IQuest-Coder-V1 Technical Report
In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dy…
Authors: Jian Yang, Wei Zhang, Shawn Guo
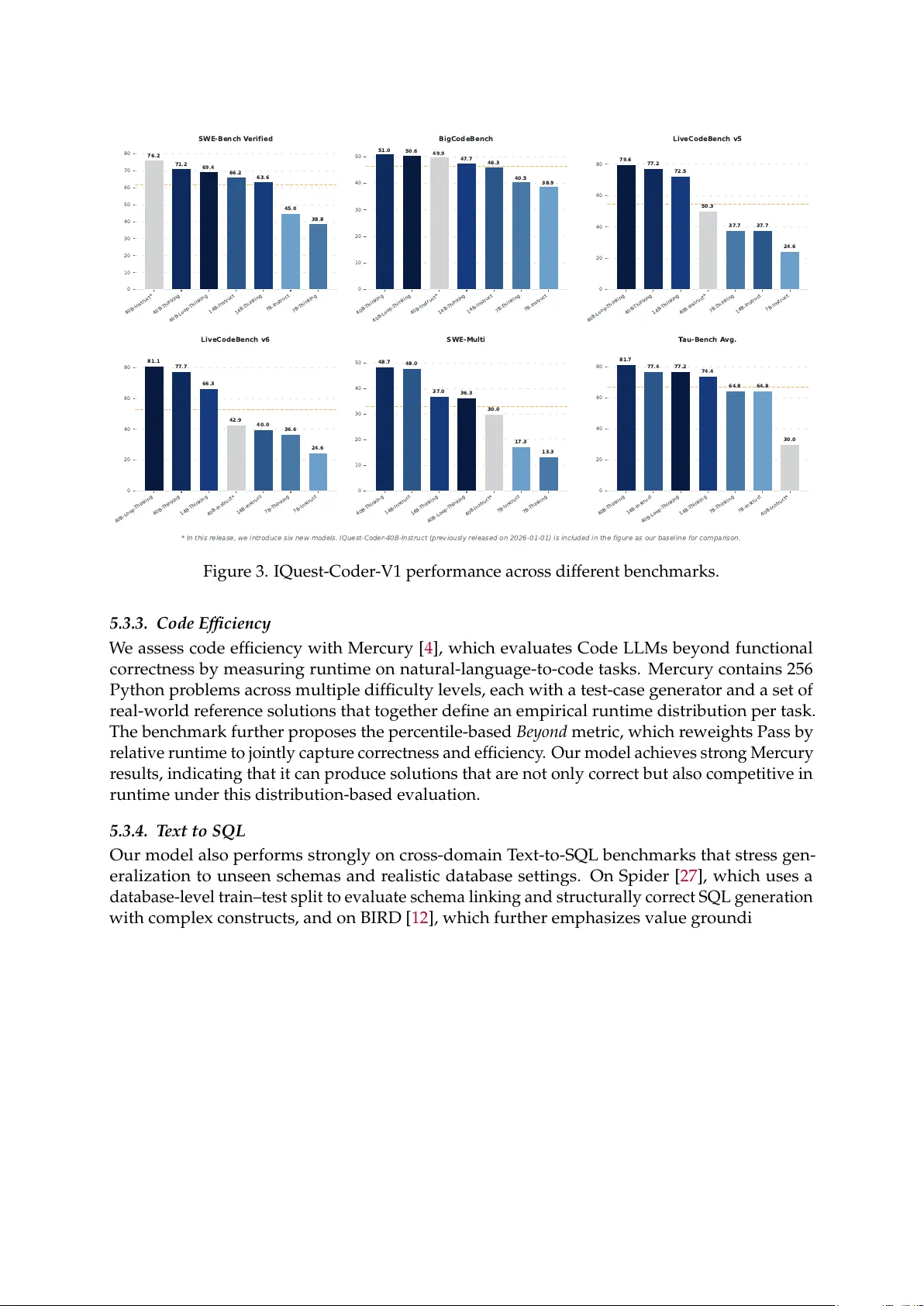
-Coder -V1 T echnical Report IQuest Coder T eam Abstract In this report, we introduce the IQuest-Coder -V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code repr esentations, we pro- pose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic thr ough differ ent phases of the pipeline. Our models are developed thro ugh the evolutionary pipeline, starting with the initial pre-training consisting of code facts, r epository , and completion data. Following that, we implement a specialized mid-training stage that inte- grates reasoning and agentic trajectories in 32k-context and r epository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models acr oss critical dimensions of code intelligence: agentic softwar e engineering, competitive pr ogramming, and complex tool use. T o address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurr ent mechanism designed to optimize the trade-of f between model capacity and deploy- ment footprint, of fering an ar chitecturally enhanced path for ef ficacy-ef ficiency trade-of f. W e believe the release of the IQuest-Coder -V1 series, including the complete white-box chain of checkpoints from pr e-training bases to the final thinking and instr uction models, will advance resear ch in autonomous code intelligence and r eal-world agentic systems. Sonnet-4.5 GPT -5.1 IQuest-Coder Kimi-K2 Qwen3-Coder 0 10 20 30 40 50 60 70 77.2 T op 1 76.3 76.2 69.2 67.0 SWE-Bench V erified IQuest-Coder Kimi-K2 Qwen3-Coder Gemini-3-P r o -P r eview GPT -5.1 0 10 20 30 40 50 49.9 T op 1 49.8 49.4 47.1 46.8 BigCodeBench GPT -5.1 IQuest-Coder Sonnet-4.5 Qwen3-Coder Kimi-K2 0 20 40 60 80 87.0 T op 1 81.1 73.0 53.9 53.7 LiveCodeBench v6 IQuest-Coder Sonnet-4.5 Qwen3-Coder Kimi-K2 GPT -5.1 0 10 20 30 40 50 60 70 69.9 T op 1 62.5 61.3 60.4 53.3 Bird-SQL IQuest-Coder Kimi-K2 Qwen3-Coder K A T -Dev GPT -5.1 0 10 20 30 40 50 60 70 73.8 T op 1 70.3 68.7 64.7 64.4 BFCL IQuest-Coder Sonnet-4.5 GPT -5.1 Qwen3-Coder Kimi-K2 0 10 20 30 40 50 60 62.5 T op 1 58.6 55.1 53.9 53.4 Mind2W eb IQuest-Coder Sonnet-4.5 Kimi-K2 Qwen3-Coder GPT -5.1 0 10 20 30 40 50 51.3 T op 1 51.0 44.5 37.5 35.0 T erminal-Bench-v1.0 IQuest-Coder Qwen3-Coder GPT -5.1 Kimi-K2 K A T -Dev 0 10 20 30 40 50 60 70 68.3 T op 1 66.4 64.9 63.5 58.8 F ullStackBench Figure 1. IQuest-Coder-V1 performance acr oss different benchmarks. The score of LiveCodeBench v6 is from IQuest-Coder -V1-40B-Loop-Thinking model, and the rest are IQuest-Coder-V1-40B-Loop-Instr uct model. The orange dash line represents the average scor e of the selected models. 1. Introduction The curr ent generation of lar ge language models (LLMs) has demonstrated that general-purpose intelligence can be significantly amplified through domain-specific specialization [ 25 ]. How- ever , in the field of code intelligence, a wide gap r emains between open-weights models and proprietary leaders like Claude 4.5 Sonnet 1 . This gap is most evident in long-horizon reasoning and the ability to navigate complex, multi-file codebases [ 19 ]. W e introduce IQuest-Coder-V1 series, a family of dense models ranging fr om 7B to 40B parameters, built to close this gap by maximizing the intelligence density through a str uctured, multi-phase evolution of logic. Our technical contributions are center ed around a four-pillar Code-Flow pipeline ( Figure 2 ): • Pre-training & High-Quality Annealing: W e begin with a two-stage pre-training pr ocess that transitions from stage-1 general data to stage-2 broad code data. This is followed by a targeted annealing phase using high-quality curated code, ensuring the model’s base repr esentations are primed for the complex logical tasks that follow . • Dual-Phase Mid-training: T o bridge the gap between static knowledge and agentic action, we introduce a dedicated mid-training stage with reasoning, agentic, and long-context coding data. • Bifurcated Post-training: Recognizing that dif ferent use cases requir e different optimization profiles, we of fer two distinct post-training paths focusing on instruction tuning and thinking paths. • Efficient Architectures: Our loop model incorporates a recurr ent structure to enable iterative computation over complex code segments, providing a scalable ar chitectural path within the constraints of real-world deployment. IQuest-Coder models ar e developed thr ough a rigorous training methodology that combines large-scale pr etraining on extensive code repositories with specialized instruction tuning. Our pretraining corpus encompasses billions of tokens fr om diverse sources, including public code repositories, technical documentation, and programming-r elated web content. W e employ sophisticated data cleaning and filtering techniques to ensur e high-quality training data, im- plementing both r epository-level and file-level pr ocessing strategies to capture code str ucture and context ef fectively . The model series demonstrates thr ee key characteristics: (1) Supe- rior Performance: Our flagship IQuest-Coder-40B model achieves state-of-the-art results on major coding benchmarks, demonstrating competitive performance with leading pr oprietary models. (2) Compr ehensive Coverage: W ith three distinct model sizes ranging fr om 2B to 40B parameters, IQuest-Coder addresses the diverse needs of the developer community , from resour ce-constrained edge deployment to high-performance cloud applications. (3) Balanced Capabilities: Beyond code generation, IQuest-Coder maintains strong performance in general language understanding and mathematical reasoning, making it suitable for multi-faceted development tasks. Through our systematic exploration of the IQuest-Coder -V1 training pipeline, we identified several pivotal findings that of fer a deeper understanding of how logical intelligence and agentic capabilities emerge within language models. These insights, derived from extensive ablations of our code-flow data and mid-training strategies, challenge several conventional assumptions in code LLM development: • Finding 1 : The repository transition data (the flow of commits) provides a superior signal for task planning compared to training on usual static snapshot files alone. 1 https://www .anthropic.com/claude/sonnet 2 1. Pre-T raining & Annealing Pre-train Phase 1 General Data/Code Data Annealing Phase 2 High Quality Code 2. Mid-T raining Mid-train Phase 1 32k Reasoning / Agentic / Code /... Mid-train Phase 2 128k Reasoning / Agentic / Code /... 3a. Post-T raining: Thinking 3b. Post-T raining: Instruct IQuest-Coder- Stage1 IQuest-Coder- Loop-Stage1 IQuest-Coder- Stage2 IQuest-Coder- Loop-Stage2 Phase 1: SFT General & Code SFT IQuest-Coder-Instruct (Loop) Phase 2: RL Instruct RL Phase 1: SFT Thinking Data Phase 2: RL Reasoning RL IQuest-Coder-Thinking (Loop) Figure 2. Code-Flow T raining pipeline of IQuest-Coder-V1. • Finding 2 : Injecting 32k reasoning and agentic trajectories after high-quality code anneal- ing—but before post-training—serves as a critical logical scaffold that stabilizes model performance under distribution shifts. • Finding 3 : The thinking path (utilizing RL) triggers an emergent ability for autonomous error -recovery in long-horizon tasks (e.g. SWE and code contest tasks) that is largely absent in standard Instr uct SFT post-training paths. Our post-training process leverages carefully curated datasets covering a wide spectrum of programming paradigms, languages, and real-world coding scenarios. This ensures that IQuest- Coder models can serve as effective coding assistants, capable of understanding complex requir ements, generating robust solutions, and providing helpful explanations as r evealed in Figure 1 and Figur e 3 . W e conduct extensive evaluations across popular benchmarks to validate the effectiveness of our appr oach, with r esults demonstrating significant impr ovements over existing open-source alternatives ( r ef. section 5 ). By releasing the complete evolutionary chain from stage 1 to the final post-training checkpoints, we provide a white-box resource for the community to study the forging of agentic code intelligence. 2. Model Architecture 2.1. LoopCoder LoopCoder Architecture. The LoopCoder architectur e employs a loop transformer design where transformer blocks with shar ed parameters are executed in two fixed iterations. In the first iteration, input embeddings are processed thr ough transformer layers with position-shifted hidden states. During the second iteration, the model computes two types of attention: global attention (where queries from iteration 2 attend to all key-value pairs from iteration 1) and local attention (where queries attend only to pr eceding tokens within iteration 2 to maintain causality). These two attention outputs ar e combined using a learned gating mechanism based on query repr esentations, with the gate contr olling the weighted mixtur e of global context r efinement and local causal dependencies. This approach differs fr om the original Parallel Loop T ransformer by omitting token-shifting mechanisms and inference-specific optimizations. LoopCoder T raining. The training pipeline for LoopCoder consists of three main stages, as illustrated in Figure 2 . 3 Model Size Layers Hidden Size Intermediate Size Attention Max Context Query Heads KV Heads V ocabulary Base Models (Stage 1) IQuest-Coder-V1-7B-Base-Stage1 14 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-14B-Base-Stage1 28 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-40B-Base-Stage1 80 5120 27648 GQA 131072 40 8 76800 Base Models (Stage 2) IQuest-Coder-V1-7B-Base 14 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-14B-Base 28 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-40B-Base 80 5120 27648 GQA 131072 40 8 76800 Instruct Models IQuest-Coder-V1-7B-Instruct 14 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-14B-Instruct 28 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-40B-Instruct 80 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-40B-Loop-Instruct (LoopCoder-Instruct) 80 5120 27648 GQA 131072 40 8 76800 Thinking Models IQuest-Coder-V1-7B-Thinking 14 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-14B-Thinking 28 5120 27648 GQA 131072 40 8 76800 IQuest-Coder-V1-40B-Thinking 80 5120 27648 GQA 131072 40 8 76800 T able 1. Architecture of IQuest-Coder -V1. Stage 1: Pre-T raining & Annealing. The training begins with a pre-training phase using a mixture of general data and code data, followed by an annealing phase that focuses on high- quality code corpora. This stage establishes the foundational language understanding and code generation capabilities of the model. Stage 2: Mid-T raining. The mid-training stage is divided into two phases with progr essively increasing context lengths. In Mid-train Phase 1, we train the model on 32k context data comprising reasoning, agentic, and code tasks, yielding IQuest-Coder -V1-Base-Stage1. In Mid- train Phase 2, we further extend the context length to 128k and continue training on similar data distributions. This phase produces IQuest-Coder-V1-Base, which serve as the base models for subsequent post-training. Stage 3: Post-T raining. W e develop two variants of LoopCoder thr ough distinct post-training recipes: • Thinking Models: W e first perform supervised fine-tuning (SFT) on thinking data that contains explicit reasoning traces, followed by r einforcement learning (RL) optimized for reasoning capabilities. • Instruct Models: W e apply SFT on general and code instruction-following data, then conduct RL training to enhance instruction-following abilities. This produces LoopCoder- Instruct. 2.2. Infra for LoopCoder This document describes the thr ee-stage training methodology and infrastructur e from Loop- Coder . The training progr esses from (1) pr e-training on general and code data with annealing on high-quality code, to (2) mid-training with progressively longer contexts (32k then 128k) on reasoning, agentic, and code tasks, and finally (3) post-training via two pathways—SFT and RL for either thinking models (with explicit reasoning) or instruct models (for instruction- following). Supporting this multi-million GPU-hour training ef fort, the infrastructure prioritizes computational efficiency thr ough fused gated attention kernels that r educe memory bandwidth overhead, context parallelism that enables ultra-long context training via point-to-point KV shard transmission with reduced memory costs, and r eliability through silent err or detection using deterministic re-computation and tensor fingerprint validation to catch hardwar e failures that don’t trigger explicit exceptions. 4 3. Pre-training W e adopt the pre-training guideline [ 23 ] for the code pre-training, which has direct implications for constructing multilingual code corpora. When training tokens are limited, prioritizing mixing syntactically-related PLs can further bring more impr ovement compared to naively upsampling a single PL. The positive synergy effects suggest that linguistic diversity , particularly when it spans across the code domain, acts as a form of data augmentation that improves model robustness. T aking into account the syner gistic effects of differ ent programming languages (PL), we ultimately construct code pr e-training data through a r easonable data allocation. 3.1. Stage1: General Pre-training General Corpus Proccessing T o construct the foundational corpus for IQuest-Coder , we cu- rated a massive dataset primarily sour ced from Common Crawl 2 . Our pre-processing pipeline begins with a rigorous cleaning stage utilizing r egular expressions to r emove low-quality noise and non-informative fragments. W e ensure data integrity through a hierarchical deduplication strategy , combining exact match filtering with fuzzy deduplication driven by high-dimensional embedding models. T o safeguard the validity of our evaluations, a compr ehensive decontam- ination procedure is implemented to eliminate any overlaps with common benchmarks. For programming data retrieved fr om Common Crawl, we perform deep Abstract Syntax T ree (AST) analysis to verify syntactic structure and structural integrity , a critical step for our code-flow training paradigm. T o scale quality control, we train a suite of domain-specific proxy classifiers specialized for general text, code, and mathematics. These proxies ar e designed to emulate the quality assessment capabilities of much larger models, which provide annotation samples across dimensions such as information density , educational value, and toxic content. Empirical r esults on validation sets confirm that these small proxy models outperform traditional FastT ext-based approaches, pr oviding a far more precise signal for selecting high-utility tokens. T o enhance the code-related factuality of LLM, we use CodeSimpleQA-Instr uct [ 24 ], a lar ge-scale instruction corpus with 66 million samples, into the pre-training stage. LLMs are adopted to automatically generate factual question-answer pairs from each cluster through a structured pipeline that incor- porates explicit constraints to ensure questions ar e objective, unambiguous, and time-invariant with single correct answers. This appr oach produces high-quality , objective technical assess- ments suitable for knowledge evaluation platforms while ensuring time-invariant accuracy and requiring minimal ongoing maintenance. T o construct a dataset suitable for learning repository evolution patterns, we design a triplet construction strategy based on project lifecycle. For each code repository , the system constructs triplets of the form ( R 𝑜𝑙 𝑑 , P , R 𝑛𝑒𝑤 ) , where R 𝑜𝑙 𝑑 repr esents the pr oject’s code state at a stable development phase, P denotes the patch information capturing differ ences between two code states, and R 𝑛𝑒𝑤 repr esents the code state after a series of development iterations. The starting point selection follows a project maturity principle : commits are selected within the 40%-80% percentile range of the pr oject lifecycle. This interval corr esponds to the matur e development phase of the project, where the codebase is relatively stable, avoiding both the uncertainty of early development and the fragmented changes typical of late-stage maintenance. This approach ensur es that training data r eflects authentic software development patterns. Based on the selected starting point, the system searches forward for appropriate endpoint commits to form complete triplets. The search strategy considers the quality and r epresentativeness of code changes, ensuring that each triplet captur es meaningful development iteration pr ocesses. This construction method generates training data that maintains the temporal continuity of code evolution while ensuring data diversity and information density , providing a theoretically 2 https://commoncrawl.org/ 5 sound foundational dataset for LLM to learn complex code transformation patterns. Code Completion Code completion is a fundamental capability of code intelligence. This proficiency is primarily enhanced by training on data constructed in the Fill-In-the-Middle (FIM) [ 1 ] format. In the FIM paradigm, a code document is partitioned into three segments: prefix, middle, and suffix. The training objective is to predict the middle content based on the provided prefix and suffix. File-level FIM focuses on individual documents, where the segments are concatenated for training with Fill-In-the-Middle (FIM) pattern. Furthermore, Repo-level FIM extends this approach by incorporating semantically similar code snippets from the same repository as additional context to assist in predicting the middle segment. W e primarily employ two strategies for code completion data construction: heuristic-based and multi-level syntax-based construction [ 22 ]. The heuristic-based approach consists of two techniques: random boundary splitting and ran- dom line splitting. Random boundary splitting partitions code documents at a character-level granularity , which enhances the model’s generalization and improves its performance in generat- ing lar ge code blocks or continuing fr om specific characters. In contrast, random line splitting se- lects a specific line within the document as the target for completion, which better aligns with typ- ical user interaction patterns. The syntax-based appr oach leverages the inherent structural prop- erties of source code. By utilizing abstract syntax tree (AST) repr esentations, we extract code seg- ments from various nodes with dif fer ent characteristics. This method ensures both the random- ness of the training data and the str uctural integrity of the code. W e implement several hierarchi- cal levels, including expression-level, statement-level, and function-level. Based on these nodes, we construct multiple PLs and multi-level completion data for both file-level and repo-level tasks, significantly enhancing the diversity of the training samples.The task structur e for file-level com- pletion is <|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf}<|fim_middle|>{code_mid}<|im_end|> and the task structur e for repository-level completion is <|repo_name|>{repo_name} <|file_sep|>{file_path1} {file_content1} <|file_sep|>{file_path2} {file_content2} <|file_sep|>{file_path3} <|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf} <|fim_middle|>{code_fim}<|im_end|> 3.2. Stage2: Mid-T raining This mid-training pr ocess uses a two-stage appr oach (Stage 2.1 at 32K context and Stage 2.2 at 128K context) to efficiently scale model capabilities while managing computational costs. Both stages train on the same core data categories: Reasoning QA (math, coding, logic), Agent trajec- tories, code commits, and file/repository-level fill-in-the-middle (FIM) data. The Reasoning QA component acts as a "r easoning runtime" that encourages structured problem decomposition and consistency checking rather than simple pattern matching, while Agent trajectory data teaches "closed-loop intelligence" by exposing the model to complete action-observation-r evision cycles with dense environmental feedback (commands, logs, errors, test results). This combination provides both symbolic reasoning scaf folding and grounded “code world” experience, enabling the model to handle long-horizon tasks, r ecover from err ors, and maintain coher ent plans acr oss extended contexts, with Stage 2.2 specifically extending these capabilities to repository-level reasoning by incorporating dedicated 128K sequence length samples. 4. Post-T raining Post-training transforms pre-trained models into specialized code intelligence systems through supervised fine-tuning and reinforcement learning. This phase uses instructional data spanning code engineering, mathematics, agentic capabilities, and conversation, employing model-in-the- 6 loop synthesis with execution-based verification. 4.1. Data Construction W e employ a model-centric framework where fr ontier LLMs generate training data under rigorous automated verification, using deterministic execution-based validation for objective do- mains and ensemble mechanisms combining rule-based checks, r eward models, and multi-agent debate for subjective domains. Our methodology spans API orchestration, full-stack engineering, competitive programming, code r easoning, text-to-SQL, code editing, terminal benchmarking, repository-scale engineering, tool use, and GUI agents, synthesizing data thr ough techniques like stochastic perturbations, test-driven synthesis, reverse pipeline generation, and multi-stage filtering with automated environment construction. This is followed by large-scale supervised fine-tuning that pr ocesses token counts near pre-training scale to inject dense task-specific knowledge, utilizing optimization infrastructur e such as aggressive sequence packing, conser - vative cosine annealing learning rates, and a three-phase curriculum that sequences data by difficulty to ensur e stable convergence and superior performance on complex benchmarks. 4.2. Large-Scale Supervised Fine-T uning Post-training processes match pr e-training scale to inject specialized knowledge through opti- mized infrastructur e, including sequence packing with cross-sample masking, cosine learning rate schedules with extended low-rate phases, and three-phase curriculum learning progr essing from basic instruction-following to adversarial examples. Quality control ensures only verified samples enter training through comprehensive sandboxed execution, capturing traces and metrics, symbolic mathematical verification, multi-agent debate for subjective evaluation, and aggressive contamination pr evention via n-gram matching and MinHash LSH deduplication, prioritizing quality over quantity for improved generalization on complex benchmarks. 4.3. Multi-Objective Optimization This section includes three main components: (1) Alignment tax mitigation thr ough replay buffers, dynamic mixtur e adaptation, and compositional design to pr eserve general capabilities while specializing; (2) Reinforcement learning fr om verifiable feedback using GRPO algorithm with clip-Higher strategy on competition coding tasks, trained on test case pass rates without KL penalties; and (3) SWE-RL framework built on scalable cloud-based sandbox infrastructur e that formulates real-world softwar e engineering as interactive RL environments, wher e agents use tool-based actions acr oss multiple steps and ar e trained via GRPO with r ewards based on test suite passage plus regularization for efficiency , enabling parallel trajectory execution for stable long-horizon code reasoning and debugging capabilities—together yielding emergent capabilities like self-debugging, cross-language transfer , and improved uncertainty calibration. 5. Evaluation 5.1. Baselines In our evaluation, we compar e our model against a br oad set of state-of-the-art code-focused language models covering instruction-tuned, base, and reasoning-enhanced variants. The base- lines span leading closed-sour ce and open-sour ce systems known for strong performance on programming and reasoning tasks, including repr esentative models from Anthr opic (Claude 4.5), OpenAI (GPT -5.1), Google (Gemini 3), Alibaba (Qwen and Qwen-Coder series), DeepSeek (Coder and V3 series), Mistral (CodeStral), Moonshot (Kimi), ZhiPu (GLM), Kuaishou (Kwaipi- lot/KA T), and BigCode (StarCoder2). These models cover a wide parameter range and different 7 Model Python Java T ypeScript C# A verage EM ES EM ES EM ES EM ES EM ES 6B+ Models DeepSeek-Coder-6.7B-Base 41.1 79.2 39.9 80.1 46.3 82.4 55.0 86.9 45.6 82.1 DS-Coder-V2-Lite-Base 41.8 78.3 46.1 81.2 44.6 81.4 58.7 87.9 47.8 82.2 CodeQwen1.5-7B 40.7 77.8 47.0 81.6 45.8 82.2 59.7 87.6 48.3 82.3 Qwen2.5-Coder-7B 42.4 78.6 48.1 82.6 46.8 83.4 59.7 87.9 49.3 83.1 StarCoder2-7B 10.9 63.1 8.3 71.0 6.7 76.8 7.3 72.1 8.3 70.8 14B+ Models Qwen2.5-Coder-14B 47.7 81.7 54.7 85.7 52.9 86.0 66.4 91.1 55.4 86.1 StarCoder2-15B 28.2 70.5 26.7 71.0 24.7 76.3 25.2 74.2 26.2 73.0 20B+ Models DS-Coder-33B-Base 44.2 80.4 46.5 82.7 49.2 84.0 55.2 87.8 48.8 83.7 Qwen2.5-Coder-32B 49.2 82.1 56.4 86.6 54.9 87.0 68.0 91.6 57.1 86.8 CodeStral-22B 49.3 82.7 44.1 71.1 51.0 85.0 53.7 83.6 49.5 80.6 IQuest-Coder-V1-40B 49.0 81.7 57.9 86.2 61.9 88.5 63.4 85.5 57.8 85.7 T able 2. Performance comparison on CrossCodeEval T asks. Model EvalPlus BigCodeBench FullStackBench HumanEval HumanEval+ MBPP MBPP+ Full Hard 6B+ Models DeepSeek-Coder-V2-Lite-Instruct 81.1 75.6 85.2 70.6 37.8 18.9 49.4 Qwen2.5-Coder-7B-Instruct 87.2 81.7 84.7 72.2 37.8 13.5 42.2 Seed-Coder-8B-Instruct 81.1 75.6 86.2 73.3 44.6 23.6 55.8 IQuest-Coder-V1-7B-Instruct 79.9 73.2 73.5 63.5 38.9 23.0 39.7 IQuest-Coder-V1-7B-Thinking 76.8 70.7 73.5 63.5 40.5 19.6 32.3 13B+ Models Qwen2.5-Coder-14B-Instruct 62.8 59.8 88.6 77.2 47.0 6.1 53.1 Qwen3-Coder-30B-A3B-Instruct 93.9 87.2 90.7 77.2 46.9 27.7 60.9 IQuest-Coder-V1-14B-Instruct 83.5 78.7 79.6 68.5 46.3 26.4 48.6 IQuest-Coder-V1-14B-Thinking 92.7 86.0 90.5 72.0 47.7 23.7 46.6 20B+ Models Deepseek-V3.2 93.9 88.4 93.4 77.2 48.1 27.0 64.9 Qwen2.5-Coder-32B-Instruct 93.3 86.6 90.2 77.8 48.0 24.3 57.4 Qwen3-235B-A22B-Instruct-2507 96.3 91.5 92.3 77.8 47.4 25.7 62.7 Qwen3-235B-A22B-Thinking-2507 98.8 93.3 95.5 81.5 44.1 23.0 - Qwen3-Coder-480B-A35B-Instruct 97.6 92.7 94.2 80.2 49.4 27.7 66.4 Kimi-Dev-72B 93.3 86.0 79.6 68.8 45.4 31.8 38.6 Kimi-K2-Instruct-0905 94.5 89.6 91.8 74.1 49.8 30.4 63.5 Kimi-K2-Thinking 98.2 92.7 97.4 82.3 46.8 28.4 - KA T -Dev 90.9 86.6 89.4 76.2 46.2 25.7 58.8 KA T -Dev-72B-Exp 88.4 81.7 85.2 69.3 48.3 26.4 52.9 GLM-4.7 87.2 79.9 90.5 75.7 45.7 26.4 70.2 IQuest-Coder-V1-40B-Instruct 96.3 90.2 91.8 77.8 54.2 33.1 71.4 IQuest-Coder-V1-40B-Thinking 93.9 87.8 91.0 75.1 51.1 29.1 54.8 IQuest-Coder-V1-40B-Loop-Instruct 97.6 91.5 92.9 77.2 49.9 27.7 68.3 IQuest-Coder-V1-40B-Loop-Thinking 97.6 89.6 91.0 76.2 50.6 29.7 59.5 Closed-APIs Models Gemini-3-Flash-preview 88.4 84.8 92.3 79.1 44.5 25.6 - Gemini-3-Pro-pr eview 100.0 94.5 71.2 64.8 47.1 25.0 - Claude-Opus-4.5 98.8 93.3 96.8 83.9 53.3 35.1 72.3 Claude-Sonnet-4.5 98.8 93.3 95.2 82.3 51.4 29.1 69.7 GPT -5.1 97.0 90.0 92.6 72.2 46.8 29.1 64.9 T able 3. Performance comparison on code generation tasks. tuning strategies, ensuring that our comparison r eflects current capability boundaries in code generation, understanding, and complex task execution. 8 Model CruxEval LiveCodeBench Input-COT Output-COT V5 V6 6B+ Models DeepSeek-Coder-V2-Lite-Instruct 57.1 56.2 13.2 19.4 Qwen2.5-Coder-7B-Instruct 66.9 66.0 14.4 18.9 Seed-Coder-8B-Instruct 62.0 66.6 19.2 22.3 IQuest-Coder-V1-7B-Instruct 45.8 54.2 24.6 24.6 IQuest-Coder-V1-7B-Thinking 57.6 81.5 37.7 36.6 13B+ Models Qwen2.5-Coder-14B-Instruct 75.6 79.2 22.8 24.6 Qwen3-Coder-30B-A3B-Instruct 76.9 80.5 43.1 36.0 IQuest-Coder-V1-14B-Instruct 52.6 57.6 37.7 40.0 IQuest-Coder-V1-14B-Thinking 80.5 90.6 72.5 66.3 20B+ Models DeepSeek-v3.2 82.1 94.2 - 83.3 Qwen2.5-Coder-32B-Instruct 78.8 84.0 30.5 27.4 Qwen3-235B-A22B-Instruct-2507 62.0 89.5 53.9 51.8 Qwen3-235B-A22B-Thinking-2507 15.2 46.9 80.2 74.1 Qwen3-Coder-480B-A35B-Instruct 87.1 90.4 48.6 53.9 Kimi-Dev-72B 33.0 64.2 46.1 40.0 Kimi-K2-Instruct-0905 86.8 89.5 52.1 53.7 Kimi-K2-Thinking 92.2 86.2 - 83.1 KA T -Dev 42.5 65.1 32.9 32.6 KA T -Dev-72B-Exp 71.4 81.1 13.8 16.0 GLM-4.7 65.6 81.2 - 84.9 IQuest-Coder-V1-40B-Instruct 93.5 87.0 55.7 46.9 IQuest-Coder-V1-40B-Thinking 87.4 94.0 77.3 77.7 IQuest-Coder-V1-40B-Loop-Instruct 91.1 85.5 48.6 48.5 IQuest-Coder-V1-40B-Loop-Thinking 76.5 75.2 79.6 81.1 Closed-APIs Models Gemini-3-Flash-preview 96.5 97.6 - 90.8 Gemini-3-Pro-preview 98.8 99.1 - 91.7 Claude-Opus-4.5 98.4 98.0 - 87.1 Claude-Sonnet-4.5 96.2 96.2 - 73.0 GPT -5.1 70.8 71.1 - 87.0 T able 4. Performance comparison on Code Reasoning Evaluation. 5.2. Experiments on Base Models 5.2.1. Code Completion W e evaluate cross-file code completion on CrossCodeEval [ 3 ], a multilingual benchmark encom- passing Python, Java, T ypeScript, and C#. This benchmark explicitly targets repository-level completion scenarios, serving as a cor e metric for assessing the fundamental capabilities of code LLMs in leveraging cross-file context. 5.3. Evaluation on Instruct Models and Reasoning model 5.3.1. Code Generation Across a wide range of code-generation evaluations, our model achieves consistently strong performance. W e validate functional correctness and robustness using EvalPlus [ 13 ] (including HumanEval+ and MBPP+ with substantially expanded test suites), and measure composi- tional, library-intensive problem solving on BigCodeBench [ 28 ]. W e further demonstrate broad full-stack capability on FullStackBench [ 14 ], and strong results under contamination-aware, continuously refr eshed testing on LiveCodeBench [ 8 ]. 5.3.2. Code Reasoning W e further evaluate code r easoning with CRUXEval [ 5 ], which tests both forward execution (Input-to-Output, I2O) and inverse infer ence (Output-to-Input, O2I) over 800 concise Python functions. Our model performs strongly on I2O and also shows clear gains on the more challenging O2I setting, indicating improved ability to reason about code behavior beyond surface-level execution and to solve inverse constraints implied by a target r eturn value. 9 40B-Instruct* 40B- Thinking 40B-L oop- Thinking 14B-Instruct 14B- Thinking 7B-Instruct 7B- Thinking 0 10 20 30 40 50 60 70 80 76.2 71.2 69.4 66.2 63.6 45.0 38.8 SWE-Bench V erified 40B- Thinking 40B-L oop- Thinking 40B-Instruct* 14B- Thinking 14B-Instruct 7B- Thinking 7B-Instruct 0 10 20 30 40 50 51.0 50.6 49.9 47.7 46.3 40.5 38.9 BigCodeBench 40B-L oop- Thinking 40B- Thinking 14B- Thinking 40B-Instruct* 7B- Thinking 14B-Instruct 7B-Instruct 0 20 40 60 80 79.6 77.2 72.5 50.3 37.7 37.7 24.6 LiveCodeBench v5 40B-L oop- Thinking 40B- Thinking 14B- Thinking 40B-Instruct* 14B-Instruct 7B- Thinking 7B-Instruct 0 20 40 60 80 81.1 77.7 66.3 42.9 40.0 36.6 24.6 LiveCodeBench v6 40B- Thinking 14B-Instruct 14B- Thinking 40B-L oop- Thinking 40B-Instruct* 7B-Instruct 7B- Thinking 0 10 20 30 40 50 48.7 48.0 37.0 36.3 30.0 17.3 13.3 SWE-Multi 40B- Thinking 14B-Instruct 40B-L oop- Thinking 14B- Thinking 7B- Thinking 7B-Instruct 40B-Instruct* 0 20 40 60 80 81.7 77.4 77.2 74.4 64.8 64.8 30.0 T au-Bench A vg. * In this release, we introduce six new models. IQuest-Coder -40B -Instruct (previously released on 2026-01-01) is included in the figure as our baseline for comparison. Figure 3. IQuest-Coder-V1 performance acr oss different benchmarks. 5.3.3. Code Ef ficiency W e assess code efficiency with Mercury [ 4 ], which evaluates Code LLMs beyond functional correctness by measuring runtime on natural-language-to-code tasks. Mercury contains 256 Python problems across multiple diffi culty levels, each with a test-case generator and a set of real-world refer ence solutions that together define an empirical r untime distribution per task. The benchmark further pr oposes the per centile-based Beyond metric, which reweights Pass by relative runtime to jointly capture correctness and ef ficiency . Our model achieves strong Mercury results, indicating that it can pr oduce solutions that are not only corr ect but also competitive in runtime under this distribution-based evaluation. 5.3.4. T ext to SQL Our model also performs strongly on cross-domain T ext-to-SQL benchmarks that str ess gen- eralization to unseen schemas and realistic database settings. On Spider [ 27 ], which uses a database-level train–test split to evaluate schema linking and str ucturally correct SQL generation with complex constructs, and on BIRD [ 12 ], which further emphasizes value gr ounding from database contents, real-world database scale, and execution-r elated practicality , our model achieves competitive results, indicating r obust semantic parsing and reliable query generation in both schema-centric and content-grounded scenarios. 5.3.5. Agentic Coding T asks W e further evaluate our model in agentic, end-to-end software workflows where success de- pends on corr ect tool use, long-horizon planning, and tight interaction with the execution environment. T erminal-Bench [ 20 ] measur es whether an agent can reliably complete r ealistic terminal workflows (for example, building softwar e fr om source, configuring services, manag- ing dependencies, and debugging) inside containerized sandboxes with automated verification, while also standar dizing execution via its r unner for r epr oducible leaderboard evaluation. In parallel, SWE-bench [ 10 ] tar gets real-world software engineering by r equiring models to pr o- 10 Model Mercury Beyond@1 Pass@1 6B+ Models DeepSeek-Coder-V2-Lite-Instruct 76.8 91.4 Qwen2.5-Coder-7B-Instruct 69.9 84.8 Seed-Coder-8B-Instruct 78.5 93.8 IQuest-Coder-V1-7B-Instruct 42.1 50.4 IQuest-Coder-V1-7B-Thinking 43.2 53.5 13B+ Models Qwen2.5-Coder-14B-Instruct 76.7 88.3 Qwen3-Coder-30B-A3B-Instruct 81.1 95.3 IQuest-Coder-V1-14B-Instruct 63.3 76.2 IQuest-Coder-V1-14B-Thinking 62.0 74.2 20B+ Models DeepSeek-v3.2 81.6 96.9 Qwen2.5-Coder-32B-Instruct 79.1 96.1 Qwen3-235B-A22B-Instruct-2507 80.4 96.9 Qwen3-235B-A22B-Thinking-2507 61.2 70.3 Qwen3-Coder-480B-A35B-Instruct 80.2 96.1 Kimi-Dev-72B 59.1 69.5 Kimi-K2-Instruct-0905 76.1 90.6 Kimi-K2-Thinking 73.0 85.2 KA T -Dev 75.1 89.1 KA T -Dev-72B-Exp 79.0 94.5 GLM-4.7 74.1 86.7 IQuest-Coder-V1-40B-Instruct 83.6 95.3 IQuest-Coder-V1-40B-Thinking 71.1 83.2 IQuest-Coder-V1-40B-Loop-Instruct 82.2 94.1 IQuest-Coder-V1-40B-Loop-Thinking 79.6 94.9 Closed-APIs Models Gemini-3-Flash-preview 78.4 89.5 Gemini-3-Pro-pr eview 83.1 96.1 Claude-Opus-4.5 82.9 96.9 Claude-Sonnet-4.5 82.5 97.7 GPT -5.1 81.9 96.1 T able 5. Performance comparison on code efficiency task. duce patches from issue descriptions that turn failing repositories into passing ones under unit-test verification; SWE-bench V erified further improves reliability with 500 curated instances evaluated in a standardized Docker envir onment, where our model achieves a score of 76.2. 5.3.6. Other Agentic T asks Beyond coding-centric agents, we additionally evaluate general tool-use and interactive decision making across web, API, and conversational-agent settings. Mind2W eb [ 2 ] targets generalist web agents that must follow natural-language instr uctions to complete open-ended tasks on r eal websites, str essing cr oss-site generalization and long-horizon UI interaction. BFCL [ 16 ] tests tool- use across heter ogeneous programming and API settings (for example, Java, JavaScript, Python, SQL, and REST APIs), with successive versions increasing r ealism from br oad coverage (v1) to real tool execution (v2), multi-turn multi-step function calling (v3), and holistic agent evaluation that emphasizes autonomous planning and sequential decision making (v4). Finally , 𝜏 -bench [ 26 ] evaluates conversational agents that must interact naturally with users while following policy constraints, and its extension 𝜏 2 -bench further introduces dual-contr ol environments where both the agent and the user can act on a shar ed world via tools, enabling fine-grained diagnosis of failures in r easoning versus coordination. 5.3.7. Safety Evaluation W e adopt the T ulu 3 benchmarking suite [ 11 ] to evaluate safety boundaries, balancing two objectives: maximizing refusals on harmful prompts while minimizing over -refusal on benign inputs in XST est [ 17 ] and W ildGuardT est [ 6 ]. Response validity is adjudicated by the W ildGuard model [ 6 ], and we report macr o-averaged accuracy across all benchmarks, where higher scor es 11 Model Bird Spider Execution Accuracy Execution Accuracy 6B+ Models DeepSeek-Coder-V2-Lite-Instruct 41.6 72.4 Qwen2.5-Coder-7B-Instruct 53.1 79.8 Seed-Coder-8B-Instruct 44.7 72.7 IQuest-Coder-V1-7B-Instruct 37.7 67.7 IQuest-Coder-V1-7B-Thinking 30.5 56.4 13B+ Models Qwen2.5-Coder-14B-Instruct 59.1 81.3 Qwen3-Coder-30B-A3B-Instruct 59.0 80.9 IQuest-Coder-V1-14B-Instruct 50.0 75.8 IQuest-Coder-V1-14B-Thinking 46.9 69.3 20B+ Models DeepSeek-v3.2 52.6 77.9 Qwen2.5-Coder-32B-Instruct 62.1 83.9 Qwen3-235B-A22B-Instruct-2507 62.8 81.1 Qwen3-235B-A22B-Thinking-2507 35.2 42.6 Qwen3-Coder-480B-A35B-Instruct 61.3 81.2 Kimi-K2-Instruct-0905 60.4 81.1 Kimi-K2-Thinking 40.6 49.6 KA T -Dev 52.2 77.6 KA T -Dev-72B-Exp 35.2 60.3 GLM-4.7 46.5 62.4 IQuest-Coder-V1-40B-Instruct 70.5 92.2 IQuest-Coder-V1-40B-Thinking 53.6 78.1 IQuest-Coder-V1-40B-Loop-Instruct 69.9 84.0 IQuest-Coder-V1-40B-Loop-Thinking 54.8 77.8 Closed-APIs Models Gemini-3-Flash-preview 66.6 87.2 Gemini-3-Pro-pr eview 67.5 87.0 Claude-Opus-4.5 66.0 76.0 Claude-Sonnet-4.5 62.5 80.1 GPT -5.1 53.3 77.6 T able 6. Performance comparison on T ext2SQL T asks. indicate better overall safety behavior . Concretely , we evaluate refusals on BeaverT ails [ 9 ] (1,483 harmful prompts), HarmBench [ 15 ] (300 examples fr om Standar d, Contextual, and Copyright subsets), Do-Anything-Now [ 18 ] (300 DAN-templated malicious prompts), Do-not-Answer [ 21 ] (939 harmful prompts), T rustLLM [ 7 ] (1,400 jailbreak prompts), and W ildGuardT est [ 6 ] (780 harmful prompts within 1,725 items), r eporting Refusal Rate (RT A) based on whether W ildGuard classifies the r esponse as a r efusal; for XST est [ 17 ], we r eport aggregate accuracy by requiring refusals on unsafe pr ompts and compliance on adversarial benign prompts. Conclusion In this work, we present IQuest-Coder-V1, a family of code LLMs that advance the state-of- the-art in autonomous software engineering thr ough the code-flow pre-training paradigm and multi-phase evolutionary training. By capturing dynamic repository transitions and integrating extensive r easoning trajectories with repository-scale context during mid-training, our mod- els establish r obust logical foundations for complex code intelligence tasks. IQuest-Coder-V1 demonstrates exceptional performance acr oss diverse benchmarks spanning agentic softwar e engineering, competitive pr ogramming, and tool use, validating the effectiveness of our training methodology . The IQuest-Coder-V1 (Loop variant) further addresses practical deployment challenges through recurr ent architectural innovations that optimize the capacity-efficiency 12 Model Agentic Coding General T ool Use T erminal-Bench T erminal-Bench (2.0) SWE-V erified Mind2W eb BFCL V3 6B+ Models DeepSeek-Coder-V2-Lite-Instruct 5.0 0.0 - 26.7 - Qwen2.5-Coder-7B-Instruct 6.3 0.0 - 38.4 54.2 Seed-Coder-8B-Instruct 7.5 2.5 - 38.2 - IQuest-Coder-V1-7B-Instruct 22.5 11.2 45.0 40.5 34.0 IQuest-Coder-V1-7B-Thinking 21.3 6.9 38.8 10.8 43.3 13B+ Models Qwen2.5-Coder-14B-Instruct 8.8 0.0 - 42.7 59.9 Qwen3-Coder-30B-A3B-Instruct 23.8 23.8 51.9 36.1 63.4 IQuest-Coder-V1-14B-Instruct 36.3 16.9 66.2 47.1 55.1 IQuest-Coder-V1-14B-Thinking 26.3 14.1 63.6 28.7 53.6 20B+ Models DeepSeek-v3.2 23.8 46.4 73.1 47.2 68.8 Qwen2.5-Coder-32B-Instruct 5.0 4.5 - 32.5 62.3 Qwen3-235B-A22B-Instruct-2507 15.0 13.5 45.2 49.0 71.2 Qwen3-235B-A22B-Thinking-2507 8.8 3.4 44.6 43.2 71.9 Qwen3-Coder-480B-A35B-Instruct 37.5 23.6 67.0 54.0 68.7 Kimi-Dev-72B - 2.3 60.4 - 55.5 Kimi-K2-Instruct-0905 44.5 27.8 69.2 53.4 70.3 Kimi-K2-Thinking 47.1 33.7 71.3 55.7 - KA T -Dev 17.5 10.1 62.4 33.7 64.7 KA T -Dev-72B-Exp 21.3 7.9 74.6 - - GLM-4.7 36.3 41.0 73.8 53.7 64.8 IQuest-Coder-V1-40B-Instruct 52.5 33.0 70.4 64.3 51.7 IQuest-Coder-V1-40B-Thinking 30.0 22.3 71.2 47.6 64.2 IQuest-Coder-V1-40B-Loop-Instruct 51.3 33.0 76.2 62.5 73.9 IQuest-Coder-V1-40B-Loop-Thinking 30.0 18.8 76.2 62.5 73.9 Closed-APIs Models Gemini-3-Flash-preview 53.8 47.6 78.0 60.6 - Gemini-3-Pro-pr eview 46.3 54.2 76.2 60.3 78.2 Claude-Opus-4.5 47.5 59.3 80.9 57.9 78.9 Claude-Sonnet-4.5 51.0 50.0 77.2 58.6 77.7 GPT -5.1 35.0 47.6 76.3 55.1 64.4 T able 7. Combined performance on agentic coding tasks (T erminal-Bench, T erminal-Bench 2.0, SWE-V erified) and general tool-use tasks (Mind2W eb, BFCL V3). Model BeaverT ails HarmBench Do-Anything-Now Do-not-Answer T rustLLM WildGuardT est XST est Overall Qwen2.5-Coder-32B-Instruct 68.0 47.5 69.7 53.7 70.2 73.9 90.6 67.7 Qwen3-Coder-480B-A35B-Instruct 70.5 94.2 95.7 69.9 88.4 85.0 90.1 84.8 IQuest-Coder-V1-40B-Instruct 67.5 57.3 63.3 53.9 65.0 78.1 89.3 67.8 IQuest-Coder-V1-40B-Thinking 76.7 94.8 97.7 58.6 86.4 86.8 94.3 85.0 T able 8. Safety performance comparison, highlighting IQuest-Coder-V1. trade-off. W e deliver specialized models tailored for both deep analytical reasoning and general assistance scenarios. By open-sourcing the complete training pipeline and model checkpoints, we aim to catalyze further r esear ch in code intelligence and accelerate the development of production-r eady agentic systems capable of tackling real-world software engineering chal- lenges. 13 6. Contributions and Acknowledgements The authors of this paper are listed in order as follows: Jian Y ang, W ei Zhang, Shawn Guo, Zhengmao Y e, Lin Jing, Shark Liu, Y izhi Li, Jiajun W u, Cening Liu, X. Ma, Y uyang Song, Siwei W u, Y uwen Li, L. Liao, T . Zheng, Ziling Huang, Zelong Huang, Che Liu, Y an Xing, Renyuan Li, Qingsong Cai, Hanxu Y an, Siyue W ang, Shikai Li, Jason Klein Liu, An Huang, Y ongsheng Kang, Jinxing Zhang, Chuan Hao, Haowen W ang, W eicheng Gu, Ran T ao, Mingjie T ang, Peihao W u, Jianzhou W ang, Xianglong Liu, W eifeng Lv , Bryan Dai. Core Contributors: Jian Y ang, W ei Zhang, Shawn Guo, Zhengmao Y e, Lin Jing, Shark Liu, Y izhi Li, Jiajun W u. Contributors Cening Liu, Xi Lin, Y uyang Song, Siwei W u, Y uwen Li, L. Liao, T ianyu Zheng, Ziling Huang, Zelong Huang, Che Liu, Y an Xing, Renyuan Li, Qingsong Cai, Hanxu Y an, Siyue W ang, Shikai Li, Jason Klein Liu, An Huang, Y ongsheng Kang, Jinxing Zhang, Chuan Hao, Jing Y ang, Haowen W ang, W eicheng Gu, IQuest Coder . Leadership and Senior Advisory Committee: Ran T ao, Mingjie T ang, Peihao W u, Jianzhou W ang, Xianglong Liu, W eifeng Lv . Corresponding Authors: Bryan Dai. References 1 Mohammad Bavarian, Heewoo Jun, Nikolas T ezak, John Schulman, Christine McLeavey , Jerry T worek, and Mark Chen. Efficient training of language models to fill in the middle, 2022. URL . 2 Xiang Deng, Y u Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi W ang, Huan Sun, and Y u Su. Mind2web: T owards a generalist agent for the web. Advances in Neural Information Processing Systems , 36:28091–28114, 2023. 3 Y angruibo Ding, Zijian W ang, W asi Uddin Ahmad, Hantian Ding, Ming T an, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion, 2023. URL . 4 Mingzhe Du, Anh T uan Luu, Bin Ji, Qian Liu, and See-Kiong Ng. Mercury: A code efficiency benchmark for code large language models, 2024. URL . 5 Alex Gu, Baptiste Rozièr e, Hugh Leather , Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. W ang. Cr uxeval: A benchmark for code r easoning, understanding and execution. arXiv preprint arXiv:2401.03065 , 2024. 6 Seungju Han, Kavel Rao, Allyson Ettinger , Liwei Jiang, Bill Y uchen Lin, Nathan Lambert, Y ejin Choi, and Nouha Dziri. W ildguard: Open one-stop moderation tools for safety risks, jailbreaks, and r efusals of llms. Advances in Neural Information Processing Systems , 37:8093– 8131, 2024. 7 Y ue Huang, Lichao Sun, Haoran W ang, Siyuan W u, Qihui Zhang, Y uan Li, Chujie Gao, Y ixin Huang, W enhan L yu, Y ixuan Zhang, et al. T rustllm: T rustworthiness in large language models. arXiv preprint , 2024. 14 8 Naman Jain, King Han, Alex Gu, W en-Ding Li, Fanjia Y an, T ianjun Zhang, Sida W ang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contami- nation free evaluation of lar ge language models for code. arXiv preprint , 2024. 9 Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Y izhou W ang, and Y aodong Y ang. Beavertails: T owards impr oved safety alignment of llm via a human-pr eference dataset. Advances in Neural Information Pr ocessing Systems , 36: 24678–24704, 2023. 10 Carlos E. Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The T welfth International Conference on Learning Representations, ICLR 2024, V ienna, Austria, May 7-11, 2024 . OpenReview .net, 2024. URL https://openreview.net/forum?id=VTF8yNQM 66 . 11 Nathan Lambert, Jacob Morrison, V alentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane L yu, et al. T ulu 3: Pushing frontiers in open language model post-training. arXiv preprint , 2024. 12 Jinyang Li, Binyuan Hui, Ge Qu, Binhua Li, Jiaxi Y ang, Bowen Li, Bailin W ang, Bowen Qin, Rongyu Cao, Ruiying Geng, et al. Can llm already serve as a database interface. A big bench for large-scale database grounded text-to-sqls. CoRR, abs/2305.03111 , 2023. 13 Jiawei Liu, Chunqiu Steven Xia, Y uyao W ang, and Lingming Zhang. Is your code generated by chatGPT r eally correct? rigorous evaluation of lar ge language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems , 2023. URL h t t p s : //openreview.net/forum?id=1qvx610Cu7 . 14 Siyao Liu, Ge Zhang, Boyuan Chen, Jialiang Xue, and Zhendong Su. FullStack Bench: Evaluating llms as full stack coders. arXiv preprint , 2024. URL h tt p s: //arxiv.org/abs/2412.00535 . 15 Mantas Mazeika, Long Phan, Xuwang Y in, Andy Zou, Zifan W ang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated r ed teaming and r obust r efusal. arXiv preprint , 2024. 16 Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Y an, V ishnu Sur esh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): Fr om tool use to agentic evaluation of large language models. In Advances in Neural Information Processing Systems , 2024. 17 Paul Röttger , Hannah Kirk, Bertie V idgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy . Xstest: A test suite for identifying exaggerated safety behaviours in large language models. In Pr oceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies (V olume 1: Long Papers) , pages 5377–5400, 2024. 18 Xinyue Shen, Zeyuan Chen, Michael Backes, Y un Shen, and Y ang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak pr ompts on large language models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages 1671–1685, 2024. 15 19 swebench. swebench, 2025. URL https://www.swebench.com/original.html . 20 The T erminal-Bench T eam. T erminal-bench: A benchmark for ai agents in terminal environ- ments, Apr 2025. URL https://github.com/laude- institute/terminal- bench . 21 Y uxia W ang, Haonan Li, Xudong Han, Preslav Nakov , and T imothy Baldwin. Do-not-answer: A dataset for evaluating safeguards in llms. arXiv preprint , 2023. 22 Jian Y ang, Jiajun Zhang, Jiaxi Y ang, Ke Jin, Lei Zhang, Qiyao Peng, Ken Deng, Y ibo Miao, T ianyu Liu, Zeyu Cui, et al. Execrepobench: Multi-level executable code completion evalua- tion. arXiv preprint , 2024. 23 Jian Y ang, Shawn Guo, Lin Jing, W ei Zhang, Aishan Liu, Chuan Hao, Zhoujun Li, W ayne Xin Zhao, Xianglong Liu, W eifeng Lv , et al. Scaling laws for code: Every programming language matters. arXiv preprint , 2025. 24 Jian Y ang, W ei Zhang, Y izhi Li, Shawn Guo, Haowen W ang, Aishan Liu, Ge Zhang, Zili W ang, Zhoujun Li, Xianglong Liu, et al. Codesimpleqa: Scaling factuality in code large language models. arXiv preprint , 2025. 25 Jian Y ang, W ei Zhang, Shark Liu, Jiajun W u, Shawn Guo, and Y izhi Li. From code foundation models to agents and applications: A practical guide to code intelligence. arXiv preprint arXiv:2511.18538 , 2025. 26 Shunyu Y ao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. taubench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint , 2024. 27 T ao Y u, Rui Zhang, Kai Y ang, Michihiro Y asunaga, Dongxu W ang, Zifan Li, James Ma, Irene Li, Qingning Y ao, Shanelle Roman, et al. Spider: A large-scale human-labeled dataset for com- plex and cross-domain semantic parsing and text-to-sql task. arXiv preprint , 2018. 28 T erry Y ue Zhuo, Minh Chien V u, Jenny Chim, Han Hu, W enhao Y u, Ratnadira W idyasari, Imam Nur Bani Y usuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Bench- marking code generation with diverse function calls and complex instructions. arXiv preprint arXiv:2406.15877 , 2024. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment