Distributed Equilibrium-Seeking in Target Coverage Games via Self-Configurable Networks under Limited Communication
We study a target coverage problem in which a team of sensing agents, operating under limited communication, must collaboratively monitor targets that may be adaptively repositioned by an attacker. We model this interaction as a zero-sum game between…
Authors: Jayanth Bhargav, Zirui Xu, Vasileios Tzoumas
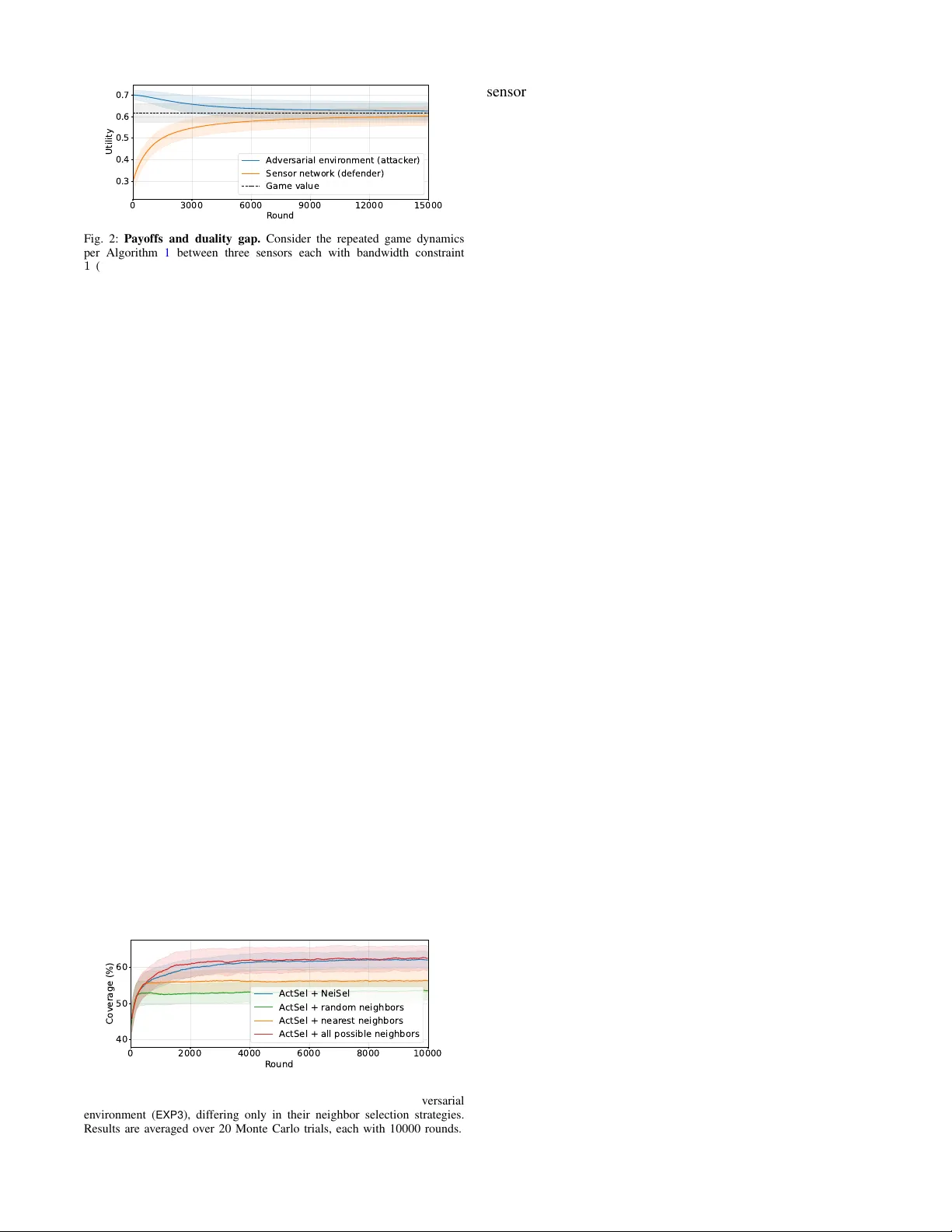
Distrib uted Equilibrium-Seeking in T ar get Cov erage Games via Self-Configurable Networks under Limited Communication Jayanth Bharg av 1 ∗ , Zirui Xu 2 ∗ , V asileios Tzoumas 2 † , Mahsa Ghasemi 1 † , Shreyas Sundaram 1 † Abstract — W e study a target cov erage problem in which a team of sensing agents, operating under limited communication, must collaboratively monitor targets that may be adaptively repositioned by an attacker . W e model this interaction as a zero-sum game between the sensing team (kno wn as the defender) and the attacker . Howev er , computing an exact Nash equilibrium (NE) for this game is computationally prohibitiv e as the action space of the defender grows exponentially with the number of sensors and their possible orientations. Exploiting the submodularity property of the game’ s utility function, we propose a distributed framework that enables agents to self- configure their communication neighborhoods under bandwidth constraints and collaborativ ely maximize the target coverage. W e establish theoretical guarantees showing that the resulting sensing strategies con verge to an appr oximate NE of the game. T o our knowledge, this is the first distributed, communication- aware appr oach that scales effectively f or games with combi- natorial action spaces while explicitly incorporating commu- nication constraints. T o this end, we leverage the distributed bandit-submodular optimization framework and the notion of V alue of Coordination that were introduced in [ 1 ]. Through simulations, we show that our approach attains near -optimal game value and higher target coverage compar ed to baselines. Index T erms — Nash equilibrium, distributed submodular optimization, bandit learning, sensor networks. I . I N T RO D U C T I O N In today’ s ev olving landscape of security and surveillance, effecti ve deployment of sensors is critical to ensure compre- hensiv e monitoring and target coverage [ 2 ]. Game-theoretic framew orks are widely used to model adversarial sensing and cov erage problems. Many existing formulations model the coordination among sensing agents through a centralized decision-making process [ 3 ]. Ho wev er, in practice, large surveillance areas and limited communication make it infea- sible to have a central coordinator [ 4 ]–[ 6 ]. These challenges instead necessitate distributed coordination, in which agents ∗ These authors contributed equally to this work. † These authors contributed equally to this work. 1 Elmore F amily School of Electrical and Computer Engineering, Pur- due University , W est Lafayette, IN 47907 USA; {jbhargav,mahsa, sundara2}@purdue.edu 2 Department of Aerospace Engineering, University of Michigan, Ann Arbor , MI 48109 USA; {ziruixu,vtzoumas}@umich.edu This work was supported in part by the National Science F oundation (NSF) CAREER A ward No. 2337412, the Army Research Office (ARO) Early Career Program A ward W911NF-25-1-0280, the Office of Nav al Re- search (ONR) and Saab, Inc. under the Threat and Situational Understanding of Networked Online Machine Intelligence (TSUNOMI) program (grant no. N00014-23-C-1016) and the National Aeronautics and Space Administra- tion (NASA) under grant 80NSSC24M0070. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the NSF , ARO, ONR, Saab, Inc., and/or NASA. Orientation selection based on with approximation performance captured by V alue of Coordination ( ) Neighborhood design given to maximize based on ... T arget deployment strategy based on sensor orientations Fig. 1: Distributed T arget Coverage Game. T eam of sensing agents choose communication neighbors and orientations to maximize target coverage. Simultaneously , the attacker selects a target deployment strategy to achieve the least cov erage for the sensing agents. The algorithms ActSel , NeiSel , and their interaction framework via the V alue of Coordination , follows [ 1 ]. selectiv ely communicate with local neighbors and adapt their local actions to maximize ov erall team performance. In this work, we consider a target co verage task where a team of sensing agents (defender) must coordinate to cover targets deployed in an environment. The utility function of the defender , for a giv en target deployment by the attacker , is the fraction of targets the agents collectively cover . This util- ity function is submodular—a property that captures dimin- ishing returns due to overlapping coverage among agents [ 7 ]. This structure enables the use of efficient approximation algorithms for utility maximization [ 8 ]. Howe ver , leveraging submodularity becomes more challenging when the utility value changes over time due to the attacker adaptiv ely repositioning the targets. W e model this interaction as a zero- sum game between the sensing team and an adapti ve attack er . Then, at Nash equilibrium (NE), neither the sensing team nor the attacker can improve their objective through unilateral deviation, yielding sensing strategies that are robust to such strategic adaptations. Solving this game for the exact NE strategies, ho wev er, can become computationally intractable due to the combinatorial growth of the defender’ s action space with the number of sensors and their orientations, as well as the need to propagate global information with- out a central coordinator . T o address this, we propose a distributed, scalable and communication-ef ficient frame work for approximately solving this game. Our approach draws on and unifies ideas from online learning, game theory , and distributed bandit-submodular optimization. Related W ork. Sev eral recent works study large zero- sum games, including analyses of equilibrium dynamics [ 9 ] and algorithms for estimating equilibria [ 10 ]–[ 13 ]. In [ 10 ], [ 11 ], the authors study subnetwork games with Lipschitz continuous utilities and require a strongly connected network to ensure con vergence to an NE. In [ 12 ], the authors present a multilinear extension–based technique with an approx- imation guarantee in a centralized setting. On the other hand, the re gret minimization approach of [ 13 ] does not provide guarantees on the quality of the resulting strategies. In contrast to these works, we establish near-optimality guar- antees in a distributed setting without requiring connecti vity assumptions on the communication network. Related work also focuses on solving distributed submodu- lar optimization problems in real-time, which are challenging since such problems are kno wn to be NP-hard [ 14 ]. Although existing algorithms achie ve near-optimal solutions in polyno- mial time, they often need significant runtime to terminate in distributed settings due to limited communication speeds and bandwidths [ 5 ], [ 15 ], [ 16 ]. In distributed settings, multiple works ha ve focused on online submodular maximization in unknown (dynamic) en vironments [ 4 ], [ 17 ]. They study these in a bandit feedback setting, and provide bounded subopti- mality guarantees with respect to optimal time-(in)variant actions through regret minimization [ 18 ]. Ho wev er, these works (i) can require extensi ve communication rounds as in [ 5 ], [ 15 ], [ 16 ], and (ii) require a connected network for information propagation, which is not always feasible [ 19 ]. Contributions. W e propose a distributed framework for a submodular target coverage game where a set of sens- ing agents coordinate their orientations to maximize the target coverage, while the attacker adaptiv ely relocates the deployed targets to minimize the cov erage (Algorithm 1 ). Our frame work enables a near-optimal coordination strategy for sensing agents that simultaneously configure communi- cation neighborhoods under limited bandwidth budgets and coordinate orientations, assuming a no-regret attacker that can learn the best response. T o this end, we lev erage the distributed bandit-submodular optimization framework in [ 1 ] and extend it to the game-theoretic setting. The framew ork can asymptotically achiev e an approximate NE of the game. During the repeated play of the game, sensing agents alter- nate between selecting their orientations and neighbors to adapt to the time-v arying target deployments by the attacker . In particular , our frame work has the follo wing key properties. a) P erformance Guar antees: It enables the distrib uted team of agents to asymptotically achieve an approximate NE. Despite the communication bandwidth constraints, the agents achiev e near-optimal performance by each acti vely adapting the neighborhood ov er time, enabled by optimizing its V alue of Coordination ( V oC ), a quantity introduced in [ 1 ]. b) Anytime Self-Configuration: Our framework enables each agent to choose its actions and neighbors individually using local information, enabling seamless adaptation to near-optimal orientations and neighborhoods as agents join or leave the network ( e.g. , sensor failures or additions). Finally , through simulations, we demonstrate that the sensing agents achiev e game utility arbitrarily close to the NE v alue and higher target coverage compared to baselines. I I . P RO B L E M F O R M U L A T I O N In this section, we formalize the Distributed Adversarial T ar get Covera ge Game and lay down the framework about the defender , attacker and game utility . T o this end, we use the notation: V N ≜ Q i ∈ N V i is the cross product of sets {V i } i ∈ N ; [ T ] ≜ { 1 , . . . , T } for any positive integer T ; f ( a | A ) ≜ f ( A ∪ { a } ) − f ( A ) is the marginal gain of set function f : 2 V 7→ R for adding a ∈ V to A ⊆ V ; and |A| is the cardinality of a discrete set A . Communication network. The communication network is denoted by G = ( N , E ) , where N is the set of nodes/agents and E refers to edges between agents. E is unspecified a priori; instead, the agents must form and optimize this com- munication network internally to coordinate their orientation actions and maximize their joint utility . Communication neighborhood. When a communication channel exists from agent j to i , i.e. , ( j → i ) ∈ E , then i can receive, store, and process information from j . The set of all agents that i recei ves information from is denoted by N i —agent i ’ s neighborhood . When we say that an agent exchanges information , we mean that it communicates the set of targets it currently cov ers under its chosen orientation ( e.g . , by encoding and sharing unique identifiers for tar gets). Communication constraints. Each agent i can recei ve infor- mation from up to α i other agents due to onboard bandwidth constraints. Thus, it must be |N i |≤ α i . Also, we denote by M i the set of agents that hav e agent i within reach – not all agents may hav e agent i within reach because of distance or obstacles. Therefore, agent i can pick its neighbors by choosing at most α i agents from M i . Evidently , N i ⊆ M i . Defender’ s action space. F or each sensing agent i ∈ N , we denote the agent’ s sensing action space by the set of feasible orientations V i . An action a i ∈ V i corresponds to a specific orientation of sensor i . The joint action of the sensing team is giv en by A = ( a 1 , . . . , a |N | ) ∈ V N . W e denote a mixed strategy of the defender by x ∈ ∆ | X | , where X = V N is the set of joint actions, and ∆ denotes a probability simplex. Attacker’ s action space. The attacker places a fixed number of tar gets according to one of finitely many deplo yment configurations Y = { b 1 , . . . , b m } , where each b i ∈ Y is a distinct spatial arrangement/deployment of these targets in the en vironment. W e denote the mixed-strate gy of the attacker by y ∈ ∆ | Y | , where ∆ denotes a probability simplex. Game Utility . The game utility f ( A , b ) for a pure-strategy pair ( A , b ) , is the fraction of tar gets covered by the sensing team with the joint orientation A under the target deploy- ment configuration b . The team of sensing agents aim to maximize f , while the attacker aims to minimize f , which results in a zero-sum game. W e denote the game matrix by G ∈ R | X |×| Y | , where G ij = f ( A i , b j ) , A i ∈ X , b j ∈ Y . W ith the notation introduced abov e, we no w formalize the Distributed T ar get Coverage Game below . Problem 1 (Distributed T arget Coverage Game) . The zer o- sum game between the team of sensing agents and the attack er is given by the following optimization pr oblem. max x ∈ ∆ | X | min y ∈ ∆ | Y | x ⊤ Gy = max x ∈ ∆ | X | min y ∈ ∆ | Y | E A∼ x,b ∼ y f ( A , b ) . (1) The solution to the zero-sum game in Problem 1 , i.e., the NE strategies, can be obtained by solving eq. ( 1 ). As stated earlier , exact NE computation is impractical due to the combinatorial action space of the defender ( e.g. , 10 sensors with 4 orientations yield 4 10 joint actions) and the absence of a central coordinator . This motiv ates the design of an ef ficient, distrib uted algorithm that relies only on local coordination between the agents and achie ves near-optimal performance relative to the centralized NE. In zero-sum games, near-optimality is formalized through the notion of an ϵ -Nash equilibrium. Definition 1 ( ϵ -Nash Equilibrium ( ϵ -NE) [ 3 ]) . A pair of mixed strate gies ( x ⋆ , y ⋆ ) is an ϵ -Nash equilibrium of the zer o-sum game with payoff matrix G if x ⋆ ⊤ Gy ⋆ ≥ x ⊤ Gy ⋆ − ϵ, ∀ x ∈ ∆ | X | and x ⋆ ⊤ Gy ⋆ ≤ x ⋆ ⊤ Gy + ϵ, ∀ y ∈ ∆ | Y | . In other words, an ϵ -NE ensures that neither player can improv e their payoff by more than ϵ relative to the game value (NE value) through unilateral deviation. I I I . S C A L A B L E E Q U I L I B R I U M A P P R OX I M A T I O N In this section, we introduce our main algorithm which estimates an ϵ -NE of the Distributed T ar get Coverage Game. W e begin by characterizing ke y structural properties of the game’ s utility function. A. Preliminaries Definition 2 (Normalized and Non-Decreasing Submodular Set Function [ 7 ]) . A set function g : 2 V 7→ R is normalized and non-decreasing submodular if and only if • (Normalization) g ( ∅ ) = 0 ; • (Monotonicity) g ( A ) ≤ g ( B ) , ∀ A ⊆ B ⊆ V ; • (Submodularity) g ( s | A ) ≥ g ( s | B ) , ∀ A ⊆ B ⊆ V , s ∈ V . Definition 3 (2nd-order Submodularity [ 20 ]) . A set function g : 2 V 7→ R is 2nd-order submodular if and only if g ( s | C ) − g ( s | A ∪ C ) ≥ g ( s | B ∪ C ) − g ( s | A ∪ B ∪ C ) , (2) for any disjoint A , B , C ⊆ V ( A ∩ B ∩ C = ∅ ) and s ∈ V . For a target deployment configuration b ∈ Y , we define f ( a | A , b ) ≜ f ( A ∪ { a } , b ) − f ( A , b ) to be the marginal gain of the game utility function for adding a ∈ V to A ⊆ V , giv en b ∈ Y . Then, for a gi ven b ∈ Y , the game’ s utility function f ( · , b ) is normalized, monotone, submodular, and 2nd-order submodular over the set of sensing actions (sensor orientations), with submodularity arising from overlapping cov erage areas among the sensing agents [ 6 ]. W e leverage these properties to guide our algorithm design. B. Main Algorithm Algorithm 1 outlines the iterativ e interaction between the attacker and the defender . Following standard game- theoretic modeling, we assume that the attacker is a rational agent that follo ws a no-regret learning strategy [ 21 ]. Such learning dynamics are known to con ver ge to NE in zero-sum games [ 22 ]. Under this modeling, the interaction between the sensing agents and the attacker induces an iterative game-play dynamic. W e sho w that, within this dynamic, the decision-making problems faced by the attacker and each sensing agent can be naturally formulated as adversarial multi-armed bandits (A-MAB) [ 18 ], because the agents and the attacker are una ware of each other’ s actions a priori. From the defender’ s perspecti ve, at each round the attacker selects a target deployment configuration, and the sensing team must choose an orientation strategy to maximize target cov erage. When the attacker adapti vely changes the deploy- ment over time, the sensing team must learn an orientation- selection policy that maximizes the expected cov erage utility . This setting corresponds to an A-MAB problem, where each arm represents an orientation strategy and the rew ard at each round is a function of the game’ s utility based on the target deployment strategy chosen by the attacker in that round. Similarly , from the attacker’ s perspectiv e, the sensing team’ s adaptiv e orientation choices induce an adversarially ev olving en vironment. The attacker then seeks a target deployment policy that minimizes the e xpected cov erage achiev ed by the sensing team. This also constitutes an A- MAB problem, where the arms correspond to tar get deploy- ment configurations and the reward is defined by the negati ve of game’ s utility function, which the attacker is trying to maximize. The attacker follo ws a classical no-regret learning strategy EXP3 [ 18 ] by updating a distribution over target deployment strategies against a sequence of defender actions. The defending team operates in a fully distributed manner , with each sensing agent maintaining two A-MAB instances: (i) ActSel (Algorithm 2 ) - for selecting sensing actions; Algorithm 1: Repeated Play Dynamics of the Dis- tributed T arget Coverage Game Input: Number of time steps T ; neighbor candidate sets M i , neighborhood sizes α i , and action sets V i for all sensing agent i ∈ N ; attacker’ s action set Y ; game’ s utility function f . Output: A pair of ϵ -NE strategies ( ¯ x T , ¯ y T ) . 1: N i, 0 ← ∅ , ∀ i ∈ N ; 2: η b ← p 2 log | Y | / ( | Y | T ) ; 3: w 1 ← w 1 , 1 , . . . , w | Y | , 1 ⊤ with w b, 1 = 1 , ∀ b ∈ Y ; 4: q 1 ← w 1 / ∥ w 1 ∥ 1 ; 5: for each time step t ∈ [ T ] do 6: sample target deployment config. b t ∈ Y fr om q t ; 7: p i,t , a i,t ← ActSel ( b 1: t − 1 , T , V i , f ) , ∀ i ∈ N ; 8: N i,t ← NeiSel ( a i,t , b 1: t − 1 , T , M i , α i , f ) , ∀ i ∈ N ; 9: recei ve neighbors’ actions { a j,t } j ∈ N i,t , ∀ i ∈ N ; 10: update ActSel (per lines 6–8 of Algorithm 2 ) & NeiSel (per lines 6–11 of Algorithm 3 ); 11: r b,t ← f ( { a i,t } i ∈N , b t ) 12: ˆ r b, t ← 1 − 1 ( b t = b ) p b,t (1 − r b,t ) , ∀ b ∈ Y ; 13: w b,t +1 ← w b,t exp ( − η b ˆ r b,t ) ; 14: get distribution q t +1 ← w t +1 / ∥ w t +1 ∥ 1 ; 15: end f or 16: estimate joint-strate gy ¯ p t ≜ Π i ∈N p i,t , ∀ t ∈ [ T ] . 17: ¯ x T ← 1 T P t ∈ [ T ] ¯ p t , ¯ y T ← 1 T P t ∈ [ T ] q t . and (ii) NeiSel (Algorithm 3 ) - for selecting communica- tion neighbors (see Appendix for details). W e sho w that this decomposition is highly beneficial, since under limited information exchange each agent can only e valuate the local utility , based on the subset of agents with which it communicates. Consequently , an agent’ s utility is inherently determined by its communication neighborhood. As a result, choosing communication neighbors N i,t ⊆ M i has a direct and non-trivial impact on the optimality of the sensing actions selected by each agent. This coupling makes neighbor selection an integral component of the overall decision process rather than a secondary design choice. T o capture this formally , we leverage the notion of V alue of Coordination. Definition 4 (V alue of Coordination ( V oC ) [ 1 ]) . Denote f t ( · ) ≜ f ( · , b t ) . At any t ∈ [ T ] with a targ et deployment b t ∈ Y , for an agent i ∈ N with an action a i,t and neighbors N i,t , its V alue of Coordination is defined as V oC f t ,t ( a i,t ; N i,t ) ≜ f t ( a i,t ) − f t ( a i,t | { a j,t } j ∈N i,t ) . (3) V oC measures the overlap of utility between its action and its neighbors’ actions, and per eq. ( 11 ), the equilibrium approximation performance ( R d T as in eq. ( 4 )) will be tighter when V oC is improved. Although V oC is not computable a priori, according to [ 1 , Lemma 1], it is normalized, non- decreasing, and submodular in N i,t giv en that f is 2nd-order submodular (Definition 3 ). Therefore, maximizing V oC takes the form of bandit submodular maximization that can be solved by NeiSel with bounded suboptimality (Algorithm 3 ). I V . P E R F O R M A N C E G U A R A N T EE S W e now establish performance guarantees for the proposed algorithm by characterizing bounds on the near-optimality of the resulting strate gies relati ve to the NE of the game. W e first present our main theoretical result that extends [ 1 , Theorem 1], which is for a fixed utility function f , by generalizing it to a time-v arying setting in which the utility function value f ( · , b t ) changes o ver time o wing to attacker’ s actions. Over t ∈ [ T ] , each agent i ∈ N selects ac- tions { a i,t } t ∈ [ T ] and neighborhoods {N i,t } t ∈ [ T ] against a sequence of attacker’ s tar get deployments { b t } t ∈ [ T ] (Algo- rithm 1 ). Let A OPT = { a OPT 1 , . . . , a OPT |N | } denote the best joint action of the sensing team in hindsight. The cumulativ e regret of the defender against A OPT is: R d T = T X t =1 f ( A OPT , b t ) − T X t =1 f ( A t , b t ) . (4) Definition 5 (Curvature [ 23 ]) . The curvatur e of a normalized monotone submodular function g : 2 V 7→ R is defined as κ g ≜ 1 − min v ∈V ( g ( V ) − g ( V \ { v } )) /g ( v ) . (5) κ g measures how far g is from modularity: if κ g = 0 , then g ( V ) − g ( V \ { v } ) = g ( v ) , ∀ v ∈ V , i.e. , g is modular . Using this definition, we present our theoretical result. Theorem 1 (Defender’ s A verage Re gret Bound) . After run- ning Algorithm 1 for T r ounds, the defender achie ves: R d T T ≤ κ f − β ρ ( κ I , ¯ α ) X i ∈N E t ∼ T [ V oC ( a i,t ; N ⋆ i )] + ˜ O |N | q ¯ α 2 | ¯ M| + | ¯ V | /T , (6) wher e κ I ≜ max i ∈N κ I ,i , ¯ α ≜ max i ∈N α i , | ¯ V | ≜ max i ∈N |V i | , | ¯ M| ≜ max i ∈N |M i | , κ f , κ I ∈ [0 , 1] , β ≜ κ f (1 − κ f ) and ρ ( κ I , ¯ α ) ∈ [1 − 1 /e, 1] . Here κ f is the curvatur e of f , κ I ,i is the curvatur e of V oC of agent i ∈ N and N ⋆ i ≜ arg max N i,t ⊆M i ; |N i,t |≤ α i P t ∈ [ T ] V oC f t ,t ( a i,t ; N i,t ) . Similarly , for a sequence of actions of the sensing agents {A t = { a 1 ,t , . . . , a |N | ,t }} t ∈ [ T ] , let b OPT denote the attack er strategy that is best in hindsight. The cumulative regret of the attacker with respect to this strategy is R a T = T X t =1 f ( A t , b t ) − T X t =1 f ( A t , b OPT ) . (7) Since the attacker follows the standard EXP3 regime (lines 12–13 of Algorithm 1 ), we have the following [ 24 ]. Lemma 1 (Attacker’ s A verage Regret Bound) . After running Algorithm 1 for T r ounds, the attac ker achieves: R a T T ≤ ˜ O p | Y | /T . (8) Combining the bounds from Lemma 1 and Theorem 1 with [ 21 , Theorem 2] yields the following near-optimality guarantee for the strategies produced by Algorithm 1 . Theorem 2 (Duality Gap) . Let ( ¯ x T , ¯ y T ) denote the str ate gies obtained after Algorithm 1 runs for T r ounds. Then, the strate gies ( ¯ x T , ¯ y T ) ar e ϵ T -NE of the Distributed T ar get Covera ge Game , where ϵ T = κ f − β ρ ( κ I , ¯ α ) X i ∈N E t ∼ T V oC a i,t ; N ⋆ i,t } + ˜ O q |N | 2 ¯ α 2 | ¯ M| + | ¯ V | + | Y | /T . (9) As T → ∞ , the limiting near-optimality parameter ϵ ∞ depends on κ f and the agents’ V oC . By selectively coordi- nating with the most informative neighbors, we maximize V oC , thereby tightening the bound on ϵ ∞ by compensating for the suboptimality term κ f . V . N U M E R I C A L E V A L U A T I O N Through two simulated scenarios of the target cov erage game defined in Problem 1 , we demonstrate that (i) Algo- rithm 1 con verges to an approximate NE per Theorem 2 (Figure 2 ), and (ii) optimizing the network topology per Algorithm 3 leads to cov erage performance that outperforms sev eral baselines for neighborhood design, such as the near- est and random selection that are common in controls, and is ev en comparable to the best possible performance with unlimited bandwidth b udgets (Figure 3 ). 0 3000 6000 9000 12000 15000 R ound 0.3 0.4 0.5 0.6 0.7 Utility A dversarial envir onment (attack er) Sensor network (defender) Game value Fig. 2: Pay offs and duality gap. Consider the repeated game dynamics per Algorithm 1 between three sensors each with bandwidth constraint 1 (defender) and an | Y | = 20 possible target deployments (attacker). As T → ∞ , the players asymptotically achiev e the approximate NE, with the duality gap, i.e. , the difference between the players’ payoffs, decreasing to its minimum, as shown in Theorem 2 . Results are averaged ov er 20 Monte Carlo trials, each with 15000 rounds. The experimental setup for both scenarios is as follows. The sensors N have fixed locations and need to each choose its orientation a i,t from the 16 cardinal directions V i , ∀ t . Each sensor i is unaware of a j,t , j ∈ N \ { i } ; thus, they hav e to communicate to know about peers’ actions. The attacker has a time-v arying target distribution b t updated via EXP3 (per Algorithm 1 ). f ( { a i,t } i ∈N , b t ) is the percentage of cov ered target area by the sensors when they select orientations { a i,t } i ∈N under the tar get distrib ution b t . a) Conver gence to Appr oximate NE of the Game: W e run Algorithm 1 which simulates an iterativ e game play between the sensing agents (which alternate between ActSel and NeiSel ) and a rational attacker . W e do 20 Monte Carlo trials, each with 15000 rounds. In Figure 2 , we observe that (i) the sensing team asymptotically approaches the game’ s equillbirum per Theorem 1 , and (ii) the duality gap, i.e. , the difference between the defenders’ payoff and the attacker’ s payoff, decreases per Theorem 2 . b) Impact of Network Optimization: W e demonstrate the effecti veness of network optimization per Algorithm 3 ( NeiSel ). W e consider a 30 × 30 environment. The sensors hav e FO V radius r i = 8 , A O V θ i = π / 3 , communication range c i = 16 , and heterogeneous bandwidth budgets α i randomly chosen from { 1 , 2 , 3 } . W e compare our framework with three benchmarks: (i) ActSel + Nearest Neighbors: Ac- tion selection follows Algorithm 2 , while each sensor i will always have the same closest peers as neighbors; (ii) ActSel + Random Neighbors: Action selection follows Algorithm 2 , while each sensor i will uniformly sample its neighbors from M i at each round; and (iii) ActSel + All P ossible Neighbors: Action selection follows Algorithm 2 , while each 0 2000 4000 6000 8000 10000 R ound 40 50 60 Coverage (%) A ctSel + NeiSel A ctSel + random neighbors A ctSel + near est neighbors A ctSel + all possible neighbors Fig. 3: Comparison of neighbor selection strategies. Four algorithms are compared under the same action selection strategy ( ActSel ) and adversarial en vironment ( EXP3 ), dif fering only in their neighbor selection strategies. Results are av eraged over 20 Monte Carlo trials, each with 10000 rounds. sensor i has no bandwidth constraint and will always hav e all M i as neighbors (since V oC is non-decreasing in M i , this should achiev e the best possible cov erage). W e conduct 20 Monte Carlo trials, each with 10000 rounds. From Figure 3 , we observe: (i) our frame work consistently outperforms the benchmarks with the same bandwidth b udgets, and (ii) de- spite limited bandwidth, it is comparable to the best possible cov erage with unlimited bandwidth. V I . C O N C L U S I O N In this paper , we proposed a distributed, game-theoretic framew ork for adversarial target coverage under limited communication. By modeling the interaction between the sensing team and the attacker as a zero-sum game with a combinatorial action space, we developed a decentralized algorithm that conv erges to an approximate NE while re- specting communication constraints. Our approach enabled each agent to adaptiv ely configure its communication neigh- borhood through an information-driven mechanism, allowing the system to scale efficiently . W e established theoretical guarantees on con vergence and quantified the near -optimality of the resulting strategies relative to the centralized game value. Through simulations, we showed that the proposed method con ver ges to an approximate NE of the game and provides high coverage utility compared to other neighbor selection baselines. R E F E R E N C E S [1] Z. Xu and V . Tzoumas, “Self-configurable mesh-networks for scalable distributed submodular bandit optimization, ” arXiv pr eprint:2602.19366 , 2026. [2] M. A. Guvensan and A. G. Y avuz, “On coverage issues in directional sensor networks: A survey , ” Ad Hoc Networks , vol. 9, pp. 1238–1255. [3] J. Bharga v , S. Sundaram, and M. Ghasemi, “Sensor scheduling in intrusion detection games with uncertain payoffs, ” in Learn. for Dyn. & Cont. (L4DC) . PMLR, 2025, pp. 606–618. [4] Z. Xu, X. Lin, and V . Tzoumas, “Bandit submodular maximization for multi-robot coordination in unpredictable and partially observable en vironments, ” in Robotics: Science and Systems (RSS) , 2023. [5] N. Atanasov , J. Le Ny , K. Daniilidis, and G. J. Pappas, “Decentralized activ e information acquisition: Theory and application to multi-robot SLAM, ” in IEEE Inter . Conf. Rob . Auto. (ICRA) , 2015, pp. 4775–4782. [6] M. Corah and N. Michael, “Distributed submodular maximization on partition matroids for planning on large sensor networks, ” in IEEE Confer ence on Decision and Contr ol (CDC) , 2018, pp. 6792–6799. [7] M. L. Fisher , G. L. Nemhauser , and L. A. W olsey , “ An analysis of approximations for maximizing submodular set functions–II, ” in P olyhedral Combinatorics , 1978, pp. 73–87. [8] J. Bharga v , M. Ghasemi, and S. Sundaram, “Submodular information selection for hypothesis testing with misclassification penalties, ” in Learn. for Dyn. & Cont. (L4DC) . PMLR, 2024, pp. 566–577. [9] R. Konda, R. Chandan, D. Grimsman, and J. R. Marden, “Best response sequences and tradeof fs in submodular resource allocation games, ” IEEE T ransactions on Automatic Contr ol , 2025. [10] S. Huang, J. Lei, Y . Hong, U. V . Shanbhag, and J. Chen, “No- regret distributed learning in subnetwork zero-sum games, ” IEEE T ransactions on Automatic Contr ol , no. 10, pp. 6620–6635, 2024. [11] L. Liao, D. Y uan, D. W . Ho, W . X. Zheng, B. Zhang, and Z. Y u, “Distributed dynamic no-regret learning in two-network zero-sum games, ” IEEE T ransactions on Automatic Contr ol , 2025. [12] B. Wilder , “Equilibrium computation and robust optimization in zero sum games with submodular structure, ” in Pr oceedings of the AAAI Confer ence on Artificial Intelligence , vol. 32, no. 1, 2018. [13] S. Li, Y . Zhang, X. W ang, W . Xue, and B. An, “Cfr-mix: Solving imperfect information extensiv e-form games with combinatorial action space, ” in International Joint Confer ence on Artificial Intelligence (IJCAI) , 2021, pp. 3663–3669. [14] U. Feige, “ A threshold of ln ( n ) for approximating set cover , ” Journal of the ACM (J ACM) , vol. 45, no. 4, pp. 634–652, 1998. [15] A. Robey , A. Adibi, B. Schlotfeldt, H. Hassani, and G. J. Pappas, “Optimal algorithms for submodular maximization with distributed constraints, ” in Learn. for Dyn. & Cont. (L4DC) , 2021, pp. 150–162. [16] R. Konda, D. Grimsman, and J. R. Marden, “Execution order matters in greedy algorithms with limited information, ” in American Contr ol Confer ence (ACC) , 2022, pp. 1305–1310. [17] M. Streeter and D. Golovin, “ An online algorithm for maximizing submodular functions, ” Adv . Neu. Inf. Proc. Sys. , vol. 21, 2008. [18] P . Auer , N. Cesa-Bianchi, Y . Freund, and R. E. Schapire, “The non- stochastic multiarmed bandit problem, ” SIAM Journal on Computing , vol. 32, no. 1, pp. 48–77, 2002. [19] Q. Wu, J. Xu, Y . Zeng, D. W . K. Ng, N. Al-Dhahir, R. Schober , and A. L. Swindlehurst, “ A comprehensive overview on 5G-and- beyond networks with U A Vs: From communications to sensing and intelligence, ” IEEE Journal on Selected Ar eas in Communications , vol. 39, pp. 2912–2945. [20] S. F oldes and P . L. Hammer , “Submodularity , supermodularity , and higher-order monotonicities of pseudo-boolean functions, ” Mathemat- ics of Operations Researc h , vol. 30, no. 2, pp. 453–461, 2005. [21] G. Farina, C. Kroer, and T . Sandholm, “Regret minimization in behaviorally-constrained zero-sum games, ” in International Confer - ence on Machine Learning . PMLR, 2017, pp. 1107–1116. [22] C. Daskalakis and I. Panageas, “Last-iterate con vergence: Zero-sum games and constrained min-max optimization, ” in Innovations in Theor etical Computer Science Conference (ITCS) . Schloss Dagstuhl– Leibniz-Zentrum für Informatik, 2019, pp. 27–1. [23] M. Conforti and G. Cornuéjols, “Submodular set functions, matroids and the greedy algorithm: T ight worst-case bounds and some general- izations of the rado-edmonds theorem, ” Discrete Applied Mathematics , vol. 7, no. 3, pp. 251–274, 1984. [24] T . Lattimore and C. Szepesvári, Bandit Algorithms . Cambridge Univ ersity Press, 2020. A P P E N D I X A. Theoretical Pr oofs In the interest of space, we outline only the essential steps emphasizing the main technical ideas of the proofs. a) Proof of Theor em 1 : Consider a sequence of { b t } t ∈ [ T ] that is selected by the attacker ov er [ T ] . Then, replacing f with f t in [ 1 , eq. (14)] (this preserves validity of the original ar gument), we ha ve: T X t =1 f t ( A t ) ≥ (1 − κ f ) T X t =1 f t ( A OPT ) + κ f (1 − κ f ) ρ ( κ I , ¯ α ) × X i ∈N T X t =1 V oC f t ,t ( a i,t ; N ⋆ i ( { a i,t } t ∈ [ T ] ; α i , M i )) − ˜ O |N | q T ¯ α 2 | ¯ M| + | ¯ V | , (10) where N ∗ i ( · ) is the optimizer of V oC ( 3 ). Therefore, R d T = T X t =1 f t ( A OPT ) − T X t =1 f t ( A t ) ≤ κ f T X t =1 f t ( A OPT ) − κ f (1 − κ f ) ρ ( κ I , ¯ α ) × X i ∈N T X t =1 V oC f t ,t ( a i,t ; N ⋆ i ( { a i,t } t ∈ [ T ] ; α i , M i )) + ˜ O |N | q T ¯ α 2 | ¯ M| + | ¯ V | . (11) Since 0 ≤ f t ( A OPT ) ≤ 1 , ∀ t , Theorem 1 is prov ed. b) Proof of Lemma 1 : Since the attacker adopts EXP3 , according to [ 18 , Theorem 3.1], we have R a T ≤ p 2 T | Y | log | Y | , and thus Lemma 1 holds. c) Proof of Theorem 2 : Consider the repeated-play dynamic induced by Algorithm 1 , which generates a se- quence of actions { ( A t , b t ) } t ∈ [ T ] . Since the payoff for a player is linear in other player’ s mixed strategy , the best fixed comparator in the regret definition is attained at an extreme point of the simplex, and thus can be taken to be a pure strategy . Theorem 1 and Lemma 1 then bound the av erage regrets with respect to these best fixed comparators, as ϵ 1 ≜ R d T /T and ϵ 2 ≜ R a T /T , respecti vely . Inv oking [ 21 , Theorem 2] with ϵ 1 and ϵ 2 , we get the result. B. The ActSel and NeiSel Algorithms Below , we outline Algorithms 2 and 3 in detail. Algorithm 2: ActSel for Agent i [ 1 ] Input: Attacker’ s actions ( b 1 ..., b t − 1 ) , Number of time steps T , agent’ s action set V i , objectiv e function f Output: Agent i ’ s distrib ution p i,t and action a i,t . 1: η a i ← p 2 log |V i | / ( |V i | T ) ; 2: ˆ w 1 ← ˆ w 1 , 1 , . . . , ˆ w |V i | , 1 ⊤ with ˆ w a, 1 = 1 , ∀ a ∈ V i ; 3: p i, 1 ← ˆ w 1 / 1 ⊤ ˆ w 1 4: draw action a i,t ∈ V i from p i,t ; receive neighbors’ actions { a j,t } j ∈N i,t ; 5: r a i,t ,t ← f ( a i,t | { a j,t } j ∈N i,t , b t ) and normalize r a i,t ,t to [0 , 1] ; 6: ˆ r a, t ← 1 − 1 ( a i,t = a ) p a,t 1 − r a i,t ,t , ∀ a ∈ V i ; 7: ˆ w a,t +1 ← ˆ w a,t exp ( η n i ˆ r a,t ) , ∀ a ∈ V i ; 8: get distrib ution p i,t +1 ← ˆ w t +1 / 1 ⊤ ˆ w t +1 ; Algorithm 3: NeiSel for Agent i [ 1 ] Input: Actions a i,t , ( b 1 ..., b t − 1 ) , Number of time steps T , Agent i ’ s M i , α i , and objecti ve function f Output: Agent i ’ s neighbors N i,t at each t ∈ [ T ] . 1: η n i ← p 2 log |M i | / ( |M i | T ) ; 2: z ( k ) 1 ← h z ( k ) 1 , 1 , . . . , z ( k ) α i , 1 i ⊤ ; z ( k ) j, 1 = 1 , ∀ v ∈ M i , ∀ k ∈ [ α i ] ; 3: for k = 1 , . . . , α i do 4: get distribution ψ ( k ) t ← z ( k ) t / ∥ z ( k ) t ∥ 1 ; 5: draw agent j ( k ) t ∈ M i from ψ ( k ) t ; 6: recei ve action a j ( k ) t ,t from j ( k ) t ; 7: r j ( k ) t ,t ← V oC f t ,t ( a i,t ; { a j (1) t ,t , . . . , a j ( k ) t ,t } ) − V oC f t ,t ( a i,t ; { a j (1) t ,t , . . . , a j ( k − 1) t ,t } ) and normalize r j ( k ) t ,t to [0 , 1] ; 8: ˆ r ( k ) j,t ← 1 − 1 ( j ( k ) t = j ) q ( k ) j,t 1 − r j ( k ) t ,t , ∀ j ∈ M i ; 9: z ( k ) j,t +1 ← z ( k ) j, t exp ( η n i ˆ r ( k ) j,t ) , ∀ j ∈ M i ; 10: end f or 11: N i,t ← { j ( k ) t } k ∈ [ α i ] ;
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment