Implementation of tangent linear and adjoint models for neural networks based on a compiler library tool
This paper presents TorchNWP, a compilation library tool for the efficient coupling of artificial intelligence components and traditional numerical models. It aims to address the issues of poor cross-language compatibility, insufficient coupling flex…
Authors: Sa Xiao, Hao Jing, Honglu Sun
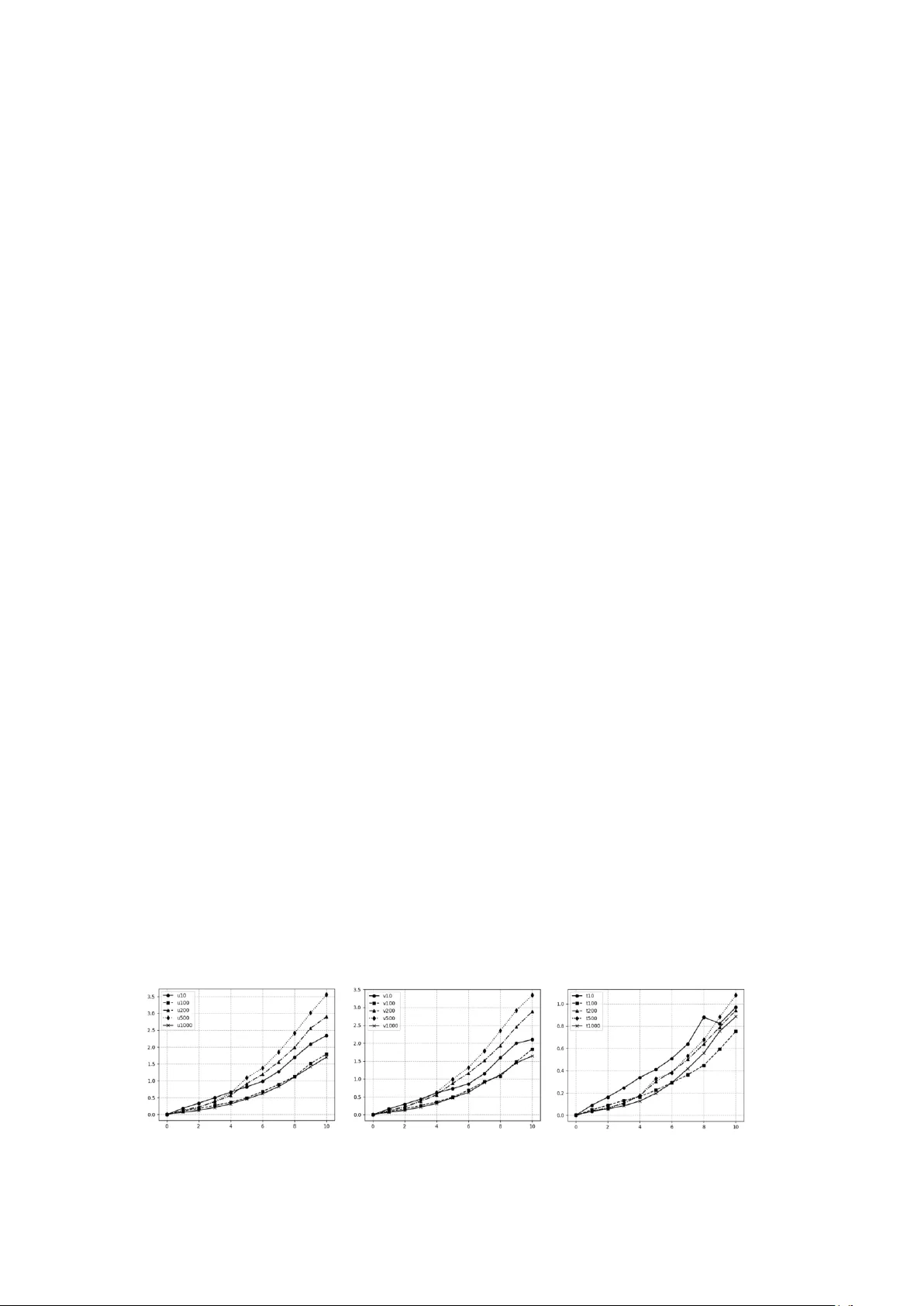
Implem entation of tangent line ar and adjoint m odels for ne ural network s based on a compiler library to ol Sa Xiao, a,b Hao Jing*, a,b Honglu Sun, a,b Haoy u Li, a,b a State Key Laboratory of Severe Weather Meteorological Science and Technology (LaSW), Beijing, China b CMA Earth System Modeling and Prediction Centre (CEMC), Beijing, China Abstract This paper presents Torch NWP, a compilation library tool for the e fficient coupling of ar tificial intelligence co mponents and traditional numerical model s. It aims to address the issues of poor cross-language co mpatibility , insufficient coupling flexibility , and low data transfer efficiency b etween operational numerical models developed in Fortran and P ython-based deep learning fra meworks. The tool consists of s tandalone, pluggable, and uniformly configurable compilation and runtime scripts . Based on LibTorch, it op timizes and designs a uni fied applicatio n -layer calli ng inter face, converts deep learning models under the P yTorch framework into a static binar y for mat, a nd provides C/C++ interfaces. T hen, using h ybrid For tran/C/C++ pr ogramming, it enables t he deplo yment of deep learning models within n umerical mod els. Integrating Torc hNWP into a numerical model o nly requires compiling it into a callable link librar y and linking it during the co mpilation a nd linking phase to generate the e xecutable. On this basis, tangent linear and a djoint model based on neural networks are implemented at t he C/C++ level , which can shield the i nternal structure of ne ural network m odels a nd simplify the co nstruction process o f four -di mensional variat ional data assimilation systems. Meanwhile, it supports deplo yment on heter ogeneous platforms, is compatib le with mainstream neural network models, and enable s m apping of different parallel granularities and efficient par allel execution. Usi ng this tool requires minimal code modifications to the original numerical model, thus red ucing coupling costs. It can b e ef ficiently inte grated into numerical weather prediction models such as C MA-GFS and MCV, and has been applied to the coupling o f deep lear ning -based physical p arameterization schemes (e.g., radiatio n, non-oro graphic gravit y wave drag) a nd th e develop ment of their ta ngent linear and adjoint models, sig nificantly improving the accurac y and eff iciency of nu merical weather pr ediction. 1. Introduction There are two technical routes for artificial intelligence to empower weather forecasting. One takes numerical weather predictio n (NW P) as the core, and use s artificial intelligence techniq ues to improve the accurac y and co mputational e fficiency o f the w hole workf low, incl uding observatio n processi ng, data assimilation, model pr ediction, and pro duct interpretati on. T he other takes arti ficial intelligence as the co re, and establishes d ata -driven meteorological forecasting models that i ntegrate physical mechanisms. For the firs t rout ine, trad itional numerical w eather prediction models are mainl y developed in Fortran as the standard p rogramming language. However, the co re components of artificial intelli gence models are mostly trai ned o r dep loyed using machine learni ng frame works based on the dynamically t yped language Python. This m eans th at AI models ca nnot b e d irectly invoked as functions by numerical weather pred iction models written in the staticall y typed language Fortran. Traditional numerical models and machine lear ning m odels are independent modules with their own internal data str uctures, data distributions, a nd parallel dec ompositions. It is d esirable to achieve flexible data transmission bet ween them witho ut introduci ng e xtra dep endencies and excessive cod e modifications to the o riginally intact progra m, while s upporting the functions o f full variable -field data restructuring and fine -grained data exchange, whic h address es the i ssue o f data transmissio n flexibility. To couple dee p learning models with tr aditional numerical models , one app roach is to export parameters (such as weights and biases) from the trai ned deep learning models and embed the m into Fortran code in the f orm of hard coding. Howev er, this approach suffers from low develop ment efficiency: any modification to the p ara meters of the deep learning model requires c orresponding changes to the relevant code. Meanwhile, the lac k of mature and user - friendly machine learning frameworks and too ls in the Fortran eco system re sults in a very high cost for porting deep learning models. One appro ach is the artificial intelligence model inter face similar to the For tran -Keras Deep Learning Bridge (Ott et al., 2 020), which can i mport trained dee p learning parameters fro m o utside the Fortran pro gram, store them in T XT files, and ca ll t hem during inference and pred iction of the dee p learning model. T he Fortran -based implementation en sures relatively flexible dep loyment in numerical models, allo wing model rep lacement by simpl y modifying the par ameters i n the TXT files without altering the network structure of the deep learning model, yet t his interface mainly suppo rts deep learning models based on fu lly co nnected la yers and cannot s upport many state - of -the-art ne twork architectures such as Stab le Diffusion or T ransformer models. Another commo nly used co upling approach separ ates the Fortran -based host model a nd Python-based deep learni ng components into t wo groups of pro cesses, and achieves data transmission through i nter-process co mmunication (I PC) with s ynchronization control during cou ple d r unning (Wang et al., 2022). During coupled executio n, the IP C data interface receives input variab les fro m the host model, per forms gatheri ng operatio ns on the raw dat a to improve data transmissio n efficiency, then ca rries out floati ng-point endian co nversion and sends the data to the ar tificial i ntelligence model via IPC mechanisms. The I PC data interface s upports multiple communication methods, in cluding MPI , FIFO pipes, and high- speed d ata buffers. After the artifici al intelligence i nference engine co m pletes computation, it first writes the data b ack to the IPC data interface, and then returns the results to the host model through data gathering and floati ng -point endian conversion. Throughout the entire data coupling p rocess, a synchronizatio n contr ol ler gover ns the operational synchronizatio n between t he host model and the arti ficial intelligence infere nce engine. Fortran T orch Adapter (FTA) is a general-purpose to ol based on LibTorch that provides users with an interface for directly manipulating neural network models in Fortran via the FT A library (M u et al., 2023). T his tool supports converting d eep lear ning models under the P yTorch frame work into a static binary format and provides C/C++ interfaces; then, using hybrid Fortran and C/C++ p rogramming techniques, it deploys deep learning models within numerical models. Compared with o ther coupling methods, FT A offers hi gher flexibility, but cer tain code compatibilit y issues still exi st during hybrid programming. Meanwhile, since LibT orch follows C/C++ pr ogramming co nventions, debugging a nd stability testing during couple d execution re main insufficie ntly flexible and efficient, and the limited functionality of FT A ca nnot meet t he full requirements for the inte gration of ar tificial intelligence and numerical weather pred iction. The coupling o f artificial intelligence m odels an d numerical models ty pically involves frequent invocations of the same network for fast in ference and intensive comm unicat ion, which is suitable for real-time linking using LibT orch-based co mpilation library tools to ensure efficient runtime exec ution of the hybrid model. T herefore, develop ing a co mprehensive co upling middle ware that supp orts heterogeneous platform d eplo yment, is compatible with mainstream neural net work models, and enables mapp ing of different parallel granularities as well as efficient p arallel execution represents a core requirement for achieving the d eep integration o f artificial intelligence and num e rical weather prediction. 2. Introduction to T orchNWP To address technical challe nges in t he co upling p rocess between ar tificial intelligence inference modules and numerical mode ls, including inconsistent cross -language interface designs, incompatible operation modes, and non -unifo rm data transmission met hods, we have developed TorchNWP -- a f ully functional, highly efficient, stable, and ad aptable compilation library to ol for the effective coupling of artificial intelli gence compo nents with traditional numeric al models. B ased on standard ized inter face design, cr oss-language binding, efficient model loadin g and infere nce, co mprehensive perfor mance optimization, and r igorous testing and validatio n, T orchNWP enables low -cost, high-efficienc y integration o f deep learning models with traditional numerical weather p rediction model s. Meanwhile, through t he standardized construction of tangent linear and adjoint models, it simpli fies the development of four-di mensional variational data assimilation syste ms, provides co re support for the deep integration o f artificia l intelligence and numerical weather p rediction technologie s, and helps improve t he accurac y a nd co mputational e fficiency o f numerical weather prediction. The structural flowchart of this compilation library tool is shown i n Figure 1. Deta iled descriptions ar e given as follows: (1) Interface Design. The inte rface design is developed based on C++ -based T orchScript, with the cor e objective o f build ing a concise, unified, and efficient interac tion brid ge bet ween Fortr an nu merical models and PyTorch deep learning models, shielding underlying technical co mplexities and reducing the difficulty of user invocatio n. Specificall y, b y explicitly defining three core interface fu nctions at the C++ la yer, the full-proce ss i nteraction between Fortr an and P yTorch models is re alized. The functio ns and roles of each function are as follows: The model_new function: It is mainly responsible for model i nitialization, including alloca ting memory resources required for model op eration, loading model configuration par ameters, and initializing t he Lib Torch runtime en vironment, laying the groundwork for subsequent model lo ading and inference. This function supports rec eiving user -configured parameters such as model storage paths and runtime devices (CPU/GPU) , featuring good flexibility to adapt to model initialization requirements in different scen arios. The model_forw ard f unction: As the core inter face for model inference, it is responsib le for receiving input d ata transmitted fro m the For tran nu merical model, invoking the model to co mplete inference calculations, and returning the i nference results to th e Fo rtran numerical model. B uilt-in auxiliar y functions such as data format verification and dimension co nversion are integrated within this functio n to ensure that input data meet s the requirements of model i nference, while guarantee ing the accurac y and completeness of in ference results. The model_delete function: It is primarily r esponsible fo r resource release after model o peration, including freeing up memory resources occupied by the model, destroying the LibTorch runtime environment, a nd clearing input and outp ut data c aches. This p revents m emory leakage issues, ensures the long -term stab le op eration of the tool, and ad apts to the o perational requirements of n umerical models for long -term continuous inte gration. The above three core inter face functions work in coor dinati on to form a complete link f or Fortran numerical models to call P yTorch models. Users do not need to focus on the i mplementation details of the underl ying C++ and LibT orch; the y o nly need to call the correspo nding interface functions to complete the initia lization, inference, and resource release of d eep lear ning models, whic h significa ntly reduces the difficulty of cross -langua ge coupling. (2) Binding of Fortran and C++. Due to the inherent language barr iers between trad itional numerical models developed in Fortran and deep learning model interfaces encap sulated in C++ , including differences in data types, memory layouts, a nd function ca ll specifications , this invention adopts Fortran/C/C++ mixed programming technology and leverages the ISO_C_Bindin g module to achieve deep binding bet ween Fortran and C++. T his thoroughly r esolves cross -la nguage co mpatibilit y issues and enables efficie nt data transmission and functio n calls bet ween the two languages. As a standardized interface pro vided by the For tran language, the ISO_C_Bind ing module defines clear co rrespondences between various data types in For tran and C++. It can accuratel y convert b asic data types (e. g., integ ers, floating-point numbers, logical values), array ty pes, and pointer ty pes in Fo rtran into their corresponding types in C++, eli minating issues such as call failures and d ata co rruption caused b y incompatible data types. Fo r instance, it converts the RE A L(8) t ype in Fortran to the d ouble t ype in C++, and two-dimensiona l arrays in Fortran to pointe r arrays in C++, ensuring correct data transmission between the two langua ges. (3) Model Loading and Infer ence. In ter ms o f model loading, this tool leverages the to rch::jit::load function pro vided by LibT orch to load pre -trained and exported deep learning models ( typically stored in .pt file for mat) developed under the P yTorch frame work. T he .pt file fully preserves all structural information of the model (including the number of network la yers, the number o f neurons per layer, convolution kernel p arameter s, activat ion function types, etc.) and parameter i nformation (including weights, biases, nor malization p arameters, etc.). T he torch::jit::load function ca n accuratel y read the information in this file, reconstruct t he model str ucture, load model para meters, and complete the initial loading of the model. T his loading method suppo rts various mai nstream P yTorch models, incl uding Convolutional Neural Networks (CNNs), Transformers, Diffusion models, Residual Neural Net works (ResNets), etc., ad apting to var ious application scenarios i n the field o f numerical weather predictio n. It also feat ures fast loadi ng spee d and high stability, meeting the real -time oper ation req uirements of numerical models. In terms of model inference, after the model is loaded, the module.forward function is called to execute inference calc ulations on the input d ata . As a standard ized inference interface provided by t he LibTorch framework, the modul e.forward function can receive input data that has u ndergone format conversion, execute t he calculation operations of eac h la yer in seque nce ac cording to the model's network structure, and f inally output the in ference r esults. T his functio n s upports batch infere nce, enabling e fficient processing of large -scale input data transmitted b y numerical models and improving inference efficiency. It is important to note that d ue to the fu ndamental differences i n array memor y la yout between Fortran and C++ (Fo rtran uses co lumn -major storage, while C++ uses row -major storage), directl y passing inp ut data from Fo rtran to the model for inference will lead to d ata corruption and compro mis e the accurac y of infere nce results. T herefore, during the inference pr ocess, thi s tool ad justs the dimensions of the i nput data to ad apt to Fortran's memory la yout, ensuring that the input data can be correctly reco gnized and processed by the model. Speci fically, b y adjusting the ord er of data dimensions, arrays stored in For tran's colu mn -major format are converted into the row -major format recognizable b y the m odel. T his a voids inference errors caused by differences i n me mory layout while minimizing perfor mance loss d uring data adjustment. The entire process of model l oading and inference is enca psulated within C++ i nterface functions. Fortran users do not need to focus on u nderlying implementation details , they only need to pass input data and obtain inference results t hrough the interface functions to complete the invocatio n of deep learning models. T his significantly reduces the dif ficulty of coupling and i mproves coupling ef ficiency. (4) Performance Op timization. T o address issues suc h as lo w data trans mission efficienc y, excessive memory usage, and slow runtime speed during the coupli ng of deep learning models and numerical models, and to ensure t hat t he tool can meet the demands of long -term co ntinuous integration and large-scale data processing i n numerical models, this tool ad opts a variet y o f tar geted measures for performance optimization to comprehensivel y improve its op erating efficiency and stability. The specific optimization strategie s are as follo ws: First, to reduce the performance o verhead caused b y memory layout di fferences bet ween For tran and C++, the permute function in PyTorch is used to adjust the dimensions o f inp ut and output data, enabling adaptive conversion of data layouts and av oiding unnecessary data cop ies. The permute functi on can rapid ly rearrange the di mension ord er, co nverting Fortran ’s colu mn - major stored data into C++’s ro w -major format or vice versa. T he en tire pro cess only modifies index mappings w ithout additional data copying, which sig nificantly reduces performance overhead during d ata tr ansmission and improves data trans fer efficiency. Second, the to ol suppor ts multi-device execut ion. Users ca n flexibly choo se to r un the deep learning model o n either CPU or GP U acco rding to actual co mputing resources, achieving rati onal allocation of computational resources and acce lerating model inference. W hen GPU r esources are available, the tool automatically enables GP U -accelerated inference, leveragi ng the parallel co mputing po wer of GPUs t o greatly i mprove infere nce efficiency for large-scale d ata. When no GP U is availa ble, the too l automatically switches to CP U mode to ensure normal operation. In addition, this tool adopts an instant me mory relea se mechanism that immediatel y frees memor y occupied by input/output data and inter mediate computatio nal r esults after inference is completed, preventing memory leaks a nd excessive memory co nsumption. To handle th e large d ata volumes typical in nu merical weather pred iction, a blocked data processing technique is used to split large -scale data into s mall chunks, which are loaded and inferred in b atches to avoid runtime lag and memor y overflow caused b y excessivel y large single-batch data. Meanwhile, the s torage sc heme of model parameters is opti mized using effic ient co mpression algorithms, which reduce storage and memory overhead without co mpromising i nference acc uracy. T hese strategies jointly i mprove the overall performance of the tool. (5) Standardized Construction of Tangent Linear and Adjo int Mod els. T angent l inear and adjo int technologies based on neural networks are implemented at the C++ la yer to shield the impact o f the internal str ucture o f neural network models a nd pro vide standardized tangent linea r and adjoint interfaces. The specific i mplementation proce ss is as follows: Forward Calculatio n: P hysical q uantities input b y the numerical model (including various physical parameters in t he numerical weather pr ediction proce ss, such as temperature, humidity, wind speed, etc.) are converted through th e app lication interface la yer and the n passed to the deep learning m odel encapsulated at the C/C++ layer to complete the forward inference p rocess and o btain model output results. Tangent Linear Calculation: Using the auto matic di fferentiation tool o f L ibTor ch, all differentiable operations (such as convolutio n, matrix multiplication, activatio n functio ns, etc.) in the for ward calculation p rocess ar e tracked, and the J acobian matrix of the deep learning model’s output with respect to the inpu t is calculat ed to generate t he tange nt linear mod el. The tangent linear model satisfies , w here is the i nput pertur bation, is th e outp ut perturb ation, and is the J acobian matrix, which can accuratel y characterize the impact o f input perturbatio ns on output results. Adjoint Calcula tion: A scalar loss functio n is constructe d (where y is the forward output result of the model and is the ad joint variab le). Using the auto matic d ifferentiation tool of LibTorch, the grad ient of the scalar loss function with respec t to the input ph ysical quantities is calculated to obtain the adjo int model result (where is the transpose of the Jaco bian matrix ). Interface Encapsulatio n: T he above tangent linear calculat ion process and adj oint ca lculation process are encapsulated into standardized C/C++ interfaces, which are bound to the Fortran langu age t hrough the ISO_ C_Binding module. This enables Fortran numeric al models to d irectly call these interfaces, shielding differences in t he intern al structures of neural net works. In addition, it is necessary to verify the co nsistency betwee n the calculated derivatives o f neura l network parameters obtained by the auto matic differentiation algorithm and the gradients of the forward model, a s well as the co nsistency b etween the machine learning ad joint model c onstructed by automatic differentiation and the traditional g radient method based on adjoint models. Through a rigorous verificatio n pro cess, the correctness a nd r eliability of the tangent l inear and ad joint models are ensured, providing stron g supp ort for the construction of the fo ur -dimensio nal variational data assimilation system. (6) T esting and Validation. Strict testing and validation have been conducted d uring the development of this tool, co vering functional testing, performance testing, compatibilit y tes ting, and other aspects. Tests have bee n carried out on various Fo rtran co des and PyTo rch models to ensure its stabilit y and efficiency under diverse sce narios. Figure 1. Struct ural Flowchart of the T orchNWP Compiler Library Tool . 3. Construction of neura l network-base d tangent linea r and adjoint models using T orchNWP This section uses a co ncrete example to illustrate the i mplementation and operatio nal workflow o f TorchNWP. The CMA Global Forecast System (CM A -GFS) developed by the China Meteo rological Administration is used as the app lication platfor m. As a n ational-level core o perational n umerical weather prediction model, CMA-GFS run s operationally four times p er day and provides high-precision 10 -day global weather forec asts. A s one of its core p hysical proce sses, the non-orographic gravity wa ve dr ag modul e consumes a significant portion of the computational time in physical process simulations. W e couple the well-trained high-precisio n neural network parameterization scheme for non -orographic gravity wave drag into the CM A -GFS mo del usin g the TorchNWP library. Mean while, tangent li near and adjoint models corresponding to t he neural network are cons tructed based on TorchNWP to support the four -dimensional variationa l data assimilation system. Detailed i mplementation is described as follows: 3.1 Training and co upling i mplementation of the high-precision neural netw ork model for non-orogra phic gravity wave drag First, based o n the p hysical mechanis m of non -orographic gravity wave drag, the input and output physical quantities for the deep lear ning model are se le cted, and a high -quality training datase t covering different seasons and w eather situations is constructed. This aims to enable the dee p learning model to accuratel y identify a nd learn the nonlinear characteristics, spatiotemporal evolutio n laws, and complex in fluencing factors i n the non-orograp hic gravit y wave drag process, la ying a data foundation for subsequent model traini ng and numerical model coupling. Specifically, the input physical quantities include 11 co re meteorological parameters s uch as tem perature, humidity, wind sp eed, pressure, geopotential height, a nd latitude; the output physical q uantities include 5 key physical qua ntities related to non-orographic gravit y wave drag. T he total duration of the dataset is one year. Mod el integration is performed using a cold -start ap proach w ith 10 -day integratio n p er case and hourly d ata output, resulting in a total data volume of 41 TB. All data have undergone strict q uality control, outlier removal, missing value imputation, and standardized prepro cessi ng to guara ntee data accuracy and integrity. Considering the operational characteristics of numerical models, the d eep -lear ning-based non-orographic gravit y wave d rag parameterization sc heme adopts a design philosoph y o f independen t processing for single vertical grid columns. That is, the model takes a single vertical grid column fro m the CM A-GFS m odel as the basic processing unit, and both input and output data are one -dimensional vectors composed o f multi-physical variables. T his design can perfectl y matc h the grid structure a nd computational logic of the o riginal numerical model, signi ficantly red ucing t he coupling difficult y between the neural network model and the numerical model, and improving oper ational stabilit y after coupling. A ccordingly, the input and output data of the deep learning model are two -di mensional arrays with size s of (11 , 89) and (5, 8 9), respectively, wh ere the first dimension co rresponds to the number o f input/o utput p hysical variables and the second di mension corr esponds to the number o f vertical model levels. It should b e p articularly noted that latitude has a significant i nfluence on the simulation accuracy of non-oro graphic gravity wave drag. T herefore, latitude is included in the model as a core inp ut variable to ensure that the model can adap t to the character istics o f n on -orographic gravity wave drag in di fferent latitude regions. In the data preproce ssing stag e, the choice of normalization method directly a ffects model training performance and inference accurac y. After multiple ro unds of comparative experi ments, the o ptimal normalization strategy was d etermined as follows . For input variables, a per -variable per -level normalization method is adopted . T hat is, normalization is perfor med separately for each input ph ysical variable and each vertical model level. T his eliminates magnitude d ifferences across variables and vertical levels and avoid s the do minance of certain variab les or levels durin g model training. For output variables, per-variable global normalization is used, meaning each output physical variable is normalized globall y and uniformly to ensure the consisten cy and rationalit y of the outp ut results. The advantage of this nor malization strateg y is that it accurate ly adapts to the significant dif ferences i n physical characteristics at d ifferent altitude level s during non -orographic gravi ty wave drag proce sses, effectively improves the model’s ability to capture weak signals, a nd reduces systematic b ias. The architecture of the deep learning m odel ad opts an op timized residual neural network ( ResNet), to minimize t he nu mber of model para meters and co mputational over head while en suring in ference accuracy, so as to meet the de mand o f long -term conti nuous integration in numerical models. B y u sing one-dimensional co nvolutio nal neural networks, t he model can efficientl y e xtract the spatiote mporal features of physical quantities in the vertical d irection and capture the vertical evolution of the non-orographic gravity wave drag pr ocess; the last few la yers of the network are f ully co nnected la yers for d eeply mini ng the nonlin ear correlations among d ifferent physical variables, thus impro ving the model’s fitting and genera lization capabilities. T o further enhance coupling efficiency, the normalization and d enormalization operati ons for input and o utput data are integrated internal ly into the deep learning model, eliminating t he need for additional code implementation i n t he nu merical model and simplifying the cou pling workflow. Experimental res ults sho w that, increasing the numbe r o f para meters in t he deep learning m odel has a significant positive e ffect o n i mproving p rediction accuracy; however, a larger number of para meters also leads to slo wer inference speed. T aking both pred iction accurac y and inference speed into comprehensive co nsideration, after multiple rounds of opti mization on the network structure, the current opti mal ne twork consists o f two residual modules with 16 output channels, where each m odule contains two one-dimensional convolutional layers, follo wed b y a n addi tional one-dimensional convolutional layer that reduc es the number of channels fro m 1 6 to 5 after the second residual m odule. Since the model outpu t consis ts of three vectors and t wo sca lars, t wo parallel full y connect ed layers are attached after the con volutional layers to perform predictio ns for the vectors and scalars separ ately. The neural network model for non-orographic gravity wave drag was tr ained and optimized offline . On the test set, t he deviations between the no n-orograp hic gravity wave drag-related physica l quantities predicted by the neural net work and the r eference values output b y the model were m inimal, indicating that the trai ned surrogate model can accuratel y fi t the non-orograp hic gravity wave drag p rocess. B ased on the TorchNWP co mpilation librar y tool, the above -trained dee p learning model was c oupled to the original numerical weather predictio n model CMA -GF S. First, the trained PyTor ch model was saved as a .pt file, which fully pr eserves all structural information, parameter information, a nd nor malization configurations o f the deep learning model to ensure lossless accuracy d uring model co nversion and invocation. Second, the .pt file was co mpiled and converted using the compilation scripts provided by the T orchNWP library to generate a C++ link librar y that can be called by the Fortran m odel; during compilation, para meters such as compiler type, P yTorch version, and r untime device ( CPU/GPU) can be flexibly co nfigured to adapt to the operational environment of the CMA -GFS m odel. Third, when compiling and linking the CMA -GFS model to generate an executable progra m, t he above - generated C++ link library was lin ked with the original model; mean while, a small amount o f interface callin g code was written a t t he p ositions in t he o riginal model where the deep lear ning mod el needs to be enabled to invoke the three co re interfaces ( model_new, model_forward, model_delete) p rovided by TorchNWP, completing model initialization , inference, and resource relea se. Long-term continuous inte gration tests and accuracy verificatio n were conducted on the coupled hybrid model. The result s sho w that after 6 hours of i ntegration, co mpared with the orig inal numerical model, t he hybrid model yields a mean absol ute er ror (MAE) o f 0. 055 m /s for 10- m wind speed, 0.027 m /s for 500 hPa wind speed, and 0.013 K for 500 hPa temperature. The detailed evaluation o f the forecast p erformance is sho wn in Figure 2. The hy brid model can stably co mplete 10 -day co ntinuous integration witho ut memory leaks, runti me lag, or solution divergence, th us meeting t he op erational requirements of nu merical weather pred iction. In terms of co mputational speed, b oth the original model and the deep learning model are curren tly executed on CPUs; when the p arallel scale is belo w 8 000 cores, the inference speed of the deep learning model outper forms t he original non -orographic gravity wave drag physical scheme, with a twofold improvement in computational efficienc y. Ho wever, at larger parallel scales, the deep learning version e xhibits a r everse speedup ano maly, whic h can be avoided by offloading t he deep lear ning co mponents to GP U execution. During the entire coupling procedure, the numerical mo del and the ar tificial in telligen ce i nference mod ule compute within the same proce ss without additional inter -process communication, which completely el iminates t he overhead caused by i nter-process communicatio n and further enhances coupli ng efficienc y and runtime stability. Figure 2. Evaluatio ns of forecast perfor mance after coupling with the high -precision neural network model for non-oro graphic gravity W a ve Drag. 3.2 Implementation of Tangent Linear a nd Adjoint M odes for Neural Netwo rk s After coupling the neural network model with t he numerical model, to adapt to the four -dimensional variational data assimilation s ystem, it is necessar y to cons truct tangent linear and adjoint models corresponding to the neural network m odel. When traditional meth ods are used to build tangent linear and ad joint models, it is requi red to deeply understand t he internal structure of the neural network and manually d erive tan gent li near relationships a nd adjoint equation s. T his ap proach not o nly inv olves an enormous workload and cumbersome p rocesses but also is hi ghly pr one to d erivation errors . Meanwhile, it cannot adapt to neural network models with different structures, r esulting in poor generality. In this inventio n, by imple menting neural networ k-based ta ngent li near and ad joint technologies at the C/C++ la yer and relying on t he auto matic differentiatio n tool o f LibTorch to shield the i mpact of the in ternal structure of neural network models, standardized tangent linear and adj oint models can be constr ucted quickly and accuratel y . Let denote the input, the output, and the neural netwo rk, then the tangent li near model is given by , where is the input perturbation, and is the outp ut perturbation. 11 1 1 ... ... ... ... ... n mm n yy xx J yy xx represents the Jacobian matrix of the neural network with respect to the input. For the adjoint model, the adjoint model at point can b e defined as , and the following relation also holds: k z y 0 00 () | T T xx k y k M x z x x y x , Combined with the co mputation graph in Fig ure 3, given the adj oint at point is known as , the inference state is obtained by f eeding into the neural network m odel . A scalar is then constructed via the dot product b etween and . T he gra dient o f the scalar with respect to gives the adjo int result at point . Based on the above derivation, in Python, the calculation of the Jaco bian matrix and the grad ient of with respect to can both b e implemented using the auto matic differentiatio n tool o f PyTorch. The fundamental reason is that a neural net work is a composite function composed of a series o f differentiable operatio ns ( such as convolution, acti vation functio ns, and matrix multiplication), and automatic d ifferentiation ca n accurately track the c hain rule -based derivative calculati on p rocess o f these op erations. While avoiding numerical differentiation erro rs and redundant co mputations in symbolic differenti ation, it efficientl y o utputs the J acobian matrix (full partial d erivatives for multi-input multi-output scen arios) and gradients (partial derivatives of a single o utput with respect to multiple inputs), which caters to the derivative calc ulation req uireme nts of neural networks . Meanwhile, this also indicate s t hat the mechanism o f calc ulating gradients via a utomatic differentiation is essentially identical to the computational sche me of traditional tange nt linear and adj oint models. Considering the need for coupling with a Fortran -based four-dime nsional variational data assimilation (4D-Var) system, we levera ge compiler librar y tools. B y usin g t he C++ ver sion of To rch, we imple ment a utomatic differentiation fu nctionality in the coupli ng middle la yer via C++, thereb y realizing a neural net work-bas ed tangent linear and ad joint model. Since the m odel information is full y preserved in .pt files, this implementation scheme for the tangent linear and adj oint models can shield the impact o f the inter nal mod el structure and simplify the co nstruction proce ss of the four -dimensional variational data assi milation system. Figure 3. Computational graph of the tangent li near and adjoint model. 4. Conclusion TorchNWP has been successfully i ntegrated into national -level n umerical weather p rediction (NW P) models s uch as CMA -GFS, supp orting the couplin g of deep learning p arameterization schemes for multiple physical pr ocesses including rad iation and non -orograp hic gravit y wave drag. I ts core advantages are summarized as follows: (1) Compatibility: It resolves the cro ss -language co mpatibility issue bet ween Fortran -based numerical models and Python-based d eep learning frameworks, supports mainstream deep learning models suc h as residual net works (Re sNets) and Transfor mers, and is compatible with CPU/GP U heterogeneous platforms; (2) Efficiency: Model invocation is completed within t he same process, eli minating co mmunication overhead and achieving high data transmission e fficie ncy and fast model inference speed; (3) L ow invasive ness: Onl y compilation/lin king and a small a mount o f interface calling code are required, without the need for substantial modifications to the original numerical model, thus reducing the coupling cost; (4) Scalabilit y: It supports flexible co nfiguration of compilers, model p arameters, and parallel granularity, adapting to t he customized require ments of different numerical models; (5) Assimilation adaptab ility: It standard izes the interfaces for tangent l i near/adjoint models, shields the black-box c haracteristics o f neural net works, simplifies the construction proce ss o f four -dimensional variational data assi milation (4D -Var) systems, and reduces the cost of assimilatio n adaptation. Acknowledg ment This work was supp orted by the National Natural Sc ience Foundation o f China (Grant No . U23 42220). We also thank Dr. Zhang Lin and Dr. Liu Yongzhu for t heir discussions. Reference [1] Ott J, Pritchard M, Best N, et al. A fortran -keras deep learning brid ge for scientific computing. Scientific Progra mming, 2020, 2020: 1 - 13. [2] Wang X, Han Y, Xue W, e t al. Stable cli mate simulations using a realist ic general circulation model with neural net work parameter izations for at mospheric moist ph ysics and radiati on processes. Geoscientific Model Deve lopment, 20 22, 15(9):3923 -3940. [3] Mu B, Chen L, Yuan S, et al. A radiative tr ansfer d eep learning model co upled into wrf with a generic fortran torch adap tor. Frontiers in Earth Scie nce, 2023, 11: 1 149566.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment