Benchmarking PDF Parsers on Table Extraction with LLM-based Semantic Evaluation
Reliably extracting tables from PDFs is essential for large-scale scientific data mining and knowledge base construction, yet existing evaluation approaches rely on rule-based metrics that fail to capture semantic equivalence of table content. We pre…
Authors: Pius Horn, Janis Keuper
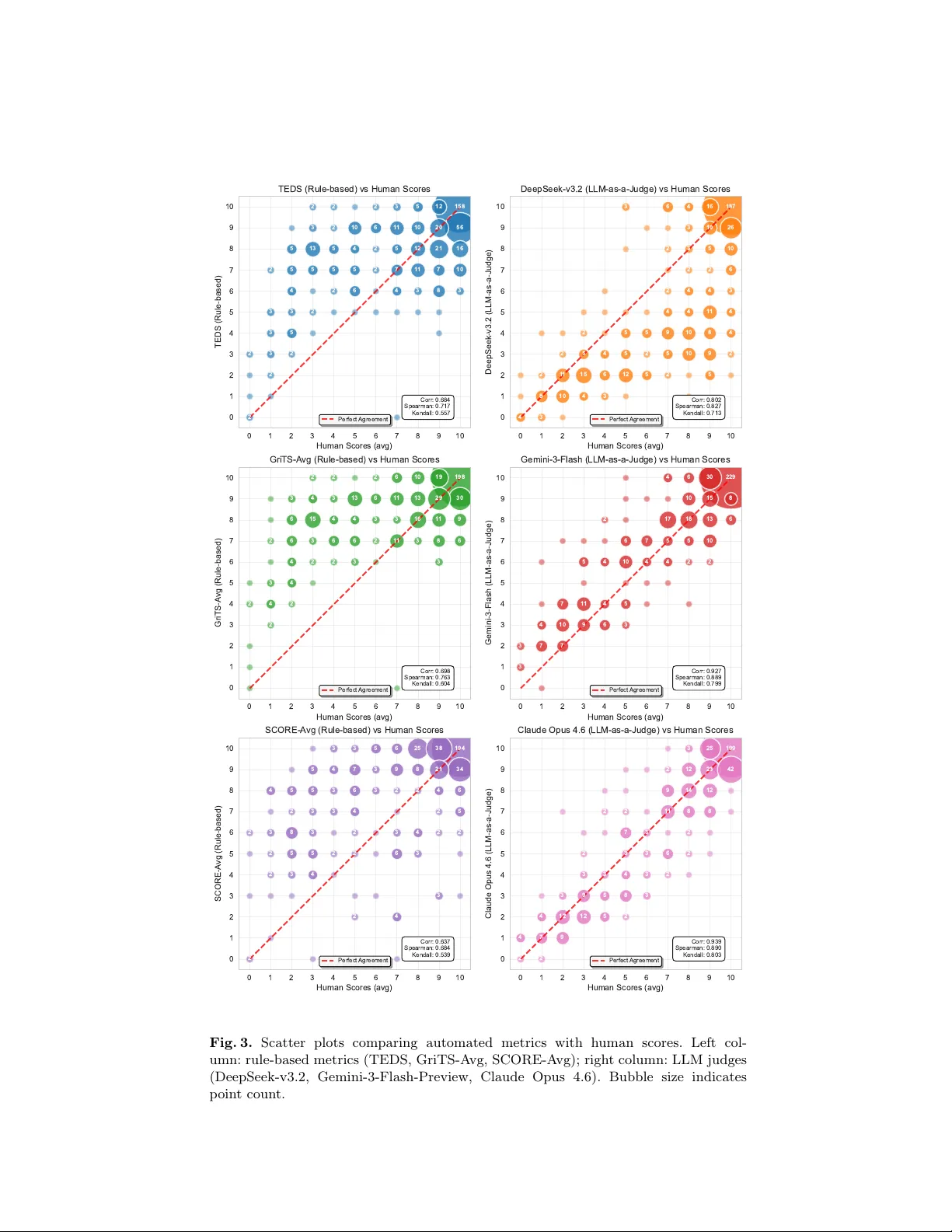
Benc hmarking PDF P arsers on T able Extraction with LLM-based Seman tic Ev aluation Pius Horn 1 [0009 − 0004 − 1911 − 1138] and Janis Keup er 1 , 2 [0000 − 0002 − 1327 − 1243] 1 Institute f or Mac hine Learning and Analytics (IMLA), Offen burg Universit y , Offen burg, German y pius.horn@hs-offenburg.de 2 Univ ersity of Mannheim, Mannheim, German y Abstract. Reliably extracting tables from PDF s is essential for large- scale scien tific data mining and knowledge base construction, y et existing ev aluation approac hes rely on rule-based metrics that fail to capture se- man tic equiv alence of table conten t. W e present a benchmarking frame- w ork based on synthetically generated PDF s with precise LaT eX ground truth, using tables sourced from arXiv to ensure realistic complexit y and div ersity . As our central methodological contribution, w e apply LLM-as- a-judge for seman tic table ev aluation, in tegrated into a matc hing pip eline that accommo dates inconsistencies in parser outputs. Through a human v alidation study comprising ov er 1,500 quality judgments on extracted table pairs, we show that LLM-based ev aluation achiev es substantially higher correlation with human judgment (Pearson r=0.93) compared to T ree Edit Distance-based Similarit y (TEDS, r=0.68) and Grid T able Similarit y (GriTS, r=0.70). Ev aluating 21 contemporary PDF parsers across 100 synthetic do cumen ts containing 451 tables reveals significant p erformance disparities. Our results offer practical guidance for selecting parsers for tabular data extraction and establish a reproducible, scalable ev aluation metho dology for this critical task. Keyw ords: PDF Document Parsing · T able Extraction · LLM-based Ev aluation · OCR Benchmarking. 1 In tro duction Muc h of the structured knowledge in scientific publications, financial rep orts, and tec hnical documents is organized in tables. As do cumen t parsing b ecomes central to language mo del pretraining, retriev al-augmen ted generation, and scien tific data mining [43,31], the abilit y to accurately and reliably extract tabular data from PDF s has b ecome increasingly imp ortan t. The landscap e of PDF do cumen t parsing has evolv ed rapidly , with approaches ranging from rule-based extraction to ols and sp ecialized OCR mo dels to end-to- end vision-language mo dels [33,1]. Existing b enc hmarks ev aluate table extrac- tion at scales from cropp ed table images [46,36] to full document-lev el assess- men ts [28,27], and the accompanying metrics hav e progressed from cell adjacency relations [7] to tree-based [46] and grid-based [37] comparison (see Section 2.2). 2 P . Horn and J. Keup er Y et all of these approaches rely on structural matching and surface-level string comparison, unable to assess whether the actual information conv eyed by a table has b een correctly preserv ed. Consequen tly , a parser that pro duces a structurally differen t but semantically equiv alent represen tation ma y b e p enalized unfairly , while one that preserves structure but corrupts cell con tent may receiv e an in- flated score. The LLM-as-a-judge paradigm [44] offers a promising solution, having demon- strated effectiv eness for ev aluating complex outputs where traditional metrics fall short [14]. F or table assessmen t, where conten t correctness and structural fidelit y must b e jointly ev aluated, LLM-based ev aluation can capture semantic n uances that surface-level sim ilar ity metrics miss. W e com bine this ev aluation approach with a b enc hmarking framework that em b eds real arXiv tables into syn thetic PDF s, pro viding exact LaT eX ground truth without man ual annotation. T ogether, these contributions address b oth the metric and b enc hmark gaps: – W e pioneer LLM-as-a-judge for semantic table ev aluation, demonstrating substan tially higher agreement with human judgmen t than rule-based met- rics. – W e provide 1,554 h uman ratings on 518 table pairs, enabling meta-ev aluation of existing and future table extraction metrics against human judgment. – W e in tro duce a b enc hmarking framework that embeds real tables from arXiv in to syn thetic PDF s, combining realistic table div ersity with exact LaT eX ground truth, and develop an LLM-based matching pip eline that reliably aligns eac h parsed table to its ground truth despite v ariations in parser output formats. – W e establish a public leaderboard ev aluating 21 contemporary document parsers across 100 syn thetic pages containing 451 tables, revealing significant p erformance disparities and providing practical guidance for practitioners. 2 Related W ork 2.1 PDF Parsing Benchmarks Existing b enc hmarks for table extraction fall into t wo broad categories: table r e c o gnition datasets that op erate on cropped table images, and do cument-level b enchmarks that ev aluate table extraction in the con text of full pages. T able recognition datasets hav e driven progress in table structure recog- nition from isolated images. Large-scale datasets such as PubT abNet [46] (568K images from PubMed Central), FinT abNet [45] (113K tables from financial re- p orts), T ableBank [15] (417K tables via weak sup ervision), PubT ables-1M [36] (nearly one million scien tific tables), and SynthT abNet [26] (600K synthetic ta- bles with con trolled structure and style v ariation) provide extensive training and ev aluation resources, while SciTSR [4] contributes 15K tables with structure la- b els derived from LaT eX sources. These datasets also gav e rise to the dominan t ev aluation metrics: PubT abNet introduced TEDS, and GriTS [37] later prop osed Benc hmarking PDF Parsers on T able Extraction 3 grid-lev el ev aluation as an alternativ e. The ICDAR 2021 comp etition [11] com- plemen ted these efforts by targeting table image to LaT eX conv ersion, a task recen tly adv anced by reinforcement learning ov er m ultimo dal language mod- els [20]. While instrumental for adv ancing table recognition, these datasets pro- vide cropp ed table images rather than full do cumen ts, making them unsuitable for b enc hmarking end-to-end PDF parsing pip elines where tables must first b e detected within a page of mixed con tent. Do cumen t-lev el b enc hmarks ev aluate table extraction from complete pages where tables app ear alongside text and figures. The OmniAI OCR Bench- mark [27] ev aluates ov erall docume n t extraction accuracy but lacks table-sp ecific metrics, while olmOCR-Bench [31] includes 1,020 table-sp ecific unit tests across 1,402 PDF s but fo cuses on cell-level pass/fail v erification rather than holistic table qualit y assessment. OmniDocBench [28] (1,355 pages) and READo c [19] (3,576 do cumen ts, 15 parsing systems) go further by including explicit table ev aluation, yet b oth rely on TEDS and edit distance metrics that capture struc- tural similarit y without assessing semantic equiv alence. PubT ables-v2 [35] pro- vides the first large-scale b enc hmark for full-page and multi-page table extraction (467K single pages with 548K tables and 9,172 multi-page do cumen ts), extending PubT ables-1M from cropp ed images to do cumen t-level ev aluation using GriTS. The ICDAR table comp etitions [7,6] established early document-lev el b enc h- marks on small collections using cell adjacency relations, and SCORE [16] more recen tly addresses ev aluation metho dology by prop osing interpretation-agnostic metrics that handle legitimate structural am biguity , though still operating at the structural rather than semantic lev el. Soric et al. [38] b enc hmark nine extraction metho ds across three do cumen t collections totaling approximately 37K pages, relying on TEDS and GriTS for ev aluation. 2.2 T able Extraction Ev aluation Metrics Ev aluating extracted tables against ground truth requires metrics that join tly assess structural fidelit y and con tent correctness. Directed adjacency relations (D AR) [7], introduced in the ICDAR 2013 T able Comp etition as the first metric designed sp ecifically for table structure ev aluation, captured local cell neighbor- ho ods but could not represen t global table structure, motiv ating the tree-lev el and grid-lev el approaches that follo wed. T ree Edit Distance-based Similarity (TEDS). TEDS [46], introduced alongside PubT abNet, has b ecome the de facto standard for table recognition ev aluation. Both predicted and ground-truth tables are represen ted as HTML trees whose leaf no des ( ) carry colspan, ro wspan, and c haracter-level tok- enized conten t. The tree edit distance is computed with a unit cost for struc- tural mismatches and normalized Lev enshtein distance for cell conten t, yielding TEDS = 1 − d / max( | T pred | , | T gt | ) , where d is the edit distance and | T | the n umber of no des in eac h tree. Since b oth structure and con tent are compared at the character level, the score is sensitiv e to markup choices (e.g., vs. , or vs. ) and surface-lev el string differences. 4 P . Horn and J. Keup er Grid T able Similarity (GriTS). GriTS [37] addresses the HTML sensi- tivit y of TEDS by operating directly on the table’s 2D grid representation, using factored ro w and column alignment via dynamic programming. It defines sep- arate metrics for structural top ology ( GriTS T op , via intersection-o v er-union on relativ e span grids) and conten t ( GriTS Con , via longest common subsequence similarit y), each yielding precision, recall, and F-score. By av oiding the tree represen tation, GriTS treats ro ws and columns symmetrically and is robust to markup v ariations, though conten t comparison remains string-based. SCORE. Although SCORE [16] presen ts itself as a “semantic ev aluation framew ork” addressing the format rigidity of TEDS and GriTS, it normalizes tables into format-agnostic cell tuples and ev aluates index ac cur acy by chec k- ing whether cells o ccup y correct grid p ositions and c ontent ac cur acy via edit distance on cell text, with tolerance for small ro w/column offsets. This av oids p enalizing markup differences across output formats, though the structural toler- ance may also mask genuine errors, and the underlying cell comparison remains string-based, lea ving true semantic equiv alence (such as notational v arian ts or equiv alen t v alue formats) unaddressed. T ext-based metrics such as Lev enshtein edit distance [13] or BLEU [29] op erate at a strictly lo wer level of granularit y: while the metrics ab o v e preserve cell-lev el structure, text-based approaches flatten the table into a token sequence, making scores dep enden t on serialization order and unable to distinguish struc- tural from con tent errors. While LLM-based ev aluation has recently sho wn promise for formula extrac- tion from PDF s [10], substan tially outperforming text-based, tree-based, and image-based metrics in correlation with human judgment, no comparable study exists for table extraction. Our w ork addresses both gaps: on the benchmark side, we use syn thetic PDF s whose LaT eX source serves as exact ground truth, eliminating the need for man ual annotation. On the metric side, w e apply LLM-as-a-judge for semantic table ev aluation. T ogether with a broad comparison of 21 contemporary parsers, this yields a repro ducible ev aluation framework that w e v alidate against human judgmen t in Section 4. 3 Metho dology Our b enc hmarking metho dology rests on tw o key design decisions: (1) using real tables extracted from arXiv to ensure realistic diversit y , and (2) em b edding them in to synthetically generated PDF s to obtain exact ground truth without manual annotation. This section describ es the resulting b enc hmark construction and the matc hing pip eline that aligns parser outputs to ground truth tables. 3.1 Benc hmark Dataset: Synthetic PDF s with Ground T ruth W e collect LaT eX table sources from arXiv papers published in December 2025 to a void o verlap with established datasets [46,36] that ma y already b e part Benc hmarking PDF Parsers on T able Extraction 5 of parser training data. All top-lev el tabular / tabular* en vironments are ex- tracted, cleaned of non-conten t commands (citations, cross-references), and com- piled standalone to v erify v alidit y and record rendered dimensions; inv alid tables are discarded. Each v alid table is classified by structural complexit y using an LLM-based classifier: simple (regular grid), mo der ate (limited cell merging), or c omplex (multi-dimensional merging, nested structures). Eac h b enc hmark page is generated by sampling a random lay out configu- ration (do cumen t class, font family , page margins, font size, line spacing, and single- or tw o-column lay out) and iteratively appending con tent blo c ks, either filler text or tables from the extracted p ool. The do cumen t is recompiled with pdflatex after eac h addition; blo c ks that trigger ov erflow or typesetting warn- ings are discarded, and the pro cess terminates when no further con ten t fits. T ables are pre-filtered b y their recorded dimensions against the remaining page space and scaled to column width via adjustbox when mo derately ov ersized. T o ensure deterministic p ositioning, tables are placed as non-floating centered blo c ks, a voiding the unpredictable reordering of LaT eX float en vironments that w ould complicate ground truth alignment. Figure 1 giv es an ov erview of the pip eline. Fig. 1. Overview of the b enc hmark generation pip eline. Randomly sampled conten t blo c ks and lay out templates yield a JSON ground truth, which is assembled into L A T E X and compiled to PDF. 3.2 Ev aluation Pip eline: T able Matching Before tables can b e ev aluated, each ground truth table must be matched to its counterpart in the parser output. This is non-trivial because parsers pro duce tables in div erse formats (HTML, Markdown, LaT eX, plain text), may split or merge tables, reorder conten t in multi-column lay outs, or fail to recognize tables en tirely . 6 P . Horn and J. Keup er W e address this with an LLM-based matc hing pipeline using Gemini-3-Flash- Preview [8]. Giv en the list of ground truth tables (as LaT eX) and the full parser output, the model iden tifies and extracts the corresponding parsed representa- tion for eac h ground truth table. Since the LLM may in tro duce minor artifacts suc h as whitespace changes, a rule-based p ost-v alidation step verifies and cor- rects each returned table against the original parser output, yielding a robust mapping b et w een ground truth and parsed tables. 4 Assessmen t of T able Ev aluation Approac hes Once ground truth and parsed tables hav e been aligned, the central question b ecomes ho w to quantify extraction quality . This section exp oses the limitations of existing rule-based metrics on concrete parser outputs, introduces LLM-based seman tic ev aluation as an alternativ e, and v alidates b oth approaches against h uman judgment. 4.1 Limitations of Rule-based Metrics Since TEDS, GriTS, and SCORE compare structure and conten t purely syn- tactically , they cannot distinguish b et ween discrepancies that alter the seman tic con tent of a table and those that are merely represen tational. Figure 2 illustrates this with a constructed example highlighting discrepancy patterns we frequen tly observ ed in parser outputs. Several difference t yp es are semantically insignificant y et incur large edit distances: – Structur al r e or ganization : parsers flatten multi-lev el headers or resolve row- spans—often b ecause the output format lacks supp ort for spanning cells (e.g., Markdo wn, unlike HTML, has no colspan / rowspan mec hanism), leading to w orkarounds such as rep eating v alues or inserting empt y padding cells. – Symb ol enc o ding : formulas app ear as Unico de symbols instead of LaT eX commands (e.g., α instead of $\alpha$ ). – V alue e quivalenc e : “85.0%” vs. “85%” or “—” vs. “N/A”. – Markup artifact : visual attributes are enco ded as raw commands (e.g., \textbf{} ). In con trast, the only seman tically critical differences, c ontent err ors suc h as a lost decimal p oin t (1.12 → 112) and a flipp ed sign (+2.8 → − 2.8), c hange merely a single character each, contributing minimally to the edit distance. String-based metrics consequently assign lo w scores driven by harmless representational v aria- tion, while the few-c haracter errors that fundamentally alter the table’s meaning are barely reflected. 4.2 LLM-as-a-Judge for T able Ev aluation Building on the LLM-as-a-judge paradigm [44,14], we prop ose using LLMs to assess table extraction quality semantically . Giv en a ground truth table and its Benc hmarking PDF Parsers on T able Extraction 7 (a) Ground T ruth Group Method T ask 1 T ask 2 Score Diff Score Diff Group 1 Baseline 85.0% — 0.72 ± 0.03 — Method α 91.2% +6.2 ( p ≤ 0.1) 1.12 +0.17 Group 2 Baseline 79.3% — 0.65 — Method β 82.1% +2.8 1.31 +0.66 (b) P arser Output Group Method T ask 1 Score T ask 1 Diff T ask 2 Score T ask 2 Diff Group 1 Baseline 85% N/A $0.72 \pm 0.03$ N/A Group 1 Method $\alpha$ \textbf {91.2\%} +6.2 ($p \leq 0.1$) 112 +0.17 Group 2 Baseline 79.3% N/A 0.65 N/A Group 2 Method $\beta$ 82.1% − 2.8 \textbf {1.31} +0.66 Fig. 2. Structural metrics p enalize harmless v ariation while ov erlo oking critical errors. The parser output (b) largely preserves the semantics of (a), yet incurs heavy edit dis- tance from representational differences ( structural reorganization , sym b ol enco ding , v alue equiv alence , markup artifact ). The only meaning-altering errors—a lost deci- mal and a sign flip ( conten t error )—barely affect the score. parsed coun terpart, an LLM ev aluates the pair on a 0–10 scale for conten t accu- racy and structural preserv ation, i.e., whether every cell v alue can b e unam bigu- ously mapp ed to its row and column headers. W e ev aluate four p opular LLMs as judges: DeepSeek-v3.2 [21], GPT-5-mini [34], Gemini-3-Flash-Preview [8], and Claude Opus 4.6 [2], selected for their strong p erformance on public b enc hmarks across differen t price p oin ts. 4.3 Human Ev aluation Proto col T o v alidate automated metrics against human judgmen t, we collected ov er 1,500 h uman ratings co vering 518 pairs of ground truth and parsed tables. Each pair w as rated on a 0–10 scale reflecting whether the semantic c on ten t of the table— all v alues, headers, and their asso ciations—has b een correctly , completely , and unam biguously preserved. The pairs were sampled across all parse r s whose out- puts span div erse formats (HTML, Markdo wn, LaT eX, plain text) and table complexities, ensuring broad cov erage. Since tables can b e large and discrepan- cies subtle, w e prompted Claude Opus 4.6 to pre-identify potential differences in each pair. Ev aluators were then presented with a web interface showing b oth 8 P . Horn and J. Keup er tables alongside these LLM-generated hints on p oten tial discrepancies, ensuring that subtle issues are surfaced for h uman judgment while the final score remains en tirely a human decision. In ter-annotator agreement. T o assess the reliability of the human refer- ence scores, we rep ort agreement among the three indep enden t ev aluators who eac h rated all 518 pairs. Krippendorff ’s α (in terv al) is 0.77, indicating accept- able agreement [12]. A v erage pairwise Pearson correlation b et w een annotators is r = 0 . 85 , with individual pairs ranging from 0.81 to 0.91 and a mean absolute score difference of 1.2 on the 0–10 scale. As a human p erformance ceiling, the lea ve-one-out correlation of eac h annotator with the mean of the other t wo yields an a verage Pearson r = 0 . 89 . 4.4 Correlation with Human Judgmen t W e compute Pearson, Sp earman, and Kendall correlations b et ween eac h auto- mated metric and the h uman reference scores to quan tify how well eac h approac h captures human notions of table extraction qualit y . All metrics are scaled to a 0–10 range for comparability; T able 1 summarizes the results and Figure 3 vi- sualizes the relationship for a subset of metrics. T able 1. Correlation of automated metrics with av eraged human scores ( n = 518 table pairs, each rated b y three ev aluators). Metric T yp e P earson r Sp earman ρ Kendall τ TEDS Rule-based 0.684 0.717 0.557 GriTS T op Rule-based 0.633 0.735 0.597 GriTS Con Rule-based 0.700 0.742 0.595 GriTS-A vg Rule-based 0.698 0.763 0.604 SCORE Index Rule-based 0.558 0.681 0.558 SCORE Conten t Rule-based 0.641 0.654 0.522 SCORE-A vg Rule-based 0.637 0.684 0.539 DeepSeek-v3.2 LLM 0.802 0.827 0.713 GPT-5-mini LLM 0.888 0.827 0.739 Gemini-3-Flash-Preview LLM 0.927 0.889 0.799 Claude Opus 4.6 † LLM 0.939 0.890 0.804 † Also used to generate error hints sho wn to ev aluators; see text. Rule-based metrics achiev e only mo derate correlation with human judg- men t. Since GriTS and SCORE each decomp ose in to separate structure and con- ten t sub-metrics, unlike TEDS and LLM-based judges which assess b oth aspects join tly , we additionally compute their arithme tic means (GriTS-A vg, SCORE- A vg) to enable direct comparison. All rule-based metrics, whether structure- fo cused, conten t-fo cused, or av eraged, fall within a narrow band of r = 0 . 56 – 0 . 70 (T able 1), confirming the limitations analyzed in Section 4.1. Benc hmarking PDF Parsers on T able Extraction 9 0 1 2 3 4 5 6 7 8 9 10 Human Scores (avg) 0 1 2 3 4 5 6 7 8 9 10 TEDS (Rule-based) 5 158 10 56 10 3 2 12 12 6 5 20 2 10 5 2 2 1 1 13 2 5 2 2 1 1 5 21 5 16 2 8 3 7 7 2 5 3 4 3 2 2 5 2 3 4 3 3 6 5 4 3 2 Corr: 0.684 Spearman: 0.717 Kendall: 0.557 TEDS (Rule-based) vs Human Scores Perfect Agreement 0 1 2 3 4 5 6 7 8 9 10 Human Scores (avg) 0 1 2 3 4 5 6 7 8 9 10 DeepSeek-v3.2 (LLM-as-a-Judge) 4 187 26 2 8 5 4 5 12 10 6 5 1 1 10 6 2 4 9 15 4 3 4 10 5 9 3 10 3 1 1 6 10 3 16 8 4 4 2 2 3 2 2 5 2 2 4 2 5 4 5 3 4 5 2 Corr: 0.802 Spearman: 0.827 Kendall: 0.713 DeepSeek-v3.2 (LLM-as-a-Judge) vs Human Scores Perfect Agreement 0 1 2 3 4 5 6 7 8 9 10 Human Scores (avg) 0 1 2 3 4 5 6 7 8 9 10 GriTS-A vg (Rule-based) 10 198 9 2 19 6 6 3 3 2 6 6 8 2 3 30 1 1 4 6 13 3 15 6 4 16 29 2 3 3 3 6 13 1 1 2 2 2 1 1 2 2 3 4 4 2 4 3 4 Corr: 0.698 Spearman: 0.763 Kendall: 0.604 GriTS-A vg (Rule-based) vs Human Scores Perfect Agreement 0 1 2 3 4 5 6 7 8 9 10 Human Scores (avg) 0 1 2 3 4 5 6 7 8 9 10 Gemini-3-Flash (LLM-as-a-Judge) 10 229 2 7 15 6 7 6 8 4 7 30 3 5 17 3 4 1 1 2 18 6 4 10 4 7 10 10 4 9 13 4 2 5 5 5 6 3 Corr: 0.927 Spearman: 0.889 Kendall: 0.799 Gemini-3-Flash (LLM-as-a-Judge) vs Human Scores Perfect Agreement 0 1 2 3 4 5 6 7 8 9 10 Human Scores (avg) 0 1 2 3 4 5 6 7 8 9 10 SCORE-A vg (Rule-based) 25 194 5 3 34 8 4 38 6 3 2 3 3 7 5 21 8 2 9 3 6 3 2 4 5 3 5 5 2 3 6 4 5 2 2 2 4 3 4 6 2 3 2 4 2 5 2 3 2 3 2 3 4 2 Corr: 0.637 Spearman: 0.684 Kendall: 0.539 SCORE-A vg (Rule-based) vs Human Scores Perfect Agreement 0 1 2 3 4 5 6 7 8 9 10 Human Scores (avg) 0 1 2 3 4 5 6 7 8 9 10 Claude Opus 4.6 (LLM-as-a-Judge) 14 199 4 12 3 3 7 23 42 3 3 25 9 4 2 3 1 1 3 12 2 12 5 8 3 5 7 12 9 2 6 2 2 9 8 2 2 2 2 8 3 2 4 3 Corr: 0.939 Spearman: 0.890 Kendall: 0.803 Claude Opus 4.6 (LLM-as-a-Judge) vs Human Scores Perfect Agreement Fig. 3. Scatter plots comparing automated metrics with h uman scores. Left col- umn: rule-based metrics (TEDS, GriTS-A vg, SCORE-A vg); right column: LLM judges (DeepSeek-v3.2, Gemini-3-Flash-Preview, Claude Opus 4.6). Bubble size indicates p oin t count. 10 P . Horn and J. Keup er LLM-based ev aluation substan tially outperforms all rule-based metrics. Ev en the w eakest LLM judge (DeepSeek-v3.2, r = 0 . 80 ) exceeds the best rule- based metric (GriTS-A vg, r = 0 . 70 ), confirming that semantic assessment cap- tures dimensions of table quality that string-lev el comparison systematically misses. Claude Opus 4.6 achiev es the highest correlation ( r = 0 . 94 ), though the h uman reference scores may b e sk ewed tow ard its assessments since it also gener- ated the error hin ts sho wn to ev aluators ( † in T able 1). Gemini-3-Flash-Preview ( r = 0 . 93 ) and GPT-5-mini ( r = 0 . 89 ), which had no role in the annotation pro- cess, still far surpass all rule-based metrics, confirming that the LLM adv an tage is indep enden t of this confound. F or the parser b enc hmark in Section 5, w e adopt Gemini-3-Flash-Preview as it offers near-ceiling correlation at substantially lo wer inference cost than Claude Opus 4.6. 5 Exp erimen ts and Results Using the v alidated Gemini-3-Flash-Preview judge, we ev aluate 21 parsers on 100 synthetic PDF pages containing 451 tables with diverse structural c harac- teristics. W e selected 21 parsers spanning the full sp ectrum of con temp orary docu- men t parsing approaches. Among sp ecialized OCR mo dels, we ev aluate Chan- dra [30], DeepSeek-OCR [42], dots.o cr [17], GOT-OCR2.0 [41], Ligh tOnOCR-2- 1B [39], Mathpix [24], MinerU2.5 [40], Mistral OCR 3 [25], Monk eyOCR-3B [18], Nanonets-OCR-s [23], and olmOCR-2-7B [31]. These range from compact end-to- end vision-language mo dels with under 1B parameters (LightOnOCR, DeepSeek- OCR) to full-page decoders built on larger VLM bac kb ones (Chandra on Qwen3- VL, Monk eyOCR) and commercial API services (Mathpix, Mistral OCR 3). W e also ev aluate general-purpose multimodal mo dels including Gemini 3 Pro and Flash [8], Gemini 2.5 Flash [5], GLM-4.5V [9], Qwen3-VL-235B [3], GPT-5 mini and nano [34], and Claude Sonnet 4.6 [2]; since these mo dels lack a dedicated do cumen t parsing mode, they were prompted to con v ert each page to Markdo wn with tables rendered as HTML. A dditionally , w e include PyMuPDF4LLM [32], a rule-based to ol that ex- tracts text directly from the PDF text la yer, and the scientific do cumen t parser GR OBID [22]. All 100 pages are pro cessed through each parser and the extracted tables are ev aluated against ground truth using the LLM-based pip eline describ ed in Sec- tions 3.2 and 4.2. T able 2 rep orts the resulting scores alongside the appro ximate cost or time for parsing all 100 pages: API pricing in USD at the time of writing or wall-clock time on a single NVIDIA R TX 4090. As most mo dels offer multiple deplo yment options and we did not use a uniform inference framework (e.g., vLLM or Hugging F ace T ransformers), reported runtimes are rough estimates. Our co de rep ository provides ready-to-use implementations for all 21 parsers together with the exact prompts, configurations, and soft ware v ersions used to pro duce the leaderb oard results, enabling full reproducibility . Benc hmarking PDF Parsers on T able Extraction 11 0 5 10 0 20 40 60 80 % of tables Gemini 3 Pro 0 5 10 Gemini 3 Flash 0 5 10 LightOnOCR-2-1B 0 5 10 0 20 40 60 80 % of tables Mistral OCR 0 5 10 dots.ocr 0 5 10 Mathpix 0 5 10 0 20 40 60 80 % of tables Chandra 0 5 10 Qwen3- VL-235B-A22B-Instruct 0 5 10 Monk eyOCR-pro-3B 0 5 10 0 20 40 60 80 % of tables GLM-4.5V 0 5 10 GPT -5 mini 0 5 10 Claude Sonnet 4.6 0 5 10 0 20 40 60 80 % of tables Nanonets-OCR-s 0 5 10 Gemini 2.5 Flash 0 5 10 MinerU2.5 0 5 10 0 20 40 60 80 % of tables GPT -5 nano 0 5 10 DeepSeek-OCR 0 5 10 P yMuPDF4LLM 0 5 10 Scor e 0 20 40 60 80 % of tables GOT -OCR2.0 0 5 10 Scor e olmOCR-2-7B-1025-FP8 0 5 10 Scor e GROBID Fig. 4. P er-parser score distributions across 451 tables. Each subplot shows the p er- cen tage of tables receiving each integer score (0–10); the dashed line marks the mean. P arsers are ordered by mean score (top-left to bottom-right). 12 P . Horn and J. Keup er T able 2. T able extraction p erformance across 451 tables from 100 syn thetic pages, scored 0–10 b y Gemini-3-Flash-Preview and brok en do wn b y structural complexity , with TEDS scores (0–1 scale) for comparison. Parsers are ranked by ov erall score. LLM Score (0–10) P arser Ov erall Simple Mo derate Complex TEDS Inference Cost / Time Gemini 3 Pro 9.55 9.58 9.57 9.49 0.85 API $10.00 Gemini 3 Flash 9.50 9.53 9.38 9.61 0.85 API $0.57 LightOnOCR-2-1B 9.08 9.41 8.90 8.91 0.83 GPU 30 min Mistral OCR 3 8.89 8.92 8.69 9.07 0.88 API $0.20 dots.ocr 8.73 9.01 8.43 8.76 0.81 GPU 20 min Mathpix 8.53 9.32 8.40 7.77 0.74 API $0.35–0.50 Chandra 8.43 8.96 8.14 8.15 0.77 GPU 4 h Qwen3-VL-235B 8.43 9.23 8.27 7.67 0.78 API/GPU $0.20 MonkeyOCR-3B 8.39 8.60 8.10 8.47 0.80 GPU 20 min GLM-4.5V 7.98 9.19 7.59 7.00 0.78 API $0.60 GPT-5 mini 7.14 8.03 6.82 6.48 0.68 API $1.00 Claude Sonnet 4.6 7.02 6.94 7.10 7.01 0.63 API $3.00 Nanonets-OCR-s 6.92 8.27 6.51 5.82 0.69 GPU 50 min Gemini 2.5 Flash 6.85 7.93 6.52 5.94 0.72 API $0.40 MinerU2.5 6.49 7.07 6.03 6.35 0.78 API/GPU — ‡ GPT-5 nano 6.48 7.63 6.18 5.47 0.32 API $0.35 DeepSeek-OCR 5.75 7.45 5.34 4.20 0.66 GPU 4 min PyMuPDF4LLM 5.25 6.78 4.86 3.91 — § CPU 30 s GOT-OCR2.0 5.13 5.89 4.95 4.45 0.58 GPU 20 min olmOCR-2-7B 4.05 4.64 3.78 3.68 0.35 GPU 25 min GROBID 2.10 2.27 1.94 2.09 — § CPU 2 min Cost: API pricing (USD) for 100 pages. Time: w all-clo c k on a single NVIDIA R TX 4090. ‡ T ested via free-tier API; also av ailable for lo cal GPU deploymen t. § TEDS not applicable; output lacks tabular structure en tirely . 6 Discussion LLM sc or es vs. TEDS. The TEDS scores in T able 2 reinforce the metric limita- tions discussed in Section 4.1. When parsers that frequen tly fail to detect tables en tirely are excluded, TEDS clusters within 22% of its scale (0.66–0.88), painting a misleading picture of comparable quality . LLM-based scores, by contrast, span 38% (5.75–9.55), far better reflecting the substantial quality differences visible up on manual insp ection. Parser p erformanc e p atterns. Ov erall scores range from 2.10 to 9.55, reveal- ing that parser choice can largely determine whether extracted tables are us- able or nearly unusable. The top-p erforming systems are the Gemini 3 mo dels, whic h are general-purp ose m ultimo dal models rather than dedicated OCR to ols, suggesting that broad visual-linguistic capabilities transfer well to table extrac- tion. Ho w ever, targeted design can riv al m uch larger models: the sp ecialized Ligh tOnOCR-2-1B ac hieves 9.08 with only 1B parameters, and dots.o cr (8.73) and MonkeyOCR-3B (8.39) also run on a single consumer GPU, narrowing the gap b et ween proprietary API services and self-hosted pip elines for applications with data priv acy constraints or limited API budgets. At the other end of the Benc hmarking PDF Parsers on T able Extraction 13 sp ectrum, rule-based tools (PyMuPDF4LLM, GROBID) require no GPU but lag substan tially b ehind all learning-based approaches. Bey ond ov erall ranking, the complexit y breakdown in T able 2 reveals that table complexity affects parsers unev enly: while most show declining scores from simple to complex tables, the magnitude v aries widely , from negligible drops (Gemini 3 Flash actually scores higher on complex tables) to severe degradation (GLM-4.5V: − 2.19, Qw en3-VL: − 1.56, Mathpix: − 1.55), indic a ting that handling multi-dimensional cell merg- ing remains a key differentiator. Even the top-scoring Gemini 3 mo dels exhibit errors up on man ual inspection, including misaligned spanning cells, subtly al- tered v alues, and incorrect header-cell asso ciations, confirming that accurate table extraction from PDF s remains an unsolved problem. Sc or e distributions. The p er-parser histograms in Figure 4 exp ose failure pat- terns that mean scores obscure. T op parsers (Gemini 3, LightOnOCR) concen- trate > 70% of tables at score 10, while Claude Sonnet 4.6 and olmOCR show strongly bimo dal distributions: they frequen tly omit tables entirely (score 0) but extract them near-p erfectly when they do. Mid-tier parsers such as GPT-5 mini and Gemini 2.5 Flash pro duce broad distributions cen tered around scores 5–8, indicating p erv asive partial errors rather than clean successes or outrigh t failures. Dep ending on the application, a missed table may b e preferable to a corrupted one, making bimo dal parsers with high-quality successes more useful than those with uniformly medio cre output. Limitations. Synthetic PDF s do not capture the full diversit y of real-world ta- bles (suc h as scanned do cumen ts or non-standard la y outs), and the table dataset is sourced exclusiv ely from arXiv, which may bias to ward scientific table for- mats, leaving domains such as financial rep orts or medical records unrepresented. While LLM-as-a-judge substantially outperforms rule-based metrics, it is not in- fallible and requires proprietary mo dels, though ev aluation costs remain mo dest: scoring all 451 tables costs approximately $0.20, and a full b enc hmark run for one parser totals roughly $1 in API costs. F utur e W ork. F uture work includes incorp orating more diverse do cumen t for- mats and lay outs, ev aluating parsers’ ability to extract information from figures, and extending the b enc hmark tow ard holistic do cumen t parsing cov ering tables, form ulas, and text jointly . Co de and Data Availability. The syn thetic PDF generation pipeline, ready-to- use configurations for all 21 parsers, the ev aluation pip eline, and the b enc h- mark dataset (100 pages with ground truth) are publicly a v ailable. 3 The meta- ev aluation of table extraction metrics, including all metric implementations and the h uman ev aluation study , is provided in a separate rep ository . 4 3 https://github.com/phorn1/pdf- parse- bench 4 https://github.com/phorn1/table- metric- study 14 P . Horn and J. Keup er Disclosure of In terests. The authors hav e no comp eting interests to declare that are relev ant to the con tent of this article. A ckno wledgmen ts. W e thank Sarah Cebulla and Martin Spitznagel for their patience and thoroughness in rating table extraction quality across hundreds of table pairs. This work has been supp orted by the German F ederal Ministry of Researc h, T ec hnology , and Space (BMFTR) in the program “F orsch ung an F ach- ho c hsc hulen in Kooperation mit Unternehmen (FH-Koop erativ)” within the joint pro ject LLMpr axis under grant 13FH622KX2. References 1. A dhik ari, N.S., Agarwal, S.: A comparative study of p df parsing to ols across diverse do cumen t categories. arXiv preprint arXiv:2410.09871 (2024) 2. An thropic: In tro ducing Claude Opus 4.6. https://www.anthropic.com/news/c la ude- opus- 4- 6 (2025), accessed: 2026-01-10 3. Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl tec hnical report. arXiv preprint (2025) 4. Chi, Z., Huang, H., Xu, H.D., Y u, H., Yin, W., Mao, X.L.: Complicated table structure recognition. arXiv preprin t arXiv:1908.04729 (2019) 5. Comanici, G., Bieb er, E., Schaek ermann, M., P asupat, I., Sac hdev a, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the fron tier with adv anced reasoning, multimodality , long con text, and next generation agen tic capabilities. arXiv preprint arXiv:2507.06261 (2025) 6. Gao, L., Huang, Y., Déjean, H., Meunier, J.L., Y an, Q., F ang, Y., Kleb er, F., Lang, E.: Icdar 2019 competition on table detection and recognition (ctdar). In: Proceed- ings of the 15th International Conference on Document Analysis and Recognition (ICD AR). pp. 1510–1515 (2019) 7. Göb el, M., Hassan, T., Oro, E., Orsi, G.: Icdar 2013 table comp etition. In: Pro ceed- ings of the 12th International Conference on Document Analysis and Recognition (ICD AR). pp. 1449–1453 (2013) 8. Go ogle DeepMind: A new era of intelligence with Gemini 3. https://blog.googl e/products/gemini/gemini- 3/ (2025), accessed: 2026-01-10 9. Hong, W., Y u, W., Gu, X., W ang, G., Gan, G., T ang, H., Cheng, J., Qi, J., Ji, J., P an, L., et al.: Glm-4.5 v and glm-4.1 v-thinking: T ow ards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint (2025) 10. Horn, P ., Keuper, J.: Benc hmarking do cumen t parsers on mathematical formula extraction from p dfs. arXiv preprint arXiv:2512.09874 (2025) 11. Ka yal, P ., Anand, M., Desai, H., Singh, M.: Icdar 2021 competition on scientific ta- ble i m age recognition to latex. In: Pro ceedings of the 16th International Conference on Do cumen t Analysis and Recognition (ICDAR). pp. 754–766 (2021) 12. Kripp endorff, K.: Computing krippendorff ’s alpha-reliability (2011) 13. Lev enshtein, V.I.: Binary codes capable of correcting deletions, insertions, and rev ersals. So viet Physics Doklady 10 (8), 707–710 (1966) 14. Li, H., Dong, Q., Chen, J., Su, H., Zhou, Y., Ai, Q., Y e, Z., Liu, Y.: Llms-as- judges: a comprehensiv e survey on llm-based ev aluation methods. arXiv preprint arXiv:2412.05579 (2024) Benc hmarking PDF Parsers on T able Extraction 15 15. Li, M., Cui, L., Huang, S., W ei, F., Zhou, M., Li, Z.: T ablebank: T able b enc hmark for image-based table detection and recognition. In: Pro ceedings of the T welfth Language Resources and Ev aluation Conference (LREC). pp. 1918–1925 (2020) 16. Li, R., Y ep es, A.J., Y ou, Y., Pluciński, K., Op erlejn, M., W olfe, C.: Score: A seman tic ev aluation framework for generative document parsing. arXiv preprint arXiv:2509.19345 (2025) 17. Li, Y., Y ang, G., Liu, H., W ang, B., Zhang, C.: dots. o cr: Multilingual document la yout parsing in a single vision-language mo del. arXiv preprint (2025) 18. Li, Z., Liu, Y., Liu, Q., Ma, Z., Zhang, Z., Zhang, S., Guo, Z., Zhang, J., W ang, X., Bai, X.: Monkey o cr: Do cumen t parsing with a structure-recognition-relation triplet paradigm. arXiv preprin t arXiv:2506.05218 (2025) 19. Li, Z., Abulaiti, A., Lu, Y., Chen, X., Zheng, J., Lin, H., Han, X., Sun, L.: READo c: A unified benchmark for realistic document structured extraction. In: Findings of the Asso ciation for Computational Linguistics (ACL). pp. 21889–21905 (2025) 20. Ling, J., Qi, Y., Huang, T., Zhou, S., Huang, Y., Y ang, J., Song, Z., Zhou, Y., Y ang, Y., Shen, H.T., W ang, P .: T able2latex-rl: High-fidelit y latex co de generation from table images via reinforced multimodal language models. In: Adv ances in Neural Information Pro cessing Systems (NeurIPS) (2025) 21. Liu, A., Mei, A., Lin, B., Xue, B., W ang, B., Xu, B., W u, B., Zhang, B., Lin, C., Dong, C., et al.: Deepseek-v3. 2: Pushing the frontier of op en large language mo dels. arXiv preprint arXiv:2512.02556 (2025) 22. Lop ez, P .: Grobid: Com bining automatic bibliographic data recognition and term extraction for scholarship publications. In: Pro ceedings of the 13th European Con- ference on Research and Adv anced T echnology for Digital Libraries (ECDL). pp. 473–474 (2009) 23. Mandal, S., T alew ar, A., Ahuja, P ., Juv atk ar, P .: Nanonets-o cr-s: A mo del for trans- forming do cumen ts into structured markdown with intelligen t conten t recognition and semantic tagging (2025) 24. Mathpix, Inc.: Mathpix: Do cument conv ersion for stem. h t tp s: / / m at hp i x . co m (2025), accessed: 2026-02-10 25. Mistral AI: Introducing mistral o cr 3. https://mistral.ai/news/mistral- ocr- 3 (2025), accessed: 2026-02-01 26. Nassar, A., Liv athinos, N., Lysak, M., Staar, P .: T ableformer: T able structure un- derstanding with transformers. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and P attern Recognition (CVPR). pp. 4614–4623 (2022) 27. OmniAI T echnology , Inc.: Omni OCR Benchmark. Hugging F ace Dataset, https: / / h ug g i n g f a ce . c o / d a ta s e t s / g et o m n i- a i /o c r- b e n ch m a rk (2025), accessed: 2026-01-10 28. Ouy ang, L., Qu, Y., Zhou, H., Zh u, J., Zhang, R., Lin, Q., W ang, B., Zhao, Z., Jiang, M., Zhao, X., et al.: Omnido cbench: Benc hmarking diverse p df do cumen t parsing with comprehensive annotations. In: Pro ceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 24838–24848 (2025) 29. P apineni, K., Roukos, S., W ard, T., Zhu, W.J.: BLEU: A metho d for automatic ev aluation of machine translation. In: Proceedings of the 40th Ann ual Meeting of the Asso ciation for Computational Linguistics (ACL). pp. 311–318 (2002) 30. P aruch uri, V., Datalab T eam: Chandra: OCR mo del for complex do cumen ts with full lay out preserv ation. GitHub rep ository , https://github.com/datalab- to / c h andra (2025), accessed: 2026-02-10 16 P . Horn and J. Keup er 31. P oznanski, J., Soldaini, L., Lo, K.: olmo cr 2: Unit test rew ards for do cumen t ocr. arXiv preprint arXiv:2510.19817 (2025) 32. PyMuPDF Con tributors: PyMuPDF4LLM: Pdf extraction for large language mo d- els. GitHub rep ository , h tt p s: //g ith ub . co m/p ymu pd f/P yMu PDF 4L LM (2025), ac- cessed: 2026-02-01 33. Salaheldin Kasem, M., Ab dallah, A., Berendeyev, A., Elk ady , E., Mahmoud, M., Ab dalla, M., Hamada, M., V ascon, S., Nurseitov, D., T a j-Eddin, I.: Deep learning for table detection and structure recognition: A survey . ACM Computing Surveys 56 (12), 1–41 (2024) 34. Singh, A., F ry , A., Perelman, A., T art, A., Ganesh, A., El-Kishky , A., McLaughlin, A., Low, A., Ostrow, A., Anan thram, A., et al.: Openai gpt-5 system card. arXiv preprin t arXiv:2601.03267 (2025) 35. Smo c k, B., F aucon-Morin, V., Sok olov, M., Liang, L., Khanam, T., Courtland, M.: Pubtables-v2: A new large-scale dataset for full-page and multi-page table extraction. arXiv preprint arXiv:2512.10888 (2025) 36. Smo c k, B., Pesala, R., Abraham, R.: Pubtables-1m: T ow ards comprehensiv e ta- ble extraction from unstructured do cumen ts. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4634–4642 (2022) 37. Smo c k, B., Pesala, R., Abraham, R.: Grits: Grid table similarity metric for table structure recognition. In: Pro ceedings of the International Conference on Do cumen t Analysis and Recognition (ICD AR). pp. 535–549 (2023) 38. Soric, M., Gracianne, C., Manolescu, I., Senellart, P .: Benchmarking table extraction from heterogeneous scientific extraction documents. arXiv preprint arXiv:2511.16134 (2025) 39. T aghadouini, S., Ca v aillès, A., Aub ertin, B.: Lightonocr: A 1b end-to-end m ultilingual vision-language model for state-of-the-art o cr. arXiv preprint arXiv:2601.14251 (2026) 40. W ang, B., Xu, C., Zhao, X., Ouyang, L., W u, F., Zhao, Z., Xu, R., Liu, K., Qu, Y., Shang, F., et al.: Mineru: An open-source solution for precise do cumen t con tent extraction. arXiv preprint arXiv:2409.18839 (2024) 41. W ei, H., Liu, C., Chen, J., W ang, J., Kong, L., Xu, Y., Ge, Z., Zhao, L., Sun, J., Peng, Y., et al.: General o cr theory: T o wards ocr-2.0 via a unified end-to-end mo del. arXiv preprint arXiv:2409.01704 (2024) 42. W ei, H., Sun, Y., Li, Y.: Deepseek-ocr: Con texts optical compression. arXiv preprin t arXiv:2510.18234 (2025) 43. Zhang, Q., W ang, B., Huang, V.S.J., Zhang, J., W ang, Z., Liang, H., He, C., Zhang, W.: Do cumen t parsing unv eiled: T echniques, challenges, and prosp ects for structured information extraction. arXiv preprint arXiv:2410.21169 (2024) 44. Zheng, L., Chiang, W.L., Sheng, Y., Zh uang, S., W u, Z., Zh uang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with m t-b enc h and chatbot arena. A dv ances in neural information pro cessing systems 36 , 46595–46623 (2023) 45. Zheng, X., Burdick, D., Popa, L., Zhong, X., W ang, N.X.R.: Global table extrac- tor (gte): A framew ork for joint table identification and cell structure recognition using visual con text. In: Proceedings of the IEEE/CVF Win ter Conference on Applications of Computer Vision (W A CV). pp. 697–706 (2021) 46. Zhong, X., ShafieiBa v ani, E., Jimeno Y epes, A.: Image-based table recognition: data, model, and ev aluation. In: Pro ceedings of the Europ ean Conference on Com- puter Vision (ECCV). pp. 564–580 (2020)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment