Contextual Preference Distribution Learning
Decision-making problems often feature uncertainty stemming from heterogeneous and context-dependent human preferences. To address this, we propose a sequential learning-and-optimization pipeline to learn preference distributions and leverage them to…
Authors: Benjamin Hudson, Laurent Charlin, Emma Frejinger
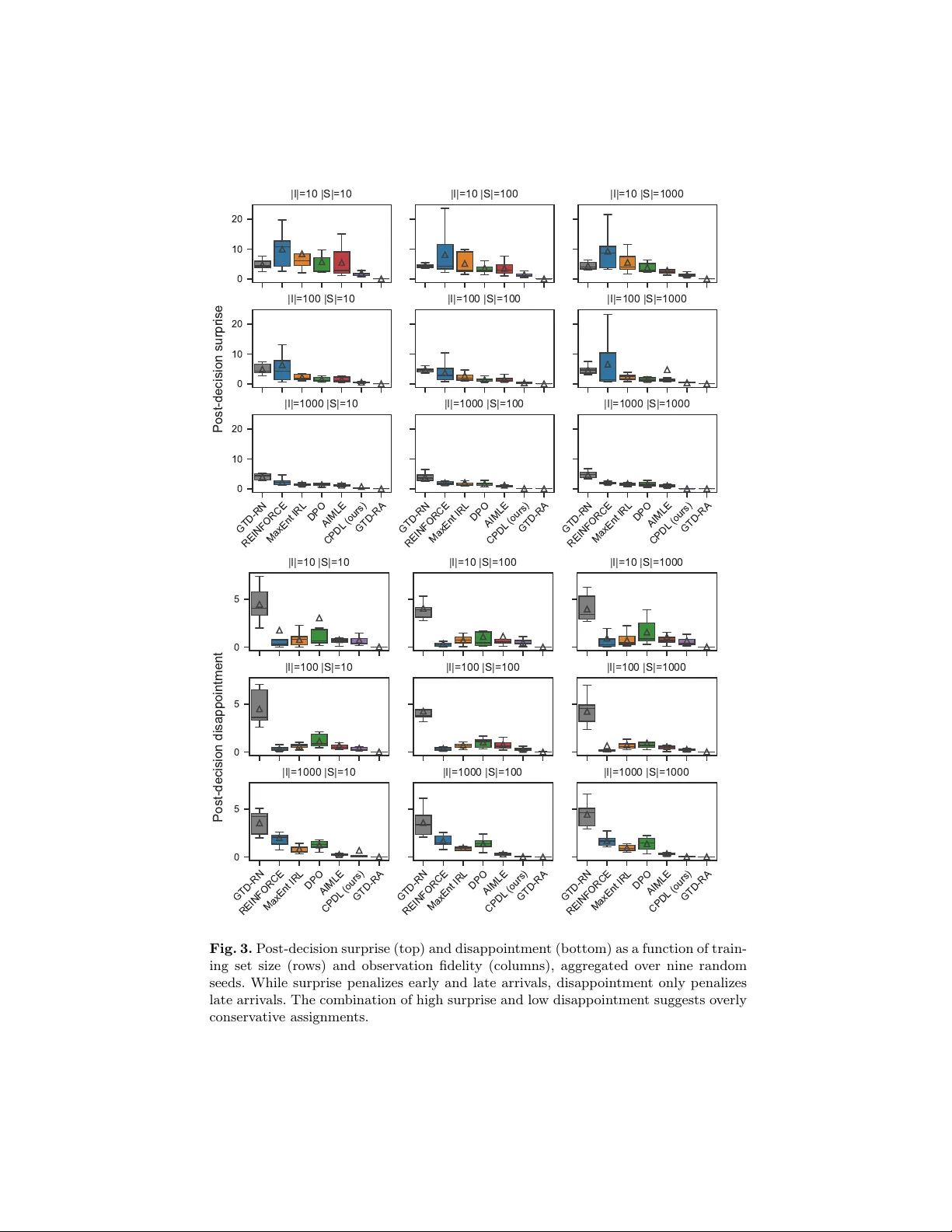
Con textual Preference Distribution Learning Benjamin Hudson 1 , 2 [0000 − 0002 − 9461 − 5895] , Lauren t Charlin 1 , 2 , 3 [0000 − 0002 − 6545 − 9459] , and Emma F rejinger 1 , 2 [0000 − 0003 − 1930 − 607 X ] 1 Mila – Queb ec Artificial In telligence Institute, Mon treal, Quebec, Canada ben.hudson@mila.quebec 2 Départemen t d’informatique et de recherc he opérationnelle (DIR O), Univ ersité de Mon tréal, Mon treal, Quebec, Canada 3 HEC Mon tréal, Montreal, Queb ec, Canada Abstract. Decision-making problems often feature uncertain ty stem- ming from heterogeneous and context-dependent human preferences. T o address this, we propose a sequen tial learning-and-optimization p ipeline to learn preference distributions and leverage them to solv e downstream problems, for example risk-a verse form ulations. W e fo cus on h uman choice settings that can b e formulated as (in teger) linear programs. In such set- tings, existing inv erse optimization and choice modelling methods infer preferences from observ ed c hoices but typically produce point estimates or fail to capture con textual shifts, making them unsuitable for risk- a verse decision-making. Using a bounded-v ariance score function gradi- en t estimator, we train a predictive model mapping contextual features to a rich class of parameterizable distributions. This approac h yields a maxim um likelihoo d estimate. The mo del generates scenarios for unseen con texts in the subsequent optimization phase. In a synthetic ridesharing en vironment, our approach reduces av erage p ost-decision surprise by up to 114 × compared to a risk-neutral approac h with p erfect predictions and up to 25 × compared to leading ri sk-a v erse baselines. Keyw ords: In v erse optimization · Preference learning · Sequential learning- and-optimization · Estimate-then-optimize. 1 In tro duction Human preferences v ary across individuals and contexts [6], often causing p ost- de cision surprise [20] in decision-making problems that dep end on human choices. W e tak e driver-rider assignment in ridesharing as an illustrative example: while platforms recommend routes using real-time traffic [35], driv ers often choose al- ternate routes to optimize their own ob jectives, based on p ersonal preferences or tacit knowledge of the road netw ork [29]. These discrepancies in tro duce un- certain ty in to do wnstream problems; for example, if a driver takes an alternate route, their realized arriv al time ma y differ from the platform’s estimate, leading to the p erception of unreliability . T o address this issue, we prop ose a sequen- tial learning-and-optimization approach (illustrated in Fig. 1): we first predict h uman preference distributions given some contextual features (i.e. co v ariates), 2 B. Hudson et al. and then leverage them to explicitly minimize the resulting downstream risk. Ultimately , w e aim to reduce p ost-decision surprise in decision-making problems where uncertain ty stems from h uman choices. Obs. con text X Pref. c ( s ) ∼ q θ ( c | X ) Choice p ro blem arg min z ∈Z c ( s ) ⊤ z Pred. c hoice stats ˆ ϕ Obs. c hoice stats ¯ ϕ (a) T raining pip eline Loss L Unseen con text X Pref. dist. q θ ( c | X ) Risk-a verse decision arg min w ∈W f ( q θ , w ) Prescrib ed decision w ∗ (b) Infe rence pipeline Fig. 1. Our sequential learning-and-optimization approach. (a) During train- ing, we learn a mo del mapping contextual features to preference (ob jective function co efficien t) distributions in the choice problem (an ILP). (b) At inference, we lev er- age the mo del to generate scenarios in a risk-av erse estimate-then-optimize problem, allo wing us to minimize risk in tro duced by uncertain h uman preferences. Existing approac hes mo delling h uman choice b eha viour with mathematical programs, suc h as inv erse optimization [4, 9, 31, 49] and p erturbed utilit y mo d- els [1, 17, 28], are typically limited by predicting p oin t estimates rather than distributions or b y failing to account for ho w preferences shift with con text. This renders them unsuitable for risk-av erse decision-making: distributional in- formation is necessary to quantify risk, while conditioning on context helps to a void o verly conserv ative decisions. Con tribution statemen t. Our contributions are summarized as follo ws: 1. W e prop ose a metho d to learn con text-dep enden t preference (i.e. ob jective function co efficien t) distributions in in teger linear programs (ILPs) from paired context and aggregated solution statistic observ ations. This is ideal when directly observing the uncertain quant ities is imp ossible or undesirable. 2. Our approac h yields a maximum likelihoo d estimate (MLE), inheriting the desirable statistical prop erties of consistency and efficiency . 3. Our score function gradien t estimator has bounded v ariance and did not require p ost hoc v ariance reduction in our experiments. 4. W e demonstrate our approach as part of a sequen tial learning-and-optimization pip eline for decision-making under human preference uncertaint y . In a syn- thetic ridesharing environmen t, it reduces av erage p ost-decision surprise by Con textual Preference Distribution Learning 3 2.4 – 114 × compared to a risk-neutral approach with p erfect predictions and b y 1.6 – 25 × compared to leading risk-av erse baselines. 2 Related W ork W e frame our work as in verse optimization (IO), as we recov er parameters of an optimization formulation from observed solutions. It relates closely to p er- turb ed utility mo dels (PUMs) and in verse reinforcement learning (IRL), whic h mo del c hoice behaviour as optimization problems or Marko v decision pro cesses (MDPs). W e leverage integrated learning-and-optimization (ILO) techniques during training and deplo y our model in a sequential learning-and-optimization (SLO) pip eline [40]. In verse optimization. Recent research in IO addresses settings where obser- v ations are corrupted b y noise or bounded rationalit y [9, 31] yet the underlying problem formulation is deterministic. The learning task is to recov er parameters of this form ulation. Contextual IO addresses settings in which these v ary via kno wn mappings [4, 49]. In contrast, we tac kle a setting where the latent pa- rameters are random and the feature mapping function is unkno wn. The closest IO approach to ours is that of Lin et al. [24], who reco ver uncertain ty sets ov er problem parameters, but do not consider a con textual setting. P erturb ed utilit y mo dels. PUMs generalize the classical discrete choice set- ting [1, 27, 46] and sp ecialized v ariants like bundle [5, 10, 28] and route choice [16, 17]. These mo dels express c hoice probabilities as solutions to conv ex, constrained optimization problems. Most current approaches mo del a single individual rep- resen tative of the p opulation [1]: that is, they learn a function mapping from observ ed features to a point prediction of exp ected utility (negative cost). Birge et al. [5] explore learning Dirac-Uniform and von Mises-distributed utilities as sp ecial cases. A distributional approac h enables sim ulating c hoices in unseen con texts, something we explore in our experiments. In verse reinforcement learning. In contrast to IO and PUMs, IRL frame- w orks model complex choice problems as MDPs, aiming to reco v er their param- eters from observ ed decisions [7, 8, 23, 50, 51]. The applicability of IRL hea vily relies on whether a problem fits the MDP paradigm. In contrast, our approach accepts any ILP formulation and is agnostic to problem substructure and the underlying solution metho d. In tegrated learning-and-optimization. ILO, or decision-focused learning (DFL) [26], trains a mo del b y considering the impact of its predictions on do wn- stream decisions (typically measured b y regret). Our training pip eline can b e seen as an optimal action imitation ILO task, where the goal is to repro duce ob- serv ed actions given con text [40]. While many methods demonstrated on regret 4 B. Hudson et al. minimization can be readily applied to action imitation [2, 30, 36, 45, 41, 47], we con tribute a nov el approac h for back-propagating through ILPs using a b ounded- v ariance score function gradien t estimator. Sequen tial learning-and-optimization. W e take an SLO approac h, using predictions from our trained mo del in a distinct optimization problem. While estimate-then-optimize (ETO) [3, 13, 14, 19, 22, 43] and conditional robust op- timization (CRO) [11, 12, 37, 38, 39, 44] predict conditional distributions and uncertain ty sets for risk-av erse decision-making, both rely on direct observ ations of the uncertain parameters. In con trast, our approach requires only aggregated solutions to a related problem (the c hoice problem), making it ideal when direct observ ation is impossible or undesirable, e.g., for priv acy concerns. 3 Con textual Preference Distribution Learning In this section, we introduce Contextual Preference Distribution Learning (CPDL), demonstrate that it yields an MLE of the mo del parameters, and discuss the v ariance of its stochastic gradien t estimator. 3.1 Learning problem formulation W e model h uman choice b eha viour as an ILP with binary v ariables (the “c hoice problem”). This formulation is compact, yet can represen t a wide v ariety of choice settings where an individual selects from a discrete set of alternatives, suc h as shortest paths [2, 17], k -subset selection [5, 28, 36], and discrete c hoice [1, 27, 46]. Giv en a vector of preferences c , the c hoice problem yields optimal solutions Z ∗ ( c , u ) := arg min z { c ⊤ z | z ∈ Z ( u ) , z ∈ { 0 , 1 } m } , where Z ( u ) defines the feasible region given some exogenous v ariables u . W e assume an individual selects an optimal solution uniformly at random, denoted b y z ∗ ∈ R Z ∗ ( c , u ) . This defines the conditional c hoice distribution p ( z | c , u ) as ha ving equal mass o ver all elemen ts in the optimal set. T o reduce notational clutter, we omit conditioning on u where the context is unambiguous. Human preferences are v aried, context-dependent, and can b e represented by a distri- bution p ( c | X ) , where X is a m × n contextual feature matrix, containing an n -dimensional feature v ector for each element of c . Thus, we can express the p opulation c hoice distribution as p ( z | X ) = Z p ( z | c ) p ( c | X ) d c . W e now describ e the learning problem. Our goal is to recov er the distribution p ( c | X ) in a wa y that can generalize to previously unobserv ed con texts. W e lever- age amortized inference to approximate this distribution using a parameterized Con textual Preference Distribution Learning 5 mo del q θ ( c | X ) shared across instances. W e model the target and predicted c hoice distributions p ( z | X ) and q θ ( z | X ) = R p ( z | c ) q θ ( c | X ) d c as discrete exp onen tial- family distributions, allowing us to obtain an MLE of the mo del parameters θ b y optimizing them sub ject to a moment matching condition [34, 36, 51]. F or our mo del, this condition is giv en b y E p ( z | X ) [ ϕ ( z )] − E q θ ( c | X ) E p ( z | c ) [ ϕ ( z )] = 0 , where ϕ ( z ) are sufficien t statistics of the distribution of z (target or predicted). W e define the in verse problem as θ ∗ ∈ arg min θ ∈ Θ E p ( z | X ) [ ϕ ( z )] − E q θ ( c | X ) E p ( z | c ) [ ϕ ( z )] 2 2 . Unlik e previous work [36], we optimize this ob jective directly using sto c hastic gradien t descent. 3.2 Solution approach Let X b e an observed feature matrix and ¯ ϕ := E p ( z | X ) [ ϕ ( z )] b e the sufficient statistics of the observed c hoice distribution. Let the exp ected sufficient statistics under the predicted distribution b e ˆ ϕ := E q θ ( c | X ) E p ( z | c ) [ ϕ ( z )] . In this pap er, w e define ϕ ( z ) = z , corresp onding to first-moment matching, although we exp er- imen t with matc hing higher-order moments in App. B.6. The loss of the inv erse problem and its gradien t are given b y L ( X , ¯ ϕ , θ ) = ¯ ϕ − ˆ ϕ 2 2 , (1) ∇ θ L ( X , ¯ ϕ , θ ) = ¯ ϕ − ˆ ϕ ∇ θ E q θ ( c | X ) E p ( z | c ) [ ϕ ( z )] = ¯ ϕ − ˆ ϕ E q θ ( c | X ) E p ( z | c ) [ ϕ ( z )] ∇ θ log q θ ( c | X ) . (2) W e appro ximate ˆ ϕ with the Mon te Carlo estimate: ˆ ϕ ≈ 1 K L K X k =1 L X l =1 ϕ z ∗ ( kl ) where z ∗ ( kl ) ∈ R Z ∗ ( c ( k ) , u ) and c ( k ) ∼ q θ ( c | X ) . The hyperparameters K and L are the n umber of samples drawn from the learned cost distribution and the conditional choice distribution, resp ectiv ely . W e find L = 1 is sufficient to approximate E p ( z | c ) [ ϕ ( z )] , as the choice problem typically has a single solution for a giv en cost v ector. While this estimate in v olves solving the c hoice problem K L times, the instances in our setting are not computation- ally challenging. Computation can b e accelerated with warm-starting, solution cac hing [33], or GPU parallelization [25]. W e compute a sto c hastic gradient es- timate b y re-weigh ting eac h solution by the score of the generating sample from q θ ( c | X ) : ∇ θ L ( X , ¯ ϕ , θ ) ≈ ¯ ϕ − ˆ ϕ 1 K K X k =1 1 L L X l =1 ϕ z ∗ ( kl ) ! ∇ θ log q θ ( c ( k ) | X ) ! . 6 B. Hudson et al. While the solution distribution is restricted to the discrete exponential family , q θ ( c | X ) can b e any parametrizable distribution with a tractable score function (e.g., normalizing flows). Despite b eing unconstrained, our exp erimen ts sho w we reco ver the ground-truth distributional parameters up to an in v arian t transfor- mation when the distribution is correctly sp ecified. V ariance of the gradient estimator. Mohamed et al. [32] sho w the v ari- ance of a score function gradient estimate of a function f under a smo othing distribution p θ ( x ) is giv en by V ar( ˆ ∇ θ f ) = E p θ ( x ) ( f ( x ) ∇ θ log p θ ( x )) 2 − ( ˆ ∇ θ f ) 2 . Large magnitudes of f cause this v ariance to explode, leading to training insta- bilit y . In our approac h, f := E p ( z | c ) [ ϕ ( z )] represents the moments of the c hoice distribution. Because these are b ounded in [0 , 1] , the v ariance of our gradient es- timate is bounded from ab o ve b y E p θ ( x ) ( ∇ θ log p θ ( x )) 2 , whic h corresp onds to the diagonal elemen ts of the Fisher information matrix. Empirically , this allo ws CPDL to use higher learning rates than metho ds with unbounded f (e.g., RE- INF ORCE [42]) without p ost ho c v ariance reduction. W e compare CPDL and REINF ORCE in detail in App. A.1. 4 Numerical Exp erimen ts W e benchmark CPDL against other metho ds capable of generating scenarios in a syn thetic ridesharing environmen t. 4.1 Exp erimen tal setting Our environmen t comprises a synthetic data-generating pro cess represen ting driv er route choice for the “estimate” phase and a risk-a verse driver-rider as- signmen t problem for the “optimize” phase. Route c hoice problem. Our data-generating pro cess is similar to previous w ork [2, 24, 36, 47], but features sto c hastic edge costs whose distributions are feature-dep enden t. W e generate a set of choices (the samples S ) for each con text (the instanc e , i ∈ I ). This is standard in settings with categorical features, where m ultiple observ ations p er category are expected [7, 18]. W e b egin by uniformly sampling t wo global n -dimensional vectors β µ and β σ . W e generate instances representing grid graphs, eac h ha ving a |E | × n con tex- tual feature matrix X i sampled from a standard normal distribution and edge cost distributions LogNormal( X i β µ , X i β σ ) . W e use a log-normal distribution for its p ositiv e support and use in tra vel-time estimation literature [15, 21, 48]. F or each instance, we generate samples by drawing edge costs and solving the resulting shortest path problems { z ∗ ( s ) i | ∀ s ∈ S } . W e define ϕ ( z ) = z , corre- sp onding to matc hing the first c hoice distribution moment: the exp ected edge Con textual Preference Distribution Learning 7 selection probability ¯ p i = 1 |S | P S z ∗ ( s ) i . The learner observes only X i and ¯ p i . The expression of the data-generating pro cess is sho wn in App. B.1. Risk-a verse assignmen t problem. W e leverage the trained mo del to solv e a risk-a verse v ariant of the driv er-rider assignment problem, directly addressing risk introduced by uncertain human preferences. Giv en unseen features X , we sample preferences from the predicted distribution q θ ( c | X ) . F or each scenario k ∈ K , we determine the p erceiv ed-shortest paths from all drivers to all riders and compute their cost according to a decision cost vector g — the first column of X in our experiments. W e assemble these into a cost matrix G ( k ) , represen ting a scenario. Finally , w e obtain an assignment W ∗ b y solving the conditional v alue- at-risk (CV aR) minimization problem form ulation in App. B.2 with α = 0 . 95 . 4.2 Ev aluation metrics P erception of unreliability is caused by b oth early and late arriv als. Thus, we define post-decision surprise as the squared difference b et ween the exp ected de- cision cost under the ground-truth distribution p ( c | X ) and the predicted distri- bution q θ ( c | X ) . Mathematically , L P D S ( W ∗ , q θ ) = E ξ ∼ p ( c | X ) [ g ( W ∗ , ξ )] − E ζ ∼ q θ ( c | X ) [ g ( W ∗ , ζ )] 2 , (3) where g is the decision cost in a given scenario (i.e. giv en a realization of uncer- tain ty ξ or ζ ). W e appro ximate b oth exp ectations with Monte Carlo estimates (App. B.2). Because our risk-av erse assignment formulation effectiv ely penalizes only late arriv als, we also rep ort this one-sided p ost-decision disapp ointment in App. B.4. Finally , to measure the mo dels’ capacity to learn the underlying prefer- ence distributions, we rep ort the test loss and the squared correlation coefficient ( R 2 ) b et w een the predicted and ground-truth parameters (App. B.5). 4.3 Baselines W e compare against four baselines mapping context to distributions: DPO [2], AIMLE [30], REINFOR CE [42], and MaxEnt IRL [51]. W e omit IO and PUM [17] baselines b ecause they make p oin t predictions, and do not allow sampling scenar- ios. While all baselines share the same enco der (an MLP with t wo 32-dimensional hidden la yers) and loss (1), they estimate gradien ts through the choice problem differen tly . The enco der parameters are shared across edges. Additionally , we ev aluate tw o baselines with p erfect predictions: GTD-RN solves a risk-neutral assignmen t using ground-truth exp ected preferences, while GTD-RA solves the risk-a verse assignmen t with the ground-truth preference distributions. F urther baseline details are in App. B.3. 8 B. Hudson et al. 4.4 Results Fig. 2 demonstrates that our method reconstructs the c hoice distribution in un- seen contexts with the highest accuracy (measured by test loss) and generates realistic scenarios, yielding prescrib ed assignments with low p ost-decision sur- prise. Interestingly , while baselines can pro duce assignments with post-decision high surprise, they rarely lead to post-decision disapp oin tment (Fig. 3); w e com- pare these metrics and discuss this phenomenon further in App. B.4. Finally , App. B.5 details the mo dels’ ability to reco ver the underlying preference distri- butions, and App. B.6 explores the effects of matching higher-order moments. 0.00 0.01 0.02 |I|=10 |S|=10 |I|=10 |S|=1000 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) 0.00 0.01 0.02 |I|=1000 |S|=10 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) |I|=1000 |S|=1000 T est loss 0 10 20 |I|=10 |S|=10 |I|=10 |S|=1000 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA 0 10 20 |I|=1000 |S|=10 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA |I|=1000 |S|=1000 Post-decision surprise Fig. 2. Mo del performance across dataset scale and fidelity . T est loss (left) and p ost-decision surprise (right) as a function of training set size (ro ws) and observ ation fidelit y (columns), for nine random seeds. Increasing the num ber of instances ( |I | ) helps the model learn the con text-to-distribution mapping, while increasing the num b er of samples p er i nstance ( |S | ) reduces noise in the c hoice distribution statistics ( ¯ ϕ ). 5 Conclusion W e propose a metho d to learn contextual preference distributions from observed con texts and aggregated solution statistics. By leveraging a b ounded-v ariance sto c hastic gradient estimator, our approach yields an MLE of the model pa- rameters. W e demonstrate its ability to generate realistic scenarios for unseen con texts in a synthetic ridesharing environmen t, where w e prescribe driver-rider assignmen ts accounting for the uncertain t y stemming from human c hoices. Our approac h reduces av erage p ost-decision surprise by 2.4–114 × compared to a risk- neutral approac h with p erfect predictions, and b y 1.6–25 × compared to leading risk-a verse baselines. F uture work will explore normalizing flows and broader c hoice settings, like discrete c hoice and tour choice (VRP) problems. Bibliograph y [1] Allen, R., Reh b ec k, J.: Identification With A dditiv ely Separable Het- erogeneit y . Econometrica 87 (3), 1021–1054 (2019). https://doi.org/ 10.3982/ECTA15867 , https://onlinelibrary.wiley.com/doi/abs/10. 3982/ECTA15867 [2] Berthet, Q., Blondel, M., T eb oul, O., Cuturi, M., V ert, J.P ., Bach, F.: Learning with Differentiable Perturbed Optimizers. In: A dv ances in Neural Information Pro cessing Systems. vol. 33, pp. 9508–9519. Cur- ran Associates, Inc. (2020), https://papers.nips.cc/paper/2020/hash/ 6bb56208f672af0dd65451f869fedfd9- Abstract.html [3] Bertsimas, D., McCord, C., Sturt, B.: Dynamic optimization with side information. Europ ean Journal of Op erational Research 304 (2), 634–651 (Jan 2023). https://doi.org/10.1016/j.ejor.2022.03.030 , https:// www.sciencedirect.com/science/article/pii/S0377221722002545 [4] Besb es, O., F onseca, Y., Lob el, I.: Contextual In verse Optimiza- tion: Offline and Online Learning. Op erations Researc h 73 (1), 424– 443 (Jan 2025). https://doi.org/10.1287/opre.2021.0369 , https: //pubsonline.informs.org/doi/full/10.1287/opre.2021.0369 , pub- lisher: INF ORMS [5] Birge, J., Li, X., Sun, C.: Learning from Sto c hastically Rev ealed Preference. A dv ances in Neural Information Processing Systems 35 , 35061–35071 (Dec 2022), https://proceedings.neurips.cc/paper_files/paper/2022/ hash/e3c3473812173643147170188ef2b141- Abstract- Conference.html [6] Burton, J.W., Stein, M.K., Jensen, T.B.: A systematic review of algo- rithm av ersion in augmented decision making. Journal of Behavioral Deci- sion Making 33 (2), 220–239 (2020). https://doi.org/10.1002/bdm.2155 , https://onlinelibrary.wiley.com/doi/abs/10.1002/bdm.2155 [7] Cano y , R., Bucarey , V., Mandi, J., Guns, T.: Learn and route: learn- ing implicit preferences for vehicle routing. Constraints 28 (3), 363–396 (Sep 2023). https://doi.org/10.1007/s10601- 023- 09363- 2 , https:// doi.org/10.1007/s10601- 023- 09363- 2 [8] Cano y , R., Guns, T.: V ehicle Routing b y Learning from Historical Solutions. In: Schiex, T., de Givry , S. (eds.) Principles and Practice of Constrain t Programming. pp. 54–70. Springer International Publishing, Cham (2019). https://doi.org/10.1007/978- 3- 030- 30048- 7_4 [9] Chan, T.C.Y., Mahmoo d, R., Zh u, I.Y.: Inv erse Optimization: Theory and Applications. Operations Research 73 (2), 1046–1074 (Mar 2025). https:// doi.org/10.1287/opre.2022.0382 , https://pubsonline.informs.org/ doi/10.1287/opre.2022.0382 , publisher: INF ORMS [10] Chen, N., F ara jollahzadeh, S., W ang, G.: Learning Consumer Preferences from Bundle Sales Data (Sep 2022). https://doi.org/10.48550/arXiv. 2209.04942 , http://arxiv.org/abs/2209.04942 , arXiv:2209.04942 [stat] 10 B. Hudson et al. [11] Chenreddy , A., Delage, E.: End-to-end Conditional Robust Optimiza- tion (Mar 2024). https://doi.org/10.48550/arXiv.2403.04670 , http: //arxiv.org/abs/2403.04670 , arXiv:2403.04670 [cs] [12] Chenreddy , A.R., Bandi, N., Delage, E.: Data-Driven Con- ditional Robust Optimization. A dv ances in Neural Infor- mation Pro cessing Systems 35 , 9525–9537 (Dec 2022), https://papers.nips.cc/paper_files/paper/2022/hash/ 3df874367ce2c43891aab1ab23ae6959- Abstract- Conference.html [13] Deng, Y., Sen, S.: Predictive sto c hastic programming. Computational Man- agemen t Science 19 (1), 65–98 (Jan 2022). https://doi.org/10.1007/ s10287- 021- 00400- 0 , https://doi.org/10.1007/s10287- 021- 00400- 0 [14] Elmac htoub, A.N., Lam, H., Zhang, H., Zhao, Y.: Estimate-Then-Optimize v ersus Integrated-Estimation-Optimization versus Sample A v erage Approx- imation: A Sto c hastic Dominance Perspective (May 2025). https://doi. org/10.48550/arXiv.2304.06833 , http:// arxiv.org/abs/2304.06833 , arXiv:2304.06833 [stat] [15] Elmasri, M., Labb e, A., Laro cque, D., Charlin, L.: Predictiv e inference for trav el time on transp ortation netw orks (Mar 2023). https://doi. org/10.48550/arXiv.2004.11292 , http:// arxiv.org/abs/2004.11292 , arXiv:2004.11292 [stat] [16] F osgerau, M., F rejinger, E., Karlstrom, A.: A link based net work route c hoice model with unrestricted choice set. T ransp ortation Researc h P art B: Metho dological 56 , 70–80 (Oct 2013). https://doi.org/10.1016/j. trb.2013.07.012 , https://www.sciencedirect.com/science/article/ pii/S0191261513001276 [17] F osgerau, M., P aulsen, M., Rasmussen, T.K.: A p erturbed utility route c hoice mo del. T ransp ortation Researc h Part C: Emerging T ech- nologies 136 , 103514 (Mar 2022). https://doi.org/10.1016/j.trc. 2021.103514 , https://www.sciencedirect.com/science/article/pii/ S0968090X21004976 [18] Guo, C., Y ang, B., Hu, J., Jensen, C.S., Chen, L.: Context-a ware, preference-based v ehicle routing. The VLDB Journal 29 (5), 1149–1170 (Sep 2020). https://doi.org/10.1007/s00778- 020- 00608- 7 , https:// doi.org/10.1007/s00778- 020- 00608- 7 [19] Hannah, L., Po well, W., Blei, D.: Nonparametric Density Estimation for Stochastic Optimization with an Observ able State V ariable. In: A d- v ances in Neural Information Pro cessing Systems. vol. 23. Curran As- so ciates, Inc. (2010), https://proceedings.neurips.cc/paper_files/ paper/2010/hash/e1e32e235eee1f970470a3a6658dfdd5- Abstract.html [20] Harrison, J.R., March, J.G.: Decision Making and Postdecision Surprises. A dministrative Science Quarterly 29 (1), 26–42 (1984). https://doi.org/ 10.2307/2393078 , https://www.jstor.org/stable/2393078 , publisher: [Sage Publications, Inc., Johnson Graduate School of Management, Cor- nell Univ ersity] [21] Hun ter, T., Herring, R., Abb eel, P ., Bay en, A.: Path and tra v el time inference from GPS prob e vehicle data. NIPS Analyzing Netw orks and Con textual Preference Distribution Learning 11 Learning with Graphs 12 , 1–8 (2009), https://snap.stanford.edu/ nipsgraphs2009/papers/hunter- paper.pdf [22] Kannan, R., Bayraksan, G., Luedtke, J.R.: Residuals-based distribu- tionally robust optimization with co v ariate information. Mathematical Programming 207 (1), 369–425 (Sep 2024). https://doi.org/10.1007/ s10107- 023- 02014- 7 , https://doi.org/10.1007/s10107- 023- 02014- 7 [23] Kristensen, D.: On inv erse reinforcement learning and dynamic discrete c hoice for predicting path choices (Nov 2021), http://hdl.handle.net/ 1866/26530 [24] Lin, B., Delage, E., Chan, T.C.: Conformal In verse Optimization. Adv ances in Neural Information Processing Systems 37 , 63534–63564 (Dec 2024), https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 7423902b5534e2b267438c85444a54b1- Abstract- Conference.html [25] Lu, H., P eng, Z., Y ang, J.: MP AX: Mathematical Programming in JAX (F eb 2025). https://doi.org/10.48550/arXiv.2412.09734 , http://arxiv. org/abs/2412.09734 , arXiv:2412.09734 [math] [26] Mandi, J., K otary , J., Berden, S., Mulamba, M., Bucarey , V., Guns, T., Fioretto, F.: Decision-F o cused Learning: F oundations, State of the Art, Benc hmark and F uture Opportunities. Journal of Artificial Intelligence Researc h 80 , 1623–1701 (Aug 2024). https://doi.org/10.1613/jair.1. 15320 , http://arxiv.org/abs/2307.13565 , arXiv:2307.13565 [cs] [27] McF adden, D.: Econometric mo dels of probabilistic c hoice. Structural anal- ysis of discrete data with econometric applications 198272 (1981), pub- lisher: MIT Press [28] McF adden, D., F osgerau, M.: A theory of the p erturbed consumer with general budgets. T ech. rep., National Bureau of Economic Researc h (2012), https://www.nber.org/papers/w17953 [29] Merc hán, D., Arora, J., Pac hon, J., Konduri, K., Winken bach, M., Parks, S., Noszek, J.: 2021 Amazon Last Mile Routing Researc h Challenge: Data Set. T ransp ortation Science 58 (1), 8–11 (Jan 2024). https://doi. org/10.1287/trsc.2022.1173 , https://pubsonline.informs.org/doi/ full/10.1287/trsc.2022.1173 , publisher: INF ORMS [30] Minervini, P ., F ranceschi, L., Niepert, M.: Adaptiv e Perturbation-Based Gradien t Estimation for Discrete Latent V ariable Mo dels. Pro ceedings of the AAAI Conference on Artificial Intelligence 37 (8), 9200–9208 (Jun 2023). https://doi.org/10.1609/aaai.v37i8.26103 , https://ojs.aaai.org/ index.php/AAAI/article/view/26103 [31] Moha jerin Esfahani, P ., Shafieezadeh-Abadeh, S., Hanasusanto, G.A., Kuhn, D.: Data-driv en inv erse optimization with imp erfect infor- mation. Mathematical Programming 167 (1), 191–234 (Jan 2018). https://doi.org/10.1007/s10107- 017- 1216- 6 , https://doi.org/10. 1007/s10107- 017- 1216- 6 [32] Mohamed, S., Rosca, M., Figurnov, M., Mnih, A.: Monte Carlo Gradien t Estimation in Mac hine Learning (Sep 2020). https://doi. org/10.48550/arXiv.1906.10652 , http://arxiv.org/abs/1906.10652 , arXiv:1906.10652 [stat] 12 B. Hudson et al. [33] Mulam ba, M., Mandi, J., Diligenti, M., Lom bardi, M., Bucarey , V., Guns, T.: Contrastiv e Losses and Solution Caching for Predict-and-Optimize (Jul 2021). https://doi.org/10.48550/arXiv.2011.05354 , http://arxiv. org/abs/2011.05354 , arXiv:2011.05354 [cs] [34] Murph y , K.P .: Probabilistic Mac hine Learning: A dv anced T opics. The MIT Press, Cam bridge, Massach usetts (2023) [35] Nguy en, T.: ET A Phone Home: How Uber Engineers an Effi- cien t Route (No v 2015), https://www.uber.com/en- EG/blog/ engineering- routing- engine/ [36] Niep ert, M., Minervini, P ., F ranceschi, L.: Implicit MLE: Bac kpropagating Through Discrete Exp onen tial F amily Distributions. In: A dv ances in Neu- ral Information Pro cessing Systems. vol. 34, pp. 14567–14579. Curran As- so ciates, Inc. (2021), https://proceedings.neurips.cc/paper_files/ paper/2021/hash/7a430339c10c642c4b2251756fd1b484- Abstract.html [37] Ohmori, S.: A Predictive Prescription Using Minimum V olume k-Nearest Neigh b or Enclosing Ellipsoid and Robust Optimization. Mathematics 9 (2), 119 (Jan 2021). https://doi.org/10.3390/math9020119 , https://www. mdpi.com/2227- 7390/9/2/119 , publisher: Multidisciplinary Digital Pub- lishing Institute [38] P atel, Y., Ra yan, S., T ew ari, A.: Conformal Contextual Robust Optimiza- tion (Oct 2023). https://doi.org/10.48550/arXiv.2310.10003 , http: //arxiv.org/abs/2310.10003 , arXiv:2310.10003 [stat] [39] P eršak, E., Anjos, M.F.: Contextual Robust Optimisation with Uncer- tain ty Quantification. In: Cire, A.A. (ed.) Integration of Constraint Pro- gramming, Artificial Intelligence, and Op erations Research. pp. 124–132. Springer Nature Switzerland, Cham (2023). https://doi.org/10.1007/ 978- 3- 031- 33271- 5_9 [40] Sadana, U., Chenreddy , A., Delage, E., F orel, A., F rejinger, E., Vidal, T.: A surv ey of contextual optimization metho ds for decision-making un- der uncertaint y . Europ ean Journal of Op erational Researc h 320 (2), 271– 289 (Jan 2025). https://doi.org/10.1016/j.ejor.2024.03.020 , https: //www.sciencedirect.com/science/article/pii/S0377221724002200 [41] Saho o, S.S., Vlastelica, M., Paulus, A., Musil, V., Kuleshov, V., Martius, G.: Gradien t Backpropagation Through Com binatorial Algorithms: Identit y with Pro jection W orks (May 2022). https://doi.org/10.48550/arXiv. 2205.15213 , http://arxiv.org/abs/2205.15213 , arXiv:2205.15213 [cs] v ersion: 1 [42] Silv estri, M., Berden, S., Mandi, J., Mahmutoğulları, A.I., Amos, B., Guns, T., Lom bardi, M.: Score F unction Gradien t Estimation to Widen the Applicabilit y of Decision-F o cused Learning (Jun 2024). https://doi. org/10.48550/arXiv.2307.05213 , http://arxiv.org/abs/2307.05213 , arXiv:2307.05213 [cs] [43] Sriv asta v a, P .R., W ang, Y., Hanasusanto, G.A., Ho, C.P .: On Data-Driv en Prescriptiv e Analytics with Side Information: A Regularized Nadaray a- W atson Approach (Oct 2021). https://doi.org/10.48550/arXiv.2110. 04855 , http://arxiv.org/abs/2110.04855 , arXiv:2110.04855 [math] Con textual Preference Distribution Learning 13 [44] Sun, C., Liu, L., Li, X.: Predict-then-Calibrate: A New P er- sp ectiv e of Robust Contextual LP. Adv ances in Neural In- formation Pro cessing Systems 36 , 17713–17741 (Dec 2023), https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 397271e11322fae8ba7f827c50ca8d9b- Abstract- Conference.html [45] Sun, C., Liu, S., Li, X.: Maximum Optimality Margin: A Unified Ap- proac h for Contextual Linear Programming and Inv erse Linear Program- ming (Ma y 2023). https://doi.org/10.48550/arXiv.2301.11260 , http: //arxiv.org/abs/2301.11260 , arXiv:2301.11260 [cs] [46] T rain, K.E.: Discrete Choice Metho ds with Sim ulation. Cam- bridge Universit y Press, Cambridge, 2 edn. (2009). https: //doi.org/10.1017/CBO9780511805271 , https://www.cambridge. org/core/books/discrete- choice- methods- with- simulation/ 49CABD00F3DDDA088A8FBFAAAD7E9546 [47] Vlastelica, M., Paulus, A., Musil, V., Martius, G., Rolínek, M.: Differ- en tiation of Blac kb o x Combinatorial Solvers (F eb 2020). https://doi. org/10.48550/arXiv.1912.02175 , http://arxiv.org/abs/1912.02175 , arXiv:1912.02175 [cs] [48] W estgate, B.S., W o o dard, D.B., Matteson, D.S., Henderson, S.G.: Large- net work trav el time distribution estimation for ambulances. Europ ean Jour- nal of Operational Research 252 (1), 322–333 (Jul 2016). https://doi. org/10.1016/j.ejor.2016.01.004 , https://www.sciencedirect.com/ science/article/pii/S0377221716000102 [49] Zattoni Scro ccaro, P ., Ataso y , B., Moha jerin Esfahani, P .: Learn- ing in Inv erse Optimization: Incen ter Cost, Augmented Sub optimalit y Loss, and Algorithms. Op erations Research (Sep 2024). https://doi. org/10.1287/opre.2023.0254 , https://pubsonline.informs.org/doi/ full/10.1287/opre.2023.0254 , publisher: INF ORMS [50] Zhao, Z., Liang, Y.: A deep in v erse reinforcement learning approac h to route choice modeling with con text-dep enden t rewards. T ransp ortation Re- searc h Part C: Emerging T echnologies 149 , 104079 (Apr 2023). https: //doi.org/10.1016/j.trc.2023.104079 , https://www.sciencedirect. com/science/article/pii/S0968090X23000682 [51] Ziebart, B.D., Maas, A., Bagnell, J.A., Dey , A.K.: Maximum entrop y in- v erse reinforcement learning. In: Pro ceedings of the 23rd National Confer- ence on Artificial Intelligence - V olume 3. pp. 1433–1438. AAAI’08, AAAI Press, Chicago, Illinois (Jul 2008), https://cdn.aaai.org/AAAI/2008/ AAAI08- 227.pdf 14 B. Hudson et al. A A dditional theoretical results A.1 Comparison to REINFOR CE CPDL computes the loss (1) for each datap oin t using a batch of samples from the learned distribution q θ ( c | X ) . REINFOR CE do es the opp osite: it computes the loss for a batc h of datap oin ts for eac h sample from the learned distribution. This approac h effectiv ely treats the en tire distribution-to-loss pip eline as a blac k b o x and yields a differen t gradient from (2) [42]. Mathematically , L REINFOR CE ( X , ¯ ϕ , θ ) = E q θ ( c | X ) ∥ ¯ ϕ − E p ( z | c ) [ ϕ ( z )] ∥ 2 2 , ∇ θ L REINFOR CE ( X , ¯ ϕ , θ ) = E q θ ( c | X ) ∥ ¯ ϕ − E p ( z | c ) [ ϕ ( z )] ∥ 2 2 ∇ θ log q θ ( c | X ) . As discussed in Section 3.2, this gradien t estimator can suffer from high v ari- ance because the loss for a giv en batc h is un b ounded. T o mitigate this, our implemen tation of REINFOR CE employs a baseline [32]. B A dditional exp erimen tal details B.1 Data-generating pro cess W e can express our syn thetic data-generating pro cess mathematically as β µ ∼ Uniform([0 , 1] n ) β σ ∼ Uniform([0 , 1] n ) X i ∼ Normal( 0 , I |E |× n ) ∀ i ∈ I c ( s ) i ∼ LogNormal( X i β µ , X i β σ ) ∀ i ∈ I , s ∈ S z ∗ ( s ) i ∈ R Z ∗ ( c ( s ) i , u ) ∀ i ∈ I , s ∈ S ¯ p i = 1 |S | X s ∈ S z ∗ ( s ) i ∀ i ∈ I , where β µ and β σ are global n -dimensional vectors. X i is a |E | × n matrix, and c ( s ) i , z ∗ ( s ) i , and ¯ p i are |E | -dimensional v ectors. I is the set of instances and S is the set of samples for a giv en instance. Con textual Preference Distribution Learning 15 B.2 Risk-a verse assignmen t form ulation The risk-a verse assignmen t problem is formulated as min u ∈ R |K| ,v ∈ R , W v + 1 1 − α 1 |K| X k ∈K u k s . t . u k ≥ X d ∈D X r ∈R G ( k ) dr W dr − v ∀ k ∈ K u k ≥ 0 ∀ k ∈ K X D W dr = 1 ∀ r ∈ R X R W dr = 1 ∀ d ∈ D W dr ∈ { 0 , 1 } ∀ d ∈ D , r ∈ R , (4) where u is a |K | -dimensional v ector with u k represen ting the exp ected shortfall of scenario k , v is the v alue-at-risk, W is a |D| × |R| assignment matrix with W dr = 1 indicating driv er d is assigned to rider r , and α is the risk-level (0.95 in our exp erimen ts). Giv en a kno wn cost vector g and exogenous v ariables u dr ∀ d ∈ D , r ∈ R , w e generate a cost scenario G ( k ) according to the follo wing pro cess c ( d ) ∼ q θ ( c | X ) ∀ d ∈ D z ∗ ( dr ) ∈ R Z ∗ ( c ( d ) , u dr ) ∀ d ∈ D , r ∈ R G ( k ) dr = g ⊤ z ∗ ( dr ) ∀ d ∈ D , r ∈ R , where G k dr is an element of the scenario cost matrix G ( k ) . The exp ected solution cost under the predicted distribution is E ζ ∼ q θ ( c | X ) [ g ( W ∗ , ζ )] = 1 |K| X k ∈K X d ∈D X r ∈R G ( k ) dr W ∗ dr . B.3 Baselines Our PyT orc h implementation including all baselines is av ailable at https:// github.com/ben- hudson/contextual- preference- distribution- learning . W e use the blac k-box h yp erparameter optimization to ol in W eights & Biases to select hyperparameters for each metho d: b eginning with 25 randomly sampled exp erimen ts, we acquire 25 more by minimizing v alidation loss with Ba yesian optimization. Eac h experiment trains the giv en mo del on a randomly generated dataset with |I | = 100 and |S | = 1000 , with an 80-20 train-v alidation split. The h yp erparameter sets with the lo west v alidation loss are shown in T able 1. 16 B. Hudson et al. T able 1. Hyp erparameters used in our experiments. Perturbation scale defines the v ariance of the perturbing distribution; a hyperparameter in some methods and a learned qu a ntit y in others. Dashes (–) indicate not applicable to giv en baseline. P arameter AIMLE DPO MaxEn t IRL REINF ORCE CPDL Starting LR 1.06e-6 5.61e-2 8e-4 3e-4 2.5e-3 LR p a tience (epo c hs) 20 15 5 7 15 LR p a tience rel. tol. 6.92% 0.2% 3.64% 4.08% 3.31% P erturbations ( K ) 400 300 – 500 300 P erturbation scale 0.6 0.9 – Learned Learned P erturbation sides 2 – – – – Fixed-p oin t max iters. – – 600 – – Fixed-p oin t rel. tol. – – 3e-8 – – Batc h size 128 128 5 128 128 T raining epo c hs 200 500 200 200 200 B.4 P ost-decision surprise and disapp oin tment Fig. 3 sho ws p ost-decision surprise (computed according to (3)), which p enalizes b oth early and late arriv als, alongside p ost-decision disappointmen t, which p e- nalizes only late arriv als. W e observ e that the baselines consisten tly achiev e m uch lo wer disapp oin tment than surprise. This suggests they make ov erly conserv ative decisions: the assignments rarely result in late drivers (low disapp oin tment) but frequen tly result in early ones (high surprise). Coun terintuitiv ely , baseline performance degrades with more data. W e exam- ined sp ecific predictions pro duced by these mo dels — esp ecially REINFOR CE, giv en its similarity to our approach — and compared them to ours. W e h yp othe- size is that this phenomenon is a result of asp ects of the data-generating pro cess and training pro cess. The synthetic data-generating pro cess (App. B.1) tends to generate correlated edge costs and edge scales b ecause the co efficien ts β µ and β σ are strictly p ositiv e. With small training sets, the mo del can learn the cor- rect relationship for the distribution lo cation, but an inv erse relationship for the distribution scale (i.e., a p ositiv e R 2 score but a negativ e correlation coefficient). Consequen tly , the model predicts edges with high cost or high v ariance, when in realit y they tend to hav e b oth. This results in o verly conserv ativ e decisions. While our model is susceptible to this same issue, it corrects itself with less data, whic h explains why its p erformance closely trac ks GTD-RA, the risk-av erse baseline with access to the ground-truth distributions. This merits further study . B.5 Preference distribution recov ery Figure 4 sho ws test loss for additional com binations of training set size and fidelit y , which measures the mo dels’ ability to reconstruct the observed choice distributions. Figure 5 shows the squared correlation co efficien t ( R 2 ) b et w een predicted and ground-truth preference distribution parameters, which measures their reco very up to an affine transformation. Con textual Preference Distribution Learning 17 0 10 20 |I|=10 |S|=10 |I|=10 |S|=100 |I|=10 |S|=1000 0 10 20 |I|=100 |S|=10 |I|=100 |S|=100 |I|=100 |S|=1000 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA 0 10 20 |I|=1000 |S|=10 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA |I|=1000 |S|=100 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA |I|=1000 |S|=1000 Post-decision surprise 0 5 |I|=10 |S|=10 |I|=10 |S|=100 |I|=10 |S|=1000 0 5 |I|=100 |S|=10 |I|=100 |S|=100 |I|=100 |S|=1000 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA 0 5 |I|=1000 |S|=10 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA |I|=1000 |S|=100 GTD-RN REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) GTD-RA |I|=1000 |S|=1000 Post-decision disappointment Fig. 3. Post-decision surprise (top) and disapp oin tment (bottom) as a function of train- ing set size (rows) and observ ation fidelity (columns), aggregated ov er nine random seeds. While surprise p enalizes early and late arriv als, disapp oin tmen t only p enalizes late arriv als. The com bination of high surprise and lo w disapp oin tment suggests o verly conserv ativ e assignmen ts. 18 B. Hudson et al. 0.00 0.02 |I|=10 |S|=10 |I|=10 |S|=100 |I|=10 |S|=1000 0.00 0.02 |I|=100 |S|=10 |I|=100 |S|=100 |I|=100 |S|=1000 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) 0.00 0.02 |I|=1000 |S|=10 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) |I|=1000 |S|=100 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) |I|=1000 |S|=1000 T est loss Fig. 4. T est loss as a function of training set size (rows) and observ ation fidelity (columns), aggregated o ver nine random seeds. B.6 Matc hing momen ts b ey ond the mean Figure 6 sho ws the impact of matching the first and second raw moments of the c hoice distribution, i.e. ϕ ( z ) = [ z , zz ⊤ ] , instead of just the first. Con textual Preference Distribution Learning 19 0.0 0.5 1.0 |I|=10 |S|=10 |I|=10 |S|=100 |I|=10 |S|=1000 0.0 0.5 1.0 |I|=100 |S|=10 |I|=100 |S|=100 |I|=100 |S|=1000 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) 0.0 0.5 1.0 |I|=1000 |S|=10 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) |I|=1000 |S|=100 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) |I|=1000 |S|=1000 R 2 l o c a t i o n p a r a m . 0.0 0.5 1.0 |I|=10 |S|=10 |I|=10 |S|=100 |I|=10 |S|=1000 0.0 0.5 1.0 |I|=100 |S|=10 |I|=100 |S|=100 |I|=100 |S|=1000 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) 0.0 0.5 1.0 |I|=1000 |S|=10 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) |I|=1000 |S|=100 REINFORCE MaxEnt IRL DPO AIMLE CPDL (ours) |I|=1000 |S|=1000 R 2 s c a l e p a r a m . Fig. 5. Reco very of the ground-truth preference distribution lo cation (top) and scale (b ottom) up to an affine transformation as a function of training set size (rows) and observ ation fidelity (columns), aggregated o ver nine random seeds. The maximum score is one and the minim um score is zero. Only REINF ORCE and CPDL are able to learn parameters b ey ond the lo cation. 20 B. Hudson et al. 0 2 |I|=10 |S|=10 |I|=10 |S|=100 |I|=10 |S|=1000 0 2 |I|=100 |S|=10 |I|=100 |S|=100 |I|=100 |S|=1000 1st moment 1st + 2nd moments GTD-RA 0 2 |I|=1000 |S|=10 1st moment 1st + 2nd moments GTD-RA |I|=1000 |S|=100 1st moment 1st + 2nd moments GTD-RA |I|=1000 |S|=1000 Post-decision surprise 0 1 |I|=10 |S|=10 |I|=10 |S|=100 |I|=10 |S|=1000 0 1 |I|=100 |S|=10 |I|=100 |S|=100 |I|=100 |S|=1000 1st moment 1st + 2nd moments GTD-RA 0 1 |I|=1000 |S|=10 1st moment 1st + 2nd moments GTD-RA |I|=1000 |S|=100 1st moment 1st + 2nd moments GTD-RA |I|=1000 |S|=1000 Post-decision disappointment Fig. 6. Post-decision surprise (top) and disapp oin tment (bottom) for CPDL matc hing only the first moment compared to the first and second momen ts. On small (lo w |I | ) and lo w-fidelity (low |S | ) datasets, matching only the first moment tends to yield b etter p erformance. W e h yp othesize that the first momen t is a less informativ e learning signal but is more robust to noise. Thus, the tradeoff shifts in fav our of higher momen ts as dataset size and fid e lity increase.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment