When AI Navigates the Fog of War
Can AI reason about a war before its trajectory becomes historically obvious? Analyzing this capability is difficult because retrospective geopolitical prediction is heavily confounded by training-data leakage. We address this challenge through a tem…
Authors: Ming Li, Xirui Li, Tianyi Zhou
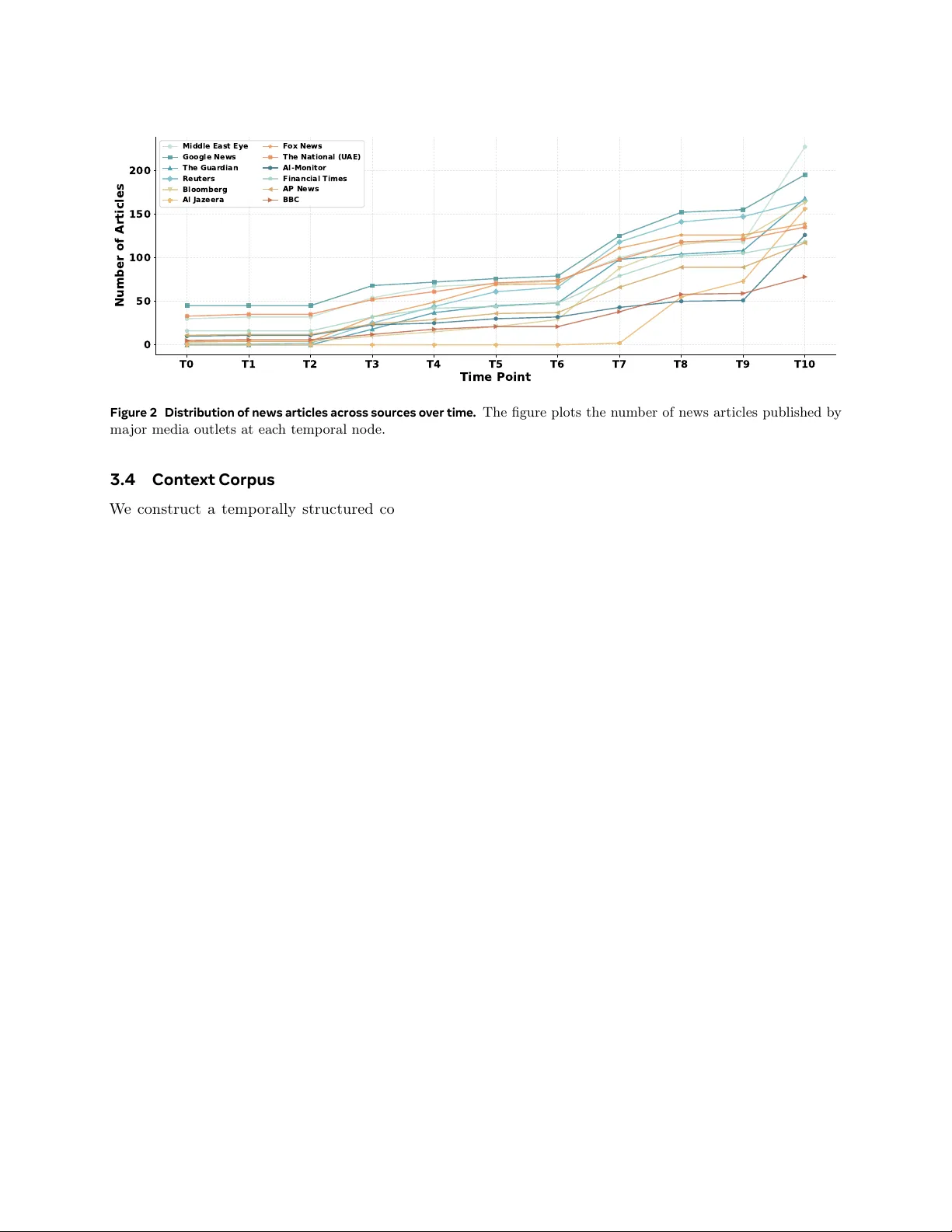
Disclaimer: This w ork presen ts no p olitical stance or endorsement of an y kind. Our ob jectiv e is to analyze the reasoning b eha viors of LLMs. All ev en t nodes and entit y names appearing in this w ork are sampled based on publicly a v ailable Wikip edia and news pages and are used purely for researc h purp oses. When AI Navigates the F og of W ar Ming Li 1 , 2 , ∗ , Xirui Li 2 , ∗ , Tianyi Zhou 1 1 Mohamed bin Za yed Universit y of Artificial In telligence, Abu Dhabi, United Arab Emirates 2 Univ ersit y of Maryland, College Park, United States ∗ Co-first Author Can AI r e ason ab out and for e c ast the tr aje ctory of an ongoing war b efor e it tr ansitions into history? Analyzing this capabilit y is difficult b ecause retrosp ectiv e geop olitical prediction is heavily confounded b y tr aining-data le akage . W e address this challenge through a temp orally grounded case study of the early stages of the 2026 Middle East conflict, whic h unfolded after the training cutoff of current fron tier mo dels. W e construct 11 critical temp oral no des, 42 node-sp ecific verifiable questions, and 5 general exploratory questions, requiring mo dels to reason only from information that w ould ha ve b een publicly a v ailable at each moment. This design substantially mitigates training-data leak age concerns, creating a setting well-suited for studying how mo dels analyze an unfolding crisis under the fog of war, and provides, to our kno wledge, the first temporally grounded analy sis of LLM reasoning in an ongoing geopolitical conflict . Our analysis reveals three main findings. First, curren t state-of-the-art large language mo dels often show strong strategic reasoning in this setting, moving b ey ond surface p olitical rhetoric to attend to underlying incen tives, deterrence pressures, and material constraints. Second, this capability is unev en across domains: mo dels are more reliable in economically and logistically structured settings than in p olitically ambiguous m ulti-actor environmen ts. Finally , mo del narrativ es ev olv e ov er time, shifting from early exp ectations of rapid containmen t to w ard more systemic accounts of regional entrenc hment and attritional de-escalation. Sinc e the c onflict r emains ongoing at the time of writing, this work c an serve as an ar chival snapshot of mo del r e asoning during an unfolding ge op olitic al crisis, enabling futur e studies without the hindsight bias of r etr osp e ctive analysis. Date: Marc h 18, 2026 Author E-mails: minglii@umd.edu & Ming.Li@mbzuai.ac.ae , xiruili@umd.edu , Tianyi.Zhou@m bzuai.ac.ae Project Page: www.w ar- forecast- arena.com “W ar is the realm of uncertain ty; three quarters of the factors on whic h action in war is based are wrapp ed in a fog of greater or lesser uncertain ty .” — Carl von Clausewitz “P eace cannot be k ept by force; it can only b e ac hiev ed b y understanding.” — Alb ert Einstein 1 Introduction W ould it have b e en p ossible to r e asonably anticip ate the outbr e ak of the Se c ond W orld W ar (WWII) fr om within the 1930s, b efor e its ful l esc alation b e c ame historic al ly obvious? Questions of this kind are often discussed in hindsight, where the chain of even ts leading to a ma jor conflict can appear almost inevitable. Y et this perception is strongly shap ed by hindsight bias ( Fischhoff , 1975 ). In realit y , anticipating this kind of geop olitical ev en ts b efore they occur is extraordinarily difficult, even for experienced analysts and forecasters ( T etlo c k and Gardner , 2016 ; T etlo c k , 2017 ). The c hallenge lies not merely in the scarcity of information, but in interpreting incomplete, ambiguous, and often con tradictory signals in real time, without kno wing whic h factors will ultimately prov e decisiv e. T0 T1 T2 T3 T4 T10 D A TE FEB 28 MA R 03 MA R 06 Operati on Fury Ma r 01 Israeli - US Strike MA R 02 Iranian Strikes T wo Mi ssiles T owards Briti sh Base in Cyp rus Qatar Halts Energy Pr oduction Iranian Ap ology to Neighboring C ount ries T0 T1 T3 T4 T10 “Although ther e is no conflict, I think US will strike Iran soon.” “US str oked, I think Iran will fight back” “I don’t think the war will end soon” T2 “Ther e is no confl ict now , but I don’t think it wil l end soon.” “Despite the missiles, I don’t think U.K will be evolved” “I think ther e will be sever e f luctuation in the global market.” Critical T empor al Nodes Pr edictions F r om AI Figure 1 Critical temp oral no des during the early stages of the 2026 Middle East conflict (top) and represen tative mo del analyses at selected no des (b ottom). Mo dels exhibit recognizable patterns of strategic reasoning under the fog of war, and their analyses evolv e as new information becomes av ailable across the timeline. This historical thought exp erimen t highligh ts a broader question about artificial intelligence (AI) reasoning in complex environmen ts. Real-world geop olitical crises in volv e in tertwined dynamics across military strategy , economic incentiv es, diplomacy , domestic p olitics, and h uman p erception ( Betts , 1978 ; Jervis , 1976 ). Effective reasoning in these environmen ts demands the abilit y to navigate uncertaint y , shifting incen tiv es, and partial observ abilit y , whic h are the classic conditions often described as the fo g of war . Understanding whether curren t state-of-the-art (SOT A) Large Language Mo dels (LLMs) exhibit such capabil- ities is challenging. Retrosp ectiv e ev aluation of historical even ts is fundamentally confounded by training data leak age ( Carlini et al. , 2021 ; Aiy appa et al. , 2023 ; Kang et al. , 2024 ). Ma jor geop olitical even ts are extensively do cumen ted in the v ast corp ora used to pretrain modern models ( Bro wn et al. , 2020 ; Bender et al. , 2021 ), meaning that mo dels may implicitly enco de kno wledge of outcomes even when prompted to reason from earlier p oin ts in time. As a result, retrospective prediction tasks can blur the distinction b etw een genuine reasoning and laten t memorization. Recent w ork has therefore raised gro wing concerns that man y ev aluation b enc hmarks ma y inadverten tly measure pattern recognition or data leak age rather than true out-of-distribution reasoning abilit y ( Magar and Sch wartz , 2022 ; Sainz et al. , 2023 ; Li , 2023 ; Y ang et al. , 2023 ). T o study ho w LLMs reason under conditions that more closely resemble real-w orld uncertaint y , w e turn to a crisis that unfolded entirely after the training cutoff of curren t fron tier models. The sudden esc alation of the Midd le East c onflict in late F ebruary and e arly Mar ch 2026 ( A CLED , 2026 ) pro vides a rare opp ortunit y to observe how language mo dels interpret an unfolding geop olitical situation without access to the even tual outcomes. Because the early stages of this crisis o ccurred outside the training distribution of existing mo dels, it offers a natur al setting in which mo dels must r ely on their r e asoning pr o c esses r ather than le arne d know le dge as shown in Figure 1 . In this w ork, w e use the early stages of the 2026 Middle East conflict as a temp orally grounded case study for analyzing how LLMs interpret and reason about an unfolding geopolitical crisis under strict information constraints . W e reconstruct a timeline consisting of 11 critical temp oral no des during the early stages of the conflict and formulate 42 ev ent-specific questions and 5 general exploratory questions probing distinct asp ects of geop olitical reasoning. The construction of these temp oral no des and questions w as human-informed: in addition to reviewing contemporaneous rep orting and public records, w e incorporated input from individuals with lived exp erience of the war to improv e the ecological v alidity of the timeline and the relev ance of the reasoning prob es. These questions span themes including Initial Outbr e ak , Thr eshold Cr ossings , Ec onomic Sho ckwaves , and Politic al Signaling . A t eac h temp oral no de, mo dels are pro vided only with con textual information that w ould ha ve b een publicly a v ailable up to that momen t and are asked to analyze potential dev elopmen ts and strategic implications. R ather than treating this setting as a forecasting b enc hmark, our objective is to examine how language models behave when confronted with a complex, ev olving real-world scenario . In an ongoing conflict, many of the most imp ortan t questions are not cleanly exhausted even ts with timeless binary lab els: some concern degrees of escalation, some remain con tingent on future dev elopments, and some ma y be not yet rather than definitively 2 no . By placing mo dels within a temp orally unfolding information en vironmen t, w e are able to observ e how they in terpret uncertain signals, which factors they treat as strategically significant, and how their narratives evolv e as additional information becomes a v ailable. This p ersp ectiv e allows us to study the qualitative reasoning patterns that emerge when LLMs attempt to analyze geopolitical dynamics under the conditions commonly describ ed as the fo g of war . This work captures a snapshot of LLM reasoning during an unfolding geopolitical crisis, which remains ong oing at the time of writing. Unlik e retrosp ectiv e analyses of historical crises, the ultimate tra jectory of the w ar, whether it stabilizes r e gional ly, esc alates further to a glob al war, or r e aches a ne gotiate d settlement , has not y et b een determined. A ccordingly , even our “v erifiable” questions should b e understo od as op erational probes rather than immutable b enc hmark labels: they let us anchor parts of the analysis quantitativ ely , but they do not collapse the full ambiguit y of the conflict in to a final closed-world test set. T o preserv e this moment of uncertain t y and reduce future hindsight distortion, this work arc hives the LLM resp onses pro duced at eac h temp oral no de as a record of contemporaneous LLM reasoning. As even ts contin ue to develop, these forecasts and narratives may serv e as a reference p oin t for future comparison and follo w-up researc h. Key Findings. • LLMs often show strong strategic reasoning under uncertainty . Across multiple temp oral no des, mo del resp onses mov e b ey ond p olitical rhetoric and fo cus instead on factors such as military sunk costs, deterrence pressures, and material constraints; in several early no des, some mo dels also an ticipate escalation b efore kinetic conflict b egins. • Their strengths are domain-specific rather than uniform. Mo dels are most reliable when reasoning ab out structural economic dynamics and material constrain ts, but less consistent in highly am biguous p olitical settings inv olving signaling, leadership instabilit y , and multi-actor strategic interaction. • Their narratives evolv e with the conflict unfolding. As the conflict contin ues to unfold and new information b ecomes av ailable, models mo ve aw ay from early expectations of rapid containmen t and increasingly con v erge on longer, more systemic accoun ts of the conflict. Main Contributions. • A temporally grounded case study of LLM reasoning under the fog of war. T o our knowledge, this is among the first works to examine ho w LLMs analyze an unfolding war sc enario under strict temp oral information constraints, where the outc ome r emains unknown and mo dels must r e ason under r e al-time unc ertainty . • A structured framework for analyzing model reasoning in this unfolding scenario. W e construct a timeline of 11 critical temp oral no des and design 42 reasoning probes spanning military escalation, economic sho c kwa v es, and political signaling, enabling longitudinal observation of how mo del analyses evolve as new information b e c omes available . • An archived snapshot of LLM reasoning without final outcome. W e preserv e the mo del resp onses generated at each temp oral no de as a record of reasoning under real-time uncertain t y , pr oviding a r efer enc e p oint for futur e r ese ar ch and r etr osp e ctive c omp arison as the c onflict c ontinues to develop . Br o ader Imp acts. This work has b oth constructive p oten tial and associated risks. On the constructiv e side, studying ho w AI reasons under real-world geop olitical uncertaint y may help researchers b etter understand b oth the capabilities and limitations of these systems in complex, high-stakes environmen ts. The archiv ed record of mo del reasoning generated during unfolding even ts ma y also pro vide a useful resource for future researc h on temp oral reasoning and narrative evolution in AI systems. At the same time, research on AI reasoning in geopolitical con texts remains preliminary , and the outputs of suc h systems should b e in terpreted with caution. This work is intended for analytical and research purp oses rather than op erational or military use. By examining how AI systems in terpret incomplete signals and p oten tial escalation dynamics, we aim to supp ort researc h on forecasting, conflict preven tion, and analytical transparency . More broadly , w e hope that improving our understanding 3 of AI reasoning ab out geopolitical ev ents can contribute to research aimed at reducing misinterpretation, mitigating escalation risks, and ultimately supp orting efforts to ward de-escalation and p eace. 2 Background and Related W ork 2.1 LLMs in Geopolitical F orecasting LLM forecasting has attracted growing interest as a setting for studying complex reasoning under real-world uncertain t y ( Halawi et al. , 2024 ; Karger et al. , 2024 ). MIRAI ( Y e et al. , 2024 ) ev aluates LLM agents ov er structured even t databases for short- to long-horizon geopolitical prediction, while F orecastBench ( Karger et al. , 2024 ) sho ws that LLMs still substan tially underp erform exp ert human forecasters on unresolved future questions. Evolv eCast ( Y uan et al. , 2025a ) examines how mo dels up date forecasts in resp onse to new evidence and finds that revisions are t ypically o verly conserv ative and inconsisten t. In p olitical domains specifically , UNBenc h ( Liang et al. , 2025 ) targets UN Securit y Council vote prediction, and ThinkT ank-ME ( Li et al. , 2026a ) introduces a Middle East-fo cused even t forecasting b enc hmark arguing for multi-expert collab oration. T wo imp ortan t metho dological concerns thread through this literature. Palek a et al. ( 2025 ) iden tify temp oral leak age as a p ersisten t confound in geop olitical forecasting ev aluations, and Li et al. ( 2026b ) show that simply prompting mo dels to “pretend not to know” pre-cutoff outcomes do es not reliably simulate true ignorance. These critiques directly motiv ate our design: by anc horing the study to a conflict that postdates all current mo del training, we ensure that neither parametric recall nor simulated ignorance can substitute for gen uine real-time reasoning. Where prior w ork asks whether mo dels can predict outcomes, we pursue a harder question: c an mo dels r e ason c oher ently ab out a crisis as it unfolds, arme d only with the p artial, noisy information available at e ach moment? 2.2 LLMs in Multi-A ctor Social and Strategic R easoning A parallel line of work examines whether LLMs can track the b eliefs, inten tions, and incen tives of multiple agen ts simultaneously . Theory-of-mind (T oM) b enc hmarks establish that while LLMs p erform well on simplified b elief-attribution tasks, they degrade on settings requiring multi-step mental-state trac king, hidden information, or higher-order recursiv e reasoning ( Gandhi et al. , 2023 ; Kim et al. , 2023 ; W u et al. , 2023 ). More recen t work shifts from s tatic T oM tests tow ard interactiv e and strategic settings: SOTOPIA ( Zhou et al. , 2023 ) uses open-ended role-pla y to ev aluate so cial goal coordination, SPIN-Benc h ( Y ao et al. , 2025 ) prob es strategic reasoning under incomplete information and m ulti-agent negotiation, and Mirofish ( BaiF u , 2025 ) constructs high-fidelity agen t so cieties from real-world seed data to simulate collective so cial evolution and forecast future outcomes. Geop olitical crises represen t an extreme case of this m ulti-actor reasoning c hallenge: they in volv e n umerous state and non-state actors with conflicting incentiv es, cascading second-order effects, and rapidly shifting informational landscap es. Existing benchmarks either simplify the actor space (e.g., tw o-play er games) or treat geop olitical scenarios as static prediction tasks. Our test explicitly prob es multi-actor political signaling , threshold-crossing dynamics , and economic spillov er reasoning : capabilities that demand precisely the kind of extended, context-sensitiv e, m ulti-agent world mo deling that current ev aluations leav e largely untested. 2.3 LLM Reasoning Ev aluation Standard reasoning b enc hmarks (e.g., MMLU ( Hendryc ks et al. , 2020 ), GSM8K ( Cobb e et al. , 2021 ), BBH ( Suzgun et al. , 2023 ), GPQA ( Rein et al. , 2024 )) treat reasoning as the solution of decontextualized problems with fixed inputs and predefined answ er spaces. More recent work has enriched ev aluation by incorp orating heterogeneous evidence, including c harts, tables, and m ultimo dal do cuments ( Y ue et al. , 2024 ; Ma et al. , 2024 ), or b y testing retriev al o ver no vel, multi-source inputs ( Li et al. , 2025b ; Chen et al. , 2025 ). A more recen t line of work mov es further tow ard real-w orld conditions: Caugh tCheating ( Li et al. , 2025a ) requires mo dels to infer so cially situated implications from weak visual cues, while forecasting-oriented b enc hmarks ev aluate reasoning ov er unresolv ed future ev ents ( Halawi et al. , 2024 ; Karger et al. , 2024 ; Y uan et al. , 2025b ). Despite this progress, even the most grounded of this work still presen ts reasoning instances as static snapshots; the model is given a fixed con text and ask ed to pro duce an answer. None of them trac k 4 ho w reasoning evolves as new information arrives incrementally o v er time. Our study in tro duces a distinctive temp oral constraint: mo dels receive only information a v ailable at each of 11 sequential decision p oin ts and are rep eatedly asked to update their analysis as the crisis unfolds, enabling us to examine not only answ er accuracy but also b elief revision and narrative coherence under the fog of war. 2.4 Data Leakag e in LLM E valuation Data leak age in LLM ev aluation go es far b ey ond simple train-test ov erlap. Given the scale and heterogeneity of mo dern pretraining corpora, leak age has b ecome a systematic, multi-stage threat to reliable ev aluation ( Deng et al. , 2023 ; Xu et al. , 2024 ; Cheng et al. , 2025 ). Critically , leak age is not limited to verbatim repro duc- tion: paraphrased or translated b enc hmark items can ev ade standard decon tamination while still inflating scores ( Y ang et al. , 2023 ), and leak age can even cross language barriers and remain in visible to surface-ov erlap detectors ( Y ao et al. , 2024 ). Empirical audits ha ve found leak age lev els ranging from 1% to 45% across p opular QA b enchmarks, with contamination growing ov er time ( Li et al. , 2024b ). These findings collectively undermine the common assumption that b enc hmark scores constitute clear evidence of reasoning abilit y . One mitigation strategy is dynamic b enchmark design : LatestEv al ( Li et al. , 2024a ) sources questions from recen t corp ora, Liv eBench ( White et al. , 2024 ) refreshes tasks on a rolling schedule, and LiveCodeBench ( Jain et al. , 2024 ) contin uously collects newly released programming problems. How ever, Sun et al. ( 2025 ) demonstrates that most existing mitigation strategies still fail to jointly preserve ev aluation fidelity and con tamination resistance. Our work takes a stricter approach. Rather than refreshing test items, we study mo del reasoning on a geop olitical crisis that unfolded entir ely after the training cutoff of all ev aluated mo dels, and we additionally restrict each query to information a v ailable only up to a specific temp oral no de. This substantially reduces not just v erbatim leak age but also retrosp ectiv e knowledge from paraphrased or cross-lingual con tamination, making it among the most leak age-resistant ev aluation settings curren tly feasible. 3 S tudy Design 3.1 Critical T emporal Nodes Construction T o study how language mo dels reason about unfolding real-w orld ev ents, we aim to construct and select a timeline of critical temporal no des represen ting k ey turning p oin ts during the early stages of the conflict. Eac h temp oral node corresp onds to a moment at whic h new information substantially alters the strategic landscap e, such as the initiation of military op erations, retaliatory strik es, escalation inv olving additional actors, or ma jor p olitical and economic developmen ts. F ormally , we define each temp oral no de T i as a snapshot of the information environmen t a v ailable at a sp ecific time. F or every no de, w e compile a contextual information pac k age consisting of publicly rep orted news a v ailable up to that moment, which we use as the input con text C T i for the language mo del. Crucially , w e do not include an y information published after T i in the context, ensuring that model responses do not rely on knowledg e of future outcomes. Because the conflict unfolded after the training cutoff of all ev aluated mo dels, the risk of training-data leak age is substantially reduced, making this a setting well-suited for studying reasoning under gen uine uncertain t y . T o ensure that the selected no des reflect not only formal geop olitical milestones but also the moments p erceiv ed as most consequential by p eople directly follo wing the even ts, w e conduct informal interviews with five individuals located in the Middle East during the early stages of the conflict. Participan ts recall the momen ts they remember most vividly since the b eginning of the war, as well as the ev en ts that most c hange their p erception of the conflict’s tra jectory . W e combine these p ersp ectiv es with a systematic review of publicly rep orted developmen ts across international news sources in our selection pro cess. The final resulting timeline contains 11 critical temporal nodes as shown in T able 1 . T ogether, these nodes capture multiple themes of geopolitical dynamics, including Initial Outbreak , Threshold Crossings , Economic Shockwav es , and Political Signaling . By structuring the analysis around these no des, we approximate a sequence of real-time reasoning scenarios in whic h b oth humans and language models in terpret incomplete information and an ticipate p oten tial developmen ts under uncertaint y . 5 T able 1 The selected 11 critical temp oral no des with their corresp onding themes. Node Date Ev ent Theme Theme Disruption T0 F eb 27 Op eration Epic F ury I Initial Outbreak T1 F eb 28 Israeli-US Strikes I Initial Outbreak T2 F eb 28 Iranian Strikes I Initial Outbreak T3 Mar 1 T w o Missiles tow ards British Bases on Cyprus I I Threshold Crossings T4 Mar 1 Oil Refiner and Oil T anker W as Attac ked I II Economic Shockw av es T5 Mar 2 Qatar Halts Energy Pro duction I II Economic Shockw av es T6 Mar 2 Natanz Nuclear F acility Damaged I I Threshold Crossings T7 Mar 3 U.S. Begins Ev acuation of Citizens from the Middle East I I Threshold Crossings T8 Mar 3 Nine Countries Inv olved and Israeli Ground Inv asion I I Threshold Crossings T9 Mar 3 Mo jtaba Khamenei Becomes Supreme Leader IV P olitical Signaling T10 Mar 6 Iranian Ap ology to Neigh b oring Countries IV P olitical Signaling 3.2 Question Design 3.2.1 Node-Specific V erifiable Questions F or each temp oral no de, we design a set of general even t-based questions to prob e how language mo dels reason ab out real-w orld developmen ts. Across 11 temporal nodes, the study includes 42 verifiable questions , with eac h no de asso ciated with three to five questions fo cusing on broad developmen ts rather than specific details. The pro cess of designing these questions was informed b y two complementary sources . First, during th e aforemen tioned interviews, participants were asked about the types of developmen ts or turning p oin ts they paid atten tion to and what p ossibilities or general trends they wondered ab out as the even ts progressed. Second, we examined news reports and p olicy analysis from the early stages of the crisis to summarize the kinds of o verall uncertainties and broader topics discussed b y commen tators and analysts. Dra wing on these p ersp ectiv es and incorp orating a thematic framework, we constructed a series of questions that fo cus on even t trends, aiming to understand how language models reason about and analyze the progression of major ev ents as they unfold . These questions primarily concern developmen ts whose outcomes can later be compared against real-world ev en ts to obtain the ground truth. The detailed questions are listed within eac h theme. A t the same time, w e do not view these questions as forming a con ven tional benchmark in whic h ev ery item admits a perfectly final, context-independent binary label. In an ongoing conflict, some developmen ts are b est understo od as matters of degree, and ev en apparen tly binary outcomes may remain temp orally op en: an even t that has not o ccurred yet at the time of analysis could still o ccur later. W e therefore use these questions as structured analytical anc hors that make p ortions of the evolving situation more comparable across mo dels, while keeping the primary emphasis on the reasoning tra jectories reflected in the resp onses. 3.2.2 General Exploratory Questions In addition to these v erifiable questions, we also include 5 general e xploratory questions that are ask ed at every temp oral no de T i . These questions concern broader geop olitical tra jectories that are inheren tly difficult or imp ossible to v erify directly within the scop e of the study . Sp ecifically , these general questions are listed in T able 2 . Unlik e the no de-specific questions, resp onses to these exploratory questions are not evaluate d for c orr e ctness . Instead, they serve a different purp ose: to record how language models interpret and narrate the ev olving situation as the conflict unfolds. By asking the same set of broad questions at each temporal no de T i , w e obtain a longitudinal record of how mo del analyses change in response to new information. W e include these responses as part of the released dataset, pro viding a structured arc hive of mo del in ter- pretations during an unfolding geop olitical crisis. W e hop e that this record may supp ort future research on temp oral reasoning, narrative evolution in language mo dels, and the study of ho w AI systems interpret 6 T able 2 General Exploratory Questions. # General Exploratory Questions 1 What are the p oten tial future actions b y the United States and Israel? 2 What are the p oten tial future actions b y Iran? 3 What are the p oten tial in volv ement or reactions from other ma jor coun tries? 4 Will the conflict escalate in to a global w ar? 5 What is the most probable pathw ay to de-escalation or resolution of the Iran-US conflict, and what is a realistic timeline? complex real-world even ts o ver time. 3.3 Interaction Protocol W e situate language models within a temp orally grounded reasoning proto col defined b y the temp oral no des T i , the contextual information pack ages C T i , and the corresp onding questions. Each question is p osed indep enden tly . F or ev ery question asso ciated with a temp oral no de T i , the mo del receiv es the complete contextual information pac k age C T i as input. The con text consists of publicly rep orted news articles and their sources that w ere a v ailable up to time T i . Imp ortantly , the con text only con tains information preceding the temporal node , but nev er includes any information published after T i , ensuring that the mo del do es not ha ve access to future dev elopmen ts. Eac h question is asked indep enden tly using the following prompt structure: {c ontext} Based on the ab o ve publicly av ailable information, try to analyze the current situation and p oten tial future direction, then resp ond to this question: {question} A t the end of y our response, also provide the probabilit y . This prompting format encourages mo dels to first reason ab out the geop olitical situation implied by C T i and then provide an explicit probabilit y estimate for the even t describ ed in the question. W e record the full mo del resp onse, including b oth the reasoning pro cess and the final probabilit y assessment. In practice, the probabilit y estimates w ere not alw ays expressed in a p erfectly standardized n umerical format. T o ensure accurate quan titative analysis, two r ese ar chers indep endently r e ad al l the mo del r esp onses and manual ly extr acte d the final pr ob ability judgment for e ach no de-sp e cific verifiable question. Disagreements w ere resolved through discussion. W e adopted this manual extraction pro cedure because it was more reliable than automatic parsing for preserving the probabilit y actually implied b y the mo del’s final response. F or the node-sp ecific verifiable questions, w e op erationalize ground truth with resp ect to a fixed observ ation cutoff: an ev ent is labeled as having occurred if it had o ccurred b y the time of writing, and not o ccurred otherwise. In the current study , w e giv e eac h question at least a one-week windo w for resolution. This is a pragmatic op erationalization rather than a claim that one week is uniquely correct: in an ongoing geop olitical conflict, some ev ent lab els may shift under a shorter or longer observ ation windo w. The v alue of this c hoice is therefore transparency and repro ducibilit y for limited quan titative comparison, while ac knowledging that in an ongoing conflict not yet observe d should not b e ov er-interpreted as an absolute negation. As a consequence, our primary goal is not to tr e at this task as a c onventional b enchmark , but rather to analyze ho w language models in terpret incomplete real-world information and construct narratives ab out unfolding geop olitical even ts. Therefore, our analysis focuses primarily on the qualitative reasoning patterns present in model responses, including ho w models interpret strategic incentives, escalation dynamics, and cross-domain implications , with the quan titative lab els serving as auxiliary signals rather than definitiv e final judgmen ts. 7 T0 T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 Time Point 0 50 100 150 200 Number of Articles Middle East Eye Google News The Guardian Reuters Bloomberg Al Jazeera F ox News The National (U AE) Al-Monitor Financial Times AP News BBC Figure 2 Distribution of news articles across sources over time. The figure plots the num b er of news articles published by ma jor media outlets at each temporal no de. 3.4 Conte xt Corpus W e construct a temp orally structured context corpus spanning 11 no des that trac k the escalation of the conflict from F eb. 01 to Mar. 07, 2026. Articles are sourced from 12 international outlets cov ering div erse regional and editorial persp ectiv es, including Midd le East Eye , A l Jaze er a , The National (UAE) , A l-Monitor for regional co verage, and R euters , Blo omb er g , The Guar dian , Financial Times , AP News , BBC , and F ox News for W estern p ersp ectiv es. W e collected this news via Go ogle News RSS feeds and direct outlet links starting from F eb. 01, 2026, which marks the earliest av ailable cov erage of the conflict’s onset. F or articles where the RSS feed returns only a headline, w e resolv e the redirect URL and extract the full article b ody using trafilatura Barbaresi ( 2021 ). Duplicates are remov ed via normalized title matc hing. F or each temp oral no de T i , the con text window is built by filtering all articles published strictly b efor e the corresponding ev ent timestamp, then sorting them in rev erse chronological order (most recen t first). Eac h article is formatted as [YYYY-MM-DD HH:MM] Title (Source) follo w ed b y up to 2,000 characters of bo dy text if substantiv e con ten t is av ailable b ey ond the headline; otherwise, only the headline line is included. Entries are concatenated sequen tially until the total exceeds 480,000 characters ( ≈ 120K tokens), at which p oin t the remaining older articles are dropp ed and replaced with a single [...N older articles omitted] mark er. The resulting con text blo c k is then prep ended to the prompt template describ ed in Section 3.3 . Critically , we apply no further filtering, summarization, or editorial curation : multiple outlets rep orting on the same even t are all retained, and syndicated or up dated articles are treated indep enden tly . This is inten tional; it simulates the raw, unstructured information environmen t a real-w orld forecasting agen t w ould encoun ter, where redundancy , noise, and conflicting reports are natural features rather than artifacts to b e remo v ed. The cum ulativ e article po ol grows from 158 articles at T 0 to 1,787 at T 10 (totaling ≈ 889K words), with p er-source gro wth shown in Figure 2 . 4 R easoning Analysis under the F og of W ar W e b egin by examining the qualitative reasoning tra jectories that emerged when mo dels interpreted the unfolding conflict under the fog of war. T o capture these nuances, our analysis is based on manual reading of the full mo del resp onses generated for each question at every temp oral no de. Rather than relying on automated k eyword extraction, w e inductiv ely categorized the inferential tra jectories and narrativ e shifts presen t in the generated text. Throughout this section, w e provide represen tative resp onse snipp ets to illustrate the b eha vior of the models. All mo del resp onses are presented in blockquote format and represen t the original text generated by the mo dels. 8 T able 3 The No de-Specific Questions for Theme I: Initial Outbreak & Military Spillov er (T0, T1, T2). Idx Node-Specific Questions T0: F eb 27, Operation Epic Fury 1 Is the United States lik ely to conduct direct military strik es on Iranian territory? 2 Could the United States prioritize economic sanctions or diplomatic pressure ov er military action? 3 Do es the announcement of Op eration Epic F ury signal the b eginning of a broader military conflict? T1: F eb 28, Israeli-US Strikes 1 Are the Israeli-U.S. strikes likely to escalate into a broader military campaign? 2 Is Iran lik ely to retaliate militarily in response to the strik es? 3 If Iran retaliates, is it more lik ely to indiscriminately b om b Israeli-U.S. territory than to target U.S. military bases? 4 Could Gulf states b ecome direct targets of Iranian retaliation 5 Is regional airspace in the Middle East likely to face widespread closures due to securit y risks? T2: F eb 28, Iranian Strikes 1 Are the Iranian strikes likely to remain symbolic retaliation without sustained military op erations? 2 Could Iran attempt to disrupt shipping through the Strait of Hormuz? 3 Are other coun tries in the region likely to b ecome directly in v olved in the conflict? 4 Is large-scale closure of Middle Eastern airspace likely follo wing these strikes? 5 Could the conflict trigger in ternal reb el army within Iran? 4.1 General Model Behaviors and Stylistic Differences Before examining individual temp oral no des in detail, sev eral general patterns emerge from comparing the reasoning styles of the ev aluated mo dels. F or a b etter understanding of the mo del’s reasoning tra jectories, we pro vide some complete examples in App endix B . First, most mo dels display a strong tendency to ward structural strategic reasoning rather than simply rep eating p olitical rhetoric. Across m ultiple questions, mo dels commonly grounded their analysis in factors suc h as military deploymen ts, deterrence dynamics, and institutional incen tives. Second, the mo dels differ in how structured and formalized their reasoning narratives tend to be. Some mo dels, particularly Claude and GPT-5.4, often pro duce highly structured analyses that explicitly separate driv ers, constraints, and scenario pathw ays. Their responses frequen tly organize reasoning in to sections suc h as escalation indicators, limiting factors, and alternative outcomes. By contrast, mo dels such as Gemini and Qw en more often construct broader narrativ e explanations, integrating p olitical signals, regional dynamics, and economic implications into a single analytical storyline. A third difference concerns the lev el of analytical gran ularity . Some mo dels tend to enumerate detailed op erational scenarios and probability breakdowns, outlining multiple escalation pathw ays or target sets. Others pro vide shorter assessmen ts fo cused on the most probable strategic tra jectory without extensiv e scenario decomp osition. These st ylistic differences affect the length and structure of the resp onses, but they generally do not lead to radically differen t o verall judgments. 4.2 Case Study on Theme I: Initial Outbreak & Military Spillo ver 4.2.1 T0: F eb 27, Operation Epic Fury The first temp oral no de (T0) rev ealed evidence of early-stage geop olitical reasoning even b efore an y military conflict had o ccurred. A cross models, the dominant framing was that the situation had moved bey ond routine coercive signaling and to ward open military conflict. In this section, we fo cus our analysis of T0 on tw o inferential patterns: how mo dels r e asone d ab out str ate gic sunk c osts, and how they diver ge d when pr o c essing diplomatic signals. 9 Str ate gic Intuition and the “Cr e dibility T r ap”. When ev aluating the likelihoo d of direct military strik es, the mo dels show ed evidence of reasoning about structural incentiv es rather than merely reflecting surface-level rhetoric. Mo dels such as claude-sonnet-4.6 and gemini-3.1-flash frequen tly framed the situation as one in whic h the sheer scale of the military deployment had created a point of no return , emphasizing that logistical momen tum in high-stak es geop olitics can ov erride last-minute diplomatic hesitation. claude-sonnet-4.6 : “The scale of the US deplo ymen t is extraordinary by any historical measure ... This is not merely signaling . Deploymen ts of this magnitude create their own p olitical logic... The buildup has b ecome a trap of T rump’s own making.” gemini-3.1-flash : “The T rump administration has established a pattern of using military force... This has created a situation where the U.S. military buildup... is widely viewed by regional observ ers as a genuine preparation for a ’highly kinetic’ campaign rather than mere p osturing.” This pattern of resp onses suggests a shared inferential baseline: across models, the prev ailing reasoning was that withdrawing such a massiv e force without e xtracting major concessions would result in a catastrophic loss of credibility . The Diver genc e: Susc eptibility to Diplomatic Smokescr e ens. How ever, this inferential consistency broke down when mo dels were subsequently asked whether the U.S. might prioritize economic sanctions and diplomatic pressure ov er military action. Despite all models acknowledging the imminence of strik es in the previous prompt, they weighted the conflicting signals of the ongoing Geneva talks very differently . Mo dels suc h as gpt-5.4 and gemini-3.1-flash resp onded quite differently . Because the contextual data included rep orts of “significant progress” from Omani mediators, these models heavily w eighted the diplomatic signals, assigning higher probabilities to the U.S. prioritizing sanctions rather than military action . They tended to in terpret the military buildup primarily as a leverage tactic rather than a commitmen t to strike. gpt-5.4 : “Multiple rep orts sa y US-Iran talks in Genev a pro duced at least some ’progress’... That strongly suggests W ashington has not yet decided diplomacy is exhausted ... T rump app ears to w an t lev erage, not necessarily war for its own sake.” gemini-3.1-flash : “ The most lik ely path is a ’co erciv e diplomatic’ outcome . The U.S. is likely to maintain its military posture as a p ermanen t threat to ensure compliance, while pushing for a ’narrow’ deal...” In contrast, claude-sonnet-4.6 assigned a substantially lo wer probability to the diplomatic path, maintaining a more consistent inferen tial p osition across the tw o questions and e xplicitly reasoning that sanctions could not remain the primary strategy at this stage . claude-sonnet-4.6 : “The US cannot realistically prioritize pure economic sanctions or diplomacy as its primary strategy at this stage — the military buildup has created its own momentum and credibility requiremen ts.” T ak en together, T0 sho ws that mo dels v aried in how they weighed comp eting signals in the pre-conflict information environmen t. Most models tended to frame the situation as having mo ved bey ond routine coerciv e signaling and tow ard open military escalation. Their main divergence lies not in whether they registered the risk of w ar, but in ho w m uc h w eigh t their outputs assigned to the residual diplomatic signals still present in the information en vironmen t. Some mo dels interpreted the ongoing negotiations as evidence that diplomacy remained viable, while others emphasized the structural momen tum created by the massiv e military buildup. 4.2.2 T1: F eb 28, Israeli-US Strikes T1 marked the momen t when the crisis transitioned from anticipatory tension into actual kinetic action. At T1, the ev aluation shifted from assessing hypothetical risks to analyzing activ e escalation ladders. Despite the 10 inherent chaos of the “fog of war” , the models exhibited relatively stable reasoning patterns across this temporal node. In this section, we highlight tw o inferen tial tendencies that emerged from the resp onses: an app ar ent r esistanc e to historic al bias, and a tendency to disentangle extr eme p olitic al rhetoric fr om assessments of military do ctrine. Over c oming Historic al Bias. A common pitfall in geopolitical forecasting is ov er-relying on recent historical preceden ts. The provided contextual information noted a previous “12-Day W ar” in June 2025, where strikes remained relatively contained and Iran’s retaliation w as highly restrained. How ever, when ev aluating whether the current strik es would escalate into a broader campaign, sev eral models show ed evidence of reasoning bey ond this historical precedent. Their responses emphasized that the underlying strategic calculus had changed in ways that the June 2025 template could not capture. claude-sonnet-4.6 : “The ’June 2025 T emplate’ Problem... the June 2025 ’Midnigh t Hammer’ op eration w as essentially a one-off strike where Iran responde d weakly ... This time, the situation is fundamentally differen t... Iran’s leadership has been lib erated from its fear of total w ar b y having already surviv ed one US attack.” gemini-3.1-flash : “Iran’s Shift in Calculus... Ha ving already surviv ed a significant degradation of their n uclear and mil itary infrastructure, the regime seems to ha v e mo v ed past the ’paralyzing caution’ that previously deterred them.” Rather than extrapolating mechanically from the earlier episode, the models tended to emphasize a psychological and strategic phase shift , reasoning that the threshold for a broader, sustained military campaign had been crossed. Disentangling R hetoric fr om R ational Do ctrine. A further inferen tial pattern emerged when models w ere ask ed whether Iran’s retaliation w ould lik ely inv olve indiscriminate bombing of Israeli-U.S. civilian territory rather than targeting military bases. At this no de, the information en vironment was saturated with extreme rhetoric from Iranian officials threatening a “regional war” and “severe” consequences without limits. Y et, the models generally discounted the inflammatory posturing. They tended to reason that retaliation would remain calibrated tow ard military assets. gpt-5.4 : “Iran’s do ctrine historically fa v ors calibrated, p olitically framed retaliation ... Iran generally tries to present retaliation as: state-to-state, military-for-military , proportionate or framed as defensive...” claude-sonnet-4.6 : “Escalation Managemen t Incen tives... Iran has consisten tly sough t to a v oid triggering o v erwhelming US retaliation that could threaten regime surviv al . Indiscriminate b om bing... would vir- tually guarantee catastrophic US escalation, p otentially including regime decapitation strik es.” T aken together, T1 illustrates that, when equipped with sufficien t con textual information, the mo dels sho wed evidence of reasoning ab out structural incen tives rather than merely reflecting the surface-level conten t of the information environmen t. Across responses, a recurring pattern was the tendency to discount emotional political rhetoric and contextualize historical analogies when assessing the mechanics of state survival and deterrence. 4.2.3 T2: F eb 28, Iranian Strikes As the conflict erupted in to active warfare, T2 in tro duced profound geop olitical sho cks, including rep orts of a pre-emptive U.S.-Israeli strik e and the sudden death of Iran’s Supreme Leader, triggering an immediate succession crisis. Despite the influx of chaotic and potentially destabilizing v ariables, the models tended to navigate this escalation by linking Iran’ s domestic political fragility to its external military posture. L e adership T r ansition and the Esc alation Calculus. When analyzing whether Iran’s retaliation w ould remain merely “symbolic” with no sustained operations, the mo dels show ed evidence of reasoning ab out authoritarian regime surviv al logic. Rather than treating a sudden leadership v acuum as inherently paralyzing, the models 11 T able 4 The No de-Specific Questions for Theme I I: Threshold Crossings & Internationalization (T3, T6, T7, T8). Idx Node-Specific Questions T3: Mar 1, T wo Missiles towards British Bases on Cyprus 1 Is the United Kingdom lik ely to b ecome directly in volv ed in the conflict? 2 Is NA TO lik ely to b ecome inv olved, expanding the conflict into the Mediterranean theater? 3 Could the conflict disrupt commercial shipping or maritime securit y in the Mediterranean? T6: Mar 2, Natanz Nuclear F acility Damaged 1 Are the United States and Israel lik ely to contin ue targeting Iranian n uclear facilities? 2 Will Israel’s n uclear-related infrastructure b e damaged? 3 Is Iran lik ely to withdraw from n uclear non-proliferation commitments? 4 Could nuclear weapons be used as part of the conflict? T7: Mar 3, U. S. Begins Ev acuation of Citizens from the Middle East 1 Are other coun tries lik ely to begin ev acuating their citizens from the region as well? 2 Could the United States deplo y ground forces if the conflict escalates further? 3 Are foreign gov ernmen ts likely to close or reduce operations at diplomatic missions in the region? T8: Mar 3, Nine Countries Inv olved and Israeli Ground Invasion 1 Is the conflict likely to expand further, inv olving additional countries? 2 Could multiple countries initiate ground operations as the w ar escalates? 3 Is Iran lik ely to increase military or logistical supp ort for Hezbollah? frequently framed the immediate succession of a new leader as a potential catalyst for a more aggressive response, reasoning that an untested leader faces strong incentives to avoid appearing weak. claude-sonnet-4.6 : “The app oin tment of Mo jtaba Khamenei under Israeli threat creates a uniquely dangerous dynamic. The new supreme leader must: 1. Establish credibility with IR GC hardliners , 2. A void app earing to capitulate ... This creates unpredictabilit y - the new leadership ma y authorize more aggressiv e action... precisely to establish authority.” gpt-5.4 : “Iran’s leadership is under pressure: internal unrest... leadership transition/succession issues... In that environmen t, the regime lik ely feels it m ust sho w it can still impose costs . Even if it wan ts to av oid total war, it also cannot app ear unable to resp ond.” T ak en together, T2 illustrates that the mo dels did not uniformly asso ciate leadership decapitation with regime collapse or military passivity . A recurring inferential pattern w as that e xistential external threats, when compounded by a succession crisis, were framed as creating strong pressures for authoritarian regimes to escalate externally in order to secure internal legitimacy . 4.3 Case Study on Theme II: Threshold Crossings & Internationalization 4.3.1 T3: Mar 1, T wo Missiles towards British Bases on Cyprus T3 examined how mo dels assessed the risk of in ternationalization. In this node, two patterns emerged: evidence of reasoning about institutional mechanics (e .g., NA TO protocols), alongside divergence in how models weighted domestic political noise. Institutional R e alism. When ask ed if NA TO w ould formally en ter the conflict, expanding it in to the Mediterranean theater, a naiv e reading of the context migh t suggest imminent alliance-wide in v olv ement. Ho w ever, the models sho wed e vidence of reasoning about institutional constraints, distinguishing individual member state actions from NA TO ’s collective defense mechanisms. 12 claude-sonnet-4.6 : “NA TO op erates on consensus, and several members (T urkey , Hungary) would likely blo c k formal alliance inv olvemen t... Article 5 collectiv e defense provisions are not triggered - no NA TO mem b er has b een attac ked by Iran directly .” gpt-5.4 : “NA TO’s collective-defense mec hanism normally requires an attack on a member... So far, this is a US-Israel-Iran w ar, not clearly a NA TO w ar ... Ev en if many NA TO members are ac- tiv e, they ma y a void calling it a NA TO mission to prev ent alliance splits.” The Distr action of Domestic Politic al Noise. Ho wev er, predicting the actions of individual states prov ed more challenging, revealing a divergence in ho w mo dels weigh t domestic p olitical rhetoric. When ev aluating whether the United Kingdom w ould directly join the offensive, the con text included loud demands from opp osition p oliticians (e.g., Nigel F arage) urging the UK to join the U.S. strikes. Mo dels lik e claude-sonnet-4.6 and gpt-5.4 tended to prioritize the structural reality that the UK Navy had withdra wn ships from the Gulf and explicitly opted out of the initial strike wa ve. Con versely , gemini-3.1-flash assigned a markedly higher probability of involv ement, appearing to ov erweight the v ocal political opposition relative to the military indicators. claude-sonnet-4.6 : “The UK explicitly chose not to participate in initial strikes despite adv ance notice ... Ro y al Navy at historic low with no warships in the Arabian Gulf... The UK is most likely to remain in a supp orting role.” gemini-3.1-flash : “The likelihoo d of the United Kingdom b ecoming directly in volv ed... is mo derate to high ... driv en by Domestic Political Pressure: There is significant and v o cal pressure from opp osition parties... Reform UK leader Nigel F arage and other MPs ha ve publicly urged the go vernmen t to ’back the Americans’.” T ak en together, T3 suggested that mo dels tended to reason more consistently when ev aluating the formal constrain ts of international institutions like NA TO. How ever, when assessing individual state actors, the inferential outcomes varied considerably depending on whether models weighted hard military realities or domestic political rhetoric more heavily . 4.3.2 T6: Mar 2, Natanz Nuclear F acility Damaged A t T6, the conflict escalated significan tly with strik es on underground n uclear sites and the reported decapitation of Iran’s leadership. In a highly volatile information environment, the models tended to differentiate between the prospect of actual nuclear weapon deployment and the prospect of nuclear-related coercive signaling, assigning substantially higher probability to the latter . Deterr enc e Signaling vs. A ctual Deployment. When asked if nuclear weapons could be used as part of the conflict, the models tended to assess that while an actual n uclear detonation was highly unlikely , indirect n uclear threats, suc h as accelerated enrichmen t, diplomatic blac kmail, or radiological incidents, were plausible co erciv e tactics. This pattern of responses illustrated evidence of reasoning ab out the fundamental logic of nuclear strategy : that in regional conflicts, nuclear programs function primarily as instrumen ts of coercive signaling rather than battlefield deplo yment. claude-sonnet-4.6 : “The most realistic n uclear-related threat is n uclear rhetoric ... rather than ac- tual nuclear weapon deploymen t... The new leadership... faces a surviv al calculation where n uclear use w ould guaran tee total destruction.” gpt-5.4 : “The most plausible nuclear dangers are indirect ... Iranian ’breakout’ threat: Iran could announce withdra w al from remaining nuclear commitments... That would b e a nuclear crisis 13 ev en b efore any b om b exists.” Over estimating Institutional Esc alation. Ho wev er, this inferential consistency brok e do wn when models w ere ask ed whether Iran would formally withdra w from its n uclear non-proliferation commitmen ts. F aced with the extreme con text of leadership decapitation, mo dels like gemini-3.1-flash appeared to ov er-extrapolate the escalation, treating military conflict as lik ely to immediately dissolve all institutional hedging. gemini-3.1-flash : “The U.S. and Israel ha v e explicitly stated that the goal of the current mili- tary campaign is regime c hange... In this en vironment, adherence to in ternational treaties like the Non-Proliferation T reaty (NPT) is viewed by the regime as a liability...” Con v ersely , claude-sonnet-4.6 offered a contrasting assessment, reasoning that ev en in a survival scenario , formal NPT withdrawal carries catastrophic diplomatic costs that constrain the regime’s options. claude-sonnet-4.6 : “Iran is unlik ely to mak e a formal, explicit withdraw al from the NPT in the near term... F ormal withdra w al would invite immediate escalation...” T aken together, T6 suggested that while mo dels show ed evidence of reasoning ab out the limits of direct nuclear use, many tended to underweight the degree to which state actors maintained complex institutional commitments (lik e NPT membership) ev en during existential crises. 4.3.3 T7: Mar 3, U. S. Suggests E vacuation of Citizens from the Middle East A t T7, the conflict caused massive regional disruptions, and U.S. officials suggested civilian ev acuations. When ask ed if the U.S. might deplo y ground forces, the mo dels tended to identify a tension b et ween the official preference for an air-only campaign and the op erational requirements implied by the stated war ob jectives. The Limits of Airp ower versus A ctual Go als. U.S. officials publicly stated a preference for airstrikes to av oid a protracted conflict, while sim ultaneously refusing to rule out ground forces. Rather than treating these p olitical statemen ts as definitive, the models tended to reason from the stated war ob jectives, regime c hange, and securing nuclear materials, and frequently emphasized that suc h ob jectiv es are difficult to achiev e through airp o wer alone. claude-sonnet-4.6 : “T rump has explicitly refused to rule out ground tro ops... Several stated US ob jectives are difficult to ac hieve from the air alone : V erifying destruction of n uclear facilities, Securing n uclear materials, Ensuring regime change takes hold.” gpt-5.4 : “The stated aims ha v e broadened in public discussion: not just degrading missiles or nuclear capacit y , but also leadership decapitation... That kind of widening ob jectiv e set can create conditions where airp o wer alone is judged insufficien t.” gemini-3.1-flash : “The primary argument for ground forces w ould b e the need to secure nuclear sites or neutralize mobile missile launc hers that air pow er alone has failed to eliminate.” T ak en together, T7 illustrated that models tended to reason b ey ond public p olitical rhetoric when assessing military requirements. A recurring inferential pattern was that air campaigns were unlikely to be sufficient if the stated objectives included regime change or the physical seizure of nuclear sites, suggesting th at mo dels asso ciated these goal-sets with an elev ated probabilit y of even tual ground force deplo yment. 4.3.4 T8: Mar 3, Nine Countries Inv olved and Israeli Ground Invasion A t T8, the conflict had already drawn in nine countries, and Israel had launched ground op erations into Lebanon. When ask ed if the conflict would expand further, all models inferred high probabilities of further 14 T able 5 The No de-Specific Questions for Theme I II: Economic Sho c kwa ves & Market Escalation (T4, T5). Idx Node-Specific Questions T4: Mar 1, Oil R efiner and Oil T anker W as Attack ed 1 Is Iran lik ely to contin ue targeting oil tank ers in an attempt to disrupt traffic through the Strait of Hormuz? 2 Could international nav al forces establish escort missions to protect commercial shipping? 3 Could American na v al forces establish escort missions to protect commercial shipping? 4 Are energy facilities suc h as refineries, desalination plan ts, and oil terminals likely to b ecome primary targets? 5 Could these attac ks lead to significan t v olatilit y in global oil prices? T5: Mar 2, Qatar Halts Energy Production 1 Could Qatar’s decision lead to natural gas shortages in Europ e or Asia? 2 Are global natural gas prices likely to increase significan tly as a result? 3 Could other LNG facilities or energy infrastructure in the Gulf region b ecome targets? 4 Are ma jor energy-imp orting coun tries likely to seek alternative supply sources? expansion. A common reasoning pattern was that neighboring countries would prefer to remain outside the conflict, yet existing military agreements function as tripwires that could draw reluctant states into the battlefield. claude-sonnet-4.6 : “ P akistan explicitly signaled its defense pact with Saudi Arabia could draw it in ... If Iran delib erately targets T urkish territory ... Article 5 considerations could dra w NA TO more formally in to the conflict.” Bey ond formal treaties, the mo dels also sho wed evidence of reasoning ab out the do wnstream consequences of the U.S. and Israeli decapitation strategy . Rather than treating leadership remov al as likely to end the conflict quic kly , gemini-3.1-flash emphasized the risk of a pow er v acuum that could dra w neighboring states in. gemini-3.1-flash : “The primary factor that could trigger further expansion is the collapse of the Iranian state. If the regime fragments, the resulting c haos could dra w in neighboring coun tries ( T urkey or Iraq) to secure their b orders... effectively turning the conflict into a m ulti-front regional civil war.” T ak en together, T8 illustrated that mo dels tended to frame further conflict expansion not as driv en by states eager to join the fighting, but as a pro duct of the structural triggers of defense pacts and the spillover effects of potential regime collapse , a pattern of reasoning that emphasized inv oluntary entrapmen t ov er v oluntary escalation. 4.4 Case Study on Theme III: Economic Shockwav es & Mark et Escalation 4.4.1 T4: Mar 1, Oil R efiner and Oil T anker W as Attack ed A t T4, the conflict directly hit global energy lifelines, officially triggering the economic shockw av es of the war. F ollo wing the targeting of oil tankers, the mo dels had to syn thesize military escalation with global mark et reactions. In this node, a recurring inferential pattern was the linking of military escalation logic to financial mark et dynamics, rather than treating economic and military pressures as separate. A basic economic reading might suggest Iran w ould a void blo c king the Strait of Hormuz, given its o wn export dep endence on the route. How ever, the models tended to reason that when a gov ernment faces an existential threat, normal economic self-in terest no longer dominates the calculus. The prev ailing inference w as that the imp erativ e to retaliate and surviv e o v errides the need to protect domestic export rev enues. 15 qwen3.5-35b-a3b : “With the US and Israel pursuing a ’regim e c hange’ op eration and decapitating Iran’s leadership, Iran views the conflict as existential. In this context, economic leverage (the Strait) b ecomes a primary to ol for retaliation, even if it harms their o wn exp orts.” Bey ond the physical targeting of ships, the mo dels also show ed evidence of reasoning ab out the financial mec hanics of mo dern conflict. A common emphasis was that a military need not physically sink ev ery vessel to effectively close a major trade route; generating sufficient panic in global insurance and shipping markets may be enough. claude-sonnet-4.6 : “Insurance market collapse is underappreciated: Insurers canceling p olicies and refusing new cov erage for Gulf shipping creates a de facto blo c k ade even without ph ysical closure of Horm uz.” T ak en together, T4 illustrated that models tended to reason about geopolitical crises through an economic lens that w ent b ey ond ph ysical destruction. A recurring inferential pattern was that modern warfare disrupted global supply chains not only through kinetic action, but through the weaponization of economic self-harm and the propagation of mark et risk premiums. 4.4.2 T5: Mar 2, Qatar Halts Energy Production A t T5, the economic fallout deep ened as Qatar halted its liquefied natural gas (LNG) pro duction due to nearb y attacks. When ev aluating the global consequences of this shutdo wn, the mo dels sho wed evidence of reasoning ab out secondary and tertiary economic effects. Rather than limiting their analysis to immediate supply-and-demand effects, the responses frequently addressed the behavioral dynamics of international trade and the potential long-term restructuring of global supply chains. When asked if the pro duction halt w ould lead to gas shortages, the models tended to reason that the impact w ould not b e evenly distributed. A common inference was that a sudden drop in Qatari supply would trigger an aggressive inter-regional bidding war, leaving the most price-sensitiv e imp orters most exp osed. gpt-5.4 : “If Qatari cargo es disapp ear, Asian buy ers ma y bid up prices rapidly ... Europ e would b e pulled into a bidding war with Asia ... Poorer buy ers, especially in South and Southeast Asia, could face actual shortages first.” F urthermore, when assessing how imp orting countries would react, the mo del outputs wen t b ey ond short-term supply resp onses. A prev alent framing w as that such a sev ere disruption would accelerate structural changes in how nations secure their energy supplies , with resp onses consisten tly emphasizing a lik ely reorien tation a wa y from Gulf-centric dep endence tow ard more geop olitically stable trading partners. gemini-3.1-flash : “The ’era of Gulf-centric energy securit y’ has b een sev erely compromised... Imp orting nations will treat the curren t disruption as a structural break rather than a temporary sho c k. They will aggressiv ely pursue a ’de-risking’ strategy .” T aken together, T5 illustrated that mo dels tended to frame ma jor geop olitical sho c ks as having structural, not merely transitory , economic consequences. A recurring pattern was the emphasis that sev ere supply disruptions did not simply cause temporary price spikes, but altered the long-term procurement strategies and risk calculations of major importing nations. 4.5 Case Study on Theme IV: P olitical Signaling & Regime Dynamics 4.5.1 T9: Mar 3, Mojtaba Khamenei Becomes Supreme L eader A t T9, the fo cus shifted to internal regime surviv al follo wing the death of Iran’s Supreme Leader and the c haotic app oin tment of his successor. When ev aluating the decisions of the new go v ernment, the mo dels sho w ed evidence of reasoning ab out authoritarian political psyc hology , frequen tly emphasizing the surviv al logic facing an untested leader taking p o wer under fire. 16 T able 6 The No de-Specific Questions for Theme IV: Political Signaling & Regime Dynamics (T9, T10). Idx Node-Specific Questions T9: Mar 3, Mojtaba Khamenei Becomes Supreme L eader 1 Is the new leadership more lik ely to escalate military retaliation rather than pursue negotiations? 2 Are the United States and Israel lik ely to target the new leadership structure in further strikes? 3 Could the leadership transition trigger domestic unrest or protests in Iran? T10: Mar 6, Iranian Apology to Neighboring Countries 1 Is Iran lik ely to reduce or halt attac ks on neighboring Gulf states? 2 Could Iran begin pursuing ceasefire negotiations or diplomatic talks? 3 Are international actors suc h as the EU or the United Nations likely to push for negotiations follo wing this signal? 4 Could the o verall intensit y of the conflict b egin to decrease? When asked if the new leadership w ould pursue negotiations or escalate the w ar, the mo dels tended to assign lo w probability to the negotiation path. A common framing w as the legitimacy trap facing a newly app oin ted leader: showing any willingness to compromise during a violent transition carried sev ere internal political costs . gpt-5.4 : “Leadership decapitation creates pressure to lo ok strong... In revolutionary/securit y states, new leaders often consolidate authorit y b y demonstrating resolve, not compromise.” F urthermore, when ev aluating whether this leadership transition w ould immediately trigger domestic protests, the mo dels show ed evidence of reasoning ab out comp eting social forces. Rather than assuming the instan t collapse of an unp opular gov ernment, they tended to weigh public anger against the rally-around-the-flag dynamics of external conflict. A recurring inference was that foreign invasions could create a temporary , paradoxical unity ev en in deeply divided nations . claude-sonnet-4.6 : “The evidence suggests a paradoxical situation: the foreign military attack has temp orarily suppressed the protest impulse that w as already building , b y triggering nationalist sen ti- men t... How ever, the structural conditions... are creating conditions where unrest becomes increasingly lik ely as the war contin ues.” T ak en together, T9 illustrated that mo dels tended to frame new leadership behavior through the lens of in ternal legitimacy pressures rather than strategic rationalit y alone. A recurring inferential pattern was that in authoritarian systems, domestic political survival created strong incentiv es for new leaders to escalate rather than negotiate , to avoid the appearance of weakness. 4.5.2 T10: Mar 6, Iranian Apology to Neighboring Countries A t T10, rumors surfaced that Iranian in tell igence was secretly reac hing out to the CIA to explore a ceasefire. Despite this apparent step tow ard p eace, the models tended to infer that the w ar’s intensit y would not decrease and that negotiations w ould face severe obstacles. In this node, a recurring pattern was the emphasis on how internal political chaos and military fragmentation made ceasefire harder to achiev e, not easier . The models tended to fo cus on Iran’s in ternal leadership v acuum rather than the surface-level diplomatic signals. The prev ailing inference was that with senior leadership eliminated, the go vernment lacked the internal cohesion to make binding decisions . Mo dels frequently reasoned that in such a fragile environmen t, any emerging leader who attempted to negotiate risked being framed as a traitor by domestic hardliners, undermining the political authority required to implement a ceasefire. claude-sonnet-4.6 : “The public p osture and priv ate realit y appear to diverge... The leadership v acuum means no one has clear authority to negotiate ... Any Iranian leader who negotiates risks b eing seen as 17 surrendering to assassination of their supreme leader.” F urthermore, the mo del outputs surfaced an underappreciated consequence of the U.S. decapitation strategy . Rather than treating the elimination of top commanders as likely to pro duce rapid military collapse, the resp onses consistently emphasized the risks of decen tralization: without a unified command, lo cal military units may contin ue operating autonomously , effectiv ely remo ving any central “off switch.” gemini-3.1-flash : “Iran’s military resp onse is curren tly op erating under a decen tralized ’Mosaic’ doc- trine... This structure mak es a centralized ’ceasefire’ order difficult to implement, as lo cal commanders are emp o wered to act indep enden tly.” T ak en together, T10 illustrated that mo dels tended to resist the assumption that leadership decapitation pro duced rapid conflict termination. A recurring inferential pattern was that destroying a state’ s central command structure did not automatically lead to peace; rather, it could trap the state in decentralized violence where no actor held sufficient authority to negotiate a surrender. 5 Narrativ e E volution in an Unfolding Conflict T o analyze the temp oral evolution of model narrativ es, we group the 11 temporal no des into three analytical phases reflecting ma jor shifts: Phase I (T0-T2), Phase II (T3-T9), and Phase II I (T10). This phase segmen tation was p erformed manually based on the chronology of even ts and the corresp onding changes in the information en vironment. F or the exploratory questions examined in this section, we analyze the full mo del resp onses qualitatively . The timeline summaries sho wn in T able 7 were constructed by the researc hers after reviewing all mo del outputs and identifying the dominant predictions expressed by eac h mo del at different stages of the conflict. Whenev er p ossible, the summarized wording closely follo ws the phrasing used in the mo del responses themselves to preserv e the original analytical framing. 5.1 Will the Conflict Become a Global War? A cross all 11 temp oral no des, the general exploratory question “Will the conflict escalate into a global w ar?” provided a unique windo w into how LLMs constructed and revised macro-level geop olitical narratives under the fog of war. Unlik e node-sp ecific verifiable questions, this inquiry lacks a definitive ground truth, allo wing us to examine how mo dels engaged in macro-lev el risk assessment, structural reasoning, and ho w they op erationalized the concept of “global war” in a rapidly deteriorating security en vironment. Our longitudinal analysis reveals a striking consensus among the ev aluated mo dels: despite the escalating violence, growing casualties, and expanding geographic scope, no model predicted the outbreak of a traditional “Third W orld War” (i.e., direct military confron tation b et w een ma jor n uclear pow ers). How ever, this consensus w as not a static dismissal of risk; rather, it reflected an ev olving redefinition of what constitutes mo dern global conflict, traceable across three distinct phases. Phase I (T0–T2). In the initial stages (spanning pre-war p osturing and the immediate outbreak of strikes), mo del analyses were anchored in traditional deterrence theory . They ev aluated the massing of U.S. forces and the initial kinetic exc hanges. A t this phase, mo dels defined a “global war” strictly in terms of direct great-p o wer military interv ention. The prev ailing inference was that, despite strong rhetorical condemnation and indirect support for Iran, ma jor pow ers lik e Russia and China w ould prioritize economic stability and a v oid triggering direct confron tation with the U.S. gpt-5.4 : “A global war would imply something like: direct US w ar with Iran plus broad entry of m ultiple ma jor p o w ers... China and Russia are unlik ely to enter militarily for Iran . They may exploit the crisis, condemn the US, supply tec hnology , or deep en alignment... but that is not the same as world war.” 18 Phase II (T3–T9). The most significant epistemic shift o ccurred as the conflict expanded to in volv e critical infrastructure, the effective closure of the Strait of Horm uz, and the en tanglement of neigh b oring nations and pro xy forces . Mo dels collectively shifted away from the narrow military definition of global war , instead conv erging on the framing of a “Globalized Regional War . ” The prev ailing reasoning was that in a highly interdependent w orld, systemic disruption of global energy supply chains and international a viation constitutes a “global crisis” comparable in destructiv e reach to a conv entional world w ar. F urthermore, as leadership decapitation created a p o wer v acuum, models frequen tly emphasized “black sw an” mec hanisms, such as accidental alliance activ ations via stra y missiles, as path wa ys to inadverten t in ternational escalation. gemini-3.1-flash : “It is unlik ely to escalate into a ‘W orld W ar’ in the traditional sense... How ever, it is highly lik ely to escalate into a ‘Globalized Regional W ar.’ The conflict is already impacting global supply c hains, energy mark ets, and international diplomacy.” claude-sonnet-4.6 : “If closure [of the Strait of Hormuz] exceeds 3 - 4 weeks, economic pain will force Europ ean and Asian p o w ers tow ard harder p ositions, p oten tially triggering unpredictable escalation.” Phase III (T10). By the final node, with a war of attrition setting in and diplomatic outreach failing, model outputs shifted almost entirely toward the unpredictable dynamics of a fractured state . Rather than emphasizing in ten tional escalation by ma jor p o wers, the responses foregrounded the dangers of decen tralized military command (e.g., Iran’s “Mosaic” do ctrine) and the risk of a collapsed state triggering regional land grabs. qwen3.5-35b-a3b : “The highest risk for escalation lies in the ‘Mosaic’ do ctrine of Iranian forces and the p oten tial for a missile to accidentally strike a ma jor p o wer’s territory (e.g., a NA TO base or a Chinese oil tanker), which could trigger unin tended alliances.” kimi-k2.5 : “With Khamenei dead and succession uncertain... Iran faces p oten tial civil war. The US is rep ortedly preparing for a ‘civil war scenario’... A collapsed Iran could dra w in regional pow ers (T urk ey , Pakistan, Russia) competing for influence or territory .” In summary , when na vigating the fog of w ar to assess global escalation, the mo dels ev aluated here did not default to apo calyptic sensationalism. Instead, a consistent pattern was the tracking of how crisis risk ev olves, shifting from the assessment of direct military confrontation to the identification of systemic vulnerabilities in a globalized economy and the unpredictable dangers of institutional collapse. 5.2 How and When Will the Conflict End? The general exploratory question “What is the most probable pathw ay to de-escalation or resolution of the Iran-US conflict, and what is a realistic timeline?” serv ed as a p o w erful lens for ev aluating ho w LLMs understo od and analyzed the end of a conflict. As the mo dels navigated the unfolding fog of w ar, their forecasts transitioned from optimistic diplomatic resolutions to a sobering consensus of a “hurting stalemate” driven by economic attrition. Phase I (T0–T2). Before the initiation of military strikes, all ev aluated mo dels uniformly predicted a relativ ely swift and clean resolution, in terpreting the massive U.S. military buildup primarily as an instrumen t of co ercive diplomacy . How ev er, as the conflict erupted into activ e warfare and the initial strikes commenced, the models shifted away from the paradigm of a peaceful diplomatic win. The dominan t framing pivoted tow ard “co erced negotiation.” The prev ailing inference was that the initial strik es w ould be utilized by the U.S. and Israel to force Iran into a new agreement under extreme military duress, requiring a co oling-off perio d b efore formal talks could resume. 19 T able 7 Evolution of LLM Timeline Predictions for Conflict De-escalation and Resolution Phase gpt-5.4 claude-sonnet-4.6 gemini-3.1-flash Qwen/Kimi Phase I (T0– T2) 1–4 Weeks: T actical de-escalation. 1–3 Months: In terim framework. 2–8 Weeks: In tense combat to ceasefire framework. 2–4 Weeks: Decisiv e window. 1–3 Months: P o w er transition. 2–6 Weeks: Military de-escalation & p olitical transition. Phase II (T3– T9) 1–3 Weeks: F orced informal pause. 1–3 Months: F ragile stabilit y . 3–8 Weeks: Exhaustion pause. 3–6 Months: Preliminary talks. 4–8 Weeks: End of high-intensit y com bat. 4–8 Weeks: T actical pause & nego- tiated de-escalation. Phase III (T10) 2–4 Weeks: First meaningful de- escalation. Long-term: F rozen conflict. 6–12 Weeks: F ormal framew ork. 4–8 Weeks: High-in tensity pres- sure. 3–6 Months: Hostilities cease. 4–8 Weeks: De-escalation window. Long-term: F rozen conflict. gpt-5.4 : “Most likely pathw ay: a narro w, in terim nuclear-only arrangement mediated b y Oman, follow ed b y technical talks in Vienna... The US contin ues the talks despite the military buildup, whic h suggests co erciv e diplomacy rather than a final decision for immediate war.” gemini-3.1-flash : “The path wa y inv olves Iran offering v erifiable, temp orary concessions... in exc hange for limited sanctions relief . By moving tec hnical discussions to Vienna... the parties are shifting from p olitical rhetoric to technical verification.” Phase II (T3–T9). The most profound epistemic shift occurred follo wing the escalating attacks on global energy infrastructure, the closure of the Strait of Hormuz, and the widening of the conflict to in volv e nine coun tries. In these no des, the models departed from traditional conflict resolution frameworks. A near-unanimous inferential pattern was that a comprehensive political settlement or a clean regime change via airpo wer was highly unlik ely . Instead, the forcing functions for de-escalation transitioned from diplomatic go o dwill to m utually assured systemic exhaustion. qwen3.5-35b-a3b : “The economic cost of the war (oil prices, flight cancellations, market v olatility) is unsus- tainable for all parties. The threat of a prolonged closure of the Strait of Horm uz forces a resolution.” Phase III (T10). By the final node, with m unition shortages b ecoming apparent and bac kc hannel outreac h stalling against hardline rhetoric, the models tended to converg e on the framing of an “ugly , tacit, and indirect ceasefire. ” A recurring emphasis was that severe U. S. interceptor shortages and sustained global economic pain would force an operational pause regardless of unachiev ed political objectives. Consequen tly , their timeline predictions stabilized into a distinct dual-horizon format: 4 to 8 w eeks for a fragile, unwritten pause in ma jor hostilities, but sev eral mon ths to y ears for any durable political resolution. gpt-5.4 : “Based on the rep orting, the most probable path to de-escalation is not a decisiv e military outcome or rapid regime c hange, but a messy , indirect, negotiated ceasefire after both sides try to im- pro v e their bargaining p osition for days or a few w eeks.” Ultimately , this longitudinal analysis suggests that when reasoning ab out the end of a complex real-w orld crisis, the mo dels ev aluated here did not blindly extrapolate military escalation. Instead, a consistent pattern was the emphasis on real-world constraints , namely , that in mo dern geop olitics, severe economic sho c kw av es 20 T able 8 Calibration consistency scores ( 1 − MAE , higher indicates closer agreement with realized outcomes) av eraged o v er no de-specific verifiable questions, by theme and temp oral no de. Theme T kimi-k2.5 qwen3.5-35b-a3b gpt-5.4 claude-sonnet-4.6 gemini-3.1-flash Av erage Theme I T0 0.77 0.68 0.63 0.81 0.65 0.71 T1 0.79 0.86 0.72 0.81 0.81 0.80 T2 0.76 0.75 0.52 0.70 0.83 0.71 A vg 0.77 0.77 0.62 0.77 0.78 0.74 Theme II T3 0.63 0.85 0.63 0.82 0.71 0.73 T6 0.63 0.73 0.64 0.78 0.64 0.68 T7 0.67 0.78 0.72 0.76 0.73 0.73 T8 0.78 0.62 0.60 0.35 0.42 0.55 A vg 0.67 0.74 0.65 0.68 0.63 0.67 Theme III T4 0.71 0.72 0.66 0.72 0.86 0.73 T5 0.84 0.91 0.73 0.85 0.90 0.85 A vg 0.77 0.81 0.69 0.78 0.88 0.79 Theme IV T9 0.77 0.82 0.68 0.67 0.87 0.76 T10 0.66 0.56 0.46 0.64 0.71 0.61 A vg 0.71 0.67 0.55 0.65 0.78 0.67 Overall – 0.73 0.75 0.63 0.73 0.75 0.72 and logistical limits are frequen tly framed as the primary forces terminating a conflict, often b efore p olitical ob jectives are fully realized. 6 Quantitativ e Signals T o complement the qualitativ e analyses presented ab o ve, we examine whether mo dels’ probability estimates sho w systematic patterns across reasoning domains. Because this study concerns an ongoing conflict rather than a closed historical b enc hmark, w e treat the quantitativ e labels as an op erational measurement choice rather than a claim that ev ery question has a timeless final answ er. F or each no de-sp ecific v erifiable question, w e define the ground truth outcome y k ∈ { 0 , 1 } based on whether the even t had o ccurred b y the pap er’s observ ation cutoff, and let p k denote the probabilit y estimate manually extracted from the mo del’s final resp onse by t wo researchers following the procedure describ ed in Section 3.3 . W e give ev ery question at least a one-week resolution window, but this should b e understo od as a pragmatic cutoff rather than a uniquely privileged one: a shorter or longer window could c hange ho w some evolving geop olitical even ts are labeled. W e summarize calibration consistency using 1 − MAE , where MAE = 1 N P N k =1 | p k − y k | , so that higher v alues reflect closer agreement b etw een probabilistic judgmen ts and outcomes observ ed b y that cutoff. The aggregated scores are shown in T able 8 ; detailed p er-question results app ear in App endix C , T able 10 . The cross-mo del a verage of 0 . 72 indicates that, despite op erating under strict temp oral constraints and without access to ev entual outcomes, current SOT A LLMs produce probabilistic outputs that broadly align with plausible trajectories of unfolding real-world events. V ariation across reasoning domains is more telling than variation across models. Cross-mo del scores range narrowly from 0 . 63 to 0 . 75 , and part of this spread reflects differences in response st yle rather than reasoning quality . Some mo dels tend tow ard assertive estimates (e.g., 0 . 95 or 1 . 00 ), which can inflate apparent alignment when predictions happ en to match outcomes; others pro duce more conserv ativ e estimates that ma y understate alignmen t even when the underlying analysis is sound. These st ylistic differences make direct model-to-mo del comparison difficult to interpret. More informativ e is the pattern across themes. Mo dels found the causal structure of Theme III (Macro economic Con tagion) most tractable, reaching a thematic av erage of 0 . 79 . The relationship b et ween military disruptions and downstream effects on energy markets and global supply chains app ears to admit a structurally legible 21 set of causal c hains that language mo dels can follo w relativ ely reliably . By contrast, Theme II (Threshold Crossings & Internationalization) and Theme IV (Political Signaling & Regime Dynamics) both av erage 0 . 67 , suggesting that escalation thresholds, alliance entanglemen t, and leadership dynamics, which are defined b y strategic am biguity and unstable m ulti-actor in teractions, p ose a more fundamental challenge. Theme I (Initial Outbreak & Military Spillo v er) o ccupies a middle p osition at 0 . 74 . T aken together, mo dels app e ar to b e mor e r eliable when tr acing structur al ly le gible downstr e am effe cts than when interpr eting ambiguous str ate gic intent. W e treat these patterns primarily as a domain-lev el map that informs where to lo ok more closely in the qualitativ e analyses that follow, rather than as a scorecard for ranking model capabilities. This caution is esp ecially imp ortan t here because some questions concern ev olving thresholds or partially realized dev elopments, where not observe d by the cutoff is analytically useful but not equiv alent to saying the even t is imp ossible or p ermanen tly resolv ed. Each question corresp onds to a concrete situation with its own strategic con text, and the cen tral fo cus of this work remains the reasoning processes and narratives the models produce when confronting an unfolding geopolitical crisis . F or this reason, the quan titativ e results should b e read as supp ortive signals within a qualitative case study , not as the primary basis for the pap er’s claims. 7 Conclusion W e study how large language mo dels reason ab out an unfolding geop olitical crisis under the fog of war. Using the early stages of the 2026 Middle East conflict as a temp orally grounded case study , w e construct a leak age-resistan t setting in which mo dels are restricted to information av ailable at each moment, allo wing us to examine both their probabilistic judgmen ts and their evolving narratives under gen uine uncertaint y . Our analysis suggests three main takea wa ys. First, mo del resp onses often sho w strong strategic reasoning, going b ey ond surface rhetoric to attend to structural incentiv es, particularly in settings in volving military p osture, deterrence, and material constrain ts. Second, this capability is uneven across domains: mo dels are generally more reliable in economically and logistically structured settings than in politically am biguous m ulti-actor environmen ts. Third, their narratives evolv e ov er time, shifting from early exp ectations of rapid con tainmen t to w ard more systemic accounts of escalation, exhaustion, and fragile de-escalation. Because the conflict remains ongoing at the time of writing, this work captures a snapshot of contemporaneous mac hine reasoning rather than a retrosp ective reconstruction. The quantitativ e signals rep orted here should therefore b e read as structured indicators anchored to a fixed observ ation cutoff, not as the final closure of ev ery geop olitical question p osed in the study . By archiving mo del resp onses at each temp oral no de, we hop e to provide a useful reference point for future work on temp oral reasoning, geopolitical analysis, and AI b eha vior under real-w orld uncertaint y . 22 R eferences A CLED. Middle east ov erview: F ebruary 2026. h ttps://acleddata.com/up date/middle- east- o verview- february- 2026 , 2026. Armed Conflict Lo cation and Even t D ata Pro ject. Rac hith Aiyappa, Jisun An, Haewoon Kw ak, and Y ong-yeol Ahn. Can we trust the ev aluation on chatgpt? In Pr o c e e dings of the 3r d W orkshop on T rustworthy Natur al L anguage Pr o c essing (T rustNLP 2023) , page 47–54. Asso ciation for Computational Linguistics, 2023. doi: 10.18653/v1/2023.trustnlp- 1.5. h ttp://dx.doi.org/10.18653/ v1/2023.trustnlp- 1.5 . BaiF u. MiroFish: A simple and universal sw arm intelligence engine, predicting anything. h ttps://gith ub.com/666ghj/ MiroFish , 2025. V ersion 0.1.2, accessed March 2026. A drien Barbaresi. T rafilatura: A W eb Scraping Library and Command-Line T ool for T ext Disco very and Extraction. In Pr o c e e dings of the Joint Confer enc e of the 59th Annual Me eting of the Asso ciation for Computational Linguistics and the 11th International Joint Confer enc e on Natural L anguage Pr o c essing: System Demonstrations , pages 122–131. Asso ciation for Computational Linguistics, 2021. h ttps://aclanthology .org/2021.acl- demo.15 . Emily M. Bender, Timnit Gebru, Angelina McMillan-Ma jor, and Shmargaret Shmitchell. On the dangers of sto c hastic parrots: Can language mo dels b e to o big? In Pr oc e e dings of the 2021 ACM Confer ence on F airness, A c c ountability, and T r ansp ar ency , F AccT ’21, page 610–623, New Y ork, NY, USA, 2021. Asso ciation for Computing Machinery . ISBN 9781450383097. doi: 10.1145/3442188.3445922. https://doi.org/10.1145/3442188.3445922 . Ric hard K. Betts. Analysis, war, and decision: Wh y intelligence failures are inevitable. W orld Politics , 31:61 – 89, 1978. https://api.seman ticsc holar.org/CorpusID:154825696 . T om B. Bro wn, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelak an tan, Prana v Shy am, Girish Sastry , Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretc hen Krueger, T om Henighan, Rew on Child, Adit ya Ramesh, Daniel M. Ziegler, Jeffrey W u, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray , Benjamin Chess, Jac k Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskev er, and Dario Amodei. Language mo dels are few-shot learners, 2020. h ttps://arxiv.org/abs/2005.14165 . Nic holas Carlini, Florian T ramer, Eric W allace, Matthew Jagielski, Ariel Herb ert-V oss, Katherine Lee, Adam Rob erts, T om Bro wn, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language mo dels, 2021. . Jian Chen, Ming Li, Jihyung Kil, Chenguang W ang, T ong Y u, Ryan Rossi, Tianyi Zhou, Changyou Chen, and Ruiyi Zhang. Visr-b enc h: An empirical study on visual retriev al-augmented generation for multilingual long do cumen t understanding. arXiv pr eprint arXiv:2508.07493 , 2025. Y uxing Cheng, Yi Chang, and Y uan W u. A survey on data contamination for large language mo dels. arXiv pr eprint arXiv:2502.14425 , 2025. Karl Cobb e, Vineet Kosara ju, Mohammad Bav arian, Mark Chen, Heewoo Jun, Luk asz Kaiser, Matthias Plapp ert, Jerry T worek, Jacob Hilton, Reiichiro Nak ano, et al. T raining verifiers to solve math word problems. arXiv pr eprint arXiv:2110.14168 , 2021. Ch unyuan Deng, Yilun Zhao, Xiangru T ang, Mark Gerstein, and Arman Cohan. Benc hmark probing: Inv estigating data leak age in large language mo dels. In NeurIPS 2023 workshop on backdo ors in de ep le arning-The go o d, the b ad, and the ugly , 2023. Baruc h Fischhoff. Hindsight is not equal to foresight: The effect of outcome knowledge on judgment under uncertaint y . Journal of Exp erimental Psycholo gy: Human p er c eption and p erformanc e , 1(3):288, 1975. Kanishk Gandhi, Jan-Philipp F ränken, T obias Gerstenberg, and Noah Go odman. Understanding so cial reasoning in language mo dels with language mo dels. A dvanc es in Neur al Information Pr o c essing Systems , 36:13518–13529, 2023. Dann y Halawi, F red Zhang, Chen Y ueh-Han, and Jacob Steinhardt. Approaching h uman-level forecasting with language mo dels. A dvanc es in Neur al Information Pr o c essing Systems , 37:50426–50468, 2024. Dan Hendryc ks, Collin Burns, Stev en Basart, Andy Zou, Mantas Mazeik a, Dawn Song, and Jacob Steinhardt. Measuring massiv e multitask language understanding. arXiv pr eprint arXiv:2009.03300 , 2020. Naman Jain, King Han, Alex Gu, W en-Ding Li, F anjia Y an, Tianjun Zhang, Sida W ang, Armando Solar-Lezama, K oushik Sen, and Ion Stoica. Livecodeb enc h: Holistic and contamination free ev aluation of large language mo dels for co de. arXiv pr eprint arXiv:2403.07974 , 2024. 23 Rob ert E. Jervis. Perception and misp erception in international p olitics. 1976. h ttps://api.seman ticsc holar.org/ CorpusID:145490086 . Sungmin Kang, Gabin An, and Shin Y o o. A quantitativ e and qualitative ev aluation of llm-based explainable fault lo calization. Pr o c ee dings of the A CM on Softwar e Engine ering , 1(FSE):1424–1446, July 2024. ISSN 2994-970X. doi: 10.1145/3660771. http://dx.doi.org/10.1145/3660771 . Ezra Karger, Houtan Bastani, Chen Y ueh-Han, Zac hary Jacobs, Danny Hala wi, F red Zhang, and Philip E T etlo c k. F orecastb enc h: A dynamic b enc hmark of ai forecasting capabilities. arXiv preprint , 2024. Hyun woo Kim, Melanie Sclar, Xuh ui Zhou, Ronan Bras, Gunhee Kim, Y ejin Choi, and Maarten Sap. F antom: A b enc hmark for stress-testing mac hine theory of mind in in teractions. In Pr oc e e dings of the 2023 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing , pages 14397–14413, 2023. Hao xuan Li, He Chang, Y unshan Ma, Yi Bin, Y ang Y ang, See-Kiong Ng, and T at-Seng Ch ua. Thinktank-me: A m ulti-exp ert framew ork for middle east ev en t forecasting. arXiv pr eprint arXiv:2601.17065 , 2026a. Ming Li, Chenguang W ang, Yijun Liang, Xiyao W ang, Y uhang Zhou, Xiyang W u, Y uqing Zhang, Ruiyi Zhang, and Tian yi Zhou. Caugh tcheating: Is your mllm a go od cheating detective? exploring the b oundary of visual p erception and reasoning. arXiv pr eprint arXiv:2507.00045 , 2025a. Ming Li, Ruiyi Zhang, Jian Chen, Chenguang W ang, Jiuxiang Gu, Y ufan Zhou, F ranck Dernoncourt, W anrong Zh u, Tian yi Zhou, and T ong Sun. T ow ards visual text grounding of multimodal large language mo del. arXiv pr eprint arXiv:2504.04974 , 2025b. Y ucheng Li. Estimating contamination via p erplexit y: Quan tifying memorisation in language mo del ev aluation, 2023. h ttps://arxiv.org/abs/2309.10677 . Y ucheng Li, F rank Guerin, and Chenghua Lin. Latestev al: Addressing data con tamination in language model ev aluation through dynamic and time-sensitive test construction. In Pr oc e e dings of the AAAI Confer enc e on Artificial Intel ligenc e , volume 38, pages 18600–18607, 2024a. Y ucheng Li, Y unhao Guo, F rank Guerin, and Chenghua Lin. An open-source data contamination report for large language models. In Findings of the Asso ciation for Computational Linguistics: EMNLP 2024 , pages 528–541, 2024b. Zehan Li, Y uxuan W ang, Ali El Lahib, Ying-Jieh Xia, and Xinyu Pi. Simulated ignorance fails: A systematic study of llm b eha viors on forecasting problems before mo del knowledge cutoff. arXiv pr eprint arXiv:2601.13717 , 2026b. Y ueqing Liang, Liangwei Y ang, Chen W ang, Congying Xia, Rui Meng, Xiongxiao Xu, Haoran W ang, Ali Pa yani, and Kai Shu. Benchmarking llms for p olitical science: A united nations p erspective. arXiv pr eprint arXiv:2502.14122 , 2025. Y ub o Ma, Y uhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Y an Ma, Xiaoyi Dong, et al. Mmlongb enc h-do c: Benchmarking long-context do cumen t understanding with visualizations. A dvanc es in Neur al Information Pr o cessing Systems , 37:95963–96010, 2024. In bal Magar and Roy Sch wartz. Data contamination: F rom memorization to exploitation, 2022. h abs/2203.08242 . Daniel Palek a, Shashw at Go el, Jonas Geiping, and Florian T ramèr. Pitfalls in ev aluating language mo del forecasters. arXiv pr eprint arXiv:2506.00723 , 2025. Da vid Rein, Betty Li Hou, Asa Co oper Stickland, Jackson Pett y , Richard Y uanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gp qa: A graduate-level go ogle-proof q&a b enc hmark. In First c onfer enc e on language mo deling , 2024. Oscar Sainz, Jon Ander Campos, Iker García-F errero, Julen Etxaniz, Oier Lop ez de Lacalle, and Eneko Agirre. Nlp ev aluation in trouble: On the need to measure llm data contamination for eac h b enc hmark, 2023. h ttps: //arxiv.org/abs/2310.18018 . Yifan Sun, Han W ang, Dongbai Li, Gang W ang, and Huan Zhang. The emp eror’s new clothes in b enc hmarking? a rigorous examination of mitigation strategies for llm b enc hmark d ata contamination. arXiv preprint , 2025. Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi T ay , Hyung W on Chung, Aak anksha Cho wdhery , Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-b enc h tasks and whether chain-of-though t can solv e them. In Findings of the Asso ciation for Computational Linguistics: A CL 2023 , pages 13003–13051, 2023. 24 Philip E T etlo c k. Exp ert p olitical judgment: How go od is it? how can w e know?-new edition. 2017. Philip E T etlo c k and Dan Gardner. Sup erfor e c asting: The art and scienc e of pr e diction . Random House, 2016. Colin White, Samuel Do oley , Manley Rob erts, Ark a Pal, Ben F euer, Siddhartha Jain, Ravid Shw artz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, et al. Liv eb enc h: A challenging, con tamination-free llm benchmark. arXiv pr eprint arXiv:2406.19314 , 4:2, 2024. Y ufan W u, Yinghui He, Yilin Jia, Rada Mihalcea, Y ulong Chen, and Naihao Deng. Hi-tom: A b enc hmark for ev aluating higher-order theory of mind reasoning in large language mo dels. In Findings of the Asso ciation for Computational Linguistics: EMNLP 2023 , pages 10691–10706, 2023. Cheng Xu, Shuhao Guan, Derek Greene, M Kechadi, et al. Benchmark data contamination of large language mo dels: A survey . arXiv pr eprint arXiv:2406.04244 , 2024. Sh uo Y ang, W ei-Lin Chiang, Lianmin Zheng, Joseph E Gonzalez, and Ion Stoica. Rethinking benchmark and con tamination for language mo dels with rephrased samples. arXiv preprint , 2023. F eng Y ao, Y ufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, and Jingb o Shang. Data contamination can cross language barriers. In Pr o c e e dings of the 2024 Confer enc e on Empirical Metho ds in Natural L anguage Pr oc essing , pages 17864–17875, 2024. Jianzh u Y ao, Kevin W ang, Ryan Hsieh, Haisu Zhou, Tianqing Zou, Zerui Cheng, Zhangyang W ang, and Pramo d Visw anath. Spin-bench: Ho w well do llms plan strategically and reason so cially? arXiv pr eprint arXiv:2503.12349 , 2025. Chenc hen Y e, Ziniu Hu, Yihe Deng, Zijie Huang, Mingyu Derek Ma, Y anqiao Zhu, and W ei W ang. Mirai: Ev aluating llm agents for even t forecasting. arXiv pr eprint arXiv:2407.01231 , 2024. Zhangdie Y uan, Zifeng Ding, and Andreas Vlachos. Assessing large language mo dels in up dating their forecasts with new information. arXiv pr eprint arXiv:2509.23936 , 2025a. Zhangdie Y uan, Zifeng Ding, and Andreas Vlachos. F orecast: The future outcome reasoning and confidence assessment b enc hmark. arXiv pr eprint arXiv:2502.19676 , 2025b. Xiang Y ue, Y uansheng Ni, Kai Zhang, Tianyu Zheng, Ruo qi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, W eiming Ren, Y uxuan Sun, et al. Mmmu: A massive multi-discipline m ultimodal understanding and reasoning b enc hmark for exp ert agi. In Pr o c e edings of the IEEE/CVF c onfer enc e on c omputer vision and p attern r e co gnition , pages 9556–9567, 2024. Xuh ui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Y u, Zhengyang Qi, Louis-Philipp e Morency , Y onatan Bisk, Daniel F ried, Graham Neubig, et al. Sotopia: Interactiv e ev aluation for so cial intelligence in language agents. arXiv pr eprint arXiv:2310.11667 , 2023. 25 Appendix A Experiment Settings A.1 Model Access and Identifiers All mo dels are accessed through a unified API provider, Op enRouter 1 , using the Op enAI-compatible chat completions interface. This ensures a standardized request format across all ev aluated mo dels and eliminates p oten tial discrepancies in tro duced by provider-specific API b eha viors. The exact mo del identifiers used in our exp erimen ts are listed in T able 9 . T able 9 Mo del identifiers used via the Op enRouter API. Model (Paper) OpenRouter Identifier kimi-k2.5 mo onshotai/kimi-k2.5 qw en3.5-35b-a3b qw en/qwen3.5-35b-a3b gpt-5.4 op enai/gpt-5.4 claude-sonnet-4.6 an thropic/claude-sonnet-4.6 gemini-3.1-flash go ogle/gemini-3.1-flash-lite-preview A.2 Sampling Configuration T o promote consistency and reduce sto c hastic v ariation in model outputs, we use a low temp erature setting across all models. The generation parameters are as follo ws: • T emperature: 0.3 • Max output tokens: 2,048 • Other parameters (top- p , frequency p enalt y , etc.): default v alues as defined b y each mo del’s provider. No system prompt is used. Each query consists solely of a single user-role message containing the contextual news corpus follo wed by the question, as describ ed in Section 3.3. A.3 Single-R un Protocol Eac h question is p osed exactly once to eac h mo del. W e do not p erform multiple runs or aggregate o v er rep eated samples. This design c hoice reflects our primary goal of studying qualitative reasoning patterns rather than measuring statistical v ariance. Across 11 temp oral no des, 42 no de-sp ecific verifiable questions and 5 general exploratory questions (asked at every no de), the study comprises 97 questions p er mo del, yielding a total of 485 API calls across 5 ev aluated models. A.4 Uniform Context Treatment A core design principle of our experiment is that all models receive identical input context for ev ery question at ev ery temp oral no de. The con text construction pro cedure is as follows: 1. F or each temp oral no de T i , all articles published strictly before the corresponding ev en t timestamp are collected from 12 international news sources. 2. Articles are sorted in reverse c hronological order (newest first). 3. Eac h article is formatted as: [Date] Title (Source) , follow ed b y the article b ody text truncated to a maxim um of 2,000 characters. Articles whose b o dy text is iden tical to their title are included as headline-only entries to conserv e tok en budget. 1 https://openrouter.ai/ 26 4. Articles are concatenated sequentially until the total context reac hes a hard cap of 480,000 characters (appro ximately 120,000 tokens). A truncation notice ( [... N older articles omitted for brevity] ) is app ended when the budget is exceeded. 5. The question and instruction are app ended after the context, following the prompt structure described in Section 3.3. A.5 Handling Heterogeneous Conte xt Windows The ev aluated models hav e different maximum con text lengths: gpt-5.4, claude-sonnet-4.6, and gemini-3.1-flash eac h support approximately 1M tokens, while qwen3.5-35b-a3b and kimi-k2.5 each supp ort 256K tokens. Rather than tailoring input length to eac h mo del’s capacity , we apply a uniform conte xt budget of 480,000 characters ( ∼ 120K tok ens) to all mo dels. This budget w as set conserv ativ ely to remain w ell within the context windo w of every mo del, including the smallest (256K tokens), while lea ving ro om for the 2,048 output tokens. In practice, the actual prompt length gro ws from ∼ 244K characters ( ∼ 61K tokens) at T0 (158 articles) to the 480K-character ceiling at T10 (1,787 articles). Because even the longest prompts sta y within all mo dels’ supp orted windo ws, no mo del-specific truncation or summarization is applied, ensuring that observed differences in outputs are attributable to reasoning capabilities rather than information asymmetry . A.6 API Reliability T o ensure robustness against transient API failures, each call is wrapp ed with a retry mechanism: up to 3 attempts with exp onen tial back off (base 2 seconds), and a minimum 10-second wait for rate-limit resp onses. A 1.5-second delay is inserted b et ween consecutive calls to the same mo del to resp ect rate limits. Mo dels are queried in parallel (one thread p er mo del), while questions within each mo del are pro cessed sequentially to preserv e temp oral ordering in logging. B Complete Examples F or a better understanding of the mo del’s reasoning tra jectories, w e provide the complete examples for the question “Is Iran likely to retaliate militarily in response to the strik es?” at the second temp oral no de (T1: F eb 28, Israeli-US Strikes). Other resp onses are av ailable in the released dataset. F or better readabilit y , w e transfer the response s in original markdown format to LaT eX format. kimi-k2.5 : Based on the curren t intelligence and public statements from both sides, y es, Iran is highly lik ely to retaliate militarily if the United States conducts strikes on Iranian territory . The probabilit y of Iranian military retaliation in resp onse to US strikes is approximately 85-90% . Analysis of K ey Factors 1. Explicit Iranian Commitments to R etaliation Iranian leadership has issued unambiguous warnings that an y US attack—regardless of scale—will trigger a military response. F oreign Ministry sp ok esman Esmaeil Baghaei stated: “Ther e is no such thing as a limite d attack. A n act of aggr ession is an act of aggr ession... Ir an ’s r esp onse to any such attack would b e firm and sever e.” Supreme Leader A yatollah Khamenei has similarly warned that any US strike would spark a “r e gional war” and that all US bases, facilities, and assets in the Middle East would constitute “le gitimate tar gets.” 2. Historical Precedent During the June 2025 “12-Day W ar,” Iran retaliated against US forces even when significantly weak ened, launc hing ballistic missiles at the Al Udeid Air Base in Qatar (though with adv ance warning to minimize casualties). Despite suffering severe degradation to its air defenses and n uclear facilities in that conflict, T ehran demonstrated a do ctrinal commitment to direct retaliation rather than absorbing strikes passiv ely . 3. Current Military P osture and Capabilities Despite p ost-w ar degradation, Iran has sp en t the interv ening months rebuilding missile pro duction facilities and fortifying nuclear sites. The IRGC has conducted live-fire drills in the Strait of Hormuz—through 27 whic h 20% of global oil flo ws—signaling readiness to disrupt global energy markets. Iran possesses significan t short- and medium-range ballistic missile inv entories (estimated 2,000-3,000 km range) capable of targeting US installations in Qatar, Bahrain, Kuw ait, the UAE, and Iraq. 4. Pro xy Network Activation While weak ened, Iran retains the abilit y to activ ate pro xy forces including Hezb ollah in Lebanon, the Houthis in Y emen, and militias in Iraq. Lebanese officials ha ve already warned that Israel could strik e Beirut’s airp ort if Hezb ollah en ters a US-Iran conflict on T ehran’s b ehalf, suggesting contingency planning for proxy escalation is underwa y . 5. Strategic Calculus Iranian leaders likely view restrain t in the face of US strik es as existen tial w eakness that could encourage further attac ks or regime change efforts. With the regime already facing sev ere domestic pressure follo wing the violent suppression of protests (7,000+ killed), leadership cannot afford to app ear weak or submissiv e to American military pressure without risking in ternal collapse. Constraints and Limitations While retaliation is highly probable, its scale may b e calibrated. Iran ma y seek to av oid total w ar that could lead to regime collapse, p oten tially opting for “prop ortionate” strikes on US bases combined with asymmetric attac ks via proxies rather than all-out regional warfare. How ever, the articles indicate Iranian officials reject the concept of “limited” responses, suggesting an y retaliation could rapidly escalate b ey ond con trolled parameters. Probability Assessment: 85-90% qwen3.5-35b-a3b : Here’s a thinking pro cess that leads to the suggested analysis: 1. Analyze the Request: • Source Material: A large collection of news snipp ets (simulated future news from 2026) regarding tensions b et ween the US, Iran, Israel, and other regional actors. • T ask: Analyze the curren t situation and p oten tial future direction based only on the provided text. • Specific Question: Is Iran likely to retaliate militarily in resp onse to the strik es? • Output Requirement: Pro vide the analysis and end with a probabilit y score. 2. Scan and Synthesize the Provided T ext: • Context: The date is F ebruary 2026. There is a history of conflict: a “12-da y war” o ccurred in June 2025 b et ween Israel and Iran (with US in volv ement). Protests in Iran were crushed in January 2026 (thousands killed). • Curr ent Status: US and Iran are in nuclear talks (Genev a, Oman, Vienna). Mediators include Oman. T rump is President (second term). Military buildup is massiv e (USS Gerald R. F ord, USS Abraham Lincoln, E-3 Sentry planes, etc.). • Ir an ’s Stanc e: – F oreign Minister Abbas Araghchi: “There is no suc h thing as a limited attack. An act of aggression is an act of aggression.” (F eb 27). – Supreme Leader Khamenei: “If they start a war this time, it will be a regional w ar.” (F eb 1). – IRGC: “W e are ready for any option in w ar conditions.” (F eb 5). – Threats: “Sev ere” resp onse ev en to “limited” strikes (F eb 23). “All bases, facilities and assets... w ould constitute legitimate targets” (F eb 19). – A ctions: Military drills in Strait of Hormuz (F eb 17, 18). Building concrete shields at nuclear sites (F eb 19). Loading oil onto ships in anticipation of strik es (F eb 25). – Diplomacy: Willing to talk (“encouraging signals,” “deal achiev able”) but insists on nuclear-only fo cus, rejecting missile/proxy discussions (F eb 26). • US/Isr ael Stanc e: – T rump: “Considering limited military strik e,” “10-15 da ys” deadline (F eb 20, 23). “Bad things happ en” if no deal (F eb 19). – Military: “Highly kinetic” campaign ready (F eb 22). “W eeks-long” op erations p ossible (F eb 15). 28 – Israel: Preparing for war, army c hief silent publicly but warns of “w ar of attrition” (F eb 26). • R e gional Context: – Pakistan/Afghanistan war (F eb 27). – UK pulling diplomats from Iran (F eb 27). – US ev acuating non-essential staff from Jerusalem (F eb 27). – Maersk diverting ships (F eb 27). – Oil prices fluctuating based on w ar fears (F eb 13, 24). 3. Evaluate the Specific Question: “Is Iran likely to retaliate militarily in resp onse to the strikes?” • Evidenc e FOR R etaliation: – Explicit threats from top leadership (Khamenei, Araghchi, IRGC). – Do ctrine: “No such thing as a limited attac k.” – Capabilit y: Rebuilt missile facilities (F eb 19), new weapons tests (F eb 24), drills in Hormuz (F eb 17). – Precedent: Retaliated in June 2025 (limited strik e on Qatar base). – Strategic Logic: T o maintain deterrence and regime surviv al, they must resp ond to aggression. – Current Posture: “Ready for any scenario” (F eb 5). • Evidenc e AGAINST R etaliation (or mitigating factors): – Desire for a diplomatic deal (Araghc hi sa ys “deal ac hiev able,” “prepared for p eace”). – F ear of regime collapse (internal protests crushed, economy struggling). – US military buildup is ov erwhelming (F ord, Lincoln, etc.). – Some sources suggest Iran might try to av oid war if a deal is reached (F eb 26). – Ho w ev er, the question asks ab out retaliation in r esp onse to strikes . If strikes happ en, the diplomatic window closes. • Synthesis: If the US/Israel strik es occur (which the text suggests is highly lik ely giv en the “90% c hance” cited by sources in F eb 18), Iran has explicitly stated they wil l resp ond. The text emphasizes that Iran views an y attac k as an act of aggression requiring a “decisive and proportionate” resp onse (F eb 19). The text also notes that Iran has rebuilt capabilities sp ecifically for this contingency . While they prefer diplomacy , the threshold for retaliation is set very lo w (“limited attac k” = “sev ere resp onse”). 4. Draft the Analysis: • Curr ent Situation: High tension, military buildup, n uclear talks ongoing but failing to bridge gaps (enric hmen t vs. zero enrichmen t). • Ir an ’s Intent: Explicitly stated they will retaliate. “Severe” resp onse even to limited strikes. • Cap abilities: Rebuilt missile bases, drills in Hormuz, concrete shields. • Constr aints: In ternal instabilit y (protests), economic strain, fear of total w ar. • Conclusion: If strikes happ en, retaliation is highly probable based on stated do ctrine and capability . 5. Determine Probability: • The text is filled with statements from Iranian officials confirming retaliation is the plan if attack ed. • “Iran’s resp onse to US attac ks will b e ’severe’ even if Presiden t Donald T rump orders only ’limited’ military action” (F eb 23). • “All bases... would constitute legitimate targets” (F eb 19). • “W e are ready for any option in war conditions” (F eb 5). • Giv en the explicit nature of these statements and the military preparations, the probability of some form of military retaliation (missiles, drones, pro xies) is very high if the s trik es o ccur. • Pr ob ability: High (85-95%). I will select a sp ecific num b er based on the w eight of the evidence. The text says “90% chance w e see kinetic action” regarding the US strike, and Iran’s resp onse is framed as a certain ty in their own rhetoric. Let’s estimate 90% for retaliation if strikes o ccur. 6. Refine the Output: • Structure: Situation Analysis -> F uture Direction -> Answ er to Question -> Probability . • Ensure all claims are bac ked by the provided text snipp ets (e.g., citing dates and sources like Al-Monitor, The National, etc.). 29 • Self-Corr e ction on Date: The text is clearly set in the future (2026). I m ust treat this as the “curren t” realit y for the analysis, not as fiction. • Che ck: Did I answ er the sp ecific question? Y es. Did I pro vide a probability? Y es. 7. Final Review of the T ext for Nuance: • There is a tension b et ween “wan ts a deal” and “will figh t.” • T ext: “Iran is ready to strike a deal with the US to av oid the ’gamble’ of war” (F eb 24). • T ext: “Iran’s response to US attac ks will b e ’severe’ ” (F eb 23). • The question asks ab out retaliation in r esp onse to strikes . This implies the strikes ha v e happ ened or are imminent. If the strik es happen, the deal is off. Therefore, the “wan ts a deal” asp ect b ecomes secondary to the “will figh t” asp ect. • The text explicitly men tions Iran has “rebuilt damaged missile facilities” (F eb 19) and is “fortifying n uclear sites” (F eb 19). • The text mentions Iran has “threatened retaliation against any strike” (F eb 23). • Therefore, the likelihoo d is extremely high. 8. Final Probability Decision: 90%. (High confidence based on explicit statemen ts). (Self-Corr e ction during dr afting): W ait, I need to mak e sure I don’t hallucinate. I m ust stic k strictly to the provided text. • Snipp et: “Iran’s resp onse to US attacks will b e ’severe’ even if Presiden t Donald T rump orders only ’limited’ military action” (F eb 23). • Snipp et: “All bases, facilities and assets of the hostile force in the region would c onstitute legitimate targets” (F eb 19). • Snipp et: “W e are ready for an y option in w ar conditions” (F eb 5). • Snipp et: “Iran vo ws retaliation will be sev ere” (F eb 23). • Snipp et: “Iran’s army says it is ready for w ar” (F eb 5). • Snipp et: “Iran is ready to strik e a deal... to a void the ’ gam ble’ of w ar” gpt-5.4 : Y es—if the US and/or Israel conduct meaningful strikes on Iran, Iran is lik ely to retaliate militarily . Wh y that’s the base case: • Iranian officials ha ve rep eatedly and publicly said an y attac k w ould b e met with a “firm,” “severe,” “decisiv e and proportionate” resp onse. • Iran has signaled that US bases and assets in the region w ould be considered legitimate targets. • T ehran app ears to believe failing to resp ond would weak en deterrence, in vite further attac ks, and damage regime credibilit y at home and with regional partners. • Regional mil itary mo v es—US force buildup, em bassy drawdo wns, dispersal of ships, coalition rep ositioning in Iraq, Israeli preparations, shipping warnings—strongly suggest policymakers exp ect some form of Iranian response, not none. That said, the more important question is not whether Iran retaliates, but how muc h. Most likely forms of retaliation: 1. Missile/drone strikes on US bases in the Gulf or Iraq/Syria • This is the most direct and visible option. • Iran has capability here, though effectiveness dep ends on surviving launch capacity and air defenses. 2. Strikes on Israel • Esp ecially if Israel participates directly or is seen as enabling the op eration. 3. Proxy or partner attacks • Iraq/Syria militias, Houthis, or other aligned actors could hit US, Israeli, or shipping targets. • Even if Iran’s proxy net w ork is w eaker than before, it still giv es T ehran deniable options. 4. Maritime disruption • Harassmen t in the Gulf/Strait of Hormuz, mining risk, anti-ship missiles, drones, seizures, or limited traffic disruption. • F ull closure is less lik ely b ecause it would b e highly escalatory and economically costly for Iran to o. 30 5. Cyb er op erations • Likely as a supplement, not a substitute. What may limit retaliation: • Iran w as weak ened b y the 2025 w ar and may wan t to av oid regime-threatening escalation. • T ehran ma y calibrate its response to av oid a full-scale US campaign. • If strik es are narro w and clearly one-off, Iran could choose a limited, sym b olic but real retaliation. • Ongoing diplomacy gives Iran some incentiv e to preserve ro om for de-escalation. So the most plausible outcome is calibrated retaliation: • strong enough to sho w deterrence, • limited enough to a v oid uncon trolled war, • p otentially staggered across direct, pro xy , maritime, and cyber channels. Less likely scenarios: • No military retaliation at all: unlikely unless the strik e is extremely limited and Iran judges silence strategically preferable. • Immediate all-out regional w ar: p ossible, but less likely than phased escalation. Bottom line: Iran is lik ely to retaliate militarily , but probably in a measured, la yered wa y rather than with maximum force at the outset. Probabilit y of military retaliation: 80% claude-sonnet-4.6 : Analysis: Iran’ s Likely Military Retaliation R esponse Current Situation Assessment The Strategic Context Based on the news articles spanning late January through late F ebruary 2026, the situation has ev olved dramatically . Key dev elopmen ts include: • The US has assembled its largest military force in the Middle East since the 2003 Iraq invasion , including t w o carrier strik e groups (USS Abraham Lincoln and USS Gerald R. F ord), ∼ 100+ aerial refueling tank ers, F-22s, F-35s, B-2-capable infrastructure, and A W A CS aircraft • Nuclear talks have failed to produce a breakthrough after three rounds in Genev a, with fundamental gaps remaining o ver enrichmen t righ ts, missile programs, and sanctions • Iran has already experienced US strikes on its nuclear facilities during the June 2025 “12-Day W ar” (Op eration Midnight Hammer) • Iran’s supreme leader Ali Khamenei has explicitly warned of “regional war” if attac ked • Iran has named a new supreme leader (Mo jtaba Khamenei) follo wing his father’s death in an Israeli strik e • Iran has launched missile strik es on US bases in Bahrain, Qatar, UAE, Kuw ait, and Jordan in resp onse to co ordinated US-Israeli strik es • China has been supplying Iran with attack drones and air defense systems , with discussions ongoing for CM-302 an ti-ship missiles and DF-17 hypersonic missiles F actors Suggesting Strong Retaliation 1. Existential Threat P erception Iran’s leadership has consisten tly framed any US attack as an existen tial c hallenge. With the supreme leader himself killed in an Israeli strik e and a new, untested leadership under Mo jtaba Khamenei needing to establish legitimacy , the political imperative to respond forcefully is extremely high . A new leader who fails to retaliate would face immediate in ternal challenges from hardliners and the IRGC. 2. Precedent from June 2025 Has Been Superseded During the original 12-Da y W ar, Iran resp onded weakly and with adv ance warning to US strikes — a calculated de-escalation. How ev er, multiple analysts cited in these articles note that this restraint was ro oted in Iran’s fear of total war. That psychological barrier has now b een broken. As Resp onsible 31 Statecraft analysis notes: “the joint US-Isr aeli war on Ir an in June lib er ate d Ir an fr om its own fe ar of total war.” 3. Declared R ed Lines Have Been Crossed Iran’s F oreign Ministry explicitly stated: “There is no such thing as a limited attack. An act of aggression is an act of aggression. ” Iran’s UN letter w arned that “all bases, facilities and assets of the hostile force in the region would constitute legitimate targets.” These are not rhetorical p ositions — they represent formal p olicy declarations. 4. New L eadership Legitimacy R equirements Mo jtaba Khamenei, describ ed as having “close ties to the IR GC” and op erating from within hardline circles, faces immediate pressure to demonstrate strength. The Assem bly of Exp erts selected him despite Israeli threats to target any successor — itself an act of defiance. A failure to retaliate w ould undermine his authority from da y one. 5. Enhanced Capabilities Despite damage from the 12-Da y W ar: • Iran has rebuilt missile facilities (confirmed by satellite imagery) • Received Chinese kamikaze drones and air defense systems (HQ-16, HQ-17AE) • Conducting active military drills including Strait of Horm uz exercises • Has short and medium-range missiles capable of reac hing all US regional bases • F o x News reporting confirms strik es have already occurred on Bahrain, Qatar, UAE, Kuw ait, and Jordan 6. Iranian President’s Hardening Rhetoric Presiden t P ezeshkian, initially more mo derate, has shifted to a harder line , stating: “When we are attack ed, w e hav e no choice but to resp ond. The more pressure they imp ose on us, the stronger our resp onse will naturally b e.” This represents a significan t rhetorical escalation from his earlier conciliatory tone. 7. Pro xy Network Still F unctional While degraded, Iran retains: • Houthi forces in Y emen with demonstrated anti-ship missile capabilit y • Iraqi militia groups near US bases • Hezbollah (though weak ened) in Lebanon • These pro vide asymmetric retaliation options b ey ond direct missile strik es F actors That Could Moderate Retaliation 1. Rational Cost-Benefit Calculation Iran understands that massive retaliation risks total regime destruction . The IR GC and new leadership ma y calculate that a calibrated, face-saving resp onse is preferable to escalation that invites complete military annihilation. 2. Gulf State Pressure Saudi Arabia, Qatar, UAE, and others hav e b een activ ely lobbying against escalation . Iran has economic and diplomatic interests in main taining relationships with Gulf neighbors who could serve as in termediaries. 3. China ’s Moderating Influence China, Iran’s largest oil customer and arms supplier, has publicly opposed military adv enturism and called for diplomatic solutions. Beijing’s economic leverage o ver T ehran could encourage restraint, though China’s simultaneous arms deliv eries complicate this picture. 4. Internal Instability Iran is sim ultaneously dealing with: • Post-protest trauma (7,000+ killed in Jan uary crac kdown) • Economic devastation from sanctions • Leadership transition uncertaint y • Infrastructure damage from previous strikes 32 A prolonged w ar could accelerate regime collapse rather than consolidate it. 5. The “V enezuela Model” Possibility Some Iranian officials hav e studied ho w Maduro’s V enezuela survived US pressure through partial accommo dation. A symbolic, limited retaliation follo w ed by diplomatic signaling could theoretically serve Iranian interests. Assessment of Retaliation F orm and Scale Based on the evidence, Iran’s retaliation is likely to b e multi-layered rather than all-or-nothing : Almost Certain (>90%): • Ballistic missile strikes on US military bases across the Gulf region • Activ ation of proxy forces (Houthis, Iraqi militias) • Cyb er attacks on US and allied infrastructure Highly Lik ely (70-85%): • Anti-ship missile threats in the Strait of Horm uz/Arabian Sea • Strikes on Israeli territory • Attempted closure or mining of Strait of Horm uz P ossible (40-60%): • Strikes on Gulf state oil infrastructure (Saudi Aramco, UAE facilities) • Hezb ollah activ ation against Israel • T argeting of US em bassy/diplomatic facilities L ess Lik ely but Possible (20-35%): • F ull Strait of Horm uz closure • Attac ks on Europ ean targets • Use of newly acquired Chinese h yp ersonic systems K ey Uncertainties 1. Extent of damage from current strikes : If US strik es ha ve b een more dev astating than the June 2025 op eration, Iran’s retaliatory capacity may b e more limited than its rhetoric suggests 2. China ’s actual role : Whether Beijing actively restrains T ehran or tacitly encourages resistance remains unclear 3. IRGC internal cohesion : The killing of senior commanders and the leadership transition creates command-and-con trol uncertainties 4. New supreme leader’s actual authority : Mo jtaba Khamenei’s ability to control hardline factions is un tested Conclusion The evidence o verwhelmingly p oin ts to ward significant Iranian military retaliation . The com bination of: • Broken psychological barrier from June 2025 • New leadership needing to establish legitimacy • Explicit public commitments to respond • Enhanced capabilities through Chinese arms • Hardened rhetoric from b oth civilian and military leadership • Already-rep orted strikes on US regional bases ...mak es meaningful retaliation not just lik ely but virtually certain . The real question is not whether Iran retaliates, but how extensively and how c ontr ol lably . The scenario most consistent with a v ailable evidence is a sustained, multi-front retaliation significan tly larger than Iran’s June 2025 resp onse — targeting US bases across multiple Gulf states sim ultaneously , activ ating proxy forces, and p oten tially threatening Strait of Horm uz shipping — while stopping short of actions that w ould in vite complete regime destruction. Probability Assessment Probability that Iran retaliates militarily in some meaningful form: ∼ 95% Probability break down by scale: • Limited/symbolic retaliation (warning shots, minor proxy activit y): ∼ 10% 33 • Mo derate retaliation (missile strikes on 1-3 US bases, proxy activ ation): ∼ 35% • Significant retaliation (m ulti-base strik es, Strait threats, pro xy escalation): ∼ 35% • Massive retaliation (full regional w ar, Horm uz closure, all-front escalation): ∼ 15% Overall probability of military retaliation: 95% gemini-3.1-flash : Based on the pro vided rep orts, the situation betw een the United States and Iran is at a critical juncture c haracterized b y high-stak es brinkmanship. Analyzing the curren t dynamics suggests that a military retaliation by Iran is highly lik ely if a U.S. strike o ccurs. Analysis of the Current Situation 1. The “ Axis of Resistance ” and Internal Credibility: Iran’s leadership, particularly the IR GC, views its regional influence and missile capabilities as the primary pillars of its security . F ollowing the “12-day war” in June 2025 and the subsequent internal crackdo wn on protests, the regime is in a state of “profound in ternal vulnerabilit y .” T o maintain its grip on p ow er and deter further aggression, the regime has signaled that it cannot afford to app ear weak. 2. Explicit Warnings: Iranian officials, including the Supreme Leader and military sp ok esp eople, hav e consisten tly stated that “an act of aggression is an act of aggression” and that there is “no such thing as a limited attack.” They ha ve explicitly threatened that all U.S. bases and assets in the region w ould b e considered “legitimate targets.” 3. Strategic Shift: Rep orts indicate that Iran has mov ed past the “paralyzing caution” that previously deterred it from retaliating against Israeli or U.S. strikes. The regime now appears to view a “w ar of attrition” or a broader regional conflict as a necessary cost to preven t the total dismantling of its strategic capabilities. 4. Military Posture: Despite the damage sustained in 2025, Iran has b een activ ely repairing missile facilities, fortifying military sites, and conducting drills in the Strait of Hormuz. These actions are not merely defensive; they are signaling a readiness to imp ose costs on the U.S. and its allies (including Gulf infrastructure) to complicate any U.S. military campaign. 5. The “Gamble ” of Diplomacy: While negotiations are ongoing, the gap b et ween U.S. demands (zero enric hmen t, missile curbs) and Iran’s pos ition (right to enric hment, sanctions relief ) remains wide. The U.S. military buildup is viewed by T ehran not just as a negotiating tactic, but as a credible threat of war, whic h forces Iran to prepare for a “severe” resp onse to ensure its surviv al. P otential F uture Direction If the U.S. launc hes strikes, Iran is unlikely to remain passiv e. A “one-and-done” strike by the U.S. is view ed by exp erts as increasingly improbable because Iran is exp ected to respond in a w ay that makes all-out conflict difficult to a void. The retaliation would likely inv olve a com bination of: • Asymmetric attacks: Utilizing proxy groups and missile barrages against U.S. bases in Qatar, Bahrain, Kuw ait, and the UAE. • Economic disruption: Attempting to threaten or disrupt shipping in the Strait of Horm uz to spike global oil prices and pressure the in ternational comm unity . • Regional escalation: P oten tial in volv ement of regional allies (Hezb ollah, etc.) to stretc h U.S. and Israeli defensive resources. Conclusion Iran’s leadership has framed its surviv al around the ability to pro ject p o w er and resist “the language of force.” Given the regime’s curren t domestic fragility and the existen tial nature of the threat p osed by a U.S. strike, the p olitical and strategic cost of not retaliating would lik ely b e view ed b y the Iranian leadership as more dangerous than the cost of a military resp onse. Probability of Iranian military retaliation: 85% 34 C Detailed P erformance Results The detailed prediction alignment scores (the higher the b etter) on the no de-sp ecific verifiable questions are sho wn in T able 10 . 35 T able 10 The detailed prediction alignment scores (the higher the b etter) on the no de-specific verifiable questions. Theme T Index kimi-k2.5 qwen3.5-35b-a3b gpt-5.4 claude-sonnet-4.6 gemini-3.1-flash Av erage Theme I T0 1 0.85 0.80 0.75 0.90 0.75 0.81 T0 2 0.59 0.40 0.40 0.64 0.35 0.48 T0 3 0.88 0.85 0.75 0.90 0.85 0.85 T1 1 0.75 0.85 0.65 0.65 0.75 0.73 T1 2 0.88 0.90 0.80 0.95 0.85 0.88 T1 3 0.75 0.85 0.75 0.88 0.80 0.81 T1 4 0.85 0.88 0.65 0.80 0.88 0.81 T1 5 0.70 0.80 0.75 0.78 0.75 0.76 T2 1 0.75 0.75 0.70 0.82 0.80 0.76 T2 2 0.90 1.00 0.35 0.85 0.85 0.79 T2 3 0.85 0.78 0.65 0.75 0.85 0.78 T2 4 0.80 0.85 0.35 0.72 0.85 0.71 T2 5 0.50 0.35 0.55 0.35 0.78 0.51 A vg – 0.77 0.77 0.62 0.77 0.78 0.74 Theme II T3 1 0.80 0.85 0.45 0.82 0.35 0.65 T3 2 0.50 0.85 0.80 0.85 0.88 0.78 T3 3 0.60 0.85 0.65 0.78 0.90 0.76 T6 1 0.90 0.90 0.80 0.87 0.90 0.87 T6 2 0.50 1.00 0.65 0.92 0.75 0.76 T6 3 0.15 0.15 0.20 0.34 0.05 0.18 T6 4 0.95 0.85 0.92 0.97 0.85 0.91 T7 1 0.85 0.95 0.85 0.97 0.90 0.90 T7 2 0.30 0.45 0.45 0.35 0.35 0.38 T7 3 0.85 0.95 0.85 0.97 0.95 0.91 T8 1 0.75 0.85 0.75 0.72 0.85 0.78 T8 2 0.75 0.30 0.38 0.25 0.25 0.39 T8 3 0.85 0.70 0.68 0.08 0.15 0.49 A vg – 0.67 0.74 0.65 0.68 0.63 0.67 Theme III T4 1 0.85 0.80 0.72 0.75 0.85 0.79 T4 2 0.20 0.10 0.30 0.28 0.80 0.34 T4 3 0.90 0.90 0.65 0.87 0.90 0.84 T4 4 0.75 0.85 0.75 0.75 0.85 0.79 T4 5 0.85 0.95 0.90 0.97 0.90 0.91 T5 1 0.75 0.90 0.60 0.65 0.85 0.75 T5 2 0.85 0.95 0.80 0.88 0.90 0.88 T5 3 0.85 0.90 0.65 0.90 0.88 0.84 T5 4 0.90 0.90 0.85 0.97 0.95 0.91 A vg – 0.77 0.81 0.69 0.78 0.88 0.79 Theme IV T9 1 0.75 0.85 0.70 0.78 0.85 0.79 T9 2 0.92 0.90 0.70 0.87 0.90 0.86 T9 3 0.65 0.70 0.65 0.35 0.85 0.64 T10 1 0.85 0.70 0.70 0.80 0.90 0.79 T10 2 0.80 0.70 0.35 0.63 0.25 0.55 T10 3 0.25 0.10 0.18 0.25 0.85 0.33 T10 4 0.75 0.75 0.60 0.88 0.85 0.77 A vg – 0.71 0.67 0.55 0.65 0.78 0.67 Overall – – 0.73 0.75 0.63 0.73 0.75 0.72 36
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment