ALARA for Agents: Least-Privilege Context Engineering Through Portable Composable Multi-Agent Teams
Industry practitioners and academic researchers regularly use multi-agent systems to accelerate their work, yet the frameworks through which these systems operate do not provide a simple, unified mechanism for scalably managing the critical aspects o…
Authors: Christopher J. Agostino, Nayan D'Souza
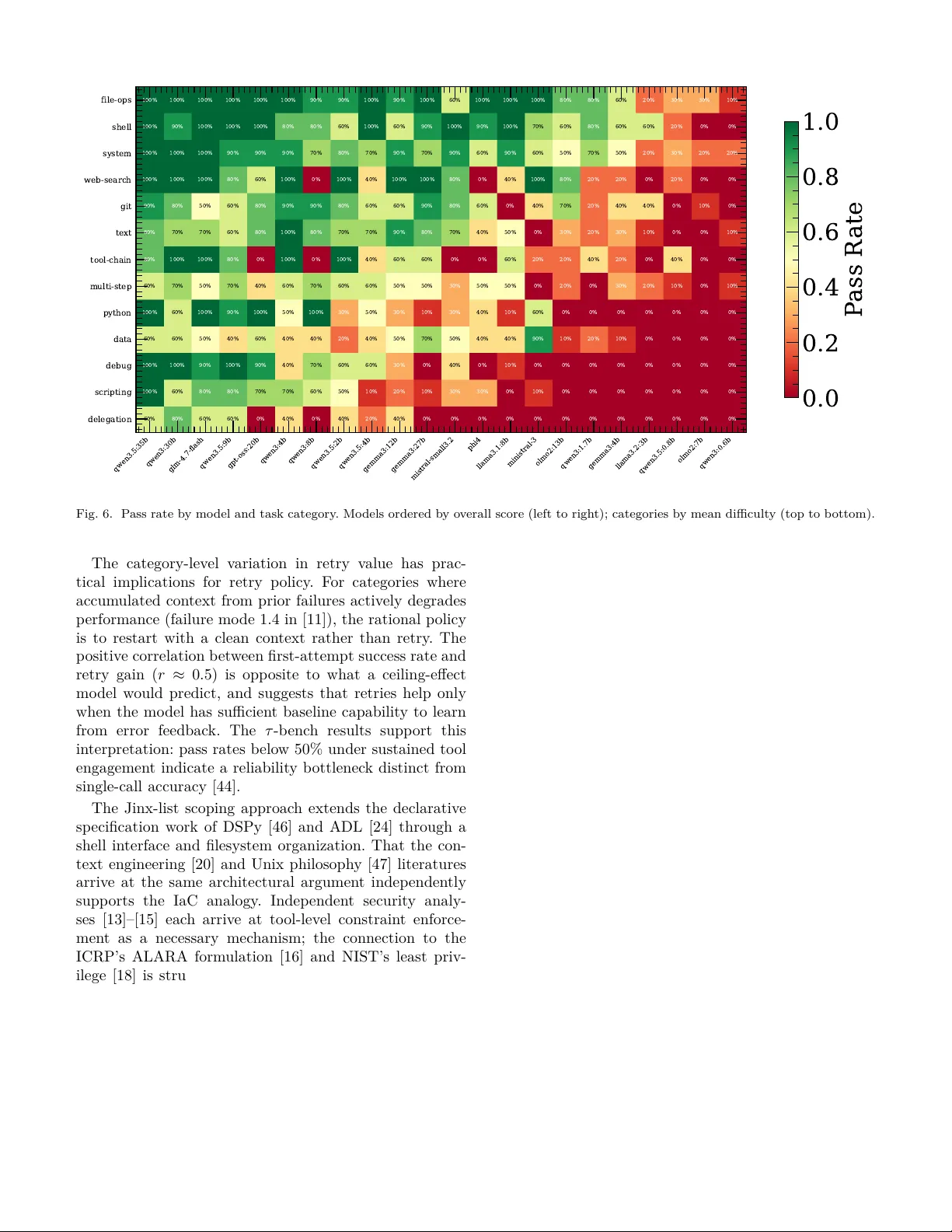
ALARA for Agen ts: Least-Privilege Con text Engineering Through P ortable Comp osable Multi-Agen t T eams Christopher J. Agostino ∗ , Na y an D’Souza ∗ † , ∗ NPC W orldwide , Bloomington, IN, USA Email: cjp.agostino@gmail.com † Dep artment of Linguistics, Indiana University , Blo omington, IN, USA A bstr act —Industry practitioners and academic re- searc hers regularly use m ulti-agen t systems to accel- erate their w ork, y et the framew orks through whic h these systems op erate do not pro vide a simple, unified mec hanism for scalably managing the critical asp ects of the agent harness, impacting b oth the qualit y of individual h uman-agent interactions and the capacity for practitioners to co ordinate tow ard common goals through shared agen t infrastructure. Agen t framew orks ha v e enabled increasingly sophisticated m ulti-agen t systems, but the b ehavioral specifications that define what these agen ts can do remain fragmen ted across prose instruction files, framew ork-internal configura- tion, and mechanisms lik e MCP servers that op erate separately from individual agent definitions, making these sp ecifications difficult to share, v ersion, or collab- orativ ely main tain across teams and pro jects. Applying the ALARA principle from radiation safety (exp osures k ept as low as reasonably ac hiev able) to agent con text, w e introduce a declarative context-agen t-to ol (CA T) data la y er expressed through in terrelated files that scop e each agen t’s to ol access and context to the mini- m um its role requires, and npcsh , a command-line shell for executing it. Because the system parses and enforces these files structurally , mo difying an agent’s to ol list pro duces a guaranteed b eha vioral c hange rather than a suggestion the model may or may not follo w. W e ev aluate 22 locally-hosted mo dels from 0.6B to 35B parameters across 115 practical tasks spanning file op erations, web searc h, multi-step scripting, to ol c hain- ing, and multi-agen t delegation, characterizing whic h mo del families succeed at which task categories and where they break down across ∼ 2500 total executions. The framework and b enc hmark are op en source at h ttps://gith ub.com/NPC- W orldwide/npcsh. Index T erms —human-agen t interaction, multi-agen t systems, composable automation, agen t ev aluation, co- creativ e systems I. Intr oduction Multi-agen t systems built on large language mo dels ha v e b ecome ev eryday tools for practitioners across soft ware dev elopmen t, researc h, and creativ e w ork, and as these systems hav e grown more sophisticated, the infrastructure surrounding them (the agen t harness that go verns tool ac- cess, b ehavioral b oundaries, and in ter-agent co ordination) has b ecome a distinct engineering concern [1]. Practition- ers who w ant to sp ecify what their agen ts can do, what to ols they ha v e access to, and how they should co ordinate curren tly express these specifications through a combi- nation of prose instruction files (Cursor’s .cursorrules , Claude Co de’s CLAUDE.md , Aider’s con v en tion files [2], the emerging AGENTS.md standard), programmatic frame- w ork co de (LangGraph [3], A utoGen [4], CrewAI [5]), and to ol registration proto cols like MCP serv ers. Each of these mechanisms addresses a piece of the harness, but they do not comp ose with each other: prose files rely on interpretiv e compliance that cannot be guaran teed in principle, giv en that meaning-pro duction in language mo dels is con textual in the formal sense, generated in the act of interpretation rather than retrieved from pre- existing asso ciations [6]–[9], framework co de embeds b e- ha vioral sp ecification in application logic that is difficult to insp ect or mo dify without deep exp ertise, and MCP serv ers scop e tool access to the server rather than to individual agents. The result is that the asp ects of the harness most consequen tial for the qualit y of human-agen t in teraction are fragmen ted across mechanisms that cannot b e v alidated programmatically and are difficult for teams of practitioners to collab orativ ely maintain. The empirical evidence for the cost of this fragmen tation has accumulated from sev eral directions. Language mo del p erformance on retriev al tasks degrades significan tly when relev ant information app ears in the middle of the con- text windo w, with the low est accuracy at precisely the p ositions where accum ulated con v ersation history pushes the b eha vioral instructions that an agen t most needs to follo w [10]. An analysis of 1,600 execution traces across sev en m ulti-agent framew orks found that specification and system design failures account for 44% of all breakdowns, making undersp ecification, rather than mo del capabilit y or netw ork failures, the plurality failure mode [11], [12]. F rom the securit y side, work on privilege control for LLM agen ts has iden tified o v er-privileged to ol access as the structural enabler of prompt injection attac ks: agents giv en access to tools they do not need for a giv en role create attac k surface that injected con ten t can exploit [13]. The Prompt Flo w Integrit y w ork reaches the same con- clusion: in a system that combines untrusted data with privileged to ols, least privilege enforcement is necessary but inheren tly unreliable when implemen ted through prose instructions [14]. The plan-then-execute pattern resists injection b ecause the agent commits to a to ol plan b e- fore pro cessing un trusted conten t, leaving no in terpretiv e surface for injected frames to act on [15]. T ak en together, these findings iden tify the prose in terface betw een a h u- man’s sp ecification of agent b ehavior and the mo del’s enactmen t of it as the common origin of b oth capabilit y degradation and securit y vulnerabilities. The principle that the exp osure of a system to risk should be kept as lo w as reasonably ac hiev able, co dified b y the International Commission on Radiological Protection in 1977 [16] and formalized by the US Nuclear Regu- latory Commission as a contin uing optimization tow ard the minimum that the purp ose of the activity actually demands [17], predates the modern in ternet but maps directly onto the problem of agen t tool access, where its structural analog in computer security (least privilege, the restriction of access to the minim um necessary to accom- plish assigned tasks [18]) has already been iden tified as the necessary response to the o v er-privileged tool catalogs that enable prompt injection [13]–[15]. The constraint in b oth form ulations holds regardless of what the agent in terprets or misin terprets from its context, b ecause tools not present in an agent’s schema cannot be inv oked through a sc hema en try that was nev er pro vided, and exp erimen ts on to ol catalog size confirm the practical stakes: tool inv o cation accuracy falls from ∼ 95% to ∼ 25% as catalog size grows from one to eight [19], with the degradation concentrated in the space b etw een what a mo del is given access to and what it should actually b e using. The accumulation of transient, unauditable configura- tion artifacts across agentic systems [20] resembles the problem that Infrastructure as Co de solv ed for deploymen t through the in tro duction of declarativ e sp ecification files that a system could parse and enforce rather than prose that a human would read and enact. In this work, we in tro duce a declarative context-agen t-to ol (CA T) data la y er that expresses the agen t harness through in terrelated files scoping each agen t’s tool access and con text to the minim um its role requires, and npcsh , a command-line shell for executing it. The remainder of the paper describes the design of the framew ork (Section I I) and presen ts a 115-task b enchmark ev aluated across 22 lo cally-hosted mo dels from 0.6B to 35B parameters, with trace-lev el analysis of 2,530 task executions characterizing when and ho w agen t reliabilit y breaks do wn across model families, task categories, and retry strategies (Section I I-F). I I. Design and Methods Scoping eac h agen t’s tool access and context to the minim um its role requires demands a sp ecification format that a system can parse and enforce structurally rather than one that relies on interpretiv e compliance. W e de- scrib e b elo w the declarativ e data lay er through which we represen t the agent harness (Section I I-A) and the file t yp es that comp ose it (Sections I I-B–I I-E). A. The CA T Data L ayer W e represent the agent harness through three interre- lated file t yp es: context files that scop e shared resources and designate orchestrators, NPC files that define indi- vidual agents with their mo del configurations and to ol p ermissions, and Jinxes (Jinja Execution templates) that sp ecify the to ols themselv es as executable Y AML defini- tions. The relationships among these file types are sho wn in Figure 1. Context files sit at the team level and de- termine which agen t serves as orc hestrator and what sub- teams exist within the hierarch y . Eac h NPC file references a subset of Jinxes from the av ailable catalog, and because Jinxes can inv oke other Jinxes as execution steps, the to ol la y er forms a directed acyclic graph of composable capabilities. Because the entire sp ecification consists of files on disk rather than framework-in ternal state, the same directory transfers without modification across ev ery in terface the system pro vides, including an interactiv e shell ( npcsh ), an API serv er ( npc serve ), a desktop application ( npcts ), a browser-based IDE ( incognide ), and direct Python imp ort. sub-team/ team/ context orchestrator agent a agent b context sub orch specialist python chat sh web search screenshot react delegate computer use Fig. 1. The CA T data lay er. L eft: context files (orange) scope teams of NPCs (blue). R ight: Jinxes (green) compose as a DA G rooted at python . Lev el-1 Jinxes ( chat , sh , web search , screenshot ) each use python as their engine. Level-2 Jinxes com bine level- 1 steps: react chains chat + python , computer use chains chat + screenshot + sh , and delegate uses chat + sh . Shared parents (e.g. chat used by all three comp osites) make the graph a DA G rather than a tree. Dashed arro ws show to ol-catalog assignment to NPCs. B. Jinxes A Jinx is a Y AML file sp ecifying a name, a natural- language description, typed inputs, and a sequence of execution steps, where each step names an engine ( python , bash , llm , or another Jinx) and contains Jinja-templated co de rendered with input v alues at execution time. W e deriv e tool-calling sch emas directly from the Jinx’s inputs and description, so the file serv es as both the definition and the executable artifact, eliminating the sc hema-definition la y er where drift b etw een specification and b ehavior accu- m ulates in programmatic framew orks. Because to ol-use capabilit y v aries substan tially across mo del families and cannot b e assumed from parameter coun t or benchmark performance on other tasks [21], w e use the Jinx to provide deterministic scaffolding (execu- tion order, data flow betw een steps, error handling) that b ounds the interpretiv e surface to individual steps where mo del-driv en in terpretation adds v alue. Where the ReA ct pattern treats reasoning traces and to ol actions as a unified lo op [22], w e decomp ose this lo op in to a deterministic sk eleton whose interpretiv e demands are scoped to individ- ual steps. When a step names another Jinx as its engine, that Jinx expands in place with argumen ts substituted and results threading through shared context, so that single- agen t workflo ws comp ose into directed acyclic execution graphs from individually simple files (Figure 1, green no des). In practice, a research pip eline c hains h yp othesis generation, sub-agen t searc h, iterativ e writing, and review- revision cycles as a single Jinx whose steps in vok e other Jinxes three levels deep, and a desktop automation work- flo w c hains screenshot capture, vision analysis, and action execution in a deterministic lo op. In b oth cases the user who wan ts to understand what the system do es reads the top-lev el file, and the user who w ants to c hange it edits one step. Because Jinxes execute through prompt-based flows rather than requiring nativ e function-calling supp ort, they w ork with an y mo del regardless of whether it implements structured to ol calling, whic h enables agen t w orkflo ws on small locally-hosted mo dels that would otherwise b e excluded from to ol-using architectures entirely . The same Jinx that a user inv okes as a slash command serv es as the to ol-call target when an agent selects it during reasoning, presen ting an interactiv e interface when a human inv okes it directly and executing the same co de with the same parameters when an agent calls it autonomously [23]. A correction made to a Jinx propagates to every agen t that uses it, providing the kind of unified human-agen t to ol definition that declarative agen t sp ecification has b een identified as requiring [24]. W e organize Jinxes in a categorized directory hierarc h y and reference them by name through template resolution rather than b y path, so that reorganizing the capabilit y taxonom y do es not break agen t definitions. C. NPCs An NPC file defines an agen t through a name, a natural- language directiv e, a mo del and provider sp ecification, and a Jinx list that simultaneously constitutes the to ol catalog and the permission set. W e use the Jinx list to scop e each agent to the minim um set of to ols its role requires, an interv ention motiv ated b y the finding that tool selection accuracy undergo es a structural phase transition as catalog size grows [19], [25] and that agents op erating with the smallest set of high-signal tokens outperform those giv en o verlapping to ols [1]. The Jinx list enforces its constrain t structurally rather than interpretiv ely . A prose instruction file can request that an agen t limit itself to certain to ols, but the mo del is free to ignore or misinterpret the instruction, and at- ten tion dilution makes this increasingly lik ely ov er long con texts [10]; to ols not on the Jinx list do not exist in the agent’s schema, and no amount of prompt injection or attention drift can inv oke what w as never provided. The securit y literature arrives at this conclusion through analysis of attack surfaces [13]–[15], and we implemen t it through the definition format rather than through a separate enforcemen t la yer. The same mechanism op erationalizes autonom y as a con tin uous design parameter. An NPC with a narro w Jinx list and no delegation to ol op erates at low autonom y , one with the delegation Jinx and a broad catalog op erates at higher autonomy , and the user repositions any agen t on this sp ectrum b y editing a Y AML list. That high automa- tion and high user control are indep endently achiev able rather than opp osed [26] is what the NPC file makes concrete, operationalizing the automation taxonomy [27] and the autonomy levels that require explicit tradeoffs at eac h stage [28] through a mec hanism simple enough that users actually edit it, addressing the gap that existing co- creativ e systems lea ve op en [29]. D. T e ams A team is a directory con taining NPC files, a Jinxes sub directory , and a context file designating the orches- trator and configuring shared resources. Role sp ecializa- tion and focused con text produce gains across multi- agen t systems [30]–[33], and separating planning, calling, and summarizing in to fo cused roles substan tially improv es p erformance in the sub-24B range [34]; in this frame- w ork, decomp osition is reorganization, b ecause moving NPC files into subdirectories, each with its o wn con text file and orchestrator, creates sub-teams whose internal complexit y is invisible to the top-level router. When the top-lev el orc hestrator routes to a sub-team it sees only the sub-team’s description rather than the full p ersona descriptions and to ol catalogs of every agent within it, k eeping the routing decision tractable for small mo dels whose context budgets are constrained and preven ting con text from the wrong scope from en tering the routing decision. Loss of conv ersation history is a top failure mode in existing multi-agen t frameworks [11], and the sub-team b oundary addresses it by construction. W e implement del- egation b et w een NPCs as a Jinx rather than a framew ork primitiv e, so that the user mo difies completion criteria, feedbac k mec hanisms, and iteration limits b y editing a file, and the same delegation Jinx serv es b oth human-in vok ed and agen t-in vok ed paths. E. Skil ls Skills are Jinxes that deliv er instructional conten t rather than execute co de, pro viding agents with metho dology and domain knowledge through the same to ol mechanism used for any other capabilit y . Because they are Jinxes, skills app ear in agen t to ol catalogs alongside executable to ols and are assigned through the same Jinx list. W e implemen t section-level retriev al within skills so that an agen t requests only the p ortion of a metho dology docu- men t it needs rather than loading the full file in to con- text, managing the token budget under which contextual in terpretation m ust op erate. F. Benchmark Existing agen tic benchmarks (SWE-bench [35], Hu- manEv al [36], T erminal-Bench [37], AgentBenc h [38]) re- p ort scores that conflate model reasoning with framew ork orc hestration [39], are highly sensitive to unreported im- plemen tation details [40], and in the case of SWE-b enc h reflect data quality problems in a substan tial fraction of passes [41]. Enterprise applications introduce requiremen ts (high reliability , auditable traces, complex interaction patterns) that existing benchmarks rarely address [42], and b enc hmarks calibrated for frontier mo dels pro duce uniformly low scores against 1B–35B mo dels, obscuring whether the framework’s tool orc hestration and error re- co v ery are functioning at all. W e designed a b enchmark of 115 tasks spanning 13 capabilit y categories, each sp ecifying a natural-language instruction and a v erification command that c hecks filesystem state. T asks range from single-to ol inv o cations through multi-step sequencing to delegation chains and to ol comp osition, extending b eyond co de-focused tasks to include web search, multi-agen t delegation, and to ol c haining. The design is framew ork-agnostic: the same instructions and verification commands can ev aluate any agen t system that accepts natural-language input, en- abling cross-framew ork comparison holding the mo del con- stan t. I II. Resul ts W e ev aluated 22 lo cally-hosted mo dels from 9 mo del families, spanning 0.6B to 35B parameters, all running via Ollama on consumer hardw are with a 360-second timeout p er task and up to 5 retry attempts with error feedback. T able I presents ov erall scores and Figure 2 sho ws score as a function of parameter count. W e extract p er-task trace data from the 2,530 task executions: attempt coun ts, to ol call counts, and task durations split b y success and failure. Cloud-hosted fron tier mo dels (GPT-4o, Claude Sonnet, Gemini Pro) score abo ve 90% on these same tasks, confirming that the b enc hmark measures mo del capabilit y rather than limitations of the declarative scaffolding. Within-family scaling is monotonic, but betw een-family differences dominate (Figure 2). The b et w een-family v ari- ance exceeds the within-family v ariance at ev ery param- eter coun t where m ultiple families ov erlap, indicating that the qualit y of tool-use training v aries enough across families to ov erwhelm order-of-magnitude differences in parameter count. T ool use is a trained capability [21], and these results show that models trained for it achiev e T ABLE I Benchmark resul ts across model f amilies. F amily Model Params Score Qwen3.5 0.8b 0.8B 12/115 (10%) 2b 2B 72/115 (63%) 4b 4B 67/115 (58%) 9b 9B 90/115 (78%) 35b 35B 101/115 (88%) Qwen3 0.6b 0.6B 5/115 (4%) 1.7b 1.7B 32/115 (28%) 4b 4B 84/115 (73%) 8b 8B 75/115 (65%) 30b 30B 93/115 (81%) GLM 4.7-flash 9B 92/115 (80%) GPT-OSS 20b 20B 84/115 (73%) Gemma3 4b 4B 30/115 (26%) 12b 12B 67/115 (58%) 27b 27B 65/115 (57%) Mistral small3.2 24B 62/115 (54%) ministral-3 3B 49/115 (43%) Llama 3.2:3b 3B 17/115 (15%) 3.1:8b 8B 50/115 (43%) Phi phi4 14B 51/115 (44%) OLMo2 7b 7B 6/115 (5%) 13b 13B 37/115 (32%) 0.5 1 2 4 8 16 32 P arameters (B) 0 20 40 60 80 100 Score (%) Qwen3.5 Qwen3 GLM GPT -OS S Gemma3 Mistral Llama Phi OLMo2 Fig. 2. Benchmark score versus parameter count across model families. scores at 4B that models not trained for it fail to reac h at 27B. Models b elo w 3B can parse the agentic prompt and occasionally select the correct to ol but cannot reliably form argumen ts or sequence m ulti-step op erations. Cross-referencing benchmark scores with MMLU reveals a linear relationship ( r ≈ 0 . 8, p < 10 − 3 ) b et w een gen- eral capability and agentic p erformance (Figure 3). The outliers from this trend identify mo dels whose training transfers disprop ortionately well or p o orly to to ol-use scenarios, consistent with the BFCL finding that single- turn accuracy and multi-turn reliability diverge in wa ys general b enc hmarks do not predict [43]. The mean n um b er of tool calls p er task is a stronger 50 55 60 65 70 75 80 85 Intelligence (MML U %) 0 20 40 60 80 Agency (npcsh Score %) qwen3:0.6b qwen3:1.7b qwen3:4b qwen3:8b qwen3:30b gemma3:4b gemma3:12b gemma3:27b llama3.2:3b llama3.1:8b phi4 olmo2:7b olmo2:13b r = 0 . 8 3 1 = 1 3 . 5 % Qwen3 Gemma3 Llama Phi OLMo2 Fig. 3. Agency (np csh score) versus intelligence (MMLU). The regression line ( r ≈ 0 . 8) with 1 σ band; outliers b eyond 1 σ are lab eled. predictor of benchmark score ( r ≈ 0 . 7, p < 10 − 3 ) than either mean task duration ( r ≈ 0 . 3) or mean attempt coun t ( r ≈ 0 . 5), sho wn in Figure 4. Higher-scoring mo dels mak e more to ol calls rather than sp ending more time or retrying more often. The relationship b etw een to ol use on successful versus failed tasks reveals tw o b eha v- ioral clusters: mo dels that use substantially more to ols when failing (p ersisting without conv ergence) and mo dels that use more to ols when succeeding (gen uine m ulti-step problem solving with fast failure exits). Pass rates b elow 50% for leading models on realistic m ulti-turn tasks [44] indicate that reliability under sustained to ol engagement is the op erativ e b ottleneck. 0 2 4 6 8 10 12 Mean tool calls per task 0 20 40 60 80 100 Agency (npcsh Score %) gemma3:12b gemma3:27b gemma3:4b glm-4.7-flash gpt-oss:20b llama3.1:8b llama3.2:3b ministral-3 mistral-small3.2 olmo2:13b olmo2:7b phi4 qwen3.5:0.8b qwen3.5:2b qwen3.5:35b qwen3.5:4b qwen3.5:9b qwen3:0.6b qwen3:1.7b qwen3:30b qwen3:4b qwen3:8b r = 0 . 7 1 1 = 1 7 . 9 % Gemma3 GLM GPT -OS S Llama Mistral OLMo2 Phi Qwen3.5 Qwen3 Fig. 4. Mean to ol calls p er task versus agency score ( r ≈ 0 . 7). A cross all mo dels, ∼ 80% of successful task completions o ccur on the first attempt. The correlation b et w een first- attempt success rate and retry gain is p ositiv e ( r ≈ 0 . 5, p < 0 . 05), suggesting that retries help only when the mo del can learn from error feedbac k. Retry v alue v aries b y an order of magnitude across task categories (Figure 5): w eb search gains ∼ 20 p ercen tage p oints from retries, to ol- c hain ∼ 15, m ulti-step and text ∼ 15 eac h, while delegation gains ∼ 3. F or categories where the marginal gain per retry is low, the accumulated context from prior failures may activ ely degrade p erformance through loss of con v ersation history , failure mo de 1.4 in the MAST taxonomy [11]. 0 10 20 30 40 50 60 70 80 P ass rate (%) delegation python git data scripting system debug file-ops shell text multi-step tool-chain web-search +3% +6% +7% +8% +8% +9% +9% +12% +13% +15% +15% +17% +21% First attempt Retry gain Fig. 5. First-attempt pass rate (green) and additional gain from retries (orange) by task category . The 13 task categories span from file operations ( ∼ 80% mean pass rate) and shell tasks ( ∼ 75%) through w eb search ( ∼ 55%) to scripting ( ∼ 30%) and delega- tion ( ∼ 20%). The difficult y ordering holds across mo del families but the magnitude of degradation v aries (Fig- ure 6). Delegation is the hardest category for every mo del, and categories requiring m ulti-step reasoning are difficult across all families while categories requiring only correct to ol inv o cation are easy . IV. Discussion The b etw een-family v ariance in agen tic capabilit y , whic h exceeds the within-family v ariance at every ov erlapping parameter count, confirms that to ol-use reliabilit y is a distinct trained capability that general b enc hmarks un- derpredict [43], [45]. The same pattern has b een found in the sub-24B range [34], where separating planning, cal ling, and summarizing in to fo cused roles pro duced substantial gains. Our delegation results, which sho w the highest failure rate and the low est retry gain of any category , are consisten t with the 44% sp ecification-and-design failure rate in the MAST taxonom y [11], suggesting that the failures w e observ e in delegation are primarily sp ecification failures rather than capability failures. qwen3.5:35b qwen3:30b glm-4.7-flash qwen3.5:9b gpt-oss:20b qwen3:4b qwen3:8b qwen3.5:2b qwen3.5:4b gemma3:12b gemma3:27b mistral-small3.2 phi4 llama3.1:8b ministral-3 olmo2:13b qwen3:1.7b gemma3:4b llama3.2:3b qwen3.5:0.8b olmo2:7b qwen3:0.6b file-ops shell system web-search git text tool-chain multi-step python data debug scripting delegation 100% 100% 100% 100% 100% 100% 90% 90% 100% 90% 100% 60% 100% 100% 100% 80% 80% 60% 20% 30% 30% 10% 100% 90% 100% 100% 100% 80% 80% 60% 100% 60% 90% 100% 90% 100% 70% 60% 80% 60% 60% 20% 0% 0% 100% 100% 100% 90% 90% 90% 70% 80% 70% 90% 70% 90% 60% 90% 60% 50% 70% 50% 20% 30% 20% 20% 100% 100% 100% 80% 60% 100% 0% 100% 40% 100% 100% 80% 0% 40% 100% 80% 20% 20% 0% 20% 0% 0% 90% 80% 50% 60% 80% 90% 90% 80% 60% 60% 90% 80% 60% 0% 40% 70% 20% 40% 40% 0% 10% 0% 80% 70% 70% 60% 80% 100% 80% 70% 70% 90% 80% 70% 40% 50% 0% 30% 20% 30% 10% 0% 0% 10% 80% 100% 100% 80% 0% 100% 0% 100% 40% 60% 60% 0% 0% 60% 20% 20% 40% 20% 0% 40% 0% 0% 60% 70% 50% 70% 40% 60% 70% 60% 60% 50% 50% 30% 50% 50% 0% 20% 0% 30% 20% 10% 0% 10% 100% 60% 100% 90% 100% 50% 100% 30% 50% 30% 10% 30% 40% 10% 60% 0% 0% 0% 0% 0% 0% 0% 60% 60% 50% 40% 60% 40% 40% 20% 40% 50% 70% 50% 40% 40% 90% 10% 20% 10% 0% 0% 0% 0% 100% 100% 90% 100% 90% 40% 70% 60% 60% 30% 0% 40% 0% 10% 0% 0% 0% 0% 0% 0% 0% 0% 100% 60% 80% 80% 70% 70% 60% 50% 10% 20% 10% 30% 30% 0% 10% 0% 0% 0% 0% 0% 0% 0% 60% 80% 60% 60% 0% 40% 0% 40% 20% 40% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0.0 0.2 0.4 0.6 0.8 1.0 P ass R ate Fig. 6. Pass rate by mo del and task category . Mo dels ordered by ov erall score (left to right); categories by mean difficulty (top to b ottom). The category-level v ariation in retry v alue has prac- tical implications for retry p olicy . F or categories where accum ulated context from prior failures actively degrades p erformance (failure mode 1.4 in [11]), the rational p olicy is to restart with a clean context rather than retry . The p ositiv e correlation betw een first-attempt success rate and retry gain ( r ≈ 0 . 5) is opposite to what a ceiling-effect mo del would predict, and suggests that retries help only when the mo del has sufficient baseline capability to learn from error feedbac k. The τ -b ench results supp ort this in terpretation: pass rates b elow 50% under sustained to ol engagemen t indicate a reliability b ottlenec k distinct from single-call accuracy [44]. The Jinx-list scoping approac h extends the declarativ e sp ecification work of DSPy [46] and ADL [24] through a shell interface and filesystem organization. That the con- text engineering [20] and Unix philosoph y [47] literatures arriv e at the same arc hitectural argument indep enden tly supp orts the IaC analogy . Indep endent security analy- ses [13]–[15] each arrive at tool-level constrain t enforce- men t as a necessary mechanism; the connection to the ICRP’s ALARA formulation [16] and NIST’s least priv- ilege [18] is structural rather than metaphorical, as both describ e the same optimization of minimizing exp osure to the lev el the task actually requires. The co-creative design of the NPC file, in which the Jinx list is b oth the to ol catalog and the permission set, addresses the gaps iden tified in concrete mec hanisms for shared agency [29], following the mixed-initiativ e frame- w ork of [23] and the finding of [26] that high automation and high user con trol are join tly achiev able. Guidelines call for transparency and correctability [48]; the Jinx list pro vides both through a file the user can read and edit. F or organizational deploymen t, the filesystem-organized con- figuration addresses lifecycle management requirements iden tified [49], [50]. The degradation we observ e as to ol catalog size in- creases is predicted by the contextualit y established by seman tic Bell inequalit y violations in LLMs [6]–[9], which sho w that meaning-pro duction in these systems is gener- ated in the act of in terpretation rather than retriev ed from pre-existing asso ciations. This provides an information- theoretic basis for why prose-based b ehavioral constrain ts cannot b e guaran teed to pro duce the intended b eha vior regardless of scale, and why structural enforcement at the sc hema lev el is necessary . V. Conclusions In this work, w e in tro duced a declarative con text-agent- to ol (CA T) data lay er for scoping agen t to ol access and con text, and ev aluated it across 22 lo cally-hosted models and 2,530 task executions. W e summarize the main results. 1) The CA T data lay er, consisting of context files, NPC definitions, and Jinxes, enforces tool access constrain ts structurally rather than in terpretiv ely . T ools not present in an agen t’s Jinx list do not exist in its schema and cannot b e in v ok ed regardless of prompt con ten t. 2) Betw een-family differences in agen tic capability dominate within-family scaling, confirming that to ol-use reliability is a distinct trained capabilit y . Mo dels trained for to ol use achiev e scores at 4B parameters that mo dels not trained for it fail to reac h at 27B. 3) MMLU and agen tic p erformance correlate ( r ≈ 0 . 8), but outliers iden tify mo dels whose training transfers disprop ortionately w ell or p o orly to to ol-use scenar- ios. 4) T ool call v olume is the strongest predictor of agen tic p erformance ( r ≈ 0 . 7), stronger than task duration ( r ≈ 0 . 3) or attempt count ( r ≈ 0 . 5). 5) ∼ 80% of successful completions o ccur on the first attempt. Retry v alue v aries by an order of magnitude across task categories, from ∼ 20 percentage p oints for web searc h to ∼ 3 for delegation, arguing for category-a w are resource allo cation. 6) Delegation is the hardest category for ev ery model. The lo w retry gain for delegation suggests that accu- m ulated context from prior failures degrades rather than aids con v ergence. 7) The framew ork and b enchmark are op en source at h ttps://gith ub.com/NPC- W orldwide/np csh. References [1] Anthropic, “Building effectiv e agents,” 2024. [Online]. A v ailable: https://www.an thropic.com/research/building- effective- agents [2] P . Gauthier, “Aider,” 2023. [Online]. A v ailable: https://gith ub. com/paul- gauthier/aider [3] H. Chase, “Langchain,” 2022. [Online]. A v ailable: h ttps: //github.com/langc hain- ai/langchain [4] Q. W u et al. , “Autogen: Enabling next-gen LLM applications via multi-agen t conv ersation,” 2023. [5] J. ao Moura, “Crewai,” 2024. [Online]. A v ailable: https: //github.com/crew ai/crewai [6] C. J. Agostino, Q. Le Thien, M. Apsel, D. P ak, E. Lesyk, and A. Ma jumdar, “A quan tum semantic framework for natural language pro cessing,” in International Confer enc e on Quan- tum A rtificial Intel ligenc e and Natur al L anguage Pr o c essing . Springer, 2025, pp. 134–155. [7] C. J. Agostino et al. , “The pro duction of meaning in the pro- cessing of natural language,” in Pr o c. HAXD , 2026, submitted. [8] P . T rouillas, A Quantum The ory of Syntax . No v a Science Publishers, 2024. [9] C. K. Thomas and M. Chen, “F undamen tal limits of quantum semantic comm unication via sheaf cohomology ,” arXiv preprint arXiv:2601.10958 , 2026. [10] N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P . Liang, “Lost in the middle: How language models use long contexts,” T r ans. A sso c. Comput. Linguist. , vol. 12, pp. 157–173, 2024, [11] M. Cemri, M. Z. Pan, S. Y ang, L. A. Agraw al, B. Chopra, R. Tiwari, K. Keutzer, A. Paramesw aran, D. Klein, K. Ram- chandran, M. Zaharia, J. E. Gonzalez, and I. Stoica, “Wh y do multi-agen t LLM systems fail?” in Pro c. NeurIPS Datasets and Benchmarks , 2025, [12] A. Chan et al. , “Harms from increasingly agentic algorithmic systems,” in Pr oc. F Ac cT , 2023. [13] T. Shi, J. He, Z. W ang, L. W u, H. Li, W. Guo, and D. Song, “Progent: Programmable privilege control for LLM agents,” 2025. [14] others, “Prompt flow integrit y to preven t privilege escalation in LLM agents,” 2025. [15] F. T ram ` er et al. , “Design patterns for securing LLM agents against prompt injections,” 2025. [16] ICRP, “Recommendations of the international commission on radiological protection,” ICRP Publication 26, Annals of the ICRP , vol. 1, no. 3, 1977. [17] U.S. Nuclear Regulatory Commission, “ALARA. ” [On- line]. A v ailable: https://www.nrc.go v/reading- rm/basic- ref/ glossary/alara.html [18] National Institute of Standards and T ec hnology, “Least privilege,” nIST SP 800-53 Rev. 5. [Online]. A v ailable: https://csrc.nist.go v/glossary/term/least privilege [19] Y. Shen et al. , “T askb enc h: Benchmarking large language mo d- els for task automation,” in Pr o c. NeurIPS , 2024. [20] X. Xu et al. , “Ev erything is con text: Agen tic file system abstrac- tion for context engineering,” 2025. [21] T. Schic k, J. Dwiv edi-Y u, R. Dess ` ı, R. Railean u, M. Lomeli, L. Zettlemoy er, N. Cancedda, and T. Scialom, “T o olformer: Language mo dels can teach themselves to use to ols,” in Pr oc. NeurIPS , 2023. [22] S. Y ao, J. Zhao, D. Y u, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “ReAct: Synergizing reasoning and acting in language models,” in Pro c. ICLR , 2023. [23] E. Horvitz, “Principles of mixed-initiativ e user interfaces,” in Pr o c. CHI . ACM, 1999, pp. 159–166. [24] S. Zeng and X. Y an, “ADL: A declarative language for agen t- based chatbots,” 2025. [25] X. Li, “When single-agent with skills replace multi-agen t sys- tems and when they fail,” 2026. [26] B. Shneiderman, Human-Center ed AI . Oxford University Press, 2022. [27] R. Parasuraman, T. B. Sheridan, and C. D. Wick ens, “A mo del for t yp es and levels of human interaction with automation,” IEEE T rans. Syst. Man Cybern. A , vol. 30, no. 3, pp. 286–297, 2000. [28] K. F eng et al. , “Levels of autonomy for AI agents,” 2025. [29] S. Zhang et al. , “Exploring collab oration patterns and strategies in human-AI co-creation through the lens of agency: A scop- ing review of the top-tier HCI literature,” Pr o c. A CM Hum.- Comput. Inter act. , 2025, [30] S. Hong et al. , “MetaGPT: Meta programming for a m ulti-agent collaborative framework,” in Pro c. ICLR , 2024. [31] W. Chen et al. , “Agen tverse: F acilitating multi-agent collabora- tion and exploring emergent b ehaviors,” in Pr o c. ICLR , 2024. [32] Z. Liu et al. , “A dynamic LLM-p ow ered agent netw ork for task- oriented agent collab oration,” in Pr o c. COLM , 2024. [33] C. Qian et al. , “ChatDev: Communicative agen ts for softw are developmen t,” in Pr o c. ACL , 2024. [34] W. Shen et al. , “Small LLMs are weak to ol learners: A multi- LLM agent,” in Pro c. EMNLP , 2024, pp. 16 658–16 680. [35] C. E. Jimenez et al. , “SWE-bench: Can language mo dels resolv e real-world GitHub issues?” in Pro c. ICLR , 2024. [36] M. Chen et al. , “Ev aluating large language mo dels trained on code,” 2021. [37] M. A. Merrill et al. , “T erminal-bench,” 2026. [38] Y. Liu et al. , “Agentbench: Ev aluating LLMs as agents,” in Pr o c. ICLR , 2024. [39] S. Kap oor et al. , “AI agents that matter,” T r ans. Mach. L earn. R es. , 2025. [40] S. Biderman et al. , “Lessons from the trenches on repro ducible ev aluation of language mo dels,” 2024. [41] R. Aleithan et al. , “SWE-Bench+: Enhanced co ding benchmark for LLMs,” 2024. [42] “Ev aluation and benchmarking of LLM agen ts: A survey ,” in Pr o c. KDD , 2025, [43] S. G. P atil, H. Mao et al. , “The b erk eley function calling leaderboard (BFCL): F rom to ol use to agen tic ev aluation of large language models,” in Pro c. ICML , 2025. [44] S. Y ao, N. Shinn, P . Razavi, and K. Narasimhan, “ τ -b ench: A b enchmark for to ol-agent-user interaction in real-world do- mains,” 2024. [45] S. G. Patil et al. , “Gorilla: Large language model connected with massive APIs,” in Pro c. NeurIPS , 2024. [46] O. Khattab et al. , “DSPy: Compiling declarative language model calls into self-improving pip elines,” in Pro c. ICLR , 2024. [47] D. B. Piskala, “F rom everything-is-a-file to files-are-all-you- need: How unix philosophy informs the design of agentic AI systems,” 2026. [48] S. Amershi et al. , “Guidelines for human-AI in teraction,” in Pr o c. CHI . ACM, 2019. [49] C. Lop es et al. , “Engineering AI agen ts for clinical w orkflo ws: A case study in architecture, MLOps, and gov ernance,” in Pr o c. CAIN , 2026. [50] D. Kreuzberger, N. K¨ uhl, and S. Hirschl, “Machine learning operations (MLOps): Overview, definition, and architecture,” IEEE A c c ess , vol. 11, pp. 31 866–31 879, 2023.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment