Translation Invariance of Neural Operators for the FitzHugh-Nagumo Model
Neural Operators (NOs) are a powerful deep learning framework designed to learn the solution operator that arise from partial differential equations. This study investigates NOs ability to capture the stiff spatio-temporal dynamics of the FitzHugh-Na…
Authors: Luca Pellegrini
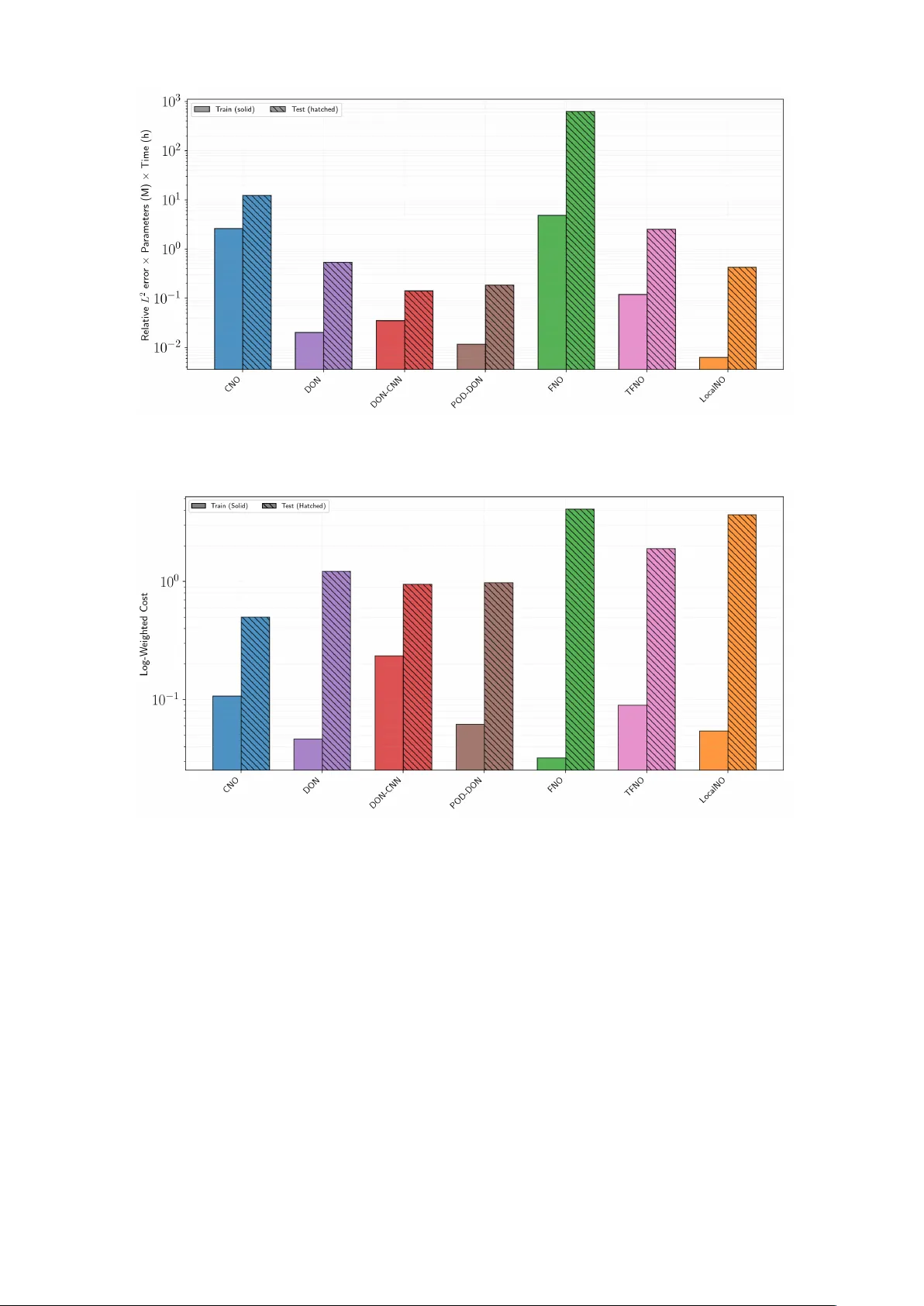
T ranslation In v ariance of Neural Op erators for the FitzHugh–Nagumo Mo del Luca P ellegrini 1,2 1 Departmen t of Mathematics, Universit y of P avia, P a via, Italy 2 Euler Institute, F acult y of Informatics, Univ ersit` a della Svizzera italiana, Lugano, Switzerland Abstract Neural Op erators (NOs) are a pow erful deep learning framewo rk designed to learn the solution op erator that arise from partial differen tial equations. This study inv estigates NOs abilit y to capture the stiff spatio-temp oral dynamics of the FitzHugh-Nagumo mo del, whic h describ es excitable cells. A key contribution of this work is ev aluating the translation inv ariance using a nov el training strategy . NOs are trained using an applied curren t with v arying spatial lo cations and in tensities at a fixed time, and the test set introduces a more c hallenging out-of- distribution scenario in which the applied curren t is translated in both time and space. This approac h significantly reduces the computational cost of dataset generation. Moreo ver we b enc hmark seven NOs architectures: Conv olutional Neural Operators (CNOs), Deep Operator Net works (DONs), DONs with CNN encoder (DONs-CNN), Proper Orthogonal Decomposition DONs (POD-DONs), F ourier Neural Op erators (FNOs), T uck er T ensorized FNOs (TFNOs), Lo calized Neural Operators (Lo calNOs). W e ev aluated these mo dels based on training and test accuracy , efficiency , and inference sp eed. Our results reveal that CNOs p erforms w ell on translated test dynamics. Ho wev er, they require higher training costs, though their performance on the training set is similar to that of the other considered architectures. In contrast, FNOs ac hieve the low est training error, but hav e the highest inference time. Regarding the translated dynamics, FNOs and their v ariants provide less accurate predictions. Finally , DONs and their v ariants demonstrate high efficiency in b oth training and inference, how ev er they do not generalize well to the test set. These findings highlight the current capabilities and limitations of NOs in capturing complex ionic mo del dynamics and provide a comprehensiv e b enc hmark including their application to scenarios inv olving translated dynamics. Keywor ds : Neural Op erators, FitzHugh-Nagumo model, stiff PDEs, computational electrophys- iology 1 In tro duction The FitzHugh-Nagumo (FHN) mo del [ 7 ] is widely used in computational electrophysiology [ 4 , 14 ], with significant applications in b oth computational neuroscience [ 13 ] and computational cardiology [ 6 ]. Originally derived as a simplification of the bioph ysically detailed Ho dgkin-Huxley mo del [ 11 ], the FHN system accurately captures the essential dynamics of action p oten tial propagation while significan tly reducing computational cost. This balance b et ween physical fidelity and efficiency is the reason why the mo del remains so widely used to da y [ 4 ]. Mathematically , the system is c haracterized by a parab olic reaction-diffusion partial differential equation (PDE) coupled with a stiff ordinary differential equation (ODE). In recent y ears, there has b een significant interest in applying Scientific Machine Learning (SciML) tec hniques to computational electroph ysiology [ 5 , 8 , 12 , 26 , 29 , 30 , 32 ], that aim to exploit the non-linear approximation capabilities of Artificial Neural Netw orks (ANNs) to solve b oth forw ard and inv erse problems. Among the many ANN- based methods, Neural Op erators (NOs) [ 16 ] represent a paradigm shift. These architectures are designed to learn mappings b et ween infinite-dimensional function spaces. While numerous NOs arc hitectures hav e b een prop osed in recent years, a comprehensive comparison of every av ailable 1 v arian t is practically unfeasible. In particular, w e consider the following: Conv olutional Neural Op erators (CNOs) [ 27 ], Deep Op erator Netw orks (DONs) [ 23 ] including v arian ts such as DONs with CNN enco ders (DONs-CNN) [ 16 ] and Prop er Orthogonal Decomp osition DON (POD-DONs) [ 24 ] F ourier Neural Op erators (FNOs) [ 20 ] and the follo wing v ariants T uc ker T ensorized F ourier Neural Op erators (TFNOs) [ 31 ], and Localized Neural Op erators (Lo calNOs) [ 22 ]. The aim of this work is to pro vide a comprehensive and rigorous comparison by ev aluating the accuracy in b oth train and test set, as w ell as the asso ciated computational costs (training and inference). F urthermore, w e exploit a fundamental ph ysical prop ert y of the FHN mo del, whic h we will refer to as translation inv ariance. Given a constant set of parameters, the solution with resp ect to an applied current remains inv arian t regardless of its translation in time. W e inv estigate whether NOs can in trinsically capture this prop ert y . Consequently , we prop ose a no vel training strategy in which the training dataset is generated with an applied current that v aries in spatial p osition and intensit y while remaining fixed in time, while the test set in tro duces a more challenging out-of-distribution scenario in whic h the applied current is translated in b oth time and space. This approach enables us to assess which architectures effectively learn the underlying in v ariance prop ert y , which could help to reduce the computational burden of generating large-scale datasets. The pap er is organized as follows: Section 2 defines the mathematical formulation of the FHN mo del and the nov el training strategy that exploits translation inv ariance. F urthermore, we provide a formal in tro duction to NOs and to the specific arc hitectures considered (CNOs, DONs, DONs-CNN, POD-DONs, FNOs, TFNOs, and Lo calNOs). Section 3 presents the numerical results obtained for each architecture. Section 4 provides an in-depth comparison of the mo dels based on accuracy , computational efficiency , inference sp eed, and cost functions that will b e introduced that take in to account accuracy , training time, and the num b er of trainable parameters. Finally , Section 5 summarizes our findings, and outlines directions for future researc h. 2 Mathematical mo dels and metho ds The FHN mo del is describ ed by a coupled system of a parab olic reaction-diffusion PDE for the transmem brane p oten tial V and a stiff ODE for the gating v ariable w . χC m ∂ V ∂ t − div( D ( x ) ∇ V ) + χI ion ( V , w ) = I app , in Ω T ∂ w ∂ t − R ( V , w ) = 0 , in Ω T n T D m ∇ V = 0 , on Γ T V ( x, 0) = V 0 ( x ) , w ( x, 0) = w 0 ( x ) , in Ω (1) where Ω T = Ω × (0 , T ]. A more detailed description of the mo del is provided in App endix A.1 . Throughout this work, we fo cus on the op erator that maps the applied current I app to the solution ( V , w ): G † : A → D (2) I app 7→ ( V , w ) where the applied curren t is defined as a piecewise constant function: I app ( i, x, t ) = ( i, ( x, t ) ∈ Ω T ,stim 0 , ( x, t ) / ∈ Ω T ,stim (3) Here, Ω T ,stim = Ω stim × [ T min , T max ], where Ω stim ⊂ Ω represents the region affected by the stim ulus. As previously underlined, the FHN mo del exhibits a prop ert y that we refer as: translation in v ariance. This implies that, for a fixed set of parameters for the FHN mo del ( 1 ) , stimulus in tensity i , and spatial p osition Ω stim , shifting the stim ulus with respect to time results in an identical solution that has merely translated in time. This behaviour is illustrated in Figure 1 . Our ob jective is to leverage this inv ariance by generating a training set in which the stimulus in tensity i and the spatial p osition Ω stim are v aried, while keeping the stimulus time ( T min and T max ) fixed. This strategy is depicted in Figure 2 . While, for the test and v alidation datasets, we v ary the stimulus intensit y i and the spatial-temp oral p osition Ω T ,stim (see Figure 3 ). This approac h significantly reduces the computational cost of generating data by eliminating the need to sample the stimulus at different times. In this study , we ev aluate the capacity of several 2 Figure 1: Example of translation in v ariance of the FHN mo del. Eac h column shows the evolution of the voltage V (second row) and the reco very v ariable w (third row) in resp onse to an applied curren t I app ( 3 ) (first ro w), with an intensit y of i = 3, a duration of 1 ms, and spatial width 0.04 at 0.5. The stimulus I app is applied at three different times: 5 ms (first column), 35 ms (second column), and 25 ms (third column). These results were obtained using the Firedrake finite element library [ 10 ]. Figure 2: Examples from the training dataset for the FHN mo del. Eac h column illustrates the ev olution of the v oltage V (second row) and the recov ery v ariable w (third row) in resp onse to an applied current I app ( 3 ) (first row). In particular, the first column has an intensit y i = 3 at p osition 0.1, the second column has intensit y of i = 0 . 5 at p osition 0.5, and the third column has an intensit y of i = 1 . 5 at p osition 0.7. The stimulus b egins at the same time for all three examples and has the same duration and spatial width: 5 ms, 1 ms, and 0.04, resp ectiv ely . These results w ere obtained using the Firedrake finite element library [ 10 ]. NOs architectures to learn the translation inv ariance property . More details ab out the dataset generation can b e found in the App endix A.2 . 2.1 Neural Op erators NOs ha ve emerged as a promising framework for learning mappings b et ween infinite-dimensional function spaces, making them particularly well-suited for solving PDEs [ 17 ]. Unlike traditional neural net works, which op erate on finite-dimensional spaces, NOs can learn contin uous op erators that map b et ween function spaces. This section introduces NOs following the formalism presented in [ 1 , 17 ], for the FHN mo del ( 1 ). In particular, we can rewrite our system Eq. ( 1 ) as follows: M V ( I app , V , w ; x, t ) = 0 , ( x, t ) ∈ Ω T N w ( V , w ; x, t ) = 0 , ( x, t ) ∈ Ω T Boundary and Initial conditions. As previously mentioned, w e are interested in the mapping defined by Eq. ( 2 ) . Despite the fact that the applied current is explicitly present only in the first equation, it has an effect on b oth v ariables 3 Figure 3: Examples from the test and v alidation datasets for the FHN mo del. Eac h column illustrates the ev olution of the voltage V (second row) and the recov ery v ariable w (third row) in resp onse to an applied current I app ( 3 ) (first ro w). In particular, the first column has an intensit y i = 0 . 1 at t = 32 ms and p osition 0 . 25; the second column has an intensit y i = 0 . 5 at t = 2 ms and p osition 0 . 5; and the third column has an intensit y i = 1 . 5 at t = 20 ms and position 0 . 7. F or all three cases, the stimulus duration and spatial width are held constant at 1 ms and 0.04, resp ectiv ely . These results were obtained using the Firedrake finite element library [ 10 ]. due to the c oupled nature of the mo del. Therefore, the solution op erator is defined as G † = Φ − 1 I app where Φ I app := ( M , N ). F urthermore, it is essential to emphasize that the tw o op erators, denoted b y M and N , exhibit distinct scales and dynamics, which makes the learning the dynamics of stiff ionic mo dels, with NOs particularly challenging [ 5 , 26 ]. In general, NOs can b e expressed as a comp osition of different op erators: G θ := Q ◦ L L ◦ · · · ◦ L 1 ◦ P : ( I app , θ ) 7→ ( V , w ) (4) where the three main comp onen ts are: • A lifting op erator P whic h maps the input function (i.e. the applied current I app ) to a higher-dimensional space. This op erator is typically implemen ted either as a shallow p oin twise Multila yer Perceptron (MLP) or a single linear lay er. • A comp osition of integral op erators L ℓ pro cessing the lifted representation through L lay ers in order to capture global dep endencies and interactions in the input function through a sequence of transformations. Each L ℓ has the follo wing structure: L ℓ ( v )( y ) := σ W ℓ v ( x ) + b ℓ + K ℓ ( θ ℓ ) v ( y ) (5) where v is the output of the previous la yer, W ℓ is a matrix, b ℓ is a vector, θ ℓ ∈ Θ ℓ ⊂ Θ is a subset of the trainable parameters, and σ is a non-linear activ ation function. Finally , K ℓ ( θ ℓ ) is a trainable linear op erator. • A pro jection op erator Q whic h maps the internal represen tation back to the output space. This op erator is also implemented as a p oin twise MLP . F or a more thorough description of the mathematical prop erties of NOs, the reader is referred to [ 2 , 18 ]. In the following sections we will give a brief introduction to the NOs architecture that will b e tak en into consideration thought this w ork (i.e. CNOs, DONs, DONs-CNN, POD-DONs, FNOs, TFNOs, and Lo calNOs). 2.1.1 Con v olutional Neural Op erators CNOs [ 27 ] are a mo dification of Conv olutional Neural Netw orks (CNNs) designed to enforce the structure-preserving contin uous equiv alence and ensure the architecture is a representation- equiv alen t neural op erator [ 17 ], which are fundamental asp ects of NOs. While a detailed deriv ation is b eyond the scop e of this work, we outline the essential comp onen ts here, a complete technical definition is rep orted in [ 27 ]. The mathematical foundation of CNOs is built up on the space of bandlimited functions, whic h are defined as follows: 4 B ω ( D , R d v ) : = { f ∈ L 2 ( D , R d v : supp[ F ( f )] ⊂ [ − ω , ω ] 2 ) } . Where, F is the F ourier transform and ω > 0 is the bandlimit frequency . The integral operator Eq. 5 in the case of CNO is defined as follo ws: v ℓ +1 = L ℓ ( v ℓ ) : = P ℓ ◦ Σ ℓ ◦ K ℓ ( v ℓ ) . Here, P ℓ is either the upsampling or do wnsampling op erator, K ℓ is the conv olution op erator and Σ ℓ is the activ ation op erator. F ollowing this, we will give a brief ov erview of the CNO’s components, for more details refer to [ 9 , 27 ]. • Upsampling U ω , ¯ ω : This op erator takes a function f ∈ B ω ( D , R ) and upsamples it to a higher bandlimit frequency space B ¯ ω ( D , R ), where ¯ ω > ω . Since B ω ( D , R ) ⊂ B ¯ ω ( D , R ) , the op eration is simply the identit y: U ω , ¯ ω f ( x ) = f ( x ) , ∀ x ∈ D . • Do wnsampling D ω ,ω : This op erator tak es a function f ∈ B ω ( D , R ) and do wnsamples it to a lo wer bandlimit frequency space B ω ( D , R ), where ω > ω . It is defined as follo ws: D ω ,ω f ( x ) = ω ω 2 ( h ω ∗ f )( x ) . Where, h ω is the sinc filter defined as: h ω ( x ) = d Y i =1 sin (2 π ω x i ) 2 π ω x i , ∀ x ∈ R d . • Activ ation op erator Σ ω : This op erator is designed such that it maps functions from a bandlimited space B ω ( D , R ) bac k to the same space (i.e., if f ∈ B ω ( D , R ) then Σ ω ( f ) ∈ B ω ( D , R )). It is defined as: Σ ω f ( x ) = ( D ¯ ω,ω ◦ σ ◦ U ω , ¯ ω f )( x ) , ∀ x ∈ D Where, σ is an activ ation function, and ¯ ω is c hosen large enough such that σ ( B ω ( D , R )) ⊂ B ¯ ω ( D , R ) • Con volution Operator K ℓ : With a slight abuse of notation, we denote K ℓ as K ω ,θ , where ω is the bandwidth and θ are the learnable parameters. W e assume there is a function κ ω ,θ called the k ernel function, such that the op erator can b e rewritten as the following conv olution: K ω ,θ f ( x ) = ( f ∗ κ ω ,θ )( x ) = Z D κ ω ,θ ( y ) f ( x − y ) dy , f ∈ B ω ( D , R d v ) , ∀ x ∈ D . The in tegral can then b e approximated as: K ω ,θ f ( x ) ≈ k X i,j =1 κ ω ,θ ( y ij ) f ( x − y ij ) ∀ x ∈ D . Where in this context, k is the kernel size of the conv olution and d v is the channel dimension. If w e are dealing with a vector-v alued function f ∈ B ω ( D , R d v ), the operators are applied component- wise. The aforementioned op erators are then assem bled into a U-Net architecture [ 28 ] featuring skip connection, the t wo additional op erators describ ed b elo w. • Skip Connection (ResNet Blo c ks) R ω ,θ : These blo c ks connect the enco der and deco der la yers at the same spatial resolution. They are useful for transferring high-frequency information to the output b efore it is filtered by the downsampling op eration. The block is defined as: R ω ,θ ( v ) = v + K ω ,θ ◦ Σ ω ◦ K ω ,θ ( v ) , ∀ v ∈ B ω ( D , R d v ) . The output of the residual blo c k is concatenated with the input of the corresp onding deco der blo c k. • In v ariant Blo cks I ω ,θ : At every la yer of the U-Net, after the concatenation of the residual blo c k output with the deco der input, we apply an inv ariant block, defined as: I ω ,θ = Σ ω ◦ K ω ,θ ( v ) , ∀ v ∈ B ω ( D , R d v ) A visual represen tation of the CNO architecture is shown in Fig 4 . 5 64 2 × 1 64 2 × C 32 2 × C 32 2 × 2 C 16 2 × 2 C 16 2 × 4 C 8 2 × 4 C N res P Q N res N res N res,neck Conv olutional Blocks legend: Residual Downsampling Upsampling Inv ariant Figure 4: Visual representation of a Conv olutional Neural Op erator with channel multiplier C and initial resolution equal to 64 with four la yers. 2.1.2 Deep Op erator Netw orks DONs [ 23 ] were among the first architectures prop osed to learn the infinite-dimensional mappings arising from PDEs. How ever, it is imp ortan t to observe that their v anilla formulation do es not strictly corresp ond to the iterativ e structure defined by Eq. ( 4 ) . But as demonstrated in the recent study [ 16 ], under certain assumptions, DONs can b e mathematically defined as NOs. In terms of arc hitecture, a DON is defined as tw o sub-netw orks: the branch and the trunk. The branch takes as input the I app and outputs a set of co efficien ts, [ b 1 , ..., b p ], where p denotes the n umber of basis functions. The trunk takes the spatio-temp oral co ordinates, ( x, t ) as input and has outputs the basis functions [ T 1 , ...T p ]. The final output is obtained by merging these tw o comp onen ts via a dot pro duct. G θ ( I app )( x, t ) = p X i =1 b i ( I app ) T i ( x, t ) , ∀ ( x, t ) ∈ Ω T . Here, θ represen ts the trainable parameters of b oth the branch and trunk netw orks. T o handle the coupled system of PDEs, one could p oten tially employ t wo separate DONs architectures and optimize them through a joint loss function. In this work, how ev er, w e employ a single DONs and split the output into tw o comp onen ts. In particular, for a total of p basis, we employ p/ 2 basis and their corresp onding co efficien ts for the p oten tial V , and the remaining p/ 2 for the gating v ariable w . This can b e written as: G θ ( I app )( x, t ) = p/ 2 X i =1 b i ( I app ) T i ( x, t ) | {z } V θ + p X i = p/ 2+1 b i ( I app ) T i ( x, t ) | {z } w θ , ∀ ( x, t ) ∈ Ω T . W e adopted this single-arc hitecture approach based on the idea that a unified netw ork should capture the ionic mo del’s intrinsic cross-dep endencies and coupled dynamics. A visual represen tation of this arc hitecture is shown in Fig. 5 . Moreo ver, we will consider the following modification of the DON: • DONs with CNN enco ders (DONs-CNN): In this v ariant, the input of the branch I app is not giv en directly to a fully connected ANN, but Instead, but instead first passes through a series of con volutional lay ers. 6 . . . . . . · · · FNN Branch Output I app ( x, t ) Input . . . . . . · · · . . . FNN ( x, t ) Input T runk Output × ( V , w )( x, t ) Outputs Figure 5: Visual representation of a DON arc hitecture. • Prop er Orthogonal Decomp osition DONs (POD-DONs) [ 24 ]: This architecture combines the op erator learning capabilities of DONs with the dimensionality reduction technique POD. Rather than using an ANN for the trunk netw ork, the output is a linear combination of POD mo des extracted from the training data. 2.1.3 F ourier Neural Op erators FNOs [ 17 , 20 ] are a class of NOs that employs the F ourier transform to efficiently parameterize the in tegral kernel op erator K ℓ ( θ ℓ ) Eq. ( 5 ) . By op erating in the frequency domain, FNOs effectiv ely capture global dep endencies within input functions. In the case of FNOs, the in tegral kernel op erator is defined as follows: K ℓ,θ ℓ v ( y ) = Z T d κ ℓ,θ ℓ ( y , s ) v ( s ) ds = Z T d κ ℓ,θ ℓ ( y − s ) v ( s ) ds = ( κ ℓ,θ ℓ ∗ v )( y ) (6) where T d is the d -dimensional torus, and κ ℓ,θ ℓ is a kernel function, whic h dep ends on the learnable parameters θ ℓ . W e can apply the conv olution theorem for the F ourier transform in order to rewrite the con volution in ( 6 ) in the F ourier domain: ( κ ℓ,θ ℓ ∗ v )( y ) = F − 1 ( F ( κ ℓ,θ ℓ )( k ) · F ( v )( k )) ( y ) . The key step in FNOs is the parameterization of F ( κ ℓ,θ ℓ )( k ) using a complex-v alued matrix of learnable parameters R θ ℓ ( k ) ∈ C d v × d v for eac h frequency mo de k ∈ Z d , obtaining: ( K ℓ,θ ℓ v )( y ) = F − 1 ( R θ ℓ ( k ) · F ( v )( k )) ( y ) . Since w e consider real-v alued functions, the parameterized matrix R θ ℓ ( k ) m ust b e Hermitian, i.e., R θ ℓ ( − k ) = R θ ℓ ( k ) for all k ∈ Z d and ℓ = 1 , . . . , L . F urthermore, in order to apply the F ast F ourier T ransform (FFT) for the numerical implementation of the F ourier transform, the mesh considered m ust b e structured and uniform. In our implemen tation, we hav e considered tw o versions of ( 5 ): v C lassic ℓ +1 = L C lassic ℓ ( v ℓ ) := σ W ℓ v ℓ + b ℓ + K ℓ,θ ℓ v ℓ , (7) v M LP ℓ +1 = L M LP ℓ ( v ℓ ) := σ W ℓ v ℓ + b ℓ + M LP ( K ℓ,θ ℓ v ℓ ) , (8) where v Classic ℓ +1 has the exact structure describ ed in ( 5 ) , while v MLP ℓ +1 generalizes the classic architecture b y incorp orating a p oin twise MLP applied to the output of the integral k ernel op erator. Moreo ver, w e will consider tw o mo difications of the FNOs: • Lo cal Neural Op erators (LocalNOs) [ 22 ]: It employs lo calized integral k ernels to capture high-frequency lo cal features and discontin uities. 7 I app ( x, t ) Input P Lifting L 1 L t L L Q Pr oje ction ( V , w )( x, t ) Outputs F ourier L ayers v t ( y ) F R θ t F − 1 W t , b t + σ v t +1 ( y ) Figure 6: Visual representation of a FNO. • T uck er T ensorized FNOs (TFNOs) [ 31 ]: It com bines T uc ker tensor decomp osition with FNOs b y applying tensor decomp osition to the F ourier weigh ts, significantly reducing the mo del memory requiremen t and computational cost in high-dimensional spaces. 3 Numerical Results In this section, we present the results of the n umerical tests p erformed. W e employ ed Hyp erNOs [ 9 ] a PyT orc h library , which implements automatic h yp erparameter tuning of NOs based on Ray [ 21 ]. All tests w ere p erformed on a Linux cluster. Two no des, eac h with tw o NVIDIA A16 GPUs, w ere used for the automatic h yp erparameter tuning. F or single training, we used one no de with an NVIDIA A16 GPU. F or inference time, we used a laptop with an NVIDIA GeF orce R TX 4070 GPU. More details ab out automatic hyperparameter tuning are rep orted in App endix B . In the following T able 1 we rep orts the results obtained by the different architectures in terms of the num b er of trainable parameters, training time, training error and test error. The training time is rep orted as b oth the total time required for training and the av erage time p er ep och. T raining and test errors are rep orted in terms of L 2 and L 1 relativ e norms, with resp ectiv e means and standard deviations across five runs with different random seeds. A more detailed comparison of the results obtained by the differen t architectures is discussed in Section 4 . Architecture Number of T raining Time T raining Error T est parameters T otal Epo c h L 2 L 2 L 1 Mean Median Mean Median CNO 8.2 M 10 h 36.4 sec 0 . 0323 ± 0 . 0059 0 . 1501 ± 0 . 0443 0 . 0985 ± 0 . 0152 0 . 0941 ± 0 . 0332 0 . 0535 ± 0 . 0123 DON 1.5M 30m 1.73 sec 0 . 0273 ± 0 . 0041 0 . 7190 ± 0 . 0380 0 . 8161 ± 0 . 0001 0 . 5756 ± 0 . 0536 0 . 6532 ± 0 . 0132 DON-CNN 0.5M 15 min 0.88 sec 0 . 1701 ± 0 . 0066 0 . 6861 ± 0 . 0068 0 . 7772 ± 0 . 0178 0 . 6008 ± 0 . 0155 0 . 6559 ± 0 . 0241 POD-DON 1M 16m 0.98 sec 0 . 0439 ± 0 . 0012 0 . 6953 ± 0 . 0007 0 . 8146 ± 0 . 0009 0 . 5535 ± 0 . 0028 0 . 6497 ± 0 . 0010 FNO 151.1 M 4 h 15.8 sec 0 . 0081 ± 0 . 0003 1 . 0333 ± 0 . 6000 0 . 5393 ± 0 . 1218 1 . 4655 ± 1 . 0330 0 . 4894 ± 0 . 1041 LocalNO 0.15 M 1h 4.91 sec 0 . 0423 ± 0 . 0121 2 . 8717 ± 2 . 3716 1 . 4850 ± 1 . 4840 4 . 2232 ± 3 . 5578 1 . 5667 ± 1 . 6579 TFNO 0.3 M 9h 35.95 sec 0 . 0444 ± 0 . 0067 0 . 9378 ± 0 . 1813 0 . 4378 ± 0 . 1259 1 . 5174 ± 0 . 4191 0 . 4070 ± 0 . 0905 T able 1: Summary of the results obtained b y the different architecture. In the following sections, we will provide a detailed description of the results obtained by each arc hitecture. Each architecture has b een trained using AdamW with w eight decay regularization ω for 1000 ep o c hs. W e also use a learning rate scheduler that decreases the learning rate η b y a factor of γ ev ery ten ep ochs. The dataset has 2000 examples for training and 500 for the test, more details are in the App endix A.2 . 3.1 Con v olutional Neural Op erators results The h yp erparameters that are employ ed for the CNO [ 27 ], as w ell as the range considered for the automatic h yp erparameter tuning, are listed in the App endix B.1 in particular, in T able 4 . Figure 7 sho ws the ev olution of relative L 2 training loss and relative L 1 and L 2 test losses, av eraged o ver fiv e random seeds (Fig. 7a ), as well as the bar plots illustrating the distribution of errors for the training and test sets (Fig. 7b ). 8 (a) Loss v alues for the CNO. (b) Bar plot for the CNO. Figure 7: CNO p erformance metrics: (a) Evolution of the relative L 2 training loss (blue), relative L 1 test loss (green), and relative L 2 test loss (red) across ep o c hs. (b) Distribution of the relative L 2 error for the training and test sets. F rom the error distribution in Figure 7b , w e can observe that CNO p erforms well in the training with a relative L 2 error around 10 − 2 . How ever, there are some outliers. Concerning the test set, w e observe that we hav e higher errors. Even considering this, w e see that CNOs can capture the translation inv ariance of the FHN mo del with slightly less accuracy . Figure 8 shows four randomly selected examples from the training and test sets to visualize the results. Figure 8: CNO visualization: F our randomly selected examples from the training and test sets are sho wn. Within each column, the rows illustrate: the applied curren t I app , high-fidelit y reference for p oten tial V , CNO prediction V θ for V , point wise error for V , high-fidelit y reference for recov ery v ariable w , CNO prediction w θ for w , p oin twise error w . 3.2 Deep Op erator Netw orks results W e rep ort the results obtained for the DON [ 23 ] without any mo dification, i.e., b oth the branch and the trunk are feed-forward neural netw orks (FNNs). The hyperparameters that are employ ed and the range considered for the automatic hyperparameter tuning, are listed in the App endix B.2 in particular, in T able 5 . Figure 9 shows the evolution of relative L 2 training loss and relative L 1 and L 2 test losses, a veraged ov er five random seeds (Fig. 9a ), as w ell as the bar plots illustrating the distribution of errors for the training and test sets (Fig. 9b ). F rom the error distribution in Figure 9b , we can observe that DON p erforms well in the training with a relative L 2 error around 10 − 2 . Ho wev er, when it comes to the test set, we see that DONs face challenges replicating the 9 (a) Loss v alues for the DONs. (b) Bar plot for the DONs. Figure 9: DON p erformance metrics: (a) Evolution of the relative L 2 training loss (blue), relative L 1 test loss (green), and relative L 2 test loss (red) across ep o c hs. (b) Distribution of the relative L 2 error for the training and test sets. FHN translation inv ariance prop ert y . T o further highligh t this, we visualize the results, Figure 10 sho ws four randomly selected examples from the training and test sets to visualize the results. Figure 10: DON visualization: F our randomly selected examples from the training and test sets are sho wn. Within each column, the rows illustrate: the applied curren t I app , high-fidelit y reference for p oten tial V , DON prediction V θ for V , p oint wise error for V , high-fidelity reference for recov ery v ariable w , DON prediction w θ for w , p oin twise error w . 3.3 Deep Op erator Netw orks with CNN enco ders results W e rep ort the results obtained for the DON-CNN i.e., the branch has a CNN enco der b efore the FNN. The h yp erparameters that are emplo yed and the range considered for the automatic h yp erparameter tuning, are listed in the App endix B.3 in particular, in T able 6 . Figure 11 shows the ev olution of relative L 2 training loss and relative L 1 and L 2 test losses, av eraged o ver five random se eds (Fig. 11a ), as well as the bar plots illustrating the distribution of errors for the training and test sets (Fig. 11b ). As shown in Figure 11b , we can observ e that DON-CNN can capture the dynamics in the training set with a accuracy of around 10 − 1 . How ever, when it comes to the test set, w e see that DONs-CNN face challenges replicating the FHN translation in v ariance prop ert y . Figure 12 shows four randomly selected examples from the training and test sets to visualize the results. 10 (a) Loss v alues for the DON-CNN. (b) Bar plot for the DON-CNN Figure 11: DON-CNN p erformance metrics: (a) Ev olution of the relativ e L 2 training loss (blue), relativ e L 1 test loss (green), and relative L 2 test loss (red) across ep o c hs. (b) Distribution of the relativ e L 2 error for the training and test sets. Figure 12: DON-CNN visualization: F our randomly selected examples from the training and test sets are shown. Within each column, the rows illustrate: the applied current I app , high-fidelity reference for p oten tial V , DON-CNN prediction V θ for V , p oin twise error for V , high-fidelity reference for reco very v ariable w , DON-C NN prediction w θ for w , p oin twise error w . 3.4 Prop er Orthogonal Decomp osition DONs results W e rep ort the results obtained for the POD-DON [ 24 ] i.e., the trunk is a linear combination of the POD mo des. The hyperparameters that are employ ed and the range considered for the automatic h yp erparameter tuning, are listed in the App endix B.4 in particular, in T able 7 . Figure 13 shows the ev olution of relative L 2 training loss and relative L 1 and L 2 test losses, av eraged o ver five random se eds (Fig. 13a ), as well as the bar plots illustrating the distribution of errors for the training and test sets (Fig. 13b ). F rom the error distribution in Figure 13b , w e can observe that POD-DON ac hieve a relativ e L 2 error around 0 . 05 on the training set. How ever, when it comes to the test set, we see that POD-DONs face challenges replicating the FHN translation in v ariance prop ert y . Figure 14 shows four randomly selected examples from the training and test sets to visualize the results. 11 (a) Loss v alues for the POD-DON. (b) Bar plot for the POD-DON. Figure 13: POD-DON p erformance metrics: (a) Ev olution of the relativ e L 2 training loss (blue), relativ e L 1 test loss (green), and relative L 2 test loss (red) across ep o c hs. (b) Distribution of the relativ e L 2 error for the training and test sets. Figure 14: POD-DON visualization: F our randomly selected examples from the training and test sets are shown. Within each column, the rows illustrate: the applied current I app , high-fidelity reference for p oten tial V , POD-DON prediction V θ for V , p oin twise error for V , high-fidelity reference for reco very v ariable w , POD-DON prediction w θ for w , p oin twise error w . 12 3.5 F ourier Neural Op erators W e rep ort the results obtained for the FNO [ 20 ]. The h yp erparameters that are employ ed and the range considered for the automatic hyperparameter tuning, are listed in the App endix B.5 in particular, in T able 8 . Figure 15 shows the evolution of relative L 2 training loss and relative L 1 and L 2 test losses, av eraged ov er fiv e random seeds (Fig. 15a ), as well as the bar plots illustrating the distribution of errors for the training and test sets (Fig. 15b ). (a) Loss v alues for the FNO. (b) Bar plot for the FNO. Figure 15: FNO p erformance metrics: (a) Ev olution of the relative L 2 training loss (blue), relative L 1 test loss (green), and relative L 2 test loss (red) across ep o c hs. (b) Distribution of the relative L 2 error for the training and test sets. The error distribution in Figure 15b indicates that the FNO performs well on the training set, ac hieving errors as low as 10 − 3 . How ev er, the FNOs successfully repro duces some cases on the test set. Still, it faces challenges in reliably capturing the mo del’s translation in v ariance prop ert y . In fact, man y examples hav e errors around 10 0 . F urthermore, the loss ev olution in Figure 15a shows a non-negligible standard deviation for the test loss, indicating sensitivity to initialization. Figure 16 sho ws four randomly selected examples from the training and test sets to visualize the results. Figure 16: FNO visualization: Five test examples are shown, three randomly selected, and the tw o with the highest relative L 2 error. Within each column, the rows illustrate: the applied current I app , high-fidelit y reference for p oten tial V , FNO prediction V θ for V , p oin t wise error for V , high-fidelit y reference for reco very v ariable w , FNO prediction w θ for w , p oin twise error w . 13 3.6 T uck er T ensorized FNOs W e rep ort the results obtained for the TFNO [ 31 ]. The hyperparameters that are employ ed and the range considered for the automatic hyperparameter tuning, are listed in the App endix B.6 in particular, in T able 9 . Figure 17 shows the evolution of relative L 2 training loss and relative L 1 and L 2 test losses, av eraged ov er fiv e random seeds (Fig. 17a ), as well as the bar plots illustrating the distribution of errors for the training and test sets (Fig. 17b ). (a) Loss v alues for the TFNO. (b) Bar plot for the TFNO. Figure 17: TFNO p erformance metrics: (a) Evolution of the relative L 2 training loss (blue), relativ e L 1 test loss (green), and relative L 2 test loss (red) across ep o c hs. (b) Distribution of the relative L 2 error for the training and test sets. F rom the error distribution in Figure 17b , we can observe that TFNO achiev es a relative L 2 error around 0 . 05 on the training set. Ho wev er, on the test set, the TFNOs successfully repro duces some cases, yet it still faces challenges in reliably capturing the model’s translation inv ariance prop ert y . In fact, there is the presence of examples with errors bigger then 10 0 . F urthermore, the loss ev olution in Figure 17a shows a non-negligible standard deviation for the test loss, indicating sensitivit y to initialization. Figure 18 shows four randomly selected examples from the training and test sets to visualize the results. Figure 18: TFNO visualization: F our randomly selected examples from the training and test sets are shown. Within each column, the rows illustrate: the applied current I app , high-fidelity reference for p oten tial V , TFNO prediction V θ for V , p oint wise error for V , high-fidelity reference for recov ery v ariable w , TFNO prediction w θ for w , p oin twise error w . 14 3.7 Lo cal Neural Op erators W e rep ort the results obtained for the Lo calNO [ 22 ]. The hyperparameters that are employ ed and the range considered for the automatic hyperparameter tuning, are listed in the App endix B.7 in particular, in T able 10 . Figure 19 shows the evolution of relative L 2 training loss and relative L 1 and L 2 test losses, av eraged ov er fiv e random seeds (Fig. 19a ), as well as the bar plots illustrating the distribution of errors for the training and test sets (Fig. 19b ). (a) Loss v alues for the Lo calNO. (b) Bar plot for the LocalNO. Figure 19: Lo calNO p erformance metrics: (a) Evolution of the relative L 2 training loss (blue), relativ e L 1 test loss (green), and relative L 2 test loss (red) across ep o c hs. (b) Distribution of the relativ e L 2 error for the training and test sets. F rom the error distribution in Figure 19b , we can observe that Lo calNO achiev e a relative L 2 error around 0 . 05 on the training set. Ho wev er, on the test set, the Lo calNOs successfully repro duces some cases, yet it still faces challenges in reliably capturing the model’s translation inv ariance prop ert y . In fact, there is the presence of examples with errors bigger then 10 0 . F urthermore, the loss ev olution in Figure 19a shows a non-negligible standard deviation for the test loss, indicating sensitivit y to initialization. Figure 20 shows four randomly selected examples from the training and test sets to visualize the results. Figure 20: Lo calNO visualization: F our randomly selected examples from the training and test sets are shown. Within each column, the rows illustrate: the applied current I app , high-fidelity reference for p otential V , Lo calNO prediction V θ for V , p oin twise error for V , high-fidelity reference for reco very v ariable w , Lo calNO prediction w θ for w , p oin twise error w . 15 4 Comparison The following section provides a detailed comparison of the results obtained by the different arc hitectures. W e will compare them in terms of training and test errors, training time, and the n umber of trainable parameters. Additionally , we will compare the error and inference time for a single example from the test set. In Figure 21 w e rep ort the b o x plots of the training and test errors for the differen t architectures. Figure 21: Box plots illustrating the distribution of relative L 2 errors for b oth the training and test sets for all arc hitectures taken into consideration. As illustrated in Figure 21 , FNO ac hieve the highest accuracy in the training set. The other arc hitectures exhibit comparable p erformance, with the exception of DON, which yield a higher error. How ever, a differen t trend emerges in the test set, where the mo dels must account for the translated dynamics. Here, only CNO demonstrate the ability to generalize effectively . In con trast, DON and its v ariants (DON-CNN and POD-DON) faces c hallenges in replicating the mo del’s translation in v ariance prop ert y (see Figs. 10 , 12 , and 14 ). While FNOs and its v ariants (TFNOs and Lo calNOs) can pro duce accurate results for certain test examples, but there are man y examples with high L 2 relativ e errors (see Figs. 15b , 17b , and 19b ). This comparison suggests a trade-off: while FNO is the optimal choice for the training set in terms of accuracy , while CNO provides a more reliable and robust solution for out-of-distribution tasks in volving translations. How ev er, accuracy alone is not a comprehensive ev aluation of deep learning metho ds. T o provide a more comprehensiv e comparison, w e must also accoun t for computational efficiency , sp ecifically training time and the n umber of trainable parameters. T o this end, we ev aluate the following tw o metrics: C : = E × P × T C log : = E × h 1 + α log 10 ( P P min ) i × h 1 + β log 10 ( T T min ) i Where E denotes the relative L 2 error, P is the num b er of trainable parameters (in millions), and T represen ts the total training time in hours. The terms P min and T min corresp ond to the minimum n umber of parameters and the shortest training time, resp ectively , among all architectures rep orted in T able 1 . The weigh ting co efficien ts α and β are b oth fixed at 0 . 5. Figure 22 sho ws the cost function C v alues for training and test errors of each arc hitecture. As illustrated in Figure 22 , the FNO has the highest ov erall cost, primarily due to its large n umber of trainable parameters (151 M). On the other hand, DON and their v ariants hav e the low est computational cost b ecause of their limited num b er of parameters and fast training. How ev er, it’s imp ortan t to note that despite their efficiency , they hav e difficulty in repro ducing the system’s translated dynamics. The CNO has high costs in b oth training and test, largely due to its intensiv e computational requirements during training (10 h). Due to the significant differences in scale among these mo dels, we adopted the log-weigh ted metric C log . This metric mitigates the significan t scale disparities among these mo dels. This ensures a more balanced comparison b et ween compact arc hitectures and o ver-parameterized mo dels. Figure 23 shows the cost function C log v alues for training and test errors of eac h architecture 16 Figure 22: Histogram of the C cost v alues for each arc hitecture. The cost related to the training error is sho wn in solid color, while the test is indicated by the hatc hed pattern. Figure 23: Histogram of the C log Cost for each architecture. The cost related to the training error is sho wn in solid color, while the test is indicated by the hatched pattern. Figure 23 illustrates the log-weigh ted cost ( C log ), which provides a more fair comparison of the ev aluated architectures. The FNO achiev es a comp etitiv e score b ecause its lo w training time and training error effectively mitigate the cost asso ciated with its large num b er of trainable parameters. Ho wev er, in the test dataset, the FNO and its v arian ts (TFNO and Lo calNO) hav e the highest costs because they cannot maintain reliable p erformance for the translated dynamics. Similarly , Deep Op erator Net works (DONs, DONs-CNN, and POD-DONs) demonstrate consistently high costs for the test dataset, reflecting the difficulty of the generalization for the out-of-distribution scenario. How ever this mo dels exhibit a low er cost for the training set due to their fast training and limited num ber of trainable parameters. How ever, DON-CNN incurs a slightly higher cost than its coun terparts due to the added complexity introduced by its enco ders. In contrast, the CNO exhibits consisten t p erformance in b oth training and testing. This stability highlights its unique ability to reliably capture translated dynamics, b eing the only architecture to do so effectively . Its total cost remains comparable to that of other architectures, mainly due to the high computational cost of training. A final k ey metric ev aluated is the inference latency for a single test instance, compared against the time required to generate a high-fidelit y reference solution. This b enchmark solution w as pro duced using the Firedrake library [ 10 ] on a laptop equipp ed with an Intel(R) Core(TM) i7-14700HX CPU. 17 (a) Mean relative L 2 error vs. inference time. (b) Median relative L 2 error vs. inference time. Figure 24: Comparison of error and inference time for the different architectures. The plots show the inference time relative to the high-fidelity solution time, alongside the accuracy achiev ed on the training and test sets. F rom Figure 24 , we can observe a clear trade-off exists b et ween training and test precision and inference efficiency . While the FNO achiev es the lo west training error, it is the most computationally exp ensiv e arc hitecture during inference. This limitation is also observ ed in the TFNO v arian t. DON and their v arian ts, how ev er, emerge as the most efficien t mo dels for real-time ev aluation. The CNO and Lo calNO offer a balanced middle ground. How ever, w e must note that the Lo calNO ac hieves comp etitive inference sp eeds due to its limited num b er of trainable parameters. 18 5 Conclusion In this study , we ev aluated several Neural Op erator architectures, including CNOs, DONs, DONs- CNNs, POD-DONs, FNOs, TFNOs, and Lo calNOs, to determine their ability to learn the stiff dynamics and the translation in v ariance prop ert y of the FitzHugh-Nagumo mo del. W e b enc hmarked these architectures based on their predictive accuracy in training and test datasets, computational efficiency for the training, and inference sp eed. Our findings reveal that CNOs are the only mo dels capable of accurately repro ducing translated dynamics in the test set, ac hieving a median L 2 relativ e error of 0.09. How ev er, this robustness comes at the cost of a higher computational effort for the training, requiring approximately 10 hours for a mo del with 8.2M trainable parameters. In con trast, despite having a significantly larger n umber of trainable parameters (151.1M), FNOs required a low er training time (4 hours) than CNOs. Ho wev er, FNOs and their v ariants hav e giv en less accurate predictions for the translated test cases, with man y examples yielding high errors. F urthermore, FNOs and TFNOs suffer from substantial inference costs. The LocalNO v arian t achiev ed faster inference, though this was primarily due to its significantly low er num b er of trainable parameters. Regarding DONs and their v ariants (DONs-CNN and POD-DONs), we observ ed that they didn’t generalize well in the translated dynamics of the test set. Nevertheless, DONs architectures demonstrated sup erior computational efficiency , providing the fastest training and inference sp eeds among all the mo dels tested. F urthermore, their architecture offers a distinct adv an tage in terms of flexibilit y , b ecause they can naturally accommo date non-square geometries without requiring structural mo difications. In terms of the training set accuracy , FNOs had the b est p erformance, ac hieving a relativ e L 2 training error of 0.0081. The accuracy of the other arc hitectures was low er though similar to each other. Ho wev er, our analysis revealed a critical c hallenge common to all ev aluated NOs: determining whether the applied curren t is sufficient to trigger an action p otential, a phenomenon kno wn as the threshold effect. This threshold is difficult to iden tify b ecause there is no single, precise v alue for the curren t. Rather, it dep ends on the stim ulated area and the stimulus duration. F or example, incorrectly predicting an action p oten tial when the stimulus is insufficient creates a significan t outlier and degrades the NOs ability to accurately capture the correct system dynamics. F uture research will fo cus on impro ving the ability of NOs to correctly identify whether a stimulus is strong enough to initiate an action p otential. In summary , this w ork provides a rigorous b enchmark for NOs, highlighting the trade-offs b et ween computational efficiency and the capacity to learn the stiff dynamics of the FHN mo del and its translation in v ariance prop ert y . 19 Ac kno wledgemen ts The author would like to thank Massimiliano Ghiotto for helpful discussions regarding Neural Op erators and his library , and Luca F ranco Pa v arino for insigh tful discussions on ionic mo dels. The author hav e b een supp orted b y grants of MIUR PRIN P2022B38NR, funded by Europ ean Union - Next Generation EU, and b y the Istituto Nazionale di Alta Matematica (INdAM - GNCS), Italy . Author Con tributions LP: Conceptualization, Metho dology , Soft ware, V alidation, F ormal analysis, Inv estigation, Data Curation, W riting - Original Draft, W riting - Review & Editing, Visualization. Declarations Comp eting Interests The author declare no comp eting interests. Data Av ailabilit y The code and dataset will b e made av ailable on GitHub and Zeno do following the publication of the pap er. References [1] Kam yar Azizzadenesheli, Nikola Kov achki, Zongyi Li, Miguel Liu-Schiaffini, Jean Kossaifi, and Anima Anandkumar. “Neural op erators for accelerating scientific sim ulations and design”. In: Natur e R eviews Physics 6.5 (2024), pp. 320–328. [2] F rancesca Bartolucci, Emmanuel de B´ ezenac, Bogdan Raoni´ c, Rob erto Molinaro, Siddhartha Mishra, and Rima Alaifari. “Are neural op erators really neural op erators? frame theory meets op erator learning”. In: SAM R ese ar ch R ep ort 2023 (2023). [3] James Bergstra, R´ emi Bardenet, Y oshua Bengio, and Bal´ azs K´ egl. “Algorithms for hyper- parameter optimization”. In: A dvanc es in neur al information pr o c essing systems 24 (2011). [4] Daniel Cebri´ an-Lacasa, Pedro Parra-Riv as, Daniel Ruiz-Reyn ´ es, and Lendert Gelens. “Six decades of the FitzHugh–Nagumo mo del: A guide through its spatio-temp oral dynamics and influence across disciplines”. In: Physics R ep orts 1096 (2024), pp. 1–39. [5] Edoardo Cen tofanti, Massimiliano Ghiotto, and Luca F Pa v arino. “Learning the Hodgkin– Huxley model with operator learning tec hniques”. In: Computer Metho ds in Applie d Me chanics and Engine ering 432 (2024), p. 117381. [6] Piero Colli F ranzone, Luca F. Pa v arino, and Simone Scacchi. Mathematic al Car diac Ele ctr o- physiolo gy . V ol. 13. Cham: Springer, 2014. [7] Ric hard FitzHugh. “Impulses and ph ysiological states in theoretical mo dels of nerve mem- brane”. In: Biophysic al Journal 1.6 (1961), pp. 445–466. [8] Luca Ghafourpour, V alen tin Duruisseaux, Bahareh T olooshams, Philip H W ong, Costas A Anastassiou, and Anima Anandkumar. “NOBLE–Neural Op erator with Biologically-informed Laten t Embeddings to Capture Exp erimen tal V ariability in Biological Neuron Mo dels”. In: arXiv pr eprint arXiv:2506.04536 (2025). [9] Massimiliano Ghiotto. “Hyp erNOs: Automated and Parallel Library for Neural Op erators Researc h”. In: arXiv pr eprint arXiv:2503.18087 (2025). [10] Da vid A. Ham et al. Fir e dr ake User Manual . First edition. Imp erial College London et al. Ma y 2023. doi : 10.25561/104839 . [11] Alan L. Ho dgkin and Andrew F. Huxley. “A quantitativ e description of membrane current and its application to conduction and excitation in nerve”. In: The Journal of Physiolo gy 117.4 (1952), p. 500. [12] Matthias H¨ ofler, F rancesco Regazzoni, Stefano Pagani, Elias Karab elas, Christoph Augustin, Gundolf Haase, Gernot Plank, and F ederica Caforio. “Physics-informed neural netw ork estimation of active material prop erties in time-dep enden t cardiac biomec hanical mo dels”. In: arXiv pr eprint arXiv:2505.03382 (2025). 20 [13] Eugene M. Izhik evich. Dynamic al Systems in Neur oscienc e . MIT press, 2007. [14] James Keener and James Sneyd. Mathematic al Physiolo gy: II: Systems physiolo gy . Springer, 2009. [15] Jean Kossaifi et al. “A Library for Learning Neural Op erators”. In: arXiv pr eprint (2025). [16] Nik ola Kov ac hki, Zongyi Li, Burigede Liu, Kam yar Azizzadenesheli, Kaushik Bhattachary a, Andrew Stuart, and Anima Anandkumar. “Neural op erator: Learning maps b et ween function spaces with applications to p des”. In: Journal of Machine L e arning R ese ar ch 24.89 (2023), pp. 1–97. [17] Nik ola Kov ac hki, Zongyi Li, Burigede Liu, Kam yar Azizzadenesheli, Kaushik Bhattachary a, Andrew Stuart, and Anima Anandkumar. “Neural op erator: Learning maps b et ween function spaces with applications to p des”. In: Journal of Machine L e arning R ese ar ch 24.89 (2023), pp. 1–97. [18] Sam uel Lanthaler, Zongyi Li, and Andrew M. Stuart. “Nonlo calit y and nonlinearity implies univ ersality in op erator learning”. In: arXiv pr eprint arXiv:2304.13221 (2023). [19] Liam Li, Kevin Jamieson, Afshin Rostamizadeh, Ek aterina Gonina, Jonathan Ben-Tzur, Moritz Hardt, Benjamin Rech t, and Ameet T alwalk ar. “A system for massively parallel h yp erparameter tuning”. In: Pr o c e e dings of machine le arning and systems 2 (2020), pp. 230– 246. [20] Zongyi Li, Nik ola Kov achki, Kam yar Azizzadenesheli, Burigede Liu, Kaushik Bhattachary a, Andrew M. Stuart, and Anima Anandkumar. “F ourier neural op erator for parametric partial differen tial equations”. In: arXiv pr eprint arXiv:2010.08895 (2020). [21] Ric hard Liaw, Eric Liang, Rob ert Nishihara, Philipp Moritz, Joseph E. Gonzalez, and Ion Stoica. “T une: A Researc h Platform for Distributed Mo del Selection and T raining”. In: arXiv pr eprint arXiv:1807.05118 (2018). [22] Miguel Liu-Schiaffini, Julius Berner, Boris Bonev, Thorsten Kurth, Kamy ar Azizzadenesheli, and Anima Anandkumar. “Neural op erators with lo calized integral and differen tial kernels”. In: arXiv pr eprint arXiv:2402.16845 (2024). [23] Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George E. Karniadakis. “Learning nonlinear op erators via DeepONet based on the univ ersal appro ximation theorem of op erators”. In: Natur e Machine Intel ligenc e 3.3 (2021), pp. 218–229. [24] Lu Lu, Xuh ui Meng, Shengze Cai, Zhiping Mao, Somdatta Goswami, Zhongqiang Zhang, and George Em Karniadakis. “A comprehensive and fair comparison of tw o neural op erators (with practical extensions) based on fair data”. In: Computer Metho ds in Applie d Me chanics and Engine ering 393 (2022), p. 114778. [25] Lu Lu, Xuhui Meng, Zhiping Mao, and George Em Karniadakis. “DeepXDE: A deep learning library for solving differential equations”. In: SIAM R eview 63.1 (2021), pp. 208–228. doi : 10.1137/19M1274067 . [26] Luca Pellegrini, Massimiliano Ghiotto, Edoardo Centofan ti, and Luca F Pa v arino. “Learning high-dimensional ionic mo del dynamics using F ourier neural op erators”. In: Machine L e arning for Computational Scienc e and Engine ering 1.2 (2025), p. 46. [27] Bogdan Raonic, Rob erto Molinaro, T obias Rohner, Siddhartha Mishra, and Emmanuel de Bezenac. “Conv olutional neural operators”. In: ICLR 2023 Workshop on Physics for Machine L e arning (2023). [28] Olaf Ronneb erger, Philipp Fischer, and Thomas Bro x. “U-net: Conv olutional netw orks for biomedical image segmen tation”. In: International Confer enc e on Me dic al image c omputing and c omputer-assiste d intervention . Springer. 2015, pp. 234–241. [29] Matteo Salv ador, Marina Stro cc hi, F rancesco Regazzoni, Christoph M Augustin, Luca Dede’, Stev en A Niederer, and Alfio Quarteroni. “Whole-heart electromechanical sim ulations using laten t neural ordinary differential equations”. In: NPJ Digital Me dicine 7.1 (2024), p. 90. [30] Simin Shek arpaz, F anhai Zeng, and George Karniadakis. “Splitting Physics-Informed Neural Net works for Inferring the Dynamics of Integer-and F ractional-Order Neuron Mo dels”. In: Communic ations in Computational Physics 35.1 (2024), pp. 1–37. 21 [31] Guanc heng Zhou, Zelin Zeng, Yisi Luo, Qi Xie, and Deyu Meng. “T uck er-FNO: T ensor T uck er-F ourier Neural Op erator and its Universal Appro ximation Theory”. In: The F ourte enth International Confer enc e on L e arning R epr esentations . 2026. url : https : / / openreview . net/forum?id=UJvkXnuozY . [32] Gio v anni Ziarelli, Edoardo Cen tofanti, Nicola Parolini, Simone Scacchi, Marco V erani, and Luca F P av arino. “Learning cardiac activ ation and rep olarization times with operator learning”. In: PLOS Computational Biolo gy 22.1 (2026), e1013920. 22 A Mo del description and dataset generation This section details the mathematical mo del under consideration, the dataset generation pro cess, and the range of v alues employ ed for the applied current I app . A.1 FitzHugh-Nagumo Mo del In this study , we considered the one-dimensional FitzHugh-Nagumo mo del [ 6 , 7 ]. Which is a widely used b enc hmark for capturing the essential dynamics of excitable cells [ 4 ]. The system is gov erned b y the following parab olic reaction-diffusion equations: χC m ∂ V ∂ t − div( D ∇ V ) − χbV ( V − c )( δ − V ) + β w = I app , ( x, t ) ∈ [0 , 1] × [0 , 40 ms ] , ∂ w ∂ t = η V − γ w , ( x, t ) ∈ [0 , 1] × [0 , 40 ms ] , (9) where V represen ts the transmembrane p oten tial and w is the reco very v ariable. The parameters used in ( 9 ) are summarized in T able 2 . P arameter χ C m D b c δ β η γ V alue 1 1 0.001 5 0.1 1 1 0.1 0.25 T able 2: P arameters assigned to the FHN mo del in ( 9 ). A.2 Dataset generation The dataset was generated using Firedrak e [ 10 ], a finite elemen t library . F or the spatial discretization, w ere emplo y ed second-degree Lagrange polynomials ov er a mesh consisting of 200 interv als. T emp oral in tegration was p erformed using the forward Euler metho d with a constant time step of ∆ t = 0 . 05. W e solved the resulting nonlinear systems using the Newton metho d, and we handled the underlying linear systems using the generalized minimal residual metho d. T o ensure efficien t conv ergence, we utilized a generalized additive Sch w arz metho d as a preconditioner. The applied curren t, as defined in ( 3 ), the stim ulated region is defined as: Ω T ,stim = [ x min , x min + 0 . 04] × [ T min , T min + 1] . The parameter ranges and v alues used for the training, v alidation, and test datasets are summarized in T able 3 . Name Range of v alues of i Time of the stimulus Position of the stimulus Number of examples min max T min x min T rain 0.1 3 5 0-0.96 2000 V alidation / T est 0.1 3 0-37 0-0.96 500 T able 3: FHN mo del: Range of v alues of the training, v alidation and test set. B Automatic h yp erparameter tuning In this section, w e provide details on the automatic hyperparameter tuning used for eac h of the arc hitectures considered in this work. W e p erformed 100 distributed and parallel trials for each arc hitecture, employing an automatic h yp erparameter optimization algorithm implemented in the Hyp erOptSearc h library . In particular, we employ ed the T ree-structured Parzen Estimator algorithm [ 3 ], and the ASHA scheduler [ 19 ] to automatically stop trials that were not satisfactory . Eac h mo del w as trained using the data-driven relative L 2 norm as the loss function. Loss ( u, G θ ( I app )) = 1 2 2 X j =1 ∥ u j − G θ ( I app ) j ∥ L 2 (Ω T ) ∥ u j ∥ L 2 (Ω T ) ≈ 1 2 2 X j =1 P n points k =1 | u j ( x k , t k ) − G θ ( I app ) j ( x k , t k ) | 2 1 / 2 P n points k =1 | u j ( x k , t k ) | 2 1 / 2 , 23 where u is the solution of the system ( 1 ) and G θ is the op erator defined in ( 4 ) . This leads to the follo wing optimization problem: arg min θ ∈ Θ 1 n train n train X i =1 Loss u i , G θ ( I i app ) , where { ( I i app , u i ) } n train i =1 is the dataset consisted of input-output pairs. B.1 Con v olutional Neural Op erators h yp erparameters T able 4 summarizes the hyperparameters for the CNOs [ 27 ], detailing the configuration of the searc h space and the optimal v alues identified by the automatic hyperparameter tuning. Hyp erparameter Description Searc h Space F ound Arc hitecture N lay ers Num b er of lay ers of the U-Net 1 ≤ N lay ers ≤ 5 4 C Dimension of channel mu ltiplier C ∈ { 8 , 16 , 24 , 32 , 40 , 48 } 32 N res,neck Num b er residual blo c k of the last lay er 1 ≤ N res,neck ≤ 6 2 N res Num b er residual blo c k 1 ≤ N res ≤ 8 7 k Kernel size k ∈ { 3 , 5 , 7 } 3 Optimizer η Initial learning rate 1e-4 ≤ η ≤ 1e-2 1.9e-4 ω W eight deca y regularization factor 1e-6 ≤ ω ≤ 1e-3 3.2e-3 γ Rate scheduler factor 0 . 75 ≤ γ ≤ 0 . 99 0.91 T able 4: CNOs h yp erparameters and the search space used for hyperparameter tuning. B.2 Deep Op erator Netw ork hyperparameters The DONs implementation is tak en from the DeepXDE library [ 25 ]. T able 5 summarizes the h yp erparameters for the DONs [ 23 ], detailing the configuration of the search space and the optimal v alues identified by the automatic h yp erparameter tuning. Hyp erparameter Description Searc h Space F ound p Num b er of basis functions 200 ≤ p ≤ 800 762 Branc h Net work N branch Num b er of hidden la yers 1 ≤ N branch ≤ 6 6 W branch Net work width (neurons) 64 ≤ W branch ≤ 200 124 σ branch Activ ation function σ branch ∈ { relu, gelu, silu } relu T runk Net work N trunk Num b er of hidden la yers 1 ≤ N trunk ≤ 6 4 W trunk Net work width (neurons) 64 ≤ W trunk ≤ 200 148 σ trunk Activ ation function σ trunk ∈ { relu, gelu, silu } relu Optimizer η Initial learning rate 10 − 4 ≤ η ≤ 10 − 2 1.8e-3 ω W eigh t decay factor 10 − 6 ≤ ω ≤ 10 − 3 4.5e-4 γ Rate scheduler factor 0 . 75 ≤ γ ≤ 0 . 99 97 T able 5: DONs h yp erparameters and the search space used for hyperparameter tuning. B.3 Deep Op erator Netw ork with CNN enco ders hyperparameters T able 6 summarizes the hyperparameters for the DONs-CNN, detailing the configuration of the searc h space and the optimal v alues identified by the automatic hyperparameter tuning. B.4 Prop er Orthogonal Decomp osition DeepONets hyperparameters The POD-DONs implementation is taken from the DeepXDE library [ 25 ]. T able 7 summarizes the h yp erparameters for the POD-DONs [ 24 ], detailing the configuration of the search space and the optimal v alues identified by the automatic h yp erparameter tuning. 24 Hyperparameter Description Searc h Space F ound p Number of basis functions 200 ≤ p ≤ 500 332 Branch Netw ork N conv Number of conv olutional lay ers 3 ≤ N conv ≤ 7 3 C start Starting number of channels (first layer) C start ∈ { 10 , 20 , 30 , 40 } 40 C step Channel increment p er lay er C step ∈ { 10 , 20 , 30 } 30 C ch Channel configuration - [40, 70, 100] N F N N ,branch Number of lay ers for the FNN 2 ≤ N F N N ,branch ≤ 7 3 N neuron,br anch Number of neurons per dense lay er N neuron,br anch ∈ { 16 , 32 , 64 , 128 , 256 } 16 σ branch Activ ation function σ branch ∈ { tanh, relu, leaky relu, sigmoid, silu, gelu } relu Normalization Type of lay er normalization Normalization ∈ { none, batch, lay er } none T runk Netw ork N F N N ,trunk Number of lay ers for the FNN 2 ≤ N F N N ,trunk ≤ 7 4 N neuron,tr unk Number of neurons per dense lay er N neuron,tr unk ∈ { 16 , 32 , 64 , 128 , 256 } 16 σ trunk Activ ation function σ trunk ∈ { tanh, relu, leaky relu, sigmoid } leaky relu Architecture Use of residual connections Classic or Residual Classical Lay er Norm Apply layer normalization T rue or F alse F alse Optimizer η Initial learning rate 1e-4 ≤ η ≤ 1e-2 6.6e-3 ω W eigh t decay regularization factor 1e-6 ≤ ω ≤ 1e-3 4.6e-4 γ Rate scheduler factor 0 . 75 ≤ γ ≤ 0 . 99 0.84 T able 6: DONs-CNN h yp erparameters and the search space used for hyperparameter tuning Hyp erparameter Description Searc h Space F ound p Num b er of basis functions ( n basis ) 200 ≤ p ≤ 800 500 Branc h Netw ork N branch Num b er of hidden lay ers 1 ≤ N branch ≤ 6 6 W branch Net work width 64 ≤ W branch ≤ 200 92 σ branch Activ ation function σ branch ∈ { relu, gelu, silu } gelu Optimizer η Initial learning rate 1e-4 ≤ η ≤ 1e-2 6 . 7 × 10 − 4 ω W eight decay factor 1e-6 ≤ ω ≤ 1e-3 4 . 25 × 10 − 4 γ Rate scheduler factor 0 . 75 ≤ γ ≤ 0 . 99 0.92 T able 7: POD-DONs h yp erparameters and the search space used for hyperparameter tuning. B.5 F ourier Neural Op erators hyperparameters T able 8 summarizes the hyperparameters for the FNOs [ 20 ], detailing the configuration of the searc h space and the optimal v alues identified by the automatic hyperparameter tuning. Hyp erparameter Description Searc h Space F ound Arc hitecture d v Hidden dimension d v ∈ { 4 , 8 , 16 , 32 , 64 , 96 , 128 , 160 , 192 , 220 } 128 L Number of hidden lay ers 1 ≤ L ≤ 6 4 k max Number of F ourier mo des k max ∈ { 2 , 4 , 8 , 12 , 16 , 20 , 24 , 28 , 32 } 24 σ Activation function σ ∈{ tanh, relu, gelu, leaky relu } relu n pad Number of padding p oin ts p er direction 1 ≤ n pad ≤ 16 1 Architecture F ourier architecture ( 7 ), ( 8 ) or residual Classic, MLP or Residual Classic Optimizer η Initial learning rate 1e-4 ≤ η ≤ 1e-2 1.8e-3 ω W eight decay regularization factor 1e-6 ≤ ω ≤ 1e-3 4e-6 γ Rate scheduler factor 0 . 75 ≤ γ ≤ 0 . 99 0.85 T able 8: FNOs h yp erparameters and the search space used for hyperparameter tuning. B.6 T uck er T ensorized FNOs h yp erparameters The TFNOs implementation is taken from the Neural Op erator library [ 15 ]. T able 9 summarizes the h yp erparameters for the TFNOs [ 31 ], detailing the configuration of the searc h space and the optimal v alues identified by the automatic h yp erparameter tuning. B.7 Lo cal Neural Op erators hyperparameters The Lo calNOs implementation is tak en from the Neural Op erator library [ 15 ]. T able 10 summarizes the hyperparameters for the Lo calNOs [ 22 ], detailing the configuration of the search space and the optimal v alues identified by the automatic h yp erparameter tuning. 25 Hyp erparameter Description Search Space F ound Arc hitecture d v Hidden dimension d v ∈ { 4 , 8 , 16 , . . . , 192 } 192 L Num b er of hidden lay ers 1 ≤ L ≤ 5 1 k max Num b er of F ourier mo des k max ∈ { 2 , 4 , 8 , . . . , 32 } 8 σ Activ ation function σ ∈ { gelu, relu, leaky relu } leaky relu Domain Padding Domain padding fraction { 0 , 0 . 1 , 0 . 2 } 0.2 MLP skip Skip connection in MLP { Linear, identit y , soft-gating, None } identit y FNO skip Skip connection in FNO { Linear, identit y , soft-gating, None } soft-gating MLP Usage of Channel MLP T rue or F alse F alse Rank T ensor rank ratio { 0 . 05 , 0 . 1 , 0 . 2 , 0 . 5 } 0.2 Optimizer η Initial learning rate 1e-4 ≤ η ≤ 1e-2 5.5e-3 ω W eigh t decay factor 1e-6 ≤ ω ≤ 1e-3 5.5e-4 γ Rate sc heduler factor 0 . 75 ≤ γ ≤ 0 . 99 0.8 T able 9: TFNOs h yp erparameters and the search space used for hyperparameter tuning. Hyp erparameter Description Searc h Space F ound Arc hitecture d v Hidden dimension d v ∈ { 4 , 8 , 16 , 32 , 64 , 96 , 128 , 160 , 192 } 8 L Number of hidden lay ers 1 ≤ L ≤ 6 2 k max Number of F ourier mo des k max ∈ { 2 , 4 , 8 , 12 , 16 , 20 , 24 , 28 , 32 } 24 σ Activ ation function σ ∈{ relu, gelu, leaky relu } relu Padding Type of padding reflect or zeros zeros F actorization T yp e of F actorization None, T uc ker, CP , TT TT MLP skip Skip connection in MLP Linear, identit y and soft-gating linear local skip Skip connection in Lo calNO Linear, identit y and soft-gating iden tity Differential kernel size Finite difference kernel size { 3,5,7 } 7 MLP Usage of MLP T rue or F alse T rue Rank T ensor rank for factorization { 0.05,0.1,0.2,0.5,1 } 0.1 Disco Lay er Usage of Disco (integral) lay er T rue or F alse F alse Optimizer η Initial learning rate 1e-4 ≤ η ≤ 1e-2 1.4e-3 ω W eight decay regularization factor 1e-6 ≤ ω ≤ 1e-3 2.8e-4 γ Rate scheduler factor 0 . 75 ≤ γ ≤ 0 . 99 0.97 T able 10: Lo calNOs hyperparameters and the search space used for hyperparameter tuning. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment