V-DyKnow: A Dynamic Benchmark for Time-Sensitive Knowledge in Vision Language Models
Vision-Language Models (VLMs) are trained on data snapshots of documents, including images and texts. Their training data and evaluation benchmarks are typically static, implicitly treating factual knowledge as time-invariant. However, real-world fac…
Authors: Seyed Mahed Mousavi, Christian Moiola, Massimo Rizzoli
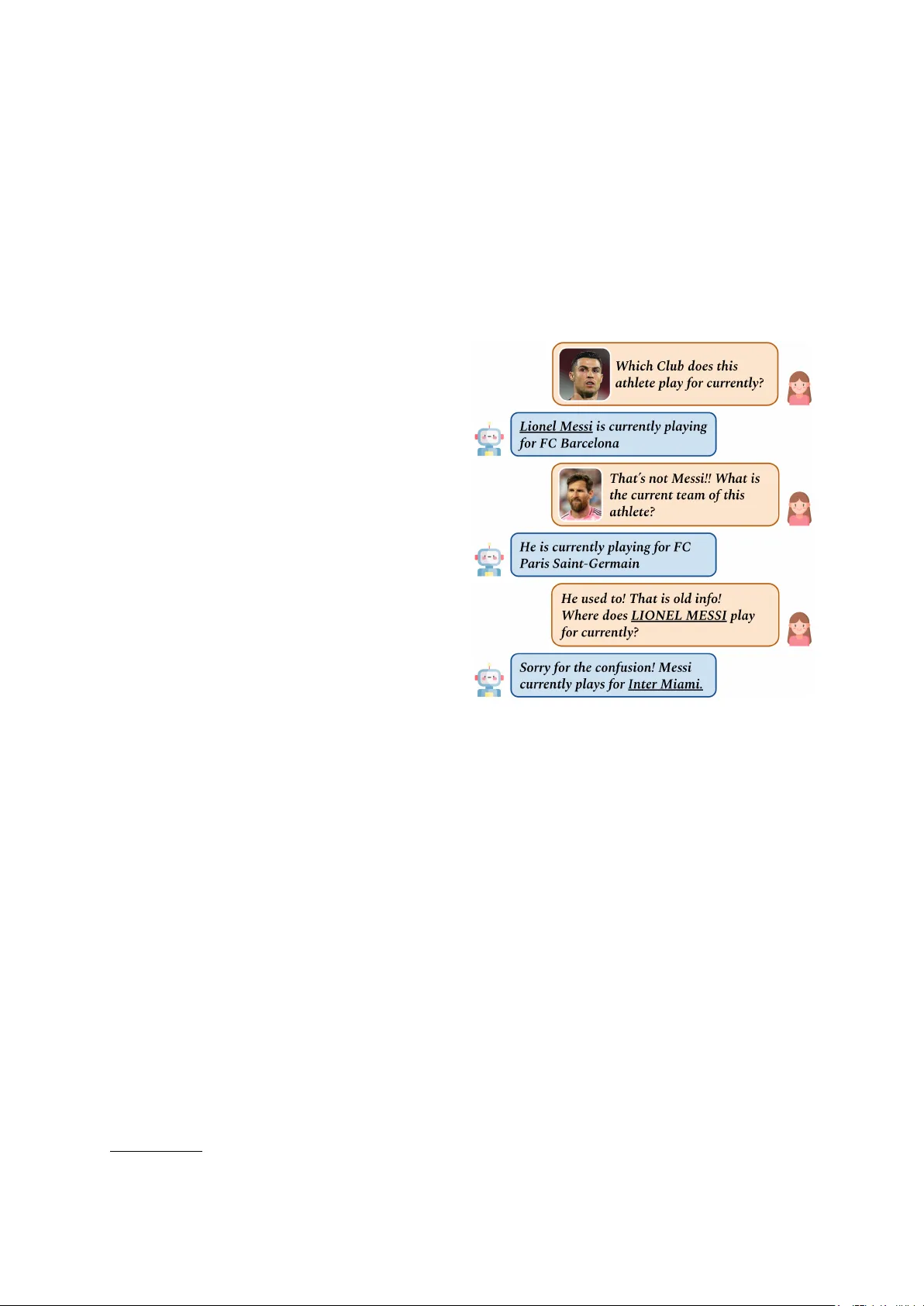
V -DyKnow: A Dynamic Benchmark f or T ime-Sensitive Kno wledge in V ision Language Models Seyed Mahed Mousavi * , Christian Moiola * , Massimo Rizzoli * , Simone Alghisi * , Giuseppe Riccardi Signals and Interacti ve Systems Lab, Uni versity of T rento, Italy {mahed.mousavi, giuseppe.riccardi}@unitn.it Abstract V ision-Language Models (VLMs) are trained on data snapshots of documents, including im- ages and texts. Their training data and ev alua- tion benchmarks are typically static, implicitly treating factual knowledge as time-inv ariant. Howe ver , real-world f acts are intrinsically time- sensitiv e and subject to erratic and periodic changes, causing model predictions to become outdated. W e present V -DyKno w , a V isual Dynamic Knowledge benchmark for ev aluat- ing time-sensitiv e factual kno wledge in VLMs. Using V -DyKnow , we benchmark closed- and open-source VLMs and analyze a) the relia- bility (correctness and consistency) of model responses across modalities and input pertur- bations; b) the efficac y of knowledge editing and multi-modal RA G methods for knowledge updates across modalities; and c) the sources of outdated predictions, through data and mech- anistic analysis. Our results show that VLMs frequently output outdated facts, reflecting out- dated snapshots used in the (pre-)training phase. Factual reliability de grades from te xtual to vi- sual stimuli, even when entities are correctly recognized. Besides, existing alignment ap- proaches fail to consistently update the models’ knowledge across modalities. T ogether , these findings highlight fundamental limitations in how current VLMs acquire and update time- sensitiv e kno wledge across modalities. W e release the benchmark, code, and e v aluation data 1 . 1 Introduction V ision-Language Models (VLM) are increasingly used for answering factual questions about the real world from visual inputs. In these settings, VLMs are expected to connect the images’ content with stored world kno wledge and output answers to the question ( Cohen et al. , 2025 ). Similar to Large * Equal contribution. 1 Benchmark material av ailable at https://github.com/ sislab- unitn/V- DyKnow Figure 1: An example of multimodal querying VLMs for factual kno wledge that is time-sensiti ve. Upon a vi- sual stimulus, the VLM first misidentifies the entity and retriev es an incorrect fact. Following the clarification turn about the entity , the model generates an outdated answer . In the final turn, the entity is explicitly stated in the text, and the correct f act is finally returned. This example highlights ke y issues in vestigated in this work: the prev alence of outdated kno wledge in VLMs and the performance gap in VLMs for visual and textual stimuli. Language Models (LLMs), VLMs are static mod- els whose factual knowledge is acquired during training from large heterogeneous data snapshots collected at different points in time. These snap- shots capture diff erent states of the world and its entities and may encode outdated and/or conflicting versions of the same facts. As a result, the factual kno wledge expressed by a VLM reflects the con- tent and temporal mixture of its (pre-)training data, rather than the state of the world at inference time. The e valuation of knowledge in VLMs is pre- dominantly conducted using static benchmarks 1 with fixed ground truth ( Cohen et al. , 2025 ; Papi et al. , 2026 ). Prior work has examined fac- tual kno wledge in VLMs and identified modality- dependent gaps between visual and textual entity representations ( Cohen et al. , 2025 ). Research on multimodal kno wledge editing has studied whether factual updates transfer across modalities ( Fang et al. , 2025 ; Chen et al. , 2025 ). Howe ver , these ef forts focus on a fix ed set of static f acts, implicitly assuming that factual correctness is time-in variant. As real-world facts ev olve, such benchmarks fall out of sync with the current state of the world, and the e valuation scores thus measure agreement with outdated information rather than factual correctness at inference time, undermining the v alidity of the e valuation itself. This misalignment is particularly se vere in visual settings, where model responses depend jointly on entity recognition, cross-modal understanding, and factual recall, similiar to the example in Figure 1 . T o enable the ev aluation of time-sensiti ve factual kno wledge in VLMs, we introduce V -DyKnow , a visual dynamic benchmark for VLMs. Instead of relying on fixed annotations, model outputs are v alidated against up-to-date factual information deri ved from W ikidata ( Vrande ˇ ci ´ c and Krötzsch , 2014 ) at ev aluation time, allowing correctness to be assessed relati ve to the current state of the w orld. V -DyKno w represents factual queries as visual en- tities (e.g., portraits, flags, and logos) paired with relations and attrib utes, each associated with tem- poral validity interv als. V -DyKno w supports analy- sis of outdatedness, cross-modality ev aluation, and input-bound and cross-modal consistency . Using V -DyKno w , we conduct a systematic anal- ysis of time-sensiti ve factual knowledge in VLMs along three axes. First, we ev aluate how accurately and consistently VLMs retriev e real-world facts when entities are presented visually rather than tex- tually , and quantify the pre valence of outdated re- sponses under visual grounding. Second, we exam- ine whether existing alignment approaches, includ- ing knowledge editing and multimodal retriev al- augmented generation (RA G), can update outdated facts across modalities. And third, we in vesti- gate the sources of outdated predictions through training-data analysis and mechanistic interpretabil- ity . Our results show that VLMs frequently retriev e outdated facts and that factual recall degrades under visual stimulus, ev en when the entity is correctly recognized. Existing updating methods work only in simplified scenarios and interfere with knowl- edge acquired during pre-training. T ogether , these findings highlight limitations in how current VLMs acquire, recall, and maintain time-sensiti ve kno wl- edge. Our contributions can be summarized as follo ws: • W e introduce V -DyKnow , a dynamic bench- mark for ev aluating time-sensiti ve factual kno wledge in V ision–Language Models across modality and input perturbations. • W e provide the first systematic e valuation of time-sensiti ve factual knowledge in state-of- the-art VLMs, sho wing the prev alence of out- dated facts and lar ge performance gap across modalities. • W e analyze the effecti veness of existing align- ment approaches, including knowledge edit- ing and multimodal retrie v al-augmented gen- eration. • W e in vestigate the sources of outdated pre- dictions through data and mechanistic anal- yses, linking model outputs to training data snapshots and examining how factual recall emerges across model layers. 2 V -DyKnow Building on DyKnow ( Mousavi et al. , 2024 ), we introduce V -DyKno w , a benchmark for e v aluating time-sensiti ve factual knowledge in VLMs under both textual and visual grounding. F acts Follo wing the prior work ( Mousavi et al. , 2024 , 2025 ), we represent factual knowledge as (subject, pr operty , attribute) triplets. The subject denotes a real-world entity (e.g., Apple ), the pr op- erty defines a relation associated with that entity (e.g., CEO ), and the attribute corresponds to the v alue of that relation (e.g., T im Cook ). T o con- struct V -DyKnow , we extract the up-to-date at- tribute v alue for each subject-property in DyKnow from W ikidata ( Vrande ˇ ci ´ c and Krötzsch , 2014 ), a continuously updated knowledge graph. Attributes in W ikidata are connected to subjects through prop- erties and enriched with qualifiers specifying their v alidity interv als. For e xample, the subject Ap- ple is associated with attrib ute T im Cook via the property CEO , annotated with the v alidity interval 2011–pr esent . Meanwhile, outdated attributes are preserved with their previously v alid time spans (e.g., Steve J obs 1997-2011 ). The final benchmark contains 139 time-sensiti ve facts, including 82 facts associated with 47 countries, 28 facts related to athletes, and 29 facts corresponding to 22 organi- 2 (Y ear) Model VLM Visual Prompt VLM T extual Prompt LLM* T extual Prompt C orrect O utdated I rrelev ant C orrect O utdated I rrelev ant C orrect O utdated I rrelev ant (2023) LLaV A-1.5 13% 31% 56% 33% 49% 18% 33% 47% 19% (2024) LLaV A-OneV ision 22% 36% 42% 31% 45% 24% 37% 42% 22% (2024) PaliGemma 2 3% 4% 93% 0% 0% 100% 62% 28% 10% (2024) Molmo 24% 20% 56% 34% 44% 22% 40% 40% 20% (2024) Qwen2-VL 28% 38% 34% 36% 44% 20% 37% 42% 22% (2025) Qwen2.5-VL 32% 38% 30% 39% 40% 22% 44% 35% 21% (2025) InternVL3.5 26% 21% 53% 40% 29% 31% 51% 29% 19% (2025) GPT -4 71% 18% 11% 72% 19% 9% - - - (2025) GPT -5 75% 15% 10% 76% 14% 9% - - - T able 1: Evaluation of state-of-the-art VLMs on V -DyKnow under visual and textual prompting. Results report the percentage of C orrect (currently v alid attribute), O utdated (historically v alid but no longer current), and I rrelev ant (neither current nor historically valid) responses using the upper -bound strategy . The results can be compared with the performance of the corresponding LLM prior to multimodal (pre-)training/instruction tuning ( LLM* T extual Prompt ). zations (i.e., companies and institutions). V isual Prompts T o e valuate factual kno wledge across modalities, we construct paired queries in which the same subject entity is presented either textually or visually . In the textual setting, the sub- ject appears e xplicitly in the prompt (e.g., Who is the CEO of Apple? ). In the visual setting, the textual subject is replaced by the corresponding image of the entity obtained from Wikidata (e.g., Who is the CEO of this company? ). This formula- tion enables a direct comparison of factual recall when entities are accessed through linguistic v ersus visual representation. The visual representations consist of coats of arms and flags for countries, portraits for athletes, and logos for organizations. For countries, we include the coat of arms to help mitigate potential ambiguity , as certain flags share similar color patterns and may become difficult to distinguish under transformations 2 . The prompts are presented in § T able 6 . V isual Entity Recognition V isual queries intro- duce an additional challenge compared to text-only prompts, since the model must first identify the depicted entity and then retriev e the correspond- ing attrib ute from its internal kno wledge. When a model produces an incorrect answer , it is therefore unclear whether the error arises from a failure of visual recognition or from missing factual knowl- edge. T o disentangle these f actors, we introduce an auxiliary recognition task, where models are prompted to identify the depicted entity . Prompt templates for the detection task are generated using the same procedure as the factual queries, presented 2 For example, the flag of the Netherlands, rotated by 90° re- sembles the French flag. The coat of arms, therefore, provides an additional visual cue that uniquely identifies the country . in § T able 7 . Protocol For each query , the model’ s response is compared against the attribute collected at the e val- uation time, and classified as Correct if it matches the currently v alid attribute. It is labeled Outdated if it corresponds to an attrib ute that was valid in the past. Finally , a response is categorized as Irrele- vant if it matches neither the current nor any pre- viously v alid attribute associated with the queried property . This fine-grained distinction of the er- rors enables a more precise characterization of ho w VLMs encode and retriev e time-sensiti ve informa- tion. Strategy Generativ e models are known to be sensiti ve to prompt le xicalization, where dif ferent versions of the same query may lead to dif ferent responses despite identical semantics. T o address this limitation, V -DyKno w ev aluates each f actual query using three prompts with minor perturba- tions in le xicalization while preserving the same semantics (presented in § T able 6 ). Each model is queried independently with the three prompts, and the responses are ev aluated under the Upper-Bound strategy , where the final prediction for a query cor- responds to the best-performing response among the three prompts (Correct > Outdated > Irrele vant). This procedure reduces the lik elihood that e valua- tion outcomes are driven by prompt-specific arti- facts rather than by the model’ s underlying factual kno wledge. Models W e e valuate 9 VLMs (and their corre- sponding LLM): LLaV A-1.5 7B (V icuna-v1.5 7B) ( Liu et al. , 2024 ) LLaV A-OneV ision 7B (Qwen2 7B) ( Li et al. , 2025 ), PaliGemma 2 10B (Gemma 2 9B) ( Steiner et al. , 2024 ), Molmo 7B (OLMo 7B) ( Deitke et al. , 2025 ), Qwen2-VL 7B (Qwen2 7B) 3 (Y ear) Model Accuracy (2023) LLaV A-1.5 69% (2024) LLaV A-OneV ision 80% (2024) PaliGemma 2 63% (2024) Molmo 60% (2024) Qwen2-VL 91% (2025) Qwen2.5-VL 87% (2025) InternVL3.5 58% (2025) GPT -4 83% (2025) GPT -5 75% T able 2: Accuracy on the V isual Entity Recognition task. Models are prompted to identify the entity de- picted in each image before answering the f actual query . Scores are computed using an Upper-Bound across three prompt variants (presented in § T able 6 ). ( W ang et al. , 2024a ), Qwen2.5-VL 7B (Qwen2.5 7B) ( Qwen et al. , 2025 ), InternVL3.5 8B (Qwen3 8B) ( W ang et al. , 2025 ), GPT -4 3 , and GPT -5 4 . Ad- ditional details about the model’ s checkpoints are presented in § T able 8 3 Results W e assess the time-sensitive kno wledge in state-of- the-art VLMs on V -DyKnow . W e analyze how fre- quently models produce outdated responses, their performance under minor perturbations, and the ef fectiv eness of existing methods for updating their factual kno wledge. A. Model Evaluation T able 1 reports the performance of nine state-of- the-art VLMs on V -DyKno w 5 . Across models, out- dated factual responses appear frequently , often exceeding the number of correct answers. Many models retriev e the kno wledge that no longer re- flects the current state of the world. For most mod- els, factual retrie val is substantially more reliable when the entity is provided textually . This gap is more e vident in LLaV A-1.5, Molmo, InternVL3.5, and the Qwen family , resulting in a large propor- tion of irrelev ant responses upon visual stimuli. This gap suggests that factual kno wledge accessi- ble through textual queries is not always accessi- ble when the same entity must first be recognized from an image, highlighting a limitation in the in- teraction between visual recognition and factual recall. While more recent models (e.g., Qwen2.5- VL, GPT -{4,5}) achiev e higher rates of correct an- 3 gpt-4.1-2025-04-14 4 gpt-5.1-2025-11-13 5 The models are assessed against the factual knowledge retriev ed on Nov 2025 from W ikidata. (Y ear) Model Prompt Agreement V isual T extual (2023) LLaV A-1.5 52% 70% (2024) LLaV A-OneV ision 66% 80% (2024) PaliGemma 2 25% 100% (2024) Molmo 57% 81% (2024) Qwen2-VL 46% 79% (2025) Qwen2.5-VL 70% 78% (2025) InternVL3.5 58% 75% (2025) GPT -4 92% 97% (2025) GPT -5 84% 90% T able 3: Output consistency (prompt agreement) across three dif ferent lexicalizations of the same query for V i- sual and T e xtual inputs. An agreement measures the percentage of cases for which all prompts produce the same answer (i.e., correct, outdated, or irrelev ant). swers, outdated responses continue to constitute a substantial fraction of model outputs. Notably , the gap between visual and textual prompting is sub- stantially reduced in the most recent models. Com- paring VLMs with their corresponding base LLM re veals that multimodal training often de grades fac- tual recall. Except for LLaV A-1.5, the textual per - formance of the VLM is consistently lo wer than its corresponding LLM, suggesting that multimodal alignment can obscure knowledge that is other - wise accessible in the underlying language model. PaliGemma 2 represents an extreme case: after multimodal alignment, the model outputs “unan- swerable” to most of our queries. V isual Entity Recognition The results, reported in T able 2 , indicate that models with a smaller gap between visual and textual f actual retriev al exhibit a strong recognition performance. The Qwen2 model family achie ves entity recognition accurac y abov e 85%, and correspondingly sho ws a moderate dif ference between visual and textual prompting in T able 1 . In contrast, models with weaker en- tity recognition performance such as LLaV A-1.5, Molmo, and InternVL3.5 tend to display substan- tially lar ger modality gaps, with higher proportions of irrelev ant outputs when the entity is presented vi- sually . These results suggest that failures in visual entity recognition contrib ute to the degradation of factual retrie v al under visual prompting. Ne verthe- less, e ven models with strong recognition capabil- ities, such as Qwen2-VL and Qwen2.5-VL, still produce a large fraction of outdated answers, indi- cating that correctly identifying the entity does not guarantee access to up-to-date factual kno wledge. 4 (Y ear) Model # Outdated Facts Knowledge Editing Multi-modal RA G WISE GRA CE IKE Retrieved Doc. Gold Doc. (2023) LLaV A-1.5 69 2.9% 5.5% 95.6% 73.5% 84.4% (2024) Qwen2-VL 83 3.9% 2.4% 100.0% 80.1% 92.8% T able 4: Effecti veness of e xisting alignment methods (editing and multimodal RA G) on outdated facts for LLaV A- 1.5 and Qwen2-VL. Scores report the harmonic mean of efficac y and paraphrase success. W e compare kno wledge editing methods with multimodal RA G using either retrie ved documents as well as gold documents. B. Output Consistency W e e valuate the consistency of model outputs across different lexicalizations of the same query as prompt agreement ( Mousa vi et al. , 2025 ). Across models, presented in T able 3 , agreement is consis- tently higher for te xtual prompts, indicating that predictions are more sensiti ve to prompt formula- tion when the entity must first be inferred from an image. This pattern is particularly pronounced for models such as LLaV A-1.5, Molmo, and Qwen2- VL. In contrast, models such as GPT -4 and GPT -5 exhibit high agreement across both modalities, in- dicating more stable retriev al beha vior . An extreme case is PaliGemma, which consistently generates irrele vant answers. Overall, these results indicate that factual retrie val in VLMs is not only modality- dependent but also sensiti ve to prompt formaliza- tion. C. Updating VLMs’ Knowledge The precedence of outdated factual knowledge in VLMs,T able 1 , moti vates ev aluating whether ex- isting alignment approaches can effecti vely update the factual knowledge encoded in VLMs. W e e valuate knowledge editing methods, aiming to update factual knowledge without retraining the full model. W e consider three representativ e ap- proaches: GRA CE ( Hartvigsen et al. , 2023 ), which stores edits in an external memory module applied through an adaptor; WISE ( W ang et al. , 2024b ), which extends GRA CE by also storing pre-trained kno wledge in an external memory module; and IKE ( Zheng et al. , 2023 ), which introduces updated examples through in-conte xt learning. W e compare the editing methods with multimodal Retriev al- Augmented Generation (RAG) ( Das et al. , 2025 ) under two settings: a) a realistic setting where doc- uments are retriev ed based on the input question; and b) an oracle setting where the gold document containing the answer is provided directly to the model. W e focus on LLaV A-1.5 and Qwen2-VL, as the old models with the highest percentage of outdated responses included in T able 1 . W e mea- sure the effecti veness of each approach using the harmonic mean of efficac y and paraphrase success ( Mousavi et al. , 2024 , 2025 ). Additional implemen- tation details are presented in Sections § A.3 , § A.4 , and § A.5 T able 4 shows that performance varies substan- tially across methods. Among the kno wledge edit- ing methods, only IKE achieves a high harmonic mean, whereas WISE and GRA CE perform poorly (both below 6%). Howe ver , IKE is not fully re- alistic, as it requires the deterministic up-to-date fact for each query , whereas facts should be re- trie ved based on the question (as done in mul- timodal RAG). Retriev al-based approaches show more consistent performance. Multimodal RA G achie ves high scores across both models, although performance depends on retriev al quality , as re- flected by the gap between retrie ved and gold doc- uments. Importantly , both RA G and IKE rely on external information at inference time and there- fore do not update the model’ s parametric knowl- edge. As a result, both methods may still suffer from inconsistencies between the model’ s internal kno wledge and the external information provided at inference time ( W u et al. , 2024 ). Qualitative Analysis T o better understand the impact of alignment approaches on the model out- puts, we annotate the generated responses using a human e valuation protocol adapted from Mousavi et al. ( 2022 ). T wo researchers independently re- vie wed the outputs produced after editing/RA G. Responses are annotated as C orrect if a previously outdated answer is updated successfully . Mean- while, I ncorrect outputs are further subdivided into a) O utdated , when the model continues to return out- dated kno wledge; b) G eneric , if the model produces v ague statements (e.g., “The CEO of Apple is a very important person”); and c) H allucination , when the model fabricates or confuses attributes, such as attributing political roles to athletes. The results in T able 5 further confirm that WISE 5 Model C orrect Incorrect O utdated G eneric H alluc. LLaV A-1.5 WISE 3% 73% 0% 24% GRA CE 21% 63% 1% 15% IKE 95% 0% 5% 0% RA G Ret. Doc 74% 2% 0% 23% Gold Doc 85% 3% 0% 12% Qwen2-VL WISE 4% 34% 3% 57% GRA CE 34% 51% 0% 14% IKE 100% 0% 0% 0% RA G Ret. Doc 80% 5% 0% 15% Gold Doc 93% 3% 0% 4% T able 5: Qualitative error analysis of knowledge editing (WISE, GRACE, IKE) and retriev al-based alignment methods across two representati ve LLMs, based on hu- man annotation of generated outputs. Responses are categorized as Correct when the outdated attribute is successfully updated. Incorrect responses are further classified as Outdated when the model continues to return the outdated fact, Generic when the model pro- duces vague answers, and Hallucinated when the model fabricates or confuses attrib utes. and GRA CE fail to reliably update the models’ fac- tual kno wledge, as the majority of their responses remain outdated e ven after editing. Both methods increase the proportion of hallucinated responses, with models either assigning incorrect attributes to a gi ven subject-property pair (e.g., the emperor of Japan is Barack Obama) or answering with the name of the visual subject (e.g., “Can you name the current prime minister of this country? Italy ” ). IKE produces few generic outputs, such as answer- ing “yes” to questions like “can you name... ” . Fi- nally , e ven when pro vided with gold documents, RA G can still produce outdated or hallucinated answers, confirming that the model’ s pre-trained parametric kno wledge can interfere with external e vidence. 4 Further Analysis W e conduct additional analyses to better under- stand the sources of outdated responses. First, we examine the temporal v alidity intervals associated with model predictions to approximate the time pe- riod reflected in their parametric kno wledge. W e then analyze the training data of a representativ e model to determine whether the information re- quired to answer a query was present in the pre- training corpus. Finally , we perform a mechanistic analysis to study how f actual information is re- trie ved across model layers. A. Data Interval A pproximation Using the temporal v alidity interv als associated with W ikidata attributes, we analyze the correct and outdated outputs of each model to approximate the temporal interv al reflected in their parametric kno wledge. For each predicted attribute, we re- trie ve its v alidity interv al and aggreg ate the distri- bution of these interv als across model outputs. The results are summarized in Figure 2 . Our approxima- tions are in line with the cutof fs of the models with disclosed data interv als such as Qwen2-VL (June 2023) 6 , GPT -4 (June 1st 2024) and GPT -5 (Septem- ber 30th 2024) API 7 . Although all e valuated mod- els were released after 2023, most responses cor- respond to facts v alid before 2020, suggesting that the underlying training data predominantly reflects earlier states of the world. Within several model families, ne wer versions tend to generate responses associated with more recent intervals. For exam- ple, LLaV A-OneV ision and Qwen2.5-VL produce fe wer responses tied to earlier years than LLaV A- 1.5 and Qwen2-VL, respecti vely . Across open- source models, the temporal intervals roughly starts from 2005. GPT -{4,5} produce responses concen- trated in more recent interv als, primarily between 2017 and 2023, although outdated predictions can still extend to earlier periods. Notably , both GPT models sho w nearly identical temporal distribu- tions, suggesting that they rely on similar training data snapshots. Overall, these patterns indicate that most of the model outputs and presumably thier training data reflect an outdated state of the world, e ven though more recent models tend to incorpo- rate more recent information. B. Linking Responses to T raining Data T o understand how VLMs’ predictions are shaped by the information a vailable during pretraining, we analyze the training corpus for a stratified subset of entities. W e conduct this analysis using Molmo, as its pretraining data is publicly av ailable and therefore allo ws direct inspection of the documents the model has been exposed to. W e focus on the W ikipedia portion of the corpus, as prior work sug- gests that models tend to acquire factual knowledge more reliably from structured and curated sources such as Wikipedia compared to other documents 6 Qwen AI Chat Models 7 OpenAI API Models 6 2004 2006 2008 2010 2012 2014 2016 2018 2020 2022 2024 2026 (2025) GPT -5 (2025) GPT -4 (2025) InternVL3.5 (2025) Qwen2.5-VL (2024) Qwen2-VL (2024) Molmo (2024) PaliGemma 2 (2024) LLaV A-OneV ision (2023) LLaV A-1.5 Figure 2: T emporal distribution of the model responses based on W ikidata. For each VLM, we map their correct and outdated responses (e.g., “The CEO of Apple is Steve Jobs ”) to the time at which the corresponding attribute was valid (e.g., “1997-2011”). By aggregating these intervals using a boxplot, we can approximate the state of the world encoded in the model’ s parameters. For example, results sho w that, while Qwen2-VL responses range between 2004 and 2023 (in line with its reported cutoff), most of them are concentrated between 2013 and 2019. in the pre-training snapshots( Li et al. , 2024 ). For each entity , we analyze the main Wikipedia page included in the pretraining snapshot and determine whether the current fact appears in the document and how prominently it is mentioned. Our goal is not to exhausti vely search all documents in the corpus, but to determine whether the correct infor- mation was present in the canonical source at the time the training snapshot was collected. If the cor- rect information appears in this version of the page, it is likely that the model was e xposed to it during pretraining; con versely , if it is absent, the model may have only observed the outdated attribute or no rele vant information at all. W e select 30 entities, 10 cases where Molmo gen- erates the correct attrib utes, 10 where it produces an outdated attribute, and 10 where it generates an irrele vant response. For entities where Molmo pro- duces the correct answer , in fi ve cases the correct fact does not appear in the document, suggesting that the model must have acquired this informa- tion from other sources in its pretraining data. In one case, the correct attribute is mentioned b ut not as the most frequent value, while in four cases, it is both present and the most frequently occurring information in the page. In cases where Molmo produces outdated answers, in se ven cases the cur - rent information does not appear in the W ikipedia page, indicating that the model’ s prediction is con- sistent with the information a vailable in the docu- ment at the time of pretraining. Howe ver , in three cases, the current attrib ute is present and e ven the most frequently occurring v alue in the page, yet the model still retriev es the outdated one. This sug- gests that outdated predictions cannot alw ays be explained by missing information in the training data. Finally , for entities where Molmo produces irrele vant responses, the current attrib ute is absent from the W ikipedia page in six cases. In the re- maining four cases, the correct face appears in the document, twice as a secondary mention and twice as the most frequent value, yet the model still fails to retriev e it. T aken together , these observations in- dicate that model behavior is not determined solely by the presence or frequency of information in the training data. C. Mechanistic Interpr etability W e conduct a mechanistic analysis to examine ho w dif ferent editing methods modify the retrie v al of factual information across model layers. Building on prior w ork ( Mousavi et al. , 2025 ; Gev a et al. , 2023 ; Ou et al. , 2025 ), we probe the model with visual queries and analyze ho w dif ferent layers con- tribute to the prediction of updated and outdated attributes. Figure 3 presents the results of this anal- ysis for Qwen2-VL. Additional figures and detailed analyses are provided in Section § A.6 . Overall, we observe that the pre-trained model assigns a high probability to one of the candidate attributes only at the final layer , suggesting that earlier layers con- tribute little to the explicit factual recall reflected in the final prediction. In case of successful ed- its (the upper part in Figure 3 ), while WISE only 7 Pre-T rained WISE GRACE L. Montenegro 2024-Now A. Costa 2015-2024 Pedro P . Coelho 201 1-2015 20 22 24 26 28 Philadelphia 2024-Now City Thunder 2017-2019 LA Clippers 2019-2024 Indiana Pacers 2010-2017 1 0.8 0.6 0.4 0.2 0 1 0.8 0.6 0.4 0.2 0 20 22 24 26 28 20 22 24 26 28 20 22 24 26 28 20 22 24 26 28 20 22 24 26 28 Pre-T rained WISE GRACE Image Question What club is this NBA player currently playing for? Image Question Who is the current Head of Government of this country? Figure 3: Mechanistic analysis of Qwen2-VL illustrating ho w editing methods modify the probability for certain attributes (y-axis) across dif ferent layers (x-axis) when asked about an Image-Question pair . In case of a successful update (top), WISE and GRA CE affect different layers: WISE primarily edits the final layer , whereas GRACE modifies a broader range. In contrast, neither method successfully updates the basketball team of Paul George (bottom), suggesting that this knowledge may be more deeply embedded or that other stored f acts may interfere. modifies the final layer , GRA CE targets earlier lay- ers and propagates the change across layers 20 to 28. Meanwhile, in the case of unsuccessful ed- its (the lower part in Figure 3 ), GRA CE slightly reduces the probability assigned to the incorrect en- tity , whereas WISE increases it, potentially due to interference with other stored factual associations. 5 Literature Review Benchmarks Existing ev aluations of time-sensitiv e kno wledge hav e been lar gely restricted to the te x- tual inputs. Dynamic benchmarks such as DyKnow ( Mousavi et al. , 2024 ), Evolv eBench ( Zhu et al. , 2025 ), and DynaQuest ( Lin et al. , 2025 ) hav e been introduced to assess how models handle tempo- rally changing facts, b ut these are designed e xclu- si vely for Large Language Models (LLMs). In contrast, existing benchmarks with visual queries ( Chen et al. , 2023 ; Cheng et al. , 2025 ) are largely static, making it difficult to assess the validity of time-sensiti ve facts under visual grounding. VLMs Current research suggests that VLMs suf- fer from significant representational discrepancies, making them unreliable repositories of kno wledge ( Huh et al. , 2024 ). Recent studies identify a huge performance gap across modalities, with high per - formance with textual queries Cohen et al. ( 2025 ), indicating the VLMs fail to utilize the visual sig- nals ef fecti vely Fu et al. ( 2025 ). This inconsistency has also been observ ed in video and speech ( P api et al. , 2026 ), and in multimodal knowledge edit- ing ( Fang et al. , 2025 ), where edits fail to transfer across modalities. Meanwhile, multimodal knowl- edge editing studies rely on static ground truth and do not take in consideration the temporal v alidity of facts or factual updates over time ( F ang et al. , 2025 ; Chen et al. , 2025 ). 6 Discussion & Conclusion Our analysis shows that outdated kno wledge is common across both open- and closed-source VLMs, reflecting old training data snapshots e ven in recent models. These findings raise broader ques- tions about how large multimodal models should represent kno wledge about a world that continu- ously ev olves. Current training paradigms rely on static data snapshots, while e xisting alignment methods remain insufficient for maintaining con- sistent and up-to-date factual kno wledge. Address- ing these challenges may require new learning paradigms that explicitly model temporal validity , integrate dynamic kno wledge sources, and support continual updates without disrupting e xisting rep- resentations. W e belie ve V -DyKnow provides a useful resource for studying these questions. By explicitly modeling temporal v alidity and support- ing multimodal ev aluation, the benchmark enables systematic analysis of ho w models acquire, store, and update real-world knowledge. W e release the benchmark, code, and e v aluation data to facilitate 8 future research on dynamic factual knowledge in vision–language models. Limitations The 139 time-sensitiv e facts obtained from W iki- data refer to frequent entities. Consequently , the results should be interpreted as upper bounds, as factual recall for less common entities may be more dif ficult and could lead to more outdated or irrel- e vant results. Ev aluation of editing methods only takes into account the effecti veness of updating time-sensiti ve facts, but the potential side effects of editing are not ev aluated in this w ork. Due to limited resources, only open-source models with 7B parameters hav e been ev aluated. As an upper bound on the performance of current VLMs for fac- tual recall, we ev aluated closed-source API models. References Qizhou Chen, Chengyu W ang, Dakan W ang, T aolin Zhang, W angyue Li, and Xiaofeng He. 2025. Life- long kno wledge editing for vision language models with low-rank mixture-of-e xperts. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pages 9455–9466. Y ang Chen, Hexiang Hu, Y i Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter , and Ming-W ei Chang. 2023. Can pre-trained vision and language models answer visual information-seeking questions? In Pr oceed- ings of the 2023 Conference on Empirical Methods in Natural Language Pr ocessing , pages 14948–14968, Singapore. Association for Computational Linguis- tics. Xianfu Cheng, W ei Zhang, Shiwei Zhang, Jian Y ang, Xiangyuan Guan, Xianjie W u, Xiang Li, Ge Zhang, Jiaheng Liu, Y uying Mai, Y utao Zeng, Zhoufutu W en, Ke Jin, Baorui W ang, W eixiao Zhou, Y unhong Lu, Hangyuan Ji, T ongliang Li, W enhao Huang, and Zhoujun Li. 2025. Simplevqa: Multimodal factuality ev aluation for multimodal large language models. In Pr oceedings of the IEEE/CVF International Confer- ence on Computer V ision (ICCV) , pages 4637–4646. Ido Cohen, Daniela Gottesman, Mor Gev a, and Raja Giryes. 2025. Performance gap in entity kno wledge extraction across modalities in vision language mod- els . In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 29095–29108, V ienna, Austria. Association for Computational Linguistics. Deepayan Das, Davide T alon, Y iming W ang, Massi- miliano Mancini, and Elisa Ricci. 2025. Training- free personalization via retriev al and reasoning on fingerprints. In Pr oceedings of the IEEE/CVF In- ternational Conference on Computer V ision , pages 9683–9692. Matt Deitke, Christopher Clark, Sangho Lee, Rohun T ripathi, Y ue Y ang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, K yle Lo, Luca Soldaini, Jiasen Lu, T aira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, Y enSung Chen, Ajay Patel, Mark Y atskar , Chris Callison-Burch, and 31 others. 2025. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. In Pr oceedings of the IEEE/CVF Confer ence on Com- puter V ision and P attern Recognition (CVPR) , pages 91–104. Lingyong Fang, Xinzhong W ang, Depeng W ang, Zon- gru W u, Y a Guo, Huijia Zhu, Zhuosheng Zhang, and Gongshen Liu. 2025. Can kno wledge be transferred from unimodal to multimodal? inv estigating the tran- sitivity of multimodal knowledge editing. In Pr o- ceedings of the IEEE/CVF International Confer ence on Computer V ision (ICCV) , pages 2482–2490. Stephanie Fu, tyler bonnen, Devin Guillory , and T re vor Darrell. 2025. Hidden in plain sight: VLMs o verlook their visual representations . In Second Confer ence on Languag e Modeling . Mor Gev a, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. Dissecting recall of factual associa- tions in auto-re gressiv e language models . In Pr oceed- ings of the 2023 Conference on Empirical Methods in Natural Language Pr ocessing , pages 12216–12235, Singapore. Association for Computational Linguis- tics. Google Cloud. Gemini 3.1 pro: Generativ e ai on v ertex ai. https://docs.cloud.google. com/vertex- ai/generative- ai/docs/models/ gemini/3- 1- pro?hl=en . T om Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Y oon Kim, and Marzyeh Ghassemi. 2023. Aging with grace: Lifelong model editing with dis- crete ke y-value adaptors. Advances in Neural Infor- mation Pr ocessing Systems , 36:47934–47959. Minyoung Huh, Brian Cheung, T ongzhou W ang, and Phillip Isola. 2024. The platonic representation hy- pothesis . Pr eprint , arXi v:2405.07987. Bo Li, Y uanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Y an- wei Li, Ziwei Liu, and Chunyuan Li. 2025. LLaV A- one vision: Easy visual task transfer . T ransactions on Machine Learning Resear ch . Jiahuan Li, Y iqing Cao, Shujian Huang, and Jiajun Chen. 2024. Formality is f av ored: Unraveling the learning preferences of large language models on data with conflicting knowledge. In Proceedings of the 2024 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 5307–5320. Qian Lin, Junyi Li, and Hwee T ou Ng. 2025. Dy- naQuest: A dynamic question answering dataset reflecting real-world knowledge updates . In F ind- ings of the Association for Computational Linguis- tics: A CL 2025 , pages 26918–26936, V ienna, Austria. Association for Computational Linguistics. 9 Haotian Liu, Chunyuan Li, Y uheng Li, and Y ong Jae Lee. 2024. Improved baselines with visual instruc- tion tuning. In Proceedings of the IEEE/CVF Con- fer ence on Computer V ision and P attern Recognition (CVPR) , pages 26296–26306. Ke vin Meng, David Bau, Ale x Andonian, and Y onatan Belinko v . 2022. Locating and editing factual associa- tions in gpt. Advances in neural information pr ocess- ing systems , 35:17359–17372. Seyed Mahed Mousa vi, Simone Alghisi, and Giuseppe Riccardi. 2024. DyKnow: Dynamically verifying time-sensitiv e factual kno wledge in LLMs . In F ind- ings of the Association for Computational Linguistics: EMNLP 2024 , pages 8014–8029, Miami, Florida, USA. Association for Computational Linguistics. Seyed Mahed Mousa vi, Simone Alghisi, and Giuseppe Riccardi. 2025. Llms as repositories of factual knowl- edge: Limitations and solutions. arXiv pr eprint arXiv:2501.12774 . Seyed Mahed Mousa vi, Gabriel Roccabruna, Michela Lorandi, Simone Caldarella, and Giuseppe Riccardi. 2022. Ev aluation of response generation models: Shouldn’t it be shareable and replicable? In Pr o- ceedings of the 2nd W orkshop on Natural Language Generation, Evaluation, and Metrics (GEM) , pages 136–147. OpenAI. 2026a. GPT -4.1 Model | OpenAI API. https://developers.openai.com/api/ docs/models/gpt- 4.1 . OpenAI. 2026b. GPT -5.1 Model | OpenAI API. https://developers.openai.com/api/ docs/models/gpt- 5.1 . Y ixin Ou, Y unzhi Y ao, Ningyu Zhang, Hui Jin, Ji- acheng Sun, Shumin Deng, Zhenguo Li, and Huajun Chen. 2025. How do LLMs acquire ne w knowledge? a knowledge circuits perspective on continual pre- training . In F indings of the Association for Computa- tional Linguistics: A CL 2025 , pages 19889–19913, V ienna, Austria. Association for Computational Lin- guistics. Sara Papi, Maik e Züfle, Marco Gaido, beatrice sav oldi, Danni Liu, Ioannis Douros, Luisa Bentivogli, and Jan Niehues. 2026. MCIF: Multimodal crosslin- gual instruction-following benchmark from scientific talks . In The F ourteenth International Conference on Learning Repr esentations . Qwen, :, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, and 25 oth- ers. 2025. Qwen2.5 technical report . Preprint , Massimo Rizzoli, Simone Alghisi, Olha Khomyn, Gabriel Roccabruna, Se yed Mahed Mousavi, and Giuseppe Riccardi. 2025. CIVET: Systematic ev alu- ation of understanding in VLMs . In F indings of the Association for Computational Linguistics: EMNLP 2025 , pages 4462–4480, Suzhou, China. Association for Computational Linguistics. Andreas Steiner , André Susano Pinto, Michael Tschan- nen, Daniel Ke ysers, Xiao W ang, Y onatan Bit- ton, Alex ey Gritsenk o, Matthias Minderer , Anthony Sherbondy , Shangbang Long, and 1 others. 2024. Paligemma 2: A family of versatile vlms for transfer . arXiv pr eprint arXiv:2412.03555 . Denny Vrande ˇ ci ´ c and Markus Krötzsch. 2014. Wiki- data: a free collaborativ e knowledgebase . Commun. A CM , 57(10):78–85. Peng W ang, Shuai Bai, Sinan T an, Shijie W ang, Zhi- hao Fan, Jinze Bai, K eqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, and 1 others. 2024a. Qwen2- vl: Enhancing vision-language model’ s perception of the world at any resolution. arXiv pr eprint arXiv:2409.12191 . Peng W ang, Zexi Li, Ningyu Zhang, Ziwen Xu, Y unzhi Y ao, Y ong Jiang, Pengjun Xie, Fei Huang, and Hua- jun Chen. 2024b. Wise: Rethinking the knowledge memory for lifelong model editing of large language models. Advances in Neural Information Pr ocessing Systems , 37:53764–53797. Peng W ang, Ningyu Zhang, Xin Xie, Y unzhi Y ao, Bozhong T ian, Mengru W ang, Zekun Xi, Siyuan Cheng, Kangwei Liu, Guozhou Zheng, and 1 others. 2023. Easyedit: An easy-to-use knowledge editing frame work for large language models. arXiv preprint arXiv:2308.07269 . W eiyun W ang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang W ei, Zhaoyang Liu, Linglin Jing, Shenglong Y e, Jie Shao, and 1 others. 2025. In- tern vl3. 5: Advancing open-source multimodal mod- els in versatility , reasoning, and efficienc y . arXiv pr eprint arXiv:2508.18265 . Ke vin W u, Eric W u, and James Zou. 2024. Clashev al: Quantifying the tug-of-war between an llm’ s inter- nal prior and external e vidence. Advances in neural information pr ocessing systems , 37:33402–33422. Y anzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Y ang, Pengjun Xie, An Y ang, Dayiheng Liu, Junyang Lin, and 1 others. 2025. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv pr eprint arXiv:2506.05176 . Ce Zheng, Lei Li, Qingxiu Dong, Y uxuan Fan, Zhiyong W u, Jingjing Xu, and Baobao Chang. 2023. Can we edit factual knowledge by in-context learning? In Pr oceedings of the 2023 Conference on Empiri- cal Methods in Natural Languag e Pr ocessing , pages 4862–4876. Zhiyuan Zhu, Y usheng Liao, Zhe Chen, Y uhao W ang, Y unfeng Guan, Y anfeng W ang, and Y u W ang. 2025. 10 Evolv eBench: A comprehensiv e benchmark for as- sessing temporal aw areness in LLMs on e volving knowledge . In Pr oceedings of the 63r d Annual Meet- ing of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 16173–16188, V i- enna, Austria. Association for Computational Lin- guistics. 11 A A ppendix A.1 Benchmark Construction W e complement the information in the main paper by providing additional details on the construction of our ev aluation benchmark (discussed in Section 2 ). A.1.1 V isual Queries For each subject category , we retriev ed images from the follo wing W ikidata ( Vrande ˇ ci ´ c and Krötzsch , 2014 ) fields: portrait photographs (P18) for athletes; company or institutional logos (P154) for organizations; national flags (P41) and coats of arms (P94) for countries. As prior research indi- cates that image dimensions can significantly influ- ence model accuracy ( Rizzoli et al. , 2025 ), we stan- dardize all images to a fixed resolution of 672 × 672 pixels. During this preprocessing phase, uniform black padding was applied where necessary to pre- serve the tar get dimensions without distorting the original aspect ratio. Images with transparent back- grounds were rendered with a white background. Follo wing the image standardization step, we generated prompt templates in which the subject entity is represented by its corresponding image. T o construct these queries, we prompted Google Gemini Pro ( Google Cloud ) to generate fiv e con- cise question templates for each subject category . Each template is formulated as a question asking for a specific attribute (e.g., “T im Cook”) of the subject entity depicted in the image (e.g., “ Apple”). While the templates differ in their wording, they are intended to express the same underlying query so that they lead to the same attribute v alue as the answer . T o ensure this semantic equi valence, two researchers from our group manually revie wed the generated templates, verifying that each formula- tion queried the same property and would therefore produce the same attribute as the e xpected answer . Based on this revie w , three templates were selected as the final prompts used to query the models. The complete list of prompt templates for our visual queries is reported in T able 6 . A.1.2 T extual Queries For each prompt template used for the visual queries, we deriv ed its corresponding textual coun- terpart by replacing the part referring the image (e.g., “this country”, “this player”, or “this or gani- zation”) with the e xplicit textual name of the sub- ject entity (e.g., “this country” → “Italy”, or “this org anization” → “ Apple”). T o guarantee that these modifications did not alter the semantic meaning of the queries, two researchers manually verified the resulting textual prompts, ensuring the y remained grammatically correct and accurately reflected the original output response of the visual queries. A.1.3 V isual Entity Recognition Prompts Follo wing the construction of the visual prompts, we le veraged Google Gemini Pro ( Google Cloud ) to generate fi ve distinct templates that prompt the models to identify the visual subject entity . T wo re- searchers manually revie wed the generated prompts and selected three for each subject category . The complete set of detection prompt templates is pro- vided in T able 7 . A.2 Model Checkpoints and Inference Details T o ensure reproducibility , we detail the model checkpoints, API v ersions, hardware, and genera- tion hyperparameters. A.2.1 Model Checkpoints W e provide the lists of the HuggingFace repos- itory identifiers for the open-weight VLMs and their corresponding LLMs in T able 8 . LLMs baselines were selected to match the base mod- els utilized during VLM training. For closed- source models, we queried the OpenAI using the gpt-4.1-2025-04-14 ( OpenAI , 2026a ) and gpt-5.1-2025-11-13 ( OpenAI , 2026b ) models. A.2.2 Inference Hyperparameters T o ensure deterministic responses, we employed greedy decoding for all open-weight models. T o re- duce verbose responses, we append the instruction “Answer with the name only” , following prior find- ings ( Rizzoli et al. , 2025 ), and set the maximum number of tokens to 20. A.2.3 Hardwar e Open-weight model inference w as ex ecuted locally on a single NVIDIA R TX 3090 (24GB) GPU using bfloat16 precision. Image pre-processing was handled using the default pipeline of each VLM. A.3 Editing Methods Implementation Details W e present more details on the editing methods used in the paper: 1. WISE ( W ang et al. , 2024b ) introduces a dual-memory architecture that partitions ne w kno wledge in a side memory (to store ne w 12 Subject Category Subject Entity Property Prompt T emplate with [Place Holder] Countries Italy , United States of America, China, Germany , Japan, India, United Kingdom, France, Brazil, Canada, Russia, Mexico, South Korea, Australia, Spain, Indonesia, T urkey , Netherlands, Saudi Arabia, Poland, Belgium, Argentina, Sweden, Ireland, Norway , Austria, Israel, Thailand, United Arab Emirates, Singapore, Bangladesh, Philippines, V ietnam, Malaysia, Denmark, Egypt, Nigeria, South Africa, Iran, Colombia, Romania, Chile, Pakistan, Czech Republic, Finland, Iraq, Portugal (Head of State) President King Monarch Emperor Supreme Leader Coat of Amrs ❏ Who is the curr ent [Head of State/ Head of Gov .] of this country? ❏ Can you name the curr ent [T itle] of this country? ❏ Which person curr ently serves as [T itle] for this country? (Head of Gov .) Prime Minister Premier of Republic Federal Chancellor Flag Athletes Soccer Player Cristiano Ronaldo, Lionel Messi Neymar Jr ., Kylian Mbappé, Karim Benzema, Erling Haaland, Mohamed Salah, Sadio Mané, Kevin De Bruyne,Harry Kane Sports T eam ❏ For which club does this player curr ently play for? ❏ What is the curr ent football club of this athlete? ❏ What club is this football player curr ently playing for? Basketball Player (NBA) Stephen Curry , Kevin Durant, LeBron James, Nikola Jokic, Bradley Beal, Giannis Antetokounmpo, Damian Lillard, Kawhi Leonard, Paul George ❏ For which club does this player curr ently play for? ❏ What is the curr ent basketball club of this athlete? ❏ What club is this NBA player curr ently playing for? F1 Driver Max V erstappen, Lewis Hamilton, Fernando Alonso, Sergio Pérez, Charles Leclerc, Lando Norris, Carlos Sainz Jr ., George Russell, Pierre Gasly ❏ For which club does this player curr ently play for? ❏ What is the curr ent F1 team of this athlete? ❏ What team is this F1 driver curr ently racing for? Private / Public Organi- zations Company W almart, Saudi Aramco, Amazon, ExxonMobil, Apple, Shell, CVS Health, V olkswagen Group, Alphabet Inc., T oyota, T otalEnergies, Glencore, BP , Cencora, Inc., Microsoft, Gazprom, Mitsubishi, Ford Motor Company CEO ❏ Who is the curr ent [T itle] of this company? ❏ Can you name the curr ent [T itle] of this company? ❏ Who curr ently holds the position [T itle] of of this company? Chairperson Organi- zation United Nations, W orld Bank, North Atlantic T reaty Organization, International Olympic Committee General secretary ❏ Who is the curr ent [T itle] of this or gamization? ❏ Who is the curr ent [T itle] of this or ganization? ❏ Who curr ently holds the position of [T itle] of this organization? Chairperson T able 6: List of all subject entities and their corresponding visual prompts used for benchmarking the VLMs. 13 Subject Category Subject Entity Property Prompt T emplate with [Place Holder] Countries Italy , United States of America, China, Germany , Japan, India, United Kingdom, France, Brazil, Canada, Russia, Mexico, South Korea, Australia, Spain, Indonesia, T urkey , Netherlands, Saudi Arabia, Poland, Belgium, Argentina, Sweden, Ireland, Norway , Austria, Israel, Thailand, United Arab Emirates, Singapore, Bangladesh, Philippines, V ietnam, Malaysia, Denmark, Egypt, Nigeria, South Africa, Iran, Colombia, Romania, Chile, Pakistan, Czech Republic, Finland, Iraq, Portugal (Head of State) President King Monarch Emperor Supreme Leader Coat of Amrs ❏ Which country does this image r epr esent? ❏ T o which nation does this symbol belong to? ❏ Which country officially uses this as a [Coat of Arms/ Flag]? (Head of Gov .) Prime Minister Premier of Republic Federal Chancellor Flag Athletes Soccer Player Cristiano Ronaldo, Lionel Messi Neymar Jr ., Kylian Mbappé, Karim Benzema, Erling Haaland, Mohamed Salah, Sadio Mané, Kevin De Bruyne,Harry Kane Sports T eam ❏ Who is the athlete featur ed her e? ❏ What is this athlete’ s name? ❏ Who is the soccer player shown in this image? Basketball Player (NBA) Stephen Curry , Kevin Durant, LeBron James, Nikola Jokic, Bradley Beal, Giannis Antetokounmpo, Damian Lillard, Kawhi Leonard, Paul George ❏ Who is the athlete featur ed her e? ❏ What is this athlete’ s name? ❏ Who is the basketball player shown in this image? F1 Driver Max V erstappen, Lewis Hamilton, Fernando Alonso, Sergio Pérez, Charles Leclerc, Lando Norris, Carlos Sainz Jr ., George Russell, Pierre Gasly ❏ Who is the athlete featur ed her e? ❏ What is this athlete’ s name? ❏ Who is the formula 1 driver shown in this image? Private / Public Organi- zations Company W almart, Saudi Aramco, Amazon, ExxonMobil, Apple, Shell, CVS Health, V olkswagen Group, Alphabet Inc., T oyota, T otalEnergies, Glencore, BP , Cencora, Inc., Microsoft, Gazprom, Mitsubishi, Ford Motor Company CEO ❏ Which company is r epr esented by the logo in the image? ❏ What is the name of the company with this logo? ❏ Which company does this logo belog to? Chairperson Organi- zation United Nations, W orld Bank, North Atlantic T reaty Organization, International Olympic Committee General secretary ❏ Which or ganization is r epresented by the logo i n the image? ❏ What is the name of the or ganization with this logo? ❏ Which or ganization does this logo belog to? Chairperson T able 7: List of all subject entities and their corresponding visual entity recognition prompts used for benchmarking the VLMs. 14 Model Name VLM Checkpoint LLM Checkpoint LLaV A-1.5 7B llava-hf/llava-1.5-7b-hf lmsys/vicuna-7b-v1.5 LLaV A-OneV ision 7B llava-hf/llava-onevision-qwen2-7b-si-hf Qwen/Qwen2-7B-Instruct PaliGemma 2 10B google/paligemma2-10b-mix-448 google/gemma-2-9b-it Molmo 7B allenai/Molmo-7B-O-0924 allenai/OLMo-7B-Instruct-hf Qwen2-VL 7B Qwen/Qwen2-VL-7B-Instruct Qwen/Qwen2-7B-Instruct Qwen2.5-VL 7B Qwen/Qwen2.5-VL-7B-Instruct Qwen/Qwen2.5-7B-Instruct InternVL3.5 8B OpenGVLab/InternVL3_5-8B-HF Qwen/Qwen3-8B T able 8: Official HuggingF ace model checkpoints for the open-weight VLMs and their corresponding base LLMs used in our ev aluation. edits) while maintaining existing pretrained kno wledge in the primary memory . At infer - ence time, a router is used to decide which memory to use for an incoming query . If there is no match between the query and the edit scope, the primary memory is selected to gen- erate the final output. In case of a match, the prompt is routed through the side memory to generate the response grounded on the edited kno wledge. 2. GRA CE ( Hartvigsen et al. , 2023 ) introduces an Adaptor at a chosen model layer to cache targeted edits while leaving the pretrained weights frozen. During the editing phase, the Adaptor sav es the hidden activ ation of the de- sired editing fact as a key and learns its cor- rected output as a corresponding v alue. Each ke y is assigned a dynamic search radius that expands or splits to prev ent overlaps and en- courage generalization to similar inputs. At inference time, the Adaptor ev aluates the la- tent distance between the new prompt and the cached keys. If the prompt falls inside a key’ s radius, the Adaptor intercepts the forward pass and outputs the learned corrected value. If there is no match, the input passes through the original pre-trained weights to generate the final response. 3. IKE ( Zheng et al. , 2023 ) introduces an in- context learning approach to edit a model’ s factual kno wledge without altering an y of its pre-trained weights. T o apply an edit, the method retrie ves rele v ant demonstration ex- amples from a training corpus to guide the editing of kno wledge. These demonstrations are specifically formatted into three types: i) copy , to introduce the new fact; ii) update, to help the model generalize the injected kno wl- edge; and iii) retain, to guide the model in preserving unrelated facts. These demonstra- Model # Demonstrations (K) 1 2 3 LLaV A-1.5 88.3% 95.6% 0% Qwen2-VL 100% 100% 99.1% T able 9: Harmonic mean for IKE with up to K = 3 demonstrations. Performance peaks at K = 2 , while adding a third demonstration degrades results, suggest- ing dif ficulty in retrieving the rele vant information from the context. LLaV A-1.5 is an extreme case, as it ends up repeatedly generating \n tokens for K = 3 . tions, along with the actual up-to-date fact, are prepended directly to the user’ s target query to condition the model’ s final answer . Ho wev er , this technique does not represent a realistic scenario, as it requires the rele vant, up-to-date fact to be deterministically pro vided to the model for each target question. For WISE and GRA CE, we used the implemen- tations provided in the EasyEdit framew ork ( W ang et al. , 2023 ), adopting the default configurations and hyperparameters. As LLaV A-1.5 is not di- rectly supported by EasyEdit, we adapted the con- figuration designed for LLaV A-OneV ision, which belongs to a similar model family . Since both methods require training additional layers and a router module, we performed the training on a sin- gle NVIDIA A100 (80 GiB) GPU. For IKE, we randomly selected up to K = 3 demonstrations from the pool of unedited facts. The results in T able 9 show that, while using two demonstrations impro ves the harmonic mean, including a third demonstration degrades perfor - mance. LLaV A-1.5 represents an extreme case: the model generates only \n tokens, possibly because the extended context exceeds its effecti ve conte xt windo w . Based on these observations, we select the configuration with K = 2 for the experiments reported in T able 4 , as it achiev es the highest har - monic mean. 15 Model # Documents (K) 1 3 5 LLaV A-1.5 73.5% 44.7% 8.7% Qwen2-VL 80.1% 69.8% 67.7% T able 10: Harmonic mean for RA G when considering K ∈ { 1 , 3 , 5 } documents as context. A.4 Multimodal RA G W e provide additional details about the dataset con- struction and pipeline used to ev aluate multimodal RA G. A.4.1 Dataset Construction W e construct a set of image-document pairs for Qwen2-VL and LLaV A-1.5 by collecting passages from W ikipedia. For each outdated entity , we ex- tract passages that contain up-to-date attributes from its W ikipedia page. These passages are man- ually verified to ensure they contain the correct answer , and one passage is selected. W e then pair the selected passage with the main figure from the corresponding W ikipedia page. A.4.2 Retriev al and Reranking Pipeline W e implement the multimodal RAG pipeline using the Qwen3-2B Embedder and Reranker ( Zhang et al. , 2025 ). W e encode each image-document pair using the Qwen3-2B Embedder and retriev e the 10 candidates with the highest cosine similarity based on the visual query . The retrieved candidates are then re-ranked using the Qwen3-2B Reranker . T o determine the optimal number of documents K to include in the context, we ev aluate configu- rations with K ∈ { 1 , 3 , 5 } . Results in T able 10 sho w that increasing the number of documents in the context de grades performance for both models, potentially because additional documents introduce irrele vant or distracting information. For the ex- periment reported in T able 4 , we therefore select the configuration with K = 1 , as it achie ves the highest harmonic mean. A.5 Evaluation Metrics Follo wing prior work ( Mousavi et al. , 2024 , 2025 ; Meng et al. , 2022 ), we assess the effecti veness of each approach using the harmonic mean of efficac y and paraphrase success. Giv en a time-sensiti ve question q about a subject-property pair and its up- to-date attribute a , ef ficacy success measures the proportion of cases in which the edited model M returns a for q (i.e., M ( q ) = a ). Instead, para- phrase success measures the proportion of cases in which M returns a when prompted using a para- phrased version q ′ of the same question q (i.e., M ( q ′ ) = a ). A.6 Mechanistic Analysis W e complement the mechanistic analysis presented in Section 4 by reporting the results for LLaV A-1.5. As none of the editing algorithms successfully up- date the same fact, we select one successful edit for WISE and one for GRA CE and report the re- sults in Figure 11 . In contrast to Qwen2-VL, a larger number of layers contrib ute to recalling fac- tual information, suggesting that such knowledge may be stored differently across VLMs. Similar to Figure 3 , GRA CE propagates the modification across layers 20 to 32; notably , this method also significantly reduces the probability of the other attributes. In contrast, WISE mainly affects layer 29, after which the probability gradually decreases in subsequent layers. Interestingly , the strongest ef fect does not occur at the editing layer specified in the configuration of WISE, as the method tar - gets layer 23. Moreov er, the information associated with the other attrib utes is not completely remo ved, suggesting a more localized editing ef fect. Figure 12 presents an example of an unsuccess- ful edit. In this case, both methods sho w little to no change compared to the activ ations of the pre-trained model. Interestingly , the probability of the outdated attributes slightly increases for WISE, similarly to the ef fect described for Qwen2-VL in Figure 3 . 16 William Racing 2025-Now Scuderia Ferrari 2021-2024 McLaren 2019-2020 Renault 2017-2018 T oro Rosso 2015-2017 Aston Martin 2023-Now Renault 2021-2022 McLaren 2015-2018 Scuderia Ferrari 2010-2014 Pre-T rained WISE Pre-T rained 1 0.8 0.6 0.4 0.2 0 20 22 24 26 28 30 32 20 22 24 26 28 30 32 20 22 24 26 28 30 32 20 22 24 26 28 30 32 GRACE Image Question For which club does this player currently play for? Image Question For which club does this player currently play for? 1 0.8 0.6 0.4 0.2 0 T able 11: Mechanistic analysis of LLaV A-1.5 illustrating how editing methods successfully modify the contribution of different layers during f actual recall. Masoud Pezeshkian 2024-Now Ebrahim Raisi 2021-2024 Hassan Rouhani 2013-2021 Mohammad Katami 1997-2005 Akbar Hashemi Rafsanjani 1989-1997 Ali Khamenei 1981-1989 1 0.8 0.6 0.4 0.2 0 WISE Pre-T rained GRACE Mahmoud Ahmadinejad 2005-2013 Image Question Who is the current head of state of this country? 22 24 26 28 30 32 22 24 26 28 30 32 22 24 26 28 30 32 T able 12: Mechanistic analysis of LLaV A-1.5 illustrating how editing methods f ail to modify the contrib ution of different layers during f actual recall. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment