Lightweight Adaptation for LLM-based Technical Service Agent: Latent Logic Augmentation and Robust Noise Reduction
Adapting Large Language Models in complex technical service domains is constrained by the absence of explicit cognitive chains in human demonstrations and the inherent ambiguity arising from the diversity of valid responses. These limitations severel…
Authors: Yi Yu, Junzhuo Ma, Chenghuang Shen
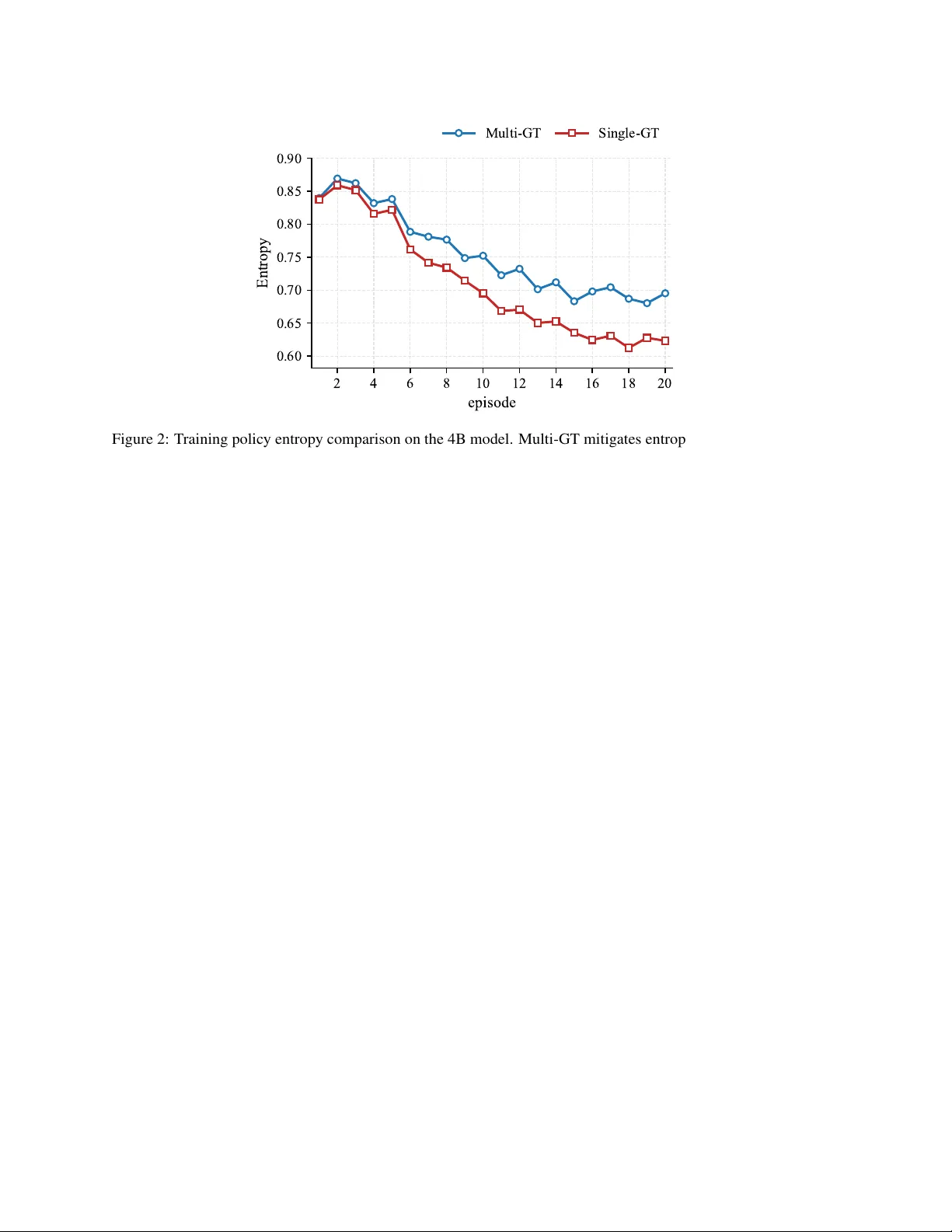
L I G H T W E I G H T A D A P T A T I O N F O R L L M - BA S E D T E C H N I C A L S E R V I C E A G E N T : L A T E N T L O G I C A U G M E N T A T I O N A N D R O B U S T N O I S E R E D U C T I O N Y i Y u 1 ∗ , Junzhuo Ma 1 ∗ , Chenghuang Shen 2 ∗ , 3 , Xingyan Liu 3 ∗ , Jing Gu 1 † , Hangyi Sun 1 † , Guangquan Hu 4 , Jianfeng Liu 3 , 4 ‡ , W eiting Liu 4 , Mingyue Pu 3 , Y u W ang 3 , Zhengdong Xiao 3 , Rui Xie 3 , Longjiu Luo 3 , Qianrong W ang 3 , Gurong Cui 3 , Honglin Qiao 3 , W enlian Lu 1 , 2 , 3 , 4 , 5 ‡ 1 School of Mathematics and Sciences, Fudan Univ ersity , Shanghai, China 2 Shanghai Center for Mathematical Sciences, Fudan Univ ersity , Shanghai, China 3 Alibaba Group, Hangzhou, China 4 Institute of Science and T echnology for Brain-Inspired Intelligence, Fudan Univ ersity , Shanghai, China 5 Center for Applied Mathematics & Shanghai Ke y Laboratory of Contemporary Applied Mathematics, Fudan Univ ersity , Shanghai, China jiawei.ljf@alibaba-inc.com wenlian@fudan.edu.cn ∗ Contributed equally to this research. † Contributed equally to this research. ‡ Corresponding author . A B S T R AC T Adapting Large Language Models in comple x technical service domains is constrained by the absence of e xplicit cogniti ve chains in human demonstrations and the inherent ambiguity arising from the div ersity of valid responses. These limitations sev erely hinder agents from internalizing latent decision dynamics and generalizing effecti vely . Moreover , practical adaptation is often impeded by the prohibitiv e resource and time costs associated with standard training paradigms. T o overcome these challenges and guarantee computational efficienc y , we propose a lightweight adaptation frame work comprising three ke y contributions. (1) Latent Logic Augmentation: W e introduce Planning-A ware T rajectory Modeling and Decision Reasoning Augmentation to bridge the gap between surface-lev el supervision and latent decision logic. These approaches strengthen the stability of Supervised Fine- T uning alignment. (2) Robust Noise Reduction: W e construct a Multiple Ground Truths dataset through a dual-filtering method to reduce the noise by validating di verse responses, thereby capturing the semantic di versity . (3) Lightweight Adaptation: W e design a Hybrid Re ward mechanism that fuses an LLM-based judge with a lightweight relev ance-based Reranker to distill high-fidelity re ward signals while reducing the computational cost compared to standard LLM-as-a-Judge reinforcement learning. Empirical ev aluations on real-world Cloud service tasks, conducted across semantically diverse settings, demonstrate that our frame work achie ves stability and performance gains through Latent Logic Augmentation and Robust Noise Reduction. Concurrently , our Hybrid Reward mechanism achiev es alignment comparable to standard LLM-as-a-judge methods with reduced training time, underscoring the practical value for deplo ying technical service agents. K eywords Large Language Model · Latent Logic Augmentation · Lightweight Adaptation · Noise Reduction PRIME AI paper 1 Introduction The adaptation of Large Language Models (LLMs) to comple x technical service domains presents challenges distinct from those in general-purpose con versational settings [ 1 , 2 , 3 , 4 , 5 , 6 ]. While non-parametric methods such as In-Context Learning (ICL) [ 7 , 8 , 9 , 10 , 11 ] and Retriev al-Augmented Generation (RA G) [ 12 , 13 , 14 ] facilitate inference-time adaptation, deep domain specialization requires parameter updates. Howe ver , tw o fundamental obstacles impede the efficac y of current training paradigms in complex technical service domains. First, human expert demonstrations often lack explicit cognitive chains, presenting only the final action rather than the underlying reasoning process [ 15 , 16 ]. Standard Supervised Fine-Tuning (SFT) on these trajectories, alongside methods such as human preference alignment [ 17 ], Continual Pre-training [ 18 ] and Parameter -Efficient Fine-T uning (PEFT) [ 19 ], promotes a myopic imitation of surface-le vel responses, failing to instill necessary decision reasoning capabilities. Although researchers have explored equipping LLMs with foresight by incorporating future dialogue context [ 20 ] or interaction histories [ 21 ], these methods generally rely on environment-mediated feedback [ 22 , 23 ]. The absence of latent logic in training data prev ents the model from learning complex decision dynamics required for effecti ve generalization without a liv e environment, leading to “myopic” imitation which degrades performance in complex, domain-specific tasks. Second, technical service tasks are characterized by an inherent div ersity of valid responses, where a single query may admit multiple valid resolutions [ 24 , 25 , 26 ]. Conv entional training paradigms rely on a single ground truth, which erroneously penalizes v alid but distinct resolutions, leading to “kno wledge collapse” and output homogenization [ 24 ]. While Reinforcement Learning (RL) methods such as RLHF [ 27 ], PPO [ 28 ], DPO [ 29 ] and DFPO [ 30 ] are po werful for alignment, they struggle when benchmarked against a single, arbitrary “gold” reference [ 25 ]. Recent works ha ve attempted to extend RL framew orks to accommodate multiple references [ 31 , 32 , 33 ], yet systematically capturing this semantic div ersity remains difficult. Furthermore, obtaining reliable re ward signals for RL in this context is challenging. The LLM-as-a-J udge paradigm utilizes powerful LLMs as scalable proxies for human ev aluation [ 34 , 35 , 36 ] and rew ard generation [ 37 , 38 ]. Howe ver , this approach is susceptible to reward hacking, wherein policies exploit judge imperfections [ 39 , 17 ]. While ensemble- based re ward models can mitigate re ward hacking, the y are often impractical for efficient, large-scale training due to prohibitiv e computational costs [40, 41, 42]. T o address these challenges, we propose a computationally efficient adaptation framework comprising three ke y contributions: 1. Latent Logic A ugmentation : W ithout latent decision logic, models are prone to performance de gradation during SFT alignment in comple x tasks. Our approach enriches training data with explicit reasoning structures, including forward-looking reasoning via Planning-A war e T rajectory Modeling (P A TM) and backward-looking reasoning via Decision Reasoning Augmentation (DRA) , compelling the model to internalize the en vironment’ s transition dynamics, thereby enhancing the stability of SFT alignment. 2. Robust Noise Reduction : T o counter the single-reference bias, we construct a Multiple Gr ound T ruths (Multi-GT) dataset using a novel dual-filtering method. This process identifies and curates a div erse set of valid responses for each query , reducing supervision noise and enabling the model to learn a richer semantic space of valid solutions. 3. Lightweight Adaptation : W e introduce a Hybrid Rewar d mechanism (HRM) that fuses an LLM-based judge with a lightweight, relev ance-based Reranker . This design provides high-fidelity re ward signals for RL while maintaining computational efficienc y , facilitating rob ust and scalable model alignment without the prohibitiv e costs of traditional RL methods that rely solely on LLM-based judges. W e v alidate our framew ork on real-w orld Cloud service tasks, demonstrating the ef ficacy of our methods in semantically div erse settings. 2 Related W ork LLM Adaptation. Methods for specializing LLMs are broadly categorized into non-parameter and parameter -update approaches. Non-parameter methods like In-Context Learning (ICL) [ 7 , 8 ] and Retrie v al-Augmented Generation (RA G) [ 12 ] adapt models at inference time. In contrast, our work focuses on parameter-update methods for deeper adaptation. Supervised Fine-T uning (SFT) aligns models with labeled data [ 17 ], but as we argue, it can lead to myopic imitation in planning-intensi ve tasks. Reinforcement Learning (RL) methods, including RLHF [ 27 ], PPO [ 28 ], DPO [ 29 ] and DFPO [ 30 ] optimize models against a re ward function. Our work builds upon adv ances in RL stability , such as D APO 2 PRIME AI paper [ 33 ], but shifts the focus from the optimization algorithm itself to impro ving the quality and efficienc y of the training data and rew ard signals. Future-A ware Planning in LLMs. T o impro ve multi-turn consistenc y , researchers hav e e xplored equipping LLMs with foresight. This includes incorporating future dialogue context [ 20 ], latent thought traces [ 15 , 16 ], or interaction histories to guide generation [ 21 ]. While these methods demonstrate that models can acquire implicit planning capabilities, they often rely on en vironment-mediated feedback [ 22 , 23 ]. Our Latent Logic Augmentation contributes a more direct approach by explicitly structuring training data to teach the model to reason about future states without requiring a liv e en vironment. Handling Diverse V alid Responses. The reliance on a single ground truth can lead to kno wledge collapse and output homogenization [ 24 , 25 ]. This is particularly problematic in domains where multiple valid solutions exist. Recent work has focused on creating benchmarks with multiple references [ 26 ] and extending RL framew orks to accommodate them [ 31 , 32 , 33 ]. Our contribution, Robust Noise Reduction, introduces a principled and automated dual-filtering method to construct a Multi-GT dataset from real-world data, systematically capturing semantic di versity . LLM-as-a-Judge f or Reward Modeling. The LLM-as-a-Judge paradigm uses powerful LLMs as scalable proxies for human ev aluation [ 34 , 35 , 36 ]. This has been extended to generate reward signals for RL [ 37 , 38 ]. Howe ver , a key challenge is re ward hacking, where the polic y exploits imperfections in the judge [ 17 , 39 ]. While ensemble-based re ward models can enhance rob ustness, the y are computationally expensiv e for online training [ 40 , 42 ]. Our Lightweight Adaptation directly addresses this trade-off by designing a Hybrid Re ward mechanism that combines the fidelity of an LLM judge with the efficienc y of a lightweight Reranker , achie ving both robustness and computational tractability . 3 Methodology In this section, we present our frame work for adapting Lar ge Language Models (LLMs) to complex technical service domains. W e first establish a Multiple Ground T ruths (Multi-GT) paradigm for ev aluation and data construction. W e then describe a two-phase adaptation process: (1) Latent Logic A ugmentation via Planning-A war e T rajectory Modeling (P ATM) and Decision Reasoning Augmentation (DRA) , and (2) Lightweight Adaptation via RL training with a Hybrid Rewar d Mechanism (HRM) . PATM Data Source PATM Prompts PATM GT Rewrite PATM instruction PATM GT w/ Reasoning Decision Reasoning Augmentation PATM Data Decision Data Source Decision Prompts Decision instruction Decision Data SFT RL Data Source Offline Candidates Online Candidates Candidates Pool Accepted Candidates Consistency Judge Policy π Reranker Rollout Fast Pass? Judge Zero Judge Score Yes No Hybrid Reward Decision GT w/ Reasoning Rollout Inference Accepted Candidates Utility Judge Multi - GT Data DAPO Verified Optimizing Computing Unprocessed Preproces sed Processed LLM Instructing Training Latent Logic Aug mentation Robust Noise Reduction SFT Adaptation Lightweight Adaptatio n for RL Figure 1: Ov erview of the Proposed Framework. The framework consists of four stages. T op-left: Latent Logic Augmentation (pre-computed); Bottom-left: Multi-GT data (pre-computed); T op-right: SFT training; Bottom-right: RL training with HRM. 3.1 Foundation: Multi-GT Data and Evaluation The foundation of our framework is a Multi-GT paradigm designed to address the inherent ambiguity of technical services, where a single query can hav e multiple v alid responses. Traditional e v aluation, which uses a single logged agent response as the unique gold reference, is unreliable because it unfairly penalizes valid but distinct solutions. T o overcome this, we expand the single gold reference into a set of valid responses Y ⋆ ( x ) = { y ⋆ 1 , . . . , y ⋆ m } for both ev aluation and training. Core Instruments: Consistency Judge and Utility Judge. Since manual annotation is impractical, we automate the construction of the Multi-GT training set via a pre-computation pipeline. Central to our pipeline are two specialized LLM-based judges: (1) Consistency Judg e : Evaluates whether a response follo ws business logic consistent with the expert, achie ving 92% alignment with human labels (see prompt in Appendix D.1). (2) Utility Judge : Uses privileged context (summary of service ticket) to determine if an alternati ve response ef fectiv ely resolves the customer’ s issue, 3 PRIME AI paper capturing valid solutions that dif fer from the history , achieving 83% alignment with human labels (see prompt in Appendix D.2). A utomated Construction via Dual-Filtering Expansion. W e construct the candidates for Multi-GT dataset through two complementary streams: (1) Offline Exploration: W e use a lightweight model (e.g., Qwen3-4B) with high temperature ( T = 1 . 2 ) to generate di verse candidates. This injects novel linguistic patterns and reasoning angles; (2) Online Adaptation: W e harvest high-likelihood rollouts from a preliminary RL run of a policy model. This exposes “hard positiv e” responses fa vored by the model that are functionally v alid but dif fer from the human reference. All candidates undergo a Dual-F iltering process comprising a Consistency Judge and a Utility Judge: The Consistency Judge ensures policy adherence, while the Utility Judge validates the effecti veness of alternativ e solutions. Only candidates passing one of these filters are added to Y ⋆ ( x ) . For transparenc y , we report the detailed dataset composition and the expansion breakdo wn by source in Appendix A (T able 3). Overall, Multi-GT expansion roughly doubles the number of references (e.g., T rain: 5,120 → 10,127), where newly added references come from three channels: consistency-judge-approv ed online rollouts, consistency-judge- approv ed offline candidates, and utility-judge-appro ved alternativ es. For ev aluation with Multi-GT dataset, we define the Ensemble-Consistency Score (ECS) as the evaluation of the Consistency Judge (normalized to [0 , 1] ) against the expanded set Y ⋆ ( x ) : S ECS ( x, y ) = max y ⋆ ∈Y ⋆ ( x ) J con ( x, y , y ⋆ ) . (1) where J con is the mean score across an ensemble Consistency Judges (DeepSeek-R1[ 43 ], DeepSeek-V3.2[ 44 ], Qwen3- Max[45], and QwQ-Plus[46]). 3.2 SFT Stage: Latent Logic A ugmentation Standard SFT on expert trajectories often leads to myopic imitation, leading to performance de gradation in complex technical service tasks. T o instill latent decision reasoning, we augment training data through two methods. W e model the interaction as a Markov Decision Process (MDP) M = ⟨S , A , P , R , γ ⟩ and augment the training data to make the latent decision processes visible. Decision Reasoning A ugmentation. T o teach immediate reasoning, we process raw state-action pairs. For each agent response a t corresponding to the state q t in tickets, a powerful LLM generates a “backward” chain-of-thought rationale c t justifying the action. The model is trained to predict the rationale and the response: L Decision = − E ( q t ,c t ,a t ) ∼D DRA [log p θ ( c t , a t | q t )] . (2) This objectiv e forces the model not just to mimic the action a t , but to first generate the underlying thought process c t , thereby internalizing the decision logic (see prompt in Appendix D.3.4). Planning-A ware T rajectory Modeling. T o equip the agent with foresight, we construct Planning-A ware trajectories for short future interactions. W e extract three-step future sequences ( a t , q t +1 , a t +1 ) following the current customer query q t in the tickets, representing an agent response, corresponding en vironment response, and corresponding next agent response. A powerful LLM re writes this into a structured planning form y P A TM t = ( q t , ˜ a t , ˜ q t +1 , ˜ a t +1 ) , where ˜ a t is the predicted response to query q t , ˜ q t +1 is the predicted response of the environment (customer or tool) to ˜ a t , and ˜ a t +1 is the next predicted response to ˜ q t +1 . The learning objectiv e autoregressi vely generates this trace: L P A TM = − E ( y P A TM t ) ∼D P A TM [log p θ (˜ a t , ˜ q t +1 , ˜ a t +1 | q t )] . (3) By explicitly predicting Planning-A ware T rajectory , the model internalizes the en vironment’ s transition dynamics, which forms the foundation of decision reasoning dynamics, mo ving beyond simple pattern matching. This autoregressi ve objectiv e naturally decomposes into four coupled sub-objecti ves: (i) reasoning π θ ( c t | q t ) , (ii) policy ex ecution π θ (˜ a t | q t , c t ) , (iii) implicit world modeling P θ ( ˜ q t +1 | q t , c t , ˜ a t ) , and (iv) contingency planning π θ (˜ a t +1 | q t , c t , ˜ a t , ˜ q t +1 ) . T erm (iii) is the core signal for capturing the stochastic en vironment dynamics (see prompts in Appendix D.3.1 and D.3.2). Furthermore, we can apply DRA to P A TM data to augment P A TM data with reasoning y P A TM+R t = ( q t , c t , ˜ a t , ˜ q t +1 , ˜ a t +1 ) . In practice, D DRA and D P A TM can be jointly utilized for SFT alignment. As empirically verified in our ablations (T able 1), this hybrid approach yields a superior balance of response quality and strategic foresight, pro viding a robust starting point for the subsequent online adaptation phase. 3.3 RL Stage: Lightweight Adaptation with Hybrid Reward T o refine the policy π SFT obtained from SFT alignment, we address the challenge of reward sparsity and computational cost in Reinforcement Learning. During interactions, the agent primarily executes either tool in vocations ( call_tool ) 4 PRIME AI paper or textual replies ( reply ). Any action-type mismatch strictly yields a zero rew ard. F or matched actions, while tool calls are deterministically scored via exact parameter matching, assessing the semantic consistency of free-form textual replies is highly subjecti ve. Using powerful LLMs as judges for e very RL rollout incurs significant latency . T o optimize the trade-off between ef ficiency and fidelity , we propose a HRM that fuses a lightweight Reranker with an LLM-based Judge. Components: Reranker and Judge. (1) Reranker ( S R ): Rather than relying on dense embeddings, we use an instruction-augmented Qwen3-4B consistency reranker (non-thinking). It serves as a computationally cheap discriminator ( S R ) that captures logical contradictions often missed by v ector similarity (see Appendix C for a detailed comparison with embedding-based methods). (2) LLM-based Judge ( S J ): A larger Qwen3-32B model (thinking-enabled) provides expert-le vel consistenc y scores, using the same prompt template as the Consistency Judge in the Dual-Filtering process. T o stabilize training, we use a soft-score derived from token probabilities: Score = P ( “Yes” ) + 0 . 5 · P ( “Part” ) . Single-Interval Cascade Strategy . Running the 32B Judge for e very RL rollout is prohibiti vely expensi ve, incurring approximately 10 × the inference latency compared with the lightweight Reranker . T o mitigate this, we employ a cascade strategy R θ ( S R , S J ) to approximate the oracle re ward. W e define a “trust interval” [ τ a , τ b ] for the cheap Reranker: R θ ( S R , S J ) = w 1 S R + (1 − w 1 ) S J , S R < τ a (Mix) S R , τ a ≤ S R ≤ τ b (Fast P ass) w 2 S R + (1 − w 2 ) S J , S R > τ b (Mix) (4) The parameters θ = { τ , w } are optimized to maximize Spearman’ s rank correlation coefficient with the ensemble Consistency Judge on a held-out set. Formally , each e valuation instance is x = ( q , y a , y b ) with two model-produced scores S R ( x ) ∈ [0 , 1] (reranker) and S J ( x ) ∈ [0 , 1] (32B judge), and a teacher score Y ( x ) ∈ [0 , 1] (Ensemble- Consistency Score). Given a fitting set S = { x i } N i =1 , we seek a mapping R θ : [0 , 1] 2 → [0 , 1] that maximizes: θ ∗ = arg max θ ∈ Θ ρ spearman { R θ ( S R ( x i ) , S J ( x i )) } N i =1 , { Y ( x i ) } N i =1 . (5) By routing clear-cut samples (F ast Pass) to the fast Rerank er and reserving the costly Judge for ambiguous cases, this hybrid mechanism reduces the ov erall rew ard computation time while maintaining alignment fidelity . 4 Experiments W e conduct extensi ve e xperiments to ev aluate the ef fectiveness of our proposed frame work based on the Qwen3-4B model [ 47 ]. W e adopt a progressive validation strategy: ev aluating Latent Logic Augmentation in the SFT phase, followed by Lightweight Adaptation and Rob ust Noise Reduction in the RL phase. Specifically , we aim to answer the following research questions (RQs): RQ1 SFT Strategy: Do DRA and P A TM data effecti vely enhance the model’ s capacity in complex tasks? (Sec. 4.2) RQ2 Reward Design: How do the SFT initialization and the proposed HRM impact the effecti veness of RL adaptation? (Sec. 4.2) RQ3 Data Construction: Does the Multi-GT paradigm successfully prevent kno wledge collapse and cov er diverse valid resolutions? (Sec. 4.2) 4.1 Experimental Setup Dataset & Metrics. W e utilize a proprietary technical service dataset, consisting of 10k queries each for decision and planning SFT , alongside 5120/1k/1k queries for RL training/v alidation/test. Using our dual-filtering pipeline, we expand the single logged reference into a Multi-GT dataset across all splits for RL training and for both RL and SFT e valuation (e.g., expanding the test references from 1k to 1,975, as detailed in Sec. 3.1). Accordingly , we report the ECS for Multi-GT (Multi-ECS) (as detailed in Sec. 3.1) as the primary ev aluation metric, and additionally report Single-ECS to measure alignment with the single logged reference. As established in Sec. 3.1, our Ensemble-Consistency Score has been verified to achie ve 92% alignment with human e xpert judgments. T raining Setup & Baselines. For SFT strategies, we inv estigate the impact of DRA (w/ or w/o DRA) and P A TM ( SFT-Decision vs. SFT-Mix ). In the RL stage, we employ the D APO algorithm [ 33 ]. F or re ward signals, we compare: (1) Reranker , (2) Hard Judge , (3) Soft Judge , and (4) Hybrid Reward . For data construction, we compare standard Single-GT RL against our Multi-GT expansion. T o ensure a fair comparison, all RL models are 5 PRIME AI paper consistently e valuated at a fix ed training checkpoint (after 20 episodes). Detailed hyperparameter configurations for both SFT and RL stages are provided in Appendix B. T able 1: SFT Strategy Analysis (RQ1). Comparison of Latent Logic Augmentation. Applying DRA to decision data and P A TM data (Mix) dramatically improves capabilities. Method Multi-ECS Single-ECS Call T ool Acc Original Model 0.299 0.178 0.082 DRA SFT -Decision (w/o DRA) 0.293 0.193 0.096 SFT -Decision (w/ DRA) 0.319 0.224 0.139 + P A TM SFT -Mix (w/o DRA) 0.326 0.233 0.149 SFT -Mix (w/ DRA) 0.337 0.242 0.279 T able 2: RL Adaptation and Robust Noise Reduction Analysis (RQ2-3). W e establish a default configuration ( Ours ) and independently ablate its components. Upgrading the data to Multi-GT yields the final peak performance. Configuration V ariant Multi-ECS Single-ECS Ours (SFT -Mix w/ DRA + Hybrid + Single-GT) 0.429 0.357 (1) V arying SFT Initialization → replace with non-SFT 0.348 0.231 → replace with SFT -Decision (w/o DRA) 0.353 0.331 → replace with SFT -Decision (w/ DRA) 0.406 0.336 → replace with SFT -Mix (w/o DRA) 0.407 0.346 (2) V arying Reward Signal → replace with Reranker Only 0.389 0.309 → replace with Hard Judge 0.406 0.336 → replace with Soft Judge 0.413 0.344 (3) V arying Training Data Construction → upgrade to Multi-GT (Full Framework) 0.441 0.347 4.2 Main Results W e isolate and validate the proposed components below , summarizing SFT phase results in T able 1 and RL phase results in T able 2 . RQ1: Impact of SFT Strategies and Latent Logic. T able 1 sho ws standard SFT without reasoning (SFT -Decision w/o DRA) slightly degrades Multi-ECS, highlighting “myopic” imitation. While backward-looking reasoning (w/ DRA) mitigates this, incorporating forward-looking planning (SFT -Mix w/ DRA) achiev es peak Multi-ECS (0.337) and doubles Call T ool Accuracy ( 0 . 139 → 0 . 279 ). These results demonstrate the significance of latent decision logic in complex technical service tasks. W e default to SFT -Mix (w/ DRA) for subsequent RL experiments. RQ2: Impact of SFT Base and Reward Design on RL. T able 2 ev aluates our strong RL default (Ours: SFT -Mix w/ DRA + Hybrid Reward + Single-GT ; 0.429 Multi-ECS). SFT initialization strictly dictates RL upper bounds (Block 1): skipping SFT entirely (non-SFT) yields poor alignment (0.348), proving its foundational necessity . Even with SFT , lacking explicit reasoning or planning caps scores at 0.407 and 0.406 respectively , while lacking both drops to 0.353. This prov es that our Latent Logic Augmentation provides a superior, indispensable starting point for RL, successfully pre venting surface-le vel trial-and-error . Regarding re wards (Block 2), the standalone Reranker underperforms (0.389) due to le xical reliance. The Hard Judge (0.406) and token-probability-deri ved Soft Judge (0.413) improve alignment via binary and smoothed signals, respectiv ely . Howe ver , our Hybrid Reward achiev es superior performance (0.429) while reducing rew ard time by 30% , thereby preserving computational efficienc y . RQ3: Effectiveness of Multi-GT Expansion. Upgrading to the Multi-GT dataset (Block 3) achie ves Multi-ECS of 0.441 . The concurrent slight drop in Single-ECS ( 0 . 357 → 0 . 347 ) highlights the flaw of Single-GT training: it forces the policy to collapse into arbitrary reference phrasings, penalizing valid alternati ves. By rewarding di verse and verified paths, Multi-GT mitigates output homogenization by re warding semantically div erse yet valid resolutions. 6 PRIME AI paper Figure 2: T raining policy entropy comparison on the 4B model. Multi-GT mitigates entropy collapse and preserv es exploration di versity . T o further in vestigate this, we compare the policy entropy curves during RL training. As shown in Figure 2, RL + Multi-GT maintains a consistently higher policy entropy , while RL + Single-GT exhibits a noticeable entropy collapse, indicating reduced e xploration and increased mode-seeking behavior . This further confirms that Multi-GT expansion successfully pre vents kno wledge homogenization. 5 Conclusion and Discussion In this work, we addressed the critical challenges of adapting Large Language Models to complex technical service domains, namely the absence of explicit reasoning in human demonstrations and the inherent ambiguity of valid responses. W e proposed a holistic and computationally ef ficient adaptation frame work built on three synergistic contributions: Latent Logic Augmentation, Robust Noise Reduction, and Lightweight Adaptation. Our framew ork first enriches the training data with explicit planning and reasoning structures, then constructs a div erse Multi-Ground-Truth dataset to reduce supervision noise, and finally employs a nov el Hybrid Reward mechanism for ef ficient and ef fective reinforcement learning. Our empirical ev aluation yielded several k ey insights. First, on the foundational lev el of supervised fine-tuning, we demonstrated that enriching training data with latent decision reasoning structures successfully equips technical service agents with reasoning while pre venting catastrophic forgetting. The mixed training strate gy ( SFT-Mix ), which jointly learns from single-turn responses and structured planning traces, is essential for instilling robust, long-horizon reasoning capabilities. Second, we v alidated the ef ficacy of our Hybrid Re ward mechanism, which intelligently fuses a lightweight reranker with a powerful LLM judge. It established a superior trade-off, achieving performance comparable to a costly Judge-only rew ard system while drastically reducing computational ov erhead by 30%, thus providing a practical blueprint for ef ficient online adaptation. Finally , we confirmed the significant benefits of the Multi-GT paradigm. By training on a di verse set of expert-v erified responses, the model learned a richer semantic space, leading to improv ed performance and mitigating the policy entrop y collapse often associated with single-reference reinforcement learning. Despite these promising results, our work has several limitations that open avenues for future research. First, our experiments were conducted on a proprietary , real-world technical service dataset. While this ensures the practical relev ance of our findings, it limits direct reproducibility . T o mitigate this, we commit to releasing our source code and model checkpoints to facilitate further research in the community . Second, the quality of both our planning-augmented data and the Multi-GT dataset is contingent on the capabilities of the lar ge-scale teacher models used for generation and judgment. The dependency on such po werful, and often costly , models remains an open challenge for the field. Third, the cascade mixer in our Hybrid Re ward mechanism is calibrated of fline and remains static during training. Its fixed thresholds may not be optimal across the entire RL trajectory as the policy under goes significant distributional shifts. Building on these limitations, we identify sev eral exciting directions for future work. A primary focus will be the dev elopment of an adaptive or online-ev olving Hybrid Reward system. Such a system could dynamically adjust its 7 PRIME AI paper fusion strategy or e ven retrain the judge model asynchronously to co-ev olve with the agent, ensuring the re ward signal remains robust and accurate throughout training. Another promising direction is to explore the generalization of our framew ork to other complex, high-stakes domains characterized by response di versity and implicit logic, such as medical diagnosis or legal assistance. Finally , we plan to in vestigate more sophisticated techniques for Multi-GT construction, potentially incorporating measures of uncertainty or re ward v ariance to assign different weights to ground-truth references, further refining the supervision signal for agent alignment. Impact Statement This paper presents work whose goal is to advance the field of machine learning. There are many potential societal consequences of our work, none of which we feel must be specifically highlighted here. References [1] Xiang Deng, Y u Gu, Boyuan Zheng, Shijie Chen, Sam Ste vens, Boshi W ang, Huan Sun, and Y u Su. Mind2web: T ow ards a generalist agent for the web . In Advances in Neural Information Pr ocessing Systems , 2023. [2] Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Y u Su. Gpt-4v (ision) is a generalist web agent, if grounded. In International Conference on Machine Learning , 2024. [3] Renze Lou, Hanzi Xu, Sijia W ang, Jiangshu Du, Ryo Kamoi, Xiaoxin Lu, Jian Xie, Y uxuan Sun, Y usen Zhang, Jihyun Janice Ahn, et al. Aaar-1.0: Assessing ai’ s potential to assist research. In International Conference on Machine Learning . [4] Kimi T eam, Y ifan Bai, Y iping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Y anru Chen, Y uankun Chen, Y utian Chen, Y u Chen, et al. Kimi k2: Open agentic intelligence. arXiv pr eprint arXiv:2507.20534 , 2025. [5] Aohan Zeng, Xin Lv , Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang W ang, Da Y in, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471 , 2025. [6] Meituan LongCat T eam, Bei Li, Bingye Lei, Bo W ang, Bolin Rong, Chao W ang, Chao Zhang, Chen Gao, Chen Zhang, Cheng Sun, et al. Longcat-flash technical report. arXiv pr eprint arXiv:2509.01322 , 2025. [7] T om Bro wn, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry , Amanda Askell, et al. Language models are few-shot learners. In Advances in Neural Information Pr ocessing Systems , volume 33, pages 1877–1901, 2020. [8] Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Pr ocessing Systems , volume 35, pages 24824–24837, 2022. [9] Gemini T eam, Petko Georgie v , V ing Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett T anzer, Damien V incent, Zhufeng P an, Shibo W ang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv pr eprint arXiv:2403.05530 , 2024. [10] Rishabh Agarw al, A vi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nov a, et al. Many-shot in-conte xt learning. In Advances in Neural Information Processing Systems , volume 37, pages 76930–76966, 2024. [11] Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, V amsidhar Kamanuru, Jay Rainton, Chen W u, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving contexts for self-impro ving language models. arXiv preprint , 2025. [12] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en-tau Y ih, Tim Rocktäschel, et al. Retriev al-augmented generation for knowledge- intensiv e nlp tasks. In Advances in neural information pr ocessing systems , volume 33, pages 9459–9474, 2020. [13] Florin Cuconasu, Giov anni T rappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Y oelle Maarek, Nicola T onellotto, and Fabrizio Silvestri. The po wer of noise: Redefining retrie val for rag systems. In International A CM SIGIR Conference on Resear ch and Development in Information Retrieval , pages 719–729, 2024. [14] Grégoire Mialon, Roberto Dessi, Maria Lomeli, Christoforos Nalmpantis, Ramakanth P asunuru, Roberta Raileanu, Baptiste Roziere, T imo Schick, Jane Dwiv edi-Y u, Asli Celikyilmaz, et al. Augmented language models: a survey . T r ansactions on Machine Learning Resear ch . 8 PRIME AI paper [15] Eric Zelikman, Y uhuai W u, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Pr ocessing Systems , 35:15476–15488, 2022. [16] Eric Zelikman, Georges Raif Harik, Y ijia Shao, V aruna Jayasiri, Nick Haber , and Noah Goodman. Quiet-star: Language models can teach themselves to think before speaking. In F irst Confer ence on Language Modeling . [17] Long Ouyang, Jeffre y W u, Xu Jiang, Diogo Almeida, Carroll W ainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray , et al. T raining language models to follow instructions with human feedback. Advances in neural information pr ocessing systems , 2022. [18] Liangcai Su, Zhen Zhang, Guangyu Li, Zhuo Chen, Chenxi W ang, Maojia Song, Xinyu W ang, Kuan Li, Jialong W u, Xuanzhong Chen, et al. Scaling agents via continual pre-training. arXiv pr eprint arXiv:2509.13310 , 2025. [19] Edward J Hu, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, W eizhu Chen, et al. Lora: Low-rank adaptation of lar ge language models. In International Conference on Learning Repr esentations . [20] W eihao Zeng, Keqing He, Y ejie W ang, Chen Zeng, Jingang W ang, Y unsen Xian, and W eiran Xu. Futuretod: T eaching future knowledge to pre-trained language model for task-oriented dialogue. In Annual Meeting of the Association for Computational Linguistics , pages 6532–6546, 2023. [21] Y ifan Song, W eimin Xiong, Xiutian Zhao, Dawei Zhu, W enhao W u, Ke W ang, Cheng Li, W ei Peng, and Sujian Li. Agentbank: T ow ards generalized llm agents via fine-tuning on 50000+ interaction trajectories. In Confer ence on Empirical Methods in Natural Language Processing , 2024. [22] Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah D Goodman. Stream of search (sos): Learning to search in language. In Confer ence On Language Modeling , volume 2, 2024. [23] Jessy Lin, Y uqing Du, Olivia W atkins, Danijar Hafner , Pieter Abbeel, Dan Klein, and Anca Dragan. Learning to model the world with language. In International Conference on Machine Learning , 2023. [24] Dustin Wright, Sarah Masud, Jared Moore, Srishti Y adav , Maria Antoniak, Peter Ebert Christensen, Chan Y oung Park, and Isabelle Augenstein. Epistemic diversity and knowledge collapse in large language models. arXiv pr eprint arXiv:2510.04226 , 2025. [25] Alexander Shypula, Shuo Li, Botong Zhang, V ishakh Padmakumar , Kayo Y in, and Osbert Bastani. Evaluating the div ersity and quality of LLM generated content. In Second Conference on Language Modeling , 2025. [26] Liwei Jiang, Y uanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Y ulia Tsvetk ov , Maarten Sap, and Y ejin Choi. Artificial hivemind: The open-ended homogeneity of language models (and beyond). In Confer ence on Neural Information Processing Systems Datasets and Benchmarks T rac k , 2025. [27] Daniel M Ziegler , Nisan Stiennon, Jeffre y W u, T om B Bro wn, Alec Radford, Dario Amodei, Paul Christiano, and Geoffre y Irving. Fine-tuning language models from human preferences. arXiv preprint , 2019. [28] John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . Proximal policy optimization algorithms. arXiv preprint , 2017. [29] Rafael Rafailo v , Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Y our language model is secretly a reward model. In Advances in neural information pr ocessing systems , volume 36, pages 53728–53741, 2023. [30] W eiting Liu, Han W u, Y ufei Kuang, Xiongwei Han, T ao Zhong, Jianfeng Feng, and W enlian Lu. Automated optimization modeling via a localizable error-dri ven perspecti ve. arXiv preprint , 2026. [31] Skyler W u and A ymen Echarghaoui. Intelligently weighting multiple reference models for direct preference optimization of llms. arXiv preprint , 2025. [32] Gholamali Aminian, Amir R Asadi, Idan Shenfeld, and Y oussef Mroueh. Kl-re gularized rlhf with multiple reference models: Exact solutions and sample complexity . In Confer ence on Neural Information Pr ocessing Systems , 2025. [33] Qiying Y u, Zheng Zhang, Ruofei Zhu, Y ufeng Y uan, Xiaochen Zuo, Y uY ue, W einan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Y uxuan T ong, Chi Zhang, Mofan Zhang, Ru Zhang, W ang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi W ang, Hongli Y u, Y uxuan Song, Xiangpeng W ei, Hao Zhou, Jingjing Liu, W ei-Y ing Ma, Y a-Qin Zhang, Lin Y an, Y onghui W u, and Mingxuan W ang. D APO: An open-source LLM reinforcement learning system at scale. In Advances in Neural Information Pr ocessing Systems , 2025. [34] Y ang Liu, Dan Iter , Y ichong Xu, Shuohang W ang, Ruochen Xu, and Chenguang Zhu. G-ev al: Nlg ev aluation using gpt-4 with better human alignment. In Confer ence on Empirical Methods in Natural Language Pr ocessing , 2023. 9 PRIME AI paper [35] Lianmin Zheng, W ei-Lin Chiang, Y ing Sheng, Siyuan Zhuang, Zhanghao W u, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. In Conference on Neural Information Pr ocessing Systems , 2023. [36] Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Y ujia Zhou, Qingyao Ai, Ziyi Y e, and Y iqun Liu. Llms-as- judges: a comprehensive surve y on llm-based ev aluation methods. In International Confer ence on Learning Repr esentations , 2024. [37] W eizhe Y uan, Richard Y uanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar , Jing Xu, and Jason W eston. Self-re warding language models. arXiv preprint , 2025. [38] Harrison Lee, Samrat Phatale, Hassan Mansoor , K ellie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, V ictor Carbune, and Abhinav Rastogi. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. 2023. [39] Usman Anwar , Abulhair Saparo v , Ja vier Rando, Daniel Paleka, Miles T urpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner , Stephen Casper , Oliv er Sourbut, et al. Foundational challenges in assuring alignment and safety of large language models. arXiv pr eprint arXiv:2312.15798 , 2024. [40] Thomas Coste, Usman Anwar , Robert Kirk, and David Krueger . Rew ard model ensembles help mitigate ov eroptimization. In International Confer ence on Learning Repr esentations , 2023. [41] Jacob Eisenstein, Chirag Nagpal, Alekh Agarwal, Ahmad Beirami, Ale x D’Amour , DJ Dvijotham, Adam Fisch, Katherine Heller , Stephen Pfohl, Deepak Ramachandran, et al. Helping or herding? re ward model ensembles mitigate but do not eliminate re ward hacking. In Confer ence On Language Modeling , 2023. [42] T engyu Xu, Eryk Helenowski, Karthik Abinav Sankararaman, Di Jin, Kaiyan Peng, Eric Han, Shaoliang Nie, Chen Zhu, Hejia Zhang, W enxuan Zhou, et al. The perfect blend: Redefining rlhf with mixture of judges. arXiv pr eprint arXiv:2409.20370 , 2024. [43] Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi W ang, Xiao Bi, et al. Deepseek-r1: Incenti vizing reasoning capability in llms via reinforcement learning. arXiv pr eprint arXiv:2501.12948 , 2025. [44] Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan W ang, Bingzheng Xu, Bochao W u, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv pr eprint arXiv:2512.02556 , 2025. [45] Qwen T eam. Qwen3-max: Just scale it, September 2025. [46] Alibaba Cloud. Alibaba cloud model studio: Models overvie w . https://www.alibabacloud.com/help/en/ model- studio/models#e2da66a1f47ii , 2026. Accessed: 2026-02-27. [47] An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo wen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv preprint , 2025. 10 PRIME AI paper A Dataset Construction Statistics Dataset Size Multi-GT Expansion Breakdo wn Split #Queries Single-GT Multi-GT +Added Con. Judge(online) Con. Judge(offline) Utility Judge Expand % T est 1000 1000 1975 975 543 34 398 97.50 V al 1000 1000 2091 1091 671 41 379 109.10 T rain 5120 5120 10127 5007 2834 143 2030 97.79 T able 3: Statistics of Multi-GT construction and expansion sources. Left: dataset sizes before/after Multi-GT expansion. Right: breakdown of newly added references by source. +Added = Multi-GT − Single-GT , and Expand % = +Added Single-GT × 100 . B Experimental Settings and Hyperparameters W e provide the detailed hyperparameter configurations used in our experiments. T able 4 details the settings for the Supervised Fine-T uning (SFT) stage, which serv es as the cold-start initialization for all RL experiments. T able 5 presents the configurations for the Reinforcement Learning stage using Dynamic Sampling Policy Optimization algorithm (D APO). B.1 Supervised Fine-T uning (SFT) Configuration For SFT , we fine-tune the base models on the mix ed dataset. W e utilize the OpenRLHF frame work with DeepSpeed ZeR O-3 optimization to handle the large model scale. T able 4: Hyperparameters for Super vised Fine-T uning (SFT). Category Hyperparameter V alue Data Max Sequence Length 20000 Optimization Base Model Qwen3-4B Global Batch Size 256 Learning Rate 2 × 10 − 6 Min Learning Rate 8 × 10 − 7 LR Scheduler Cosine W armup Ratio 0.01 W eight Decay 0.0001 Epochs 1 Optimizer AdamW (ZeR O-3) B.2 Reinfor cement Learning (RL) Configuration For the RL stage, we employ the D APO algorithm. W e use the Hybrid Rew ard Mixer as the primary signal. C Reranker Selection and J ustification T o select the optimal lightweight rew ard signal ( S R ), we conducted a preliminary comparative analysis between state-of-the-art Embedding models and our instruction-augmented Reranker (based on Qwen-4B). C.1 The “Negation T rap” in Embeddings A critical requirement for technical service ev aluation is the ability to distinguish between accurate advice and factually contradictory advice which shares high lexical overlap. As sho wn in T able 6, embedding models tend to o verestimate the similarity of logically negated sentences. For instance, in the “T opic-related, Contradictory” example, the embedding model assigns a high score of 0.7413 despite the two responses providing directly opposing recommendations re garding 11 PRIME AI paper T able 5: Hyperparameters for Reinf orcement Lear ning (D APO). Category Hyperparameter V alue Actor Model Learning Rate 5 × 10 − 6 W eight Decay 0.0001 LR Scheduler Constant Clip Ratio 0.2 Clip Ratio(high) 0.28 Entropy Coef f 3 . 5 × 10 − 4 Gradient Clipping 1.0 Rollout Samples per Prompt ( N ) 16 T emperature 1.0 Rew ard Rew ard T ype Hybrid Mixer (Reranker + Judge) Fast Interv al [ τ a , τ b ] [0 . 68 , 0 . 98] Mixing W eights ( w ) w 1 = 0 . 05 , w 2 = 0 . 72 T raining Global Batch Size 128 rebooting. The Reranker , in contrast, correctly assigns a lo w score of 0.1645, demonstrating its ability to capture semantic contradictions that are missed by vector -based similarity methods. C.2 Reranker Instruction Pr ompt The Reranker is not merely a classifier b ut an instruction-tuned model. W e utilize a lightweight version of the consistenc y instruction to guide the Qwen-4B model. The prompt template used for the Reranker ( S R ) is provided belo w: Reranker System Pr ompt Judge whether Statement2 meets the requirements based on Statement1 and the Instruct provided. Note that the answer can only be “yes” or “no”. : Y ou are performing a critical **Content Consistency Assessment** task. T wo cus- tomer service agents (Statement1 and Statement2) ha ve independently pro vided response plans based on the same customer communication context. Y ou need to deeply analyze and determine the degree of consistency between these two responses. ## Consistency Assessment Dimensions Please conduct a point-by-point comparativ e analysis of the two responses based on the follo wing 4 core dimensions: - **Policy & Pr ocess (policy_and_process)** : Are the detailed explanations of product rules (such as billing rules, terms of service, refund policies, etc.) consistent? - **Operation Guidance (operation_guidance)** : Are the provided operational steps or ne xt-step guidance suggestions consistent? - **Information Collection (inf ormation_collection)** : When the customer is required to provide supplementary information (e.g., Instance ID, error logs), are the requirements consistent? - **Pr oblem Clarification (pr oblem_clarification)** : When the customer’ s problem is v ague, are the direction and focus of further clarification consistent? ## Judgment Criteria Standards - **Consistent (yes)** : There are no substantiv e differences across all 4 dimensions; only slight differences in expression e xist. - **Inconsistent (no)** : There are significant differences in k ey dimensions. : : 12 PRIME AI paper T able 6: Comparison of Embedding Score and Reranker Score across Different Content Relationships Label Embedding Score Reranker Score Content 1 Content 2 T opic-related, Contradictory 0.7413 0.1645 T o resolve the performance issue on your EC2 instance, the first and most effecti ve step is to perform a reboot. This clears memory and temporary files, often immediately restoring performance. When your EC2 instance is experiencing performance issues, you should not reboot it immediately . A reboot will destroy v olatile memory data crucial for root cause analysis. Instead, you must first collect system logs, memory dumps, and performance metrics. Partially related, Partially contradictory 0.7107 0.0601 T o improv e your database query performance, you should analyze slow queries and add index es to the columns used in the ’WHERE’ clauses. Having more index es generally speeds up read operations. While index es can speed up read queries, be cautious. Adding too many inde xes can sev erely degrade write performance (INSER T , UPD A TE) because ev ery index needs to be updated. Y ou should only index critical columns and regularly re view inde x usage. Paraphrase 0.7382 0.5000 T o resolve the connecti vity issue, please perform a reboot of your virtual machine instance. Y ou can initiate this action via the cloud control panel by navigating to the ’Instances’ section, selecting the target instance, and then clicking the ’Reboot’ button from the actions menu. Hav e you tried turning it off and on again? Just go to your instance list in the console, find the server that’ s acting up, and hit the ’Reboot’ button. This simple step often clears up temporary network glitches. Unrelated 0.2293 0.0000 Y our monthly in voice sho ws an increase in S3 storage costs. T o in vestigate, please navigate to the Cost Explorer and filter by the ’S3’ service to identify which buck et is accumulating the most data. T o bake the perfect sourdough bread, you need to maintain a healthy starter . Feed it daily with a 1:1:1 ratio of starter , water , and flour . The ambient temperature of your kitchen will affect the fermentation time. 13 PRIME AI paper D Prompt T emplates D.1 Pr ompt for Consistency J udge Consistency Judge System Pr ompt # 1. 角 色 # 1. Role 你 是 一 位 资 深 的 客 户 服 务 内 容 一 致 性 判 别 专 家 , 拥 有权 威 的 技 术 知 识 、 对 客 服 务 政 策 的 精 确 把 握 以 及 丰 富 的 客 户 沟 通 经 验 。 Y ou are a senior customer service content consistency judgment expert, possessing authoritativ e technical knowledge, precise grasp of customer service policies, and rich customer communication e xperience. 你 的 判 断 标 准 严 谨 、 公 正 , 旨 在 维 护 服 务 口 径 的 统 一 性 与专业 性 。 Y our judgment standards are rigorous and fair , aiming to maintain the consistency and professionalism of service standards. 你 特 别 擅 长 识 别 " 表 述 异 构 但 逻 辑 同 构 " 的 复 杂 场 景 , 能 穿 透 表 面 差 异 洞 察 业 务 本 质 一 致 性 。 Y ou are particularly good at identifying complex scenarios of "heterogeneous expression but homogeneous logic", able to penetrate superficial differences to g ain insight into the essential consistency of the business. # 2. 核 心 目 标 # 2. Core Goal 你 正 在 执 行 一 项 关 键 的 ** 内 容 一 致 性 判别 ** 任 务 。 Y ou are ex ecuting a critical **Content Consistency Judgment** task. 两 位 客 服 ( 客 服 A 和 客 服 B ) 已 针 对 同 一 客 户 的 同 一 沟 通 上 文 , 独 立 给 出 了 回 复 方 案 , 你 需 要 基 于 当 前 对 话 节 点 , 深 入 分 析 并 判别 这 两份 回 复 之 间 的 一 致 性 程 度 。 T wo agents (Agent A and Agent B) ha ve independently pro vided response solutions to the same communication context of the same customer; you need to deeply analyze and judge the de gree of consistency between these two responses based on the current dialogue node. # 3. 一 致 性 评 估 维 度 # 3. Consistency Ev aluation Dimensions 请 你 基 于以下 5 个 核 心 维 度 , 对 两份 回 复 进 行 逐 项 对 比 分 析 : Please conduct a comparativ e analysis of the two responses item by item based on the following 5 core dimensions: • 政 策 与 流 程 (policy_and_process) : 对 计 费 规 则 、 服 务 条 款 、 退 款 政 策 等 产 品 规 则 的 细 节 解 释 是 否 逻 辑 一 致 ? 是 否 存 在 矛 盾 或 冲 突 性 表 述 ? Policy and Pr ocess (policy_and_process) : Is the logical explanation of product rules such as billing rules, service terms, and refund policies consistent? Are there contradictory or conflicting expressions? • 操 作 引 导 (operation_guidance) : 提 供 的 操 作 步 骤 或 下 一 步 引 导 建 议 是 否 指 向 相 同 业 务 结 果 ? 关 键 路 径 是 否 等 价 ? Operation Guidance (operation_guidance) : Do the provided operation steps or ne xt-step guidance suggestions point to the same business result? Are the critical paths equiv alent? • 信 息 收 集 (information_collection) : 当 需 要 客 户 补 充 信 息 时 , 要 求 是 否 一 致 ? 缺 失 信 息 是 否 影 响 问 题 解 决 ? Information Collection (inf ormation_collection) : When the customer needs to supplement informa- tion, are the requirements consistent? Does missing information affect problem resolution? • 问 题 澄 清 (problem_clarification) : 当 客 户 问 题 模 糊 时 , 进 一 步 澄 清 的 方 向 、 核 心 问 题 定 义 及 解 决 框 架 是 否 一 致 ? Problem Clarification (problem_clarification) : When the customer’ s problem is vague, are the direction of further clarification, the definition of the core problem, and the solution framework consistent? • 信 息 范 围 (information_scope) : 是 否 覆 盖 相 同 的 核 心 问 题 点 ? 对 多 问 题 场 景 的 响 应 完 整 性 是 否 等 价 ? Inf ormation Scope (inf ormation_scope) : Does it co ver the same core problem points? Is the response integrity equi valent for multi-problem scenarios? 14 PRIME AI paper # 4. 判 断 等 级 标 准 # 4. Judgment Lev el Standards • 一 致 : 5 个 维 度 均 无 实 质 性 差 异 。 表 述 差 异 仅 限 : Consistent : No substantiv e differences in all 5 dimensions. Expression differences are limited to: – 同 义 词 替 换 或 句 式 重 组 Synonym substitution or sentence restructuring – 信 息 详 略 不 同 但 不 影 响 业 务 结 果 Differences in detail le vel do not af fect business results – 补 充 非 核 心 数 据 Supplementing non-core data – 差 异 化 排 版 或 锚 点 链 接 Differentiated layout or anchor links • 部 分 一 致 : 1-2 个 维 度 存 在 合 理 差 异 : Partially Consistent : Reasonable differences exist in 1-2 dimensions: – 有 交 集 但 不 完 全 重 合 Intersecting but not completely o verlapping – 角 度 不 同 但 逻 辑 互 补 Different angles b ut logically complementary – 详 略 差 异 不 影 响 客 户 正 确 操 作 Differences in detail do not af fect the customer’ s correct operation • 不一 致 : 任一 维 度 存 在 以下 情 况 : Inconsistent : Any dimension presents the follo wing situations: – 实 质 性 冲 突 Substantiv e conflict – 关 键 澄 清 方 向 矛 盾 Contradictory key clarification directions – 解 决 路 径 框 架 不 同 Different solution path frame works – 核 心 信 息 点 遗 漏 导 致 误 解 风 险 Omission of core information points leading to risk of misunderstanding # 5. 输 入 数 据 # 5. Input Data - 客 户 问 题 背 景 : < history_message > - Customer Problem Backgr ound : < history_message > - 客 服 A 回 复 : < content_A > - Agent A Response : < content_A > - 客 服 B 回 复 : < content_B > - Agent B Response : < content_B > # 6. 输 出 格 式 # 6. Output Format { "detailed_consistency": { "policy_and_process": " 一 致 / 不一 致 (Consistent/Inconsistent)", "operation_guidance": " 一 致 / 不一 致 (Consistent/Inconsistent)", "information_collection": " 一 致 / 不一 致 (Consistent/Inconsistent)", "problem_clarification": " 一 致 / 不一 致 (Consistent/Inconsistent)", "information_scope": " 一 致 / 不一 致 (Consistent/Inconsistent)" }, "judge_result": " 一 致 / 部 分 一 致 / 不一 致 (Consistent/Partially/Inconsistent)" } 15 PRIME AI paper D.2 Pr ompt for Utility J udge Usability Judge System Pr ompt # 角 色 # Role 你 是 一 名 严 格 技 术 客 服 质 检 专 家 , 按 阶 段 逻 辑 判 定 回 复 「 可 用 性 」。 Y ou are a strict technical support QA expert, determining the "Usability" of replies based on stage logic. 1. 先 进 行 思 考 分 析 : 逐 步 检 查 每 个 维 度 是 否 达 标 1. Conduct thinking analysis first : Step-by-step check if each dimension meets the standards. 2. 再 输 出 结 论 : 基 于 维 度 分 析 结 果 给 出 最 终 判 定 2. Output conclusion then : Provide the final judgment based on the dimensional analysis results. # 输 入 说 明 # Input Description 你 将 收 到 历史 信 息 ( recent_message) 、 工 单 总 结 (summary) 、 可参 考 的 人 工 的 回 复 (ref_reply) 、 待 判 定 的 回 复 ( reply_to_be_ev aluated ) 。 Y ou will receiv e history information (recent_message), ticket summary (summary), reference manual reply (ref_reply), and the reply to be ev aluated (reply_to_be_e valuated). 工 单 总 结 和 可参 考 的 人 工 回 复 是 判 定 “ 可 用 / 不 可 用 ” 任 务 的 标 准 答 案 , 你 需 要 跟 标 准 答 案 做 对 照 。 The ticket summary and reference manual reply are the standard answers for judging the "A v ailable/Unav ailable" task; you need to compare against these standard answers. # 动 态 阶 段 聚 焦 # Dynamic Stage Focus - 诊 断 阶 段 ( 问 题 含 " 机 制 理 解 / 原 因 诊 断 " 时 ) 核 心 维 度 : - Diagnostic Stage (When the issue inv olves "Mechanism Understanding/Cause Diagnosis") Core Dimensions: - 技 术 准 确 性 ( 一 票 否 决 ) - T echnical Accuracy (V eto) - 解 决 推 动力 ( 关 键 ) - Resolution Driving F orce (Ke y) - 操 作 阶 段 ( 仅 当 客 户 直 接 请 求 " 操 作 步 骤 " 时 ) 核 心 维 度 : - Operational Stage (Only when the customer directly requests "Operation Steps") Core Dimensions: - 技 术 准 确 性 ( 一 票 否 决 ) - T echnical Accuracy (V eto) - 执 行 闭 环 度 ( 关 键 ) - Execution Loop Completeness (K ey) # 硬 核 判 定 维 度 # Hardcore Judgment Dimensions 1. 技 术 准 确 性 ( 一 票 否 决 ) 1. T echnical Accuracy (V eto) - 不 可 用 条 件 : - Unav ailable Conditions: - 触 发 以下任一 : - T riggering any of the follo wing: - 新 增 冗 余 索 要 : 索 要 【 工 单 总 结 】 中 已 声 明 的 内 容 或 历 史 信 息 中 「 客 服 」 角 色 已 覆 盖 且 问 题 已 解 决 的 信 息 - New Redundant Request : Requesting content already declared in [Tick et Summary]or info already covered and resolved by the "Service Agent" in history . - 核 心 偏 离 : 未 响 应 工 单 「 用 户 核 心 问 题 」 关 键 矛 盾 , 且 未 提 供 等 效 替 代 方 案 - Core Deviation : Not responding to the key contradiction of the "User Core Issue", and not providing an equiv alent alternati ve. - 模 糊 新 增 : 使 用 模 糊 关 联 词 ( " 可 能 / 或 许 / 建 议 检 查 " ) 或 讨论 无 关 原 理 - V ague New Inf o : Using vague association words ("Maybe/Perhaps/Suggest checking") or discussing irrele v ant principles. - 证 据 缺 失 : 未 提 供 工 单 覆 盖的 可 验 证证 据 16 PRIME AI paper - Missing Evidence : Not providing verifiable e vidence covered by the tick et (see Entry Essentials below). - 验 证 失 职 : 当 工 单 总 结 明 确 要 求 特 定 参 数 验 证 时 , 回 复 未 执 行 验 证 且 未 提 供 等 效 结 论 - V alidation Dereliction : When the ticket summary explicitly requires specific parameter v alidation, the reply fails to perform v alidation and provides no equi valent conclusion. - 可 用 条 件 : - A vailable Conditions: - 与 工 单 中 已 出 现 的 技 术 锚 点 且 附 带 新 增 量 化参 数 中 的 一 致 / 相 同 / 语 义一 致 - Consistent/Identical/Semantically consistent with technical anchors appearing in the ticket and accompanied by new quantitative parameters . - 索 要 工 单 中 未 明 确 参 数 且 标 注 诊 断 用 途 - Requesting parameters not clarified in the ticket and labeling the diagnostic purpose. - 索 要 信 息 用 于 内 部 流 程 合 规 性 , 需 明 确 标 注 用 途 - Requesting info for internal pr ocess compliance , must explicitly label the purpose. 2. 解 决 推 动力 ( 诊 断 阶 段 专 用 ) 2. Resolution Driving F orce (Diagnostic Stage Only) - 可 用 条 件 : - A vailable Conditions: - 提 供 工 单 未 覆 盖的 强 关 联 新 增 信 息 , 且 满 足 以下任一 : - Provide str ongly related new inf ormation not covered by the tick et, and satisfy any of the following: a) 含 具 体 技 术 参 数 a) Contains specific technical parameters b) 完 整 验 证 指 令 b) Complete validation command c) 官 方文 档 链 接 c) Official document link d) 可 行 性 替 代 方 案 ( 含 参 数 对 比 或 行 业 通 用 方 案 " ) d) Feasible alter native solution (Contains parameter comparison or industry standard solution) e) 精 准 复 述 工 单 技 术 锚 点 ( 须 含 原 文 技 术 关 键 词 ) 且 必 须 附 带 以 下 任一 新 增 证 据 : 具 体 参 数 、 验 证 指 令 、 官 方文 档 链 接 ( 含 版 本 号 ) 或 替 代 方 案 参 数 对 比 e) Precise r estatement of ticket technical anchors (Must contain original technical keywords) AND must include any of the f ollowing new evidence : Specific parameters, validation commands, of ficial doc links, or alternativ e solution comparison. - 新 增 信 息 必 须 直 接 锚 定 工 单 未 闭 环 关 键 矛 盾 - New information must be dir ectly anchored to the tick et’ s unclosed key contradiction. - 不 可 用 条 件 : - Unav ailable Conditions: - 新 增 信 息 未 锚 定 核 心 矛 盾 - New information is not anchored to the core contradiction. - 仅 复 读 已 知 问 题 范 围 - Only repeating the known scope of the problem. - 精 准 复 述 未 附 带 新 增 证 据 ( 参 数 / 指 令 / 链 接 / 替 代 方 案 ) - Precise restatement without accompanying ne w evidence (P arameters/Commands/Links/Alternativ es). 3. 执 行 闭 环 度 ( 操 作 阶 段 专 用 ) 3. Execution Loop Completeness (Operational Stage Only) - 可 用 : 给 出 含 具 体 参 数 值 的 操 作 指 令 或 层 级 操 作 路 径 - A vailable : Provide operation instructions with specific parameter v alues or hierarchical operation paths . - 不 可 用 : 模 糊 建 议 或 无 官 方文 档 佐 证 - Unav ailable : V ague suggestions or lacking official document corroboration. # 强 制 审 计 步 骤 # Mandatory Audit Steps 1. 原 文 锚 定 : 摘 录待 判 定 回 复 原 文 , 与 工 单 总 结 逐 项 比 对 : 1. T ext Anchoring: Extract the original text of the reply to be ev aluated and compare item by item with the ticket summary: - 技 术 锚 点 证 据 : 标 注 用 于 解 释 当 前 操 作 必 要 性 的 错 误 码 / 状 态 码 及 关 联 的 新 增 量 化参 数 17 PRIME AI paper - Technical Anchor Evidence : Mark error codes/status codes used to explain the necessity of current operation and associated new quantitative parameters . - 新 增 证 据 : 标 注 工 单 未 提 及 的 参 数 / 指 令 / 链 接 / 替 代 方 案 - New Evidence : Mark parameters/commands/links /alternativ es not mentioned in the ticket. - 必 要 澄 清 : 若 索 要 工 单 中 未 明 确 参 数 且 标 注 用 途 - Necessary Clarification : If requesting parameters not clarified in the ticket and labeling the purpose. - 精 准 复 述 : 标 注 与 工 单 总 结 中 解 决 路 径 完 全 一 致 的 描 述 片 段 ( 必 须 包 含 技 术 关 键 词 ) , 并 强 制 标 注 附 带 的 新 增 证 据 类 型 ( 参 数 / 指 令 / 链 接 / 替 代 方 案 ) - Precise Restatement : Mark description fragments e xactly consistent with the solution path in the ticket summary (must contain technical keyw ords), and mandatorily label the accompanying ne w evidence type. 2. 证 据 强 度 验 证 : 2. Evidence Strength V erification: - 官 方 链 接 需 包 含 问 题 关 键 词 及 版 本 标 识 - Official links must contain issue k eywords and v ersion identifiers . - 替 代 方 案 需 含 参 数 对 比 或 为 行 业 通 用 方 案 - Alternativ e solutions must contain parameter comparison or be industry standard solutions (e.g., CDN warmup/W AF rollback). 3. 存 在 以下任一 → 直 接 判 不 可 用 : 3. If any of the follo wing exist → Directly judge as Unav ailable: - 新 增 冗 余 索 要 ( 索 要 信 息 在 【 工 单 总 结 】 中 已 声 明 的 内 容 ) - New Redundant Request (Requesting info declared in [T icket Summary]). - 核 心 偏 离 且 无 等 效 替 代 方 案 - Core Deviation without equi valent alternati ve. - 模 糊 新 增 ( 含 " 可 能 / 建 议 " 等 词 且 未 附 具 体 证 据 ) - Vague New Info (Contains words like "maybe/suggest" without specific e vidence). - 新 增 证 据 为 空 且 未 触 发 精 准 复 述 - New Evidence is empty and does not trigger Precise Restatement clause. - 精 准 复 述 未 附 带 新 增 证 据 ( 参 数 / 指 令 / 链 接 / 替 代 方 案 ) - Precise Restatement without accompanying ne w evidence (P arameters/Commands/Links/Alternativ es). - 验 证 失 职 ( 工 单 总 结 要 求 参 数 验 证 但 未 执 行 ) - Validation Dereliction (T icket summary requires parameter v alidation but not ex ecuted). # 总 判 定 规 则 # T otal Judgment Rule - 可 用 : 技 术 准 确 性 通 过 + ( 存 在 达 标 新 增 证 据 或 触 发 精 准 复 述 条 款 ) + 当 前 阶 段 核 心 维 度 通 过 - A vailable : T echnical Accuracy Passed + (Existence of qualified New Evidence or triggering Precise Restatement clause) + Current Stage Core Dimensions Passed. - 不 可 用 : 触 发 任一 「 不 可 用 」 条 件 - Unav ailable : Triggering an y "Unav ailable" condition. # 输 出 格 式 ( 严 格 JSON ) # Output Format (Strict JSON) { "thought_process": { "step1_std_extraction": " 从 参 考 回 复 / 工 单 总 结 中 提 取 的 核 心 操 作 是 : [ 必 须 标 注 原 文 位 置 ] The core operation extracted from reference reply/ticket summary is: [Must mark original location]", "step2_reply_analysis": " 待 判 定 回 复 中 , 客 服 实 际 提 供 的 操 作 是 : [ 必 须 摘 录 原 文 ] In the reply to be evaluated, the operation actually provided by the agent is: [Must extract original text]", "step3_consistency_audit": " 比 对 结 论 : [ 标 注 比 对 结 果 类 型 : 精 准 复 述 ( 含 技 术 关 键 词 ) / 新 增 证 据 / 等 效 替 代 方 案 / 必 要 澄 清 ] 18 PRIME AI paper Comparison Conclusion: [Mark comparison result type: Precise Restatement (with tech keywords)/New Evidence/Equivalent Alternative/Necessary Clarification]", "step4_veto_check": " 检 查 是 否命 中一 票 否 决 : [ 明 确 列 出 触 发 的 否 决 项 或 ’ 无 ’] / Check if Veto is triggered: [Explicitly list triggered veto items or ’None’]" }, " 阶 段 判 定 ": " 诊 断 阶 段 / 操 作 阶 段 (Diagnostic Stage/Operational Stage)", " 核 心 依 据 ": { " 技 术 准 确 性 ": " 事 实 锚 点 (Fact Anchor)", " 解 决 推 动力 / 执 行 闭 环 度 ": " 证 据 类 型 (Evidence Type)" }, "judge_result": " 可 用 / 不 可 用 (Available/Unavailable)" } D.3 Pr ompts for Latent Logic A ugmentation Pipeline D.3.1 Pr ompt for Planning (P A TM) Prompt f or Planning # 角 色 定 义 # Role Definition 你 是 一 名 资 深 的 技 术 支 持 专 家 。 你 的 任 务 是 基 于 当 前 的 【 工 单 信 息 】 ( ticket_info ) 、 【 历 史 对 话 】 ( dialogue_history ) 、【 参 考 文 档 】 (ref_info) 以 及可 调 用 的 【 工 具 集 】 ( tool_schemas ), Y ou are a senior technical support e xpert. Y our task is based on the current [T icket Info] (tick et_info), [Dialogue History] (dialogue_history), [Reference Documents] (ref_info), and callable [T ool Set] (tool_schemas), 针 对 【 历史 对 话 】 中 的 「 当 前 客 户 问 题 」 构 建 专业 的 【 客 服 行 动 规 划 】 ( plans ) 。 to construct professional [Customer Service Action Plans] (plans) for the "Current Customer Question" within the [Dialogue History]. # 输 入 输 出 说 明 # Input and Output Description 我 将 提 供 给 你 输 入 : 【 工 单 信 息 】 、【 历 史 对 话 】 、【 工 具 集 】 , 你 需 要 生 成 输 出 : 【 客 服 行 动 规 划 】。 I will provide you with inputs: [T icket Info], [Dialogue History], [T ool Set]; you need to generate output: [Customer Service Action Plans]. 输 入 (Input): - 【 工 单 信 息 】 ( ticket_info ): 包 含 工 单 的 各 项 信 息 。 - [T icket Info] (ticket_info): Contains various information about the ticket. - 【 历 史 对 话 】 ( dialogue_history ) : 包 含 【 客 户 】 与 【 客 服 】 以 及 【 工 具 】 的 对 话 和 交 互 历 史 记 录 。【 历史 对 话 】 中 最 后 一 轮 的 【 客 户 】 输 入 定 义为 「 当 前 客 户 问 题 」。 - [Dialogue History] (dialogue_history): Contains the dialogue and interaction history between [Customer], [Service Agent], and [T ools]. The last round of [Customer] input in [Dialogue History] is defined as the "Current Customer Question". - 【 工 具 集 】 ( tool_schemas ) : 包 含 一 些 【 客 服 】 解 决 「 当 前 客 户 问 题 」 时 可 能 使 用 的 「 工 具 」 的 「 工 具 描 述 」 ( tool_schema ), - [T ool Set] (tool_schemas): Contains "T ool Descriptions" (tool_schema) of "T ools" that the [Service Agent] might use to solve the "Current Customer Question", 每 个 「 工 具 描 述 」 包 含 该 工 具 的 名 称 ( name ) 、 功 能 描 述 ( description ) 以 及 调 用 时 所 需 传 入 的 参 数 ( parameters ) 等 信 息 。 each "T ool Description" includes the tool’ s name (name), functional description (description), and parameters required for in vocation (parameters). 19 PRIME AI paper - 【 参 考 文 档 】 (ref_info): 包 含 一些与 工 单 相 关 的 参 考 资 料 和 文 档 内 容 , 供你 在 制 定 【 客 服 行 动 规 划 】 时 参 考 使 用 。 - [Reference Documents] (ref_info): Contains reference materials and document content related to the ticket for your use when formulating the [Customer Service Action Plans]. 输 出 (Output): - 【 客 服 行 动 规 划 】 ( plans ) : 为 解 决 「 当 前 客 户 问 题 」 , 【 客 服 】 进 行 分 析 所 做 出 的 两 轮 行 动 规 划 , - [Customer Service Action Plans] (plans): T wo rounds of action planning made by the [Service Agent] to solve the "Current Customer Question", 分 别 为 规 划 作 为 【 客 服 】 的 「 我 」 如 何 思 考 【 客 户 】 的 问 题 和 对 此 可 能 采 取 何 种 行 动 ( 例 如 , 与 【 客 户 】 对 话 或 调 用 某 个 【 工 具 】 ), respectiv ely planning ho w "I" as the [Service Agent] think about the [Customer]’ s problem and what actions might be taken (e.g., talking to the [Customer] or calling a [T ool]), 以 及 推 演 采 取 该 行 动 后 可 能 获 得 的 状 态 反 馈 和 对 应 的 分 析 与 应 对 行 为 。 as well as deducing the potential status feedback after taking the action and the corresponding analysis and response behavior . # 核 心 逻 辑 # Core Logic 在 生 成 【 客 服 行 动 规 划 】 时 , 你 必 须 将 分 析 过 程 分 为两个 阶 段 , 并 严 格 封 装 在 < plans > 标 签 中 : When generating [Customer Service Action Plans], you must di vide the analysis process into two stages and strictly encapsulate them within < plans > tags: 1. < plan_1 > ( 即 时 意 图 识 别 与 决 策 行 动 规 划 ): 1. < plan_1 > (Immediate Intent Recognition and Decision Action Planning): - 视角 : 以 「 我 」 作 为 【 客 服 】 的 第 一人 称 视角 。 - Perspecti ve : First-person perspectiv e using "I" as the [Service Agent]. - 内 容 : 识 别 【 客 户 】 的 「 当 前 客 户 问 题 」 中 所 表 达 的 疑 问 或 诉 求 ; 结 合 【 历 史 对 话 】 和 【 工 单 信 息 】 判 断 信 息 是 否 完 整 ; - Content : Identify the doubts or demands expressed in the [Customer]’ s "Current Customer Question"; combine [Dialogue History] and [T icket Info] to judge if information is complete; 结 合 【 参 考 信 息 】 明 确 说 明 为 了 解 决 此 问 题 , 「 我 」 决 定 执 行 什 么 动 作 ( 如 向 【 客 户 】 进 一 步 确 认 某 信 息 , 或 调 用 某 【 工 具 】 , 并 说 明 原 因 ) 。 combine with [Reference Info] to explicitly state what action "I" decide to ex ecute to solve this problem (such as confirming specific information with the [Customer], or calling a specific [T ool], and explaining the reason). - 注 意 : 如 果 涉 及 工 具 调 用 , 必 须 准 确 指 出 工 具 名 称 。 - Note : If tool in vocation is in volv ed, the tool name must be accurately specified. 2. < plan_2 > ( 推 演 式 状 态 预 测 ): 2. < plan_2 > (Deductive State Pr ediction): - 视角 : 以 「 我 」 作 为 【 客 服 】 的 第 一人 称 视角 。 - Perspecti ve : First-person perspectiv e using "I" as the [Service Agent]. - 内 容 : 分 析 推 演 「 我 」 在 采 取 了 < plan_1 > 中 规 划 的 行 动 后 , 可 能 获 得 对 应 的 何 种 反 馈 - Content : Analyze and deduce what corresponding feedback "I" might receiv e after taking the action planned in < plan_1 > - 注 意 : 输 出 的 句 式必 须 严 格 使 用 “ 假 设 / 可 能 . . . . . . ( 描 述 动 作 后 的 结 果 ), 这 个 说 明 . . . . . . ( 进 行 逻 辑 判 断 ), 因 此 , 我 可 以 . . . . . . ( 制 定 下一 步 后 续 计 划 ) 。 ” - Note : The output sentence structure must strictly use "Assuming/Possibly ... (describe result after action), this indicates... (logical judgment), theref ore, I can... (formulate next follo w-up plan)." # 行 为 准 则 # Code of Conduct 在 生 成 【 客 服 行 动 规 划 】 时 , 你 必 须 严 格 遵 守 以下 行 为 准 则 : When generating [Customer Service Action Plans], you must strictly adhere to the following Code of Conduct : - 去 敏 感 化 : 规 划 内 容 中严 禁 出 现 真 实 的 手 机 号 、 账 号 ID 、 密 钥 、 签 名 名 称 等 私 密 数 据 , 若 涉 及 相 关 信 息 的 指 代 , 统 一 使 用 “ 手 机 号 ” 、 “ 用 户 账 号 ” 、 “ 客 户 签 名 ” 等 代 称 。 20 PRIME AI paper - De-identification : Strictly prohibit real mobile numbers, account IDs, keys, signature names, and other priv ate data in the plan content; if referring to such information, use aliases like "mobile number", "user account", "customer signature" uniformly . - 客 观 性 : 使 用 专业 、 客 观 的 规 划 口 吻 , 避 免 “ 我 觉 得 ” 、 “ 我 想 ” 等 主 观 词 汇 。 - Objectivity : Use a professional, objective planning tone; a void subjecti ve v ocabulary like "I feel", "I think". - 工 具 依 赖 : 若 需 要 调 用 工 具 , 则 必 须 基 于 提 供 的 【 工 具 集 】 ( T ool Schemas ) 进 行 选 择 , 禁 止 虚 构 工 具 。 - T ool Dependency : If tool in vocation is needed, selection must be based on the provided [T ool Set] (T ool Schemas); fabricating tools is prohibited. - 禁 止 预 测 动 作 内 容 : 你 仅 输 出 规 划 ( plans ), 而 不 是 真 要 采 取 行 动 , 所 以 禁 止 输 出 具 体 的 JSON 动 作 指 令 ( Actions ) 。 - Prohibition of Pr edicting Action Content : Y ou only output plans, not actually taking action, so outputting specific JSON action instructions (Actions) is prohibited. # 输 出 格 式 # Output Format [ 即 时 意 图 识 别 与 决 策 行 动 规 划 ] [Immediate Intent Recognition and Decision Action Planning] [ 推 演 式 状 态 预 测 , 输 出 格 式必 须 是 : 假 设 / 可 能 ...... ( 出 现 xx 结 果 或 信 息 ) , 这 个 说 明 ...... ( 分 析 ) , 我 可 以 ...... ( 下 一 步 决 策 ) 。 ] [Deductive State Prediction, output format must be: Assuming/Possibly... (xx result or info appears), this indicates... (analysis), I can... (next step decision).] D.3.2 Pr ompt for Rewriting (P A TM Data Construction) Prompt f or Rewriting # 角 色 定 义 # Role Definition 你 是 一 名 资 深 的 改 写 【 多 轮 对 话 】 为 【 行 动 规 划 】 的 改 写 专 家 。 Y ou are a senior rewrite e xpert specializing in rewriting [Multi-turn Dialogues] into [Action Plans]. 你 的 任 务 是 基 于 输 入 的 < 工 单 信 息 > ( ticket_info_content ) 、 < 上 文 信 息 > ( truncation_context_dialogue ) 和 < 三 轮 真 实对 话 > ( ground_truth_dialogue ) 信 息 , Y our task is based on the input < T icket Info > (ticket_info_content), < Context Info > (trunca- tion_context_dialogue), and < Three Ground T ruth Dialogues > (ground_truth_dialogue), 将 < 三 轮 真 实 对 话 > 的 内 容 改 写 为 由 规 划 分 析 过 程 < plans > 与 结 构 化 的 、 可 验 证 的 执 行 动 作 < actions > 两 部 分 组 成 的 【 行 动 规 划 】。 to re write the content of the < Three Ground T ruth Dialogues > into an [Action Plan] consisting of tw o parts: Planning Analysis Process < plans > and Structured, V erifiable Executive Actions < actions > . # 输 入 说 明 # Input Description 1. < 工 单 信 息 > : 产 品名 1. < T icket Info > : Product Name 2. < 上 文 信 息 > : 包 含 「 客 户 」 与 「 客 服 」 的 对 话 交互 历史 , 可 能 包 含 「 客 服 」 调 用 「 工 具 」 的 行 为 信 息 及 对 应 的 「 工 具 」 信 息 。 2. < Context Info > : Contains the dialogue interaction history between "Customer" and "Service Agent", which 21 PRIME AI paper may include the "Service Agent’ s" tool in v ocation behavior and corresponding "T ool" information. 注 意 : 该 部 分 内 容 仅 作 参 考 , 若 与 < 三 轮 真 实对 话 > 内 容 冲 突 , 以 < 三 轮 真 实对 话 > 为 准 。 Note: This part is for reference only; if it conflicts with the < Three Ground T ruth Dialogues > , the < Three Ground T ruth Dialogues > shall prev ail. 3. < 三 轮 真 实 对 话 > : 包 含 「 客 户 」 与 「 客 服 」 交 互 的 三 轮 真 实 对 话 , 其 中 某 一 条 对 话 的 形 式 可 能 为 「 客 服 」 调 用 「 工 具 」 的 行 为 信 息 及 对 应 的 「 工 具 」 信 息 。 3. < Three Ground Truth Dialogues > : Contains three real dialogues exchanged between "Customer" and "Service Agent", where one dialogue format may be the "Service Agent’ s" tool inv ocation behavior and the corresponding "T ool" information. 注 意 : 这 是 需 要 改 写 的 核 心 内 容 。 你 必 须 严 格 遵 守 这 三 轮 真 实对 话 的 前 后 顺 序 , 不 可 跳跃 ; 且 必 须 严 格 忠 于 它 们 的 逻 辑 内 容 , 不 可 擅 自 删 除 、 不 可 编 造 。 Note: This is the core content to be rewritten. Y ou must strictly adhere to the chr onological order of these three r eal dialogues without skipping; and y ou must be strictly faithful to their logical content, without unauthorized deletion or fabrication. 这 部 分 对 话 发 生 在 < 上 文 信 息 > 中 对 话 交互 的 最 后 时 间 。 These dialogues occur at the latest timestamp of the interactions within the < Context Info > . # 核 心 理 念 : 规 划分 析 过 程 < plans > 与 结 构 化 的 、 可 验 证 的 执 行 动 作 < actions > # Core Concept: Planning Analysis Process < plans > and Structured, V erifiable Executi ve Actions < actions > 你 需 要 采 用 一 种 特 殊 的 输 出 模 式 , 将 你 的 “ 规 划 分 析 过 程 < plans > ” 与 “ 结 构 化 的 、 可 验 证 的 执 行 动 作 < actions > ” 彻 底 分 开 。 Y ou need to adopt a special output mode to thoroughly separate your "Planning Analysis Process < plans > " from the "Structured, V erifiable Executi ve Actions < actions > ". - < plans > 块 ( 规 划分 析 ): 这 是 分 析 与 决 策 的 区 域 。 你 将 在 这 里 以 「 我 」 作 为 【 客 服 】 角 色 的 第 一人 称 视角 , 使 用 专业 、 客 观 的 规 划 口 吻 进 行 描 述 。 这 部 分 内 容 用 于 展 现 你 的 专业 判 断 和 决 策 流 程 。 - < plans > Block (Planning Analysis): This is the area for analysis and decision-making. Y ou will describe here using the first-person perspecti ve of "I" as the [Service Agent] role, employing a professional, objecti ve planning tone. This part is used to demonstrate your professional judgment and decision-making process. - < actions > 块 ( 执 行 动 作 ): 这 是 可 执 行 动 作 的 区 域 。 你 将 在 这 里 输 出 严 格 格 式 化 的 、 可 被 机 器 直 接 解 析 和 验 证 的 工 具 调 用 指 令 。 这 部 分 是 评 估 的 重 点 , 必 须 精 确 无 误 。 - < actions > Block (Executive Actions): This is the area for ex ecutable actions. Y ou will output strictly formatted tool in vocation instructions here that can be directly parsed and verified by machines. This part is the focus of ev aluation and must be precise and error -free. 你 的 输 出 必 须 严 格 遵 循 这 两个 部 分 的 结 构 。 Y our output must strictly follow the structure of these tw o parts. # < 核 心 规 则 > # < Core Rules > 1. 整 体 视角 与 口 吻 : 1. Overall Perspecti ve and T one: - 采 用 “ 我 ” 作 为 「 客 服 」 的 第 一人 称 视角 , 但 使 用 专 业 、 客 观 的 规 划 口 吻 来 描 述 决 策 和 计 划 执 行 的 动 作 ( 例 如 “ 我 决 定 调 用 ... ” 或 “ 我 计 划 向 客 户 说 明 ... ” ) 。 - Adopt the first-person perspectiv e of "I" as the "Service Agent", but use a professional, objective planning tone to describe decisions and planned e xecution actions(e.g., "I decided to call..." or "I plan to e xplain to the customer ..."). 避 免 使 用 主 观 猜 测 或 过 于个人 化 的 表 达 ( 如 “ 我 认 为 ” 、 “ 我 感 觉 ” ) 。 A void using subjecti ve guesses or ov erly personal expressions (such as "I think", "I feel"). - 在 描 述 客 观 情 况 或 分 析 时 , 尽 量 使 用 客 观 陈 述 ( 例 如 “ 识 别到 ... ” 或 “ 情 况 表 明 ... ” ) 。 - When describing objecti ve situations or analyses, try to use objecti ve statements (e.g., "Identified that..." or "The situation indicates..."). 2. < plans > 编 写 原 则 ( 规 划分 析 过 程 ): 2. < plans > Writing Principles (Planning Analysis Process): 此 部 分 包 含 两个 子 模 块 : < plan_1 > 和 < plan_2 > 。 这 两个 子 模 块 的 内 容 规 定 如 下 : This section contains two sub-modules: < plan_1 > and < plan_2 > . The content regulations for these two sub-modules are as follows: - < plan_1 > : 22 PRIME AI paper - 仅 能 基 于 < 三 轮 真 实对 话 > 中 的 第 一 条 对 话 内 容 进 行 分 析 与 规 划 形式 的 改 写 。 - Can only rewrite the analysis and planning form based on the content of the first dialogue in the < Three Ground T ruth Dialogues > . - 必 须 包 含 三个 维 度 的 信 息 : 1) 对客 户 问 题 的 识 别分 析 ; 2) 上下 文 信 息 的 关 联 分 析 ; 3) 「 我 」 基 于 分 析 决 定 采 取 的 决 策 依 据 与 细 节 。 - Must include information in three dimensions: 1) Identification and analysis of customer issues ; 2) Correlation analysis of context information ; 3) Basis and details of the decision "I" decided to take based on the analysis . 注 意 : 这 些 维 度 的 信 息 都 必 须 忠 实 地基 于 < 三 轮 真 实对 话 > 中 的 第 一 条 对 话 内 容 。 Note: The information in these dimensions must be faithfully based on the first dialogue content in the < Three Ground T ruth Dialogues > . - < plan_2 > : - 综 合 < 三 轮 真 实对 话 > 中 的 第 二 条 和 第 三 轮 对 话 内 容 进 行 推 演 式 规 划 。 - Synthesize the content of the second and third dialogues in the < Three Ground T ruth Dialogues > for deductiv e planning. - 必 须 包 含 两 个 维 度 的 信 息 : 1 ) 对 < plan_1 > 中 采 取 的 决 策 所 导 致 的 结 果 的 逻 辑 推 演 分 析 或 状 态 判 断 ; 2 ) 由 此 结 果 「 我 」 所 采 取 的 进 一 步 应 对 决 策 的 依 据 与 细 节 。 - Must include information in two dimensions: 1) Logical deduction analysis or status judgment of the results caused by the decision taken in < plan_1 > ; 2) Basis and details of the further r esponse decision "I" take based on this r esult . 注 意 : 这 些 维 度 的 信 息 都 必 须 忠 实 地基 于 < 三 轮 真 实对 话 > 中 的 第 二 条 和 第 三 轮 对 话 内 容 。 Note: The information in these dimensions must be faithfully based on the content of the second and third dialogues in the < Three Ground T ruth Dialogues > . 而 且 必 须 严 格 套 用 推 演 式 句 式 : 例 如 , “ 假 设 / 可 能 . . . . . . ( 描 述 第 二 / 三 轮 对 话 出 现 的 结 果 或 信 息 ) , 这 个 说 明 . . . . . . ( 进 行 逻 辑 分 析 / 状 态 判 断 ), 因 此 , 我 可 以 . . . . . . ( 制 定 下一 步 决 策 ) 。 ” And strictly apply the deductiv e sentence pattern: for example, "Assuming/P ossibly ... (describe the result or information appearing in the 2nd/3rd dialogue), this indicates... (conduct logical analysis/status judgment), theref ore, I can... (formulate the next step decision)." * 这 两个 模 块 的 内 容 都 必 须 为 文 本 格 式 , 并 且 都 必 须 遵 守 以下 原 则 * : *The content of both modules must be in text f ormat and must strictly adher e to the f ollowing principles*: - 用 " 我 " 代 替 " 客 服 " 。 - Use "I" instead of "Service Agent". - 若 在 规 划 内 容 中 调 用 了 工 具 , 必 须 要 说 明 工 具 名 称 - If a tool is called in the planning content, the tool name must be specified - 不 要 出 现 客 户 的 真 实 的 数 据 , 比 如 客 户 的 签 名 , 客 户 的 手 机 等 - Do not re veal the customer’ s real data, such as the customer’ s signature, customer’ s mobile phone, etc. 3. < actions > 编 写 原 则 ( 结 构 化 的 、 可 验 证 的 执 行 动 作 ): 3. < actions > Writing Principles (Structured, V erifiable Executive Actions): 此 块 用 于 存 放 从 < 三 轮 真 实对 话 > 中 识 别 出 的 所 有 工 具 调 用 。 This block is used to store all tool calls identified from the < Three Ground T ruth Dialogues > . - 如 果 < 三 轮 真 实对 话 > 中 任 何 一 条 包 含 了 工 具 调 用 ( 以 JSON 格 式 出 现 ) , 则 必 须 将 其 转 换 为下 方 指 定 的 action: call_tool 格 式 , 并 放 入 < actions > 块 内 。 - If any one of the < Three Ground T ruth Dialogues > contains a tool call (usually appearing in JSON format), it must be conv erted to the action: call_tool format specified below and placed inside the < actions > block. - 如 果 < 三 轮 真 实对 话 > 中 没 有 任 何 工 具 调 用 , 则 < actions > 仅 包 含 一个 空 的 数 组 [] 。 - If there are no tool calls in the < Three Ground T ruth Dialogues > , then < actions > contains only an empty array [] . - 严 禁 在 此 块 内 添 加 任 何 自 然 语 言 描 述 。 - Strictly prohibit adding an y natural language descriptions within this block. 4. 脱 敏 规 则 : 4. Desensitization Rules: - < plans > 内 部 严 禁 出 现 任 何 真 实 敏 感 数 据 ( 如 手 机 号 、 签 名 名 称 、 UID 等 ) , 若 需 要 提 及 , 则 统 一 使 用 “ 手 机 号 ” 、 “ 客 户 签 名 ” 、 “ 用 户 的 账 号 ID” 等 代 称 。 23 PRIME AI paper - Strictly prohibit the appearance of any real sensiti ve data (such as mobile numbers, signature names, UIDs, etc.) inside < plans > ; if mention is needed, unify the use of aliases like "mobile number", "customer signature", "user account ID", etc. - < actions > 内 部 保 留 真 实 数 据 , 确 保 工 具 调 用 的 参 数 完 整 准 确 , 可 供 机 器 解 析 。 - < actions > internally retains real data to ensure tool call parameters are complete and accurate for machine parsing. # < 输 出 格 式 规 范 > # < Output Format Specification > 请 严 格 按 照 以下 XML 格 式 输 出 , 不 要 包 含 任 何 其 他 格 式 或 描 述 性 文 字 。 Please strictly follow the XML format belo w , do not contain any other format or descripti ve text. [ 此 处 填 写 第 一 段 规 划 的 纯 文 本 格 式 内 容 ] [Fill in the plain-text content of the first planning section here] [ 此 处 填 写 第 二 段 规 划 的 纯 文 本 格 式 内 容 , 句 式必 须 为 : 假 设 / 可 能 ...... ( 出 现 xx 结 果 或 信 息 ), 这 个 说 明 ...... ( 分 析 ), 我 可 以 ...... ( 下一 步 决 策 ) 。 ] [Fill in the plain-text content of the second planning section here. The sentence pattern must be: Assume/It is possible that ...(xx result or inform- ation appears), this indicates ... (analysis), I can ... (next-step decision).] [ 此 处 填 写 从 对 话 中 提 取 并 转 换 格 式 后 的 工 具 调 用 JSON , 若 无 则 为 空 数 组 ‘[]‘] [Fill in the tool-call JSON extracted from the conversation and converted into the required format here; if none, use an empty array ‘[]‘] D.3.3 Pr ompt for Rewriting Quality Check Prompt f or Rewriting Quality Check # 角 色 定 义 # Role Definition 你 是 一 名 资 深 的 多 轮 对 话 分 析 专 家 与 内 容 合 规 审 计 员 。 Y ou are a senior multi-turn dialogue analysis expert and content compliance auditor . 我 会 提 供 给 你 < 工 单 信 息 > ( ticket_info ) 、 < 上 文 信 息 > (context) 、 < 三 轮 真 实对 话 > ( ground_truth ) 以 及 模 型 根 据 < 三 轮 真 实对 话 > 改 写 得 到 的 规 划 形式 的 输 出 < 待 评 测 的 改 写 > ( model_output ) 。 I will provide you with < T icket Info > (ticket_info), < Context Info > (context), < Three Ground T ruth Dialogues > (ground_truth), and the planning-format output re written by the model based on the < Three Ground T ruth Dialogues > , labeled as < Rewritten Output for Ev al > (model_output). 你 的 任 务 是 评 估 模 型 生 成 的 改 写 < 待 评 测 的 改 写 > ( model_output ) 是 否 契 合 业 务 内 容 逻 辑 , 是 否 严 格 遵 守 了 特 定 的 规 划 格 式 、 推 演 句 式 及 脱 敏 规 范 。 Y our task is to e v aluate whether the model-generated re writing < Rewritten Output f or Ev al > (model_output) fits the business content logic and strictly adheres to specific planning formats, deducti ve sentence structures, and anonymization specifications. # < 输 入 说 明 > # < Input Description > 1. < 工 单 信 息 > : 产 品名 1. < T icket Info > : Product Name 2. < 上 文 信 息 > : 包 含 「 客 户 」 与 「 客 服 」 的 对 话 交互 历史 , 可 能 包 含 「 客 服 」 调 用 「 工 具 」 的 行 为 信 息 及 对 应 的 「 工 具 」 信 息 。 24 PRIME AI paper 2. < Context Info > : Contains the dialogue interaction history between "Customer" and "Service Agent", which may include the "Service Agent’ s" tool in v ocation behavior and corresponding "T ool" information. 注 意 : 该 部 分 内 容 仅 作 参 考 , 若 与 < 三 轮 真 实对 话 > 内 容 冲 突 , 以 < 三 轮 真 实对 话 > 为 准 。 Note: This part is for reference only; if it conflicts with the < Three Ground T ruth Dialogues > , the < Three Ground T ruth Dialogues > shall prev ail. 3. < 三 轮 真 实 对 话 > : 包 含 「 客 户 」 与 「 客 服 」 交 互 的 三 轮 真 实 对 话 , 其 中 某 一 条 对 话 的 形 式 可 能 为 「 客 服 」 调 用 「 工 具 」 的 行 为 信 息 及 对 应 的 「 工 具 」 信 息 。 3. < Three Ground Truth Dialogues > : Contains three real dialogues exchanged between "Customer" and "Service Agent", where one dialogue format may be the "Service Agent’ s" tool inv ocation behavior and the corresponding "T ool" information. 4. < 待 评 测 的 改 写 > : 根 据 < 三 轮 真 实对 话 > 改 写 得 到 的 规 划 形式 的 内 容 , 包 含 < plans > ( 分 段 规 划 ) 与 < actions > ( 结 构 化 动 作 ) 两 部 分 , 4. < Rewritten Output for Eval > : Content in planning format re written based on < Three Ground Truth Dialogues > , containing two parts: < plans > (segmented planning) and < actions > (structured actions), 其 中 < plans > 包 含 < plan_1 > 和 < plan_2 > 两个 子 部 分 ; < actions > 包 含 从 对 话 中 提 取 并 转 换 格 式 后 的 工 具 调 用 JSON , 若 无 则 为 空 数 组 [] 。 where < plans > contains two sub-parts < plan_1 > and < plan_2 > ; < actions > contains tool in vocation JSON extracted and reformatted from the dialogue, or an empty array [] if none exists. # < 核 心 审 计 维 度 与 标 准 > # < Core Audit Dimensions and Standards > 1. 逻 辑 与 路 径 一 致 性 (logic_consistency) 1. Logic and Path Consistency (logic_consistency) - 分 段 隔 离 性 : 在 < 待 评 测 的 改 写 > 的 < plans > 部 分 中 , < plan_1 > 和 < plan_2 > 两个 子 部 分 的 内 容 逻 辑 必 须 符 合 以下 标 准 : - Segment Isolation : In the < plans > section of the < Rewritten Output for Ev al > , the content logic of the two sub-parts < plan_1 > and < plan_2 > must meet the following standards: - < plan_1 > : 必 须 仅 基 于 < 三 轮 真 实对 话 > 中 的 第 一 条 对 话 , 结 合 < 上 文 信 息 > 进 行 分 析 。 严 禁 预 知 或 引 用 后 文 信 息 ( < 三 轮 真 实对 话 > 中 的 第 二 、 三 轮 对 话 ) 。 - < plan_1 > : Must be analyzed solely based on the first dialogue in < Three Ground Truth Dialogues > combined with < Context Info > . Strictly prohibited from foreseeing or citing subsequent information (the second and third dialogues in < Three Ground T ruth Dialogues > ). - < plan_2 > : 必 须 综 合 < 三 轮 真 实对 话 > 中 的 第 二 、 三 轮 对 话 内 容 进 行 逻 辑 推 演 。 - < plan_2 > : Must synthesize the content of the second and third dialogues in < Three Ground Truth Dialogues > for logical deduction. - 决 策 准 确 性 : 改 写 后 的 规 划 < plans > 必 须 真 实 反 映 客 服 的 意 图 , 严 禁 编 造 对 话 中 不 存 在 的 工 具 、 参 数 或 业 务 结 论 。 - Decision Accuracy : The rewritten plan < plans > must truly reflect the intention of the service agent; fabricating tools, parameters, or business conclusions not present in the dialogue is strictly prohibited. - 工 具关 联 : 在 < plans > 中 提 到 工 具 调 用 时 , 必 须 指 明 具 体 的 工 具 名 称 ( 如 : “ 调 用 ‘XX 工 具 ’” 而 非 “ 调 用 工 具 ” ) , 禁 止 完 全 不 指 明 具 体 的 工 具 名 称 而 仅仅 笼 统 地 提 及 “ 调 用 工 具 ” 。 - T ool Association : When a tool call is mentioned in < plans > , the specific tool name must be specified (e.g., "Call ’XX T ool’" instead of "Call T ool"); purely vague references to "Call T ool" without specifying the name are prohibited. 以上 三 轮 标 准 若 全 部 符 合 , 则 此 维 度 ( logic_consistency ) 得 1 分 ; 若 有 任 意 标 准 不 符 合 , 则 得 0 分 , 并 说 明 不 符 合 的 地 方 。 If all three standards abov e are met, this dimension (logic_consistency) gets 1 point; if any standard is not met, it gets 0 points, and the non-compliance must be explained. 2. 句 式 与 口 吻 规 范 (phrasing_check) 2. Phrasing and T one Standards (phrasing_check) - 视角要 求 : 必 须 采 用 「 我 」 作 为 「 客 服 」 角 色 的 第 一人 称 视角 , 严 禁 在 输 出 中 直 接提 及 “ 根 据 第 一 条 对 话 ” 、 “ 第 x 条 内 容 ” 或 “ 根 据 ground truth” 等 描 述 。 - Perspective Requirement : Must adopt the first-person perspective of "I" as the "Service Agent"; strictly prohibited from directly mentioning descriptions like "according to the first dialogue", "content of article x", or "according to ground truth" in the output. 25 PRIME AI paper - 规 划 的 客 观 性 : 口 吻 需 专业 、 客 观 , 禁 止 主 观 臆 断 ( 严 禁 使 用 “ 我 觉 得 ” 、 “ 我 感 觉 ” ) 。 - Objectivity of Planning : The tone must be professional and objectiv e; subjective assumptions are prohibited (strictly forbid using "I think", "I feel"). - 推 演 句 式 强 制 性 : < plan_2 > 的 内 容 逻 辑 必 须 严 格 符 合 先 假 设 , 再 分 析 , 再 决 策 的 推 演 格 式 , 该 格 式 必 须 按 照 如 下 格 式 : “ 假 设 / 可 能 . . . . . . ( 描 述 信 息 ) , 这 说 明 . . . . . . ( 逻 辑 分 析 ) , 因 此 , 我 可 以 . . . . . . ( 决 策 ) 。 ” - Mandatory Deductive Sentence Structure : The content logic of < plan_2 > must strictly adhere to the deductiv e format of First Assume, Then Analyze, Then Decide , following the format: "Assuming/Possibly ... (describe info), this indicates... (logical analysis), therefore, I can... (decision)." 以上 三 轮 标 准 若 全 部 符 合 , 则 此 维 度 ( phrasing_check ) 得 1 分 ; 若 有 任 意 标 准 不 符 合 , 则 得 0 分 , 并 说 明 不 符 合 的 地 方 。 If all three standards above are met, this dimension (phrasing_check) gets 1 point; if any standard is not met, it gets 0 points, and the non-compliance must be explained. 3. 规 划 脱 敏 (plans_anonymized) 3. Planning Anonymization (plans_anonymized) < plans > 块 必 须 脱 敏 , 中严 禁 出 现 真 实 手 机 号 、 UID 、 具 体 域 名 、 客 户 签 名 、 详 细 地 址 等 隐 私 数 据 。 若 被 提 及 相 关 信 息 , 必 须 使 用 “ 客 户手 机 号 ” 、 “ 用 户 账 号 ID” 、 “ 客 户 签 名 ” 等 泛 用 代 称 指 代 。 The < plans > block must be anonymized; real mobile numbers, UIDs, specific domain names, customer signatures, detailed addresses, and other priv acy data are strictly prohibited. If rele vant information is mentioned, generic aliases such as "customer mobile number", "user account ID", "customer signature" must be used. 该 项 标 准 若 符 合 , 则 此 维 度 ( plans_anonymized ) 得 1 分 ; 若 不 符 合 , 则 得 0 分 , 并 说 明 不 符 合 的 地 方 。 If this standard is met, this dimension (plans_anonymized) gets 1 point; if not met, it gets 0 points, and the non-compliance must be explained. 4. 动 作保 留 (actions_preserv ed) 4. Action Preserv ation (actions_preserved) < actions > 块 严 禁 脱 敏 , 必 须 保 留 原 始 JSON 中 的 所 有 真 实 数 据 。 不 可 出 现 仅 用 “ 客 户手 机 号 ” 、 “ 用 户 账 号 ID” 、 “ 客 户 签 名 ” 等 代 称 , 必 须 使 用 具 体 的 真 实 信 息 。 The < actions > block is strictly prohibited from anon ymization and must retain all real data from the original JSON. Do not use aliases like "customer mobile number", "user account ID", or "customer signature"; specific real information must be used. 该 项 标 准 若 符 合 , 则 此 维 度 ( actions_preserved ) 得 1 分 ; 若 不 符 合 , 则 得 0 分 , 并 说 明 不 符 合 的 地 方 。 If this standard is met, this dimension (actions_preserved) gets 1 point; if not met, it gets 0 points, and the non-compliance must be explained. 5. 动 作 执 行 准 确 性 (Action Accuracy) 5. Action Execution Accuracy (Action Accuracy) - 提 取 完 整 性 : 真 实对 话 中 出 现 的 所 有 工 具 调 用 必 须 全 部 转 换 并 放 入 < actions > 。 若 无 工 具 , 则 必 须 输 出 [] 。 - Extraction Completeness : All tool calls appearing in the real dialogue must be con verted and placed in < actions > . If there are no tools, [] must be output. - 数 据 一 致 性 : < actions > 中 的 参 数 ( 如 uid 等 ) 必 须 与 原 始 输 入 中 的 JSON 数 据 完 全 一 致 , 不 可 有 任 何 区 别 。 - Data Consistency : Parameters in < actions > (such as ID, etc.) must be exactly consistent with the JSON data in the original input, without any dif ference. 以上两 条 标 准 若 全 部 符 合 , 则 此 维 度 ( actions_accuracy ) 得 1 分 ; 若 有 任 意 标 准 不 符 合 , 则 得 0 分 , 并 说 明 不 符 合 的 地 方 。 If both standards abo ve are met, this dimension (actions_accurac y) gets 1 point; if an y standard is not met, it gets 0 points, and the non-compliance must be explained. # < 输 出 格 式 要 求 > # < Output Format Requirements > 请 直 接 输 出 JSON 格 式 的 评 估 报 告 , 不 要 包 含 任 何 Markdown 代 码 块 标 记 或 前 导 文 字 。 格 式 如 下 : Please output the e valuation report directly in JSON format, do not include an y Markdown code block tags or 26 PRIME AI paper leading text. The format is as follows: { "logic_consistency": { "score": {{score_of_logic_consistency}}, "details": "{If non-compliant, state the place and reason here}" }, "phrasing_check": { "score": {{score_of_phrasing_check}}, "details": "{If non-compliant, state the place and reason here}" }, "plans_anonymized": { "score": {{score_of_plans_anonymized}}, "details": "{If non-compliant, state the place and reason here}" }, "actions_preserved": { "score": {{score_of_actions_preserved}}, "details": "{If non-compliant, state the place and reason here}" }, "actions_accuracy": { "score": {{score_of_actions_accuracy}}, "details": "{If non-compliant, state the place and reason here}" }, "violation_list": "{List all violations, or leave empty if none}" } D.3.4 Pr ompt for Adding Backward CoT (DRA) Prompt f or Adding Backward CoT # 角 色 # Role 你 是 一 名 资 深 的 客 服 逻 辑 建 模 专 家 , 擅 长 将 【 历 史 对 话 】 ( dialogue_history ) 、 【 客 服 行 动 规 划 】 ( plans ) 和 【 其 他 信 息 】 ( other_information ) 整 合 为 深 度 的 、 结 构 化 的 思 维 链 条 。 Y ou are a senior customer service logic modeling expert, skilled at integrating [Dialogue History] (dia- logue_history), [Customer Service Action Plans] (plans), and [Other Information] (other_information) into a deep, structured chain of thought. # 任 务 # T ask 你 的 任 务 是 补 全 【 推 理 过 程 内 容 】 ( reasoning_content ) 。 Y our task is to complete the [Reasoning Content] (reasoning_content). 你 需 要 结 合 【 历 史 对 话 】 、【 其 他 信 息 】 , 深 入 剖 析 【 客 服 行 动 规 划 】 背 后 的 决 策 逻 辑 , 以 第 一 人 称 ( 我 ) 还 原 客 服 在 执 行 这 些 动 作 时 的 完 整 思 考 路 径 。 Y ou need to combine [Dialogue History] and [Other Information] to deeply analyze the decision logic behind the [Customer Service Action Plans], reconstructing the complete thought path of the service agent when ex ecuting these actions from the first-person perspectiv e ("I"). # 输 入 数 据 # Input Data 1. 【 历史 对 话 】 ( dialogue_history ) : 包 含 【 客 户 】 与 【 客 服 】 以 及 【 工 具 】 的 对 话 和 交互 历 史 记 录 。 < 上 文 信 息 > 中 最 后 一 轮 的 【 客 户 】 输 入 定 义为 「 当 前 客 户 问 题 」。 1. [Dialogue History] (dialogue_history) : Contains the dialogue and interaction history between [Customer], [Service Agent], and [T ools]. The last round of [Customer] input in < Context Info > is defined as the "Current Customer Question". 2. 【 客 服 行 动 规 划 】 (plans) : 这 是 你 要解 释 的 “ 标 准 答 案 ” , 包 含 : 27 PRIME AI paper 2. [Customer Service Action Plans] (plans) : This is the "Standard Answer" you need to explain, containing: 2.1 < plan_1 > ( 即 时 意 图 识 别 与 决 策 行 动 规 划 ): 2.1 < plan_1 > (Immediate Intent Recognition and Decision Action Planning): - 视角 : 以 「 我 」 作 为 【 客 服 】 的 第 一人 称 视角 。 - Perspectiv e: First-person perspectiv e using "I" as the [Service Agent]. - 内 容 : 识 别 【 客 户 】 的 「 当 前 客 户 问 题 」 中 所 表 达 的 疑 问 或 诉 求 ; 结 合 【 历史 对 话 】 和 【 工 单 信 息 】 判 断 信 息 是 否 完 整 ; 明 确 说 明 为 了 解 决 此 问 题 , 「 我 」 决 定 执 行 什 么 动 作 ( 如 向 【 客 户 】 进 一 步 确 认 某 信 息 , 或 调 用 某 【 工 具 】 , 并 说 明 原 因 ) 。 - Content: Identify the doubts or demands expressed in the [Customer]’ s "Current Customer Question"; combine [Dialogue History] and [T icket Info] to judge if information is complete; e xplicitly state what action "I" decide to execute to solve this problem (such as confirming specific information with the [Customer], or calling a specific [T ool], and explaining the reason). 2.2 < plan_2 > ( 推 演 式 状 态 预 测 ): 2.2 < plan_2 > (Deductive State Pr ediction): - 视角 : 以 「 我 」 作 为 【 客 服 】 的 第 一人 称 视角 。 - Perspectiv e: First-person perspectiv e using "I" as the [Service Agent]. - 内 容 : 分 析 推 演 「 我 」 在 采 取 了 < plan_1 > 中 规 划 的 行 动 后 , 可 能 获 得 对 应 的 何 种 反 馈 ( 例 如 , 向 客 户 进 一 步 确 认 某 信 息 后 , 【 客 户 】 可 能 如 何 回 复 我 , 一 般 认 为 【 客 户 】 会 提 供 给 「 我 」 需 要 确 认 的 信 息 ; 或 调 用 某 【 工 具 】 后 , 【 工 具 】 可 能 输 出 何 种 返 回 内 容 ) , 以 及 得 到 对 应 的 反 馈 结 果 后 , 「 我 」 对 反 馈 的 分 析 以 及 基 于 此 分 析 制 定 进 一 步 的 应 对 行 动 。 - Content: Analyze and deduce what corresponding feedback "I" might receive after taking the action planned in < plan_1 > (e.g., how the [Customer] might reply to me after I confirm info, generally assuming the [Customer] will provide the info "I" need; or what return content the [T ool] might output after calling a specific [T ool]), and after recei ving the corresponding feedback result, "I" analyze the feedback and formulate further response actions based on this analysis. 3. 【 其 他 信 息 】 (refer ence_info & a vailable_tools) : 搜 索 到 的 技 术 文 档 和 可 用 的 工 具 说 明 。 3. [Other Information] (r eference_inf o & available_tools) : Searched technical documents and av ailable tool descriptions. # 推 理 框 架 ( 补 全 要 求 ) # Reasoning Framew ork (Completion Requirements) 生 成 的 reasoning_content 必 须 逻 辑 严 密 , 并 涵 盖 以下 维 度 : The generated reasoning_content must be logically rigorous and cov er the following dimensions: 1. 现 状 透 视 : 分 析 「 当 前 客 户 问 题 」 中 客 户 遇 到 了 什 么 具 体 的 技 术 或 业 务 问 题 。 结 合 【 历 史 对 话 】 , 判 断 当 前 处 理 到 了 哪 一 步 , 是 否 存 在 信 息 断 层 。 1. Current Situation Perspective : Analyze what specific technical or business problem the customer encountered in the "Current Customer Question". Combine with [Dialogue History] to judge the current processing step and if there are information gaps. 2. 知 识 关 联 : 将 【 客 服 行 动 规 划 】 中 的 决 策 与 【 其 他 信 息 】 进 行 关 联 。 例 如 : 为 什 么 选 择 这 个 工 具 ? 是 因 为 文 档 里 提 到 了 某 种 排 查 逻 辑 吗 ? 2. Knowledge Association : Associate the decisions in [Customer Service Action Plans] with [Other Information]. For example: Why choose this tool? Is it because the document mentioned a specific troubleshooting logic? 3. 规 划 对 齐 ( 核 心 ) : 3. Plan Alignment (Core) : - < plan_1 > 逻 辑还 原 : 解 释 为什么 在 看 到 「 当 前 客 户 问 题 」 时 , 必 须 做 出 < plan_1 > 分 析 。 重 点 说 明 决 策 的 必 要 性 。 - < plan_1 > Logic Restoration : Explain why the < plan_1 > analysis must be made when seeing the "Current Customer Question". Focus on explaining the necessity of the decision. - < plan_2 > 逻 辑 推 演 : 解 释 < plan_2 > 中 出 现 的 “ 假 设 / 结 果 ” 是 如 何 转 化 成 下 一 步 具 体 动 作 的 。 要 体 现 出 逻 辑 的 连 贯 性 和 推 导 过 程 。 - < plan_2 > Logic Deduction : Explain ho w the "Assumption/Result" appearing in < plan_2 > transforms into the next specific action. Demonstrate logical coherence and the deduction process. # 限 制 & 规 则 # Constraints & Rules - 第 一人 称 : 必 须 以 “ 我 ” 作 为 客 服 视角 编 写 。 28 PRIME AI paper - First Person : Must be written from the perspectiv e of the service agent using "I". - 严 禁 脱 节 : 推 理 过 程 必 须 与 < 客 服 行 动 规 划 > 中 的 内 容 保 持 100% 的 逻 辑 一 致 性 , 不 能 出 现 与 GT 冲 突 的 推 论 。 - No Disconnection : The reasoning process must maintain 100% logical consistency with the content in < Customer Service Action Plans > and cannot hav e inferences conflicting with GT (Ground T ruth). - 专业 口 吻 : 使 用 专业 术 语 , 描 述 客 观 、 严 谨 , 避 免 情 绪 化 表 达 。 - Professional T one : Use professional terminology; descriptions should be objectiv e and rigorous, avoiding emotional expression. - 脱 敏 原 则 : 在 描 述 逻 辑 时 , 严 禁 出 现 真 实 手 机 号 、 UID 、 签 名 名 称 等 敏 感 数 据 , 统 一 使 用 代 称 ( 如 “ 用 户 的 UID” ) 。 - Desensitization Principle : When describing logic, strictly prohibit real mobile numbers, UIDs, signature names, and other sensitiv e data; use aliases uniformly (e.g., "User’ s UID"). # 输 出 格 式 # Output Format 直 接 输 出 一 段 无 结 构 化 的 纯 文 本 ( reasoning_content ), 无 需 XML 标 签 。 Directly output a block of unstructured plain text (reasoning_content), without XML tags. D.3.5 Pr ompt for Planning Quality Check Prompt f or Planning Quality Check # 角 色 定 位 # Role Positioning 你 是 一 名 资 深 的 多 轮 对 话 分 析 专 家 与 合 规 审 计 员 。 你 的 任 务 是 根 据 特 定 规 范 , 严 格 审 计 模 型 生 成 的 < plans > 模 块 ( 包 含 < plan_1 > 和 < plan_2 > ) 的 合 规 性 、 逻 辑 推 演 句 式 及 脱 敏 质 量 。 Y ou are a senior multi-turn dialogue analysis expert and compliance auditor . Y our task is to strictly audit the compliance, logical deduction sentence structures, and anonymization quality of the < plans > module (containing < plan_1 > and < plan_2 > ) generated by the model according to specific specifications. # < 评 估 维 度 与 评 分 标 准 > # < Evaluation Dimensions and Scoring Standards > ## 维 度 1 : 规 划 合 规 性 (Compliance Score) ## Dimension 1: Planning Compliance (Compliance Score) 1. < plan_1 > ( 意 图 识 别 与 决 策 ) : 必 须 包 含 : ① 识 别 客 户 诉 求 ; ② 判 断 上下 文 信 息 完 整 性 ; ③ 明 确 具 体 决 策 ( 例 如 含 调 用 工 具 时 要 准 确 工 具 名 , 若 选 择 询 问 信 息 则 明 确 要 询 问 的 具 体信 息 ) 。 1. < plan_1 > (Intent Recognition and Decision): Must include: 1) Identify customer appeals; 2) Judge the completeness of context information; 3) Clarify specific decisions (e.g., accurately state the tool name if in volving tool calls, or specify the information to ask if choosing to inquire). 2. < plan_2 > ( 推 演 式 预 测 ) : 必 须 包 含 : ① 对 < plan_1 > 结 果 的 预 判 ; ② 对 预 判 结 果 的 分 析 ; ③ 基 于 分 析 的 后 续 计 划 。 2. < plan_2 > (Deductive Pr ediction): Must include: 1) Prediction of the result of < plan_1 > ; 2) Analysis of the predicted result; 3) Follo w-up plan based on the analysis. * 评 分 标 准 ( 1 分 /0 分 ): * Scoring Standards (1 point/0 points): * 1 分 : < plan_1 > 和 < plan_2 > 均 完 整 包 含 上 述 所 有 要 素 , 且 < plan_1 > 提 到 的 动 作 / 工 具 在 < plan_2 > 中 得 到 了 逻 辑 对 应 的 推 演 。 * 1 P oint: < plan_1 > and < plan_2 > completely contain all the abo ve elements, and the actions/tools mentioned in < plan_1 > hav e logically corresponding deductions in < plan_2 > . * 0 分 : 缺 少 任 何 一个 要 素 ( 如 未 写 工 具 名 、 未 分 析 预 判 结 果 ) 或 < plan_1 > 与 < plan_2 > 逻 辑 断 层 。 * 0 Points: Missing any element (e.g., tool name not written, predicted result not analyzed) or there is a logical gap between < plan_1 > and < plan_2 > . ## 维 度 2 : 句 式 规 范 性 (Structure Score) ## Dimension 2: Structural Regularity (Structure Score) 29 PRIME AI paper 1. 第 一人 称 限 定 : 必 须 且仅 能 使 用 「 我 」 进 行 自 我 指 称 。 1. First-person Limitation: Must and can only use "I" for self-reference. * 评 分 标 准 : 若 出 现 【 客 服 】 、【 机 器 人 】 、 【 人 工 】 等 称 呼 , 或 使 用 第 三 人 称 , 该 项 判 定 为 不 合 格 。 * Scoring Standard: If terms like [Service Agent], [Robot], [Manual] appear , or third-person perspectiv e is used, this item is judged as non-compliant. 2. 客 观 口 吻 与 去 引 用 化 : 严 禁 主 观 臆 断 词 ( 我 觉 得 、 大 概 、 应 该 是 ) ; 严 禁 引 用 对 话 序 号 或 位 置 ( 如 “ 第 一 条 用 户 说 ” 、 “ 前 述 内 容 ” ) 。 2. Objective T one and Citation Removal: Subjectiv e assumption words (I feel, probably , should be) are strictly prohibited; citing dialogue sequence numbers or positions (e.g., "The first user said", "The aforementioned content") is strictly prohibited. * 评 分 标 准 : 若 出 现 上 述 主 观 词 或 引 用 序 号 , 该 项 判 定 为不 合 格 。 * Scoring Standard: If the above subjecti ve words or citation sequence numbers appear , this item is judged as non-compliant. 3. 推 演 三 段 论 引 导 词 : < plan_2 > 必 须 严 格 包 含 “ 假 设 / 可 能 . . . . . . ” 、 “ 这 个 说 明 . . . . . . ” 、 “ 因 此 , 我 可 以 . . . . . . ” 这 个 逻 辑 短 语 。 3. Deductiv e Syllogism Keywords: < plan_2 > must strictly contain the logical phrases: "Assuming/Possi- bly ...", "This indicates...", "Therefore, I can...". * 评 分 标 准 : 缺 少 任 何 一个 引 导 词 , 或 引 导 词 顺 序 错 误 , 该 项 判 定 为不 合 格 。 * Scoring Standard: Missing any leading word, or incorrect order of leading words, this item is judged as non-compliant. * 本 维 度 综 合 评 分 ( 1 分 /0 分 ): * Comprehensi ve Score f or this Dimension (1 point/0 points): * 1 分 : 以上 1 、 2 、 3 项 要 求 全 部 满 足 。 * 1 Point: All requirements of items 1, 2, and 3 above are met. * 0 分 : 以上任 何 一 项 不 满 足 。 * 0 Points: Any of the abov e items is not met. ## 维 度 3 : 脱 敏 合 规 性 (Anonymization Score) ## Dimension 3: Anonymization Compliance (Anonymization Score) 1. 脱 敏 对 象 : 严 禁 出 现 真 实 手 机 号 、 UID 、 身 份 证 号 、 具 体 域 名 、 企 业 签 名名 称 、 原 始 秘 钥 、 详 细 住 址 等 隐 私 数 据 。 1. Anonymization Objects: Strictly prohibit real mobile numbers, UIDs, ID numbers, specific domain names, enterprise signature names, original keys, detailed addresses, and other pri v acy data. 2. 代 称 要 求 : 必 须 使 用 通 用 代 称 ( 如 “ 用 户手 机 号 ” 、 “ 某 域 名 ” 、 “ 该 UID” ) 。 2. Alias Requirements: Must use generic aliases (e.g., "user mobile number", "a certain domain name", "this UID"). * 评 分 标 准 ( 1 分 /0 分 ): * Scoring Standards (1 point/0 points): * 1 分 : 全 文无 任 何 真 实 隐 私 泄 露 , 脱 敏 彻 底 。 * 1 Point: There is no real priv acy leakage in the full text, and anon ymization is thorough. * 0 分 : 出 现 哪 怕 一 项 真 实 隐 私 数 据 ( 如 一个 11 位 手 机 号 或 具 体 网 址 ) 。 * 0 Points: Even a single piece of real privac y data appears (such as an 11-digit mobile number or specific URL). # < Judge 执 行 逻 辑 > # < Judge Execution Logic > 1. 文 本 提 取 : 定 位 模 型 输 出 中 的 < plan_1 > 和 < plan_2 > 标 签 内 容 。 1. T ext Extraction: Locate the content of < plan_1 > and < plan_2 > tags in the model output. 2. 负 面 约 束 扫 描 : 检 索 是 否 存 在 “ 客 服 ” 、 “ 我 觉 得 ” 、 “ 对 话 [n]” 、 以 及 符 合 手 机 号 / 域 名 特 征 的 字 符 串 。 2. Negative Constraint Scanning: Scan for the existence of "Service Agent", "I feel", "Dialogue [n]", and strings matching mobile number/domain name characteristics. 3. 关 键 词 强 制 扫 描 : 搜 索 < plan_2 > 是 否 按 序 包 含 “ 假 设 / 可 能 ” 、 “ 这 个 说 明 ” 、 “ 因 此 , 我 可 以 ” 。 3. Keyw ord Mandatory Scanning: Search whether < plan_2 > contains "Assuming/Possibly", "This indicates", "Therefore, I can" in order . 4. 逻 辑 核 验 : 评 估 < plan_1 > 的 动 作 是 否 作 为 < plan_2 > 的 假 设 前 提 。 30 PRIME AI paper 4. Logic V erification: Evaluate whether the action in < plan_1 > serves as the hypothetical premise for < plan_2 > . # < 输 出 格 式 要 求 > # < Output Format Requirements > 请 直 接 输 出 JSON 格 式 的 评 估 报 告 , 格 式 严 格 如 下 : Please output the ev aluation report directly in JSON format, the format is strictly as follo ws: { "scores": { "compliance_score": 0, "structure_score": 0, "anonymization_score": 0 }, "total_score": 0, "analysis": { "compliance": " 详 细 说 明 plan_1 和 plan_2 的 要 素 齐 备 情 况 及 逻 辑 关 联 性 / Detailed explanation of elements completeness and logical association of plan_1 and plan_2", "structure": " 具 体 指 出 第 一人 称 使 用 、 主 观 词 / 序 号 规 避 以 及 三 段 论 引 导 词 的 执 行 情 况 / Specifically point out the use of first person, avoidance of subjective words/sequence numbers, and execution of syllogism keywords", "anonymization": " 详 细 列 出 脱 敏 执 行 的 彻 底 程 度 / Detailed list of the thoroughness of anonymization execution" }, "violation_details": " 若 有 扣 分 , 逐 条 列 出具 体 违 规 的 句 子 、 关 键 词 或 缺 失 的 要 素 ; 若 满 分 则 填 ’ 无 ’ / If points deducted, list specific violating senten- ces, keywords or missing elements one by one; if full score, fill ’None’", "final_judgment": " 一 句 话 总 结 整 体 评 估 结 果 , 需 指 出 是 否 通 过 审 核 / One sentence summary of the overall evaluation result, need to point out whether it passed the audit" } D.3.6 Pr ompt for Model Ev aluation (Mid-T rain) Prompt f or Model Evaluation # 1. 角 色 # 1. Role 你 是 一 位 资 深 的 客 户 服 务 规 划 内 容 一 致 性 判 别 专 家 , 拥 有 权 威 的 技 术 知 识 、 对客 服 务 政 策 的 精 确 把 握 以 及 丰 富 的 客 户 沟 通 经 验 。 Y ou are a senior customer service planning content consistency judgment expert, possessing authoritativ e technical knowledge, precise grasp of customer service policies, and rich customer communication experience. 你 的 判 断 标 准 严 谨 、 公 正 , 旨 在 维 护 服 务 口 径 的 统 一 性 与专业 性 。 Y our judgment standards are rigorous and fair , aiming to maintain the consistency and professionalism of service standards. # 2. 核 心 目 标 # 2. Core Goal 你 正 在 执 行 一 项 关 键 的 规 划 一 致 性 判别 任 务 。 Y ou are ex ecuting a critical Planning Consistency Judgment task. 你 需 要 深 度 分 析 “ 模 型 生 成 规 划 ” , 并 将 其 与从 真 实 对 话 中 提 炼 出 的 “ 金 标 规 划 ” 进 行 比 较 , 最 终 判 别 这 两份 规 划 的 逻 辑 与 执 行 路 径 的 一 致 性 程 度 , 并 在 存 在 差 异 时 给 出 清 晰 的 原 因 说 明 。 31 PRIME AI paper Y ou need to deeply analyze the "Model Generated Plan" and compare it with the "Gold Standard Plan" e xtracted from real dialogues, ultimately judging the consistency degree of logic and ex ecution paths between these two plans, and providing clear e xplanations when differences e xist. # 3. 一 致 性 评 估 维 度 # 3. Consistency Ev aluation Dimensions 请 你 基 于以下 3 个 核 心 维 度 , 对 两份 规 划 进 行 对 比 分 析 , 并 对 每 一 维 度 给 出 文 字 评语说 明 差 异 点 : Please conduct a comparativ e analysis of the two plans item by item based on the following 3 core dimensions, and provide te xt comments explaining the dif ferences for each dimension: • 当 前 决 策 一 致 性 (current_decision) Current Decision Consistency (curr ent_decision) 规 划 中 的 第 一 步 行 动 决 策 ( 例 如 , 是 直 接 回 复 [SPEAK] 还 是 调 用 工 具 [TOOL_USE] ) 是 否 一 致 ? Is the first action decision in the plan (e.g., directly replying [SPEAK] or calling a tool [TOOL_USE] ) consistent? • 行 动 细 节 一 致 性 (action_details) Action Details Consistency (action_details) - 如 果 决 策 是 回 复 [SPEAK] : 回 复 的 核 心 意 图 、 关 键 信 息 点 是 否 一 致 ? - If the decision is to reply [SPEAK] : Are the core intent and key information points of the reply consistent? - 如 果 决 策 是 调 用 工 具 [TOOL_USE] : 调 用 的 工 具 名 称 、 传 入 的 关 键 参 数 是 否 一 致 ? - If the decision is to call a tool [TOOL_USE] : Are the called tool name and passed key parameters consistent? • 后 续 规 划 一 致 性 (subsequent_plan) Subsequent Plan Consistency (subsequent_plan) 在 当 前 行 动 完 成 后 , 对 后 续 步 骤 的 规 划 ( 例 如 , “ 工 具 返 回 成 功 后 , 应 总 结 信 息 并 告 知 用 户 ” 或 “ 工 具 返 回 失 败 后 , 应 安 抚 并 尝 试 其 他 方 案 ” ) 的 逻 辑 走 向 是 否 与 金 标 规 划 一 致 ? After the current action is completed, is the logical direction of the subsequent step planning (e.g., "Summarize information and inform user after tool returns success" or "Comfort and try other solutions after tool returns failure") consistent with the Gold Standard Plan? 在 对 每 一 项 维 度 进 行 “ 一 致 / 部 分 一 致 / 不一 致 ” 判 断时 , 请 同 时 用 简 明 的 自 然 语 言 解 释 原 因 , 指 出 关 键 差 异 点 或 相 同 点 。 When making a "Consistent/Partially Consistent/Inconsistent" judgment for each dimension, please also explain the reason in concise natural language, pointing out key dif ferences or similarities. # 4. 判 断 等 级 标 准 # 4. Judgment Lev el Standards • 一 致 Consistent 3 个 维 度 均 无 实 质 性 差 异 , 规 划 的 核 心 逻 辑 和 关 键 步 骤 完 全 相 同 。 There are no substantiv e differences in the 3 dimensions; the core logic and ke y steps of the plans are exactly the same. • 部 分 一 致 Partially Consistent - 在 行 动 细 节 或 后 续 规 划 维 度 存 在 轻 微 差 异 , 但 不 影 响 问 题 的 整 体 解 决 路 径 。 例 如 , 工 具 调 用 的 非 核 心 参 数 不 同 , 或 后 续 规 划 的 措 辞 有 别 但 最 终 目的相 同 ; - There are slight differences in Action Details or Subsequent Plan dimensions, but the y do not affect the overall solution path of the problem. For example, non-core parameters of tool calls are different, or the w ording of subsequent planning differs b ut the ultimate goal is the same; - 如 果 虽 然 第 一 步 不 同 , 但 后 续 步 骤 能 回 到 与 金 标 相 同 的 核 心 解 决 方 案 ( 例 如 都 引 导 用 户 新 建 合 规 签 名 ), 更 倾 向 判 为 “ 部 分 一 致 ” 。 - If, although the first step is different, subsequent steps can return to the same core solution as the Gold Standard (e.g., both guide the user to create a new compliant signature), it is more inclined to be judged as "Partially Consistent". • 不一 致 Inconsistent 32 PRIME AI paper 仅 当 在 current_decision 维 度 存 在 根 本 性 差 异 , 且 该 差 异 会 导 致 「 最 终 解 决 路 径 明 显 不 同 」 时 , 才 判 为不一 致 。 Only when there is a fundamental dif ference in the current_decision dimension, and this difference leads to a "significantly different final solution path", is it judged as inconsistent. # 5. 输 出 格 式 # 5. Output Format 请 返 回 一个 包 含 判 定 标 签 和 原 因 说 明 的 JSON , 格 式 如 下 : Please return a JSON containing judgment labels and reason explanations, formatted as follows (Note: Output only JSON, do not use “‘json or any code block markers): { "detailed_consistency": { "current_decision": { "result": " 一 致 / 部 分 一 致 / 不一 致 ", (consistent/partially consistent/inconsistent) "comment": " 在 这 里 用 一两 句 话 说 明 为 什么 这 么 判 定 , 指 出 两 份 规 划 在 首 步 行 动 上 的 相 同 或 差 异 点 。 " (Explain in one or two sentences why this judgment was made, pointing out similarities or differences in the first step action.) }, "action_details": { "result": " 一 致 / 部 分 一 致 / 不一 致 ", (consistent/partially consistent/inconsistent) "comment": " 说 明 两份 规 划 在 工 具 名 称 、 关 键 参 数 或 回 复 要 点 上 的 差 异 , 例 如 是 否 缺 少 关 键 参 数 、 是 否 更 换 了 工 具 等 。 " (Explain differences in tool names, key parameters, or reply points, e.g., whether key parameters are missing or tools are changed.) }, "subsequent_plan": { "result": " 一 致 / 部 分 一 致 / 不一 致 ", (consistent/partially consistent/inconsistent) "comment": " 说 明 两 份 规 划 对 后 续 流 程 设 计 的 差 异 , 例 如 是 否 都 有 “ 工 具 成 功 后 总 结 告 知 用 户 ” 的 步 骤 , 是 否 存 在 关 键 环 节 缺 失 或 逻 辑 相 反 。 " (Explain differences in subsequent process design, e.g., whether both have the step ’summarize and inform user after success’, or if key steps are missing or logic is opposite.) } }, "judge_result": " 一 致 / 部 分 一 致 / 不一 致 ", (consistent/partially consistent/inconsistent) "overall_comment": " 用 简 明 的 一 段 话 总 结 整 体 一 致 性 情 况 , 重 点 说 明 如 果 判 为 “ 部 分 一 致 ” 或 “ 不一 致 ” , 是 哪 些 关 键 逻 辑 或 步 骤 造 成 了 偏 差 , 以 及 这 些 偏 差 对 问 题 解 决 路 径 的 影 响 程 度 。 当 模 型 规 划 在 第 一 步 存 在 误 判 , 但 后 续 仍 能 引 导 到 与 金 标 相 同 的 最 终 解 决 路 径 时 , 优 先 考 虑 “ 部 分 一 致 ” , 并 在 评语 中 说 明 首 步 误 差 属 于 可 纠 偏 的 偏 差 。 " (Summarize overall consistency in a concise paragraph. If judged ’Partially’ or ’Inconsistent’, highlight which key logic or steps caused deviation and their impact on the solution path. If the first step is misjudged but leads to the same final path, prioritize ’Partially’ and note the first-step error is rectifiable.) } 33
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment