Meta-Reinforcement Learning with Self-Reflection for Agentic Search
This paper introduces MR-Search, an in-context meta reinforcement learning (RL) formulation for agentic search with self-reflection. Instead of optimizing a policy within a single independent episode with sparse rewards, MR-Search trains a policy tha…
Authors: Teng Xiao, Yige Yuan, Hamish Ivison
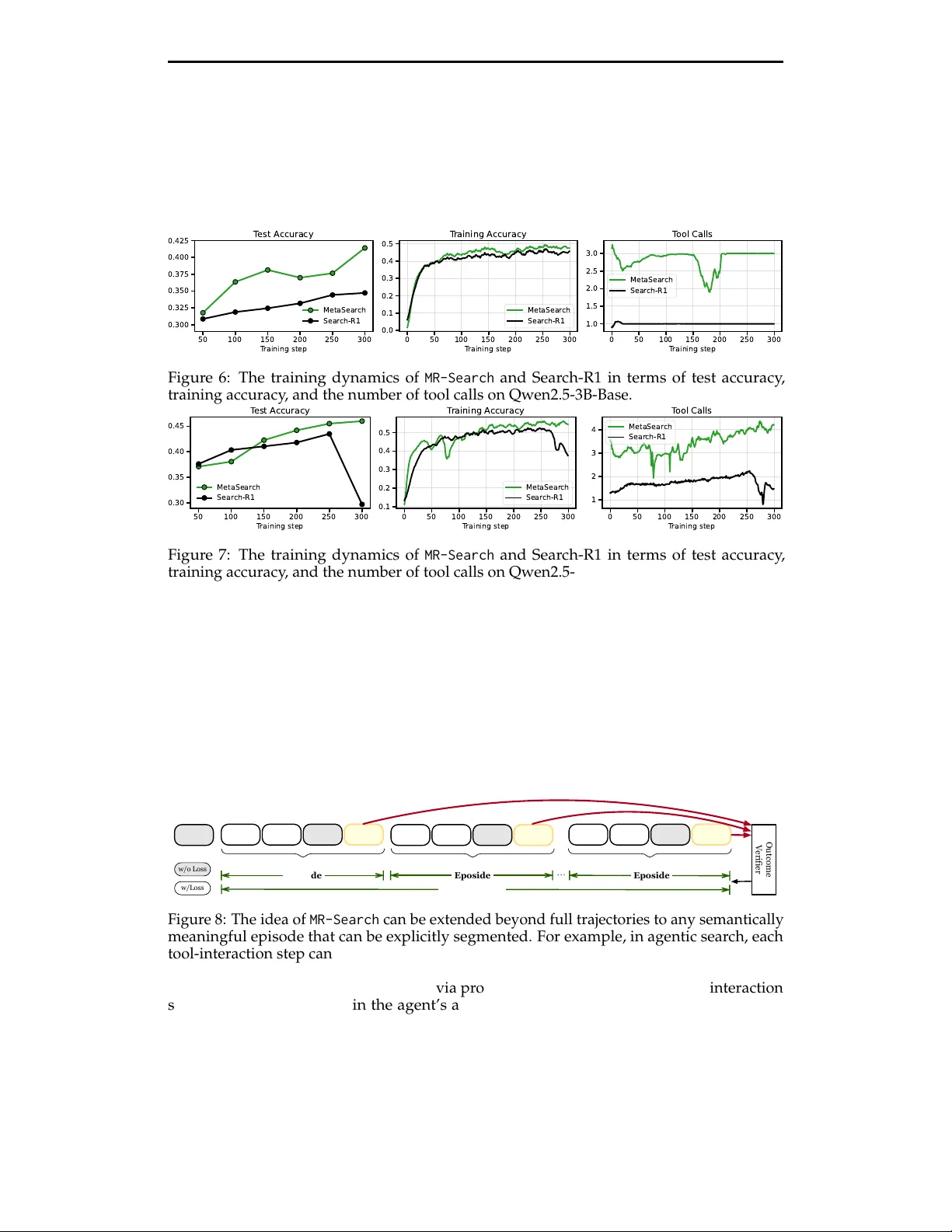
Preprint. Meta-Reinforcement Learning with Self-Reflection for Agentic Search T eng Xiao 1,2 ∗ Y ige Y uan 2 ∗ Hamish Ivison 1,2 Huaisheng Zhu 3 Faeze Brahman 1 Nathan Lambert 1 Pradeep Dasigi 1,† Noah A. Smith 1,2,† Hannaneh Hajishirzi 1,2,† 1 Allen Institute for AI 2 University of W ashington 3 Independent Abstract This paper introduces MR-Search , an in-context meta r einforcement learn- ing (RL) formulation for agentic search with self-r eflection. Instead of optimizing a policy within a single independent episode with sparse re- wards, MR-Search trains a policy that conditions on past episodes and adapts its search strategy across episodes. MR-Search learns to learn a search strategy with self-reflection, allowing search agents to improve in-context exploration at test-time. Specifically , MR-Search performs cross-episode ex- ploration by generating explicit self-r eflections after each episode and lever - aging them as additional context to guide subsequent attempts, thereby promoting more effective exploration during test-time. W e further intro- duce a multi-turn RL algorithm that estimates a dense relative advantage at the turn level, enabling fine-grained cr edit assignment on each episode. Empirical results acr oss various benchmarks demonstrate the advantages of MR-Search over baselines based RL, showing str ong generalization and relative impr ovements of 9.2 % to 19.3 % across eight benchmarks. Our code and data are available at https://github.com/tengxiao1/MR- Search . 1 Introduction Language models with advanced reasoning capabilities have driven substantial pr ogress toward mor e autonomous and multi-step decision-making behaviors in complex tasks ( Guo et al. , 2025 ; Jaech et al. , 2024 ). Examples include agentic search such as deep r esearch ( Du et al. , 2025 ; Shao et al. , 2025 ) and other information seeking ( Mialon et al. , 2023 ; Jin et al. , 2025a ), where LMs use sear ch tools and engage in dynamic, multi-turn interactions. Rein- forcement learning (RL) with the ReAct paradigm ( Y ao et al. , 2022 ) has emerged as a primary framework for training search agents ( Jin et al. , 2025a ; Zheng et al. , 2025 ), replacing the traditional reliance on supervised data collection. Specifically , these methods mainly focus on the correctness of the final answer and only receive sparse rewar ds at the end of each trajectory , without providing precise cr edit assignment for intermediate steps. Due to the sparse nature of outcome rewar ds, the agent often struggles to learn more complex processes and is susceptible to issues such as inefficient exploration at the early stage, local optima, and inefficient search dynamics ( Zhang et al. , 2025 ; Feng et al. , 2025 ). These challenges become more pr onounced in agentic search tasks, where multi-turn interactions with tools could amplify small errors and obscur e credit assignment ( Feng et al. , 2025 ). T o address the key challenge of sparse rewar ds, several works have explored using process rewar d models ( Luo et al. , 2024 ; W ang et al. , 2023 ) or LM judges ( Zheng et al. , 2024 ; Deng et al. , 2025 ). However , these approaches rely on external annotations, which are both costly and difficult to reuse when task requir ements change. Moreover , model-based rewar ds inevitably lead to rewar d hacking and bias ( W ang et al. , 2025a ) and incur additional computational overhead in the RL training ( Y uan et al. , 2024 ). In this paper , we introduce MR-Search , a simple yet effective meta-RL approach that enables search agents to improve in-context exploration at test time. Our work is most closely ∗ Equal contribution. Correspondence to tengx@allenai.org . † Equal senior authors. 1 Preprint. (b) Meta-Reinforcement Learning for Search … (a) Reinforcement Learning for Search … Q Episode 1 … Q Answer Toolcall ToolObs Self-Reflection Question Q … … … Q N inner-episodes per meta-episode T interactions per inner-episode Episode N Episode 1 Episode N Figure 1: RL-based agents (a) condition solely on the current episode, and episodes are inde- pendent , whereas meta-RL-based agents (b) leverage context accumulated acr oss episodes. MR-Search performs sequential self-reflection over past episodes to guide exploration in subsequent episodes. In MR-Search , we have inner-episodes, each consisting of a maximum of T interactions steps with an answer . A sequence of N episodes forms a meta-episode. related to in-context meta-reinfor cement learning methods ( Duan et al. , 2016 ; Stadie et al. , 2018 ; Laskin et al. , 2023 ), which leverage in-context histories from a few initial explo- ration episodes to guide subsequent exploitation episodes. Unlike traditional meta-RL approaches ( Duan et al. , 2016 ; Stadie et al. , 2018 ; Laskin et al. , 2023 ) in r obotics and games, we focus on open-domain agentic search tasks with tool interactions and self-reflection, without any rewar d feedback from the environment during infer ence. As illustrated in Figure 1 , MR-Search formulates agentic search as an iterative, self-reflection driven process instead of performing exploration thr ough multiple independent episodes that operate in isolation in RL-base agents. In MR-Search , each complete interaction trajectory with an answer is an episode and followed by an explicit r eflection step. This design enables sequential self-reflection and cross-episode knowledge consolidation in a multi-turn setting, transforming exploration from a set of disconnected attempts into a progressively informed search pr ocess. Thus, the agent learns to balance exploration and exploitation end-to-end by updating its search strategy according to final task performance. Our method can be seen as an instance of meta-learning where we meta-learn how to generate ef fective self-reflection. T o optimize the policy with multi-turn reflection, we use a multi-turn RL algorithm that estimates unbiased grouped r elative advantages ( Ahmadian et al. , 2024 ) at the turn level to assign localized credit to self-reflection turns. As a result, MR-Search remains critic-fr ee and eliminates the need for auxiliary value models compared to PPO ( Schulman et al. , 2017 ). Our main contributions are: (i) W e advocate for and formalize in-context meta-r einforcement learning as a practical and scalable bridge between meta-learning and reinfor cement learn- ing for agentic search, where ground-truth rewar ds are absent at inference time. (ii) W e propose MR-Search , an eff ective multi-turn agentic sear ch framework that performs cr oss- episode exploration by generating an explicit self-reflection after each interaction episode. (iii) Empirically , we validate the effectiveness of MR-Search across multiple multi-hop QA benchmarks, showing that it significantly outperforms prior methods. Specifically , MR-Search achieves an average relative impr ovement of 9.2 % to 19.3 % over strong baselines. 2 Related W ork RL for Agentic Search. RL has emerged as a promising training paradigm for developing adaptive and autonomous search agents ( Jin et al. , 2025a ; W u et al. , 2025b ; Li et al. , 2025a ). Specifically , agentic search with RL trains LLMs as decision-making agents that interact with a search envir onment through reasoning, r eceive feedback, and iteratively refine their strategies to maximize task rewar ds. For instance, Search-R1 and ReSear ch ( Jin et al. , 2025a ; Chen et al. , 2025 ) propose training LLM-based agents end-to-end using RL algorithms such as PPO ( Schulman et al. , 2017 ) or GRPO ( Shao et al. , 2024 ) under the ReAct paradigm ( Y ao et al. , 2022 ). Despite significant progress, these methods rely solely on sparse outcome rewar ds, without providing pr ecise credit assignment for ef fective exploration Feng et al. ( 2025 ). Recently , several works ( Deng et al. , 2025 ; W ang et al. , 2025b ) have attempted to design process r ewards for agentic search. However , these approaches r equire annotations at every intermediate step or rely on external evaluators, both of which are expensive 2 Preprint. ToolObs … Episode n Reason Toolcall Answer … Q Episode 1 Reason Answer Self-Reflection ToolObs The answer is April 3, 1969 Reflect on .. I need to check if Marcus Dupree was born in … I need to find out who made his debut for the Los Angeles Rams against the New York … Question When was the player who made his debut for the Los Angeles against the … born? Toolcall Who made the debut for the Los Angeles Rams against … … Los Angeles, Nov 11 1990, Marcus Dupree made his NFL debut against the New York … When was the player Marcus Dupree born? Marcus Dupree (born May 22 1964) is a former American football player … The answer is May 22, 1964 1) Reflect on the current answer 2) Search additional information 3) Provide another improved answer Figure 2: An overview of our proposed MR-Search framework. Given a question, the agent first completes an initial episode by interleaving reasoning and tool calls. It then enters an iterative self-reflection loop, where previous episodes serve as experience to inform subsequent searches and answer revisions, enabling iterative impr ovement across episodes. to obtain. In contrast, our MR-Search aligns with in-context meta-reinforcement learning, enabling progr essively targeted exploration driven by explicit cross-episode r eflection. Meta-Reinforcement Learning. Our work is related to meta-RL methods that leverage in-context histories to guide exploration, with the goal of maximizing r ewards in subsequent exploitation episodes in robotics and game domains ( Melo , 2022 ; Laskin et al. , 2023 ). Duan et al. ( 2016 ) and W ang et al. ( 2017 ) concurrently proposed the RL 2 framework, which formulates meta-reinforcement learning by feeding in-context episodes into a recurr ent neural network (RNN) whose hidden state serves as a memory mechanism. Qu et al. ( 2025 ) formulate the optimization of test-time compute for LLMs as a meta-reinfor cement learning problem. A concurrent work ( Jiang et al. , 2025 ) proposes meta-RL to encourage exploration in LLM agents with ground-tr uth state feedback. In contrast, we focus on LLM open-domain agentic task and do not access to any environment feedback during infer ence. LLMs with Self-Reflection. Previous studies investigate prompting-based strategies that en- able LLMs to iteratively and sequentially r efine their own generations via intrinsic feedback, effectively scaling test-time computation. These approaches include self-correction ( Huang et al. , 2023 ), self-reflection ( Shinn et al. , 2023 ), and self-refine ( Madaan et al. , 2023 ). Beyond prompting alone, several subsequent works ( W an et al. , 2025 ; Qu et al. , 2024 ; Kumar et al. , 2024 ; Xiong et al. , 2025 ; Y uksekgonul et al. , 2026 ) employ finetuning to train models for intrinsic self-correction. A recent concurrent work ( Shi et al. , 2026 ) also proposes experi- ential reinfor cement learning to incorporate textual reflection feedback. In contrast, our work offers a novel meta-RL perspective on agentic search with tool interaction to catalyze continuous self-reflection, enabling the model to mor e effectively explore better answers. T est-time Scaling. The paradigm of scaling test-time compute has emerged as a critical avenue for enhancing reasoning capabilities ( Guo et al. , 2025 ). Prior work explores two main dimensions: parallel sampling ( W ang et al. , 2022b ) and sequential refinement ( Madaan et al. , 2023 ; Snell et al. , 2024 ). Parallel sampling generates multiple answers independently , whereas sequential refinement generates answers sequentially , with each attempt condi- tioned on previous ones. Our work is most closely related to the sequential refinement paradigm. However , unlike these methods, which operate purely at inference time, this work proposes cr oss-episode meta-learning to enable continuous self-reflection in context, showing that meta-RL induces effective in-context exploration for agentic sear ch. 3 MetaSearch: Meta-Reinforcement Learning for Agentic Search 3.1 Background Given a dataset D consisting of question–answer pairs and an external search engine E , our goal is to train a LLM agent to give the answer by iteratively performing reasoning and interacting with E . Many search agent frameworks build upon the ReAct paradigm ( Y ao 3 Preprint. Figure 3: W e evaluate MR-Search , Search-R1 with sequential reflection infer ence (Search-R1- S), and Search-R1 with parallel sampling (Sear ch-R1-P), selecting the most frequent answer among the generated trajectories. Shaded regions show the standard deviation across 3 runs. W e observe that MR-Search achieves the best performance. See § 4.3 for details et al. , 2022 ; Jin et al. , 2025a ), wher e agents execute iterative cycles of reasoning and acting until a final answer is r eached. When presented with a query , the agent conducts multiple rounds of thought-action-observation sequences. During each round, the RL-based agent π θ formulates a internal Thought ( τ ) based on the current context, executes a external Action ( α ) such as query , and receives corresponding feedback from sear ch engines as tool Observation ( x ) as shown in Figure 1 . The interaction trajectory is denoted as: a = ( τ 0 , α 0 , x 0 , τ 1 , α 1 , x 1 , . . . , τ T − 1 ) . (1) The first round contains the pr ompt, while the final r ound τ T − 1 contains only the thought with the final answer o , without any further actions. Given this interaction process, we can directly maximize the RL objective with the final outcome r ewards to optimize the policy: J ( π θ ) = E a ∼ π θ [ f verifier ( o , o ∗ ) ] , (2) where o denotes the final answer extracted from the completed trajectory a , o ∗ is the gr ound- truth answer , and f verifier repr esents either a rule-based or model-based verifier . Although agentic search based on outcome r ewards has demonst rated promising performance ( Jin et al. , 2025a ; Sun et al. , 2025 ; Chen et al. , 2025 ; Shi et al. , 2025 ; W u et al. , 2025b ), the outcome rewar ds are sparse and delayed, leading to ambiguous cr edit assignment and ineffective search exploration ( Liu et al. , 2021 ; Feng et al. , 2025 ; W ang et al. , 2025b ). 3.2 Meta-RL Framework for Agentic Search In this section, we introduce MR-Search , a Meta-RL framework for agentic search built on a cross-episode meta training scheme. Each meta-episode is modeled as a sequence of episodes, encouraging early exploration and subsequent exploitation of accumulated context, as shown in Figure 1 . By modeling prior episodes in context through a standardized self-reflection paradigm and propagating this information across episodes, MR-Search en- ables increasingly informed sear ch, leading to br oader exploration and reduced r edundancy . Algorithm 1 MR-Search : One Sample Update 1: Input: policy π θ , sample ( x , o ∗ ) ∼ D , group size G , reflection steps N 2: for i = 1, . . . , G do ▷ Group of meta-episodes 3: C ← x ▷ Initialize context 4: for n = 0, . . . , N − 1 do ▷ Inner episodes 5: a i , n ∼ π θ ( · | C ) 6: C ← C ⊕ a i , n ⊕ R E FL E C T ( C ) ▷ Self-reflection 7: r i , n ← f ( a i , n , o ∗ ) ▷ Reward 8: Compute A i , n via Eq. (7–8) ▷ RLOO advantage 9: θ ← R L U P D AT E ( θ , { r i , n } ) with Eq. ( 9 ) The key motivations are twofold: (i) For LLM agents, model lim- itations often stem from insuffi- cient exploration within a single trajectory rather than inadequate reasoning capacity ( Shen et al. , 2025 ); incorrect answers may con- sistently appear across multiple samples in parallel, as shown by Fan et al. ( 2025 ); Si et al. ( 2026 ). (ii) LLMs exhibit strong self-reflection capabilities, enabling inference- time adaptation that accumulates information from prior interac- tions across episodes, naturally leveraging in-context learning mechanisms. As shown 4 Preprint. in Figure 3 , MR-Search substantially improves over baselines both with sequential reflection and parallel sampling and its performance grows with more turns, suggesting that the ability for self-reflection emer ges as models become stronger in-context meta-learners. Given an input question, the search agent π θ first generates the first episode, in which it interacts with external tools until reaching the final answer , following the procedure in § 3.1 . a 0 ∼ π θ ( a ) . (3) Unlike standard RL-based search agents ( Jin et al. , 2025a ; Song et al. , 2025 ), where episodes are independent, MR-Search conditions each episode on the preceding one. After each episode, the search agent invokes the tool to iteratively impr ove its answer under the self- reflection paradigm. Specifically , given an initial episode, we apply a reflection prompt (Appendix A.1.3 ) that triggers the model to r efine its answer by conditioning on previous episodes as context and producing an additional episode with another answer . a 1 ∼ p θ ( a 1 | a 0 ) , a 2 ∼ p θ ( a 2 | a 0 , a 1 ) . . . (4) By repeating the multi-turn self-reflection process N − 1 times, in MR-Search , each meta- episode consists of N episodes sequentially generated by the search agent: y = ( a 0 , a 1 , · · · , a N ) , (5) where we can compute rewards independently for each episode a using the answer y n extracted from the n th episode by the verifier . Given this multi-turn process, we can define the meta-level objective as maximizing the expected rewar d of the meta-episode: J meta ( π θ ) = E y ∼ π θ h ∑ N − 1 n = 0 γ n R ( s n , a n ) i = E y ∼ π θ h ∑ N − 1 n = 0 γ n f verifier ( o n , o ∗ ) i , (6) where s n = a < n denotes the accumulated meta context up to episode n , o n is the answer extracted from the episode a n , and γ ∈ ( 0, 1 ] is the discount factor accounting for future returns. Unless otherwise specified, we set γ = 1 in this work. In this work, MR-Search conditions on trajectories and explicit reflections from all previous episodes, causing the context length to incr ease linearly with the number of r eflection steps N . T o mitigate this scalability issue, one can retain only the immediately preceding episode as context, or adopt a context management protocol that summarizes prior episodes before carrying them forward to subsequent episodes. In § 4.4 , we empirically find that only keeping the immediately preceding episode as context also also works well for MR-Search . 3.3 Policy Optimization with Multi-T urn Advantages T o optimize the policy , instead of estimating advantages using separate value functions as in PPO ( Schulman et al. , 2017 ), we propose an approach that incorporates turn-level rewar d signals while maintaining unbiased policy optimization. Specifically , for each question, we sample a group of G meta-episodes, G = { y i } G i = 1 . T o make rewards comparable acr oss episodes and reduce variance, we aggr egate rewar ds at the same episode over meta-episodes and apply Leave-One-Out (RLOO) estimation ( Kool et al. , 2019 ; Ahmadian et al. , 2024 ): ˜ r i , n = r ( s i , n , a i , n ) − mean j = i r ( s j , n , s j , n ) = r ( s i , n , a i , n ) − 1 G − 1 ∑ j = i r ( s j , n , a j , n ) , (7) where ˜ r i , n is the rewar d of the n th episode in the i th meta-episode (i.e., y i , n ). Compared to GRPO ( Shao et al. , 2024 ), RLOO provides an unbiased advantage estimation ( Bereket & Leskovec , 2025 ). While ˜ r i , n captures the r elative quality of each episode, it reflects immediate effects and ignores the impact of futur e. T o include long-horizon dependencies, we compute a discounted cumulative advantage to propagate r ewards backward to earlier turns: A i , n = ∑ N n ′ = n γ n ′ − n ˜ r i , n ′ . (8) As the baseline used in RLOO, mean j = i r ( s j , n , s j , n ) , does not depend on the current action y i , n , it provides an unbiased estimate of the turn-level advantage ( Sutton et al. , 1999 ). W ith the discounted turn-level advantages above, we optimize the policy using a clipped surrogate of f-policy objective in PPO ( Schulman et al. , 2017 ). Formally , the objective is: 5 Preprint. 1 G G ∑ i = 1 1 | y i | | y i | ∑ n = 1 min π ( y i , n | x , y i , < n ; θ ) π ( y i , n | x , y i , < t ; θ ) A i , n , clip π ( y i , n | x , y i , < n ; θ ) π ( y i , n | x , y i , < n ; θ ) , 1 − ε , 1 + ε A i , n , (9) where π ( y i , n | x , y i , < n ; θ ) and π ( y i , n | x , y i , < n ; θ ) denote the curr ent and old policy models over the steps, and we broadcast each step’s advantage signal to all tokens in that step ( Shao et al. , 2024 ). ϵ is the is the clipping ratio. W e additionally mask out tool output tokens from the loss, following previous work ( Jin et al. , 2025a ). Optimizing the policy with the above objective enables the policy to capture both global trajectory quality and local step effectiveness. In § 4.2 , we compare our objective with PPO ( Schulman et al. , 2017 ) and MT -GRPO ( Zeng et al. , 2025 ) using our designed process rewar ds. The results show that our objective consistently achieves better performance under the meta-RL framework. The full algorithm of MR-Search (one-sample training) is summarized in Algorithm 1 . 3.4 Discussion Exploration & Exploitation . As discussed above, MR-Search leverages experience from previous episodes to guide subsequent exploration. By default, all episodes contribute rewar ds according to Eq. ( 8 ) . T o promote unstructured exploration, we can optionally mask rewar ds for designated exploration episodes while retaining r ewards for exploitation episodes ( Stadie et al. , 2018 ). Exploration episodes are fully visible during the forward pass but receive zero reward during backpropagation, so gradients are driven only by exploitation episodes. Concretely , the advantage is computed using a masked return: A i , n = ∑ N n ′ = n γ n ′ − n ˜ r i , n ′ m n ′ , (10) where m n ′ ∈ { 0, 1 } indicates exploitation (1) or exploration (0). The policy gradient is therefor e computed using this masked return rather than the standard discounted r eturn. By zeroing out exploration r ewards, we encourage the policy to prioritize long-term gains from improved context adaptation rather than short-term episode feedback. Although exploration episodes do not directly contribute to the gradient, they serve as contextual adaptation steps that improve environment identification and lead to higher rewards in subsequent exploitation episodes. W e provide empirical analysis of this strategy in § 4.4 and find that it is helpful for ASearcher , which requires multi-turn sear ch. Meta-RL at the Step Level . While MR-Search models agentic search as a meta-episode composed of multiple reflection episodes, it treats each full trajectory with an answer as a single optimization unit. However , in long-horizon r easoning, inefficiencies often arise at a finer granularity , such as individual tool calls or intermediate reasoning steps. The same principle of MR-Search extends naturally to semantically meaningful sub-episodes. For instance, in agentic search, each tool-interaction step can be tr eated as a micro-episode. During training, we pr ompt the model to pr oduce an intermediate answer after each tool call as shown in Figure 8 in Appendix and evaluate it with the verifier to obtain step- level rewar ds. Converting these substructures into micro-episodes enables localized cr edit assignment, transforming long trajectories into reflection steps. This dense supervision promotes informative intermediate reasoning and reduces redundant exploration. W e empirically show that this extension also achieves strong performance (§ 4.4 ). 4 Experiments 4.1 Experimental Setup Datasets W e conduct evaluations on the following datasets: (1) General Question Answering : NQ ( Kwiatkowski et al. , 2019 ), T riviaQA ( Joshi et al. , 2017 ), and PopQA ( Mallen et al. , 2022 ); and (2) Multi-Hop Question Answering : HotpotQA ( Y ang et al. , 2018 ), 2W ikiMultiHopQA ( Ho et al. , 2020 ), Musique ( T rivedi et al. , 2022 ), and Bamboogle ( Press et al. , 2022 ). For training, we merge the NQ and HotpotQA training sets to construct a unified dataset for all finetuning approaches, following the setup in ( Jin et al. , 2025b ). For evaluation, we use the test or 6 Preprint. T able 1: Main accuracy (%) on search-based QA benchmarks. The best results are marked in boldface . W e compare with baselines that rely on outcome r ewards (ReSearch and Sear ch- R1) and those that use process r ewards with external models (PPRM and StepResearch). Method Single-Hop QA Multi-Hop QA NQ T riviaQA PopQA HotpotQA 2wiki Musique Bamboogle A vg. Qwen2.5-3b Direct Infer ence 10.6 28.8 10.8 14.9 24.4 2.0 2.4 13.4 Search-o1 23.8 47.2 26.2 22.1 21.8 5.4 32.0 25.5 ReSearch 42.7 59.7 43.0 30.5 27.2 7.4 11.5 30.4 Search-R1 46.2 62.2 45.6 32.6 31.0 7.7 17.6 34.7 PPRM 42.3 56.5 41.1 35.3 34.0 12.7 28.0 35.7 StepResearch 44.6 61.5 45.6 37.3 33.8 10.5 32.5 38.0 MR-Search 47.7 63.5 46.0 41.9 40.1 16.5 34.4 41.4 Qwen2.5-7b Direct Infer ence 13.4 40.8 14.0 18.3 25.0 3.1 12.0 18.1 Search-o1 15.1 44.3 13.1 18.7 17.6 5.8 29.6 20.6 ReSearch 36.6 60.5 39.1 37.8 38.6 16.6 37.6 38.1 Search-R1 45.9 63.2 44.9 43.9 38.7 18.1 40.0 42.1 PPRM 45.8 61.0 43.7 38.6 35.5 14.7 35.5 39.3 StepResearch 47.3 63.6 43.1 43.9 41.8 20.5 43.5 43.4 MR-Search 50.2 66.6 47.2 46.8 43.6 22.1 45.2 46.0 1 2 3 4 Evaluation metric 0.3 0.4 0.5 0.6 0.413 0.369 0.565 0.513 Evaluation A ccuracy MR -Sear ch Sear ch-R1 0 100 200 300 T raining step 0.1 0.2 0.3 0.4 0.5 0.6 T raining A ccuracy MR -Sear ch Sear ch-R1 0 100 200 300 T raining step 2 4 6 T ool Calls MR -Sear ch Sear ch-R1 Figure 4: T est performance, training curves of reward and sear ch frequency on ASear cher , evaluated with Qwen2.5-7B-Base. Additional results are pr ovided in Appendix A.2.1 . development splits of the seven datasets listed above. W e additionally include a synthetic dataset, ASearcher ( Gao et al. , 2025 ), which is more complex than NQ/HotpotQA and requir es long multi-turn search. W e split ASearcher into 90% training and 10% evaluation sets. W e split ASear cher into 90% training and 10% evaluation sets. Detailed dataset descriptions and statistics are pr ovided in Appendix A.1.1 . Evaluation Metrics For evaluation metrics, we follow Jin et al. ( 2025b ): we first normalize both the predicted and gr ound-truth answers, and then compute Exact Match (EM) scor e. EM achieves true if and only if the predicted answer exactly matches any ground-truth answer . For all methods, we sample a single trajectory per question and report the average EM for the last valid prediction for questions following Jin et al. ( 2025a ). Setup W e mainly conduct experiments using Qwen-series models ( Y ang et al. , 2024 ) (Qwen2.5-3B-Base and Qwen2.5-7B-Base). Following ( Jin et al. , 2025b ), we use the 2018 W ikipedia dump ( Karpukhin et al. , 2020 ) as the knowledge source and E5 ( W ang et al. , 2022a ) as the retriever . W e fix the number of retrieved documents to three across all methods for a fair comparison. Unless otherwise specified, we report r esults at turn 3 for our models. The detailed implementation settings are pr ovided in Appendix A.1.3 . Baselines T o evaluate the effectiveness of MR-Search , we compare it against the following recent baselines: (1) Inference without finetuning: methods that directly use the base model, including direct infer ence without retrieval and Sear ch-o1 ( Li et al. , 2025b ) with retrieval. (2) Finetuning-based methods that learn a policy to integrate the search tool without step-level supervision, including ReSearch ( Chen et al. , 2025 ) and Search-R1 ( Jin et al. , 2025a ). (3) Finetuning-based methods that learn a policy to integrate the search tool with step-level supervision, including PPRM ( Anonymous , 2026 ) and StepResearch ( W ang et al. , 2025b ). 7 Preprint. Figure 5: MR-Search , Sear ch-R1 with sequential reflection turns (Search-R1-S), and Sear ch-R1 with parallel sampling (Search-R1-P), selecting the most fr equent answer among them. T able 2: Ablation of discount factor and training algorithm evaluated on Qwen2.5-7B-Base. Method Single-Hop QA Multi-Hop QA NQ T riviaQA PopQA HotpotQA 2wiki Musique Bamboogle A vg. ReSearch 36.6 60.5 39.1 37.8 38.6 16.6 37.6 38.1 Search-R1 46.4 64.1 44.8 43.0 42.5 19.5 44.0 43.5 MR-Search w . γ = 0 49.3 63.9 45.6 44.3 41.7 19.3 42.6 43.8 MR-Search w . PPO 43.9 63.7 42.5 41.3 40.5 18.6 43.5 42.0 MR-Search w . MT-GRPO 46.1 64.5 44.5 44.7 44.2 20.7 45.1 44.3 MR-Search 50.2 66.6 47.2 46.8 43.6 22.1 45.2 46.0 W e also compare with Search-R1 with our multi-turn reflection mechanism during infer ence. in § 4.3 . The detailed description of baselines are given in Appendix A.1.2 . 4.2 Main Results T able 1 summarizes main results on benchmarks. Among the approaches, our MR-Search achieves a substantial margin over GRPO with outcome rewar ds (Search-R1), yielding 9.2% and 19.3% relative improvements on average for the Qwen2.5-7B-Base and Qwen2.5-3B- Base, respectively . This highlights the significant benefits of designing process rewar ds for agentic search. Remarkably , MR-Search remains highly ef fective on the small Qwen2.5- 3B model, whereas RL methods that rely only on sparse outcome rewar ds struggle to elicit multi-turn search behavior for good performance. Compared to other methods that rely on external models to obtain the process reward such as StepResearch and PPRM, our MR-Search achieves better performance. This confirms that agentic sear ch can benefit greatly fr om our designed free pr ocess rewar ds, and that MR-Search can effectively leverage this process supervision to achieve better performance. Figure 4 shows the r esults on the ASearcher datasets. Compared to Multi-Hop QA, ASearcher requir es longer-horizon, multi- turn search ( Gao et al. , 2025 ). From the results, we observe that MR-Search significantly outperforms Search-R1, achieving 10.2% and 9.5% relative improvements in EM and F1, respectively , demonstrating the ef fectiveness of MR-Search on complex ASearcher tasks. Ablation Study . W e study the effects of the key design choices of MR-Search . Specifically , we consider the following ablations: (i) we compare our optimization algorithm (Section § 3.3 ) with PPO ( Schulman et al. , 2017 ) and MT -GRPO ( Zeng et al. , 2025 ) within our Meta-RL framework; (ii) we set the discount factor γ = 0, which removes futur e credit assignment. From the results in T able 2 , we observe that our proposed multi-turn RL algorithm con- sistently outperforms PPO and MT -GRPO when trained with episode turn-level rewar ds, demonstrating the effectiveness of our optimization strategy in leveraging dense feedback from r eflection. Moreover , both PPO and MT -GRPO underperform GRPO with outcome rewar ds (Search-R1) on single-hop NQ and PopQA, whereas our method does not, indicat- ing stronger generalization and r obustness. W e further observe that removing the discount factor substantially degrades performance and causes the training process to conver ge to poor local optima. As discussed above, a possible explanation is that an incorrect episode does not necessarily imply that intermediate episodes are uninformative. 8 Preprint. T able 3: Comparison with variants of MR-Search : encouraging exploration, MR-Search at the step level and context management (keeping one preceding episode as context). Method NQ T riviaQA PopQA HotpotQA 2wiki Musique Bamboogle ASearcher Search-R1 45.9 63.2 44.9 43.9 38.7 18.1 40.0 36.9 MR-Search 50.2 66.6 47.2 46.8 43.6 22.1 45.2 41.3 MR-Search Exploration 48.3 65.1 46.4 44.7 39.4 21.8 44.0 43.2 MR-Search Step Level 48.6 64.6 45.7 42.3 41.4 16.3 41.6 38.4 MR-Search Short Context 48.1 65.9 45.2 44.6 41.0 19.3 47.2 40.5 4.3 Further Analysis T raining Dynamics. For a more comprehensive understanding of MR-Search , we visualize its training dynamics. Figure 4 shows the training rewar d dynamics and of Search-R1 and MR-Search . W e observe that MR-Search exhibits stable convergence during training and consistently achieves higher training rewar d than Search-R1. This indicates that MR-Search effectively leverages iterative reflection to refine answers, leading to progressively improved final answers throughout training of multi-turn RL training. W e can observe that MR-Search calls the search engine mor e frequently than Search-R1, demonstrating that MR-Search can dynamically adjust the number of search calls accor ding to the complexity of tasks. T est-time Scaling. W e also evaluate how MR-Search scales with additional reflection turns at test time. W e extrapolate the number of reflection turns beyond training (3 turns) by appending the entire interaction history to the context at each turn. As shown in Figures 3 and 5 , the single-turn method Search-R1 with our reflection mechanism yields only mar ginal gains when additional reflection turns ar e allowed, since its training objective is optimized for a single turn. However , when additional reflection turns are allowed, MR-Search achieves significantly higher performance, exhibiting the steep improvement curve. These results suggest that multi-turn reflection with MR-Search enhances the model’s ability to iteratively refine and optimize its sear ch across turns and enables effective extrapolation. Case Study . W e present inference cases of models trained with MR-Search . As illustrated by the examples in Appendix A.2.2 , the model is able to execute multi-turn agentic tasks through iterative tool calls and autonomous information aggr egation. During subsequent reasoning episode, the model revisits and r evises answers in light of newly acquired evi- dence, ultimately producing corr ect final answers. These observations highlight the benefits of self-reflection for agentic search. Moreover , when the answer is alr eady accurate as shown in Cases 2 and 3, the model can preserve it and avoid unnecessary revisions, demonstrating its ability to selectively refine r easoning based on retrieved information. 4.4 Extensions In this section, we conduct preliminary experiments to investigate the effects of explo- ration vs. exploitation, step-level meta-RL (discussed in § 3.4 ), and context management (i.e., retaining only the immediately preceding episode as context). T o study exploration and exploitation, we designate the first two episodes as exploration and the last two as exploitation. T able 3 in provides detailed results. From T able 3 , we observe that all variants significantly outperform the baseline Sear ch-R1, demonstrating the effectiveness of these variants. Moreover , MR-Search with step-level meta-RL achieves a substantial improvement over GRPO with outcome rewar ds (Search-R1). This result suggests that agentic search can benefit from pr ocess-level rewards under meta-RL training, and that MR-Search effectively leverages such process supervision to achieve better performance. Furthermore, as shown in T able 3 , encouraging exploration by assigning r ewards to the first episode is beneficial for the more complex ASear cher dataset, which requires mor e interaction with tools. 5 Conclusions W e study agentic search under sparse outcome rewards and propose MR-Search , an in- context meta-reinfor cement learning framework that enables structur ed cross-episode ex- 9 Preprint. ploration via explicit self-reflection. By conditioning each episode on prior trajectories and reflections, MR-Search transforms independent search attempts into a progressively informed search pr ocess, improving exploration without relying on external process r eward models. T o support this multi-turn reflective setting, we introduce a turn-level grouped advantage formulation that provides unbiased and fine-grained credit assignment while re- maining critic-free. Extensive experiments across diverse benchmarks show that MR-Search consistently outperforms outcome-only RL baselines. Overall, our results highlight the im- portance of in-context meta-learning for effective agentic r einforcement learning of LLMs. Acknowledgment This material is based upon work supported by the National Science Foundation under A ward No. 2413244. The views expressed are those of the author and do not reflect the official policy or position of the Department of Defense or the U.S. Government. Limitations Despite its effectiveness, MR-Search has several limitations. First , we do not evaluate our method on long-form benchmarks, wher e responses are substantially longer . V erification in such settings is inherently challenging, and how to reliably assess progress and final correctness for long-form generation r emains an open resear ch question. Second , our current study focuses on agentic search with a fixed W ikipedia search tool. Extending MR-Search to environments involving multiple heter ogeneous tools, such as combined web search and web browsing. W e leave the investigation of these dir ections to future work. It would be also particularly interesting to scale MR-Search to large agentic RL training runs and further study the scaling properties of Meta-RL with fr ontier base models. Ethics Statement This paper advances r einforcement learning for agentic search by improving training effi- ciency and credit assignment under sparse rewards. By enabling more effective training of language-model-based agents, this work may benefit practical applications that r equire efficient and reliable reasoning. This resear ch shares the societal implications of machine learning systems more br oadly and does not introduce additional ethical concerns beyond those commonly associated with large language models and r einforcement learning. References Arash Ahmadian, Chris Cremer , Matthias Gall ´ e, Marzieh Fadaee, Julia Kreutzer , Olivier Pietquin, Ahmet ¨ Ust ¨ un, and Sara Hooker . Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , pp. 12248– 12267, 2024. Anonymous. Principle process rewar d for search agents. In Submitted to The Fourteenth International Conference on Learning Representations , 2026. Michael Bereket and Jur e Leskovec. Uncalibrated reasoning: Grpo induces overconfidence for stochastic outcomes. arXiv preprint , 2025. Mingyang Chen, Linzhuang Sun, T ianpeng Li, Haoze Sun, Y ijie Zhou, Chenzheng Zhu, Haofen W ang, Jeff Z Pan, W en Zhang, Huajun Chen, et al. Learning to reason with search for llms via reinfor cement learning. arXiv preprint , 2025. Y ong Deng, Guoqing W ang, Zhenzhe Y ing, Xiaofeng W u, Jinzhen Lin, W enwen Xiong, Y uqin Dai, Shuo Y ang, Zhanwei Zhang, Qiwen W ang, et al. Atom-searcher: Enhancing agentic deep resear ch via fine-grained atomic thought rewar d. arXiv preprint , 2025. 10 Preprint. Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui W ang, and Zhendong Mao. Deepr e- search bench: A comprehensive benchmark for deep resear ch agents. arXiv preprint arXiv:2506.11763 , 2025. Y an Duan, John Schulman, Xi Chen, Peter L Bartlett, Ilya Sutskever , and Pieter Abbeel. Rl 2 : Fast reinfor cement learning via slow reinfor cement learning. arXiv preprint arXiv:1611.02779 , 2016. Y uchen Fan, Kaiyan Zhang, Heng Zhou, Y uxin Zuo, Y anxu Chen, Y u Fu, Xinwei Long, Xuekai Zhu, Che Jiang, Y uchen Zhang, et al. Ssrl: Self-search reinforcement learning. arXiv preprint arXiv:2508.10874 , 2025. Lang Feng, Zhenghai Xue, T ingcong Liu, and Bo An. Group-in-gr oup policy optimization for llm agent training. arXiv preprint , 2025. Jiaxuan Gao, W ei Fu, Minyang Xie, Shusheng Xu, Chuyi He, Zhiyu Mei, Banghua Zhu, and Y i W u. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl. arXiv preprint , 2025. Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Peiyi W ang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinfor cement learning. arXiv preprint , 2025. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for compr ehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060 , 2020. Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams W ei Y u, Xinying Song, and Denny Zhou. Large language models cannot self-corr ect reasoning yet. arXiv preprint arXiv:2310.01798 , 2023. Aaron Jaech, Adam Kalai, Adam Ler er , Adam Richardson, Ahmed El-Kishky , Aiden Low , Alec Helyar , Aleksander Madry , Alex Beutel, Alex Carney , et al. Openai o1 system card. arXiv preprint arXiv:2412.16720 , 2024. Y ulun Jiang, Liangze Jiang, Damien T eney , Michael Moor , and Maria Brbic. Meta-rl induces exploration in language agents. arXiv e-prints , pp. arXiv–2512, 2025. Bowen Jin, Hansi Zeng, Zhenrui Y ue, Jinsung Y oon, Sercan Arik, Dong W ang, Hamed Zamani, and Jiawei Han. Search-r1: T raining llms to reason and leverage search engines with reinfor cement learning. arXiv preprint , 2025a. Bowen Jin, Hansi Zeng, Zhenrui Y ue, Jinsung Y oon, Sercan O Arik, Dong W ang, Hamed Zamani, and Jiawei Han. Search-r1: T raining LLMs to reason and leverage search engines with reinfor cement learning. In Second Conference on Language Modeling , 2025b. URL https://openreview.net/forum?id=Rwhi91ideu . Mandar Joshi, Eunsol Choi, Daniel S W eld, and Luke Zettlemoyer . T riviaqa: A large scale distantly supervised challenge dataset for reading compr ehension. arXiv preprint arXiv:1705.03551 , 2017. Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell W u, Ser gey Edunov , Danqi Chen, and W en-tau Y ih. Dense passage retrieval for open-domain question answer- ing. In EMNLP (1) , pp. 6769–6781, 2020. W outer Kool, Herke van Hoof, and Max W elling. Buy 4 reinfor ce samples, get a baseline for free! ICLR 2019 workshop: Deep RL Meets Structured Prediction , 2019. A viral Kumar , V incent Zhuang, Rishabh Agarwal, Y i Su, John D Co-Reyes, A vi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al. T raining language models to self-correct via r einforcement learning. arXiv preprint , 2024. 11 Preprint. T om Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering resear ch. T ransactions of the Association for Computational Linguistics , 7:453–466, 2019. Michael Laskin, Luyu W ang, Junhyuk Oh, Emilio Parisotto, Stephen Spencer , Richie Steiger- wald, DJ Strouse, Steven Stenber g Hansen, Angelos Filos, Ethan Brooks, et al. In-context reinfor cement learning with algorithm distillation. In The Eleventh International Conference on Learning Representations , 2023. Kuan Li, Zhongwang Zhang, Huifeng Y in, Liwen Zhang, Litu Ou, Jialong W u, W enbiao Y in, Baixuan Li, Zhengwei T ao, Xinyu W ang, et al. W ebsailor: Navigating super-human reasoning for web agent. arXiv preprint , 2025a. Xiaoxi Li, Guanting Dong, Jiajie Jin, Y uyao Zhang, Y ujia Zhou, Y utao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced lar ge reasoning models. arXiv preprint arXiv:2501.05366 , 2025b. Evan Z Liu, Aditi Raghunathan, Per cy Liang, and Chelsea Finn. Decoupling exploration and exploitation for meta-reinfor cement learning without sacrifices. In International conference on machine learning , pp. 6925–6935. PMLR, 2021. Ilya Loshchilov and Frank Hutter . Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 , 2017. Liangchen Luo, Y inxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Y unxuan Li, Lei Shu, Y un Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint , 2024. Aman Madaan, Niket T andon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah W iegref fe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Y iming Y ang, et al. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems , 36: 46534–46594, 2023. Alex Mallen, Akari Asai, V ictor Zhong, Rajarshi Das, Hannaneh Hajishirzi, and Daniel Khashabi. When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories. arXiv preprint , 7, 2022. Luckeciano C Melo. T ransformers ar e meta-reinfor cement learners. In international conference on machine learning , pp. 15340–15359. PMLR, 2022. Gr ´ egoire Mialon, Cl ´ ementine Fourrier , Thomas W olf, Y ann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. In The T welfth International Conference on Learning Representations , 2023. Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narr owing the compositionality gap in language models. arXiv preprint arXiv:2210.03350 , 2022. Y uxiao Qu, T ianjun Zhang, Naman Garg, and A viral Kumar . Recursive introspection: T eaching language model agents how to self-improve. Advances in Neural Information Processing Systems , 37:55249–55285, 2024. Y uxiao Qu, Matthew YR Y ang, Amrith Setlur , Lewis T unstall, Edward Emanuel Beech- ing, Ruslan Salakhutdinov , and A viral Kumar . Optimizing test-time compute via meta reinfor cement fine-tuning. arXiv preprint , 2025. John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . Proximal policy optimization algorithms. arXiv preprint , 2017. Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, V arsha Kishore, Jing- ming Zhuo, Xinran Zhao, Molly Park, Samuel G Finlayson, David Sontag, et al. Dr tulu: Reinforcement learning with evolving rubrics for deep research. arXiv preprint arXiv:2511.19399 , 2025. 12 Preprint. Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y ang W u, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models. arXiv preprint , 2024. Junhong Shen, Hao Bai, Lunjun Zhang, Y ifei Zhou, Amrith Setlur , Shengbang T ong, Diego Caples, Nan Jiang, T ong Zhang, Ameet T alwalkar , et al. Thinking vs. doing: Agents that reason by scaling test-time interaction. arXiv preprint , 2025. T aiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Y ang, and Jieyu Zhao. Experien- tial reinfor cement learning. arXiv preprint , 2026. Y aorui Shi, Shihan Li, Chang W u, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, and Xiang W ang. Search and refine during think: Autonomous retrieval-augmented reasoning of llms. NeurIPS , 2025. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Y ao. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems , 36:8634–8652, 2023. Chenglei Si, Zitong Y ang, Y ejin Choi, Emmanuel Cand ` es, Diyi Y ang, and T atsunori Hashimoto. T owards execution-grounded automated ai r esearch. arXiv preprint arXiv:2601.14525 , 2026. Charlie Snell, Jaehoon Lee, Kelvin Xu, and A viral Kumar . Scaling llm test-time compute opti- mally can be more effective than scaling model parameters. arXiv preprint , 2024. Huatong Song, Jinhao Jiang, Y ingqian Min, Jie Chen, Zhipeng Chen, W ayne Xin Zhao, Lei Fang, and Ji-Rong W en. R1-searcher: Incentivizing the search capability in llms via reinfor cement learning. arXiv preprint , 2025. Bradly C Stadie, Ge Y ang, Rein Houthooft, Xi Chen, Y an Duan, Y uhuai W u, Pieter Abbeel, and Ilya Sutskever . Some considerations on learning to explore via meta-reinfor cement learning. arXiv preprint , 2018. Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Y ingyan Hou, Y ong Jiang, Pengjun Xie, Y an Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching. arXiv preprint , 2025. Richard S Sutton, David McAllester , Satinder Singh, and Y ishay Mansour . Policy gradient methods for reinfor cement learning with function approximation. Advances in neural information processing systems , 12, 1999. Harsh T rivedi, Niranjan Balasubramanian, T ushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition. T ransactions of the Association for Computational Linguistics , 10:539–554, 2022. Zhongwei W an, Zhihao Dou, Che Liu, Y u Zhang, Dongfei Cui, Qinjian Zhao, Hui Shen, Jing Xiong, Y i Xin, Y ifan Jiang, et al. Srpo: Enhancing multimodal llm reasoning via reflection-awar e reinforcement learning. arXiv preprint , 2025. Jane W ang, Zeb Kurth-Nelson, Hubert Soyer , Joel Leibo, Dhruva T irumala, Remi Munos, Charles Blundell, Dharshan Kumaran, and Matt Botvinick. Learning to reinfor cement learn. In Proceedings of the Annual Meeting of the Cognitive Science Society , volume 39, 2017. Liang W ang, Nan Y ang, Xiaolong Huang, Binxing Jiao, Linjun Y ang, Daxin Jiang, Rangan Majumder , and Furu W ei. T ext embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533 , 2022a. Peiyi W ang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Y ifei Li, Deli Chen, Y u W u, and Zhifang Sui. Math-shepherd: V erify and reinforce llms step-by-step without human annotations. arXiv preprint , 2023. 13 Preprint. T eng W ang, Zhangyi Jiang, Zhenqi He, Shenyang T ong, W enhan Y ang, Y anan Zheng, Zeyu Li, Zifan He, and Hailei Gong. T owards hierarchical multi-step reward models for enhanced reasoning in lar ge language models. arXiv preprint , 2025a. Xuezhi W ang, Jason W ei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery , and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint , 2022b. Ziliang W ang, Xuhui Zheng, Kang An, Cijun Ouyang, Jialu Cai, Y uhang W ang, and Y ichao W u. Stepsearch: Igniting llms search ability via step-wise pr oximal policy optimization. arXiv preprint arXiv:2505.15107 , 2025b. Jiahao W u, Zhongwen Xu, Qiang Fu, and W ei Y ang. Buy 4 reinforce samples, get a baseline for free! Cut the Bill, Keep the T urns: Affordable Multi-T urn Search RL , 2025a. Jialong W u, Baixuan Li, Runnan Fang, W enbiao Y in, Liwen Zhang, Zhengwei T ao, Dingchu Zhang, Zekun Xi, Gang Fu, Y ong Jiang, et al. W ebdancer: T owards autonomous informa- tion seeking agency . arXiv preprint , 2025b. W ei Xiong, Hanning Zhang, Chenlu Y e, Lichang Chen, Nan Jiang, and T ong Zhang. Self- rewar ding correction for mathematical reasoning. arXiv preprint , 2025. An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115 , 2024. Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, W illiam W Cohen, Ruslan Salakhutdi- nov , and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint , 2018. Shunyu Y ao, Jeffr ey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Y uan Cao. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning repr esentations , 2022. Lifan Y uan, W endi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process r ewards without process labels. arXiv preprint arXiv:2412.01981 , 2024. Mert Y uksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong W ang, Jan Kautz, Y ejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time. arXiv preprint , 2026. Siliang Zeng, Quan W ei, W illiam Brown, Oana Frunza, Y uriy Nevmyvaka, and Mingyi Hong. Reinforcing multi-turn r easoning in llm agents via turn-level cr edit assignment. arXiv preprint arXiv:2505.11821 , 2025. Kai Zhang, Xiangchao Chen, Bo Liu, T ianci Xue, Zeyi Liao, Zhihan Liu, Xiyao W ang, Y uting Ning, Zhaor un Chen, Xiaohan Fu, et al. Agent learning via early experience. arXiv preprint arXiv:2510.08558 , 2025. Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Y u, Dayi- heng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process err ors in mathematical reasoning. arXiv preprint , 2024. Y uxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, L yumanshan Y e, Pengrui Lu, and Pengfei Liu. Deepresearcher: Scaling deep resear ch via reinforcement learning in real- world environments. arXiv preprint , 2025. 14 Preprint. Generation Prompt Answer the given question. Y ou must conduct reasoning inside and first every time you get new information. After reasoning, you must call a search engine by query , and it will return the top search results between and . After every time you get new information, you must try to provide the answer inside and without detailed illustrations. For example, xxxx . Question: { question } A Appendix A.1 Experimental Details A.1.1 The Details of Datasets NQ ( Kwiatkowski et al. , 2019 ): NQ is question answering (QA) data set. Questions consist of real anonymized, aggregated queries issued to the Google search engine. The training and test sets contain 79,168 and 3,610 samples, respectively . T riviaQA ( Joshi et al. , 2017 ): T riviaQA is a challenging reading comprehension dataset containing over question-answer-evidence triples, which pr ovide high quality distant su- pervision for answering the questions. The test sets we used contain 11,313 samples. PopQA ( Mallen et al. , 2022 ): PopQA is a large-scale open-domain question answering dataset, consisting of 14,267 entity-centric QA pairs. Each question is created by converting a knowledge tuple retrieved fr om W ikidata using a template. HotpotQA ( Y ang et al. , 2018 ): HotpotQA is a large-scale multi-hop QA benchmark featuring W ikipedia-based Q&A pairs with sentence-level supporting evidence. The training and test sets contain 90,447 and 7,405 samples, respectively . 2W ikiMultiHopQA ( Ho et al. , 2020 ): 2W ikiMultiHopQA is a multi-hop question an- swering dataset designed to more reliably test a model’s infer ence across multiple pieces of evidence. The test set contains 7,405 QA pairs. Musique ( T rivedi et al. , 2022 ): MuSique is a multihop question answering dataset con- structed to enfor ce genuine multi-step reasoning. The test set contains 2,417 QA pairs. Bamboogle ( Press et al. , 2022 ). Bamboogle is a dataset with multi-hop questions, where all questions are suf ficiently difficult to be unanswerable by a popular internet search engine, but where both supporting pieces of evidence can be found in W ikipedia. Bamboogle contains 125 test QA pairs. ASearcher ( Gao et al. , 2025 ). ASearcher is a synthetic multi-turn dataset whose synthesis pipeline is largely based on W ikipedia. W e use the preprocessed version from ( W u et al. , 2025a ), which applies a three-step filtering pipeline, including the r emoval of Chinese and math samples as well as rejection sampling, resulting in 14k samples. W e split ASearcher into 90% training and 10% evaluation sets to decouple the effects of data distribution. A.1.2 The Details of Baselines W e provide detailed descriptions of baselines. W e consider three types of baselines: Inference without fine-tuning, Fine-tuning-based methods without step-level supervision and Fine- tuning-based methods with step-level supervision. Search-o1 ( Li et al. , 2025b ) is the sear ch-enhanced reasoning framework, which integrates the agentic RAG mechanism and reason-in-document module. 15 Preprint. Reflection Prompt Reflect on your current answer to the question and pr ovide another answer by searching for additional external information using search engines. Y ou must conduct reasoning inside and first every time you get new information. After reasoning, if you find you lack some knowledge, you can call a search engine by query and it will return the top searched r esults between and . Y ou can search as many times as your want. If you find no further external knowledge needed, you can directly pr ovide the answer inside and ., without detailed illustrations. ReSearch ( Chen et al. , 2025 ) is an RL-based framework that trains LLMs to interleave reasoning with explicit search actions, deciding when and how to query and then using retrieved evidence to continue multi-hop r easoning. Search-R1 ( Jin et al. , 2025a ) extends RL-based r easoning by enabling LLMs to autonomously generate search queries during multi-turn r easoning. PPRM ( Anonymous , 2026 ) is a principle process reward model that provides step-wise signals to guide GRPO-based RL. StepResearch ( W ang et al. , 2025b ) trains search agents with step-wise PPO using intermedi- ate rewar ds and token-level supervision to better guide multi-hop retrieval and reasoning. A.1.3 The Details of Implementation Our implementation is built upon Search-R1 based on V eRL. The generation prompt and reflection Pr ompt are given in the colored box. Hyperparameters . For training, we use AdamW ( Loshchilov & Hutter , 2017 ) as the opti- mizer and set the learning rate to 1e-6 without warmup. The top-p and temperature for rollout are both set to 1. The total number of training steps is 300. The number of documents returned by the retrieval engine is 3. The group size for advantage calculation is set to 5. The context length is set to 8K and 16K for the NQ/HotpotQA and Asearcher datasets, respectively . W e also set the maximum number of tool calls in each episode to 3 and 5 for the NQ/HotpotQA and Asearcher datasets, r espectively . For evaluation, all other settings (e.g., the retriever configuration) ar e kept the same as in training; the only difference is that we disable sampling and use greedy decoding with temperature = 0, and top p = 1.0. Computation Resources All RL training is performed on 8 × NVIDIA T esla H100 (80GB) GPUs, and we use an additional 2 × NVIDIA T esla H100 (80GB) GPUs to serve the retriever . A.2 Additional Experimental Results A.2.1 More Results of T raining Dynamics In Figures 6 and 7 , we further visualize the training dynamics of MR-Search . W e can observe that MR-Search exhibits more stable conver gence during training and consistently achieves higher rewar d than Search-R1 baseline. These results indicate that the pr ocess rewar ds at episode level with self-r eflection introduced by MR-Search provide mor e informative and reliable learning signals, leading to impr oved stability and training effectiveness. A.2.2 Case Study In T ables 4 - 7 , we provide some inference trajectory of the model trained by MR-Search . 16 Preprint. 50 100 150 200 250 300 T raining step 0.300 0.325 0.350 0.375 0.400 0.425 T est A ccuracy MetaSear ch Sear ch-R1 0 50 100 150 200 250 300 T raining step 0.0 0.1 0.2 0.3 0.4 0.5 T raining A ccuracy MetaSear ch Sear ch-R1 0 50 100 150 200 250 300 T raining step 1.0 1.5 2.0 2.5 3.0 T ool Calls MetaSear ch Sear ch-R1 Figure 6: The training dynamics of MR-Search and Search-R1 in terms of test accuracy , training accuracy , and the number of tool calls on Qwen2.5-3B-Base. 50 100 150 200 250 300 T raining step 0.30 0.35 0.40 0.45 T est A ccuracy MetaSear ch Sear ch-R1 0 50 100 150 200 250 300 T raining step 0.1 0.2 0.3 0.4 0.5 T raining A ccuracy MetaSear ch Sear ch-R1 0 50 100 150 200 250 300 T raining step 1 2 3 4 T ool Calls MetaSear ch Sear ch-R1 Figure 7: The training dynamics of MR-Search and Search-R1 in terms of test accuracy , training accuracy , and the number of tool calls on Qwen2.5-7B-Base. Meta-Eposide ToolCall ToolObs Think turn 1 Answe r Question ToolCall ToolObs Think Answe r tur n 2 ToolCall ToolObs Think Answe r tur n T … Eposide … Eposide Eposide w/o Loss w/Loss Outcome Verifier Figure 8: The idea of MR-Search can be extended beyond full trajectories to any semantically meaningful episode that can be explicitly segmented. For example, in agentic search, each tool-interaction step can naturally form an episode. W e can decompose the one interaction process into multiple self-reflective trials, where each tool-interaction step contributes a candidate answer to the original query via prompting. During training, at each interaction step, we monitor changes in the agent’s accuracy with respect to the target and use this signal as a dense training objective to promote ef fective exploration. 17 Preprint. T able 4: Case study 1: An early intermediate answer is incorrect due to ambiguous retrieval results, but is subsequently reconsidered through additional search and self-reflection, leading to the correct final answer . Question : During a major geopolitical event in the early Cold W ar , Robert Menzies exploited rising tensions to portray the Labor Party as ’soft on Communism,’ leading to the defeat of a Prime Minister who attended a religious school. In the same period, which British maritime patrol aircraft, known for its role in anti-submarine warfare and derived fr om the world’s first jet airliner , was frequently deployed to a U.S. military base in the Atlantic to support anti-submarine operations during the latter stages of the Cold W ar? Ground T ruth : 2002 MR-Search : T o determine the year in which the V ictorian government department responsible for agriculture and ener gy policy was established, we need more information about the department and its merger with another department in 2013. Query: V ictorian government department responsible for agriculture and ener gy policy merged with another department administering conservation strategy involving biodiversity offsets in 2013. When was this department established? Document (T itle: Department of the Environment (Australia, 2013–16)) by way of an Administrative Arrangements Order issued on 18 September 2013. It absorbed the responsibilities of the former Department of Sustainability , Environment, W ater , Population and Communities (DSWEPaC) and climate change from the former Department of Industry , Innovation, Climate Change, Science, Research and T ertiary Education. The department was dissolved in July 2016 and its functions, along with energy policy functions, wer e moved to the newly established Department of the Environment and Ener gy . From when it... It seems the search did not directly pr ovide the information. Let’s try another search with a specific focus on the department related to agricultur e and energy policy: Query: When was the Department of Economic Development, Jobs, T ransport and Resources established in V ictoria? Document (T itle: Department of Economic Development, Jobs, T ransport and Resources) Department of Economic Development, Jobs, T ransport and Resources The Department of Economic Development, Jobs, T ransport and Resources (DEDJTR) is a department of the Government of V ictoria. It was created on 1 January 2015 by the government of Pr emier Daniel Andrews when the number of government departments was r educed from 9 to 7, and assumed responsibility for ministerial portfolios pr eviously spread across 5 departments. The department was established after the 2014 V ictorian election by the new Labor government, using the powers of the Premier of V ictoria and the Governor-in-council under the Public ... This information indicates that the Department of Economic Development, Jobs, T ransport and Resources was established on 1 January 2015. Therefore, the year in which the V ictorian government department r esponsible for agricultur e and ener gy policy was established is: 2015 Reflect on your current answer to the question and provide an improved answer by searching for additional external information using search engines. Let’s first confirm the details we have about the mer ger with the department administering a conservation strategy involving biodiversity offsets. W e need to ensure that the department we identified merged with another department in 2013 as stated in the question. Query: Which department was merged with the Department of Economic Development, Jobs, T ransport and Resources in 2013 that administered a conservation strategy involving biodi- versity offsets? Document (T itle: Department of Economic Development, Jobs, T ransport and Resources) Department of Economic Development, Jobs, T ransport and Resources The Department of Economic Development, Jobs, T ransport and Resources (DEDJTR) is a department of the Government of V ictoria. It was created on 1 January 2015 by the government of Pr emier Daniel Andrews when the number of government departments was r educed from 9 to 7, and assumed responsibility for ministerial portfolios pr eviously spread across 5 departments. The department was established after the 2014 V ictorian election by the new Labor government, using the powers of the Premier of V ictoria and the Governor-in-council under the Public Administration Act 2004 and the Administrative Arrangements Act 1983... It seems the information does not dir ectly state which department was merged in 2013. However , the question specifies that the department collaborated with Field and Game Australia to establish the Game Council of V ictoria in 2012. Let’s consider if this collaboration might provide a clue: 18 Preprint. Query: When was the Department of Environment and Primary Industries, which collaborated with Field and Game Australia to establish the Game Council of V ictoria in 2012, merged with another department in 2013? Document (T itle: Department of Primary Industries (V ictoria)) Bureau of Animal W elfare branch Does this Department need investigation if Rosewarne had anything to do with it? DPI had primary responsibility for administering legislation governing agricultur e, animal welfar e, fisheries, hunting and energy and earth resources in V ictoria. The department administered and responded to queries regar ding 38 major Acts and is responsible for collecting fees under regulations for fishing licences, mining rights, and exploration licences. In 2012 DPI also created the Game Council of V ictoria to with the Bureau of Animal W elfare and or ganisations such as Field and Game Australia to manage sustainable and responsible hunting in V ictoria... This information indicates that the Department of Environment and Primary Industries was merged with the Department of Sustainability and Environment to form the Department of Environment and Primary Industries in April 2013. However , we need to confirm if this is the department responsible for agriculture and ener gy policy . Given the context, it seems likely that the Department of Environment and Primary Industries was the one r esponsible for agriculture and energy policy before the merger . Therefore, the year in which the V ictorian government department responsible for agricultur e and energy policy was established is: 2002 Reflect on current answer to the question and provide an improved answer by searching for additional external information using search engines. Let’s verify the year of establishment for the Department of Environment and Primary Industries, which was merged in 2013 and was responsible for agriculture and energy policy: Query: When was the Department of Environment and Primary Industries established in V ictoria? Document (T itle: Department of Envir onment and Primary Industries (V ictoria)) 1 January 2015. The Agriculture portfolio was moved to the new Department of Economic Development, Jobs, T ransport and Resources. Department of Environment and Primary Industries (V ictoria) The Department of Environment and Primary Industries (DEPI) was a state government department responsible for protecting the envir onment, boosting productivity in V ictoria’s food and fibre sector , management of natural resources and managing water resour ces in the state of V ictoria, Australia. It was created in April 2013 by merging the Department of Primary Industries with the Department of Sustainability and Environment... This information confirms that the Department of Envir onment and Primary Industries was established in April 2013 by merging with the Department of Sustainability and Environment. However , we need to find the year when the Department of Primary Industries, which was mer ged to form the Department of Environment and Primary Industries, was established. Since the Department of Primary Industries was established in 2002, we can conclude that the Department of Environment and Primary Industries, which was r esponsible for agriculture and ener gy policy , was established in 2002. 2002 T able 5: Case study 2: MR-Search subsequently revisits the problem through additional search and self-r eflection, ultimately producing the correct final answer . Question : During a major geopolitical event in the early Cold W ar , Robert Menzies exploited rising tensions to portray the Labor Party as ’soft on Communism,’ leading to the defeat of a Prime Minister who attended a religious school. In the same period, which British maritime patrol aircraft, known for its role in anti-submarine warfare and derived fr om the world’s first jet airliner , was frequently deployed to a U.S. military base in the Atlantic to support anti-submarine operations during the latter stages of the Cold W ar? Ground T ruth : Hawker Siddeley Nimrod MR-Search : T o determine the name of the British maritime patrol aircraft that was frequently deployed to a U.S. military base in the Atlantic to support anti-submarine operations during the latter stages of the Cold W ar , let’s first consider the time frame of the event involving Robert Menzies and the Prime Minister who attended a religious school. Then we can perform a search to find the information about the British maritime patrol air craft. 19 Preprint. Query: British maritime patrol aircraft derived from the world’s first jet airliner , fre- quently deployed to a U.S. military base in the Atlantic during the Cold W ar Document (T itle: Maritime patrol aircraft) also been located in these areas: U.S. Navy and Canadian aircraft based in Gr eenland, Iceland, and Newfoundland; British air craft based in Scotland and Northern Ir eland; and Norwegian, Dutch, and German aircraft based in their home countries. Since the end of the Cold W ar the threat of a large-scale submarine attack is a remote one, and many of the air forces and navies have been downsizing their fleets of ... Let’s try one more time with the exact model derived fr om the first jet airliner: Query: Air aztros 2000 maritime patrol air craft frequently deployed to a U.S. military base in the Atlantic during the Cold W ar Document (T itle: Kindley Air Force Base) P-3B air craft from various bases in the eastern United States, as well as NA TO/Allied support consisting of Royal Air Force Hawker Siddeley Nimrod MR2s, Canadian Armed Forces CP-140 Auroras and other similar maritime patrol and r econnaissance aircraft fr om other NA TO nations. During one period in 1985 that was characterized by exceptionally heavy Soviet Navy submarine activity off the ... This information does not directly name the aircraft. However , the mention of P-3C aircraft being fr equently deployed to a U.S. military base in the Atlantic suggests that we should focus on this model. Given that P-3C is a well-known maritime patrol aircraft and the question specifies a connection to the first jet airliner , let’s consider if P-3C has any such connection. The P-3C is derived from the Lockheed P-3 Orion, which is itself a derivative of the Lockheed Model 85 Electra airliner . The first jet airliner was the de Havilland Comet, not directly related to the Electra. Therefor e, we might need to r e-evaluate our query to ensure we ar e considering the corr ect aircraft. Given the context and the need for accuracy , let’s consider the aircraft derived from the de Havilland Comet, which is the de Havilland Sea V ixen. However , the P-3C is more directly related to the Lockheed 1049C Hercules transport air craft, which is not derived from the Comet but rather the Lockheed Electra. Given the specificity of the question, it seems likely that the aircraft in question is the P-3C Orion, which is frequently deployed and fits the timeframe. P-3C Orion Reflect on current answer to the question and provide an improved answer by searching for additional external information using search engines. Let’s first confirm the details we have and then r efine our search to ensur e we are identi- fying the corr ect aircraft. W e know the air craft is a British maritime patr ol aircraft derived fr om world’s first jet airliner and was frequently deployed to a U.S. military base in the Atlantic during Cold W ar . Given that P-3C Orion is the most likely candidate based on previous sear ch, let’s verify if there is any specific information about a British air craft derived from a jet airliner . Query: British maritime patrol aircraft derived fr om a jet airliner , frequently deployed to a U.S. military base in the Atlantic during the Cold W ar Document (T itle: Maritime patrol aircraft) also been located in these areas: U.S. Navy and Canadian aircraft based in Gr eenland, Iceland, and Newfoundland; British air craft based in Scotland and Northern Ir eland; and Norwegian, Dutch, and German aircraft based in their home countries. Since the end of the Cold W ar the threat of a large-scale submarine attack is a remote one, and many of the air forces and navies have been downsizing their fleets of ... It appears that the information did not dir ectly name the air craft. However , the mention of the P-3C Orion being frequently deployed suggests that we should consider if there is another British aircraft that fits the description. Given the specificity of the question, let’s consider if there is a British counterpart to the P-3C. The P-3C is derived from the Lockheed 1049C Hercules, which is not a jet airliner . Therefor e, we need to consider if there is a British jet airliner-derived maritime patrol air craft. Given the context and the need for accuracy , let’s consider the British counterpart to the P-3C, which is the Lockheed P-3 Orion. The P-3 Orion is derived from the Lockheed Electra, not a jet airliner . Therefore, we need to consider if ther e is another British aircraft derived from a jet airliner . Let’s consider the Hawker Siddeley Nimrod, which is a British maritime patrol air craft. The Nimrod is derived fr om the Hawker Siddeley T rident, which is a jet airliner . The Nimrod was indeed frequently deployed to a U.S. military base in the Atlantic during the Cold W ar . Hawker Siddeley Nimrod Reflect on current answer to the question and provide an improved answer by searching for additional external information using search engines. Let’s consider the details we have and ensur e we are identifying the corr ect aircraft. W e know it is a British maritime patr ol aircraft derived from a jet airliner and was frequently deployed to a U.S. military base in the Atlantic during the Cold W ar . Given the specific context, let’s consider if there is a dir ect match for the P-3C Orion in terms of derivation from a jet airliner . The Hawker Siddeley Nimrod is a str ong candidate, as it is derived from the Hawker Siddeley T rident, which is a jet airliner . Additionally , the Nimrod was indeed frequently deployed to a U.S. military base in the Atlantic during the Cold W ar for anti-submarine operations. Given this reasoning, we can conclude that the aircraft in question is the Hawker Siddeley Nimr od. Hawker Siddeley Nimrod 20 Preprint. T able 6: Case study 3: MR-Search subsequently revisits the problem through additional search and self-r eflection, ultimately producing the correct final answer . Question : Who directed the 1909 Italian silent film in which the actor who played the castle castellan in the 1928 German silent film The Mysterious Mirr or portrayed the titular character of Shakespeare’s Macbeth? Ground T ruth : Mario Caserini MR-Search : T o determine who directed the 1909 Italian silent film in which the actor who played the castle castellan in the 1928 German silent film ’The Mysterious Mirror ’ portrayed the titular character of Shakespear e’s ’Macbeth’, let’s first identify the actor and then find the Italian silent film he appeared in during 1909. Query: Italian silent film from 1909 in which the actor who played the castle castellan in the 1928 German silent film The Mysterious Mirr or portrayed the titular character of Shakespeare’s ’Macbeth’ directed by whom? Document (T itle: Macbeth (1916 film)) Macbeth (1916 film) Macbeth is a silent, black- and-white 1916 film adaptation of the W illiam Shakespeare play Macbeth. It was directed by John Emerson, assisted by Erich von Stroheim, and produced by D. W . Griffith, with cinematography by V ictor Fleming. The film starred Herbert Beerbohm T ree and Constance Collier , both famous from the stage and for playing Shakespearean parts. Although r eleased during the first decade of feature filmmaking, it was already the seventh version of Macbeth to be produced, one of eight during the silent film era. It is considered to be a lost film. In the companion book to his ... It appears that the search did not directly provide the name of the actor . Let’s try the search again with a focus on the actor who played the castle castellan in The Mysterious Mirr or and then find the film he portrayed Macbeth in 1909. Query: The actor who played the castle castellan in the 1928 German silent film The Mysterious Mirror and also portrayed the titular character of Shakespear e’s Macbeth in an Italian silent film from 1909. Who directed that Italian film? Document (T itle: Maria Caserini) 1907, along with appearing in another thirteen films through 1909. One of those films was the 1909 production Macbeth, which was directed by her husband. From 1910 to 1927 she appeared in sixty five films, all produced in Italy , most of which were dir ected by her husband, and many of which were Shakespear ean adaptations. She continued to perform in theater productions well after she left her film career . She was residing in Milan at the time of her death on 15 April 1969. Maria Caserini Maria Caserini (n ´ ee Gasperini; 24 July 1884 – 15 April 1969) was an Italian stage ... This information does not dir ectly name the actor but mentions Maria Caserini and her husband. Let’s consider the top search result more carefully: One of the films was the 1909 production Macbeth, which was directed by her husband. So, the director of the 1909 Italian silent film in which the actor portrayed Macbeth is Maria Caserini’s husband. Her husband Reflect on current answer to the question and provide an improved answer by searching for additional external information using search engines. Let’s first confirm the name of Maria Caserini’s husband and then determine if we can find the director of the 1909 Italian silent film Macbeth with this information. Query: Who was the husband of Maria Caserini and what was his name? Also, find the director of the 1909 Italian silent film Macbeth. Document (T itle: Maria Caserini) 1907, along with appearing in another thirteen films through 1909. One of those films was the 1909 production Macbeth, which was directed by her husband. From 1910 to 1927 she appeared in sixty five films, all produced in Italy , most of which were dir ected by her husband, and many of which were Shakespear ean adaptations. She continued to perform in theater productions well after she left her film career . She was residing in Milan at the time of her death on 15 April 1969. Maria Caserini Maria Caserini (n ´ ee Gasperini; 24 July 1884 – 15 April 1969) was an Italian stage ... This information tells us that Maria Caserini’s husband directed several of her films, including the 1909 Italian silent film Macbeth. Since the search did not return the name of her husband directly , let’s consider if we can infer the director ’s name from the context or search for it directly: Query: Who was the director of the 1909 Italian silent film Macbeth? 21 Preprint. Document (T itle: Macbeth (1916 film)) Macbeth (1916 film) Macbeth is a silent, black- and-white 1916 film adaptation of the W illiam Shakespeare play Macbeth. It was directed by John Emerson, assisted by Erich von Stroheim, and produced by D. W . Griffith, with cinematography by V ictor Fleming. The film starred Herbert Beerbohm T ree and Constance Collier , both famous from the stage and for playing Shakespearean parts. Although r eleased during the first decade of feature filmmaking, it was already the seventh version of Macbeth to be produced, one of eight during the silent film era. It is considered to be a lost film. In the companion book to his ... This information does not directly name the dir ector . However , it mentions that the 1909 film Macbeth was directed by Maria Caserini’s husband. Given the previous context, let’s consider the most likely candidate based on the available information: Mario Caserini Reflect on current answer to the question and provide an improved answer by searching for additional external information using search engines. Let’s re-evaluate the information we have. W e know that the 1909 Italian silent film Macbeth was directed by Maria Caserini’s husband. Since the previous sear ches did not provide the name of her husband, let’s consider if we can infer this information from the context or search for it directly: Query: Who was the husband of Maria Caserini who directed the 1909 Italian silent film Macbeth? Document (T itle: Maria Caserini) Maria Caserini Maria Caserini (n ´ ee Gasperini; 24 July 1884 – 15 April 1969) was an Italian stage and film actress, as well as a pioneer of filmmaking during the early 20th-century . She often starr ed in adaptations of stage and film pr oductions for the works of W illiam Shakespeare. Born in Milan, she started acting in stage productions at a young age. Her first film was in 1906, in what is believed to be the earliest film adaptation of Shakespeare’s Othello, titled Otello, which was directed by her husband, Mario Caserini. She appeared in a film adaptation of Romeo and Juliet in ... This information confirms that Maria Caserini’s husband directed the 1909 Italian silent film Macbeth. Since we have the name Mario Caserini fr om the context, we can dir ectly answer: Mario Caserini T able 7: Case study 4: MR-Search subsequently revisits the problem through additional search and self-r eflection, ultimately producing the correct final answer . Question : In which country did Itamar Zorman make his first public appearance at a r enowned festival in the early 2010s, and where is he scheduled to perform a concerto at a historic venue in a city with a rich Norman heritage and a famous opera house? Ground T ruth : Switzerland MR-Search : T o determine the country where Itamar Zorman made his first public appearance at a renowned festival in the early 2010s and where he is scheduled to perform a concerto at a historic venue in a city with a rich Norman heritage and a famous opera house, let’s first search for information about Itamar Zorman’s early public appearances and then find the details about his upcoming concert. Query: Itamar Zorman first public appearance at a r enowned festival in the early 2010s and upcoming concerto at a historic venue in a city with rich Norman heritage and famous opera house Document (T itle: Itamar Zorman) Hamburg and Kronberg Academy Festival in Frankfurt as well as with Y uri Bashmet. His first CD is planned to be released sometime in 2014 with his recitals the Louvre. In November of the same year he, Daniel Or en and Musicians fr om Marlboro gr oup, will perform Ludwig van Beethoven’s concerto at the T eatro Massimo in Palermo. For the past five years he has traveled through Israel and North America during which he was a founder of the Israeli Chamber Project as well as a L ysander Piano T rio member . On March 9, 2014 he performed one of Johannes Brahms’ sonatas in Detroit ... 22 Preprint. Itamar Zorman made his first public appearance at the V erbier Festival in Switzerland in 2010. Now , let’s find out where he is scheduled to perform a concerto at a historic venue in a city with a rich Norman heritage and a famous opera house. Query: Itamar Zorman concerto at a historic venue in a city with rich Norman heritage and famous opera house Document (T itle: Semperoper) Semper oper The Semperoper is the opera house of the S ¨ achsische Staatsoper Dr esden (Saxon State Opera) and the concert hall of the Staatskapelle Dresden (Saxon State Orchestra). It is also home to the Semperoper Ballett. The building is located near the Elbe River in the historic centre of Dresden, Germany . The opera house was originally built by the ar chitect Gottfried Semper in 1841. After a devastating fir e in 1869, the opera house was rebuilt, partly again by Semper , and completed in 1878. The opera house has a long history of premier es, including major works by Richard W agner and Richard Strauss. The ... This information does not directly state the location of the upcoming concert. However , it mentions the T eatro Massimo in Palermo, which is in Italy . Let’s verify if this matches the criteria of a city with a rich Norman heritage and a famous opera house. Query: T eatro Massimo in Palermo, Italy Document (T itle: T eatro Massimo) T eatro Massimo The T eatro Massimo V ittorio Emanuele is an opera house and opera company located on the Piazza V erdi in Palermo, Sicily . It was dedicated to King V ictor Emanuel II. It is the biggest in Italy , and one of the largest of Eur ope (the third after the Op ´ era National de Paris and the K. K. Hof-Opernhaus in V ienna), renowned for its perfect acoustics. An international competition for the creation of the opera house was announced by the Palermo Council in 1864 at the instigation of the mayor , Antonio Starrabba di Rudin ` ı. For many years there had been talk of building ... The T eatro Massimo in Palermo is indeed a famous opera house. Now , let’s confirm if Palermo has a rich Norman heritage: Query: Norman heritage in Palermo Document (T itle: Arab-Norman Palermo and the Cathedral Churches of Cefal ` u and Monreale) Arab-Norman Palermo and the Cathedral Chur ches of Cefal ` u and Monreale Arab- Norman Palermo and the Cathedral Churches of Cefal ` u and Monreale is a series of nine r eligious and civic structures located on the northern coast of Sicily dating from the era of the Norman Kingdom of Sicily (1130-1194): two palaces, thr ee churches, a cathedral, and a bridge in Palermo, as well as the cathedrals of Cefal ` u and Monreale. They have been designated together as a UNESCO W orld Heritage Site. The new Norman rulers built various structur es in what has become known as the Arab-Norman style. They incorporated the best practices of ... This information confirms that Palermo has a rich Norman heritage. Therefore, Itamar Zorman is scheduled to perform a concerto at the historic venue in Palermo, Italy . Italy Reflect on your current answer to the question and provide an improved answer by searching for additional external information using search engines. The answer remains the same as our previous conclusion based on the available informa- tion: Italy Reflect on your current answer to the question and provide an improved answer by searching for additional external information using search engines. Let’s verify the details of Itamar Zorman’s first public appearance at a renowned festival in the early 2010s to ensure we have the correct information. W e’ll confirm the country where the festival is held. Query: Itamar Zorman first public appearance at a r enowned festival in the early 2010s and the country of the festival Doc 1(T itle: ¨ Itamar Zorman ¨ ) at the Juilliard Berg Concerto Competition/ His first public appearance, however , was not until next year at the V erbier Festival, which was broadcast live fr om Switzerland. The same year he did nine concerts with the Israel Philharmonic Orchestra under guidance from David Robertson and performed at the T okyo Symphony of Japan’s Suntory Hall, where he played with Baden Baden Philharmonic and both Russian and Saint Petersburg Philharmonic Or chestra, as well as the American South Bay Conservatory , the Israeli Haifa Symphony and the Dominican Fundaci ´ on Sinfonia of Santo Domingo. As of October 2013, he has participated at both the Laeiszhalle in ... This information confirms that Itamar Zorman made his first public appearance at the V erbier Festival in Switzerland in 2010. Therefore, the country where he made his first public appearance at a renowned festival in the early 2010s is Switzerland. Switzerland 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment