Omanic: Towards Step-wise Evaluation of Multi-hop Reasoning in Large Language Models
Reasoning-focused large language models (LLMs) have advanced in many NLP tasks, yet their evaluation remains challenging: final answers alone do not expose the intermediate reasoning steps, making it difficult to determine whether a model truly reaso…
Authors: Xiaojie Gu, Sherry T. Tong, Aosong Feng
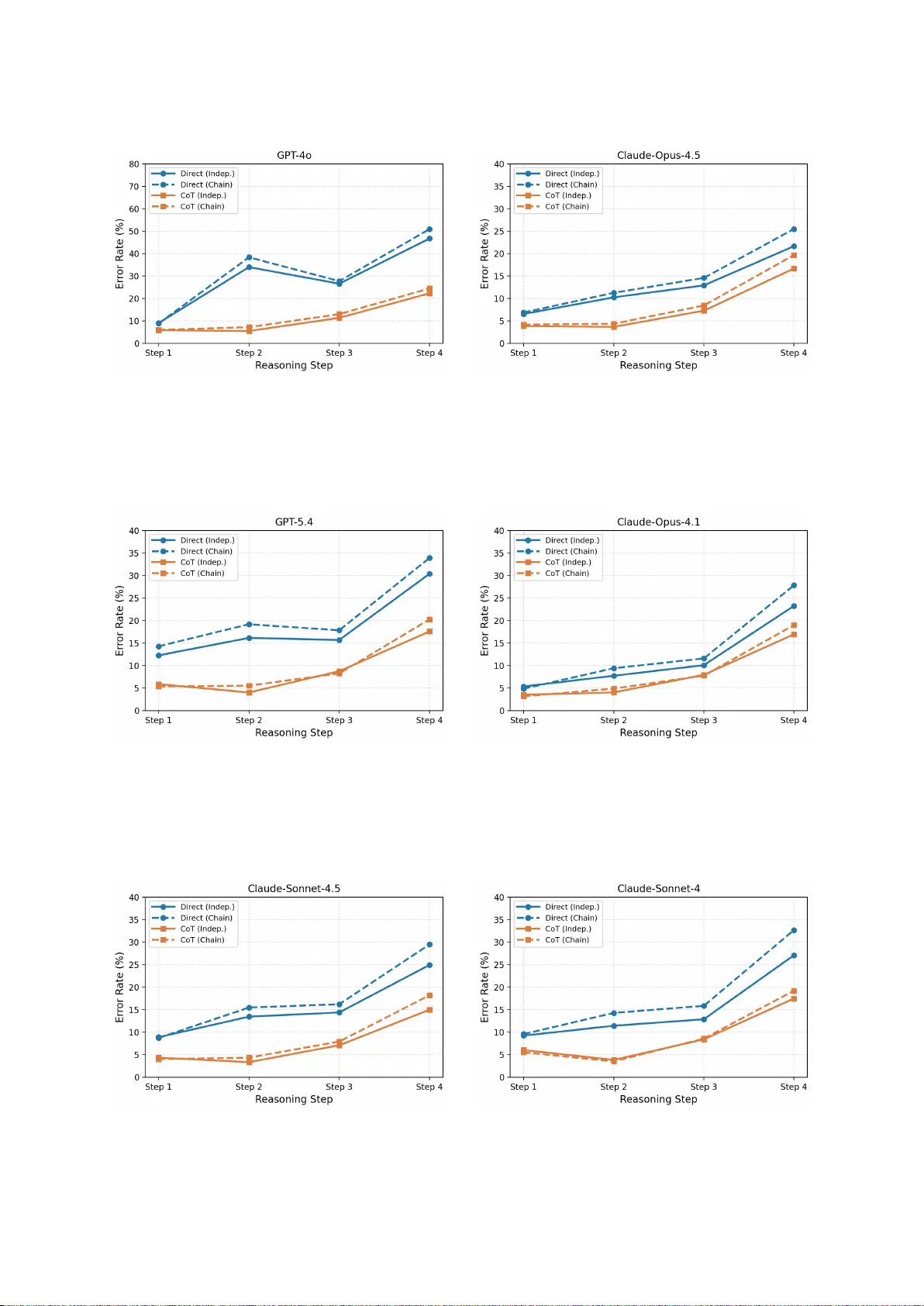
Omanic: T owards Step-wise Ev aluation of Multi-hop Reasoning in Large Language Models Xiaojie Gu 1 , Sherry T . T ong 1 , Aosong F eng 2 , Sophia Simeng Han 3 , Jinghui Lu 4 , Y ingjian Chen 1 , Y usuke Iwasawa 1 , Y utaka Matsuo 1 , Chanjun Park 5 , Rex Y ing 2 , Irene Li 1 1 The Uni versity of T okyo, 2 Y ale Univ ersity , 3 Stanford Uni versity , 4 Xiaomi EV , 5 Soongsil Uni versity Abstract Reasoning-focused large language models (LLMs) hav e adv anced in many NLP tasks, yet their e v aluation remains challenging: fi- nal answers alone do not expose the inter- mediate reasoning steps, making it dif ficult to determine whether a model truly reasons correctly and where failures occur , while ex- isting multi-hop QA benchmarks lack step- lev el annotations for diagnosing reasoning fail- ures. T o address this gap, we propose Omanic, an open-domain multi-hop QA resource that provides decomposed sub-questions and in- termediate answers as structural supervision for analyzing reasoning processes. It con- tains 10,296 machine-generated training exam- ples (OmanicSynth) and 967 e xpert-re vie wed human-annotated e valuation e xamples (Oman- icBench). Systematic ev aluations show that state-of-the-art LLMs achiev e only 73.11% multiple-choice accuracy on OmanicBench, confirming its high dif ficulty . Stepwise analy- sis rev eals that CoT’ s performance hinges on factual completeness, with its gains diminish- ing under kno wledge gaps and errors ampli- fying in later hops. Additionally , supervised fine-tuning on OmanicSynth brings substan- tial transfer gains (7.41 a verage points) across six reasoning and math benchmarks, v alidat- ing the dataset’ s quality and further supporting the effecti veness of OmanicSynth as supervi- sion for reasoning-capability transfer . W e re- lease the data at https://huggingface.co/ datasets/li- lab/Omanic . 1 1 Introduction As Large Language Models (LLMs) ma- ture ( Google , 2025 ; OpenAI , 2025 ; Qwen , 2026 ), the research frontier has progressi v ely mov ed beyond single-task proficienc y to ward complex reasoning, with Chain-of-Thought (CoT) ( W ei et al. , 2022 ) prompting emerging as a central 1 Code at https://github.com/XiaojieGu/Omanic technique for eliciting intermediate logical steps. Y et growing evidence re v eals that LLMs often exhibit reasoning shortcuts ( Shojaee et al. , 2025 ; Hammoud et al. , 2025 ), arriving at correct final answers through heuristic pattern matching rather than rigorous deduction, and that high end-to-end accuracy can mask systematic failures in interme- diate steps ( Jaco vi et al. , 2024 ). This concern is especially acute in multi-hop reasoning, where existing benchmarks such as HotpotQA ( Y ang et al. , 2018 ) and MuSiQue ( T ri v edi et al. , 2022 ), despite adv ancing evidence synthesis across documents, lack step-level structural annotations needed to diagnose wher e and why models fail along a reasoning chain. The absence of such fine-grained ground truth creates a fundamental blind spot, making it difficult to distinguish genuine compositional reasoning from superficial shortcut exploitation ( Gu et al. , 2026 ). T o bridge this gap, we introduce Oman- icBench ( O pen-domain M ulti-hop questions with AN notated reason I ng C hain), a multi-hop reason- ing benchmark centered on a human-annotated e v aluation set with step-le vel structural annotations, enabling fine-grained analysis of model reasoning behavior . OmanicBench consists of 967 multi-hop questions, each manually annotated and expert- re viewed (o ver 300 hours of annotation effort), providing high-quality ground truth for analyz- ing reasoning beha vior . Crucially , e very question is decomposed into four cross-domain single-hop sub-questions with intermediate answers, drawing on rich factual knowledge and connected through mathematical reasoning. These reasoning chains are org anized under distinct graph topologies. Be- sides, we also release OmanicSynth, a machine- generated training set containing 10,296 instances for supervised training and transfer experiments. Le veraging the step-wise annotations in Omanic, we conduct a systematic analysis of multi-hop rea- soning behaviors in state-of-the-art LLMs. Our 1 Figure 1: Ov erview of Omanic construction pipeline, where rectangles denote entities and circles denote single-hop questions. study re veals tw o ke y phenomena. First, we iden- tify a knowledge floor ef fect, where CoT gains diminish sharply as required atomic facts become missing, e ventually disappearing be yond a critical threshold. Second, we observe err or pr opagation along reasoning chains: later hops consistently ex- hibit higher error rates, indicating that reasoning errors inherently amplify during sequential multi- hop inference. T ogether , these findings provide ne w evidence that reasoning and kno wledge re- trie v al constitute separable capabilities of LLMs. In summary , we make three main contrib utions. First, we propose Omanic, the open-domain 4- hop QA benchmark with structural annotations for step-le vel reasoning diagnosis, containing 10,296 training and 967 expert-re vie wed testing instances, where state-of-the-art LLMs only achie ve 73.11% accuracy . Second, we ev aluate various LLMs and fine-tune open-source models on OmanicSynth, ob- taining 7.41 av erage points improv ement across six external benchmarks, sho wing strong transferabil- ity and high data quality . Third, using single-hop decomposition, we empirically analyze the knowl- edge floor ef fect and err or pr opagation in multi- hop reasoning, re vealing that CoT benefits rely on factual completeness and errors amplify along the reasoning chain. 2 Omanic Construction Pipeline The ov erview of the dataset construction pipeline is illustrated in Figure 1 . T riplets Retrie val T o construct the Omanic dataset, we be gin with the answers to the original 2-hop questions in MuSiQue ( Tri vedi et al. , 2022 ), which are themselves composed of two single-hop questions. These answers serve as anchor subjects for retrie ving correspond- ing ( subj ect, rel ation, obj ect ) triplets from W iki- data5M ( W ang et al. , 2021 ), a lar ge-scale knowl- edge graph deri ved from W ikipedia. These re- trie ved triplets function as the foundational b uild- ing blocks for our 4-hop expansion. Constrained Synthesis T o construct 4-hop queries, we mer ge original MuSiQue components with ne w single-hop questions synthesized from retrie ved triplets, utilizing Claude-Sonnet-4.5. This process is governed by domain constraints and reasoning-graph topology . Each synthesized single- hop question is assigned to one of eight predefined domains (e.g., History and Liter atur e , Art and Ar- chitectur e ), and the source W ikidata triplet is con- textually refined to improv e fluency and coherence. Each 4-hop instance is also required to contain at least one mathematically grounded hop. Numerical, temporal, or countable attributes are re written into sub-questions that require explicit quantitati ve rea- soning, such as comparison, aggregation, counting, arithmetic composition, or temporal calculation. This mathematical hop is embedded into the chain rather than appended independently , so its inputs depend on earlier hops and its output can support later ones. For each query , we randomly choose one of three reasoning graph topologies ( T rivedi et al. , 2022 ) (Figure 6 ), which determines both question synthesis and final assembly . F or exam- ple, under the Bridge pattern (T able 1 ), the second hop depends on the first, and the fourth depends on both the second and third, pre venting shortcut solutions that bypass intermediate reasoning. Fi- nally , each single-hop question is paired with three distractors, and the answer and options of the last hop are used as the ground truth and candidate set for the full 4-hop query . A utomated Filtering T o maintain a great diffi- culty ceiling, we filter the synthesized dataset using an ensemble of four models 2 . Any question an- swered correctly by two or more models is deemed too simple and discarded. After pruning, 3,415 instances were removed, yielding a final training set of 10,296 examples. Expert Review T o ensure the high quality of the OmanicBench, 1,172 candidate instances under go rigorous human audit conducted by 10 trained un- dergraduates and postgraduates over approximately 300 person-hours via the Label Studio platform 3 . For each instance, annotators first verify the fac- 2 Including Llama-3.1-8B-Instruct, Qwen3-8B, Mistral-7B- Instruct-v0.3, and Gemma-3-4b-it 3 https://labelstud.io/ 2 Reasoning Graph Multi-hop Question Single-hop Composition In the country of citizenship of the author of Candida, which political party was founded the same number of years before 1968 as the number of distinct 3-member committees that can be formed from a group of 7 candi- dates? Fine Gael [A: F ine Gael B: Labour P arty C: Fianna Fáil D: Sinn Féin] 1. Who is the author of Candida? Bernard Shaw 2. What is the country of citizenship of Bernard Sha w ? Ireland 3. How man y distinct 3-member committees can be formed from a group of 7 candidates? 35 4. In Ireland , which political party was founded 35 years before 1968? Fine Gael T able 1: An example illustrating the multi-hop reasoning graph and its step-by-step question decomposition. tual correctness of ev ery sub-question and its an- swer by consulting the W ikipedia articles linked to the underlying triplets; for questions in volving mathematical reasoning, annotators are addition- ally required to provide detailed step-by-step com- putations. They then examine the logical coher- ence of the full 4-hop reasoning chain, checking whether it conforms to the designated graph topol- ogy , and then assign quality scores across multiple dimensions (factual accurac y , distractor plausibil- ity , fluency , and reasoning integrity) following a standardized rubric (detailed in Appendix A ). They also verify the correctness of the required numer- ical operations in mathematically grounded hops, ensuring that intermediate calculations and final deri ved v alues are arithmetically consistent. Where deficiencies are identified, annotators directly cor - rect the instance or supplement supporting refer- ences and deriv ations. Instances failing to meet predefined quality thresholds were excluded, yield- ing a final set of 967 high-quality instances as the e v al set. An instance is shown in T able 1 . 3 Experiments and Analysis 3.1 Models and Setup T o assess the quality and utility of Omanic, we ev al- uate a div erse set of proprietary and open-source LLMs under multiple settings. For proprietary models (e.g., GPT -5 ( Singh et al. , 2025 )), we e val- uate both direct answering and CoT prompting. For open-source models (e.g., Qwen3-8B ( Qwen , 2025 )), we additionally fine-tune selected models on the Omanic training set via supervised fine- tuning (SFT) and GRPO-based ( Shao et al. , 2024 ) reinforcement learning. T o examine whether train- ing on OmanicSynth transfers to broader reason- ing capabilities, we further e v aluate the fine-tuned models across multiple reasoning benchmarks (e.g., MA TH ( Hendrycks et al. , 2021 )). For ev aluation on OmanicBench, we report three complementary metrics across two e valuation paradigms. For the multiple-choice question setting, we use Multiple- Choice Question(MCQ) accuracy ( Xinjie et al. , 2025 ), which measures selection accuracy ov er four candidate options. F or the open-ended genera- MCQ Exact Match F1-Score Proprietary LLMs GPT -5.4 49.22 22.85 32.22 GPT -5.4 CoT 70.84 27.09 43.58 Claude-Sonnet-4.6 55.43 20.73 37.15 Claude-Sonnet-4.6 CoT 73.11 14.81 † 32.27 † Gemini-3.1-flash-lite 44.88 23.47 32.31 Gemini-3.1-flash-lite CoT 72.60 23.99 35.72 Qwen3-Max 49.02 17.79 26.31 Qwen3-Max CoT 72.08 35.99 45.51 Open-source LLMs Qwen2.5-72B 42.19 13.24 19.43 Qwen3-32B 52.22 12.10 18.35 Qwen3-8B 25.65 9.26 13.77 Qwen3-8B SFT 53.62 10.97 16.60 Qwen3-8B SFT+GRPO 53.77 11.79 17.98 LLaMA-3.3-70B 40.04 11.77 20.47 LLaMA-3.3-70B SFT 57.55 19.42 29.04 T able 2: Performance comparison of proprietary and open-source LLMs on OmanicBench. Subscripts indi- cate dif ferent prompting and training settings. Bold marks the best result per metric. † : discuss in Ap- pendix B.2 . tion setting, we report Exact Match (EM), which requires strict string equi valence with the gold an- swer , and F1-Score, which captures partial credit at the token le vel ( Rajpurkar et al. , 2016 ). Figure 2: Comparison of accuracy across benchmarks between the vanilla model and its counterparts fine- tuned on OmanicSynth. 3.2 Main Results T able 2 presents the overall performance of all e valuated models on OmanicBench. Proprietary 3 LLMs consistently outperform open-source coun- terparts, and CoT prompting yields notable gains across all proprietary models on MCQ. Among proprietary models, Claude-Sonnet-4.6 CoT achie ves the highest MCQ accuracy (73.11), while Qwen3- Max CoT leads in open-ended generation. For open- source models, after training on OmanicSynth, we observe substantial improv ements across all fine- tuned models (e.g., Qwen3-8B MCQ: 25.65 → 53.77), confirming that OmanicBench poses a gen- uine challenge for current LLMs while remaining amenable to targeted training. Notably , we also compare the output length, as sho wn in T able 10 , the performance gains from CoT for some models come at substantially higher inference costs. While Qwen3-Max CoT achie ves the best open-ended per - formance, its output token length far e xceeds that of all other models. In contrast, GPT -5.4 CoT is con- siderably more ef ficient in practice. T o further assess the transferability of skills ac- quired from OmanicSynth, we ev aluate the fine- tuned models on established reasoning ( Y u et al. , 2020 ; Liu et al. , 2021 ; W ang et al. , 2022 ; Saparo v and He , 2023 ) and mathematics ( Cobbe et al. , 2021 ) benchmarks. As shown in Figure 2 , fine-tuned mod- els consistently outperform their vanilla counter- parts, demonstrating that OmanicSynth comprises high-quality , non-trivial instances that culti vate genuine complex logical reasoning and mathemat- ical reasoning capabilities rather than superficial pattern matching or factual kno wledge retrie val alone. All implementation details are provided in the Appendix B.1 . 3.3 Key Obser vations Beyond aggre gate performance, the step-le vel an- notations in OmanicBench allow us to quantita- ti vely e xamine two research questions about multi- hop reasoning behavior . RQ1: T o what extent does CoT r ely on a suffi- cient knowledge f oundation? ( W ang et al. , 2023 ) Figure 3: Results a veraged across LLMs under Direct and CoT prompting. Left: Multi-hop accuracy by num- ber of single-hop errors. Right: Step-wise error rates under independent and chain ev aluation. T o in vestigate this question, we group multi-hop questions by the number of constituent single-hop questions answered incorrectly , and then measure multi-hop accuracy within each group. As shown in Figure 3 (left), even in the zero-error group, multi-hop accuracy under Direct prompting reaches only about 60%, well belo w ceiling, indicating that multi-hop reasoning and single-hop knowledge re- trie v al are not equi valent. Meanwhile, CoT gain de- creases monotonically as the number of erroneous single-hop steps increases, dropping to near zero ( − 0.7) when three steps are incorrect, while the largest gain (+21.9) is observed in the zero-error group. These results quantify a clear kno wledge floor on OmanicBench: ef fectiv e CoT requires suf- ficient factual grounding, sharpening compositional inference but not substituting for missing f acts. RQ2: T o what extent do err ors amplify toward the end of a multi-hop reasoning chain? ( Press et al. , 2023 ) T o quantify this ef fect, we compare two e v aluation protocols: independent e valuation, where each step recei ves the gold an- swer to prior single-hop questions; and chain e valu- ation, where answers from previous steps propagate to subsequent steps. As sho wn in Figure 3 (right), e ven under independent e valuation, Step 4 already exhibits a substantially higher error rate than ear- lier steps, re vealing an inherent dif ficulty gradient in OmanicBench beyond pure propagation ef fects. Under chain e valuation, errors compound: Step 4 reaches a 33.0% error rate under Direct prompting, 4.7 points higher than under independent ev alua- tion. While CoT reduces absolute error rates at e very step, the amplification pattern remains in- tact, suggesting that sequential multi-hop inference is intrinsically more fragile in later hops. T aken together , these analyses sho w that OmanicBench is not only a benchmark for end-to-end accuracy , but also a diagnostic testbed for quantifying where reasoning breaks down and how strongly errors compound across hops. 4 Conclusion W e present Omanic, an open-domain multi-hop QA benchmark inte grating mathematical reasoning and factual inference, with decomposed single-hop sub- questions as reasoning annotations. Analysis sho ws that CoT gains depend on factual completeness and that errors propagate along the reasoning chain. W e release Omanic as a diagnostic benchmark to facilitate future research on multi-hop reasoning. 4 Limitations Omanic has se veral limitations that suggest direc- tions for future work. First, the benchmark is re- stricted to English only , limiting its applicability to multilingual reasoning e v aluation. Second, while 4-hop questions represent a meaningful increase in complexity o ver e xisting 2-hop benchmarks, ex- tending to longer reasoning chains (e.g., 6-hop or 8-hop) would further test the limits of composi- tional reasoning. Third, although Omanic spans eight knowledge domains, certain specialized do- mains (e.g., legal, biomedica l) remain underrepre- sented. Fourth, the dataset scale (10,296 training and 967 test instances) is moderate; scaling up through broader kno wledge graph cov erage could improv e both training utility and ev aluation robust- ness References Karl Cobbe, V ineet Kosaraju, Mohammad Bav arian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training v erifiers to solve math word prob- lems. arXiv pr eprint arXiv:2110.14168 . Google. 2025. Gemini-3-pro. https://docs.cloud. google.com/vertex- ai/generative- ai/docs/ models/gemini/3- pro . Retriev ed December 12, 2025. Ke n Gu, Advait Bhat, Mik e A Merrill, Robert W est, Xin Liu, Daniel McDuf f, and T im Althoff. 2026. Synth- worlds: Controlled parallel worlds for disentangling reasoning and knowledge in language models. Hasan Abed Al Kader Hammoud, Hani Itani, and Bernard Ghanem. 2025. Be yond the last answer: Y our reasoning trace uncovers more than you think. ArXiv preprint arXi v:2504.20708. Dan Hendrycks, Collin Burns, Saura v Kadav ath, Akul Arora, Stev en Basart, Eric T ang, Dawn Song, and Ja- cob Steinhardt. 2021. Measuring mathematical prob- lem solving with the math dataset. arXiv pr eprint arXiv:2103.03874 . Edward J Hu, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, W eizhu Chen, and 1 others. 2023. Lora: Lo w-rank adaptation of large language models. In International Conference on Learning Repr esentations . Alon Jacovi, Y onatan Bitton, Bernd Bohnet, Jonathan Herzig, Or Honovich, Michael Tseng, Michael Collins, Roee Aharoni, and Mor Gev a. 2024. A chain-of-thought is as strong as its weakest link: A benchmark for verifiers of reasoning chains. In Pr oc. of A CL . Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Y ile W ang, and Y ue Zhang. 2021. Logiqa: a challenge dataset for machine reading comprehen- sion with logical reasoning. In Pr oceedings of the T wenty-Ninth International Conference on Interna- tional J oint Confer ences on Artificial Intelligence , pages 3622–3628. OpenAI. 2025. Gpt5.1. https://openai.com/ ja- JP/index/introducing- gpt- 5/ . Retrie ved December 12, 2025. Ofir Press, Muru Zhang, Sew on Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. 2023. Measuring and narro wing the compositionality gap in language models. In F indings of the Association for Computa- tional Linguistics: EMNLP 2023 , pages 5687–5711. Qwen. 2025. Qwen3 technical report . Pr eprint , Qwen. 2026. Pushing qwen3-max-thinking be yond its limits. Pranav Rajpurkar , Jian Zhang, Konstantin Lop yrev , and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proc. EMNLP . Abulhair Saparo v and He He. 2023. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. In The Eleventh International Confer ence on Learning Representations . Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Hao wei Zhang, Mingchuan Zhang, YK Li, Y ang W u, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 . Parshin Shojaee, Iman Mirzadeh, Kei van Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad F ara- jtabar . 2025. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity . arXiv preprint arXiv:2506.06941 . Aaditya Singh, Adam Fry , Adam Perelman, Adam T art, Adi Ganesh, Ahmed El-Kishky , Aidan McLaughlin, Aiden Low , AJ Ostro w , Akhila Ananthram, and 1 oth- ers. 2025. Openai gpt-5 system card. arXiv pr eprint arXiv:2601.03267 . Harsh T ri vedi, Niranjan Balasubramanian, T ushar Khot, and Ashish Sabharwal. 2022. Musique: Multi- hop questions via single-hop question composition. T ACL . Siyuan W ang, Zhongkun Liu, W anjun Zhong, Ming Zhou, Zhongyu W ei, Zhumin Chen, and Nan Duan. 2022. From lsat: The progress and challenges of com- plex reasoning. IEEE/ACM T ransactions on Audio, Speech, and Languag e Processing , 30:2201–2216. 5 Xiaozhi W ang, Tian yu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian T ang. 2021. Kepler: A unified model for kno wledge embedding and pre-trained language representation. T ransac- tions of A CL . Xuezhi W ang, Jason W ei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery , and Denny Zhou. 2023. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Confer ence on Learning Repr esentations . Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language models. Pr oc. of NeurIPS . Jian W u, Linyi Y ang, Zhen W ang, Manabu Okumura, and Y ue Zhang. 2025. Cofca: A step-wise counter- factual multi-hop qa benchmark. In Pr oc. of ICLR . Zhao Xinjie, Fan Gao, Xingyu Song, Y ingjian Chen, Rui Y ang, Y anran Fu, Y uyang W ang, Y usuke Iwa- sawa, Y utaka Matsuo, and Irene Li. 2025. ReAgent: Rev ersible multi-agent reasoning for kno wledge- enhanced multi-hop QA . In Pr oceedings of the 2025 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 4067–4089, Suzhou, China. Association for Computational Linguistics. Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, W illiam Cohen, Ruslan Salakhutdinov , and Christo- pher D Manning. 2018. Hotpotqa: A dataset for div erse, explainable multi-hop question answering. In Pr oc. of EMNLP . W eihao Y u, Zihang Jiang, Y anfei Dong, and Jiashi Feng. 2020. Reclor: A reading comprehension dataset re- quiring logical reasoning. In International Confer- ence on Learning Repr esentations . Andrew Zhu, Alyssa Hwang, Liam Dugan, and Chris Callison-Burch. 2024. Fanoutqa: A multi-hop, multi- document question answering benchmark for large language models. In Pr oceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (V olume 2: Short P apers) , pages 18–37. 6 A Human Annotation Guidance & Dataset Statistics W e recruit 10 undergraduate and graduate students to conduct the human correction and scoring pro- cess. T o ensure ethical research practices, all an- notators are compensated at a rate exceeding the local minimum wage. The entire project encom- passes a cumulativ e total of 200 person-hours. The detailed human annotation guidance is listed in the follo wing: For single-hop questions: • F actuality and Accuracy : This criterion as- sesses the truthfulness and precision of the question-answer pair within real-world con- texts, specific subject areas, or the pro vided kno wledge source. Annotators follow four steps: 1. Cor e Element Extraction. Identify ke y en- tities (names, locations, e vents, dates) and logical relationships in the question. 2. Cr oss-Sour ce V erification. V erify each en- tity’ s attributes using reliable databases, en- cyclopedias, or authoritati ve references. 3. T erminology and V alue Audit. Check that specialized terms are spelled correctly and that any numerical computations are error - free. 4. F inal Scoring. Assign a score based on the number and sev erity of errors (critical vs. minor). – 5 (Excellent) : All ke y terms, concepts, dates, and numerical values are entirely accurate. The content is supported by authoritativ e e vidence, remains free of "hallucinations" or misleading information, and utilizes pre- cise terminology consistent with field con ven- tions. – 4 (Good) : Most facts are accurate, with only minor flaws in non-core details that do not hinder ov erall understanding. T erminology is generally correct, though it may be slightly simplified while remaining acceptable within the domain. – 3 (Satisfactory) : Core facts are fundamen- tally correct, b ut errors e xist that could lead to partial misunderstanding. Some ke y terms may be poorly translated or e xpressed, requir- ing the reader to infer the true intent based on common sense. – 2 (Poor) : Multiple critical facts or numerical v alues are incorrect, significantly impacting the understanding of the problem. Evident misuse of terminology or factual conflicts se verely damages the professionalism of the content. – 1 (V ery Poor) : Contains se vere factual errors, false statements, or entirely f abricated "hal- lucinations." The question and answer fail to correspond, or most content contradicts kno wn facts. • Distractor Quality : This criterion ev aluates whether the three incorrect options (distractors) are suf ficiently decepti ve and belong to a plau- sible logical category . Annotators follow four steps: 1. Cate gory Consistency Check. V erify that all distractors belong to the same logical category as the correct answer (e.g., if the answer is a location, distractors must also be locations). 2. Domain Relevance Analysis. Assess whether distractors share geographic, tem- poral, or thematic proximity with the correct answer within the same domain. 3. T rap Logic Identification. Examine whether distractors exploit plausible intermediate- step errors or common o ver -simplifications (e.g., arithmetic near-misses or temporally adjacent entities). 4. F inal Scoring. Assign a score: if distractors are nearly indistinguishable without full rea- soning, score 5; if they span unrelated cate- gories, score 1–2. – 5 (Highly Deceptive) : All distractors belong to the same domain. Numerical options rep- resent logical "traps" (e.g., calculation near- misses), while semantic options consist of easily confused synonyms, similar institu- tions, or entities derived from intermediate reasoning steps. – 4 (Effectiv e) : Distractors are within a reason- able scope (e.g., for a question about Europe, all distractors are European). The format is highly consistent with the answer , making them impossible to exclude via simple word- class or logical loopholes. – 3 (Moderate) : Distractors share attrib utes with the answer (e.g., both are years or loca- tions), but one or tw o options can be quickly 7 excluded using general kno wledge or obvious context clues. – 2 (W eak) : Distractors belong to the same broad category b ut possess obvious attribute dif ferences (e.g., asking for a univ ersity name while providing a country name as a distrac- tor) or inconsistent formatting. – 1 (Non-existent) : Distractors are completely irrele vant or cross-domain (e.g., a "year" question with "apple" as an option). These are illogical "fillers" that can be instantly identified. • Fluency and Completeness : This criterion e valuates whether the language is natural, the logic is clear , the grammar is correct, and all necessary constraints for a unique answer are provided. Annotators follo w four steps: 1. Naturalness F irst-Read. Read the question as a native speaker , checking for awkward phrasing, in verted word order, or logical discontinuities—paying special attention to subordinate clauses and pronoun references in longer sentences. 2. Constraint Completeness Scan. V erify that the question stem contains e very constraint necessary to deriv e a unique correct answer (e.g., specific years, inclusiv e/exclusi ve con- ditions). 3. Grammar and Spelling Chec k. Inspect punc- tuation, capitalization of proper nouns, and tense consistency . 4. F inal Scoring. Assign a score: fla wless grammar with a self-contained information loop scores 5; translation artifacts or missing critical constraints lower the score accord- ingly . – 5 (Excellent) : Expression is extremely natu- ral and smooth, fully adhering to nati ve usage habits. The structure is rigorous with appro- priate logical connecti ves and zero grammati- cal errors. All original details and necessary constraints are preserved without omission. – 4 (Good) : Expression is basically natural with only minor linguistic flaws. The main meaning is preserved, though some non- critical descriptive details may be missing. Sentence structures follow standard norms with negligible errors. – 3 (Satisfactory) : Expression is slightly rigid or exhibits a "translation-ese" tone. While the core meaning is con ve yed, it may omit some important constraints or include irrele- v ant information; grammar errors are present but the meaning remains clear . – 2 (Poor) : Lacks fluency with abrupt transi- tions and unclear logical connections. Core information is incomplete, containing signif- icant omissions or serious errors that affect the ability to judge the correct answer . – 1 (V ery P oor) : Language is extremely un- natural or unintelligible, containing sev ere grammatical and logical errors. The content org anization is chaotic and fails to reflect the original intent of the question. For 4-hop questions: • Logical Integrity and T echnical F ormatting : This criterion ev aluates the structural rigor of the multi-hop reasoning chain and the standard- ized use of LaT eX, technical terminology , and code formatting. Annotators follow four steps: 1. Logic Chain Decomposition. Break the multi-hop question into an explicit path A → B → C → D and identify each inter - mediate node. 2. Input–Output Matching . V erify that the out- put of each preceding hop is correctly used as the input condition for the subsequent hop. 3. Symbol and Code A udit. Check that all La- T eX formulas, mathematical notation, cur- rency symbols, and code blocks are cor- rectly rendered and unaltered. 4. Consistency Determination. Confirm that the logic chain forms a closed loop with no breaks or circular reasoning. – 5 (Excellent) : The reasoning chain is per- fectly airtight without gaps or circularity . All LaT eX symbols, mathematical formulas, and currency signs ($) are technically flawless and correctly rendered. – 4 (Good) : The logical chain is complete and sound, though the natural language transi- tions between hops may feel slightly rigid. T echnical formatting is basically standard- ized with only negligible layout fla ws. – 3 (Satisfactory) : A minor logical flaw e xists (e.g., ambiguous pronoun reference like "the artist" when multiple artists are mentioned), requiring the reader to re-read to clarify the 8 steps. T erminology or LaT eX symbols may sho w slight formatting de viations. – 2 (P oor) : Relationships between multiple hops are unclear , or critical premises are lost due to poor phrasing, preventing a successful logical "closed-loop." F ormatting is chaotic, with LaT eX symbols or code blocks appear - ing garbled. – 1 (V ery P oor) : The logical chain is entirely broken or results in a paradox (e.g., asking for a "year" b ut requiring a "monetary amount" as the answer). T erminology is highly un- professional, and formatting has completely collapsed. • Contextual Fact Consistency : This criterion verifies whether all single-hop facts remain fac- tually accurate and conflict-free when amalga- mated into a multi-hop narrati ve. Annotators follo w four steps: 1. Atomic F act Backtrac king. Compare each background claim in the multi-hop question (e.g., a date, a title, a numeric v alue) against the original single-hop data. 2. Spatiotemporal Conflict Detection. V erify that the combined timeline is logically co- herent (e.g., an appointment in 1877 re- quires the predecessor’ s tenure to o verlap or precede that date). 3. Modifier V erification. Check whether qual- ifiers added during composition (e.g., “the large art school”) inadv ertently alter the original meaning. 4. F inal Scoring. If all intermediate-node facts are correct and transitions are natural, assign the full score. – 5 (Excellent) : All integrated facts (dates, lo- cations, v alues) are logically consistent with one another and the real-world background. The combined scenario is realistic (e.g., a museum established in 2000 is correctly de- scribed as existing in 2005). – 4 (Good) : Core facts are accurate, but mi- nor descriptiv e biases in non-essential details (e.g., secondary institutional titles or hon- orifics) occur during amalgamation without af fecting the final answer . – 3 (Satisfactory) : Core facts remain funda- mentally correct, but the timeline or logical background across hops feels slightly "a wk- ward" or strained, though no direct factual conflict is present. – 2 (Poor) : Significant factual fla ws appear in intermediate steps (e.g., a single-hop answer is "11 years" but is treated as "12 years" dur- ing the multi-hop calculation), rendering the final result unreliable. – 1 (V ery Poor) : A severe factual error exists in at least one intermediate step, or the time- line is logically impossible (e.g., a div orce occurring before the marriage). • Answer Obscurity and Leakage Pr evention : This criterion e valuates whether the question stem accidentally rev eals the final answer or if the reasoning steps pro vide a suf ficient chal- lenge. Annotators follow four steps: 1. K eywor d F iltering. Search the question stem for the final answer itself or any strongly characteristic cues that directly point to it. 2. Shortcut T est. Attempt to reach the correct answer without completing the intermediate hops—relying only on the final se gment of the question or general kno wledge. 3. Distractor Elimination Chec k. Assess whether the stem provides enough non- logical information to rule out all incorrect options without genuine reasoning. 4. F inal Scoring. If ev ery reasoning step is in- dispensable for reaching the answer , score 5; if the final segment alone makes the answer obvious, lo wer the score accordingly . – 5 (Excellent) : No leakage. The solver must complete e very reasoning step to find the an- swer . The final answer or its distinct charac- teristics do not appear , directly or indirectly , within the question stem. – 4 (Good) : The reasoning chain is intact, though some background descriptions might allo w a model to narrow do wn the answer range via a process of elimination rather than pure deduction. – 3 (Satisfactory) : P artial leakage occurs. Cer - tain phrasing is too direct (e.g., mentioning a highly unique year or rare proper noun), al- lo wing experienced annotators or models to "guess" the answer via shortcuts or common sense. – 2 (P oor) : The question contains obvious hints that make the reasoning chain signif- icantly easier to bypass. 9 – 1 (V ery Poor) : Direct leakage. The final answer appears within the multi-hop descrip- tion, or the question is phrased in a w ay that renders the logical steps meaningless. • Semantic Completeness and Linguistic Flu- ency : This criterion e valuates the retention of all necessary constraints and the naturalness of the linguistic expression. Annotators follo w four steps: 1. Grammar and Rhetoric Scan. Check long, complex sentences for grammatical errors and ambiguous references (e.g., multiple uses of “the artist” when se veral artists are mentioned). 2. Constraint Condition Checklist. Confirm that all critical constraints from the single- hop questions (e.g., “since 1855, ” “prior to”) are faithfully carried o ver into the multi-hop question. 3. Logical Connector Check. V erify that con- nectors such as “prior to, ” “who, ” and “where” accurately reflect the inter-hop rela- tionships. 4. F inal Scoring. A question that reads flu- ently and preserves all constraints scores 5; noticeable “translation-ese” or ambiguous references lo wer the score to 3 or belo w . – 5 (Excellent) : All necessary constraints (e.g., specific year ranges, "inclusi ve," rounding requirements) are perfectly preserved. The language is natural, smooth, and adheres to nati ve-speak er habits with precise logical con- necti ves. – 4 (Good) : Constraints are complete, b ut the phrasing is slightly wordy . Language is flu- ent, though the choice of logical connectors (e.g., "prior to," "who") may be repetiti ve. – 3 (Satisfactory) : The core meaning is clear , but some non-essential constraints are omitted (e.g., missing a rounding instruc- tion). The expression is rigid and exhibits "translation-ese" or a formulaic tone. – 2 (Poor) : Critical constraints required for deri v ation are missing, or redundant informa- tion is added that interferes with understand- ing. Logical connectors are used incorrectly . – 1 (V ery Poor) : Ke y constraints are missing, making it impossible to determine a unique answer . The language is broken and the log- ical relationships are erroneous, making the text unreadable. • Reasoning Complexity and Domain Diver - sity : This criterion measures the degree of cross-domain complexity and the depth of the logical jumps. Annotators follow four steps: 1. Domain Counting. Identify the number of distinct knowledge domains spanned by the question (e.g., Literature, Geography , Art History , Arithmetic). 2. Hop Counting. Count the number of explicit logical transitions from the starting entity to the final answer . 3. Depth and Dependency Analysis. Determine whether each hop requires domain-specific kno wledge that cannot be bypassed through common sense alone. 4. Level Determination. Assign a score based on the number of domains crossed (4+ do- mains = top tier) and the number of non- tri vial hops. – 5 (Excellent) : The logical chain spans 4 or more distinct domains (e.g., Art History → Geography → Law → Financial Arithmetic). Each step is strictly dependent on the previ- ous one and cannot be bypassed via common sense. – 4 (Good) : The logic spans 3 distinct domains and in volves at least 4 e xplicit logical jumps. – 3 (Satisfactory) : The reasoning chain in- volv es 3 or more deep logical steps within at least 2 distinct domains. It ef fecti vely dis- tinguishes models with single-domain knowl- edge. – 2 (P oor) : The chain in volves 2 domains but only 1–2 simple logical jumps, or one of the domains relies on common kno wledge. – 1 (V ery Poor) : "Pseudo-multi-hop." The logic is extremely simple, consisting merely of the additi ve stacking of facts within the same domain. 10 Figure 4: Annotation interface for single-hop question. Single-hop Sub-questions F actuality Distractor Fluency Mean STD 4 . 62 0 . 54 4 . 31 0 . 72 4 . 47 0 . 61 4-hop Questions Logic Consistency Obscurity Mean STD 4 . 53 0 . 58 4 . 41 0 . 65 4 . 18 0 . 79 Fluency Complexity Mean STD 4 . 44 0 . 62 4 . 56 0 . 53 T able 3: Human annotation scores on a 1–5 scale over 967 test instances. Each cell reports the mean score with the standard deviation in subscript (mean std ). 11 Figure 5: Annotation interface for 4-hop question. 12 Reasoning Graph Multi-hop Question Single-hop Composition If a political regime be gan in 1969 and lasted for a number of years equal to 7 times the count of Apollo moon landing missions that oc- curred during the presidency of Eisenho wer’s vice president, and if the U.S. w as one of 2 ma- jor po wers that recognized this regime’ s leader early on, what was the other major power? So- viet Union [A: United Kingdom B: F rance C: Soviet Union D: W est Germany] 1. Who served as Eisenhower’ s vice president? Nixon 2. How man y successful Apollo moon landing missions occurred while Nixon was president of the U.S.? 6 3. If a political regime lasted for 6 times 7 years starting from 1969, whose face was most closely associated with Libya’ s government during this period? Gaddafi 4. If the U.S. was one major power that recognized Gaddafi ’ s government at an early date, and there were 2 major po wers total that did so early on, what w as the other major po wer besides the U.S.? Soviet Union Great American Ball Park is the home stadium of an MLB team that has won the W orld Series multiple times. Multiply their total champi- onship count by the number of players perma- nently banned for fixing the 1919 W orld Series in the Black Sox Scandal. The carrier named after the president with that ordinal number replaced which vessel at Na val Station Y oko- suka, Japan, in 2015? USS George W ashing- ton [A: USS Nimitz B: USS Carl V inson C: USS Geor ge W ashington D: USS John C. Stennis] 1. In which U.S. city is Great American Ball Park located? Cincin- nati 2. How man y W orld Series championships ha ve the Cincinnati Reds won in total? 5 3. Eight Chicago White Sox players were permanently banned from baseball for their role in fixing the 1919 W orld Series (the Black Sox Scandal). Multiply this number by the Cincinnati Reds’ total W orld Series championships ( 5 ). Which U.S. President held the ordinal number equal to this product? Ronald Reagan 4. USS Ronald Reagan replaced which aircraft carrier as the U.S. Navy’ s forward-deployed vessel at Na val Station Y okosuka, Japan, in 2015? USS George W ashington T able 4: Example multi-hop reasoning graph and its step-by-step question decomposition. Dataset Open Domain # Hops Explicit step-wise chain # T opologies Math reasoning Expert-review MuSiQue ( T riv edi et al. , 2022 ) Y es 2-4 No 3 No Y es FanOutQA ( Zhu et al. , 2024 ) Y es 5-6 Y es 1 No Y es CofCA ( W u et al. , 2025 ) Y es 2-4 No 3 No No SynthW orlds ( Gu et al. , 2026 ) No 2-4 No 3 No No OmanicBench (ours) Y es 4 Y es 3 Y es Y es T able 5: Qualitativ e comparison between OmanicBench and representativ e multi-hop or reasoning benchmarks. “# Hops” reports the supported hop range; for MuSiQue and CofCA, around 80% of the questions are 2-hop. “Explicit step-wise chain” indicates whether a benchmark provides explicit step-le vel annotations, such as decomposed sub-questions and intermediate answers, for diagnosing reasoning f ailures. “# T opologies” counts the number of reasoning topologies defined for questions at the maximum hop lev el of each benchmark. 13 (a) Bridge (b) Chain (c) Con verging Figure 6: Three reasoning graph topologies used in Omanic for or ganizing 4-hop questions. Figure 7: Domain distribution of single-hop sub-questions across OmanicSynth, OmanicBench, and the overall dataset. Figure 8: Reasoning graph topology distrib ution across OmanicSynth, OmanicBench, and the ov erall dataset. 14 B Full Results B.1 Implementation details For supervised fine-tuning, we construct a mixed training set in which half of the instances are formatted as multi-choice question examples and the other half are formatted as open-ended gen- eration examples. For Qwen3-8B, we adopt a two-stage training framew ork: we first perform full-parameter SFT , and then conduct GRPO- based ( Shao et al. , 2024 ) reinforcement learning starting from the fine-tuned model. For LLaMA- 3.3-70B, we perform LoRA-based ( Hu et al. , 2023 ) SFT on the same mix ed training data. All exper - iments are conducted on four 96GB H100 NVL GPUs, and the detailed training hyperparameters are reported in T ables 7 , 8 , and 9 . The e v aluation templates are summarized in T able 6 . Setting T emplate Direct multi-choice question Select the correct option from four candidates and return only the answer letter (A/B/C/D). Direct open-ended Answer as concisely as possible and provide only the final answer without explanation. CoT multi-choice question Think step by step and end the response with “The answer is X”, where X is A, B, C, or D. CoT open-ended Think step by step and write the final answer on a separate line in the format “FIN AL ANSWER: ”. T able 6: Ev aluation templates for direct and CoT prompting. Parameter V alue Cutoff length 2048 Per-de vice batch size 32 Gradient accumulation 2 Learning rate 1 . 0 × 10 − 5 Epochs 3.0 LR scheduler Cosine W armup ratio 0.1 Precision BF16 T able 7: Hyperparameters for Qwen3-8B Full SFT . Parameter V alue T rain batch size 512 Max prompt length 1024 Max response length 1024 Actor learning rate 1 . 0 × 10 − 5 PPO mini-batch size 512 PPO micro-batch size / GPU 32 PPO epochs 1 KL loss Enabled KL coefficient 0.01 Number of rollouts 5 T otal epochs 3 T able 8: Hyperparameters for Qwen3-8B GRPO train- ing. Parameter V alue LoRA rank 8 Cutoff length 2048 Per-de vice batch size 32 Gradient accumulation 2 Learning rate 1 . 0 × 10 − 4 Epochs 3.0 Precision BF16 T able 9: Hyperparameters for LLaMA-3.3-70B LoRA SFT . B.2 Discussion As marked by † in T able 2 , Claude-Sonnet-4.6 e x- hibits a unique failure mode under CoT prompting: its MCQ accuracy impro ves substantially , yet open- ended performance (EM/F1) degrades. Manual inspection rev eals that Claude’ s CoT responses are substantially longer (a vg. 1,812 tok ens vs. GPT - 5.4’ s 451 tokens), with the final answer frequently buried in extended prose rather than presented in an extractable format. This suggests the de gradation reflects an answer extraction failure rather than a reasoning regression, underscoring the importance of e v aluating reasoning capability (MCQ) and an- swer articulation (EM/F1) as complementary , not interchangeable, axes. 15 Direct CoT OpenAI GPT -5.4 13 451 GPT -5.2 15 502 GPT -5.1 12 1,126 GPT -4o 16 1,314 Anthropic Claude-Sonnet-4.6 611 1,812 Claude-Sonnet-4.5 82 1,379 Claude-Opus-4.5 332 1,469 Claude-Opus-4.1 196 1,221 Claude-Sonnet-4 76 1,316 Claude-Opus-4 112 1,223 Google Gemini-3.1-flash-Lite 10 1,423 Gemini-3-Flash-Previe w 9 1,587 Gemini-2.5-Flash 8 3,837 Gemini-2.5-Flash-Lite 8 6,453 Meta LLaMA-3.3-70B 38 1,694 LLaMA-3-8B 22 1,469 LLaMA-3-70B 11 735 Alibaba Qwen3-Max 14 4,841 Qwen3-32B 33 920 Qwen3-8B 24 357 Qwen2.5-72B 12 1,260 Qwen2.5-7B 15 1,313 DeepSeek DeepSeek-V3.2 11 2,548 DeepSeek-R1-Distill-LLaMA-70B 111 652 DeepSeek-R1-Distill-Qwen-32B 68 429 T able 10: A verage output length under Direct and CoT prompting. MCQ Exact Match F1-Score OpenAI GPT -5.2 38.51 18.20 29.09 GPT -5.2 CoT 65.98 34.13 46.93 GPT -5.1 39.40 18.55 26.62 GPT -5.1 CoT 71.68 39.96 51.18 GPT -4o 39.50 16.65 28.93 GPT -4o CoT 66.91 37.85 47.04 Anthropic Claude-Sonnet-4.5 51.24 24.56 34.04 Claude-Sonnet-4.5 CoT 75.88 44.40 54.89 Claude-Opus-4.5 61.97 10.17 16.00 Claude-Opus-4.5 CoT 76.68 44.50 55.44 Claude-Opus-4.1 54.40 19.31 28.50 Claude-Opus-4.1 CoT 76.95 39.75 49.81 Claude-Sonnet-4 51.40 21.92 31.80 Claude-Sonnet-4 CoT 74.15 39.09 49.40 Claude-Opus-4 52.02 22.45 32.16 Claude-Opus-4 CoT 73.10 40.44 50.18 Google Gemini-3-Flash-Previe w 67.22 21.30 31.34 Gemini-3-Flash-Previe w CoT 75.90 40.54 50.19 Gemini-2.5-Flash 62.77 18.20 25.10 Gemini-2.5-Flash CoT 54.60 27.71 36.55 Gemini-2.5-Flash-Lite 32.68 9.31 14.04 Gemini-2.5-Flash-Lite CoT 32.26 22.54 29.24 T able 11: Expanded proprietary LLMs results on Oman- icBench. MCQ Exact Match F1-Score Meta LLaMA-3.3-70B 40.04 11.77 20.47 LLaMA-3.3-70B CoT 59.57 31.33 39.43 LLaMA-3-8B 25.23 4.96 8.78 LLaMA-3-8B CoT 42.50 16.55 22.78 LLaMA-3-70B 38.47 12.10 18.84 LLaMA-3-70B CoT 57.39 29.09 37.49 Alibaba Qwen3-32B 52.22 12.10 18.35 Qwen3-32B CoT 54.86 30.37 38.98 Qwen3-8B 25.65 9.26 13.77 Qwen3-8B CoT 56.44 21.76 29.97 Qwen2.5-72B 42.19 13.24 19.43 Qwen2.5-72B CoT 60.81 32.06 41.31 Qwen2.5-7B 30.51 7.76 14.31 Qwen2.5-7B CoT 46.85 19.44 25.60 DeepSeek DeepSeek-V3.2 43.33 12.82 19.36 DeepSeek-V3.2 CoT 70.94 35.92 46.19 DeepSeek-R1-Distill-LLaMA-70B 75.92 1.72 13.71 DeepSeek-R1-Distill-LLaMA-70B CoT 72.67 41.27 51.08 DeepSeek-R1-Distill-Qwen-32B 69.52 11.92 22.99 DeepSeek-R1-Distill-Qwen-32B CoT 69.29 35.51 46.00 T able 12: Expanded Open-source LLMs results on OmanicBench. 16 B.3 Full results on Knowledge Floor and the Error Pr opagation For the step-wise error rates under chain e v alua- tion, we e xclude single-hop questions that can be answered without relying on preceding steps, since they do not reflect dependency-sensiti ve error prop- agation. F or example, under the Bridge topology , the third hop is omitted because it can be answered independently of earlier hops. Figure 9: Multi-hop accuracy by number of single-hop errors for GPT -5.2. Figure 10: Multi-hop accuracy by number of single-hop errors for GPT -5.1. Figure 11: Multi-hop accuracy by number of single-hop errors for GPT -4o. Figure 12: Multi-hop accuracy by number of single-hop errors for GPT -5.4. Figure 13: Multi-hop accuracy by number of single-hop errors for Claude-Sonnet-4.5. 17 Figure 14: Multi-hop accuracy by number of single-hop errors for Claude-Opus-4.5. Figure 15: Multi-hop accuracy by number of single-hop errors for Claude-Opus-4.1. Figure 16: Multi-hop accuracy by number of single-hop errors for Claude-Sonnet-4. Figure 17: Multi-hop accuracy by number of single-hop errors for Claude-Opus-4. Figure 18: Multi-hop accuracy by number of single-hop errors for Claude-Sonnet-4.6. Figure 19: Multi-hop accuracy by number of single-hop errors for Gemini-3-Flash-Previe w . 18 Figure 20: Multi-hop accuracy by number of single-hop errors for Gemini-2.5-Flash. Figure 21: Multi-hop accuracy by number of single-hop errors for Gemini-2.5-Flash-Lite. Figure 22: Multi-hop accuracy by number of single-hop errors for Gemini-3.1-flash-lite. Figure 23: Multi-hop accuracy by number of single-hop errors for Qwen3-Max. Figure 24: Step-wise error rates under independent and chain ev aluation for GPT -5.2. Figure 25: Step-wise error rates under independent and chain ev aluation for GPT -5.1. 19 Figure 26: Step-wise error rates under independent and chain ev aluation for GPT -4o. Figure 27: Step-wise error rates under independent and chain ev aluation for GPT -5.4. Figure 28: Step-wise error rates under independent and chain ev aluation for Claude-Sonnet-4.5. Figure 29: Step-wise error rates under independent and chain ev aluation for Claude-Opus-4.5. Figure 30: Step-wise error rates under independent and chain ev aluation for Claude-Opus-4.1. Figure 31: Step-wise error rates under independent and chain ev aluation for Claude-Sonnet-4. 20 Figure 32: Step-wise error rates under independent and chain ev aluation for Claude-Opus-4. Figure 33: Step-wise error rates under independent and chain ev aluation for Claude-Sonnet-4.6. Figure 34: Step-wise error rates under independent and chain ev aluation for Gemini-3-Flash-Previe w . Figure 35: Step-wise error rates under independent and chain ev aluation for Gemini-2.5-Flash. Figure 36: Step-wise error rates under independent and chain ev aluation for Gemini-2.5-Flash-Lite. Figure 37: Step-wise error rates under independent and chain ev aluation for Gemini-3.1-flash-lite. 21 Figure 38: Step-wise error rates under independent and chain ev aluation for Qwen3-Max. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment