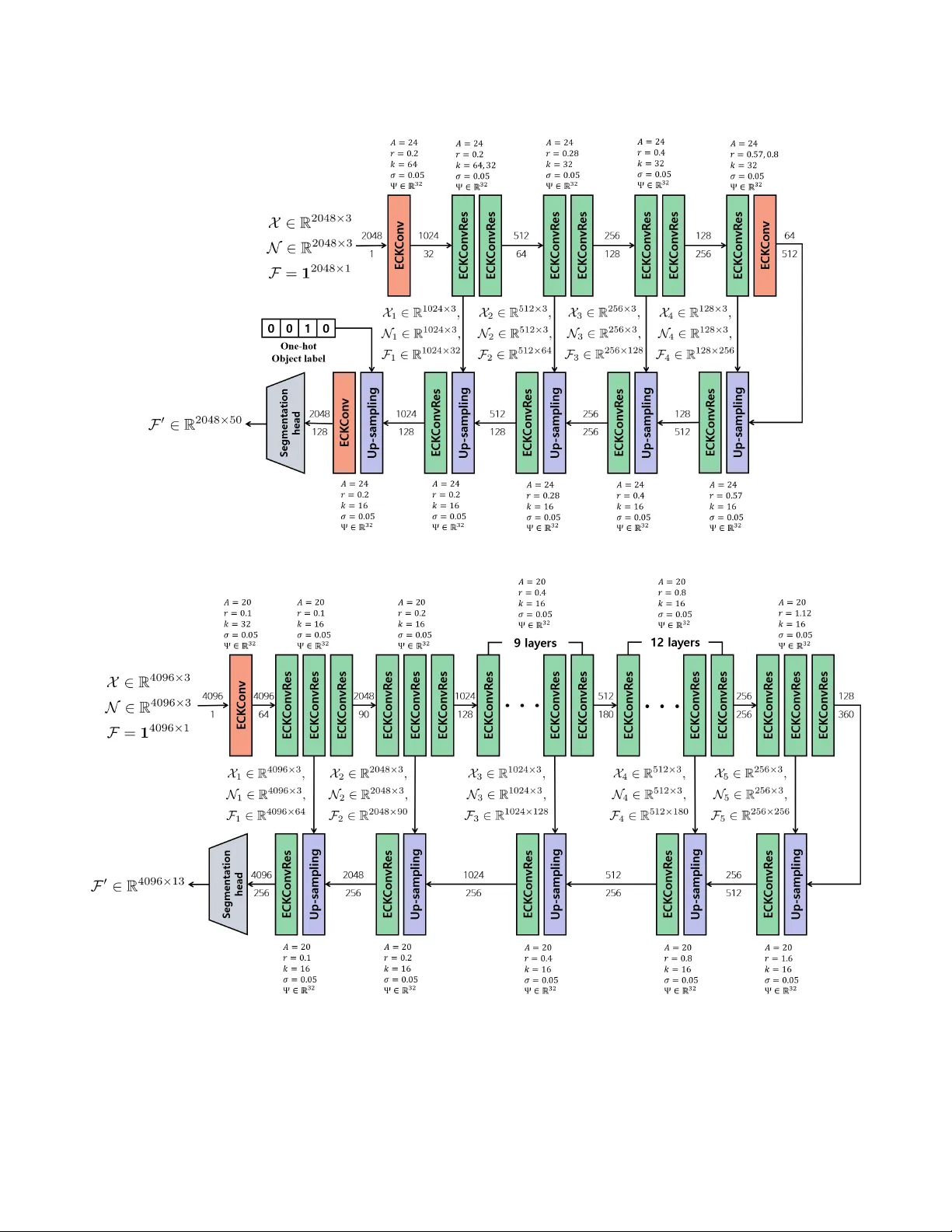
Learning Coordinate-based Convolutional Kernels for Continuous SE(3) Equivariant and Efficient Point Cloud Analysis
A symmetry on rigid motion is one of the salient factors in efficient learning of 3D point cloud problems. Group convolution has been a representative method to extract equivariant features, but its realizations have struggled to retain both rigorous…
Authors: Jaein Kim, Hee Bin Yoo, Dong-Sig Han
Learning Coordinate-based Con volutional K ernels f or Continuous SE(3) Equiv ariant and Efficient Point Cloud Analysis Jaein Kim 1 , Hee Bin Y oo 2 * , Dong-Sig Han 3 * , Byoung-T ak Zhang 1 , 4 1 Interdisciplinary Program in Neuroscience, Seoul National Uni versity 2 D ´ epartement d’Informatique, ´ Ecole Normale Sup ´ erieure (ENS) 3 Department of Computing, Imperial College London 4 Department of Computer Science and Engineering, Seoul National Uni versity { jykim, btzhang } @bi.snu.ac.kr Abstract A symmetry on rigid motion is one of the salient factors in efficient learning of 3D point cloud pr oblems. Gr oup con- volution has been a repr esentative method to extract equiv- ariant features, but its realizations have strug gled to retain both rigor ous symmetry and scalability simultaneously . W e advocate utilizing the intertwiner framework to r esolve this trade-of f, but pre vious works on it, which did not achie ve complete SE(3) symmetry or scalability to lar ge-scale pr ob- lems, necessitate a mor e advanced kernel ar chitectur e. W e pr esent Equivariant Coordinate-based K ernel Convolution, or ECKCon v . It acquires SE(3) equivariance fr om the ker- nel domain defined in a double coset space, and its explicit kernel design using coordinate-based networks enhances its learning capability and memory efficiency . The e xperiments on diverse point cloud tasks, e.g., classification, pose r e gis- tration, part se gmentation, and lar ge-scale semantic se g- mentation, validate the rigid equivariance, memory scala- bility , and outstanding performance of ECKCon v compar ed to state-of-the-art equivariant methods. 1. Introduction Modern deep learning on point clouds has been dom- inating various tasks and applications in the 3D vision do- main [ 11 , 16 , 18 ]. Y et, it has often exploited the prior that an input is aligned to the canonical pose, deteriorating its fea- sibility to the real-world problems [ 11 ]. While training with data augmentation induces transformation robustness, many studies [ 2 , 11 , 14 , 23 ] ha ve shown that the reliance on aug- mentation is inefficient or underperforms compared to the model retaining symmetry in its architecture. Thus, design- ing pose-equiv ariant model has been a significant topic in * The majority of the work for this publication was done while these authors were in Seoul National Univ ersity . Figure 1. On the left, random SE(3) transformations are applied on the identical object point cloud. The black dots are centroids and colored plus signs designate neighbor points, where the y are iden- tical points with different poses. If these point clouds are trans- formed as the reference points are met on the subgroup, or the SO(2) axis, it is guaranteed that points with the identical topology lie on the disjoint orbit, or double coset , around the axis. There- fore, the SE(3) equiv ariant operation is achiev able by utilizing the unique parameter defining those orbits. W e visualized this concept with an example dra wn from the ModelNet40 [ 42 ]. the 3D deep learning. Group con volution is one of the repre- sentativ e approaches to grant such symmetry , which deriv es the analogy from the translation equiv ariance of standard con volution to wards the equiv ariance to group actions [ 5 ]. Group con volution on the 3D point clouds has the trade- off between the strict equiv ariance and model scalabil- ity [ 4 , 49 ]. On the one hand, one can exploit a discrete group structure and directly expand kernel parameters to achiev e scalability with restricted operations. Howe ver , it causes a discrepancy between the model and the continuity of groups, e.g ., discretizing 3D rotations from a compact SO(3) space [ 12 ]. On the other hand, strict equiv ariance for continuous group spaces is guaranteed with the steerable con volution framework [ 6 ], which confines its features and kernels decomposable into the irreducible features and the 1 direct sum of maps between them [ 13 , 35 ]. Such complex operations typically require expensiv e computational costs, restraining its applicability to large-scale 3D tasks. One of the extended framew ork of group con volution, the intertwiner kernel conv olution [ 7 , 8 ], has been pro- posed to substitute the domain space from group to quotient space, which is more plausible to represent the operation ov er the physical space. Indeed, previous works based on this frame work suggest more ef ficient discrete SE(3) equi v- ariant con volution [ 49 ] or embed symmetry to continuous SO(3) actions [ 20 ] using implicit kernel [ 29 , 30 , 46 ]. How- ev er , a continuous SE(3) equi variant method has not been presented within the intertwiner framew ork, and their ap- plications are not scalable enough to cover the large-scale 3D problems in the real-world. This paper proposes Equiv ariant Coordinate-based Ker - nel Con volution ( ECKCon v ), a continuous SE(3) equiv ari- ant conv olutional netw ork with scalability using intertwiner kernel frame work. W e configure the domain of kernel to embed SE(3) symmetry and parse the symmetric parame- ters from the normalized local neighbors using coordinate- based networks. W ith the explicit kernel design, the parsed information outputs linear maps equi variant to complete SE(3) with the enhanced local features and the scalability in terms of memory efficienc y . Our method is verified through various translation/rotation inv ariant tasks and validates its symmetry on continuous rigid motions and practicality . Our contributions are summarized as follo ws: • W e introduce ECKCon v which adopts the interwtiner framew ork and computes the conv olutional kernel from the parameters of a double coset space. It ensures a rigid symmetry against SE(3) from these parameters which corresponds to motion-in variant orbits as Figure 1 . • ECKConv extracts normalized double coset parameters from the local neighbors and computes the explicit kernel maps using coordinate-based networks. It dev elops an en- hanced learning of local geometries and the scalability of our method. W e prove the ef ficiency of explicit kernel with respect to the backpropagation. • W e verify the strict SE(3) equi variance and memory scal- ability of ECKConv through the classification and pose registration tasks in ModelNet40 [ 42 ]. The part segmen- tation in ShapeNet [ 3 ] and the semantic segmentation in S3DIS [ 1 ] also validate its advanced local feature learning and practicability to the large-scale problems. 2. Related W orks 2.1. Deep Learning f or 3D Point Cloud PointNet [ 25 ] and PointNet++ [ 26 ] are early representa- tiv e methods in point cloud deep learning. They introduce a weight-sharing MLP , i.e ., a one-dimensional conv olution, to learn point features, and PointNet++ especially utilizes lo- cal grouping and multi-scale (or resolution) mechanisms to enhance local geometry learning. Despite such techniques, they are inef fective in aggregating local features, relying on av eraging or pooling among grouped points. Con volution methods in point cloud learning retain the inductiv e bias of locality in ev ery layer while coping with irregularly distributed samples in the cloud. Some early methods such as PointCNN [ 21 ] and PointCon v [ 39 ] project distributed local features into regular features by learnable permutations or estimated density . KPConv [ 33 ] defines its kernel for irregular grid as the combination of weight bases, whose coef ficients are gated by the distance between input and anchor coordinates. DGCNN [ 37 ] constructs a local cluster at each point by K-NN in the latent feature space, which aggregates point features independently to the dis- tance in the coordinate space. It is also notew orthy that some studies adopt attention mechanisms and dynamically adjust the adjacency among point features [ 15 , 40 , 41 , 45 ]. Y et, they are dependent on the data augmentations to induce symmetry to rigid motions only acting globally . 2.2. Group Equi variant Point Cloud Con volution Group con volution is founded on either discrete group or steerable con volution, rooted from GCNN [ 5 ] and Steer- able CNN [ 6 ]. TFN [ 35 ] decomposes the action of SO(3) and parametrizes the combination of equiv ariant bases to receiv e coordinate differences between points. Fuchs et al. [ 13 ] attach the attention mechanism among neighbors in TFN, where query and key are also the direct sum of learn- able equi variant bases. As these steerable methods are not scalable to practical 3D vision problems, EPN [ 4 ] and E2PN [ 49 ] suggest discrete group methods based on KP- Con v [ 33 ], prescribing the assignment between discrete group or quotient space elements to replace the distance- based gate function. They show a capacity comparable to non-equiv ariant methods, but their symmetry is biased to the discretized rotations due to their attentiv e pooling ov er group dimensions. Recent studies hav e aimed to address both limitations in the previous works. CSECon v [ 20 ] sug- gests an implicit kernel in variant to continuous SO(3) by mapping double coset coordinates with learnable netw orks. W eijler and Hermosilla [ 38 ] propose a stochastic and ef fi- cient SE(3) con volution with lifted and sampled local coor- dinates. Ho wever , the symmetry of CSEConv is restricted to SO(3), and their performance in object-level analysis is limited compared to existing point cloud methods. 2.3. Equivariance outside Gr oup Con volution It is possible to implement symmetric networks out- side the group conv olution framework to av oid its trade- off. Some studies suggest model-agnostic framew orks that embed group equiv ariance into non-equiv ariant networks. For instance, V ector Neuron [ 9 ] suggests SO(3) equi vari- 2 ant framew ork that augments a feature space into a bundle of 3D vectors. Frame A veraging [ 24 ] proposes a theoreti- cal frame work that approximate integration ov er group into av eraging over equiv ariant frame , the finite subset of the group. Kaba et al. [ 19 ] and Mondal et al. [ 22 ] introduce to canonicalize the input orientation via additional equiv ariant networks. Although the y retain the capacity of their founda- tion networks, they have limited symmetry to global SO(3) actions [ 9 ], or require high computational costs, pretrained networks [ 19 ], or the prior to the input orientation [ 22 ]. Meanwhile, there are studies that e xtract rotation in- variant coordinate representations among point cloud clus- ters [ 32 , 43 , 44 ]. They have a similarity to ours in uti- lizing information in variant to rigid transformations during the operation. Howe ver , their heuristic design and selection of such information make these methods susceptible to lo- cal references [ 43 ], utilize ambiguous representations to a certain situation [ 44 ], or rely on the assumption that global transformation is equally applied to e very local region [ 32 ]. These limitations necessitate the study that addresses the trade-off by the group con volution within its field. 3. Group Equivariant Con volution Framew ork using Intertwiner K ernel This section outlines the mathematical framework and the motiv ation of our architectural design. W e refer the readers to the previous works [ 7 , 8 , 20 , 49 ] for a better un- derstanding of detailed deriv ations. A group conv olution is naturally derived from the standard con volution, simply substituting its symmetry against shifts into in verse actions closed on the group space [ 5 , 8 ]: ( f ∗ κ )( g ) = Z G κ ( g − 1 h ) f ( h ) dh, (1) where f is an input feature, κ is a kernel, and g is a co- ordinate of point in the group space. This expression is sufficient for modelling the equi variance to discrete groups. Howe ver , real-world problems often require the symmetry to continuous groups, and a naiv e integration on continuous group space is computationally intractable for data acquired from a physical space. Cohen et al. [ 7 , 8 ] propose the framework that models the group equi variant conv olution as a general linear map between fields by introducing the intertwiner Hom ( V 1 , V 2 ) to the kernel function. V 1 and V 2 are fields of the input and output feature spaces, whose coordinates are from a homo- geneous space. Notably , the conv olution over group can be replaced into the equiv alent operation ov er a quotient space, such as a 3D sphere, with κ : G/H 1 → Hom ( V 1 , V 2 ) : ( f ∗ κ )( x ) = Z G/H 1 κ ( s 2 ( x ) − 1 y ) ρ 1 (h 1 ( y , s 2 ( x ) − 1 )) f ( y ) dy , (2) where ρ 1 : G → GL ( V 1 ) is a representation, s 2 : G/H 2 → G is a section map for group G and subgroup H 2 , and h 1 ( x, g ) = s 1 ( g x ) − 1 g s 1 ( x ) for g ∈ G , a section map s 1 for subgroup H 1 , and x ∈ G/H 1 . For conv enience, when G = S O (3) and H 2 = S O (2) , assume that s 2 ( x ) − 1 trans- forms x to the reference of H 2 , e.g ., the north pole. The constraint on kernel κ ( · ) is required to retain the equiv ari- ance over group G as Equation ( 3 ), where the kernel pre- serves the symmetry to actions of subgroup H 2 : κ ( hy ) = ρ 2 ( h ) κ ( y ) ρ 1 (h 1 ( y , h ) − 1 ) , h ∈ H 2 . (3) Cohen et al. [ 7 , 8 ] also derive that κ ( · ) with Equation ( 3 ) has an equi valent function whose domain is in double coset space, where double cosets are disjoint bundles of quotient space elements transiti ve to H 2 actions. T o concretize G - equiv ariant operation, pre vious works [ 20 , 49 ] specify some configurations that H 1 = H 2 = SO(2) and ρ 1 = ρ 2 = id, assuming that V 1 and V 2 are inv ariant. Consequently , the kernel function becomes an unconstrained function as: ( f ∗ κ )( x ) = Z G/H 1 κ ( s 2 ( x ) − 1 y ) f ( y ) dy , s.t. κ : H 2 \ G/H 1 → Hom ( V 1 , V 2 ) , (4) where the map from quotient space to double coset space is omitted with an abuse of notation. Those previous meth- ods, howev er , simplified the operation to the integration on the discretized SE(3) / SO(2) quotient space [ 49 ] or confined symmetry to continuous SO(3) [ 20 ]. 4. Method This section delineates the methodology of ECKCon v . First, we briefly mention how the domain of kernel is de- fined for the SE(3) equi variance of conv olution. Then, we explain how the explicit kernel architecture computes our kernel value from double cosets using coordinate-based net- works with the theoretical analysis on its scalability . Fi- nally , we suggest the con volution block and its residual ar- chitecture for solving the point cloud problems. 4.1. Continuous SE(3) Equivariant Con volution ECKCon v expands the double coset space ( 4 ) equipped with rotation and translation symmetry by configuring G into SE(3) = SO(3) ⋉ R 3 . W e adopt the deriv ation by Zhu et al. [ 49 ]; an element g in the double coset space is expressible as the pair of ZYZ Euler angles and transla- tion when G = SE(3) and H 1 = H 2 = SO(2). Let us de- note that g ≡ R z ( α g ) R y ( β g ) R z ( γ g ) , [ x g , y g , z g ] ∈ G , h 1 = R z ( γ h 1 ) ∈ H 1 , and h 2 = R z ( γ h 2 ) ∈ H 2 . Then, we can write a double coset element g as follows: H 2 g H 1 = n R z ( α g + γ h 2 ) R y ( β g ) R z ( γ g + γ h 1 ) , R z ( γ h 2 + γ t )[ r g , 0 , z g ] ⊤ ∀ h 1 , h 2 ∈ SO(2) o , (5) 3 (a) (b) Figure 2. The implementation details in ECKConv . (a) The neighbor points within a radius r around each centroid are sub-sampled by ball query [ 26 ]. After they are aligned by the in verse of section map as Equation ( 6 ), ¯ β g , ¯ r g , and ¯ z g , which correspond to the double coset parameters, are acquirable as depicted. These neighbor points are actually computed from the ModelNet40 [ 42 ] object with normal v ectors. (b) The computation of explicit kernel in ECKConv . First, it maps a double coset parameter ¯ x i = [ ¯ β i , ¯ r i , ¯ z i ] into Gaussian embedding [Ψ( ¯ β i / π ) , Ψ( ¯ r i ) , Ψ( ( ¯ z i +1) / 2 )] [ 47 , 48 ]. Then the embedding is projected by F θ to ω ( ¯ x ; θ ) , a coefficient v ector with the dimension A . The kernel v alue of κ ( · ) is gained from the weighted summation of learnable bases [ W j ] A j =1 by ω ( ¯ x i ; θ ) , i.e ., P A j =1 ω j ( ¯ x i ; θ ) W j . where γ t = atan2( y g , x g ) and r g = q x 2 g + y 2 g denote dis- placements. These notations are useful since the whole set grouped by Z-axis rotations from SO(2) is an ele- ment of double coset. T o summarize, a double coset ele- ment in SO(2) \ SE(3) / SO(2) are uniquely representable as [ β g , r g , z g ] , and the conv olution equiv ariant to continuous SE(3) can be built with the k ernel depends on them. 4.2. Implementations of ECKCon v W e realize the framework in Section 4.1 actually equi v- ariant to continuous SE(3) actions unlike the pre vious work symmetric to discrete SE(3) [ 49 ]. Let us suppose the local- ity assumption and the integration approximation rule from Kim et al. [ 20 ]. Then, the formulation of ECKCon v is writ- ten as follows: ( f ∗ κ )( x ) = X x i ∈N ( x ) κ ( s ( x ) − 1 x i ) f ( x i ) , s.t. κ : SE(3) / SO(2) → R C out × C in , f : SE(3) / SO(2) → R C in × 1 , (6) where s : S E (3) /S O (2) → S E (3) is a section map. The domain space of Equation ( 6 ) is factorizable into R 3 × S 2 since SE(3) = SO(3) ⋉ R 3 and SO(3) / SO(2) ≡ S 2 . The coordinates of point clouds naturally represent R 3 . The S 2 space is manifestible with any representations equiv ariant to SE(3) that map 3D coordinates to unit v ectors. For instance, we can use either the surface normal vectors or heuristic augmentation as Algorithm 1 in the supplementary material. 4.2.1. Local Neighboring and Double Coset Encoding As we augment the domain into R 3 × S 2 , let us assume a point cloud is composed of tuples of coordinate and normal vector ( x , n ) . Then, the local neighborhood, i.e ., the re- gion where we integrate, is determined by a ball query [ 26 ], which is defined as N (( x , n ); r, k ) = { ( x i , n i ) ∈ P | ∥ x − x i ∥ 2 ≤ r, i = 1 , ..., k } , where r is a radius and k is the maximal number of samples in ball query algorithm. It is a well-established approach that helps utilize the geometry of input points in the Euclidean space and normalize the scale of recepti ve field by con volution, suggested by many pre vi- ous works with the locality assumption [ 4 , 26 , 33 , 49 ]. W e encode the double coset parameters [ ¯ β i , ¯ r i , ¯ z i ] of each neighbor point x i = ( x i , n i ) referring to the lo- cal coordinate system of ball query centroid x = ( x , n ) . These parameters correspond to [ β g , r g , z g ] of s ( x ) − 1 x i from Equations ( 5 ) and ( 6 ) and are acquired as follows: ¯ x i = [ ¯ β i , ¯ r i , ¯ z i ] , s.t. ¯ β i = arccos( n ⊤ · n i ) , ¯ z i = ( n ⊤ · ∆ i ∥ ∆ i ∥ ) · ∥ ∆ i ∥ /r , ¯ r i = s 1 − ( n ⊤ · ∆ i ∥ ∆ i ∥ ) 2 · ∥ ∆ i ∥ /r , (7) where ∆ i = x i − x and r is a ball query raidus. The geomet- ric interpretation of Equation ( 7 ) is in Figure 2a , where the local coordinate system by x is aligned to a zero-centered Z- axis and SE(3) in variant information of x i is encoded to ¯ x i . Thus, the operation only processes the double coset param- eters in the scale-normalized re gion and enables each ECK- Con v layer to learn SE(3)-equiv ariant local geometries. 4.2.2. Explicit K ernel using Coordinate-based Networks An explicit kernel function κ ( · ) consists of the combi- nation of learnable linear maps as Equation ( 8 ), inspired by various con volution methods that compute the integration ov er irregular samples [ 4 , 33 , 34 , 49 ]. κ ( s ( x ) − 1 x i ; θ , W j A j =1 ) = A X j =1 ω j ( ¯ x i ; θ ) W j , s.t. s ( x ) − 1 x i ∈ R 3 × S 2 , ¯ x i ∈ SO(2) \ SE(3) / SO(2) , (8) where input s ( x ) − 1 x i from the quotient space is mapped to the double coset ¯ x i by Equation ( 7 ), W j ∈ R C out × C in , and A 4 is the number of anchor bases. Previous studies determine the values of gate functions ω j ( · ) by the distance between input coordinates and anchor points in the 3D space. How- ev er , they do not fit in our kernel function, as it is obscure to measure the distance in the double coset space. Instead, we incorporate the coordinate-based networks to surrogate the metric ov er the double coset space inspired by CSEConv [ 20 ]. Neural networks F θ ( · ) map coordinates ¯ x i into unbounded coefficients ω j for each anchor basis as: ω ( ¯ x i ; θ ) = [ ω j ] A j =1 = F θ Gau ( ¯ x i ) ∈ R A , s.t. Gau ([ ¯ β i , ¯ r i , ¯ z i ]) = [Ψ( ¯ β i / π ) , Ψ( ¯ r i ) , Ψ( ( ¯ z i +1) / 2 )] , Ψ( x ) = [ ψ ( x, 0) , ψ ( x, 1 / d ) , · · · , ψ ( x, ( d − 1) / d )] , (9) where ψ ( x, y ) = exp − ( x − y ) 2 / 2 σ 2 is a Gaussian ker- nel with σ = 0 . 05 and Gau ( · ) ∈ R 3 d is referred to as Gaussian embedding [ 47 , 48 ]. By mapping [ ¯ β i , ¯ r i , ¯ z i ] into a range [0 , 1] , Zheng et al. [ 47 , 48 ] showed that Gaussian embedding provides the balance between memorization and generalization of coordinate learning with its bounded rank. Then, combining Equations ( 6 ) and ( 8 ) is written as: ( f ∗ κ )( x ) = X x i ∈N ( x ) A X j =1 ω j ( ¯ x i ; θ ) W j f ( x i ) . (10) This might be interpretable as an implicit kernel since ω ( · ) is a coordinate-based networks. Howe ver , we separate ω ( · ) and basis maps W j as an explicit kernel, and reorder Equa- tion ( 10 ) as follows inspired by W u et al. [ 39 ]: ( f ∗ κ )( x ) = A X j =1 W j X x i ∈N ( x ) ω j ( ¯ x i ; θ ) f ( x i ) , (11) which is the final formulation of ECKCon v . 4.3. Scalability Impro vement in ECKCon v Now we show the significance of this modification with respect to the computational benefit of Equation ( 11 ), al- though the operations in Equations ( 10 ) and ( 11 ) are equi v- alent [ 39 ], through the following proposition. Proposition 4.1. Let C in be the dimension of input fea- tur e, C out be the dimension of output featur e, K be the car dinality of neighbors, and A be the cardinality of an- chor bases. Then the cost from the derivative by θ , which is the parameter of ω , reduces from O ( A K C in C out ) to O ( A ( K C in + C in C out )) . Pr oof. Let us denote Y = ( f ∗ κ )( x ) ∈ R C out . Since the modification does not influence ω ( x ) , the computation cost of ∇ θ ω is constant. Then one can distinguish the formulas Figure 3. Architectures of ECKConv and its residual connection. W e apply batch normalizations and activ ations ( σ ) in the order shown in the figure. As we only visualize abstract flow of the ECKCon v block and its residual block, please refer to Section 7.1 in the supplementary material for more details. of ∇ ω j Y according to the operations as follo ws: ∇ ω j Y = P K i =1 W j f ( x i ) from Equation ( 10 ), W j P K i =1 f ( x i ) from Equation ( 11 ). (12) The cost by the summation of products between W j and f ( x i ) is O ( K C in C out ) , and the cost by the product between W j and the summation of f ( x i ) s is O ( K C in + C in C out ) . Since ∇ θ Y = ∇ ω j Y A j =1 ∇ θ ω , the cost by ∇ θ Y alters from O ( A K C in C out ) to O ( A ( K C in + C in C out )) . Proposition 4.1 states that Equation ( 11 ) is equiv alent to Equation ( 10 ) with reduced memory cost during the back- propagation. Considering the equiv alence of Equation ( 10 ) to the implicit kernel, such as CSECon v [ 20 ], it necessitates the explicit kernel for the scalability , enabling more param- eters on each layer and deeper network architecture. 4.4. Architectur e of ECKConv Block and Residuals The preceding components coalesce into a single block of ECKConv as Figure 3 . W e denote the input with N points as ( X in , F in ) where X in = { x n | x n = ( x n , n n ) } N n =1 , F in = { f n | f n = f ( x n ) } N n =1 , and x n , n n , and f n are the coordinate, normal vector , and feature of n th point. A far- thest point sampling [ 26 ] chooses centroid points X cnt and the block gathers features F cnt that correspond to these cen- troids. After a ball query finds neighbor points N ( x n ) for each centroid x n and their corresponding features are also gathered, the ECKConv operates the conv olution in Equa- tion ( 11 ) and outputs F con v . The pair of ( X cnt , F con v ) be- comes an output point cloud of the ECKCon v block. 5 Furthermore, we implement the residual connection block [ 17 ] of ECKCon v for the enhanced model capability as Figure 3 , inspired by previous point conv olution meth- ods [ 33 , 49 ]. The features of centroids F cnt are propagated by a linear layer , summed with F con v , and become ne w out- put features F res paired with X cnt . 5. Experiments W e conducted classification and pose registration task in the ModelNet40 [ 42 ] to verify the memory scalability , en- hanced model capability , and rigorous SE(3) equiv ariance of ECKCon v . Then it is validated on more complex tasks, i.e ., object part and indoor semantic segmentation, to v erify its understanding of local geometries with equiv ariance and scalability to the real world. Please refer to the supplemen- tary material for detailed training configurations. Classification: It is the most standard task where a model classifies an input point cloud to one of 40 object categories. As in pre vious studies [ 20 , 49 ], we trained and ev aluated models with or without applying SO(3) rotations, meaning 4 cases were reported for each model. Pose Registration: In this task, a model predicts the rel- ativ e SE(3) transformation between two identical objects with different poses. W e measured the relati ve angle error and translation RMSE between the estimated and ground truth transformations for assessment. Object Part Segmentation: ShapeNet [ 3 ] contains objects ov er 16 categories, and point samples of the object are an- notated with 50 part segmentation labels defined disjointly by their object category . A model outputs part segmenta- tion labels classifiable into 50 categories per ev ery sample point, giv en the whole point cloud and its object label. The segmentation performances were measured with mIoUs av- eraged ov er instances or part classes. Indoor Semantic Segmentation: W e conducted a seman- tic segmentation using the S3DIS [ 1 ] that contains indoor scenes sampled from real-w orld en vironments. This bench- mark is challenging due to its enormous scale, where point clouds are densely sampled from 271 rooms across 6 differ - ent areas covering o ver 6000 m 2 and labeled with one of 13 semantic classes. W e used Area 5 as the test set and trained with the rest of Areas following pre vious works [ 32 – 34 ]. 5.1. Classification and Scalability Evaluation W e prepared two v ariations of our classification models: they either used the true normal vector or Algorithm 1 as the S 2 input ( ECKCon v-Normal and ECKCon v ). Base- lines were categorized into three types: the non-equi variant methods [ 15 , 26 , 33 , 37 , 39 , 41 ], the model-agnostic meth- ods [ 9 , 19 , 22 , 24 ] based on DGCNN [ 37 ], and the group con volution methods [ 4 , 13 , 20 , 35 , 49 ] including both dis- crete and steerable methods. Furthermore, we experimented ECKCon v-mini which has identical model setups, e.g ., the T able 1. Classification accuracy on the ModelNet40 dataset. Since PRLC [ 22 ] requires the prior that input has an aligned orientation, it is impossible to apply SO(3) augmentation during its training. † denotes the results reported from previous w orks [ 20 , 49 ]. Models Classification Accuracy (%) I /I I / SO(3) SO(3) /I SO(3) / SO(3) PointNet++ [ 26 ] † 89.13 9.58 81.16 80.29 PointCon v [ 39 ] 92.31 5.29 88.14 87.74 KPCon v [ 33 ] † 91.25 14.56 84.84 83.39 DGCNN [ 37 ] 91.41 14.34 88.24 87.97 PCT [ 15 ] † 91.25 15.84 86.39 84.20 PTv3 [ 41 ] 92.54 13.65 86.91 88.17 VN [ 9 ] 90.52 90.52 90.40 90.28 F A [ 24 ] † 82.25 82.25 82.01 82.01 LC [ 19 ] 88.33 88.87 88.09 88.12 PRLC [ 22 ] 88.49 88.45 - - TFN [ 35 ] † 62.28 62.28 62.64 62.64 SE(3)-T [ 13 ] † 71.60 71.60 73.01 73.01 EPN [ 4 ] † 91.45 31.08 86.60 86.60 E2PN [ 49 ] † 91.58 44.47 89.47 88.58 CSECon v [ 20 ] † 83.79 83.75 83.83 83.75 ECKCon v-mini 87.40 87.40 87.32 87.36 ECKCon v 90.52 90.52 90.19 90.19 ECKCon v-Normal 91.37 91.37 90.92 90.92 T able 2. Cost table of the equivariant classification baselines. Models (Batch Size = 12) Memory (GB) ↓ # Batch / sec ↑ #params T rain Eval T rain Eval VN [ 9 ] 6.10 1.98 4.34 8.70 2.9M EPN [ 4 ] 13.40 6.34 2.11 3.36 3.2M E2PN [ 49 ] 3.94 2.41 8.94 18.97 2.7M ECKCon v 4.89 1.28 7.74 15.09 27.7M CSECon v [ 20 ] 2.95 0.44 30.71 59.77 2.1M ECKCon v-mini 0.72 0.28 23.13 42.74 1.9M number of layers, layer-wise input/output dimensions, and the size of neighbors, to CSECon v [ 20 ] for the fair scalabil- ity comparison and substantiation of Proposition 4.1 . T able 1 shows that ECKConv-Normal reached the best accuracy o ver 91% when either the training or test set were rotated. Even without the normal vector input, ECKCon v reached comparable accuracy to V ector Neurons [ 9 ] which is only equiv ariant to SO(3), and ECKCon v-mini achieved nearly 4%p higher accuracy than CSECon v . These results validate the performance benefit of ECKCon v against rely- ing on augmentation and previous equi variant methods. W e measured the efficiency of equiv ariant baselines and ECKCon v v ariants in T able 2 . While ECKCon v maintained an efficienc y comparable to E2PN, the comparison between CSECon v and ECKCon v-mini revealed the benefit of ex- plicit kernel in terms of memory as stated in Proposition 4.1 . In conclusion, ECKCon v demonstrates its scalability re- garding both model capacity and memory ef ficiency . 6 T able 3. Pose registration results on the ModelNet40. W e repro- duced the methods by Chen et al. [ 4 ] and Zhu et al. [ 49 ] for KP- Con v , EPN, and E2PN, which do not estimate the translation dif- ference. Models were ev aluated 10 times with different seeds. Models Mean ( ◦ ) Median ( ◦ ) Max ( ◦ ) tRMSE KPCon v [ 33 ] 128 . 57 ± 0 . 97 123 . 22 ± 0 . 52 180 . 00 ± 0 . 00 - DGCNN + DCP-v1 [ 36 ] 121 . 29 ± 0 . 90 137 . 19 ± 1 . 95 179 . 60 ± 0 . 00 0.081 DGCNN + DCP-v2 [ 36 ] 120 . 07 ± 1 . 28 132 . 54 ± 1 . 94 179 . 60 ± 0 . 00 0.072 w/ SO(3) Aug 121 . 61 ± 1 . 58 137 . 62 ± 1 . 85 179 . 60 ± 0 . 00 0.075 EPN [ 4 ] 1 . 62 ± 0 . 02 2 . 40 ± 0 . 08 110 . 14 ± 45 . 53 - E2PN [ 49 ] 11 . 70 ± 0 . 25 13 . 71 ± 0 . 19 163 . 62 ± 15 . 70 - CSECon v [ 20 ] + DCP-v2 9 . 34 ± 0 . 16 2 . 93 ± 0 . 07 178 . 95 ± 1 . 06 0.17 ECKCon v + DCP-v2 0 . 63 ± 0 . 00 0 . 53 ± 0 . 00 8 . 57 ± 2 . 40 0.010 5.2. Pose Registration Our pose re gistration model consisted of ECKConv local feature extractor and DCP method [ 36 ] to compute the rel- ativ e pose between objects. Models experimented by W ang and Solomon [ 36 ] were compared as baselines since they utilize DGCNN [ 37 ] as a feature extractor . W e also included models from Zhu et al. [ 49 ] and the CSEConv model shar- ing the identical architecture to ours as the equi variant base- lines. Each metric represents the mean, median, maximum of error angles by rotations and RMSE of translation error . The training was conducted with randomly sampled poses from S E (3) and the entire object cate gories. T able 3 demonstrates the definite performance gap be- tween our model and others in ev ery metric. Baselines with DGCNN backbones could not handle the rotation difference sampled from the complete SO(3) space. W e also verified that applying SO(3) augmentation on the source object dur- ing the training of DGCNN + DCP-v2 was unav ailing ei- ther . Other baselines, only structurally equiv ariant to dis- crete group or SO(3), were de graded by high maximum an- gle errors. ECKConv with the closest point approach fit best to the pose re gistration task thanks to its embedded and thorough symmetry to any SE(3) actions. 5.3. Object Part Segmentation Our part segmentation model adopted U-Net [ 31 ] in- spired approach by Qi et al. [ 26 ] and adopted the fea- ture interpolation module to up-sample the features of K- closest points. Please refer to Section 7.3 in the supple- mentary material for the interpolation details. W e prepared Pointent++ [ 26 ], original DGCNN, model-agnostic meth- ods based on DGCNN, and CSECon v baseline implemented with similar setups to ECKCon v as baselines. T able 4 sho ws that ECKConv achiev ed the instance aver - aged mIoUs ov er 83%, the best among the baselines when the SO(3) is applied during the e valuation. The part class av eraged mIoUs (mcIoUs) of ECKCon v also reached com- parable scores to the augmented and model-agnostic base- lines. A qualitativ e analysis in Figure 4 re vealed that CSEC- T able 4. Part segmentation on the ShapeNet. mIoU denotes the IoU per object averaged among every instance, and mcIoU denotes that IoUs are av eraged per part class before the total mean. Models I /I I / SO(3) SO(3) / SO(3) mIoU mcIoU mIoU mcIoU mIoU mcIoU PointNet++ [ 26 ] 85.56 82.24 28.97 32.95 82.10 78.02 DGCNN [ 37 ] 85.13 85.41 31.48 32.19 77.60 78.24 VN [ 9 ] 81.74 82.06 81.73 82.05 81.76 82.10 LC [ 19 ] 81.04 81.43 81.07 81.45 81.05 81.53 PRLC [ 22 ] 79.38 79.90 79.39 79.91 - - CSECon v [ 20 ] 35.80 32.23 35.80 32.23 35.51 33.20 ECKCon v 83.78 81.19 83.78 81.19 83.68 80.99 Figure 4. V isualization of the part segmentation in the ShapeNet by ECKCon v (Ours), V ector Neurons [ 9 ], and CSECon v [ 20 ]. on v failed to discern local geometries e ven in the simple objects. Contrarily , ECKConv distinguished fine local fea- tures, e.g ., the saddle and wheel of the bike, more accu- rately than other baselines. Unlike the previous experiments where learning the global shape was enough to solve the task, the performance g ap in the segmentation task v alidates the outstanding capability of learning local geometries by ECKCon v among the intertwiner con volution framew ork. 5.4. Indoor Semantic Segmentation Our indoor segmentation model cropped 4 m 2 square sub-regions and sampled the points from a single scene dur- ing its training due to the large scale of S3DIS, following previous researches [ 10 , 32 ]. Similar to the part segmen- tation model, its U-Net architecture consisted of 30 layers of ECKCon v and recei ved point clouds with normal vec- tors but without colors. It was e valuated to cover the whole points of each aligned scene in the Area 5; we divided the scene to sub-re gions with one meter strides, and ev ery point in each region was split to uniformly sampled point clouds. W e also voted 3 times to decide the final prediction as pre- vious works [ 10 , 32 – 34 ] and measured the segmentation performance with ov erall accuracy (O A), mean accuracy (mA CC), and mean intersection over unit (mIoU). W e compared ECKConv to DGCNN and KPConv trained with SO(3) augmentation and rotation in variant 7 Figure 5. Semantic segmentation results by ECKCon v on the Area 5 of S3DIS [ 1 ]. The ceiling and wall points that obscure the view point are omitted in the figures for the better visualization. (Left) The input, ground truth label, and prediction results of office 28 , lobby 1 , and confer ence room 2 in the Area 5. V arious indoor objects, e.g ., bookcase, table, chair , and sofa, are successfully segmented from the scenes by our method. (Right) The simulation by randomly placing chair objects from ModelNet40 [ 42 ] in the hallway 8 of Area 5. Even though the chair objects are out-of-distribution from the S3DIS, our method se gments every object from the simulated scenes. T able 5. Semantic segmentation results on the Area 5 of S3DIS. † denotes the result reported in RI-MAE [ 32 ]. Models O A mAcc mIoU DGCNN [ 37 ] w/ SO(3) Aug 74.78 45.06 35.78 KPCon v [ 33 ] w/ SO(3) Aug 84.50 64.66 57.42 RICon v++ [ 44 ] 84.68 66.41 56.94 RI-MAE [ 32 ] † - - 60.3 ECKCon v-Normal 86.38 70.38 61.80 baselines, e.g ., RIConv++ [ 44 ] and RI-MAE [ 32 ]. T able 5 shows that the degradation by SO(3) augmentation was se- vere enough to drop the performance of non-equiv ariant methods lower than the rotation-in variant baselines; it ne- cessitates the SE(3) symmetric model scalable enough to learn large-scale problems. Indeed, our ECKConv success- fully conducted the segmentation as in the left of Figure 5 and reached the best performance in ev ery metric, espe- cially 61.80 in mIoU, which is the state-of-the-art perfor- mance among rotation-in variant methods in the S3DIS se g- mentation to the best of our knowledge. W e also conducted a simulation where chair objects from ModelNet40, out-of-distribution data to S3DIS, were ran- domly placed in the hallway 8 of Area 5. As shown in the right of Figure 5 , our method discerned the chairs regard- less of their poses on the floor . Please refer to Figure 9 in the supplementary material for more qualitativ e simulation results. They verified that not only ECKConv is scalable enough but also its locally SE(3) equiv ariant features plays an essential role in resolving large-scale problems. 6. Conclusion W e propose ECKCon v , SE(3) equi variant con volutional networks for point clouds using the intertwiner frame work. W e formalize the kernel domain as the double coset space of SE(3) acted by SO(2) subgroups and acquire the parame- ters defining SE(3)-in variant and disjoint orbits, guarantee- ing the equi variance and injecti veness of the k ernel domain. Utilizing the coordinate-based networks with the Gaussian embedding, the double coset parameters from the normal- ized recepti ve field in a ball shape of ECKCon v are mapped to the weights for the basis kernel maps, enhancing the ca- pability to learn local geometries. W e also reformulate the explicit kernel computation and grant the memory scalabil- ity to ECKConv . Extensive experiments in the ModelNet40, ShapeNet, and S3DIS empirically v alidated the enhanced performance and ef ficiency of ECKCon v , which achie ved the best performance among the state-of-the-art equi vari- ant or rotation-in v ariant point cloud methods in diverse syn- thetic and real-world problems. 8 Acknowledgement This work was partly sup- ported by grants from the IITP (RS-2021-II211343- GSAI/10%, RS-2022-II220951-LB A/15%, RS-2022- II220953-PICA/15%), the NRF (RS-2024-00353991- SP ARC/15%, RS-2023-00274280-HEI/15%), the KEIT (RS-2025-25453780/15%), and the KIA T (RS-2025- 25460896/15%), funded by the Korean gov ernment. References [1] Iro Armeni, Ozan Sener , Amir R Zamir , Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Sav arese. 3d seman- tic parsing of large-scale indoor spaces. In Pr oceedings of the IEEE conference on computer vision and pattern r ecog- nition , pages 1534–1543, 2016. 2 , 6 , 8 , 5 [2] Johann Brehmer, S ¨ onke Behrends, Pim De Haan, and T aco Cohen. Does equi variance matter at scale? T ransactions on Machine Learning Resear ch , 2025. 1 [3] Angel X Chang, Thomas Funkhouser , Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Sa varese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository . arXiv pr eprint arXiv:1512.03012 , 2015. 2 , 6 , 5 [4] Haiwei Chen, Shichen Liu, W eikai Chen, Hao Li, and Ran- dall Hill. Equiv ariant point network for 3d point cloud analy- sis. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 14514–14523, 2021. 1 , 2 , 4 , 6 , 7 [5] T aco Cohen and Max W elling. Group equiv ariant con vo- lutional networks. In International confer ence on machine learning , pages 2990–2999. PMLR, 2016. 1 , 2 , 3 [6] T aco S Cohen and Max W elling. Steerable cnns. arXiv pr eprint arXiv:1612.08498 , 2016. 1 , 2 [7] T aco S Cohen, Mario Geiger , and Maurice W eiler . Inter- twiners between induced representations (with applications to the theory of equi variant neural networks). arXiv preprint arXiv:1803.10743 , 2018. 2 , 3 [8] T aco S Cohen, Mario Geiger , and Maurice W eiler . A gen- eral theory of equi variant cnns on homogeneous spaces. Ad- vances in neural information pr ocessing systems , 32, 2019. 2 , 3 [9] Congyue Deng, Or Litany , Y ueqi Duan, Adrien Poulenard, Andrea T agliasacchi, and Leonidas J Guibas. V ector neu- rons: A general framework for so (3)-equiv ariant networks. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 12200–12209, 2021. 2 , 3 , 6 , 7 [10] Runpei Dong, Zekun Qi, Linfeng Zhang, Junbo Zhang, Jian- jian Sun, Zheng Ge, Li Y i, and Kaisheng Ma. Autoen- coders as cross-modal teachers: Can pretrained 2d image transformers help 3d representation learning? arXiv pr eprint arXiv:2212.08320 , 2022. 7 , 2 [11] Jiajun Fei and Zhidong Deng. Rotation inv ariance and equiv- ariance in 3d deep learning: a survey . Artificial Intelligence Revie w , 57(7):168, 2024. 1 [12] Marc Finzi, Samuel Stanton, Pav el Izmailov , and An- drew Gordon W ilson. Generalizing con volutional neural net- works for equivariance to lie groups on arbitrary continuous data. In International conference on machine learning , pages 3165–3176. PMLR, 2020. 1 [13] Fabian Fuchs, Daniel W orrall, V olker Fischer , and Max W elling. Se (3)-transformers: 3d roto-translation equiv ariant attention netw orks. Advances in neural information pr ocess- ing systems , 33:1970–1981, 2020. 2 , 6 [14] Jan Gerken, Oscar Carlsson, Hampus Linander , Fredrik Ohlsson, Christoffer Petersson, and Daniel Persson. Equi v- ariance versus augmentation for spherical images. In In- ternational Confer ence on Machine Learning , pages 7404– 7421. PMLR, 2022. 1 [15] Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, T ai-Jiang Mu, Ralph R Martin, and Shi-Min Hu. Pct: Point cloud transformer . Computational V isual Media , 7:187–199, 2021. 2 , 6 [16] Y ulan Guo, Hanyun W ang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. Deep learning for 3d point clouds: A surv ey . IEEE tr ansactions on pattern analysis and machine intelligence , 43(12):4338–4364, 2020. 1 [17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Pr oceed- ings of the IEEE conference on computer vision and pattern r ecognition , pages 770–778, 2016. 6 [18] Anastasia Ioannidou, Elisav et Chatzilari, Spiros Nikolopou- los, and Ioannis K ompatsiaris. Deep learning advances in computer vision with 3d data: A survey . A CM computing surve ys (CSUR) , 50(2):1–38, 2017. 1 [19] S ´ ekou-Oumar Kaba, Arnab Kumar Mondal, Y an Zhang, Y oshua Bengio, and Siamak Ravanbakhsh. Equiv ariance with learned canonicalization functions. In International Confer ence on Machine Learning , pages 15546–15566. PMLR, 2023. 3 , 6 , 7 [20] Jaein Kim, Hee Bin Y oo, Dong-Sig Han, Y eon-Ji Song, and Byoung-T ak Zhang. Continuous so (3) equi variant conv olu- tion for 3d point cloud analysis. In European Confer ence on Computer V ision , pages 59–75. Springer , 2024. 2 , 3 , 4 , 5 , 6 , 7 [21] Y angyan Li, Rui Bu, Mingchao Sun, W ei W u, Xinhan Di, and Baoquan Chen. Pointcnn: Con volution on x-transformed points. Advances in neural information pr ocessing systems , 31, 2018. 2 [22] Arnab K umar Mondal, Siba Smarak Panigrahi, Oumar Kaba, Sai Rajeswar Mudumba, and Siamak Ravanbakhsh. Equiv- ariant adaptation of large pretrained models. Advances in Neural Information Processing Systems , 36:50293–50309, 2023. 3 , 6 , 7 , 2 [23] Philip M ¨ uller , Vladimir Golko v , V alentina T omassini, and Daniel Cremers. Rotation-equivariant deep learning for dif- fusion mri. arXiv pr eprint arXiv:2102.06942 , 2021. 1 [24] Omri Puny , Matan Atzmon, Heli Ben-Hamu, Ishan Misra, Aditya Grov er, Edward J Smith, and Y aron Lipman. Frame av eraging for inv ariant and equi variant network design. In 10th International Confer ence on Learning Repr esentations, ICLR 2022 , 2022. 3 , 6 [25] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference 9 on computer vision and pattern r ecognition , pages 652–660, 2017. 2 [26] Charles Ruizhongtai Qi, Li Y i, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information pr ocessing systems , 30, 2017. 2 , 4 , 5 , 6 , 7 , 1 [27] Ali Rahimi and Benjamin Recht. Random features for lar ge- scale kernel machines. Advances in neural information pr o- cessing systems , 20, 2007. 3 [28] Nikhila Ravi, Jeremy Reizenstein, David Novotny , T ay- lor Gordon, W an-Y en Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv pr eprint arXiv:2007.08501 , 2020. 1 [29] David W Romero, Robert-Jan Bruintjes, Jakub M T omczak, Erik J Bekkers, Mark Hoogendoorn, and Jan C van Gemert. Flexcon v: Continuous kernel con volutions with differen- tiable kernel sizes. arXiv pr eprint arXiv:2110.08059 , 2021. 2 [30] David W Romero, Anna Kuzina, Erik J Bekkers, Jakub M T omczak, and Mark Hoogendoorn. Ckcon v: Continu- ous kernel con volution for sequential data. arXiv preprint arXiv:2102.02611 , 2021. 2 [31] Olaf Ronneberger , Philipp Fischer , and Thomas Brox. U- net: Con volutional networks for biomedical image segmen- tation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international confer ence, Munich, Germany , October 5-9, 2015, pr oceedings, part III 18 , pages 234–241. Springer , 2015. 7 , 5 [32] Kunming Su, Qiuxia Wu, P anpan Cai, Xiaogang Zhu, Xue- quan Lu, Zhiyong W ang, and Kun Hu. Ri-mae: Rotation- in variant masked autoencoders for self-supervised point cloud representation learning. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , pages 7015–7023, 2025. 3 , 6 , 7 , 8 , 2 [33] Hugues Thomas, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ ois Goulette, and Leonidas J Guibas. Kpconv: Flexible and deformable con volution for point clouds. In Pr oceedings of the IEEE/CVF international confer ence on computer vision , pages 6411–6420, 2019. 2 , 4 , 6 , 7 , 8 [34] Hugues Thomas, Y ao-Hung Hubert Tsai, T imothy D Bar- foot, and Jian Zhang. Kpcon vx: Modernizing kernel point con volution with kernel attention. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pages 5525–5535, 2024. 4 , 6 , 7 [35] Nathaniel Thomas, T ess Smidt, Stev en K earnes, Lusann Y ang, Li Li, Kai K ohlhoff, and Patrick Riley . T ensor field networks: Rotation-and translation-equivariant neural net- works for 3d point clouds. arXiv pr eprint arXiv:1802.08219 , 2018. 2 , 6 [36] Y ue W ang and Justin M Solomon. Deep closest point: Learn- ing representations for point cloud registration. In Pr oceed- ings of the IEEE/CVF international conference on computer vision , pages 3523–3532, 2019. 7 , 2 [37] Y ue W ang, Y ongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds. ACM T ransactions on Graphics (tog) , 38(5):1–12, 2019. 2 , 6 , 7 , 8 [38] Lisa W eijler and Pedro Hermosilla. Efficient continuous group con volutions for local se (3) equiv ariance in 3d point clouds. arXiv pr eprint arXiv:2502.07505 , 2025. 2 [39] W enxuan W u, Zhongang Qi, and Li Fuxin. Pointconv: Deep con volutional networks on 3d point clouds. In Pr oceedings of the IEEE/CVF Confer ence on computer vision and pattern r ecognition , pages 9621–9630, 2019. 2 , 5 , 6 [40] Xiaoyang W u, Y ixing Lao, Li Jiang, Xihui Liu, and Heng- shuang Zhao. Point transformer v2: Grouped vector atten- tion and partition-based pooling. Advances in Neural Infor- mation Pr ocessing Systems , 35:33330–33342, 2022. 2 [41] Xiaoyang W u, Li Jiang, Peng-Shuai W ang, Zhijian Liu, Xi- hui Liu, Y u Qiao, W anli Ouyang, T ong He, and Hengshuang Zhao. Point transformer v3: Simpler faster stronger . In Pr o- ceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pages 4840–4851, 2024. 2 , 6 [42] Zhirong W u, Shuran Song, Aditya Khosla, Fisher Y u, Lin- guang Zhang, Xiaoou T ang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 1912–1920, 2015. 1 , 2 , 4 , 6 , 8 [43] Zhiyuan Zhang, Binh-Son Hua, David W Rosen, and Sai-Kit Y eung. Rotation in variant conv olutions for 3d point clouds deep learning. In 2019 International confer ence on 3d vision (3D V) , pages 204–213. IEEE, 2019. 3 [44] Zhiyuan Zhang, Binh-Son Hua, and Sai-Kit Y eung. Ricon v++: Effecti ve rotation inv ariant conv olutions for 3d point clouds deep learning. arXiv preprint arXiv:2202.13094 , 2022. 3 , 8 , 2 [45] Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS T orr , and Vladlen K oltun. Point transformer . In Pr oceedings of the IEEE/CVF international confer ence on computer vision , pages 16259–16268, 2021. 2 [46] Maksim Zhdanov , Nico Hof fmann, and Gabriele Cesa. Im- plicit con volutional kernels for steerable cnns. Advances in Neural Information Pr ocessing Systems , 36, 2024. 2 [47] Jianqiao Zheng, Sameera Ramasinghe, and Simon Lucey . Rethinking positional encoding. arXiv preprint arXiv:2107.02561 , 2021. 4 , 5 [48] Jianqiao Zheng, Sameera Ramasinghe, Xueqian Li, and Si- mon Lucey . T rading positional complexity vs deepness in coordinate networks. In Eur opean Conference on Computer V ision , pages 144–160. Springer, 2022. 4 , 5 [49] Minghan Zhu, Maani Ghaffari, W illiam A Clark, and Huei Peng. E2pn: Efficient se (3)-equiv ariant point network. In Pr oceedings of the IEEE/CVF Conference on Computer V i- sion and P attern Recognition , pages 1223–1232, 2023. 1 , 2 , 3 , 4 , 6 , 7 10 Learning Coordinate-based Con volutional K ernels f or Continuous SE(3) Equiv ariant and Efficient Point Cloud Analysis Supplementary Material Algorithm 1 The coset augmentation from the coordinates Input: coordinates set X ∈ R N × 3 , neighborhood size K Output: augmented cosets N ∈ R N × 3 , s.t. N ⊂ S 2 1: x n , { x n i } K i =1 N n =1 ← K-NN ( X , X ; K ) 2: for n = 1 to N do 3: { n n 1 , · · · , n n K } ← { x n 1 − x n , · · · , x n K − x n } 4: n n ← 1 K P i n n i 5: if ∥ n n ∥ 2 > 1e − 5 then 6: ˆ n n ← n n ∥ n n ∥ 2 7: else 8: ˆ n n ← the least eigen vector of PCA ( { n n i } K i =1 ) 9: end if 10: end for 11: N ← ˆ n 1 , · · · , ˆ n N ⊤ 12: return N 7. Model Architectur es and T raining Setups W e explain the details of ECKCon v implementation and enumerate the training configurations of our models. Ev- ery ECKCon v model is conducted on a single R TX 3090 GPU. Their architectures are illustrated in Figures 7a , 7b , 8a and 8b . When applying neighboring algorithms speci- fied for point clouds, e.g ., farthest point sampling, k-nearest neighbors, ball query , and PCA among point groups, we utilized the implementations from PyT orch3D [ 28 ]. 7.1. Details of ECKCon v Block This section delineates the detailed computation of ECK- Con v block, which is also illustrated in Figure 6 . Given the input point cloud { ( x n , f n ) | x n = ( x n , n n ) , f n = f ( x n ) } N n =1 , the centroids for con volution { ( x m , f m ) } M m =1 , where M ≤ N , are sampled first by farthest point sam- pling [ 26 ] using the coordinate x m s. Then, a ball query groups the local neighbors with maximal k neighbors N ( x m ) = { x m i | x m i = ( x m i , n m i ) } k i =1 from the input points for each centroid x m . It gathers features in { f n } N n =1 into {{ f m i } k i =1 } M m =1 by ev ery N ( x m ) , and the ECKConv layer operates on ev ery neighborhood and its gathered feature, yielding the output features { ( f ∗ κ ) m } M m =1 . After the block, batch normalization and GELU activ ation are applied on the { ( f ∗ κ ) m } M m =1 , and the pair of { ( x m , ( f ∗ κ ) m ) } M m =1 is propagated as a new point cloud towards the ne xt layer . The abov e process is summarized in Algorithm 2 . Algorithm 2 The process of ECKCon v block Input: coordinates X in ∈ R N × 6 , features F in ∈ R N × C in Output: { x m } M m =1 , { f n } N n =1 1: { x n } N n =1 ← X in ; { f n } N n =1 ← F in 2: { x m } M m =1 ← farthest-point-sampling ( { x n } N n =1 , M ) 3: Gather { f m } M m =1 for { x m } M m =1 4: X cnt ← { x m } M m =1 , F cnt ← { f m } M m =1 5: {N ( x m ) } M m =1 ← ball-query ( { x m } M m =1 , { x n } N n =1 , k ) 6: Gather {{ f m i } k i =1 } M m =1 for {N ( x m ) } M m =1 7: { ( f ∗ κ ) m } M m =1 ← ECKConv ( { x m } M m =1 , {N ( x m ) } M m =1 , {{ f m i } k i =1 } M m =1 ) 8: F con v ← { ( f ∗ κ ) m } M m =1 9: return X cnt , F cnt , F con v ▷ F cnt is utilized only in the residual connection 7.2. Coset A ugmentation of Point Clouds If the ground truth normal vector were not giv en in the inputs, we heuristically lift the 3D coordinate to the coset in S 2 as Algorithm 1 . It averages e very difference between the neighbor points and the centroid and normalize the av- erage into a unit v ector unless its norm is not too small. If it is, it exploits PCA on the neighbors to estimate the normal vector for the centroid. W e also experimented exploiting only the normal v ectors estimated by PCA before the ECK- Con v layers, but Algorithm 1 empirically performed better in the ModelNet40 experiments. W e applied this to ev ery our models except ECKConv-Normal in the ModelNet40 classification and the S3DIS segmentation e xperiments. 7.3. Point F eature Pr opagation Module W e adopt this module suggested by Qi et al. [ 26 ] in our segmentation models, up-sampling point features from a coarse point cloud X ′ ∈ R M × 3 onto a fine one X ∈ R N × 3 such that N > M . Querying the top-K nearest points from the coarse point cloud per each fine point, local features from queried points are gathered with normalized weights reciprocal to distances and concatenated to features of the query point: f FP i = P K k =1 w ik f ′ ik P K k =1 w ik , w ik = 1 ∥ x i − x ′ ik ∥ 2 2 , (13) where x i ∈ X , and x ′ ik ∈ X ′ is queried to x i by KNN with corresponding feature f ′ ik . Then the upsampled feature f FP i is concatenated to f i , the feature of x i before the feature 1 Figure 6. Detailed architectures of ECKConv block. W e substitute abstract variables from Figure 3 with actual computational v ariables. propagation, and the module propag ates a ne w point feature set f i , f FP i N i =1 to the following ECKConv layer . W e set K = 1 and K = 3 for object part and indoor semantic segmentation model each. 7.4. T raining Configurations 7.4.1. ModelNet40 Classification W e let ev ery baseline training follow its original con- figuration of training: the number of input points, whether to utilize a normal vector , augmentation except SO(3) rota- tion, and other optimizer hyperparameters. For our method, we sampled 1024 points for each point cloud and applied the scaling augmentation during the training, i.e ., the scales of the object in XYZ directions were randomly rescaled in range ( 2 3 , 1 . 5) . Each minibatch contained 16 point clouds, and its cross entropy loss was smoothed with parameter 0.2 and minimized by Adam optimizer , whose initial learning rate w as 1e − 4 and scheduled to 1e − 6 by cosine annealing scheduler during 200 epochs. 7.4.2. ModelNet40 Pose Registration Our ECKCon v layers extracted local features from the two distinct inputs, named the source and target. W e adopted Deep Closest Point [ 36 ] to determine the proper in- terpolation value of source coordinates that match the tar get coordinates. A variant of the transformer encoder-decoder structure plays a critical role in DCP to find the interpola- tion score between points. Every deep learning module here shares its parameters for both source and target. Finally , the relativ e pose T pred = ( R pred , t pred ) from the source to tar- get can be readily computed by applying the singular value decomposition and mean difference. Following W ang and Solomon [ 36 ], the following loss w as minimized: L ( T pred , T gt ) = ∥ R pred R ⊤ gt − I ∥ 2 2 + ∥ t pred − t gt ∥ 2 2 . (14) The training was conducted for 50 epochs, and each mini- batch contains 16 pairs without augmentation. Adam opti- mizer minimizes the loss with 1e − 4 initial learning rate scheduled to 1e − 6 by cosine annealing scheduler . 7.4.3. ShapeNet Part Segmentation W e configured the number of points in a point cloud to 2048 in ev ery model for fair comparison, since the number of samples in a point cloud af fects the IoU metrics. It might influence the performance discrepancy of PRLC [ 22 ] be- tween its reported result and our e xperiment, whose number of points is 1024 in its original implementation. W e applied an identical augmentation protocol from our classification model training. A cross-entropy loss was computed on ev- ery point of each input and smoothed with parameter 0.2. The loss on minibatch containing 16 point clouds was min- imized by Adam optimizer with hyperparameter β 1 = 0 . 5 , and its initial learning rate was scheduled from 1e − 4 to 1e − 6 by the cosine annealing during 250 epochs. 7.4.4. S3DIS Semantic Segmentation As stated in Section 5.4 , we adopted the training proto- cols by Dong et al. [ 10 ], Su et al. [ 32 ], Zhang et al. [ 44 ] to crop a 4 m 2 region and sample 4096 points within it. A single room in the area was resampled multiple times in a single epoch to cov er its whole scene with the cropped re- gions. The cropped regions were randomly scaled in range ( 2 3 , 1 . 5) along the XY directions and flipped along the X- axis with probability 0.5 during the training. Besides, the label weight for cross-entropy loss was precomputed since the imbalance among the semantic category is sev ere in the S3DIS. The cross entropy loss was minimized by Adam op- timizer with learning rate 1e − 4 during 80 epochs. 8. Setups f or CSECon v Baselines Since CSEConv [ 20 ] is our main baseline with respect to the scalability , we detail the setups for CSECon v base- lines in the pose registration and part segmentation, which were not experimented in its original paper . Every CSEC- on v baseline followed the initial feature generation protocol suggested by Kim et al. [ 20 ]. 2 T able 6. Memory and time costs during the training, compared between ECKCon v and CSECon v baselines from the pose regis- tration and part segmentation tasks. Models Memory (GB) ↓ #Batch/sec ↑ batch size #params pose reg CSECon v 39.09 3.37 16 10.8M ECKCon v 5.37 7.39 16 4.1M part seg CSECon v 66.46 2.04 6 14.9M ECKCon v 10.26 3.80 16 22.5M 8.1. Pose Registration As stated in the main paper, it shared the identical model and training configurations to the ECKCon v model, e.g., the basis dimension of coordinate-based networks (though CSECon v uses random F ourier feature [ 27 ]), the number of layers, the dimension of each hidden layer , the cardinality of neighbors per layer, and training h yperparameters. How- ev er , 6 GPUs were required to train this model in our work- station. It shifted both source and target point clouds to the origin by subtracting geometric means since CSECon v only preserves SO(3) symmetry . After the extraction, the model replaced do wn-sampled point clouds to the original center coordinates before DCP method. 8.2. Part Segmentation Our CSEConv baseline also followed U-Net style archi- tecture but had only three down-sampling and up-sampling layers each. It shared the identical training hyperparame- ters to the ECKCon v experiment except for the batch size and training epochs, which reduced to 6 point clouds and 100 epochs. This configuration also utilized 6 GPUs for the training in our workstation. 8.3. Scalability Comparisons W e additionally measure the cost of CSEConv baselines during the training and compare them with our models in T able 6 . Since the training setups which affected their ef fi- ciency varied among experiments, their batch and parameter sizes are reported as well. W e observed the consistency in their training efficienc y , which matches the scalability statement in Proposition 4.1 . When models shared the identical architecture as the pose registration task, ECKCon v was more efficient than CSEC- on v both in memory and time costs. Our method also consumed fe wer resources than CSECon v while processing more parameters and inputs in the part segmentation e xper- iment. These results supplement the scalability of ECK- Con v , which ef fectiv ely exploits computation resources and is scalable to obtain sufficient model capacity . T able 7. Ablation experiments on the hyperparamters of ECKCon v in the ModelNet40 classification task, where models receiv ed ran- domly rotated inputs only during the e valuation ( I / SO(3)). De- fault v alues are A = 22 , Ψ ∈ R 64 , and K = 32 . Ablation Studies #Anchor Bases Gau ( · ) Bandwidth #Neighbors for Alg 1. A = 1 A = 64 Ψ ∈ R 4 Ψ ∈ R 256 K = 8 K = 128 Acc (%) 89.22 90.19 88.86 90.32 90.32 89.95 Mem (GB) ↓ 4.36 6.57 1.90 14.51 4.90 4.90 # Batch / sec ↑ 10.20 5.62 10.65 2.69 7.58 6.83 9. Ablations on Hyperparameter Sensitivity As the kernel structure and the coordinate lifting to coset space of ECKCon v hav e div erse hyperparameters, we con- ducted ablation experiments in the ModelNet40 classifica- tion task to verify the sensiti vity of ECKCon v against such hyperparameters. The experiments varied the number of an- chor bases ( A ), the bandwidth of Gaussian embedding ( Ψ ), and the number of neighbors during the coset lifting in Al- gorithm 1 ( K ) to extreme values. T able 7 demonstrates that the efficiencies of the variants were af fected significantly when the hyperparameters related to the kernel ( A, Ψ ) var - ied, but their performances remained relati vely robust. W e conjecture that linear layers from skip connections in our method help maintain their performances. 10. Discussion on the Limitations Although ECKCon v proposes an SE(3)-symmetric and scalable conv olution applicable to large-scale point cloud problems, its kernel is isotropic to SE(3) actions due to the utilization of the double coset element, which is composed of coset elements grouped by left actions of SO(2), and the confinement to scalar -type features. These factors de- crease the directional expressi vity of ECKConv to certain types of point cloud tasks where the point feature should be anisotropic, e.g ., normal estimation, molecule structure prediction, and n-body problems. Expanding the resolvable domain of ECKCon v would be an important future research direction that balances our scalable architecture with the inefficient yet expressiv e kernel designs from the previous steerable con volution studies. 3 (a) Classification model. (b) Pose registration model. Figure 7. Architectures of ECKCov models for ModelNet40 [ 42 ] experiments. Since point clouds only contain 3D coordinates, we initialize its point feature as one vector per e very point. An arro w between ECKCon v layers designates the number of points and the dimension of each feature on its above and belo w . W e also specify ECKCon v hyperparameters belo w , such as the number of anchor points ( A ), a ball query radius ( r ), the maximal number of sampled points ( k ), the standard deviation of Gaussian kernel ( σ ), and the basis dimension of Gaussian embedding ( Ψ ) [ 47 , 48 ]. Linear layers map every point feature with weight-sharing networks, and we omit batch normalization and activ ation next to these layers in the abov e figures. 4 (a) Part segmentation model for ShapeNet [ 3 ]. (b) Semantic segmentation model for S3DIS [ 1 ]. Figure 8. Architectures of ECKConv models fors segmentation tasks in the ShapeNet and S3DIS. W e applied U-Net [ 31 ] style architecture and up-sampled point features using Point Feature Propagation [ 26 ] module, which assigns coarse point features to its top-K closest neighbors skipped from previous layers, weighted by the reciprocal of the point distance in the coordinate space. 5 Figure 9. Qualitative results in S3DIS simulation experiments. (top) W e di versified the objects from the chair category of ModelNet40. Our model consistently succeeded to discern chair objects with different shapes and poses. (bottom) W e diversified the object category , adding the table object from ModelNet40. Our model sho wed consistent results on segmenting the table objects regardless of their numbers or poses, although noisy results on the bottom part of tables were also observed. 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment