Nonlinear Information Theory: Characterizing Distributional Uncertainty in Communication Models with Sublinear Expectation
A mathematical framework for information-theoretic analysis is established, with a new viewpoint of describing transmitted messages and communication channels by the nonlinear expectation theory, beyond the framework of classical probability theory. …
Authors: Wen-Xuan Lang, Shaoshi Yang, Jianhua Zhang
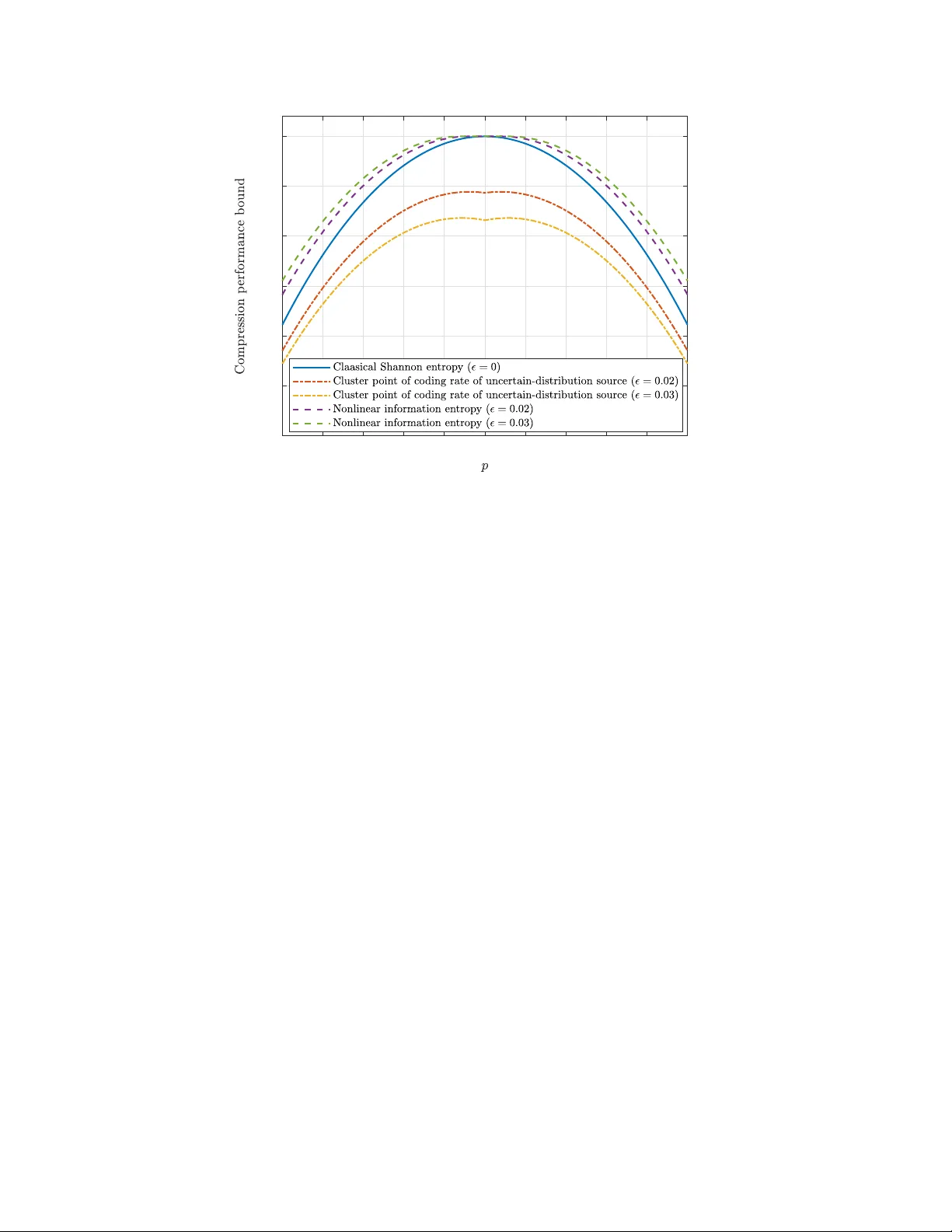
1 Nonlinear Information Theory: Characterizing Distributional Uncertain t y in Comm unication Mo dels with Sublinear Exp ectation W en-Xuan Lang, Shaoshi Y ang, Jianh ua Zhang, Zhiming Ma Abstract A mathematical framew ork for information-theoretic analysis is established, with a new viewp oin t of describing transmitted messages and communication c hannels by the nonlinear exp ectation theory , b ey ond the framew ork of classical probability theory . The ma jor motiv ation of this research is to emphasize the probabilistic distribution uncertaint y within the ever increasingly complex comm unication netw orks, where random phenomena are often nonstationary , heterogeneous, and cannot b e characterized by a single probabilit y distribution. Based on the nonlinear exp ectation theory , in this pap er we rst explicitly dene sev eral fundamen tal concepts, such as nonlinear information en trop y , nonlinear joint entrop y , nonlinear conditional entrop y and nonlinear m utual information, and establish their basic prop erties. Secondly , b y using the strong law of large num b ers under sublinear exp ectations, we prop ose a nonlinear source co ding theorem, which shows that the nonlinear information entrop y is the upp er b ound of the ac hiev able co ding rate of sources whose distributions are uncertain under the maxim um error probabilit y criterion, and determines a cluster p oin t of the co ding rate of such sources under the minimum error probability criterion. Thirdly , we propose a nonlinear c hannel co ding theorem, which gives the explicit expression of the upper b ound under the maxim um error probability criterion and a cluster p oint under the minimum error probabilit y criterion, resp ectively , for the achiev able co ding rate of comm unication c hannels whose W en-Xuan Lang is with the National Center for Mathematics and Interdisciplinary Sciences, Academ y of Mathematics and Systems Science, Chinese Academ y of Sciences, Beijing 100190, China (e-mail: langwx@amss.ac.cn). Shaoshi Y ang is with the School of Information and Communication Engineering, Beijing Univ ersity of P osts and T elecommunications, with the Key Lab oratory of Univ ersal Wireless Communications, Ministry of Education, and also with the Key Lab oratory of Mathematics and Information Netw orks, Ministry of Education, Beijing 100876, China (e-mail: shaoshi.y ang@bupt.edu.cn). Jianh ua Zhang is with the School of Information and Comm unication Engineering, Beijing Univ ersity of Posts and T elecommunications, and also with the State Key Lab oratory of Net working and Switching T echnology , Beijing 100876, China (e-mail: jhzhang@bupt.edu.cn). Zhiming Ma is with the National Center for Mathematics and In terdisciplinary Sciences, A cademy of Mathematics and Systems Science, Chinese A cademy of Sciences, and also with Universit y of Chinese Academ y of Sciences, Beijing 100190, China (e-mail: mazm@am t.ac.cn). 2 distributions are uncertain. Additionally , we prop ose a nonlinear rate-distortion source co ding theorem, pro ving that the rate distortion function based on the nonlinear m utual information is a cluster point of the lossy compression performance of uncertain-distribution sources under the minimum exp ected distortion criterion. Finally , we show some examples and applications of uncertain-distribution sources and uncertain- distribution c hannels in the framew ork of nonlinear information theory , and present simulation results to consolidate our theoretic study . Index T erms Nonlinear exp ectation theory , nonlinear information theory , sublinear exp ectation, uncertain-distribution source, uncertain-distribution channel, strong law of large num b ers under sublinear expectations. I. Introduction A. Motiv ation The notion of uncertain t y pla ys a central role in information theory , whic h is built on the theory of probability and sto chastic pro cesses [1]. By assuming sp ecic individual distributions for information sources, comm unication c hannels, noises, and in terferences, the k ey concepts of Shannon information theory , such as m utual information, en trop y , and channel capacit y , are dened. The classical Shannon information theory can b e view ed as only considering the uncertaint y of one degree, i.e., the probabilit y distributions are dened for random ev ents only and the probabilit y space dened with the measure theory is deterministic and explicitly kno wn. In other w ords, the probabilit y mo dels in classical Shannon information theory are assumed to hav e no uncertain t y . Ho w ev er, in the complex ph ysical world fraugh t with a signicant amoun t of unanticipated and nonstationary random phenomena, the assumption of precise and w ell-dened probability distributions to describ e uncertainties is somewhat idealized. In many cases that, for instance, ha v e only limited observ ations or small sample size, there may not be a single, xed probability distribution that accurately captures the underlying randomness. This reality c hallenges the traditional approac h of relying on deterministic probabilit y mo dels, which typically assume the existence of an underlying “true” probabilit y distribution. As p ointed out in [2], probability is not an ob jectiv e prop ert y of the world but rather a construct based on sub jective judgmen ts and assumptions. In most practical scenarios, the assessments of probability are not estimates of some “true” probabilit y but rather expressions of p ersonal or collectiv e view of uncertaint y . This p ersp ectiv e underscores the need of developing more exible and realistic metho ds to c haracterize uncertain t y , moving b eyond the limitations of assuming xed and kno wn probabilistic distributions. 3 Giv en these insights, it is imp ortant to recognize that the classical Shannon information theory , while foundational, still has limitations when applied to real-world scenarios. Sp ecically , it relies on deterministic probabilit y mo dels and linear exp ectation op erations, b oth of which ma y not b e sucien t for capturing the complex randomness of real physical world. The probabilit y mo dels in classical Shannon information theory are c haracterized b y quantitativ e measures, i.e., moments, which are essen tially dep endent on the linear exp ectation op erations. Therefore, the classical information theory can b e view ed as linear information theory . Although the traditional probabilit y theories and metho ds can help us understand the la ws and structures of random systems to some degree, w e are often unable to completely eradicate the higher-level uncertainties inheren t in the probability mo dels themselv es that underlie these metho ds. This is particularly the case when the method adopted do es not matc h the underlying probabilit y mo del studied. An imp ortant question naturally arises: Can the classical Shannon information theory b e extended to characterize scenarios that hav e m ultiple levels of uncertaint y or uncertaint y of uncertaint y? If y es, how to extend the classical Shannon information theory to such scenarios? These are the tw o ma jor motiv ational questions b ehind this study . A t the time of writing, the telecommunications comm unity has b egun to fo cus on the p otential candidate tec hnologies for 6G [3]–[8]. The higher precision requirements for v arious algorithms asso ciated with information sources and communication channels in 6G require us to consider the impact of uncertaint y in the probability mo del itself as w ell. Therefore, new fundamental theories, as w ell as the related strong and trustw orthy analysis, are muc h needed. In ligh t of this, it is imp erativ e to consider a more holistic landscap e of uncertainties in wireless communications. B. Related W ork T raditionally , there are t wo types of uncertain t y aected by the probability mo dels used in comm unication systems. The rst is the uncertain t y inherent in information sources. Information en trop y , a w ell known concept for measuring uncertaint y in information sources, derives from the linear exp ectation of a deterministic probabilit y space. Among v arious denitions of information en trop y , the most famous one, Shannon entrop y [9], provides a mathematical to ol for quantifying information and analyzing the eciency of data compression. It pla ys a key role in solving practical problems and helps people deeply understand the essence of information and pro cess data. The successful application of Shannon en tropy has prompted researc hers to extend it from v arious aspects, leading to the emergence of concepts that can b e more generalized than Shannon entrop y . More sp ecically , Rényi entrop y , whic h w as in tro duced b y Rén yi [10], can b e regarded as an extension of Shannon entrop y . Marichal rst established the notion of Cho quet capacit y entrop y [11], which is 4 fundamen tally dep endent on Choquet capacit y and Cho quet exp ectation. There are also many other w orks dev oted to the generalization of entrop y based on the deterministic probability distribution, suc h as [12]–[15]. Ho w ev er, for all these metho ds, it is crucial to provide an explicit expression for the probability mo del, regardless of using the Cho quet capacit y or the probability measure. As a result, bias or e rror ma y b e imp osed on signal or information pro cessing algorithms once the real distribution of the information source div erges from the estimated distribution. F urthermore, in source co ding, Ziv prop osed fundamental concepts and frameworks for universal source co ding [16], [17], and a universal algorithm for sequential data compression w as presented [18]. A univ ersal W yner–Ziv co ding setup w as introduced in [19], where the distribution of the source is assumed unkno wn while the conditional distribution of the side-information channel is p erfectly kno wn. In [20], the authors used a single distribution chosen from a family of candidate distributions to describ e the information sources, and the distribution c hosen v aries with a set of given parameters that either c hange from sym b ol to sym b ol or remain constan t for a while. T o elab orate a little further, for the theoretical analysis of univ ersal sources, the op en literature t ypically assumes the existence of a particular distribution c haracterizing the random v ariable, ev en though the sp ecic parameters and/or form of this distribution are uncertain. In other words, although univ ersal source co ding can directly enco de sources with uncertain or unkno wn distributions, in theoretical analysis, the existing metho ds still assume that the underlying probabilit y mo del (i.e., the probabilit y space) is deterministic. In essence, traditional research on information sources is restricted to analyzing the uncertaint y c haracterized by random v ariables and the corresp onding well-dened probabilit y distributions, and is incapable of dealing with the uncertain t y inherent in probabilit y models themselv es. Therefore, it is dicult to use traditional theoretical framework to supp ort dynamic compatibility with v arious individual sources, hybrid sources, and unknown sources. This limitation ma y result in a high degree of inaccuracy when mo deling the physical law dominated but still randomly changing complex real w orld. Instead of assuming the existence of a xed probabilit y distribution, it makes more sense to recognize that the underlying randomness ma y not b e captured b y an y deterministic probabilit y mo del. Universal source co ding is a pow erful and elegant solution for compressing data without kno wing the exact source distribution. Our work aims to use nonlinear exp ectation theory to directly mo del and analyze distributional uncertain t y , without relying on any single underlying distribution. This approach do es not conict with universal source co ding, but instead helps to strengthen its theoretical basis in handling distributional uncertain t y . The second is the uncertain t y inherent in communication c hannel. The mathematical mo del used 5 to c haracterize the uncertaint y of the c hannel is typically describ ed as a deterministic transition probabilit y matrix. In 1959, Blac kw ell et al. rst generalized Shannon’s basic theorem on the capacit y of a channel to a class of memoryless c hannels [21], whic h can b e viewed as accounting for the uncertain t y of the transition probabilit y matrix itself. Afterwards, the concept of arbitrarily v arying c hannels (A V C) was established [22] in order to sim ulate communication channels with unknown transition probability matrices that ma y v ary with time in an arbitrary manner. An arbitrarily v arying c hannel can b e c haracterized by a family of transition probability matrices C = { P s ( ·|· ) , s ∈ S } , where s ∈ S is the index of a sp ecic transition probabilit y matrix P in the set C , under the classical comm unication framew ork. The denition of random co ding capacity was prop osed in [23] and deriv ed for A V C under the maxim um error probabilit y or a v erage error probabilit y criterion [24]– [27]. In [28], Ahlswede presented a strong theoretical p erformance guarantee that A V C can achiev e the random co ding capacity in some situations under the maximum error probability criterion. In recen t years, there is a renewed in terest in studying the impacts imp osed b y a family of transition probabilit y matrices, such as [29]–[31]. All the previous w orks based on the concept of a family of transition probabilit y matrices actually still assumed that the c hannel follo ws a certain distribution of this family within a sp ecic observ ation slot in time, frequency or spatial domain. In other w ords, the probability model remains conditionally deterministic, but its sp ecic expression may not b e known to the enco der or deco der. As we ha ve noted previously , in the complex ph ysical w orld, the uncertain ty inherent in probabilit y mo dels themselv es cannot b e eliminated. This means that even if we theoretically restrict the channel to a family of transition probabilit y matrices, in realit y we are still unable to conclude with any degree of condence that the channel m ust b e a mem b er of this family . Existing researc h on c hannels with a family of transition probability matrices has made signicant and impressiv e progress, providing v aluable insigh ts and practical solutions. Inspired b y these adv ancements, w e also aim to take a complemen tary theoretical approac h b y directly studying c hannels whose distributions are uncertain through the framework of nonlinear exp ectation theory . C. Nov el Contributions Against the ab o ve background, in this pap er, w e show that the recen tly dev elop ed nonlinear exp ectation theory [32], which extends classical probabilit y theory that inv olves linear exp ectation op erations to nonlinear exp ectation scenarios, can b e utilized to analyze the multi-lev el uncertain ties em b edded in the probabilit y mo dels of comm unication systems in the complex physical world. Stim ulated by the idea of nonlinear exp ectation theory , in this pap er we prop ose a nonlinear information theory , by considering a new nonlinear communication mo del, whic h has multi-lev el 6 uncertain ties in probabilit y distributions. The new theory inno v atively c haracterizes the uncertaint y in comm unications by using sublinear exp ectation to deal with the underlying families of probability distributions. Our main results demonstrate that the prop osed nonlinear information theory shares man y c haracteristics with classical linear information theory , while ha ving a far wider range of applications. The main contributions can b e summarized as follows: • Based on the nonlinear exp ectation theory , we generalize sev eral fundamental concepts related to information en tropy . Supp ose the messages from information sources are from a sublinear exp ectation space (Ω , H , E ) , where Ω is a sample space, H is a linear space consisting of real v alued functions dened on Ω , E is a sublinear exp ectation dened on (Ω , H ) . The corresp onding uncertain probabilit y distributions for the message is p oten tially c haracterized by { p θ } θ ∈ Θ , where θ is the index of a sp ecic distribution p in { p θ } θ ∈ Θ . W e deduce a nonlinear information en tropy as the form of ˆ H ( X ) := sup θ ∈ Θ X x p θ ( x ) log 1 p θ ( x ) (1) from a set of new hypotheses. Nonlinear joint entrop y , nonlinear conditional en trop y and nonlinear mutual information are also explicitly dened. Some imp ortant prop erties, such as the c hain rule and the F ano inequalit y , are generalized as well. • W e prop ose a nonlinear source coding theorem. Sp ecically , we use random pro cesses in nonlinear exp ectation spaces to represent message sequences, which can o v ercome the limitations of traditional indep enden t and identically distributed (i.i.d.) assumptions. W e also redene the metric for characterizing the p erformance of source enco der/deco der by sublinear exp ectation. Then, based on the mathematical concept of capacit y 1 , whic h is dierent from the concept of “channel capacity” in the con text of communications, and the strong la w of large n um b ers under sublinear exp ectations [33], we sho w that the nonlinear information en tropy ˆ H ( X ) is the upp er b ound of the achiev able co ding rate of uncertain-distribution sources under the maxim um error probabilit y criterion, and also determines a cluster p oint 2 inf θ ∈ Θ P x p θ ( x ) log 1 V ( x ) of the co ding rate of uncertain-distribution sources under the minimum error probabilit y criterion. This constitutes the nonlinear source co ding theorem. W e dra w an imp ortant conclusion that, within the framework of nonlinear information theory , the achiev able fundamental limit under the minim um error probability criterion m ust b e redened and no longer coincides with the classical source co ding limit deriv ed under a single probabilit y measure. 1 The mathematical “capacit y” is originally dened in measure theory , and the explicit form of mathematical “capacity” used in this pap er is given in Denition 5 of Section I I. 2 A cluster p oint of a sequence S is a p oint x , to which there is a subsequence of S that conv erges. 7 • W e prop ose a nonlinear channel co ding theorem to characterize v arying channels whose distri- butions are uncertain. T o this end, we dene an uncertain-distribution channel mo del, where all random v ariables, regardless of input or output, are deriv ed from sublinear expectation space (Ω , H , E ) under the foundational assumptions. Supp ose X is the input alphab et and Y is the output alphab et. The uncertain-distribution channel mo del is p oten tially characterized b y a family of transition probability matrices P λ ∈ [0 , 1] X ×Y λ ∈ Λ . After denoting R c as the ac hiev able channel co ding rate of comm unication systems that rely on the prop osed uncertain- distribution channel mo del, the upp er b ound and a cluster p oin t of R c for any giv en scenario are determined under the maximum error probabilit y criterion and the minim um error probability criterion, resp ectively , th us preliminarily characterizing the p erformance of communications systems describ ed by the prop osed uncertain-distribution channel mo dels. • W e also prop ose a generalized nonlinear rate-distortion co ding theorem. On the sublinear exp ectation space (Ω , H , E ) , we characterize the lossy compression for uncertain-distribution sources by the sublinear exp ectation, and establish the concept of maxim um exp ected distortion and minim um exp ected distortion. Then, the rate distortion function is extended in the sublinear exp ectation space and dened based on the nonlinear mutual information. On this basis, we pro v e that the rate distortion function based on the nonlinear mutual information is a cluster p oin t of the lossy compression p erformance of uncertain-distribution sources under the minimum exp ected distortion criterion. Being the rst to study information theory from the nonlinear exp ectation theory p ersp ective, this work represents a paradigm shift, extending the classical information theory and comm unication mo dels from linear to nonlinear. This new framework not only accommo dates the complex randomness of real-world scenarios but also pro vides nov el insigh ts in to the b ehavior of information sources and comm unication systems under higher-level of uncertain t y . D. Organization The remainder of the pap er is organized as follows. In Section I I, we briey in tro duce the basics of nonlinear exp ectation theory , the sp ecic denitions of mathematical capacity generated b y sublinear exp ectation, and the strong law of large n um b ers under sublinear exp ectations. In Section I I I, we establish a nonlinear communication mo del, and present the denitions of uncertain-distribution sources and uncertain-distribution c hannels, together with the corresponding denitions of nonlinear information measures. In Section IV, the main results of our nonlinear information theory are presen ted, including fundamen tal prop erties and co ding theorems for uncertain-distribution sources 8 and uncertain-distribution channels under nonlinear exp ectations. In Section V we sho w some examples and applications of uncertain-distribution sources and uncertain-distribution c hannels in the framew ork of nonlinear information theory , and present simulation results to consolidate our theoretic study . W e draw conclusions in Section VI. In App endix A, we provide an intuitiv e explanation of wh y we use the nonlinear exp ectation theory and compare it with traditional probabilistic metho ds to highligh t the dierences and adv an tages, and the pro ofs are deferred to the app endices B-E. I I. Basic Notions of Nonlinear Exp ectation Theory P eng [32] established the nonlinear exp ectation theory , which extends classical probabilit y theory b y using sublinear exp ectations instead of linear exp ectations. This theory is an emerging eld of mathematics and has oered signicant b enets to practical applications suc h as nance and risk managemen t [34]. The central idea of this theory is that random v ariables ha v e uncertain ty in the distribution itself. By incorp orating the distribution uncertain ty , this theory provides a more general framew ork for mo deling complex stochastic systems. In this section, we briey in tro duce the ma jor concepts of nonlinear exp ectation theory . T o facilitate readers’ understanding of this theory , we will pro vide some interpretativ e statements as we introduce the ma jor concepts. Readers may also rst refer to the main results and the intuitiv e explanations provided in later sections and come back to this section as needed. Nonlinear exp ectation theory is a no v el axiomatic system that is parallel to probability theory . Just as probabilit y theory starts from the axiomatized system of probabilit y space, the theory of nonlinear exp ectation establishes its basic theoretical framew ork at the lev el of the axiomatized system of sublinear exp ectation space. The developmen t of this theory commences with directly dening the sublinear exp ectation functional for uncertain quan tities (i.e. random v ariables). It is imp ortan t to note that although terms like “exp ectation” and “distribution” contin ue to b e used in this new theory , their meanings are to b e reundersto o d. F or details of the follo wing denitions and theorems, readers can refer to [35], [36]. Let Ω b e a sample set 3 . Let H b e a linear space of real v alued functions dened on Ω . Supp ose that H satises the following three conditions: 1) c ∈ H for each constan t c ∈ R . 2) | X | ∈ H if X ∈ H . 3) ϕ ( X 1 , · · · , X n ) ∈ H for each ϕ ∈ L ∞ ( R n ) if X 1 , · · · , X n ∈ H . Here L ∞ ( R n ) denotes the space of b ounded Borel-measurable functions on R n . The functions in H are called random v ariables. The tuple (Ω , H ) is called the space of random v ariables. 3 The set Ω here plays the same role as the sample space Ω in probability theory . 9 Denition 1: A sublinear exp ectation E : H → R is a functional dened on the space H satisfying the follo wing prop erties: 1) Monotonicity: E [ X ] ≥ E [ Y ] , if X ≥ Y . 2) Constant preserving: E [ c ] = c, ∀ c ∈ R . 3) Sub-additivity: E [ X + Y ] ≤ E [ X ] + E [ Y ] , ∀ X , Y ∈ H . 4) Positiv e homogeneity: E [ λX ] = λ E [ X ] , for λ ≥ 0 . The triplet (Ω , H , E ) is called a sublinear exp ectation space. If E satises only 1) and 2), then E is called a nonlinear exp ectation and (Ω , H , E ) is called a nonlinear exp ectation space. Remark 1: Note that a sublinear exp ectation E has p ositive homogeneit y , and for λ ∈ R , we only ha v e E [ λX ] = λ + E [ X ] + λ − E [ − X ] , (2) where λ + = max { λ, 0 } and λ − = max {− λ, 0 } . A dditionally , given a sublinear exp ectation E , the conjugate exp ectation E of sublinear exp ectation E is dened as E [ X ] := − E [ − X ] , ∀ X ∈ H . (3) Up on giving the Denition 1 of sublinear expectation, the following theorem shows that a sublinear exp ectation E can b e represented as the upp er exp ectation of a subset of linear exp ectations { E θ : θ ∈ Θ } , i.e. E [ X ] = sup θ ∈ Θ E θ [ X ] . Here the linear exp ectation is the notion in classical probabilit y theory . Theorem 1: Let E b e a sublinear exp ectation dened on (Ω , H ) . Then there exists a family of linear functionals { E θ : θ ∈ Θ } dened on H , such that E [ X ] = sup θ ∈ Θ E θ [ X ] , X ∈ H . (4) If E also satises E [ X i ] ↓ 0 for each sequence { X i } ∞ i =1 of random v ariables in H such that X i ↓ 0 , then for eac h θ ∈ Θ , there exists a probability measure P θ dened on the measurable space (Ω , σ ( H )) suc h that E θ [ X ] = Z Ω X dP θ , ∀ X ∈ H . (5) Then E θ is also denoted as E P θ and E [ · ] = sup θ ∈ Θ E P θ [ · ] . Here “ X i ↓ 0 ” means X i monotonically decreases to zero, and σ ( H ) is the smallest σ -algebra generated by H . The ab ov e theorem is called the represen tation theorem of sublinear exp ectation. This theorem indicates that a sublinear exp ectation can b e equiv alently characterized by a probabilit y measure family P = { P θ } θ ∈ Θ . In the remainder of this pap er, w e exclusively fo cus on the sublinear expectation E satisfying the conditions in Theorem 1 unless otherwise sp ecied. 10 Remark 2: W e call the family P the uncertain probabilit y measures asso ciated with the sublinear exp ectation E . F or a given n -dimensional random v ariable X dened on a sublinear exp ectation space (Ω , H , E ) , the probabilit y measure family P gives rise to a family of probability distributions { F X ( θ , A ) = P θ ( X ∈ A ) , A ∈ B ( R n ) } θ ∈ Θ , where B ( R n ) is the Borel σ -algebra on R n . F or notational con v enience, we also denote this family of probabilit y distributions as { p θ ( X ) } θ ∈ Θ . In such a case, w e claim the corresp onding uncertain probability distributions of X are { p θ ( X ) } θ ∈ Θ . Remark 3: In Theorem 1, the sublinear exp ectation is considered from the persp ective of the suprem um v alue of a family of linear exp ectations. F or certain scenarios, if p eople prefer the p ersp ective of the inm um v alue, they can also consider the term E [ X ] = − E [ − X ] = inf θ ∈ Θ E θ [ X ] . (6) Therefore, the essence of Theorem 1 lies in its abilit y to deriv e a family of probabilit y measures. Whether to consider the supremum or inm um v alue dep ends on the direction of interest. In this new framew ork, the nonlinear versions of the notions of indep endence and identical distribution pla y imp ortant roles, and these notions are shown in the following tw o denitions. Denition 2: Let X 1 and X 2 b e tw o n -dimensional random v ariables dened on sublinear exp ecta- tion spaces (Ω , H , E 1 ) and (Ω , H , E 2 ) , resp ectively . They are called identically distributed, denoted b y X 1 d = X 2 , if for any ϕ ∈ L ∞ ( R n ) we hav e E 1 [ ϕ ( X 1 )] = E 2 [ ϕ ( X 2 )] . (7) W e say that the distribution of X 1 is stronger than that of X 2 if E 1 [ ϕ ( X 1 )] ≥ E 2 [ ϕ ( X 2 )] , for each ϕ ∈ L ∞ ( R n ) . Remark 4: The stronger the distribution of random v ariables on sublinear expectation space, the greater the uncertaint y of their distribution families. Denition 3: In a sublinear exp ectation space (Ω , H , E ) , a random v ariable Y is said to b e indep enden t of another random v ariable X under E [ · ] , if for an y ϕ ∈ L ∞ ( R 2 ) w e hav e E [ ϕ ( X , Y )] = E [ E [ ϕ ( x, Y )] x = X ] . (8) It is imp ortan t to observe that, under a sublinear exp ectation, the statement “ Y is indep enden t of X ” do es not in general imply that “ X is indep endent of Y ” . This is considerably dieren t from traditional indep endence in classical probabilit y theory , in which these t wo statemen ts are equiv alent. W e give an example b elow, which also app ears in [35]. Consider the case where E is a sublinear exp ectation and X , Y ∈ H are identically distributed. W e assume that E [ X ] = − E [ − X ] = 0 , σ 2 = E [ X 2 ] > σ 2 = − E [ − X 2 ] , and E [ | X | ] > 0 . Then w e ha ve 11 E [ X + ] = 1 2 E [ | X | + X ] = 1 2 E [ | X | ] > 0 . W e now calculate E [ X Y 2 ] . In the case of Y indep endent of X , we rst hav e E [ xY 2 ] = x + E [ Y 2 ] + x − E [ − Y 2 ] = x + σ 2 − x − σ 2 , then E [ xY 2 ] x = X = X + σ 2 − X − σ 2 , where X + = max { X , 0 } and X − = max {− X , 0 } . Therefore, we ha ve E [ X Y 2 ] = E [ E [ xY 2 ] x = X ] = E [ X + σ 2 − X − σ 2 ] = ( σ 2 − σ 2 ) E [ X + ] > 0 . (9) In the case of X independent of Y , due to y 2 ≥ 0 , we hav e E [ X y 2 ] = y 2 E [ X ] = 0 . Therefore, we obtain E [ X Y 2 ] = E [ E [ X y 2 ] y = Y ] = 0 . (10) In fact, cases of asymmetric indep endence b etw een random v ariables in the real world are more common than cases of symmetric indep endence [37], [38]. This is esp ecially true for random v ariables related to time order. W e know that time has directionalit y , and there is a signicant asymmetry b et w een random v ariables that hav e o ccurred and those that will o ccur. Although random v ariables ma y not satisfy traditional indep endence in practice, it is p ossible that they satisfy the indep endence under sublinear exp ectation. Motiv ated by the notion of indep endent and iden tically distributed in a sublinear exp ectation space, w e also adopt the concept of I ID 4 random v ariables sequence under sublinear exp ectation, whic h is shown in Denition 4 b elow. Denition 4: Supp ose that { X 1 , X 2 , · · · , X n , · · · } is a sequence of random v ariables dened on a sublinear exp ectation space (Ω , H , E ) . 1) X 1 , X 2 , · · · , X n , · · · are said to b e iden tically distributed if for each pair of X i , X j , i = j and for eac h Borel-measurable function ϕ such that ϕ ( X i ) , ϕ ( X j ) ∈ H , there holds E [ ϕ ( X i )] = E [ ϕ ( X j )] . (11) 2) Random v ariable X n is said to b e indep enden t to X := ( X 1 , · · · , X n − 1 ) under sublinear exp ectation E if for each Borel-measurable function ϕ on R n with ϕ ( X , X n ) ∈ H and ϕ ( x , X n ) ∈ H for each x ∈ R n − 1 , w e hav e E [ ϕ ( X , X n )] = E [ E [ ϕ ( x , X n )] x = X ] . (12) 3) A sequence of random v ariables { X 1 , X 2 , · · · , X n , · · · } is said to b e I ID if X 1 , X 2 , · · · , X n , · · · are iden tically distributed and X i is indep endent to X := ( X 1 , · · · , X i − 1 ) for each i ≥ 1 . In order to analyze information sources under the framework of nonlinear information theory , it is necessary to introduce the mathematical concept of capacity generated by a sublinear exp ectation E . 4 Note that the notion of “IID” is dened under the framework of nonlinear exp ectation theory , and it is dieren t from “i.i.d. ” in classical probability theory . 12 Denition 5: A pair of capacities ( V , v ) is said to b e generated by a sublinear exp ectation E , if V ( A ) := E [ I A ] , v ( A ) := − E [ − I A ] , ∀ A ∈ F , (13) where I A ( ω ) = 1 , if ω ∈ A 0 , otherwise (14) is the indicator function of ev en t A , and F is a σ -algebra. Note that due to E [ X ] = sup θ ∈ Θ E P θ [ X ] , we can intuitiv ely understand the pair ( V , v ) in Denition 5 as V ( A ) = sup θ ∈ Θ P θ ( A ) and v ( A ) = inf θ ∈ Θ P θ ( A ) . A conclusion that is drawn from the strong law of large num b ers under sublinear exp ectations and is instrumental in dev eloping our nonlinear information theory is presented as follo ws. Theorem 2: Let { X i } ∞ i =1 b e a sequence of I ID random v ariables dened on a sublinear expectation space (Ω , H , E ) where E [ · ] = sup θ ∈ Θ E P θ [ · ] . Supp ose that { P θ } θ ∈ Θ is a coun tably-dimensional weakly compact family of probability measures on (Ω , σ ( H )) in the sense that, for any b ounded Y 1 , Y 2 , · · · ∈ H and an y sequence { P n } ⊂ { P θ } θ ∈ Θ , there is a subsequence { n k } and a probabilit y measure P ∈ { P θ } θ ∈ Θ suc h that lim k →∞ P n k ( ϕ ( Y 1 , · · · , Y d )) = P ( ϕ ( Y 1 , · · · , Y d )) . (15) Supp ose that C ( { x n } ) is the set of cluster p oints of the sequence { x n } . Then, for an y b ∈ [ − E [ − X 1 ] , E [ X 1 ]] w e ha ve V b ∈ C P n i =1 X i n = 1 . (16) In summary , as we delve in to the application of nonlinear exp ectation theory in our subsequen t studies, it is crucial to b ear in mind that this theory oers a robust to ol for mo deling and understanding the complexities of real pro cesses, particularly in the presence of randomly dynamic en vironmen tal changes and probability mo del uncertaint y . I I I. Establishmen t of Nonlinear Information Theory In this section, w e rst prop ose a new nonlinear comm unication mo del, and then derive the denitions of the essen tial new measures, including nonlinear information entrop y , nonlinear joint en trop y , nonlinear conditional entrop y and nonlinear m utual information, for nonlinear information theory on sublinear exp ectation space. The communication model in classical information theory t ypically p osits that a random v ariable describing messages ob eys a sp ecic probabilit y distribution. A clear denition of the probability mo del is crucial to exploring classical information theory . How ever, uncertaint y plays a central role 13 in the emergence of a signican t amount of unanticipated and heterogeneous data trac transmitted o v er a n um b er of randomly v arying c hannels which ma y not hav e sp ecic distribution. Although the metho ds of statistics and probabilit y theory can aid us in understanding the laws and structures of information sources and comm unication channels, it is challenging to completely eliminate the higher-lev el unce rtain ties inherent in these metho ds themselves. If the realistic circumstances deviate from the predetermined distributions, the classical comm unication mo del b ecomes inadequate. The probabilit y mo del itself is usually imprecise in practice. It is often dicult to adequately characterize the distributions of information sources and comm unication channels by assuming prior kno wn probabilit y mo dels, b ecause of the high degree of uncertain ties inheren t in b oth information sources and comm unication channels. In some scenarios, one can only determine the range of probability distributions. The newly developed nonlinear exp ectation theory can b e utilized to analyze the uncertainties of probability models themselves in the complex ph ysical world. This motiv ates us to consider c haracterizing the comm unication mo del on a sublinear exp ectation space, resulting in a nonlinear comm unication mo del with uncertain distributions, as shown in Fig. 1. Fig. 1: Nonlinear comm unication model with uncertain distributions. Compared with the classical communication mo del, in the proposed nonlinear comm unication mo del, we assume that the random v ariables describing the messages sent b y information sources are dened on the sublinear exp ectation space (Ω , H , E ) . In this case the information source is referred to as uncertain-distribution information source. The implicit meaning is that there are higher-lev el uncertain ties inherent in the distributions of the random v ariables describing information sources, whic h do not ob ey a deterministic probability distribution. Therefore, it is necessary to use families of probability distributions to c haracterize these individual random v ariables. W e also assume that the in terference and noise that aect signal transmission ov er the communication channel are random v ariables dened on a sublinear exp ectation space, meaning that the transition probabilit y matrices of communication channels are also uncertain. In this case the communication c hannel is 14 called uncertain-distribution channel. In summary , there are tw o types of uncertainties regarding the probability mo dels in volv ed in the transmission process X → Y according to our nonlinear comm unication mo del. One is the uncertain t y of the probability distributions of X and the other is the uncertain t y of the transition probability matrices of X → Y . F or uncertain-distribution information sources, it is imp ossible to study them using a deterministic probabilit y framework, because of the ambiguities asso ciated with the probability models themselves. As a result, several fundamental concepts, including information entrop y , joint en tropy and con- ditional en tropy , are not directly applicable. Each of them needs to b e reformulated under the framew ork of the nonlinear information theory . T o elab orate a little further, for a random v ariable dened on a sublinear exp ectation space, we aim to consider the amoun t of information it contains from the standp oin t of the circumstance with the highest uncertaint y . Let ˆ H ( X ) denote the measurement of the amoun t of information contained in X , where X is a discrete random v ariable on a sublinear exp ectation space (Ω , H , E ) and the corresp onding uncertain probabilit y distributions of X are c haracterized b y { p θ ( X ) } θ ∈ Θ . In order to reduce the mismatc hing error b etw een the probabilistic model of a system and the practical system itself, it is crucial to carefully analyze a series of random v ariables that hav e unkno wn distributions. Esp ecially , if the family of uncertain probability distributions of a random v ariable contains the uniform distribution, then the uniform distribution should b e used for analyzing the amoun t of information em b edded in the random v ariable, b ecause uniform distribution represents the highest uncertain t y case. F urthermore, it makes intuitiv e sense that the amount of information em b edded in a random v ariable increases with the size of the uncertain probability distributions family the random v ariable may follow. In ligh t of the ab ov e discussions, it is reasonable to make the following assumptions: Assumptions: 1) ˆ H ( X ) ≤ sup θ ∈ Θ P x p θ ( x ) log 1 p θ ( x ) and ˆ H ( X ) is contin uous with each distribution in the set { p θ ( X ) } θ ∈ Θ . 2) If the n um b er of states for X is N and the uniform distribution p ( i ) = 1 N , i = 1 , 2 , · · · , N , is a mem b er of the distribution family { p θ ( X ) } θ ∈ Θ , then ˆ H ( X ) = log N . 3) Let X and Y b e t wo random v ariables dened on the sublinear exp ectation spaces (Ω , H , E 1 ) and (Ω , H , E 2 ) , resp ectiv ely . If the distribution of Y is stronger than that of X , then ˆ H ( X ) ≤ ˆ H ( Y ) . 4) If a random choice 5 can b e broken down in to t w o successive random choices, the original ˆ H 5 Here the meaning of “random choice” can b e understo o d as an action that has m ultiple possible outcomes, as detailed in Section 6 of [9]. 15 corresp onding to the single random choice should b e no greater than the supremum of the w eigh ted sum of individual v alues of ˆ H corresp onding to the tw o successive random c hoices. Based on the ab ov e four assumptions, we derive the following theorem, which presents the mathematical expression of the amount of information con tained in discrete random v ariables dened on a sublinear exp ectation space. F urthermore, in Section IV, we will show that several imp ortant prop erties can b e attained by merely relying on these four fundamental assumptions. Theorem 3: Let X b e a discrete random v ariable on a sublinear exp ectation space (Ω , H , E ) . The corresp onding uncertain probability distributions of X are { p θ ( X ) } θ ∈ Θ . Then the amoun t of information con tained in X can b e expressed as ˆ H ( X ) = sup θ ∈ Θ P x p θ ( x ) log 1 p θ ( x ) . Pro of : See App endix B. ■ Without loss of generality , in this pap er we consider only discrete random v ariables. Then, based on Theorem 3, the nonlinear information entrop y of discrete random v ariables is formally dened b elo w. Denition 6: Let X b e a discrete random v ariable on a sublinear exp ectation space (Ω , H , E ) . The corresp onding uncertain probability distributions of X are { p θ ( X ) } θ ∈ Θ . The nonlinear information en trop y , or abbreviated as nonlinear entrop y , is formulated as ˆ H ( X ) := sup θ ∈ Θ X x p θ ( x ) log 1 p θ ( x ) . (17) The amoun t of information embedded in uncertain-distribution information sources is describ ed b y the nonlinear information en tropy presen ted abov e. F urthermore, to describe the uncertain ty in v olv ed in information transmission pro cesses, w e dene nonlinear join t entrop y and nonlinear conditional en trop y of tw o discrete random v ariables on a sublinear exp ectation space, as follows. Denition 7: Let X , Y b e t w o discrete random v ariables on a sublinear exp ectation space (Ω , H , E ) . The corresp onding uncertain probabilit y distributions of X are { p θ ( X ) } θ ∈ Θ , and the corresp onding uncertain transition probability matrices of Y given X are { P λ ( Y | X ) } λ ∈ Λ . Then 1) the nonlinear join t entrop y of X and Y is dened as: ˆ H ( X , Y ) := sup θ ∈ Θ sup λ ∈ Λ X x,y p θ ( x ) p λ ( y | x ) log 1 p θ ( x ) p λ ( y | x ) , (18) 2) the nonlinear conditional entrop y of Y given X is dened as: ˆ H ( Y | X = x ) := sup λ ∈ Λ X y p λ ( y | x ) log 1 p λ ( y | x ) (19) and ˆ H ( Y | X ) := sup θ ∈ Θ X x p θ ( x ) ˆ H ( Y | X = x ) . (20) 16 The example b elow may help us develop an intuitiv e understanding of ho w nonlinear information en trop y is aected by the uncertain ty of the distributions. Let p and ϵ b e t wo constants in the in terv al [0 , 1] . Consider a discrete random v ariable X with tw o p ossible v alues { 0 , 1 } . Supp ose that the probability of the even t { X = 0 } is uncertain but takes v alue in [max( p − ϵ, 0) , min( p + ϵ, 1)] and Pr ( X = 1) = 1 − Pr ( X = 0) . The uncertain probability distributions of X are characterized as a family of probability distributions, whic h is denoted b y { p q ( X ) } q ∈ [max( p − ϵ, 0) , min( p + ϵ, 1)] . More sp ecically , we ha v e { p q ( X ) } q ∈ [max( p − ϵ, 0) , min( p + ϵ, 1)] = { p q = { q , 1 − q }| q ∈ [max( p − ϵ, 0) , min( p + ϵ, 1)] } . (21) Note that the larger ϵ , the greater the uncertaint y of distributions of X . 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Fig. 2: ˆ H ( X ) v ersus p , where ϵ = 0 , ϵ = 0 . 05 and ϵ = 0 . 1 . A simple calculation tells us ˆ H ( X ) = sup q ∈ [max( p − ϵ, 0) , min( p + ϵ, 1)] q log 1 q + (1 − q ) log 1 1 − q . (22) The relation b etw een ˆ H ( X ) and p is shown in Fig. 2, where the red dashed line and the y ellow dash- dotted line represent nonlinear information entrop y ˆ H ( X ) with ϵ = 0 . 05 and ϵ = 0 . 1 , resp ectively , while the blue solid line represents H p = p log 1 p + (1 − p ) log 1 1 − p with the logarithmic base b eing 2. W e observe that the v alue of the nonlinear information entrop y ˆ H ( X ) increases with the v alue of ϵ , which determines the degree of uncertaint y of distributions of X . This is consistent with the in tuition. 17 F or uncertain-distribution channel mo del dened with sublinear exp ectation space, it is necessary to dene new measures related to the signal transmission pro cess X → Y , where X and Y are tw o discrete random v ariables dened on a sublinear exp ectation space (Ω , H , E ) . In order to describ e the uncertain t y of the transmission pro cess clearly , it is necessary to dene nonlinear mutual information under the framework of nonlinear information theory , in accordance with the concepts of nonlinear exp ectation and the uncertaint y of distributions. Denition 8: Let X , Y b e t w o discrete random v ariables on a sublinear exp ectation space (Ω , H , E ) . The corresp onding uncertain probabilit y distributions of X are { p θ ( X ) } θ ∈ Θ , and the corresp onding uncertain transition probabilit y matrices of Y giv en X are { P λ ( Y | X ) } λ ∈ Λ . Then the nonlinear m utual information b etw een X and Y is dened as I [ X ; Y ] := sup θ ∈ Θ sup λ ∈ Λ X x,y p θ ( x ) p λ ( y | x ) log p λ ( y | x ) P x p λ ( y | x ) p θ ( x ) . (23) If there is also a discrete random v ariable Z suc h that the corresp onding uncertain transition probabilit y matrices of X giv en Z are { P λ 1 ( X | Z ) } λ 1 ∈ Λ 1 and the corresp onding uncertain transition probabilit y matrices of Y giv en X , Z are { P λ 2 ( Y | X , Z ) } λ 2 ∈ Λ 2 , then the nonlinear conditional m utual information is dened as I [ X ; Y | Z ] := sup λ 1 ∈ Λ 1 sup λ 2 ∈ Λ 2 X x,y p λ 1 ( x | z ) p λ 2 ( y | x, z ) log p λ 2 ( y | x, z ) P x p λ 2 ( y | x, z ) p λ 1 ( x | z ) . (24) Remark 5: W e also use the notation I [ { p θ ( X ) } θ ∈ Θ ; { P λ ( Y | X ) } λ ∈ Λ ] to denote nonlinear m utual information. This indicates that the uncertain t y of distributions, rather than messages or random v ariables themselves, is the more signicant factor within the framew ork of nonlinear information theory . Consider an uncertain-distribution channel with input alphab et X and output alphab et Y . Due to the uncertaint y of the actual transmission pro cess, the corresp onding uncertaint y of the uncertain- distribution c hannel can b e expressed as a family of transition probabilit y matrices { P λ ∈ [0 , 1] X ×Y } λ ∈ Λ . W e denote this uncertain-distribution channel by [ X , { P λ ∈ [0 , 1] X ×Y } λ ∈ Λ , Y ] . Denition 9: Let (Ω , H , E ) b e a sublinear expectation space where E [ · ] = sup θ ∈ Θ E P θ [ · ] . An uncertain- distribution channel [ X , { P λ ∈ [0 , 1] X ×Y } λ ∈ Λ , Y ] is called memoryless if for any input co dewords x 1 , · · · , x n and output co dewords y 1 , · · · , y n , the uncertain-distribution channel satises { P θ ( Y 1 = y 1 , · · · , Y n = y n | X 1 = x 1 , · · · , X n = x n ) } θ ∈ Θ = { n Y i =1 p λ ( y i | x i ) } λ ∈ Λ . (25) where X 1 , · · · , X n denote the input random v ariables, Y 1 , · · · , Y n denote the output random v ariables. Without loss of generality , in this pap er we only consider discrete memoryless uncertain-distribution c hannel, which is the most commonly used channel mo del. 18 T o summarize, we newly dene several fundamental concepts for nonlinear information theory , presen ting a nov el framework for understanding the uncertain ties of information sources and com- m unication channels b y using nonlinear exp ectation theory . This study extends classical information theory to accommo date the complexities in tro duced b y the uncertain ty of probabilit y models, oering new insigh ts into the analysis of information and comm unication systems. IV. Main Results of Nonlinear Information Theory In this section w e present the main results of our nonlinear information theory relying on a sublinear expectation space (Ω , H , E ) , where the uncertaint y of the probability measures asso ciated with E is characterized b y P = { P θ } θ ∈ Θ , i.e., E [ X ] = sup θ ∈ Θ Z Ω X dP θ , ∀ X ∈ H . (26) In Section IV-A, we prov e some imp ortant prop erties for nonlinear information entrop y , nonlinear join t en trop y , nonlinear conditional entrop y and nonlinear m utual information. W e demonstrate that some prop erties in the nonlinear information theory are consistent with their counterparts in the classical information theory , such as the data pro cessing inequality , while others diverge, suc h as the chain rule and F ano inequality . In Section IV-B, we describ e the pro cess of source co ding in nonlinear information theory and prop ose the nonlinear source co ding theorem. In Section IV-C, w e discuss the pro cess of channel coding in nonlinear information theory and prop ose the nonlinear c hannel co ding theorem. In Section IV-D, w e analyze the source co ding with distortion in nonlinear information theory and prop ose the nonlinear rate-distortion source co ding theorem. W e dra w an imp ortan t conclusion that when conducting source co ding researc h under the frame- w ork of nonlinear information theory , the achiev able fundamen tal limit under the minimum error probabilit y criterion must b e redened and no longer coincides with the classical source co ding limit. W e also make progress in the fundamental limits of channel co ding and source co ding with distortion under the framework of nonlinear information theory . These discov eries are signican t and can b e used to explain v arious phenomena that o ccur in the complex physical world. A. Prop erties of New Measures in Nonlinear Information Theory In this subsection, w e pro v e some imp ortant prop erties for nonlinear information measures. These prop erties can b e prov ed by taking appropriate supremum and inmum op erations o v er the underlying set of probability measures, and the pro ofs are therefore omitted. 19 Theorem 4: Let X , Y b e tw o discrete random v ariables on a sublinear expectation space (Ω , H , E ) . The corresp onding uncertain probabilit y distributions of X are { p θ ( X ) } θ ∈ Θ , and the corresp onding uncertain transition probability matrices of Y given X are { P λ ( Y | X ) } λ ∈ Λ . Then, we hav e ˆ H ( X , Y ) ≤ ˆ H ( X ) + ˆ H ( Y | X ) . (27) The equalit y holds when the distributions of X and transition probabilit y matrices of Y given X b ecome deterministic. Moreov er, when ˆ H ( Y | X ) = 0 , the ab ov e inequalit y degenerates into the equalit y ˆ H ( X , Y ) = ˆ H ( X ) . ■ A ccording to this theorem, w e can observ e that in con trast to nonlinear join t en tropy , nonlinear conditional entrop y is increased more due to the introduction of the uncertaint y of transition probabilit y matrices. Note that the prop erty presen ted by Theorem 4 is dieren t from its counterpart in classical information theory , where only the equalit y holds. Nonlinear mutual information describ es the amount of information obtained ab out a group of random v ariables b y observing the other group of random v ariables, under the framew ork of nonlinear exp ectation theory . This concept is intimately related to nonlinear information en trop y and nonlinear conditional entrop y of random v ariables. Based on the ab ov e observ ation, the relation b etw een nonlinear m utual information, nonlinear information entrop y and nonlinear conditional entrop y is also dieren t from the coun terpart in classical information theory , as demonstrated by the follo wing theorem. Theorem 5: Let X , Y b e tw o discrete random v ariables on a sublinear expectation space (Ω , H , E ) . The corresp onding uncertain probabilit y distributions of X are { p θ ( X ) } θ ∈ Θ , and the corresp onding uncertain transition probability matrices of Y given X are { P λ ( Y | X ) } λ ∈ Λ . Then, we hav e I ( X ; Y ) ≥ ˆ H ( X ) − ˆ H ( X | Y ) . (28) The equalit y holds when the distributions of X and transition probabilit y matrices of Y given X b ecome deterministic. Moreov er, when ˆ H ( X | Y ) = 0 , the ab ov e inequalit y degenerates into the equalit y I ( X ; Y ) = ˆ H ( X ) . ■ Remark 6: Note that ˆ H ( X | Y ) ≤ ˆ H ( X ) do es not hold in nonlinear information theory . How ever, in classical information theory , we ha ve H ( X | Y ) ≤ H ( X ) , where H ( X | Y ) and H ( X ) are the conditional en trop y and the en trop y , resp ectiv ely . As the case extends to more than tw o random v ariables, the chain rule regarding nonlinear join t en trop y and nonlinear conditional entrop y exhibits an inequality form, and so do es the chain rule of nonlinear mutual information. These insigh ts are shown in Theorem 6 and Theorem 7, resp ectiv ely . 20 Theorem 6: F or a discrete random v ariable sequence X 1 , · · · , X n dened on a sublinear exp ectation space (Ω , H , E ) , we ha ve ˆ H ( X 1 , · · · , X n ) ≤ n X i =1 ˆ H ( X i | X i − 1 , · · · , X 1 ) . (29) ■ Theorem 7: F or a discrete random v ariable sequence X 1 , · · · , X n and a discrete random v ariable Y , b oth dened on a sublinear exp ectation space (Ω , H , E ) , we hav e I ( X 1 , X 2 , · · · , X n ; Y ) ≤ n X i =1 I ( X i ; Y | X i − 1 , · · · , X 1 ) . (30) ■ Let X , ˆ X b e t wo discrete random v ariable dened on a sublinear exp ectation space (Ω , H , E ) . X denotes the set of the states of X . Consider the signal transmission pro cess X → ˆ X , where X and ˆ X represen t input and output messages, resp ectively . Because of the uncertain ty of the input probabilit y distributions and the uncertaint y of the transition probability matrices, the probability of the communication error ev en t { ˆ X = X } is also uncertain. That is, it obeys a family of probabilities { P θ ( ˆ X = X ) } θ ∈ Θ . F or notational con venience, in what follows we shall simply denote P θ ( ˆ X = X ) b y P e,θ and denote the set { P θ ( ˆ X = X ) } θ ∈ Θ b y P e . The F ano inequality , which describ es the relation b et w een conditional entrop y and error probabilit y , is an imp ortant property in classical information theory . In the framew ork of nonlinear comm unication mo dels, we can also deriv e a relation b etw een nonlinear conditional entrop y and a family of error probabilities, as stated b elow. Theorem 8: Let X , ˆ X b e tw o discrete random v ariables on a sublinear exp ectation space (Ω , H , E ) . X denotes the set of the states of X , P e,θ = P θ ( ˆ X = X ) , and P e = { P θ ( ˆ X = X ) } θ ∈ Θ . Then w e hav e ˆ H X | ˆ X ≤ sup P e,θ ∈P e P e,θ log 1 P e,θ + (1 − P e,θ ) log 1 1 − P e,θ + sup P e,θ ∈P e P e,θ log ( ∥ X ∥ − 1) , (31) where ∥ X ∥ indicates the cardinalit y of the set X . ■ The follo wing theorem sho ws that the data pro cessing inequalit y in nonlinear information theory tak es the same form as in the classical situation. Theorem 9: Consider the nonlinear Marko v pro cess X → Y → Z , where X , Y , Z are discrete random v ariables dened on a sublinear exp ectation space (Ω , H , E ) . W e hav e I ( X ; Z ) ≤ min( I ( X ; Y ) , I ( Y ; Z )) . (32) ■ The insights revealed b y the ab ov e theorems are crucial in adv ancing the nonlinear information theory . They demonstrate the conclusion that the uncertainties inheren t in the distributions of 21 information sources and communication channels can lead to a v ariety of no vel information-theoretic results. B. Source Co ding in Nonlinear Information Theory In the framew ork of nonlinear information theory , in order to reduce information redundancy and impro v e communication eciency , it is necessary to enco de and deco de for the uncertain-distribution information sources, similar to the case in classical information theory . Source co ding in nonlinear information theory refers to the pro cess of enco ding and deco ding for uncertain-distribution sources that is incorp orated in a nonlinear communication mo del. The pro cesses of enco ding and deco ding for uncertain-distribution sources are similar to those of source co ding in classical information theory . Ho w ev er, it is imp ortant to note that information sources are dened on a sublinear exp ectation space (Ω , H , E ) , whic h implies that the sources hav e distribution uncertaint y . Therefore, the probability mo dels for analyzing the asso ciated problems are uncertain as well, and the p erformance measure of the transmission pro cess need to b e redened. The enco ding and deco ding for source co ding pro cesses in nonlinear information theory can still b e represented as functions. Sp ecically , a ( ||W || , n, f n , g n ) nonlinear source co de consists of: • A source enco ding function f n : X n → W that assigns an index W ∈ W to each X n ∈ X n . • A source deco ding function g n : W → X n that assigns an estimate ˆ X n ∈ X n to each index W ∈ W . F or the abov e nonlinear source co de, the source co ding rate R s is dened as log ||W || n . After the uncertain-distribution information source generates source messages X n = ( X 1 , · · · , X n ) , the source messages are enco ded in to an index W ∈ W b y the encoding function f n : X n → W . After determining the index W ′ b elonging to W , W ′ is pro cessed by the deco ding function g n : W → X n , to estimate the original message as ˆ X n = ( ˆ X 1 , · · · , ˆ X n ) = g ( W ′ ) . Within the framework of nonlinear exp ectation theory , due to the existence of the family of uncertain probabilit y measures { P θ } θ ∈ Θ asso ciated with the sublinear exp ectation, the p erformance of the ab ov e nonlinear source co de is measured by the maxim um and the minim um probabilities of the ev en t that the estimate of the message is dieren t from the message actually sent. Here, these probabilities are calculated as E h I { ˆ X n = X n } i = sup θ ∈ Θ P θ ( ˆ X n = X n ) = sup θ ∈ Θ P ( n ) e,θ , (33) E h I { ˆ X n = X n } i = inf θ ∈ Θ P θ ( ˆ X n = X n ) = inf θ ∈ Θ P ( n ) e,θ , (34) where E represents the conjugate expectation of E and is dened by (3). In tuitively , the ab o ve men tioned terms “maximum probabilit y” and “minimum probabilit y” corresp ond to the conserv ative 22 and the aggressive strategies of designing nonlinear source co de, respectively . Based on this insight, there are tw o criteria for ev aluating the p erformance of nonlinear source co de, namely the maximum error probability criterion and the minim um error probability criterion. The former refers to ensuring E h I { ˆ X n = X n } i to b e suciently small, while the latter refers to ensuring E h I { ˆ X n = X n } i to b e suciently small. The notions of nonlinear iden tically distributed in Denition 2 and nonlinear indep endence in Denition 3 pla y a key role in nonlinear exp ectation theory , since they reasonably c haracterize the correlation of data in the real w orld. The main purp ose of nonlinear information theory is to handle actual messages that exhibit high uncertaint y , hence it is crucial to characterize message sequences using I ID random v ariables on sublinear exp ectation space. Denition 10: A sequence of messages denoted by X 1 , X 2 , · · · , X n , · · · is said to be an IID source if X 1 , X 2 , · · · , X n , · · · are I ID. Remark 7: It is frequently fav ored in classical information theory to assume that the sequence of random v ariables are i.i.d. in the sense as dened in classical probability theory . Ho w ev er, if actual messages in complex physical w orld are considered, generally one cannot ensure that the messages strictly satisfy the traditional i.i.d. requirements. On the other hand, it is demonstrated that in most cases actual messages can more easily satisfy the I ID requirements under the framew ork of nonlinear exp ectation theory [36]. F or a discrete I ID source sequence X 1 , X 2 , · · · , X n , · · · on a sublinear exp ectation space, it is imp ortan t to study the fundamental limit of its source co ding rate. Note that ˆ H ( X 1 ) = ˆ H ( X 2 ) = · · · = ˆ H ( X n ) = · · · holds true, since we consider an I ID source sequence. Theorem 10: Let X 1 , X 2 , · · · , X n , · · · b e a discrete I ID source sequence dened on a sublinear exp ectation space (Ω , H , E ) where the uncertain probability measures asso ciated with sublinear exp ectation E are denoted as { P θ } θ ∈ Θ , i.e., E [ · ] = sup θ ∈ Θ E P θ [ · ] . The corresp onding uncertain probability distributions of X 1 are { p θ ( X 1 ) } θ ∈ Θ . ( V , v ) is the pair of capacities generated by E (see Denition 5). Supp ose that { P θ } θ ∈ Θ is a coun tably-dimensional w eakly compact family of probabilit y measures on (Ω , σ ( H )) (see Theorem 2). Then, we ha ve 1) for an y R s ≥ inf θ ∈ Θ P x p θ ( x ) log 1 V ( x ) and any ϵ of p ositiv e v alue, there is a suciently large n and a ( ||W || , n, f n , g n ) nonlinear source co de with source co ding rate R s suc h that E h I { ˆ X n = X n } i < ϵ ; 2) for an y R s ≥ ˆ H ( X 1 ) and an y ϵ of p ositiv e v alue, there is a suciently large n and a ( ||W || , n, f n , g n ) nonlinear source co de with source co ding rate R s suc h that E h I { ˆ X n = X n } i < ϵ . Pro of : See App endix C. ■ W e call Theorem 10 the nonlinear source coding theorem. It demonstrates that inf θ ∈ Θ P x p θ ( x ) log 1 V ( x ) 23 is a cluster point of the achiev able co ding rate of uncertain-distribution sources under the minim um error probabilit y criterion, with the condition that { P θ } θ ∈ Θ is a countably-dimensional weakly compact family of probabilit y measures on (Ω , σ ( H )) . This condition is imp osed only to ensure the v alidity of the strong law of large num b ers under sublinear exp ectations, as describ ed in Theorem 2. It also demonstrates that ˆ H ( X 1 ) is closely related to the limit of the source co ding rate R s of uncertain-distribution sources in our nonlinear communication mo del. In other w ords, ˆ H ( X 1 ) is the upp er b ound of the achiev able co ding rate of uncertain-distribution sources under the maximum error probabilit y criterion. It is worth noting that the source co ding rate limit in the rst statement of Theorem 10 can ac hiev e or impro ve up on the classical source co ding rate limit. In classical Shannon information theory , for an information source X with probability distribution p ( X ) , the limit of source co ding rate is P x p ( x ) log 1 p ( x ) , i.e., Shannon entrop y . F urthermore, if the random v ariable is assumed to follow a sp ecic probabilit y distribution from a family of distributions { p θ ( X ) } θ ∈ Θ but the exact one is unkno wn, then the limit of source co ding rate can b e optimized to inf θ ∈ Θ P x p θ ( x ) log 1 p θ ( x ) under the minim um error probability criterion. By con trast, in the nonlinear information theory dev elop ed in this pap er, we consider a more general case that the random v ariable is describ ed by a family of distributions { p θ ( X ) } θ ∈ Θ but it do es not follo w any sp ecic distribution within the family . Instead, the family of distributions is used as a conceptual to ol to characterize the random v ariable’s b eha vior without assuming it follo ws an y particular distribution. This more general scenario and the relaxation of the traditional i.i.d. assumption make it p ossible to exceed the traditional source co ding rate limit. Because V ( x ) is greater than p θ ( x ) for any θ ∈ Θ , we know that the v alue of inf θ ∈ Θ P x p θ ( x ) log 1 V ( x ) in the rst statement of Theorem 10 is smaller than the v alue of inf θ ∈ Θ P x p θ ( x ) log 1 p θ ( x ) . Remark 8: Note that Theorem 10 do es not sp ecify the limit of source co ding rate in nonlinear information theory . The pro of of Theorem 10 is based signican tly on the prop erty of the cluster p oin t of a sequence that there alwa ys exists a subsequence conv erging to the cluster p oin t. As a result, this theorem is neither an asymptotic nor a nite-length sequence conclusion. It only shows that there is a sucien tly large n to satisfy the conclusion that E [ I { ˆ X n = X n } ] < ϵ or E [ I { ˆ X n = X n } ] < ϵ . That is, if n 0 can fulll the conclusion, it do es not automatically mean that n 0 + 1 can satisfy this conclusion. Despite the p oten tial gap, theoretically , a more accurate representation of uncertain-distribution sources can b e made by using Theorem 10, compared with traditional representation of information sources. Although w e hav e not formulated the precise asymptotic b ounds of the source co ding rate in nonlinear information theory , the metho dology w e ha ve introduced to study nonlinear source coding 24 is also v aluable for studying the other parts of nonlinear information theory . C. Channel Co ding in Nonlinear Information Theory In this subsection, we rst consider the pro cess of c hannel co ding under the nonlinear information theory framew ork as data passes through the uncertain-distribution c hannels, i.e. comm unication c hannels with uncertain ty inherent in transition probabilit y matrices. A ( M , n, φ n , ψ n ) nonlinear c hannel co de consists of: • A message set S = { 1 , 2 , · · · , M } . • A channel enco ding function φ n : S → X n that assigns a co deword X n ∈ X n to eac h message S ∈ S . • A c hannel deco ding function ψ n : Y n → S that assigns an estimate ˆ S ∈ S to each received sequence Y n ∈ Y n . The c hannel co ding rate of the ( M , n, φ n , ψ n ) nonlinear channel co de is dened as log M n . Supp ose we w an t to transmit a message S from the message set S . F or the ab ov e ( M , n, φ n , ψ n ) nonlinear c hannel co de, the enco ding function φ n : S → X n is applied to conv ert the message S into a co dew ord X n ∈ X n . This co deword is then transmitted ov er the uncertain-distribution c hannel [ X , P λ ∈ [0 , 1] X ×Y λ ∈ Λ , Y ] . The uncertain-distribution channel pro cesses the transmitted co dew ord X n and pro duces an output sequence Y n . The decoding function ψ n : Y n → S is subsequently applied to the receiv ed sequence Y n to estimate the original message, yielding the deco ded message ˆ S = ψ n ( Y n ) . The ab o ve transmission pro cess using the uncertain-distribution channel co ding scheme can b e characterized as: S φ n − → X n { P λ ∈ [0 , 1] X ×Y } λ ∈ Λ − − − − − − − − − − − → Y n ψ n − → ˆ S . (35) Note that S is a random v ariable dened on a sublinear exp ectation space (Ω , H , E ) . Based on the nonlinear exp ectation theory , the error p erformance in the ab ov e message transmission pro cess (35) is characterized as the maximum and the minimum probabilities of the ev en t that the estimate of the message is dierent from the message actually sent. Here, these probabilities are calculated as E h I { ˆ S = S } i = sup θ ∈ Θ P θ ˆ S = S = sup θ ∈ Θ P ( n ) e,θ , (36) E h I { ˆ S = S } i = inf θ ∈ Θ P θ ˆ S = S = inf θ ∈ Θ P ( n ) e,θ . (37) In tuitiv ely , the ab ov e men tioned terms “maximum probability” and “minimum probability” cor- resp ond to the conserv ativ e and the aggressive strategies of designing nonlinear channel co de, resp ectiv ely . Therefore, similar to the research of source coding in Section IV-B, there are also t w o criteria for ev aluating the p erformance of nonlinear c hannel co de, namely the maxim um error 25 probabilit y criterion and the minimum error probabilit y criterion. The former refers to ensuring E h I { ˆ X n = X n } i to b e suciently small, while the latter refers to ensuring E h I { ˆ X n = X n } i to b e suciently small. The purp ose of channel coding in our nonlinear information theory is to mak e the maximum probabilit y or the minim um probabilit y of errors o ccurring as small as p ossible, while making the c hannel co ding rate as large as p ossible. Remark 9: The deco ded message ˆ S is related to the output sequence of the uncertain-distribution c hannel, whic h is c haracterized b y P λ ∈ [0 , 1] X ×Y λ ∈ Λ . Therefore, the calculations of (36) and (37) are also aected b y the family of transition probabilit y matrices P λ ∈ [0 , 1] X ×Y λ ∈ Λ . Ho w ev er, in (36) and (37), only θ and Θ are presen t. This is because λ and Λ are implicitly but closely related to θ and Θ . Essentially , all distribution families considered in this pap er are derived from the family of probabilit y measures P = { P θ } θ ∈ Θ , whic h is asso ciated with sublinear exp ectation. F or the sake of notational conv enience, in this pap er we generally use θ, Θ to represen t the distributions of random v ariables and λ, Λ to represent the transition probabilit y matrices. The num b er R c ≥ 0 represen ts an achiev able co ding rate for the uncertain-distribution c hannel under the maxim um error probability criterion or the minimum error probabilit y criterion, if there exist a sequence of ( M , n, φ n , ψ n ) nonlinear c hannel co des with co ding rate R c suc h that sup θ ∈ Θ P ( n ) e,θ or inf θ ∈ Θ P ( n ) e,θ tends to 0 as n → ∞ . F or an y uncertain-distribution channel [ X , P λ ∈ [0 , 1] X ×Y λ ∈ Λ , Y ] , one of fundamen tal researc h problems is to determine the upper and the low er b ounds of achiev able c hannel co ding rate under the maximum error probability criterion or the minimum error probability criterion. Let C := sup { p θ }⊂{ p ( x ) ,x ∈X } I { p θ } θ ∈ Θ ; { P λ ∈ [0 , 1] X ×Y } λ ∈ Λ = sup p ( x ) sup λ ∈ Λ X x ∈X ,y ∈Y p ( x ) p λ ( y | x ) log p λ ( y | x ) P x p ( x ) p λ ( y | x ) . (38) Then, w e derive the upp er b ound of achiev able co ding rate for uncertain-distribution c hannels under the maxim um error probabilit y criterion in the following theorem, which guarantees that, if the probabilit y mo del itself has uncertain t y , C represents the upp er b ound of the ac hiev able channel co ding rate under the maxim um error probability criterion. Theorem 11: Dene a discrete memoryless uncertain-distribution channel [ X , P λ ∈ [0 , 1] X ×Y λ ∈ Λ , Y ] with a sublinear exp ectation space (Ω , H , E ) . F or an y sequence of ( M , n, φ n , ψ n ) nonlinear channel co des with coding rate R c , if the maximum probability of errors o ccurring, i.e., sup θ ∈ Θ P ( n ) e,θ , tends to 0 as n → ∞ , then R c ≤ C must hold. Pro of : See App endix D. ■ 26 By using the strong la w of large n um b ers under sublinear exp ectations (Theorem 2), we obtain the following theorem. How ever, a similar issue as pointed out in Remark 8 exists, i.e., Theorem 12 is neither an asymptotic nor a nite-length sequence conclusion. Theorem 12: Dene a discrete memoryless uncertain-distribution channel [ X , P λ ∈ [0 , 1] X ×Y λ ∈ Λ , Y ] with a sublinear exp ectation space (Ω , H , E ) where the uncertain probability measures asso ciated with sublinear expectation E are { P θ } θ ∈ Θ , i.e., E [ · ] = sup θ ∈ Θ E P θ [ · ] . ( V , v ) is the pair of capacities generated by E (see Denition 5). Supp ose that { P θ } θ ∈ Θ is a coun tably-dimensional w eakly compact family of probability measures on (Ω , σ ( H )) (see Theorem 2). Then, for any R c < C and any ϵ of p ositiv e v alue, there is a suciently large n and a ( M , n, φ n , ψ n ) nonlinear c hannel code with co ding rate R c suc h that E h I { ˆ S = S } i = inf θ ∈ Θ P ( n ) e,θ < ϵ. (39) Pro of : See App endix D. ■ Theorem 12 shows that C is a cluster p oint of the channel co ding rate of uncertain-distribution c hannels under the minim um error probability criterion, with the condition that { P θ } θ ∈ Θ is a coun tably-dimensional weakly compact family of probabilit y measures on (Ω , σ ( H )) . This condi- tion is imp osed only to ensure the v alidity of the strong law of large num b ers under sublinear exp ectations, as described in Theorem 2. F urthermore, Theorem 11 and Theorem 12 are collectiv ely called the nonlinear channel co ding theorems. These theorems provide a theoretical foundation for b etter characterizing the p erformance of communications systems. Although we hav e not established the suprem um of the achiev able co ding rate for uncertain-distribution channels, it oers a fresh p ersp ective on exploring the p erformance of channel co ding under uncertain-distribution channel mo dels. D. Source Co ding with Distortion in Nonlinear Information Theory In this subsection w e discuss source coding mo del with a non-negligible distortion under the nonlinear information theory framework. W e rst consider the transmission process denoted by X → ˆ X . Supp ose X and ˆ X are t wo random v ariables dened on a sublinear exp ectation space (Ω , H , E ) . The corresp onding uncertain probability distributions of X are { p θ ( X ) } θ ∈ Θ , and the corresp onding uncertain transition probabilit y matrices of ˆ X giv en X are { Q λ ( ˆ X | X ) } λ ∈ Λ . F or an uncertain-distribution source enco ding pro cess f : X n → W and deco ding pro cess g : W → ˆ X n , the source co ding rate R s has already b een dened in Section IV-B as log ||W || n . In reality , the information sources, esp ecially the uncertain-distribution sources, cannot alwa ys communicate fully error-free, and a certain distortion t ypically exists. Therefore, it 27 is necessary to sp ecify a distortion measure d ( X , ˆ X ) on X × ˆ X , and use sublinear exp ectation to describ e the distortion. Denition 11: Let X b e a discrete random v ariable on a sublinear exp ectation space (Ω , H , E ) . The distortion measure is denoted as d ( X , ˆ X ) . F or a transmission pro cess X → ˆ X , the maxim um exp ected distortion and the minim um exp ected distortion are resp ectively dened as: E [ d ( X , ˆ X )] = sup θ ∈ Θ sup λ ∈ Λ X x, ˆ x p θ ( x ) q λ ( ˆ x | x ) d ( x, ˆ x ) , (40) E [ d ( X , ˆ X )] = inf θ ∈ Θ inf λ ∈ Λ X x, ˆ x p θ ( x ) q λ ( ˆ x | x ) d ( x, ˆ x ) . (41) Remark 10: Similar to the metho dology used in Section IV-C, in the ab ov e description, we ha ve in tro duced a family of transition probability matrices { Q λ ( ˆ X | X ) } λ ∈ Λ to show that the maximum and minimum expected distortions can still b e calculated in the general case where b oth the source distribution and the transition probabilit y matrix are uncertain. In this formulation, t wo families of distributions are inv olved, which implies that in a scenario where the distribution of the source is uncertain and the b ehavior of the source enco der is not fully known (e.g., in non-co op erativ e games of military applications), the uncertaint y in b oth the source and the transition probability matrix can b e signicant and should not b e ov erlo oked. Then, it is feasible to only nd out the family of p ossible source enco ders that can p otentially satisfy the design constraints imp osed by the principles of source co ding with distortion under our nonlinear information theory framework. On the other hand, incorporating such uncertaint y w ould substan tially increase the analytical complexity , and in most cases the goal of source co ding with distortion is to nd a source compression sc heme, i.e., a transition probability matrix Q ( ˆ X | X ) , that maximizes the co ding eciency under a giv en distortion. Hence, in the subsequen t formulations, we do not assume uncertaint y in the transition probability matrix and simplify the problem to consider only a single transition probability matrix. F or notational conv enience, we write E Q [ d ( X , ˆ X )] and E Q [ d ( X , ˆ X )] as the v alue of E [ d ( X , ˆ X )] and E [ d ( X , ˆ X )] when the transition probability matrices of ˆ X given X b ecome a deterministic transition probability matrix Q ( ˆ X | X ) . Then, the rate distortion function based on the nonlinear m utual information is dened as follo ws. Denition 12: Let X b e a discrete random v ariable on a sublinear exp ectation space (Ω , H , E ) and the distortion measure is denoted as d ( X , ˆ X ) . The rate distortion function based on the nonlinear m utual information is dened as: ˆ R I ( D ) := inf Q ( ˆ X | X ) : E Q [ d ( X, ˆ X )] ≤ D I h { p θ ( X ) } θ ∈ Θ ; Q ( ˆ X | X ) i . (42) 28 It is easy to chec k that the prop erties describ ed in Theorem 13 hold for the rate distortion function based on the nonlinear mutual information. Theorem 13: The rate distortion function based on the nonlinear m utual information, i.e., ˆ R I ( D ) , satises: 1) ˆ R I ( D ) decreases with resp ect to D . 2) ˆ R I ( D ) is a conv ex function on [0 , + ∞ ) . Pro of : See App endix E. ■ Theorem 14: Let X 1 , X 2 , · · · , X n , · · · b e a discrete I ID source sequence dened on a sublinear exp ectation space (Ω , H , E ) where the uncertain probability measures asso ciated with sublinear exp ectation E are { P θ } θ ∈ Θ , i.e., E [ · ] = sup θ ∈ Θ E P θ [ · ] . The distortion measure is denoted as d ( X , ˆ X ) . ( V , v ) is the pair of capacities generated b y E (see Denition 5). Supp ose that { P θ } θ ∈ Θ is a countably- dimensional w eakly compact family of probabilit y measures on (Ω , σ ( H )) (see Theorem 2). Then, for an y R s > ˆ R I ( D ) and ϵ > 0 , there must exist a suciently large n and a ( ||W || , n, f n , g n ) nonlinear source code, whic h has a co ding rate R s and the corresp onding transition probability matrix Q ( ˆ X | X ) , suc h that E Q [ d ( X n , ˆ X n )] ≤ D + ϵ . Pro of : See App endix E. ■ Theorem 14 is called the nonlinear rate-distortion source co ding theorem. It sho ws that ˆ R I ( D ) is the cluster p oint of the lossy compression limit of uncertain-distribution information sources under the minim um exp ected distortion criterion. In practice, due to the uncertain ty of distributions, it is challenging to ensure error-free transmission of messages. The classical rate-distortion source co ding theorem pro vides the limit of source co ding rate to con trol distortion when the distributions are deterministic. As far as the uncertaint y of distributions is concerned, the prop osed nonlinear rate-distortion source co ding theorem is more suitable in real world circumstances. V. Application Examples A. Bernoulli Type Uncertain-Distribution Information Sources In this subsection, an example of application is giv en for uncertain-distribution information sources b y analogy with the Bernoulli type exp eriments ha ving ambiguit y , whic h demonstrates the imp ortance of considering the uncertaint y of probabilit y mo dels. Consider binary message sequences comp osed of 0 and 1 . Under the classical information theory , a transmitter sends 0 or 1 each time and the individual probabilities of sending 0 and 1 remain unc hanged throughout the sending pro cess. Ho w ev er, under the nonlinear information theory , the transmitter does not ha v e xed probabilities of sending 0 and 1 . In other words, these probabilities 29 ma y v ary under the nonlinear exp ectation theory throughout the sending pro cess. F or example, let us consider a random v ariable X with input alphab et X = { 0 , 1 } . Supp ose that the probability of the ev en t { X = 0 } is uncertain and it takes v alue in the in terv al [ 1 3 , 1 2 ] . Therefore, the probabilit y of the even t { X = 1 } is also uncertain and it tak es v alue in the interv al [ 1 2 , 2 3 ] . Then, the uncertaint y probabilit y distributions of X are expressed as { p q ( X ) } q ∈ [ 1 3 , 1 2 ] := { p q = { q , 1 − q }| q ∈ [ 1 3 , 1 2 ] } . (43) Consider the message sequence of length N denoted b y X 1 , · · · , X N , where X i and X are identically distributed for i = 1 , · · · , N . F or this message sequence, the traditional probabilit y theory and metho ds do not work eectively no matter whic h deterministic Bernoulli distribution is used for appro ximating. The condence lev el of tting any deterministic Bernoulli distribution to the samples of the ab o ve message sequence of length 1024 are sho wn in Fig. 3. The abscissas p means that the Bernoulli distribution B (1 , p ) is used for approximating the samples of the message sequence. The ordinate represen ts the condence level of this appro ximation. W e can see that even the b est tting result can only ac hiev e a condence lev el of ab out 95% , whic h may b e regarded unreliable in situations that require very high accuracy , suc h as the application scenarios of autonomous driving and precision man ufacturing. In this context, it may b e a b etter c hoice to consider message sequences directly under the sublinear exp ectation framew ork. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Fig. 3: The condence lev el of tting deterministic Bernoulli distributions to the samples of a length- 1024 message sequence with uncertain distributions { p q ( X ) } q ∈ [ 1 3 , 1 2 ] . 30 Consider the ab ov e random v ariable X and the probability distributions family { p q ( X ) } q ∈ [ 1 3 , 1 2 ] . The sublinear exp ectation is dened as E [ X ] := sup p q ∈{ p q ( X ) } q ∈ [ 1 3 , 1 2 ] E p q [ X ] , and the pair of capacities ( V , v ) is dened as: V ( A ) := sup p q ∈{ p q ( X ) } q ∈ [ 1 3 , 1 2 ] p q ( A ) , (44) v ( A ) := inf p q ∈{ p q ( X ) } q ∈ [ 1 3 , 1 2 ] p q ( A ) . (45) It is easy to verify that E [ X i ] = 2 3 and ˆ H ( X ) = 1 . F or any p q ∈ { p q ( X ) } q ∈ [ 1 3 , 1 2 ] , w e hav e µ = E log 1 p q ( X ) = 1 2 log 1 q + log 1 1 − q , (46) µ = − E − log 1 p q ( X ) = 1 3 log 1 q + 2 3 log 1 1 − q . (47) Then, based on the strong law of large n umbers under sublinear exp ectations, for an y b ∈ [ µ, µ ] , w e ha v e lim sup n →∞ V | − log p q ( X 1 ) · . . . · p q ( X n ) n − b | < ϵ = 1 . (48) More generally , consider an uncertain-distribution information source X with tw o input v alues { 0 , 1 } . Supp ose that the probabilit y of the even t { X = 0 } is uncertain and takes v alue in the in terv al Θ = [max( p − ϵ, 0) , min( p + ϵ, 1)] and Pr ( X = 1) = 1 − Pr ( X = 0) . Then the uncertain probabilit y distributions of X are represented by a family of probabilit y distributions { p q ( X ) } q ∈ Θ , whic h expressed as { p q ( X ) } q ∈ Θ = { p q = { q , 1 − q }| q ∈ Θ } . (49) F or the uncertain-distribution information source X , we visualize the results of Theorem 10 in Fig. 4. The dash-dotted lines represent the cluster p oin t of the source coding rate of the uncertain- distribution source with ϵ = 0 . 02 and ϵ = 0 . 03 under the minimum error probability criterion, and are calculated b y inf θ ∈ Θ P x p θ ( x ) log 1 V ( x ) . The dashed lines represen t the nonlinear information en trop y of the uncertain-distribution sources with ϵ = 0 . 02 and ϵ = 0 . 03 , and are calculated by sup θ ∈ Θ P x p θ ( x ) log 1 p θ ( x ) . F or the conv enience of comparison, w e also draw the classical Shannon entrop y of the information source without distribution uncertain ty , which is corresp onding to the case ϵ = 0 and represen ted b y the solid line in Fig. 4. W e observ e that the cluster p oint of the source co ding rate of the uncertain-distribution source that w e found is notably smaller than the classical Shannon en trop y of the information source without distribution uncertaint y . According to Theorem 10, this observ ation means that there is alwa ys a suciently large co de length that allows the compression p erformance of source co ding in nonlinear information theory to achiev e or improv e up on that of source co ding without distribution uncertain t y (i.e., a smaller rate corresp onds to b etter compression under the minimum error probabilit y criterion). 31 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.7 0.75 0.8 0.85 0.9 0.95 1 Fig. 4: Comparison of the compression p erformance bound of an uncertain-distribution information source and of the corresp onding information source without distribution uncertaint y . B. Uncertain-Distribution Binary Symmetric Channels In this subsection, we pro vide an example of uncertain-distribution c hannel, in order to illustrate ho w the family of transition probability matrices of an uncertain-distribution channel arises and visualize the result of Theorem 12. In the classical information theory , a t ypical and commonly used discrete channel mo del is the binary symmetric channel (BSC), and its transition probabilit y matrix is represen ted as Q = 1 − p p p 1 − p , (50) where p denotes the probabilit y of state transition. This mo del assumes that the c hannel in tro duces errors with a xed probability p , which is indep endent of the input signal. How ever, in practical comm unication systems, the probabilit y mo dels may not alw a ys b e precisely known due to v arious factors such as noise, in terference, and imp erfections in the channels or systems. Therefore, it is necessary to consider the uncertaint y of probabilit y mo dels. F or a BSC characterized by (50), an example 6 can b e given as Y = X ⊕ Z , (51) where X is the input signal, Y is the output signal, and Z is the noise, all taking binary v alues from { 0 , 1 } . The noise Z is mo deled as a Bernoulli random v ariable with parameter p , meaning that 6 This is one p ossible realization of a BSC. 32 Pr ( Z = 1) = p and Pr ( Z = 0) = 1 − p . This mo del implies that the output Y is the mo dulo-2 sum of the input X and the noise Z . F or instance, if X = 0 and Z = 1 , then Y = 1 ; if X = 1 and Z = 1 , then Y = 0 . This represen tation highlights that the distribution of noise Z is precisely known. Ho w ev er, as we men tioned in Section I ab out the research motiv ation of nonlinear information theory , the exact distribution of Z ma y not exist in practical applications [2]. In this case, we can assume that the probability of Z = 1 lies within an in terv al Θ = [max( p − ϵ, 0) , min( p + ϵ, 1)] , where ϵ represen ts the degree of uncertaint y of the distribution of Z , and this uncertaint y naturally leads to an uncertaint y of the transition probability matrix of the c hannel. Giv en the uncertain t y of the distributions of Z , the transition probability matrix of the c hannel mo del Y = X ⊕ Z is no longer xed but v aries within a set of p ossible matrices. Dene 1 − Θ as the set { 1 − q | q ∈ Θ } , then the uncertain t y of transition probability matrix is expressed as 1 − q q q 1 − q q ∈ Θ , (52) and the corresp onding uncertain-distribution BSC is shown in Fig. 5. Fig. 5: An example of uncertain-distribution BSC, where Θ is the interv al [max( p − ϵ, 0) , min( p + ϵ, 1)] . F or an uncertain-distribution channel, to obtain the family of transition probabilit y matrices, the φ -max-mean algorithm [36] within the nonlinear exp ectation theory can b e employ ed to estimate the required parameters. W e still take the aforementioned uncertain-distribution BSC as an example. Then the parameters we need to estimate for obtaining the family of transition probability matrices are p and ϵ , which can b e estimated based on min( p + ϵ, 1) = E [ Z ] , max( p − ϵ, 0) = − E [ − Z ] . (53) More sp ecically , upon obtaining a nite sample set { z i } n × m i =1 of random v ariable Z , we can calculate E [ Z ] = max 1 ≤ i ≤ m 1 n n X j =1 z n ( i − 1)+ j (54) and E [ Z ] = min 1 ≤ i ≤ m 1 n n X j =1 z n ( i − 1)+ j (55) 33 to get the estimates of E [ Z ] and − E [ − Z ] . According to [39], these estimates are also un biased 7 . Therefore, similar to classical information theory , we can still use a relatively short training sequence to learn the parameters of a given channel mo del. W e plot the upp er limit of the ac hiev able co ding rate of the uncertain-distribution BSC that is c haracterized by (52) with ϵ = 0 . 02 and 0 . 04 under the minimum error probability criterion, by the dashed lines in Fig. 6. Note that the upp er limit is denoted as C , which is given by join tly considering Theorem 11 and Theorem 12. F or the con venience of comparison, w e also draw the Shannon capacity of the classical BSC that is characterized b y (50), with the solid line in Fig. 6. W e observ e that under the given degrees of distribution uncertain t y , the upp er limit C is substantially larger than the Shannon capacit y of the classical BSC, which assumes no distribution uncertaint y . A ccording to Theorem 12, this observ ation indicates that there is alw a ys a sucien tly large co de length that allows the p erformance of channel co ding in nonlinear information theory to attain or impro v e up on that of channel co ding without distribution uncertaint y (i.e., a larger rate corresponds to higher transmission eciency under the minimum error probabilit y criterion). 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Fig. 6: Comparison of the transmission p erformance b ound of uncertain-distribution BSC and classical BSC. 7 In a sublinear exp ectation space (Ω , H , E ) , a statistic T n ( X 1 , ..., X n ) is called an unbiased estimator of µ if E [ T n ( X 1 , ..., X n )] = µ . 34 C. Distinction Be t w een Uncertain-Distribution Channel and A Class of Channels In the con text of classical information theory , the concept of “a class of c hannels” 8 has b een prop osed and researc hed (for example in [21]–[28] and so on). In this pap er, we prop ose a concept “uncertain-distribution c hannel” . Both concepts utilize a family of transition probabilit y matrices to c haracterize the channel b ehavior, but they dier fundamen tally in how these distributions are applied and interpreted. In this subsection, w e aim to clarify the distinctions b et w een the tw o concepts through theoretical denitions and an illustrative example. A class of c hannels is describ ed by a family of transition probabilit y matrices. Ho w ev er, the b eha vior of a class of channels conforms to one of the transition probability matrices within this family at any given observ ation slot (e.g., time slot). This implies a level of resolv ability where the c hannel’s sto chastic b eha vior can b e pinp ointed to a sp ecic transition probability matrix within the family under certain conditions. As a to y example, consider the simple communication c hannel Y = X ⊕ Z , where X is the input signal taking v alues in { 0 , 1 } , and Z is a noise random v ariable also taking v alues in { 0 , 1 } . Then, the family of transition probabilit y matrices is derived from sp ecic observ ations of Z . Supp ose we observe the v alue of Z at a given time slot. If Z = 0 , the c hannel b ehavior corresp onds to one sp ecic transition probabilit y matrix 1 0 0 1 , and if Z = 1 , it corresp onds to 0 1 1 0 . This c hannel can also b e view ed as a channel mo del for a jamming scenario in whic h the jammer c ho oses the states. An uncertain-distribution channel is also characterized by a family of transition probabilit y matrices. Ho wev er, similar to the explanation presented in App endix A, the actual b ehavior of the c hannel do es not conform to an y single transition probability matrix within this family . Instead, it represents a general concept where the c hannel’s b ehavior is inherently uncertain and cannot b e precisely captured b y a sp ecic transition probability matrix. F or example, w e still consider Y = X ⊕ Z , and in this scenario, the distribution of Z is uncertain and cannot b e precisely sp ecied. Based on the nonlinear exp ectation theory , the corresp onding uncertain probability distributions of Z are c haracterized as a family of probability distributions. Therefore, the transition probabilit y matrix of the c hannel Y = X ⊕ Z is also uncertain. This uncertaint y reects the inherent ambiguit y in the sto chastic behavior of the channel. The distinction b et ween the tw o concepts mainly lies in the resolv ability of their sto chastic b eha viors. “Uncertain-distribution c hannel” em b o dies an inherent and persistent uncertaint y , whereas 8 Both comp ound channels and arbitrarily v arying channels fall within the broader framework of comm unication ov er a class of channels. Here, we use the term a class of channels as a generic reference. 35 “a class of channels” implies conditional determinability . This distinction is critical in modeling comm unication systems, as it reects the fundamental dierences in how uncertain t y is handled in c hannels that are randomly dynamic across a wide range of physical propagation en vironments, such as in high mobilit y cross-medium communications encoun tered in space-air-ground-sea in tegrated wireless net wo rks [40]–[42]. VI. Conclusion In this pap er, we hav e established a nonlinear information theory under the framework of non- linear exp ectation theory . W e consider some fundamen tal problems on b oth uncertain-distribution information sources and uncertain-distribution comm unication c hannels, whose dened on sublinear exp ectation space. The concepts of nonlinear information entrop y , nonlinear joint entrop y , nonlinear conditional en tropy and nonlinear m utual information are newly dened, and sev eral imp ortan t prop erties such as the c hain rule and the F ano inequality are generalized. Based on the strong law of large num b ers under sublinear exp ectations, we establish the nonlinear source co ding theorem, nonlinear channel co ding theorem and nonlinear rate-distortion source co ding theorem. These results c haracterize fundamental p erformance limits for uncertain-distribution sources and c hannels under dieren t criteria. The results of this pap er constitute a generalization from classical Shannon information theory based on deterministic probabilit y models to nonlinear information theory based on uncertain probability mo dels. When the distributions of source messages and the transition probabilit y matrices of communication c hannels b ecome deterministic, the conclusions in this study degenerate into the conclusions in classical information theory . This w ork represents a p otential paradigm shift in information theory , and provides a theoretical foundation for further inv estigations of information-theoretic problems under distributional uncertain t y . App endix A Wh y Use Nonlinear Exp ectation Theory–An Intuitiv e Explanation In this appendix, w e explain the necessit y of employing nonlinear exp ectation theory to c haracterize the uncertaint y of probabilit y distributions. T o this end, we m ust rst distinguish b etw een tw o cases that c haracterize random v ariables with a distribution family . These cases reect dierent levels of knowledge and assumptions ab out the underlying probability distributions, whic h inuence the applicabilit y and eectiveness of traditional probabilistic metho ds. In the rst case, if the classical probabilit y theory framework is used, a random v ariable is alwa ys assumed to follow a single sp ecic probabilit y distribution. How ever, if the single sp ecic distribution is unknown, the random v ariable is usually assumed to follow a distribution selected from a family of candidate distributions, with 36 the selection dep ending on the v alue of sp ecic control v ariables. In the second case, i.e., the case that emplo ys the nonlinear exp ectation theory , we assume that the random v ariable do es not follow an y sp ecic distribution within a family of distributions. Instead, the entire family of distributions is used in a general manner to describ e the random v ariable. These tw o cases are fundamen tally dieren t. Existing researc h works based on the classical probability theory corresp ond to the rst case, where the probability mo del (i.e., the probabilit y space) is deterministic. How ever, in many applications the probability mo del itself can also b e uncertain, which leads to the emergence of the second case. In the rst case, w e ackno wledge the existence of a particular distribution c haracterizing the random v ariable, but the sp ecic form or parameters of this distribution are uncertain. Consequen tly , the random v ariable is described by assuming that there exists a family of candidate distributions, to account for all p ossible b ehaviors. F or example, consider a scenario where the random v ariable is b elieved to follo w a normal distribution, but the precise v alues of the mean and v ariance are unkno wn. Then, w e can consider a family of normal distributions with v arying means and v ariances under dierent observ ation slots, and each observ ation slot corresp onds to a single sp ecic normal distribution. This approac h allo ws us to capture the range of p ossible b eha viors of the random v ariable while ackno wledging the uncertaint y of the distribution’s parameters to some degree. How ev er, it is w orth noting that at each observ ation slot the uncertain distribution is degraded to a deterministic distribution. T raditional probabilistic metho ds, suc h as maxim um likelihoo d estimation and Bay esian inference, are commonly employ ed to infer the unkno wn parameters from observ ed data. These metho ds assume that the underlying probability mo del (i.e., the probability space) is deterministic but unkno wn, and they aim to iden tify the most lik ely distribution that ts the observ ed data, within the family . T o elab orate a little further, let us consider a practical application in v olving a dataset { x 1 , · · · , x n } . Ev en when w e do not know the exact distribution that this dataset follows, w e can still rely on the la w of large n um b ers in probabilit y theory to estimate the exp ectation of the underlying distribution. Sp ecically , w e compute the sample mean P n i =1 x i as an estimate of the distribution’s exp ectation. This common practice is based on the implicit assumption that the underlying probabilit y mo del is deterministic. In other w ords, w e assume that the data are generated from a single, alb eit unkno wn, distribution, and the sample mean pro vides a consisten t estimate of the true exp ectation as the sample size grows. This approac h aligns well with traditional probabilistic metho ds, which assume a deterministic but unkno wn probabilit y mo del and aim to infer its parameters from observ ed data. In con trast, the second case represents a more general and abstract framew ork. Here, the random 37 v ariable do es not follow an y sp ecic distribution within the family . Instead, the family of distributions is used as a conceptual to ol to describ e the random v ariable’s b eha vior without assuming that it follo ws any sp ecic distribution. This approac h is particularly useful when dealing with complex systems or when the exact nature of the random v ariable is not well understo o d. F or instance, in highly complex or randomly dynamic systems, suc h as those encountered in nancial mark ets, biological netw orks, communication netw orks, or quantum information pro cessing, the b ehavior of random v ariables ma y b e inuenced by numerous factors that are dicult to mo del explicitly . In these situations, using a family of distributions to describ e the unpredictable nature of random v ariables pro vides a more general framework. It allows for a broader range of p ossibilities and ackno wledges the inherent uncertaint y of the system model, which ma y not b e captured b y an y single distribution within the family . T o further demonstrate the uncertaint y of distribution of a random v ariable, one can randomly se- lect a set of actual data samples to p erform the follo wing calculations. Here, we randomly choose 10000 samples, denoted b y { x i } 10000 i =1 , from a random v ariable X whose probabilit y distribution is uncertain and characterized by { p q ( X ) } q ∈ [ 1 3 , 1 2 ] := { p q = { q , 1 − q }| q ∈ [ 1 3 , 1 2 ] } . 9 F or n = 5000 , 5001 , · · · , 10000 , w e calculate E n := max 1 ≤ i ≤ 10 1 500 500 X j =1 x n − 5000+( i − 1) × 500+ j (56) and E n := min 1 ≤ i ≤ 10 1 500 500 X j =1 x n − 5000+( i − 1) × 500+ j . (57) The statistics E n and E n reect the upp er means and the low er means of samples, resp ectively . The v alues of E n and E n are sho wn in Fig. 7. The statistic E n represen ts the maxim um a v erage v alue of 500 consecutiv e samples within a specic sliding window of 5000 samples (from x n − 5000 to x n ). This window is divided into 10 non-ov erlapping sub-windo ws, eac h con taining 500 samples. Eq. (56) calculates the av erage of each sub-window and then tak es the maximum of these a v erages. The statistic E n represen ts the minimum a v erage v alue of 500 consecutive samples within the same sliding window of 5000 samples (from x n − 5000 to x n ). Similar to E n , the window is divided into 10 sub-windo ws, and Eq. (57) calculates the av erage of eac h sub-window and then takes the minim um of these av erages. W e can observe in Fig. 7 that there is a signicant gap 10 b et w een E n and E n . The fact that the maxim um and minim um av erages within this windo w dier substantially suggests that the b eha vior 9 This random v ariable is also describ ed in Section V-A. 10 The gap remains visible even with an increased sample size. W e use a sample size of 10000 merely as an example. 38 5000 5500 6000 6500 7000 7500 8000 8500 9000 9500 10000 0.45 0.5 0.55 0.6 0.65 0.7 Fig. 7: The upper means and low er means of samples of the random v ariable X whose distribution is uncertain. of X is not consisten t across dierent sub-windows. By contrast, let us consider a sequence of i.i.d. (indep enden t and iden tically distributed in classical probability theory) random v ariables that follow a deterministic distribution, and also calculate (56) and (57). In such a case, the gap b etw een the maxim um and minimum a verages w ould b e small, as observed in Fig. 8, esp ecially as the window size b ecomes large. This is b ecause the la w of large n umbers dictates that the sample means corresp onding to the sliding window of 5000 samples shall conv erge to the true mean of the distribution, as the sample size increases. As a result, the sample means b ecome less v ariable and more representativ e of the true mean of the distribution. The large gap observed in Fig. 7 suggests that the random v ariable ma y not follo w a single distribution. Instead, it could exhibit a b eha vior that is more complex or randomly dynamic, possibly inuenced b y multiple factors, such as randomly c hanging conditions o ver time. This insight is consisten t with the idea that the probabilit y mo del itself may b e uncertain or unpredictable, leading to the emergence of the ab o ve mentioned second case where the random v ariable do es not follo w an y sp ecic distribution within the family . The ab ov e mentioned second case highlights the limitations of traditional probabilistic approac hes when faced with more complex and uncertain system mo dels. In such scenarios, the probability mo del itself may b e uncertain or ill-dened, necessitating a more general and exible framework. This is where the nonlinear exp ectation theory comes in to pla y . By relaxing the assumption of a deterministic probability mo del, the nonlinear exp ectation theory provides a p ow erful to ol for 39 5000 5500 6000 6500 7000 7500 8000 8500 9000 9500 10000 0.45 0.5 0.55 0.6 0.65 0.7 Fig. 8: The upper means and low er means of samples of the random v ariable X with a known Bernoulli distribution B (1 , 0 . 58) . mo deling and analyzing systems with in trinsic model uncertain t y . It allo ws for a holistic consideration of m ultiple p ossible distributions, thus v aluable for capturing the ambiguit y and unpredictabilit y inheren t in complex random systems. In summary , while traditional probabilistic metho ds ha ve prov en eective in analyzing the abov e men tioned rst case, where the probability mo del is deterministic but unknown, they fall short in addressing the complexities and uncertainties asso ciated with the second case. The increasing prev alence of complex random systems and the need to mo del uncertaint y more accurately hav e led to the gro wing imp ortance of the nonlinear exp ectation theory . By providing a more general and exible framework, this theory enables researchers to b etter understand and handle uncertain t y in mo dern probabilistic mo deling. App endix B PR OOF OF THEOREM 3 F or the discrete random v ariable X with n p ossible states { x 1 , · · · , x i , · · · , x n } dened on a sublinear exp ectation space (Ω , H , E ) , the corresp onding uncertain probability distributions of X are { p θ ( X ) } θ ∈ Θ . If there is a θ 0 ∈ Θ with p θ 0 ( x i ) = p i suc h that p 1 , · · · , p n are all rational n umbers, supp ose p i = k i ∑ n i =1 k i , where k 1 , · · · , k n are all p ositiv e in tegers, and i = 1 , 2 , · · · , n . In addition, supp ose one w an ts to choose a state from P n i =1 k i states. Similar to Shannon’s idea, w e can still divide P n i =1 k i states into n groups, with k 1 , · · · , k n states in eac h group, resp ectiv ely . F or con venience, 40 w e also use k i to denote a sp ecic group. W e rst randomly choose a group k i from the groups k 1 , · · · , k n , and then randomly c ho ose a state from group k i . Dieren t from Shannon’s methodology , our random choice of a group is assumed to b e made on sublinear exp ectation space. Th us, the c hoice of a single group from the groups k 1 , · · · , k n can b e describ ed as the random v ariable X . That is, this c hoice has the same distribution uncertain t y with X . W e use random v ariable Y i without distribution uncertaint y to describ e the state choice from group k i , and the distribution of Y i is c haracterized b y the uniform distribution of q = 1 k i . Therefore, on the whole, the states are chosen from P n i =1 k i , where the uniform distribution 1 ∑ n i =1 k i is only a mem b er of the uncertain distribution family for state choice. Th us, w e can obtain from Assumptions 2) and 4) in Section I I I that log n X i =1 k i ≤ ˆ H ( X ) + sup θ ∈ Θ n X i =1 p θ ( x i ) ˆ H ( Y i ) = ˆ H ( X ) + log n X i =1 k i + E [log p θ 0 ( X )] . (58) Hence, ˆ H ( X ) ≥ − E [log p θ 0 ( X )] ≥ inf θ ∈ Θ X x p θ ( x ) log 1 p θ ( x ) . (59) If ˆ H ( X ) < sup θ ∈ Θ P x p θ ( x ) log 1 p θ ( x ) , then there exists some ϵ > 0 such that ˆ H ( X ) + ϵ < sup θ ∈ Θ X x p θ ( x ) log 1 p θ ( x ) . (60) Therefore, there exists a subset { p θ } θ ∈ Θ ∗ con tained in { p θ ( X ) } θ ∈ Θ suc h that X x p θ ( x ) log 1 p θ ( x ) > ˆ H ( X ) + ϵ, ∀ θ ∈ Θ ∗ . (61) Let Z b e a random v ariable for whic h the uncertain probabilit y distributions are c haracterized b y { p θ } θ ∈ Θ ∗ . Then, according to Assumption 3), we hav e ˆ H ( X ) ≥ ˆ H ( Z ) ≥ inf θ ∈ Θ ∗ X x p θ ( x ) log 1 p θ ( x ) ≥ ˆ H ( X ) + ϵ > ˆ H ( X ) , (62) whic h itself yields a con tradiction. Consequen tly , ˆ H ( X ) = sup θ ∈ Θ P x p θ ( x ) log 1 p θ ( x ) . If some probabilit y distributions in { p θ ( x ) } θ ∈ Θ are incommensurable n um b ers, they can b e ap- pro ximated by rationals. Then, the same expression m ust hold due to our contin uity assumption, namely Assumption 1). This concludes the pro of of Theorem 3. ■ 41 App endix C PR OOF OF THEOREM 10 Since X 1 , X 2 , · · · , X n , · · · is a discrete I ID source sequence, for any i = 2 , ..., n , the uncertain probabilit y distributions of X i can also b e denoted as { p θ ( X 1 ) } θ ∈ Θ . F or the statement 1), let Y i := log 1 V ( X i ) ∈ H and S n := P n i =1 Y i . F or any µ ∈ [ − E [ − Y i ] , E [ Y i ]] and an y ϵ > 0 , based on the strong law of large num b ers under sublinear exp ectations, there exists a monotonically increasing sequence { n k } suc h that V ω | S n k ( ω ) n k − µ | ≤ ϵ ≥ 1 − ϵ. (63) Let M ( k ) ϵ := { x n k | − log V ( x n k ) n k − µ | ≤ ϵ } . Then, we hav e V M ( k ) ϵ ≥ 1 − ϵ , and for any x n k ∈ M ( k ) ϵ , w e obtain 2 − n k ( µ + ϵ ) ≤ V ( x n k ) ≤ 2 − n k ( µ − ϵ ) . (64) A ccording to [43], we know that for an y x n k , ˜ x n k ∈ M ( k ) ϵ , there is V ( x n k , ˜ x n k ) = V ( x n k ) V ( ˜ x n k ) . Therefore, w e can get 1 − ϵ ≤ V M ( k ) ϵ ≤ ∥M ( k ) ϵ ∥ 2 − n k ( µ − ϵ ) , (65) ∥M ( k ) ϵ ∥ 2 − n k ( µ + ϵ ) ≤ V M ( k ) ϵ ≤ 1 . (66) Consequen tly , we ha ve (1 − ϵ )2 n k ( µ − ϵ ) ≤ ∥M ( k ) ϵ ∥ ≤ 2 n k ( µ + ϵ ) . (67) As a result, for any δ > 0 , there is a sucien tly large k and the source enco ding function assigns a unique index to each sequence in M ( k ) ϵ . This source enco ding function is a one-to-one mapping, whose outputs are easily deco dable. Therefore, this nonlinear source co de satises E h I { ˆ X n k = X n k } i = v ( M ( k ) ϵ ) c = 1 − V M ( k ) ϵ < ϵ, (68) and the source co ding rate satises R s = log ∥M ( k ) ϵ ∥ n k ≥ log(1 − ϵ ) n k + µ − ϵ ≥ inf θ ∈ Θ X x p θ ( x ) log 1 V ( x ) + ϵ ′ . (69) Based on the arbitrariness of µ and ϵ , the statemen t 1) is prov ed. F or the statemen t 2), let x n = ( x 1 , x 2 , · · · , x n ) and W ( n ) ϵ b e the set ∪ θ ∈ Θ x n | − log [ p θ ( x n )] n − H p θ ( X 1 ) | < ϵ , (70) where H p θ ( X 1 ) = P x p θ ( x ) log 1 p θ ( x ) . Then, for any θ ∈ Θ , there is ∥W ( n ) ϵ ∥ ≥ (1 − ϵ )2 n ( H p θ ( X 1 ) − ϵ ) . (71) 42 F or an y x n ∈ W ( n ) ϵ , there exists θ ∈ Θ suc h that x n ∈ { x n | − log [ p θ ( x n )] n − H p θ ( X 1 ) | < ϵ } . Therefore, w e ha ve 2 − n ( ˆ H ( X 1 )+ ϵ ) ≤ p θ ( x n ) ≤ V ( x n ) . (72) Based on the prop erty that for an y x n k , ˜ x n k ∈ W ( n ) ϵ , there is V ( x n k , ˜ x n k ) = V ( x n k ) V ( ˜ x n k ) , we ha v e ∥W ( n ) ϵ ∥ · 2 − n ( ˆ H ( X 1 )+ ϵ ) ≤ V W ( n ) ϵ < 1 . (73) Inequalities (71) and (73) show that (1 − ϵ )2 n ( ˆ H ( X 1 ) − ϵ ) ≤ ∥W ( n ) ϵ ∥ ≤ 2 n ( ˆ H ( X 1 )+ ϵ ) . (74) As a result, for an y ϵ > 0 , there is a suciently large n and the source enco ding function assigns a unique index to each sequence in W ( n ) ϵ . This nonlinear source co de satises E h I { ˆ X n = X n } i = V ( W ( n ) ϵ ) c < ϵ. (75) This concludes the pro of of Theorem 10. ■ App endix D PR OOFS OF THEOREMS IN SECTION IV-C Pro of of Theorem 11: Supp ose the transmission pro cess using the nonlinear channel coding sc heme is characterized as S φ n − → X n { P λ ∈ [0 , 1] X ×Y } λ ∈ Λ − − − − − − − − − − − → Y n ψ n − → ˆ S . (76) Since S → X n → Y n satises the condition in Theorem 9, we hav e I ( S ; Y n ) ≤ I ( X n ; Y n ) . (77) F or any ϵ > 0 and a sequence of ( M , n, φ n , ψ n ) nonlinear c hannel co des with co ding rate R c , whic h satisfy lim n →∞ sup θ ∈ Θ P ( n ) e,θ = 0 , (78) there exists a suciently large n and a ( ||X || nR , n, φ n , ψ n ) nonlinear c hannel co de such that the maxim um probabilit y of errors o ccurring satises sup θ ∈ Θ P ( n ) e,θ < ϵ . Let us dene the random v ariable U = I { ˆ S = S } , then the corresp onding uncertain probabilities of the ev en t { U = 1 } is characterized as { P ( n ) e,θ } θ ∈ Θ , and E [ U ] = sup θ ∈ Θ P ( n ) e,θ . Since the random v ariables Y n and S uniquely determine the random v ariable U , we ha ve ˆ H ( U | S , Y n ) = 0 . (79) 43 Therefore, according to Theorem 4, w e obtain ˆ H ( U, S | Y n ) = ˆ H ( S | Y n ) (80) and ˆ H ( U, S | Y n ) ≤ ˆ H ( U | Y n ) + ˆ H ( S | U, Y n ) . (81) Consider the term ˆ H ( U | Y n ) . Ob viously , w e hav e ˆ H ( U | Y n ) ≤ 1 . (82) F urthermore, the term ˆ H ( S | U, Y n ) satises ˆ H ( S | U, Y n ) = sup θ ∈ Θ h (1 − P ( n ) e,θ ) ˆ H ( S | Y n , U = 0) + P ( n ) e,θ ˆ H ( S | Y n , U = 1) i . (83) Since ˆ H ( S | Y n , U = 0) = 0 and ˆ H ( S | Y n , U = 1) ≤ log ( ||S || − 1) ≤ nR c , w e obtain ˆ H ( S | U, Y n ) ≤ sup θ ∈ Θ P ( n ) e,θ nR c . (84) Join tly considering (80), (81), (82) and (84), we ha ve ˆ H ( S | Y n ) ≤ ˆ H ( U | Y n ) + ˆ H ( S | U, Y n ) ≤ 1 + sup θ ∈ Θ P ( n ) e,θ nR c . (85) Supp ose that the uncertain probability distributions of the message S ∈ S = { 1 , 2 , · · · , M } to b e sen t is denoted as { p σ ( S ) } σ ∈ Σ , and the uniform distribution p ( s ) = 1 M is a mem b er of the family of uncertain probabilit y distributions { p σ ( S ) } σ ∈ Σ . Then, we hav e nR c = ˆ H ( S ) ≤ ˆ H ( S | Y n ) + I ( S ; Y n ) ≤ ˆ H ( S | Y n ) + I ( X n ; Y n ) . (86) Let p ( y 1 ) · · · p ( y n ) = p ( y n ) := P x n p θ ( x n ) p λ ( y n | x n ) , then we hav e I ( X n ; Y n ) = sup θ ∈ Θ sup λ ∈ Λ X x n , y n p θ ( x n ) p λ ( y n | x n ) log p λ ( y n | x n ) p ( y n ) = sup θ ∈ Θ sup λ ∈ Λ X x n , y n p θ ( x n ) p λ ( y n | x n ) log 1 p ( y n ) − X x n , y n p θ ( x n ) p λ ( y n | x n ) log 1 p λ ( y n | x n ) ! ≤ sup θ ∈ Θ sup λ ∈ Λ n X i =1 X x i ,y i p θ ( x i ) p λ ( y i | x i ) log p λ ( y i | x i ) p ( y i ) ≤ n X i =1 sup θ ∈ Θ sup λ ∈ Λ X x i ,y i p θ ( x i ) p λ ( y i | x i ) log p λ ( y i | x i ) p ( y i ) ≤ n X i =1 sup p ( x i ) sup λ ∈ Λ X x i ,y i p ( x i ) p λ ( y i | x i ) log p λ ( y i | x i ) p ( y i ) = nC . (87) 44 Substitute Eqs. (85) and (87) in to (86), we ha ve nR c ≤ 1 + sup θ ∈ Θ P ( n ) e,θ nR c + nC . (88) As a result, R c ≤ 1 n + sup θ ∈ Θ P ( n ) e,θ R c + C . (89) The ab ov e inequality (89) holds for any sucien tly large n . Note that as n → ∞ , b oth 1 n and sup θ ∈ Θ P ( n ) e,θ tend to 0. Therefore, we ha v e R c ≤ C . This concludes the pro of of Theorem 11. ■ Pro of of Theorem 12: Because of R c < C , there exists a constant R ′ suc h that R c < R ′ < C . Let G n = ( ( x n , y n ) sup p ( x n ) sup λ ∈ Λ log p λ ( y n | x n ) ∑ x n p ( x n ) p λ ( y n | x n ) > nR ′ ) . Based on the pro of of Theorem 10, for an y ϵ > 0 , we hav e a set M ( k ) ϵ that is a subset of the sample sequence of { X i } n k i =1 . M ( k ) ϵ satises V M ( k ) ϵ ≥ 1 − ϵ 3 . Let G ∗ = n ( x n k , y n k ) ( x n k , y n k ) ∈ G n k , x n k ∈ M ( k ) ϵ o . F or the codeb o ok { x 1 , x 2 , · · · , x ||X || n k R } with the co de length n k , w e set the deco ding rule as follo ws: Supp ose the uncertain-distribution channel [ X , P λ ∈ [0 , 1] X ×Y λ ∈ Λ , Y ] pro cesses the transmitted codeword x i and produces an output sequence y n k . Then the receiver considers the set G ∗ ( y n k ) = x n k ( x n k , y n k ) ∈ G ∗ . If there is only a single elemen t ˆ x n k in the set G ∗ ( y n k ) , the deco ding function is applied to y n k to estimate the original message as this element. If there are more than one element in the set G ∗ ( y n k ) , an error o ccurrs. F or this nonlinear channel co ding sc heme, we hav e E I { ˆ x n k = x n k } = inf P ( n k ) e ∈P ( n k ) P ( n k ) e ≤ v n ω X n k ( ω ) / ∈ G ∗ ( Y n k ( ω )) o + X ˜ X n k = X n k V n ω ˜ X n k ( ω ) ∈ G ∗ ( Y n k ( ω )) o := I 1 + I 2 . (90) F or the term I 1 , there exists a probability measure P such that I 1 ≤ P n ω ( X n k ( ω ) , Y n k ( ω )) / ∈ G n k o + v n ω X n k ( ω ) / ∈ M ( k ) ϵ o := I 1 , 1 + I 1 , 2 . (91) Due to R ′ < C , there exists a probability distribution p ( X ) and a transition probability matrix P λ ( Y | X ) suc h that P x,y p ( x ) p λ ( y | x ) log p λ ( y | x ) ∑ x p ( x ) p λ ( y | x ) > R ′ . Therefore, there exists a sucien tly large n k suc h that I 1 , 1 < ϵ 3 . Due to V M ( k ) ϵ ≥ 1 − ϵ 3 , w e hav e I 1 , 2 < ϵ 3 . As a result, I 1 < 2 ϵ 3 . 45 F or the term I 2 , w e hav e I 2 ≤ E [ ||X || sup p ( X n k ) sup λ ∈ Λ log p λ ( Y n k | X n k ) ∑ X n k p ( X n k ) p λ ( Y n k | X n k ) ] ||X || n k ( R ′ − R c ) ≤ L ||X || n k ( R c − R ′ ) . (92) Note that we hav e R ′ > R , hence there exists a suciently large n k suc h that I 2 < ϵ 3 . Therefore, w e hav e inf P ( n k ) e ∈P ( n k ) P ( n k ) e < ϵ . This concludes the pro of of Theorem 12. ■ App endix E PR OOFS OF THEOREMS IN SECTION IV-D Pro of of Theorem 13: 1) This prop ert y is obvious. 2) ∀ D 1 , D 2 ≥ 0 , λ ∈ (0 , 1) , ∀ ϵ > 0 , there exists transition probability matrices Q 1 and Q 2 suc h that I h { p θ ( X ) } θ ∈ Θ ; Q 1 ˆ X | X i ≤ ˆ R I ( D 1 ) + ϵ, (93) I h { p θ ( X ) } θ ∈ Θ ; Q 2 ˆ X | X i ≤ ˆ R I ( D 2 ) + ϵ. (94) Due to E λ Q 1 +(1 − λ ) Q 2 h d X , ˆ X i ≤ λD 1 + (1 − λ ) D 2 , w e can get ˆ R I ( λD 1 + (1 − λ ) D 2 ) ≤ I h { p θ ( X ) } θ ∈ Θ ; λ Q 1 ˆ X | X + (1 − λ ) Q 2 ˆ X | X i ≤ λI h { p θ ( X ) } θ ∈ Θ ; Q 1 ˆ X | X i + (1 − λ ) I h { p θ ( X ) } θ ∈ Θ ; Q 2 ˆ X | X i ≤ λ ˆ R I ( D 1 ) + (1 − λ ) ˆ R I ( D 2 ) + ϵ. (95) Since ϵ is an arbitrary p ositive v alue, ˆ R I ( D ) is a conv ex function. ■ Pro of of Theorem 14: Let the transition probabilit y matrix Q ( ˆ X | X ) b e the one that attains the inmum of ˆ R I ( D ) . Because of R s > ˆ R I ( D ) , there exists a constan t R ′ suc h that R s > R ′ > I h { p θ ( X ) } θ ∈ Θ ; Q ( ˆ X | X ) i . Let L n = { ( x n , ˆ x n ) inf θ ∈ Θ log q ( ˆ x n | x n ) ∑ x n q ( ˆ x n | x n ) p θ ( x n ) < nR ′ } . F or any ϵ > 0 , let B k ϵ = { ( x n k , ˆ x n k ) | d ( x n k , ˆ x n k ) − E Q [ d ( X , ˆ X )] | < ϵ 3 } . Based on the pro of of Theorem 10, for any ϵ ′ > 0 , we also ha ve a set M ( k ) ϵ ′ satisfying v ( M ( k ) ϵ ′ ) c ≤ ϵ ′ 3 . Let L ∗ = { ( x n k , ˆ x n k ) ( x n k , ˆ x n k ) ∈ B k ϵ ∩ L n k , x n k ∈ M ( k ) ϵ ′ } . F or the vector x n k , nd an index W ∈ { 1 , 2 , · · · , ||W ||} such that ( x n k , ˆ x n k ( W )) ∈ L ∗ . If there are m ultiple such indices, choose the smallest one among them. If there is no such index, set W = 1 . The deco der makes the estimated sequence as ˆ x n k = ˆ x n k ( W ) . 46 Let d max = max x, ˆ x ∈X d ( x, ˆ x ) , there holds E Q h d X n k , ˆ X n k i ≤ D + ϵ 3 + E Q h I { ( X n k , ˆ X n k ) / ∈L ∗ } i d max . (96) Consider the term E Q h I { ( X n k , ˆ X n k ) / ∈L ∗ } i , w e hav e E Q [ I { ( X n k , ˆ X n k ) / ∈L ∗ } ] ≤ E Q h Π 2 nR ω =1 V ( { ω | ( x n k , ˆ X n k ( ω )) / ∈ L ∗ } ) | x n k = X n k i + ϵ ′ 3 ≤ E Q " [1 − X ˆ x n k q ( ˆ x n k | x n k )2 − n k R ′ ] 2 n k R s | x n k = X n k # + ϵ ′ 3 ≤ E Q h e − 2 − n k R ′ 2 n k R s i + ϵ ′ 3 = e − 2 n k ( R s − R ′ ) + ϵ ′ 3 . (97) Note that w e ha v e R ′ < R s , hence there exists a sucien tly large n k and a sucien tly small ϵ ′ suc h that E Q h I { ( X n k , ˆ X n k ) / ∈L ∗ } i ≤ 2 ϵ 3 d max . Therefore, we hav e E Q h d ( X n , ˆ X n ) i ≤ D + ϵ . This concludes the pro of of Theorem 14. ■ References [1] T. M. Cov er and J. A. Thomas, Elemen ts of Information Theory , 2nd ed. Hob ok en, New Jersey , USA: John Wiley & Sons, Inc., 2006. [2] D. Spiegelhalter, “Do es probability exist?” Nature, vol. 636, pp. 560–564, Dec. 2024. [3] M. Z. Chowdh ury , M. Shahjalal, S. Ahmed, and Y. M. Jang, “6G wireless communication systems: Applications, requiremen ts, technologies, c hallenges, and research directions,” IEEE Op en Journal of the Communications So ciety , vol. 1, pp. 957–975, Jul. 2020. [4] H. T ataria, M. Sha, A. F. Molisc h, M. Dohler, H. Sjöland, and F. T ufvesson, “6G wireless systems: Vision, requirements, c hallenges, insights, and opp ortunities,” Pro ceedings of the IEEE, v ol. 109, no. 7, pp. 1166–1199, Jul. 2021. [5] K. Nikitop oulos, “Massively parallel, nonlinear pro cessing for 6G: Poten tial gains and further research c hallenges,” IEEE Comm unications Magazine, v ol. 60, no. 1, pp. 81–87, Jan. 2022. [6] G. Zh u, Z. Lyu, X. Jiao, P . Liu, M. Chen, J. Xu, S. Cui, and P . Zhang, “Pushing AI to wireless netw ork edge: An ov erview on in tegrated sensing, comm unication, and computation to wards 6G,” Science China Information Sciences, vol. 66, no. 3, pp. 1–19, F eb. 2023. [7] J. Zhang, J. Lin, P . T ang, Y. Zhang, H. Xu, T. Gao, H. Miao, Z. Chai, Z. Zhou, Y. Li, H. Gong, Y. Liu, Z. Y uan, L. Tian, S. Y ang, L. Xia, G. Liu, and P . Zhang, “Channel measurement, mo deling, and simulation for 6G: A survey and tutorial,” Mar. 2024. [Online]. A v ailable: [8] X.-Y. W ang, S. Y ang, J. Zhang, C. Masouros, and P . Zhang, “Clutter suppression, time-frequency synchronization, and sensing parameter asso ciation in async hronous p erceptive v ehicular netw orks,” IEEE Journal on Selected Areas in Comm unications, vol. 42, no. 10, pp. 2719–2736, Oct. 2024. [9] C. E. Shannon, “A mathematical theory of communication,” The Bell System T echnical Journal, v ol. 27, no. 3, pp. 379–423, Jul. 1948. [10] A. Rényi, “On measures of entrop y and information,” in Proceedings of the F ourth Berkeley Symp osium on Mathematical Statistics and Probability , V olume 1: Contributions to the Theory of Statistics, Berkeley , California, Jan. 1961, pp. 547–561. 47 [11] J.-L. Marichal, “Entrop y of discrete Cho quet capacities,” Europ ean Journal of Op erational Research, vol. 137, no. 3, pp. 612–624, Mar. 2002. [12] B. D. Sharma and I. J. T aneja, “Entrop y of type ( α , β ) and other generalized measures in information theory ,” Metrika, v ol. 22, no. 1, pp. 205–215, Dec. 1975. [13] M. Rao, Y. Chen, B. C. V emuri, and F. W ang, “Cumulativ e residual entrop y: A new measure of information,” IEEE T ransactions on Information Theory , vol. 50, no. 6, pp. 1220–1228, Jun. 2004. [14] C. T sallis, “The nonadditive entrop y S q and its applications in physics and elsewhere: Some remarks,” Entrop y , vol. 13, no. 10, pp. 1765–1804, Sep. 2011. [15] F. Nielsen and R. No ck, “A closed-form expression for the Sharma-Mittal entrop y of exp onential families,” Journal of Ph ysics A: Mathematical and Theoretical, vol. 45, no. 3, pp. 1–8, Dec. 2011. [16] J. Ziv, “Co ding of sources with unknown statistics-i: Probabilit y of enco ding error,” IEEE T ransactions on Information Theory , vol. 18, no. 3, pp. 384–389, May 1972. [17] J. Ziv, “Coding of sources with unknown statistics-ii: Distortion relative to a delit y criterion,” IEEE T ransactions on Information Theory , vol. 18, no. 3, pp. 389–394, May 1972. [18] J. Ziv and A. Lemp el, “A univ ersal algorithm for sequential data compression,” IEEE T ransactions on Information Theory , v ol. 23, no. 3, pp. 337–343, May 1977. [19] S. Jalali, S. V erdú, and T. W eissman, “A universal sc heme for W yner-Ziv co ding of discrete sources,” IEEE T ransactions on Information Theory , vol. 56, no. 4, pp. 1737–1750, Apr. 2010. [20] E. Dupraz, A. Roumy , and M. Kieer, “Source co ding with side information at the deco der: Mo dels with uncertaint y , p erformance b ounds, and practical co ding schemes,” in Pro ceedings of 2012 International Symp osium on Information Theory and its Applications, Honolulu, USA, Oct. 2012, pp. 170–174. [21] D. Blackw ell, L. Breiman, and A. Thomasian, “The capacit y of a class of channels,” The Annals of Mathematical Statistics, v ol. 30, no. 4, pp. 1229–1241, Dec. 1959. [22] D. Blackw ell, L. Breiman, and A. Thomasian, “The capacities of certain channel classes under random co ding,” The Annals of Mathematical Statistics, vol. 31, no. 3, pp. 558–567, Sep. 1960. [23] R. Ahlswede and J. W olfowitz, “Correlated deco ding for channels with arbitrarily v arying c hannel probability functions,” Information and Control, vol. 14, no. 5, pp. 457–473, May . 1969. [24] R. Ahlswede and J. W olfowitz, “The capacity of a channel with arbitrarily v arying channel probabilit y functions and binary output alphab et,” Zeitsc hrift für W ahrscheinlic hk eitstheorie und verw andte Gebiete, vol. 15, no. 3, pp. 186–194, Sep. 1970. [25] R. Ahlswede, “A note on the existence of the w eak capacit y for c hannels with arbitrarily v arying channel probability functions and its relation to Shannon’s zero error capacity ,” The Annals of Mathematical Statistics, vol. 41, no. 3, pp. 1027–1033, Jun. 1970. [26] R. Ahlswede, “Channels with arbitrarily v arying channel probability functions in the presence of noiseless feedback,” Zeitsc hrift für W ahrscheinlic hkeitstheorie und verw andte Gebiete, vol. 25, no. 3, pp. 239–252, Sep. 1973. [27] R. Ahlswede, “Elimination of correlation in random co des for arbitrarily v arying channels,” Zeitschrift für W ahrschein- lic hkeitstheorie und v erwandte Gebiete, vol. 44, no. 2, pp. 159–175, Jun. 1978. [28] R. Ahlswede, “A metho d of co ding and its application to arbitrarily v arying channels,” Journal of Combinatorics, Information and System Sciences, vol. 5, no. 1, pp. 10–35, Jan. 1980. [29] J. Chen, H. Perm uter, and T. W eissman, “Tigh ter b ounds on the capacity of nite-state channels via Mark ov set-chains,” IEEE T ransactions on Information Theory , v ol. 56, no. 8, pp. 3660–3691, Aug. 2010. [30] S. Y ang, R. Xu, J. Chen, and J.-K. Zhang, “Intrinsic capacity ,” IEEE T ransactions on Information Theory , vol. 65, no. 3, pp. 1345–1360, Mar. 2018. [31] M. T. V u, T. J. Oech tering, M. Skoglund, and H. Bo che, “Uncertaint y in identication systems,” IEEE T ransactions on Information Theory , vol. 67, no. 3, pp. 1400–1414, Mar. 2020. 48 [32] S. Peng, “G-Bro wnian motion and dynamic risk measure under v olatility uncertaint y ,” arXiv preprint No v. 2007. [33] L. X. Zhang, “The sucient and necessary conditions of the strong law of large num b ers under sub-linear exp ectations,” A cta Mathematica Sinica, English Series, vol. 39, no. 12, pp. 2283–2315, Dec. 2023. [34] S. Peng, S. Y ang, and J. Y ao, “Improving v alue-at-risk prediction under model uncertain ty ,” Journal of Financial Econometrics, vol. 21, no. 1, pp. 228–259, F eb. 2023. [35] S. Peng, Nonlinear Exp ectations and Sto chastic Calculus under Uncertain ty: with Robust CL T and G-Brownian Motion. Springer Nature, 2019. [36] S. Peng, “Theory , metho ds and meaning of nonlinear exp ectation theory ,” SCIENTIA SINICA Mathematica, vol. 47, pp. 1223–1254, Oct. 2017. [37] H. Manner, “T esting for asymmetric dep endence,” Studies in Nonlinear Dynamics & Econometrics, vol. 14, no. 2, pp. 1–32, Mar. 2010. [38] H. Vino d, “Asymmetric dep endence measuremen t and testing,” arXiv preprint arXiv:2211.16645, Nov. 2022. [39] H. Jin and S. Peng, “Optimal unbiased estimation for maximal distribution,” Probability , Uncertaint y and Quantitativ e Risk, vol. 6, no. 3, pp. 189–198, Sep. 2021. [40] W.-Y. Dong, S. Y ang, P . Zhang, and S. Chen, “Sto chastic geometry based mo deling and analysis of uplink co op erative satellite-aerial-terrestrial netw orks for nomadic communications with weak satellite cov erage,” IEEE Journal on Selected Areas in Communications, vol. 42, no. 12, pp. 3428–3444, Dec. 2024. [41] W.-Y. Dong, S. Y ang, P . Zhang, and S. Chen, “Mo deling and p erformance analysis of IoT-ov er-LEO satellite systems under realistic op erational constraints: A sto chastic geometry approach,” IEEE Internet of Things Journal, vol. 12, no. 15, pp. 30 576–30 593, Aug. 2025. [42] W.-Y. Dong, S. Y ang, and S. Chen, “Uplink p erformance analysis of heterogeneous non-terrestrial netw orks in harsh en vironments: A nov el sto chastic geometry model,” IEEE T ransactions on Comm unications, vol. 73, no. 8, pp. 6734–6747, A ug. 2025. [43] Z. Chen, “Strong la ws of large num b ers for sub-linear exp ectations,” Science China Mathematics, vol. 59, pp. 945–954, Dec. 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment