Topology-Preserving Deep Joint Source-Channel Coding for Semantic Communication
Many wireless vision applications, such as autonomous driving, require preservation of global structural information rather than only per-pixel fidelity. However, existing Deep joint source-channel coding (DeepJSCC) schemes mainly optimize pixel-wise…
Authors: Omar Erak, Omar Alhussein, Fang Fang
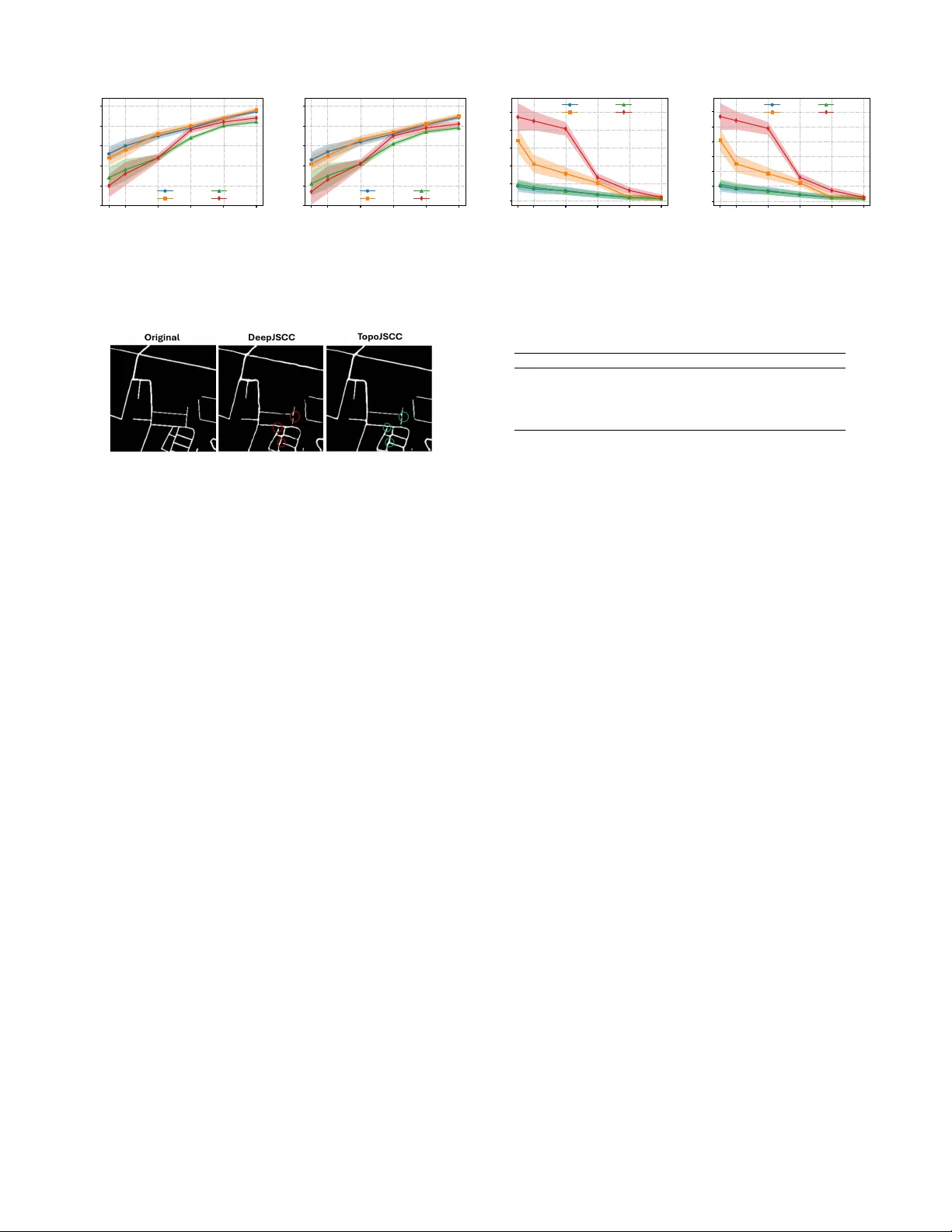
T opology-Preserving Deep Joint Source-Channel Coding for Semantic Communication Omar Erak, Member , IEEE , Omar Alhussein, Senior Member , IEEE , Fang F ang, Senior Member , IEEE , and Sami Muhaidat, Senior Member , IEEE Abstract —Many wireless vision applications, such as au- tonomous driving, requir e preser vation of global structural information rather than only per-pixel fidelity . Howev er , existing Deep joint source-channel coding (DeepJSCC) schemes mainly optimize pixel-wise losses and pro vide no explicit protection of connectivity or topology . This letter proposes T opoJSCC, a topology-aware DeepJSCC framework that integrates persistent- homology regularizers to end-to-end training . Specifically , we enfor ce topological consistency by penalizing W asserstein dis- tances between cubical persistence diagrams of original and reconstructed images, and between Vietoris–Rips persistence of latent features before and after the channel to promote a rob ust latent manifold. T opoJSCC is based on end-to-end learning and requires no side information. Experiments show impro ved topology preser vation and peak signal-to-noise ratio (PSNR) in low signal-to-noise ratio (SNR) and band width-ratio r egimes. Index T erms —Semantic communication, deep joint-source channel coding, persistent homology , topological data analysis I . I N T RO D U C T I O N Next-generation wireless systems are expected to support safety-critical and perception-centric applications such as au- tonomous driving and telemedicine [1]. In these scenarios, the structure of the receiv ed visual data is often more important than exact pix el-wise fidelity: a broken road segment can mislead a path planner , and a missing branch in a retinal vascular tree may in validate a diagnosis. Small topological errors can cause downstream semantic modules to fail even when traditional signal-lev el metrics such as peak signal-to- noise ratio (PSNR) remain high, highlighting the need for communication schemes that explicitly protect topology and other task-rele vant semantics. Con ventional wireless image transmission typically follo ws the separation principle, combining source compression with error-control coding and modulation. While spectrally effi- cient, such systems are sensitiv e to channel mismatch and suffer the “cliff effect, ” where reconstruction quality collapses once the signal-to-noise ratio (SNR) drops below the design point. Deep joint source-channel coding (DeepJSCC) instead learns an end-to-end mapping from pixels to comple x channel symbols using encoder/decoder networks with a dif feren- tiable channel layer , yielding graceful degradation and strong Omar Erak, Omar Alhussein and Sami Muhaidat are with the KU 6G Research Center, College of Computing and Mathematical Sci- ences, Khalifa Univ ersity , Abu Dhabi, UAE (e-mail: omarerak@ieee.org, omar .alhussein@ku.ac.ae). Fang Fang is with the Department of Electrical and Computer Engineering, and also with the Department of Computer Science, W estern University , London, ON N6A 3K7, Canada (e-mail: f ang.fang@uwo.ca). performance in low-SNR or bandwidth-limited regimes [2]. Howe v er , existing DeepJSCC methods optimize only pixel- wise or geometric distortions and may fail to preserve global structure, so reconstructions of structured images such as roads or retinal vascular trees can still contain broken, missing, or incorrectly connected se gments. T opological data analysis (TD A), in particular persistent homology (PH), provides compact descriptors of multi-scale connectivity and loop structure through persistence diagrams [3], [4]. TD A has shown promising results in computer vi- sion [5], [6] and recently , TD A has been introduced into communication systems. T opoCode [7] encodes persistence- diagram information as side information for error detection and correction in image communication, transmitting a com- pact topological signature alongside con v entional data. While effecti v e at correcting semantically significant errors at low SNR with limited redundancy , such schemes operate on top of classical digital coding and do not exploit TD A inside an end-to-end learned physical layer . T o the best of our knowledge, persistent-homology-based losses hav e not been integrated directly into DeepJSCC for wireless image transmission, nor has topology preservation been systematically ev aluated in this context. This leav es a gap between topology-aware perception and learned physical- layer schemes, especially for applications where the topology of thin structures, such as road networks, is critical. This letter addresses this gap with the following contributions: • W e propose T opoJSCC, a topology-aware DeepJSCC framew ork that augments the mean squared error (MSE) distortion with an image-domain persistent-homology loss based on a W asserstein distance (WD) between per- sistence diagrams of original and reconstructed images. • W e introduce a latent-space topological loss that applies PH to V ietoris–Rips complexes built from encoder fea- tures before and after the channel, promoting a channel- robust latent manifold without changing the architecture. • W e ev aluate T opoJSCC on two topology-rich datasets un- der additive white Gaussian noise (A WGN) and Rayleigh fading, comparing against DeepJSCC, BPG+LDPC, and a T opoCode-based baseline, and show that T opoJSCC substantially reduces persistence-diagram distortion and topological errors while maintaining PSNR comparable to DeepJSCC. I I . S Y S T E M M O D E L W e consider a point-to-point wireless semantic communica- tion system designed for topology-sensitiv e image data, such Figure 1. T opoJSCC system model and losses as road networks or retinal vasculature. The source image is represented by X ∈ R H × W × C , where H and W denote height and width, and C is the number of channels. For processing, X is reshaped into a vector x ∈ R n with n = H W C . The transmitter employs a semantic encoder, modeled as a deterministic mapping f θ : R n → R 2 k parameterized by a deep neural network (DNN) with weights θ . Gi ven x , the encoder produces s = f θ ( x ) ∈ R 2 k , which is grouped into k complex channel symbols z ℓ = s 2 ℓ − 1 + j s 2 ℓ , ℓ = 1 , . . . , k , forming the complex channel input vector z ∈ C k . Unlike conv entional separation-based schemes, f θ jointly performs source and channel coding. W e impose an av erage po wer constraint normalized by the number of channel uses, 1 k E [ ∥ z ∥ 2 2 ] ≤ P , where the e xpectation is taken over the source distribution. The channel bandwidth ratio is defined as ρ ≜ k /n , and we focus on the bandwidth-limited regime ρ < 1 . The encoded symbol vector z is transmitted o ver a complex baseband wireless channel. The receiv ed signal y ∈ C k is giv en by y = h z + n , where h ∈ C is the complex channel gain and n ∼ C N ( 0 , N 0 I k ) denotes A WGN. W e consider two channel en vironments: a static A WGN channel with h = 1 , and a slo w Rayleigh fading channel with h ∼ C N (0 , 1) , which is constant for the duration of one image transmission and varies independently between images. A normalization layer enforces the power constraint. With E [ | h | 2 ] = 1 , the average receiv e signal-to-noise ratio is SNR = P / N 0 , and we report SNR dB = 10 log 10 ( P / N 0 ) . At the receiv er , a semantic decoder g ϕ : R 2 k → R n , parameterized by a DNN with weights ϕ , processes the noisy signal. In implementation, the real and imaginary parts of y are concatenated into a real vector ˜ y ∈ R 2 k , and the decoder outputs ˆ x = g ϕ ( ˜ y ) , which is reshaped back to ˆ X ∈ R H × W × C for e valuation. I I I . P R O P O S E D T O P O L O G Y - A W A R E D E E P J S C C T opology-rich images, such as road networks or vascular structures, are characterized by their connectivity , branching structure, and loop patterns. Standard pixel-wise losses such as MSE do not explicitly enforce preservation of these structures. T o address this, we augment the DeepJSCC objectiv e with two PH-based re gularizers: an image-domain topological loss that matches the topology of the input and reconstructed images, and a latent-space topological loss that constrains the topology of the latent representations before and after the channel. PH characterizes how the homology of a space changes along a filtration (i.e., nested sequence of cell complexes). Each filtration yields a persistence diagram, a multiset of birth–death pairs ( b m i , d m i ) , indicating when a m -dimensional feature appears and disappears [4]. W e compare diagrams using a p -W asserstein distance [8]. For both losses we compute PH in dimensions m ∈ { 0 , 1 } , where m = 0 corresponds to connected components, and m = 1 to one-dimensional c ycles. A. Image-Domain T opolo gical Loss For the image-domain loss, we represent the H × W pixel grid as a cubical complex, and denote by Q ij = [ i, i + 1] × [ j, j + 1] the unit square associated with pixel ( i, j ) , together with its edges and vertices. The union of these cells forms a cubical complex K ( X ) . The image intensities define values X ij ∈ [0 , 1] on the pixels, which we identify with the squares Q ij . T o emphasize bright foreground structures, we adopt a superlev el-set filtration. For a threshold τ ∈ [0 , 1] , we define X τ = [ i,j : X ij ≥ τ Q ij . (1) As τ is decreased, more pixels enter the complex. In imple- mentation we consider a finite, strictly decreasing sequence of thresholds 1 = τ 0 > τ 1 > · · · > τ T = 0 , which yields the nested filtration ∅ ⊆ X τ 0 ⊆ X τ 1 ⊆ · · · ⊆ X τ T = K ( X ) . Persistent homology applied to this filtration tracks the cre- ation and destruction of connected components and loops in the bright re gions of the image. W e denote the resulting persistence diagrams by D img m ( X ) = PH m {X τ t } T t =0 , m ∈ { 0 , 1 } , and analogously obtain D img m ( ˆ X ) from the reconstructed image ˆ X using the same threshold sequence. T o quantify topological discrepancies, we compare persistence diagrams using a p - W asserstein distance. Let D and D ′ be two persistence dia- grams (multisets of points in R 2 ). W e augment each diagram with the diagonal ∆ = { ( t, t ) : t ∈ R } of infinite multiplicity so that unmatched points can be paired with the diagonal. Let η : D ∪ ∆ → D ′ ∪ ∆ be a bijection. For p ≥ 1 , the p -W asserstein distance between D and D ′ is d W,p ( D , D ′ ) = inf η X x ∈ D ∪ ∆ ∥ x − η ( x ) ∥ p ∞ ! 1 /p , (2) where for a point x = ( a, b ) we use the ℓ ∞ norm ∥ ( a, b ) ∥ ∞ = max {| a | , | b |} . Intuiti vely , η matches birth–death pairs in D to those in D ′ , and pairs that cannot be matched are mapped to the diagonal. In all our experiments we fix p = 2 and write d W, 2 . Compared with the bottleneck distance, which is dominated by the single largest mismatch between diagrams, the 2-W asserstein distance aggregates discrepancies over all features and provides a more informati ve signal when used as a regularizer in our DeepJSCC training. For each homology dimension m ∈ { 0 , 1 } , we measure the discrepancy between the topologies of X and ˆ X as d img m X , ˆ X = d W, 2 D img m ( X ) , D img m ( ˆ X ) , and define the image-domain topological loss L img top ( X , ˆ X ) = X m ∈{ 0 , 1 } d img m X , ˆ X . Minimizing L img top encourages the reconstruction to preserve the connected components and loops of the bright structures in the image, which is crucial for road networks and retinal vasculature. B. Latent-Space T opological Loss W e also promote robustness of the latent representation to channel noise. Consider a mini-batch of B images { X i } B i =1 with vectorized forms x i ∈ R n . The encoder f θ produces real latent vectors before the channel, namely s i = f θ ( x i ) ∈ R 2 k for i = 1 , . . . , B . Let C r ( · ) denote the dif ferentiable channel layer in its real-valued implementation; it maps s i to the stacked real and imaginary parts of the receiv ed complex channel output. The noisy latent vectors are then ˜ s i = C r ( s i ) ∈ R 2 k . W e interpret the sets = { s 1 , . . . , s B } , ˜ S = { ˜ s 1 , . . . , ˜ s B } as point clouds in R 2 k endowed with the Eu- clidean distance. T o summarize the geometry of these point clouds, we construct a V ietoris–Rips filtration [4]. Gi ven a finite metric space ( S, d ) , the V ietoris–Rips comple x at scale ε ≥ 0 is the abstract simplicial comple x R ε ( S ) = σ ⊆ S σ finite and max u,v ∈ σ d ( u, v ) ≤ ε . W e consider a strictly increasing sequence of scales 0 = ε 0 < ε 1 < · · · < ε T = ε max , which yields the V ietoris–Rips filtration R ε 0 ( S ) ⊆ R ε 1 ( S ) ⊆ · · · ⊆ R ε T ( S ) , using the Euclidean metric d ( u, v ) = ∥ u − v ∥ 2 on R 2 k . Applying PH to this filtration produces, for m ∈ { 0 , 1 } , persistence diagrams D lat m ( S ) = PH m {R ε t ( S ) } T t =0 and D lat m ( ˜ S ) = PH m {R ε t ( ˜ S ) } T t =0 . Using the same 2 -W asserstein distance, we quantify the topological distortion introduced by the chan- nel via d lat m ( S, ˜ S ) = d W, 2 D lat m ( S ) , D lat m ( ˜ S ) , and define the latent-space topological loss as follows L lat top ( S, ˜ S ) = X m ∈{ 0 , 1 } d lat m ( S, ˜ S ) . Minimizing L lat top encourages the encoder to learn latent man- ifolds whose global shape (clusters, branches, and loops) is preserved after the stochastic channel perturbation. C. Final T raining Loss For a mini-batch of B image pairs { ( X i , ˆ X i ) } B i =1 with corresponding vectorized forms ( x i , ˆ x i ) and latent sets ( S, ˜ S ) constructed from the whole batch as above, we train the topology-aware DeepJSCC by minimizing the batch objecti ve L batch = 1 B B X i =1 h L MSE ( x i , ˆ x i ) + λ img L img top ( X i , ˆ X i ) i + λ lat L lat top ( S, ˜ S ) , (3) where L MSE ( x i , ˆ x i ) = 1 n ∥ x i − ˆ x i ∥ 2 2 . The first term is an average over samples in the batch; the latent-space term is naturally defined at the batch level because the persistence diagrams are computed from the point clouds S and ˜ S that contain all B latent codes. In practice, B is fixed and the relative contribution of the latent-space term is controlled by the hyperparameter λ lat . Gradients of both topological losses are obtained through dif ferentiable PH layers [5], [9] and are backpropagated jointly with the MSE term to update the encoder and decoder parameters. Using MSE as the base distortion keeps the training objective and the e valuation metric (PSNR, which is deriv ed from MSE) aligned across all e xperiments similar to prior works [2]. D. Choice of T opological Hyperparameters The additional topological terms in the training objective operate on different numerical scales than the MSE recon- struction loss. T o giv e them a meaningful b ut not dominating influence, we choose the weights λ img and λ lat in two stages. W e first train a baseline DeepJSCC model using only the MSE loss. After con ver gence, we freeze its parameters and ev aluate, on a held-out v alidation batch, the typical magnitudes of the reconstruction loss and of the unweighted image- and latent-domain topological losses. W e then set initial v alues for λ img and λ lat so that, on this batch, each weighted topological term contributes only a small fraction of the reconstruction loss. This provides a starting point where topology af fects the gradients without o verwhelming the reconstruction objective. Starting from these initial weights, we perform a short grid search ov er nearby values on a validation set, selecting the pair ( λ img , λ lat ) that best trades off PSNR and topological fidelity (smaller W asserstein distances between input and re- construction diagrams). T o further stabilize training, we apply an annealing schedule λ img ( t ) = λ img 1 − e − t/T , λ lat ( t ) = λ lat 1 − e − t/T , where t is the training epoch index and T is a time constant. This gradually increases the influence of the topological losses, allowing the network to first learn a coarse reconstruction and then refine topology . In practice, we find that the image- domain coefficient can be chosen larger than the latent-space coefficient, since the batch-level latent loss may otherwise dominate the gradients. W e find that setting λ img = 10 − 4 and λ lat = 10 − 5 , provides the most fav ourable results. I V . R E S U LT S A N D D I S C U S S I O N A. Experimental Setup Datasets. W e ev aluate on two topology-rich datasets: Om- niglot [10], with 1623 handwritten characters from 50 al- phabets, and the DeepGlobe Road Extraction dataset [11], consisting of binary road-segmentation masks from satellite imagery . W e represent all inputs as single-channel continuous images normalized to [0 , 1] , and train the JSCC models with an MSE reconstruction loss, aligning the training objectiv e with 0 5 10 15 20 SNR (dB) 10 15 20 25 30 35 PSNR (dB) T opoJSCC DeepJSCC T opoCode BPG+LDPC (a) PSNR vs. SNR (A WGN) 0 5 10 15 20 SNR (dB) 10 15 20 25 30 35 PSNR (dB) T opoJSCC DeepJSCC T opoCode BPG+LDPC (b) PSNR vs. SNR (Rayleigh) 0 5 10 15 20 SNR (dB) 0 100 200 300 400 500 600 W asserstein distance T opoJSCC DeepJSCC T opoCode BPG+LDPC (c) Wdist vs. SNR (A WGN) 0 5 10 15 20 SNR (dB) 0 200 400 600 800 W asserstein distance T opoJSCC DeepJSCC T opoCode BPG+LDPC (d) Wdist vs. SNR (Rayleigh) Figure 2. Omniglot results under an SNR sweep. Bandwidth ratio is fixed at 0.40 and T opology-re gularized DeepJSCC exhibits the most pronounced impro vements in the low-SNR regime under both A WGN and Rayleigh fading. the PSNR metric and enabling a unified treatment of Omniglot and road masks. JSCC Architectur e and Channel. All neural JSCC schemes use the same CNN autoencoder backbone as in [2]. The encoder applies input normalization follo wed by five 5 × 5 con volutional layers with PReLU activ ations (strides 2 , 2 , 1 , 1 , 1 ). The final con volution outputs a length- 2 k real vector , which is power -normalized and grouped into k complex channel symbols, so that the bandwidth ratio is ρ = k/n with n = H W C . A non-trainable differentiable channel layer is inserted between encoder and decoder . The decoder mirrors the encoder with fiv e transpose-con volution layers, using PReLU after each layer except the last; a final sigmoid produces the reconstructed image. For each bandwidth ratio ρ , we train a separate encoder-decoder pair; our topology-aware method differs only in the training loss. Comparison Schemes. W e compare the proposed T opo- JSCC with the original CNN-based DeepJSCC scheme [2] implemented with the same architecture but trained only with MSE, a classical separation-based scheme using the BPG image codec [12] followed by 5G LDPC codes [13] and T opoCode [7], a topology-aware digital error detection and correction scheme. T raining Protocol. All neural models are implemented in PyT orch and trained from scratch using the Adam optimizer with learning rate 10 − 4 and batch size of 128 . For each dataset and bandwidth ratio ρ , we employ an early stopping strategy to ensure con ver gence without ov erfitting. During training, the instantaneous channel SNR is randomly sampled for each mini-batch from a discrete set covering low-to-high SNRs ( { 0 , 5 , 10 , 15 , 20 } dB), and the same SNR distribution is used for all JSCC-based methods to enable SNR-adaptive beha vior without retraining. W e note that the PH computations intro- duce additional training-time cost, but they do not affect the inference-time complexity , as the deployed encoder/decoder do not perform an y topological calculations. Evaluation Metrics. At test time, we ev aluate performance under two complementary sweeps: (1) SNR sweep at fixed bandwidth, where we fix the bandwidth ratio ρ and vary the channel SNR, and (2) bandwidth sweep at fixed SNR, where we fix the SNR and vary ρ across the considered compression ratios. In the bandwidth sweep we consider ρ ∈ { 0 . 05 , 0 . 10 , 0 . 20 , 0 . 30 , 0 . 40 , 0 . 50 } , corresponding to increas- ing numbers of channel uses. For each operating point, we report the average PSNR between the input and reconstructed images, and the average 2 -W asserstein distance between the persistence diagrams of the input and reconstructed images, computed on cubical complexes with a fixed threshold grid and homology dimensions m ∈ { 0 , 1 } . PSNR measures pixel-wise fidelity , while the W asserstein distance quantifies preservation of the underlying topological structure. All results are averaged over multiple independent runs, with the shaded region indicating variability across 10 different runs. B. Experimental Results Fig. 2 reports the Omniglot results under an SNR sweep for both A WGN and Rayleigh channels. In terms of PSNR, the proposed T opoJSCC consistently outperforms the purely MSE-trained DeepJSCC at low SNR and remains within about 0 . 5 dB of DeepJSCC at high SNR for both channel models. F or example, at SNR = 0 dB over A WGN Fig. 2(a), T opoJSCC achiev es roughly 2 dB gain ov er DeepJSCC and 7 – 8 dB over T opoCode and BPG+LDPC, mainly due to the cliff effect. As the SNR increases, all schemes improve and the gap between them narrows, but T opoJSCC consistently outperforms T opoCode and nearly matches the performance of DeepJSCC at a high SNR. The benefit of the proposed method becomes more pronounced in the topological metric. At low and moderate SNR, T opoJSCC yields a substantially smaller WD between persistence diagrams compared to Deep- JSCC and BPG+LDPC, indicating better preservation of the underlying topology . At SNR = 0 dB ov er A WGN Fig. 2(c), the WD of T opoJSCC is roughly four to five times lower than that of DeepJSCC and BPG+LDPC, while remaining close to that of T opoCode. T opoCode attains very small WDs but at the cost of significantly degraded PSNR, whereas T opoJSCC offers a more fav orable tradeoff between pixel fidelity and topological consistency . Similar trends are observed under Rayleigh fading Figs. 2(b),(d), confirming that the topology- aware loss improv es robustness to channel variations without sacrificing reconstruction quality . Fig. 3 shows the results on the DeepGlobe road extraction data as a function of the bandwidth ratio ρ = k /n . Under both A WGN and Rayleigh channels, the PSNR curves Figs. 3(a),(b) 0.05 0.10 0.20 0.30 0.40 0.50 Bandwidth ratio k / n 10 15 20 25 30 35 PSNR (dB) T opoJSCC DeepJSCC T opoCode BPG+LDPC (a) PSNR vs. BW ratio (A WGN) 0.05 0.10 0.20 0.30 0.40 0.50 Bandwidth ratio k / n 10 15 20 25 30 35 PSNR (dB) T opoJSCC DeepJSCC T opoCode BPG+LDPC (b) PSNR vs. BW ratio (Rayleigh) 0.05 0.10 0.20 0.30 0.40 0.50 Bandwidth ratio k / n 0 100 200 300 400 500 W asserstein distance T opoJSCC DeepJSCC T opoCode BPG+LDPC (c) Wdist vs. BW ratio (A WGN) 0.05 0.10 0.20 0.30 0.40 0.50 Bandwidth ratio k / n 0 100 200 300 400 500 600 W asserstein distance T opoJSCC DeepJSCC T opoCode BPG+LDPC (d) Wdist vs. BW ratio (Rayleigh) Figure 3. DeepGlobe Road Extraction dataset results under a bandwidth-ratio sweep. SNR is fixed at 15 dB. T opology- regularized DeepJSCC yields larger topology improvements at low bandwidth ratios under both A WGN and Rayleigh fading. Figure 4. Reconstructions showing topological preserv ation at SNR = 5 dB. demonstrate that T opoJSCC remains competitiv e with Deep- JSCC and BPG+LDPC across all ratios, despite the additional topological regularization. At very low bandwidth ratios T opo- JSCC attains the highest PSNR among all schemes in both channel conditions, highlighting the benefit of topology-aware features in the heavily compressed regime. As ρ increases, the performance of all schemes con v erges and the PSNR gap between T opoJSCC and DeepJSCC becomes negligible, while BPG+LDPC and T opoCode remain slightly below . Figs. 3(c),(d), report the WD as a function of ρ . For all rates and both channel models, T opoJSCC significantly reduces the topological distortion compared with DeepJSCC and BPG+LDPC. At ρ = 0 . 05 , the WD for T opoJSCC is again sev eral times lower than for the digital baseline and the MSE- only DeepJSCC, indicating markedly better preservation of road connectivity and loop structure in the reconstructed maps. T opoCode achie ves one of the smallest distances as well, but its PSNR degradation relative to T opoJSCC underlines the advantage of joint semantic and topological optimization o ver purely topology-protected digital transmission. Qualitati ve ex- amples further illustrate the structural benefits of T opoJSCC. In Fig. 4, reconstructions produced by T opoJSCC exhibit fe wer broken connections and holes compared to DeepJSCC under low SNR or bandwidth. These observations are consistent with the quantitative trends in Figs. 2 and 3. Finally , the ablation in T able I sho ws that the image-domain topological loss provides the main reduction in persistence-diagram distortion, while the latent-space loss offers a smaller b ut complementary gain and combining both yields the best overall results. V . C O N C L U S I O N This letter introduced T opoJSCC, a topology-aw are Deep- JSCC framework that integrates persistent-homology regular- T ABLE I. Ablation on Omniglot (SNR=0 dB, ρ = 0 . 4 ). Method PSNR ↑ Wdist ↓ DeepJSCC 22.1 415 + L img top only 22.9 132 + L lat top only 22.4 271 Full T opoJSCC 23.2 94 izers in both the image domain and the latent space to better preserve connectivity and loop structure in wireless image transmission. Experiments on topology-rich datasets under A WGN and Rayleigh fading show that T opoJSCC consistently reduces persistence-diagram distortion and achie ves superior PSNR in low-SNR and low-bandwidth regimes, achieving a more fav orable tradeoff than MSE-only DeepJSCC and digital baselines like T opoCode. R E F E R E N C E S [1] C.-X. W ang et al. , “On the road to 6g: V isions, requirements, key technologies, and testbeds, ” IEEE Commun. Surveys Tuts. , v ol. 25, no. 2, pp. 905–974, 2023. [2] E. Bourtsoulatze, D. B. Kurka, and D. Gündüz, “Deep joint source- channel coding for wireless image transmission, ” IEEE Tr ans. Cogn. Commun. Netw . , vol. 5, no. 3, pp. 567–579, 2019. [3] H. Edelsbrunner, D. Letscher, and A. Zomorodian, “T opological persis- tence and simplification, ” Discrete Comput. Geom. , vol. 28, no. 4, pp. 511–533, 2002. [4] F . Chazal and B. Michel, “ An introduction to topological data analysis: Fundamental and practical aspects for data scientists, ” F r ont. Artif. Intell. , vol. V olume 4 - 2021, 2021. [5] X. Hu, F . Li, D. Samaras, and C. Chen, “T opology-preserving deep image segmentation, ” Adv . Neural Inf. Process. Syst , v ol. 32, 2019. [6] M. Moor , M. Horn, B. Rieck, and K. Borgw ardt, “T opological autoen- coders, ” in Proc. Int. Conf. Mach. Learn. (ICML) , 2020, pp. 7045–7054. [7] H. Guo, “T opocode: T opologically informed error detection and correc- tion in image communication systems, ” IEEE Commun. Lett. , vol. 29, no. 5, pp. 1003–1007, 2025. [8] T . Kaczynski, K. Mischaiko w , and M. Mrozek, Computational homol- ogy . Springer Science & Business Media, 2006, vol. 157. [9] R. B. Gabrielsson, B. J. Nelson, A. Dwaraknath, and P . Skraba, “ A topology layer for machine learning, ” in Pr oc. Int. Conf. Artif. Intell. Stat. (AIST ATS) , 2020, pp. 1553–1563. [10] B. M. Lake, R. Salakhutdinov , and J. B. T enenbaum, “Human-level concept learning through probabilistic program induction, ” Science , vol. 350, no. 6266, pp. 1332–1338, 2015. [11] I. Demir et al. , “Deepglobe 2018: A challenge to parse the earth through satellite images, ” in Pr oc. IEEE Conf. Comput. V is. P attern Recognit. (CVPR) W orkshops , June 2018. [12] F . Bellard, “Bpg image format (release 0.9.8), ” T ech. Rep., 2018. [Online]. A v ailable: https://bellard.org/bpg/ [13] T . Richardson and S. Kudekar, “Design of lo w-density parity check codes for 5g new radio, ” IEEE Commun. Mag. , vol. 56, no. 3, pp. 28–34, 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment