Predicting power grid frequency dynamics with invertible Koopman-based architectures
The system frequency is a critical measure of power system stability and understanding, and modeling it are key to ensure reliable power system operations. Koopman-based autoencoders are effective at approximating complex nonlinear data patterns, wit…
Authors: Eric Lupascu, Xiao Li, Benjamin Schäfer
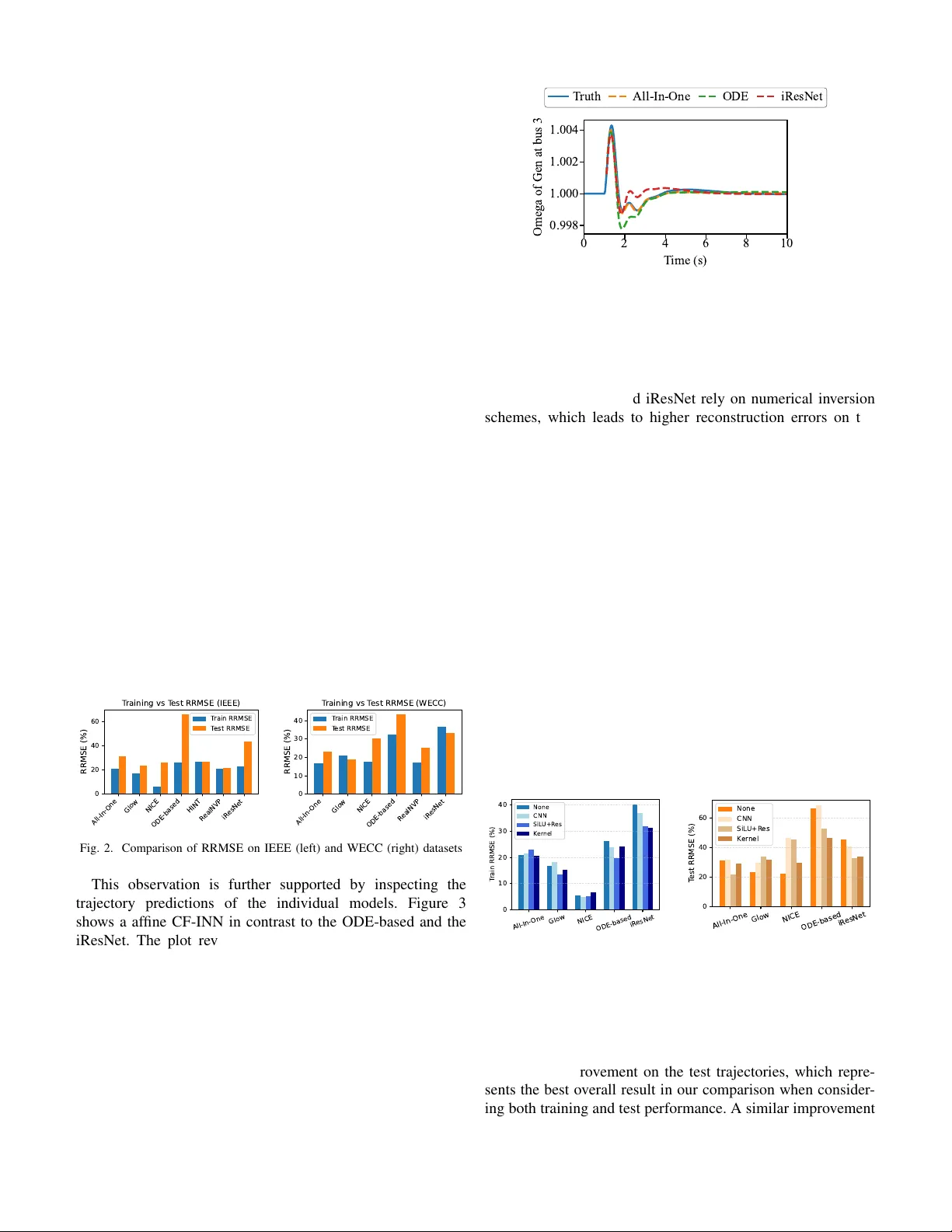
Predicting po wer grid frequenc y dynamics with in v ertible K oopman-based architectures Eric Lupascu Institute of Automation and Applied Informatics Karlsruhe Institute of T echnology Eggenstein-Leopoldshafen, Germany uiqte@student.kit.edu Xiao Li * Institute of Automation and Applied Informatics Karlsruhe Institute of T echnology Eggenstein-Leopoldshafen, Germany lixiao000@yeah.net Benjamin Sch ¨ afer * Institute of Automation and Applied Informatics Karlsruhe Institute of T echnology Eggenstein-Leopoldshafen, Germany benjamin.schaefer@kit.edu Abstract —The system frequency is a critical measure of power system stability and understanding, and modeling it are key to ensure r eliable power system operations. K oopman-based autoen- coders are effectiv e at approximating complex nonlinear data patterns, with potential applications in the frequency dynamics of power systems. However , their non-in vertibility can result in a distorted latent repr esentation, leading to significant prediction errors. Invertible neural networks (INNs) in combination with the Koopman operator framew ork provide a pr omising approach to address these limitations. In this study , we analyze different INN architectur es and train them on simulation datasets. W e further apply extensions to the networks to address inherent limitations of INNs and evaluate their impact. W e find that coupling-layer INNs achieve the best performance when used in isolation. In addition, we demonstrate that hybrid appr oaches can improv e the performance when combined with suitable INNs, while reducing the generalization capabilities in combination with disadvantageous architectur es. Overall, our results provide a clearer ov erview of how architectural choices influence INN performance, offering guidance f or selecting and designing INNs for modeling power system frequency dynamics. Index T erms —Frequency oscillation, Koopman operator , In- vertible neural network, Power system I . I N T R O D U C T I ON The electric power grid is one of the most critical infras- tructures of modern society , supporting essential sectors such as healthcare, industry , communication, and public services. A central challenge in power system operation is ensuring system stability , which means that the grid can continue to operate safely and effecti vely after disturbances or sudden changes in load. The increasing integration of rene wable energy sources, which are often in verter-based and pro vide little inherent inertia [1], makes maintaining this stability increasingly challenging, especially the frequency stability [2]. Therefore, predicting how these states e volve ov er time is crucial. One widely used method for obtaining a linear approximation of system dynamics directly from data is K oopman operator-based modeling (see, for example, [3]). Corresponding author: Xiao Li (lixiao000@yeah.net) and Benjamin Sch ¨ afer (benjamin.schaefer@kit.edu). This research is funded by Sino-German (CSC- D AAD) Postdoc Scholarship Program(91870333) and the Helmholtz Associ- ation’ s Initiative and Networking Fund through Helmholtz AI under grant no. VH-NG-1727. One implementation of this method is dynamic mode decom- position (DMD), which finds the best-fitting linear operator that describes the ev olution of the systems dynamic from state at time k to the state at time k + 1 . Since this linear operator acts globally on all system states, it cannot capture nonlinear dynamics, which require a state-dependent operator . W ith the increasing application of neural networks, another approach emerged. Instead of fitting a linear operator directly to the nonlinear dynamics, we use autoencoders to learn an observable space in which the dynamics can be approximated linearly . The linear operator is applied in this space, and the prediction is then mapped back to the original state space, as demonstrated in [4], [5]. These approaches are purely data-driv en and ha ve significant advantages over traditional model-driv en simulation methods, particularly when models are unav ailable or unreliable. Howe ver , the usefulness of Koopman-based models criti- cally depends on the quality of the learned observables. Since K oopman analysis decomposes the dynamics into eigen values, eigenfunctions, and K oopman modes, any loss of information in the mapping from the physical state space to the observ able space directly af fects the accuracy of the reco vered spectral quantities. This motiv ates the use of INNs, which enforce a bijectiv e mapping between state space and latent space by design. Because no information is lost, the latent representa- tion supports a more reliable approximation of the underlying dynamics and enables a rob ust estimation of K oopman spectral components. Recent literature therefore increasingly combines INN architectures with Koopman-operator –based modeling to improv e both predictive performance and the interpretability of learned dynamical structures. While INNs provide bijective representations by design, they can be constructed using markedly dif ferent architectural strategies, each associated with different properties. Examples include coupling-based flows, residual flows and neural ODEs. Nev ertheless, INNs hav e their o wn limitations. Their expres- siv eness is significantly lower than that of conv entional neural networks, and the requirement for equal input and output dimensionality conflicts with the Koopman operator’ s need for dimensional lifting, which embeds low-dimensional non- linear dynamics in higher-dimensional linear spaces [6]. One possible solution for this problem is the Augmented In vertible K oopman Autoencoder (AIKAE) proposed by Frion et al. [7]. As shown in Fig. 1, it parallels the extension network and the INN. This mitigates the dimensionality limitations of standard INNs by introducing additional latent augmentation variables, enabling ef fective dimension lifting while preserving in vertibility . T o further explore these architectural considerations, this study focuses on the following two key research questions: 1) How does the architectural choice of the INN influence the ov erall performance of our model? 2) How can we combine in vertible and non-in vertible layers to achiev e better performance? The remainder of this paper is organized as follows. In Chapter II we look deeper into the architectural strategies of INNs. Chapter III shows our experiments done regarding base INNs III-A and hybrid models III-B before we discuss our results in chapter IV and finally draw our conclusion. I I . A R C H I T E C T U R E O F I N N S INNs are characterized by bijective and dif ferentiable map- pings that enable ef ficient forward and inv erse computations, as well as tractable Jacobians. These properties ensure a lossless information flow between inputs and latent represen- tations. A. Cate gories of INNs 1) Coupling Layers: The most common strate gy for INNs is the use of coupling layers. A general coupling layer parti- tions the input vector into tw o disjoint sub-vectors ( x A , x B ) and defines a bijective transformation g : R D → R D such that the transformation for the output sub-vectors ( y A , y B ) is giv en by y A = x A and y B = h ( x B ; Q ( x A )) . Here, h is an in vertible coupling function parameterized by Q ( x A ) , with Q being an arbitrary conditioner function that depends only on x A . This construction leads to a block-triangular Jacobian, which simplifies determinant computation and ensures easy in version using the in verse coupling function h − 1 . A simple special case is the additi ve coupling layer, where h ( x B ; Q ( x A )) = x B + Q ( x A ) . This layer is trivially inv ertible via subtraction and has a unit Jacobian determinant, making it computationally attractiv e (applied in NICE [8]). Howe ver , the limited expressi veness of additiv e coupling motiv ated the development of more flexible layers, called affine coupling layers. An affine coupling layer extends the additiv e case by introducing learned scale and translation functions: y A = x A , y B = x B ⊙ exp( Q s ( x A )) + Q t ( x A ) , (1) The inv erse is obtained by corresponding subtraction and rescaling. Because the Jacobian remains block-triangular, the determinant is easy to compute and independent of deri vati ves of Q s or Q t , allowing these subnetworks to be arbitrarily expressi ve. T o ensure that all dimensions are e ventually transformed, successiv e coupling layers alternate the input partition. Stack- ing such layers yields the class of Coupling Flow INNs (CF- INNs). Affine coupling layers form the core of influential flow architectures, including RealNVP [9] and Glo w [10]. Nev ertheless, even with alternating partitions, only transform- ing half of the input limits the expressi veness of indi vidual blocks. Hierarchical In vertible Neural T ransport ( HINT ) [11] addresses this constraint by introducing a multi-le vel, recursi ve partitioning of the input space. 2) Residual blocks: Residual Flo ws are constructed through the composition of functions of the form g ( x ) = x + F ( x ) , known as residual connections with a residual block F . Such residual connections were first used for rev ersible neural networks in i-RevNet [12] and RevNet [13]. These networks split the input, similar to additiv e coupling layers, and transform the vector x = ( x A , x B ) by calculating y A = x A + F ( x B ) and subsequently y B = x B + G ( y A ) . While this transformation is easily in vertible, computing the Jacobian matrix is challenging. Moreov er, these structures also rely on dimension partitioning. A different approach is proposed by Behrmann et al. [14] in the iResNet , who showed that residual connections are in vertible if the Lipschitz constant is constrained to be less than one. In practice, this is enforced via spectral normaliza- tion of the weight matrices, and the in verse is approximated using a fixed-point iteration. Howe ver , restricting the Lipschitz constant reduces expressi veness and the iResNet is not suited for memory-efficient applications [15]. In the context of Koopman operator theory , INNs based on residual flow structures have been used, for e xample in [16] and [17], where they provide inv ertible and expressi ve models for learning linear dynamics in latent space. 3) ODE-based appr oaches: Another class of in vertible neural architectures is based on Neural Ordinary Differential Equations (ODEs) [18], [19]. This approach interprets residual connections as the discretization of first-order ODEs, thereby replacing discrete layers with a continuous transformation solved via a black-box ODE solver . While memory-ef ficient and expressiv e, continuous-time Neural ODEs are inherently unsuitable for K oopman operator learning, which requires discrete-time mappings from t to t + 1 . B. Hybrid INNs Maintaining the in vertibility property requires that the latent representation cannot hav e a reduced dimensionality . Conse- quently , less relev ant features must be preserved in the feature space. Howe ver , it is often desirable to augment or modify the latent space to impro ve the e xpressiv eness and performance of the model, which can conflict with the in vertibility constraints. Previous works attempted to address this issue by appending zero padding to the state v ector [17], [20], but this forces the model to reconstruct the artificial zeros and breaks the exact mathematical transformations needed for probability computations. Fig. 1. Schematic representation of a hybrid INN inspired by the architecture introduced by [7]. INN i and a non-in vertible extension network a are paralleled as an encoder, but only INN i is also used as a decoder . Koopman operator K is in the middle of the encoder and decoder . Frion et al. [7] proposes another approach (see Fig. 1). In order to obtain additional features for a more expressi ve approximation of the K oopman operator , the input is processed not only by an in vertible network i but also by a non- in vertible netw ork a . The outputs of the two networks, z i t with dimension p and z a t with dimension m , are concatenated into a single vector z t in latent space which is then passed to the K oopman operator . The K oopman operator , no w defined on this higher -dimensional space, performs the state ev olution on the concatenated vector . The Koopman prediction ˆ z t +1 is subsequently split back into its two components ˆ z i t +1 and ˆ z a t +1 , where only the in vertible part ˆ z i t +1 of dimension p is used to reconstruct the original state x t +1 . A key adv antage of this design is that the extension network a is free of INN structural constraints, allo wing any neural netw ork architecture and the use of do wnsampling or dimensionality reduction to efficiently generate additional features. The ov erall in vertibility of the model is not compromised, since only the in vertible part of the concatenated feature vector is used for reconstruction. In this work, we extend this idea by ev aluating this archi- tecture not only with various base INN architectures, which has already been ev aluated indi vidually , but also with different types of extension layers. The goal is to gain further insight into which combination of INN and extension yields the best performance. For the extensions, we employ three distinct types, each designed to capture complementary features and enhance the representation power of the INNs for Koopman operator approximation. First, we introduce a CNN-based extension, which le verages multi-scale con volutional kernels to extract local structures from the input data and to capture temporal patterns. Second, we use a kernel-based e xtension, which maps the input into high-dimensional feature spaces us- ing nonlinear kernels, thereby modeling complex relationships and emphasizing similarity structures in the data; specifically , we employ the radial basis function (RBF) kernel. Finally , we apply a deep residual extension, also referred to as the multitimescale extension, which consists of a fully connected residual network with SiLU activ ations and skip connections to capture long-term dependencies and integrate frequency components across multiple scales. I I I . E X P E R I M E N T S T o properly ev aluate the revie wed structures, we integrate the different INN architectures as well as the hybrid INNs into the Higher-Order Dynamic Mode Decomposition (HODMD) pipeline provided by [21] and assess their performance on two benchmark systems: the IEEE-14 b us system and the WECC- 179 b us system. The IEEE system exhibits faster -decaying dynamics, whereas the WECC system sho ws weaker damping and significant inter-area oscillations. Dynamic trajectories are generated using the ANDES Python package [22] by applying temporary short-circuit faults at selected b uses, with each fault lasting 0.1 seconds. For the IEEE system, 11 trajectories are produced, of which 9 are used for training and 2 for testing, while the WECC system yields 99 trajectories, with 90 allocated for training and 9 for testing. Besides the ODE-based network, all INN architectures used in this work were implemented using the FrEIA package [23], leveraging its modular design to construct each network from reusable coupling and transformation blocks. The models are trained by jointly optimizing prediction accuracy and latent-space consistency . The prediction loss measures the discrepancy between the predicted and true trajectories, the K oopman loss enforces consistency of the latent-space representation under the learned K oopman operator . Prediction and K oopman losses are logarithmically scaled to improv e numerical stability . Hy- perparameters such as network depth, hidden sizes, time delay , learning rate, batch size, and acti vation functions are optimized for each INN architecture, while model-le vel parameters are fixed across architectures to preserve comparability . V alidation losses on unseen trajectories are used to guide hyperparameter selection and ensure generalization. The code we used for the experiments can be found online 1 . It provides a modular HODMD pipeline in which any INN architecture can be integrated as a drop-in component and augmented with arbitrary non-inv ertible networks. Addition- ally , scripts for generating power system fault trajectories for both benchmark systems are included. A. Base INNs As a first step, we e valuate the performance of the INNs without any extensions within the Koopman pipeline. The recommended metric for assessing HODMD-based models is the relative root mean squared error (RRMSE) [24], defined as RRMSE = v u u u u t P N traj i =1 x ( i ) true − x ( i ) pred 2 P N traj i =1 x ( i ) true 2 , where N traj denotes the number of trajectories, x true the ground truth, and x pred the model prediction. In addition to the previously presented INNs, we also ev aluate the All-In-One Model from the FrEIA library , which utilizes a sequential combination of affine coupling layers with soft-clamping and inv ertible permutations and global 1 https://github .com/KIT -IAI-DRACOS/inn-koopman-freqdyn-po wergrid affine transformation (ActNorm) to ensure high expressiv eness while maintaining exact in vertibility . Overall, the results in Figure 2 sho w that the class of CF-INNs achie ves the most accurate predictions on both training and test trajectories. Among them, the affine CF-INNs (All-in-One, Glow , HINT , RealNVP) demonstrate particularly strong generalization ca- pabilities, likely due to the mechanistic structure of coupling layers, which update only a subset of the state dimensions at each step and thereby preserve stability in the learned transformations. In contrast, NICE as an additiv e CF-INN exhibits weaker performance on unseen trajectories, while performing well on test trajectories, reflecting the limited expressi veness of additiv e coupling layers and the resulting difficulty in capturing more complex nonlinear dynamics, an effect that becomes visible on the WECC dataset with its longer observation horizons. W e further observe that the ODE- based INN performs the worst across both datasets and shows limited generalization ability , producing ov erly smooth map- pings that f ail to capture the detailed dynamics and thus exhibit limited generalization ability . The iResNet also underperforms compared to the CF-INNs, although on the WECC dataset it reaches accuracy levels that are partially comparable to some of the affine coupling models. A possible explanation for this is that the Lipschitz constant ov erly constrains the learned mapping, and numerical inaccuracies in the fixed-point iteration lead to approximation errors. On the IEEE 14-bus system dataset, the lowest RRMSE on the training trajectories is obtained by NICE (5.81%), while RealNVP achiev es the best performance on the test trajectories (21.66%). For the WECC system, the All-In-One model attains the lowest error on the training trajectories (16.77%), whereas Glow yields the best results on the test data (18.79%). All-In- One Glow NICE ODE-based HINT R ealNVP iR esNet 0 20 40 60 RRMSE (%) T raining vs T est RRMSE (IEEE) T rain RRMSE T est RRMSE All-In- One Glow NICE ODE-based R ealNVP iR esNet 0 10 20 30 40 RRMSE (%) T raining vs T est RRMSE (WECC) T rain RRMSE T est RRMSE Fig. 2. Comparison of RRMSE on IEEE (left) and WECC (right) datasets This observation is further supported by inspecting the trajectory predictions of the indi vidual models. Figure 3 shows a af fine CF-INN in contrast to the ODE-based and the iResNet. The plot rev eals that the ODE-based INN and the iResNet struggle to reproduce a clean frequency ev olution. Both models exhibit noticeable de viations in the predicted trajectories, which aligns with their poor RRMSE perfor- mance. Furthermore, we observe that the different classes of INNs introduce different types of errors, which reflects the architectural differences visible in the resulting trajectories. W e further examine the in vertibility loss, which is computed solely from the forward and in verse transformations, without in volving the K oopman prediction. For CF-INNs, the in vert- 0 2 4 6 8 10 T ime (s) 0 . 9 9 8 1 . 0 0 0 1 . 0 0 2 1 . 0 0 4 Omega of Gen at bus 3 T ruth All-In-One ODE iResNet Fig. 3. Comparison of modeling performance for different INN structures on the IEEE 14-bus system dataset ibility error remains at the le vel of machine precision, as in- vertibility is guaranteed by architectural design. In contrast, the ODE-based network and iResNet rely on numerical in version schemes, which leads to higher reconstruction errors on the order of 10 − 9 and reflects the degree of practical inv ertibility of these architectures. B. Hybrid INNs T o e valuate the effect of the introduced extension networks on model performance, we next analyze the results of the Hybrid INN architectures. Figure 4 shows the RRMSE of the trajectories for the IEEE 14-bus system. W e observe that the CF-INNs do not benefit from the e xtensions: the af fine CF- INNs remain at a similar performance level, while Glo w ev en exhibits a slight degradation on unseen trajectories. NICE, as an additiv e CF-INN, also performs worse when combined with an extension on the test trajectories. In contrast, the ODE- based INN and iResNet clearly benefit from the extension, achieving improv ements of up to 5–10% in RRMSE. The over - all best performance on the training trajectories is achie ved by NICE with the CNN extension (4.88%), whereas on the test trajectories the All-In-One model with the Multitimescale extension performs best (21.63%). All-In- One Glow NICE ODE-based iR esNet 0 10 20 30 40 T rain RRMSE (%) None CNN SiL U+R es K er nel All-In- One Glow NICE ODE-based iR esNet 0 20 40 60 T est RRMSE (%) None CNN SiL U+R es K er nel Fig. 4. Comparison of the RRMSE on T raining (left) and T est (right) T rajectories on the IEEE-14 bus system W e additionally ev aluate the best-performing hybrid ap- proaches on the WECC dataset. The All-In-One network shows clear syner gy with the Multitimescale extension, achiev- ing slight improvements on the training trajectories and more than a 4% improv ement on the test trajectories, which repre- sents the best o verall result in our comparison when consider- ing both training and test performance. A similar improvement had already been observed for the unseen trajectories on the IEEE dataset, suggesting that combining the All-In-One model with the Multitimescale extension leads to enhanced generalization capabilities. In contrast, neither the CNN nor the kernel extension yields improved results. Moreover , we observe that the performance trends found on the IEEE dataset transfer reasonably well to the WECC dataset. Although the two datasets are not identical, their consistent behavior suggests that our results are not ov erly sensiti ve to the specific choice of dataset. T ABLE I R R MS E E R RO R O N T R A IN I N G A N D T E ST T R A JE C T OR I E S F O R H Y BR I D I N N M O DE L S F O R T H E W E CC S Y S T EM . RRMSE [%] Extension Base Model T rain T est All-In-One 16.77 23.28 Glow 20.84 18.79 - NICE 17.76 30.35 RealNVP 16.96 25.30 ODE-based 32.36 43.59 iResNet 36.41 33.34 CNN All-In-One 18.24 ↓ 26.04 ↓ SiLU + Residual NICE 14.10 ↑ 29.76 ↑ iResNet 36.65 ↓ 32.12 ↑ All-In-One 16 . 39 ↑ 19 . 57 ↑ Glow 22.32 ↓ 30.93 ↓ Kernel All-In-One 20.64 ↓ 29.13 ↓ NICE 18.72 ↓ 28.20 ↑ Note. ↑ indicates improvement compared to the base model, while ↓ indicates degradation. W e further examine these observations by analyzing specific trajectory predictions. Figure 5 illustrates the model perfor- mance on a representati ve test trajectory for the WECC 179- bus system. In the figure, a comparison is shown between the All-In-One network without any extension and with the SiLU + Residual extension (Multitimescale). In the initial peak of the trajectory , the network combined with the Multitimescale extension tracks the ground truth significantly better, while both networks exhibit similar error on the second peak. 0 2 4 6 8 10 T ime (s) 0 . 9 9 8 1 . 0 0 0 1 . 0 0 2 Omega of Gen on Bus 3 (p.u.) T ruth All-In-One + SiLU All-In-One Fig. 5. Comparison of models on test trajectory 3 on Bus 3 on the WECC dataset T o accurately assess the indi vidual contribution of the non- in vertible extension network a in the hybrid architecture, we conduct an ablation study by replacing the complex in vertible transformation i with the identity function. This step effec- tiv ely isolates the ef fect of the added features z a on the linear K oopman operator approximation. This configuration, where the latent space is the concatenation of the original state and the extended features, is equiv alent to performing Extended Dynamic Mode Decomposition (EDMD) using the extension a as a pre-defined set of K oopman observables. Comparing these results to the full hybrid models allows us to determine if the performance gains originate primarily from the learned in vertible feature extraction or the static, expressiv e feature augmentation. T ABLE II R R MS E C O M P A R I S ON O F I D EN T I T Y M A P ( B A S E LI N E E D MD ) W I T H F E A T U R E E X TE N S I ON S Models RRMSE T raining T est Identity 41.46 % 40.43 % Identity + CNN Extension 36.66 % 45.94 % Identity + Kernel Extension 42.69 % 44.65 % Identity + Multitimescale Extension 23.03 % 31.46 % In T able II, we can see that the Identity Map, which serves as our benchmark in this case, has a Training RRMSE of 41 . 46 % and a T est RRMSE of 40 . 43 %. The CNN Extension features provide a seemingly better value on the training trajectories, but ultimately lead to poorer generalization ca- pability , a problem that generally aligns with the observations in Figure 4 and T able I. The kernel Extension degrades the performance of EDMD on both test and training trajectories, which suggests that the learned K oopman observables are unsuitable. This observation also correlates with the findings regarding the hybrid INNs mentioned above. Only the SiLU + Residual extension significantly improves the RRMSE on both training and test data, suggesting that the learned additional observables accurately reflect the underlying dynamics and can explain the performance increase in combination with networks such as the All-In-One network. In total, we see that the extensions strongly influence the performance of EDMD, both positiv ely and negativ ely , which motiv ates their use. A phenomenon that repeatedly occurs in this study is that models achieve better performance on the test trajectories than on the training data. This behavior can be explained by the structure of the dataset. Each trajectory corresponds to a time-domain simulation of the system’ s frequency response to a short 0.1 s fault applied at a single bus, which results in trajectories that v ary in their learning difficulty . Since multiple models are in vestigated, it is therefore of interest to analyze which trajectories are best learned by which model and whether model extensions alter these properties. In Figure 6, we observe that the INNs encounter particularly strong difficulties with a few specific trajectories. On the left, it can be seen that the Glow and iResNet networks exhibit a different structure compared to the other INNs. On the right, we notice that the e xtension for iResNet hardly affects the learning properties of the trajectories, whereas the All-In-One extension significantly improv es the learning of trajectory 3 but slightly worsens trajectory 6. T est trajectory 3, also sho wn in Figure 5, displays a distinctly irregular structure with many 0 2 4 6 8 T rajectory Index 0 40 80 120 160 RRMSE [\%] AIO Glow ODE iResNet 0 2 4 6 8 T rajectory Index 25 50 75 100 RRMSE [\%] AIO+ iResNet+ AIO iResNet Fig. 6. RRMSE per trajectory of test trajectories for base INNs (left) and with Multitimescale extension (right) on the WECC dataset. Models marked with ’+’ denote the hybrid variant incorporating the proposed Multitimescale extension layer . small fluctuations, which poses challenges for the models, but can be improved by the Multitimescale extension. This further illustrates how the application of extensions can alter the characteristics of model behavior . I V . D I S C U S S I O N This work inv estigated the suitability and synergy of var- ious INN architectures and their hybrid extensions within a K oopman operator framework for po wer system dynamics. W e find that prediction accuracy and generalization are highly dependent on the INN architecture. CF-INNs consistently achiev ed the lowest error values and strongest generalization due to the inherent structural stability . The integration of non-in vertible feature extensions into the hybrid architecture rev ealed a highly architecture-specific synergy , substantially benefiting weaker base models like the ODE-based INN and iResNet (improving RRMSE by up to 10% ), b ut failing to yield gains for the already strong CF-INNs. The All- In-One model combined with the Multitimescale extension achiev ed the best overall result on the challenging WECC test set ( 19 . 57% ), confirming that optimal performance relies on identifying the right hybrid combination in the specific use case. The combination of the feature space extensions with the identity map provides insights into which extensions deliv er effecti ve features for K oopman Lifting. This establishes a good a-priori ev aluation method for assessing the suitability of an extension and enables a targeted selection of promising architectures. V . C O N C L U S I O N This study concludes that Af fine Coupling INNs performed best consistently , offering an optimal balance between struc- tural stability and expressi ve power . Thus, INNs using the K oopman approach enable accurate trajectory prediction with- out the need for a model-based simulation tool. While non- in vertible feature extensions can enhance the performance of weaker base models, such as the ODE-based INN and iResNet, they may also pro vide improv ements for some already strong models, such as All-In-One. Howe ver , we also observ ed cases where extensions de graded performance. This demonstrates that the benefits of extensions are highly architecture- and dataset-dependent, requiring careful ev aluation for each ap- plication. R E F E R E N C E S [1] Hosseinzadeh, Nasser, et al. ”V oltage stability of power systems with renew able-energy inverter -based generators: A review . ” Electronics 10.2 (2021): 115. [2] N. Hatziargyriou et al., ”Definition and Classification of Power System Stability – Revisited & Extended, ” IEEE T ransactions on Power Systems 36.4 (2021): 3271-3281. [3] Schmid, Peter J. ”Dynamic mode decomposition and its variants. ” Annual Revie w of Fluid Mechanics 54.1 (2022): 225-254. [4] Lusch, Bethany , J. Nathan Kutz, and Stev en L. Brunton. ”Deep learning for univ ersal linear embeddings of nonlinear dynamics. ” Nature com- munications 9.1 (2018): 4950. [5] T akeishi, Naoya, Y oshinobu Kawahara, and T akehisa Y airi. ”Learning K oopman in variant subspaces for dynamic mode decomposition. ” Ad- vances in neural information processing systems 30 (2017) [6] Mezi ´ c, Igor . ”Spectral properties of dynamical systems, model reduction and decompositions. ” Nonlinear Dynamics 41.1 (2005): 309-325. [7] Frion, A., Drumetz, L., Mura, M. D., T ochon, G., & A ¨ ıssa-El-Bey , A. (2025). Augmented Inv ertible Koopman Autoencoder for long-term time series forecasting. arXiv preprint [8] Dinh, Laurent, David Krueger , and Y oshua Bengio. ”Nice: Non-linear independent components estimation. ” arXi v preprint arXi v:1410.8516 (2014). [9] Dinh, Laurent, Jascha Sohl-Dickstein, and Samy Bengio. ”Density estimation using real n vp. ” arXi v preprint arXiv:1605.08803 (2016). [10] Kingma, Durk P ., and Prafulla Dhariwal. ”Glow: Generative flow with in vertible 1x1 conv olutions. ” Advances in neural information processing systems 31 (2018). [11] Kruse, Jakob, et al. ”HINT : Hierarchical invertible neural transport for density estimation and Bayesian inference. ” Proceedings of the AAAI Conference on Artificial Intelligence. V ol. 35. No. 9. 2021. [12] Jacobsen, J ¨ orn-Henrik, Arnold Smeulders, and Edouard Oyallon. ”i- revnet: Deep inv ertible networks. ” arXiv preprint (2018). [13] Gomez, Aidan N., et al. ”The rev ersible residual network: Backprop- agation without storing acti vations. ” Advances in neural information processing systems 30 (2017). [14] Behrmann, J., Grathwohl, W ., Chen, R. T ., Duvenaud, D., & Jacobsen, J. H. (2019, May). In vertible residual networks. In International conference on machine learning (pp. 573-582). PMLR. [15] Behrmann, J., V icol, P ., W ang, K. C., Grosse, R., & Jacobsen, J. H. (2021, March). Understanding and mitigating exploding inv erses in in vertible neural networks. In International Conference on Artificial Intelligence and Statistics (pp. 1792-1800). PMLR. [16] Jin, Y ., Hou, L., Zhong, S., Y i, H., & Chen, Y . (2023). In vertible K oopman network and its application in data-driven modeling for dynamic systems. Mechanical Systems and Signal Processing, 200, 110604. [17] Jin, Y uhong, Lei Hou, and Shun Zhong. ”Extended dynamic mode decomposition with in vertible dictionary learning. ” Neural networks 173 (2024): 106177. [18] Chen, R. T ., Rubanov a, Y ., Bettencourt, J.,& Duvenaud, D. K. (2018). Neural ordinary dif ferential equations. Advances in neural information processing systems, 31. [19] Grathwohl, W ., Chen, R. T ., Bettencourt, J., Sutskever , I., & Duvenaud, D. (2018). Ffjord: Free-form continuous dynamics for scalable re versible generativ e models. arXiv preprint [20] Meng, Y ., Huang, J., & Qiu, Y . (2024). K oopman operator learning using inv ertible neural networks. Journal of Computational Physics, 501, 112795. [21] Li, Xiao, Xinyi W en, and Benjamin Sch ¨ afer . ”Learning the Frequency Dynamics of the Power System Using Higher-order Dynamic Mode Decomposition. ” arXiv preprint arXiv:2502.06186 (2025). [22] H. Cui, F . Li, and K. T omsovic, “Hybrid Symbolic-Numeric Framework for Power System Modeling and Analysis, ” IEEE T rans. Power Syst., vol. 36, no. 2, pp. 1373–1384, Mar . 2021. [23] L ynton Ardizzone, Till Bungert, Felix Draxler, Ullrich K ¨ othe, Jakob Kruse, Robert Schmier , and Peter Sorrenson. Framew ork for Easily In vertible Architectures (FrEIA), 2018-2022. [24] V ega, Jose Manuel, and Soledad Le Clainche. Higher order dynamic mode decomposition and its applications. Academic Press, 2020.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment