renders probabilistic structure observ able through mea- sured co delengths. The present approach is related in spirit to the Mini- m um Description Length (MDL) principle [ 26 ], in which compression is used for mo del selection by balancing go odness of fit against mo del complexity . In this work, by con trast, the probabilistic representation is fixed based on ph ysical considerations, and compression is used di- agnostically to quan tify distributional mismatch b etw een datasets rather than to select among comp eting mo dels. Recen t w ork on learned and neural compression fo cuses on optimizing representations to ac hiev e higher compres- sion rates [ 27 , 28 ], while in contrast we hold the proba- bilistic represen tation fixed and use lossless compression to exp ose missing or broken physical correlations through irreducible excess co delength. Within our framew ork, calibration and consistency tests are form ulated directly in terms of achiev ed co de- length. Data that resp ect the correlations enco ded in the reference representation compress efficiently , while viola- tions of those correlations incur an expected excess code- length. The resulting diagnostic is global—sensitive to the full joint distribution ov er the chosen represen tation rather than to selected observ ables or low-dimensional pro jections—interpretable, with deviations expressed di- rectly in bits, and additive, allo wing in this work contri- butions from detector subsystems or data comp onents to b e accumulated and compared consistently . F rom a statistical p erspective, increasing sample size impro ves the stability of this diagnostic by reducing finite-sample fluctuations and driving the measured av- erage co delength to ward its asymptotic v alue, lim N →∞ 1 N N X i =1 ℓ ( x i ) = H ( p ) + D KL ( p ∥ q ) , (1) where p denotes the true data-generating distribution and q the reference probabilistic representation. F rom a computational standp oin t, arithmetic co ding scales lin- early with the n um b er of enco ded symbols, and prac- tical implementations may employ blo c king, stream- ing, or parallelization without altering the underlying information-theoretic interpretation. Lossless compression do es not replace existing fidelity diagnostics, but pro vides a representation-consisten t and information-theoretic realization of them. Unlike k ernel- based distances or em b edding-space metrics, compres- sion do es not rely on externally defined feature spaces or test functions: all correlations present in the data con tribute automatically to the achiev able co delength. In this sense, compression probes fidelit y at the level of the full data distribution. Using controlled p ertur- bations and independent reference samples, we demon- strate that physics-a w are arithmetic co ding provides a calibrated and in terpretable diagnostic of distributional inconsistency for multimodal detector readout data, com- plemen tary to conv en tional distributional tests. Com- pression is th us elev ated from a data-reduction tec hnique to a quantitativ e instrument for v alidating physical struc- ture in complex datasets. The structure of this pap er is as follows. Section I I describ es the dataset used in this w ork. Section II I in- tro duces the conceptual framew ork. Section IV presen ts the results and their interpretation. Section V summa- rizes the main conclusions. I I. D A T A AND REPRESENT A TION W e use simulated electromagnetic calorimeter data from the CLAS12 detector, including the PCAL, ECIN, and ECOUT subsystems, as describ ed in Refs. [ 29 , 30 ]. The calorimeter consists of alternating lead and scintilla- tor la yers read out in three stereo views (U/V/W) rotated b y approximately 60 ◦ , pro viding complementary pro jec- tions of the transverse show er profile. Eac h even t is represented b y integer-v alued detec- tor re adout and particle-level quan tities: hits adc and hits strips store arrays of shap e ( N , 9 , 20) with up to 20 hit slots p er lay er; max adc and max strips ha ve shap e ( N , 9) and record the maximum response per la yer; 1 and part input has shap e ( N , 3) and con tains the particle momen tum comp onen ts ( p x , p y , p z ). The nine la yers corresp ond to PCAL (U/V/W), ECIN (U/V/W), and ECOUT (U/V/W). In this study , we consider data from a single calorimeter sector; the nine readout lay- ers hav e different num bers of ph ysical strips, namely 68 (PCAL-U), 62 (PCAL-V), 62 (PCAL-W), and 36 strips for each of the ECIN and ECOUT U/V/W la yers. F or these studies, w e use a dataset comprising O (10 6 ) ev en ts. P adding is enco ded using strip = − 999, which is paired (b y construction) with the unph ysical v alue adc = − 999; this in v arian t is verified and enforced throughout. Hit- slot indices carry no geometric meaning across la yers or views: correlations arise solely from the joint statistics of the readout, not from p ositional alignment of slots. 1 max adc and max strips can b e deriv ed from hits adc and hits strips and for this reason are not used in this work. 3 The dataset is inherently multimodal, combining sparse, hea vy-tailed discrete detector responses, categor- ical strip identifiers with geometry-dep endent correla- tions, lay er-dependent o ccupancy patterns, and con tin- uous particle kinematics: X = { hits adc , hits strips , part input } , (2) No lossy preprocessing is applied to the stored dataset. All quantities are used at full integer precision, with no clipping, binning, or thresholding b ey ond the detec- tor’s in trinsic digitization. The representation is there- fore lossless with respect to the recorded detector readout and particle kinematics; any compression gain arises ex- clusiv ely from exploiting statistical structure rather than from information remov al. This representation motiv ates the physics-a w are factorization used b y the co dec and un- derpins the fidelity studies presented in Sec. IV . Dataset splits T o disentangle mo del training, refer- ence ev aluation, and fidelity testing, w e rep eat inde- p enden t random splits (70/30%) of the same reference dataset R . The first split ( A (1) , B (1) ) is used to prov e in vertibilit y of the test dataset in Sec. IV A and to study compression prop erties in Sec. IV B ; this split is also used to define the p erturbed simulation in Sec. IV E : a p er- turb ed sample C is constructed by applying a con trolled transformation ( e.g. , an ADC scale distortion) to B (1) , ensuring that C and B (1) share iden tical even t indices while differing only through the imposed effect. A second indep enden t split ( A (2) , B (2 ) provides an unbiased refer- ence sample for statistical comparisons, av oiding reuse of the data that seeded the p erturbation. Finally , a third split ( A (3) , B (3) ) is used to create the training dataset A (3) to train the arithmetic co dec, thereby fixing a refer- ence probability mo del q A (3) ( x ) that is in go od appro xi- mation statistically independent of b oth C and B (2) . All fidelit y tests are then p erformed by enco ding C and B (2) under the same co dec trained on A (3) . This separation ensures that observ ed codelength differences reflect gen- uine distributional inconsistencies rather than artifacts of training–testing o verlap or sample reuse. F or notational simplicit y , the dataset lab el ( i ) is suppressed when it does not affect the interpretation. I II. CONCEPTUAL FRAMEW ORK W e now formalize the information-theoretic framew ork underlying our approach. Our central premise is that c ompr ession itself is not the sour c e of physic al under- standing : arithmetic co ding is an optimal executor of a giv en probability mo del, while ph ysical structure enters only through the probabilistic representation used to as- sign probabilities to the data. The achiev ed co delength therefore provides an op era- tional measuremen t of ho w w ell a fixed, ph ysics-informed mo del explains a dataset, expressed directly in bits. A. Arithmetic Co ding and Shannon Optimality Arithmetic co ding [ 24 , 25 ] is a lossless entrop y co d- ing algorithm that maps a sequence of discrete sym b ols to a binary string whose length approac hes the negativ e log-probabilit y of that sequence under a specified mo del. Let x = ( x 1 , . . . , x T ) b e a sequence with mo del proba- bilit y q ( x ) = Q T t =1 q ( x t | x 0 indicates that even ts in the p erturb ed sample C ε are, on a verage, less typical under the fixed reference mo del q A than ev ents in the indep endent base- line sample B . Equiv alen tly , ∆ L ( ε ) ≈ H ( ˆ p C ε , q A ) − H ( ˆ p B , q A ) = E x ∼ ˆ p C ε − log 2 q A ( x ) − E x ∼ ˆ p B − log 2 q A ( x ) . (13) Here ˆ p C ε and ˆ p B denote the empirical distributions of C ε and B , resp ectiv ely . Thus, ∆ L ( ε ) is the difference b e- t ween tw o cross-en tropies ev aluated under the same fixed reference mo del q A —trained once on dataset A —with exp ectations taken o ver independent samples from the baseline and perturb ed datasets. This yields a model- conditional consistency test that assesses whether C ε re- mains typical under the physical assumptions enco ded b y the reference co dec, rather than testing equality in an externally sp ecified feature or em b edding space. In the fidelit y studies (Sec. IV ), statistical significance is assessed b y estimating ∆ L ( ε ) on K approximately in- dep enden t even t blocks and applying a one-sided h yp oth- esis test to the resulting blo c kwise estimates. The out- come is expressed in bits p er ev ent, enabling a direct and additiv e in terpretation of the degree to whic h distri- butional structure is violated under the fixed reference represen tation. IV. ANAL YSIS AND RESUL TS A. In vertibilit y T o verify the lossless and inv ertible nature of the pro- p osed arithmetic co ding framework, we perform a direct comparison betw een detector-lev el observ ables computed from the original data and from the data obtained after a full compression–decompression cycle. The dataset R is split into disjoint training ( A ) and v alidation ( B ) subsets, with mo dels trained on A and ev aluated on B . Figure 1 rep orts representativ e results for dataset B . The top row compares the distributions of the maxi- m um ADC v alue p er even t, resolv ed by detector la yer and view, for the original data (left) and the deco ded data af- ter compression (right). The bottom ro w shows the hit m ultiplicity p er sho w er as a function of the particle mo- men tum | p | for the same tw o cases. Across all panels, the decoded distributions are indistinguishable from the originals within statistical precision, demonstrating exact preserv ation of b oth lo w-level detector readout and de- riv ed, ph ysics-relev ant observ ables. These results confirm that the arithmetic coding pro cedure is fully lossless and in vertible at the even t level. Imp ortantly , the same level of agreement is obtained for both the unconditional co dec and the codec conditioned on particle kinematics, indi- cating that inv ertibilit y is intrinsic to the co ding scheme and indep endent of the sp ecific factorization used in the T ABLE I. Lossless compression comparison. Relative factors are quoted with resp ect to unconditional (U.-A C) and condi- tional (C.-A C) arithmetic coding. Method Size [MB] Ratio Rel. to U.-A C Rel. to C.-AC Uncompressed 95.16 – – – U.-A C 7.02 13.55 × – 0.97 × C.-A C 7.22 13.18 × 1.03 × – gzip-9 11.21 8.49 × 1.60 × 1.55 × gzip-6 11.86 8.02 × 1.69 × 1.64 × gzip-1 15.25 6.24 × 2.17 × 2.11 × probabilistic mo del. This establishes arithmetic co ding as a reliable compression–decompression mechanism suit- able for do wnstream physics analysis, with no degrada- tion of detector-level information. B. Compression Ratio Studies T o assess the practical p erformance of physics-a w are arithmetic co ding b eyond its role as a fidelity diagnos- tic, we compare its lossless compression efficiency against a widely used general-purp ose compressor, gzip . All comparisons are p erformed on identical raw con tent (see Eq. ( 2 )), using a common canonicalized represen tation— i.e. , a fixed, deterministic, and lossless serialization of the data—to ensure strict lossless and a fair, like-for-lik e ev aluation across metho ds. Arithmetic co ding is applied using the same physics-informed probabilistic factoriza- tion described earlier, while gzip is ev aluated at multiple compression lev els ( -1 , -6 , and -9 ) [ 31 ]. The compression ratios rep orted in T able I are defined as the ratio of the original (uncompressed) data size to the compressed size, sho wn separately for the unconditional and kinematics- conditioned cases. Sev eral conclusions emerge from these results. Arith- metic co ding consisten tly outperforms gzip at all com- pression levels. Ev en at the strongest gzip setting ( gzip-9 ), arithmetic coding pro duces files that are ap- pro ximately 1.6 × smaller. A t low er gzip levels, the ad- v an tage increases to nearly a factor of tw o. This demon- strates that generic compressors are unable to fully ex- ploit the structured, physics-driv en regularities present in detector data. The achiev ed compression ratios indi- cate that arithmetic co ding op erates close to the Shannon limit implied by the chosen probabilistic representation. Because arithmetic coding maps probability assignments directly into co de length, the resulting a verage descrip- tion length provides a direct estimate of the cross-en trop y b et w een the data and the ph ysics-informed factorized mo del. In contrast, gzip lacks an explicit probabilis- tic mo del and therefore cannot systematically approac h this b ound. As shown in T able I I and I I I , while the calorimeter hit information dominates the compressed pa yload (approximately 90% of the total size), particle kinematics still contribute non-negligibly (ab out 10%). Imp ortan tly , including kinematic information incurs only 6 0 20000 40000 60000 80000 max ADC per event (within layer - view) 1 0 8 1 0 7 1 0 6 1 0 5 1 0 4 Density (log) original: max- ADC distribution by layer - view PCAL -U PCAL - V PCAL - W ECIN-U ECIN- V ECIN- W ECOUT -U ECOUT - V ECOUT - W 0 20000 40000 60000 80000 max ADC per event (within layer - view) 1 0 8 1 0 7 1 0 6 1 0 5 1 0 4 Density (log) decoded: max- ADC distribution by layer - view PCAL -U PCAL - V PCAL - W ECIN-U ECIN- V ECIN- W ECOUT -U ECOUT - V ECOUT - W 0 2 4 6 8 10 | p | [ G e V ] 0 20 40 60 80 100 Number of hits per shower o r i g i n a l : H i t m u l t i p l i c i t y v s | p | 1 0 0 1 0 1 1 0 2 Events per bin 0 2 4 6 8 10 | p | [ G e V ] 0 20 40 60 80 100 Number of hits per shower d e c o d e d : H i t m u l t i p l i c i t y v s | p | 1 0 0 1 0 1 1 0 2 Events per bin FIG. 1. Comparison b et w een original and deco ded detector-lev el observ ables. (T op row) ADC distributions by detector lay er for the original data (left) and the deco ded data after compression (right). (Bottom row) Hit multiplicit y as a function of particle momentum p for the original (left) and deco ded data (right). Arithmetic co ding is lossless and in vertible, and the exact agreemen t across all panels demonstrates that the compression–decompression cycle preserv es b oth low-lev el and deriv ed detector features. This result holds for b oth co decs (unconditional and conditional to the particle kinematics). a mo dest c ompression cost, while remaining essen tial for do wnstream fidelit y , calibration, and consistency studies. With resp ect to computational p erformance, we ob- serv e that the enco ding time of the AC implemen ta- tion is appro ximately a factor of tw o slo w er than that of gzip , while the deco ding time is slo w er b y a factor of O (10 2 ). This difference is exp ected: gzip relies on a highly optimized, production-grade implementation writ- ten in low-lev el compiled code, whereas the A C imple- men tation used here is a reference, purely Python-based realization that prioritizes clarit y , flexibility , and direct access to probabilistic structure ov er ra w throughput. As suc h, the reported timing ratios should be interpreted as indicativ e rather than fundamental limitations of arith- metic coding itself; optimized implementations are well kno wn to achiev e substantially higher performance. A detailed optimization of encoding and deco ding sp eed is therefore b eyond the scope of the present w ork, whose fo cus is on compression efficiency and the information- theoretic interpretation of code length. As w e will expand (see Sec. IV C and IV D ), our studies establish ph ysics-aw are arithmetic co ding as more than an efficient lossless compressor. It provides a principled, in terpretable, and near-optimal baseline for compression, while sim ultaneously enabling information-theoretic di- agnostics of distributional fidelity . This dual role—as a compression metho d and as a quantitativ e scientific measuremen t to ol—distinguishes arithmetic co ding fun- damen tally from generic, task-agnostic compressors. C. Comparison b et ween Shannon Entrop y and Av erage Sequence Length T ables I I and I I I rep ort the empirical entrop y H ( q ), the cross-en trop y H ( p, q ), and the achiev ed av erage code length L (all in bits p er even t) for the unconditional and conditional co decs, resp ectively . Results are shown separately for the calorimeter hits and for the particle- kinematics payload, as w ell as for the total even t repre- 7 T ABLE II. Shannon en tropy , cross-en tropy , and ac hieved av- erage code length for the unc onditional arithmetic co dec. Comp onen t H ( q ) H ( p, q ) L Ov erhead (%) ( A ) Hits 755.01015 779.55374 779.55376 3 . 0 × 10 − 6 ( A ) P art 82.41942 82.42861 82.42940 9 . 6 × 10 − 4 ( A ) T otal 837.42957 861.98234 861.98316 9 . 5 × 10 − 5 ( B ) Hits 749.72386 782.17784 782.17797 1 . 7 × 10 − 5 ( B ) Part 82.41024 82.43129 82.43372 2 . 96 × 10 − 3 ( B ) T otal 832.13410 864.60912 864.61169 2 . 97 × 10 − 4 T ABLE II I. Shannon en tropy , cross-entrop y , and ac hieved a v- erage code length for the c onditional arithmetic co dec. Comp onen t H ( q ) H ( p, q ) L Ov erhead (%) ( A ) Hits 717.88968 798.01378 798.01380 2 . 0 × 10 − 6 ( A ) P art 82.41942 82.42861 82.42940 9 . 6 × 10 − 4 ( A ) T otal 800.30910 880.44238 880.44320 9 . 3 × 10 − 5 ( B ) Hits 695.99810 806.13961 806.13969 1 . 1 × 10 − 5 ( B ) Part 82.41024 82.43129 82.43372 2 . 96 × 10 − 3 ( B ) T otal 778.40833 888.57089 888.57342 2 . 8 × 10 − 4 sen tation, and for b oth the training dataset A and the v alidation B . Several features are w orth highligh ting. First, in all cases the ac hieved co de length closely matc hes the empirical cross-entrop y , with discrepancies at the level of O (10 − 3 ) bits p er even t, corresp onding to relativ e ov erheads b elo w 10 − 3 %. This demonstrates that the arithmetic co dec operates essen tially at the Shannon- optimal limit for the sp ecified probabilistic mo dels. Second, the cross-entrop y ev aluated on the v alidation dataset B is systematically larger than that obtained on the training dataset A . This increase is consistent with the expected additional “surprise” incurred when enco d- ing previously unseen data dra wn from the same under- lying pro cess, reflecting finite-sample estimation effects rather than a true distributional difference, since the ref- erence mo del is trained on A rather than on B [ 25 ]. Third, conditioning the hit mo del on particle momen- tum reduces the empirical entrop y H ( q ) by capturing additional ph ysical correlations. A t the same time, the cross-en tropy H ( p, q ) increases due to the added mo del structure and finite-sample effects within each condition- ing bin. Despite this increased complexity , the achiev ed co de length remains tightly matched to H ( p, q ), confirm- ing that conditioning do es not in tro duce an y inefficiency in the co ding pro cedure. Ov erall, these results demonstrate that physics-a w are arithmetic co ding is not only lossless and inv ertible, but also ac hiev es compression at the Shannon-optimal limit. The excess code length H ( p, q ) − H ( p ) = D KL ( p ∥ q ) pro- vides a direct, information-theoretic measure of distribu- tional mismatc h, while the residual difference L − H ( p, q ) quan tifies the finite-precision ov erhead of the implemen- PCAL -U PCAL - V PCAL - W ECIN-U ECIN- V ECIN- W ECOUT -U ECOUT - V ECOUT - W 0 20 40 60 80 100 120 Bits per event bit-budget by layer - view hits: occupancy hits: strips hits: adc FIG. 2. Bit-budget decomp osition for unconditional arithmetic coding. The achiev ed co delength p er even t is decomp osed by calorimeter lay er and stereo view (U/V/W), and further split in to o ccupancy , strip, and ADC contribu- tions. The sum ov er all la y er–views yields the total detector- lev el contribution to the achiev ed codelength. PCAL -U PCAL - V PCAL - W ECIN-U ECIN- V ECIN- W ECOUT -U ECOUT - V ECOUT - W 0 20 40 60 80 100 120 140 Bits per event bit-budget by layer - view hits: occupancy hits: strips hits: adc FIG. 3. Bit-budget decomp osition for conditional arithmetic coding. The achiev ed co delength p er even t is decomp osed by calorimeter lay er and stereo view (U/V/W), and further split in to o ccupancy , strip, and ADC contribu- tions. Conditioning the hit mo del on particle kinematics mod- ifies the distribution of bits across lay ers while preserving the same additiv e decomposition. tation. This prop ert y underpins the use of arithmetic co ding as a principled diagnostic for assessing distribu- tional fidelity in high-dimensional scientific data. D. Information and Bit-Budget Decomp osition Lossless compression provides a natural and physi- cally in terpretable decomposition of information con ten t. Because arithmetic coding assigns bits according to an explicit probabilistic factorization, the ac hieved co de- length can b e written as a sum of additive con tributions asso ciated with detector subsystems, readout channels, and mo deled conditional structure. This enables a fine- grained interpretation of where information resides in the data and which comp onents dominate the ov erall descrip- tion length. Figure 2 shows the achiev ed bit budget for the un- c onditional arithmetic co ding mo del trained on split A, decomp osed by calorimeter lay er and stereo view. F or eac h la yer–view (L V), the total contribution is further separated into o ccupancy , strip index, and ADC ampli- 8 tude terms. T able IV rep orts the corresp onding numer- ical v alues. The dominan t con tribution arises from ADC amplitudes, follo wed b y strip indices, while o ccupancy carries a smaller but non-negligible fraction of the to- tal information. The PCAL la y ers contribute the largest share of the bit budget, reflecting b oth higher hit m ul- tiplicities and a broader ADC amplitude range, while ECIN and ECOUT contribute progressively less. The final column reports the mean hit m ultiplicity p er la y er– view, illustrating the close corresp ondence betw een de- tector activity and information conten t. Summing ov er all nine la yer–views yields a detector-level contribution of appro ximately 779 . 55 bits p er ev en t, which can b e com- pared to T able I I . The particle kinematic information, enco ded separately using a generic b yte-lev el mo del, con- tributes an additional 82 . 43 bits per even t. The resulting total ac hieved co delength of ≈ 862 bits p er ev ent defines the unconditional reference baseline. Any p ossible re- duction in co delength ac hiev ed by conditional or enric hed probabilistic mo dels can therefore be interpreted directly as reco v ered ph ysical correlations, rather than c hanges in the co ding algorithm. W e now rep eat the same information-theoretic decom- p osition for the c onditional arithmetic co ding mo del, in whic h the detector hit probabilities are conditioned on bins of the particle momentum magnitude. Figure 3 and T able V show the ac hieved bit budget for split A using this conditional co dec. Summing ov er all nine la yer–views yields a detector-level con tribution of ap- pro ximately 798 . 01 bits p er even t, which can b e com- pared to T able I II . Compared to the unconditional case, conditioning redistributes the bit budget across detec- tor comp onen ts. In particular, the o ccupancy contribu- tion is reduced across all la y ers, reflecting the fact that hit presence b ecomes more predictable once kinematic information is provided. Con v ersely , the ADC contri- bution increases, indicating that amplitude distributions are ev aluated within finer kinematic contexts, whic h in- curs additional cross-entrop y at finite statistics. As a result, the total achiev ed co delength increases modestly . This behavior is consistent with conditioning being ap- plied only to the hit mo del, while particle kinematics are enco ded separately using a fixed, generic represen tation. E. Fidelit y Studies W e study the sensitivit y of ph ysics-a ware lossless com- pression as a global diagnostic of distributional fidelity by constructing p erturbed datasets with controlled strength. Starting from an indep enden t real-data split, w e con- struct a family of calibration “stress tests” C ε b y ap- plying a con trolled ADC scale perturbation a = 1 + ε to o ccupied calorimeter hits, follow ed by rounding, clipping, and enforcemen t of the padding conv en tion. Each per- turb ed sample C ε is then compared to an indep enden t baseline sample drawn from the same p opulation. All compression results use a fixe d reference co dec trained T ABLE IV. P er-lay er–view decomp osition of the ac hieved cross-en tropy H ( q , p ) for detector hits in the unconditional arithmetic co ding model trained on split A. All v alues are rep orted in bits p er ev ent. L V Occ. Strip ADC Sum ⟨ N hit ⟩ PCAL–U 9.47 32.36 54.05 95.88 5.72 PCAL–V 10.21 39.64 63.93 113.79 6.82 PCAL–W 11.79 48.08 71.60 131.48 8.27 ECIN–U 9.92 30.27 53.32 93.51 6.20 ECIN–V 9.26 27.78 51.75 88.79 5.66 ECIN–W 8.95 26.60 49.60 85.15 5.41 ECOUT–U 6.54 17.75 32.90 57.19 3.65 ECOUT–V 6.71 18.18 33.13 58.01 3.70 ECOUT–W 6.50 17.59 31.67 55.76 3.58 Hits total 779.55 P article kinematics — 82.43 T otal — 861.98 T ABLE V. Per-la y er–view decomp osition of the achiev ed cross-en tropy H ( q , p ) for detector hits in the c onditional arith- metic coding model trained on split A. All v alues are reported in bits per even t. L V Occ. Strip ADC Sum ⟨ N hit ⟩ PCAL–U 8.44 32.36 57.03 97.83 5.72 PCAL–V 8.84 39.64 67.75 116.23 6.82 PCAL–W 9.90 48.08 75.45 133.43 8.27 ECIN–U 8.63 30.27 56.03 94.93 6.20 ECIN–V 8.08 27.77 54.61 90.46 5.66 ECIN–W 7.81 26.59 52.39 86.80 5.41 ECOUT–U 5.50 17.75 36.09 59.34 3.65 ECOUT–V 5.62 18.17 36.76 60.55 3.70 ECOUT–W 5.42 17.59 35.45 58.46 3.58 Hits total 798.01 P article kinematics — 82.43 T otal — 880.44 once on the training split ( i.e. , its CDFs are held fixed throughout the scan). W e rep ort results for b oth the un- c onditional co dec and a c onditional co dec in which hit mo dels are conditioned on | p | via momen tum bins, and w e compare against a standard kernel tw o-sample test based on the Maxim um Mean Discrepancy , ev aluated on a fixed, physics-motiv ated feature representation. a. Compr ession-b ase d fidelity sc or e under a fixe d r ef- er enc e mo del. Let q A denote the probabilistic mo del (CDFs) learned from the reference sample A and then held fixed. F ollowing Eqs. ( 11 ) and ( 12 ), for a dataset D = { x i } N i =1 the arithmetic co dec induces an a verage p er-ev en t co delength (in bits p er even t), L A ( D ), up to negligible termination o verhead (Sec. IV C ). W e define the exc ess c o delength ∆ L ( ε ) ≡ L A ( C ε ) − L A ( B ) , (14) where B is an indep endent baseline sample dra wn from the same target distribution as the unp erturb ed data 9 used to construct C ε . 3 A p ositiv e ∆ L indicates that ev ents in C ε are, on a verage, less typical under the fixed reference mo del q A than ev ents in the indep endent base- line sample B , i.e. , they incur a larger cross-en tropy under the same scoring rule. This admits a likelihoo d- based in terpretation: differences in mean codelength cor- resp ond directly to differences in av erage negativ e log- lik eliho o d ev aluated under the fixe d mo del q A . Accord- ingly , ∆ L serves as a model-conditional log-likelihoo d sc or e differ enc e (expressed in bits p er ev en t), rather than a formal likelihoo d-ratio test. More generally , the same construction supp orts a dis- tributional fidelit y measure betw een real and synthetic data. Let R denote a r e al reference dataset used to de- fine the probabilistic representation of the co dec, and let S b e a synthetic dataset pro duced, for example, by a generativ e model. W e define the fidelity gap ∆ L fid ≡ L R ( S ) − L R ( R ) , (15) where b oth co delengths are ev aluated under the same fixed reference mo del learned from R . A p ositive ∆ L fid indicates that the syn thetic sample is, on av erage, less t ypical than real data under the ph ysical correlations enco ded b y the co dec, while ∆ L fid ≃ 0 indicates that no statistically resolv able distributional mismatch is ob- serv ed under the fixed probabilistic represen tation and a v ailable statistics. 4 b. Blo cke d design and empiric al ly c alibr ate d test statistic. Because arithmetic co ding pro duces a single compressed payload p er dataset, replicate measurements are obtained through a blo ck ed design. The baseline sample B and the p erturbed sample C ε are each par- titioned into K disjoint blo c ks of equal size, { B k } K k =1 and { C ε,k } K k =1 . F or each blo c k we compute the a verage co delength L A ( D k ) ≡ | pa yload A ( D k ) | | D k | (bits/ev ent) , (16) ev aluated under the same fixed reference co dec trained on A . Let µ C ( ε ) and µ B denote the sample means of { L A ( C ε,k ) } and { L A ( B k ) } , resp ectively , with sample standard deviations s C ( ε ) and s B . W e define the mean excess co delength ∆ L ( ε ) ≡ µ C ( ε ) − µ B , (17) 3 T o minimize correlations b etw een the p erturbed sample and the reference used for hypothesis testing, we employ the three-wa y data-splitting strategy in tro duced in Sec. II . Briefly , the pertur- bation C ε is constructed from B (1) , the reference codec is trained once on A (3) (fixing q A (3) ), and excess codelengths are ev aluated relative to an independent baseline sample B (2) drawn from the same target distribution. 4 In expectation, ∆ L fid ≥ 0 when R is drawn from the same dis- tribution used to define the reference co dec. Negative v alues of ∆ L fid may o ccur at finite sample size and should be interpreted as statistical fluctuations. and its asso ciated standard error SE ∆ L ( ε ) = r s 2 C ( ε ) K + s 2 B K . (18) The corresp onding standardized statistic is t ( ε ) = ∆ L ( ε ) SE ∆ L ( ε ) . (19) Although Eq. ( 19 ) coincides with a W elch-t ype test statistic under Gaussian assumptions [ 32 ], w e do not rely on its analytic reference distribution. Instead, statisti- cal significance is assessed using an empiric al calibration of the n ull distribution of t , obtained from r e al –vs– r e al comparisons constructed under the same blo ck ed pro ce- dure [ 33 , 34 ]. This ensures v alid inference in the presence of finite-sample effects and blo ck-to-block heterogeneity . Throughout this work w e use K = 10 blo cks. c. Comp arison to MMD under a blo cke d design. As a complemen tary , mo del-agnostic baseline, we ev aluate distributional fidelit y using the Maximum Mean Discrep- ancy (MMD) with a Gaussian RBF kernel [ 4 ]. T o enable a statistically comparable analysis, we adopt the same blo c k ed design used for the compression-based tests. Sp ecifically , for eac h p erturbation strength ε , we con- struct K approximately indep enden t random blocks from the p erturbed sample C ε and from tw o independent real- data baselines B (1) and B (2) (Sec. I I ). F or block index k , w e define the blockwise contrast d k ( ε ) = MMD 2 C (1) ε,k , B (2) k − MMD 2 B (1) k , B (2) k , (20) where B (1) k , B (2) k , and C (1) ε,k are indep enden tly constructed blo c ks of equal size. The subtraction remo ves the intrin- sic r e al –vs– r e al discrepancy arising from finite-sample fluctuations and isolates the excess MMD induced by the imp osed p erturbation, without requiring even t- or blo c k-lev el pairing. The resulting blo c kwise differences { d k ( ε ) } K k =1 are treated as approximately indep enden t measuremen ts. Rather than relying solely on asymp- totic analytic distributions, statistical significance is as- sessed using an empirically calibrated null distribution constructed from r e al –vs– r e al blo c k comparisons. This mirrors the empirical calibration pro cedure used for the compression-based test and con trols the false-positive rate under the null hypothesis of no distributional dif- ference. Analytic one-sided t -statistics are used inter- nally as test statistics to construct empirically calibrated p -v alues; the calibrated p -v alues are rep orted and used to assess sensitivity . Throughout this analysis we use K = 10 blo cks. In practice, MMD is ev aluated on a fixed-dimensional (57-dimensional) real-v alued even t representation. F or eac h of the nine calorimeter la y er–view combinations, we compute (i) the o ccupancy fraction, defined as the frac- tion of the 20 hit slots with strip = pad strip , (ii) summary statistics of the ADC amplitudes o ver o ccupied slots (mean, standard deviation, and maxim um), and (iii) 10 summary statistics of the o ccupied strip indices (mean and standard deviation). W e then concatenate these 9 × 6 = 54 features with the three components of the par- ticle momentum, yielding 57 features per ev en t. This en- gineered represen tation balances ph ysical interpretabilit y and statistical conditioning of the k ernel estimator. As a result, MMD prob es consistency only within this en- gineered fixed-dimensional summary space, whereas the compression-based test op erates directly on the full dis- crete hit representation used by the co dec. d. R esults and interpr etation. Figure 4 shows the mean excess co delength ∆ L (left axis) for unconditional and conditional arithmetic co ding, together with the c hange in ∆MMD 2 (righ t axis). Both ∆ L curves in- crease smoothly with ε , reflecting the monotonic increase in cross-entrop y under the fixed reference co dec as ADC sym b ols mov e across integer quantization boundaries and the heavy-tailed ADC distribution is progressively dis- torted. Figure 5 rep orts the corresponding one-sided t- test p -v alues, with the conv en tional p = 0 . 05 threshold indicated by the dashed line, and ov erla ys the empirical fraction of ADC entries that change under the p ertur- bation (right axis). The conditional co dec rejects the n ull hypothesis at ε ≃ 1 × 10 − 4 , whereas the uncon- ditional co dec becomes significant only at substan tially larger p erturbations corresponding to ε ≳ 10 − 2 . MMD exhibits a distinct sensitivity profile, remaining relativ ely flat at small ε and then dropping sharply once the p er- turbation is large enough ( ε ≳ 4 × 10 − 3 ) to induce a clear global shift in the kernel distance. As mentioned, all fidelity tests are calibrated using an empirical null constructed from real data. As a result, the probability of falsely rejecting the null h yp othesis when comparing r e al –vs– r e al is controlled at the nominal significance lev el α . F or α = 0.05, the conditional AC method becomes sensitiv e to p erturbations starting at ϵ ∼ O (10 − 4 ). T a- ble VI summarizes the scan across ε , rep orting ∆ L and p -v alues for b oth codecs, as well as ∆MMD 2 and its cor- resp onding p -v alue. It is worth emphasizing that the compression-based and MMD-based diagnostics prob e differ ent nul l hyp othe- ses . The compression test assesses whether C ε remains equally typic al under a fixed, ph ysics-informed reference mo del, as quan tified b y its achiev ed co delength. In con- trast, MMD tests for equality of distributions in a repro- ducing kernel Hilb ert space, indep endent of an y compres- sion mo del. As a result, a dataset ma y b e statistically distinguishable from the reference under MMD while re- maining approximately compression-consistent with the fixed physics-a w are represen tation, and vice v ersa. In this sense, compression-based fidelity is mo del- c onditional : enriching the probabilistic structure of the co dec ( e.g. , adding additional hit–kinematics correla- tions) changes the notion of fidelit y b eing probed and can sharp en sensitivity . As the sample size increases, MMD b ecomes asymptotically sensitiv e to arbitrarily small dis- tributional differences, so its p -v alues quantify statisti- cal detectabilit y rather than practical or physical signif- 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 A D C s c a l e p e r t u r b a t i o n 2 0 2 4 6 8 10 L [ b i t s / e v e n t ] Unconditional A C Conditional A C MMD 0 . 2 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 M M D 2 × 1 0 5 A C C o m p r e s s i o n a n d M M D v s FIG. 4. Sensitivity of arithmetic coding and MMD to ADC scale p erturbations ε . Mean excess co delength ∆ L (left axis) for unconditional and conditional arithmetic coding is compared to the corresp onding change in ∆MMD 2 (righ t axis). A C shows a smo oth, monotonic response to increasing p erturbations, while MMD remains relatively insensitive at small ε and increases sharply only at larger deviations. 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 A D C s c a l e p e r t u r b a t i o n 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 p- value p = 0.05 F idelity Studies Unconditional A C Conditional A C MMD ADC fraction 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 ADC fraction changed FIG. 5. Fidelit y tests under controlled ADC scale p erturbations ε . One-sided t-test p -v alues are sho wn for unconditional and conditional arithmetic co ding (A C) and for the MMD-based test as a function of the ADC p erturbation ε . The horizontal dashed line indicates the p = 0 . 05 signifi- cance threshold. Conditional AC detects statistically signif- ican t deviations at substan tially smaller ε than MMD. The righ t axis rep orts the empirical fraction of ADC v alues that c hange under the p erturbation, illustrating the relationship b et w een ph ysical modification rate and statistical sensitivity . icance. In contrast, b ecause the compression-based test ev aluates all samples under a fixe d physics-informed ref- erence mo del, the excess co delength ∆ L conv erges to a finite and interpretable measure of mo del mismatch, ex- pressed in bits p er even t. Correlations b etw een ADC v alues across strips are a fundamental feature of elec- tromagnetic show ers, arising from lateral sho wer dev el- opmen t, detector geometry , and b oundary effects in the readout. Fidelity tests that op erate only on marginal or p er-channel distributions therefore miss precisely the 11 T ABLE VI. Comparison of sensitivit y metrics as a function of ADC scale perturbation ε . F or each metho d, w e report the excess co delength ∆ L for unconditional and conditional arithmetic co ding, the squared Maximum Mean Discrepancy ∆MMD 2 , and the corresp onding one-sided p -v alues. Boldface indicates statistically significant deviations ( p < 0 . 05) for the corresponding metho d. ε ∆ L (uncond) p (uncond) ∆ L (cond) p (cond) ∆MMD 2 p (MMD) 1 . 00 × 10 − 6 − 8 . 25 × 10 − 3 5 . 150 × 10 − 1 − 1 . 11 × 10 − 2 5 . 130 × 10 − 1 0 5 . 163 × 10 − 1 2 . 15 × 10 − 6 − 8 . 25 × 10 − 3 5 . 150 × 10 − 1 − 1 . 11 × 10 − 2 5 . 130 × 10 − 1 0 5 . 163 × 10 − 1 4 . 64 × 10 − 6 − 8 . 25 × 10 − 3 5 . 150 × 10 − 1 − 1 . 11 × 10 − 2 5 . 130 × 10 − 1 0 5 . 163 × 10 − 1 1 . 00 × 10 − 5 2 . 30 × 10 − 2 5 . 017 × 10 − 1 2 . 18 × 10 − 2 5 . 043 × 10 − 1 − 1 . 69 × 10 − 10 7 . 535 × 10 − 1 2 . 15 × 10 − 5 3 . 98 × 10 − 1 3 . 578 × 10 − 1 6 . 49 × 10 − 1 3 . 464 × 10 − 1 − 4 . 73 × 10 − 10 5 . 643 × 10 − 1 4 . 64 × 10 − 5 7 . 89 × 10 − 1 2 . 372 × 10 − 1 1 . 84 1 . 186 × 10 − 1 1 . 37 × 10 − 8 2 . 625 × 10 − 1 1 . 00 × 10 − 4 1 . 04 1 . 726 × 10 − 1 2 . 94 2 . 798 × 10 − 2 4 . 02 × 10 − 8 2 . 258 × 10 − 1 2 . 15 × 10 − 4 1 . 17 1 . 479 × 10 − 1 3 . 93 8 . 661 × 10 − 3 1 . 02 × 10 − 7 2 . 012 × 10 − 1 4 . 64 × 10 − 4 1 . 23 1 . 306 × 10 − 1 4 . 67 2 . 665 × 10 − 3 2 . 48 × 10 − 7 1 . 785 × 10 − 1 1 . 00 × 10 − 3 1 . 28 1 . 206 × 10 − 1 5 . 10 2 . 665 × 10 − 3 6 . 11 × 10 − 7 1 . 486 × 10 − 1 1 . 43 × 10 − 3 1 . 31 1 . 153 × 10 − 1 5 . 22 2 . 665 × 10 − 3 9 . 49 × 10 − 7 1 . 279 × 10 − 1 2 . 03 × 10 − 3 1 . 34 1 . 099 × 10 − 1 5 . 31 1 . 999 × 10 − 3 1 . 50 × 10 − 6 1 . 059 × 10 − 1 2 . 89 × 10 − 3 1 . 38 1 . 006 × 10 − 1 5 . 40 1 . 999 × 10 − 3 2 . 45 × 10 − 6 7 . 462 × 10 − 2 4 . 12 × 10 − 3 1 . 45 9 . 260 × 10 − 2 5 . 49 1 . 999 × 10 − 3 4 . 10 × 10 − 6 4 . 464 × 10 − 2 5 . 88 × 10 − 3 1 . 54 8 . 328 × 10 − 2 5 . 58 1 . 999 × 10 − 3 7 . 08 × 10 − 6 2 . 132 × 10 − 2 8 . 38 × 10 − 3 1 . 67 7 . 062 × 10 − 2 5 . 73 1 . 999 × 10 − 3 1 . 26 × 10 − 5 9 . 327 × 10 − 3 1 . 19 × 10 − 2 1 . 83 5 . 330 × 10 − 2 5 . 87 1 . 332 × 10 − 3 2 . 30 × 10 − 5 2 . 665 × 10 − 3 1 . 70 × 10 − 2 2 . 08 3 . 664 × 10 − 2 6 . 07 6 . 662 × 10 − 4 4 . 31 × 10 − 5 1 . 332 × 10 − 3 2 . 42 × 10 − 2 2 . 42 2 . 332 × 10 − 2 6 . 36 6 . 662 × 10 − 4 8 . 20 × 10 − 5 6 . 662 × 10 − 4 3 . 46 × 10 − 2 2 . 88 1 . 266 × 10 − 2 6 . 73 6 . 662 × 10 − 4 1 . 58 × 10 − 4 6 . 662 × 10 − 4 4 . 92 × 10 − 2 3 . 55 3 . 997 × 10 − 3 7 . 28 6 . 662 × 10 − 4 3 . 09 × 10 − 4 6 . 662 × 10 − 4 7 . 02 × 10 − 2 4 . 49 1 . 999 × 10 − 3 8 . 07 6 . 662 × 10 − 4 6 . 05 × 10 − 4 6 . 662 × 10 − 4 1 . 00 × 10 − 1 5 . 80 6 . 662 × 10 − 4 9 . 11 6 . 662 × 10 − 4 1 . 19 × 10 − 3 6 . 662 × 10 − 4 m ulti-channel structure that distinguishes physically re- alistic detector data. By op erating directly on the join t detector readout, compression-based fidelit y tests remain sensitiv e to thes e correlations without requiring an ex- plicit even t-lev el em b edding. Building on this sensitivity to joint detector struc- ture, the compression-based test ev aluates whether a can- didate dataset remains typic al under a fixed, physics- informed probabilistic representation. A large p -v alue in this framew ork do es not constitute evidence that a dataset is “real”; rather, it indicates that the dataset is statistically indistinguishable from real data under the tested representation and av ailable statistics. Conv ersely , small p -v alues signal that the imp osed p erturbation in- duces systematic violations of the ph ysical correlations enco ded b y the reference mo del. The ε -scan therefore serv es as a calibrated sensitivity study , quantifying the smallest con trolled distortions of the detector resp onse that can b e reliably resolv ed while main taining a con- trolled false-rejection rate on unp erturbed real data. In this sense, the scan characterizes not only detectability , but also the smallest p erturbation scale that can b e sta- tistically resolved under the fixed probabilistic represen- tation and av ailable statistics. Ov erall, these studies demonstrate that physics-a ware arithmetic co ding pro vides an in terpretable, information- theoretic measure of distributional fidelit y , expressed di- rectly in bits per ev ent and equipped with a statistically principled decision threshold via blo ck ed h ypothesis test- ing. Its b eha vior is complementary to kernel-based tw o- sample tests, whic h probe distributional equality in an abstract feature space, whereas compression tests consis- tency with resp ect to a fixed, ph ysically motiv ated refer- ence representation. V. CONCLUSIONS In this w ork, we hav e demonstrated that ph ysics- a ware, lossless, and in vertible compression pro vides a principled and op erational framew ork for b oth data re- duction and quantitativ e fidelit y assessment in multi- mo dal scien tific datasets. W e fo cused in particular on calorimeter detector readout, where structured correla- tions, discreteness, and detector symmetries play a cen- tral role. Using arithmetic co ding with explicitly factor- ized probabilistic mo dels, w e ac hieve compression p er- formance that saturates the Shannon-optimal limit up to negligible finite-precision o verheads, while preserving ex- act inv ertibility of the original detector-level information. Bey ond compression efficiency , a central result of this study is that achiev ed co delengths admit a di- rect information-theoretic in terpretation. Differences in a verage co delength b et w een datasets enco ded under a fixed reference mo del corresp ond to differences in cross- en tropy , and therefore quan tify distributional mismatch 12 in physically meaningful units of bits p er even t. In this wa y , lossless compression b ecomes a global, mo del- conditional fidelity diagnostic: datasets that remain sta- tistically consistent with the same underlying physics compress equally well, while deviations manifest as an excess description length. W e hav e shown that even minimal probabilistic struc- ture—enco ding only essen tial detector symmetries and factorization assumptions—already yields in terpretable “bit p enalties” that lo calize discrepancies to specific com- p onen ts of the readout, such as calorimeter hits or kine- matic payloads. This bit-budget decomp osition provides a transparen t mapping betw een physical effects ( e.g. , cal- ibration distortions) and their information-theoretic cost, enabling a level of interpretabilit y that is often absen t in blac k-b o x statistical tests. At the even t level, p er-even t co delengths define a meaningful scalar quantit y that can b e aggregated for global fidelity assessment and, in prin- ciple, lev eraged to prob e lo calized anomalies or rare mis- mo deling effects. Through controlled perturbation studies, we demon- strated that compression-based fidelity tests are sensi- tiv e to ph ysically meaningful detector distortions while remaining robust to transformations that preserve the mo deled structure. Compared to k ernel-based distance measures such as MMD, compression prob es a comple- men tary notion of fidelity: not whether tw o distributions are identical in a generic feature space, but whether they remain typic al under a fixed, physics-informed generative represen tation. This distinction explains the differing sensitivit y regimes observed and highligh ts the v alue of com bining information-theoretic and distributional diag- nostics. While conditional represen tations resolve addi- tional physical correlations and thereby reduce the intrin- sic en tropy of the data-generating process, their ac hiev ed co delength can exceed that of unconditional mo dels due to increased mo deling complexit y and finite-sample ef- fects. Nevertheless, our studies show that conditional co decs exhibit enhanced sensitivity in p erturbation scans, indicating that ric her structure amplifies statistically sig- nifican t deviations from the reference distribution. The framework presented here naturally supp orts a train–test paradigm: probabilistic mo dels are learned on a reference dataset and then deplo yed unchanged to ev al- uate indep endent samples, fast simulations, or systemat- ically p erturbed data. In this setting, the excess co de- length provides a single, w ell-defined scalar observ able with a clear statistical interpretation, enabling hypoth- esis testing, calibration studies, and consistency chec ks without reliance on hand-crafted observ ables or ad ho c distance measures. Lo oking forward, sev eral extensions are immediate. Ric her conditional structure—incorp orating correlations with kinematics, timing information, or even t topol- ogy—can further sharp en sensitivit y and refine the no- tion of fidelity being tested. Ev ent-lev el co delengths nat- urally supp ort anomaly detection and streaming appli- cations, while integration with fast simulation pip elines suggests a role for compression not only as a diagnos- tic, but as a design and v alidation to ol. More broadly , these results supp ort the view that lossless, ph ysics-a ware compression can serve as a foundational building block for information-centric analysis of exp erimen tal data. A CKNOWLEDGMENTS W e thank Maurizio Ungaro (Jefferson Lab) and Ric hard Tyson (Universit y of Glasgow) for generating and pro viding the Monte Carlo dataset used in this w ork. [1] E. L. Lehmann and J. P . Romano, T esting statistic al hy- p otheses (Springer, 2005). [2] L. W asserman, Al l of statistics: a c oncise c ourse in sta- tistic al inferenc e (Springer Science & Business Media, 2004). [3] T. M. Cov er, Elements of information theory (John Wi- ley & Sons, 1999). [4] Gretton, Arthur and Borgwardt, Karsten M and Rasch, Malte J and Sch¨ olkopf, Bernhard and Smola, Alexander, The journal of mac hine learning researc h 13 , 723 (2012) . [5] S. T. Rachev, L. B. Klebanov, S. V. Stoy ano v, and F. F ab ozzi, The metho ds of distanc es in the the ory of pr ob ability and statistics , V ol. 10 (Springer, 2013). [6] I. J. Go odfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-F arley , S. Ozair, A. Courville, and Y. Bengio, Adv ances in neural information pro cessing systems 27 (2014) . [7] L. Theis, A. v. d. Oord, and M. Bethge, arXiv preprint arXiv:1511.01844 (2015) . [8] T. Kynk¨ a¨ anniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila, Adv ances in neural information pro cessing sys- tems 32 (2019) . [9] M. F. Naeem, S. J. Oh, Y. Uh, Y. Choi, and J. Y o o, in International c onfer enc e on machine le arning (PMLR, 2020) pp. 7176–7185. [10] R. Kansal, A. Li, J. Duarte, N. Cherny avsk ay a, M. Pierini, B. Orzari, and T. T omei, Physical Review D 107 , 076017 (2023) . [11] K. Cranmer, J. Brehmer, and G. Louppe, Proceedings of the National Academ y of Sciences 117 , 30055 (2020) . [12] M. Paganini, L. De Oliv eira, and B. Nachman, Physical Review D 97 , 014021 (2018) . [13] A. Butter, S. Diefenbac her, G. Kasieczk a, B. Nachman, and T. Plehn, SciP ost Ph ysics 10 , 139 (2021) . [14] G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P . Perdik aris, S. W ang, and L. Y ang, Nature Reviews Physics 3 , 422 (2021) . [15] M. Deistler, J. Boelts, P . Steinbac h, G. Moss, T. Moreau, M. Gloeckler, P . L. Ro drigues, J. Linhart, J. K. Lappalainen, B. K. Miller, et al. , arXiv preprint 13 arXiv:2508.12939 (2025). [16] M. Arjo vsky and L. Bottou, arXiv preprin t arXiv:1701.04862 (2017) . [17] J. Lin, IEEE T ransactions on Information theory 37 , 145 (2002) . [18] B. F uglede and F. T opso e, in International Symp osium on Information The ory, 2004. ISIT 2004. Pr o ce e dings. (IEEE, 2004) p. 31. [19] S. Now ozin, B. Cseke, and R. T omiok a, Adv ances in neu- ral information processing systems 29 (2016). [20] A. Ramdas, S. J. Reddi, B. P´ oczos, A. Singh, and L. W asserman, in Pr o c ee dings of the AAAI Confer enc e on Artificial Intel ligenc e , V ol. 29 (2015). [21] L. W asserman, A l l of nonpar ametric statistics (Springer, 2006). [22] P . J. Bick el and K. A. Doksum, Mathematic al Statistics (CR C Press, 2015). [23] A. W. V an der V aart, Asymptotic statistics , V ol. 3 (Cam- bridge univ ersity press, 2000). [24] I. H. Witten, R. M. Neal, and J. G. Cleary , Comm unica- tions of the A CM 30 , 520 (1987) . [25] D. J. MacKay , Information the ory, inferenc e and le arning algorithms (Cambridge universit y press, 2003). [26] J. Rissanen, in Information theory and statistic al le arning (Springer, 2009) pp. 25–43. [27] J. Ball´ e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, arXiv preprin t 10.48550/arXiv.1802.01436 (2018). [28] J. T ownsend, T. Bird, J. Kunze, and D. Barb er, arXiv preprin t arXiv:1912.09953 10.48550/arXiv.1912.09953 (2019). [29] M. Ungaro, G. Angelini, M. Battaglieri, V. Burkert, D. Carman, P . Chatagnon, M. Contalbrigo, M. De- furne, R. De Vita, B. Duran, et al. , Nuclear Instruments and Metho ds in Physics Researc h Section A: Acceler- ators, Spectrometers, Detectors and Asso ciated Equip- men t 959 , 163422 (2020) . [30] M. Ungaro, in EPJ Web of Confer enc es , V ol. 295 (EDP Sciences, 2024) p. 05005. [31] J.-l. Gailly and M. Adler, GNU Op erating System , 8 (1992) , revised 2025. [32] B. L. W elch, Biometrik a 34 , 28 (1947) . [33] A. C. Davison and D. V. Hinkley , Bootstr ap metho ds and their applic ation , 1 (Cam bridge univ ersity press, 1997). [34] B. Phipson and G. K. Sm yth, Statistical Applications in Genetics and Molecular Biology 9 , 1 (2010) .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment