Anticipatory Planning for Multimodal AI Agents
Recent advances in multimodal agents have improved computer-use interaction and tool-usage, yet most existing systems remain reactive, optimizing actions in isolation without reasoning about future states or long-term goals. This limits planning cohe…
Authors: Yongyuan Liang, Shijie Zhou, Yu Gu
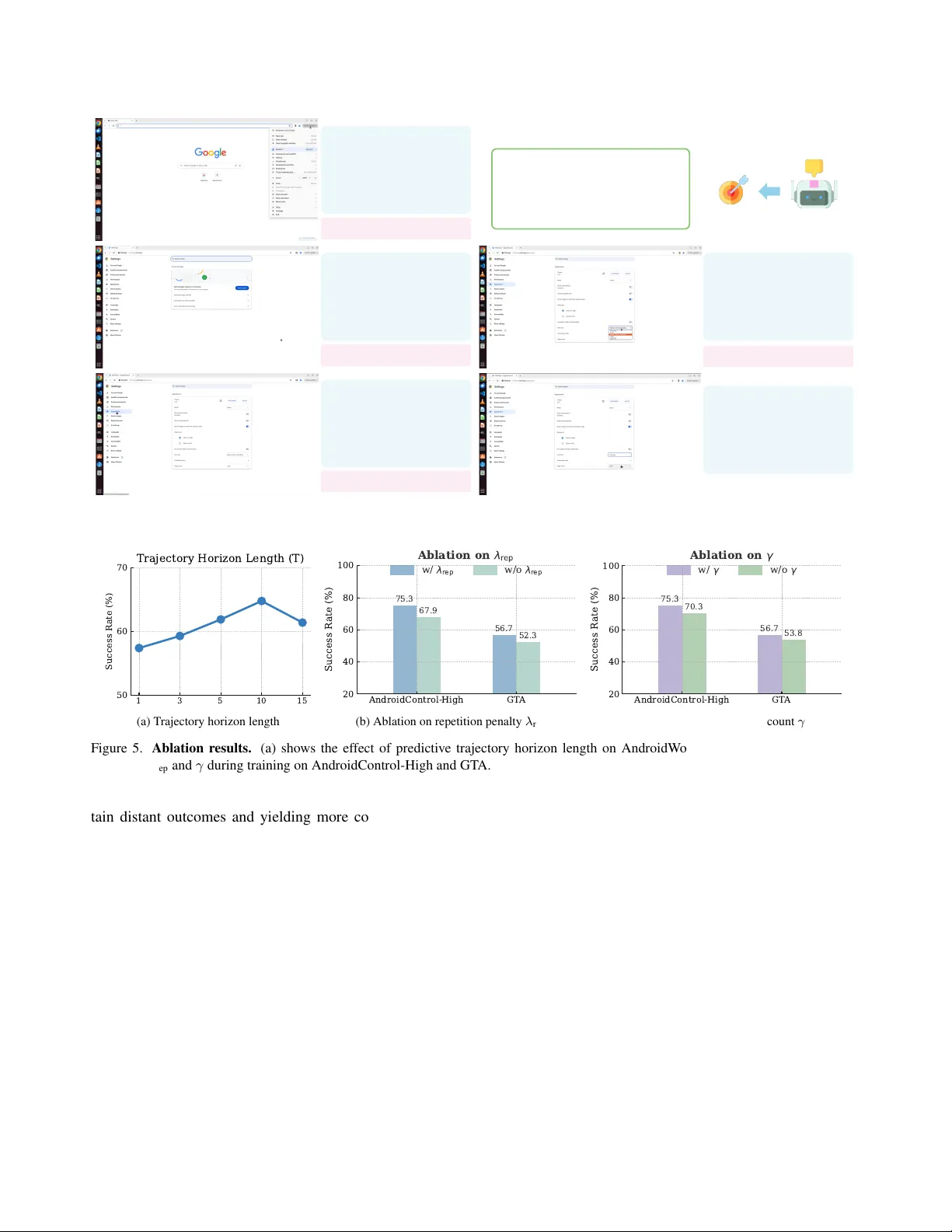
Anticipatory Planning f or Multimodal AI Agents Y ongyuan Liang 1 Shijie Zhou 4 Y u Gu 2 Hao T an 3 Gang W u 3 Franck Dernoncourt 3 Jihyung Kil 3 Ryan A. Rossi 3 Ruiyi Zhang 3 1 Univ ersity of Maryland, College P ark, 2 The Ohio State Univ ersity , 3 Adobe Research, 4 State Univ ersity of New Y ork at Buffalo Abstract Recent advances in multimodal agents have impr oved computer-use interaction and tool-usage, yet most e xist- ing systems r emain r eactive, optimizing actions in isolation without r easoning about futur e states or long-term goals. This limits planning coher ence and pr events agents fr om r eliably solving high-level, multi-step tasks. W e intr oduce T raceR1 , a two-stage r einfor cement learning framework that e xplicitly tr ains anticipatory r easoning by forecasting short-horizon tr ajectories befor e execution. The first sta ge performs trajectory-le vel reinfor cement learning with re- war ds that enforce global consistency acr oss pr edicted ac- tion sequences. The second stage applies gr ounded r ein- for cement fine-tuning , using execution feedback fr om fr ozen tool agents to r efine step-level accuracy and executability . T raceR1 is evaluated across seven benchmarks, covering online computer-use , of fline computer-use benc hmarks, and multimodal tool-use r easoning tasks, wher e it achieves sub- stantial impr ovements in planning stability , execution r o- bustness, and generalization over r eactive and single-stage baselines. These r esults show that anticipatory trajectory r easoning is a key principle for building multimodal ag ents that can r eason, plan, and act effectively in complex real- world en vir onments. 1. Introduction Building intelligent agents that can plan and act over long horizons has long been a central goal in the era of lar ge language and multimodal agents [ 2 , 3 , 29 , 45 ]. Recent advances in multimodal autonomous agents ha ve shown impressiv e capabilities in GUI interaction [ 27 ], embodied control [ 46 , 53 ], and tool-use reasoning [ 32 ]. Howe ver , despite their strong reasoning priors, most existing multi- modal agents remain fundamentally reactive : they decide the next action based only on the current observ ation, focus- ing on immediate perception without anticipating the long- term consequences of their decisions. Without anticipatory reasoning, agents tend to fail in multi-step environments where actions have delayed and compounding ef fects, caus- ing them to gradually div erge from the intended task. T o develop multimodal agentic models capable of look- ing ahead, two major directions have been explored. Model- free reinforcement learning (RL) [ 20 , 25 , 33 , 35 ] trains agents through step-lev el action correctness and designed rew ards for subgoals or sparse final outcomes. Model-based planning [ 5 , 9 , 12 , 24 ], in turn, equips agents with a world model that simulates future action sequences and e volving en vironment states, enabling them to reason about possi- ble outcomes before acting. Y et both approaches face fun- damental obstacles: constructing world models over visu- ally rich and interacti ve en vironments is notoriously dif fi- cult, and defining reasoning-oriented rewards that general- ize across diverse and open-ended tasks remains an open challenge. This raises the question: how can we efficiently train multimodal agents to develop adaptive anticipatory r easoning for complex, long-horizon tasks? W e address this challenge by introducing T raceR1 , a two-stage RL frame work designed to combine long-horizon trajectory reasoning with grounded execution refinement. In the first stage, anticipatory trajectory optimization , the model performs trajectory-lev el RL on large-scale agent tra- jectories. The re wards ev aluate global consistency between the predicted and reference action sequences, encouraging coherent planning and anticipatory reasoning ov er multiple future steps. In the second stage, gr ounded reinfor cement fine-tuning , the model is refined using step-le vel e xecutable feedback from tool agents. Grounded rew ards, such as coor- dinate accuracy and answer correctness, improv e precision and ensure that each predicted step remains feasible within the en vironment. This two-stage structure resembles how humans plan: anticipating several steps ahead and then re- fining the immediate action based on feedback. By explicitly modeling future dependencies while grounding each action in executable feedback, T raceR1 provides a general training recipe for GUI en vironments, tool-use systems, and multimodal reasoning tasks. Empir- ically , it achiev es substantial improvements in both plan- ning stability and execution robustness, attaining planning T rajectory data fo r training Step 1 Step 2 Step 3 Step 4 T ask done. User Instruction Open the Google Meet app and cancel t he Tr a n s p o r t meeting. C u r r en t S c r een s h o t ➕ His to r y T r aj ec t o r y T r ac eR 1 T ool Agents (grounding, image editing…) Planning Current step instruction : "click on the target element" GUI environment To o l -use platform Input Control Thought: T o cancel the T ransport meeting, I'll tap on the July 25 event to open its details, then select the delete/cancel option. Predicted T rajectory: Step 1: "screenshot abstraction ": "Calendar with T ransport event", "action": "click", "step" : " click T ransport event", "status": "not done" Step 2: "screenshot abstraction": "Event details page", "action": "click", "step": "click delete/cancel button", "status": "not done" Step 3: … "action": "click", "step": "click confirm button" … Figure 1. T raceR1 over view: anticipatory planning and grounded e xecution. The planning model takes a user instruction together with the current screenshot and interaction history , predicts a trajectory of future actions, wher e only the first predicted step is executed by the tool agent while later steps are unexecuted lookahead pr edictions , and generates step-level instructions for tool agents to complete tasks across div erse GUI en vironments and tool-use platforms. capability comparable to proprietary systems, significantly outperforming open-source baselines on long-horizon GUI benchmarks such as OSW orld-V erified [ 43 ] and Android- W orld [ 17 ], and demonstrating strong reasoning and exe- cution reliability on general tool-use benchmarks including GAIA [ 26 ] and GT A [ 36 ]. These results highlight anticipa- tory trajectory reasoning as a key step tow ard b uilding plan- ning agents that can reason and plan with foresight while advancing long-horizon goals in complex, real-world envi- ronments. In summary , the main contributions of this w ork are: • W e introduce T raceR1 , a unified framew ork for anticipa- tory planning that forecasts trajectories of future actions and step-lev el instructions, enabling long-horizon reason- ing and foresight beyond reacti ve decision making. • W e dev elop a two-stage reinforcement learning paradigm that first performs trajectory-lev el optimization to learn globally coherent plans and then applies grounded rein- forcement fine-tuning with e xecutable feedback, bridging high-lev el reasoning and low-le vel precision across GUI and tool-use en vironments. • W e conduct comprehensi ve ev aluations across 7 GUI and multimodal tool-use reasoning benchmarks, demonstrat- ing substantial improv ements in planning stability , ex e- cution robustness, and generalization, achieving perfor- mance comparable to proprietary systems and surpassing open-source baselines. 2. Related W ork 2.1. Planning-Oriented GUI Agents Agent frameworks. Recent GUI agent frameworks in- creasingly emphasize structured planning pipelines that combine reasoning modules with grounding and execu- tion components. Agent systems such as Aria-UI [ 49 ], UGround [ 11 ], SeeClick [ 7 ], Jedi [ 42 ], Agent S/S2 [ 1 , 2 ], and GT A1 [ 48 ] all follow this paradigm, typically em- ploying po werful API-based proprietary models such as o3 [ 29 ] or Claude 4 [ 3 ] as planners to generate high-lev el action proposals, while domain-specific modules handle grounding and execution on GUI interfaces. These frame- works have demonstrated impressive multi-step reasoning and cross-platform control, yet their progress largely de- pends on the underlying proprietary planners rather than im- proving the agent’ s intrinsic planning capability . They em- phasize precise action execution based on instructions over trajectory-lev el planning, whereas our work directly trains large multimodal models to acquire anticipatory planning through RL. Generalist agents. A parallel line of work builds general- ist agents on top of large vision–language models [ 3 , 29 , 45 ], extending them to computer use, GUI control, and a broad range of agentic tasks. Research efforts such as UI-T ARS [ 30 , 35 ], Magma [ 46 ], and OpenCUA [ 37 ] de- velop unified pipelines for interacti ve control and reason- ing across di verse GUI en vironments, while models includ- ing SeeAct [ 52 ], CogAgent [ 15 ], and OS-A TLAS [ 40 ] em- phasize perception–reasoning integration for interface un- derstanding and task decomposition. Recent R1-style ap- proaches further incorporate reinforcement signals to en- hance agent reasoning in GUI settings [ 20 , 23 , 25 ]. Unlike these methods, which still rely on grounding supervision and emphasize precise action execution during training, our approach focuses purely on planning and introduces a more general training framework that strengthens a multimodal agent’ s ability to plan, comprehend, and anticipate future History T rajecto ry Step Screenshot User Instruction Future T r ajectory T raceR1 Rollout GRPO Update T rajectory- level Rew ard Ground -truth T rajectory Action -type alignment T emporal discount γ Repetition penalty R( τ) = ∑ 𝛾 ! 𝑟 ! Anticipatory T rajectory Optimizati on H i s t o r y T r aj e c t o r y S t e p S c r e e n s h o t U s e r I n s t r u c t i o n Step Instruction To o l -calli ng T raceR1 Rollout Step -level V erified Reward Gr o u n d - tr u th Ac t i o n s G r o u n d ed R L Fi n e - tu n in g GRPO Update T o ol Agents Gr o u n d e d Ac t i o n s/ Ex e c u t i o n A c t i o n f e as i b i l i t y Ac t ion co rre ct ne s s Ans w er m at c h i n g Figure 2. T wo-stage training framework of T raceR1. Stage 1 performs anticipatory trajectory optimization using trajectory-le vel align- ment rew ards, while Stage 2 applies grounded RL fine-tuning with step-level re wards deri ved from tool-agent e xecution feedback. states. 2.2. T ool-Usage Multimodal Agents The ability to use external tools is a defining aspect of intelligent multimodal agents, allowing them to perform complex, visually grounded tasks beyond direct percep- tion and reasoning. One line of research enhances this capability through large-scale multimodal instruction tun- ing, where models learn tool selection and composition from synthetic or curated trajectories [ 19 , 34 , 47 ]. An- other line builds end-to-end architectures that couple vi- sion–language models with real executable tools or interac- tiv e en vironments, enabling stepwise control and adaptive reasoning [ 6 , 10 , 38 , 50 , 51 ]. These methods substantially improv e tool in vocation and multimodal integration but pri- marily emphasize execution reliability or reacti ve coordi- nation. In contrast, our approach focuses on strengthening the agent’ s planning capability by training models to antici- pate and organize future tool-use behaviors, using grounded feedback solely for execution validation rather than as the primary learning signal, thereby enabling more ef fectiv e and deliberate tool-use reasoning. 3. Methodology T raceR1 is trained with a two-stage RL frame work de- signed to enable anticipatory multimodal planning. In this section, we introduce the agent formulation, followed by the two training stages. Problem Formulation. At step t , the agent recei ves the current observation s t and predicts an action a t and step instruction g t . It also conditions on a compact interaction history τ 1: t − 1 = { ( ϕ ( s i ) , a i ) } t − 1 i =max(1 , t − K ) , where ϕ ( s i ) is an abstracted summary of the past observation rather than a raw screenshot. The predicted action is executed by a tool agent, and the resulting observation becomes the next state. This K -step truncated history provides lightweight temporal context while a voiding redundanc y . T o train such an agent, we adopt the two-stage reinforce- ment learning framework sho wn in Figure 2 , which inte- grates long-horizon trajectory alignment with grounded ex- ecution refinement. Stage 1 performs anticipatory trajec- tory optimization , aligning predicted and reference trajec- tories via trajectory-level rew ards that encourage globally consistent plans. Stage 2 performs gr ounded r einfor cement fine-tuning , incorporating feedback from tool agents to re- fine step-lev el accuracy and e xecution feasibility . 3.1. Anticipatory T rajectory Optimization Supervised fine-tuning (SFT) on next-step predictions en- ables an agent to imitate local beha viors b ut struggles to capture long-term dependencies. Even when trained on full trajectories, SFT optimizes token- or step-lev el likelihoods under teacher forcing, neglecting global consistency and failing to penalize redundant or unstable rollouts. T o address these limitations, T raceR1 performs trajectory-lev el RL that aligns predicted and reference trajectories within a bounded horizon, encouraging the agent to reason several steps ahead before acting. Each training sample contains a user instruction u , the cur- rent observation s t , and a reference trajectory τ ∗ = { ( a ∗ 1 , g ∗ 1 ) , . . . , ( a ∗ T , g ∗ T ) } , where a ∗ t and g ∗ t denotes the ground-truth action type and step instruction. Conditioned on ( u, s t , τ 1: t − 1 ) , the model predicts a future trajectory ˆ τ t : T = { ( ˆ a t , ˆ g t ) , . . . , ( ˆ a T , ˆ g T ) } , which is optimized via trajectory-lev el alignment re wards. T raining aligns the predicted and reference trajectories through a discounted trajectory-lev el re ward: R ( ˆ τ , τ ∗ ) = T X t =1 γ t − 1 r t , (1) where γ ∈ (0 , 1) is the temporal discount factor and r t is the per-step alignment re ward: r t = λ align sim (ˆ a t , a ∗ t ) − λ rep rep (ˆ a 1: t ) , (2) where sim ( · , · ) measures the alignment between the pre- dicted operation ˆ a t and the reference a ∗ t (GUI action type or tool call), and rep ( ˆ a 1: t ) penalizes repeated or cyclic ac- tions within the trajectory prefix. λ align and λ rep control the strengths of action alignment and loop-prev ention. The policy π θ is optimized using the group-relativ e pol- icy optimization (GRPO) objecti ve [ 14 ]: ∇ θ J ( θ ) = E ˆ τ h ˆ A ( ˆ τ , τ ∗ ) ∇ θ log π θ ( ˆ τ | u, s t , τ 1: t − 1 ) i , (3) where ˆ A ( ˆ τ , τ ∗ ) is the normalized group-relativ e advantage computed from R ( ˆ τ , τ ∗ ) . Through this stage, the model learns to anticipate long-term effects before execution, im- proving the global coherence of multi-step plans. 3.2. Grounded Reinf orcement Fine-tuning While trajectory-lev el optimization promotes consistency across steps, accurate control still depends on ground- ing—ensuring that each predicted action leads to correct and feasible execution within the en vironment or tool in- terface. Giv en ( u, s t , τ 1: t − 1 ) , the model outputs (ˆ a t , ˆ g t ) , which are ex ecuted by a frozen tool agent (e.g., GUI ex- ecutor or callable tool modules). The resulting outputs are compared with ground-truth responses to compute a step- lev el grounded re ward r G t : r G t = ( 1 [ coord match ] , for grounding steps , 1 [ answer match ] , for tool-calling steps . (4) Here, 1 [ grounding step ] and 1 [ tool-calling step ] select the appropriate reward type for different tasks. This formula- tion applies coordinate matching for GUI grounding steps and answer matching for tool-calling steps. Grounded fine-tuning follows the same GRPO update rule as Stage 1 , replacing the trajectory-le vel rew ard with the grounded step rew ard: ∇ θ J G ( θ ) = E h ˆ A ( r G t ) ∇ θ log π θ (ˆ a t , ˆ g t | u, s t , τ 1: t − 1 ) i . (5) This stage refines ex ecution precision and robustness while preserving the anticipatory structure learned during trajec- tory alignment. T raining Pipeline. In practice, both stages are trained with large-scale multimodal agent trajectory datasets, where each step, along with its subsequent action sequence, forms a training instance. Stage 1 uses the full reference trajecto- ries: for each step, the model predicts a short-horizon roll- out, and the trajectory-lev el reward measures how well the entire predicted future sequence matches the ground-truth continuation, without executing any action. Stage 2 uses the same per-step multi-step prediction setup, but only the first predicted action is e xecuted by a frozen tool agent. The tool’ s output (e.g., click coordinates or textual response) is compared with the corresponding ground-truth action or an- swer to compute a grounded reward. This offline-grounded setup enables the model to learn anticipatory planning while using offline trajectories as the source of both trajectory- lev el and ex ecution-lev el supervision. 3.3. Inference with Anticipatory Planning At inference time, T raceR1 operates in a plan–act loop. Giv en the current observation, it predicts a multi-step fu- ture trajectory ˆ τ t : T , ex ecutes only the first action via the tool agent, receives the updated environment feedback, and re- plans for the next step. This iterativ e foresight mechanism allows the model to anticipate long-term outcomes while maintaining execution stability across diverse tool-use sce- narios. Preliminary Finding T raceR1 takes one step while seeing sev eral ahead. Anticipatory r easoning allows the planning agent to account for long-term dependencies and down- str eam consequences, leading to mor e globally con- sistent and accurate planning decisions. 4. Experiment T o comprehensiv ely ev aluate T raceR1 , we focus on GUI agent benchmarks that assess agents’ planning and inter- action abilities across multiple platforms, and on tool-use benchmarks that examine general multimodal reasoning and problem-solving capability . 4.1. Setup Implementation details. Our model is initialized from Qwen3-VL-8B-Thinking [ 45 ] and trained using the EasyR1 framew ork [ 54 ]. The training covers both GUI and multi- modal tool-use datasets. For GUI tasks, Stage 1 pretraining uses trajectory datasets from AgentNet [ 37 ], AndroidControl [ 17 ], GUI- Odyssey [ 21 ], Multimodal-Mind2W eb [ 8 ], and Agent- T rek [ 44 ], adopting the structured action space defined in [ 30 ] for unified cross-platform control. Stage 2 per- forms grounded RFT using datasets from different GUI platforms with corresponding tool agents, including UI- T ARS-7B [ 30 ], UI-T ARS-1.5-7B [ 30 ], and Qwen3-VL- 32B-Thinking [ 45 ]. For multimodal tool-use, Stage 1 le verages the tool-use trajectory dataset from [ 10 ] following their standardized toolbox interface. Stage 2 grounded RFT is then conducted Agent Model Params Andr oidW orld OSW orld-V erified Pr oprietary Models o3 [ 29 ] - - 23.0 OpenAI CU A-o3 [ 29 ] - 52.5 38.1 Seed1.5-VL [ 13 ] - 62.1 36.7 Claude 4 Sonnet [ 3 ] - - 41.4 Claude 4.5 Sonnet [ 3 ] - - 62.9 UI-T ARS-1.5 [ 30 ] - 64.2 41.8 UI-T ARS-2 [ 35 ] - 73.3 53.1 Agent System (w/ Pr oprietary Models) Jedi-7B w/ o3 [ 42 ] 7B w/ - - 50.2 Agent S2 w/ GPT -5 [ 2 ] 7B w/ - - 48.8 Agent S2 w/ Claude 3.7 Sonnet [ 2 ] 7B w/ - 54.3 - Agent S2.5 w/ o3 [ 2 ] 7B w/ - - 56.0 GT A1-7B w/ o3 [ 48 ] 7B w/- - 53.1 GT A1-32B w/ o3 [ 48 ] 32B w/- - 55.4 UI-T ARS-1.5-7B w/ GPT -4.1 [ 30 ] 7B w/ - - 31.6 Qwen3-VL-32B-Thinking w/ GPT -4.1 [ 45 ] 32B w/ - - 43.2 Open-Sour ce Models Qwen2.5-vl-72b [ 4 ] 72B 35.0 5.0 UI-T ARS-1.5-7B [ 30 ] 7B - 27.4 UI-T ARS-72B-DPO [ 30 ] 72B - 27.1 OpenCU A-7B [ 37 ] 7B - 26.6 OpenCU A-32B [ 37 ] 32B - 34.8 Qwen3-VL-8B-Thinking 8B [ 45 ] 50.0 33.9 Qwen3-VL-32B-Thinking [ 45 ] 32B 61.4 35.6 Qwen3-VL-235B-A22B-Thinking [ 45 ] 236B - 38.1 T raceR1 UI-T ARS-1.5-7B w/ Ours 7B w/ 8B - 30.9 Qwen3-VL-32B-Thinking w/ Ours 32B w/ 8B 64.8 41.2 T able 1. Success rate (%) on Andr oidW orld and OSW orld-V erified. OSW orld-V erified is ev aluated under a 100-step maximum setting. with real-ex ecutable tools provided by the T3-Agent tool- box [ 10 ]. Refer to Supplementary Material for more details. Benchmarks. W e ev aluate T raceR1 across 7 benchmarks that collectiv ely measure GUI task execution and multi- modal tool-usage reasoning. The GUI benchmarks include both online agent capa- bility ev aluation, featuring dynamic and interactiv e en- vironments simulating real-world scenarios, and offline ev aluation, which measures agent performance in static, pre-defined settings. The online benchmarks comprise OSW orld-V erified [ 41 ], which examines long-horizon desk- top operations, and AndroidW orld [ 31 ], which tests mo- bile task completion on a live Android emulator with 116 tasks across 20 applications; both use task success rate as the ev aluation metric. The offline benchmarks con- sist of AndroidControl-High [ 17 ], GUI-Odyssey [ 21 ], and Multimodal-Mind2W eb [ 8 ], all ev aluated by step success rate. AndroidControl-High targets high-lev el mobile ex- ecution, GUI-Odyssey focuses on cross-application navi- gation with 203 tasks spanning six apps, and Multimodal- Mind2W eb extends Mind2W eb to test generalization across cross-task, cross-website, and cross-domain settings. The tool-use and reasoning benchmarks include GT A [ 36 ] and GAIA [ 26 ]. GT A contains 229 tasks with 252 images requiring two to eight reasoning steps, ev alu- ating perception, operation, logic, and creativity on visual data, while GAIA consists of 446 tasks inv olving 109 files (PPTX, PDF , XLSX, etc.) grouped into three difficulty lev els, assessing document understanding, web reasoning, and answer summarization. Baselines. W e compare T raceR1 with a broad range of state-of-the-art multimodal agents, cov ering three major categories. (1) Pr oprietary models include o3 and Ope- nAI CUA-o3 [ 29 ], GPT -4o, GPT -4.1 [ 29 ], GPT -5 [ 28 ], Claude 4/4.5 Sonnet and Claude Computer-Use [ 3 ], Seed 1.5-VL [ 13 ], and UI-T ARS-1.5/2 [ 30 , 35 ]. (2) Agent sys- tems with pr oprietary models combine open-source back- bones with closed-source planners or reasoning mod- ules, including Jedi-7B [ 42 ], Agent S2/S2.5 [ 2 ], GT A1- 7B/32B [ 48 ], UI-T ARS-1.5-7B w/ GPT -4.1, and Qwen3- Agent Model Params AndroidContr ol-High GUI Odyssey Multimodal-Mind2W eb Pr oprietary Models GPT -4o [ 29 ] - 21.2 5.4 4.3 Claude-computer-use [ 3 ] - 12.5 3.1 52.5 Agent System (w/ Pr oprietary Models) OmniParser -v2.0 w/ GPT -4o [ 22 ] - 58.8 62.0 41.3 UI-T ARS-7B w/ GPT -4.1 [ 30 ] 7B w/ - 74.8 89.1 66.0 Open-Sour ce Models OS-Atlas-4B [ 40 ] 4B 22.7 56.4 - OS-Atlas-7B [ 40 ] 7B 29.8 62.0 - QwenVL2.5-3B [ 4 ] 3B 38.9 50.9 - QwenVL2.5-7B [ 4 ] 7B 47.1 54.5 - GUI-R1-3B [ 25 ] 3B 46.5 41.3 - GUI-R1-7B [ 25 ] 7B 51.7 38.8 - InfiGUI-R1-3B [ 20 ] 3B 71.1 - - UI-T ARS-2B [ 30 ] 7B 68.9 83.4 53.1 UI-T ARS-7B [ 30 ] 7B 72.5 87.0 63.1 UI-T ARS-32B [ 30 ] 7B 74.7 88.6 64.7 T raceR1 UI-T ARS-7B w/ Ours 7B w/ 8B 75.3 88.2 65.3 T able 2. Step success rate (%) on AndroidControl-High, GUI-Odyssey , and Multimodal-Mind2W eb. Step SR reflects the proportion of correctly ex ecuted steps, where both the predicted action and its arguments (e.g., click coordinates) match the ground truth. Results on Multimodal-Mind2W eb are averaged ov er its cross-task, cross-website, and cross-domain ev aluation splits. VL-32B-Thinking w/ GPT -4.1 [ 45 ]. (3) Open-sour ce mod- els include OS-Atlas [ 40 ], GUI-R1 [ 25 ], Qwen2.5-VL and Qwen3-VL series [ 4 , 45 ], OpenCU A [ 37 ], UI-T ARS vari- ants [ 30 ], LLA V A-NeXT [ 18 ], DeepSeek-VL2 [ 39 ], and T3-Agent [ 10 ]. Results for all baselines are mainly taken from their official reports. For our methods, we report the mean performance ov er 3 independent runs. 4.2. Main Results on GUI En vironments T able 1 presents results on the online benchmarks, Andr oid- W orld and OSW orld-V erified . T raceR1 achie ves substantial gains ov er its grounding models and reaches performance comparable to proprietary GPT -4.1 planners, highlighting the strength of its trajectory-le vel anticipatory reasoning for long-horizon GUI control. Specifically , our method im- prov es the success rate of UI-T ARS-1.5-7B from 27 . 4% to 30 . 9% on OSW orld-V erified, and boosts Qwen3-VL-32B- Thinking from 35 . 6% to 41 . 2% , corresponding to relative gains of 12 . 8% and 15 . 7% , respectiv ely . These results demonstrate that anticipatory planning substantially en- hances stability and task success across mobile and desktop platforms, establishing new state-of-the-art results among open-source models of comparable size. As shown in T able 2 , our model exhibits strong high- lev el task planning ability across offline GUI benchmarks. Built entirely on open-source backbones, it achie ves per- formance on par with GPT -4.1–based proprietary plan- ners Compared with R1-style models trained under dis- tinct training objectives, such as GUI-R1 and InfiGUI-R1, our method deliv ers substantially stronger results on high- lev el task execution, exceeding them by more than 40% on AndroidControl-High and setting a new state of the art among open-source GUI agents. These gains underscore the advantage of trajectory-a ware reasoning, which enables the model to accurately translate complex, high-le vel task instructions into fine-grained action instructions, achieving far more reliable execution than reactiv e agents in compo- sitional GUI en vironments. 4.3. Main Results on General T ool-use Scenarios T able 3 presents results on the GAIA and GT A bench- marks. T raceR1 demonstrates robust multimodal reason- ing and tool-use ability , outperforming GPT -4o on GAIA and achieving the best performance among all open-source models. Compared with Qwen3-VL-8B, it attains a notable +8 . 7 improvement in answer accuracy , reflecting stronger reasoning consistency across the three GAIA lev els. On GT A, T raceR1 exhibits exceptional tool-execution behav- ior with particularly high T oolAcc , confirming the effec- tiv eness of training with tool-usage trajectories. In addi- Agent Model Params GAIA GT A AnsAcc Level 1 Level 2 Level 3 AnsAcc T oolAcc CodeExec Pr oprietary Models GPT -4o [ 16 ] - 33.4 47.1 31.4 11.5 57.1 63.4 95.1 GPT -4.1 [ 16 ] - 50.3 58.5 50.0 34.6 58.4 65.1 94.3 GPT -5 [ 28 ] - 59.3 67.9 58.1 46.1 60.9 68.3 98.7 Open-Sour ce Models LLA V A-NeXT -8B [ 18 ] 8B 3.6 9.4 1.2 0.0 14.1 14.9 25.1 DeepSeek-VL2 [ 39 ] 72B 14.2 19.3 12.4 10.3 23.2 49.4 57.2 Qwen2.5-VL-7B [ 4 ] 7B 10.3 16.9 9.3 0.0 44.2 50.6 69.1 Qwen2.5-VL-14B [ 4 ] 14B 15.2 24.5 11.6 3.8 46.8 55.4 69.8 Qwen3-VL-8B [ 4 ] 8B 31.5 46.2 27.6 16.3 49.2 56.8 74.2 T3-Agent [ 10 ] 7B 16.9 26.4 15.1 3.8 53.8 64.6 84.3 T raceR1 8B 40.2 55.9 35.8 24.4 56.7 65.7 87.4 T able 3. Results on the GAIA and GT A benchmarks. GAIA assesses AI assistants across three difficulty levels, where final answer accuracy ( AnsAcc ) reflects overall tool-usage reasoning correctness. GT A further e valuates multimodal tool-use ability using three metrics: AnsAcc for answer correctness, T oolAcc for accurate tool selection and summarization, and CodeExec for the percentage of generated code that ex ecutes without errors. Setting AndroidW orld OSW orld-V erified GT A w/ Stage 2 64.8 41.2 56.7 w/o Stage 2 57.2 36.3 50.2 Figure 3. T wo-stage T raining Ablation. Performance (%) com- parison on AndroidW orld, OSW orld-V erified and GT A bench- marks. Stage 2 provides consistent improv ements in both settings. tion, the second-stage tool-grounded RFT enhances the re- liability of generated code, leading to higher CodeExec suc- cess and more stable answer generation. T aken together , the results suggest that T raceR1 ’ s trajectory-lev el anticipa- tory reasoning yields more reliable tool use and more co- herent decision-making, re vealing a unified mechanism for grounded multimodal reasoning. 4.4. Ablations and Discussions Incorporating execution feedback stabilizes long- horizon planning. As shown in T able 3 , removing Stage 2 leads to an average performance drop of roughly 6%, which demonstrates the importance of grounded e xecution signals for stable plan generation. W ithout this stage, the planner is trained only with abstract trajectory-lev el rewards and receiv es no information about whether its predicted actions are actually feasible. This lack of grounding often produces unstable or overly optimistic plans, such as assuming nonexistent tools or expecting successful ex ecutions that nev er materialize. Stage 2 provides the model with con- crete execution outcomes that serve as corrective signals, enabling it to adjust its predictions and maintain coherent and feasible plans across different en vironments. Balancing prediction horizon. W e vary the predictiv e horizon T , which controls ho w many future steps the plan- ner learns to forecast during training. As shown in Fig- ure 5a , increasing T initially improves task success, as the model benefits from learning to anticipate delayed out- comes and organize temporally extended plans. Howe ver , beyond a moderate range ( T > 10 ), performance drops noticeably . When trained with excessiv ely long horizons, the planner must predict f ar-future transitions whose uncer- tainty accumulates quickly , leading to noisy trajectory re- wards and unstable credit assignment. This result suggests that training the model to look several steps ahead is bene- ficial for long-term reasoning, but forcing it to plan too far into the future overwhelms the learning signal and weakens adaptation during ex ecution. T rajectory-aware r eward design analysis. W e further an- alyze the impact of two key components in our trajectory- lev el reward: the repetition penalty λ rep and the temporal discount factor γ . As sho wn in Figure 5b and 5c , remov- ing the repetition penalty ( λ rep = 0 ) or disabling tempo- ral discounting ( γ = 1 ) consistently degrades performance, confirming that both components are crucial for stabilizing trajectory-aware reinforcement learning. W ithout the repe- tition penalty , the planner exhibits reward-hacking behavior by repeatedly issuing redundant actions, such as re-clicking the same interf ace element or re-in voking identical tools, in order to inflate short-term rewards without making real task progress. This behavior undermines both efficiency and causal consistency in long-horizon planning. The tempo- ral discount factor further mitigates instability by prioritiz- ing near-future correctness while preserving trajectory-level coherence, pre venting the planner from ov erfitting to uncer- "My grandmother has been using the Chrome lately and told me that the font size is way too small for her poor eyesight. Could you set the default font size to the largest for her?" T raceR1 UI - TA R S -1.5-7B OSW orld - V erified T raceR1 "screenshot_abstraction": "Chrome menu dropdown open", "action": "Click", "step": " click Settings option in menu ", "status": "not done" T raceR1 "screenshot_abstraction": "Settings main page displayed", "action": "Click", "step": " click Appearance in sidebar ", "status": "not done" T raceR1 "screenshot_abstraction": "Appearance page font size", "action": "Click", "step": " click Font size dropdown ", "status": "not done" T raceR1 "screenshot_abstraction": "Font size dropdown expanded", "action": "Click", "step": " click V ery large option ", "status": "not done" T raceR1 "screenshot_abstraction": "V ery large font selected", "action": "Finished", "status": "done" Grounding Agent : [1838, 90] Grounding Agent : [1580, 816] Grounding Agent : [170, 357] Grounding Agent : [1214, 730] User Instruction: Figure 4. Example trajectory: coordination between TraceR1 (planner) and UI-T ARS-1.5-7B (ex ecutor) on OSW orld-V erified. 1 3 5 10 15 50 60 70 Success R ate (%) Trajectory Horizon Length (T) (a) T rajectory horizon length AndroidControl-High GT A 20 40 60 80 100 Success R ate (%) 75.3 67.9 56.7 52.3 A b l a t i o n o n r e p w / r e p w / o r e p (b) Ablation on repetition penalty λ rep AndroidControl-High GT A 20 40 60 80 100 Success R ate (%) 75.3 70.3 56.7 53.8 A b l a t i o n o n w / w / o (c) Ablation on temporal discount γ Figure 5. Ablation results. (a) shows the effect of predictiv e trajectory horizon length on AndroidW orld. (b–c) show the impact of removing λ rep and γ during training on AndroidControl-High and GT A. tain distant outcomes and yielding more consistent, goal- directed planning. 5. Conclusion W e presented T raceR1 , a two-stage RL frame work that en- dows multimodal agents with anticipatory planning abil- ity across GUI and tool-use environments. By coupling trajectory-lev el optimization with grounded execution re- finement, T raceR1 bridges the gap between high-lev el fore- sight and lo w-level precision, achie ving substantial gains in planning stability , execution reliability , and generalization. Our experiments demonstrate that trajectory-aware reason- ing can significantly improve the coherence and adaptabil- ity of multimodal agents, establishing a scalable recipe for training open models to reason and plan ahead within dy- namic, state-changing en vironments. More broadly , this work highlights anticipatory trajectory reasoning as a gen- eral principle for building agents capable of coherent, tem- porally extended decision making across heterogeneous in- teraction modalities. Although effecti ve, the current approach is limited be- cause short-horizon updates provide local corrections and cannot reshape the agent’ s understanding of long-term fea- sibility or task structure. Future work may explore multi- round or hierarchical planning mechanisms that couple tra- jectory prediction with updates to memory , internal state, or world models, allowing the agent to revise and con- solidate plans. Another promising direction is to extend this paradigm to embodied or hybrid tool-use environments, where successful behavior requires coordinating percep- tion, reasoning, and action across longer time scales. Ad- vances along these lines may yield planning systems that not only anticipate future outcomes but also organize their predictions across multiple lev els of abstraction. References [1] Saaket Agashe, Jiuzhou Han, Shuyu Gan, Jiachen Y ang, Ang Li, and Xin Eric W ang. Agent s: An open agentic frame- work that uses computers like a human. arXiv preprint arXiv:2410.08164 , 2024. 2 [2] Saaket Agashe, Kyle W ong, V incent T u, Jiachen Y ang, Ang Li, and Xin Eric W ang. Agent s2: A compositional generalist-specialist framework for computer use agents, 2025. 1 , 2 , 5 [3] Anthropic. Introducing claude 4, 2024. 1 , 2 , 5 , 6 [4] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Sibo Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 , 2025. 5 , 6 , 7 [5] Delong Chen, Theo Moutakanni, W illy Chung, Y ejin Bang, Ziwei Ji, Allen Bolourchi, and Pascale Fung. Planning with reasoning using vision language world model. arXiv preprint arXiv:2509.02722 , 2025. 1 [6] W ei-Ge Chen, Irina Spiridonov a, Jianwei Y ang, Jianfeng Gao, and Chunyuan Li. Llava-interacti ve: An all-in-one demo for image chat, segmentation, generation and editing. arXiv pr eprint arXiv:2311.00571 , 2023. 3 [7] Kanzhi Cheng, Qiushi Sun, Y ougang Chu, Fangzhi Xu, Li Y anT ao, Jianbing Zhang, and Zhiyong W u. Seeclick: Har- nessing gui grounding for advanced visual gui agents. In Pr oceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (V olume 1: Long P apers) , pages 9313–9332, 2024. 2 [8] Xiang Deng, Y u Gu, Boyuan Zheng, Shijie Chen, Sam Stev ens, Boshi W ang, Huan Sun, and Y u Su. Mind2web: T owards a generalist agent for the web. Advances in Neural Information Processing Systems , 36:28091–28114, 2023. 4 , 5 [9] Longxi Gao, Li Zhang, and Mengwei Xu. Uishift: Enhanc- ing vlm-based gui agents through self-supervised reinforce- ment learning. arXiv preprint , 2025. 1 [10] Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaojian Ma, T ao Y uan, Y ue Fan, Y uwei Wu, Y unde Jia, Song-Chun Zhu, and Qing Li. Multi-modal agent tuning: Building a vlm-driv en agent for efficient tool usage. arXiv pr eprint arXiv:2412.15606 , 2024. 3 , 4 , 5 , 6 , 7 [11] Boyu Gou, Ruohan W ang, Boyuan Zheng, Y anan Xie, Cheng Chang, Y iheng Shu, Huan Sun, and Y u Su. Navigating the digital world as humans do: Universal visual grounding for gui agents. arXiv preprint , 2024. 2 [12] Y u Gu, Kai Zhang, Y uting Ning, Boyuan Zheng, Boyu Gou, T ianci Xue, Cheng Chang, Sanjari Sriv astav a, Y anan Xie, Peng Qi, et al. Is your llm secretly a world model of the in- ternet? model-based planning for web agents. arXiv pr eprint arXiv:2411.06559 , 2024. 1 [13] Dong Guo, Faming W u, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian W ang, Jianyu Jiang, Jiawei W ang, et al. Seed1. 5-vl technical report. arXiv preprint arXiv:2505.07062 , 2025. 5 [14] Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi W ang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 , 2025. 4 [15] W enyi Hong, W eihan W ang, Qingsong Lv , Jiazheng Xu, W enmeng Y u, Junhui Ji, Y an W ang, Zihan W ang, Y uxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pages 14281– 14290, 2024. 2 [16] Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow , Akila W eli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv pr eprint arXiv:2410.21276 , 2024. 7 [17] W ei Li, W illiam E Bishop, Alice Li, Christopher Rawles, Fola wiyo Campbell-Ajala, Divya T yamagundlu, and Oriana Riv a. On the effects of data scale on ui control agents. Advances in Neural Information Pr ocessing Systems , 37: 92130–92154, 2024. 2 , 4 , 5 [18] Haotian Liu, Chunyuan Li, Y uheng Li, Bo Li, Y uanhan Zhang, Sheng Shen, and Y ong Jae Lee. Llav a-next: Im- prov ed reasoning, ocr , and world knowledge, 2024. 6 , 7 [19] Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, T ianhe Ren, Xueyan Zou, Jianwei Y ang, Hang Su, Jun Zhu, et al. Llava-plus: Learning to use tools for creating multi- modal agents. In Eur opean conference on computer vision , pages 126–142. Springer , 2024. 3 [20] Y uhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xi- aotian Han, Shengyu Zhang, Hongxia Y ang, and Fei W u. Infigui-r1: Advancing multimodal gui agents from re- activ e actors to deliberativ e reasoners. arXiv pr eprint arXiv:2504.14239 , 2025. 1 , 2 , 6 [21] Quanfeng Lu, W enqi Shao, Zitao Liu, Lingxiao Du, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, and Ping Luo. Guiodyssey: A comprehensi ve dataset for cross-app gui navigation on mobile devices. In Proceed- ings of the IEEE/CVF International Confer ence on Com- puter V ision , pages 22404–22414, 2025. 4 , 5 [22] Y adong Lu, Jianwei Y ang, Y elong Shen, and Ahmed A wadallah. Omniparser for pure vision based gui agent, 2024. 6 [23] Zhengxi Lu, Y uxiang Chai, Y axuan Guo, Xi Y in, Liang Liu, Hao W ang, Han Xiao, Shuai Ren, Guanjing Xiong, and Hongsheng Li. Ui-r1: Enhancing efficient action predic- tion of gui agents by reinforcement learning. arXiv preprint arXiv:2503.21620 , 2025. 2 [24] Dezhao Luo, Bohan T ang, Kang Li, Georgios Papoudakis, Jifei Song, Shaog ang Gong, Jian ye Hao, Jun W ang, and K un Shao. V imo: A generativ e visual gui world model for app agents. arXiv preprint , 2025. 1 [25] Run Luo, Lu W ang, W anwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision- language action model for gui agents. arXiv preprint arXiv:2504.10458 , 2025. 1 , 2 , 6 [26] Gr ´ egoire Mialon, Cl ´ ementine Fourrier , Thomas W olf, Y ann LeCun, and Thomas Scialom. Gaia: a benchmark for gen- eral ai assistants. In The T welfth International Confer ence on Learning Repr esentations , 2023. 2 , 5 [27] Dang Nguyen, Jian Chen, Y u W ang, Gang W u, Namyong Park, Zhengmian Hu, Hanjia L yu, Junda W u, Ryan Aponte, Y u Xia, et al. Gui agents: A survey . In F indings of the As- sociation for Computational Linguistics: A CL 2025 , pages 22522–22538, 2025. 1 [28] OpenAI. Gpt-5 system card. 2025. 5 , 7 [29] OpenAI. Openai o3 and o4-mini system card. 2025. 1 , 2 , 5 , 6 [30] Y ujia Qin, Y ining Y e, Junjie Fang, Haoming W ang, Shihao Liang, Shizuo T ian, Junda Zhang, Jiahao Li, Y unxin Li, Shi- jue Huang, et al. Ui-tars: Pioneering automated gui inter- action with native agents. arXiv pr eprint arXiv:2501.12326 , 2025. 2 , 4 , 5 , 6 [31] Christopher Rawles, Sarah Clinckemaillie, Y ifan Chang, Jonathan W altz, Gabrielle Lau, Marybeth Fair , Alice Li, W illiam Bishop, W ei Li, Fola wiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents. arXiv pr eprint arXiv:2405.14573 , 2024. 5 [32] Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Y an Ma, Xiaoye Qu, Jiaqi Liu, Y anshu Li, Kaide Zeng, Zhengyuan Y ang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers. arXiv pr eprint arXiv:2506.23918 , 2025. 1 [33] Liujian T ang, Shaokang Dong, Y ijia Huang, Minqi Xiang, Hongtao Ruan, Bin W ang, Shuo Li, Zhiheng Xi, Zhihui Cao, Hailiang Pang, et al. Magicgui: A foundational mo- bile gui agent with scalable data pipeline and reinforcement fine-tuning. arXiv preprint , 2025. 1 [34] Chenyu W ang, W eixin Luo, Sixun Dong, Xiaohua Xuan, Zhengxin Li, Lin Ma, and Shenghua Gao. Mllm-tool: A multimodal large language model for tool agent learning. In 2025 IEEE/CVF W inter Confer ence on Applications of Com- puter V ision (W ACV) , pages 6678–6687. IEEE, 2025. 3 [35] Haoming W ang, Hao yang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shi- hao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning. arXiv pr eprint arXiv:2509.02544 , 2025. 1 , 2 , 5 [36] Jize W ang, Zerun Ma, Y ining Li, Songyang Zhang, Cailian Chen, Kai Chen, and Xinyi Le. Gta: A benchmark for gen- eral tool agents, 2024. 2 , 5 [37] Xinyuan W ang, Bo wen W ang, Dunjie Lu, Junlin Y ang, T ian- bao Xie, Junli W ang, Jiaqi Deng, Xiaole Guo, Y iheng Xu, Chen Henry W u, Zhennan Shen, Zhuokai Li, Ryan Li, Xi- aochuan Li, Junda Chen, Boyuan Zheng, Peihang Li, Fangyu Lei, Ruisheng Cao, Y eqiao Fu, Dongchan Shin, Martin Shin, Jiarui Hu, Y uyan W ang, Jixuan Chen, Y uxiao Y e, Danyang Zhang, Dikang Du, Hao Hu, Huarong Chen, Zaida Zhou, Haotian Y ao, Ziwei Chen, Qizheng Gu, Y ipu W ang, Heng W ang, Diyi Y ang, V ictor Zhong, Flood Sung, Y . Charles, Zhilin Y ang, and T ao Y u. Opencua: Open foundations for computer-use agents, 2025. 2 , 4 , 5 , 6 [38] Zihao W ang, Shaofei Cai, Anji Liu, Y onggang Jin, Jin- bing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Y aodong Y ang, et al. Jarvis-1: Open-world multi- task agents with memory-augmented multimodal language models. IEEE T ransactions on P attern Analysis and Ma- chine Intelligence , 2024. 3 [39] Zhiyu W u, Xiaokang Chen, Zizheng Pan, Xingchao Liu, W en Liu, Damai Dai, Huazuo Gao, Y iyang Ma, Chengyue W u, Bingxuan W ang, et al. Deepseek-vl2: Mixture-of- experts vision-language models for advanced multimodal understanding. arXiv pr eprint arXiv:2412.10302 , 2024. 6 , 7 [40] Zhiyong W u, Zhenyu W u, Fangzhi Xu, Y ian W ang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents. arXiv preprint arXiv:2410.23218 , 2024. 2 , 6 [41] T ianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, T oh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmark- ing multimodal agents for open-ended tasks in real computer en vironments. Advances in Neural Information Pr ocessing Systems , 37:52040–52094, 2024. 5 [42] T ianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Y ang, Haoyuan W u, Jixuan Chen, W enjing Hu, Xinyuan W ang, Y uhui Xu, Zekun W ang, Y iheng Xu, Junli W ang, Doyen Sa- hoo, T ao Y u, and Caiming Xiong. Scaling computer-use grounding via user interface decomposition and synthesis, 2025. 2 , 5 [43] T ianbao Xie, Mengqi Y uan, Danyang Zhang, Xinzhuang Xiong, Zhennan Shen, Zilong Zhou, Xinyuan W ang, Y anxu Chen, Jiaqi Deng, Junda Chen, Bowen W ang, Haoyuan W u, Jixuan Chen, Junli W ang, Dunjie Lu, Hao Hu, and T ao Y u. Introducing osworld-verified. xlang.ai , 2025. 2 [44] Y iheng Xu, Dunjie Lu, Zhennan Shen, Junli W ang, Zekun W ang, Y uchen Mao, Caiming Xiong, and T ao Y u. Agent- trek: Agent trajectory synthesis via guiding replay with web tutorials. arXiv preprint , 2024. 4 [45] An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 , 2025. 1 , 2 , 4 , 5 , 6 [46] Jianwei Y ang, Reuben T an, Qianhui W u, Ruijie Zheng, Baolin Peng, Y ongyuan Liang, Y u Gu, Mu Cai, Seonghyeon Y e, Joel Jang, et al. Magma: A foundation model for multi- modal ai agents. In Pr oceedings of the Computer V ision and P attern Recognition Confer ence , pages 14203–14214, 2025. 1 , 2 [47] Rui Y ang, Lin Song, Y anwei Li, Sijie Zhao, Y ixiao Ge, Xiu Li, and Y ing Shan. Gpt4tools: T eaching large language model to use tools via self-instruction. Advances in Neural Information Pr ocessing Systems , 36:71995–72007, 2023. 3 [48] Y an Y ang, Dongxu Li, Y utong Dai, Y uhao Y ang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, et al. Gta1: Gui test-time scaling agent. arXiv pr eprint arXiv:2507.05791 , 2025. 2 , 5 [49] Y uhao Y ang, Y ue W ang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-ui: V isual grounding for gui instructions. In Findings of the Association for Compu- tational Linguistics: ACL 2025 , pages 22418–22433, 2025. 2 [50] Chi Zhang, Zhao Y ang, Jiaxuan Liu, Y anda Li, Y ucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Y u. Appa- gent: Multimodal agents as smartphone users. In Pr oceed- ings of the 2025 CHI Confer ence on Human F actors in Com- puting Systems , pages 1–20, 2025. 3 [51] Zhuosheng Zhang and Aston Zhang. Y ou only look at screens: Multimodal chain-of-action agents. In F indings of the Association for Computational Linguistics: A CL 2024 , pages 3132–3149, 2024. 3 [52] Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Y u Su. Gpt-4v (ision) is a generalist web agent, if grounded. arXiv pr eprint arXiv:2401.01614 , 2024. 2 [53] Ruijie Zheng, Y ongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daum ´ e III, Andrey Kolobov , Furong Huang, and Jianwei Y ang. Trace vla: V isual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv pr eprint arXiv:2412.10345 , 2024. 1 [54] Y aowei Zheng, Junting Lu, Shenzhi W ang, Zhangchi Feng, Dongdong Kuang, and Y uwen Xiong. Easyr1: R1 reinforcement learning made simple. arXiv pr eprint arXiv:2501.12345 , 2025. 4 Anticipatory Planning f or Multimodal AI Agents Appendix A. Implementation Details A.1. T raining Hyperparameters T able 4 summarizes the GRPO and optimization hyperpa- rameters used in our e xperiments. Both Stage 1 (trajectory- lev el optimization) and Stage 2 (grounded fine-tuning) share identical training configurations; the only difference lies in their rew ard definitions. A.2. Reward F ormulation Details Based on the provided implementation, the rew ard function in Stage 1 aims to align the predicted trajectory skeleton (action types and status) with the ground truth, while strictly enforcing output formatting. The total reward R for a pre- dicted sample is a weighted sum of the accuracy re ward R acc and the format rew ard R fmt : R = (1 − λ fmt ) · R acc + λ fmt · R fmt (6) where we set λ fmt = 0 . 1 . Format Reward ( R fmt ). T o ensure the model generates parseable actions, we check for the presence of specific XML tags (e.g., , ) and JSON keys. For a generated response containing N steps, the format re- ward is the ratio of v alid steps: R fmt = 1 N N X i =1 ⊮ [ V alid ( ˆ s i )] (7) A step ˆ s i is considered valid only if it strictly contains the required keys: "screenshot abstraction" , "action" (with "action type" ), and "status" . T rajectory Alignment Accuracy ( R acc ). Unlike standard exact matching, our trajectory-lev el reward focuses on the correctness of the plan sequence (Action T ypes). Let A = [ ˆ a 1 , . . . , ˆ a N ] be the predicted action sequence and A ∗ = [ a ∗ 1 , . . . , a ∗ M ] be the ground truth. W e parse only the action type and status fields for alignment. (1) Gr eedy Alignment with P osition P enalty . W e compute the best alignment between A and A ∗ . If lengths differ , we employ a greedy matching strategy . A predicted action ˆ a i matches a ground truth action a ∗ j if: sim (ˆ a i , a ∗ j ) = ⊮ [ˆ a i . type = a ∗ j . type ] (8) T o encourage temporal consistency , we apply a position penalty P pos = | i − j | × 0 . 1 . A match is accepted only if the adjusted score ( sim − P pos ) > 0 . 5 . (2) Discounted Score . For the set of aligned pairs M , the base alignment score is calculated using a discount factor γ = 0 . 8 : S align = X ( i,j ) ∈M γ i · sim (ˆ a i , a ∗ j ) (9) W e subtract a co verage penalty of 0 . 15 for e very unmatched action in both prediction and ground truth. The score is normalized by the maximum possible discounted return of the reference trajectory . (3) Repetition P enalty . Finally , we penalize stuck loops (e.g., repeatedly predicting ”click” without state change). If three consecuti ve actions hav e the same type, it counts as a repetition. R acc = Clip [0 , 1] ¯ S align − 0 . 1 × N repetitions (10) where ¯ S align is the normalized alignment score. This design encourages the agent to follow the correct high-level plan before refining parameters in Stage 2. Category Hyperparameter V alue Actor Optimization Learning rate 1 × 10 − 6 Optimizer AdamW (bf16) W eight decay 0.01 W armup ratio 0 T raining steps 143 Max grad norm 1.0 Global batch size 128 GRPO / RL Parameters Advantage estimator GRPO Discount ( γ ) 0.8 GAE λ 1.0 KL type fixed KL target 0.1 KL coef 0.01 KL penalty low var kl Clip ratio (low) 0.2 Clip ratio (high) 0.3 Clip ratio (dual) 3.0 Rollout Generation Engine vLLM Number of rollouts (n) 5 Rollout batch size 512 T emperature 1.0 T op- p 0.99 T ensor parallel size 2 Max batched tokens 8192 Response length 2048 Reward Parameters λ align 0.8 λ rep 0.1 λ format 0.1 T able 4. GRPO training hyperparameters used for both Stage 1 and Stage 2. All reinforcement learning stages share the same GRPO and optimization settings.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment