Points-to-3D: Structure-Aware 3D Generation with Point Cloud Priors
Recent progress in 3D generation has been driven largely by models conditioned on images or text, while readily available 3D priors are still underused. In many real-world scenarios, the visible-region point cloud are easy to obtain from active senso…
Authors: Jiatong Xia, Zicheng Duan, Anton van den Hengel
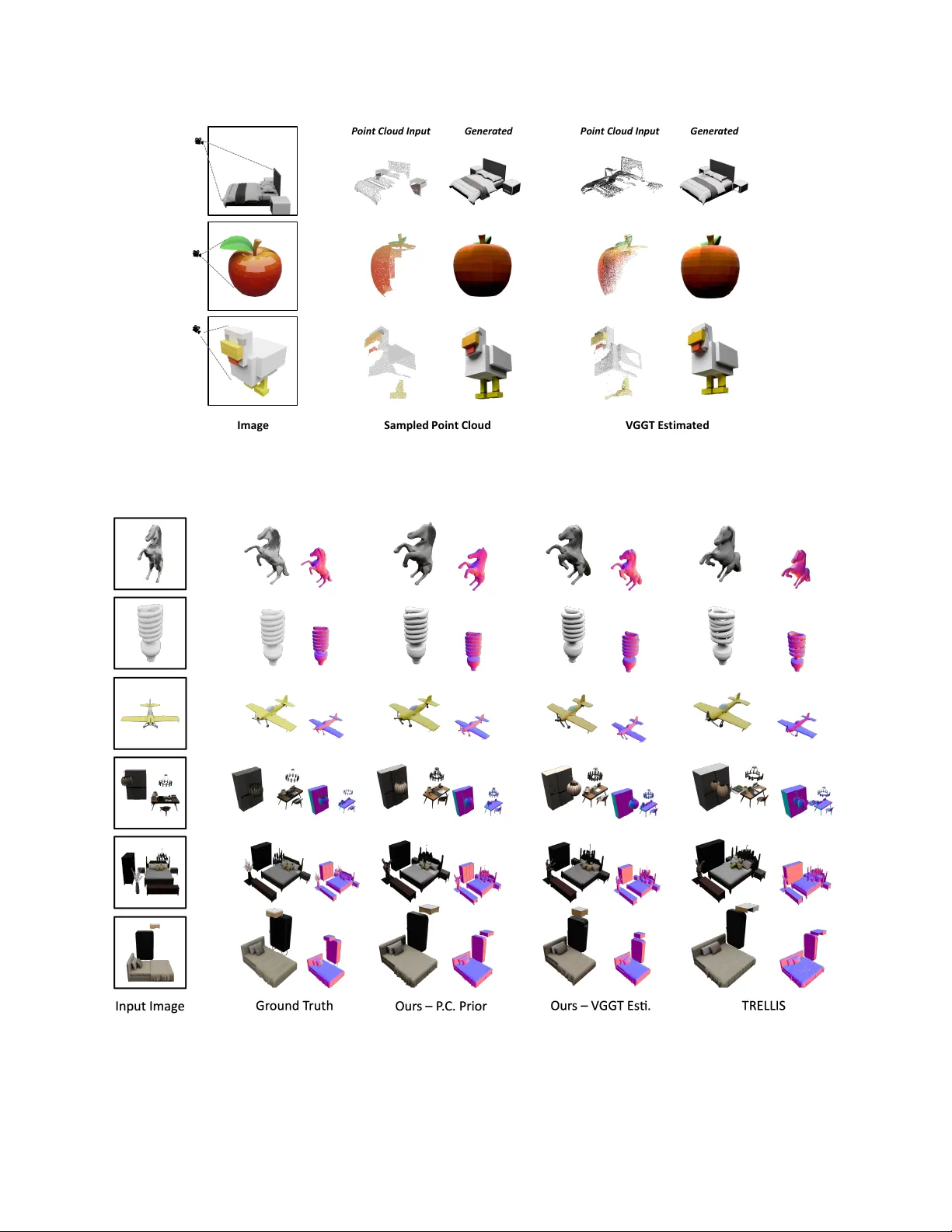
P oints-to-3D: Structur e-A war e 3D Generation with P oint Cloud Priors Jiatong Xia * , Zicheng Duan * , Anton v an den Hengel, Lingqiao Liu † Australian Institute for Machine Learning, Uni versity of Adelaide, Australia V G GT Sens i ng Voxe l i zati on an d Encoding Images 3 D Space P oint C loud P r iors In painti ng and Ge ne rat i on Spar se St r uc t ur e Latent O ut put s wit h P r ese r v ed 3 D St r uc t ur es Figure 1. W e introduce explicit 3D point cloud priors into 3D generation frame work, gi ven a pre-e xisting point cloud or a feed-forward point cloud prediction from image input, our model generates high-quality 3D assets that faithfully preserve the observed structure while plausibly completing unobserved re gions with coherent geometry . Abstract Recent pr o gr ess in 3D gener ation has been driven lar gely by models conditioned on images or te xt, while r eadily available 3D prior s ar e still underused. In many r eal- world scenarios, the visible-r e gion point cloud are easy to obtain—fr om active sensors such as LiD AR or from feed- forwar d predictors like VGGT—offering explicit geomet- ric constraints that curr ent methods fail to e xploit. In this work, we intr oduce P oints-to-3D, a diffusion-based frame work that leverag es point cloud priors for geometry- contr ollable 3D asset and scene generation. Built on a latent 3D diffusion model TRELLIS, P oints-to-3D first re- places pure-noise sparse structure latent initialization with a point cloud priors tailored input formulation.A struc- tur e inpainting network, tr ained within the TRELLIS frame- work on task-specific data designed to learn global struc- * Jiatong Xia and Zicheng Duan equally contributed to this work. † Corresponding author , e-mail: lingqiao.liu@adelaide.edu.au tural inpainting, is then used for inference with a staged sampling strate gy (structur al inpainting followed by bound- ary refinement), completing the global geometry while pr e- serving the visible re gions of the input priors.In practice, P oints-to-3D can take either accurate point-cloud priors or VGGT -estimated point clouds fr om single images as in- put. Experiments on both objects and scene scenarios con- sistently demonstrate superior performance over state-of- the-art baselines in terms of r endering quality and geo- metric fidelity , highlighting the effectiveness of explicitly embedding point-cloud priors for achieving more accurate and structurally contr ollable 3D generation. Project page: https://jiatongxia.github .io/points2-3D/ 1. Introduction Advances in 3D generation now allow models to syn- thesize realistic and div erse 3D assets from single-view images or text prompts. These “foundation” 3D mod- 1 els [ 20 , 30 , 67 , 70 , 78 ] can produce 3D assets across broad categories, supporting applications in content creation and virtual en vironments. Howe ver , conditioning solely on 2D images or text provides limited geometric controllability: while the output may appear plausible, the model lacks any mechanism to respect real 3D measurements. In practice, partial point clouds from sensors or image-based predictors provide reliable geometry for visible regions, yet current 3D generativ e pipelines make little use of this readily av ailable structural information. In this work, we address this gap by enabling geometry- controllable 3D generation driv en by point cloud pri- ors. W e focus on the setting where a visible-region point cloud—captured or predicted—is treated as a hard struc- tural constraint, requiring the generated asset to align with observed geometry while plausibly completing unobserved parts. Achieving this cannot be done by simply injecting the point cloud as an additional condition; it requires to in- tegrates the structural prior into the latent space itself. Recent latent 3D diffusion models [ 21 , 30 , 57 ], repre- sented by TRELLIS [ 67 ], factorize 3D generation into two stages: a coarse structural stage operating on a sparse occu- pancy representation, followed by a semantic and appear- ance refinement stage. This paradigm offers an explicit structure latent that could be guided by 3D priors. Y et in their default formulation, these structure latents are initial- ized purely from Gaussian noise and rely only on text or image embeddings, making them unable to anchor struc- tural generation to actual 3D observations. T o overcome this limitation, we introduce Points-to- 3D, a point-cloud–guided 3D generation framew ork that re-defines how the structural latent is initialized and com- pleted. Instead of starting from pure noise, we voxelize the visible point cloud and encode it with the TRELLIS sparse structure V AE to obtain a partially observed latent that di- rectly reflects the measured geometry . Regions supported by observations are preserved as fixed constraints, while unobserved re gions remain free to be synthesized. A mask- aware inpainting network completes this mixed latent, en- abling the model to generate coherent structures that respect real 3D measurements while plausibly filling missing areas. T o support this formulation, we construct a visibility- aware training pipeline that first produces realistic par - tial–complete structure pairs from ground-truth assets, these pairs supervise the inpainting model to generate geomet- ric cues from visible regions to invisible ones while main- taining consistency with the input point cloud. During in- ference, Points-to-3D adopts a lightweight two-stage pro- cedure: it first establishes a globally consistent structure under visibility constraints, and then performs a brief re- finement step to enhance boundary quality without disturb- ing anchored geometry . This design enables controllable and structurally faithful 3D generation from both sensor- captured and image-predicted point clouds. W e ev aluate Points-to-3D on object-level (T oys4K [ 54 ]) and scene-level (3D-FR ONT [ 14 ]) benchmarks. Across all settings, our method consistently outperforms TREL- LIS [ 67 ] and other baselines in rendered-view quality and geometric fidelity . Gains are especially significant in re- gions covered by point-cloud priors, where Points-to-3D achiev es near-perfect alignment while maintaining realistic completions in unseen areas. Furthermore, combining our point-cloud–anchored structure generation with text condi- tioning enables controllable text-to-3D generation guided by concrete 3D measurements. 2. Related W ork 2.1. 3D Modeling Recov ering the 3D model of specific scenes or ob- jects is a fundamental problem in computer vision and graphics. Classical 3D reconstruction leverages multi- images to recover geometry , including Structure-from- Motion (SfM) [ 47 ], Multi-V iew Stereo (MVS) [ 71 , 72 , 74 ], SDF-based approaches [ 42 , 52 , 76 ], e.t.c. Radiance-field models like Neural Radiance Fields (NeRF) [ 1 , 2 , 5 , 26 , 28 , 39 , 40 , 66 ] and 3D Gaussian Splatting (3DGS) [ 19 , 22 , 25 , 32 , 75 ] further enable high-fidelity reconstruction and nov el-vie w synthesis after scene-specific optimization, and recent feed-forward v ariants [ 4 , 8 , 9 ] reducing the per-scene cost. DUSt3R-related feed-forward reconstruction meth- ods [ 31 , 58 , 62 , 65 , 68 , 77 ], ex emplified by VGGT [ 61 ], predict per-pixel point cloud and implicitly handle camera poses, achie ving strong performance e ven with a single im- age. Howe v er , reco vering 3D assets from only one image is still beyond the capabilities of reconstruction methods. 3D generativ e models [ 21 , 29 , 30 , 34 , 57 , 59 , 67 ] effecti vely ad- dress this scenario: conditioned on a single reference image or ev en text prompt, the y can synthesize plausible 3D assets aligned with the reference content. 2.2. 3D Generative Models Prior 3D generation relies on GANs [ 3 , 17 , 48 ] produce con vincing results, yet their instability restricts scalabil- ity and output di versity . models [ 18 , 35 , 53 ], starting with 2D generation [ 43 , 46 , 60 ], diffusion-based meth- ods rapidly expanding across a spectrum of 3D represen- tations [ 20 , 21 , 30 , 36 , 49 , 51 , 56 , 57 , 70 , 78 ]. Recently , TRELLIS [ 67 ] introduces a novel latent representation that enables decoding into versatile 3D output formats, demon- strating strong quality , versatility , and editability , and of- fering a superior paradigm and framew ork for 3D gener- ation. Subsequent works [ 33 , 38 , 63 , 69 ] hav e leveraged TRELLIS to implement a wide range of practical applica- tions. Nev ertheless, most existing improvements focus on enhancing performance at the reference-conditioning lev el, 2 while directly embedding 3D priors into latent initialization to enable more reliable generation still remains largely un- explored in 3D generation. 2.3. Point Cloud Priors Incorporating 3D priors to assist downstream tasks has prov en to be a effecti ve strategy . Where point cloud stand out as one of the most practical and informative represen- tations. Leveraging point cloud priors has advanced a wide range of 3D perception tasks [ 50 , 64 , 80 ] as well as recon- struction tasks [ 13 , 45 ]. In particular , visible-region point clouds are easy to obtain from div erse sources, including ac- tiv e sensors such as LiD AR and structured-light depth cam- eras—now widely accessible even on mobile devices—or from reconstruction approaches such as VGGT [ 61 ]. Inte- grating these easily obtainable point cloud into 3D genera- tiv e models of fers promising potential for explicit geome- try control and accurate modeling of complex multi-object scenes. This work seeks to establish a simple yet effec- tiv e paradigm for incorporating point cloud priors into a diffusion-based 3D generation frame work. 2.4. Inpainting Inpainting is a common paradigm for completing missing content while preserving observed structures. In 2D vi- sion, dif fusion-based inpainting methods [ 6 , 23 , 37 , 73 ] use spatial masks to guide the synthesis of occluded re- gions, achieving coherent and controllable image comple- tion. Similar ideas appear in 3D completion [ 10 , 11 , 16 , 24 ] where partial scans are used to infer full geometry , b ut such approaches usually operate as separate completion modules rather than within a generative framew ork. TRELLIS, ho w- ev er , has the potential to perform inpainting directly within its sparse structured latent spaces, enabling improved global coherence without the need for external modules. Building on this perspectiv e, we formulate point-cloud–conditioned 3D generation as a latent inpainting problem, allowing ob- served geometry to be embedded and completed naturally within the generativ e process without relying on auxiliary completion components. 3. Method W e seek to achie ve geometry-controllable 3D generation by conditioning on point clouds, whether captured by real- world sensors or inferred from a single image via feed- forward prediction. This section first outlines TRELLIS, the baseline that underpins our work, then formalizes the prob- lem and introduces our method, detailing the model archi- tecture, training-data construction, and sampling strategy . 3.1. Preliminaries: TRELLIS TRELLIS [ 67 ] is a recently proposed 3D generation model that produces di verse and high-fidelity 3D assets from im- age or text prompts. Unlike con ventional diffusion mod- els that operate directly in voxel or implicit-function space, TRELLIS performs dif fusion in a compact latent space specifically designed to encode 3D structure and appear- ance. This latent space is learned via a pair of v aria- tional autoencoders (V AEs) trained to compress and re- construct 3D assets. The first V AE encodes vox elized 3D features deriv ed from the original asset into a latent rep- resentation called the structur ed latent (SLA T), denoted as z = { ( z i , p i ) } L i =1 , where z i ∈ R c slat is a local fea- ture attached to voxel position p i ∈ [0 , N − 1] 3 with N = 64 . The SLA T z can be decoded into multiple 3D output formats—Gaussian splats, radiance fields, or meshes—through corresponding decoders, enabling flexi- ble rendering backends. The second V AE ( E s , D s ) learns a compact representation of geometry by encoding a binary vox el occupancy grid M ∈ { 0 , 1 } N × N × N —whose occu- pied positions correspond to { p i } L i =1 —into a sparse struc- tur e (SS) latent q ∈ R r × r × r × c s (with r = 16 ), which can be decoded back into M . The generation process in TRELLIS proceeds in two stages following a coarse-to-fine paradigm. In the Struc- ture Generation stage, a Flo w T ransformer G s takes Gaus- sian noise ϵ s ∼ N (0 , I ) and a condition embedding c (from image or text) to sample the SS latent q , which is then de- coded by D s into a binary voxel grid M , defining the as- set’ s geometric scaffold. In the subsequent Structured La- tent Generation stage, a Sparse Flo w T ransformer G l takes noise ϵ slat ∼ N (0 , I ) , the voxel positions { p i } L i =1 , and the same condition c to generate the SLA T z , which is decoded into the final 3D asset with texture and semantics. Over- all, TRELLIS establishes a two-le vel generative hierarchy that first synthesizes a sparse geometric structure and then enriches it with detailed appearance. While the V AEs in TRELLIS possess the intrinsic ability to encode meaningful 3D geometry , the generativ e process itself is not conditioned on external 3D information. Our approach, Points-to-3D , lev erages this encoded structural capability by directly injecting point-cloud priors into the V AE latent space, thereby grounding the diffusion process to explicit 3D observ ations. 3.2. Problem Formulation In many real-world settings, we aim to generate 3D as- sets conditioned on point cloud priors—obtained either via activ e sensing (e.g., LiDAR) or model prediction (e.g., VGGT). These point cloud typically cover only the visi- ble portion of the scene. In such a case, the goal is to use the visible-region point cloud P as a prior for geometry- controllable 3D asset generation: preserving the observed foreground structure while completing unobserved regions guided by foreground cues. T o this end, we cast the task as inpainting conditioned on P , inferring missing geometry 3 SS L a ten t In pu t F ormula tion In ference Trai nin g Inpai nt in g Fl ow Tr ans for me r Inpaint ing Fl ow Tr an sfo r me r Poin t Clouds R a n d om No i se Vi si b i l i ty M a sk C h an n el - Wise C on c a t en a t ion Fillin g / Tr ain ab le / Fixed Fee d - f or w a r d Pr e d i ct i on Pr ovi d e d VGG T or 𝓖 𝒊 𝒏𝒑 𝓖 𝒊 𝒏𝒑 𝓖 𝒊 𝒏𝒑 𝓖 𝒊 𝒏𝒑 × ( 𝒕 − 𝒔 ) 𝓛 𝑪𝑭𝑴 × 𝒔 − 𝟏 Voxel i ze a n d En co d e + M a sk Ext r a ct i on Stage 1 : Str uct ur al Inpai nt in g Stage 2 : B oun da r y Refi nemen t L a ten t I n p u t St ep 1 Pred. St ep 𝒔 Pred. O u tp u t SS L a ten t St ep t Pred. G r o u n d T r u th SS L a ten t Pr e d . SS L a ten t L a ten t I n p u t Figure 2. Overall framework. Giv en point cloud priors—either pre-existing or predicted by VGGT from input image—we first voxelize and V AE-encode it to obtain an SS latent, where the empty regions are filled with random noise and concatenated with an extracted mask to form the input paradigm for our model. During training, the input training data is fed into our inpainting flow transformer G inp , which is optimized via a conditional flow matching loss. During inference, the input test data is processed by the trained G inp through a two-stage sampling procedure: (1) a structural inpainting stage with s sampling steps to inpaint the global structure. And (2) a boundary refinement stage with remaining ( t − s ) steps to refine the inpainting boundaries, yielding the final output SS latent. from the surrounding latent context. Specifically , unlike TRELLIS—which initializes genera- tion from pure noise ϵ s —our structural inpainting stage be- gins by vox elizing the visible point-cloud priors P into a binary 3D occupancy grid M ′ ∈ { 0 , 1 } N × N × N . This vox- elized structure is then encoded with the V AE encoder E s to obtain the initial SS latent q vis ∈ R r × r × r × c s (with r = 16 ), which serves as the generation starting point. Formally: q vis = E s ( M ′ ) . (1) T o indicate which SS latent regions should be preserved, we deriv e an occupancy mask m s ∈ R r × r × r × c m by down- sampling M ′ to the latent resolution. Then, we preserve the visible region SS latent with m s and fill the remaining with noise to obtain the inpainting input SS latent q comb : q comb = m s ⊙ q vis + (1 − m s ) ⊙ ϵ s . (2) Ultimately , we aim to build an inpainting model G inp based on the structure generation model G s to take q comb as input, and inpaint the final SS latent q , facilitating visible regions geometry-controllable generation. 3.3. Point Clouds Priors Driven Generative Model Model design. As shown in the purple box of Fig. 2 , to enforce the inpainting model, G inp , on distinguishing the regions to preserve and generate, we further concatenate the mask m s to the q comb along the channel dimension. This turn q comb to x inp : x inp = Concat[ q comb , m s ] , x inp ∈ R r × r × r × ( c s + c m ) (3) T o adapt G inp with more input channels, we simply replace its input layer inherited from G s by a newly registered pro- jection layer with channel dimension ( c s + c m ) , and maintain all other network structures unchanged. Then, we fully fine- tune G inp to learn to inpaint a completed sparse structure latent q pred ∈ R r × r × r × c s using Conditional Flo w Matching loss (CFM) and regard the ground-truth sparse latent q gt as supervision. This can be formulated as: L C F M = E t, q gt ,ϵ ∥G inp ( x inp , t ) − ( ϵ − q gt ) ∥ 2 2 (4) Note that the condition c and time-dependent noise schedul- ing for x inp are omitted for simplicity . T raining data from visible point clouds. W e construct div erse pairs of training data from visible point clouds to- gether with their corresponding ground-truth sparse struc- ture latent to train our model as illustrated in Fig. 3 . The main challenge lies in accurately obtaining the visible- region point clouds corresponding to the input condition images of each 3D asset. T o achiev e this, we render the depth map D t with height and width as H and W from T viewpoints with the condition images I t for each ground- truth 3D asset. F or each object, we first uniformly sample 4 Figure 3. T raining data processing . W e preserve the visible portion of the complete point cloud and con v ert it into training inputs. S surface points ˆ P = { ˆ p i = ( u i , v i , w i ) } S i =1 , and giv en the world-to-camera transformation T t = [ R t | t t ] for the t -th view , each point is transformed to the camera as: ˆ p t i = R t ( ˆ p i − t t ) = u t i , v t i , w t i ⊤ (5) The corresponding image-plane projection u t ∈ [1 , H ] × [1 , W ] is computed using the intrinsic matrix K . W e apply an observation mask O t to indicate which point is consid- ered visible in view t if its projected depth w t i is consistent with the rendered depth within a tolerance threshold τ : O t i = ( 1 , if | D t ( u i ) − w t i | < τ , 0 , otherwise. (6) The visible point cloud P t for view t is thus obtained as P t = { ˆ p t i | O t i = 1 } . Each P t is then voxelized into the sparse structure voxel, which is then encoded and calcu- lated to the SS latent q t comb . Simultaneously , the downsam- pled occupancy mask m t s is obtained to indicate the visible region of the obtained SS latent. The ground-truth SS latent q gt is deriv ed from the complete 3D structure of the object. Consequently , the samples ( q t comb , m t s , I t , q gt ) are used to supervise the model G s (green box in Fig 2 ) to learn struc- ture completion from visible-region priors. 3.4. Staged Sampling from Point Cloud Priors During inference, we split the t step generation into two separate sampling stages, namely the structural inpainting stage and the boundary refinement stage. As illustrated in Fig. 2 orange box, the first stage produces a coarse b ut glob- ally consistent skeleton structure guided by the visible point clouds using inpainting, while the second stage refines the boundary regions that connect newly generated content to the predefined visible areas. Specifically , in each sampling step of the structural inpainting stage, the trained model out- puts q pred and reconstructs the inpainting input x inp for the next iteration by concatenating q pred with the visibility mask m s following Eq. ( 3 ). W e repeat this process for s steps to obtain a draft skeleton 3D structure that is mostly coher- ent with the visible point cloud. Ho we v er , slight inconsis- tencies and missing details may appear around the bound- ary re gions between generated and predefined visible areas, mainly due to information loss introduced during down- sampling. T o address this, we define the latter ( t − s ) steps as the boundary refinement stage. Here, we replace the vis- ibility mask m s with an all-ones mask m 1 , effecti v ely con- verting inpainting into standard denoising. This allows the model to refine details on either side of the masked or un- masked regions without drastically modifying the existing global geometry , resulting in a fully completed and high- quality sparse structure. 4. Results 4.1. Experiments Setup Datasets. W e train our model on a combination of three datasets: 3D-FUTURE [ 15 ] dataset, HSSD [ 27 ] dataset and ABO [ 12 ] dataset. During training, we render T = 24 in- put views for each object and sample S = 50 , 000 point clouds from each object mesh. For each views, we compute the corresponding visible point clouds, which is then pro- cess to an initial SS latent used for training. W e ev aluate our model on two types of test datasets: the single-object dataset T oys4K [ 54 ] and the scene dataset 3D-FR ONT [ 14 ]. And our method is tested under two settings to cover a broader range of application scenarios. In the first setting, we use the sampled visible point cloud from each view as av ailable input. And in the second setting, where no prepro- cessed point cloud priors are provided, the test view condi- tion image is fed into VGGT to obtain an estimated point cloud for our model as the initial point cloud priors. W e also ev aluate our method on several real-world images from the Pix3D [ 55 ] dataset. Evaluation metrics. W e evaluate the final generation re- sults in two aspects. For the rendered images of the gener- ated 3D assets, we assess the image quality by comparing with those rendered from the ground-truth 3D asset, and us- ing PSNR, SSIM, LPIPS [ 79 ], and DINO [ 41 ] feature sim- ilarity as ev aluation metrics. For the geometric quality , we employ Chamfer Distance and F-score, as well as the ren- dered normal maps PSNR and LPIPS as e v aluation metrics. For text-to-3D generation e v aluation, we use the CLIP [ 44 ] score to measure the consistency between the generated re- sults and the input text prompts. Implementation. W e train our model for 20k iterations with a batch size of 8 on 4 Nvidia A100 GPUs, and follo w- ing the other TRELLIS [ 67 ]’ s sparse structure flow trans- former’ s training setting. During inference, we set the t = 50 sampling steps for the trained Sparse Structure Flow 5 T able 1. Comparison on single-object generation on T oy4K dataset. W e showcase the performance of our method in two scenarios: one where explicit point cloud priors are pro vided, and another where point cloud are inferred from condition images using VGGT [ 61 ]. Rendering Geometry Method PSNR ↑ SSIM (%) ↑ LPIPS ↓ DINO (%) ↓ CD ↓ F-Score ↑ PSNR-N ↑ LPIPS-N ↓ GaussianAnything [ 30 ] 20.08 89.31 0.183 26.74 0.084 0.513 20.99 0.199 Real3D [ 21 ] 19.55 90.65 0.169 27.65 0.065 0.574 21.31 0.178 LGM [ 57 ] 20.55 89.98 0.181 23.45 0.075 0.487 20.04 0.202 V oxHammer [ 33 ] (3D Inv ersion) 20.51 90.01 0.123 15.10 0.046 0.724 20.28 0.158 TRELLIS [ 67 ] 21.94 91.46 0.105 7.82 0.034 0.832 23.81 0.105 SAM3D [ 7 ] 22.42 91.45 0.111 8.01 0.033 0.835 23.85 0.101 Points-to-3D (Ours-VGGT Esti.) 22.55 92.09 0.088 7.37 0.024 0.881 24.53 0.085 Points-to-3D (Ours-P .C.Priors) 22.91 92.83 0.070 7.29 0.013 0.964 27.10 0.053 Figure 4. Single-object generation on T oys4K. For the explicit point cloud priors results, we use point cloud extracted strictly from the visible region of input images, whereas the “V GGT -estimated” results use point clouds inferred from the condition images by VGGT . T ransformer , allocating s = 25 steps for structural inpaint- ing and the remaining steps for refinement. For the other comparison methods, we use their of ficial code and settings to reproduce their results. W e reproduce the results of the 3D editing method V oxHammer [ 33 ] to represent the 3D in- version’ s results. Specifically , we use the structural voxels obtained from the same initial point clouds as in our method to define the “Unedited Region” in V oxHammer , and then apply their pipeline to obtain the final generated results. 4.2. Main Results Single-object generation. W e first present the results of single-object generation on T oys4K [ 54 ]. As shown in T ab . 1 , our method consistently outperforms existing ap- proaches across all ev aluation metrics, whether using exist- ing point cloud priors or V GGT [ 61 ]-predicted point cloud. Notably , in terms of geometric metrics, the results with point cloud priors achieve an F-score of 0.963, demonstrates our approach produces geometry closely approximates the ground-truth structure. The significant improvement in ge- ometry enhances the visual fidelity of the results. As illus- trated in Fig. 4 , our results better match the overall appear- ance of the ground-truth compared to other methods, and normal maps further highlight the superior geometric qual- ity achieved by our approach. Notably , while V oxHammer adopts the same 3D priors as ours, the image condition f ails to provide cues for the missing parts of the 3D priors, mak- ing 3D in version process struggles to complete the unknown 6 T able 2. Comparison on scene-level generation on 3D-FRONT dataset. Points-to-3D consistently outperforms state-of-the-art multi- object generation methods across all ev aluation metrics. Rendering Geometry Method PSNR ↑ SSIM (%) ↑ LPIPS ↓ DINO (%) ↓ CD ↓ F-Score ↑ PSNR-N ↑ LPIPS-N ↓ TRELLIS [ 67 ] 18.21 83.12 0.239 12.33 0.094 0.478 18.76 0.258 V oxHammer [ 33 ] (3D Inv ersion) 19.29 84.70 0.179 18.41 0.051 0.686 20.43 0.181 SceneGen [ 38 ] 18.32 83.35 0.231 14.43 0.086 0.485 19.08 0.229 MIDI [ 20 ] 19.23 85.59 0.166 14.25 0.075 0.513 20.82 0.164 Points-to-3D (Ours-VGGT Esti.) 20.52 86.51 0.152 8.90 0.040 0.743 20.97 0.160 Points-to-3D (Ours-P .C.Priors) 21.63 87.73 0.124 8.29 0.025 0.886 22.38 0.124 Figure 5. Scene-level generation on 3D-FRONT . The input point cloud priors setting is the same as in Fig. 4 . T able 3. Comparison on visible and overall geometry results on T oys4K. W e present the comparison between our method and TRELLIS. For each method, the upper row (O.) sho ws the ov erall results, while the lower ro w (V .) sho ws the visible region results. Methods CD ↓ F-Score ↑ PSNR-N ↑ LPIPS-N ↓ TRELLIS [ 67 ]-O. 0.034 0.832 23.81 0.105 TRELLIS [ 67 ]-V . 0.032 0.854 24.77 0.093 SAM3D [ 7 ]-O. 0.033 0.835 23.85 0.101 SAM3D [ 7 ]-V . 0.031 0.841 24.81 0.090 Points-to-3D -O. 0.013 0.964 27.10 0.053 Points-to-3D -V . 0.007 0.998 29.00 0.036 regions. SAM3D [ 7 ] highlights the value of 3D priors and also lev erages point maps, it integrates these priors indi- rectly through the attention mechanism of the flow trans- former block, which—as also stated in their paper—does not support explicit geometric control and exhibits limited ability to enforce precise geometric control compared to our approach. In contrast, our method le verages the trained model’ s inpainting capability to fully exploit the existing 3D priors and effecti vely infer the missing geometry . Scene-level generation. W e ev aluate our method on the scene-lev el generation dataset 3D-FR ONT [ 14 ]. As shown in T ab. 2 , incorporating point cloud priors provides substan- tial guidance for reconstructing overall geometry in com- plex scene scenarios, which support our method achieves significant improvements across all ev aluation metrics com- pared to other methods. The rendered images and nor- mal maps in Fig. 5 further demonstrate that our results better align with the ground-truth scene geometry . Unlike MIDI [ 20 ] or SceneGen [ 38 ], which implicitly utilize spa- tial information, our framework explicitly incorporates ge- ometric priors within the architecture, enabling more direct and effecti ve control over 3D geometry , of fering a promis- ing solution for generating complex 3D scenes. V isible region performance. W e also highlight the gen- eration results for the visible regions—i.e., the areas cov- ered by our point cloud priors. As shown in T ab . 3 , within these visible regions, our generated results achieve an F- Score of 0.998 and a chamfer distance of 0.007, indicating a strong alignment with the ground truth structure. This 7 T able 4. Ablation study . W e ev aluate the number of inpainting steps (Inp.) and refinement steps (Ref.) in our sampling strategy . Inp. Ref. CD ↓ F-Score ↑ PSNR-N ↑ LPIPS-N ↓ 50 0 0.014 0.960 25.88 0.065 40 10 0.013 0.962 26.49 0.059 30 20 0.013 0.963 26.89 0.056 25 25 0.013 0.963 27.10 0.053 20 30 0.013 0.962 27.03 0.055 10 40 0.014 0.961 26.72 0.061 demonstrates our structure generation pipeline effecti v ely preserves the information provided by the point cloud priors while producing high-quality overall geometry . Compared with others, both in the visible re gions and across the entire structure, our approach achiev es substantial improv ements in geometric fidelity , fulfilling the primary objectives of our work. SAM3D does not achiev e improv ed geometry ev en within the regions covered by the input pointmap (i.e., the visible areas in the table). While our method injects 3D pri- ors through a more direct and e xplicit mechanism, enabling effecti ve and reliable geometric controllability , providing current 3D generation frameworks a stronger opportunity to benefit from sensed 3D priors as well as future improve- ments in feed-forward point-map prediction methods. Figure 6. Ablation study . Allocating the full sampling to inpaint- ing (Inp.) results in geometric “holes” along the inpainting edge. 4.3. Ablation Studies V GGT point clouds estimation. When point cloud are not av ailable as input, our method can also lev erage the con- dition image to predict an initial point cloud using feed- forward methods like VGGT [ 61 ]. W e ev aluate the gen- eration results based on VGGT -estimated point cloud, as shown in T ab . 1 and T ab . 2 . Although the generation results with VGGT point cloud exhibit some gap compared to us- ing accurate point cloud priors—this is lar gely due to the in- herent prediction errors of VGGT . Nevertheless, compared to other existing approaches, it consistently achieves sub- stantial improvements in both geometric accuracy and vi- sual fidelity . These highlight the strong robustness and flex- ibility of our pipeline, with the absence of high-precision priors, our framework can still effecti vely utilize predicted Figure 7. Real-world examples on Pix3D. point cloud form image-only inputs to achiev e high-quality geometry generation. Staged sampling strategy . W e propose a staged sampling strategy in our pipeline, which lev erages a limited num- ber of last steps with noise to perform global optimization, effecti vely addressing the “holes” along inpainting bound- aries that are otherwise difficult to avoid. W e inv estigate the effect of refinement step allocation through an ablation study . In T ab . 4 , we present generation results under dif- ferent allocations of inpainting and refinement steps with the same total sampling steps. When the entire sampling process is allocated to inpainting, the geometric reconstruc- tion suffers from “holes” on inpainting edge, as further il- lustrated in Fig. 6 . By setting the sampling schedule to 25 inpainting steps followed by 25 refinement steps, the geo- metric metrics reach their best performance, and the pre- viously observed “holes” are effecti vely eliminated as in Fig. 6 , yielding the ov erall best generation results. 4.4. Real-world Input Examples W e further e v aluate the robustness of our method on real- world images from the Pix3D [ 55 ] dataset. As illustrated in Fig. 7 , our approach maintains robust performance on real image inputs, producing geometry that aligns more faithfully with the input images compared to the baseline method. 5. Conclusion W e introduce Points-to-3D, a diffusion-based framew ork that first leverages explicit 3D point cloud priors as input to enable geometry-controllable 3D asset and scene gen- eration. Built upon the latent 3D diffusion model TREL- LIS [ 67 ], we inv estigate a natural way to embed point cloud as initialization within the framework. After train- ing TRELLIS’ s structure generation network to acquire in- painting capabilities, we employ a staged sampling strat- egy—structural inpainting follo wed by boundary refine- ment—that reconstructs the global geometry while preserv- ing the input visible regions. Experiments demonstrate the benefits of explicitly embedding 3D priors, highlighting a promising direction for controllable and reliable 3D gener- ation in real-world applications. 8 References [1] Jonathan T Barron, Ben Mildenhall, Matthew T ancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Sriniv asan. Mip-nerf: A multiscale representation for anti-aliasing neu- ral radiance fields. In ICCV , pages 5855–5864, 2021. 2 [2] Jonathan T . Barron, Ben Mildenhall, Dor V erbin, Pratul P . Sriniv asan, and Peter Hedman. Zip-nerf: Anti-aliased grid- based neural radiance fields. ICCV , 2023. 2 [3] Eric R Chan, Connor Z Lin, Matthe w A Chan, K oki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay , Sameh Khamis, et al. Efficient geometry-aware 3d generati v e adversarial networks. In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 16123–16133, 2022. 2 [4] Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Y u, and Hao Su. MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo. In ICCV , pages 14124–14133, 2021. 2 [5] Anpei Chen, Zexiang Xu, Andreas Geiger , Jingyi Y u, and Hao Su. T ensorf: T ensorial radiance fields. In ECCV , pages 333–350, 2022. 2 [6] Xi Chen, Lianghua Huang, Y u Liu, Y ujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-le vel im- age customization. In Proceedings of the IEEE/CVF con- fer ence on computer vision and pattern r ecognition , pages 6593–6602, 2024. 3 [7] Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Ke vin J Liang, Alexander Sax, Hao T ang, W eiyao W ang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images. arXiv pr eprint arXiv:2511.16624 , 2025. 6 , 7 [8] Y uedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, T at-Jen Cham, and Jianfei Cai. Mvsplat: Ef ficient 3d gaussian splatting from sparse multi-view images. In ECCV , pages 370–386, 2024. 2 [9] Y uedong Chen, Chuanxia Zheng, Haofei Xu, Bohan Zhuang, Andrea V edaldi, T at-Jen Cham, and Jianfei Cai. Mvsplat360: Feed-forward 360 scene synthesis from sparse views. 2024. 2 [10] Y en-Chi Cheng, Hsin-Y ing Lee, Sergey Tulyak ov , Alexan- der G Schwing, and Liang-Y an Gui. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. In Pr o- ceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pages 4456–4465, 2023. 3 [11] Ruihang Chu, Enze Xie, Shentong Mo, Zhenguo Li, Matthias Nießner, Chi-W ing Fu, and Jiaya Jia. Dif fcomplete: Diffusion-based generative 3d shape completion. Advances in Neural Information Pr ocessing Systems , 36, 2024. 3 [12] Jasmine Collins, Shubham Goel, K enan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, T omas F Y ago V icente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object un- derstanding. In CVPR , 2022. 5 , 1 [13] Kangle Deng, Andrew Liu, Jun-Y an Zhu, and Dev a Ra- manan. Depth-supervised NeRF: Fewer views and faster training for free. In Pr oceedings of the IEEE/CVF Confer- ence on Computer V ision and P attern Recognition (CVPR) , 2022. 3 [14] Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming W ang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Bin- qiang Zhao, et al. 3d-front: 3d furnished rooms with layouts and semantics. In ICCV , 2021. 2 , 5 , 7 , 1 [15] Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng T ao. 3d-future: 3d fur- niture shape with texture. IJCV , 129:3313–3337, 2021. 5 , 1 [16] Juan D Galvis, Xingxing Zuo, Simon Schaefer, and Stefan Leutengger . Sc-diff: 3d shape completion with latent diffu- sion models. arXiv pr eprint arXiv:2403.12470 , 2024. 3 [17] Jun Gao, Tianchang Shen, Zian W ang, W enzheng Chen, Kangxue Y in, Daiqing Li, Or Litany , Zan Gojcic, and Sanja Fidler . Get3d: A generative model of high quality 3d tex- tured shapes learned from images. Advances In Neural In- formation Pr ocessing Systems , 35:31841–31854, 2022. 2 [18] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. Advances in neur al information pr ocessing systems , 33:6840–6851, 2020. 2 [19] Binbin Huang, Zehao Y u, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accu- rate radiance fields. In SIGGRAPH 2024 Confer ence P apers , 2024. 2 [20] Zehuan Huang, Y uan-Chen Guo, Xingqiao An, Y unhan Y ang, Y angguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Y an-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. In Pr oceedings of the Computer V ision and P attern Recognition Conference , pages 23646–23657, 2025. 2 , 7 [21] Hanwen Jiang, Qixing Huang, and Georgios Pavlakos. Real3d: Scaling up large reconstruction models with real- world images. 2025. 2 , 6 [22] Y ingwenqi Jiang, Jiadong T u, Y uan Liu, Xifeng Gao, Xiaox- iao Long, W enping W ang, and Y uexin Ma. Gaussianshader: 3d gaussian splatting with shading functions for reflectiv e surfaces. In CVPR , pages 5322–5332, 2024. 2 [23] Xuan Ju, Xian Liu, Xintao W ang, Y uxuan Bian, Y ing Shan, and Qiang Xu. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch dif fusion. In Eur opean Confer ence on Computer V ision , pages 150–168. Springer , 2024. 3 [24] Y oni Kasten, Ohad Rahamim, and Gal Chechik. Point cloud completion with pretrained text-to-image diffusion models. Advances in Neural Information Pr ocessing Systems , 36, 2024. 3 [25] Bernhard K erbl, Georgios Kopanas, Thomas Leimk ¨ uhler , and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. A CM TOG , 42(4), 2023. 2 [26] Justin Kerr , Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew T ancik. LERF: Language embed- ded radiance fields. In ICCV , pages 19729–19739, 2023. 2 [27] Mukul Khanna, Y ongsen Mao, Hanxiao Jiang, Sanjay Haresh, Brennan Shacklett, Dhruv Batra, Alexander Clegg, Eric Undersander, Angel X Chang, and Manolis Savv a. Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeof fs for objectgoal naviga- tion. In CVPR , 2024. 5 , 1 9 [28] Andreas Kurz, Thomas Neff, Zhaoyang Lv , Michael Zollh ¨ ofer , and Markus Steinberger . AdaNeRF: Adaptiv e sampling for real-time rendering of neural radiance fields. In ECCV , pages 254–270. Springer , 2022. 2 [29] Zeqiang Lai, Y unfei Zhao, Zibo Zhao, Haolin Liu, Qingxi- ang Lin, Jingwei Huang, Chunchao Guo, and Xiangyu Y ue. Lattice: Democratize high-fidelity 3d generation at scale, 2025. 2 [30] Y ushi Lan, Shangchen Zhou, Zhaoyang L yu, Fangzhou Hong, Shuai Y ang, Bo Dai, Xingang Pan, and Chen Change Loy . Gaussiananything: Interactiv e point cloud latent diffu- sion for 3d generation. In ICLR , 2025. 2 , 6 [31] V incent Leroy , Y ohann Cabon, and J ´ er ˆ ome Revaud. Ground- ing image matching in 3d with mast3r . In ECCV , 2024. 2 [32] Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, and Lin Gu. Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normaliza- tion. In CVPR , 2024. 2 [33] Lin Li, Zehuan Huang, Haoran Feng, Gengxiong Zhuang, Rui Chen, Chunchao Guo, and Lu Sheng. V oxhammer: T raining-free precise and coherent 3d editing in native 3d space. arXiv pr eprint arXiv:2508.19247 , 2025. 2 , 6 , 7 [34] Y angguang Li, Zi-Xin Zou, Zexiang Liu, Dehu W ang, Y uan Liang, Zhipeng Y u, Xingchao Liu, Y uan-Chen Guo, Ding Liang, W anli Ouyang, et al. T riposg: High-fidelity 3d shape synthesis using large-scale rectified flow models. arXiv pr eprint arXiv:2502.06608 , 2025. 2 [35] Y aron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generati ve mod- eling. arXiv pr eprint arXiv:2210.02747 , 2022. 2 [36] Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue W ei, Hansheng Chen, Chong Zeng, Ji- ayuan Gu, and Hao Su. One-2-3-45++: Fast single im- age to 3d objects with consistent multi-view generation and 3d diffusion. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pages 10072– 10083, 2024. 2 [37] Chenlin Meng, Y utong He, Y ang Song, Jiaming Song, Jia- jun W u, Jun-Y an Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equa- tions. arXiv pr eprint arXiv:2108.01073 , 2021. 3 [38] Y anxu Meng, Haoning W u, Y a Zhang, and W eidi Xie. Sce- negen: Single-image 3d scene generation in one feedforward pass. arXiv pr eprint arXiv:2508.15769 , 2025. 2 , 7 [39] Ben Mildenhall, Pratul P . Sriniv asan, Matthew T ancik, Jonathan T . Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. In ECCV , 2020. 2 [40] Thomas Neff, Pascal Stadlbauer , Mathias Parger , Andreas Kurz, Joerg H Mueller , Chakravarty R Alla Chaitanya, An- ton Kaplan yan, and Markus Steinberger . DONeRF: T owards real-time rendering of compact neural radiance fields using depth oracle networks. In Comput. Graph. F orum , pages 45– 59, 2021. 2 [41] Maxime Oquab, Timoth ´ ee Darcet, Th ´ eo Moutakanni, Huy V o, Marc Szafraniec, V asil Khalido v , Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby , et al. Dinov2: Learning rob ust visual features without supervision. 2024. 5 [42] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Ste ven Lo ve grov e. Deepsdf: Learning con- tinuous signed distance functions for shape representation. In The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2019. 2 [43] Dustin Podell, Zion English, Kyle Lacey , Andreas Blattmann, Tim Dockhorn, Jonas M ¨ uller , Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 , 2023. 2 [44] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. 2021. 5 [45] Barbara Roessle, Jonathan T Barron, Ben Mildenhall, Pratul P Srinivasan, and Matthias Nießner . Dense depth pri- ors for neural radiance fields from sparse input views. In CVPR , pages 12892–12901, 2022. 3 [46] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨ orn Ommer . High-resolution image synthesis with latent diffusion models. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 10684–10695, 2022. 2 [47] Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. In CVPR , pages 4104–4113, 2016. 2 [48] Katja Schwarz, Y iyi Liao, Michael Niemeyer , and Andreas Geiger . Graf: Generativ e radiance fields for 3d-aware im- age synthesis. Advances in neural information pr ocessing systems , 33:20154–20166, 2020. 2 [49] Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xin yue W ei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: a single image to consistent multi-view dif- fusion base model. arXiv preprint , 2023. 2 [50] Shaoshuai Shi, Xiaogang W ang, and Hongsheng Li. Pointr- cnn: 3d object proposal generation and detection from point cloud. In Pr oceedings of the IEEE/CVF Confer ence on Com- puter V ision and P attern Recognition (CVPR) , 2019. 3 [51] Y ichun Shi, Peng W ang, Jianglong Y e, Mai Long, Kejie Li, and Xiao Y ang. Mvdream: Multi-view dif fusion for 3d gen- eration. arXiv pr eprint arXiv:2308.16512 , 2023. 2 [52] V incent Sitzmann, Julien Martel, Ale xander Bergman, David Lindell, and Gordon W etzstein. Implicit neural representa- tions with periodic activ ation functions. Advances in neural information pr ocessing systems , 33:7462–7473, 2020. 2 [53] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 , 2020. 2 [54] Stefan Stojano v , Anh Thai, and James M. Rehg. Using shape to categorize: Low-shot learning with an explicit shape bias. 2021. 2 , 5 , 6 , 1 , 3 [55] Xingyuan Sun, Jiajun W u, Xiuming Zhang, Zhoutong Zhang, Chengkai Zhang, T ianfan Xue, Joshua B T enenbaum, 10 and W illiam T Freeman. Pix3d: Dataset and methods for single-image 3d shape modeling. In CVPR , 2018. 5 , 8 [56] Stanislaw Szymanowicz, Jason Y . Zhang, Pratul Sriniv asan, Ruiqi Gao, Arthur Brussee, Aleksander Holynski, Ricardo Martin-Brualla, Jonathan T . Barron, and Philipp Henzler . Bolt3d: Generating 3d scenes in seconds. In Pr oceedings of the IEEE/CVF International Conference on Computer V i- sion (ICCV) , pages 24846–24857, 2025. 2 [57] Jiaxiang T ang, Zhaoxi Chen, Xiaokang Chen, T engfei W ang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view g aussian model for high-resolution 3d content creation. In Eur opean Confer ence on Computer V ision , pages 1–18. Springer, 2024. 2 , 6 , 3 [58] Zhenggang T ang, Y uchen Fan, Dilin W ang, Hongyu Xu, Rakesh Ranjan, Ale xander Schwing, and Zhicheng Y an. Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds. In Proceedings of the Computer V i- sion and P attern Recognition Conference , pages 5283–5293, 2025. 2 [59] T encent Hunyuan3D T eam. Hunyuan3d 1.0: A unified framew ork for text-to-3d and image-to-3d generation, 2024. 2 [60] T eam W an, Ang W ang, Baole Ai, Bin W en, Chaojie Mao, Chen-W ei Xie, Di Chen, Feiwu Y u, Haiming Zhao, Jianx- iao Y ang, et al. W an: Open and advanced large-scale video generativ e models. arXiv pr eprint arXiv:2503.20314 , 2025. 2 [61] Jianyuan W ang, Minghao Chen, Nikita Karae v , Andrea V edaldi, Christian Rupprecht, and Da vid Novotny . Vggt: V i- sual geometry grounded transformer . In CVPR , 2025. 2 , 3 , 6 , 8 , 1 [62] Shuzhe W ang, V incent Leroy , Y ohann Cabon, Boris Chidlovskii, and Jerome Rev aud. Dust3r: Geometric 3d vi- sion made easy . In CVPR , 2024. 2 [63] Tianhao W u, Chuanxia Zheng, Frank Guan, Andrea V edaldi, and T at-Jen Cham. Amodal3r: Amodal 3d reconstruction from occluded 2d images. arXiv pr eprint arXiv:2503.13439 , 2025. 2 [64] Xiaoyang W u, Li Jiang, Peng-Shuai W ang, Zhijian Liu, Xi- hui Liu, Y u Qiao, W anli Ouyang, T ong He, and Hengshuang Zhao. Point transformer v3: Simpler faster stronger . In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 4840–4851, 2024. 3 [65] Jiatong Xia and Lingqiao Liu. T raining-free instance-aware 3d scene reconstruction and diffusion-based view synthesis from sparse images. In Pr oceedings of the SIGGRAPH Asia 2025 Conference P apers . Association for Computing Ma- chinery , 2025. 2 [66] Jiatong Xia, Libo Sun, and Lingqiao Liu. Enhancing close- up novel vie w synthesis via pseudo-labeling. In Proceed- ings of the AAAI Confer ence on Artificial Intelligence , pages 8567–8574, 2025. 2 [67] Jianfeng Xiang, Zelong Lv , Sicheng Xu, Y u Deng, Ruicheng W ang, Bowen Zhang, Dong Chen, Xin T ong, and Jiaolong Y ang. Structured 3d latents for scalable and v ersatile 3d gen- eration. In Pr oceedings of the Computer V ision and P attern Recognition Confer ence , pages 21469–21480, 2025. 2 , 3 , 5 , 6 , 7 , 8 , 1 [68] Jianing Y ang, Alexander Sax, K evin J Liang, Mikael Henaff, Hao T ang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: T owards 3d reconstruction of 1000+ images in one forward pass. In Proceedings of the Computer V ision and P attern Recognition Conference , pages 21924–21935, 2025. 2 [69] Y unhan Y ang, Y ufan Zhou, Y uan-Chen Guo, Zi-Xin Zou, Y ukun Huang, Y ing-T ian Liu, Hao Xu, Ding Liang, Y an- Pei Cao, and Xihui Liu. Omnipart: Part-a ware 3d genera- tion with semantic decoupling and structural cohesion. arXiv pr eprint arXiv:2507.06165 , 2025. 2 [70] Kaixin Y ao, Longwen Zhang, Xinhao Y an, Y an Zeng, Qix- uan Zhang, Lan Xu, W ei Y ang, Jiayuan Gu, and Jingyi Y u. Cast: Component-aligned 3d scene reconstruction from an rgb image. A CM Tr ansactions on Graphics (TOG) , 44(4): 1–19, 2025. 2 [71] Y ao Y ao, Zixin Luo, Shiwei Li, T ian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-vie w stereo. In Pr oceedings of the Eur opean conference on computer vi- sion (ECCV) , pages 767–783, 2018. 2 [72] Y ao Y ao, Zixin Luo, Shiwei Li, T ianwei Shen, T ian Fang, and Long Quan. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 5525–5534, 2019. 2 [73] Xin Y u, T ianyu W ang, Soo Y e Kim, P aul Guerrero, Xi Chen, Qing Liu, Zhe Lin, and Xiaojuan Qi. Objectmov er: Genera- tiv e object mo vement with video prior . In Pr oceedings of the Computer V ision and P attern Recognition Conference , pages 17682–17691, 2025. 3 [74] Zehao Y u and Shenghua Gao. Fast-mvsnet: Sparse-to- dense multi-vie w stereo with learned propagation and gauss- newton refinement. In Pr oceedings of the IEEE/CVF con- fer ence on computer vision and pattern r ecognition , pages 1949–1958, 2020. 2 [75] Zehao Y u, Anpei Chen, Binbin Huang, T orsten Sattler , and Andreas Geiger . Mip-splatting: Alias-free 3d g aussian splat- ting. In CVPR , pages 19447–19456, 2024. 2 [76] Jingyang Zhang, Y ao Y ao, and Long Quan. Learning signed distance field for multi-vie w surface reconstruction. Interna- tional Confer ence on Computer V ision (ICCV) , 2021. 2 [77] Junyi Zhang, Charles Herrmann, Junhwa Hur , V arun Jam- pani, T rev or Darrell, F orrester Cole, Deqing Sun, and Ming- Hsuan Y ang. Monst3r: A simple approach for estimating geometry in the presence of motion. In ICLR , 2025. 2 [78] Longwen Zhang, Ziyu W ang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, W ei Y ang, Lan Xu, and Jingyi Y u. Clay: A controllable large-scale generative model for creat- ing high-quality 3d assets. A CM T ransactions on Graphics (TOG) , 43(4):1–20, 2024. 2 [79] Richard Zhang, Phillip Isola, Alex ei A Efros, Eli Shechtman, and Oli ver W ang. The unreasonable ef fectiv eness of deep features as a perceptual metric. In CVPR , 2018. 5 , 1 [80] Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS T orr, and Vladlen Koltun. Point transformer . In Proceedings of the IEEE/CVF international conference on computer vision , pages 16259–16268, 2021. 3 11 A. Experimental Details Our training dataset consists of object collections from the 3D-FUTURE [ 15 ] (9,472 objects), HSSD [ 27 ] (6,670 ob- jects), and ABO [ 12 ] (4,485 objects) datasets. For each ob- ject, we render the image of the T = 24 views, together with the corresponding depth map, and extract the visible point cloud for each view by enforcing depth consistency with a threshold τ = 0.05 times the depth range (maximum minus minimum depth) in that view . The visible point cloud is then con verted into an initial SS latent, which is paired with the original SS latent as ground truth to train the sparse structure flow transformer for inpainting. For ev aluation, we use randomly sampled subset of the T oys4K [ 54 ] (500 objects) dataset and 3D-FR ONT [ 14 ] (500 scenes) dataset. F or each test object or scene, we render 8 views using cameras with yaw angles (0 ◦ , 45 ◦ , 90 ◦ , 135 ◦ , 180 ◦ , 225 ◦ , 270 ◦ , 315 ◦ ) and a fix ed pitch angle of 30 ◦ . The camera is positioned at a ra- dius of 1.8 from the object center . For PSNR, SSIM, and LPIPS [ 79 ], we directly compare the rendered images of generated results with the rendered images of the ground- truth objects and report the average scores. For the DINO- based similarity metric, we report the a verage discrepancy between the rendered images of the generated and ground- truth assets, quantified as (1 − S DINO ) , where S DINO denotes the DINO similarity score. For the normal-based metric, we render normal maps from the 8 views and compute the av erage score between the normal maps of the generated and ground-truth assets. For Chamfer Distance (CD) and F-score, we normalize all the objects within the range (-0.5, 0.5) and set the F-score distance threshold to 0.05. Dur- ing testing, for the point cloud priors input, we align the point cloud to the orientation of the corresponding ground- truth object to ensure that the generation conditioned on this point cloud can be directly ev aluated. B. More Results W e provide additional qualitativ e e xamples and e xperimen- tal results to further demonstrate the performance of our method. B.1. Multi-V iews Input Generation Because our flow-based model performs iterativ e denoising, it can directly incorporate multi-view reference images as conditioning inputs at different denoising steps. For VGGT - estimated point clouds, multi-vie w inputs produce more ac- curate predictions; and greater point cloud coverage con- sistently leads to better reconstruction. W e further ev aluate the case of using three input views on T oys4K [ 54 ] dataset. Specifically , we first feed the multi-view reference images into VGGT [ 61 ] to obtain a more complete predicted point cloud. As shown in T ab. 5 , while multi-vie w input natu- Figure 8. Generation results with 3 input views on T oys4K. The first column of our results uses sampled point-cloud priors ex- tracted from the visible regions of the three i nput images, whereas the “VGGT -estimated” results rely on point clouds inferred from the input images by VGGT . rally improves the baseline TRELLIS [ 67 ] geometry , our method achieves substantially higher structural accuracy , consistently maintaining controllable geometry . For accu- rate point cloud priors, we extract the visible sampled sur- face point cloud from the three vie ws using depth consis- tency and use it as the input prior . With these priors, our method produces reconstructions that are very close to the ground truth. Fig. 8 further shows the visualization com- parisons. These results demonstrate the robustness and ef- fectiv eness of our method across dif ferent numbers of input images. B.2. Point Cloud Priors Examples In Fig. 9 , we illustrate examples of the two types of point cloud priors considered in this work, which correspond to the two most common practical scenarios: (1) partial point clouds directly captured by hardware sensors (e.g., LiD AR on an iPhone), and (2) point cloud estimated from input images via feed-forward point-map prediction (e.g., VGGT [ 61 ]). This experimental setup enables a compre- hensiv e ev aluation of our method over a broader spectrum of practical cases. As shown in Fig. 9 , these visible-region priors impose reliable geometric constraints that steer our model tow ard controllable and faithful 3D generation. B.3. More Image-to-3D Examples W e provide additional visualization results for image-to-3D generation in Fig. 10 , demonstrating the effecti veness of our method. Experiments highlight that our method addresses a major limitation of existing 3D generation framew orks that struggle to fully incorporate av ailable 3D information, and 1 Imag e Samp le d Poin t C lou d VG GT Estima ted Point Cloud I np ut Gen e rat e d Point Cloud I np ut Gen e rat e d Figure 9. Input point cloud priors examples. W e show the observable point cloud priors examples for the two input modes with single- view input in this paper , along with their corresponding generation results. Figure 10. More image-to-3D examples. More single-image to 3D generation visualization results on T oy4K (row 1-3) and 3D-Front dataset (row 4-6). 2 T able 5. Comparison on single-object generation with 3 views input on T oy4K dataset. Rendering Geometry Method PSNR ↑ SSIM (%) ↑ LPIPS ↓ DINO (%) ↓ CD ↓ F-Score ↑ PSNR-N ↑ LPIPS-N ↓ TRELLIS [ 67 ] 23.19 92.63 0.075 5.79 0.025 0.904 26.22 0.066 Points-to-3D (Ours-VGGT Esti.) 23.44 93.21 0.057 5.58 0.015 0.971 28.35 0.035 Points-to-3D (Ours-P .C.Priors) 23.98 94.02 0.050 5.26 0.009 0.988 30.45 0.028 Figure 11. More real-world image generation examples. Figure 12. T ext-to-3D generation examples. achiev es substantial improvements in both single-object and scene-lev el generation. T able 6. Comparison of text-to-3D generation on T oys4K. Methods CLIP ↑ CD ↓ F-Score ↑ PSNR-N ↑ LPIPS-N ↓ LGM [ 57 ] 0.247 0.086 0.412 19.55 0.223 TRELLIS [ 67 ] 0.298 0.047 0.639 21.25 0.159 Points-to-3D 0.299 0.022 0.892 24.75 0.094 B.4. More Real-world and T ext-to-3D Examples W e showcase more results in real-world image generation in Fig. 11 , demonstrating the robustness of our method in prac- tical scenarios. Moreover , we also assess our model under text-to-3D settings on T oys4K [ 54 ], where text prompts and point cloud priors are pro vided as input. As sho wn in T ab . 6 and Fig. 12 , our method successfully generates geometries that are semantically consistent with the input prompts and structurally well-controlled by the giv en point cloud priors. 3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment