Domain-Independent Dynamic Programming with Constraint Propagation
There are two prevalent model-based paradigms for combinatorial problems: 1) state-based representations, such as heuristic search, dynamic programming (DP), and decision diagrams, and 2) constraint and domain-based representations, such as constrain…
Authors: Imko Marijnissen, J. Christopher Beck, Emir Demirović
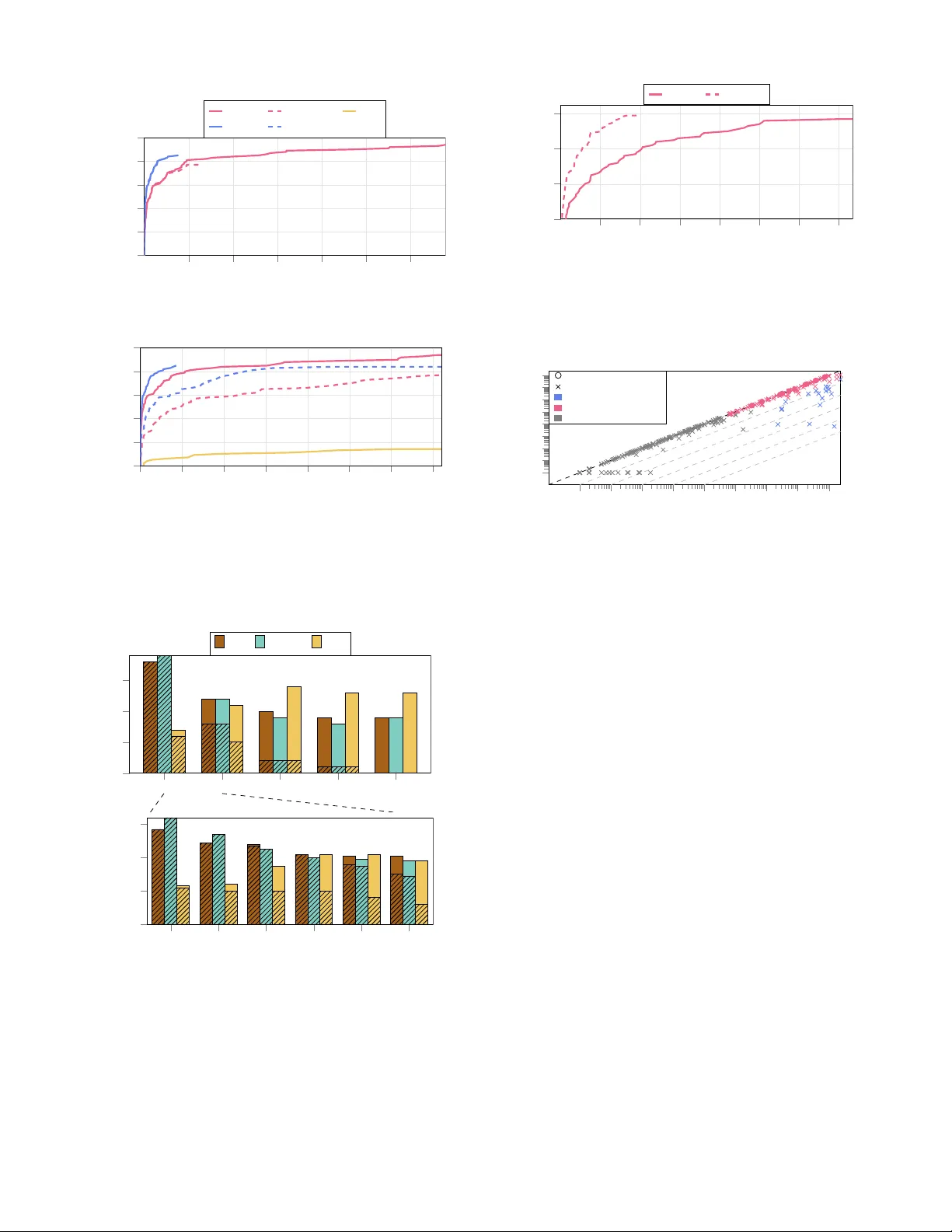
Domain-Independent Dynamic Pr ogramming with Constraint Pr opagation Imko Marijnissen 1 , J. Christopher Beck 2 , Emir Demiro vi ´ c 1 , Ryo Kur oiwa 3 1 Delft Univ ersity of T echnology , The Netherlands 2 Univ ersity of T oronto, Canada 3 National Institute of Informatics / The Graduate Univ ersity for Adv anced Studies, SOKEND AI, T okyo, Japan i.c.w .m.marijnissen@tudelft.nl, jcb@mie.utoronto.ca, e.demirovic@tudelft.nl, kuroiwa@nii.ac.jp Abstract There are two pre valent model-based paradigms for com- binatorial problems: 1) state-based representations, such as heuristic search, dynamic programming (DP), and decision diagrams, and 2) constraint and domain-based representa- tions, such as constraint programming (CP), (mixed-)integer programming, and Boolean satisfiability . In this paper, we bridge the gap between the DP and CP paradigms by in- tegrating constraint propagation into DP , enabling a DP solver to prune states and transitions using constraint prop- agation. T o this end, we implement constraint propaga- tion using a general-purpose CP solver in the Domain- Independent Dynamic Programming framework and e valu- ate using heuristic search on three combinatorial optimisa- tion problems: Single Machine Scheduling with Time W in- dows ( 1 | r i , δ i | P w i T i ), the Resource Constrained Project Scheduling Problem (RCPSP), and the Tra velling Salesper- son Problem with Time W indows (TSPTW). Our ev aluation shows that constraint propagation significantly reduces the number of state expansions, causing our approach to solve more instances than a DP solver for 1 | r i , δ i | P w i T i and RCPSP , and showing similar improvements for tightly con- strained TSPTW instances. The runtime performance indi- cates that the benefits of propagation outweigh the overhead for constrained instances, but that further w ork into reduc- ing propagation overhead could improve performance further . Our work is a k ey step in understanding the v alue of con- straint propagation in DP solvers, providing a model-based approach to integrating DP and CP . Code — https://doi.org/10.5281/zenodo.19051392 Experiments — https://doi.org/10.5281/zenodo.19051248 1 Introduction Combinatorial optimisation is ke y in Artificial Intelligence (AI), encompassing problems such as planning, schedul- ing, and variants of satisfiability . W ithin this field, Dy- namic Programming (DP) and Constraint Programming (CP) provide declarati ve model-based frame works such as Domain-Independent Dynamic Programming (Kuroiwa and Beck 2023a, 2025a) and MiniZinc (Nethercote et al. 2007; Stuckey et al. 2014) that enable users to formulate mathe- matical representations of problems that can then be solved by generic solvers. Copyright © 2026, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserv ed. While solving the same problem, the techniques used by solvers following these paradigms dif fer . DP solvers focus on heuristic search with dual bounds, using a state-based problem representation which facilitates duplicate detection and dominance detection techniques. In contrast, CP solv ers focus on using depth-first search and inference techniques to prune the search space by determining which values cannot be assigned to variables in a solution. In this work we focus on DP solv ers using heuristic search, as opposed to decision diagram branch-and-bound (Bergman et al. 2016), used by decision diagram solvers such as ddo (Gillard, Schaus, and Copp ´ e 2020) and CODD (Michel and van Hoe ve 2024). Previous w orks introduce constraint propagation in DP approaches, b ut they either only used problem-specific prop- agation (Fontaine, Dibangoye, and Solnon 2023; Brita, van der Linden, and Demirovi ´ c 2025), or did not use heuris- tic search (T anaka and Fujikuma 2012). Other , related but orthogonal, work has focused on using dominance and caching (Chu and Stucke y 2015; Chu, de la Banda, and Stuckey 2010; Smith 2005) in a CP solv er . T o the best of our knowledge, no work has been done on integrating generic constraint propagation in a model-based DP frame work. T o address this gap, we create a framework for integrat- ing constraint propagation from CP with DP modelling and implement our approach using general-purpose CP and DP solvers, pro viding: 1. A dual vie w of the problem, using a state-based DP vie w and an integer -based CP view , which provides: • Dominance and duplicate detection, and heuristic search using the DP view of the problem. • Strong inference techniques for constraints using the CP view of the problem, allo wing pruning of states and strengthening of the dual bound. 2. A generic model-based way of inte grating heuristic search with constraint propagation, allowing any form of constraint propagation rather than only relying on domain-specific inference techniques (though these tech- niques are supported by our framew ork as well). W e ev aluate our frame work on three combinatorial problems: Single Machine Schedule with T ime Win- dows ( 1 | r i , δ i | P w i T i ), the Resource Constrained Project Scheduling Problem (RCPSP), and the Tra velling Sales- person Problem with T ime W indows (TSPTW). For these problems, we show that constraint propagation significantly reduces the number of state expansions, enabling our ap- proach to solve more instances than a DP solver alone for 1 | r i , δ i | P w i T i and RCPSP , and tightly constrained TSPTW instances. The performance in terms of runtime in- dicates that the benefits of propagation outweigh the o ver- head for tightly constrained instances, but that further work into reducing the propag ation time is needed. In our in-depth analysis, we v ary 1 | r i , δ i | P w i T i and TSPTW instance con- strainedness, demonstrating that propagation performs ex- ceptionally well when instances are highly constrained. This work provides a key step in ascertaining the useful- ness of constraint propagation in DP solvers using heuristic search, allowing us to better understand the complementary strengths and weaknesses of the approaches. 2 Preliminaries W e introduce the necessary concepts related to dynamic programming, the Domain-Independent Dynamic Program- ming (DIDP) framework and its Rust interface, heuristic search in DIDP , and constraint programming. 2.1 Domain-Independent Dynamic Programming Dynamic Programming (DP) is a problem-solving method- ology based on state-based representations. Domain- Independent Dynamic Pro gramming (DIDP) is a model- based frame work for solving combinatorial optimisation problems formulated as DP models. One of its strengths is that DIDP models can be solved using generic solvers, re- moving the need to implement specialised algorithms for each DP model. It has recently seen success on combi- natorial problems, such as single machine scheduling and TSPTW (Kuroiwa and Beck 2023b). A DIDP model is a state-transition system where a solu- tion is created by starting with a tar get state S 0 and applying a sequence of transitions until a base state is reached. A suc- cessor state S J τ K is created from S by applying a possible transition τ ∈ T( S ) with weight w τ ( S ) . The cost of a solu- tion is the sum of transition weights plus the cost of the base state, where V ( S ) maps S to its optimal solution cost and the dual bound is a lo wer (upper) bound on V ( S ) in minimi- sation (maximisation) problems. Thus, the goal of a DIDP solver is to compute V ( S 0 ) . While the DIDP framework allows the user to solve generic DP models, it is limited in its expressi vity due to the restrictions of its declarative modelling language, Dynamic Programming Problem Description Language (DyPDL). The Rust Pr ogrammable Interface for DIDP (RPID) defines a DIDP model in terms of Rust functions, allowing the user to define more comple x dual bounds, state constraints and/or state variables, while also providing a significant speedup compared to DIDP (Kuroiwa and Beck 2025b). A RPID model uses three interf aces (called tr aits in Rust) to describe a DP model: 1) Dp - TargetState () defines the tar get state, IsBaseState ( S ) determines when S is a base state with cost BaseCost ( S ) , and GenSucc ( S ) gener- ates a set of successors S J τ K with transition weight w τ ( S ) , 2) Dominance - Dominates ( S , S ′ ) determines if S domi- nates S ′ to pre vent exploring redundant states and 3) Bound - Dual ( S ) returns the dual bound. Using these functions, Equation (1) recursiv ely defines the v alue V ( S ) of a state (for a minimisation problem) as the minimum value of the successor states and the transition weight, where Inequality (2) specifies the dominance rela- tionship and Inequality (3) the dual bound. Thus, solving Equation (1) provides the optimal solution. V ( S ) = ( BaseCost ( S ) if IsBaseState ( S ) min ( w τ ( S ) , S J τ K ) ∈ GenSucc ( S ) w τ ( S ) + V ( S J τ K ) else (1) V ( S ) ≤ V ( S ′ ) if Dominates ( S , S ′ ) (2) V ( S ) ≥ Dual ( S ) (3) Heuristic Search Heuristic search is a strate gy for solving problems, using a heuristic h ( S ) to influence which state to expand . In this work, we use two heuristic search algorithms implemented in RPID: A ∗ (Hart, Nilsson, and Raphael 1968) and Complete Anytime Beam Search (CABS) (Zhang 1998). In RPID, both A ∗ and CABS use the dual bound as h ( S ) and the cost to a node g ( S ) to guide the search, ex- panding the node with the minimum f ( S ) = g ( S ) + h ( S ) . Howe ver , as opposed to A ∗ , CABS stores at most b states with minimum f ( S ) in each layer (storing at most O ( n × b ) states at a time, where n is the branching factor), increasing b until termination. CABS has shown superior memory use and ability to prov e optimality/infeasibility (Kuroiwa and Beck 2023b) while also providing intermediate solutions. Pseudocode for heuristic search in DIDP can be seen in Algorithm 1; it starts with the target state, (heuristically) se- lecting a state to e xpand, and generating its successors while av oiding dominated/redundant states, iterating this process until a termination condition is met. Algorithm 1: Simplified Heuristic Search in RPID O ← { TargetState () } , E ← ∅ , P r imal ← ∞ while ¬ ShouldTerminate () do S ← min S ∈O f ( S ) , O ← O \ {S } if IsBaseState ( S ) then P r imal ← min { P r imal, g ( S ) + BaseCost ( S ) } continue for ( w τ ( S ) , S J τ K ) ∈ GenSucc ( S ) do h ( S J τ K ) ← Dual ( S J τ K ) if f ( S J τ K ) ≤ P r imal ∧ ∄ S ′ ∈ E s.t. Dominates ( S ′ , S J τ K ) ∧ g ( S ′ ) ≤ g ( S J τ K ) then O ← Insert ( O , S J τ K ) , E ← E ∪ {S J τ K } 2.2 Constraint Programming Constraint Programming (CP) is a paradigm for solving combinatorial problems in the form of a constr aint satis- faction pr oblem (CSP) , represented by the tuple ( X , C , D ) , where X is the set of variables , C is the set of constraints specifying the relations between variables , and D is the do- main which maps x ∈ X to its possible values D ( x ) ⊆ Z . The goal is to find a solution I : a mapping of each variable x ∈ X to a value v x ∈ D ( x ) which satisfies all constraints. A CSP can be transformed into a constraint optimisation pr oblem (COP) by adding an objecti ve function which maps a solution I to a v alue: o : I 7→ Z . The goal is then to find a solution that minimises (or maximises) this value. One strength of CP solvers is the use of inference tech- niques, which prune v alues from the domains of variables that cannot be part of a feasible solution. Concretely , con- straints are represented in the CP solver by one or more pr opagators . Thus, a propag ator can be seen as a function p : D 7→ D ′ such that ∀ x ∈ X : D ( x ) ⊇ D ′ ( x ) , where a propagator is at fixed-point if p ( D ) = D . W e define LB ( x ) ( UB ( x ) ) as the minimum (maximum) value that can be as- signed to x ∈ X in D . Importantly , propagators are applied independently , but multiple propagators can be used together to express comple x relationships between variables. In this work, we use two constraints and correspond- ing propagation algorithms, which are implemented in CP solvers such as Pumpkin (Flippo et al. 2024), Huub (Dekk er et al. 2025), and CP-SA T (Perron and Didier 2025): The Disjunctive constraint (Carlier 1982), states that a set of jobs should not ov erlap. Each job has a variable starting time and a (v ariable) duration. The most pre v alent propagation algorithm is edge-finding (V il ´ ım 2004), which reasons over whether scheduling a job i as early (late) as possible is not possible due to another set of jobs Ω to infer that i should be processed after (before) Ω . The Cumulative constraint (Aggoun and Beldiceanu 1992), states that the cumulativ e resource usage of a set of tasks should not e xceed the capacity at any time point. Each task has a v ariable starting time, a duration, and resource usage. The most common propagation algorithm is time- table filtering (Beldiceanu and Carlsson 2002), which rea- sons about when tasks are guaranteed to consume resources to infer that another task cannot be processed at these times. 3 Related W ork Combining constraint propagation with dynamic program- ming was discussed by Hooker and van Hoev e (2018), and while there has been work in this area, a generic approach for incorporating constraint propagation with heuristic search in a model-based way has remained elusi ve. Fontaine, Dibangoye, and Solnon (2023) apply propaga- tion after each solution to tighten time windows when solv- ing TSPTW using a v ariation of A ∗ (V adlamudi et al. 2012). Additionally , pruning techniques for DP approaches play a key role in reducing the search space for optimal decision tree problems (Brita, van der Linden, and Demirovi ´ c 2025). While these approaches apply propagation within DP , their approach, unlike ours, relies on problem-specific propaga- tion in a non-model-based approach. Generic propagation in a DP approach has been ap- plied by T anaka and Fujikuma (2012), making use of the Disjunctive for the 1 | r i , δ i | P w i T i problem. Their ap- proach uses the Lagrangian relaxation to generate tight bounds based on a netw ork representation, pruning states by propagating the Disjunctive constraint. Ho wev er , as op- posed to our work, they do not use a model-based approach, limiting the transferability of their techniques. From a CP perspecti ve, the work by Chu, de la Banda, and Stucke y (2010) proposes automatic identification and exploitation of subproblem dominance/equiv alence, which can be used to prune states in a CP solver . In a similar vein, Smith (2005) proposes to create a representation of a key based on the (reduced) CP domains for caching. In our work, rather than adjusting the CP solv er by adding domi- nance/equiv alence constraints, we take the natural definition of dominance/equi valence in a DP model and incorporate propagation into this framework rather than the other way around, which means that we are able to more easily inte- grate with heuristic search using dual bounds. Furthermore, the work of Perron (1999) transfers heuristic search to a CP solver . Howe ver , they do not le verage the dominance/duplication detection of the DP model. Lastly , Fox, Sadeh, and Baykan (1989) proposed a model for problem solving by combining constraint satisfaction and heuristic search. Howe ver , the main difference between our work and theirs is that we perform constraint propaga- tion for search in a generic model-based framew ork. 4 DIDP with Constraint Propagation W e describe our frame work for incorporating constraint propagation, and, for three problems, we describe the DP model and the incorporation of constraint propagation. 4.1 Framework There are many possible architectures for combining solvers. Part of this space has been explored by the de vel- opment of hybridisations of CP with fields such as Lin- ear Programming (Beck and Refalo 2003; Laborie and Rogerie 2016), Satisfiability (SA T) (Ohrimenko, Stuckey , and Codish 2009; Feydy and Stuckey 2009), and Mixed- Integer Programming (Hooker 2005). Additionally , there is extensi ve work on hybridisation architectures in the con- text of SA T Modulo Theories (Nieuwenhuis, Oli veras, and T inelli 2006). In our initial effort to dev elop a generic hy- bridisation of DP and CP , we chose to develop the simplest interface that would allow a DP solver to e xploit the main technology of CP: constraint propagation. T o this end, we utilise a generic CP solver implement- ing constraint propagation to provide information to the DP solver . An ov erview of the interactions between these two components can be seen in Figure 1. At its core, the CP solver provides two pieces of information: 1) when a state S is infeasible, i.e., dynamically adding state/transition pre- conditions, and 2) a dual bound DualCP ( S ) . It should be noted that this information can be determined by any ap- proach (e.g., decision diagram solvers or linear programs). DP Solver CP Solver S S is Infeasible V ( S ) ≥ DualCP ( S ) Figure 1: An ov erview of the interactions in our frame work. T o improv e usability , we do not modify the search, but replace GenSucc ( S ) in Algorithm 1 with GenSuccPropagation ( S , P rimal ) (Algorithm 2), and Dual ( S J τ K ) with max { Dual ( S J τ K ) , DualCP ( S J τ K , D ′ ) } . Algorithm 2 first creates the CP model, which is prop- agated to obtain D ′ and checked for infeasibility using IsInfeasible ( S , D ′ ) and DualCP ( S , D ′ ) ; one benefit of using CP is that D ′ can be used to strengthen the dual bound. Next, successor infeasibility is checked in IsSuccInfeasible ( S J τ K , D ′ ) ; since D ′ is valid for any successor S J τ K , D ′ is used in IsSuccInfeasible ( S J τ K , D ′ ) to a void propagation. In practice, we only initialise X and C for the target state, and adjust D to represent ev ery state. Algorithm 2: GenSuccPropagation ( S , P rimal ) ( X , C , D ) ← CPModel ( S ) D ′ ← Propagate ( X , C , D ) if IsInfeasible ( S , D ′ ) ∨ g ( S ) + DualCP ( S , D ′ ) ≥ P r imal then retur n ∅ S uccessor s ← ∅ for ( w τ ( S ) , S J τ K ) ∈ GenSucc ( S ) do if ¬ IsSuccInfeasible ( S J τ K , D ′ ) then S uccessor s ← S uccessor s ∪ { ( w τ ( S ) , S J τ K ) } retur n S uccessor s 4.2 1 | r i , δ i | P P P w i T i The single-machine scheduling problem 1 | r i , δ i | P w i T i is formulated as follo ws: giv en are n jobs J = { j 0 , · · · , j n − 1 } which need to be processed on a single machine without ov erlapping. Each job i ∈ J has a duration p i ∈ N + , a release time r i ∈ N , a deadline d i ∈ N , a weight w i ∈ N , and a latest possible finish time δ i ∈ N . The goal is to assign a start time s i to each job such that r i ≤ s i < s i + p i ≤ δ i , minimising the weighted tardiness P i ∈J w i T i , where T i = max { 0 , s i + p i − d i } . DP Model The DP model (adapted from Abdul-Razaq, Potts, and V an W assenhove (1990)) schedules one job at a time. W e track the unscheduled jobs U and current time t in S = ( U , t ) . Additionally , we define the next av ailable time after scheduling i as t ′ ( t, i ) = max { t, r i } + p i , the set of unscheduled jobs for which the time-windo w is not violated when scheduled B = { i ∈ U : t ′ ( t, i ) ≤ δ i } , and the suc- cessor state S J i K = ( U \ { i } , t ′ ( t, i )) . The Bellman equation is then defined as: V ( U , t ) = 0 if U = ∅ ∞ if U = B min i ∈U w i × T i + V ( S J i K ) else (4) V ( U , t a ) ≤ V ( U , t b ) if t a ≤ t b (5) V ( U , t ) ≥ P i ∈U w i × max { 0 , max { r i , t } + p i − d i } (6) Equation (4) states that a state is infeasible if there are jobs that cannot be scheduled due to time windows. Inequality (5) states that state a dominates state b if state a schedules the same jobs as state b but does so in less time. Inequality (6) describes a dual bound as the sum of tardinesses if all un- scheduled jobs were started at max { r i , t } . Constraint Propagation The v ariables X and domains D created in CPModel ( S ) are described in Definition (8); for each unscheduled job i , a CP variable for the start time is created, which starts after r i and all scheduled jobs. The CP constraints C are then defined by Constraint (7), which uses the Disjunctive to ensure that no jobs ov erlap. Disjunctive ([ s i | i ∈ U ] , [ p i | i ∈ U ]) (7) s i ∈ [max { r i , t } , δ i − p i ] ∀ i ∈ U (8) After Propagate ( X , C , D ) , we use the reduced domains D ′ in DualCP ( S , D ′ ) as sho wn in Inequality (9), which states a dual bound as the sum of tardinesses of all unsched- uled jobs if started at LB ( s i ) . Additionally , Equation (10) de- scribes IsSuccInfeasible ( S J τ K , D ′ ) , where a successor is infeasible if τ cannot be scheduled at t ′ ( t, τ ) . V ( U , t ) ≥ P i ∈U w i × max { 0 , LB ( s i ) + p i − d i } (9) V ( S J τ K ) = ∞ if t ′ ( t, τ ) / ∈ D ′ ( s τ ) (10) 4.3 RCPSP The Resource Constrained Project Scheduling Problem can be formulated as follows: given are n tasks T = { t 0 , · · · , t n − 1 } which are to be scheduled on a set of re- sources R where each resource r ∈ R has a capacity C r ∈ N + . Each task has a duration p i ∈ N + , and a re- source usage u ir ∈ N per resource r ∈ R . The goal is to assign a start time s i to each task such that 1) the cumulative resource usage ne ver exceeds any resource capacity , and 2) a set of precedence constraints is respected, as shown in Inequalities (11)-(12) (where H = P i ∈T p i ). W e define the predecessors of task i as P r e i . The objective is to minimise the makespan: max i ∈T s i + p i . X i ∈T : s i ≤ t ∧ s i + p i ≥ t u ir ≤ C r ∀ t ∈ [0 , H ] , r ∈ R (11) s i + p i ≤ s j ∀ ( i, j ) ∈ P (12) DP Model W e introduce a DP model based on scheduling one task at a time. W e keep track of the partial schedule P S mapping each scheduled task j to its scheduled start time P S j (and each unscheduled task to ⊥ ), and the current time t in S = ( P S, t ) . W e define the set of scheduled tasks S = { i | i ∈ T : P S i = ⊥} (and U = T \ S ). Equation (13) defines t ′ ( t, τ ) as the earliest time where 1) there is no resource conflict when scheduling τ and 2) all of the predecessors of τ ha ve finished. W e then de- fine the successor state as S J τ K = (( P S \ { ( τ , ⊥ ) } ) ∪ { ( τ , t ′ ( t, τ ) } , t ′ ( t, τ )) ; we also define Makespan ( P S, t ) = max { max i ∈ S { P S i + p i } , max i ∈U { t + p i }} , and W ( S , τ ) = ( Makespan ( S J τ K , t ′ ( t, τ )) − Makespan ( S , t )) . t ′ ( t, τ ) = min h ∈ [ t, H ] s.t. ∄ r ∈ R : u τ r + P i ∈ S : s i ≤ h ∧ s i + p i >h u ir > C r ∧ P r e τ ⊆ { j | j ∈ S ∧ s j + p j ≤ h } (13) The Bellman equation is then defined as: V ( P S, t ) = ( 0 if S = T min i ∈U : P re i ⊆ S W ( S , τ ) + V ( S J τ K ) if S = T (14) V ( S a ) ≤ V ( S b ) if S a = S b ∧ t a ≤ t b ∧ ∀ i ∈ S : max( P S a j , P S b j ) + p j > t → P S a i ≤ P S b i (15) V ( S J τ K ) ≤ V ( S J τ ′ K ) if t ′ ( t, τ ) + p τ ≤ t ′ ( t, τ ′ ) (16) V ( P S, t ) ≥ Length ( CriticalPath ( P , U )) (17) V ( P S, t ) ≥ max r ∈R P i ∈U u ir × p i C r (18) Inequality (15) describes dominance between states a and b ; if they have scheduled the same tasks b ut a has scheduled all tasks sooner than b , then a dominates b . Similarly , Inequal- ity (16) describes a transition dominance using the left-shift rule (Demeulemeester and Herroelen 1992); if there are two transitions τ , τ ′ ∈ T ( S ) , then S J τ K dominates S J τ ′ K if we can complete task τ befor e starting τ ′ . Inequality (17) states that V ( S ) is larger than the length of the longest path through the precedence graph (i.e., the critical path). Inequality (18) states an energy-based dual-bound. Constraint Propagation The v ariables X and domains D created in CPModel ( S ) are described in Definitions (22)- (24); for each task i , a CP v ariable s i for the start time is created, and a CP variable o for the objectiv e is created. The CP constraints C are defined as: Constraint (19) spec- ifies the Cumulative which ensures the resource capacity is not exceeded (where S t = [ s i | i ∈ U ] , P = [ p i | i ∈ U ] , and U r = [ u ir | i ∈ U ] ), Constraint (20) ensures that prece- dences hold, and Constraint (21) defines the makespan. Cumulative ( S t, P , U r , C r ) ∀ r ∈ R (19) s i + p i ≤ s j ∀ ( i, j ) ∈ P (20) s i + p i ≤ o ≤ P r imal ∀ i ∈ U (21) s j = P S j ∀ j ∈ S (22) s i ∈ [ t, H − p i ] ∀ i ∈ U (23) o ∈ [0 , H ] (24) After Propagate ( X , C , D ) , we use the bounds D ′ in DualCP ( S , D ′ ) as described in 1) Inequality (25), which specifies a lower -bound on the makespan based on the earliest completion time (V il ´ ım 2009), and 2) Inequal- ity (26), which states that the makespan of a state is at least as large as the maximum latest finish time of the unscheduled tasks. Additionally , Equation (27) describes IsSuccInfeasible ( S J τ K , D ′ ) , where a successor is not feasible if task τ cannot be scheduled at time t ′ ( t, τ ) . V ( S ) ≥ max r ∈R max Ω ⊆T { & C r min i ∈ Ω LB ( s i )+ P i ∈ Ω ( u ir × p i ) C r ' } (25) V ( P S, t ) ≥ max i ∈U { LB ( s i ) + p i } (26) V ( S J τ K ) = ∞ if t ′ ( t, τ ) / ∈ D ′ ( s τ ) (27) 4.4 TSPTW The Tra velling Salesperson Problem with T ime W indows can be formulated as follows: gi ven are n locations C = { l 0 , · · · , l n − 1 } which need to be visited, with a travel time c ij ∈ N between locations i and j . Each location i needs to be visited within [ r i , δ i ] ; if the salesperson arriv es at location i before r i then they wait until time r i . W e define c ∗ ij as the shortest trav el time between location i and j . The goal is to determine the order in which to visit the locations, starting and ending at the depot l 0 while visiting each location besides the depot exactly once, such that the total trav el time is minimised (excluding waiting times). DP Model The DP model (Kuroiwa and Beck 2023b) is based on visiting one location at a time. W e track the unvis- ited locations U , current location l , and current time t in S = ( U , l, t ) . Additionally , we define t ′ ( i, j ) = max { t + c ij , r j } , S J j K = ( U \ { j } , j, t ′ ( l, j )) , O = { j | j ∈ U : t + c ∗ ij > δ j } , MinTo ( l ) = min i ∈C : i = j c il , MinFrom ( l ) = min i ∈C : i = j c li , and R i = { j ∈ U | t + c ij ≤ δ j } . The Bellman equation is then defined as: V ( S ) = ∞ if O = ∅ c i 0 if U = ∅ min j ∈ R l c lj + V ( S J j K ) else (28) V ( U , l, t a ) ≤ V ( U , l , t b ) if t a ≤ t b (29) V ( U , l, t ) ≥ MinTo ( l 0 ) + P i ∈U MinTo ( i ) MinFrom ( l ) + P i ∈U MinFrom ( i ) (30) Inequality (29) states that state a dominates state b if 1) they hav e visited the same locations, 2) are at the same current location, and 3) the current time of state a is earlier than the current time of state b . Inequality (30) uses the minimum trav el time to an un visited location i from another location and the minimum travel time fr om an un visited location i to another location to calculate a dual bound on S . Constraint Propagation The v ariables X and domains D created in CPModel ( S ) are described in Definitions (33)- (35); for each unvisited location i , a CP variable s i for the arriv al time and time to next location p i is created, where the bounds on p i can be tightened if ∃ j ∈ U \ { i } : LB ( s j ) ≥ UB ( s i ) , signifying that the depot cannot be visited from i . Additionally , a CP variable o for the objecti ve is created. The constraints C , a relaxation of TSPTW , are defined as 1) Constraint (31) stating that no locations can be visited si- multaneously , and 2) Constraint (32) defining the objective. Disjunctive ([ s i | i ∈ U ∪ { l } ] , [ p i | i ∈ U ∪ { l } ]) (31) o = X i ∈C p i ≤ P r imal (32) s i ∈ [max { t, r i } , δ i ] ∀ i ∈ U ∪ { l } (33) p i ∈ { c ij | j ∈ ( U ∪ { l 0 } ) \ { i } ∧ c ij = ∞} ∀ i ∈ U ∪ { l } (34) o ∈ [0 , max i ∈U δ i + c i 0 ] (35) After Propagate ( X , C , D ) , we use the bounds D ′ in DualCP ( S , D ′ ) as described in Inequality (36), which states that a dual bound is the sum of the lower bounds of the trav el times inferred by constraint propagation. Additionally , Equation (37) describes IsSuccInfeasible ( S J τ K , D ′ ) , where visiting τ next is infeasible if its arriv al time or the trav el time from the previous location is not possible. V ( U , l, t ) ≥ P i ∈U ∪ l LB ( p i ) (36) V ( S J τ K ) = ∞ if t ′ ( l, τ ) / ∈ D ′ ( s τ ) ∨ c lτ / ∈ D ′ ( p τ ) (37) 5 Experimentation Our aim is to empirically show the impact of constraint prop- agation on the number of state expansions and runtime when integrated with a DP solver . F or all three problems, we sho w that constraint propagation reduces the search space. For 1 | r i , δ i | P w i T i and TSPTW , we show that it is especially effecti ve for tightly constrained instances. 5.1 Experimentation Setup The experiments are run single threaded on an Intel Xeon Gold 6248R 24C 3.0GHz processor (Delft High Perfor- mance Computing Centre 2024) with a limit of 30 minutes and 16GB of memory . W e use the following benchmarks: • 1 | r i , δ i | P P P w i T i - W e generate 900 instances according to Dav ari et al. (2016). The instances contain 50 jobs with duration p i ∈ [1 , 10] , release date r i ∈ [0 , τ P ] (where P is the sum of durations), deadline d i ∈ [ r i + p i , r i + p i + ρP ] , latest finish time δ i ∈ [ d i , d i + ϕP ] , and weight w i ∈ [1 , 10] . W e generate 10 instances for each combination of τ ∈ { 0 , 0 . 2 , 0 . 4 , 0 . 6 , 0 . 8 , 1 } , ρ ∈ { 0 . 05 , 0 . 25 , 0 . 5 } , ϕ ∈ { 0 . 9 , 1 . 05 , 1 . 2 , 1 . 35 , 1 . 5 } . • RCPSP - W e mak e use of the 480 J90 instances from PSPLIB (K olisch and Sprecher 1997). • TSPTW - W e consider instances used by L ´ opez-Ib ´ a ˜ nez et al. (2013), excluding too easy/difficult sets or with fractional distances; resulting in 130 instances by Gen- dreau et al. (1998) and 50 instances by Ascheuer (1996). W e use Pumpkin (Flippo et al. 2024) for propagation, and CABS and A ∗ of RPID 0.3.1 as the search for the DP-based approaches. The code and models are av ailable in the pro- vided supplements. W e ev aluate the following approaches: • A ∗ /CABS - The RPID model using A ∗ or CABS. • A ∗ /CABS+CP - The RPID model using A ∗ or CABS with constraint propagation; the propagators are e xecuted once per state. W e also considered fixed-point propaga- tion, but the computational cost was too high to be able to compete with other methods. • OR T - Uses MiniZinc 2.9.2 with OR-T ools CP-SA T 9.12 as solver (using free search, causing the solv er to make use of a portfolio approach); included in the com- parison as a reference state-of-the-art constraint-based solver . The CP models can be found in Appendix B. Experimentation Summary Overall, constraint propaga- tion significantly prunes the search space for all prob- lems. For 1 | r i , δ i | P w i T i , RCPSP , and tightly constrained TSPTW problems, our approach solves more instances than the DP approach while using considerably fe wer states. The runtime performance indicates that further work on reducing propagation time is warranted. 5.2 1 | r i , δ i | P P P w i T i Starting with 1 | r i , δ i | P w i T i , Figure 2a shows that our approach solves significantly more instances using fewer states than the baseline versions, exhibiting the ef fectiv eness of constraint propagation. This effecti veness is confirmed by Appendix A.1, which sho ws that our approach guides the search to better solutions in fewer expansions. While A ∗ +CP initially solves more instances, it plateaus sooner than CABS+CP , ultimately solving fewer instances. Looking at the number of instances solved over time, Figure 2b shows that the best performing approach is CABS+CP , which proves optimality for three more in- stances and infeasibility (at the tar get state) on thirteen more than CABS. Interestingly , CABS+CP only overtakes CABS in the number of instances solved after 500 seconds, show- ing the impact of propagation overhead. Moreover , the lack of instances solved by OR-T ools indicates that it is our com- bination of DP with pr opagation that works well. 50 100 150 200 250 300 200 250 300 350 Number of State Expansions (in millions) Number of Solved Instances CABS CABS+CP OR T A ∗ A ∗ +CP (a) 1 | r i , δ i | P w i T i instances solved compared to state expansions. Our approach is able to solve the most instances per e xpansion. 0 250 500 750 1000 1250 1500 1750 200 250 300 350 Time (s) Number of Solved Instances (b) 1 | r i , δ i | P w i T i instances solved compared to time. Our ap- proach solves the most instances. Figure 2: Number of 1 | r i , δ i | P w i T i instances solved com- pared to the number of state expansions and time. Parameter Analysis An overvie w of the number of in- stances solved across values of ϕ (where a lower value means that the instances ha ve tighter latest finish times), can be seen in Figure 3. It sho ws that CABS+CP outperforms CABS on constrained instances where ϕ is small(er), indi- cating that the constraint propagation prunes well when in- stances are tightly constrained. Furthermore, it can be ob- served that the number of solved instances decreases as ϕ increases for all approaches, but the rate of decrease differs. Specifically , when ϕ ≤ 1 . 05 , CABS+CP outperforms CABS in terms of instances proven infeasible and optimal, but for instances where ϕ ≥ 1 . 2 , CABS is equal to or outperforms CABS+CP . 0.9 1.05 1.2 1.35 1.5 0 20 40 60 80 ϕ Number of Solved Instances CABS CABS+CP OR T Figure 3: Number of 1 | r i , δ i | P w i T i instances solved over ϕ . The marked parts are instances proven infeasible and un- marked parts are instances pro ven optimal. Our approach solves the most instances when the y are tightly constrained. 5.3 RCPSP Considering RCPSP , Figure 4a sho ws that constraint prop- agation increases the number of instances solved per state expansion considerably for CABS, e xhibiting that constraint propagation is crucial when using a state-based approach for RCPSP . Appendix A.2 indicates that constraint propagation provides the most benefit when pro ving optimality . Additionally , Figure 4b shows that adding constraint propagation to CABS also increases the number of in- stances solved per second compared to CABS alone. As ex- pected, since A ∗ (+CP) rarely finds primal bounds, which are key for pruning, it falls behind CABS(+CP). OR-T ools is the best-performing solv er of all, possibly due to using a depth-first backtracking search, which is well-suited for the problem. Nonetheless, A ∗ /CABS+CP provide better primal and/or dual bounds than OR-T ools on numerous instances (as shown in Figure 11 of Appendix A.2). 5.4 TSPTW T urning to TSPTW , Figure 5a shows that constraint propaga- tion decreases the number of solved instances due to a lack of pruning. This observation is demonstrated in the number of solved instances per state e xpansion of both A ∗ /A ∗ +CP and CABS/CABS+CP overlapping, likely due to instances being too loosely constrained to make inferences. This ob- servation is further corroborated by Appendix A.3. This effect is also reflected by the number of instances solved ov er time in Figure 5b, which sho ws that adding con- straint propagation results in an increase in solving time. Howe ver , the worst-performing approach is OR-T ools. Parameter Analysis T o determine the impact of in- stance constrainedness, we inv estigate parameterised in- stances (not part of the pre vious set) introduced by Rifki 10 20 30 40 50 0 100 200 300 400 Number of State Expansions (in millions) Number of Solved Instances CABS CABS+CP OR T A ∗ A ∗ +CP (a) RCPSP instances solved compared to state expansions. Our ap- proach solves significantly more instances per state e xpansion. 0 250 500 750 1000 1250 1500 1750 0 100 200 300 400 Time (s) Number of Solved Instances (b) RCPSP instances solved compared to time; our approach out- performs the DP baseline, but the best-performing approach is CP . Figure 4: Number of RCPSP instances solved compared to the number of state expansions and time. and Solnon (2025) where n = 31 . For these instances, a low α indicates that many locations need to be vis- ited relativ e to the horizon, while a low β means that time windows are tight. W e consider two sets: 1) a gen- eral set of 135 instances where we select three instances per combination of α ∈ { 1 . 0 , 1 . 5 , 2 , 2 . 5 , 3 } and β ∈ { 0 . 2 , 0 . 3 , 0 . 4 , 0 . 5 , 0 . 6 , 0 . 7 , 0 . 8 , 0 . 9 , 1 } , and 2) a set of 540 instances where we select ten instances per combination of α ∈ { 1 . 0 , 1 . 1 , 1 . 2 , 1 . 3 , 1 . 4 , 1 . 5 } and the same v alues of β . Figure 6, shows that for α < 1 . 2 , CABS+CP outper- forms all other approaches. Examining Figure 7, sho ws that, when 1 . 0 ≤ α ≤ 1 . 5 , the number of instances solved per state expansion is significantly increased compared to Fig- ure 5a. This effect can be explained by CABS+CP reduc- ing the number of states by orders of magnitude compared to CABS (Figure 8), where especially infeasible instances benefit from constraint propagation. Overall, the DP-based methods solv e fewer instances as α increases, but the rate of decrease dif fers, causing CABS to outperform CABS+CP when α ≥ 1 . 2 . Interestingly , OR-T ools pro ves optimality on the most instances, likely due to 1) lower memory usage, and 2) stronger propagation (using Circuit (Lauri ` ere 1978)). 6 Conclusions and Future W ork W e hav e presented a framework that integrates constraint propagation into a DP solver , and implemented it in the modelling of DIDP . Our approach allows us to combine the strengths of heuristic guidance and dominance/duplicate de- 50 100 150 200 250 300 40 60 80 100 120 140 Number of State Expansions (in millions) Number of Solved Instances CABS CABS+CP OR T A ∗ A ∗ +CP (a) TSPTW instances solv ed compared to state e xpansions. Our approach expands slightly fe wer states than the DP approach. 0 250 500 750 1000 1250 1500 1750 40 60 80 100 120 140 Time (s) Number of Solved Instances (b) TSPTW instances solved compared to time. The DP approach solves the most instances. Figure 5: Number of TSPTW instances solved compared to the number of state expansions and time. 1.0 1.5 2.0 2.5 3.0 0 5 10 15 α Number of Solved Instances CABS CABS+CP OR T 1.0 1.1 1.2 1.3 1.4 1.5 0 20 40 60 α Number of Solved Instances Figure 6: Number of solved TSPTW Rifki and Sol- non (2025) instances across values of α . The mark ed parts are instances proven infeasible and unmarked parts are in- stances prov en optimal. The lower plot uses an e xtended set of instances to show 1 . 0 ≤ α ≤ 1 . 5 . Our approach solves the most instances when they are tightly constrained. 50 100 150 200 250 300 350 220 240 260 280 Number of State Expansions (in millions) Number of Solved Instances CABS CABS+CP Figure 7: Number of solved TSPTW Rifki and Sol- non (2025) instances ( 1 . 0 ≤ α ≤ 1 . 5 ) o ver state expansions. Our approach solves the most instances per e xpansion. 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 Feasible Infeasible CABS+CP ( > 10 s) Faster CABS ( > 10 s) Faster Equally Fast Number of State Expansions CABS Number of State Expansions CABS+CP Figure 8: Comparison of state expansions on TSPTW Rifki and Solnon (2025) instances ( 1 . 0 ≤ α ≤ 1 . 5 ). Our approach reduces the number of expansions by orders of magnitude. tection of DP with the inference techniques of CP . Our e val- uation on three combinatorial optimisation problems shows that adding constraint propagation significantly increases the number of instances solved per state expansion, solving more instances than a DP solver alone for 1 | r i , δ i | P w i T i , RCPSP , and tightly constrained TSPTW instances. As to runtime, the benefit of propagation outweighs the cost for tightly constrained instances, b ut further work into reducing propagation time could impro ve performance further . In our in-depth analysis, we vary 1 | r i , δ i | P w i T i and TSPTW in- stance constrainedness, which shows that propagation per - forms exceptionally well when instances are highly con- strained. Our work is a key step in understanding the v alue of constraint propagation in DP solvers, providing a model- based way of integrating DP and CP . Our interface is generic, allo wing future work to in ves- tigate the integration of DP solvers with other techniques besides CP . Another strength of our framew ork is the sim- plicity of the interface; similar to SA T Modulo Theories ar- chitecture, the interface could be enriched to inv estigate the impact of additional information on the DP solver . Another direction is to explore what is represented in the CP model, e.g., the DP model could be a relaxation, while the CP model contains the absent elements of the DP model. Finally , fu- ture work could look into reducing propagation ov erhead, e.g., by reducing redundant w ork introduced by jumping be- tween states, or by determining when to propagate. Acknowledgements Imko Marijnissen is supported by the NWO/OCW , as part of the Quantum Softw are Consortium programme (project number 024.003.037 / 3368). References Abdul-Razaq, T .; Potts, C.; and V an W assenhove, L. 1990. A surve y of algorithms for the single machine total weighted tardiness scheduling problem. Discrete Applied Mathemat- ics , 26(2): 235–253. Aggoun, A.; and Beldiceanu, N. 1992. Extending CHIP in order to solv e complex scheduling and placement problems. In Delahaye, J.; Devienne, P .; Mathieu, P .; and Y im, P ., eds., JFPL ’92, 1 ` er es Journ ´ ees F rancophones de Pr ogrammation Logique, 25-27 Mai 1992, Lille , F rance , 51. Ascheuer , N. 1996. Hamiltonian P ath Problems in the On-line Optimization of Flexible Manufacturing Systems . Ph.D. thesis, K onrad-Zuse-Zentrum f ¨ ur Informationstechnik Berlin. Beck, J. C.; and Refalo, P . 2003. A Hybrid Approach to Scheduling with Earliness and T ardiness Costs. Ann. Oper . Res. , 118(1-4): 49–71. Beldiceanu, N.; and Carlsson, M. 2002. A Ne w Multi- resource cumulatives Constraint with Negati ve Heights. In Hentenryck, P . V ., ed., Principles and Pr actice of Constr aint Pr ogramming - CP 2002, 8th International Confer ence, CP 2002, Ithaca, NY , USA, September 9-13, 2002, Pr oceedings , volume 2470 of Lectur e Notes in Computer Science , 63–79. Springer . Bergman, D.; Cir ´ e, A. A.; v an Hoeve, W .; and Hooker , J. N. 2016. Discrete Optimization with Decision Diagrams. IN- FORMS J. Comput. , 28(1): 47–66. Brita, C. E.; van der Linden, J. G. M.; and Demirovi ´ c, E. 2025. Optimal Classification T rees for Continuous Fea- ture Data Using Dynamic Programming with Branch-and- Bound. In W alsh, T .; Shah, J.; and K olter , Z., eds., AAAI-25, Sponsor ed by the Association for the Advancement of Arti- ficial Intelligence, F ebruary 25 - Marc h 4, 2025, Philadel- phia, P A, USA , 11131–11139. AAAI Press. Carlier , J. 1982. The one-machine sequencing problem. Eur opean Journal of Operational Resear ch , 11(1): 42–47. Third EUR O IV Special Issue. Chu, G.; de la Banda, M. G.; and Stuckey , P . J. 2010. Auto- matically Exploiting Subproblem Equiv alence in Constraint Programming. In Lodi, A.; Milano, M.; and T oth, P ., eds., Inte gration of AI and OR T echniques in Constraint Pro gram- ming for Combinatorial Optimization Pr oblems, 7th Inter - national Conference , CP AIOR 2010, Bologna, Italy , J une 14-18, 2010. Pr oceedings , volume 6140 of Lectur e Notes in Computer Science , 71–86. Springer . Chu, G.; and Stuckey , P . J. 2015. Dominance breaking con- straints. Constraints An Int. J . , 20(2): 155–182. Dav ari, M.; Demeulemeester , E.; Leus, R.; and Nobibon, F . T . 2016. Exact algorithms for single-machine scheduling with time windows and precedence constraints. J . Sched. , 19(3): 309–334. Dekker , J. J.; Ignatiev , A.; Stuckey , P . J.; and Zhong, A. Z. 2025. T owards Modern and Modular SA T for LCG. In de la Banda, M. G., ed., 31st International Confer ence on Prin- ciples and Practice of Constraint Pr ogramming (CP 2025) , volume 340 of Leibniz International Pr oceedings in Infor- matics (LIPIcs) , 42:1–42:12. Dagstuhl, Germany: Schloss Dagstuhl – Leibniz-Zentrum f ¨ ur Informatik. ISBN 978-3- 95977-380-5. Delft High Performance Computing Centre. 2024. Delft- Blue Supercomputer (Phase 2). https://www .tudelft.nl/dhpc/ ark:/44463/DelftBluePhase2. Demeulemeester , E.; and Herroelen, W . 1992. A Branch-and-Bound Procedure for the Multiple Resource- Constrained Project Scheduling Problem. Management Sci- ence , 38(12): 1803–1818. Feydy , T .; and Stuckey , P . J. 2009. Lazy Clause Generation Reengineered. In Gent, I. P ., ed., Principles and Practice of Constr aint Pr ogr amming - CP 2009, 15th International Confer ence, CP 2009, Lisbon, P ortugal, September 20-24, 2009, Pr oceedings , volume 5732 of Lectur e Notes in Com- puter Science , 352–366. Springer . Flippo, M.; Sidorov , K.; Marijnissen, I.; Smits, J.; and Demirovi ´ c, E. 2024. A Multi-Stage Proof Logging Frame- work to Certify the Correctness of CP Solvers. In Shaw , P ., ed., 30th International Confer ence on Principles and Practice of Constraint Pr ogramming (CP 2024) , volume 307 of Leibniz International Pr oceedings in Informatics (LIPIcs) , 11:1–11:20. Dagstuhl, German y: Schloss Dagstuhl – Leibniz-Zentrum f ¨ ur Informatik. ISBN 978-3-95977-336- 2. Fontaine, R.; Dibangoye, J.; and Solnon, C. 2023. Exact and anytime approach for solving the time dependent tra veling salesman problem with time windo ws. Eur . J . Oper . Res. , 311(3): 833–844. Fox, M. S.; Sadeh, N. M.; and Baykan, C. A. 1989. Con- strained Heuristic Search. In Sridharan, N. S., ed., Pr oceed- ings of the 11th International Joint Conference on Artificial Intelligence. Detroit, MI, USA, August 1989 , 309–315. Mor - gan Kaufmann. Gendreau, M.; Hertz, A.; Laporte, G.; and Stan, M. 1998. A Generalized Insertion Heuristic for the Tra veling Salesman Problem with T ime Windo ws. Oper . Res. , 46(3): 330–335. Gillard, X.; Schaus, P .; and Copp ´ e, V . 2020. Ddo, a Generic and Efficient Framework for MDD-Based Optimization. In Bessiere, C., ed., Pr oceedings of the T wenty-Ninth Inter- national Joint Conference on Artificial Intelligence , IJCAI 2020 , 5243–5245. ijcai.org. Hart, P . E.; Nilsson, N. J.; and Raphael, B. 1968. A For- mal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE T rans. Syst. Sci. Cybern. , 4(2): 100–107. Hooker , J. N. 2005. A Hybrid Method for the Planning and Scheduling. Constraints An Int. J . , 10(4): 385–401. Hooker , J. N.; and v an Hoeve, W . J. 2018. Constraint pro- gramming and operations research. Constraints An Int. J . , 23(2): 172–195. K olisch, R.; and Sprecher , A. 1997. PSPLIB - A project scheduling problem library: OR Software - ORSEP Oper- ations Research Software Exchange Program. Eur opean Journal of Oper ational Researc h , 96(1): 205–216. Kuroiwa, R.; and Beck, J. C. 2023a. Domain-Independent Dynamic Programming: Generic State Space Search for Combinatorial Optimization. In K oenig, S.; Stern, R.; and V allati, M., eds., Pr oceedings of the Thirty-Thir d Interna- tional Confer ence on Automated Planning and Scheduling, Prague , Czech Republic, July 8-13, 2023 , 236–244. AAAI Press. Kuroiwa, R.; and Beck, J. C. 2023b. Solving Domain- Independent Dynamic Programming Problems with Any- time Heuristic Search. Proceedings of the International Confer ence on Automated Planning and Scheduling , 33(1): 245–253. Kuroiwa, R.; and Beck, J. C. 2025a. Domain-Independent Dynamic Programming. Kuroiwa, R.; and Beck, J. C. 2025b. RPID: Rust Pro- grammable Interface for Domain-Independent Dynamic Programming. In de la Banda, M. G., ed., 31st International Confer ence on Principles and Pr actice of Constraint Pr o- gramming, CP 2025, August 10-15, 2025, Glasgow , Scot- land , v olume 340 of LIPIcs , 23:1–23:21. Schloss Dagstuhl - Leibniz-Zentrum f ¨ ur Informatik. Laborie, P .; and Rogerie, J. 2016. T emporal linear relaxation in IBM ILOG CP Optimizer . J . Sched. , 19(4): 391–400. Lauri ` ere, J. 1978. A Language and a Program for Stating and Solving Combinatorial Problems. Artif. Intell. , 10(1): 29–127. L ´ opez-Ib ´ a ˜ nez, M.; Blum, C.; Ohlmann, J. W .; and Thomas, B. W . 2013. The tra velling salesman problem with time win- dows: Adapting algorithms from travel-time to makespan optimization. Appl. Soft Comput. , 13(9): 3806–3815. Michel, L.; and van Hoev e, W . 2024. CODD: A Decision Diagram-Based Solver for Combinatorial Optimization. In Endriss, U.; Melo, F . S.; Bach, K.; Diz, A. J. B.; Alonso- Moral, J. M.; Barro, S.; and Heintz, F ., eds., ECAI 2024 - 27th Eur opean Confer ence on Artificial Intelligence, 19-24 October 2024, Santia go de Compostela, Spain - Including 13th Confer ence on Pr estigious Applications of Intelligent Systems (P AIS 2024) , volume 392 of F r ontiers in Artificial Intelligence and Applications , 4240–4247. IOS Press. Nethercote, N.; Stuckey , P . J.; Becket, R.; Brand, S.; Duck, G. J.; and T ack, G. 2007. MiniZinc: T owards a Standard CP Modelling Language. In Bessiere, C., ed., Principles and Practice of Constraint Pr ogramming - CP 2007, 13th International Conference, CP 2007, Pr ovidence, RI, USA, September 23-27, 2007, Proceedings , volume 4741 of Lec- tur e Notes in Computer Science , 529–543. Springer . Nieuwenhuis, R.; Oli veras, A.; and Tinelli, C. 2006. Solving SA T and SA T Modulo Theories: From an abstract Da vis– Putnam–Logemann–Lov eland procedure to DPLL( T ). J. A CM , 53(6): 937–977. Ohrimenko, O.; Stuckey , P . J.; and Codish, M. 2009. Prop- agation via lazy clause generation. Constraints An Int. J . , 14(3): 357–391. Perron, L. 1999. Search Procedures and Parallelism in Constraint Programming. In Jaff ar, J., ed., Principles and Practice of Constr aint Pr ogramming - CP’99, 5th Interna- tional Conference , Ale xandria, V irginia, USA, October 11- 14, 1999, Proceedings , v olume 1713 of Lectur e Notes in Computer Science , 346–360. Springer . Perron, L.; and Didier , F . 2025. CP-SA T . Rifki, O.; and Solnon, C. 2025. On the Phase T ransition of the Euclidean T rav elling Salesman Problem with Time W indows. J . Artif. Intell. Res. , 82: 2167–2188. Smith, B. M. 2005. Caching Search States in Permutation Problems. In v an Beek, P ., ed., Principles and Practice of Constr aint Pr ogr amming - CP 2005, 11th International Confer ence, CP 2005, Sitges, Spain, October 1-5, 2005, Pr o- ceedings , v olume 3709 of Lecture Notes in Computer Sci- ence , 637–651. Springer . Stuckey , P . J.; Feydy , T .; Schutt, A.; T ack, G.; and Fischer , J. 2014. The MiniZinc Challenge 2008-2013. AI Mag . , 35(2): 55–60. T anaka, S.; and Fujikuma, S. 2012. A dynamic- programming-based e xact algorithm for general single- machine scheduling with machine idle time. J. Sched. , 15(3): 347–361. V adlamudi, S. G.; Gaurav , P .; Aine, S.; and Chakrabarti, P . P . 2012. Anytime Column Search. In Thielscher , M.; and Zhang, D., eds., AI 2012: Advances in Artificial Intel- ligence - 25th A ustralasian Joint Confer ence, Sydney , A us- tralia, December 4-7, 2012. Pr oceedings , v olume 7691 of Lectur e Notes in Computer Science , 254–265. Springer . V il ´ ım, P . 2004. O(n log n) Filtering Algorithms for Unary Resource Constraint. In R ´ egin, J.; and Rueher , M., eds., In- te gration of AI and OR T echniques in Constraint Pro gram- ming for Combinatorial Optimization Pr oblems, F irst In- ternational Conference , CP AIOR 2004, Nice, F rance, April 20-22, 2004, Pr oceedings , volume 3011 of Lectur e Notes in Computer Science , 335–347. Springer . V il ´ ım, P . 2009. Edge Finding Filtering Algorithm for Dis- crete Cumulati ve Resources in O ( kn l og n ) . In Gent, I. P ., ed., Principles and Practice of Constr aint Pr ogramming - CP 2009, 15th International Confer ence, CP 2009, Lisbon, P or- tugal, September 20-24, 2009, Pr oceedings , v olume 5732 of Lectur e Notes in Computer Science , 802–816. Springer . Zhang, W . 1998. Complete Anytime Beam Search. In Mostow , J.; and Rich, C., eds., Pr oceedings of the F ifteenth National Confer ence on Artificial Intelligence and T enth In- novative Applications of Artificial Intelligence Conference , AAAI 98, IAAI 98, J uly 26-30, 1998, Madison, W isconsin, USA , 425–430. AAAI Press / The MIT Press. A ppendices A Optimality Gap Analysis W e discuss the impact of adding constraint propagation on the av erage optimality gap. For a minimisation problem, giv en a lo wer-bound D ual and an upper -bound P rimal on the objecti ve, Equation (38) defines the optimality gap . The optimality gap provides in- formation about how far the lower- and upper-bound are from each other , the closer , the better . O ptimality Gap = P r imal − D ual max { 1 , P r imal } (38) W e calculate the a verage optimality gap by starting with 1 . 0 for e very instance for which infeasibility was not prov en, and then updating the optimality gap for an instance when- ev er a ne w dual or primal bound is found, taking the a verage of all instances as the av erage optimality gap. W e do not plot A ∗ since it does not find intermediate solutions. A.1 1 | r i , δ i | P P P w i T i Figure 9a sho ws that, besides being able to solve more in- stances (as sho wn in Figure 2), our approach also reaches a better optimality gap in fewer states. This indicates that pruning also results in better bounds/solutions. Furthermore, Figure 9b shows that the optimality gap be- tween CABS and CABS+CP over time is very similar . While our approach guides the search better and is able to solv e more instances, the overhead of propagation causes a simi- larity in the optimality gap between the two approaches. 50 100 150 200 250 300 0 . 5 0 . 6 0 . 7 0 . 8 Number of State Expansions (in millions) A verage Optimality Gap CABS CABS+CP OR T (a) A verage optimality gap ov er number of state expansions for 1 | r i , δ i | P w i T i instances. Our approach achiev es a smaller opti- mality gap using fe wer states compared to CABS. 0 500 1000 1500 0 . 5 0 . 6 0 . 7 0 . 8 Time (s) A verage Optimality Gap (b) A verage optimality gap over time for 1 | r i , δ i | P w i T i in- stances. Our approach achiev es a better optimality gap than CABS. Figure 9: A verage optimality gap over the number of state expansions and time for 1 | r i , δ i | P w i T i instances. A.2 RCPSP For RCPSP , Figure 10a shows that CABS(+CP) quickly ap- proach an optimality gap of zero, indicating that it is the proving of optimality which is difficult for the approaches. Nev ertheless, in addition to our approach substantially in- creasing the number of solved instances (Figure 4), our ap- proach also reduces the optimality gap compared to CABS. These results further exhibit the importance of constraint propagation for DP-based approaches when solving RCPSP . Looking at the optimality gap ov er time, Figure 10b shows a similar trend to Figure 10a, exhibiting that the optimality gap is also reduced over time by the addition of constraint propagation. Interestingly , both CABS and CABS+CP achie ve a lower optimality gap than OR-T ools, showing the v alue of DP-based approaches for RCPSP . 5 10 15 20 0 0.05 0.1 Number of State Expansions (in millions) A verage Optimality Gap CABS CABS+CP OR T (a) A verage optimality gap ov er number of state expansions for RCPSP . Our approach achiev es a slightly better optimality gap than CABS, indicating that proving optimality is the dif ficulty . 0 500 1000 1500 0.0 0.05 0.1 Time (s) A verage Optimality Gap (b) A verage optimality gap over time for RCPSP instances. Our ap- proach achiev es a better optimality gap than CABS and OR-T ools. Figure 10: A verage optimality gap ov er the number of state expansions and time for RCPSP instances. This conclusion is further strengthened by Figure 11, which shows that, for numerous instances, our approach out- performs OR-T ools in terms of optimality gap. A.3 TSPTW Similar to the conclusions of Section 5.4, Figure 12a shows that adding constraint propagation does not improve the op- timality gap for the general instances. Since our approach times out for many instances, it reaches a higher optimality gap than CABS. The effect of propagation ov erhead with weak pruning can also be seen in Figure 12b, sho wing that the propaga- tion causes a slower con vergence. Parameter Analysis Looking at the tightly constrained instances from Section 5.4, Figure 13a shows that our ap- 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 0 . 2 0 . 4 0 . 6 Optimality Gap OR-T ools Optimality Gap CABS+CP Figure 11: Comparison of optimality gap on RCPSP in- stances. Our approach improves the optimality gap of OR- T ools for numerous instances. proach reaches a similar optimality gap as CABS, confirm- ing the findings of Figure 8 that our approach mostly reduces the number of states on infeasible instances (which are not shown in these plots). Similar to Appendix A.1, Figure 13b indicates that future work into reducing the propagation overhead is w arranted. Interestingly , while OR-T ools solves the most instances to optimality , it does not reach the lowest optimality gap. 50 100 150 200 250 300 0.2 0.4 Number of State Expansions (in millions) A verage Optimality Gap CABS CABS+CP OR T (a) A verage optimality gap ov er number of state expansions for TSPTW instances. Our approach does not improve the optimality gap and times out with fe wer state expansions than CABS. 0 500 1000 1500 0 . 2 0 . 4 Time (s) A verage Optimality Gap (b) A verage optimality gap over time. Our approach does not im- prov e the optimality gap compared to CABS for TSPTW instances. Figure 12: A verage optimality gap ov er the number of state expansions and time for TSPTW instances. B CP Models W e describe the models used for OR-T ools in the e xperi- ments. The MiniZinc models can be found in the pro vided 50 100 150 200 250 300 350 0 . 3 0 . 4 0 . 5 Number of State Expansions (in millions) A verage Optimality Gap CABS CABS+CP OR T (a) A verage optimality gap ov er number of state expansions for TSPTW instances by Rifki and Solnon (2025) where 1 . 0 ≤ α ≤ 1 . 5 . Our approach achiev es the same optimality gap as CABS. 0 500 1000 1500 0 . 3 0 . 4 0 . 5 Time (s) A verage Optimality Gap (b) A verage optimality gap ov er time for TSPTW instances by Rifki and Solnon (2025) where 1 . 0 ≤ α ≤ 1 . 5 . CABS reaches the lowest optimality g ap, closely followed by our approach. Figure 13: A verage optimality gap ov er the number of state expansions and time for TSPTW instances by Rifki and Sol- non (2025) where 1 . 0 ≤ α ≤ 1 . 5 . experimental data. B.1 1 | r i , δ i | P P P w i T i The model defines the variable s i for the start time of job i in Definition (41). Constraint (40) ensures that the tasks do not overlap. Finally , the objectiv e function (Objectiv e (39)) specifies that the sum of weighted tardinesses is minimised. min X i ∈J max { 0 , s i + p i − d i } × w i (39) Disjunctive ([ s i | i ∈ J ] , [ p i | i ∈ J ]) (40) s i ∈ [ r i , δ i − p i ] ∀ i ∈ J (41) B.2 RCPSP The model is adapted from the MiniZinc benchmarks repos- itory . The model defines two variables: s i for the start time of task i (Definition (46)) and the objectiv e variable o (Defini- tion (47)) representing the makespan. The constraints then consist of 1) Constraint (43), con- straining the makespan to be after all of the v ariables (where suc i are the successors of task i according to the prece- dences), 2) Constraint (44), constraining the precedences to be respected, and 3) Constraint (45), ensuring that the re- source capacities are respected (where T r = { i | i ∈ T : u ir > 0 ∧ p i > 0 } , S t r = [ s i | i ∈ T r ] , P r = [ p i | i ∈ T r ] , and U r = [ u ir | i ∈ T r ] ). Finally , the objectiv e function (Objectiv e (42)) specifies that the makespan v ariable is minimised. min o (42) s i + p i ≤ o ∀ i ∈ T : suc i = ∅ (43) s i + p i ≤ s j ∀ ( i, j ) ∈ P (44) Cumulative ( S t r , P r , U r , C r ) ∀ r ∈ R (45) s i ∈ [0 , H ] ∀ i ∈ T (46) o ∈ [0 , H ] (47) B.3 TSPTW W e adapt the model from the 2025 MiniZinc challenge. The model defines six v ariables: 1) Definition (55), which defines pr ed i , representing the predecessor for each loca- tion i (i.e. the location which was visited prior to this one), 2) Definition (56), which defines dur T oP r ed i , which rep- resents the trav el time from the predecessor of location i to i , 3) Definition (57), which defines arr i , representing the arriv al time at location i , 4) Definition (58), which defines dep i , representing the departure time at location i , 5) Def- inition (59), which defines depP re d i , representing the de- parture from the predecessor of location i , and 6) Defini- tion (60), which defines the objective o , representing the sum of trav el times. The following constraints are then specified: 1) Con- straint (49) constrains o to be equal to the sum of travel times, 2) Constraint (50) constrains ar r i to be equal to the departure time at the predecessor of i plus the duration from the predecessor of i to i , 3) Constraint (51) ensures that dur T oP r ed i is equal to the trav el time from the predeces- sor of location i to i , 4) Constraint (52) ensures that the latest possible visiting times are respected and that the departure at location i either occurs at its arri val or at its earliest possible release time, 5) Constraint (53) ensures that the depP r ed i is properly channelled to be equal to the value of the variable dep pred i , and 6) Constraint (54) constrains the sequence of locations to be a tour using the Circuit constraint. Finally , the objectiv e function (Objectiv e (48)) specifies that the sum of trav el times variable is minimised. min o (48) o = X i ∈ locations dur T oP r ed i (49) ar r i = depP r ed i + dur T oP r ed i ∀ i ∈ C (50) dur T oP r ed i = c pred i i ∀ i ∈ C (51) dep i = max { ar r i , r i } ≤ δ i ∀ i ∈ C (52) depP r ed i = dep pred i ∀ i ∈ C (53) Circuit ([ pr ed i | ∀ i ∈ C ]) (54) pr ed i ∈ [0 , |C | ] ∀ i ∈ C (55) dur T oP r ed ∈ [0 , max i,j ∈C c ij ] ∀ i ∈ C (56) ar r i ∈ [0 , max i ∈C δ i ] ∀ i ∈ C (57) dep i ∈ [min i ∈C r i , max i ∈C δ i ] ∀ i ∈ C (58) depP r ed i ∈ [0 , max i ∈C δ i ] ∀ i ∈ C (59) o ∈ [0 , |C | × max i,j ∈C c ij ] (60)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment