M2P: Improving Visual Foundation Models with Mask-to-Point Weakly-Supervised Learning for Dense Point Tracking
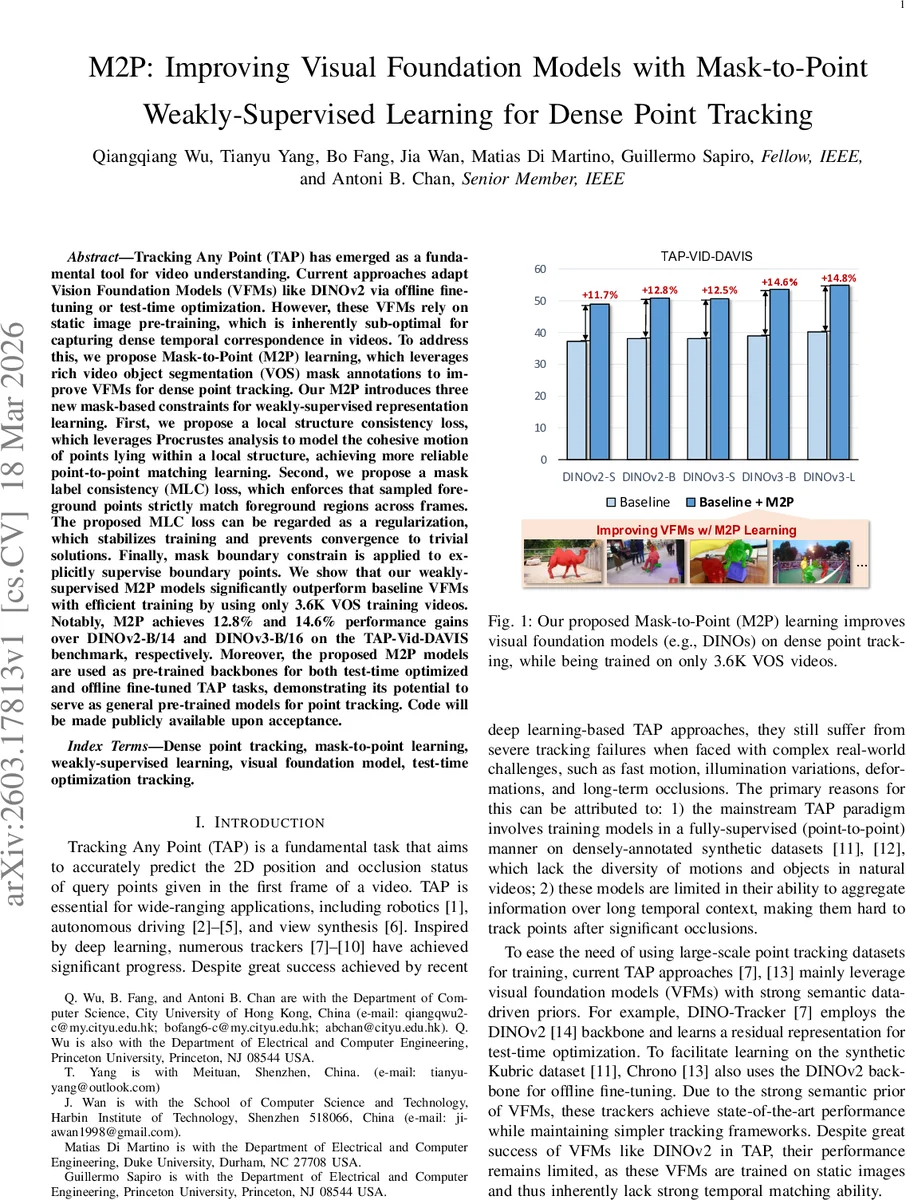
Tracking Any Point (TAP) has emerged as a fundamental tool for video understanding. Current approaches adapt Vision Foundation Models (VFMs) like DINOv2 via offline finetuning or test-time optimization. However, these VFMs rely on static image pre-training, which is inherently sub-optimal for capturing dense temporal correspondence in videos. To address this, we propose Mask-to-Point (M2P) learning, which leverages rich video object segmentation (VOS) mask annotations to improve VFMs for dense point tracking. Our M2P introduces three new mask-based constraints for weakly-supervised representation learning. First, we propose a local structure consistency loss, which leverages Procrustes analysis to model the cohesive motion of points lying within a local structure, achieving more reliable point-to-point matching learning. Second, we propose a mask label consistency (MLC) loss, which enforces that sampled foreground points strictly match foreground regions across frames. The proposed MLC loss can be regarded as a regularization, which stabilizes training and prevents convergence to trivial solutions. Finally, mask boundary constrain is applied to explicitly supervise boundary points. We show that our weaklysupervised M2P models significantly outperform baseline VFMs with efficient training by using only 3.6K VOS training videos. Notably, M2P achieves 12.8% and 14.6% performance gains over DINOv2-B/14 and DINOv3-B/16 on the TAP-Vid-DAVIS benchmark, respectively. Moreover, the proposed M2P models are used as pre-trained backbones for both test-time optimized and offline fine-tuned TAP tasks, demonstrating its potential to serve as general pre-trained models for point tracking. Code will be made publicly available upon acceptance.
💡 Research Summary
This paper tackles the problem of dense point tracking, known as Tracking Any Point (TAP), by improving visual foundation models (VFMs) that were originally pre‑trained on static images. While recent TAP methods have successfully leveraged VFMs such as DINOv2 and DINOv3 through offline fine‑tuning or test‑time optimization, these models inherently lack strong temporal correspondence abilities because their pre‑training data contain no video dynamics. To bridge this gap, the authors propose Mask‑to‑Point (M2P) learning, a weakly‑supervised framework that exploits the abundant mask annotations available in video object segmentation (VOS) datasets.
M2P introduces three mask‑driven constraints for representation learning:
-
Local Structure Consistency (LSC) loss – Points sampled from the same spatial group (obtained by K‑means clustering inside the mask followed by farthest‑point sampling) are assumed to share a locally coherent motion. The method selects the top‑Kₑ most confident point‑wise matches predicted by a VFM, then estimates a similarity transformation (rotation, isotropic scale, translation) via Procrustes analysis. This transformation is applied to the remaining points in the group to generate pseudo‑labels, and the discrepancy between predicted and pseudo‑labels forms the LSC loss. This encourages the model to learn locally consistent motion without requiring dense point‑level supervision.
-
Mask Label Consistency (MLC) loss – Foreground points sampled from the mask must remain foreground in the target frame, and background points must stay background. Implemented as a cross‑entropy term on the binary mask labels, MLC acts as a regularizer that prevents the network from collapsing to trivial solutions (e.g., mapping all points to a single location).
-
Mask Boundary Constraint – Points near object boundaries are explicitly supervised, because boundaries experience the most complex deformations. By sampling boundary‑proximal points and applying a dedicated loss (e.g., boundary cross‑entropy or distance loss), the model learns to track fine‑grained edge details, which significantly boosts overall TAP performance.
The training data consist of only 3.6 K real‑world VOS videos (YouTube‑VOS, SA‑V, etc.), a stark contrast to prior TAP work that relies on large synthetic point‑track datasets such as Kubric. Despite the modest dataset size, M2P‑enhanced DINOv2‑B/14 and DINOv3‑B/16 achieve absolute improvements of 12.8 % and 14.6 % respectively on the TAP‑Vid‑DAVIS benchmark, surpassing strong baselines that use offline fine‑tuning (Chrono) or test‑time adaptation (DINO‑Tracker).
Beyond the benchmark, the authors demonstrate that the M2P‑trained backbones can be directly plugged into downstream TAP pipelines. When used as the feature extractor for DINO‑Tracker (test‑time optimization) and Chrono (offline fine‑tuning), the models consistently deliver higher accuracy and F‑score than the original DINOv2 backbone, confirming that M2P yields a versatile pre‑trained model for both online and offline point‑tracking scenarios.
The paper also discusses limitations. The LSC loss models motion as a 2‑D similarity transform, which cannot capture highly non‑rigid or 3‑D deformations. Multi‑object scenes with overlapping masks may cause ambiguity in group assignment and boundary supervision, suggesting the need for more sophisticated grouping or multi‑mask handling. Additionally, the approach assumes reasonably clean mask annotations; noisy or incomplete masks could degrade the reliability of pseudo‑labels generated by Procrustes analysis. Future work could explore extending the transformation model to affine or deformable fields, integrating multi‑object grouping strategies, and designing robust sampling mechanisms for low‑quality masks.
In summary, M2P provides a cost‑effective, weakly‑supervised pathway to endow static‑image VFMs with strong temporal correspondence capabilities by leveraging VOS mask data. The three mask‑based losses together enable learning of dense, accurate point correspondences without explicit point‑level annotations, achieving state‑of‑the‑art results on TAP benchmarks and offering a generalizable backbone for a wide range of video understanding tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment