Exploring different approaches to customize language models for domain-specific text-to-code generation
Large language models (LLMs) have demonstrated strong capabilities in generating executable code from natural language descriptions. However, general-purpose models often struggle in specialized programming contexts where domain-specific libraries, A…
Authors: Luís Freire, Fern, a A. Andaló
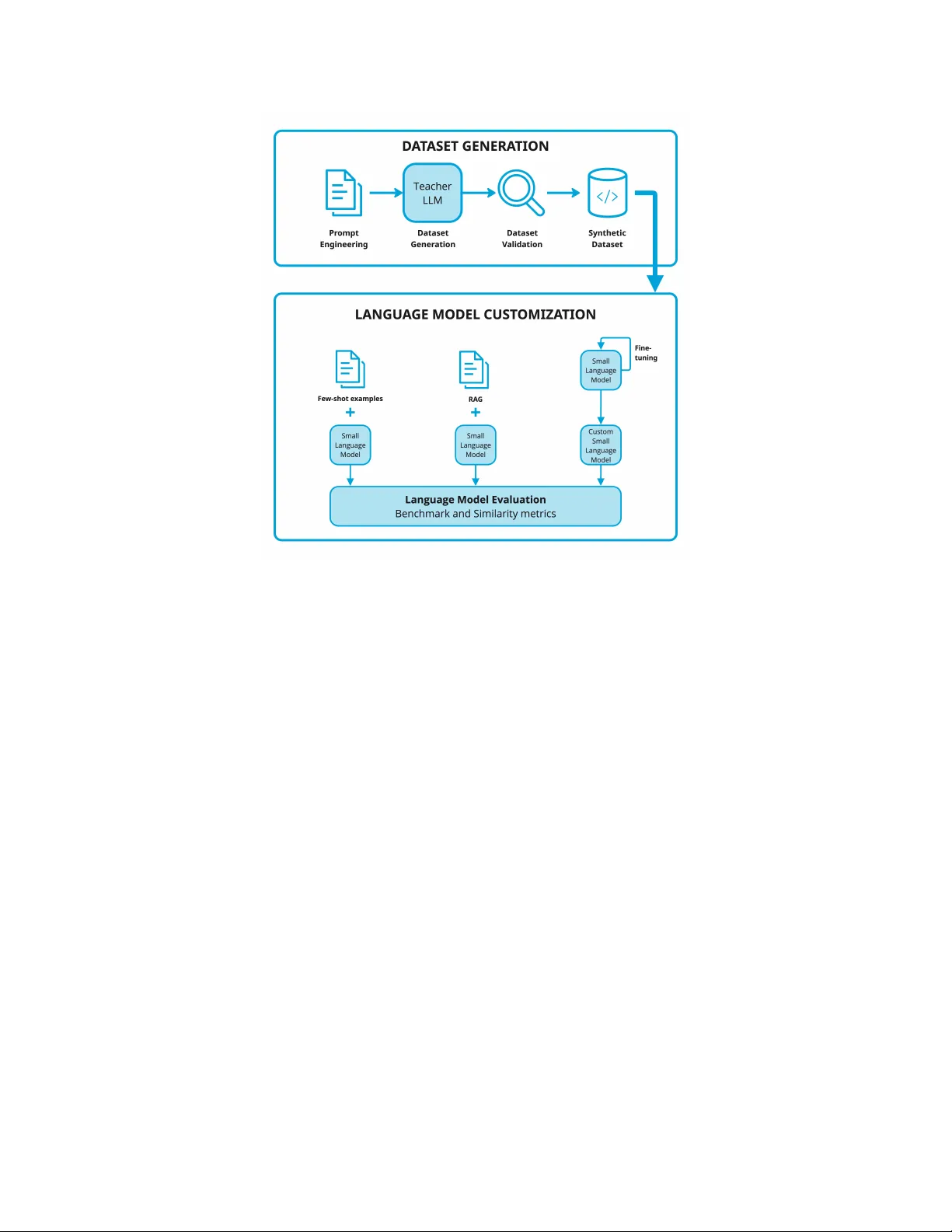
Exploring differ ent appr oaches to customize language models f or domain-specific text-to-code generation Luís Freir e ∗ T echnical Univ ersity of Denmark luis.freire@live.com.pt Fer nanda A. Andaló The LEGO Group fernanda.andalo@LEGO.com Nicki Skafte Detlefsen T echnical Univ ersity of Denmark nsde@dtu.dk Abstract Large language models (LLMs) hav e demonstrated strong capabilities in generating ex ecutable code from natural language descriptions. Howe ver , general-purpose models often struggle in specialized programming contexts where domain-specific libraries, APIs, or conv entions must be used. Customizing smaller open-source models of fers a cost-ef fectiv e alternati ve to relying on large proprietary systems. In this work, we inv estigate ho w smaller language models can be adapted for domain-specific code generation using synthetic datasets. W e construct datasets of programming ex ercises across three domains within the Python ecosystem: general Python programming, Scikit-learn machine learning workflows, and OpenCV -based computer vision tasks. Using these datasets, we e v aluate three customization strate- gies: few-shot prompting, retriev al-augmented generation (RAG), and parameter - ef ficient fine-tuning using Lo w-Rank Adaptation (LoRA). Performance is e v aluated using both benchmark-based metrics and similarity-based metrics that measure alignment with domain-specific code. Our results show that prompting-based approaches such as fe w-shot learning and RA G can impro ve domain rele v ance in a cost-ef fectiv e manner , although their impact on benchmark accuracy is limited. In contrast, LoRA-based fine-tuning consistently achiev es higher accuracy and stronger domain alignment across most tasks. These findings highlight practical trade-offs between fle xibility , computational cost, and performance when adapting smaller language models for specialized programming tasks. 1 Introduction Large Language Models (LLMs) have significantly advanced software development workflows. Recent models generate code from natural language descriptions and assist with tasks such as code completion, debugging, and documentation generation Minaee et al. [2025]. These systems translate natural language specifications into ex ecutable code. Despite these advances, most code-generation models are trained as general-purpose systems that cov er many programming languages and tasks. Although this enables strong overall performance, it can limit effecti v eness in specialized domains where code must follo w specific libraries, frameworks, or con v entions. As a result, models may produce syntactically correct solutions that are misaligned with the intended APIs or domain constraints. ∗ This work b uilds upon research originally conducted as part of Luis Freire’ s master’ s thesis Freire [2025], which contains additional methodological details and extended e xperimental analyses. Preprint. Another practical challenge is the cost and deployability of frontier models. Large proprietary systems often require substantial computational resources Kaplan et al. [2020] and are typically accessible only through external APIs. This limits their use in en vironments where data priv acy , deployment constraints, or computational cost are critical. Consequently , there is growing interest in adapting smaller open-source language models that can be customized and deployed locally while maintaining competitiv e performance. T o address these challenges, we in v estigate how smaller open-source language models can be customized for domain-specific code generation. W e compare three adaptation strategies and analyze their impact on performance, computational cost, and domain alignment in specialized programming contexts, as well as practical factors such as implementation comple xity and data requirements. Customizing a pre-trained language model for a specialized domain can be achieved through sev- eral adaptation strategies that differ in complexity , computational requirements, and the extent to which they modify model parameters. In this work, we focus on three complementary approaches: few-shot learning, which guides generation through in-context examples without updating model parameters Brown et al. [2020]; Retrie val-Augmented Generation (RA G), which augments prompts with rele vant e xamples retrie ved from an external dataset Gao et al. [2024]; and fine-tuning, where the model is specialized using domain-specific data through parameter -ef ficient techniques such as Low-Rank Adaptation (LoRA) Han et al. [2024]. Despite the growing number of language model adaptation techniques, there is limited empirical understanding of ho w they compare for domain-specific code generation with smaller open-source models. In particular, the trade-offs between prompting, retriev al-based methods, and parameter- efficient fine-tuning remain unclear when models must generate code that follo ws specialized APIs and library con ventions. T o study these trade-of fs, we e valuate customization across three programming domains within the Python ecosystem: general Python programming exercises, machine learning workflo ws using Scikit-learn Pedregosa et al. [2011], and computer vision tasks using OpenCV Bradski [2000]. These domains represent distinct programming contexts within the same language while requiring different types of domain knowledge. General Python tasks emphasize logical reasoning and language funda- mentals, whereas Scikit-learn and OpenCV tasks rely on specialized APIs and library con ventions. K eeping the programming language constant while v arying the domain allows us to isolate the effects of model adaptation on domain-specific code generation. Another challenge in domain-specific code generation is the av ailability of suitable training data. High-quality datasets pairing natural language descriptions with correct code implementations are scarce, particularly for specialized programming tasks. T o address this limitation, recent work has explored synthetic data generation, where LLMs produce training examples for smaller models. This strategy can be vie wed as a form of kno wledge distillation. Using this frame work, we evaluate two open-source code-generation models—StarCoder Li et al. [2023] and DeepSeekCoder Guo et al. [2024]—and analyze performance changes under dif ferent adaptation strategies. W e e valuate these approaches using a frame work combining benchmark-based and similarity metrics. Benchmark ev aluations measure the functional correctness of generated solutions through automated test cases, while similarity metrics capture how cl osely generated code aligns with domain-specific coding con ventions. This work makes the follo wing contributions: 1. A systematic empirical comparison of prompting, retrie val-based generation, and parameter- efficient fine-tuning for domain-specific code generation. 2. A pipeline for generating synthetic datasets of domain-specific programming tasks. 3. An e valuation frame work combining functional correctness and domain alignment metrics. 4. Empirical insights into the specialization of small code-generation models. T ogether , the contributions provide practical guidance for adapting smaller language models to specialized programming tasks while balancing performance, cost, and deployment constraints. 2 2 Background LLMs are typically trained with autoregressi ve objectives that predict the next token from the preceding context. Most modern models rely on the T ransformer architecture V aswani et al. [2017], which uses self-attention to capture dependencies between tokens. T rained on large corpora of te xt, these models can learn patterns in programming syntax and code structure, enabling tasks such as code completion and program synthesis Chen et al. [2022]. During inference, LLMs can perform in-context learning , where task beha vior is inferred from examples provided in the prompt without updating model parameters. In this setting, prompt examples act as demonstrations from which the model generalizes input–output mappings to new queries. The effecti veness of this process depends on factors such as the number and ordering of examples, the clarity of demonstrations, and the a v ailable context length. A key limitation is the fix ed-size context window , which determines the maximum number of tokens the model can process at once. All prompt instructions and previously generated tokens must fit within this window . As a result, prompt-based approaches such as few-shot learning Brown et al. [2020] can only include a limited number of examples to guide the model. Prompt-based methods can be extended by incorporating external information sources. Retriev al- Augmented Generation (RA G) retrie ves rele v ant documents or examples from an e xternal dataset at inference time Gao et al. [2024]. This approach combines parametric kno wledge with non-parametric external memory , allo wing models to access domain-specific information not encoded in their weights. Howe ver , the retriev ed content must still fit within the model’ s context windo w , which limits how much external information can be incorporated into the prompt. Another approach to adapting language models is fine-tuning , which modifies the model parameters to incorporate new kno wledge directly . Howe ver , updating all parameters can be computationally expensi ve for modern LLMs. Parameter -ef ficient fine-tuning techniques address this challenge by introducing small trainable components while keeping most parameters frozen Han et al. [2024]. A widely used method is Low-Rank Adaptation (LoRA), which adds trainable lo w-rank matrices to selected network layers to enable ef ficient task specialization Hu et al. [2022]. A practical challenge in domain-specific code generation is the limited av ailability of suitable training data. Many programming domains lack datasets pairing natural language descriptions with corresponding code implementations. Recent work addresses this limitation using synthetic datasets generated by lar ge language models, where a lar ger teacher model produces examples for training smaller models. This process can be vie wed as a form of knowledge distillation Hinton et al. [2015] and has been successfully applied in studies such as T inyStories Eldan and Li [2023] and Phi-1 Gunasekar et al. [2023]. Evaluating code generation models presents challenges be yond those in natural language generation. Benchmark-based ev aluation measures functional correctness by executing generated programs against predefined test cases, as in benchmarks such as HumanEval Chen et al. [2022], but may ov erlook dif ferences in coding style, structure, or API usage that are important in domain-specific settings. Similarity-based metrics instead measure how closely generated code aligns with reference implementations. T raditional metrics such as BLEU Papineni et al. [2002] and R OUGE Lin [2004] rely on n-gram overlap and often fail to capture the structural and semantic properties of source code, while metrics such as CodeBLEU Ren et al. [2020] incorporate syntax-tree and data-flow information. Because functional correctness and structural similarity capture complementary aspects of code quality , we combine both ev aluation strategies in our experiments. 3 Overview of the customization pipeline This work in vestig ates ho w smaller open-source language models can be customized for domain- specific code generation using synthetic datasets and different adaptation strategies. Smaller models are attractiv e because they require fe wer computational resources and can be deployed in en vironments where larger models are impractical. Figure 1 illustrates the customization pipeline used in this study . The proposed pipeline consists of four stages. First, domain-specific programming ex ercises in the Python ecosystem are generated by an LLM acting as a teacher , where each e xample pairs a natural language task description with a Python implementation. The teacher model is used only for dataset 3 Figure 1: Overview of the customization pipeline. Synthetic programming exercises are generated by a teacher LLM and filtered through a validation stage. The resulting datasets are used to adapt smaller models via few-shot prompting, RA G, and LoRA-based fine-tuning. The adapted models are ev aluated using benchmark and similarity metrics. generation. Second, the generated samples are v alidated to remov e in valid or inconsistent outputs, ensuring that the resulting datasets contain syntactically correct and semantically valid code. Third, the v alidated datasets are used to adapt smaller language models through few-shot learning, RA G, and LoRA-based fine-tuning. Finally , the adapted models are e valuated using benchmark and similarity metrics. Benchmark ev aluations measure functional correctness through automated test cases, while similarity metrics capture how closely generated code aligns with the reference implementations. The following sections describe each component of the pipeline, including dataset construction, model adaptation strategies, and the e v aluation frame work. 4 Synthetic dataset construction T o support the ev aluation of domain-specific code generation models, we construct synthetic datasets of programming e xercises using an LLM as a teacher . This follo ws a kno wledge distillation paradigm where a larger model generates training e xamples later used to adapt smaller models. In this work, synthetic data is generated using GPT -4o OpenAI [2024], an LLM with strong capabili- ties in natural language understanding and code generation. The model is used only during dataset creation to produce programming ex ercises paired with Python implementations. These examples form the basis for subsequent model adaptation experiments. 4.1 Prompt engineering Each example consists of a natural language problem description and a Python implementation. The problem statement appears as a docstring at the beginning of the code snippet, while the solution includes the required imports and commented code implementing the functionality . This structure ensures a consistent format resembling typical programming ex ercises. 4 T o produce di v erse ex ercises across domains and dif ficulty le vels, we use structured prompts with control variables that guide generation and allo w the dataset pipeline to produce tasks with different characteristics. The main variables include: • topic : programming concept or library feature targeted by the e xercise. • profession : domain context simulating a realistic application scenario. • skill_level : difficulty le vel (e.g., beginner , intermediate, advanced). • user_interaction : whether the ex ercise requires user interaction. • error_handling : whether the implementation handles in valid inputs. T o ensure suf ficient topic cov erage, an automated pipeline expanded the list of programming topics. For each domain, core topics were identified from official documentation and extended by prompting the teacher model to generate additional subtopics. By sampling combinations of these v ariables, the pipeline produces ex ercises cov ering div erse programming concepts and real-world scenarios. Figure 2 shows the prompt template used to generate Python programming exercises. Using this prompt template, the teacher model generates programming exercises that follo w a consistent structure. Figure 3 shows an e xample of a generated dataset sample. Y ou are an expert Python instructor tasked with creating specialized programming e xercises tailored to v arious professions. Create a Python programming exercise simulating a realistic scenario in the field of {profession},specifically focusing on the topic of {topic}. The exercise should be suitable for {skill_le vel} le vel, include a clear problem statement, be practical and not o verly theoretical. The user interaction should be {user_interaction} and the error handling should be {error_handling}. The output should be the code with the problem statement as a docstring, and also comments explaining the solution. Do not include any further explanations or other te xt outside the code snippet. Only import con ventional libraries. The structure of the response should be: ‘‘‘python """ Problem statement """ imports code ‘‘‘ Figure 2: Prompt template used for dataset generation This prompt-based generation pipeline enables the creation of many structured programming ex ercises for adapting small language models and e valuating domain-specific code generation. The generated samples are then processed through a validation stage to ensure syntactic and semantic correctness. 4.2 Dataset Analysis After generation, the samples were analyzed to understand dataset characteristics and identify potential issues before validation. Using this workflow , approximately 21 . 6 thousand ex ercises were generated per domain. Each request to the teacher model required about 30 seconds on av erage, with roughly 150 input tokens and a maximum generation length of up to 1500 tokens. Overall, the process produced about 9 . 7 million input tokens and 35 million output tokens, with a total cost of approximately $374 using the GPT -4o API. A subset of approximately 5000 samples per domain was analyzed to understand the generated dataset. Figure 4 shows the distribution of sample lengths, with most samples between 300 and 700 tokens including both the task description and Python implementation. The average length is about 520 tokens for general Python e xercises and about 540 tokens for Scikit-learn and OpenCV , indicating similar ex ercise sizes across domains while preserving sufficient task comple xity . T o further e xamine the structure of the generated e xercises, the lengths of the problem descriptions and the corresponding code solutions were analyzed separately . The results show that general Python ex ercises tend to contain longer textual descriptions, while tasks in volving Scikit-learn often produce longer code implementations due to additional steps such as dataset preparation, model training, and ev aluation. Exercises in the OpenCV domain exhibit similar behavior , where solutions frequently include multiple image-processing operations. 5 """ Problem Statement: In the field of bioinformatics, DNA sequences are often analyzed to find patterns or specific nucleotide occurrences. Y ou are giv en a list of DN A strands. Y our task is to write a Python function that counts the occurrence of each nucleotide (’A’, ’T’, ’C’, ’G’) in a giv en DNA strand and returns the result as a dictionary. Instructions: 1. Define a function named ‘count_nucleotides‘ that takes a single parameter: a string representing a DN A strand. 2. Initialize a dictionary to store the count of each nucleotide. 3. Iterate over the DN A strand and update the count for each nucleotide in the dictionary. 4. Return the dictionary containing the nucleotide counts. Example: Input: " A TCGA TCGA " Output: {’A’: 3, ’T’: 2, ’C’: 2, ’G’: 2} """ # Define the function to count nucleotides def count_nucleotides(dna_strand): # Initialize a dictionary to store nucleotide counts nucleotide_count = { ’A’ : 0, ’T’ : 0, ’C’ : 0, ’G’ : 0} # Iterate over each character in the DN A strand for nucleotide in dna_strand: # Update the count for the current nucleotide if nucleotide in nucleotide_count: nucleotide_count[nucleotide] += 1 # Return the dictionary with counts return nucleotide_count # Example usage dna_sequence = "A TCGA TCGA" print (count_nucleotides(dna_sequence)) # Output: {’A’: 3, ’T’: 2, ’C’: 2, ’G’: 2} Figure 3: Example of a generated programming ex ercise. Figure 4: Sample length distribution across the three domains. In addition to length statistics, the generated samples were inspected to verify whether the produced code relies on the expected libraries for each domain. The analysis shows that Python exercises primarily use standard libraries, while Scikit-learn and OpenCV tasks frequently import domain- specific libraries together with supporting packages such as numpy . This indicates that the prompt- based generation process successfully encourages the use of appropriate APIs for each domain. 6 While the analysis confirms that the generated dataset captures realistic programming patterns, it also rev eals occasional inconsistencies in formatting or execution beha vior . T o ensure dataset reliability , a validation pipeline is applied to filter in valid samples, as described in the follo wing subsection. 4.3 Dataset V alidation Although the teacher model can generate coherent programming exercises, the process may occa- sionally produce malformed or inconsistent outputs, such as incomplete code blocks, syntax errors, missing imports, or references to in v alid libraries or API methods. T o ensure dataset reliability , generated samples are processed through a two-stage validation pipeline before being used for model adaptation and ev aluation. The first stage verifies the syntactic correctness of the generated code. Each sample is parsed using Python’ s abstract syntax tree (AST) parser to ensure v alid syntax, and samples that cannot be parsed are remov ed from the dataset. The second stage performs semantic validation of imported modules and referenced attributes. Using Python’ s module inspection utilities, each import and attribute chain is checked to ensure the referenced APIs exist. Samples referencing in valid modules or attrib utes are remo ved. T able 1 summarizes the v alidation results. Most samples pass validation, with retention rates abov e 92% across all domains. The remaining samples form the final dataset. T able 1: Dataset size before and after validation. Domain Generated Samples V alid Samples Retention Rate General Python Exercises 21,745 21,042 96.8% OpenCV Exercises 22,770 21,039 92.4% Scikit-learn Exercises 20,330 20,052 98.6% 4.4 Dataset split V alidated datasets are split into training, validation, and test sets. The training set is used for fine- tuning, as the document pool for RA G retriev al, and as examples for few-shot prompting. The validation set monitors training performance and computes intermediate metrics, while the test set is reserved for final e v aluation. The datasets are split into 97% training, 1% validation, and 2% test data. This ensures a comparable number of ev aluation examples to common code-generation benchmarks, resulting in approximately 200 validation and 400 test samples per use case. 5 Language model customization This section describes the models and customization techniques used in our experiments. 5.1 Base models W e consider two open-source language models for code generation: StarCoder Li et al. [2023] and DeepSeekCoder Guo et al. [2024]. These models provide strong performance on programming benchmarks while remaining small enough to be adapted with modest computational resources. StarCoder Li et al. [2023] is a family of decoder-only models ranging from 1 B to 15 . 5 B parameters. It was trained on The Stac k K ocetkov et al. [2022], a large collection of permissi vely licensed GitHub repositories containing about one trillion tokens across more than 80 programming languages. The model supports context windows up to 8 k tokens and uses the Fill-in-the-Middle (FIM) objectiv e, enabling both code generation and infilling tasks. DeepSeekCoder Guo et al. [2024] is a decoder-only code model trained on about two trillion tokens, primarily source code from GitHub repositories across 87 programming languages. The models 7 range from 1 . 3 B to 33 B parameters and support context windo ws up to 16 k tokens. Like StarCoder , DeepSeekCoder uses the FIM objectiv e and supports code completion and infilling. In contrast, GPT -4o OpenAI [2024] is used only as a teac her model during dataset generation. Due to its large scale and proprietary nature, it is not customized in our experiments. Instead, it generates synthetic training data used to adapt the smaller open-source models to the target domains. 5.2 Customization techniques W e in vestigate three strategies for adapting language models to domain-specific code generation: few-shot learning, retrie val-augmented generation (RA G), and parameter-efficient fine-tuning. Few-shot learning guides the model during inference by pro viding example task–solution pairs in the prompt context. This approach le verages the in-context learning capabilities of language models without modifying their parameters Bro wn et al. [2020]. In our setup, examples from the synthetic training dataset are appended to the prompt to illustrate how similar tasks should be solv ed. Retrieval-A ugmented Generation (RA G) enhances prompting by dynamically retrieving rele vant examples from an external knowledge source Gao et al. [2024]. In our setup, training examples are embedded using the sentence-transformers/all-MiniLM-L6-v2 Sentence-Transformers model and stored in a vector database. During inference, the query embedding retrieves the most similar examples, which are inserted into the prompt. This extends the model’ s effecti ve memory and enables access to domain-specific examples be yond the static prompt. Fine-tuning specializes the model by updating parameters using the synthetic dataset. Instead of full fine-tuning, we use Low-Rank Adaptation (LoRA) Hu et al. [2022], a parameter-ef ficient method that freezes the original weights and introduces trainable low-rank matrices to approximate weight updates. This reduces the number of trainable parameters while preserving the base model’ s knowledge. LoRA is applied to the attention projection matrices of the T ransformer architecture following the standard PEFT setup Han et al. [2024]. 5.3 Inference and e valuation setup All experiments use a consistent inference configuration across customization techniques. Code gen- eration uses greedy decoding, selecting the most probable token at each step to ensure reproducibility . Model performance is ev aluated using both benchmark-based and similarity metrics. Benchmark evaluation measures the functional correctness of the code generated using automated test suites. For general Python tasks we use the HumanEv al benchmark Chen et al. [2022], which contains 164 programming problems with unit tests. For domain-specific tasks we use subsets of BigBenchCode Zhuo et al. [2025] for the Scikit-learn and OpenCV libraries ( BCSk with 152 tasks and BCCV with 10 tasks). While benchmarks measure functional correctness, they do not capture whether generated code aligns with domain-specific con ventions. W e therefore also consider similarity ev aluation , which measures how closely generated code matches the target dataset. Cosine similarity is computed between embeddings of generated solutions and reference implementations using the same embedding model employed for retrie val. T wo variants are used: validation similarity (to guide fine-tuning) and test similarity (for final ev aluation). T ogether, these metrics provide a complementary view of model performance, capturing both functional correctness and structural similarity to domain-specific code. 6 Results W e present the empirical e valuation of the customization techniques. W e report baseline performance and analyze the impact of fe w-shot learning, RA G, and LoRA-based fine-tuning. Performance is measured using benchmark-based metrics (P ass@1) and similarity metrics capturing alignment with the target datasets. For general Python tasks we use the HumanEval benchmark, while for library-specific tasks we use BigBenchCode subsets: BCSk for Scikit-learn and BCCV for OpenCV . T able 2 summarizes the results. For each customization technique, we report benchmark accurac y (Pass@1), similarity scores, and the change relati ve to the baseline. A detailed hyperparameter analysis is provided in Freire [2025]. 8 T able 2: Performance of customization techniques across domains. Pass@1 measures benchmark correctness, and Sim. denotes cosine similarity to reference solutions. V alues in parentheses indicate changes relati ve to the baseline (percentage points). Few-shot and RA G use 3 examples, with RA G applying a threshold of 0.5. LoRA fine-tuning uses r = 128 and α = 128 . Bold values indicate the best result per model, while the blue background highlights the best result across models. Python Scikit-learn OpenCV Method Pass@1 Sim. Pass@1 Sim. Pass@1 Sim. StarCoder -1B Baseline 16 . 0 73 . 6 13 . 2 62 . 8 0 . 0 79 . 4 Few-shot 14 . 6 (-1.4) 75 . 8 (+2.2) 3 . 9 (-9.3) 68 . 0 (+5.2) 10 . 0 (+10.0) 81 . 1 (+1.7) RA G 14 . 0 (-2.0) 80 . 9 (+7.3) 4 . 6 (-8.6) 74 . 5 (+11.7) 0 . 0 87 . 6 (+8.2) LoRA 18.3 (+2.3) 87.1 (+13.5) 20.4 (+7.2) 77.5 (+14.7) 20.0 (+20.0) 87.1 (+7.8) DeepSeekCoder -1.3B Baseline 30 . 5 84 . 2 32 . 9 73 . 2 20 . 0 85 . 9 Few-shot 39 . 0 (+8.5) 82 . 2 (-2.0) 28 . 9 (-4.0) 74 . 5 (+1.3) 0 . 0 (-20.0) 86 . 4 (+0.5) RA G 39.6 (+9.1) 85 . 6 (+1.4) 29 . 6 (-3.3) 78 . 5 (+5.3) 20 . 0 88 . 2 (+2.3) LoRA 38 . 4 (+7.9) 88.2 (+4.0) 33.9 (+1.0) 81.9 (+9.4) 50.0 (+30.0) 90.9 (+6.0) 6.1 Baseline performance Before applying customization, we e valuate the base models on the benchmarks to establish a reference point. Overall, DeepSeekCoder-1.3B outperforms StarCoder-1B in the baseline setting. On the Python benchmark, DeepSeekCoder achie ves 30 . 5% Pass@1 compared to 16 . 0% for StarCoder . A similar pattern appears in the domain-specific benchmarks. In particular , DeepSeekCoder reaches 20 . 0% Pass@1 on OpenCV , while StarCoder fails to solve an y tasks. The similarity metrics follow the same pattern, with DeepSeekCoder producing outputs closer to the reference implementations. This indicates that its stronger baseline capabilities provide a better starting point for domain-specific code generation. At the same time, the lo wer scores on the Scikit-learn and OpenCV benchmarks highlight the difficulty of generating code that correctly uses specialized APIs and library con ventions. This motiv ates the use of customization techniques to improv e domain alignment and functional correctness. 6.2 Few-shot lear ning Few-shot learning is e valuated by providing dif ferent numbers of example task–solution pairs in the prompt. W e test configurations ranging from one to ten examples, depending on the model’ s context length. In T able 2, we report the 3-shot results for simplicity . The results show that few-shot prompting can slightly increase similarity to the target dataset, particularly with three to five prompt examples. Ho wev er , improv ements in benchmark accuracy are limited. In some cases, adding more examples introduces noise or reduces performance due to context windo w limits. Overall, few-shot learning provides modest improvements with minimal implementation cost but remains limited by prompt length and the model’ s e xisting knowledge. These limitations moti v ate retriev al-augmented generation, which provides rele v ant context dynamically instead of relying on static prompt examples. 6.3 Retrieval-A ugmented Generation RA G extends fe w-shot prompting by dynamically retrieving rele vant examples instead of relying on a fixed set of prompt examples. In our setup, training examples are embedded and stored in a vector database, and the most similar ones are retriev ed at inference time and inserted into the prompt. 9 Figure 5: Training dynamics during LoRA fine-tuning for DeepSeekCoder on Python tasks ( α = r = 128 ). The plot shows v alidation similarity and HumanEval P ass@1 during training. Increases in validation similarity correlate with impro vements in benchmark accurac y . Similar to the few-shot experiments, we ev aluate different numbers of retrie ved examples and similarity thresholds for filtering retriev ed documents. In T able 2, we report results using 3 retrie ved examples with a threshold of 0 . 5 . The results show that RA G can substantially increase similarity to the tar get dataset, indicating that retriev ed examples help guide the model toward domain-specific coding patterns. This effect is particularly visible for StarCoder-1B, with similarity increases of up to +11 . 7 points for Scikit-learn and +8 . 2 points for OpenCV . Howe ver , improvements in benchmark accuracy are less consistent. DeepSeekCoder achiev es stronger Python performance with RA G ( 39 . 6% Pass@1), b ut the approach can reduce performance for StarCoder and on library-specific tasks. This suggests that retrie ved examples may improv e stylistic alignment with the dataset without consistently improving functional correctness. Overall, RA G improv es domain alignment more consistently than fe w-shot prompting, but its impact on benchmark accuracy depends on the quality of the retrie ved e xamples. 6.4 Fine-tuning W e ev aluate parameter-ef ficient fine-tuning using LoRA. The base models are adapted using the synthetic training dataset while keeping the original model weights frozen and training only the low-rank adaptation matrices. During fine-tuning, we monitor both validation similarity and benchmark performance. Figure 5 illustrates the evolution of these metrics during LoRA training for the Python tasks. In general, improv ements in validation similarity correlate with increases in benchmark accurac y , supporting its use as a signal for selecting the final model. Sev eral fine-tuning configurations were explored, including different training settings and LoRA hyperparameters. For brevity , T able 2 reports results for r = 128 and α = 128 . This corresponds to 57 . 4 M trainable parameters for StarCoder-1B and 50 . 4 M for DeepSeekCoder -1.3B. LoRA produces the largest gains among the customization techniques. Compared to the baseline, fine-tuning consistently improv es both benchmark accuracy and similarity to the target datasets. Gains are particularly pronounced for the domain-specific benchmarks. On OpenCV tasks, StarCoder gains +20 . 0 Pass@1 points and DeepSeekCoder +30 . 0 . StarCoder also gains +7 . 2 points on the Scikit-learn benchmark. 10 Fine-tuning also yields the lar gest similarity gains across domains, indicating that the models learn coding patterns closer to the target datasets. For example, StarCoder gains +14 . 7 similarity points on Scikit-learn tasks, while DeepSeekCoder gains +9 . 4 . Overall, these results sho w that LoRA-based fine-tuning is the most ef fectiv e customization strategy in our experiments, yielding substantial g ains in both functional correctness and domain alignment compared to prompting-based approaches. 6.5 Comparison of customization techniques The three customization strategies differ not only in performance but also in data requirements, computational cost, and deployment complexity . Few-shot learning is the simplest approach, requiring no additional training or infrastructure. By inserting a small number of example task–solution pairs into the prompt, the model leverages in- context learning to adapt its output. Howe ver , this approach is limited by the model’ s context windo w and relies on knowledge encoded during pre-training. In our experiments, few-shot prompting yields only modest improv ements and does not consistently improv e benchmark accuracy . RA G extends this idea by dynamically retrieving relev ant examples instead of relying on a fixed set of prompt e xamples. This allo ws the model to access more domain-specific e xamples than can fit in the prompt. In our experiments, RA G consistently increases similarity to the target datasets, indicating that retriev ed examples guide the model tow ard domain-specific coding patterns. Howe ver , its impact on benchmark accurac y is less consistent, as retrie ved e xamples may introduce unnecessary operations that reduce functional correctness. Fine-tuning requires the largest upfront in vestment in data preparation and computational resources. T raining LoRA adapters updates millions of parameters and requires GPU resources. Howe ver , once trained, the adapted model can be deployed without long prompts or retrie val infrastructure. In our experiments, LoRA-based fine-tuning yields the most consistent improv ements in both benchmark accuracy and similarity , particularly for domain-specific tasks. The ef fectiv eness of each customization strate gy also depends on the base model. DeepSeekCoder generally benefits more from in-conte xt methods such as fe w-shot learning and RA G, likely due to its stronger baseline and lar ger pre-training dataset. In contrast, StarCoder sho ws larger g ains from fine-tuning, suggesting that parameter updates better compensate for limitations in its pre-training. Figure 6 illustrates these dif ferences with example solutions for a HumanEval task. The baseline model produces an incorrect recursiv e implementation due to a missing base case, while the cus- tomized approaches generate valid solutions. In particular , the fine-tuned model produces a concise implementation that follows common coding patterns. Overall, while prompting-based approaches of fer simplicity and lo w deployment cost, LoRA-based fine-tuning provides the most reliable strate gy for adapting smaller language models to specialized domains, yielding the largest gains in both functional correctness and domain alignment. 7 Conclusion W e in vestigated ho w smaller open-source language models can be customized for domain-specific code generation using synthetic datasets and lightweight adaptation techniques. Our pipeline uses a large language model to generate synthetic programming ex ercises that are then used to adapt smaller models through prompting, retriev al, and parameter-efficient fine-tuning. Experiments across three domains—general Python, Scikit-learn, and OpenCV—sho w that cus- tomization improv es the performance of smaller models. Few-shot learning pro vides a simple and low-cost mechanism but yields modest improv ements. Retriev al-augmented generation increases similarity to the target datasets by providing rele v ant examples at inference time, although its impact on benchmark accuracy is less consistent. Among the e valuated approaches, LoRA-based fine-tuning achiev es the lar gest gains in both functional correctness and domain alignment. The results also highlight the role of the base model. DeepSeekCoder performs better in the baseline setting and benefits more from in-conte xt methods, while StarCoder sho ws larger g ains when fine- 11 Baseline - Fail if n == 0: return 0 elif n == 1: return 0 elif n == 2: return 2 else : return fib4(n − 1) + fib4(n − 2) + fib4(n − 3) + fib4(n − 4) Few-shot - P ass # Initialize the first two Fib4 numbers fib4_numbers = [0, 0, 2, 0] # Iterate through the remaining Fib4 numbers for i in range (4, n + 1): # Calculate the next Fib4 number fib4_numbers.append( fib4_numbers[i − 1] + fib4_numbers[i − 2] + fib4_numbers[i − 3] + fib4_numbers[i − 4] ) # Return the n−th Fib4 number return fib4_numbers[n] RA G - Pass # Base case if n == 0: return 0 elif n == 1: return 0 elif n == 2: return 2 elif n == 3: return 0 # Recursiv e case return fib4(n − 1) + fib4(n − 2) + fib4(n − 3) + fib4(n − 4) LoRA Fine-tuned - Pass # Initialize the list of Fib4 numbers fib4_numbers = [0, 0, 2, 0] # Iterate through the sequence up to n for i in range (4, n + 1): # Calculate the next Fib4 number using # the previous 4 numbers fib4_numbers.append( sum (fib4_numbers[−4:]) ) # Return the n−th Fib4 number return fib4_numbers[n] Figure 6: Example solutions for HumanEval task 46 across customization strate gies. tuned. This suggests that parameter-ef ficient fine-tuning can compensate for limitations in the pre-training of smaller models. Overall, these findings sho w that combining synthetic dataset generation with lightweight customiza- tion techniques provides a practical strategy for adapting smaller language models to specialized programming domains. Future work may extend this pipeline to additional domains, impro ve retriev al strategies for RA G, and develop better e valuation methods for domain-specific code generation. References Luis Freire. Exploring different approaches to customize LLMs for text-to-code generation. Master’ s thesis, T echnical Univ ersity of Denmark, 2025. Shervin Minaee, T omas Mikolov , Narjes Nikzad, Meysam Chenaghlu, Richard Socher , Xavier Amatriain, and Jianfeng Gao. Large language models: A surve y . arXiv pr eprint , 2025. Jared Kaplan, Sam McCandlish, T om Henighan, T om B. Brown, Benjamin Chess, Rew on Child, Scott Gray , Alec Radford, Jef fre y W u, and Dario Amodei. Scaling la ws for neural language models. arXiv pr eprint , arXi v:2001.08361, 2020. T om B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Sam McCandlish, Greg Brockman, and OpenAI T eam. Language models are few-shot learners. In Advances in Neural Information Pr ocessing Systems , pages 1877–1901, 2020. Y unfan Gao, Y un Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Y uxi Bi, Y i Dai, Jiawei Sun, Meng W ang, and Haofen W ang. Retriev al-Augmented Generation for large language models: A survey . arXiv pr eprint , arXi v:2312.10997, 2024. 12 Zeyu Han, Chao Gao, Jin yang Liu, Jef f Zhang, and Sai Qian Zhang. Parameter-Ef ficient Fine-T uning for large models: A comprehensiv e surve y . arXiv preprint , arXi v:2403.14608, 2024. Fabian Pedregosa, Gaël V aroquaux, Alexandre Gramfort, V incent Michel, Bertrand Thirion, et al. Scikit-learn: Machine learning in Python. Journal of Machine Learning Resear ch , 12:2825–2830, 2011. Gary Bradski. The OpenCV Library. Dr . Dobb’ s J ournal of Softwar e T ools , 2000. Raymond Li, Loubna Ben Allal, et al. StarCoder: may the source be with you! arXiv preprint , arXiv:2305.06161, 2023. Daya Guo, Qihao Zhu, Dejian Y ang, Zhenda Xie, Kai Dong, W entao Zhang, Guanting Chen, Xiao Bi, Y . W u, Y . K. Li, Fuli Luo, Y ingfei Xiong, and W enfeng Liang. DeepSeek-Coder: When the large language model meets programming – the rise of code intelligence. arXiv preprint , arXiv:2401.14196, 2024. Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser , and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Pr ocessing Systems , pages 6000–6010, 2017. Mark Chen, Jerry T worek, et al. Evaluating lar ge language models trained on code. In International Confer ence on Learning Repr esentations , pages 1–13, 2022. Edward J Hu, Y elong Shen, Phillip W allis, Ze yuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. LoRA: Low-rank adaptation of large language models. In International Confer ence on Learning Repr esentations , pages 1–10, 2022. Geoffre y Hinton, Oriol V inyals, and Jef f Dean. Distilling the knowledge in a neural network. arXiv pr eprint , arXi v:1503.02531, 2015. Ronen Eldan and Y uanzhi Li. T inyStories: How small can language models be and still speak coherent english? arXiv preprint , arXi v:2305.07759, 2023. Suriya Gunasekar , Y i Zhang, Jyoti Aneja, Caio César T eodoro Mendes, Allie Del Giorno, Siv akanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustav o de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin W ang, Sébastien Bubeck, Ronen Eldan, Adam T auman Kalai, Y in T at Lee, and Y uanzhi Li. T extbooks are all you need. arXiv pr eprint , arXiv:2306.11644, 2023. Kishore Papineni, Salim Roukos, T odd W ard, and W ei-Jing Zhu. Bleu: a method for automatic ev aluation of machine translation. In Annual Meeting of the Association for Computational Linguistics , pages 311–318, 2002. Chin-Y ew Lin. ROUGE: A package for automatic e valuation of summaries. In Annual Meeting of the Association for Computational Linguistics , pages 74–81, 2004. Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu T ang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. CodeBLEU: a method for automatic ev aluation of code synthesis. arXiv pr eprint , arXi v:2009.10297, 2020. OpenAI. Hello GPT-4o, 2024. URL https://openai.com/index/hello- gpt- 4o/ . Accessed: 2025-08-15. Denis K ocetko v , Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Y acine Jernite, Margaret Mitchell, Sean Hughes, Thomas W olf, Dzmitry Bahdanau, Leandro von W erra, and Harm de Vries. The Stack: 3 TB of permissively licensed source code. arXiv pr eprint , arXiv:2211.15533, 2022. Sentence-T ransformers. all-MiniLM-L6-v2 model on HuggingFace. URL https://huggingface. co/sentence- transformers/all- MiniLM- L6- v2 . Accessed: 2025-08-20. T erry Y ue Zhuo, Minh Chien V u, et al. BigCodeBench: Benchmarking code generation with diverse function calls and complex instructions. arXiv pr eprint , arXi v:2406.15877, 2025. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment