Detecting Transportation Mode Using Dense Smartphone GPS Trajectories and Transformer Models
Transportation mode detection is an important topic within GeoAI and transportation research. In this study, we introduce SpeedTransformer, a novel Transformer-based model that relies solely on speed inputs to infer transportation modes from dense sm…
Authors: Yu, ong Zhang, Othmane Echchabi
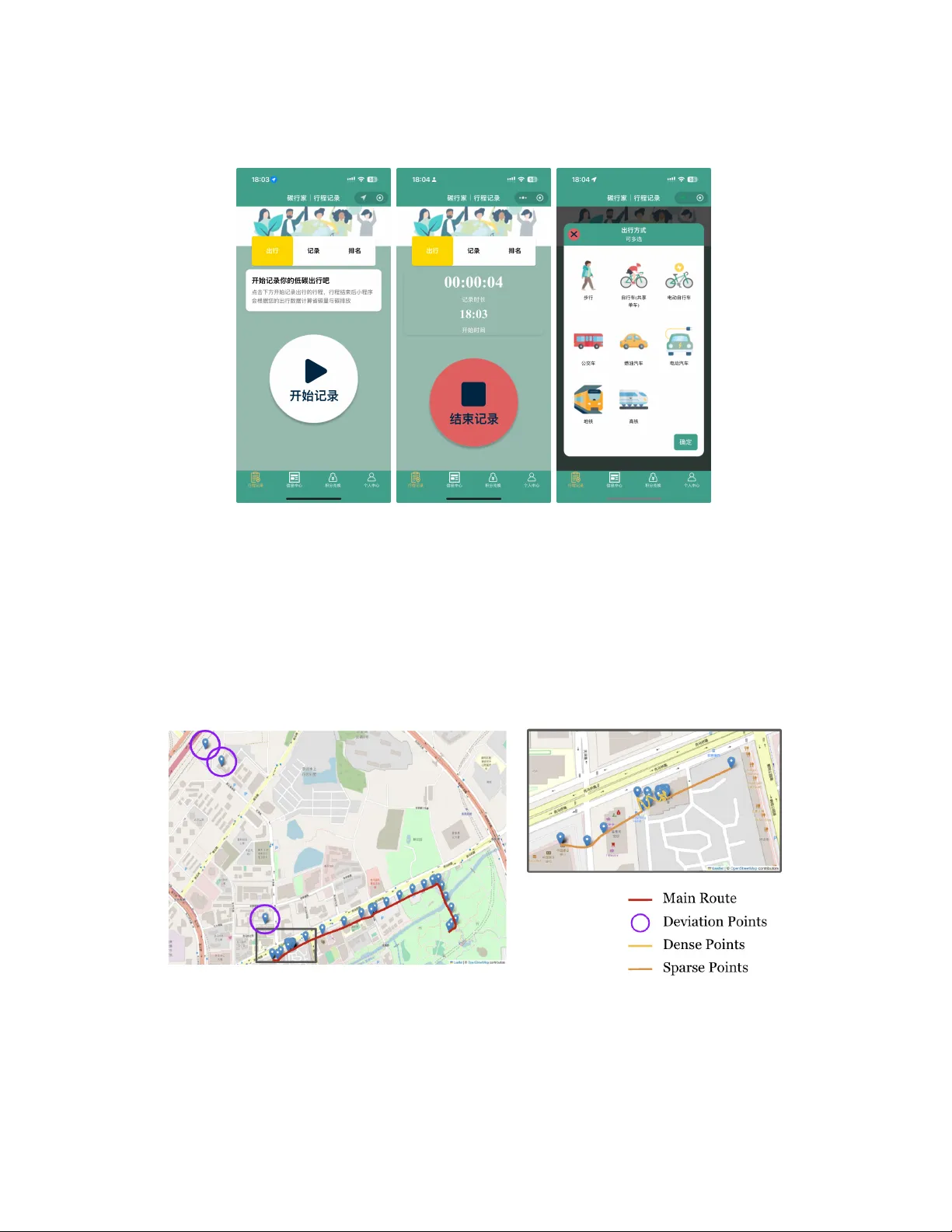
Detecting T ransportation Mode Using Dense Smartphone GPS T rajectories and T ransf ormer Models Y uandong Zhang ∗ Univ ersity of California San Diego, CA, USA Othmane Echchabi ∗ McGill Univ ersity Mila - Quebec AI Institute Montréal, QC, Canada Tianshu F eng Univ ersity of Pennsylvania Philadelphia, P A, USA W enyi Zhang Duke Kunshan Uni versity Kunshan, Jiangsu, China Hsuai-Kai Liao Duke Kunshan Uni versity Kunshan, Jiangsu, China Charles Chang † Duke Kunshan Uni versity Kunshan, Jiangsu, China Abstract T ransportation mode detection is an important topic within GeoAI and trans- portation research. In this study , we introduce S P E E D T R A N S F O R M E R , a novel T ransformer-based model that relies solely on speed inputs to infer transporta- tion modes from dense smartphone GPS trajectories. In benchmark e xperiments, S P E E D T R A N S F O R M E R outperformed traditional deep learning models, such as the Long Short-T erm Memory (LSTM) network. Moreover , the model demonstrated strong flexibility in transfer learning, achie ving high accuracy across geographical regions after fine-tuning with small datasets. Finally , we deployed the model in a real-world experiment, where it consistently outperformed baseline models under complex b uilt en vironments and high data uncertainty . These findings sug- gest that T ransformer architectures, when combined with dense GPS trajectories, hold substantial potential for advancing transportation mode detection and broader mobility-related research. Keyw ords: GeoAI; T ransformers; Dense GPS T rajectories; Deep Learning; Field Experiments; Emissions. 1 Introduction The study of human mobility patterns—ho w individuals mo ve across space—has become an important topic across geography , transportation science, public health, and climate change science [ 1 ; 2 ; 3 ; 4 ; 5 ; 6 ; 7 ; 8 ; 9 ; 10 ]. One key aspect of human mobility is transportation mode choice, the accurate estimation of which is essential for understanding individual carbon emissions and associated health benefits [11; 12]. ∗ These authors contributed equally to this w ork. † Corresponding author . Email: charles.c.chang@dukekunshan.edu.cn Accepted for publication in the International Journal of Geographical Information Science , February 2026. This is the author’ s accepted manuscript. The final version of record will appear in IJGIS (T aylor & Francis). T raditionally , transportation surv eys were used to estimate indi vidual’ s choices of transportation mode [ 13 ]. Howe ver , two major technological adv ancements in recent years ha ve reshaped transportation mode detection. First, smartphones—equipped with GPS, accelerometers, gyroscopes, and cellular network connecti vity—hav e enabled the creation of detailed mobility datasets deri ved from mobile applications [ 14 ], social media platforms [ 15 ], trav el cards [ 16 ], and cellphone signals [ 17 ]. These datasets surpassed traditional transportation surveys in dimensionality , accuracy , v ariety , and v olume [18; 19]. Second, adv ancements in machine learning (ML) have greatly impro ved the ability to e xtract mean- ingful information from mobility datasets. Machine learning techniques—from ensemble methods to deep learning models—now e xploit increasingly fine-grained spatiotemporal data, including human mobility traces, substantially improving the accuracy of transportation-mode prediction [ 20 ]. More recently , T ransformer [ 21 ] architectures are adopted for human mobility research giv en their self- attention mechanisms, which can help capture nonlinear spatiotemporal dependencies and high-order motion features. Furthermore, their capacity for inductiv e transfer enables cross-regional general- ization, potentially allo wing models to adapt to div erse transportation infrastructures using minimal labeled data. Nev ertheless, significant challenges remained. Smartphone-derived mobility datasets, while highly granular , often exhibited inconsistent quality due to the absence of standardized data collection protocols and inaccuracies in geographic information, complicating modeling process. Model perfor- mance frequently depended on deri ved features such as acceleration, while comple x preprocessing tasks—such as geocoding and geotagging—further increased data uncertainty . Moreov er , extensi ve feature engineering used to aggregate raw GPS trajectories often resulted in the loss of critical sequential information essential for accurate mobility modeling [22]. Priv acy posed another major challenge. Mobility applications commonly collected sensitiv e informa- tion, including geographic locations, trip details (e.g., start and end times), and personal or de vice identifiers. For e xample, Xu et al. [23] demonstrated that e ven anon ymized mobility data could be re-identified with 73–91% accuracy , underscoring the difficulty of ensuring priv acy protection. Such risks frequently discouraged individuals from sharing their mobility data [ 24 ], constraining data av ailability . Moreov er , mobility models have often lacked generalizability across geographic regions, particularly when trained on isolated or geographically homogeneous datasets. Human mobility behaviors v ary widely across countries and regions due to differences in road infrastructure, speed regulations, and cultural norms. Ne vertheless, most studies hav e assessed model performance using train–test splits from the same dataset [ 25 ], which fail to capture real-world adaptability . Models fine-tuned on benchmarks such as Geolife [ 26 ] frequently required substantial recalibration when applied to other contexts. The proliferation of deep learning frameworks, hyperparameter tuning strate gies, and architectural v ariations has further complicated cross-regional reproducibility in mobility modeling research [27]. Finally , existing mobility models hav e often struggled to perform reliably under real-world conditions, which are considerably more unpredictable and complex than curated research datasets suggest. Everyday trav el inv olves nuances such as short trips and unexpected errands that traditional mod- els frequently misclassified [ 20 ]. Moreov er , GPS signal quality varied across smartphone models and was highly sensitiv e to en vironmental factors, including urban canyons and signal obstruc- tions [ 28 ; 29 ]. These real-world data inconsistencies—typically underrepresented in benchmark datasets—underscore the need to v alidate mobility models under realistic conditions that reflect the full variability of human mo vement. T o address these challenges, we introduced a Transformer -based deep learning model that uses a simple input—instantaneous speed—to achie ve highly accurate transportation mode detection. W e refer to this model as S P E E D T R A N S F O R M E R . Using transportation mode classification as a case study , we demonstrate the model’ s capability and v ersatility . Our contributions are threefold. First, we show that a Transformer -based neural network can achiev e state-of-the-art performance using only speed as input. By le veraging positional encoding and multi-head attention, our model captured complex temporal patterns without elaborate feature engineering, thereby mitigating both priv acy concerns and computational demands. Second, we demonstrate robust cross-re gional generalizability through transfer learning: a model pre-trained on data primarily collected in Switzerland maintained exceptional performance when fine-tuned on samples from Beijing. Finally , we validated our approach 2 under real-world conditions by developing a novel smartphone mini-program and recruiting 348 participants for a one-month field experiment. The experimental results confirmed that our model’ s adv antages translated effecti vely from controlled en vironments to practical applications characterized by real-world uncertainty and v ariability . 2 Related W ork T ransportation mode detection represents a central dimension of human mobility research, with do wnstream applications ranging from carbon footprint estimation [ 30 ] and tourism recommendations [ 31 ] to traffic management [ 32 ] and public health interventions [ 33 ]. W ith the proliferation of GPS- enabled de vices and advances in machine learning, the field has undergone substantial progress in recent years, moving be yond traditional social scientific methods such as transportation surveys and adopting data-driven methodologies grounded in machine learning. Notable de velopments have emerged in both classical machine learning algorithms and deep learning approaches. 2.1 Machine Learning f or T ransportation Mode Detection and its Challenges Classical machine learning (ML) algorithms formed the foundation of early data-dri ven approaches to transportation mode detection. These methods typically con verted sequential GPS trajectories into statistical, tabular representations, with notable implementations including Decision T rees [ 34 ], Random Forests [ 35 ; 22 ], and Support V ector Machines [ 36 ]. Stenneth et al. [35] demonstrated the effecti veness of these models through systematic ev aluation, while Jahangiri and Rakha [22] highlighted their versatility across dif ferent transportation modes, variations, and contexts. The logic underlying classical ML algorithms was conceptually similar to that of rule-based models, which relied on indicative features computed from GPS trajectories and used them to infer travel modes statistically . For example, mobility features deri ved from dense GPS trajectories—such as average speed and acceleration rate—were often effecti ve in distinguishing between driving, walking, and cycling. Although computationally ef ficient, these approaches depended hea vily on domain expertise for feature engineering and performed poorly when handling v ariable-length inputs. In many inner -city trips, for instance, dri ving was only marginally faster than cycling, rendering average speed an unreliable discriminator . More advanced statistical features could improv e performance but required specialized expertise and local contextual knowledge that were seldom av ailable and sometimes unreliable. Moreov er , such methods posed risks to priv acy and anonymity , as ev en a small number of precise and longitudinal GPS points could be sufficient to re-identify individuals [ 37 ]. Growing concerns regarding the collection, management, and disclosure of personal GPS data, together with adv ances in re-identification techniques, hav e further raised ethical issues surrounding GPS trajectory research [ 38 ; 39 ; 40 ]. In response, scholars and regulators hav e increasingly advocated for priv acy-preserving techniques in mobility research—including applications such as transportation mode detection—as alternativ es to classical machine learning approaches that depend on rich location features and extensi ve feature engineering [41; 42; 43; 44; 45]. Recurrent neural networks (RNNs), particularly Long Short-T erm Memory (LSTM) networks [ 46 ], emerged as a dominant approach for transportation mode prediction due to their capacity to capture temporal dependencies in sequential data. Jiang et al. [47] pioneered the application of LSTMs for mobility analysis, and Asci and Guvensan [48] extended this work by incorporating attention mechanisms that improv ed performance across v aried trip lengths. Hybrid architectures combining LSTMs with other neural components further advanced model accuracy—for example, the Con v- LSTM model proposed by Nawaz et al. [49] lev eraged con volutional layers for spatial feature extraction prior to temporal processing. Other innovations included Con v olutional Neural Networks (CNNs) [ 50 ], autoregressiv e flow models [ 51 ], and semi-supervised learning approaches [ 52 ]. Despite these accuracy gains, such sophisticated architectures often required substantial computational resources and comple x pre-processing to structure data according to model specifications, thereby limiting their practicality for real-world deployment [27]. 3 2.2 T ransformers f or Mobility Modeling T ransformer architectures rev olutionized sequence modeling through their reliance on self-attention and multi-head attention mechanisms [ 53 ; 21 ]. Models such as GPT -2 [ 54 ] and BER T [ 55 ] demon- strated exceptional performance on sequence-based data, significantly surpassing classical machine learning models in capturing complex sequential patterns. This success motiv ated researchers to ex- plore whether T ransformers’ superior capacity for modeling long-range dependencies could similarly advance mobility modeling, where understanding the relationships between distant points within a trajectory is critical [56]. Recent applications of Transformer architectures to mobility studies have shown promise, although the field remains in its early stages. For example, Hong et al. [57] incorporated T ransformer components for next-location prediction while treating mode identification as a secondary task. Liang et al. [58] addressed challenges such as irregular spatiotemporal interv als but focused primarily on spatio- temporal dependencies rather than transportation mode prediction. More recently , Ribeiro et al. [59] achiev ed strong results using a vision T ransformer approach [ 60 ], although their implementation required con verting trajectories into image-based representations. Similarly , Drosouli et al. [61] con verted GPS trajectory points into word tokens to apply the original BER T model [ 55 ], achieving notable results; howe ver , this approach imposed a linguistic abstraction onto spatial data, making it less suitable for general-purpose mobility modeling. Despite these adv ances, existing T ransformer-based approaches for mobility modeling typically re- quired e xtensiv e pre-processing, multiple input features, or auxiliary contextual information—making them computationally demanding and often impractical for real-world applications where only basic GPS data are a vailable. Moreover , their generalizability across different geographical conte xts has remained largely unexplored, as most e valuations hav e focused on performance within a single dataset rather than testing transferability between regions with distinct transportation infrastructures and mobility behaviors. 3 SpeedT ransf ormer Architectur e Figure 1: Transformer architecture Our S P E E D T R A N S F O R M E R architecture adapts the Transformer encoder framework proposed by V aswani et al. [21] , incorporating sev eral key modifications to the data input, model structure, and output. First, the input sequences consist of instantaneous speeds computed from dense GPS trajectories collected via transportation applications on smartphones. These speed sequences are sampled at high frequencies—typically representing distances trav eled over fi ve to ten seconds—and therefore implicitly encoded higher-order motion features such as acceleration (the first deriv ativ e of speed) and jerk (the second deriv ati ve of speed). Given a complete speed sequence from trip start to end, each speed value serv es as a token, which is subsequently embedded and transformed into a query vector representing its relationship to all other speed positions within the sequence. Figure 1 illustrates the overall model architecture. Our model requires only raw scalar speed sequences as trajectory input. T o accommodate variable input lengths, each trajectory is segmented into fix ed- length sequences of T = 200 consecutiv e speed samples using a sliding window with a stride of 50 (see Appendix F for further discussion on windo w size selection). This segmentation is applied directly to the original speed sequences without temporal resampling, allowing the model to remain 4 robust to dif ferences in sampling frequency across datasets. 3 Shorter sequences are zero-padded, and a key-padding mask is applied to ensure that padded tokens are ignored during attention and pooling. Each scalar speed v alue s t is linearly projected into a d = 128 -dimensional embedding space (see Appendix D for details on the embedding process). The sequence of embedded speed vectors is then processed by a modified T ransformer encoder . Owing to its attention mechanism, the model is able to extract sequential dependencies—such as acceleration and jerk—from these speed embeddings, which is critical for dif ferentiating transportation modes. When trained on sufficiently lar ge empirical datasets, the model effecti vely optimizes its capacity to detect transportation modes. W e replace the standard sinusoidal positional encoding with Rotary Positional Embeddings (RoPE), which is applied directly to the query ( Q ) and key ( K ) vectors in the attention mechanism [ 62 ]. RoPE encodes positional information through position-dependent rotations indexed by the sequence order , enabling the attention mechanism to model relative temporal dependencies in a continuous and rotation-in variant manner . This formulation is particularly well-suited for sequential mobility signals such as speed trajectories, where relative temporal structure is more informati ve than absolute position. The encoder consists of L = 4 Pre-Norm Transformer blocks. Each block contains two key components: a Grouped-Query Attention (GQA) layer [ 63 ], which efficiently computes attention by grouping multiple query vectors per ke y–value pair , and a SwiGLU-activ ated feed-forward sublayer [ 64 ] that introduces non-linear transformations with improved gradient flo w and expressivity (see Appendix E for a detailed explanation of SwiGLU). The computation within each block is expressed as follows: z 1 = x + Dropout ( GQA ( LayerNorm ( x ))) , (1) z 2 = z 1 + Dropout ( FFN SwiGLU ( LayerNorm ( z 1 ))) , (2) Equation 1 describes the attention sub-layer , in which the input representation x ∈ R T × d (a sequence of T tokens, each of dimension d ) is first normalized using layer normalization before being passed to the GQA mechanism. GQA di vides the h query heads into h kv groups, each group sharing a single k ey–v alue pair . This interpolates between multi-head and multi-query attention; using an intermediate number of groups retains much of the quality of multi - head attention while reducing memory and compute cost. W e set h = 8 query heads and h kv = 4 key/v alue heads in our experiments. Equation 2 represents the feed-forward transformation that follo wed the attention mechanism. The intermediate output z 1 is normalized again and passed through a SwiGLU-activ ated feed-forward network, FFN SwiGLU ( · ) , which introduces non-linear transformations to enhance representational capacity while maintaining computational efficienc y . Each layer applies layer normalization before both the attention and the feed - forward sub - layers and uses dropout on the sub - layer outputs before adding them back to the residual input, following the “residual dropout” strategy of the original T ransformer W e employ h = 8 query heads and h kv = 4 shared key/v alue heads, following the formulation of Ainslie et al. [63] . This design reduces both memory usage and computational cost by allowing multiple query heads to share the same k ey and v alue projections while preserving di versity across query subspaces. RoPE is applied to Q and K before computing scaled dot-product attention, and padding masks are introduced to ensure that zero-padded tok ens did not contribute to the attention weights. After the encoder stack, a final layer normalization is applied, producing the sequence representation Z = [ z 1 , . . . , z T ] . The contextualized sequence is then aggregated through attention pooling. Specifically , each timestep embedding z t receiv es a learnable scalar attention score e t , which is 3 For the details of temporal sampling frequenc y , see Appendix L. 5 normalized using a masked softmax function across v alid time-steps to obtain weights α t : e t = w ⊤ a z t + b a , (3) α t = exp( e t ) · M t P T τ =1 exp( e τ ) · M τ , (4) where w a and b a are learnable parameters, and M t ∈ { 0 , 1 } is the mask for padding tokens. The pooled sequence embedding c is computed as the weighted sum c = P T t =1 α t z t . Finally , after dropout regularization, c is passed through a linear projection layer to produce the probability distribution ˆ y : ˆ y = softmax ( W c + b c ) , (5) where W c and b c represent the classifier weights and bias. 4 Datasets Figure 2: Data Pre-Processing W e utilized two longitudinal tracking datasets—the widely adopted Geolife dataset [ 26 ] and the Swiss MOBIS dataset [ 65 ]—which of fered complementary strengths for ev aluating our model. Summary statistics are presented in T able 1. As illustrated in Figure 2, we standardized their data structures through a unified pre-processing pipeline: we consolidated transportation modes into fiv e consistent categories (Bike, Bus, Car , T rain, W alk), unified the trajectory input format across datasets, excluded multi-model trajectories, con verted geographic coordinates into speed sequences, removed abnormal trips with erroneous location data, and standardized transportation mode labels. Detailed descriptions of the pre-processing procedures and raw dataset statistics are pro vided in Appendix A. 4.1 MOBIS Dataset The MOBIS dataset [ 14 ] was deriv ed from an eight-week randomized controlled trial (RCT) on transport pricing in v olving 3,680 participants in Switzerland. Each participant used the Catc h-my-Day mobile application (av ailable for both iOS and Android), which continuously recorded GPS data via the de vice’ s location services. The application captured daily trav el patterns, storing raw trajectory data locally before uploading them to the MotionT ag analytics platform, where trip segmentation and T able 1: Comparison of MOBIS and Geolife Datasets Mode Data Points Unique T rips MOBIS Geolife MOBIS Geolife Bike 4,251,028 746,098 40,171 1,555 Bus 4,606,409 1,061,196 74,324 1,847 Car 88,965,473 627,047 542,078 1,293 T rain 8,379,962 788,250 130,964 772 W alk 38,463,266 1,215,054 743,425 3,960 T otal 144,666,138 4,437,645 1,530,962 9,427 6 transportation mode inference were performed. This extensiv e data collection process produced 255.3 million GPS records and 1.58 million labeled trips in the raw dataset. After applying our standardized pre-processing pipeline described in Appendix A, the resulting MOBIS dataset contained 144.7 million data points across 1.53 million unique trips distrib uted among fiv e transportation modes, as summarized in T able 1. 4.2 Geolife Dataset Geolife [ 26 ] was a widely used benchmark in transportation mode research, collected by Microsoft Research Asia from 182 users in Beijing o ver a fi ve-year period (2007–2012). The dataset captured urban mobility through 17,000 trajectories covering approximately 1.2 million kilometers across Beijing’ s comple x transportation network. Data were recorded using v arious GPS loggers and GPS- enabled phones with dif ferent sampling rates, with 91% of trajectories collected at high density (e very 1–5 seconds or ev ery 5–10 meters). In addition to routine commutes, the Geolife dataset included leisure and sports activities such as shopping, sightseeing, and cycling, offering rich contextual div ersity in trip purposes. After pre-processing to align with the MOBIS data structure, the Geolife dataset contained 4.44 million data points and 9,427 unique trips—substantially smaller than MOBIS, yet providing v aluable geographical and temporal div ersity for ev aluating our model’ s performance. 5 Experiments W e ev aluated S P E E D T R A N S F O R M E R under three experimental conditions. First, we benchmarked it against state-of-the-art transportation mode identification models on Geolife [ 26 ], enabling direct comparison with existing approaches. Second, we e xamined performance consistency across dif ferent geographical contexts by comparing it with classical LSTM baseline models on both the Swiss (MOBIS) [ 65 ] and Chinese (Geolife) datasets. Finally , we assessed cross-regional transferability through fine-tuning experiments, in which models pretrained on Swiss data were adapted to Chinese mobility patterns using small sample subsets. 5.1 Benchmarking Perf ormance T o e v aluate SpeedT ransformer’ s ability to achie ve high accurac y with minimal input, we benchmarked against se veral state-of-the-art transportation mode identification models: • LSTM-Attention (Baseline) : Our reconstructed baseline model implementing a classical bidirectional LSTM with attention mechanism [ 46 ]. This baseline is specifically designed to test whether pure attention-based mechanisms outperform recurrent networks augmented with attention, while maintaining the same minimal input requirement (speed only). • Deep-V iT [ 59 ]: A V ision T ransformer approach that transforms GPS features (speed, acceleration, bearing) into image representations using DeepInsight methodology before processing with a V ision Transformer architecture, combining traditional feature engineering with advanced deep learning. • CE-RCRF [ 66 ]: A sequence-to-sequence framew ork (T aaS) that processes entire trajectories using a Con v olutional Encoder to extract high-le vel features and a Recurrent Conditional Random Field to maintain contextual information at both feature and label lev els, with specialized bus-related features to distinguish high-speed modes. • LSTM-based DNN [ 67 ]: An ensemble of four LSTM networks that incorporates both time- domain trajectory attributes and frequency-domain statistics dev eloped through discrete Fourier and wa velet transforms, creating a semi-supervised deep learning approach. • SECA [ 52 ]: A Semi-supervised Conv olutional Autoencoder that integrates a con volutional- decon volutional autoencoder with a CNN classifier to simultaneously le verage labeled and unlabeled GPS segments, automatically e xtracting relev ant features from 4-channel tensor representations. • Con vLSTM [ 49 ]: A hybrid architecture that uses con volutional layers to extract spatial features from GPS data, follo wed by LSTM layers to capture temporal patterns, incorporating both location and weather features to enhance mode detection. 7 T able 2: T est Accuracy Comparison on Geolife (Ordered by Performance) Model T est Acc. (%) SpeedT ransformer (Ours) 95.97 Deep-V iT [59] 92.96 LSTM-based DNN [67] 92.70 LSTM-Attention (Baseline) 92.40 CE-RCRF [66] 85.23 SECA [52] 84.80 Con vLSTM [49] 83.81 All models were ev aluated on the Geolife dataset using identical initial pre-processing and train-test splits. W e have also added architectural comparison between our model and Transformer -based Deep-V iT in Appendix M.T able 2 presents the test accuracies ranked from highest to lo west. S P E E D T R A N S F O R M E R achieved the highest test accurac y of 95.97%, outperforming all competing approaches despite using only speed as input. Deep-V iT (92.96%) and the LSTM-based DNN (92.70%) achieved strong results but required more complex pre-processing or architectural com- ponents. Our LSTM-Attention baseline (92.40%) demonstrated that while recurrent netw orks with attention could capture temporal patterns effecti vely , they still lagged behind the pure attention-based design of S P E E D T R A N S F O R M E R in predicting complex mobility patterns. The lo wer-ranked models illustrated dif ferent architectural trade-offs. The CNN-ensemble extracted localized spatial patterns but struggled with sequential dependencies; ConvLSTM impro ved temporal modeling through its hybrid design but faced generalization challenges; and CE-RCRF treated trajectories as continuous sequences yet was hindered by architectural complexity . W e also e valuated a simple rule-based model using the same process and found that it performed substantially w orse than all machine learning models (Appendix H). T o further assess performance consistency across datasets, we compared S P E E D T R A N S F O R M E R with our LSTM-Attention baseline on both the Geolife and MOBIS datasets. Figures 3 and 4 show that S P E E D T R A N S F O R M E R not only con ver ged faster and achie ved higher v alidation accuracy b ut also maintained superior F1-scores across all transportation modes. The F1-score in Figure 4, which examines accurac y by class, provided a more granular and reliable measure of model performance under class imbalance. Moreover , T able 3 presents a detailed comparison of precision and recall between S P E E D T R A N S F O R M E R and Deep-V iT—the most competiti ve alternati ve—demonstrating that S P E E D T R A N S F O R M E R achiev ed a more balanced trade-off between precision and recall across datasets, underscoring its robustness and generalizability . S P E E D T R A N S F O R M E R demonstrated two significant advantages o ver the LSTM-Attention baseline: faster con ver gence and higher accuracy across both datasets. As shown in Figure 4, the model consistently achiev ed higher validation accuracies throughout training, reaching 94.22% accuracy on MOBIS compared to 92.33% for the LSTM-Attention model. The faster con ver gence was particularly valuable when w orking with large-scale mobility datasets such as MOBIS, where training efficienc y was critical. W e also observed that S P E E D T R A N S F O R M E R achieved superior per-class F1-scores across all transportation modes in both the Geolife and MOBIS datasets. Class-wise error patterns are further summarized by the confusion matrices (Figure N6) and per-class F1 score (Figure N7) in Appendix N. Across different freezing strate gies and experimental settings, S P E E D T R A N S F O R M E R consistently outperforms the LSTM baseline, demonstrating robust performance, as shown in T a- bles C4, C5, C6, C7, and C8. Although the model required GPU resources, it remained relativ ely efficient, completing both training and inference on a single GPU node (Appendix I). 5.2 Cross-Regional T ransferability Learning from ra w trajectories was feasible for all models, including rule-based approaches. Howe ver , deep learning architectures such as T ransformers achie ved state-of-the-art accuracy through inducti ve transfer and fine-tuning of pretrained models [ 68 ]. This transfer-learning approach was particularly advantageous when cross-regional dif ferences in transportation networks and traf fic dynamics pro- 8 T able 3: V alidation Precision and Recall Comparison between Deep-V iT and SpeedTransformer on Geolife Mode Deep-V iT SpeedT ransformer Precision (%) Recall (%) Pr ecision (%) Recall (%) W alk 95.04 96.12 96.72 99.90 Bike 93.79 91.40 98.54 95.45 Bus 89.68 91.13 98.14 95.49 Car 88.96 87.26 87.33 93.65 T rain 90.00 79.41 95.66 92.93 Macro A vg. 91.89 89.86 95.68 95.08 T able 4: Model Accuracy during Cross-Dataset Fine-T uning from MOBIS to Small Geolife Subsets Model 100 trips 200 trips LSTM-Attention 75.47% 79.15% SpeedT ransformer 80.53% 86.13% duced distinct patterns of transportation modes. T o e v aluate model transferability , we fine-tuned the MOBIS-pretrained models on small subsets of the Geolife dataset to simulate lo w-shot adaptation. Both S P E E D T R A N S F O R M E R and LSTM-Attention were fine-tuned on 100 and 200 Geolife trips (approximately 1.1% and 2.2% of the dataset, respectiv ely) for 20 epochs and were subsequently ev aluated on the remaining samples. T able 4 reports the overall classification accurac y . Fine-tuning followed a standardized lo w-shot protocol using MOBIS-pretrained checkpoints. For S P E E D T R A N S F O R M E R , the encoder and attention layers were frozen, and training was performed with mixed precision for up to 20 epochs. The LSTM-Attention baseline was fine-tuned with smaller batch sizes, a lo wer learning rate, stronger regularization (dropout = 0.3, weight decay = 5e-3), and gradient clipping at 0.25. Hyperparameters were selected through a grid search to ensure optimal stability under limited supervision (see Appendix C). S P E E D T R A N S F O R M E R achieved 80.53% accuracy with only 100 trips, surpassing LSTM-Attention by more than fiv e percentage points, and further improv ed to 86.13% with 200 trips. These results confirmed its superior capacity to transfer learned mobility representations across regions with minimal labeled data. Figure 3: V alidation accuracies ov er epochs for Geolife and MOBIS. The SpeedTransformer consis- tently con ver ges faster and achie ves higher ov erall accuracy than the LSTM-Attention baseline on both datasets. 9 6 Real-W orld Field Experiment Having established S P E E D T R A N S F O R M E R ’ s superior accuracy , minimal input requirements, and strong cross-regional transferability , we next e valuated its rob ustness under real-world conditions, where GPS data were inherently noisy , irregular , and device-dependent. While curated benchmarks provided clean and controlled comparisons, they did not capture the complexities of real-world mobility data, which were subject to signal loss, user heterogeneity , and hardware variability . T o address this gap, we conducted a large-scale field experiment to assess S P E E D T R A N S F O R M E R ’ s reliability in real-world en vironments characterized by high uncertainty and unpredictability . 6.1 Smartphone Application and Data Collection W e devel oped CarbonClever , a W eChat-inte grated mini-program designed to estimate individual carbon footprints through continuous mobility tracking. 4 The application provided a streamlined interface for trip initiation, real-time monitoring, and post-trip mode v erification (Figure 5). A total of 348 participants from Jiangsu, China, were recruited through an en vironmental organization to record their daily mov ements. 5 Real-world GPS traces dif fered substantially from those collected under laboratory conditions. The sampling frequencies varied widely: older iPhone SE models recorded locations ev ery 30–60 s, whereas newer iPhone 14 Pro devices achiev ed 5–10 s intervals under identical conditions (see Appendix L for full temporal sampling comparison). As shown in Figure 6, trajectories exhibited irregular sampling densities, signal dropouts, and spurious positional jumps caused by multi-path ef fects or indoor transitions. Unlike benchmark datasets, we intentionally retained these imperfections to ev aluate the model’ s rob ustness under realistic deployment conditions. 6.2 Field Experiment Evaluation W e conducted a one-month field experiment from November 18, 2023 to December 23, 2024 that collected 649 verified trips totaling 108,823 GPS points from heterogeneous devices across both iOS and Android platforms, ensuring representati ve v ariability in sampling rates and noise profiles (see Appendix B for detailed data pre-processing). T o assess real-w orld adaptability , we fine-tuned MOBIS-pretrained SpeedTransformer and LSTM-Attention models using progressively larger subsets 4 A W eChat mini-program is a lightweight application embedded within the W eChat ecosystem. Functionally similar to a simplified smartphone app, the mini-program operates on top of the W eChat super -app, which is ubiquitously used in China. This integration enabled efficient participant recruitment and minimized testing costs across different mobile operating systems and de vice platforms. 5 The experiment was approv ed by the Duke Kunshan University Institutional Re view Board (protocol 2022CC073). See Appendix J for protocol summary . Figure 4: Per class F1-Score for Geolife and MOBIS trainings using SpeedT ransformer and LSTM. The SpeedT ransformer consistently achiev es better results than the LSTM-Attention across all classes on both datasets. 10 T able 5: Summary of the Mini-Program Dataset Mode Number of Data Points Number of Unique T rips W alk 28,985 100 Bus 32,547 259 Car 40,885 205 Bike 4,901 36 T rain 1,505 49 T otal 108,823 649 T able 6: Fine-T uning Accuracies of Models with Real-W orld Data Subsets (5-fold CV ; mean ± std, % accuracy) Data Subset (%) LSTM-Attention Acc. (%) SpeedT ransf ormer Acc. (%) 40% (251 trips) 88 . 79 ± 2 . 15 90 . 27 ± 2 . 04 50% (314 trips) 88 . 82 ± 1 . 32 89 . 98 ± 2 . 55 60% (377 trips) 89 . 34 ± 1 . 86 90 . 40 ± 2 . 17 70% (440 trips) 90 . 04 ± 2 . 26 91 . 72 ± 3 . 27 80% (502 trips) 89 . 30 ± 2 . 52 90 . 11 ± 4 . 54 of the collected data. Each model was trained for up to 20 epochs with early stopping and identical hyperparameter configurations deri ved from the grid search (Appendix C). SpeedT ransformer consistently outperformed the LSTM-Attention baseline across all real-world training subsets (T able 6). Results are reported using 5-fold cross-validation, with v alues shown as mean ± standard de viation of accuracy across folds. SpeedTransformer achiev ed its best performance at the 70% subset ( 91 . 72 ± 3 . 27 %), while LSTM-Attention peaked at 90 . 04 ± 2 . 26 %. Overall, these real-world results reinforce our earlier findings: SpeedT ransformer remains more accurate under genuine, noisy , and de vice-di verse GPS trajectories, helping bridge the gap between research prototypes and operational smart-mobility applications. W e also expanded our modeling experiments to include a per-class analysis, gi ven that our field- experiment data are imbalanced and contain relatively fe w observations for bikes and trains. This imbalance negati vely af fected classification accuracy for these modes, resulting in accuracies belo w 0.8, as sho wn in Figure N7. Nev ertheless, the per -class accuracies for bikes and trains still exceed 0.5, while the remaining classes maintain very high accuracies abo ve 0.9. 11 (a) T racking initiation (b) Active tracking (c) T rip completion Figure 5: T rip tracking interface in the CarbonCle ver application: (a) T rip initiation screen, where users start a new trip recording. (b) Activ e tracking screen showing real-time trip duration and status. (c) T rip completion and mode confirmation screen, where users select and v erify the transportation mode. All interface texts are originally in Chinese. Figure 6: Example of real-world GPS trajectories. The red line indicates the main route, with varying point density reflecting heterogeneous sampling frequencies. Purple circles mark signal interference and positioning noise. 12 7 Discussion and Conclusion Our research addressed three fundamental challenges in transportation mode detection: (1) the reliance on extensi ve feature engineering and input pre-processing, (2) limited model generalizability across distinct geographical contexts, and (3) insufficient and unpredictable real-world v alidation. By achieving state-of-the-art performance in transportation mode detection, our work demonstrated that T ransformer-based neural network architectures, when coupled with high-quality training data, could substantially improv e mode detection from GPS trajectories. More broadly , this approach had the potential to e xtract information from a wide range of mobility-based sequence data, and it contributed to a growing body of literature on transportation mode detection and its do wnstream applications in transportation research, GIS, urban analytics, and climate change science. Compared to classical and deep ML methods [ 59 ; 66 ; 67 ; 52 ; 49 ], S P E E D T R A N S F O R M E R outper- formed feature-rich models despite using only speed as input. Across dif ferent hyperparameter configurations, our model consistently outperformed the LSTM-Attention baseline by 2–3% (Ap- pendix C) and surpassed sev eral other machine learning models by more than 10% (T able 2). It also outperformed the classical rule-based model, which relied solely on speed, by ov er 30% (Ap- pendix H). This suggests that the Transformer -based model is highly ef fectiv e at extracting useful information from dense speed sequences that would otherwise underutilized, and it outperforms simpler deterministic model, classical machine-learning models, as well as other deep learning models. The model’ s strong performance w as largely attrib utable to its attention mechanism (Appendix G). Nev ertheless, our integration of S W I G L U activ ation, Grouped-Query Attention, and pre-attention Layer Normalization yielded modest yet consistent performance improvements, aligning with the findings of Shazeer [64] and T ouvron et al. [69] . Consistent with Y u and W ang [70] , our results further indicated that deeper neural netw ork architectures were better suited to capturing the semantic and sequential structures embedded within GPS trajectories. Moreov er , this strong performance relied solely on instantaneous speed, without requiring GPS coordinates or additional engineered features. This architectural choice offered se veral adv antages: it mitigates the direct exposure of sensitive location data by decoupling motion dynamics from absolute geographic coordinates[ 44 ; 37 ]. Specifically , we quantify this pri vac y benefit by contrasting the information entropy required to resolve a spatial position versus that of a speed observation. Because speed is a kinematic scalar inherently decoupled from raw geographic coordinates, it significantly limits the information av ailable to a data-profiling adversary (for detailed discussion see Appendix K. In addition, using only speed as model input simplified preprocessing procedures, thereby enhancing reproducibility across various mobile de vices and geographical contexts [71]. Furthermore, S P E E D T R A N S F O R M E R exhibited strong cross-regional transferability . In the out-of- domain e valuation, it surpassed the LSTM-Attention model by 7% (T able 4), demonstrating rob ust generalizability across distinct geographical and transportation contexts—from Swiss transportation systems (MOBIS) to Chinese urban environment (Geolife). T ravel behaviors varied substantially between these regions, and the two datasets were collected nearly a decade apart, introducing con- siderable dif ferences in travel patterns across modes such as train, cycling, and automobile use. Remarkably , with only 100 fine-tuning trips, S P E E D T R A N S F O R M E R achieved satisf actory accuracy (80.53%) on Geolife after pretraining on MOBIS. These findings suggested that S P E E D T R A N S - F O R M E R captured fundamental patterns of human mobility that persisted across infrastructural settings and regional mobility cultures. Finally , to bridge the g ap between research prototypes and real-world implementation, we validated S P E E D T R A N S F O R M E R in a large-scale real-world e xperiment via our self designed CarbonCle ver W eChat Mini-Program on personal smartphones. This mobile application collected GPS trajectories from 348 participants across div erse smartphones and operating systems in Jiangsu. This validation provides a third geographic context, representing mid-tier Asian cities that differ significantly in infrastructural scale and traffic dynamics from the European (MOBIS) and megacity (Geolife) en vironments. This dataset included unpredictable real world conditions, irregular sampling interv als, signal interferences and de vice-specific noises. S P E E D T R A N S F O R M E R consistently outperformed the LSTM-Attention baseline across all fine-tuning results, achieving 94.22% accuracy with 50% of the real-world training data, compared to 87.57% for LSTM-Attention. While accuracy decreased 13 slightly due to data irregularities, S P E E D T R A N S F O R M E R retained high stability across transportation modes, confirming its robustness for practical deplo yment. A key limitation of T ransformer -based models, including S P E E D T R A N S F O R M E R , was their sensiti vity to training data quality . As sho wn in T able 3 and Figure 4, the model performed less ef fectiv ely for the T rain class in the MOBIS dataset, where data imbalance and under-representation reduced its ability to generalize. As V an Hulse et al. [72] noted, class imbalance posed significant challenges to ML accuracy . Still, by pretraining on the larger , more balanced MOBIS dataset and fine-tuning on the smaller , imbalanced Geolife subsets, S P E E D T R A N S F O R M E R maintained strong predicti ve accuracy with minimal performance degradation under distrib utional shift. The model performed even better using our real-world experimental data, achie ving an accuracy of 89.12% with just 94 training trips, compared to 86.13% in the Geolife fine-tuning task using 200 training trips (T able 6). These results underscored the model’ s adaptability to data-sparse and heterogeneous mobility environments. These results underscored the model’ s adaptability to data-sparse and heterogeneous mobility en vironments. In addition, despite the priv acy adv antages of speed-only inputs, the approach is not entirely immune to sophisticated pri vacy attacks. Although our model a voids collecting ra w coordinates, sequential speed profiles can, in some cases, inadvertently rev eal identifiable behavioral patterns [ 73 ]. 6 If an adversary possesses extensi ve side-channel information, such as high-resolution traffic flo w databases or signal timing schedules, they could theoretically attempt to match a specific speed profile to a known corridor , potentially inferring coarse-grained route information. Future work can in vestigate the integration of enhanced techniques, such as differential priv acy and federated learning, to provide formal guarantees against such attacks. W e also conducted a targeted failure analysis (Appendix O) focusing on the T rain class, whose accuracy is notably lo wer than that of other classes. In MOBIS, the train cate gory encompasses multiple train modes—such as under ground subway , tram, and metro-style services—and is some- times intermixed with trajectories that resemble car or bus tra vel. As a result, the associated speed profiles become difficult to separate. These findings suggest that either more sophisticated models or additional mode-specific training data may be needed to further improv e classification performance. Finally , the inherent opacity of the T ransformer architecture poses a limitation regarding its interpretability-specifically the dif ficulty of attributing learned patterns to interpretable mobility features such as acceleration bursts, stop durations, or route choices. Future research could in vestigate hybrid architectures that inte grate Transformer attention mechanisms with physically interpretable mobility features and extend the framew ork to incorporate contextual signals—such as weather , traffic density , and land use—for do wnstream mobility tasks, including origin–destination flow estimation and route-lev el analysis. In addition, expanding ev aluation to regions with dif ferent road infrastructures and behavioral norms could further v alidate model uni versality . The original datasets of MOBIS and Geolife can be found at their respective project websites: the MO- BIS dataset (https://www .research-collection.ethz.ch/handle/20.500.11850/553990) and the Geolife dataset (https://www .microsoft.com/en-us/research/publication/Geolife-gps-trajectory-dataset-user - guide/), both accessible on May 26, 2025. Acknowledgments W e thank the Institute for T ransport Planning and Systems at ETH Zürich for providing the data used in our model training. W e are also grateful to Y ucen Xiao, Peilin He, Zhixuan Lu, Y ili W en, Shanheng Gu, Ziyue Zhong, and Ni Zheng for their excellent research assistance. This project was supported by the 2024 K unshan Municipal Ke y R&D Program under the Science and T echnology Special Project (No. KS2477). ChatGPT 5 was used solely for grammar checking. All remaining errors are our own. Disclosure statement No potential conflict of interest was reported by the author(s). 6 In our real-world experiment, ho wev er , all participants lived in dense urban areas , where individual speed profiles were effecti vely unrecognizable among hundreds of thousands of co-residents. 14 Data and codes a vailability statement Replication data and code can be found at: https://github.com/othmaneechc/ SpeedTransformer . The repository pro vides source code for data processing, model train- ing and ev aluation. W e have also prepared two Colab notebooks: one with the main results and most appendix results at https://shorturl.at/dzVkb , and another with the remaining appendix results at https: //shorturl.at/XZcB8 . The original datasets of MOBIS and Geolife can be found at their respecti ve project web- sites: the MOBIS dataset ( https://www.research- collection.ethz.ch/handle/20.500. 11850/553990 ) and the Geolife dataset ( https://www.microsoft.com/en- us/research/ publication/Geolife- gps- trajectory- dataset- user- guide/ ), both accessed on May 26, 2025. Additional inf ormation Funding This project was supported by the 2024 Kunshan Municipal K ey R&D Program under the Science and T echnology Special Project (No. KS2477). Notes on contributors Y uandong Zhang Y uandong Zhang is a master’ s student in Computer Science at the Uni versity of California, San Diego, USA. His research interests include deep learning and generativ e AI. He contributed to conceptualisation, methodology , softw are, validation, and writing – original draft. Othmane Echchabi Othmane Echchabi is a master’ s student in Computer Science affiliated with Mila – Quebec AI Institute and McGill Univ ersity , Canada. His research focuses on deep learning and spatial image processing. He contributed to conceptualisation, methodology , software, v alidation, and writing – original draft. Tianshu F eng T ianshu F eng is a master’ s student in Data Science at the University of Pennsylvania, USA. His interests include data engineering and experimental workflo ws for machine learning. He contributed to software, data curation, and writing – re view & editing. W enyi Zhang W enyi Zhang is an under graduate student at Duke Kunshan Uni versity , China. Her interests include data processing and applied machine learning. She contributed to software and data curation. Hsuai-Kai Liao Hsuai-Kai Liao is an undergraduate student at Duke Kunshan Uni versity , China. His interests include data science and computational experimentation. He contributed to software and v alidation. Charles Chang Charles Chang is an Assistant Professor of En vironment and Urban Studies at Duke Kunshan Univ ersity , China. His research focuses on computational social science, geospatial analysis, and deep learning applications. He contributed to conceptualisation, supervision, funding acquisition, and writing – revie w & editing. 15 References [1] Marta C Gonzalez, Cesar A Hidalgo, and Albert-Laszlo Barabasi. Understanding individual human mobility patterns. natur e , 453(7196):779–782, 2008. [2] Nadine Schuessler and Kay W Axhausen. Processing raw data from global positioning systems without additional information. T r ansportation Resear ch Recor d , 2105(1):28–36, 2009. [3] Zhenxing Y ao, Y u Zhong, Qiang Liao, Jie W u, Haode Liu, and Fei Y ang. Understanding human activity and urban mobility patterns from massive cellphone data: Platform design and applications. IEEE Intelligent T ransportation Systems Magazine , 13(3):206–219, 2020. [4] Shih-Lung Sha w , Ming-Hsiang Tsou, and Xinyue Y e. Human dynamics in the mobile and big data era. International J ournal of Geographical Information Science , 30(9):1687–1693, 2016. [5] Giov anni Bonaccorsi, Francesco Pierri, Matteo Cinelli, Andrea Flori, Alessandro Galeazzi, Francesco Porcelli, Ana Lucia Schmidt, Carlo Michele V alensise, Antonio Scala, W alter Quattrociocchi, et al. Economic and social consequences of human mobility restrictions under covid-19. Pr oceedings of the national academy of sciences , 117(27):15530–15535, 2020. [6] Celia McMichael. Human mobility , climate change, and health: Unpacking the connections. The Lancet Planetary Health , 4(6):e217–e218, 2020. [7] Hugo Barbosa, Surendra Hazarie, Brian Dickinson, Aleix Bassolas, Adam Frank, Henry Kautz, Adam Sadilek, José J Ramasco, and Gourab Ghoshal. Uncovering the socioeconomic facets of human mobility . Scientific r eports , 11(1):8616, 2021. [8] Matthew Zook, Menno-Jan Kraak, and Rein Ahas. Geographies of mobility: applications of location-based data. International Journal of Geographical Information Science , 29(11): 1935–1940, 2015. doi: 10.1080/13658816.2015.1061667. URL https://doi.org/10.1080/ 13658816.2015.1061667 . [9] Bin Guo, Zhu W ang, Zhiwen Y u, Y u W ang, Neil Y Y en, Runhe Huang, and Xingshe Zhou. Mobile crowd sensing and computing: The revie w of an emerging human-powered sensing paradigm. A CM computing surve ys (CSUR) , 48(1):1–31, 2015. [10] Y aguang T ao, Alan Both, and Matt Duckham. Analytics of movement through checkpoints. International Journal of Geo graphical Information Science , 32(7):1282–1303, 2018. [11] Bastien Girod, Detlef P v an V uuren, and Bert de Vries. Influence of trav el behavior on global co2 emissions. T r ansportation Resear ch P art A: P olicy and Practice , 50:183–197, 2013. [12] Mehrdad T ajalli and Ali Hajbabaie. On the relationships between commuting mode choice and public health. J ournal of T ransport & Health , 4:267–277, 2017. [13] Zijia W ang, Feng Chen, and T aku Fujiyama. Carbon emission from urban passenger trans- portation in beijing. T ransportation Resear ch P art D: T ransport and En vir onment , 41:217–227, 2015. [14] Joseph Molloy , Alberto Castro, Thomas Götschi, Beaumont Schoeman, Christopher Tcher- venko v , Uros T omic, Beat Hintermann, and Kay W . Axhausen. The MOBIS dataset: a large GPS dataset of mobility behaviour in Switzerland. T ransportation , 50(5):1983– 2007, October 2023. ISSN 1572-9435. doi: 10.1007/s11116- 022- 10299- 4. URL https: //doi.org/10.1007/s11116- 022- 10299- 4 . [15] Daniel Preotiuc-Pietro and T rev or Cohn. Mining user beha viours: A study of check-in patterns in location based social networks. In Pr oceedings of the 3r d Annual A CM W eb Science Confer ence (W ebSci 2013) , 2013. doi: 10.1145/2464464.2464479. [16] Jason B. Gordon, Harilaos N. Koutsopoulos, Nigel H. M. W ilson, and John P . Attanucci. Automated inference of linked transit journeys in london using fare-transaction and vehicle location data. T ransportation Resear ch Recor d , 2343:17 – 24, 2013. URL https://api. semanticscholar.org/CorpusID:109903480 . 16 [17] Xin Lu, Linus Bengtsson, and Petter Holme. Predictability of population displacement after the 2010 haiti earthquake. Pr oceedings of the National Academy of Sciences , 109(29):11576–11581, 2012. [18] H. Barbosa, F . B. de Lima-Neto, A. Evsukof f, et al. The effect of recency to human mobility . EPJ Data Science , 4:21, 2015. doi: 10.1140/epjds/s13688- 015- 0059- 8. URL https://doi. org/10.1140/epjds/s13688- 015- 0059- 8 . [19] Michael F Goodchild. The quality of big (geo) data. Dialogues in Human Geography , 3(3): 280–284, 2013. [20] Luca Pappalardo, Ed Manle y , V edran Sekara, and Laura Alessandretti. Future direc- tions in human mobility science. Natur e Computational Science , 3(7):588–600, 2023. ISSN 2662-8457. doi: 10.1038/s43588- 023- 00469- 4. URL https://doi.org/10.1038/ s43588- 023- 00469- 4 . [21] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser , and Illia Polosukhin. Attention is all you need. arXiv pr eprint arXiv:1706.03762 , 2017. doi: 10.48550/arXiv .1706.03762. URL . [22] Arash Jahangiri and Hesham A. Rakha. Applying Machine Learning T echniques to T rans- portation Mode Recognition Using Mobile Phone Sensor Data. IEEE T ransactions on In- telligent T r ansportation Systems , 16(5):2406–2417, October 2015. ISSN 1558-0016. doi: 10.1109/TITS.2015.2405759. URL https://ieeexplore.ieee.org/document/7063936 . Conference Name: IEEE Transactions on Intelligent T ransportation Systems. [23] Fengli Xu, Zhen T u, Y ong Li, Pengyu Zhang, Xiaoming Fu, and Depeng Jin. Trajectory recov ery from ash: User priv acy is not preserv ed in aggregated mobility data. In Pr oceedings of the 26th international conference on world wide web , pages 1241–1250, 2017. doi: https: //doi.org/10.1145/3038912.3052620. [24] M. Rzesze wski and P . Luczys. Care, indifference and anxiety—attitudes toward location data in everyday life. ISPRS International Journal of Geo-Information , 7(10):383, 2018. doi: 10.3390/ijgi7100383. URL https://doi.org/10.3390/ijgi7100383 . [25] Ziliang Zhao, Shih-Lung Shaw , Y ang Xu, Feng Lu, Jie Chen, and Ling Y in. Understanding the bias of call detail records in human mobility research. International Journal of Geo graphical Information Science , 30(9):1738–1762, 2016. doi: 10.1080/13658816.2015.1137298. URL https://doi.org/10.1080/13658816.2015.1137298 . [26] Y u Zheng, Xing Xie, and W ei-Y ing Ma. GeoLife: A collaborativ e social network- ing service among user , location and trajectory . IEEE Data Eng. Bull. , 33(2):32– 39, 2010. URL https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf& doi=24ccdcba118ff9a72de4840efb848c7c852ef247 . Publisher: Citeseer . [27] Anita Graser , Anahid Jalali, Jasmin Lampert, Axel W eißenfeld, and Krzysztof Janowicz. Mobil- ityDL: A revie w of deep learning from trajectory data. arXiv pr eprint arXiv:2402.00732 , 2024. doi: 10.48550/arXiv .2402.00732. URL . Submitted to Geoinformatica. [28] Paul A. Zandbergen. Accurac y of iphone locations: A comparison of assisted gps, wifi and cellular positioning. T ransactions in GIS , 13:5–25, 2009. doi: 10.1111/j.1467- 9671.2009. 01152.x. URL https://doi.org/10.1111/j.1467- 9671.2009.01152.x . [29] Y . J. Cui and S. S. Ge. Autonomous vehicle positioning with gps in urban canyon environments. In Pr oceedings 2001 ICRA. IEEE International Confer ence on Robotics and A utomation (Cat. No.01CH37164) , volume 2, pages 1105–1110, 2001. doi: 10.1109/ROBO T .2001.932759. [30] V . Manzoni, D. Manilo, K. Kloeckl, and C. Ratti. Transportation mode identification and real- time co2 emission estimation using smartphones: How co2go works - technical report. T echnical report, SENSEable City Lab, Massachusetts Institute of T echnology and Politecnico di Milano, 2010. URL http://senseable.mit.edu/co2go/images/co2go- technical- report. pdf . 17 [31] XueFei Xiao, ChunHua Li, XingJie W ang, and AnPing Zeng. Personalized tourism recom- mendation model based on temporal multilayer sequential neura l network. Scientific Reports , 15(1):382, 2025. doi: 10.1038/s41598- 024- 84581- z. URL https://doi.org/10.1038/ s41598- 024- 84581- z . [32] Adrian C. Prelipcean, Gyözö Gidófalvi, and Y usak O. Susilo. Transportation mode detection – an in-depth revie w of applicability and reliability . T ransport Reviews , 37(4):442–464, 2016. doi: 10.1080/01441647.2016.1246489. [33] A. Aleta, D. Martín-Corral, M. A. Bakker , A. Pastore Y Piontti, M. Ajelli, M. Litvinov a, M. Chinazzi, N. E. Dean, M. E. Halloran, I. M. Jr Longini, A. Pentland, A. V espignani, Y . Moreno, and E. Moro. Quantifying the importance and location of sars-cov-2 transmission ev ents in large metropolitan areas. Pr oceedings of the National Academy of Sciences of the United States of America , 119(26):e2112182119, 2022. doi: 10.1073/pnas.2112182119. URL https://doi.org/10.1073/pnas.2112182119 . [34] Y u Zheng, Quannan Li, Y ukun Chen, Xing Xie, and W ei-Y ing Ma. Understanding mobility based on GPS data. In Pr oceedings of the 10th international conference on Ubiquitous com- puting , pages 312–321, Seoul K orea, September 2008. A CM. ISBN 978-1-60558-136-1. doi: 10.1145/1409635.1409677. URL https://dl.acm.org/doi/10.1145/1409635.1409677 . [35] Leon Stenneth, Ouri W olfson, Philip S. Y u, and Bo Xu. T ransportation mode detection using mobile phones and GIS information. In Pr oceedings of the 19th A CM SIGSP ATIAL International Confer ence on Advances in Geogr aphic Information Systems , pages 54–63, Chicago Illinois, Nov ember 2011. A CM. ISBN 978-1-4503-1031-4. doi: 10.1145/2093973.2093982. URL https://dl.acm.org/doi/10.1145/2093973.2093982 . [36] Adel Bolbol, T ao Cheng, Ioannis Tsapakis, and James Haworth. Inferring hybrid trans- portation modes from sparse GPS data using a moving window SVM classification. Com- puters, En vir onment and Urban Systems , 36(6):526–537, November 2012. ISSN 0198- 9715. doi: 10.1016/j.compenvurbsys.2012.06.001. URL https://www.sciencedirect. com/science/article/pii/S0198971512000543 . [37] Yves-Ale xandre De Montjoye, César A Hidalgo, Michel V erleysen, and V incent D Blondel. Unique in the crowd: The priv acy bounds of human mobility . Scientific reports , 3(1):1376, 2013. [38] Katina Michael, Andre w McNamee, and Michael G Michael. The emerging ethics of human- centric gps tracking and monitoring. In 2006 International Confer ence on Mobile Business , pages 34–34. IEEE, 2006. [39] Predrag Klasnja, Sunny Consolv o, T anzeem Choudhury , Richard Beckwith, and Jeffrey High- tower . Exploring priv acy concerns about personal sensing. In International Confer ence on P ervasive Computing , pages 176–183. Springer , 2009. [40] Robert P Minch. Priv acy issues in location-aw are mobile de vices. In 37th Annual Hawaii International Confer ence on System Sciences, 2004. Pr oceedings of the , pages 10–pp. IEEE, 2004. [41] Grace Ng-Kruelle, Paul A Swatman, Douglas S Rebne, and J Felix Hampe. The price of con venience: Priv acy and mobile commerce. Quarterly journal of electronic commer ce , 3: 273–286, 2002. [42] John Krumm. A survey of computational location pri vac y . P er sonal and Ubiquitous Computing , 13(6):391–399, 2009. [43] Kang G Shin, Xiaoen Ju, Zhigang Chen, and Xin Hu. Priv acy protection for users of location- based services. IEEE W ir eless Communications , 19(1):30–39, 2012. [44] Stuart A Thompson and Charlie W arzel. T welv e million phones, one dataset, zero pri vac y . In Ethics of data and analytics , pages 161–169. Auerbach Publications, 2022. 18 [45] Hongbo Jiang, Jie Li, Ping Zhao, Fanzi Zeng, Zhu Xiao, and Arun Iyengar . Location priv acy- preserving mechanisms in location-based services: A comprehensi ve surve y . A CM Computing Surve ys (CSUR) , 54(1):1–36, 2021. [46] Sepp Hochreiter and Jürgen Schmidhuber . Long Short-T erm Memory. Neural Comput. , 9 (8):1735–1780, November 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735. URL https://doi.org/10.1162/neco.1997.9.8.1735 . [47] Xiang Jiang, Erico N. de Souza, Ahmad Pesaranghader , Baifan Hu, Daniel L. Silver , and Stan Matwin. TrajectoryNet: An embedded GPS trajectory representation for point-based classification using recurrent neural networks. arXiv pr eprint arXiv:1705.02636 , 2017. doi: 10.48550/arXiv .1705.02636. URL . [48] Guven Asci and M. Amac Guvensan. A nov el input set for LSTM-based transport mode detection. In 2019 IEEE International Confer ence on P ervasive Computing and Communications W orkshops (P erCom W orkshops) , pages 107–112. IEEE, 2019. doi: 10.1109/PERCOMW .2019. 8730799. URL https://ieeexplore.ieee.org/abstract/document/8730799 . [49] Asif Nawaz, Huang Zhiqiu, W ang Senzhang, Y asir Hussain, Izhar Khan, and Zaheer Khan. Con volutional LSTM based transportation mode learning from raw GPS trajectories. IET Intel- ligent T r ansport Systems , 14(6):570–577, 2020. ISSN 1751-9578. doi: 10.1049/iet- its.2019. 0017. URL https://onlinelibrary.wiley.com/doi/abs/10.1049/iet- its.2019. 0017 . _eprint: https://onlinelibrary .wile y .com/doi/pdf/10.1049/iet-its.2019.0017. [50] Sina Dabiri and K evin Heaslip. Inferring transportation modes from GPS trajectories using a con volutional neural network. T ransportation Resear ch P art C: Emerging T echnolo gies , 86: 360–371, January 2018. ISSN 0968-090X. doi: 10.1016/j.trc.2017.11.021. URL https: //www.sciencedirect.com/science/article/pii/S0968090X17303509 . [51] Sumanto Dutta and Bidyut Kr . Patra. Inferencing transportation mode using unsupervised deep learning approach exploiting GPS point-lev el characteristics. Applied Intelligence , 53 (10):12489–12503, May 2023. ISSN 1573-7497. doi: 10.1007/s10489- 022- 04140- 9. URL https://doi.org/10.1007/s10489- 022- 04140- 9 . [52] Sina Dabiri, Chang-T ien Lu, Ke vin Healip, and Chandan K. Reddy . Semi-Supervised Deep Learning Approach for T ransportation Mode Identification Using GPS Trajectory Data. IEEE T ransactions on Knowledge and Data Engineering , 32(5):1010–1023, May 2020. ISSN 1041-4347, 1558-2191, 2326-3865. doi: 10.1109/TKDE.2019.2896985. URL https://ieeexplore.ieee.org/document/8632766/ . [53] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv pr eprint arXiv:1601.06733 , 2016. [54] Alec Radford, Jeff W u, Re won Child, David Luan, Dario Amodei, and Ilya Sutske ver . Language models are unsupervised multitask learners. 2019. [55] Jacob De vlin, Ming-W ei Chang, Kenton Lee, and Kristina T outanov a. BER T: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Pr oceedings of the 2019 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, V olume 1 (Long and Short P apers) , pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19- 1423. URL https://aclanthology. org/N19- 1423/ . [56] Hao Xue, Bhanu Prakash V outharoja, and Flora D. Salim. Lev eraging language foundation models for human mobility forecasting. In Pr oceedings of the 30th International Confer ence on Advances in Geogr aphic Information Systems , SIGSP A TIAL ’22, Ne w Y ork, NY , USA, 2022. Association for Computing Machinery . ISBN 9781450395298. doi: 10.1145/3557915.3561026. URL https://doi.org/10.1145/3557915.3561026 . [57] Y e Hong, Henry Martin, and Martin Raubal. How do you go where? Improving next location prediction by learning travel mode information using transformers. In Pr oceedings of the 30th International Confer ence on Advances in Geo graphic Information Systems , pages 1–10, 19 Nov ember 2022. doi: 10.1145/3557915.3560996. URL 04095 . arXi v:2210.04095 [cs]. [58] Y uxuan Liang, Kun Ouyang, Y iwei W ang, Xu Liu, Hongyang Chen, Junbo Zhang, Y u Zheng, and Roger Zimmermann. TrajF ormer: Efficient trajectory classification with transformers. In Pr oceedings of the 31st ACM International Confer ence on Information & Knowledge Manag e- ment , CIKM ’22, pages 1229–1237, Ne w Y ork, NY , USA, 2022. Association for Computing Machinery . ISBN 9781450392365. doi: 10.1145/3511808.3557481. [59] Ricardo Ribeiro, Alina Trif an, and António J. R. Nev es. A deep learning approach for trans- portation mode identification using a transformation of GPS trajectory data features into an image representation. International Journal of Data Science and Analytics , February 2024. ISSN 2364-4168. doi: 10.1007/s41060- 024- 00510- 3. URL https://doi.org/10.1007/ s41060- 024- 00510- 3 . [60] Alex ey Dosovitskiy , Lucas Beyer , Alexander Kolesnik ov , Dirk W eissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly , Jakob Uszkoreit, and Neil Houlsby . An image is worth 16x16 words: Transformers for image recognition at scale. arXiv pr eprint arXiv:2010.11929 , 2021. doi: 10.48550/arXiv .2010.11929. URL . ICLR 2021. [61] Ifigenia Drosouli, Athanasios V oulodimos, Paris Mastorocostas, Georgios Miaoulis, and Djam- chid Ghazanfarpour . Tmd-bert: a transformer-based model for transportation mode detection. Electr onics , 12(3):581, 2023. [62] Jianlin Su, Y u Lu, Shengfeng Pan, Ahmed Murtadha, Bo W en, and Y unfeng Liu. Roformer: Enhanced transformer with rotary position embedding. arXiv pr eprint arXiv:2104.09864 , 2021. doi: 10.48550/arXiv .2104.09864. URL . [63] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Y ury Zemlyanskiy , Federico Lebrón, and Sumit Sanghai. Gqa: T raining generalized multi-query transformer models from multi-head checkpoints. arXiv preprint , 2023. doi: 10.48550/arXiv .2305.13245. URL https://arxiv.org/abs/2305.13245 . [64] Noam Shazeer . Glu variants improv e transformer . arXiv pr eprint arXiv:2002.05202 , 2020. doi: 10.48550/arXiv .2002.05202. URL . [65] Daniel Heimgartner and Kay W Axhausen. Modal splits before, during, and after the pandemic in switzerland. T r ansportation r esearc h r ecor d , 2678(7):1084–1099, 2024. [66] Jiaqi Zeng, Y i Y u, Y ong Chen, Di Y ang, Lei Zhang, and Dianhai W ang. Trajectory-as-a- sequence: A novel travel mode identification framew ork. T ransportation Resear ch P art C: Emer ging T echnologies , 146:103957, 2023. ISSN 0968-090X. doi: 10.1016/j.trc.2022.103957. URL https://www.sciencedirect.com/science/article/pii/S0968090X22003709 . [67] James J. Q. Y u. Semi-supervised deep ensemble learning for travel mode identification. T rans- portation Resear ch P art C: Emerging T echnologies , 112:120–135, March 2020. ISSN 0968- 090X. doi: 10.1016/j.trc.2020.01.003. URL https://www.sciencedirect.com/science/ article/pii/S0968090X19309416 . [68] Jeremy How ard and Sebastian Ruder . Uni versal language model fine-tuning for text classifica- tion. arXiv pr eprint arXiv:1801.06146 , 2018. [69] Hugo T ouvron, Thibaut Lavril, Gautier Izacard, Xa vier Martinet, Marie-Anne Lachaux, T imo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar , et al. Llama: Open and efficient foundation language models. arXiv pr eprint arXiv:2302.13971 , 2023. [70] W enhao Y u and Guanwen W ang. Graph based embedding learning of trajectory data for transportation mode recognition by fusing sequence and dependency relations. International Journal of Geo graphical Information Science , 37(12):2514–2537, 2023. [71] Adel Bolbol, T ao Cheng, Ioannis Tsapakis, and James Haworth. Inferring hybrid transportation modes from sparse gps data using a moving window svm classification. Computers, Envir onment and Urban Systems , 36(6):526–537, 2012. 20 [72] Jason V an Hulse, T aghi M Khoshgoftaar , and Amri Napolitano. Experimental perspecti ves on learning from imbalanced data. In Pr oceedings of the 24th international confer ence on Machine learning , pages 935–942, 2007. [73] Aliaksei Laureshyn, Kalle Åström, and Karin Brundell-Freij. From speed profile data to analysis of behaviour: classification by pattern recognition techniques. IA TSS resear c h , 33(2):88–98, 2009. [74] Haosheng Huang, Y i Cheng, and Robert W eibel. Transport mode detection based on mo- bile phone network data: A systematic revie w . T r ansportation Researc h P art C: Emerging T echnologies , 101:297–312, 2019. [75] Latanya Sweeney . k-anonymity: a model for protecting priv acy . Int. J. Uncertain. Fuzzi- ness Knowl.-Based Syst. , 10(5):557–570, October 2002. ISSN 0218-4885. doi: 10.1142/ S0218488502001648. URL https://doi.org/10.1142/S0218488502001648 . 21 A Data Pre-Pr ocessing Our pre-processing pipeline transformed raw GPS trajectories from both the Geolife and MOBIS datasets into standardized, analysis-ready data suitable for model training. The process in volved sev eral key steps: Data Consolidation : For Geolife, we first con v erted the original PL T files into CSV format, while MOBIS data was already structured appropriately . T ables A2 and A3 show the initial distrib ution of transportation modes in the raw datasets. Distance Calculation : W e computed distances between consecuti ve GPS points using the Haversine formula, which accounts for Earth’ s curv ature: d = 2 r · arcsin s sin 2 ϕ 2 − ϕ 1 2 + cos( ϕ 1 ) cos( ϕ 2 ) sin 2 λ 2 − λ 1 2 ! (6) where ϕ represents latitude, λ represents longitude (both in radians), and r is Earth’ s radius (6,371,000 meters). Speed Derivation : W e computed speeds by dividing the distance by the time difference between consecutiv e points, con verting to km/h: v = d ∆ t · 3 . 6 (7) Label Standardization : W e harmonized transportation mode labels across datasets, consolidating similar modes (e.g., merging ’taxi’ with ’car’, and ’ subway’ with ’train’) to create consistent categories across datasets. Mode-Specific Filtering : W e applied speed thresholds for each transportation mode (T able A1) to remov e physically implausible values caused by GPS errors or data anomalies. T rip Quality Control : W e removed trips with fewer than three GPS points, as these would depart from real world scenarios and they pro vide insufficient sequential information for the model to learn meaningful patterns. This pre-processing reduced the original datasets to fiv e standardized transportation modes (Bike, Bus, Car, T rain, and W alk) suitable for cross-dataset modeling. The final datasets used for model training and e valuation contained 144.7 million data points across 1.53 million trips from MOBIS and 4.44 million data points across 9,427 trips from Geolife, as detailed in T able 1. T able A1: Speed Thresholds for Each Mode Mode Min Speed (km/h) Max Speed (km/h) Bike 0.5 50 Bus 1.0 120 Car 3.0 180 T rain 3.0 350 W alk 0.1 15 B GPS T racking on Smartphone A pplication Our smartphone application, CarbonClever W eChat Mini-Program, implements real-time GPS tracking to collect high-quality mobility data while minimizing battery consumption. When a participant initiates tracking, the application activ ates the device’ s location services using a dynamic sampling strategy designed to balance data density and ener gy efficienc y . The location tracking module periodically queries the de vice’ s location sensors at interv als ranging from 10 to 30 seconds, depending on de vice capability and mo vement speed. Although the application can technically record location data at one-second intervals, a sampling rate of 10–30 seconds effecti vely preserves the accuracy of speed estimation while pre venting e xcessive battery drain on users’ smartphones. 22 T able A2: Summary of the MOBIS Dataset Mode Number of Data Points Number of Unique T rips Aerialway 109 7 Airplane 718,156 3,185 Bicycle 6,568,587 41,166 Bus 7,450,378 77,361 Car 160,348,026 553,259 Ferry 228 12 LightRail 5,824,637 39,657 RegionalT rain 3,674,625 22,413 Subway 425,223 6,917 T rain 10,166,760 34,064 T ram 3,591,472 32,428 W alk 56,539,324 767,923 T otal 255,307,525 1,578,392 T able A3: Summary of the Labeled Geolife Dataset Mode Number of Data Points Number of Unique T rips Airplane 9,196 14 Bike 951,350 1,555 Boat 3,565 7 Bus 1,271,062 1,851 Car 512,939 782 Motorcycle 336 2 Run 1,975 4 Subway 309,699 613 T axi 241,404 513 T rain 556,397 177 W alk 1,582,693 3,991 T otal 5,440,616 9,509 Each recorded sample captures the user’ s current geographic coordinates ( ϕ, λ ) and timestamp ( t ) . As new coordinates are recei ved, the application computes the great-circle distance between consecutiv e points using the Hav ersine formula (8): d = 2 r arcsin s sin 2 ϕ 2 − ϕ 1 2 + cos( ϕ 1 ) cos( ϕ 2 ) sin 2 λ 2 − λ 1 2 ! , (8) where d denotes the great-circle distance in meters, r is Earth’ s radius ( 6 , 371 , 000 meters), and ϕ 1 , λ 1 , ϕ 2 , and λ 2 are the latitudes and longitudes (in radians) of consecuti ve GPS points. The average speed between two points is then calculated as: v = d ∆ t , (A2) where ∆ t represents the elapsed time (in seconds) between successive samples. This real-time computation allo ws for efficient on-device speed estimation while maintaining priv acy , since only scalar speed values—not precise location traces—are required for model input. These calculations are performed in real time within the application’ s frontend, allowing users to recei ve immediate feedback on their trip statistics. Simultaneously , the ra w coordinate data, computed speeds, distances, and timestamps are securely transmitted to a cloud database via encrypted API 23 calls. This cloud infrastructure also hosts our pre-trained SpeedT ransformer and LSTM-Attention models, enabling real-time transportation mode prediction. During our experiments, the application’ s tracking module collected GPS trajectories from a div erse range of smartphone de vices and operating systems. T able 5 summarizes the dataset collected through the mini-program, which exhibits natural variations in sampling frequency and signal quality—characteristics typical of real-world usage. This authentic dataset proved in valuable for validating the SpeedT ransformer model under conditions that closely mirror practical deployment en vironments. C Full Grid Hyper -Parameter Space Sear ch Results & Analysis Experimental reporting con ventions. The following tables enumerate all training and fine-tuning runs conducted in this experiment. T o impro ve readability , we omit dataset size and run identifiers, and instead report the complete set of hyper -parameters that uniquely define each configuration. Unless otherwise specified, all accuracies correspond to the test split (%). Column definitions. LR , BS , DO , WD , Ep. , and Early denote learning rate, batch size, dropout, weight decay , maximum epochs, and early-stopping patience, respecti vely . For the LSTM-Attention model, additional columns include Hidden (hidden state dimension) and Layers (number of stacked LSTM layers). For the SpeedTransformer , columns include Heads (attention heads), d_model (embedding dimension), KV Heads (shared key/v alue heads when using grouped-query attention), W armup (number of warmup steps), and F r eeze P olicy (which modules were frozen or reinitialized). In fine-tuning tables, Subset (%) indicates the percentage of the tar get training data used (e.g., 15%, 20%, etc.). Summary of results. T ables C4, C5, C6, C7, C8, C9, C10, and C11 report the results. Across all training and fine-tuning e xperiments, SpeedTransformer consistently achieved higher accuracy and stronger cross-domain generalization than the LSTM-Attention baseline, particularly under limited-data and transfer learning. When trained directly on the Geolife and MOBIS datasets, both models con ver ged to high accuracy (approximately 93–96%). Howe ver , notable differences emer ged in transfer learning and fine-tuning scenarios. For in-domain training, SpeedT ransformer exhibited optimal performance with a learning rate of 2 × 10 − 4 , batch size of 512, dropout of 0.1, and embedding dimension d model = 128 with 8 attention heads. Accuracy reached 95 . 97% on Geolife and 94 . 22% on MOBIS, with stability across modest parameter variations, suggesting strong generalization capacity without o verfitting. LSTM-Attention achiev ed comparable accuracy (around 92 . 7% ) using a learning rate of 1 × 10 − 3 , hidden dimension 128–256, and two recurrent layers, b ut its performance was more sensitiv e to learning rate changes. In cross-dataset transfer (MOBIS → Geolife), fine-tuned SpeedT ransformer models surpassed 85% test accuracy under optimal configurations, while LSTM-Attention plateaued around 84%. Among transformer variants, the best results were obtained when the last block was reinitialized ( 85 . 7% ) or when no layers were frozen ( 84 . 2% ). By contrast, freezing attention or feed-forward layers caused performance to drop below 65% , confirming that full end-to-end adaptation is necessary for effecti ve transfer across mobility domains. Fine-tuning from transfer data (MOBIS → Real-W orld App Experiment) further demonstrated the efficienc y of the transformer architecture. Ev en when using only 15% of the experiment dataset, SpeedT ransformer achiev ed 89 . 1% accuracy , outperforming LSTM-Attention ( 86 . 6% ) under compa- rable settings. As the fine-tuning subset increased, SpeedTransformer’ s accuracy scaled up smoothly , reaching 94 . 2% with 50% of the target data. Embedding-freezing strategies yielded intermediate performance (up to 87 . 8% ), while partial freezing or warmup schedules of fered no clear benefit. These results indicate that SpeedT ransformer effecti vely le verages prior mobility representations with minimal data, whereas LSTM-Attention requires larger sample sizes to reach similar accurac y . Overall, the experiments re veal three consistent patterns. First, moderate learning rates ( 2 – 5 × 10 − 4 ) and full-layer fine-tuning yield the most robust con v ergence across datasets. Second, SpeedTrans- former’ s attention-based representations exhibit superior transferability and resilience to dataset heterogeneity compared with recurrent encoders, shown in Figure N7. Third, increasing the fine- tuning subset improv es performance approximately monotonically , suggesting that the pre-trained 24 T able C4: Summary of LSTM–Attention performance trained on MOBIS. All runs use Ep.=50, WD=1e-4, EarlyStop=7, unless noted. Configuration LR Batch Size Dropout Hidden Units Lay ers Accuracy (%) Base (best) 1 × 10 − 3 128 0.1 128 2 92.40 Smaller batch 1 × 10 − 3 64 0.1 128 2 92.20 Higher dropout 1 × 10 − 3 64 0.2 128 2 92.15 Deeper network 1 × 10 − 3 64 0.1 128 3 92.26 Larger hidden size 1 × 10 − 3 64 0.1 256 2 92.04 Higher learning rate 2 × 10 − 3 64 0.1 128 2 92.14 Lower learning rate 5 × 10 − 4 128 0.1 256 3 92.33 Smaller batch, lower LR 5 × 10 − 4 64 0.1 128 2 92.35 T able C5: Summary of SpeedTransformer performance trained on MOBIS. All runs use Ep.=50, WD=1e-4, EarlyStop=7. Configuration LR Batch Size Dropout d_model Heads / KV Heads Accuracy (%) Base (best) 1 × 10 − 4 512 0.1 128 8 / 4 94.22 Higher LR 2 × 10 − 4 512 0.1 128 8 / 2 94.20 Larger model 2 × 10 − 4 512 0.1 192 12 / 6 93.71 Larger embedding 2 × 10 − 4 512 0.1 256 8 / 4 93.54 Smaller batch 2 × 10 − 4 1024 0.1 128 8 / 4 93.69 Higher dropout 2 × 10 − 4 512 0.2 128 8 / 4 93.54 Higher LR 3 × 10 − 4 512 0.1 128 8 / 4 94.09 mobility embeddings capture domain-in variant mo vement structures that generalize across tracking en vironments. D Input Embeddings Each scalar speed v alue s t is linearly projected into a d model = 128 -dimensional embedding space, producing an input embedding matrix E ∈ R T × d model . This projection enables the model to represent one-dimensional scalar speeds within a high-dimensional latent space suitable for Transformer -based sequence modeling: e t = W e s t + b e , (9) where s t denotes the scalar speed at time step t , W e ∈ R 1 × d is the learnable weight matrix, and b e ∈ R d is the learnable bias vector . The resulting embeddings E = [ e 1 , e 2 , . . . , e T ] serve as the model’ s input sequence to subsequent positional encoding and self-attention layers. E SwiGLU Activation Each feed-forward subnetwork adopts the SwiGLU acti v ation [64], defined as: SwiGLU ( x ) = ( xW 1 ) ⊙ Swish ( xW 2 ) W 3 , (10) where ⊙ denotes element-wise multiplication, W 1 , W 2 , W 3 are learnable weight matrices, and Swish ( x ) = x σ ( x ) with σ ( · ) being the sigmoid activ ation function. SwiGLU enhances represen- tational expressi vity and improv es training stability relati ve to standard ReLU-based feed-forward layers. 25 T able C6: Summary of LSTM–Attention performance trained on Geolife. All runs use Ep.=50, WD=1e-4, EarlyStop=7, unless noted. Configuration LR Batch Size Dropout Hidden Units Lay ers Accuracy (%) Base (best) 1 × 10 − 3 128 0.1 128 2 92.77 Smaller batch 1 × 10 − 3 64 0.1 128 2 91.77 Higher dropout 1 × 10 − 3 64 0.2 128 2 92.71 Deeper network 1 × 10 − 3 64 0.1 128 3 92.16 Larger hidden size 1 × 10 − 3 64 0.1 256 2 92.73 Higher learning rate 2 × 10 − 3 64 0.1 128 2 92.56 Lower learning rate 5 × 10 − 4 128 0.1 256 3 92.40 Smaller batch, lower LR 5 × 10 − 4 64 0.1 128 2 91.63 T able C7: Summary of SpeedTransformer performance trained on Geolife. All models use Ep.=50, WD=1e-4, EarlyStop=7, unless noted. Configuration Learning Rate (LR) Model Size ( d model ) Attention Heads (Q/KV) Accuracy (%) Base (optimal) 2 × 10 − 4 128 8 / 4 95.97 Reduced KV heads 2 × 10 − 4 128 8 / 2 95.36 Larger model 2 × 10 − 4 192 12 / 6 94.72 Larger embedding 2 × 10 − 4 256 8 / 4 94.69 Higher LR 3 × 10 − 4 128 8 / 4 94.68 Lower LR 1 × 10 − 4 128 8 / 4 94.44 Higher batch size 2 × 10 − 4 128 8 / 4 92.72 Higher dropout 2 × 10 − 4 128 8 / 4 92.70 F Model Windo w Size Figure F1 supports our choice of T = 200 , showing that performance improves steadily with lar ger window sizes up to 200, beyond which accurac y plateaus and slightly declines. The 500-sample con- figuration also required a reduced batch size due to GPU memory constraints, potentially impacting training stability . Overall, T = 200 represents the optional size between accuracy , computational effi- ciency , and training stability , capturing suf ficient motion dynamics without introducing unnecessary redundancy or o verfitting. G SpeedT ransf ormer in Original T ransformer Model Ar chitecture W e also conduct experiments using the original Transformer architecture, proposed by V aswani et al. [21] , for a comparison. Although the core architecture shares the transformer encoder backbone with the final model presented in Section 3, this initial version employed sinusoidal positional encodings and a standard feed-forward block instead of Rotary Positional Embeddings (RoPE) and SwiGLU activ ations. The updated design described in the main text improv ed both training stability , computational efficienc y , and cross-dataset transferability . The follo wing subsections summarize the original architecture, input encoding strate gy , and optimiza- tion setup for the model. W e provide experiment results, which serves as a reference for ablation comparisons. The model architecture adapts the transformer encoder framew ork [ 21 ]. Figure G2 presents the ov erall architecture of our model. T o incorporate sequential order information, we add sinusoidal positional encoding to these embeddings, shown in Equation 11. PE ( pos, 2 i ) = sin pos 10000 2 i/d model , PE ( pos, 2 i + 1) = cos pos 10000 2 i/d model (11) 26 T able C8: Summary of fine-tuning LSTM-Attention (MOBIS → Geolife). All models use BS=128, DO=0.3, WD=1e-4, Ep.=60, and EarlyStop=7. Learning Rate (LR) Hidden Size Accuracy (%) Notes 1 × 10 − 3 64–256 84.17 Optimal configuration 5 × 10 − 4 64–256 84.13 Comparable to best 1 × 10 − 4 64–256 82.84 Slight underfitting 5 × 10 − 5 — 75.47–79.15 Lo w performance (few epochs) T able C9: Summary of fine-tuning SpeedTransformer (MOBIS → Geolife). All models use BS=512, WD=1e-4, DO=0.2, Ep.=50, and EarlyStop=7. Learning Rate (LR) Best Freeze P olicy W armup Steps Accuracy (%) 5 × 10 − 5 Reinit last block 0 85.07 1 × 10 − 4 Reinit last block 0 85.70 2 × 10 − 4 Attention frozen 0 86.38 2 × 10 − 4 Reinit last block 0 86.30 1 × 10 − 4 Embeddings frozen 0 84.22 1 × 10 − 4 None (all trainable) 0 84.08 2 × 10 − 4 None (all trainable) 0 85.01 5 × 10 − 5 to 2 × 10 − 4 Any freeze w/ warmup (100–500) — 63–67 (no gain) where pos is the position in the sequence, i is the dimension index, and d model is the embedding dimension. W e use the same 200 v ariable-length sliding window , in consistent with the main model. W e projects scalar speed v alue into high-dimensional vector representations through linear transformation followed by non-linear acti v ation in Equation 12. E = ReLU ( W e · S + b e ) (12) where S represents input speed values and E the resulting embeddings. These encoding enables the model to differentiate positions and captures temporal v ariations that are critical to distinguish transportation modes over time. For example, information such as acceleration patterns can be inferred from sequences of trajectories. After the positional encoding, the inputs are fed into a self-attention layer, which helps the encoder to check speed at other positions in the input sequence as it encodes a speed at a specific location, as shown in Figure G3. V aswani et al. [21] established that attention mechanisms compute weighted aggregations of v alue vectors where weights are determined by compatibility scores between query and key v ectors, which we adopt the scaled dot-product attention formulation as defined in Equation (1) of V aswani et al. (2017) and use their definition of scaled dot-product attention in Equation 13. Attention ( Q , K , V ) = softmax QK ⊤ √ d k V (13) In this formulation, Q represents queries that seek information, K encodes keys that store information, and V contains v alues that are aggregated according to query-k ey compatibility . For self-attention, all three matrices deri ve from the same input sequence, which enables each position to attend to all positions within the sequence. The multi-head attention mechanism extends this concept by computing attention in parallel across dif ferent representation subspaces. W e follow V aswani et al. [21] and use their definition of multihead 27 T able C10: Summary of LSTM-Attention fine-tuning results from MOBIS → Real-W orld App Experiment. All runs use 50 epochs, EarlyStop with patience = 10 (Pat. 10), dropout = 0.3, and weight decay = 1e-4. Subset (%) LR Hidden Units Batch Size Early Stop Pat. Accuracy (%) 15 5 × 10 − 4 128 128 10 P at.10 86.62 20 5 × 10 − 4 128 128 10 P at.10 88.02 30 5 × 10 − 4 128 128 10 P at.10 88.97 40 5 × 10 − 4 128 128 10 P at.10 87.45 50 5 × 10 − 4 128 128 10 P at.10 87.57 15 1 × 10 − 3 128–256 128 10 Pat.10 86.19 15 1 × 10 − 4 128–256 128 10 Pat.10 85.18 T able C11: Summary of SpeedT ransformer fine-tuning results from MOBIS → Real-W orld App Experiment. All runs used 50 epochs, EarlyStop with patience = 10 (Pat. 10), dropout = 0.2, and weight decay = 1e-4. Subset (%) Learning Rate W armup Steps Freeze Policy Batch Size Early Stop Accuracy (%) 15 5 × 10 − 4 0 None 512 Pat.10 89.12 20 5 × 10 − 4 0 None 512 Pat.10 82.53 30 5 × 10 − 4 0 None 512 Pat.10 91.15 40 5 × 10 − 4 0 None 512 Pat.10 88.78 50 5 × 10 − 4 0 None 512 Pat.10 94.22 15 1 × 10 − 4 0–100 Attention/Embedding frozen 512 Pat.10 69.3–72.9 15 2 × 10 − 4 0–100 Embeddings frozen 512 P at.10 71.6–80.6 15 5 × 10 − 4 0–100 Embeddings frozen 512 P at.10 77.2–87.8 representation in Equation 15. MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head h ) W O (14) head i = Attention ( QW Q i , KW K i , VW V i ) (15) Here, W Q i , W K i , and W V i are learned projection matrices that transform the original embeddings into dif ferent subspaces, while W O projects the concatenated outputs back to the model dimension. In line with standard deep learning practice, each encoder layer includes a position-wise feed-forward network (FFN) applied independently to ev ery position. The input to the FFN is formed by summing the token embeddings and positional encodings, as sho wn in Equation 16: z = x + PE , (16) where x denotes the token embedding and PE represents the positional encoding. T able F12: T est accuracy and loss across dif ferent window sizes (Geolife dataset). W . Size T est Acc. (%) T est Loss Run Name 20 77.58 0.5778 Geolife_ws20_lr2e-4_bs512_h8_d128_kv4_do0.1 50 84.86 0.4043 Geolife_ws50_lr2e-4_bs512_h8_d128_kv4_do0.1 100 92.07 0.2600 Geolife_ws100_lr2e-4_bs512_h8_d128_kv4_do0.1 200 95.97 0.1525 Geolife_ws200_lr2e-4_bs512_h8_d128_kv4_do0.1 300 95.04 0.1753 Geolife_ws300_lr2e-4_bs512_h8_d128_kv4_do0.1 400 94.53 0.1703 Geolife_ws400_lr2e-4_bs256_h8_d128_kv4_do0.1 500 95.03 0.1800 Geolife_ws500_lr2e-4_bs256_h8_d128_kv4_do0.1 28 Figure F1: Effect of window size on test accuracy for the Geolife dataset. A window size of 200 provides the optimal balance between temporal conte xt and computational efficiency , achieving the highest accuracy (95.97%). Figure G2: Transformer architecture for transportation mode classification. Residual connections and layer normalization are applied around each sub-layer to facilitate gradient flow and enhance training stability . T o generate a fixed-length representation from v ariable-length sequences, we employ attention-based pooling. The position-aware input z is then passed into the feed-forward network (FFN), defined in Equation 17: FFN ( x + PE ) = max (0 , ( x + PE ) W 1 + b 1 ) W 2 + b 2 , (17) where W 1 and W 2 are weight matrices, and b 1 and b 2 are bias terms. T o incorporate sequential order information, token embeddings are first augmented with sinusoidal positional encoding through the attention mechanism and softmax normalization. These position-aw are inputs are then processed by the FFN in Equation 17, enabling the model to capture complex non-linear transformations of input representations at each position. The model is trained using the cross-entropy loss function, which quantifies the div ergence between the predicted and ground-truth transportation modes, as shown in Equation 18: 29 T rajectory A (5 Hz samples) 4.2 7.8 12.1 7.8 3.0 T rajectory B (same speeds, different order) 7.8 4.2 3.0 12.1 7.8 Figure G3: T wo GPS speed sequences share the same multiset of speeds but in dif ferent orders. W ithout position information the embeddings for repeated values (e.g., 7 . 8 m/s ) are identical. W ith positional encoding we form z t = E ( v t ) + P ( t ) , allo wing attention to model order-dependent patterns. L = − N X i =1 C X c =1 y i,c log( p i,c ) , (18) where N is the number of samples, C is the number of classes, y i,c ∈ { 0 , 1 } denotes the ground-truth label (1 if sample i belongs to class c ), and p i,c is the predicted probability of class c for sample i . Final classification is performed through a linear projection of the pooled representation, followed by a softmax acti vation to generate a probability distribution over transportation modes, as defined in Equation 19: p ( y = c | c ) = exp( w ⊤ c c + b c ) P C j =1 exp( w ⊤ j c + b j ) , (19) where c denotes the pooled feature vector , and w c and b c represent the weight vector and bias term for class c , respectiv ely . W e implement AdamW optimization with weight decay , learning rate scheduling, dropout regular- ization, and gradient clipping. This architecture enables efficient discovery of complex temporal patterns in speed data, capturing the distincti ve signatures of different transportation modes without requiring additional input features or pre-processing steps. T able G13: Per-class accuracy (recall) of LSTM and T ransformer models across datasets. Each model was trained on Geolife and MOBIS, and fine-tuned from MOBIS to Geolife and Mini-Program datasets. Model T raining Setup Bike Bus Car T rain W alk LSTM Geolife 0.92 0.86 0.86 0.92 0.99 MOBIS 0.61 0.84 0.99 0.28 0.99 MOBIS → Geolife 0.59 0.84 0.57 0.79 0.72 MOBIS → Mini-Program 0.39 0.69 0.93 0.79 0.86 T ransformer Geolife 0.93 0.96 0.92 0.87 0.99 MOBIS 0.78 0.88 0.98 0.43 0.99 MOBIS → Geolife 0.75 0.88 0.75 0.80 0.99 MOBIS → Mini-Program 0.40 0.70 1.00 0.43 0.99 As shown in T able G13, the T ransformer consistently outperforms the LSTM across all datasets and transfer setups, confirming its superior ability to capture temporal dependencies and generalize across domains. 30 H Rule-based Model Sev eral prior studies on transportation mode detection rely on simple rule-based models built on handcrafted heuristics deri ved from dense GPS trajectory data [ 74 ]. Such models typically depend on a small number of summary statistics (e.g., speed percentiles, stop ratios, or acceleration variability), require no auxiliary GIS data, and are computationally inexpensiv e. Howe ver , their performance is highly sensitiv e to threshold choices and to behavioral heterogeneity across users, cities, and datasets. T o establish a strong heuristic baseline, we implemented a hierarchical rule-based classifier operating on sliding windows of ra w GPS trajectories. Unlike earlier implementations that rely exclusi vely on fixed e xpert-defined thresholds, we calibrated the rule parameters separately for each dataset using the training split, yielding dataset-specific but still purely heuristic decision rules. The rules operate as follows. First, the 95th-percentile speed within each window is used to separate low-speed modes (walk, bike) from motorized and rail modes. Second, windows exceeding a high-speed threshold are classified as rail. Finally , among remaining motorized windows, the stop ratio and acceleration variability are used to distinguish b uses from cars. T able H14 summarizes the calibrated thresholds used in our experiments. All speed values are expressed in meters per second (m/s). Rule Threshold (m/s) Description / Condition f or Mode Assignment walk_p95_max ≤ 3 . 0 W indows with 95th-percentile speed below 3.0 m/s are classified as walk . bike_p95_max ≤ 8 . 0 W indows with 95th-percentile speed between 3.0–8.0 m/s are classified as bike . road_p95_min ≥ 17 . 4 (18.0*) W indows exceeding this threshold are treated as motorized road transport ( bus or car ). rail_p95_min ≥ 27 . 5 (40.0*) W indows with very high 95th-percentile speed are classi- fied as rail . stop_thresh < 0 . 5 Speeds belo w 0.5 m/s are considered “stopped” for com- puting stop ratio. bus_stop_ratio_min ≥ 0 . 05 W ithin the motorized range, higher stop ratios indicate bus . accel_std_split < 2 . 0 Smoother acceleration patterns indicate b us ; higher v ari- ability indicates car . T able H14: Calibrated heuristic rules for transportation mode classification. Thresholds are tuned separately for each dataset using the training split. *A different threshold w as used for Geolife W e ev aluated the rule-based model on both the Geolife and MOBIS datasets using the same train–test splits employed for all learning-based models in the main text. The results are reported in T able H15. Despite dataset-specific calibration, the rule-based model achie ves only moderate ov erall accuracy on both datasets (0.3967), with substantial variation in per -class performance. On the MOBIS dataset, the model e xhibits high precision but lo w recall for the dominant car class, indicating that while man y predicted car windows are correct, a large fraction of t rue car instances are misclassified as other modes. Conv ersely , walk , bike , and tr ain achiev e relatively high recall b ut lo w precision, reflecting extensi ve confusion driv en by overlapping speed re gimes and heterogeneous trav el behavior . As a result, the weighted F1-score remains modest (0.4929) despite strong class imbalance. On the Geolife dataset, the rule-based model performs slightly more ev enly across classes b ut still struggles to distinguish between motorized road modes. In particular , bus is almost ne ver correctly identified, while train and walk benefit from their more distinctive speed profiles. These results highlight a fundamental limitation of heuristic approaches: even when carefully calibrated, fixed rules cannot adequately capture the div ersity of urban mobility patterns present in real-world GPS data. Overall, these findings reinforce our broader argument. While rule-based models are transparent, interpretable, and computationally ef ficient, they are inherently rigid and brittle. In settings where 31 large-scale trajectory data are av ailable and mobility behavior is comple x, data-driv en models that learn representations directly from raw trajectories of fer a far more rob ust and scalable solution. Dataset Mode Precision Recall F1-score Support Accuracy Geolife Bike 0.2818 0.3584 0.3155 3,200 Bus 1.0000 0.0000 0.0000 4,863 Car 0.0530 0.0871 0.0659 2,251 T rain 0.4256 0.9512 0.5881 4,119 W alk 0.9463 0.4856 0.6418 5,225 Macro A vg. 0.5413 0.3765 0.3223 W eighted A vg. 0.6400 0.3967 0.3527 Overall Accuracy 19,658 0.3967 MOBIS Bike 0.1087 0.6552 0.1864 17,389 Bus 0.1428 0.3550 0.2037 14,474 Car 0.9301 0.3278 0.4847 336,860 T rain 0.0911 0.7243 0.1618 27,607 W alk 0.9886 0.4627 0.6303 155,581 Macro A vg. 0.4523 0.5050 0.3334 W eighted A vg. 0.8581 0.3967 0.4929 Overall Accuracy 551,911 0.3967 T able H15: Performance of the calibrated rule-based model on Geolife and MOBIS datasets. I SpeedT ransf ormer’ s Computational Efficiency Like most deep learning architectures, SpeedTransformer requires substantially higher computational resources than traditional, non–deep learning models. Nev ertheless, through our adaptation of the Grouped-Query Attention (GQA) structure, the model achiev es comparativ ely high computational efficienc y . As illustrated in Figure I4, during a full training session with four processes one a single A100 GPU node, the model maintained an average GPU utilization of approximately 67% (peaking at 96%) across all de vices. Meanwhile, host memory usage a veraged around 52.9 GB (with a peak of 61.9 GB) over a training period of roughly 126.5 minutes. These measurements suggest effecti ve multi-GPU-process utilization and stable memory management, consistent with a compute-bound workload characteristic of T ransformer-based architectures. Figure I4: GPU and memory utilization of the Transformer model during training. 32 J IRB Protocol and Ethics A ppr oval Follo wing the Committee on Publication Ethics (COPE) guidance, we include our IRB protocol and ethical statement here, concerning our real-world experiment. In respect for conciseness, we summarize our IRB protocol and its approv al below . This study was approved by the Institutional Re view Board (IRB) at Duke Kunshan University (DKU) shortly before the carried out experiment. The protocol (version dated June 23, 2022) recei ved clearance to conduct randomized experiments using a W eChat-based mini-program developed by the research team. Participants were recruited from cities in China, through both online advertisements and QR-code posters in focus groups. Eligible participants (aged 18 and abov e) provided brief informed consent, consistent with standard practices in the industry , before engaging in the study . The consent process was integrated into the mini-program and clearly stated that no personal identifiers (e.g., name, phone number , W eChat ID) would be collected. Instead, a pseudonymous device ID was used to generate a non-identifiable case ID for analysis. Demographic information is purposefully not collected to protect human subjects’ priv acy . Minimal geographic and behavioral data were collected for the purpose of estimating participants’ daily carbon footprints. The study in volv ed daily interaction with the mini-program ov er a one-month period from Nov em- ber 2023 to December 2023, during which participants receiv ed v arying forms of informational stimulus—ranging from gov ernment policy content to scientific facts and social cues. W eekly questionnaires measured participants’ willingness to pay for carbon reduction. Data were stored securely on DKU-managed servers, and all members of the research team were Chinese citizens, in compliance with China’ s data sovereignty regulations. No audio, video, or photographic data were collected. Participants had the option to donate or recei ve a small monetary compensation for their time. This research posed minimal risk to participants and inv olved no clinical interventions. The IRB ensured that appropriate data security and priv acy measures were in place. W e include the full approv al letter in the journal’ s manuscript portal. K Masking Raw Coordinates as a Privacy Benefit T o demonstrate the potential benefit of our approach, we construct a hypothetical scenario where masking raw original coordinate can preserve individual pri vacy . Consider a city with a land area of A = 1000 km 2 and a GPS sampling resolution of r = 10 m . The number of unique spatial states N spatial is A/r 2 = 10 7 , yielding a spatial entropy of: H ( l ocation ) = log 2 ( N spatial ) = log 2 (10 7 ) ≈ 26 . 57 bits. (20) In contrast, assuming a speed range of 0 – 120 km/h quantized at 1 km/h increments ( 121 states), the speed entropy is: H ( speed ) = log 2 ( N speed ) = log 2 (121) ≈ 6 . 92 bits. (21) This indicates that a single speed entry provides less than one-third of the information necessary to resolve a spatial position. This reduction in entropy manifests in much higher k -anonymity [ 75 ]: while four spatio-temporal coordinates can uniquely identify 95% of individuals ( k = 1 ) [ 37 ], speed sequences in dense urban en vironments can be far less distincti ve. Numerous users share near-identical speed profiles due to shared traffic constraints such as synchronized signal timings and speed limits, making individual re-identification from speed sequences orders of magnitude more difficult than from absolute trajectories. L T emporal Sampling Frequency W e use dense GPS trajectories in this study , primarily obtained through continuous app-based tracking on personal smartphones and mobile de vices. This stands in contrast to sparse GPS trajectories deriv ed from geolocated social media posts or sporadic geotagged check-in data. As such, the temporal sampling frequency of our dense GPS data is generally high, though it still v aries across datasets. For 33 all three datasets used in this study , we retained the original sampling rates and did not perform any temporal resampling. Figure L5 shows the distribution of time interv als between consecuti ve GPS samples in each dataset. By comparing trajectories collected through our CarbonCle ver mini-program field experiment with those from Geolife and MOBIS, we observe v ariations in temporal granularity . These variations pro vide a rigorous basis for ev aluating model performance. Figure L5: Sampling Frequency Distribution M Architectural Comparison of T ransformer -based Models The number of trainable parameters in a T ransformer-based model is important because it reflects a fundamental trade-of f between model performance and computational demand. In general, models with more parameters require greater computational resources and larger training datasets to achieve strong performance. The numbers of trainable parameters for SpeedTransformer and the related T ransformer variants are summarized in T able M16. As sho wn, SpeedTransformer does not contain substantially more parameters than other state-of-the-art T ransformer-based mode-detection models. T able M16: Architectural Comparison of Transformer -based Mobility Models Model Pre -proc. Input Attention P osEnc. Params SpeedT ransf ormer Speed Calc. 1D Speed GQA RoPE 0.73M Deep-V iT [59] Image Gen. 2D Image V ision MHA Learnable 0.53M TMD-BER T [61] Discretisation T okens Bi-Directional MHA Learnable 110M Note: GQA: Grouped-Query Attention; MHA: Multi-Head Attention; RoPE: Rotary Positional Embeddings; Image Gen.: DeepInsight Transform; P arams: approximate number of trainable parameters using the best configuration. N Confusion Matrices and Class Imbalance W e examined the extent to which class imbalance in the training data—specifically the substantially smaller number of observations for Bike , Bus , and T r ain in both MOBIS and Geolife—contributes to misclassification. Figure N6 reports the confusion matrices for SpeedT ransformer on the Geolife and MOBIS test sets, respecti vely . As is typical across machine-learning algorithms, SpeedT ransformer exhibits weaker performance on classes with limited training data, namely Bike , Bus , and T r ain , relativ e to classes that are more ab undantly represented. Nev ertheless, the performance is far from abysmal: per-class accuracy remains well abo ve 50%. As sho wn in Fig. N6, the Geolife dataset yields a clear, strongly diagonal confusion matrix, indicating consistent class separation. By contrast, in MOBIS, the T rain cate gory effecti vely aggreg ates several rail- and public-transport subclasses (e.g., train, tram, and metro-style services), whose movement signatures are often highly similar . As a result, predictions for T rain more frequently diffuse into adjacent public-transport labels. Moreov er , when SpeedTransformer is first trained on MOBIS—the dataset with the largest volume of training samples—and subsequently fine-tuned using a small subset of Geolife and our CarbonClever field-experiment data, its performance remains comparativ ely strong (Figure N7). Per -class accuracy is generally abov e 0.9, and ev en in classes where MOBIS training data may be less well matched to Geolife or the field-experiment test data (e.g., the T rain class), accuracy still exceeds 0.7. 34 (a) Geolife (b) MOBIS Figure N6: Confusion matrices for SpeedT ransformer on the Geolife and MOBIS test sets. V alues are raw counts; MOBIS e xhibits stronger class imbalance, leading to larger absolute counts. Figure N7: Per class F1-Score for Fine-tuning on Geolife and our real-world field e xperiment data using SpeedT ransformer and LSTM. The SpeedT ransformer consistently achieves better results than the LSTM-Attention across all classes in both tasks. O F ailure Analysis: T rain Mode Case Studies Having sho wn that misclassification is more pre valent for certain classes, we next examine specific failure patterns using the T r ain mode as a case study . Figure O8 contrasts two dominant error profiles for train mode: a low_speed_confusion group, which is frequently misclassified as walk or b us and exhibits smooth, gradually increasing speeds; and a high_speed_confusion group, often in volving car–train mix-ups, characterized by stop–go variability and intermittent speed spik es. Both profiles encompass many distinct trajectories, suggesting systematic patterns rather than isolated anomalies. Figure O9 further sho ws substantial ov erlap in simple summary statistics (e.g., mean and standard de viation) between correctly and incorrectly classified train mode, indicating that such aggregates are insufficient to distinguish the error . As such, the model learns a dif fuse representation of the T r ain class, which in turn allows leakage into neighboring public-transport modes. By contrast, Geolife exhibits more homogeneous train trajectories, supporting a sharper and more stable decision boundary for this class. 35 Figure O8: Sequence-lev el speed dynamics for two dominant train failure profiles. The low_speed_confusion profile shows relativ ely smooth, gradual ramps; the high_speed_confusion profile has higher variance with abrupt fluctuations and spik es. Shaded regions indicate the 25–75% interquartile range across sequences. 36 Figure O9: Distributional heterogeneity in train-class speed statistics. Mean speed and joint mean–std representations overlap substantially between correct and incorrect train windows, showing that simple aggregates cannot isolate the failure profiles ( low_speed_confusion vs high_speed_confusion ). 37
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment