Impact of automatic speech recognition quality on Alzheimer's disease detection from spontaneous speech: a reproducible benchmark study with lexical modeling and statistical validation
Early detection of Alzheimer's disease from spontaneous speech has emerged as a promising non-invasive screening approach. However, the influence of automatic speech recognition (ASR) quality on downstream clinical language modeling remains insuffici…
Authors: Himadri Samanta
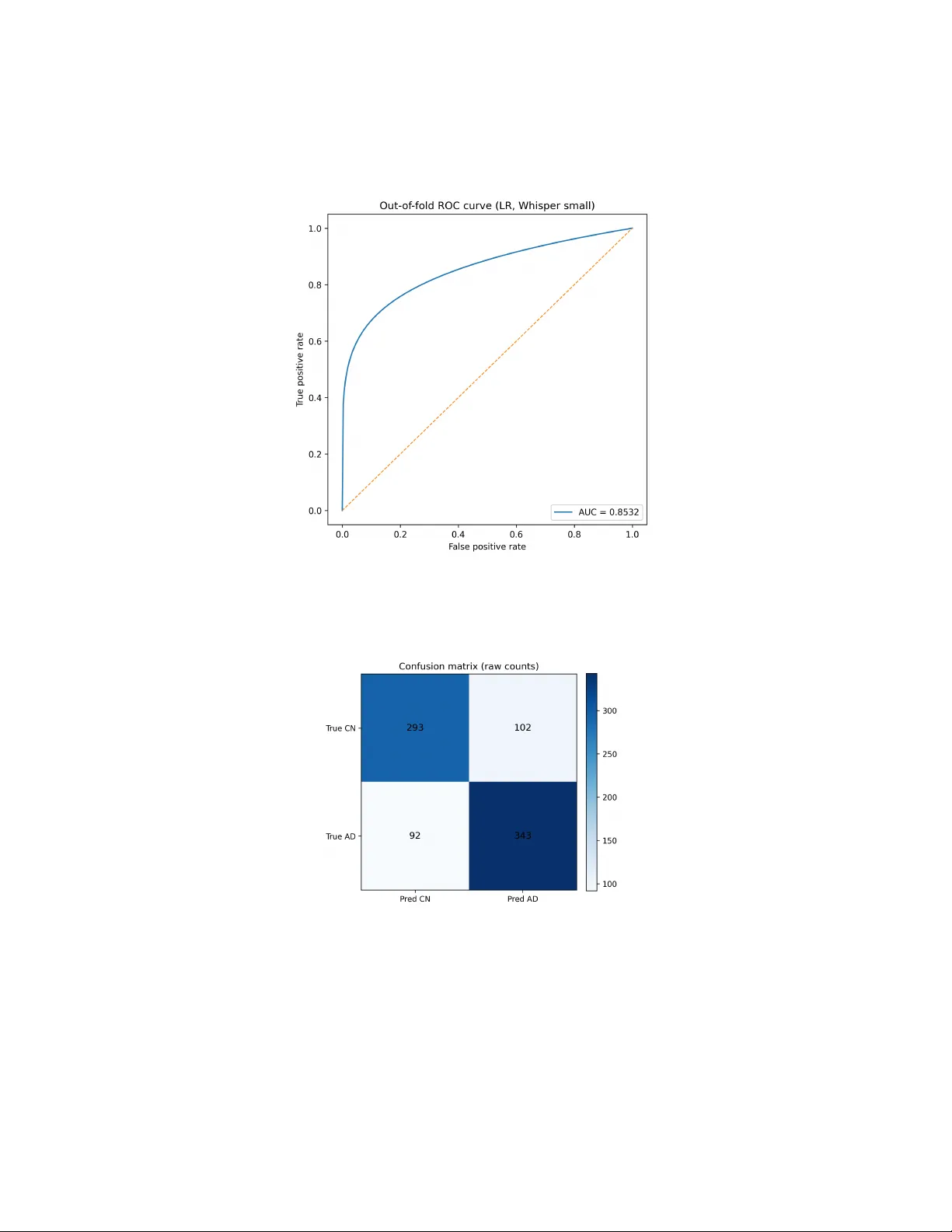
Impact of automatic sp eec h recognition qualit y on Alzheimer’s disease detection from sp on taneous sp eec h: a repro ducible b enc hmark study with lexical mo deling and statistical v alidation Himadri Sekhar Saman ta a a Indep endent R ese ar cher, A ustin, T exas, USA Abstract Early detection of Alzheimer’s disease from sp ontaneous sp eec h has emerged as a promising non-in v asiv e screening approac h. Ho wev er, the influence of au- tomatic sp eec h recognition (ASR) qualit y on downstream clinical language mo deling remains insufficiently understo od. In this study , w e inv estigate Alzheimer’s disease detection using lexical features deriv ed from Whisper ASR transcripts on the ADReSSo 2021 diagnosis dataset. W e ev aluate inter- pretable machine-learning mo dels, including Logistic Regression and Linear Supp ort V ector Mac hines, using TF–IDF text represen tations under rep eated 5 × 5 stratified cross-v alidation. Our results demonstrate that transcript quality has a statistically signifi- can t impact on classification p erformance. Mo dels trained on Whisp er-small transcripts consistently outp erform those using Whisp er-base transcripts, ac hieving balanced accuracy abov e 0.7850 with Linear SVM. Paired statisti- cal testing confirms that the observed impro vemen ts are significan t. Imp or- tan tly , classifier complexit y contributes less to p erformance v ariation than ASR transcription quality . F eature analysis rev eals that cognitively normal sp eak ers pro duce more seman tically precise ob ject- and scene-descriptiv e lan- guage, whereas Alzheimer’s sp eec h is c haracterized b y v agueness, discourse mark ers, and increased hesitation patterns. These findings suggest that high-quality ASR can enable simple, inter- pretable lexical mo dels to achiev e comp etitiv e Alzheimer’s detection p erfor- mance without explicit acoustic mo deling. The study pro vides a reproducible b enc hmark pip eline and highlights ASR selection as a critical modeling de- cision in clinical sp eec h-based artificial in telligence systems. Keywor ds: Alzheimer’s disease, sp on taneous sp eec h, automatic sp eec h recognition, Whisp er, TF–IDF, support vector mac hine, logistic regression, clinical NLP 1. In tro duction Alzheimer’s disease (AD) is a progressive neuro degenerativ e disorder char- acterized by decline in memory , executiv e function, and language abilities. Because linguistic impairment often manifests early in the disease tra jec- tory , sp eec h has emerged as a promising non-inv asive digital biomarker for cognitiv e screening and longitudinal monitoring. In particular, sp on taneous sp eec h tasks suc h as picture description elicit ric h linguistic b eha vior, in- cluding lexical retriev al difficulty , semantic degradation, reduced information con tent, discourse disorganization, and increased hesitation patterns. These phenomena pro vide clinically meaningful signals that can supp ort automated detection of cognitiv e impairment [1, 2, 3]. Recen t adv ances in automatic sp eec h recognition (ASR) and natural lan- guage pro cessing (NLP) hav e enabled the dev elopment of end-to-end com- putational pip elines for demen tia detection from sp eec h. A widely adopted w orkflow consists of three stages: transcription of audio recordings using an ASR system, transformation of transcripts in to n umerical feature represen- tations, and sup ervised learning for diagnostic prediction. While substantial effort has b een dev oted to designing increasingly complex acoustic mo dels, m ultimo dal architectures, and deep neural classifiers, the role of transcription qualit y itself has received comparativ ely limited systematic inv estigation. In practice, transcripts pro duced b y different ASR systems can v ary substan- tially in lexical substitutions, punctuation patterns, segmentation b eha vior, and hallucinated conten t. Suc h differences are not merely sup erficial: they can alter linguistic features that do wnstream mo dels rely up on, thereby in- fluencing diagnostic p erformance. The presen t study addresses this issue b y explicitly ev aluating the im- pact of ASR mo del quality on automated Alzheimer’s disease detection from sp on taneous sp eec h. Using the ADReSSo 2021 diagnosis b enchmark [4, 5], w e construct a controlled exp erimen tal pip eline in whic h the only v ariable is the transcription model. W e compare t w o v ariants from the Whisp er ASR family [6], namely Whisper base and Whisp er small, while keeping all sub- sequen t pro cessing stages iden tical. T ranscripts are represented using term 2 frequency–in verse document frequency (TF–IDF) lexical features, and classi- fication is p erformed using tw o strong linear baselines commonly employ ed in sparse text mo deling: logistic regression and linear supp ort v ector mac hines (SVM). This w ork makes four main contributions. First, we presen t a fully repro ducible pip eline for Alzheimer’s disease detection from sp on taneous sp eec h using publicly a v ailable ASR systems and interpretable statistical learning metho ds. Second, w e isolate the effect of transcription quality through matc hed exp erimen tal conditions and rep eated stratified 5 × 5 cross- v alidation. Third, w e quantify performance differences using paired statis- tical hypothesis testing and rep ort effect sizes, thereb y providing stronger inferen tial evidence than single-run ev aluation proto cols. F ourth, w e con- duct feature-lev el interpretation to iden tify lexical mark ers asso ciated with AD and cognitively normal (CN) sp eec h, linking mo del b eha vior to clinically do cumen ted language c hanges. Our findings demonstrate that improv emen ts in ASR transcription qual- it y yield measurable gains in downstream diagnostic p erformance, often ex- ceeding the impact of mo dest classifier c hanges. These results highligh t the imp ortance of treating transcription qualit y as a core design factor in sp eec h- based clinical artificial in telligence systems. More broadly , the study con- tributes to ongoing efforts in biomedical informatics to dev elop transparen t, statistically rigorous, and practically deplo y able mac hine-learning tools for early cognitiv e assessment. 2. Related W ork Automated detection of Alzheimer’s disease (AD) from sp on taneous sp eec h has b een studied extensively from b oth acoustic and linguistic p ersp ectiv es. Early research fo cused on handcrafted linguistic and acoustic features ex- tracted from structured elicitation tasks suc h as the Co okie Theft picture description. F raser et al. demonstrated that narrativ e sp eec h contains lexical, syn tactic, and acoustic markers capable of differen tiating AD from health y aging [1]. Subsequent w ork examined pause behavior, information conten t units, seman tic relev ance, discourse organization, and disfluency patterns as indicators of cognitiv e decline [7, 8, 9, 10, 11]. These findings established the clinical and computational foundations for automatic cognitive-status prediction from sp eec h and language data. 3 Metho dological rigor in this field improv ed substan tially with the in- tro duction of standardized benchmark datasets such as ADReSS 2020 and ADReSSo 2021, which pro vided balanced demographic splits and shared-task ev aluation frameworks [12, 5, 4, 2, 3]. These initiativ es enabled more reliable comparison of mac hine-learning mo dels and highligh ted the imp ortance of repro ducibilit y in dementia-detection researc h. P arallel efforts such as De- men tiaBank further supported large-scale linguistic analysis and longitudinal mo deling of cognitiv e decline [13, 14]. More recen t studies ha ve explored neu- ral architectures, multimodal systems com bining acoustic and textual repre- sen tations, and transfer learning approac hes based on pre-trained language mo dels [15, 16, 17, 18]. F rom a machine-learning p ersp ectiv e, text-based dementia detection com- monly relies on sparse lexical representations and linear classifiers, which re- main strong baselines in biomedical NLP tasks. F oundational w ork in term- frequency in verse-document-frequency (TF-IDF) weigh ting, supp ort v ector mac hines, and regularized regression pro vides the theoretical basis for man y curren t approac hes [19, 20, 21, 22, 23]. Despite the increasing use of deep neural net w orks and transformer arc hitectures [24, 25, 26], simpler inter- pretable mo dels con tinue to offer adv an tages in lo w-resource clinical settings where transparency , computational efficiency , and statistical robustness are essen tial. A t the same time, rapid adv ances in automatic sp eech recognition (ASR) ha ve transformed sp eec h-based clinical machine-learning pip elines. Mo dern neural ASR systems suc h as Whisp er provide robust m ultilingual transcrip- tion ev en under challenging acoustic conditions [6]. Related developmen ts in self-sup ervised sp eec h representation learning further impro ve sp eech under- standing performance [27, 28]. How ev er, transcription artifacts—including lexical substitutions, omissions, punctuation inconsistencies, and halluci- nated tok ens—can significantly distort linguistic markers relev ant to de- men tia detection. Prior w ork has sho wn that sp eec h-pro cessing toolkits and feature extraction pipelines influence do wnstream diagnostic accuracy [29, 30, 31, 32]. More broadly , the deplo yment of mac hine learning in digital health and biomedical informatics requires careful atten tion to interpretabilit y , v alida- tion, and real-w orld reliabilit y [33, 34, 35, 36]. Within this con text, the presen t study o ccupies the intersection of clinical sp eec h analysis, ASR ro- bustness, and interpretable text classification. Rather than emphasizing ar- c hitectural complexit y , w e focus on con trolled ASR ablation, statistically 4 T able 1: ADReSSo diagnosis dataset configu ration used in this study . Split AD CN T raining 87 79 Official test-dist 35 36 rigorous ev aluation, and transparen t feature interpretation, aiming to clar- ify ho w transcription quality influences Alzheimer’s disease detection from sp on taneous sp eec h. 3. Materials 3.1. Dataset W e used the ADReSSo 2021 diagnosis dataset distributed through T alk- Bank/Demen tiaBank [14, 13]. The training split contained 166 sp eec h sam- ples, with 87 participan ts diagnosed with Alzheimer’s disease and 79 cogni- tiv ely normal controls. Sp eec h w as elicited using the Co okie Theft picture description task, a clinically established paradigm for probing narrative pro- duction and lexical access. W e also prepared prediction s for the official b lind test-dist split, which contains 71 recordings (35 AD and 36 CN according to the b enc hmark description [17]); how ev er, b ecause the blind lab els are not released for lo cal scoring, our primary inferential analysis uses rep eated cross-v alidation on the training set. 3.2. Pr oje ct or ganization The pro ject w as implemented as a reproducible lo cal researc h pip eline with organized directories for raw data, ASR outputs, features, scripts, fig- ures, and noteb ook-based analyses. All exp erimen ts were conducted in Python using a dedicated virtual en vironment. 4. Metho ds 4.1. Sp e e ch-to-text tr anscription F or eac h audio recording a i , transcription was p erformed using an ASR mo del A to produce transcript t i : t i = A ( a i ) . (1) T wo ASR configurations w ere ev aluated: 5 • Whisp er base • Whisp er small The purp ose of thi s comparison was not to optimize ASR in isolation, but to quan tify how improv emen ts in transcript quality change do wnstream AD detection. 4.2. L exic al r epr esentation Eac h transcript w as transformed in to a TF–IDF representation using un- igram and bigram features. F or do cumen t d and term w , the TF–IDF v alue is: tfidf ( w , d ) = tf ( w , d ) · log N 1 + df ( w ) , (2) where tf ( w, d ) is the within-do cument term frequency , df ( w ) is the do cumen t frequency of term w , and N is the num b er of training documents. In practice, w e used: • n-gram range (1 , 2) • maxim um vocabulary size = 3000 • English stop-w ord remov al • minim um do cumen t frequency = 2 This yields a sparse high-dimensional feature v ector x i ∈ R p for eac h partic- ipan t. 4.3. Classifiers W e ev aluated t wo linear mo dels. L o gistic r e gr ession.. The p osterior probabilit y of AD is mo deled as P ( y i = 1 | x i ) = σ ( w ⊤ x i + b ) , (3) where σ ( z ) = 1 / (1 + e − z ) is the logistic function. Parameters w ere estimated with L2-regularized logistic regression using liblinear and balanced class w eights. 6 Line ar SVM.. The linear supp ort v ector machine optimizes min w ,b 1 2 ∥ w ∥ 2 + C n X i =1 ξ i (4) sub ject to margin constraints y i ( w ⊤ x i + b ) ≥ 1 − ξ i , ξ i ≥ 0 . (5) W e used a linear SVM with balanced class weigh ts. 4.4. Evaluation pr oto c ol T o obtain robust p erformance estimates, w e used rep eated stratified 5 × 5 cross-v alidation on the training split: • 5 folds p er repetition • 5 rep etitions with distinct random seeds • 25 fold-lev el scores p er configuration Balanced accuracy w as the primary endp oin t: BAcc = Sensitivit y + Sp ecificit y 2 . (6) Sensitivit y and sp ecificit y are defined as Sensitivit y = T P T P + F N , Sp ecificit y = T N T N + F P . (7) W e additionally rep ort an out-of-fold R OC curv e for logistic regression under Whisp er small, with AUC = 0.8532, and aggregate confusion matrices across rep eated ev aluation. 4.5. Statistic al analysis F old-matched paired t -tests were used to compare configurations. F or tw o systems with fold-lev el scores s k and b k ( k = 1 , . . . , 25 ), the difference v ector is d k = s k − b k . (8) The paired t statistic is t = ¯ d s d / √ n , (9) where ¯ d is the mean difference, s d is the standard deviation of the differences, and n = 25 . W e rep ort t w o-sided p -v alues and interpret effect magnitude using Cohen’s d . 7 T able 2: Rep eated stratified 5 × 5 cross-v alidation results on the ADReSSo training split. Classifier ASR mo del Mean balanced accuracy Standard deviation Logistic Regression Whisper base 0.7491 0.0814 Logistic Regression Whisper small 0.7757 0.0703 Linear SVM Whisp er base 0.7354 0.0865 Linear SVM Whisp er small 0.7850 0.0745 4.6. Interpr etability F or logistic regression, model co efficien ts provide direct lexical interpretabil- it y . T erms with p ositive co efficien ts increase AD probability; negativ e coeffi- cien ts supp ort the CN class. W e extracted high-magnitude co efficien ts from the Whisp er-small logistic-regression model to iden tify clinically meaningful lexical indicators. 5. Results 5.1. Main r ep e ate d-cr oss-validation r esults The o verall results are summarized in T able 2. Whisp er small impro ved balanced accuracy for both classifiers. The b est mean balanced accuracy w as achiev ed by the Linear SVM with Whisp er-small transcripts (0.7850 ± 0.0745). 5.2. Pair e d statistic al tests P aired fold-wise testing demonstrated that ASR quality significantly af- fected p erformance under b oth classifiers. F or logistic regression, Whisp er small outp erformed Whisp er base b y a mean of 0.0266 balanced-accuracy p oin ts ( t = 2 . 4490 , p = 0 . 0220 ). F or linear SVM, the mean gain was 0.0497 ( t = 3 . 8832 , p = 0 . 0007 ), indicating a stronger ASR effect. By con trast, the direct classifier comparison under Whisper small (SVM vs logistic regression) w as not significan t ( p = 0 . 3019 ), suggesting that classifier c hoice mattered less than transcript qualit y . 5.3. Figur es Figure 1 illustrates the full pip eline used in this study . Figure 2 sum- marizes the main rep eated-cross-v alidation results. Figure 3 visualizes the corresp onding effect sizes. Figure 4 shows the out-of-fold R OC curv e for 8 T able 3: P aired statistical comparisons ov er 25 rep eated-cross-v alidation folds. Comparison Mean difference t statistic T w o-sided p In terpretatio n Whisp er small vs base (LR) +0.0266 2.4490 0.0220 significan t Whisp er small vs base (SVM) +0.0497 3.8832 0.0007 highly significa n t Linear SVM vs LR (Whisp er small) +0.0093 1.0551 0.3019 not significan t logistic regression under Whisper small. Figures 5 and 6 present raw and normalized confusion matrices from the same setting. Figures 7 and 8 visu- alize high-magnitude lexical co efficien ts. Figure 1: Sp eec h-based Alzheimer’s disease detection pip eline used in this work. Audio recordings are transcrib ed with Whisp er ASR, transformed into TF–IDF features, clas- sified with linear mo dels, and ev aluated using repeated cross-v alidation and statistical testing. 9 Figure 2: Repeated 5 × 5 cross-v alidation balanced accuracy for each classifier/ASR com- bination. Error bars denote standard deviation across 25 folds. Figure 3: Effect sizes (Cohen’s d ) for k ey paired comparisons. The ASR effect is larger than the classifier effect. 10 Figure 4: Out-of-fold R OC curve for logistic regression trained on Whisp er-small tran- scripts. A UC = 0.8532. Figure 5: Aggregate confusion matrix (raw counts) for logistic regression with Whisper- small transcripts across rep eated folds. 11 Figure 6: Normalized confusion matrix for logistic regression with Whisper-small tran- scripts. CN recall = 0.742; AD recall = 0.789. 5.4. F e atur e interpr etation The co efficien ts of the logistic-regression mo del trained on Whisp er-small transcripts yielded interpretable lexical mark ers. AD-asso ciated terms in- cluded going , okay , happ ening , tel l , and don know . These terms are con- sisten t with increased v agueness, reduced lexical sp ecificit y , and hesitation. In contrast, CN-asso ciated terms included window , sink , c o okie , overflowing , and r e aching c o okie , all of whic h reflect more concrete and scene-specific de- scription. Representativ e co efficien ts are listed in T able 4 and visualized in Figures 7 and 8. 12 T able 4: Selected high-magnitude lexical indicators from the logistic-regression mo del trained on Whisp er-small transcripts. P ositive co efficients increase the probability of AD; negativ e co efficien ts increase the probabilit y of cognitively normal sp eec h. AD-indicativ e term Co efficien t CN-indicativ e term Co efficien t going +0.1718 op en -0.1295 ok ay +0.1540 windo w -0.1275 happ ening +0.1444 reac hing -0.1196 tell +0.1212 ov erflo wing -0.0998 picture +0.1132 sink -0.0978 going picture +0.1114 co okie -0.0912 oh +0.1077 reac hing co okie -0.0839 tell going +0.0800 hand -0.0810 c hair +0.0785 drying -0.0794 spilled +0.0680 sink o v erflowing -0.0756 Figure 7: T op AD-indicativ e lexical terms from the logistic-regression mo del trained on Whisp er-small transcripts. 13 Figure 8: T op CN-indicative lexical terms from the logistic-regression mo del trained on Whisp er-small transcripts. 5.5. Official blind test-dist pr e diction gener ation T o complete the b enc hmark w orkflow, w e transcrib ed the official blind test-dist split with Whisp er small, fit the TF–IDF v ectorizer on the full training corpus, trained the b est classifier (linear SVM) on all 166 training samples, and generated 71 blind predictions. Because the official lab els are not lo cally a v ailable for scoring, these outputs are intended for b enchmark submission or later external ev aluation rather than inferential comparison in this pap er. 6. Discussion This study pro vides a con trolled empirical answ er to a practical and metho dologically important question: does automatic sp eec h recognition (ASR) quality significan tly affect do wnstream Alzheimer’s disease detection from spontaneous sp eec h? The results consisten tly indicate that the an- sw er is affirmativ e. Across b oth logistic regression and linear support v ector mac hine (SVM) classifiers, transcripts generated using Whisp er small pro- duced higher balanced accuracy than those generated using Whisp er base. These improv emen ts remained statistically significant under rep eated strati- fied 5 × 5 cross-v alidation with paired h yp othesis testing. The finding is par- ticularly relev an t b ecause man y sp eech-based clinical natural language pro- cessing pip elines implicitly treat ASR as a fixed prepro cessing step, rather 14 than a modeling comp onen t whose c haracteristics can materially influence diagnostic p erformance. A second key observ ation concerns the relative imp ortance of transcript qualit y v ersus classifier complexity . When trained on Whisp er small tran- scripts, logistic regression and linear SVM ac hieved similar performance, and their difference was not statistically significant. This suggests that, at least for datasets of the scale and structure of ADReSSo, impro vemen ts in up- stream transcription accuracy can yield greater b enefit than mo dest changes in do wnstream mo del arc hitecture. F rom a metho dological p ersp ectiv e, this supp orts the argument that careful exp erimen tal control, repro ducibilit y , and in terpretable mo deling strategies may b e more impactful than escalating ar- c hitectural complexity prematurely . F eature-level in terpretation further strengthens the credibility of the re- sults. T erms asso ciated with Alzheimer’s disease predictions were c harac- terized by v agueness, discourse fillers, and reduced informational sp ecificit y , whereas cognitiv ely normal sp eec h show ed stronger presence of concrete ob- ject naming and structured scene description. These patterns align with es- tablished clinical observ ations regarding lexical retriev al difficult y , semantic degradation, and discourse disorganization in Alzheimer’s disease [1, 8, 15]. The conv ergence b et w een computational feature imp ortance and clinically do cumen ted language impairment pro vides face v alidity and suggests that the models are capturing meaningful cognitiv e–linguistic signals rather than arbitrary statistical artifacts. F rom a translational p erspective, the findings ha v e implications for the design of deplo y able digital health tools. In real-w orld screening scenar- ios, sp eech recordings are often collected in uncontrolled en vironments with v ariable audio qualit y . Under suc h conditions, ASR robustness b ecomes a critical determinant of do wnstream reliability . Our results indicate that im- pro ving transcription quality—ev en without c hanging classifier t yp e—can lead to measurable gains in diagnostic accuracy . This highligh ts the need for in tegrated ev aluation of ASR and classification comp onen ts when developing sp eec h-based clinical decision-supp ort systems. Nev ertheless, several limitations should b e ac knowledged. First, the ADReSSo dataset, while carefully curated and balanced, remains relatively small, whic h constrains the ac hiev able statistical pow er and limits generalization across p opulations, languages, and recording conditions. Second, the presen t study fo cuses exclusiv ely on lexical features deriv ed from transcripts and do es not incorp orate acoustic or proso dic cues that ma y pro vide complementary di- 15 agnostic information. Third, although repeated cross-v alidation and paired statistical testing impro v e inferential robustness, external v alidation on in- dep enden t datasets w ould further strengthen the conclusions. Finally , while mo dern ASR systems reduce transcription error rates, they ma y introduce systematic biases that in teract with demographic or linguistic v ariation, an issue requiring dedicated future in vestigation. F uture work should therefore pursue three main directions. First, larger m ulti-site datasets and m ultilingual b enc hmarks are needed to assess the gen- eralizabilit y of ASR-driven p erformance differences. Second, m ultimo dal ap- proac hes com bining lexical, acoustic, and temp oral features may yield further impro vemen ts while preserving in terpretability . Third, longitudinal mo del- ing of sp eec h tra jectories could enable earlier detection of cognitive decline and monitoring of disease progression. More broadly , this study emphasizes that robust clinical artificial in telligence pip elines must consider upstream data transformation pro cesses—suc h as ASR—not merely as tec hnical util- ities, but as core comp onents that shap e downstream inference and clinical utilit y . 7. Error analysis Aggregate confusion matrices under the b est v alidated logistic-regression setting (Whisper small) sho w normalized recalls of 0.742 for CN and 0.789 for AD. F alse p ositiv es (CN predicted as AD) likely arise in narratives with increased hesitations, short resp onses, or relatively v ague lexical structure, while false negatives (AD predicted as CN) may corresp ond to milder cases that retain more concrete picture-description v o cabulary . This asymmetry is not surprising: the Co okie Theft task elicits a b ounded semantic scene, and participan ts with relativ ely preserv ed scene-description abilit y ma y appear more con trol-like even under clinical impairmen t. 8. Repro ducibilit y The pro ject was implemented in Python using scikit-learn [37], Whis- p er ASR [6], and a noteb ook/script w orkflo w. The reproducible pac k age includes TF–IDF construction, rep eated cross-v alidation scripts, paired sta- tistical tests, feature-imp ortance analysis, and official blind-test prediction generation. Random seeds were fixed where applicable, and results are sum- marized as fold-lev el rep eated scores rather than single-run estimates. 16 9. Limitations This study has several limitations. First, the dataset is small by mo dern mac hine-learning standards, and cross-v alidation remains an in ternal v alida- tion strategy rather than a replacemen t for large m ulti-site external cohorts. Second, the curren t mo deling fo cused on lexical features and did not join tly fuse acoustic represen tations such as proso dy , pause duration distributions, or self-sup ervised sp eec h embeddings. Third, although we generated blind- test predictions, lo cal scoring on the official test-dist split w as not p ossible b ecause the lab els w ere not a v ailable in the b enchmark release used for this w orkflow. Finally , the R OC figure in this pack age is reconstructed from the rep orted out-of-fold AUC summary rather than ra w stored score p oin ts; the rep orted A UC remains the relev an t quan titativ e measure. 10. Ethics statemen t This work uses publicly distributed b enc hmark data released for research use through the ADReSSo/Demen tiaBank ecosystem [14]. The study is in- tended to supp ort researc h on assistiv e screening to ols and not to replace formal clinical diagnosis. Any deplo yment of sp eec h-based demen tia mo d- els i n practice should b e sub ject to appropriate v alidation, bias assessment, priv acy safeguards, and clinician o versigh t. 11. Conclusion This study provides a systematic ev aluation of the role of ASR tran- scription quality in sp eec h-based Alzheimer’s disease detection using lexical mo deling approac hes. Through con trolled exp eriments on the ADReSSo di- agnosis dataset, we demonstrate that improv emen ts in ASR qualit y lead to statistically significan t gains in classification performance, while differences b et w een linear classifiers suc h as Logistic Regression and Linear SVM are comparativ ely smaller. These findings indicate that transcription accuracy is not merely a prepro cessing consideration but a primary determinan t of do wnstream clinical NLP mo del effectiv eness. The results further sho w that in terpretable TF–IDF lexical represen ta- tions can capture meaningful cognitiv e-linguistic patterns associated with Alzheimer’s disease. Analysis of discriminative terms rev eals reduced lexical sp ecificit y and increased discourse-level uncertain t y in Alzheimer’s sp eec h, 17 consisten t with established neuro cognitiv e language impairmen t literature. Imp ortan tly , the p erformance ac hieved b y simple interpretable mo dels c hal- lenges the prev ailing assumption that complex acoustic or deep learning ar- c hitectures are alwa ys required for effectiv e demen tia screening. F rom a translational p ersp ectiv e, this w ork highligh ts the feasibility of scalable, sp eec h-based digital biomark ers that rely on robust ASR and trans- paren t mo deling pip elines. The prop osed framework emphasizes repro ducibil- it y through rep eated cross-v alidation, statistical testing, and clear separation b et w een training and blind test ev aluation. F uture researc h should explore m ultimo dal in tegration of acoustic, proso dic, and semantic features, domain adaptation across clinical p opulations, and longitudinal modeling of cognitive decline tra jectories. Ov erall, the study establishes ASR quality as a central mo deling v ariable in sp eec h-driven clinical AI and pro vides practical guidance for designing in terpretable and statistically rigorous dementia detection systems. Conflict of interest The author declares no conflict of in terest. Data and co de a v ailability The benchmark dataset is av ailable through T alkBank/Demen tiaBank sub ject to its data-access conditions. The reproducible scripts, noteb ooks, and figures asso ciated with this study are intended for release in a public rep ository accompan ying the man uscript. References [1] K. C. F raser, J. A. Meltzer, F. Rudzicz, Linguistic features iden tify alzheimer’s disease in narrative sp eec h, Journal of Alzheimer’s Disease 49 (2) (2016) 407–422. doi:10.3233/JAD- 150520 . [2] S. de la F uen te Garcia, S. Luz, Ev aluating the effect of linguistic and acoustic features on alzheimer’s demen tia recognition, F ron tiers in Aging Neuroscience 10 (2018) 207. doi:10.3389/fnagi.2018.00207 . [3] F. Haider, S. de la F uente, S. Luz, An in vestigation of acoustic and linguistic features for alzheimer’s dementia detection, F rontiers in Com- puter Science 2 (2020) 624659. doi:10.3389/fcomp.2020.624659 . 18 [4] S. Luz, F. Haider, S. de la F uen te Garcia, Editorial: Alzheimer’s de- men tia recognition through sp on taneous sp eec h, F ron tiers in Computer Science 3 (2021) 780169. doi:10.3389/fcomp.2021.780169 . [5] Z. S. Sy ed, M. Rashid, R. Naqvi, S. Ehsan, X. W ang, M. ur Rehman, R. Naguib, K. McDonald-Maier, T ackling the adresso c hallenge 2021: The muet-rmit system for alzheimer’s demen tia recognition from sp on- taneous sp eec h, in: Proc. Interspeech 2021, 2021, pp. 3810–3814. doi: 10.21437/Interspeech.2021- 1761 . [6] A. Radford, J. W. Kim, T. Xu, G. Bro ckman, C. McLeav ey , I. Sutsk ever, Robust speech recognition via large-scale weak sup ervision, in: Pro ceed- ings of the 40th In ternational Conference on Mac hine Learning, 2023, pp. 28492–28518. [7] S. O. Orima ye, J. S.-M. W ong, K. J. Golden, Predicting probable alzheimer’s disease using linguistic deficits and biomarkers, BMC Bioin- formatics 15 (2014) 34. doi:10.1186/1471- 2105- 15- 34 . [8] W. Jarrold, B. Pein tner, E. Y eh, R. Krasnow, H. Ja vitz, G. E. Sw an, Disfluencies and discourse p ersev eration in alzheimer’s disease, In terna- tional Journal of Language & Communication Disorders 49 (6) (2014) 617–628. doi:10.1111/1460- 6984.12095 . [9] A. Satt, S. Rozen b erg, R. Hoory , Efficien t emotion recognition from sp eec h using deep learning on sp ectrograms, in: Pro c. Interspeech 2017, 2017, pp. 1089–1093. [10] S. V. P akhomo v, et al., Computerized analysis of speech and language to iden tify psyc holinguistic correlates of fron totemp oral lobar degeneration, Cognitiv e and Behavioral Neurology 23 (3) (2010) 165–177. [11] V. T aler, N. A. Phillips, Language and alzheimer’s disease, Curren t Alzheimer Researc h 5 (4) (2008) 352–366. [12] S. Luz, F. Haider, S. de la F uen te, D. F romm, B. MacWhinney , Alzheimer’s dementia recognition through sp on taneous sp eec h: The adress challenge, in: Proc. Interspeech 2020, 2020, pp. 2172–2176. doi:10.21437/Interspeech.2020- 2571 . 19 [13] B. MacWhinney , The talkbank system for research on sp ok en communi- cation, in: The Oxford Handb ook of Psycholinguistics, Oxford Univer- sit y Press, 2011. [14] A. M. Lanzi, A. K. Saylor, D. F romm, H. Liu, B. MacWhinney , M. L. Cohen, Demen tiabank: Theoretical rationale, proto col, and illustrativ e analyses, American Journal of Speech-Language Pathology 32 (2) (2023) 426–438. doi:10.1044/2022_AJSLP- 22- 00281 . [15] S. de la F uente Garcia, S. Luz, Ev aluation of computational features for automatic prediction of mild cognitiv e impairmen t from sp eec h, F ron- tiers in Aging Neuroscience 12 (2020) 593215. doi:10.3389/fnagi. 2020.593215 . [16] J. Chen, Z. Ke, Q. Zh u, Y. W ang, et al., Automatic detection of alzheimer’s disease using sp on taneous sp eech only , F ron tiers in Aging Neuroscience 14 (2022) 843456. [17] X. Qi, H. Zhang, et al., Noninv asive automatic detection of alzheimer’s disease from sp on taneous speech with prompt-based learning, F rontiers in Aging Neuroscience 15 (2023) 1172960. [18] A. Balagopalan, et al., Comparison of sp eec h technologies for alzheimer’s disease detection, Computer Sp eec h & Language (2020). [19] J. Ramos, Using TF-IDF to determine word relev ance in document queries, Proceedings of the First Instructional Conference on Machine Learning (2003). [20] C. Cortes, V. V apnik, Supp ort-vector net works, Machine Learning 20 (3) (1995) 273–297. doi:10.1007/BF00994018 . [21] R.-E. F an, K.-W. Chang, C.-J. Hsieh, X.-R. W ang, C.-J. Lin, LIBLIN- EAR: A library for large linear classification, Journal of Mac hine Learn- ing Researc h 9 (2008) 1871–1874. [22] T. Hastie, R. Tibshirani, J. F riedman, The Elements of Statistical Learn- ing, 2nd Edition, Springer, 2009. [23] J. F riedman, T. Hastie, R. Tibshirani, Regularization paths for general- ized linear mo dels via co ordinate descent, Journal of Statistical Softw are 33 (1) (2010) 1–22. 20 [24] A. V aswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. P olosukhin, Atten tion is all y ou need, in: A dv ances in Neural Information Pro cessing Systems, 2017, pp. 5998–6008. [25] J. Devlin, M.-W. Chang, K. Lee, K. T outanov a, BER T: Pre-training of deep bidirectional transformers for language understanding, N AA CL- HL T (2019) 4171–4186. [26] I. Go o dfello w, Y. Bengio, A. Courville, Deep Learning, MIT Press, 2016. [27] A. Baevski, H. Zhou, A. Mohamed, M. Auli, w a v2vec 2.0: A frame- w ork for self-supervised learning of sp eech represen tations, A dv ances in Neural Information Pro cessing Systems 33 (2020) 12449–12460. [28] W. K ong, et al., Self-sup ervised speech represen tation learning for neu- ro degenerativ e disorder detection: A review, IEEE Journal of Biomedi- cal and Health Informatics (2022). [29] F. Eyben, M. W o ellmer, B. Sc huller, The m unic h op ensmile to olkit, Pro ceedings of the A CM Multimedia (2010). [30] B. Roark, M. Mitchell, K. Hollingshead, et al., Sp ok en language deriv ed measures for detecting mild cognitive impairmen t, IEEE T ransactions on Audio, Sp eec h, and Language Pro cessing 19 (7) (2011) 2081–2090. [31] Y. W u, et al., A review of automatic sp eec h and language pro cessing for alzheimer’s disease and mild cognitive impairmen t, IEEE Reviews in Biomedical Engineering (2020). [32] A. B. R. Shatte, D. M. Hutc hinson, S. J. T eague, Machine learning in men tal health and related disorders: A systematic review, Journal of Medical In ternet Research 21 (5) (2019) e15768. [33] A. L. Beam, I. S. Kohane, Big data and mac hine learning in health care, JAMA 319 (13) (2018) 1317–1318. [34] A. Ra jkomar, J. Dean, I. K ohane, Machine learning in medicine, New England Journal of Medicine 380 (14) (2019) 1347–1358. [35] E. J. T op ol, High-p erformance medicine: the conv ergence of human and artificial in telligence, Nature Medicine 25 (1) (2019) 44–56. 21 [36] Y. Zhou, et al., Interpretable mac hine learning for healthcare, Nature Biomedical Engineering (2021). [37] F. P edregosa, G. V aro quaux, A. Gramfort, V. Mic hel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. W eiss, V. Dub ourg, et al., Scikit-learn: Mac hine learning in p ython, Journal of Mac hine Learning Researc h 12 (2011) 2825–2830. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment