A Practical Algorithm for Feature-Rich, Non-Stationary Bandit Problems
Contextual bandits are incredibly useful in many practical problems. We go one step further by devising a more realistic problem that combines: (1) contextual bandits with dense arm features, (2) non-linear reward functions, and (3) a generalization …
Authors: Wei Min Loh, Sajib Kumer Sinha, Ankur Agarwal
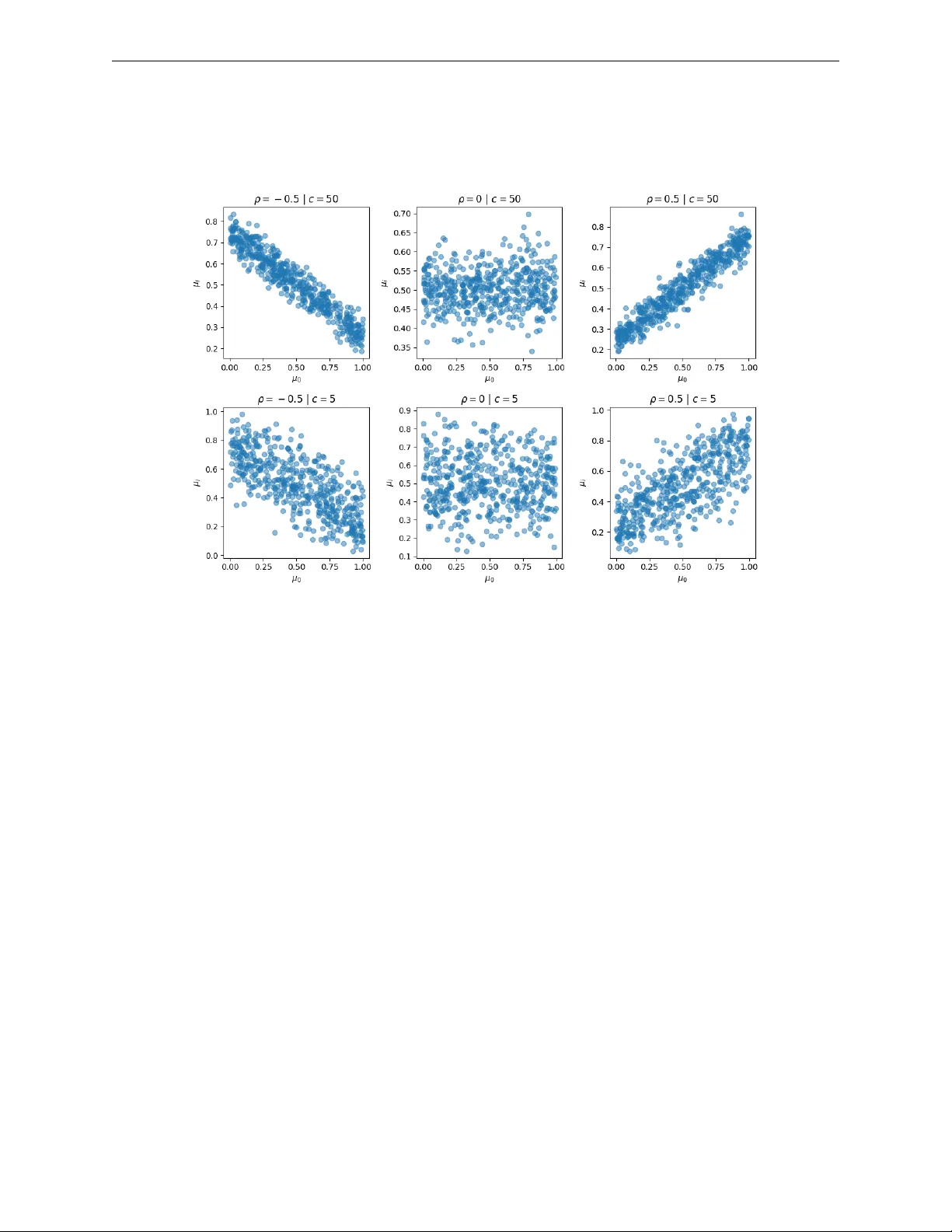
Published in T ransactions on Mac hine Learning Researc h (03/2026) A Practical Algo rithm fo r F eature-Rich, Non-Stationa ry Bandit Problems W ei Min Loh wmloh@uwaterlo o.c a University of W aterlo o, V ector Institute Sa jib Kumer Sinha Sajib_Sinha@manulife.c om Manulife Financial Ankur Agarwal A nkur_A garwal@manulife.c om Manulife Financial P ascal Poupart pp oup art@uwaterlo o.c a University of W aterlo o, V e ctor Institute Review ed on OpenReview: https: // openreview. net/ forum? id= tRbwfej9uY Abstract Con textual bandits are incredibly useful in man y practical problems. W e go one step further b y devising a more realistic problem that com bines: (1) contextual bandits with dense arm features, (2) non-linear rew ard functions, and (3) a generalization of correlated bandits where reward distributions c hange o ver time but the degree of correlation maintains. This form ulation lends itself to a wider set of applications such as recommendation tasks. T o solve this problem, we in tro duce c onditional ly c ouple d c ontextual ( C 3 ) Thompson sampling for Bernoulli bandits. It combines an improv ed Nadara ya-W atson estimator on an embedding space with Thompson sampling that allows online learning without retraining. Empirical results show that C 3 outp erforms the next b est algorithm by 5.7% low er a verage cumulativ e regret on four Op enML tabular datasets as w ell as demonstrating a 12.4% clic k lift on Microsoft News Dataset (MIND) compared to other algorithms. 1 . 1 Intro duction Multi-armed bandits are applicable in many domains where there is high sto chasticit y and limited opp or- tunities to fully explore all p ossible arms (Lattimore & Szepesvári, 2020). A more useful v ariant of the problem called c ontextual b andit (Lu et al., 2010) tac kles a significan tly harder problem where it aims to op- timize for the b est arm for a given con text. Con textual bandits find applications in many domains including recommender systems, online adv ertising, dynamic pricing, and alternativ es to A/B testing. In several applications, the arms can b e decomp osed into a set of features such that different arms share some features and therefore their reward distributions ma y b e dependent (whic h we refer to as c ouple d arms). F urthermore, the reward distributions of the arms may evolv e ov er time, leading to non-stationarity . This pap er fo cuses on non-stationary contextual bandits with coupled arms. T o motiv ate the inv estigation into coupled arms, or coupling in general, we consider an example of strong coupling in pro duct recommendation. Complemen tary go o ds such as bicycles and helmets are t ypically strongly coupled. If the demand for bicycles rises, it is lik ely that the demand for helmets would go up to o. Cycling, in some countrie s, is a seasonal activity where sales of bicycles and helmets differ during summer and win ter. 1 Our implementation can be found on GitHub ( https://github.com/wmloh/c3 ). 1 Published in T ransactions on Mac hine Learning Researc h (03/2026) This provides useful information for an agent when recommending pro ducts. Unlike time-series forecasting, w e do not directly mo del the demand ov er a future time p eriod. Instead, we capture features that migh t suggest coupling, then if one product has a high demand, it would immediately infer that a strongly coupled pro duct would also hav e a high demand. This is b eneficial for any bandit algorithm that has to balance exploration and exploitation of information. Main Contributions One of our contributions is in tro ducing the notion of coupled arms that are ubiqui- tous in many practical applications. The primary con tribution is developing an algorithm called c onditional ly c ouple d c ontextual ( C 3 ) Thompson sampling that solves con textual bandits with correlated/coupled arms in bandit or recommendation tasks. T o the b est of our kno wledge, it is the first algorithm that can solv e contex- tual bandits with correlated/coupled arms in a non-stationary setting. Unlik e man y other neural con textual bandit approaches, there are no length y gradient-based updates at inference time. C 3 can also leverage arm features, which reduces the cold-start problem on arms, with the added b enefit of w orking with a v ariable set of v alid arms. 2 Related Wo rks 2.1 Contextual Bandits On the con textual bandit front, LinUCB by Li et al. (2010) can b e considered one of the pioneering con textual bandit algorithms that demonstrated success through the use of simulated ev aluation based on the Y aho o! news dataset. Ch u et al. (2011) follow ed up with a rigorous theoretical analysis of a v arian t of LinUCB. The other p opular paradigm is the Bay esian approach where Agraw al & Goy al (2013) developed a contextual bandit algorithm with Thompson sampling with a Gaussian likelihoo d and prior, assuming a linear pay off function. Unfortunately , there was no empirical ev aluation on a practical problem. With deep neural approac hes on the rise, the con textual bandit comm unit y has b een focusing on algorithms that can learn non-linear reward functions. One of the earlier algorithms was the KernelUCB b y V alko et al. (2013) whic h extends LinUCB b y exploiting reproducing k ernel Hilbert space (RKHS). Similarly , Sriniv as et al. (2009) generalized Gaussian processes for a con textual bandit setting by introducing the GP-UCB algorithm. While b oth algorithms attain a sublinear regret, practicality is limited since b oth ha v e cubic time complexity in terms of the num b er of samples. After the breakthrough in the theoretical understanding of neural netw orks, particularly the neural tangent kernel (NTK) b y Jacot et al. (2018), Zhou et al. (2020) developed NeuralUCB which is a neural netw ork-based contextual bandit algorithm with a complete theoretical analysis and a suite of empirical analysis whic h outperforms many algorithms in tabular dataset b enc hmarks from Op enML. More recen t adv ancemen ts include SquareCB (F oster & Rakhlin, 2020) which reduces the problem of con- textual bandits to an online regression problem. Under mild conditions, SquareCB along with a blac k-b ox online regression oracle has optimal b ounded regret with no ov erhead in runtime or memory requirements. While they work on most regression mo dels, the p erformance is highly dep endent on the quality of the selected oracle. K veton et al. (2020) in tro duced their take on randomized algorithms for con textual bandits. Their nov el contributions include an additive Gaussian noise for a bandit setting that can b e introduced to complex mo dels such as neural netw orks. 2.2 Other Relevant Bandits Sev eral specialized bandit algorithms ma y b e relev ant to our problem. Basu et al. (2021) introduced a v ariant called contextual blocking bandit that handles a v ariable set of arms but assumes the selected arms of an agen t influence the future set of v alid arms. Their w ork revolv es around this idea but ultimately differs in ha ving a fixed, finite set of o v erall arms. The problem of non-stationary reward distributions in bandits is usually referred to as a restless bandit, whic h is prop osed by Whittle (1988). W ang et al. (2020) introduced the Restless-UCB algorithm which pro v ably solves restless bandits, but do es not accoun t for context in the en vironment. Chen & Hou (2024) 2 Published in T ransactions on Mac hine Learning Researc h (03/2026) impro v es up on this by leveraging con text and budget constraints. A specialized solution by Slivkins & Upfal (2008) assumes that rew ard distribution changes gradually and works by con tinuously exploring while sometimes follo wing the b est arm based on the last tw o observ ations. Ho w ev er, they assume that all arms are indep enden t and can b e mo delled as a Brownian motion which is uncommon in practice. In the realm of sleeping bandits where some arms are o ccasionally not v alid, Slivkins (2011) introduced the con textual zo oming algorithm that adaptively forms partitions in a similarit y space. Operating on a space, as opp osed to ha ving fixed arms, allows them to effectively tackle the sleeping bandit problem. While they offer an inno v ativ e framew ork, it is likely that partitions in high-dimensional spaces (e.g. from large language mo dels) would not b e tractable. Kleine Buening et al. (2024) prop osed a situation that is p otentially relev ant to man y applications from a game-theoretic p ersp ective. Goals of agents could conflict – for example, an arm could b e a video from a con ten t creator on a public platform. In the current state, “clic kbait" videos w ould maximize the reward for the con tent creator but are seen as a negativ e phenomenon ov erall on the platform. Kleine Buening et al. (2024) devised an incen tiv e-a w are learning algorithm to ensure that the learner obtains the right signal. 2.3 Recommender Systems There is growing interest in applying contextual bandits on recommender systems (Ban et al., 2024). On the topic of recommender systems, the more prev alent form of recommendation mo dels in recent years is t ypically based on neural netw orks Dong et al. (2022). A p opular approach is the tw o-tow er neural netw ork emplo y ed b y Huang et al. (2020) and Yi et al. (2019). A major b enefit of such designs includes incredibly efficien t retriev al within the learned embedding space as well as the ability to learn complex relationships of queries and items. Another design called BER T4Rec by Sun et al. (2019) leverages the pow er of transformers in sequen tial problems to provide recommendations. How ever, in the men tioned recommender designs, there is no element of exploration, unlike contextual bandits, resulting in a p ossibly greedy approach that may get stuc k in a suboptimal p olicy . This can also b e a ma jor problem when user b ehaviour changes since all gradien t updates to the mo dels are based on historical data alone, and frequent retraining of the mo dels can b e exp ensive. 3 Problem Fo rmulation 3.1 Contextual Bandit In this pap er, we fo cus on Bernoulli bandits where the conditional rew ard distribution is R ∼ Bernoulli ( µ ( c, a )) and c ∈ C is the current context. C is left to b e an arbitrary space as long as it can b e appropriately encoded. Eac h arm a ∈ A is a discrete class. The Bernoulli mean parameter µ : C × A → [0 , 1] is a contin uous function whose v alue represents the probabilit y of the rew ard b eing one. µ is assumed to b e Lipsc hitz con tin uous in C × A . 3.2 Coupled Arms: An Extension to Co rrelated Arms Gupta et al. (2021) formulated the correlated multi-armed bandit problem where pulling an arm provides some information ab out another arm that is correlated. W e view this as a sp ecial case of coupling. Conditional reward distributions tend to b e non-stationary in practice but we can still exploit some infor- mation on arms. While µ could change with time, there is an inheren t structure to how µ of certain arms c hange. F or example, the marginal probabilities of shopp ers buying sno wb oards and skis are likely to b e coupled, ev en though b oth probabilities would drop during the summer and rise during winter in a similar fashion. In reference to Figure 1, up to the present, we see that the exp ected rewards for arms 1 and 2 are v ery similar and ev olve similarly together in the time interv al. W e call these str ongly c ouple d arms . Pulling one arm will giv e some information about the other arm in an y time p erio d, in contrast to correlated arms where 3 Published in T ransactions on Mac hine Learning Researc h (03/2026) Figure 1: A three-arm example of strong and weak coupling during concept drift of exp ected reward distri- bution. Arms 1 and 2 are said to b e str ongly c ouple d , while arms 1 and 3 are said to b e we akly c ouple d . this condition is only true at a particular p oint in time. Conv ersely , arms 1 and 3 are we akly c ouple d arms since they ha v e mostly differen t historical exp ected rewards. Concept drift, in the context of bandits, can b e defined as: there exist some times t 1 , t 2 ∈ { 1 , 2 , ..., T } where P ( r | c, a, t 1 ) = P ( r | c, a, t 2 ) ( r is the reward, c is the context and a is an arm) (Lu et al., 2018). The degree of coupling b et ween arms a and a ′ for a giv en con text c is ρ ( a, a ′ , c ) = 1 − 1 T T X t =1 D JS ( P ( r | c, a, t ) , P ( r | c, a ′ , t )) (1) where D JS is the Jensen-Shannon divergence ov er the reward distributions. Arms a and a ′ are said to b e p erfectly coupled for context c if ρ ( a, a ′ , c ) = 1 . 3.3 Non-stationa ry Contextual Bandits with Coupled Arms W e extend v anilla contextual bandits to a more general problem. The Bernoulli mean parameter µ ( c, a, t ) is no w a function of time to o. W e also assume that µ is Lipschitz contin uous with resp ect to time. Eac h arm a ∈ A ⊆ R d can b e characterized with a vector of dense features, which implies that there are infinitely many p ossible arms but a finite n umber of arms are presen ted to an agent at eac h time step. W e call them valid arms when they are presented to the agent at that particular time step. In a sp ecial case where arms do not ha v e dense features, they can still b e represen ted as one-hot enco ded vectors. In the presence of concept drift, i.e. µ ( c, a, t ) = µ ( c, a, t ′ ) generally for t = t ′ , and infinitely man y possible arms, this can b e a v ery difficult task. Here, we assume that there are strongly coupled arms that can b e exploited. The degree of coupling is learnable from the arm features, conditioned on the context c . 3.4 Objective The goal in b oth problems is to minimize the cumulative r e gr et which is the cumulativ e difference b et ween the reward of the b est arm in hindsight a ∗ and the reward of the c hosen arm a t for a given context c t o v er all time steps (Lattimore & Szep esvári, 2020). Cum ulativ eRegret ( T ) = T X t =1 µ ( c t , a ∗ t , t ) − µ ( c t , a t , t ) (2) 4 Metho dology 4.1 Emb edding Mo del This section p ertains to the pro cess of training an offline regression oracle, a class of optimization oracles for con textual bandits describ ed by Bietti et al. (2021). 4 Published in T ransactions on Mac hine Learning Researc h (03/2026) Imp ortance W eighted Kernel Regression The c hosen approac h to capture coupling b etw een arms is based on the hypothesis that the empirical rewards of a relev ant subset of reference samples can b e used to estimate the rew ard of some unseen sample. Nadara y a-W atson k ernel regression (NWKR) is a w ell-known nonparametric regression metho d (Nadaray a, 1964) that uses a weigh ted av erage of lab els of neighbouring samples, w eigh ted b y a k ernel function that satisfies some conditions. Supp ose there is a learnable space S ⊂ R d that represents some joint space of contexts C and arms A , similar to the formulation by Slivkins (2011). W e could use NWKR on some reference dataset D ref = { ( s i , r i ) } n i =1 con taining historical context-arm embeddings s i ∈ S and rewards r i ∈ R , with κ : S × S → R b eing the r adial b asis function (RBF) k ernel to estimate the mean reward of an unseen sample s ∈ S , ˆ µ ( s ) = P s i ,r i ∈D κ ( s, s i ) r i P s i ∈D κ ( s, s i ) (3) Note that µ introduced in Section 3.3 is a function of context, arm, and time while ˆ µ in Equation 3 is a function of context-arm (jointly) and reference dataset D . Unlike time series algorithms, we do not directly mo del time as an indep enden t v ariable since we ha v e to make assumptions on ho w the reward distribution c hanges ov er time. Instead, we use historical examples in D that are close to the presen t time to indirectly condition on the time. An issue with NWKR is the susceptibility to bias from drifts in the sampling distribution. The ov erall w eigh t of samples may dominate the regression due to the disprop ortionately many samples in the vicinity of a query sample. This is particularly an issue in bandit algorithms where the distribution of arms selected will likely change as more data is ingested. The p oints in S provide information about µ in that subspace, but the frequency of p oints should not affect ˆ µ , except for a measure of confidence which will b e discussed in Section 4.2. T o mitigate sampling bias, we introduce imp ortanc e weights . A sample is assigned a low er imp ortance weigh t if it is lo cated in the vicinity of many samples, and a higher imp ortance w eight otherwise. More precisely , the imp ortance weigh t is defined as w ( s ) = 1 P s i ∈D κ ( s, s i ) ∈ (0 , 1] (4) The imp ortanc e weighte d kernel r e gr ession (IWKR) is defined as ˆ µ ( s ) = P s i ,r i ∈D κ ( s, s i ) w ( s i ) r i P s i ∈D κ ( s, s i ) w ( s i ) (5) Theorem 1. Supp ose a ve ctor of imp ortanc e weights w of n samples has b e en c ompute d. The time c omplexity of up dating the imp ortanc e weights, given a new sample, is O ( n ) . A naive implemen tation of the imp ortance weigh ts computation would incur a quadratic time complexity . Ho w ev er, this can b e optimized to b e linear time as shown in the pro of in Supplementary Material A.1. Theorem 2. Supp ose µ ( s ) is Lipschitz c ontinuous on S . In the limit of the size of the r efer enc e dataset D r ef wher e p oints ar e sufficiently sample d fr om the neighb ourho o d of some query p oint s , the imp ortanc e weighte d kernel r e gr ession with a r adial b asis function kernel is an appr oximate estimator of µ ( s ) . The pro of of Theorem 2 can b e found in Supplementary Material A.2. P arametrization of Embedding Space While IWKR can estimate v alues, the input space may not b e sufficien tly calibrated with resp ect to the fixed kernel function. This can b e rectified by training a multila y er p erceptron as an embedding mo del ϕ : C × A → S with IWKR to w ards a classification ob jectiv e. min ϕ E [ L BCE ( ˆ µ ( ϕ ( c, a )) , r ) + λ L ECE ( ˆ µ ( ϕ ( c, a )) , r )] (6) where L BCE is the binary cross entrop y loss and L ECE is the expected calibration error (Naeini et al., 2015). Ev ery con text-arm pair will b e embedded as s = ϕ ( c, a ) so that IWKR acts on an optimal space. 5 Published in T ransactions on Mac hine Learning Researc h (03/2026) W e incorp orate calibration as an auxiliary objective to reduce o verconfidence which is notoriously common in deep neural net works (Guo et al., 2017). In a bandit algorithm in volving neural netw orks, calibration is imp ortan t to av oid biases when facing a lack of data. An optimal mo del would tigh tly cluster strongly coupled context-arm pairs. T o encourage the learning of coupling in ϕ , we can partition the reference dataset by time interv als D ref = D (1) ref ∪ · · · ∪ D ( T ) ref so that IWKR only uses samples from the relev ant time interv al only for a giv en query . This av oids av eraging reward v alues from a different time p erio d whic h may be sub ject to concept drift. The training pro cess is describ ed in Algorithm 1. Algorithm 1 C 3 training pro cess 1: Inputs : T raining dataset D = { ( c i , a i , r i ) } n i =1 , neural net w ork ϕ 2: for ep och e do 3: Randomly split D in to D ref = ( c ref , a ref , r ref ) , and D q 4: Em b ed reference s ← ϕ ( c ref , a ref ) 5: Compute imp ortance weigh ts w for s 6: for ( c, a, r ) ∈ D q do 7: Em b ed query q ← ϕ ( c, a ) 8: s ′ , r ′ ref ← filter for samples in s , r ref suc h that they are in the same time in terv al as q 9: Compute RBF w eigh ts b et ween s ′ and q 10: Estimate w eigh ted mean rew ard ˆ µ ( q ) using the RBF weigh ts and r ′ ref 11: Compute the sum of losses with ˆ µ and r 12: P erform gradien t descen t on ϕ Algorithm Details The training is done batch-wise. The randomization in Step 3 forms a self-sup ervised learning ob jectiv e by masking certain samples and creating a predictive subtask. D ref can b e seen as the set of in-con text samples and D q con tains the training samples. All samples (b oth in D ref and D q ) are em b edded with ϕ , and the ob jectiv e is to optimize the embedding space pro duced by ϕ . Step 9 computes the RBF weigh ts b etw een q and every embedded reference sample in s ′ . Then in Step 10, we apply Equation 5 on q using the RBF weigh ts, imp ortance weigh ts, and r ′ ref to compute ˆ µ ( q ) . The gradien t up date should up date ϕ to embed context-arm pairs with similar rewards closely . 4.2 Inference This section extends the offline regression oracle b y incorporating exploration with a Beta distribution and Thompson sampling. Thompson Sampling The embedding mo del with IWKR is trained tow ards a classification ob jective for predicting the exp ected reward. T o incorp orate an element of exploration, w e adopt Thompson sampling. The conjugate prior of a Bernoulli bandit is a Beta distribution with parameters α and β , where α usually refers to the counts of r = 1 . The notion of coun ts in a con tinuous em b edding space S can b e solved using partial coun ts of rewards weigh ted by the RBF kernel. How ever, this is complicated by imp ortance weigh ts since S was learned with IWKR. The exp ected v alue of the Beta distribution should b e impacted by w ( s ) since it mak es ˆ µ less biased and robust against sampling distribution shifts. How ever, the v ariance of the Beta distribution should not b e impacted b y w ( s ) since it w ould cause α and β to lose information on the n umber of times the neighbourho o d w as sampled. A solution to this is to introduce some mo difications to the computation of the parameters to 6 Published in T ransactions on Mac hine Learning Researc h (03/2026) Figure 2: An example of Thompson sampling exploration in contin uous spaces: [left] em b edding space con- taining reference samples D ref (circles) and different arms (stars) for a given context c , and [right] constructed Beta distribution with (IWKR) and without (NWKR) imp ortance weigh ts. The true µ of b oth arms for that con text is 0.6. the conjugate prior. Let η ( s ) = P n i =1 κ ( s, s i ) . Define α ( s ) := η ( s ) P n i =1 κ ( s, s i ) w ( s i ) r i P n i =1 κ ( s, s i ) w ( s i ) = η ( s ) ˆ µ ( s ) (7) β ( s ) := η ( s ) P n i =1 κ ( s, s i ) w ( s i )(1 − r i ) P n i =1 κ ( s, s i ) w ( s i ) = η ( s )(1 − ˆ µ ( s )) (8) With this, we can sample the p osterior ˜ µ ( s ) ∼ Beta ( α ( s ) , β ( s )) from the resulting Beta distribution. The mean simplifies to E [ ˜ µ ( s )] = α ( s ) α ( s ) + β ( s ) = ˆ µ ( s ) (9) whic h is exactly IWKR. On the other hand, the information of the frequency the neigh b ourho o d w as sampled is still preserv ed b ecause it can b e shown that the total count is still a function of n , α ( s ) + β ( s ) = n X i =1 κ ( s, s i ) (10) The left side of Figure 2 illustrates tw o arms a, a ′ when join tly embedded with context c . The gra y circles refer to previously pulled arms a t ’s for different con texts c t ’s. F or a new query with con text c , arm a (blue) is embedded closer to more samples hence it has essential ly b een pulled more often for con text c . Using partial coun ts weigh ted by an RBF kernel, this manifests as a more p eak ed Beta distribution as sho wn on the righ t side, resulting in less exploration compared to a ′ (red). The combination of IWKR and Thompson sampling gives rise to c onditional ly c ouple d c ontextual Thompson sampling ( C 3 ). The term “conditionally" in C 3 refers to the degree of coupling b eing conditional on the con text. Figure 2 also shows the effectiv eness of imp ortance w eigh ts in a non-uniform sampling setting. The mean of distributions formed with IWKR is closer to 0.6 compared to NWKR, i.e. without imp ortance weigh ts. Appro ximate Ba yesian Update Recall that IWKR is dependent on a reference dataset D . The sampling of the p osterior weighs every sample with the RBF k ernel relative to some query p oin t. This can b e seen as a type of conditioning on a lo cal subspace. After an arm is pulled and the reward is observed, w e should ha v e the triplet ( c n +1 , a n +1 , r n +1 ) . Since the algorithm op erates on S and requires the up dated imp ortance 7 Published in T ransactions on Mac hine Learning Researc h (03/2026) T able 1: Comparison b etw een algorithms where linear refers to b oth LinUCB, LinTS, and SquareCB while neural refers to b oth NeuralUCB and NeuralTS. n refers to the num b er of samples seen. Algorithm Inference time Up date time Non-linear rew ards Non-stationary tasks Arm features C 3 O ( n ) O (1) ✓ ✓ ✓ Linear O (1) O (1) ✗ ✗ partially Neural O (1) O ( n ) ✓ ✗ ✗ w eigh ts, to conserv e time and memory , w e can directly store the triplet ( ϕ ( c n +1 , a n +1 ) , r n +1 , w ( n +1) n +1 ) into D . This is an appro ximate Ba y esian up date and is imp ortant for the online learning element. Ba y esian up date typically assumes that every random v ariable in a sequence is identically distributed. The information gathered is directly stored in the parameter space of some statistical distribution, which will b e up dated using some closed-form algebraic expression. F or C 3 , the information is stored in the reference dataset D em b edded on S . This allo ws flexibility to b oth app end and remov e samples from D . In problems with concept drift, the conditional reward distribution shifts as a function of time but a typical Bay esian up date do es not effectively handle this since it might simply av erage the distributions across time. T o mitigate the issues presented by non-stationarit y without frequent retraining, C 3 allo ws the remov al of older samples while app ending the latest samples. Time can b e seen as a sp ecial case of con text and since µ is assumed to b e Lipschitz contin uous, samples nearer in the time dimension would b e more relev ant. The entire inference pipeline can be summarized in Algorithm 2. The up date pro cess does not include an y gradient up dates, unlike many neural contextual bandit algorithms. The prop erties of C 3 and other con textual bandit algorithms are summarized in T able 1. Algorithm 2 C 3 inference pro cess 1: Inputs : Reference dataset D ref = ( K, r ref , w ) , con text c , set of v alid arms { a 1 , ..., a k } , trained embedding mo del ϕ 2: for eac h v alid arm index i ∈ [ k ] do 3: Em b ed queries q i ← ϕ ( c, a i ) 4: Compute α ( q i ) , β ( q i ) with resp ect to D ref 5: Sample ˆ r i ∼ Beta ( α ( q i ) , β ( q i )) 6: Pla y b est arm j ← argmax i ∈ [ k ] ˆ r i 7: Observ e rew ard r 8: App end ( q j , r ) to D ref 9: Up date w in D ref Theorem 3. L et the emb e dding sp ac e of ϕ b e S ⊂ [0 , 1] d . A ssume µ is L -Lipschitz. In a stationary b andit sc enario, C 3 incurs an exp e cte d r e gr et of E [ R T ] ∈ O L d d +2 T d +1 d +2 (log T ) 1 d +2 Pro of of Theorem 3 can b e found in App endix A.3. 5 Exp eriments Section 5.1 is the only exp erimen t using syn thetic data to demonstrate the hypothesis b etw een coupling and em b edding distance. Sections 5.2 and 5.3 use real-world datasets. 8 Published in T ransactions on Mac hine Learning Researc h (03/2026) Figure 3: Distance from the anchor arm em b edding as a function of correlation ρ with 1.96 sigma error bars o v er 10 random seeds. 5.1 Coupled Arms Simulation The following simulated example demonstrates that ϕ can capture the notion of coupling. Recall coupled arms generalize correlated arms b y ensuring that correlation p ersists ov er time. Supp ose there is a set of arms { a 0 , a 1 , ..., a 6 } . W e call a 0 the anchor arm where the corresponding reward distribution is Bernoulli ( µ 0 ) . A t time t , µ 0 is randomly sampled from a Uniform (0 , 1) distribution. Then, the remaining µ i for the rest of the arms are sampled such that they are either p ositiv ely or negatively correlated with µ 0 . The c hosen degree of correlation is fixed for an y time for all arms with resp ect to the anc hor arm. Arms can b e sampled to obtain ( a it , r it ) pairs to learn µ i un til the end of the episo de where this en tire pro cess rep eats for time t + 1 . Complete details of the generation of coupled arms are describ ed in Supplemen tary Material A.4. The c hosen true correlations for arms a 1 , ..., a 6 are - 1 . 0 , - 0 . 6 , - 0 . 2 , 0 . 2 , 0 . 6 , 1 . 0 resp ectively . F or example, since a 1 is strongly negatively correlated to the anchor, if µ 0 = 0 . 9 then it is very likely that µ 1 ≈ 0 . 1 . On the other hand, µ 5 w ould b e in the vicinity of 0.9. All µ i ’s are sampled 200 times where for eac h time, 100 rew ard samples are collected. These rew ard samples are used to train ϕ using Algorithm 1 with T = 200 time interv als. A summary of arm embeddings is visualized in Figure 3. It follows the exp ectation where the more correlated a i is to a 0 , the distance to a 0 is low er, and vice versa. T o view one example of the spatial p ositioning of the arm embeddings in a scatter plot, see Supplemen tary Material A.6. 5.2 Contextual Bandit Experiments This experiment demonstrates the efficacy of C 3 on the problem describ ed in Section 3.1. In the footsteps of the work by Zhou et al. (2020), w e ev aluate using the same datasets from the Op enML rep ository by V ansc horen et al. (2014), namely shuttle (King et al., 1995), MagicTelescope (Bo ck, 2007), covertype (Blac kard, 1998) and mnist (LeCun, 1998). F or this set of experiments, the con text space is the input space, and A is the corresp onding lab el space. The reward is one if the selected arm matches the ground truth lab el, otherwise zero. Unlik e Zhou et al. (2020), w e do not standardize the inputs because we b elieve that giv es the models some hindsight information which goes against the philosophy of multi-armed bandits. Note that this does not usually fit the t ypical setting of a bandit problem and C 3 targets a more general problem. C 3 requires historical samples for ϕ to b e trained, where historical samples are uncommon for bandit ex- p erimen ts but incredibly common for industry use cases. T o ensure a fair comparison, we ensure that other baseline metho ds, such as LinUCB (Li et al., 2010), Thompson sampling for contextual bandits (LinTS) (Agra w al & Go yal, 2013), SquareCB (F oster & Rakhlin, 2020), NeuralUCB (Zhou et al., 2020), and neural 9 Published in T ransactions on Mac hine Learning Researc h (03/2026) Figure 4: Cumulativ e regret of the test split of the four datasets with 1.96 sigma error bars ov er 10 random seeds. Note that in MNIST, LinTS cannot b e computed due to n umerical issues from the high dimensionality . In MagicT elescop e, NeuralUCB and LinTS almost completely ov erlap b ecause they all rep eatedly exploit the same action after the initial steps. Thompson sampling (NeuralTS) (Zhang et al., 2021), are giv en the same amount of information. All algo- rithms are up dated using a subset for training and ev aluated on a different test subset. This is necessary to a v oid contamination when training ϕ . The test split contains 1000 unseen samples. Appendix A.9 contains an ablation study of C 3 with differen t RBF bandwidth v alues. The results are shown in Figure 4. C 3 outp erforms most of the algorithms in most datasets. C 3 outp er- forms the next b est algorithm for each dataset by 5.7% low er cumulativ e regret on av erage. In shuttle , MagicTelescope , and covertype , these problems are of lo wer dimensionality and more linearly separable hence LinUCB and SquareCB (with a linear regression oracle) perform w ell. On the other hand, NeuralUCB excels in the MNIST dataset since the m ultila y er p erceptron works well with high-dimensional data. 5.3 News Recommendation C 3 will b e ev aluated on news recommendation which is a realistic example for the problem describ ed in Section 3.3. This pap er uses the Microsoft News Dataset (MIND) b y W u et al. (2020) for ev aluation. The con text will b e the frequency of a user’s historical visits by news category . The arm space is the set of v alid news articles to recommend. The reward is whether the user clic ks the c hosen news article. The ob jective of an algorithm is to minimize the cumulativ e regret. F or clarity in results, regret is measured relativ e to the b est p erforming algorithm where at time t , 0 is given to the b est p erforming algorithm and the rest of the algorithms are giv en their resp ectiv e relative regret. W e form dense representations of news articles from their titles using the p o oler output of a BER T model (Devlin et al., 2019). W e use principal comp onent analysis to reduce the dimensions to 64 to b e used as arm em b eddings. Whenever a user visits, there is a small collection of p ossible articles to recommend, up to eigh t articles, but the v alid arm set v aries for each user. In this set of exp eriments, C 3 will b e configured so that every 100 steps, it will randomly remov e approx- imately 20% of samples in D ref to account for the concept drift. The hypothesis is that b ecause of the Lipsc hitz assumption, more recen t samples w ould b e more relev ant in estimating the mean rewards. Due to the rigidit y of assumptions of other bandit algorithms tailored for theoretical results, some baseline algorithms in Section 5.2 could not effectively target all complexities of the problem for v arious reasons. 10 Published in T ransactions on Mac hine Learning Researc h (03/2026) Figure 5: Cumulativ e regret of the MIND dataset with 1 sigma error bars ov er 10 random seeds. “small" and “large" refers to the relativ e n um b er of parameters in the t wo tow er mo dels. Ho w ev er, w e add more sp ecialized algorithms. W e compare C 3 with one of the most p opular recent designs for recommender systems: the tw o-tow er neural netw ork. Huang et al. (2020) uses a deep enco der for query information and another deep enco der for item information then uses the cosine similarity b etw een the tw o em b eddings. A Gaussian pro cess with forgetting is also included Kaufmann et al. (2012), where the forgetting is necessary since it could not handle the entire history and needs to account for the non-stationarity . A similar baseline is using a Bay esian linear regression mo del that takes a concatenated vector of user and article features and returns the mean and standard deviation of estimated rewards, similar to the Gaussian pro cess. Linear and neural baselines from Section 5.2 are mo dified to handle the non-stationarit y elements. W e also compare with the con textual restless bandit algorithm Chen & Hou (2024). F ull exp erimental details are found in Supplemen tary Material A.11. The result can b e seen in Figure 5. C 3 demonstrates a clic k lift of 12.4% compared to the baselines. Initially , C 3 do es not do as well as the tw o tow er approaches (which are static). As the drift of click rate increases in magnitude, C 3 b egins to adapt to the drift as it remov es older samples in D ref while the other algorithms incur regret at the same rate. 6 Discussions Effectiv e Data Utilization Unlik e typical contextual bandit settings, C 3 requires the use of historical data to “w arm-start" the algorithm. In realit y , advertisemen t campaigns, pricing sc hemes, etc. will in v olv e some degree of human-designed p olicy at the initial stages whic h means there could b e some data alb eit p ossibly sub-optimal. Sub-optimality is not an issue for the training of ϕ since the main ob jective of ϕ is to learn rew ard distributions and coupling, not optimality . As a result, ϕ can effectiv ely utilize samples from prior campaigns or trials in an off-p olicy manner. F urthermore, ϕ can b e resilient to concept drifts so data from a differen t time p eriod may still b e utilized. Generalization to Embedding Mo dels This pap er demonstrates that Thompson sampling acting on an embedding space can offer a metho d of exploration. How ever, only a simple multi-la yer perceptron is used as an em b edding model. There should be no restrictions on the model design or inputs as long as it is a cost- sensitiv e regression mo del. A side effect of operating on an embedding mo del is the abilit y to visualize the learned embedding space which can be useful for applications that require some transparency/explainabilit y . Limitations of C 3 The transductive learning asp ect and imp ortance weigh t up dates can result in high n umerical instability since it relies on many sum and division op erations of floating points. This effectively disallo ws quan tization to be used. Also, as an algorithm that relies on a dataset for inference, it may not scale to millions of p oin ts without some type of sampling if sp eed is crucial in the use case. The hyperparameter tuning of ϕ can be sligh tly c hallenging because the RBF k ernel used in IWKR can result in v anishing gradien ts if p oints are to o near or far from some query p oin t, so the choice of bandwidth of the RBF kernel 11 Published in T ransactions on Mac hine Learning Researc h (03/2026) is imp ortan t. More crucially , the p erformance of C 3 is dep enden t on heuristics and whether the learned em b edding space is well-calibrated. 7 Conclusion and F uture Wo rks The design of the C 3 algorithm sets an applied persp ective of using a contextual bandit algorithm on bandits and recommendation problems. Con textual bandit algorithms ha ve built-in exploration and online learning comp onents while recommender systems hav e deep enco ders that scale w ell with high dimensional data. By combining the b est of w orlds, we gain sev eral adv antages in practice such as the ability to handle non-stationarit y from concept drift, no retraining needed, and leveraging arm features. While this work con tributes to the practical side of bandit algorithms, future w orks should include obtaining a non-stationary b ound that extends the stationary regret b ound in Theorem 3. Broader Impact Statement T o b e b est of our knowledge, our work does not hav e a direct negative impact as it outlines an algorithm to dynamically learn patterns. External factors such as the data by others on the C 3 algorithm, or the application of the algorithm on a malicious task w ould b e out of our control. A cknowledgments W e thank Manulife Financial for the funding, guidance and exp osure that motiv ated this work. Resources used in preparing this researc h w ere pro vided, in part, by the Pro vince of On tario, the Gov ernment of Canada through CIF AR, companies sponsoring the V ector Institute https://vectorinstitute.ai/partnerships/ current- partners/ , the Natural Sciences and Engineering Council of Canada and a gran t from I ITP & MSIT of K orea (No. RS-2024-00457882, AI Research Hub Pro ject). 12 Published in T ransactions on Mac hine Learning Researc h (03/2026) References Shipra Agraw al and Navin Goy al. Thompson sampling for contextual bandits with linear pay offs. In Inter- national c onfer enc e on machine le arning , pp. 127–135. PMLR, 2013. Yikun Ban, Y unzhe Qi, and Jingrui He. Neural contextual bandits for p ersonalized recommendation. In Comp anion Pr o c e e dings of the A CM W eb Confer enc e 2024 , pp. 1246–1249, 2024. Soum y a Basu, Orestis Papadigenopoulos, Constantine Caramanis, and Sanja y Shakk ottai. Contextual block- ing bandits. In International Confer enc e on A rtificial Intel ligenc e and Statistics , pp. 271–279. PMLR, 2021. Alb erto Bietti, Alekh Agarwal, and John Langford. A contextual bandit bak e-off. Journal of Machine L e arning R ese ar ch , 22(133):1–49, 2021. Jo c k Blac kard. Co v ert yp e. UCI Machine Learning Repository , 1998. DOI: h ttps://doi.org/10.24432/C50K5N. R. Bo c k. MA GIC Gamma T elescop e. UCI Mac hine Learning Rep ository , 2007. DOI: h ttps://doi.org/10.24432/C52C8B. Lars Buitinck, Gilles Loupp e, Mathieu Blondel, F abian Pedregosa, Andreas Mueller, Olivier Grisel, Vlad Niculae, Peter Prettenhofer, Alexandre Gramfort, Jaques Grobler, Rob ert La yton, Jake V anderPlas, Ar- naud Joly , Brian Holt, and Gaël V aro quaux. API design for mac hine learning softw are: exp eriences from the scikit-learn pro ject. In ECML PKDD W orkshop: L anguages for Data Mining and Machine L e arning , pp. 108–122, 2013. Xin Chen and I-Hong Hou. Con textual restless m ulti-armed bandits with application to demand resp onse decision-making. In 2024 IEEE 63r d Confer enc e on De cision and Contr ol (CDC) , pp. 2652–2657. IEEE, 2024. W ei Chu, Lihong Li, Lev Reyzin, and Rob ert Schapire. Contextual bandits with linear pay off functions. In Pr o c e e dings of the F ourte enth International Confer enc e on A rtificial Intel ligenc e and Statistics , pp. 208–214. JMLR W orkshop and Conference Pro ceedings, 2011. Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outanov a. BER T: Pre-training of deep bidirec- tional transformers for language understanding. In Jill Burstein, Christ y Doran, and Thamar Solorio (eds.), Pr o c e e dings of the 2019 Confer enc e of the North A meric an Chapter of the A sso ciation for Computational Linguistics: Human L anguage T e chnolo gies, V olume 1 (L ong and Short Pap ers) , pp. 4171–4186, Min- neap olis, Minnesota, June 2019. Asso ciation for Computational Linguistics. doi: 10.18653/v1/N19- 1423. URL https://aclanthology.org/N19- 1423 . Zhenh ua Dong, Zhe W ang, Jun Xu, R uiming T ang, and Jirong W en. A brief history of recommender systems. arXiv pr eprint arXiv:2209.01860 , 2022. Dylan F oster and Alexander Rakhlin. Beyond ucb: Optimal and efficien t contextual bandits with regression oracles. In International Confer enc e on Machine L e arning , pp. 3199–3210. PMLR, 2020. Ch uan Guo, Geoff Pleiss, Y u Sun, and Kilian Q W einberger. On calibration of mo dern neural netw orks. In International c onfer enc e on machine le arning , pp. 1321–1330. PMLR, 2017. Samarth Gupta, Shreyas Chaudhari, Gauri Joshi, and Osman Y ağan. Multi-armed bandits with correlated arms. IEEE T r ansactions on Information The ory , 67(10):6711–6732, 2021. Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani P admanabhan, Giusepp e Ottaviano, and Linjun Y ang. Em b edding-based retriev al in facebo ok searc h. In Pr o c e e dings of the 26th A CM SIGKDD International Confer enc e on K now le dge Disc overy & Data Mining , pp. 2553–2561, 2020. 13 Published in T ransactions on Mac hine Learning Researc h (03/2026) Arth ur Jacot, F ranck Gabriel, and Clément Hongler. Neural tangent kernel: Conv ergence and generalization in neural net w orks. A dvanc es in neur al information pr o c essing systems , 31, 2018. Emilie Kaufmann, Olivier Cappé, and Aurélien Garivier. On ba y esian upper confidence b ounds for bandit problems. In A rtificial intel ligenc e and statistics , pp. 592–600. PMLR, 2012. Ross D. King, Cao F eng, and Alistair Sutherland. Statlog: comparison of classification algorithms on large real-w orld problems. Applie d A rtificial Intel ligenc e an International Journal , 9(3):289–333, 1995. Thomas Kleine Buening, Aadirupa Saha, Christos Dimitrakakis, and Haifeng Xu. Strategic linear contextual bandits. A dvanc es in Neur al Information Pr o c essing Systems , 37:116638–116675, 2024. Branisla v K v eton, Manzil Zaheer, Csaba Szep esv ari, Lihong Li, Mohammad Gha v amzadeh, and Craig Boutilier. Randomized exploration in generalized linear bandits. In International Confer enc e on A rti- ficial Intel ligenc e and Statistics , pp. 2066–2076. PMLR, 2020. T or Lattimore and Csaba Szep esvári. Bandit algorithms . Cam bridge Univ ersit y Press, 2020. Y ann LeCun. The mnist database of handwritten digits. http://yann. le cun. c om/exdb/mnist/ , 1998. Lihong Li, W ei Chu, John Langford, and Rob ert E Schapire. A contextual-bandit approach to p ersonalized news article recommendation. In Pr o c e e dings of the 19th international c onfer enc e on W orld wide web , pp. 661–670, 2010. Jie Lu, Anjin Liu, F an Dong, F eng Gu, Joao Gama, and Guangquan Zhang. Learning under concept drift: A review. IEEE tr ansactions on know le dge and data engine ering , 31(12):2346–2363, 2018. T yler Lu, Dávid Pál, and Martin Pál. Contextual multi-armed bandits. In Pr o c e e dings of the Thirte enth international c onfer enc e on A rtificial Intel ligenc e and Statistics , pp. 485–492. JMLR W orkshop and Con- ference Pro ceedings, 2010. Elizbar A Nadaray a. On estimating regression. The ory of Pr ob ability & Its A pplic ations , 9(1):141–142, 1964. Mahdi Pakdaman Naeini, Gregory Co oper, and Milos Hauskrech t. Obtaining w ell calibrated probabilities using bay esian binning. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , volume 29, 2015. Y oan Russac, Claire V ernade, and Olivier Cappé. W eighted linear bandits for non-stationary environmen ts. A dvanc es in Neur al Information Pr o c essing Systems , 32, 2019. Aleksandrs Slivkins. Contextual bandits with similarity information. In Pr o c e e dings of the 24th annual Confer enc e On L e arning The ory , pp. 679–702. JMLR W orkshop and Conference Pro ceedings, 2011. Aleksandrs Slivkins and Eli Upfal. A dapting to a changing environmen t: the brownian restless bandits. In COL T , pp. 343–354, 2008. Niranjan Sriniv as, Andreas Krause, Sham M Kakade, and Matthias Seeger. Gaussian pro cess optimization in the bandit setting: No regret and exp erimental design. arXiv pr eprint arXiv:0912.3995 , 2009. F ei Sun, Jun Liu, Jian W u, Changhua Pei, Xiao Lin, W enwu Ou, and Peng Jiang. Bert4rec: Sequential recommendation with bidirectional enco der represen tations from transformer. In Pr o c e e dings of the 28th A CM international c onfer enc e on information and know le dge management , pp. 1441–1450, 2019. Mic hal V alk o, Nathaniel K orda, Rémi Munos, Ilias Flaounas, and Nelo Cristianini. Finite-time analysis of k ernelised con textual bandits. arXiv pr eprint arXiv:1309.6869 , 2013. Laurens V an der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine le arning r ese ar ch , 9(11), 2008. Joaquin V ansc horen, Jan N V an Rijn, Bernd Bisc hl, and Luis T orgo. Op enml: netw orked science in mac hine learning. A CM SIGKDD Explor ations Newsletter , 15(2):49–60, 2014. 14 Published in T ransactions on Mac hine Learning Researc h (03/2026) Siw ei W ang, Longb o Huang, and John Lui. Restless-ucb, an efficien t and low-complexit y algorithm for online restless bandits. A dvanc es in Neur al Information Pr o c essing Systems , 33:11878–11889, 2020. P eter Whittle. Restless bandits: A ctivity allo cation in a c hanging world. Journal of applie d pr ob ability , 25 (A):287–298, 1988. Thomas W olf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthon y Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan F unto wicz, et al. Huggingface’s transformers: State-of-the-art natural language pro cessing. arXiv pr eprint arXiv:1910.03771 , 2019. F angzhao W u, Ying Qiao, Jiun-Hung Chen, Chuhan W u, T ao Qi, Jianxun Lian, Dany ang Liu, Xing Xie, Jianfeng Gao, Winnie W u, et al. Mind: A large-scale dataset for news recommendation. In Pr o c e e dings of the 58th annual me eting of the asso ciation for c omputational linguistics , pp. 3597–3606, 2020. Xin y ang Yi, Ji Y ang, Lichan Hong, Derek Zhiyuan Cheng, Lukasz Heldt, Aditee Kumthekar, Zhe Zhao, Li W ei, and Ed Chi. Sampling-bias-corrected neural mo deling for large corpus item recommendations. In Pr o c e e dings of the 13th A CM Confer enc e on R e c ommender Systems , pp. 269–277, 2019. W eitong Zhang, Dongruo Zhou, Lihong Li, and Quanquan Gu. Neural thompson sampling. In International Confer enc e on L e arning R epr esentation (ICLR) , 2021. Dongruo Zhou, Lihong Li, and Quanquan Gu. Neural con textual bandits with ucb-based exploration. In International Confer enc e on Machine L e arning , pp. 11492–11502. PMLR, 2020. A App endix A.1 Memoization of Importance W eight Computation Theorem 1 Supp ose a vector of imp ortance weigh ts w of n samples has been computed. The time complexity of up dating the imp ortance weigh ts, given a new sample, is O ( n ) . Pr o of. Suppose there are n samples in the embedding space { s i ∈ S : i ∈ [ n ] } . Consider the kernel matrix L ∈ R n × n whic h holds all pairwise RBF kernel v alues b etw een every sample. F rom Equation 4, we can deduce that the sum of the i th ro w of matrix L will b e w ( s i ) , and similarly for the sum of the i th column since L is symmetric. The imp ortance weigh t of the initial reference dataset D ref can b e calculated this wa y whic h tak es on a v erage O ( n ) p er sample. Supp ose there is already the vector of importance w eigh ts for all samples in D ref denoted as w ( n ) = [ w ( n ) 1 · · · w ( n ) n ] ∈ [0 , 1] n . W e wan t to obtain an efficien t up date equation for w ( n +1) . Naiv ely computing L with a new sample will result in a O ( n 2 ) time up date. T o up date efficiently , memoization would b e useful since w ( n ) i itself stores the recipro cal of a sum. During inference, the unw eighted RBF similarity score will need to b e computed. This result can b e stored, and is denoted as z ( n +1) = [ κ ( s n +1 , s 1 ) · · · κ ( s n +1 , s n )] . There are t w o steps here: update the existing w ( n ) i for i ∈ [ n ] and app end w ( n +1) n +1 to the new vector. T o obtain w ( n +1) i for i ∈ [ n ] , the up date equation can b e expressed as a function of its previous v alue w ( n +1) i = 1 P n +1 j =1 κ ( s i , s j ) = 1 κ ( s i , s n +1 ) + P n j =1 κ ( s i , s j ) = 1 z ( n +1) i + 1 w ( n ) i 15 Published in T ransactions on Mac hine Learning Researc h (03/2026) whic h is a constant time op eration for each i ∈ [ n ] since all of the required v alues ha ve already b een computed. T o compute the new imp ortance weigh t, w ( n +1) n +1 = 1 P n +1 j =1 κ ( s n +1 , s j ) = 1 κ ( s n +1 , s n +1 ) + P n j =1 κ ( s n +1 , s j ) = 1 1 + P n j =1 z ( n +1) j whic h is an O ( n ) time operation for the new sample. Therefore, the entire up date equation for the importance w eigh t giv en a new sample is a linear time op eration. A.2 Pro of of Importance W eighted Kernel Regression App ro ximation Theorem 2 Supp ose µ ( s ) is Lipschitz contin uous on S . In the limit of the size of the reference dataset D ref where p oints are sufficiently sampled from the neighbourho o d of some query p oint s , the imp ortance w eigh ted k ernel regression with a radial basis function k ernel is an approximate estimator of µ ( s ) . Pr o of. The imp ortance weigh ted kernel regression estimator of µ with a RBF kernel is defined in Equation 5. As the n umber of samples approac hes n → ∞ ov er a space cen tered at s , the importance w eight conv erges to the inv erse of the sampling distribution. The effective con tribution of each neighbouring subspace becomes appro ximately uniform and the estimate b ecomes ˆ µ ( s ) = R S κ ( s, s ′ ) R ( s ′ ) d s ′ R S κ ( s, s ′ ) d s ′ = Z S κ ( s, s ′ ) R S κ ( s, s ′′ ) d s ′′ R ( s ′ ) d s ′ No w, w e fo cus on the fractional term and show that it is simply the density of a Gaussian distribution. κ ( s, s ′ ) R S κ ( s, s ′′ ) d s ′′ = exp − ∥ s − s ′ ∥ 2 σ 2 R S exp − ∥ s − s ′′ ∥ 2 σ 2 d s ′′ = exp − ∥ s − s ′ ∥ 2 σ 2 · (2 π ) − d 2 | σ | = Pr( X = s ′ ) where X ∼ N ( s, σ 2 I ) Since we know that the conditional reward distribution is defined as R ∼ Bernoulli ( µ ( s )) , for a sufficiently small RBF k ernel bandwidth σ , under the Lipschitz contin uit y assumption, ˆ µ ( s ) = Z S P ( X = s ′ ) R ( s ′ ) d s ′ ≈ E [ R ′ | S = s ] = µ ( s ) A.3 Pro of of Regret Bound in Theorem 3 F or a fixed embedding map ϕ ( c, a ) trained offline, S ⊂ [0 , 1] d is the learned join t em b edding space, and we analyze directly on S . Assume that the true mean rew ard function µ : S → [0 , 1] is Lipsc hitz. There exists 16 Published in T ransactions on Mac hine Learning Researc h (03/2026) L > 0 suc h that for all s, s ′ ∈ S , | µ ( s ) − µ ( s ′ ) | ≤ L ∥ s − s ′ ∥ Cum ulativ e regret is formalized as follows. Let s ∗ t = argmax s ∈ S A t µ ( s ) b e an optimal action, where S A is the set of em b eddings of all v alid arms at time t . The exp ected cumulativ e regret is R T = T X t =1 µ ( s ∗ t ) − µ ( s t ) W e standardize the notions. The RBF kernel κ h ( · , · ) has bandwidth h > 0 . The reference dataset D t − 1 = { ( s i , r i ) } t − 1 i =1 stores all em b edding-reward tuples up to time t − 1 . The v alues of the Beta parameters α t − 1 ( s ) and β t − 1 ( s ) are obtained b y comparing a query em b edding s ∈ S to ev ery em b edding in the reference dataset, and their sum is the k ernel mass η t − 1 ( s ) = t − 1 X i =1 κ h ( s, s i ) The IWKR pro cedure samples from the constructed Beta distribution Θ t ( s ) ∼ Beta ( α t − 1 ( s ) , β t − 1 ( s )) and pla ys s t = argmax s ∈ S A t Θ t ( s ) . F or the analysis of C 3 , w e use a truncated RBF k ernel (compact supp ort) for exact locality . κ h ( s, s ′ ) := exp − ∥ s − s ′ ∥ 2 2 h 2 1 {∥ s − s ′ ∥ ≤ h } Pr o of. Let S ⊆ [0 , 1] d without loss of generalit y b y rescaling if necessary . P artition [ 0 , 1] d in to axis-aligned h yp ercubes (cells) of length h . Let G denote the set of all suc h cells intersecting S . The num b er of cells satisfies |G | ≤ 1 h d ≤ 2 h d for h ≤ 1 (11) F or each cell g ∈ G , fix a represen tative p oint x g ∈ g ∩ S , i.e. any p oin t in the intersection. Define the cell index of an y p oin t s ∈ S as g ( s ) ∈ G , and the b est cell representativ e g ∗ as g ∗ = argmax g ∈G µ ( x g ) Because s ∗ ∈ S lies in some cell g ( s ∗ ) , the cell representativ e x g ( s ∗ ) is at distance of at most the cell diameter ∥ s ∗ − x g ( s ∗ ) ∥ ≤ √ dh By the Lipsc hitz prop ert y , µ ( s ∗ ) − µ ( x g ( s ∗ ) ) ≤ L √ dh Since g ∗ maximizes µ ( x g ) o v er g , we hav e µ ( x g ∗ ) ≥ µ ( x g ( s ∗ ) ) . Hence, µ ( s ∗ ) − µ ( x g ∗ ) ≤ µ ( s ∗ ) − µ ( x g ( s ∗ ) ) ≤ L √ dh 17 Published in T ransactions on Mac hine Learning Researc h (03/2026) Decomp osing regret gives µ ( s ∗ ) − µ ( s t ) = ( µ ( s ∗ ) − µ ( x g ∗ )) + ( µ ( x g ∗ ) − µ ( s t )) ≤ L √ dh + ( µ ( x g ∗ ) − µ ( s t )) (12) Up to this p oin t, w e approximated the contin uum optimum s ∗ to the b est cell representation at a regret cost of O ( Lh ) . The next step is to b ound the second term, whic h is the regret relative to the b est cell represen tation. T o do so, we exploit the lo cality of the truncated kernel. F or any query s , the k ernel sums only inv olve past p oin ts s i from the same cell g ( s ) . Let the num b er of times w e ha v e pla y ed in cell g up to time t − 1 b e N g ( t − 1) := |{ i ≤ t − 1 : g ( s i ) = g }| The cell’s resp ectiv e cumulativ e binary reward counts are S g ( t − 1) := X i ≤ t − 1: g ( s i )= g r i F g ( t − 1) := N g ( t − 1) − S g ( t − 1) No w, fix a query s ∈ g . The kernel mass is η t − 1 ( s ) = t − 1 X i =1 κ h ( s, s i ) = X i : g ( s i )= g κ h ( s, s i ) Moreo v er, within a cell g , any tw o p oin ts hav e distance at most √ dh , hence for s, s i ∈ g , exp − ∥ s − s i ∥ 2 2 h 2 ≥ exp − d 2 W e call the righ t hand side c d ∈ (0 , 1) . Therefore, c d N g ( t − 1) ≤ η t − 1 ( s ) ≤ N g ( t − 1) (13) Lemma 1. L et X ∼ Beta ( α, β ) with α, β ≥ 1 , and let p = α/ ( α + β ) . Then for any ε ∈ (0 , 1 − p ) , Pr( X ≥ p + ε ) ≤ exp( − 2( α + β − 1) ε 2 ) Similarly, for any ε ∈ (0 , p ) , Pr( X ≤ p − ε ) ≤ exp( − 2( α + β − 1) ε 2 ) Pr o of. Let X ∼ Beta ( α, β ) and Y ∼ Binomial ( n, x ) where n = α + β − 1 . By writing the regularized incomplete b eta function representation of the Beta CDF and comparing it to the Binomial tail expression, one can obtain Pr( X ≥ x ) = Pr( Y ≤ α − 1) T ak e x = p + ε . Then E [ Y ] = n ( p + ε ) . Note that p ≤ 1 , th us α − 1 ≤ np b ecause np = ( α + β − 1) α α + β = α − α α + β = α − p ≥ α − 1 18 Published in T ransactions on Mac hine Learning Researc h (03/2026) Therefore, the ev en t Y ≤ α − 1 implies Y ≤ np Pr( X ≥ p + ε ) = Pr( Y ≤ α − 1) ≤ Pr( Y ≤ np ) Note that np = n ( p + ε ) − nε = E [ Y ] − nε . Applying the Ho effding/Chernoff lo w er-tail b ound for Binomial random v ariables gives Pr( Y ≤ E [ Y ] − nε ) ≤ exp( − 2 nε 2 ) = exp( − 2( α + β − 1) ε 2 ) Connecting b oth gives Pr( X ≥ p + ε ) ≤ Pr( Y ≤ np ) = Pr( Y ≤ E [ Y ] − nε ) ≤ exp( − 2( α + β − 1) ε 2 ) Define the gap of a cell represen tativ e ∆ g := µ ( x g ∗ ) − µ ( x g ) ≥ 0 Cells with ∆ g = 0 are optimal within the grid. W e wan t to show that each suboptimal cell g is selected only O (log T / ∆ 2 g ) times in exp ectation. Fix a sub optimal cell g with ∆ g > 0 . Consider the even t at time t that IWKR selects a p oin t in cell g . This can happ en only if the Beta sample for cell g is unusually high or the Beta sample for the b est cell g ∗ is un usually lo w. Concretely , a go o d even t refers to E g := S g N g − µ ( x g ) ≤ ∆ g 4 and similarly E g ∗ := S g ∗ N g ∗ − µ ( x g ∗ ) ≤ ∆ g 4 By Ho effding’s inequality for Bernoulli sums, conditional on N g = n , Pr( E c g | N g = n ) ≤ 2 exp − 2 n ∆ g 4 2 ! = 2 exp − n ∆ 2 g 8 ! Let Θ t,g b e the cell-level random v ariable for the Beta sample corresp onding to an y query p oint in cell g at time t . They are all functions of the same within-cell data, only differing in constants via kernel w eights. Its parameters satisfy α + β = η and with Equation 13, we hav e η ≥ c d N g . On even t E g , the empirical mean is close to µ ( x g ) and b ecause the p osterior mean is equal to the IWKR mean, which (within a cell) is a weigh ted av erage of the r i ’s, we can b ound the p osterior mean deviation by the same scale (absorbing kernel-w eight constan ts into a dimension constant). Denoting F t − 1 as the history up to t − 1 , | E [Θ t,g |F t − 1 ] − µ ( x g ) | ≤ ∆ g 2 implies Pr Θ t,g ≥ µ ( x g ) + ∆ g 2 | F t − 1 ≤ exp − 2( η − 1) ∆ g 2 2 ! ≤ exp − c d n ∆ 2 g 2 ! 19 Published in T ransactions on Mac hine Learning Researc h (03/2026) when using Lemma 1 with ε = ∆ g / 2 and η ≥ c d n . Similarly , for the optimal cell g ∗ , on even t E g ∗ with N g ∗ = m , Pr Θ t,g ∗ ≤ µ ( x g ∗ ) − ∆ g 2 | F t − 1 ≤ exp − c d m ∆ 2 g 2 ! No w, define the “bad ev en t” that could cause selecting g B t ( g ) := { Θ t,g ≥ Θ t,g ∗ } If g ’s sample is b elow µ ( x g ) + ∆ g / 2 and g ∗ ’s sample is ab o ve µ ( x g ∗ ) − ∆ g / 2 , even t B t ( g ) cannot o ccur b ecause Θ t,g < µ ( x g ) + ∆ g 2 = µ ( x g ∗ ) − ∆ g 2 (∆ g = µ ( x g ∗ ) − µ ( x g )) < Θ t,g ∗ Therefore, B t ( g ) ⊆ Θ t,g ≥ µ ( x g ) + ∆ g 2 ∪ Θ t,g ∗ ≤ µ ( x g ∗ ) − ∆ g 2 Applying the union b ound on B t ( g ) gives Pr( B t ( g ) | N g = n, N g ∗ = m ) ≤ Pr( E c g | N g = n ) + Pr( E c g ∗ | N g ∗ = m ) + Pr Θ t,g ≥ µ ( x g ) + ∆ g 2 | F t − 1 + Pr Θ t,g ∗ ≤ µ ( x g ∗ ) − ∆ g 2 | F t − 1 ≤ 2 exp − n ∆ 2 g 8 ! + 2 exp − m ∆ 2 g 8 ! + exp − c d n ∆ 2 g 2 ! + exp − c d m ∆ 2 g 2 ! Since m ≥ 0 , the terms in volving m only help. T o upper b ound, we drop them and k eep only the n -dep endent deca y Pr( B t ( g ) | N g = n, N g ∗ = m ) ≤ 2 exp − n ∆ 2 g 8 ! + exp − c d n ∆ 2 g 2 ! + 3 F or it to b e a useful b ound, w e w ant to set a rule where once n exceeds a logarithmic threshold, the probabilit y of selecting g b ecomes at most 1 /T 2 . Let n g := 16 c d ∆ 2 g log T Then for all n ≥ n g , exp − c d n ∆ 2 g 2 ! ≤ exp − c d n g ∆ 2 g 2 ! ≤ exp( − 8 log T ) = T − 8 20 Published in T ransactions on Mac hine Learning Researc h (03/2026) and similarly exp( − n ∆ 2 g / 8) ≤ T − 2 for a suitable constan t. Hence, for n ≥ n g , Pr( B t ( g ) | N g = n ) ≤ C 1 T − 2 (14) for some constan t C 1 dep ending only on d . T o b ound the expected n umber of times cell g is selected, we split the sum according to whether N g ( t − 1) < n g or N g ( t − 1) ≥ n g E [ N g ( T )] = T X t =1 Pr( g ( s t ) = g ) ≤ n g + T X t =1 Pr( g ( s t ) = g , N g ( t − 1) ≥ n g ) On { N g ( t − 1) ≥ n g } , selecting g implies B t ( g ) . So, Pr( g ( s t ) = g , N g ( t − 1) ≥ n g ) ≤ Pr( B t ( g ) , N g ( t − 1) ≥ n g ) ( { g ( s t ) = g } ⊆ B t ( g )) = E [Pr( B t ( g ) |F t − 1 ) 1 { N g ( t − 1) ≥ n g } ] ( F t − 1 measurable/non-measurable split) ≤ E [ C 1 T − 2 · 1 { N g ( t − 1) ≥ n g } ] ( result from Equation 14 ) ≤ C 1 T − 2 Therefore, with C 1 /T ≤ 1 for T ≥ 3 , E [ N g ( T )] ≤ n g + T C 1 T − 2 = n g + C 1 T − 1 ≤ 2 n g and finally substituting the v alue of n g giv es E [ N g ( T )] ≤ C 2 log T ∆ 2 g for eac h sub optimal cell g where C 2 only dep ends on d . T o summarize, the cum ulativ e regret relativ e to the b est cell is E " T X i =1 µ ( x g ∗ ) − µ ( s t ) # = X g ∈G ∆ g E [ N g ( T )] ≤ X g :∆ g > 0 ∆ g · C 2 log T ∆ 2 g = C 2 log T X g :∆ g > 0 1 ∆ g (15) Next, we b ound the w orst case control of the gap-dep enden t term via an ε -split. F or an y threshold ε > 0 , split cell into: near optimal G ≤ ε = { g : ∆ g ≤ ε } , and clearly sub optimal G >ε = { g : ∆ g > ε } . T rivially , regret from near-optimal cells is at most T ε b ecause each play can b e upp er b ounded by ε regret. X g :∆ g ≤ ε ∆ g E [ N g ( T )] ≤ ε X g E [ N g ( T )] = εT 21 Published in T ransactions on Mac hine Learning Researc h (03/2026) F or clearly sub optimal cells, using Equation 15, X g :∆ g >ε ∆ g E [ N g ( T )] ≤ C 2 log T X g :∆ g >ε 1 ∆ g ≤ C 2 log T X g :∆ g >ε 1 ε ≤ C 2 log T |G | ε ≤ C 3 log T h − d ε using Equation 11 for some constan t C 3 . Com bining results from the ε splits, E " T X t =1 µ ( x g ∗ ) − µ ( s t ) # ≤ εT + C 3 log T h − d ε Since within one cell, the Lipschitz v ariation is O ( Lh ) , the grid optimum µ ( x g ∗ ) is only meaningful up to Lh , so w e set ε = Lh . Up on substitution, the cumulativ e regret relative to the b est cell is E " T X t =1 µ ( x g ∗ ) − µ ( s t ) # ≤ LhT + C 3 log T h − ( d +1) L (16) Con tin uing from Equation 12, w e can b egin to form the ov erall cumulativ e regret b ound. E [ R T ] = T X t =1 µ ( s ∗ ) − µ ( x g ∗ ) + T X t =1 µ ( x g ∗ ) − µ ( s t ) ≤ T L √ dh + T X t =1 µ ( x g ∗ ) − µ ( s t ) from Equation 12 ≤ C 4 LhT + C 3 log T h − ( d +1) L from Equation 16 and C 4 := 1 + √ d What remains is to optimize the bandwidth with a sc hedule so as to obtain a useful regret bound. By finding the stationary p oin t, f ( h ) := C 4 LhT + C 3 log T h − ( d +1) L f ′ ( h ) = C 4 LT − C 3 log T L ( d + 1) h − ( d +2) = 0 w e obtain the optimal v alue of h h = log T L 2 T 1 d +2 Plugging h in to the regret b ound gives E [ R T ] ≤ C L d d +2 T d +1 d +2 (log T ) 1 d +2 This is a standard nonparametric Lipsc hitz-t yp e rate T d +1 d +2 with a mild (log T ) 1 d +2 factor. 22 Published in T ransactions on Mac hine Learning Researc h (03/2026) A.4 Generation of Co rrelated Arms Figure 6: Visualization of impacts of v arious correlation ρ and c parameters on the µ of non-anc hor arms. Eac h subplot con tains 500 random samples. Supp ose µ 0 has b een sampled from the Uniform (0 , 1) distribution. Now, suppose we w ant to generate the rew ard distribution for arm i with a correlation ρ i with µ 0 . The mean parameter for arm i is generated as follo ws: µ i sample ∼ Beta (2 c ( ρ i ( µ 0 − 0 . 5) + 0 . 5) , 2 c ( ρ i (0 . 5 − µ 0 ) + 0 . 5)) (17) where c ≥ 1 is a hyperparameter that controls the v ariance of the reward distribution of the correlated arm; the higher c is, the low er the v ariance. In our experiments, the v alue of c is c hosen to b e 50. Examples of sampled correlated µ i ’s can b e found in Figure 6. A.5 Co rrelation Exp eriment Details The training dataset consists of 200 random but correlated v alues of µ i ’s, and 100 samples of arm-reward pairs with arms b eing uniformly sampled. ϕ is a multila yer p erceptron that tak es a 7-dimensional vector (one-hot enco ded for eac h arm including the anc hor arm), has a single hidden lay er of size 256 and an output dimension of 2. Each set of weigh ts is in terlea v ed with a Softplus activ ation lay er. The bandwidth parameter of the RBF k ernel is c hosen to b e σ = 1 . The loss function for ϕ is chosen to b e L ( ˆ µ, r ) = L BCE ( ˆ µ, r ) + 5 L ECE ( ˆ µ, r ) , where the ECE loss uses 5 bins. F or eac h of the 4 training epo chs, 50% of the entire training dataset is sampled to b e used for training, of whic h 20% will b e used as the reference dataset and the remaining 80% contains the queries. The learning rate is 10 − 3 (A dam optimizer with default configurations) with an exponential deca y rate of 0.99 p er ep o ch. Since no v alidation dataset is used, the resultant mo del of the final ep o c h will b e used. 23 Published in T ransactions on Mac hine Learning Researc h (03/2026) A.6 Scatter plot of Co rrelated Arm Emb eddings Figure 7: The left figure shows the arm embeddings prior to any fitting while the right figure sho ws the arm em b eddings after training using Algorithm 1. The blue p oint is the anchor p oint and the green p oin ts are p ositiv ely correlated to the µ of the blue p oint while the red p oints are negatively correlated. A.7 Contextual Bandit Experiment Details The four datasets were obtained using scikit-learn’s API by Buitinck et al. (2013). There is minimal data prepro cessing done in this set of exp eriments: conv erting the lab els to one-hot representations and conv erting MNIST’s pixel v alues from 8-bit unsigned integers to floating p oints b etw een 0 and 1. Only 50% of all datasets w ere used b ecause of tw o reasons: (1) using all takes a long time to ev aluate esp ecially for NeuralUCB and NeuralTS, (2) the additional 50% during ev aluation would only sho w a longer “linear" p ortion in the cum ulative regret curve since con textual bandit algorithms tend to b e unable to practically a v oid an y mistak es. All algorithms are given 4 samples to up date, follo w ed by 1 ev aluation sample (which is also used to up date the algorithm). This rep eats until 1000 ev aluation samples are provided. The datasets are shuffled at the b eginning of eac h of the 10 exp eriments, so a differen t 4000 training samples and 1000 ev aluation samples are used each time. F or the offline training of ϕ , the training split was used to optimize for ϕ . This explains wh y there m ust b e training and ev aluation split in this set of exp eriments. Let d c b e the dimension of the con text v ector and d a b e the dimension of the arm v ectors. Due to the v arying complexities of each dataset, we hav e to v ary the num b er of lay ers. Each set of weigh ts is interlea ved with a Softplus activ ation la yer. Consider the la y ers [ ℓ 1 , ..., ℓ m ] where ℓ i indicates the size of each lay er, and the leftmost and righ tmost elemen ts in the arra y represen t the input and output dimensions resp ectiv ely . 1. shuttle : [ d c + d a , 32 , 4] 2. MagicTelescope : [ d c + d a , 64 , 8] 3. covertype : [ d c + d a , 64 , 8] 4. mnist : [ d c + d a , 64 , 8] The following hyperparameters are the same for all C 3 exp erimen ts of ev ery dataset. The RBF bandwidth is σ = 1 and the loss functions L BCE ( ˆ µ, r ) + 2 L ECE ( ˆ µ, r ) where the ECE loss uses 5 bins. The learning rate is set to 10 − 3 (A dam optimizer with default configurations) with an exp onential deca y rate of 0.99 p er ep o c h. 24 Published in T ransactions on Mac hine Learning Researc h (03/2026) The batch size is 16. During each ep o ch, 10% of the entire training split is sampled to b e used for training, of which 20% will b e used as the reference dataset and the remaining 80% contains the queries. There is no partitioning of the reference dataset since this is a stationary problem. The implementation of LinUCB and LinTS was obtained from a package called striatum , while the imple- men tation of NeuralUCB and NeuralTS was obtained directly from the GitHub rep ository of the authors. SquareCB was obtained from Coba, whic h uses a linear mo del as a regression oracle. In LinUCB, w e selected α to be 1.96 whic h controls the exploration factor. In LinTS, w e select the default configurations with δ = 0 . 5 and R = 0 . 01 which are the parameters used in the theoretical regret analysis. F or epsilon, it w as set to the recipro cal of the num b er of steps which is the recommended v alue. F or NeuralUCB, we follow ed the exact h yp erparameters that w ere used in their pap er whic h is ν = 10 − 5 and λ = 10 − 5 (Zhou et al., 2020). F or NeuralTS, we set ν = 10 − 5 and λ = 10 − 5 whic h is obtained from Zhang et al. (2021)’s rep ository . The up date schedule for NeuralUCB and NeuralTS is as follows: for the first 2000 steps, the gradient descent optimization is p erformed for every step. Afterwards, it is p erformed only once every 200 steps. A.8 Scatterplot of MNIST Context-Arm Emb eddings Figure 8: Em b edding space of MNIST digits with correct arms chosen where the left shows the em b edding v ectors of ϕ with an output dimension of 2, and the right sho ws the em b edding v ectors of another ϕ with an output dimension of 8 but uses t -SNE (V an der Maaten & Hinton, 2008) for visualization. 25 Published in T ransactions on Mac hine Learning Researc h (03/2026) A.9 Ablation on RBF Bandwidth in C 3 Figure 9: Cumulativ e regret of C 3 with v arying σ parameter (for the RBF kernel) on the Co ver dataset with 1.96 sigma error bars o v er 10 random seeds. T o demonstrate the effects of v arying the RBF k ernel, we conduct an ablation study to iden tify: (1) p ossible failure cases, and (2) p otential robustness across parameters. In exp erimen ts in the main pap er, the RBF bandwidth σ was set to σ = 1 . W e v ary σ b y 2 and 3 times larger and smaller, leading to 4 new com binations: 0 . 33 , 0 . 5 , 2 , 3 . There are tw o groups of results in Figure 9. The obvious outlier is σ = 0 . 33 which essentially could not learn – a failure case. W e postulate this is because the effectiv e “search" radius is too small and did not lev erage (or condition on) neigh b ouring p oints to make an estimate. The other group, the rest of the σ ’s, show ed in v ariance to the choice of σ as they are statistically identical in p erformance. This is an adv an tage as this simplifies the h yp erparameter tuning pro cess as long as σ is not to o small. A.10 Ha rdwa re Usage for Exp eriments C 3 , NeuralUCB and NeuralTS use GPU-acceleration since they hav e man y parameters that need to be optimized. LinUCB, LinTS and SquareCB use CPU only . The GPU used for all exp erimen ts in this pap er w as NVIDIA T4V2 with 16 GB of VRAM. 12 CPU cores with 48 GB of RAM w ere used for all exp erimen ts. A.11 MIND Exp eriment Details Prior to the exp eriments, the titles of all news articles are conv erted to BER T embeddings. The sp ecific pretrained mo del for BER T from Huggingface (W olf et al., 2019) is bert-base-uncased . The resultant v ectors that summarize the entire news article are of size 768 so we used PCA to downsample to 64 dimensions and sa v ed the em b edding vectors as a file. The test dataset provided by MIND do es not include lab els (W u et al., 2020) so we could not use that split. Instead, we com bine the training and v alidation datasets that span 7 da ys. These datasets contain information on article impressions and clicks, i.e. what the users see and which ones do they interact with. Since there are many of them, w e decided to b e selective and remov e instances with nine or more articles sho wn and sample 20% of the entire dataset. This limits the initial amount of information given to the mo dels and forces the ev aluation to b e based on incremental learning and exploration strategies. The first three days were selected to b e used as training and v alidation datasets – 80% training and 20% v alidation. This implies that reference datasets during the training of ϕ will b e partitioned in to T = 3 partitions. The remaining four days will b e used as a p o ol of test data. Giv en computational constraints, esp ecially ov er 10 random seeds, we pick only 500 p oin ts to b e tested. How ev er, the chosen 500 p oints are 26 Published in T ransactions on Mac hine Learning Researc h (03/2026) T able 2: Augmen ting and diminishing probability schedules by day Da y Probabilit y 9 0.00 10 0.00 11 0.10 12 0.15 13 0.20 14 0.25 15 0.30 selected in a wa y that takes in to account the date. Sp ecifically , every j th (fixed) entry is selected as test p oin ts such that the first and last p oints are close to the start of the fourth day and end of the seven th day resp ectiv ely . T o demonstrate stronger concept drift so that its effect can b e seen in fewer test samples, w e gradually modify the click rate so that the sp orts category will hav e a higher click rate ov er time and all other categories will ha v e a low er click rate in the same time span. An optimal agent should recognize this change and adapt to it. W e augmen t the clic k rates of the sp orts category and diminish the click rate of ev ery other category . F or augmen ting, for any sp orts instance which is not a click, we sample a Bernoulli random v ariable (1 means clic k, 0 means no clic k) with probability Pr( X = 1) = p i and assign that v alue to b e click v alue. Similarly , for diminishing, for any non-sp orts instance which is a clic k, we sample a Bernoulli random v ariable with probabilit y Pr( X = 0) = p i and assign that v alue to be the clic k v alue. The probabilities by day are sho wn in T able 2. ϕ was trained with the loss function L ( ˆ µ, r ) = L BCE ( ˆ µ, r ) + 0 . 01 L ECE ( ˆ µ, r ) , where the ECE loss uses 5 bins. ϕ is initialized to b e a m ultila y er p erceptron with input dimension of 82 (18 news categories for context and 64 dimensional arm features), a single hidden lay er of dimension 512 and an output dimension of 128. The bandwidth for the RBF k ernel is chosen to b e 0.6. ϕ is trained for 20 ep o chs with a batch size of 32. The learning rate is set to 10 − 3 (A dam optimizer with default configurations) with an exp onential decay rate of 0.9. At eac h ep o ch, only 10% of the training data is used for training, where 1% of them are used as reference samples while the rest are used as query points. The ϕ chosen for testing is the one that attains the lo w est v alidation loss. F or the Ba yesian linear regression mo del, the α parameter, which con trols the degree of exploration through the co efficien t of the standard deviation of reward, is set to 1.96. λ , the parameter for numerical stability and regularization, and σ , the standard deviation of the residuals, are set to 1. T w o tow ers refer to the context enco der and arm enco der, which are both mappings to the same embedding space. The dot pro duct b et w een the context vector and arm vector represents the logits which are then passed to a softmax la y er. The tw o tow ers implemen tation has tw o v ariants: small and large. F or the small v arian t, the context encoder lay ers are [18 , 64 , 32] and the arm enco der lay ers are [64 , 128 , 32] . F or the large v arian t, the con text enco der lay ers are [ 18 , 64 , 64] and the arm enco der lay ers are [64 , 256 , 64] . The linear la y ers of b oth v arian ts are in terlea v ed with a ReLU activ ation lay er. The small v ariant was trained for 5 ep ochs while the large v ariant was trained for 40 epo chs. The learning rates are 8 × 10 − 3 (A dam optimizer with default β 1 , β 2 ) and the batc h sizes are 32. F or eac h v ariant, the mo del chosen for testing is the one that attains the lo w est v alidation loss. The mo difications to the linear baseline algorithms are sliding windo w (SW) and discounting (D). Sliding windo w means that they are refitted with the most recent subset (50000 samples), while discounting uses a weigh ted linear regression Russac et al. (2019) with a γ of 0.95. F or the neural baselines, the online mo dification is changing the buffer into a sliding windo w (2000 samples). Note that the neural models are initially trained with the en tire training size, as the sliding windo w buffer is only used during test time. 27 Published in T ransactions on Mac hine Learning Researc h (03/2026) The Gaussian pro cess, due to its cubic time complexity with resp ect to the num b er of samples, is restricted to a subsampling of 0.05. The forgetting element works by replacing the oldest sample with the newly seen sample, k eeping the buffer the same size. The con textual restless bandit (CRB) requires hea vy mo dification. Since the arms v ary with almost no rep eating arms, the state space is incredibly sparse and a transition dynamic that is unknown with minimal samples. Our problem do es not hav e a complex budget constraint so the linear programming comp onen t is ignored. A.12 MIND Time Plot Figure 10: Time taken in seconds against timesteps for each algorithm. Figure 10 shows a measure of time efficiency for eac h algorithm. The plot for some algorithms do not start at zero as they require some amoun t of warm up. The most prominent is the tw o to wer approaches as they are relatively large models. The stepwise pattern in C 3 is attributed to an unoptimized approac h of dropping samples in its buffer. As mentioned in Section 5.3, 20% of its samples are dropp ed every 100 steps. This implemen tation could b e improv ed in future work. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment