Reversible Lifelong Model Editing via Semantic Routing-Based LoRA
The dynamic evolution of real-world necessitates model editing within Large Language Models. While existing methods explore modular isolation or parameter-efficient strategies, they still suffer from semantic drift or knowledge forgetting due to continual updating. To address these challenges, we propose SoLA, a Semantic routing-based LoRA framework for lifelong model editing. In SoLA, each edit is encapsulated as an independent LoRA module, which is frozen after training and mapped to input by semantic routing, allowing dynamic activation of LoRA modules via semantic matching. This mechanism avoids semantic drift caused by cluster updating and mitigates catastrophic forgetting from parameter sharing. More importantly, SoLA supports precise revocation of specific edits by removing key from semantic routing, which restores model’s original behavior. To our knowledge, this reversible rollback editing capability is the first to be achieved in existing literature. Furthermore, SoLA integrates decision-making process into edited layer, eliminating the need for auxiliary routing networks and enabling end-to-end decision-making process. Extensive experiments demonstrate that SoLA effectively learns and retains edited knowledge, achieving accurate, efficient, and reversible lifelong model editing.
💡 Research Summary
The paper introduces SoLA (Semantic routing‑based LoRA), a novel framework for reversible lifelong model editing of large language models (LLMs). Existing editing approaches—meta‑learning, locate‑then‑edit, and memory‑based methods—are typically designed for single, isolated edits. When applied continuously, they suffer from catastrophic forgetting (due to shared parameters) and semantic drift (because clustering centers or routing representations are updated over time). Recent parameter‑efficient strategies such as LoRA, MELO, and ELDER mitigate some issues but still either update semantic representations during editing or share parameters across edits, leading to interference and loss of previously injected knowledge.
SoLA’s core idea is to treat each edit as an independent LoRA module. A LoRA module is a low‑rank adaptation (ΔW = BA) inserted into a frozen base model layer; only the matrices A and B are trainable during that edit. After training, both the LoRA module and its associated semantic key are frozen. The key is derived from the hidden state of the last token of the edit example, serving as a high‑dimensional semantic fingerprint (e ∈ ℝ^d). A memory table stores (key, LoRA) pairs.
During inference, the same hidden‑state extraction yields a query vector q. A distance metric (e.g., Euclidean) compares q to all stored keys K. If the nearest key is within a small threshold α (set to 0.01), the corresponding LoRA module is activated and its output is added to the frozen base representation; otherwise, the model falls back to the base parameters only. This “semantic routing” replaces external routing networks used in prior work, allowing the decision to be made directly inside the edited layer—what the authors call the “master decision mechanism.” The master layer computes d = dist(q, k_i) for the nearest key and decides between H(W₀) (base only) and H(W₀, W_Ri) (base plus LoRA) based on the threshold.
Key advantages of SoLA:
-
Elimination of semantic drift – because keys and LoRA modules are never updated after their respective edit, the semantic representation used for routing remains stable across all subsequent edits.
-
Prevention of catastrophic forgetting – only the currently edited LoRA module is trained; all previously created modules stay frozen, so new updates cannot overwrite earlier knowledge.
-
Exact reversibility – to rollback a specific edit, one simply removes its key from the memory table. The associated LoRA module becomes unreachable, and the model reverts to its original behavior for the corresponding inputs without any retraining. This controllable rollback is claimed to be the first of its kind in the literature.
-
Parameter efficiency – SoLA adds only about 0.08 M trainable parameters per edit, far fewer than MoE‑based ELDER or clustering‑based MELO, which require hundreds of thousands to millions of extra parameters.
-
End‑to‑end decision making – integrating routing logic into the edited layer removes the need for auxiliary networks, simplifying the architecture and reducing inference latency.
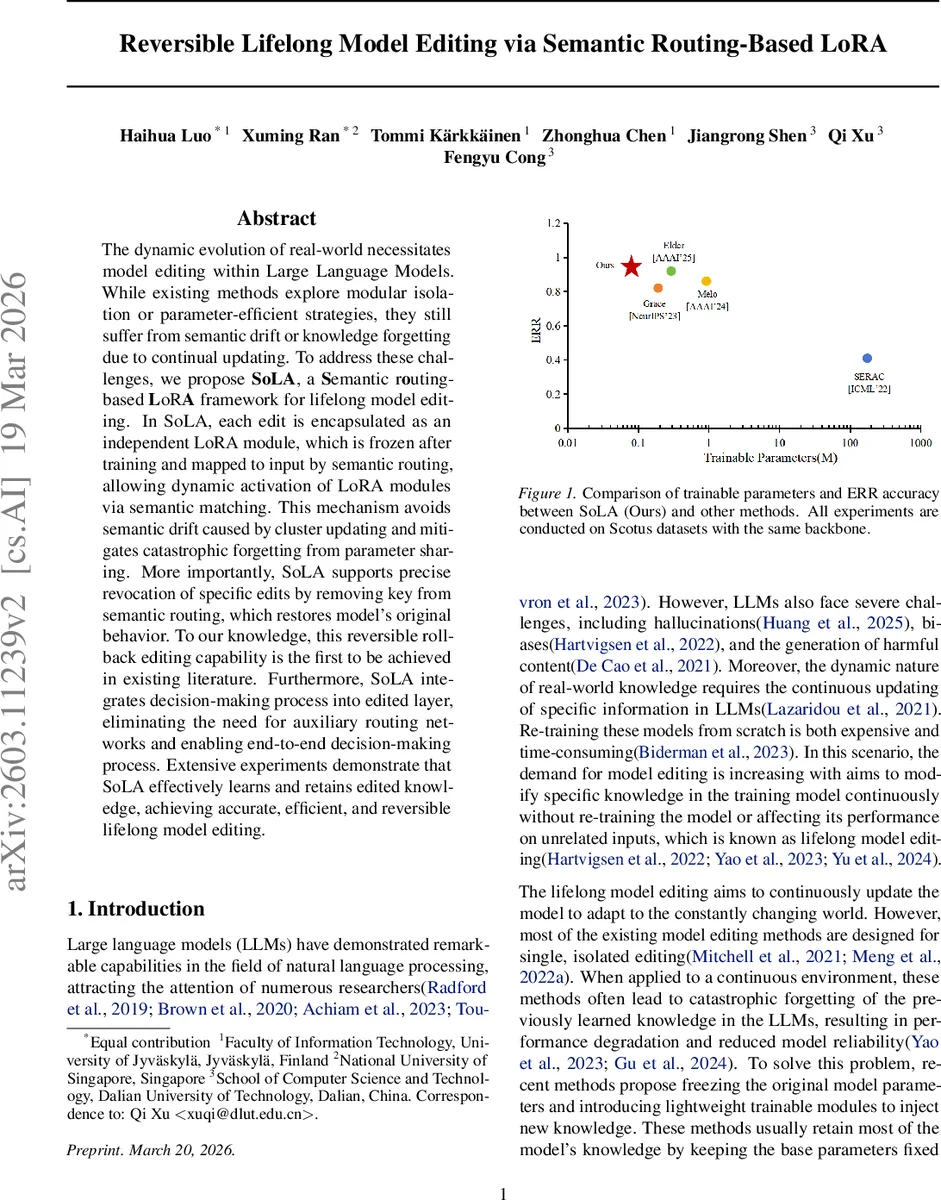
Empirical evaluation is performed on three benchmarks: SCO TUS (sentence correctness), zsRE (relation extraction F1), and a hallucination test using GPT‑2‑XL (perplexity). The authors report three metrics: Edit Reliability Rate (ERR), Task Retention Rate (TRR), and Accuracy Attention Rate (ARR). SoLA achieves the highest ERR (0.97) and TRR (0.95) among all baselines, while maintaining competitive ARR (0.86). Moreover, experiments varying the number of cluster‑center updates in MELO show that more updates lead to higher mismatches and lower performance, underscoring the drift problem that SoLA avoids by freezing keys.
In summary, SoLA provides a comprehensive solution to lifelong model editing by combining independent low‑rank adapters, stable semantic routing, and an integrated decision layer. It simultaneously addresses the four major challenges of continual editing—semantic drift, forgetting, parameter overhead, and lack of rollback—setting a new benchmark for editable, controllable, and efficient LLMs.
Comments & Academic Discussion
Loading comments...
Leave a Comment