TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
Text-to-SQL parsing has achieved remarkable progress under the Full Schema Assumption. However, this premise fails in real-world enterprise environments where databases contain hundreds of tables with massive noisy metadata. Rather than injecting the…
Authors: Ai Jian, Xiaoyun Zhang, Wanrou Du
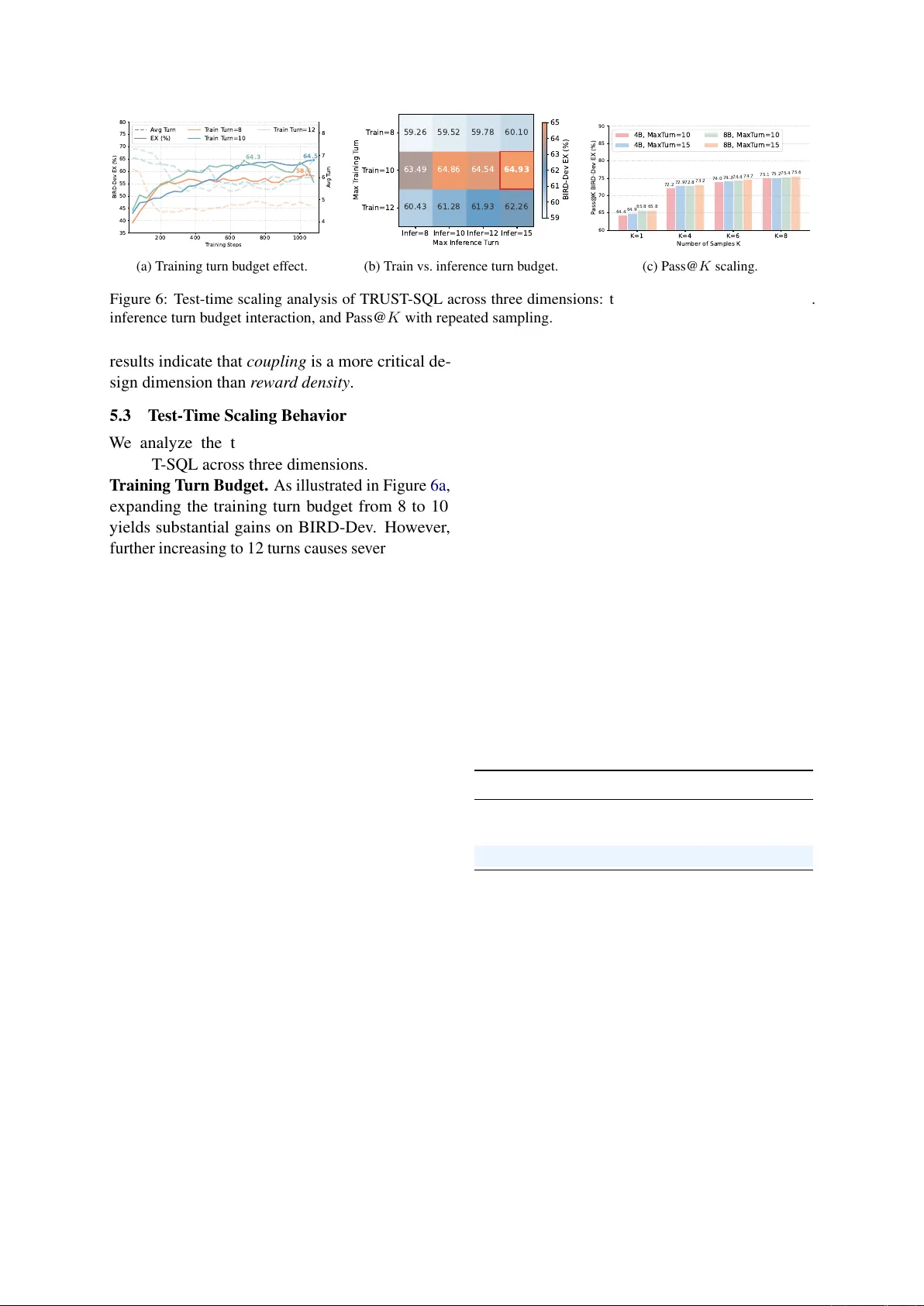
TR UST -SQL: T ool-Integrated Multi-T urn Reinf or cement Learning f or T ext-to-SQL ov er Unknown Schemas Ai Jian 1 * , Xiaoyun Zhang 2 , 3 ∗ , W anrou Du 1 , Jingqing Ruan 4 † , Jiangbo Pei 1 W eipeng Zhang 4 , K e Zeng 4 , Xunliang Cai 4 1 Beijing Uni versity of Posts and T elecommunications, Beijing, China 2 State K ey Lab of Processors, Institute of Computing T echnology , CAS 3 Uni versity of Chinese Academy of Sciences, 4 Meituan, Beijing, China jianai@bupt.edu.cn , ruanjingqing@meituan.com Abstract T ext-to-SQL parsing has achie ved remarkable progress under the Full Schema Assumption. Howe ver , this premise fails in real-w orld en- terprise en vironments where databases contain hundreds of tables with massiv e noisy metadata. Rather than injecting the full schema upfront, an agent must activ ely identify and verify only the rele v ant subset, giving rise to the Unknown Schema scenario we study in this work. T o ad- dress this, we propose TRUST -SQL ( T ruthful R easoning with U nkno wn S chema via T ools). W e formulate the task as a Partially Observ- able Marko v Decision Process where our au- tonomous agent employs a structured f our - phase protocol to ground reasoning in v er- ified metadata. Crucially , this protocol pro- vides a structural boundary for our nov el Dual- T rack GRPO strate gy . By applying tok en- lev el masked adv antages, this strategy isolates exploration re wards from e xecution outcomes to resolve credit assignment, yielding a 9.9% relati ve impro vement o ver standard GRPO. Extensiv e experiments across fi ve benchmarks demonstrate that TR UST -SQL achiev es an aver - age absolute impro vement of 30.6% and 16.6% for the 4B and 8B v ariants respecti vely ov er their base models. Remarkably , despite op- erating entirely without pre-loaded metadata, our agent consistently matches or surpasses strong baselines that rely on schema prefilling. 1 Introduction T ext-to-SQL parsing, which translates natural lan- guage questions into e xecutable SQL queries, has seen remarkable progress dri ven by Large Lan- guage Models (LLMs) ( Shkapenyuk et al. , 2025 ; W ang et al. , 2025b ). Ho wev er , this progress has been achiev ed under a critical yet often overlook ed premise, the Full Schema Assumption , which presupposes that the complete database schema * Equal contribution. † Corresponding author . Schema Grounding Active Explorer Hallucination Passive translator TRUST-SQL Paradigm Existing Paradigm Query customers who spent over one million last year ? (Context Limit) Databases The table name might be ‘vip_customers’? FROM vip_customers ERROR/ Hallucination Confirm Schema Needed FROM client_orders Tool Call Environment Hidden fact: The actual table name is 'client_orders' Success/ Grounded Figure 1: Existing methods rely on pre-loaded schemas, while the Unkno wn Schema setting requires acti ve e x- ploration. is pre-loaded into the model’ s input context. Under this paradigm, the task reduces to a static transla- tion problem and e xisting methods hav e achie ved strong performance on standard benchmarks with pre-injected schemas ( Li et al. , 2024 ; Y u et al. , 2018 ). Y et this assumption rarely holds in real- world enterprise en vironments, where databases routinely contain hundreds of tables and schemas frequently e volve through additions, deletions, and restructuring ( Zhang et al. , 2026 ). Injecting this massi ve, noisy , and potentially outdated metadata upfront is impractical for finite context windows and activ ely harmful, as irrelev ant or stale tables se verely distract the model. Consequently , as il- lustrated in Figure 1 , we formalize this necessary paradigm shift as the Unknown Schema setting, where an agent must abandon passi ve consumption and autonomously explore the database to retrie ve only the necessary metadata. Ho wev er , standard single-turn methods lack in- teracti ve capabilities and fail in unobservable en- vironments. T o o vercome this fundamental limi- tation, the parsing task must be approached as a multi-turn tool-integrated decision-making pro- cess . While recent agentic frameworks ha ve ex- plored this iterati ve direction, the y introduce new bottlenecks. Architecturally , LLMs struggle to maintain coherent reasoning across long interaction 1 horizons. W ithout explicit mechanisms to ground their exploration, they frequently lose track of in- termediate observations ( Laban et al. , 2025 ) and re vert to fabricating non-e xistent schema elements based on parametric priors. Algorithmically , as- signing credit across long interaction trajectories remains a fundamental challenge for large language models ( Zhou et al. , 2025 ; Y ang et al. , 2026 ). By re- lying on a single terminal re ward ( Y ang et al. , 2025 ; Xu et al. , 2025 ) or nai vely aggregating intermediate signals ( Hua et al. , 2026 ), these methods conflate the quality of schema exploration with SQL gen- eration, making it impossible to attrib ute the final ex ecution outcome to specific actions. In this paper , we propose TR UST -SQL ( T ruthful R easoning with U nkno wn S chema via T ools) to systematically address these challenges. T o handle the unobservable database en vironment, we formulate the task as a Partially Observ able Marko v Decision Process. W ithin this frame work, we introduce a four -phase interaction protocol comprising Explor e , Pr opose , Gener ate , and Con- firm . The Pr opose phase acts as a mandatory cogni- ti ve checkpoint that forces the agent to commit to verified metadata, thereby pre venting subsequent hallucinations. Crucially , this checkpoint provides a structural boundary for Dual-T rack GRPO , a training strategy b uilt upon Group Relativ e Policy Optimization(GRPO) ( DeepSeek-AI , 2025 ) that ap- plies token-le vel mask ed advantages to isolate ex- ploration and ex ecution rew ards for co-optimizing schema grounding and SQL generation. Our contributions are summarized as follo ws: • W e de velop TRUST -SQL , an autonomous frame- work that directly interacts with unobserv able databases to retriev e and verify metadata, suc- cessfully closing the loop from unconstrained exploration to grounded SQL generation without relying on static context. • W e propose Dual-T rack GRPO , a no vel training strategy utilizing token-le vel masked adv antages and execution-coupled schema re wards. This granular optimization yields a 9.9% relative im- pro vement in ex ecution accuracy o ver standard GRPO on BIRD-De v . • Extensi ve experiments demonstrate that TR UST - SQL yields massi ve performance leaps ov er base models in unobservable en vironments. Across fi ve di verse benchmarks, the frame work achie ves an a verage absolute improv ement of 30.6% for the 4B and 16.6% for the 8B variant. Remark- ably , despite operating without pre-loaded meta- data, our models consistently match or surpass baselines that rely on schema injection. 2 Related W ork T ext-to-SQL under Full Schema Assumption. Most existing methods operate under the premise of full schema observ ability . Supervised fine-tuning approaches such as OmniSQL ( Li et al. , 2025 ), ST AR ( He et al. , 2025 ), and R OUTE ( Qin et al. , 2024 ) internalize generation capabilities b ut rely entirely on static context. Similarly , single-turn reinforcement learning(RL) methods ( Ma et al. , 2025 ; Y ao et al. , 2025 ; Zhang et al. , 2025 ; Pour - reza et al. , 2025 ) optimize ex ecution accuracy us- ing terminal re wards while assuming the complete database structure is provided upfront. Constrained to a single-turn interaction paradigm, these mod- els act as passive translators. Consequently , the y fundamentally fail in unobservable enterprise en- vironments where acti ve database exploration is strictly required. T ool-A ugmented Database Exploration. T o han- dle complex or hidden databases, recent works in- troduce tool-integrated exploration. T raining-free frame works ( W ang et al. , 2024 , 2025a ) lev erage frozen language models to query metadata. Ho w- e ver , without gradient updates, these agents remain susceptible to parametric hallucinations and cannot strictly enforce verification protocols. More re- cently , multi-turn RL approaches ( Xu et al. , 2025 ; Hua et al. , 2026 ; Guo et al. , 2025 ) embed SQL ex ecution into the training loop to refine queries. While promising, these methods lack strict cog- niti ve boundaries to enforce metadata v erification and still ev aluate the entire exploration trajectory using conflated terminal rew ards, failing to isolate the specific signals for schema retriev al and SQL generation. Credit Assignment in Multi-T urn RL. A central challenge in multi-turn RL is attributing the final outcome to individual actions across a long tra- jectory . Existing solutions explore trajectory-le vel optimization ( W ang et al. , 2025c ; Xue et al. , 2025 ), process re wards ( Liu et al. , 2025 ), tree-structured search ( Ji et al. , 2025 ), and intrinsic motiv ation ( Ku- mar et al. , 2024 ; W an et al. , 2025 ). These tech- niques are primarily designed for homogeneous action spaces where each step contributes simi- larly to the final goal. In T ext-to-SQL, a single re ward cannot distinguish whether failures stem 2 Explore Schema Propose schema Generate SQL Confirm Answer Workflow Refine Schema Refine SQL Grounded Validated Verified T More Info Traning Process T Rollout samples ... ... Reward & Advantange T Schema Reward Full Reward t 0 t 1 t 0 t 1 t T ... ... t 2 t 2 t T-1 t T-1 t T Policy Update ... Loss Function ... Figure 2: Overvie w of the TR UST -SQL framework. (T op) The four-phase workflo w comprising Explore , Pr opose , Generate , and Confirm , with non-linear transitions enabling iterati ve schema refinement. (Bottom) The Dual-T rack GRPO training pipeline, where trajectories are decomposed into a Schema Track τ schema and a Full T rack τ full , each optimized with independent rew ards and masked adv antages. from incorrect schema retriev al or flawed genera- tion logic. TRUST -SQL resolves this by introduc- ing Dual-T rack GRPO to disentangle credit assign- ment across phases. 3 Methodology W e present TR UST -SQL to tackle T ext-to-SQL ov er unknown schemas. As illustrated in Figure 2 , it comprises an explicit four -phase interaction pro- tocol and a Dual-T rack GRPO training strategy . W e first formulate the task as a sequential decision- making process, follo wed by our re ward design and RL optimization. 3.1 Motivation: Why a F our -Phase Protocol? T o empirically justify the design of our core inter - action protocol and identify the key bottlenecks of T ext-to-SQL under the Unknown Schema setting , we conduct a pilot study on the BIRD-Dev dataset with Qwen3-8B as the base model. W e construct three agent variants with incremental structural constraints on interaction behavior , and classify all failure cases to deri ve design principles for the subsequent frame work. Protocol V ariants. EC (Explore-Confirm) is a minimal baseline where the agent freely queries metadata and directly submits a SQL answer with- out intermediate verification. EGC (Explore- Generate-Confirm) introduces an explicit Gener - ate phase , requiring the agent to ex ecute a candi- date SQL and observe its result before finalizing. EPGC (Explore-Propose-Generate-Confirm) fur- ther adds the Pr opose phase as a mandatory cog- niti ve checkpoint, compelling the agent to commit to a verified schema before SQL generation. Error T axonomy . W e classify failures into fi ve cat- egories: (1) Hallucination : the model fabricates non-existent tables or columns based on paramet- ric priors; (2) Schema Linking : the model selects wrong or missing tables and columns despite cor- rect e xploration; (3) Semantic : the model correctly identifies the rele v ant schema but generates logi- cally incorrect SQL; (4) Syntax : the SQL contains malformed statements that fail to ex ecute; (5) Gen- eration : the agent fails to produce a complete SQL, typically due to reaching the maximum turn limit. As sho wn in Figure 3 , three observ ations emer ge from the results. Obs. 1: Schema verification is critical to sup- press hallucination. In EC, hallucination ac- 3 EC EGC EPGC 0 200 400 600 800 1000 1200 1400 Er r or Count 26.4% 14.2% 33% 35% 37% 28% 31% 38% 9% 9% 11% 17% n=953 n=916 n=858 Hallucination Schema Linking Semantic Syntax Generation (a) Stacked error distrib ution. EC EGC EPGC 34 36 38 40 42 44 46 Ex ecution A ccuracy (%) 37.74% 40.16% 43.94% +6.20% (b) EX accuracy . Figure 3: Pilot study results on BIRD-De v (Qwen3-8B). counts for 26.4% of all failures. The Generate phase partially alle viates this via ex ecution feed- back (14.2%), but the most significant reduction occurs with the Pr opose in EPGC, dri ving halluci- nation to just 2.8%, a 9.4 × r eduction over EC. Obs. 2: Schema linking is the persistent bottle- neck. Schema linking errors remain consistently high across all variants, moti vating our Dual-T rack GRPO to provide an independent optimization sig- nal for schema exploration. Obs. 3: Suppr essing hallucination rev eals se- mantic errors. As hallucination decreases, seman- tic errors increase from 268 to 330, reflecting a distributional shift: once schema is correctly iden- tified, complex query logic becomes the dominant challenge, motiv ating joint optimization of schema grounding and SQL generation. These observations motiv ate the two core de- signs of our work: the Pr opose checkpoint to sup- press hallucination, and Dual-T rack GRPO to co- optimize schema exploration and SQL generation. 3.2 Problem F ormulation Based on the EPGC protocol v alidated in Sec- tion 3.1 , we formalize the T ext-to-SQL task under the Unkno wn Schema setting as a Partially Observ- able Marko v Decision Process (POMDP) , which is defined as ( S , A , T , R , Ω , Z , γ ) ov er discrete steps t = 0 , 1 , . . . , T . State and Observation Spaces. The true en viron- ment state s t ∈ S represents the complete database schema and remains hidden from the agent. Con- sequently , the agent only recei ves partial observ a- tions o t ∈ Ω dictated by the observation function Z , which consist of tool execution feedback. T o navig ate this unobservable en vironment, the agent relies on an internal context state c t = ( q , h t , K t ) . This conte xt integrates the user question q , the interaction history h t , and the V erified Schema Knowledge K t , which stores only explicitly v eri- fied metadata and initializes as K 0 = ∅ . Action Space. T o prevent hallucination, the agent selects actions a t ∈ A from four strict categories based on its current context c t . The Explor e action queries database metadata. The Pr opose action serves as a mandatory cogniti ve checkpoint at step t propose to commit to the v erified schema K t propose . The Generate action produces a candidate SQL grounded in K t , and the Confirm action submits the final SQL query y at the terminal step T . T ransition and Objective. Upon ex ecuting a t , the en vironment emits observation o t and the agent updates its conte xt state to c t +1 . A complete in- teraction sequence from the agent’ s perspectiv e is represented as a trajectory τ = { ( c t , a t , o t ) } T t =0 . The ultimate goal of the policy π θ ( a t | c t ) is to maximize the expected cumulati ve re ward J ( θ ) = E τ ∼ π θ [ P T t =0 γ t r ( c t , a t )] . 3.3 Reward Components T o ev aluate the trajectory , we define three distinct re ward signals. The specific mechanism for assign- ing these signals to individual tok ens is detailed in Section 3.4 . Execution Reward ( R exec ). This re ward e valuates the final predicted SQL y against the ground truth y ∗ via database ex ecution. The re ward is assigned as follo ws R exec ( y , y ∗ ) = 1 . 0 if Exec ( y ) = Exec ( y ∗ ) 0 . 2 if Exec ( y ) = ∅ 0 . 0 if Exec ( y ) = ∅ (1) where Exec ( y ) = ∅ denotes that the query y is ex ecutable but yields an incorrect result. F ormat Reward ( R fmt ). This constitutes a trajectory-le vel signal requiring consistent protocol adherence. The re ward is defined as R fmt ( τ ) = ( 0 . 1 if protocol is fully adhered to 0 . 0 otherwise (2) Full adherence requires that ev ery action a t con- forms to prescribed format, all four action cate- gories in A appear at least once, and no e xecution errors occur in the observ ations o t . Schema Reward ( R schema ). This re ward e valuates the quality of the schema exploration phase. It is computed as R schema ( ˆ K , K ∗ ) = f match ( ˆ K , K ∗ ) (3) 4 where ˆ K represents the schema proposed by the agent at step t propose , and K ∗ represents the mini- mal ground truth schema extracted from y ∗ . The function f match e valuates their structural o verlap. 3.4 Resolving Credit Assignment via Dual-T rack GRPO Standard RL combines exploration and generation under a single re ward, making it hard to attribute success or failure to specific actions in long tra- jectories. W e thus lev erage the structural bound- ary of the Pr opose checkpoint to introduce Dual- T rack GRPO , extending Group Relative Polic y Optimization to clearly separate the learning sig- nals for schema grounding and SQL generation. T rack Formulation and Rewards. F or each ques- tion q , we sample G trajectories and divide each τ i into tw o optimization tracks k ∈ { schema , full } , where the Schema T rack ends at T schema = t propose and the Full Track spans the entire interaction up to T full = T . A dedicated re ward R i k is assigned to each track R i k = ( R schema ( ˆ K i , K ∗ ) if k = schema R exec ( y i , y ∗ ) + R fmt ( τ i ) if k = full (4) ensuring an independent optimization signal for exploration quality re gardless of generation errors. Masked Advantage Computation. Advantages are computed via group-relativ e normalization within each track A i k = R i k − µ k σ k + ϵ (5) where µ k and σ k are the mean and standard de vi- ation of the group re wards. W e apply strict token- le vel masking where the advantage A i k is broad- cast exclusi vely to tok ens generated within the ac- ti ve steps t ∈ [0 , T k ] . This is strictly finer-grained than trajectory-lev el weighting, as it prevents ex- ploration rew ards from incorrectly crediting gener- ation tokens and vice v ersa. Consequently , tokens generated after the Pr opose checkpoint receiv e zero schema adv antage. Dual-T rack Loss Function. Let L k ( θ ) denote the GRPO loss computed over the activ e tokens for track k using the masked adv antage A i k . The total objecti ve combines both tracks L ( θ ) = L full ( θ ) + λ · L schema ( θ ) (6) where λ controls the relati ve contribution of the Schema Track. By unifying these com- ponents, Dual-T rack GRPO successfully co- optimizes schema grounding and SQL generation without mixing their learning signals. 4 Experiments 4.1 Experimental Setup Implementation Details. W e adopt Qwen3-4B and Qwen3-8B as our base models and implement all experiments using the SLIME frame work ( Zhu et al. , 2025 ), trained in two sequential stages of SFT warm-up follo wed by Dual-Track GRPO opti- mization. Details are pro vided in Appendix B . Baselines. TR UST -SQL utilizes a highly ef ficient data recipe comprising 9.2k SFT samples and 11.6k RL samples. W e compare our framework against recent strong baselines across the 3B to 8B pa- rameter scales. Single-turn models include Om- niSQL ( Li et al. , 2025 ) and SQL-R1 ( Ma et al. , 2025 ). Multi-turn RL methods include MTIR- SQL ( Xu et al. , 2025 ) and SQL-Trail ( Hua et al. , 2026 ). Full dataset construction and detailed base- line comparisons are provided in Appendix A . Evaluation Benchmarks and Metrics. W e ev al- uate on BIRD-De v ( Li et al. , 2024 ) for large- scale schema grounding and Spider-T est ( Y u et al. , 2018 ) for compositional generalization. T o stress- test model robustness, we incorporate three chal- lenging variants. Specifically , Spider -Syn ( Gan et al. , 2021a ) e valuates lexical rob ustness via syn- onym substitution, Spider-DK ( Gan et al. , 2021b ) probes for implicit domain knowledge, and Spider - Realistic ( Deng et al. , 2021 ) assesses ambigu- ity resolution. W e measure Execution Accuracy where the predicted SQL must yield the e xact same database result as the ground truth. W e report single-sample performance via Greedy decoding at temperature zero and e xecution-based Majority voting across multiple sampled queries. 4.2 Main Results T able 1 presents the ex ecution accuracy across all benchmarks. For the majority v oting e valuation, we sample trajectories at a temperature of 0.8 with a 15-turn inference budget, as analyzed in Section 5.3 . Detailed token consumption and tool in vocation statistics are provided in Appendix D.1 . Perf ormance of Compact Models. In the 3B to 4B parameter regime, TR UST -SQL deliv ers highly competiti ve performance. On the challeng- 5 T able 1: Execution Accuracy (EX%) across multiple benchmarks. Gre denotes single-sample performance; Maj denotes majority voting. Bold indicates the best result and underline indicates the second best within each group. Method Schema Prefill BIRD (dev) Spider (test) Spider-DK Spider -Syn Spider-Realistic Gre Maj Gre Maj Gre Maj Gre Maj Gre Maj 3B – 4B Models SQL-R1-3B ✓ – 54.6 – 78.9 – 70.5 – 66.4 – 71.5 SQL-T rail-3B ✓ 50.1 55.1 77.7 84.3 – – – – – – MTIR-SQL-4B ✓ 63.1 64.4 83.4 – 71.2 – 78.6 – 78.7 – TR UST -SQL-4B × 64.9 67.2 82.8 85.0 71.6 73.8 74.7 77.3 79.9 82.5 7B – 8B Models OmniSQL-7B ✓ 63.9 66.1 87.9 88.9 76.1 77.8 69.7 69.6 76.2 78.0 SQL-R1-7B ✓ 63.7 66.6 – 88.7 – 78.1 – 76.7 – 83.3 SQL-T rail-7B ✓ 60.1 64.2 86.0 87.6 76.8 77.8 72.8 77.0 79.6 83.9 MTIR-SQL-8B ✓ – 64.6 83.4 – 72.9 – 77.2 – 77.4 – TR UST -SQL-8B × 65.8 67.7 83.9 86.5 72.1 75.7 75.4 77.4 82.1 84.1 ing BIRD-De v benchmark, it achieves 64.9% with greedy decoding and 67.2% with majority v oting, outperforming the strong MTIR-SQL-4B baseline. Furthermore, TR UST -SQL-4B consistently secures the top position on rob ustness benchmarks includ- ing Spider-DK and Spider -Realistic. This proves that its active exploration polic y generalizes well to perturbed and ambiguous scenarios rather than relying on memorized schema patterns. Perf ormance of Mid-Scale Models. Scaling the base model to 8B further amplifies these benefits. TR UST -SQL-8B achiev es the highest execution accuracy on BIRD-De v with 65.8% for greedy de- coding and 67.7% for majority voting. While base- lines like OmniSQL-7B perform competiti vely on the standard Spider -T est set, they struggle when explicit mapping cues are removed. In contrast, TR UST -SQL-8B demonstrates significantly better generalization by outperforming all baselines on Spider-Syn and Spider -Realistic. The V alue of A utonomous Exploration. Cru- cially , TR UST -SQL achiev es these leading scores under the strict Unkno wn Schema setting. All baseline models rely on full schema prefilling, which consumes substantial context windo ws and assumes perfect database observability . The fact that our acti vely exploring agent can match or sur- pass models with privileged schema access vali- dates the ef fectiv eness of our four -phase protocol and Dual-T rack GRPO training. 4.3 Can Schema Prefill Boost P erf ormance? While TR UST -SQL operates without any pre- loaded schema, a natural question arises as to whether injecting the complete schema would fur - ther boost performance. W e thus introduce a Schema Prefill variant where the full schema is deli vered as a single synthetic Explor e turn at the beginning of the interaction, providing all table and column information at once. The case study is sho wn in Appendix D . T able 2: Effect of Schema Prefill (greedy decoding). Arrows denote absolute accuracy changes compared to the Unknown Schema ( × ) setting. Prefill BIRD Spider S-DK S-Syn S-Realistic Qwen3-4B × 29.3 51.2 43.7 47.4 49.2 ✓ 46.3 ↑ 17.0 67.6 ↑ 16.4 57.0 ↑ 13.3 62.6 ↑ 15.2 65.9 ↑ 16.7 TR UST -SQL-4B × 64.9 82.8 71.6 74.7 79.9 ✓ 64.8 ↓ 0.1 83.1 ↑ 0.3 69.2 ↓ 2.4 72.5 ↓ 2.2 80.1 ↑ 0.2 Qwen3-8B × 47.9 67.4 56.3 58.4 66.3 ✓ 49.9 ↑ 2.0 68.3 ↑ 0.9 57.6 ↑ 1.3 64.5 ↑ 6.1 68.1 ↑ 1.8 TR UST -SQL-8B × 65.8 83.9 72.1 75.4 82.1 ✓ 65.5 ↓ 0.3 84.0 ↑ 0.1 74.4 ↑ 2.3 75.4 80.5 ↓ 1.6 As sho wn in T able 2 , the base Qwen3 models are highly dependent on pre-loaded metadata. W ith- out schema prefilling, their performance collapses, e videnced by a massi ve 17.0% absolute drop for Qwen3-4B on BIRD. This confirms that standard models lack autonomous exploration capabilities. When equipped with our framew ork, TRUST -SQL 6 ov ercomes this limitation and achie ves massive per- formance leaps over the base models. F or instance, TR UST -SQL-4B yields a striking 35.6% absolute impro vement over Qwen3-4B on BIRD. Across all fi ve benchmarks, the frame work deliv ers an av- erage absolute impro vement of 30.6% for the 4B v ariant and 16.6% for the 8B variant compared to their respecti ve base models under the Unknown Schema setting. Furthermore, TR UST -SQL demonstrates remark- able independence from pre-loaded schemas. For both 4B and 8B variants, injecting the full schema upfront provides only negligible changes on BIRD and Spider . In fact, it actually degrades perfor- mance on robustness benchmarks. Specifically , TR UST -SQL-4B drops by 2.4% on Spider-DK and TRUST -SQL-8B drops by 1.6% on Spider- Realistic. The iterati ve policy already retrie ves necessary metadata with high precision, making full schema injection redundant and often noisy . Therefore, activ e exploration serves as a r obust alternati ve to static prefilling. 5 Analysis 5.1 How to Balance Exploration and Generation? In the Dual-T rack GRPO loss, λ controls the rela- ti ve contribution of the Schema T rack. W e ablate λ ∈ { 0 . 125 , 0 . 25 , 0 . 375 } against two single-track baselines where λ = 0 . The first optimizes solely on ex ecution outcome, and the second nai vely ag- gregates a schema re ward weighted at 0.25 into the terminal re ward without track separation. 200 400 600 800 1000 T raining Steps 40 45 50 55 60 65 70 75 80 BIRD-Dev EX (%) 60.9 58.7 64.0 64.5 54.2 = 0 w / o s c h e m a = 0 w / s c h e m a = 0 . 1 2 5 = 0 . 2 5 = 0 . 3 7 5 (a) EX (%) during training. 200 400 600 800 1000 T raining Steps 4 5 6 7 8 9 A vg T ur n 5.39 6.17 4.99 5.64 6.66 = 0 w / o s c h e m a = 0 w / s c h e m a = 0 . 1 2 5 = 0 . 2 5 = 0 . 3 7 5 (b) A vg turns during training. Figure 4: Ef fect of λ on training dynamics. As shown in Figure 4a , naiv ely mixing the schema rew ard into the terminal step yields 58.7%, worse than the 60.9% achiev ed by the pure ex e- cution baseline. This confirms that conflating ex- ploration and generation obscures the reward sig- nal. In contrast, the optimal Dual-Track setting at λ = 0 . 25 peaks at 64.5% , yielding a +5.8% gain o ver nai ve aggre gation and a +3.6% gain o ver the pure ex ecution baseline. Furthermore, λ dic- tates the balance between e xploration and gener- ation. While λ = 0 . 125 achie ves a competitive 64.0%, an excessi vely lar ge λ = 0 . 375 se verely degrades performance to 54.2%. As shown in Fig- ure 4b , this o ver-weighted schema reward incen- ti vizes the agent to remain perpetually in the explo- ration phase, causing a sharp increase in average interaction turns and ov er-optimizing metadata re- trie val at the e xpense of SQL generation. 5.2 What Makes a Good Schema Reward? W e inv estigate two ke y design dimensions for f match defined in Section 3.3 : whether R schema should be coupled with R exec , and whether f match should be sparse or dense . Specifically , Sparse + Uncoupled assigns R schema regardless of R exec with a binary f match . Sparse + Coupled ( TR UST - SQL ) conditions R schema on R exec = 1 . 0 with the same binary criterion. Dense + Coupled further replaces f match with a graduated function enforcing full recall as a hard gate before assigning partial precision-based re wards. 200 400 600 800 1000 T raining Steps 40 45 50 55 60 65 70 75 BIRD-Dev EX (%) 64.5 52.7 64.0 Sparse + Coupled Sparse + Uncoupled Dense + Coupled EX (%) A vg T ur n 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 A vg T ur n Figure 5: Ablation on schema re ward formulation. As sho wn in Figure 5 , the three variants e xhibit markedly dif ferent training dynamics. Sparse + Uncoupled achieves the lo west EX of 52.7% de- spite the highest turn count of 6.71, re vealing that decoupling schema reward from ex ecution incen- ti vizes redundant exploration rather than precise grounding. Dense + Coupled reduces turns to 5.03 but con ver ges to a suboptimal 64.0%, as the graduated f match introduces conflicting gradients between maximizing recall and minimizing unnec- essary columns. Sparse + Coupled achiev es the best EX of 64.5% with a balanced turn count of 5.64, where the binary f match provides an unam- biguous optimization target and conditioning on R exec = 1 . 0 establishes a direct causal chain be- tween exploration quality and task success. These 7 200 400 600 800 1000 T raining Steps 35 40 45 50 55 60 65 70 75 80 BIRD-Dev EX (%) 64.5 58.6 64.3 A vg T ur n EX (%) T rain T ur n=8 T rain T ur n=10 T rain T ur n=12 4 5 6 7 8 A vg T ur n (a) T raining turn budget ef fect. Infer=8 Infer=10 Infer=12 Infer=15 Max Infer ence T ur n T rain=8 T rain=10 T rain=12 Max T raining T ur n 59.26 59.52 59.78 60.10 63.49 64.86 64.54 64.93 60.43 61.28 61.93 62.26 59 60 61 62 63 64 65 BIRD-Dev EX (%) (b) T rain vs. inference turn budget. K=1 K=4 K=6 K=8 Number of Samples K 60 65 70 75 80 85 90 P ass@K BIRD-Dev EX (%) 64.4 72.2 74.0 75.1 64.9 72.9 74.3 75.2 65.8 72.8 74.4 75.4 65.8 73.2 74.7 75.6 4B, MaxT ur n=10 4B, MaxT ur n=15 8B, MaxT ur n=10 8B, MaxT ur n=15 (c) Pass@ K scaling. Figure 6: T est-time scaling analysis of TRUST -SQL across three dimensions: training turn budget, training vs. inference turn budget interaction, and P ass@ K with repeated sampling. results indicate that coupling is a more critical de- sign dimension than r ewar d density . 5.3 T est-Time Scaling Beha vior W e analyze the test-time scaling properties of TR UST -SQL across three dimensions. T raining T urn Budget. As illustrated in Figure 6a , expanding the training turn budget from 8 to 10 yields substantial gains on BIRD-Dev . Howe ver , further increasing to 12 turns causes se vere training instability where the av erage turn count spikes and ex ecution accuracy sharply declines, suggesting that an ov erly permissi ve horizon fails to penalize redundant exploration. Consequently , a 10-turn budget pro vides the optimal balance between accu- racy and e xploration efficienc y . Interaction Between Horizons. As sho wn in Fig- ure 6b , a 10-turn training budget consistently yields the strongest baseline policy . Providing additional inference turns beyond the training horizon further improv es performance, with the optimal configu- ration pairing a 10-turn training b udget with a 15- turn inference budget to achiev e a peak accuracy of 64.93% . This demonstrates that the agent effec- ti vely utilizes extra test-time compute to reco ver from early exploration mistak es. Scaling with Repeated Sampling. As sho wn in Figure 6c , all configurations exhibit monotonic ac- curacy impro vements as the sample size K gro ws, dri ven by explor ation diversity across indepen- dently sampled trajectories. The persistent gap between Pass@ K and greedy performance indi- cates that the model can generate correct solutions but has not fully con ver ged to a consistent policy , suggesting headroom for further RL training. 5.4 Is Cold-Start SFT Necessary? TR UST -SQL adopts a two-stage training pipeline where Dual-T rack GRPO is preceded by an SFT warm-up phase. T o assess its necessity , we com- pare three training configurations. As sho wn in T able 3 , applying Dual-Track GRPO directly with- out SFT warm-up yields 59.9% on BIRD and 79.6% on Spider , both significantly belo w the full pipeline. Ho we ver , these numbers are lar gely illu- sory .W ithout SFT initialization, the model quickly learns to hack the reward by exhaustively query- ing all tables and columns in the first turn , com- pleting the interaction in roughly four actions. This degenerates the Unknown Schema setting into a dis- guised Full Schema scenario, bypassing genuine acti ve exploration entirely . SFT alone achieves rea- sonable performance, confirming that the warm-up phase successfully instills structured exploration behavior . The full two-stage pipeline consistently achie ves the best results, demonstrating that Dual- T rack GRPO provides substantial gains that cannot be attributed to supervised learning alone. T able 3: Ablation on cold-start SFT for TRUST -SQL- 4B. Results are reported with greedy decoding. Configuration SFT RL BIRD (dev) Spider (test) SFT Only ✓ ✗ 46.2 66.7 RL Only ✗ ✓ 59.9 79.6 SFT + RL ✓ ✓ 64.9 82.8 6 Conclusion In this work, we re visit the Full Schema Assump- tion that underlies T ext-to-SQL research. By for- malizing the task as a POMDP under the Unknown Schema setting, TRUST -SQL demonstrates that autonomous database e xploration is both feasible and ef fectiv e in en vironments where schemas are massi ve, noisy , and continuously ev olving. The structured four-phase protocol grounds agent rea- soning in activ ely verified metadata to pre vent hal- lucinations, while its mandatory cognitiv e check- point provides a structural boundary for Dual- T rack GRPO to resolve the credit assignment bot- tleneck, yielding a 9.9% relativ e impro vement o ver 8 standard GRPO. Experiments across fiv e bench- marks demonstrate a verage absolute impro vements of 30.6% and 16.6% for the 4B and 8B variants respecti vely . Remarkably , despite operating with- out pre-loaded metadata, TR UST -SQL consistently matches or surpasses schema-prefilled baselines, establishing a ne w paradigm for reliable T ext-to- SQL in unobserv able en vironments. Limitations While TRUST -SQL demonstrates strong perfor- mance under the Unknown Schema setting, se veral limitations remain. Inference Overhead. The multi-turn interaction paradigm naturally incurs higher inference cost compared to single-turn methods, as each interac- tion step inv olves a li ve database call. Ho wev er , as sho wn in Appendix D.1 , this ov erhead remains modest in practice. Further optimizing inference ef ficiency for latency-critical deployments remains a practical direction for future work. SQLite Dialect Only . Both training and e v alua- tion are conducted on SQLite-based benchmarks, as BIRD and Spider exclusi vely use SQLite. Ex- tending to other SQL dialects such as PostgreSQL or MySQL remains a v aluable direction for future work. Fixed T urn Budget. The maximum interaction turn T is fixed at training time, which may limit exploration thoroughness for databases with ex- ceptionally complex schemas. Adapting the turn budget dynamically based on database comple xity remains an interesting direction for future work. Reproducibility Statement T o ensure full reproducibility , we release the complete source code at https://github.com/ JaneEyre0530/TrustSQL . All dataset construc- tion pipelines are detailed in Appendix A , training hyperparameters and hardw are specifications are summarized in Appendix B . All experiments are conducted on NVIDIA A100 GPUs. Upon accep- tance, we will publicly release the training datasets and model weights to further support the research community . References Google DeepMind. 2025. Gemini 2.5 pro. https:// deepmind.google/technologies/gemini/pro . DeepSeek-AI. 2025. Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning. arXiv pr eprint arXiv:2501.12948 . DeepSeek-AI. 2025. Deepseek-v3 technical report . Pr eprint , Xiang Deng, Ahmed Hassan A wadallah, Christopher Meek, Oleksandr Polozov , Huan Sun, and Matthe w Richardson. 2021. Structure-grounded pretraining 9 for text-to-sql . In Pr oceedings of the 2021 Confer- ence of the North American Chapter of the Associ- ation for Computational Linguistics: Human Lan- guage T echnologies , page 1337–1350. Association for Computational Linguistics. Y ujian Gan, Xinyun Chen, Qiuping Huang, Matthe w Purver , John R. W oodward, Jinxia Xie, and Peng- sheng Huang. 2021a. T owards rob ustness of text-to- SQL models against synonym substitution . pages 2505–2515, Online. Association for Computational Linguistics. Y ujian Gan, Xinyun Chen, and Matthew Purver . 2021b. Exploring underexplored limitations of cross-domain text-to-sql generalization . Pr eprint , T aicheng Guo, Hai W ang, ChaoChun Liu, Mohsen Go- lalikhani, Xin Chen, Xiangliang Zhang, and Chan- dan K. Reddy . 2025. Mtsql-r1: T owards long-horizon multi-turn text-to-sql via agentic training . Preprint , Mingqian He, Y ongliang Shen, W enqi Zhang, Qiuying Peng, Jun W ang, and W eiming Lu. 2025. Star-sql: Self-taught reasoner for te xt-to-sql. In Pr oceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 24365–24375. Harper Hua, Zhen Han, Zhengyuan Shen, Jeremy Lee, Patrick Guan, Qi Zhu, Sullam Jeoung, Y ueyan Chen, Y unfei Bai, Shuai W ang, and 1 others. 2026. Sql- trail: Multi-turn reinforcement learning with in- terleav ed feedback for text-to-sql. arXiv preprint arXiv:2601.17699 . Y uxiang Ji, Ziyu Ma, Y ong W ang, Guanhua Chen, Xi- angxiang Chu, and Liaoni W u. 2025. Tree search for llm agent reinforcement learning. arXiv pr eprint arXiv:2509.21240 . A viral Kumar , V incent Zhuang, Rishabh Agarwal, Y i Su, John D Co-Reyes, A vi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, and 1 oth- ers. 2024. T raining language models to self-correct via reinforcement learning, 2024. URL https://arxiv . or g/abs/2409.12917 , 2(3):4. Philippe Laban, Hiroaki Hayashi, Y ingbo Zhou, and Jennifer Neville. 2025. Llms get lost in multi-turn con versation. arXiv pr eprint arXiv:2505.06120 . Fangyu Lei, Jixuan Chen, Y uxiao Y e, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, W enjing Hu, Pengcheng Y in, and 1 others. 2024. Spider 2.0: Evaluating language mod- els on real-world enterprise text-to-sql workflows. arXiv pr eprint arXiv:2411.07763 . Haoyang Li, Shang W u, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai W ang, Tie y- ing Zhang, Jianjun Chen, Rui Shi, and 1 others. 2025. Omnisql: Synthesizing high-quality text-to-sql data at scale. arXiv pr eprint arXiv:2503.02240 . Jinyang Li, Bin yuan Hui, Ge Qu, Jiaxi Y ang, Binhua Li, Bowen Li, Bailin W ang, Bo wen Qin, Ruiying Geng, Nan Huo, and 1 others. 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Pr ocessing Systems , 36. Xiaoqian Liu, Ke W ang, Y ongbin Li, Y uchuan W u, W en- tao Ma, Aobo Kong, Fei Huang, Jianbin Jiao, and Junge Zhang. 2025. Epo: Explicit policy optimiza- tion for strategic reasoning in llms via reinforcement learning. In Proceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 15371–15396. Peixian Ma, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, and Jian Guo. 2025. Sql-r1: Training natu- ral language to sql reasoning model by reinforcement learning. arXiv pr eprint arXiv:2504.08600 . Meituan LongCat T eam. 2025. Longcat-flash technical report . Pr eprint , OpenAI. 2024. Gpt-4o system card. https://openai. com/index/gpt- 4o- system- card . OpenAI. 2025. Gpt-4.1. https://openai.com/ index/gpt- 4- 1 . Mohammadreza Pourreza, Shayan T alaei, Ruoxi Sun, Xingchen W an, Hailong Li, Azalia Mirhoseini, Amin Saberi, Sercan Arik, and 1 others. 2025. Reasoning- sql: Reinforcement learning with sql tailored partial rew ards for reasoning-enhanced te xt-to-sql. arXiv pr eprint arXiv:2503.23157 . Y ang Qin, Chao Chen, Zhihang Fu, Ze Chen, Dezhong Peng, Peng Hu, and Jieping Y e. 2024. Route: Ro- bust multitask tuning and collaboration for te xt-to-sql. arXiv pr eprint arXiv:2412.10138 . Qwen. 2025. Qwen3 technical report . Pr eprint , Vladislav Shkapenyuk, Divesh Sri vasta va, Theodore Johnson, and P arisa Ghane. 2025. Automatic metadata extraction for text-to-sql . Pr eprint , Shayan T alaei, Mohammadreza Pourreza, Y u-Chen Chang, Azalia Mirhoseini, and Amin Saberi. 2024. Chess: Contextual harnessing for ef ficient sql synthe- sis . Pr eprint , Y anming W an, Jiaxing W u, Marwa Abdulhai, Lior Shani, and Natasha Jaques. 2025. Enhancing per- sonalized multi-turn dialogue with curiosity re ward. arXiv pr eprint arXiv:2504.03206 . Bing W ang, Changyu Ren, Jian Y ang, Xinnian Liang, Ji- aqi Bai, LinZheng Chai, Zhao Y an, Qian-W en Zhang, Di Y in, Xing Sun, and Zhoujun Li. 2025a. MA C- SQL: A multi-agent collaborati ve frame work for text- to-SQL . In Pr oceedings of the 31st International Confer ence on Computational Linguistics , pages 540– 557, Abu Dhabi, UAE. Association for Computa- tional Linguistics. 10 Pengfei W ang, Baolin Sun, Xuemei Dong, Y axun Dai, Hongwei Y uan, Mengdie Chu, Y ingqi Gao, Xiang Qi, Peng Zhang, and Y ing Y an. 2025b. Agentar- scale-sql: Advancing te xt-to-sql through orchestrated test-time scaling . Pr eprint , Zhongyuan W ang, Richong Zhang, Zhijie Nie, and Jaein Kim. 2024. T ool-assisted agent on sql inspection and refinement in real-world scenarios . Preprint , Zihan W ang, Kangrui W ang, Qineng W ang, Pingyue Zhang, Linjie Li, Zhengyuan Y ang, Xing Jin, K efan Y u, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Y iping Lu, Kyunghyun Cho, Jiajun W u, Li Fei-Fei, Lijuan W ang, Y ejin Choi, and Manling Li. 2025c. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning . Preprint , Zekun Xu, Siyu Xia, Chuhuai Y ue, Jiajun Chai, Mingxue T ian, Xiaohan W ang, W ei Lin, Haoxuan Li, and Guojun Y in. 2025. Mtir-sql: Multi-turn tool- integrated reasoning reinforcement learning for text- to-sql. arXiv pr eprint arXiv:2510.25510 . Zhenghai Xue, Longtao Zheng, Qian Liu, Y ingru Li, Xiaosen Zheng, Zejun Ma, and Bo An. 2025. Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning. arXiv preprint arXiv:2509.02479 . Cehua Y ang, Dongyu Xiao, Junming Lin, Y uyang Song, Hanxu Y an, Shawn Guo, W ei Zhang, Jian Y ang, Mingjie T ang, and Bryan Dai. 2025. Agro-sql: Agen- tic group-relati ve optimization with high-fidelity data synthesis . Pr eprint , Haojin Y ang, Ai Jian, Xinyue Huang, Y iwei W ang, W eipeng Zhang, K e Zeng, Xunliang Cai, and Jingqing Ruan. 2026. Harmonizing dense and sparse signals in multi-turn rl: Dual-horizon credit assignment for industrial sales agents . Pr eprint , Zhewei Y ao, Guoheng Sun, Lukasz Borchmann, Gau- rav Nuti, Zhe yu Shen, Minghang Deng, Bohan Zhai, Hao Zhang, Ang Li, and Y uxiong He. 2025. Arctic- text2sql-r1: Simple re wards, strong reasoning in text- to-sql. arXiv pr eprint arXiv:2505.20315 . T ao Y u, Rui Zhang, Kai Y ang, Michihiro Y asunaga, Dongxu W ang, Zifan Li, James Ma, Irene Li, Qingn- ing Y ao, Shanelle Roman, Zilin Zhang, and Dragomir Radev . 2018. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic pars- ing and text-to-sql task. In Pr oceedings of the 2018 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , Brussels, Belgium. Association for Computational Linguistics. T ianshu Zhang, Kun Qian, Siddhartha Sahai, Y uan T ian, Shaddy Garg, Huan Sun, and Y unyao Li. 2026. Evoschema: T ow ards text-to-sql rob ustness against schema ev olution . Pr eprint , Y uxin Zhang, Meihao Fan, Ju F an, Mingyang Y i, Y uyu Luo, Jian T an, and Guoliang Li. 2025. Reward- sql: Boosting text-to-sql via stepwise reasoning and process-supervised rew ards. arXiv pr eprint arXiv:2505.04671 . Y ifei Zhou, Song Jiang, Y uandong T ian, Jason W e- ston, Serge y Levine, Sainbayar Sukhbaatar, and Xian Li. 2025. Sweet-rl: Training multi-turn llm agents on collaborative reasoning tasks. arXiv pr eprint arXiv:2503.15478 . Zilin Zhu, Chengxing Xie, Xin Lv , and slime Contrib- utors. 2025. slime: An llm post-training framew ork for rl scaling. https://github.com/THUDM/slime . GitHub repository . Corresponding author: Xin Lv . 11 A Data Construction A.1 Baseline T raining Data Comparison T o contextualize the data ef ficiency of TR UST - SQL, we summarize the training data configura- tions of all ev aluated baselines in T able 4 . While recent single-turn models rely on massi ve synthetic datasets containing millions of samples, and multi- turn RL frame works utilize lar ge portions of stan- dard benchmarks, TR UST -SQL achie ves superior performance using a highly constrained and curated data recipe. T able 4: Comparison of training data volume and sources. Model SFT Data RL Data OmniSQL 2.5M (SynSQL) – SQL-R1 2.5M (SynSQL) 5k (SynSQL) MTIR-SQL – 18.1k (Spider+BIRD) SQL-T rail 0.8k (SynSQL) 1k (Spider) TR UST -SQL 9.2k (SynSQL) 11.6k (Spider+BIRD) A.2 SFT T raining Data Construction T o warm up the agent prior to RL training, we construct a supervised fine-tuning dataset of high-quality exploration trajectories. The source questions are sampled from the training split of SynSQL-2.5M ( Li et al. , 2025 ). W e filter this cor- pus to retain only questions of Moderate , Complex , and Highly Complex difficulty , as simpler ques- tions provide insuf ficient training signal for multi- turn exploration. This yields 9,217 unique source questions, whose difficulty distrib ution is shown in T able 5 . T able 5: Difficulty distribution of source questions. Difficulty Count Proportion Moderate 3,821 41.5% Complex 3,243 35.2% Highly Complex 2,153 23.3% T otal 9,217 100% Annotation Pipeline. W e employ a multi-model annotation strategy using GPT -4.1-mini ( Ope- nAI , 2025 ), GPT -4o-mini ( OpenAI , 2024 ), and DeepSeek-R1 ( DeepSeek-AI , 2025 ). Each model is prompted to generate complete four-phase in- teraction trajectories following the TR UST -SQL protocol with a maximum output length of 2,048 tokens per response. A trajectory is retained if and only if it satisfies two strict conditions. First, the final SQL ex ecution result must match the ground truth answer . Second, ev ery turn must pass the format check described in Appendix C . This ex ecution-verified filtering ensures that the SFT model learns from trajectories that are both correct and structurally well-formed. Dataset Statistics. T able 6 summarizes the re- tained samples contributed by each annotation model. T able 6: SFT training data statistics by annotation model. Samples denotes the total number of retained trajectories and Unique IDs denotes the number of distinct source questions cov ered by each model. Annotation Model Samples Unique IDs DeepSeek-R1 9,972 1,442 GPT -4.1-mini 43,803 5,575 GPT -4o-mini 17,195 2,263 T otal 70,970 9,280 The majority of retained samples are contrib uted by GPT -4.1-mini (43,803 samples, 61.7%), reflect- ing its stronger instruction-follo wing capability in generating well-formatted trajectories. DeepSeek- R1 contributes 9,972 samples across 1,442 unique questions, providing di verse chain-of-thought rea- soning styles that complement the GPT -annotated data. A.3 RL T raining Data Construction Question Selection. F or RL training, we adopt the source questions from the training sets of BIRD ( Li et al. , 2024 ) and Spider ( Y u et al. , 2018 ) with iden- tical dif ficulty filtering. T o ensure effecti ve RL ex- ploration, we apply a dif ficulty-based filtering strat- egy where each question is rolled out 8 times using the SFT -initialized policy . Only questions with a pass rate strictly below 6/8 are retained. This cri- terion excludes questions that are already too easy for the current policy , as the y pro vide negligible learning signal. Ground T ruth Schema Extraction. T o com- pute the schema rew ard R schema during RL train- ing, we require the ground truth schema K ∗ = ( K ∗ table , K ∗ col ) for each training instance. Rather than relying on a single model, we adopt a multi-model consensus strategy using three strong models including GPT -4.1 ( OpenAI , 2025 ), 12 T able 7: RL training data filtering statistics. Statistic V alue T otal Candidate Questions 18,078 Retained Questions 11,642 Rejected Questions 6,436 K eep Rate 64.4% Pass Rate Threshold < 6 / 8 LongCat-Flash ( Meituan LongCat T eam , 2025 ), and Gemini-2.5-Pro ( DeepMind , 2025 ). Each model independently parses the ground truth SQL y ∗ to extract the referenced table names and column names. A schema annotation is accepted only when at least two out of three models produce consistent results. This consensus ensures the reliability of the extracted K ∗ as a robust supervision signal for e valuating the agent’ s Pr opose action. B Implementation Details W e train two model scales, namely Qwen3-4B and Qwen3-8B, each passing through a super- vised fine-tuning warm-up stage followed by Dual- T rack GRPO optimization. The 4B model adopts synchronous training under the SLIME frame- work ( Zhu et al. , 2025 ), while the 8B model adopts asynchronous training. T able 8 summarizes the hardware configuration, ke y hyperparameters, and estimated training cost for each stage. C Agent Configuration C.1 T ool Overview The agent interacts with the database en vironment through four structured tools, each corresponding to one phase of the TR UST -SQL protocol. T able 9 provides an ov erview of their roles and output tags. T able 9: Ov erview of the four tools in the TR UST -SQL action space. Action Phase Output T ag Description explore_schema Explore Query database metadata propose_schema Propose Commit to v erified schema generate_sql Generate Execute candidate SQL confirm_answer Confirm Submit final SQL answer C.2 F ormat Check Rules At each turn, the agent’ s output must conform to a strict structural protocol. The FormatCheck func- tion v alidates each turn by enforcing the following rules: 1. Think tag : The output must contain exactly one ... block. 2. Action tag : The output must contain exactly one ... block, whose con- tent must be one of the four v alid action types. 3. Content tag : Each action type requires a corresponding content tag, as specified in T able 9 . Specifically , explore_schema and generate_sql require a block; propose_schema requires a block; and confirm_answer requires an block. A turn is considered valid if and only if all three conditions are satisfied, yielding a format score of 0.1. Any violation results in a format score of 0.0 and terminates the format rew ard for the entire trajectory . C.3 Prompt T emplate The follo wing presents the complete prompt used in TR UST -SQL, comprising a system prompt that defines the agent’ s role, action protocol, and output format, follo wed by a user prompt that provides the task-specific context. T able 8: Training setup for TR UST -SQL across model scales and training stages. Model Stage GPUs Mode LR Batch Size Epochs Rollout λ T urns Time (hrs) Qwen3-4B SFT 16 × A100 sync 1 × 10 − 5 256 2 – – – 6.5 RL 8 × A100 sync 1 × 10 − 6 32 3 8 0.25 10 60 Qwen3-8B SFT 16 × A100 sync 1 . 5 × 10 − 6 256 2 – – – 12 RL 32 × A100 async 8 × 10 − 7 32 3 8 0.25 10 40 13 System Prompt # Role Y ou are an expert SQL assistant working on an unknown database. Y ou must never hallucinate tables or columns. All schema kno wledge MUST come from metadata queries only . Y ou must operate strictly through the Action Protocol . # Action Protocol Y ou must follow this sequence (can loop back if needed): 1. explore_schema — Query database metadata 2. propose_schema — Document verified schema 3. generate_sql — Create SQL query 4. confirm_answer — Output final SQL ## A CTION: explore_schema Used to query database metadata (tables, columns, foreign ke ys, etc.). • Only metadata queries allowed. • No user-intent SQL here. • V erify relationships between tables when multi-table queries are needed. ## A CTION: propose_schema Used to output the current verified schema kno wledge. • Include ONL Y tables/columns actually verified through explore_schema . • Do NO T hallucinate or assume any un verified structures. • joins is optional; include only when relationships are explicitly v erified. • Supports both single-table and multi-table structures. ## A CTION: generate_sql Used to generate the SQL answer based on the latest . • Use ONL Y verified schema from propose_schema . • If required tables/columns are missing, switch back to explore_schema or propose_schema in the next message. • SQL must be syntactically valid and e xecutable. • Consider query optimization (indexes, joins, filters). • V alidate the SQL logic matches user intent. ## A CTION: confirm_answer Used when you hav e validated the generated SQL and confirmed it meets user requirements. • Execute this action ONL Y after generate_sql validation. • Y ou MUST NO T return or describe any query results. • Y ou MUST NO T output anything other than SQL inside . • The final output must be ONL Y the SQL query in proper format. # Output F ormat EVER Y response must follow this e xact structure: 14 [Y our reasoning process here] [one of: explore_schema | propose_schema | generate_sql | confirm_answer ] [Action-specific content belo w] explore_schema reasoning explore_schema {"name": "execute_sql_query", "arguments": {"db_id": "...", "sql": "..."}} propose_schema reasoning propose_schema { "tables": ["tableA"], "columns": { "tableA": ["col1", "col2"] }, "joins": [] } generate_sql reasoning generate_sql {"name": "execute_sql_query", "arguments": {"db_id": "...", "sql": "..."}} confirm_answer reasoning confirm_answer SELECT ... FROM ... WHERE ... # T ools Y ou may call one or more functions to assist with the user query . { "type": "function", "function": { "name": "execute_sql_query", "description": "Execute SQL query and return partial 15 results containing column names. (maximum 30 records)", "parameters": { "type": "object", "properties": { "db_id": { "type": "string", "description": "The name of the database to query" }, "sql": { "type": "string", "description": "The SQL query to execute" } }, "required": ["db_id", "sql"] } } } For each function call, return a json object with function name and arguments within {"name": , "arguments": } User Prompt T ask Configuration Database Engine: SQLite Database: {db_id} External Kno wledge: {external_knowledge} User Question: {question} ? 16 D Extended Results D.1 Cost Analysis T able 10 presents a comprehensi ve inference cost analysis on BIRD-Dev , comparing accuracy , la- tency , token consumption, interaction turns, and tool call frequency across all methods. Accuracy vs. Cost T rade-off. Training-free pipeline methods such as CHESS achie ve compet- iti ve accuracy at an extremely high cost of 251.3 seconds and 320.8K tokens per query , making them impractical for real-world deployment. In contrast, TR UST -SQL-4B achie ves a higher accu- racy of 64.9% under the Unkno wn Schema setting with only 0.6 seconds latency and 2.83K tok ens, representing a 500 × reduction in latency and a 113 × reduction in token consumption compared to CHESS. Efficiency of Active Exploration. Compared to schema-prefilled baselines of similar scale, TR UST - SQL demonstrates remarkable inference efficiency . TR UST -SQL-4B without prefilling consumes only 2.83K tokens and completes interactions in 5.89 a v- erage turns, comparable to MTIR-SQL-4B which consumes 2.9K tokens under full schema access. This confirms that our activ e exploration policy retrie ves only the necessary metadata without in- curring significant ov erhead. Impact of Schema Prefilling on Base Models. A striking observ ation is the asymmetric ef fect of schema prefilling on base models versus TR UST - SQL. For Qwen3-4B, remo ving prefilling increases token consumption from 1.82K to 4.93K and de- grades accuracy from 46.3% to 29.3%, re vealing a complete dependence on pre-loaded metadata. In contrast, TR UST -SQL-4B without prefilling con- sumes only 2.83K tokens while maintaining 64.9% accuracy , demonstrating that Dual-Track GRPO training instills efficient and targeted exploration behavior . D.2 Pass@K Results on Additional Benchmarks T able 11: Pass@K results across all benchmarks (tem- perature = 0.8, max turns = 15). Size Benchmark Pass@1 Pass@4 Pass@6 Pass@8 4B Spider (test) 82.8 86.5 86.9 87.1 Spider-DK 71.6 78.8 80.3 81.2 Spider-Syn 74.7 81.6 82.3 83.1 Spider-Realistic 79.9 85.4 86.2 86.6 8B Spider (test) 83.9 86.5 87.1 87.5 Spider-DK 72.1 79.2 80.5 81.3 Spider-Syn 75.4 81.0 83.0 84.0 Spider-Realistic 82.1 85.5 86.4 87.0 Section 5.3 of the main paper reports Pass@K scaling behavior on BIRD-De v . Here we extend this analysis to the remaining four benchmarks to verify that the monotonic scaling trend general- izes across different e v aluation settings. T able 11 reports Pass@K results for K ∈ { 1 , 4 , 6 , 8 } un- der a 15-turn inference budget.Consistent with the T able 10: Inference cost analysis on BIRD-Dev . Method Prefill Acc (%) Latency (s) OutputT okens (K) T urns T ool Calls CHESS ( T alaei et al. , 2024 ) ✓ 61.5 251.3 320.8 – – SQL-R1-7B ( Ma et al. , 2025 ) ✓ 63.7 0.4 3.1 – – MTIR-SQL-4B ( Xu et al. , 2025 ) ✓ 63.1 0.5 2.9 – 1.34 MTIR-SQL-8B ( Xu et al. , 2025 ) ✓ 63.6 0.4 2.0 – 1.31 Qwen3-4B ( Qwen , 2025 ) ✓ 46.3 0.4 1.82 2.34 1.64 Qwen3-4B ( Qwen , 2025 ) ✗ 29.3 1.2 4.93 7.66 4.42 Qwen3-8B ( Qwen , 2025 ) ✓ 49.9 0.4 2.15 2.14 2.92 Qwen3-8B ( Qwen , 2025 ) ✗ 47.9 1.0 3.85 6.34 4.41 TR UST -SQL-4B ✓ 64.8 0.4 1.75 4.23 2.89 TR UST -SQL-4B ✗ 64.9 0.6 2.83 5.89 3.66 TR UST -SQL-8B ✓ 65.5 0.5 2.00 4.69 3.61 TR UST -SQL-8B ✗ 65.8 0.5 2.03 5.62 3.45 17 BIRD-De v results reported in the main paper, all benchmarks exhibit monotonic accuracy impro ve- ments as K gro ws. The persistent gap between Pass@K and greedy performance indicates that the model possesses the capability to generate correct solutions b ut has not fully con verged to a consistent policy , suggesting headroom for further training. D.3 Perf ormance on Complex Benchmark (Spider 2.0) T o ev aluate TR UST -SQL under more challenging real-world conditions, we conduct additional e xper- iments on the SQLite subset of Spider 2.0 ( Lei et al. , 2024 ), comprising 135 questions with enterprise- grade databases featuring significantly more com- plex schemas and lar ger table counts than standard Spider . This setting is particularly well-suited for assessing the Unknown Schema frame work, as the increased schema complexity makes full schema prefilling e ven more impractical. T able 12 reports execution accuracy alongside representati ve baselines. Notably , strong propri- etary models such as GPT -4o ( OpenAI , 2024 ) and DeepSeek-V3 ( DeepSeek-AI , 2025 ) achie ve only 15.6% on this benchmark, while specialized T ext- to-SQL models like OmniSQL-7B ( Li et al. , 2025 ) reach 10.4%, reflecting the substantial difficulty of this setting. T able 12: Ex ecution accuracy on the Spider 2.0 SQLite subset (135 questions). Baselines use full schema pre- filling. Pass@8 is computed o ver 8 sampled trajectories. Method Prefill Greedy Pass@8 OmniSQL-7B ✓ 10.4 – GPT -4o ✓ 15.6 – DeepSeek-V3 ✓ 15.6 – OpenSearchSQL+Qwen2.5-7B-Instruct ✓ 4.4 7.4 OpenSearchSQL+Arctic-T ext2SQL-R1-7B ✓ 14.1 20.7 TRUST -SQL-8B ✗ 14.8 24.9 Despite operating entirely without pre-loaded metadata, TR UST -SQL-8B achie ves 14.8% greedy accuracy and 24.9% Pass@8, surpassing OpenSearchSQL paired with the specialized Arctic- 7B ( Y ao et al. , 2025 ) model. The non-saturating Pass@8 curve further suggests substantial head- room for improv ement with increased sampling budgets, validating the generalizability of our frame work beyond standard academic benchmarks. E Case Study W e present a case study on BIRD-Dev instance dev_4 (database california_schools , Qwen3- 4B, greedy decoding) to qualitativ ely examine how schema a vailability shapes model beha vior . The full interaction traces are sho wn in Figure 7 . T ask. The question requires retrie ving phone num- bers of directly charter -funded schools opened after January 1, 2000. Answering correctly demands grounding the funding-type predicate in the ac- tual column values stored in the database, informa- tion absent from both the question and the external kno wledge hint. Unknown Schema Setting (6 turns). W ith- out an y prior schema kno wledge, the model adopts a systematic bottom-up exploration strat- egy . In T1 and T2, it queries sqlite_master to discover a vailable tables and retriev e their schema definitions. In T3, it probes the ac- tual v alues of Charter_Funding_Type in the frpm table, uncov ering the critical predicate value Directly_funded . Only after this v alue-lev el ver - ification does the model commit to a schema pro- posal in T4 and generate the correct SQL in T5, which is subsequently confirmed in T6. Schema Prefill Setting (4 turns). When the full schema is injected as a synthetic explore turn in T1, the model skips exploratory interactions and mov es directly to schema proposal in T2 and SQL generation in T3. Howe ver , reasoning solely from structural metadata without inspecting ac- tual column values, the model f ails to discover the Directly_funded predicate. The generated SQL filters only on Charter_School_(Y/N) = 1 , re- trie ving all charter schools regardless of funding type and producing a semantically broader answer that does not fully satisfy the question. Discussion. The contrast re veals that schema pre- filling accelerates inference but sacrifices value- le vel grounding. Interactiv e exploration enables the model to adapti vely acquire the precise data- le vel knowledge needed for accurate SQL gener - ation. This suggests that the benefit of the Un- kno wn Schema setting lies not merely in schema discov ery , but in fostering a more thorough and e vidence-driv en reasoning process. 18 Database: california_schools Decoding: Greedy Max T urns: 10 External Knowledge: Charter schools refers to ‘Charter School (Y/N)’ = 1 in frpm Question (dev_4): Please list the phone numbers of the direct c harter-funded sc hools that are opened after 2000/1/1. Unknown Schema (Qwen3-4B, 6 turns) T1 [explore_schema] SELECT name AS table_name FROM sqlite_master WHERE type IN ( ' table ' ); table_name frpm satscores schools T2 [explore_schema] SELECT sql FROM sqlite_master WHERE type IN ( ' table ' ) AND name IN ( ' frpm ' , ' schools ' ); [en vir onment feedback omitted] T3 [explore_schema] SELECT DISTINCT "Charter␣Funding␣Type" FROM frpm; [en vir onment feedback omitted] T4 [propose_schema] tables: [frpm, schools] frpm: [Charter School (Y/N), Charter Funding Type, CDSCode] schools:[Phone, OpenDate, CDSCode] join: frpm.CDSCode = schools.CDSCode T5 [generate_sql] SELECT s.Phone FROM frpm f JOIN schools s ON f.CDSCode=s.CDSCode WHERE f."Charter␣School␣(Y/N)"=1 AND f."Charter␣Funding␣Type" = ' Directly␣funded ' AND s.OpenDate > ' 2000-01-01 ' ; [en vir onment feedback omitted] T6 [confirm_answer] SELECT s.Phone FROM frpm f JOIN schools s ON f.CDSCode=s.CDSCode WHERE f."Charter␣School␣(Y/N)"=1 AND f."Charter␣Funding␣Type" = ' Directly␣funded ' AND s.OpenDate > ' 2000-01-01 ' ; Schema Prefill (Qwen3-4B, 4 turns) T1 [explore_schema] (synthetic prefill) CREATE TABLE frpm (CDSCode TEXT, ` Charter School (Y/N) ` INTEGER, ` Charter Funding Type ` TEXT, ...) CREATE TABLE schools (CDSCode TEXT, Phone TEXT, OpenDate DATE, ...) T2 [propose_schema] tables: [schools, frpm] schools:[CDSCode, Phone, OpenDate] frpm: [CDSCode,Charter School (Y/N)] join: schools.CDSCode=frpm.CDSCode T3 [generate_sql] SELECT DISTINCT s.Phone FROM schools s INNER JOIN frpm f ON s.CDSCode = f.CDSCode WHERE f."Charter␣School␣(Y/N)" = 1 AND s.OpenDate > ' 2000-01-01 ' [en vir onment feedback omitted] T4 [confirm_answer] SELECT DISTINCT s.Phone FROM schools s INNER JOIN frpm f ON s.CDSCode = f.CDSCode WHERE f."Charter␣School␣(Y/N)" = 1 AND s.OpenDate > ' 2000-01-01 ' Figure 7: Case study on BIRD-De v instance dev_4 (database california_schools , Qwen3-4B, greedy decoding). Left: Unkno wn Schema setting with interactive metadata exploration. Right: Schema Prefill variant where the complete schema is injected as a synthetic Explor e turn. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment