From the Inside Out: Progressive Distribution Refinement for Confidence Calibration
Leveraging the model's internal information as the self-reward signal in Reinforcement Learning (RL) has received extensive attention due to its label-free nature. While prior works have made significant progress in applying the Test-Time Scaling (TT…
Authors: Xizhong Yang, Yinan Xia, Huiming Wang
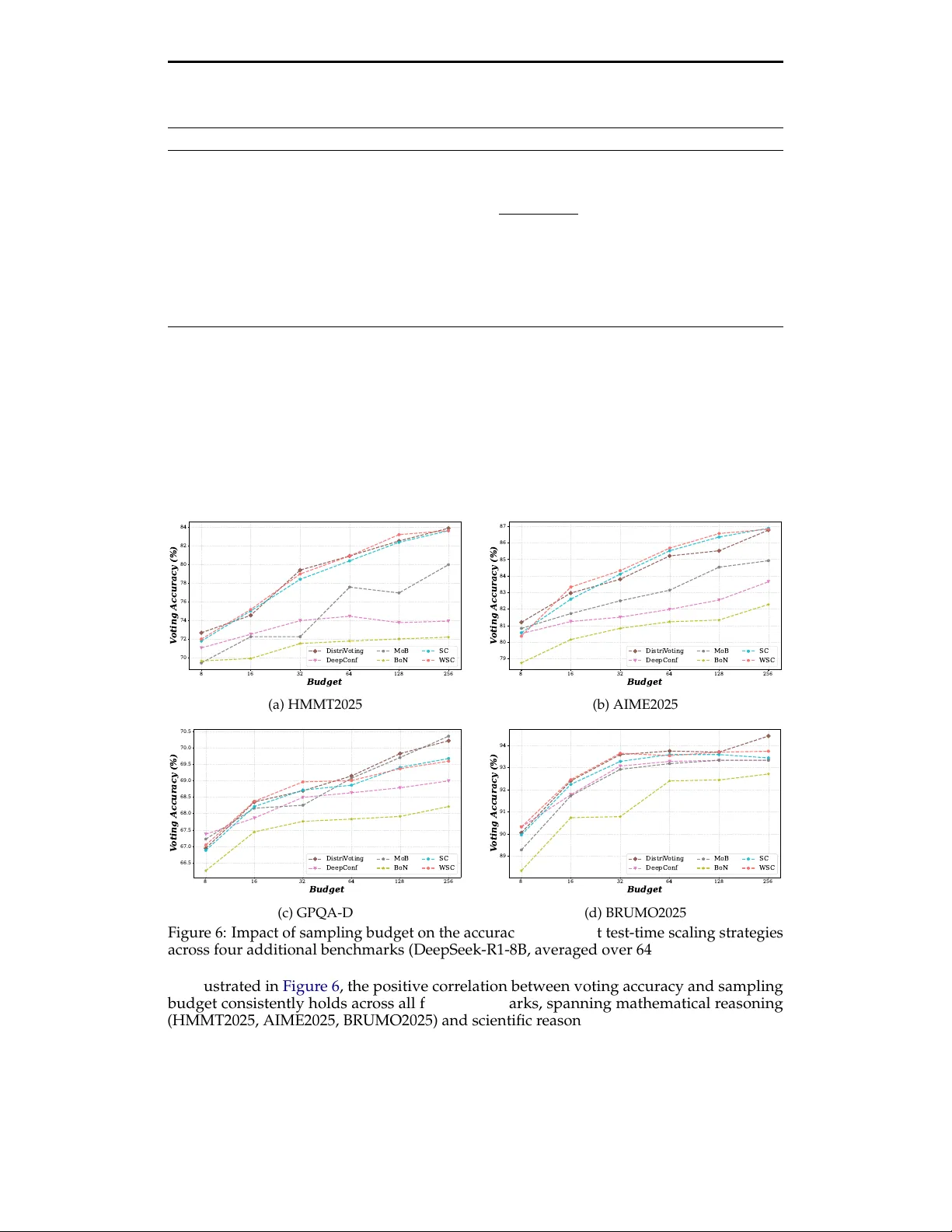
Preprint. Under review . From the Inside Out: Progressive Distribution Refinement for Confidence Calibration Xizhong Y ang 1 ∗ Y inan Xia 2 Huiming W ang 3 † Mofei Song 1† 1 Southeast University , 2 Kuaishou T echnology , 3 SUTD † huiming wang@mymail.sutd.edu.sg , † songmf@seu.edu.cn Abstract Leveraging the model’s internal information as the self-rewar d signal in Reinforcement Learning (RL) has received extensive attention due to its label-free natur e. While prior works have made significant progress in ap- plying the T est-T ime Scaling (TTS) strategies to RL, the discr epancy in inter- nal information between test and training remains inadequately addressed. Moreover , T est-T ime T raining based on voting-based TTS strategies often suffers from rewar d hacking problems. T o address these issues, we propose DistriTTRL , which leverages the distribution prior of the model’s confidence during RL to progr essively optimize the rewar d signal, rather than relying solely on single-query rollouts. Additionally , we mitigate the phenomenon of consistent rewar d hacking caused by the voting-based TTS strategies through diversity-tar geted penalties. Benefiting from this training mech- anism where model capability and self-r eward signals complement each other , and the mitigation of rewar d hacking, DistriTTRL has achieved signif- icant performance improvements across multiple models and benchmarks. Code available at https://github.com/yxizhong/DistriTTRL . 1 Introduction The development of techniques such as Chain-of-Thought ( W ei et al. , 2022 ) and Reinforce- ment Learning (RL) has significantly contributed to the performance improvement of Large Reasoning Models (LRMs) ( Guo et al. , 2025 ; Jaech et al. , 2024 ). Inspired by Reinfor cement Learning with V erifiable Rewards (RL VR) ( Guo et al. , 2025 ), an increasing number of works choose to scale up computational and data resources for training in verifiable scenarios, such as mathematics and coding. Nevertheless, unpredictable test envir onments lar gely limit the practical performance of models, a phenomenon that is particularly pronounced in the complex and variable application scenarios of LRMs. T o address the insufficient generalization caused by LRMs’ heavy r eliance on human supervision, many curr ent works turn to T est-T ime T raining (TTT) ( Aky ¨ urek et al. , 2024 ; Behrouz et al. , 2024 ) on unlabeled test-time data to achieve model adaptation ( Silver & Sutton , 2025 ). Current works that impr ove LRMs’ reasoning capabilities thr ough TTT primarily focus on how to pr ovide valuable immediate r ewards to models under label-free conditions. For instance, TTRL ( Zuo et al. , 2025 ) employs a voting-based T est-T ime Scaling (TTS) strategy , Majority V oting ( W ang et al. , 2022 ), which selects the most likely corr ect answer based on commonalities from multiple sampled results of a single question as the pseudo-label for that question at training stage, and further utilizes it to compute rewar ds. SCOPE ( W ang et al. , 2025 ) further uses the model’s internal confidence to assist the voting pr ocess, improving TTT effectiveness by mitigating confirmation bias and sparse r ewards. However , applying TTS strategies ( Lightman et al. , 2023 ; Rakhsha et al. , 2025 ) designed for fixed-parameter models at test-time to the training process may r educe their effectiveness. ∗ W ork done during an internship at Kuaishou T echnology . † Corresponding author: Huiming W ang, Mofei Song. 1 Preprint. Under review . 𝒄 𝑩 𝟏 𝒄 𝑩 𝟐 𝒄 𝑩 𝑮 … 𝒄 𝟐 𝟏 𝒄 𝟐 𝟐 𝒄 𝟐 𝑮 … 𝒒 𝑩 𝒒 𝟐 𝒒 𝟏 L L M 𝒂 𝑩 𝟏 𝒂 𝑩 𝟐 𝒂 𝑩 𝑮 … 𝒂 𝟐 𝟏 𝒂 𝟐 𝟐 𝒂 𝟐 𝑮 … 𝒂 𝟏 𝟏 𝒂 𝟏 𝟐 𝒂 𝟏 𝑮 … 𝒄 𝟏 𝟏 𝒄 𝟏 𝟐 𝒄 𝟏 𝑮 … Ca l cul a t i o n B r o ll o u t V o t in g 𝕯 ( 𝒒 𝟏 ) 𝕯 ( 𝒒 𝟏 ) 𝕯 ( 𝒒 𝟏 ) Div e r s it y C a lc ul a t io n Re wa r d Ca lcul a t io n 𝑨 𝟏 𝟏 𝑨 𝟏 𝟐 𝑨 𝟏 𝑮 … P o li c y O p t im iz a t io n G M M M o d e l i n g L o c a l Dis t r ib u t io n Co n f id e n c e D e c om p os e ෝ 𝒂 𝑩 ෝ 𝒂 𝟐 ෝ 𝒂 𝟏 C a l i br at i o n S h i f t G lo b a l Dis t r ib u t io n A l i gn S G u i d e d 𝒓 𝟏 𝟏 𝒓 𝟏 𝟐 𝒓 𝟏 𝑮 … B 𝑩 : B at c h S i z e 𝑺 : S t e p s N u m ෝ 𝒂 : P s e u d o - L ab e l 𝑨 : A d va n t ag e ⨀ : E l e m e n t M u l t i p l i c at i on N e gat i ve P os i t i ve Figure 1: Overview of DistriTTRL . During the pseudo-label estimation process at each step, we first calibrate the Global Confidence Distribution fr om previous steps using the Local Confidence Distribution of all queries in the current step, then guide the distribution of specific queries in the current step with the calibrated distribution prior . Additionally , we computes diversity from each query’s r ollouts and adjusts the advantage accordingly . W e believe one reason is that limited computational resour ces constrain the number of samples per query . Although TTRL mitigates this thr ough downsampling, it still hinders voting accuracy . Mor e importantly , dynamically updated parameters during training cause continuous changes in the model’s internal information (such as confidence and sampling distribution ( Y ue et al. , 2025 )), preventing rollouts sampled at different steps from being mutually utilized. Additionally , updatable parameters allow the model to learn inherent hacking information in TTS strategies during training, such as consistency . Motivated by these, we pr opose DistriTTRL , which improves the accuracy of RL rewar ds by progr essively constructing distributions of rollouts information at differ ent steps, and designs diversity-targeted penalties to mitigate the consistency rewar d hacking problem introduced by TTS strategies in TTT . Specifically , following DistriV oting ( Y ang et al. , 2026 ), we weight answers using the model’s internal confidence during the voting process and leverage distribution priors for confidence calibration. Building upon this, to impr ove the stability of confidence distribution prior information by increasing the number of samples, we dynamically recor d all rollouts at each step, progr essively constructing an incr easingly refined confidence distribution. Furthermore, since parameter updates between diff erent steps cause distribution shifts, we perform shift correction on the confidence of each previous step based on the curr ent step’s distribution during construction. After obtaining pseudo- labels for each query through voting, we compute r ewards similarly to other RL VR works. Differ ently , we subsequently evaluate the diversity of each query through the number of predicted answer classes in its rollouts and normalize this diversity metric within a training batch, which is then used as a penalty weight for the advantage of each query in the batch. In the experimental phase, we validate our approach using multiple models includ- ing Qwen2.5/Qwen3-Series ( Y ang et al. , 2025 ), and DeepSeek-Series ( Guo et al. , 2025 ) across dif ferent benchmarks including AIME ( AIME , 2025 ), AMC ( LI et al. , 2024 ), MA TH- 500 ( Hendrycks et al. , 2021 ), and GPQA-D ( Rein et al. , 2023 ). The results consistently demonstrate the effectiveness of DistriTTRL. Moreover , by analyzing the majority ratio (i.e., the frequency pr oportion of the voted answer among all rollout answers) of voting r esults for each query during training, we can confirm that our designed diversity-targeted penalty effectively mitigates consistency r eward hacking. 2 Preprint. Under review . 2 Related W ork 2.1 T est-time T raining T est-T ime T raining ( Liu et al. , 2021b ) has emer ged as a focus of recent r esearch in the context of generative tasks ( Shocher et al. , 2018 ; Bau et al. , 2020 ). By leveraging self-supervised learning (SSL) ( Liu et al. , 2021a ), this emerging paradigm enables models to cope with distributional shifts without r equiring additional labeled data. Recent work ( Zuo et al. , 2025 ; Zhang et al. , 2025 ) on large language models ( Guo et al. , 2025 ; Y ang et al. , 2025 ) has begun to leverage test-time training during the r einforcement learning stage, enabling models to learn from unlabeled data without relying on costly manual annotations. However , they rely on voting-based TTS strategies for test-time training, which often leads to rewar d hacking due to misaligned incentives in the reinfor cement learning process. 2.2 Intrinsic Information of LLMs Intrinsic information denotes the model’s internal confidence signals derived from next- token distribution statistics, has recently been leveraged to assess the quality of reasoning traces ( Geng et al. , 2024 ; Fadeeva et al. , 2024 ; T ao et al. , 2024 ). Owing to its label-free nature, intrinsic information has been applied in training to extend RL VR methods ( Li et al. , 2025 ; Zuo et al. , 2025 ) without relying on costly manually labeled data, and during inference to optimize multi-candidate responses through serial, parallel, and tree-based search. Several methods have been pr oposed to quantify intrinsic information: A verage Log- Probability ( Fu et al. , 2025 ) and Perplexity ( Hor gan , 1995 ) capture sentence-level confidence, while Entr opy ( R ´ enyi , 1961 ) and Self-Certainty ( Kang et al. , 2025 ) measure distribution-level confidence across multiple candidates. 3 Preliminaries 3.1 Confidence of T rajectory Prior work shows that LLM’s token distributions P i ( j ) can reveal uncertainty and trajectory quality . Following DeepConf ( Fu et al. , 2025 ), we compute confidence via token negative log- probabilities to assess quality during and after inference. For a single trajectory containing N tokens output by the model, we define the trajectory confidence as: C traj = − 1 N G × k ∑ i ∈ G k ∑ j = 1 log P i ( j ) , (1) where N G , k ∈ N + and P ∈ R N × N v . Here, G repr esents the subset of tokens among the N generated tokens that are used to compute the final trajectory-level confidence, which typically corresponds to the last tail step containing the answer . N G denotes the number of tokens in G , and k denotes the number of top- k probabilities fr om the token logits that participate in computing token-level confidence. 3.2 Distribution of Confidence For each query’s G rollouts, we compute trajectory-level confidence scores C via Equation 1 . Inspired by previous work on confidence distribution ( Kang et al. , 2025 ), we further model it as Gaussian Mixture Models (GMM) with two components, where the positive distribution N ( µ pos , σ 2 pos ) with a higher mean µ pos , and the negative distribution N ( µ neg , σ 2 neg ) with a lower mean µ neg : X pos ∼ N ( µ pos , σ 2 pos ) , X neg ∼ N ( µ neg , σ 2 neg ) . (2) 3 Preprint. Under review . 3.3 Distribution Shift During the T raining Process Unlike the T est-T ime Scaling task where model parameters ar e fixed, the confidence distri- bution obtained at differ ent stages of model training varies with model parameter updates, and this variation significantly affects the auxiliary calibration r ole of the global distribution prior on the current step. T o analyze this variation, we record and visualize the model’s confidence at differ ent steps, as shown in Figur e 2 . As training progr esses, the confidence distribution gradually shifts rightward, with the degree of shift progressively decr easing to zero at appr oximately step 100. 10 15 20 25 30 35 Confidence 0 50 100 150 200 250 F requency Step 1-15 Step 16-30 Step 31-45 Step 46-60 Step 61-75 Step 76-90 Step 91-105 Step 106-120 Step 121-135 Step 136-150 Figure 2: Confidence distribution shift across training steps. T rained on AMC using Qwen3- 8B with 32 samples per question. Each distribution aggregates 15 consecutive steps. Inspired by this phenomenon, during the progressive construction of the confidence dis- tribution in the training phase, we primarily use the current step’s distribution to perform shift correction on the global confidence, which is detailed in §4.2.1 . 3.4 Consistency Reward Hacking During TTT Caused by V oting Strategy Most existing work on improving reasoning capabilities during the test phase primarily uses consensus-based voting mechanisms to addr ess the lack of rewar d signals. However , applying scaling strategies based on fixed-parameter models to the training phase with dynamically updated parameters naturally introduces consistency reward hacking from voting strategies. Although TTRL ( Zuo et al. , 2025 ) refers to this phenomenon as Lucky Hit in their paper and considers it evidence of effective negative supervision signals, we argue that this is a major cause of rapid model convergence and limited training effectiveness. Specifically , the model tends to output consistent answers (whether corr ect or not) to obtain higher reward scor es, which constrains the role of corr ectness reward. 0 50 100 150 200 250 T raining Step 0.2 0.4 0.6 0.8 1.0 Majority R atio T T T - GT T T T - V oting 0 50 100 150 200 250 T raining Step 0.1 0.2 0.3 0.4 0.5 0.6 A vg P ass@1 T T T - GT T T T - V oting Figure 3: T rend of majority ratio (left) and accuracy (right, average of 16) during the TTT process of training Qwen2.5-7B on AIME2024. GT denotes direct supervision with ground truth, while V oting denotes using Majority V oting for pseudo-label estimation. T o demonstrate the existence and impact of this phenomenon, we track the majority ratio during training, defined as the frequency of the selected pseudo-label among all r ollouts: r maj = n maj N (3) 4 Preprint. Under review . where n maj is the count of the most fr equent answer and N is the total number of r ollouts per question. As shown in the Figure 3 , the majority ratio for pseudo-label training increases significantly faster than that of ground truth supervision as training progr esses. However , this enhanced consistency does not translate into improved accuracy . Instead, after the ratio rapidly reaches its upper limit, the accuracy also begins to conver ge (around step 125). This phenomenon indicates that the consistency voting-based TTT approach, when estimating pseudo-labels, favors consistent incorrect answers rather than r emaining faithful to correct answers. 4 Methodology 4.1 Confidence Distribution Modeling Based on §3.2 , we model the unlabeled rollouts using GMM, approximating their bimodal distribution (positive and negative reasoning paths) with two Gaussian components: p ( x ) = π 1 N ( x | µ 1 , σ 2 1 ) + π 2 N ( x | µ 2 , σ 2 2 ) , (4) where π 1 , π 2 are mixing weights satisfying π 1 + π 2 = 1 and π 1 , π 2 > 0, and each component N ( x | µ i , σ 2 i ) for i ∈ { 1, 2 } follows a normal distribution: N ( x | µ i , σ 2 i ) = 1 q 2 π σ 2 i exp − ( x − µ i ) 2 2 σ 2 i ! . (5) The mixtur e distribution form as follow , wher e µ 1 , µ 2 and σ 2 1 , σ 2 2 are the means and variances of the two distributions: p ( x ) = π 1 1 q 2 π σ 2 1 exp − ( x − µ 1 ) 2 2 σ 2 1 ! + π 2 1 q 2 π σ 2 2 exp − ( x − µ 2 ) 2 2 σ 2 2 ! . (6) 4.2 Progressively Pseudo-Label Estimation 4.2.1 Distribution Construction During the training process, we maintain a global variable C ∈ R S × B × G to record the confidence of each r ollout, where S , B , and G denote the number of training steps, the number of queries in each batch, and the number of samples per query , respectively . Note that, for simplicity , we assume that each step uses only one batch for gradient update. For pseudo-label estimation of a specific query q i at the current step k ∈ [ 1, . . . , S ] , we first model the distribution using the confidences C k , · , · ∈ R B × G of all queries at step k according to the GMM in Equation 6 . W e then partition the samples into positive and negative subsets based on the fitted Gaussian components: X k pos ∼ N µ k pos , ( σ k pos ) 2 , X k neg ∼ N µ k neg , ( σ k neg ) 2 , (7) where µ k pos = max ( µ k 1 , µ k 2 ) and µ k neg = min ( µ k 1 , µ k 2 ) correspond to the means of the high- confidence (positive) and low-confidence (negative) components, respectively . T o leverage historical rollouts while accounting for distribution shift caused by policy up- dates, we apply a shift correction to the confidence values from previous steps. Specifically , for each previous step s < k , we fit GMMs to all queries’ confidences C s , · , · to get more reliable distribution, and then obtain the corr esponding positive and negative component means µ s pos and µ s neg . W e then compute the shift offsets: ∆ s → k = µ k pos + µ k neg 2 − µ s pos + µ s neg 2 . (8) 5 Preprint. Under review . The corrected confidence fr om step s are then: ˜ C s , · , · = C s , · , · + ∆ s → k (9) Finally , for each query q i at step k , we construct the aggr egated confidence distribution by combining the current step’s confidences with the shift-corr ected historical confidences: C k agg = C k , · , · ∪ ˜ C s , · , · : s ∈ [ 1, k − 1 ] , (10) which provides a more stable and data-rich prior for pseudo-label estimation at step k . This aggregated confidences C k agg is then used for the voting process. 4.2.2 Pseudo-Label Estimation After obtaining the aggregated confidence distribution C k agg at step k , we refer to DistriV ot- ing ( Y ang et al. , 2026 ) and repeat the operations of Equation 6 and Equation 7 , but r eplace C k , · , · with C k agg , thereby obtaining the global positive and negative distributions: ˜ X k pos ∼ N ˜ µ k pos , ( ˜ σ k pos ) 2 , ˜ X k neg ∼ N ˜ µ k neg , ( ˜ σ k neg ) 2 . (11) For each query q i at step k , we then partition its samples into positive and negative subsets based on these global distributions. Specifically , for each sample j ∈ [ 1, G ] of query q i , we assign it to the positive or negative subset according to: C k , i , j ∈ ( X k , i pos , if p ( C k , i , j | ˜ X k pos ) > p ( C k , i , j | ˜ X k neg ) X k , i neg , otherwise (12) where p ( C k , i , j | ˜ X k pos ) and p ( C k , i , j | ˜ X k neg ) denote the likelihood of confidence C k , i , j under the positive and negative Gaussian distributions, respectively . This yields query-specific positive and negative sample sets X k , i pos and X k , i neg for pseudo-label assignment. Following DistriV oting, we treat X k , i pos as high-potential correct samples and X k , i neg as low- potential samples to be filtered out. T o further mitigate the overlap between the two distributions, we first vote on the negative subset with their corresponding trajectories V k , i neg = { o k , i , j | C k , i , j ∈ X k , i neg } to identify the most likely incorrect answer: A k , i neg = f vote ( V k , i neg , − X k , i neg ) , (13) where f vote can be any voting methods, we simply use the majority voting her e. W e then remove false positive samples fr om X k , i pos whose trajectories produce A k , i neg : ˆ X k , i pos = { c | c ∈ X k , i pos , answer ( o c ) = A k , i neg } , (14) and obtain the filtered trajectories ˆ V k , i pos = { o k , i , j | C k , i , j ∈ ˆ X k , i pos } . Finally , we vote on the filtered positive subset to obtain the pseudo-label: A k , i final = f vote ( ˆ V k , i pos , ˆ X k , i pos ) . (15) T rajectories producing A k , i final are assigned positive labels for policy optimization. 4.3 Diversity-T argeted Penalties in GRPO 4.3.1 Diversity Estimation Given a training batch B = { q 1 , q 2 , . . . , q B } of prompts, we sample G candidate outputs for each query q i from the old policy: o i , j ∼ π θ old ( · | q i ) , j = 1, . . . , G . (16) 6 Preprint. Under review . W e measure the answer diversity for each query as the number of unique outputs: D ( q i ) = o i , j : j = 1, . . . , G unique , (17) where | · | unique denotes the cardinality of the set of distinct elements. Higher D ( q i ) indicates greater model diversity about query q i . T o obtain batch-normalized uncertainty weights, we apply a softmax transformation over the diversity scores: ˜ D ( q i ) = exp ( D ( q i )) ∑ B k = 1 exp ( D ( q k )) . (18) W e then introduce a penalty mechanism to down-weight queries with extremely low diver- sity , which may indicate pr emature conver gence or mode collapse. Specifically , we define the final diversity weight as: D ( q i ) = ˜ D ( q i ) , if D ( q i ) ≤ τ · G 1, otherwise (19) where τ ∈ ( 0, 1 ) is a threshold hyperparameter (we use τ = 0.1 in our experiments). Queries with diversity above the threshold receive a neutral weight of 1, pr eserving the original GRPO learning dynamics, while low-diversity queries receive reduced weights proportional to their relative diversity within the batch. 4.3.2 Diversity-T argeted Advantage Calculation For each sampled output o i , j , we obtain a rewar d score R i , j from the reward function. Following GRPO, we compute the normalized advantage within each query’s sample group: ˆ A i , j = R i , j − 1 G ∑ G k = 1 R i , j q 1 G ∑ G k = 1 R i , j − ¯ R i 2 , (20) where ¯ R i = 1 G ∑ G k = 1 R i , k . When the standard deviation is zero, we set ˆ A i , j = 0. W e then apply the diversity weighting to obtain the final advantage: ˆ A ′ i , j = ˆ A i , j · D ( q i ) . (21) Note that all tokens t in output o i , j share the same weighted advantage: ˆ A ′ i , j , t = ˆ A ′ i , j . 4.3.3 The GRPO Objective Let r i , j , t ( θ ) denote the probability ratio at token position t : r i , j , t ( θ ) = π θ ( o i , j , t | q i , o i , j , < t ) π θ old ( o i , j , t | q i , o i , j , < t ) . (22) The GRPO objective is then defined as: J GRPO ( θ ) = E q i ∼ P ( Q ) E { o i , j } G j = 1 ∼ π θ old " 1 G G ∑ j = 1 1 | o i , j | | o i , j | ∑ t = 1 min r i , j , t ( θ ) · ˆ A i , j · D ( q i ) , clip r i , j , t ( θ ) , 1 − ϵ , 1 + ϵ · ˆ A i , j · D ( q i ) − β · b D ( i , j , t ) KL !# , (23) where ϵ is the PPO clipping parameter , β is the KL regularization coef ficient, and b D ( i , j , t ) KL is the per-token KL diver gence estimator . 7 Preprint. Under review . T able 1: Main Results of DistriTTRL across benchmarks (16 repeats). -GT denotes using ground tr uth directly as labels to measur e the upper bound of the method. -WSC denotes using W eighted Self-Consistency (W eighted Majority V oting) as the voting method, while -GMM denotes using DistriV oting as the voting method. Bold and underline respectively indicate the optimal and suboptimal results excluding GT . Model Method AIME2024 AMC MA TH-500 A vg. Qwen2.5-7B-Base Base Model 7.50 33.06 59.11 33.22 TTRL 22.08 52.26 80.38 51.57 TTRL-GT 62.71 82.61 90.75 78.69 TTRL-WSC 23.07 + 0.99 54.07 + 1.81 80.30 − 0.08 52.48 + 0.91 DistriTTRL-WSC 22.08 + 0.00 57.23 + 4.97 80.67 + 0.29 53.33 + 1.76 DistriTTRL-GMM 23.54 + 1.46 56.48 + 4.22 81.46 + 1.08 53.83 + 2.26 Qwen2.5-Math-7B Base Model 10.63 32.38 47.10 30.04 TTRL 25.83 56.18 81.51 54.51 TTRL-GT 41.04 58.43 84.05 61.17 TTRL-WSC 29.79 + 3.96 58.28 + 2.10 83.39 + 1.88 57.15 + 2.64 DistriTTRL-WSC 34.58 + 8.75 57.68 + 1.50 81.49 − 0.02 57.92 + 3.41 DistriTTRL-GMM 33.33 + 7.50 61.37 + 5.19 81.83 + 0.32 58.84 + 4.33 Qwen2.5-Math-1.5B Base Model 7.08 28.09 31.41 22.19 TTRL 14.14 44.38 72.19 43.57 TTRL-GT 17.94 47.85 73.45 46.41 TTRL-WSC 14.28 + 0.14 44.78 + 0.40 72.21 + 0.02 43.76 + 0.19 DistriTTRL-WSC 14.12 − 0.02 44.99 + 0.61 72.49 + 0.30 43.87 + 0.30 DistriTTRL-GMM 14.55 + 0.41 45.37 + 0.99 72.31 + 0.12 44.08 + 0.51 Llama-3.1-8B-Instruct Base Model 4.79 20.93 48.23 24.65 TTRL 7.92 30.27 58.43 32.21 TTRL-GT 21.25 37.65 75.43 44.78 TTRL-WSC 12.08 + 4.16 29.59 − 0.68 55.28 − 3.15 32.32 + 0.11 DistriTTRL-WSC 10.00 + 2.08 28.84 − 1.43 60.93 + 2.50 33.26 + 1.05 DistriTTRL-GMM 10.21 + 2.29 30.87 + 0.60 58.96 + 0.53 33.35 + 1.14 Qwen3-8B Base Model 1.46 15.44 50.13 22.34 TTRL 33.00 65.95 87.25 62.07 TTRL-GT 34.07 67.87 87.58 63.17 TTRL-WSC 34.55 + 1.55 68.80 + 2.85 86.13 − 1.12 63.16 + 1.09 DistriTTRL-WSC 37.61 + 4.61 66.57 + 0.62 86.18 − 1.07 63.45 + 1.38 DistriTTRL-GMM 33.44 + 0.44 70.31 + 4.36 87.21 − 0.04 63.65 + 1.58 5 Experiments 5.1 Implementation Details Regarding the implementation details of our methods, we primarily follow the codebase of TTRL, using AIME2024, AMC and MA TH-500 as training and test sets, with GRPO as the base RL algorithm. For the temperature in the sampling process, we set it to 1.0 for Qwen2.5-Math and LRMs such as Qwen3-8B, and 0.6 for all others. For max response length, we set it to 32K for LRMs and 3K for other non-reasoning models. Additionally , we continue the rollout downsampling operation fr om TTRL, where we sample 64 trajectories and select 32 for gradient updates. All experiments were conducted on NVIDIA H-Series GPU. Complete pseudo code is provided in Appendix §A . 5.2 Main Results In the experimental section, we evaluate DistriTTRL ’s performance acr oss differ ent bench- marks and models, analyzing: (1) the direct impact of training-time confidence on TTT (TTRL vs. TTRL-WSC), (2) the effect of diversity-targeted penalty applied to the advantage 8 Preprint. Under review . function (TTRL-WSC vs. DistriTTRL-WSC), and (3) the effectiveness of leveraging confi- dence distribution priors for pseudo-label estimation in DistriTTRL (DistriTTRL-WSC vs. DistriTTRL-GMM). As shown in T able 1 , our proposed DistriTTRL-GMM consistently out- performs baselines across five models (including Qwen2.5-7B-Base) and thr ee benchmarks (including AIME2024), achieving improvements of 0.51 ∼ 4.33. Specifically , the difference between TTRL-WSC and TTRL (0.19 ∼ 2.64) validates the ef- fectiveness of incorporating confidence scor es in DistriTTRL , demonstrating that leverag- ing model-internal confidence during training provides more reliable signals for policy optimization compared to uniform weighting. The gap between DistriTTRL-WSC and TTRL-WSC (0.11 ∼ 0.96) reflects the direct contribution of diversity-targeted penalty , which mitigates consistency r eward hacking by encouraging exploration of diverse reasoning paths rather than converging to repetitive solutions. Additionally , the performance gain of DistriTTRL-GMM over DistriTTRL-WSC (0.2 ∼ 0.92) demonstrates the advantage of calibrating confidence with distribution priors, wher e dynamically modeling the confidence distribution and applying shift correction enables more accurate pseudo-label estimation by accounting for the evolving confidence landscape throughout training. 6 Analysis 6.1 Diversity-T argeted Penalty Mitigates Consistency Reward Hacking T o further analyze the ef fectiveness of DistriTTRL in addr essing consistency rewar d hacking, beyond the accuracy r eported in the main r esults, we examine the tr end of majority ratio defined in Equation 3 during training, following the same analysis approach as in §3.4 . 0 50 100 150 200 250 T raining Step 0.2 0.4 0.6 0.8 1.0 Majority R atio T TRL DistriT TRL T TRL - GT Figure 4: Effect of diversity-tar geted penalty in DistriTTRL on mitigating consistency reward hacking, training Qwen2.5-7B on AIME2024. As shown in the Figure 4 , DistriTTRL ’s majority ratio curve rises mor e slowly and conver ges to a significantly lower value than TTRL (which directly uses test-time scaling strategy), better aligning with the gr ound truth training scenario. By mitigating consistency rewar d hacking, DistriTTRL extends effective training steps and achieves higher performance gains. 6.2 Effect of V oting Budget on Pseudo-Label Quality A key motivation for DistriTTRL stems from the observation that limited computational resour ces during training r estrict the sampling budget per query in scaling voting strategies, thereby compr omising the accuracy of pseudo-labels obtained through voting. This moti- vates the design of a mechanism that dynamically leverages r ollouts across dif ferent steps during training. T o validate this motivation, in this section we examine how the accuracy of various parallel voting strategies varies under differ ent sampling budgets. As shown in the Figur e 5 , accuracy for all TTS strategies (SC ( W ang et al. , 2022 ), WSC ( Li et al. , 2022 ), MoB ( Rakhsha et al. , 2025 ), BoN ( Lightman et al. , 2023 ), DistriV oting ( Y ang 9 Preprint. Under review . 8 16 32 64 128 256 Budget 87 88 89 90 91 92 93 94 V oting Accuracy (%) DistriV oting DeepConf MoB BoN SC WSC Figure 5: Impact of voting budget on the accuracy of different TTS strategies, evaluated on AIME2024 using DeepSeek-R1-8B (64 repeats). Complete results provided in Appendix §B . et al. , 2026 ), and DeepConf ( Fu et al. , 2025 )) increases with budget from 8 to 256, confirming a positive correlation between voting accuracy and budget. This validates DistriTTRL ’s design rationale of scaling voting information by leveraging rollouts across training steps. 7 Conclusion This paper pr oposes DistriTTRL , a method that fully leverages the model’s internal confi- dence for T est-T ime T raining (TTT). W e first analyze the pitfalls of directly adapting scaling voting strategies for pseudo-label computation in current reasoning TTT works, namely the limited voting budget and the sensitivity of learnable parameters to consistency hacking dur- ing training. Building upon a voting strategy that calibrates confidence using distribution priors, DistriTTRL dynamically constructs and progr essively refines the confidence distribu- tion during training, and at each step, applies shift correction to the global distribution from previous steps using the local distribution of the curr ent step. Furthermore, leveraging the rollouts for each query , we evaluate query-level diversity and design a diversity-tar geted penalty that is weighted into the original advantage. Through extensive experiments and analysis, we demonstrate the effectiveness of DistriTTRL for r easoning TTT . References AIME. AIME pr oblems and solutions, 2025. URL https://artofproblemsolving.com/wiki/ index.php/AIME Problems and Solutions . Ekin Aky ¨ urek, Mehul Damani, Adam Zweiger , Linlu Qiu, Han Guo, Jyothish Pari, Y oon Kim, and Jacob Andr eas. The surprising eff ectiveness of test-time training for few-shot learning. arXiv preprint , 2024. Mislav Balunovi ´ c, Jasper Dekoninck, Ivo Petrov , Nikola Jovanovi ´ c, and Martin V echev . Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/ . David Bau, Hendrik Str obelt, W illiam Peebles, Jonas W ulff, Bolei Zhou, Jun-Y an Zhu, and Antonio T orralba. Semantic photo manipulation with a generative image prior . arXiv preprint arXiv:2005.07727 , 2020. Ali Behrouz, Peilin Zhong, and V ahab Mirrokni. T itans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663 , 2024. 10 Preprint. Under review . Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov , Sergey Petrakov , Haonan Li, Hamdy Mubarak, Evgenii T symbalov , Gleb Kuzmin, Alexander Panchenko, T imothy Baldwin, et al. Fact-checking the output of large language models via token-level uncer- tainty quantification. In Findings of the Association for Computational Linguistics: ACL 2024 , pp. 9367–9385, 2024. Y ichao Fu, Xuewei W ang, Y uandong T ian, and Jiawei Zhao. Deep think with confidence. arXiv preprint arXiv:2508.15260 , 2025. Jiahui Geng, Fengyu Cai, Y uxia W ang, Heinz Koeppl, Preslav Nakov , and Iryna Gurevych. A survey of confidence estimation and calibration in large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies (V olume 1: Long Papers) , pp. 6577–6595, 2024. Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi W ang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinfor cement learning. arXiv preprint , 2025. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric T ang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint , 2021. John Horgan. From complexity to perplexity . Scientific American , 1995. Aaron Jaech, Adam Kalai, Adam Lerer , Adam Richardson, Ahmed El-Kishky , Aiden Low , Alec Helyar , Aleksander Madry , Alex Beutel, Alex Carney , et al. Openai o1 system card. arXiv preprint arXiv:2412.16720 , 2024. Zhewei Kang, Xuandong Zhao, and Dawn Song. Scalable best-of-n selection for large language models via self-certainty , 2025. URL https://arxiv . org/abs/2502.18581 , 2025. Jia LI, Edward Beeching, Lewis T unstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Y u, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Y ann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath, 2024. Y i-Chen Li, T ian Xu, Y ang Y u, Xuqin Zhang, Xiong-Hui Chen, Zhongxiang Ling, Ningjing Chao, Lei Y uan, and Zhi-Hua Zhou. Generalist reward models: Found inside large language models. arXiv preprint , 2025. Y ifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and W eizhu Chen. Making large language models better r easoners with step-aware verifier . arXiv preprint arXiv:2206.02336 , 2022. Hunter Lightman, V ineet Kosaraju, Y uri Burda, Harrison Edwards, Bowen Baker , T eddy Lee, Jan Leike, John Schulman, Ilya Sutskever , and Karl Cobbe. Let’s verify step by step. In The T welfth International Conference on Learning Representations , 2023. Xiao Liu, Fanjin Zhang, Zhenyu Hou, Li Mian, Zhaoyu W ang, Jing Zhang, and Jie T ang. Self-supervised learning: Generative or contrastive. IEEE transactions on knowledge and data engineering , 35(1):857–876, 2021a. Y uejiang Liu, Parth Kothari, Bastien V an Delft, Baptiste Bellot-Gurlet, T aylor Mordan, and Alexandre Alahi. Ttt++: When does self-supervised test-time training fail or thrive? Advances in Neural Information Processing Systems , 34:21808–21820, 2021b. Amin Rakhsha, Kanika Madan, T ianyu Zhang, Amir -massoud Farahmand, and Amir Khasahmadi. Majority of the bests: Improving best-of-n via bootstrapping. arXiv preprint arXiv:2511.18630 , 2025. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty , Richard Y uanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level google- proof q&a benchmark. arXiv preprint , 2023. 11 Preprint. Under review . Alfr ´ ed R ´ enyi. On measures of entr opy and information. In Proceedings of the fourth Berkeley symposium on mathematical statistics and pr obability , volume 1: contributions to the theory of statistics , 1961. Assaf Shocher , Nadav Cohen, and Michal Irani. “zero-shot” super -resolution using deep internal learning. In Proceedings of the IEEE conference on computer vision and pattern recognition , pp. 3118–3126, 2018. David Silver and Richard S Sutton. W elcome to the era of experience. Google AI , 1:11, 2025. Shuchang T ao, Liuyi Y ao, Hanxing Ding, Y uexiang Xie, Qi Cao, Fei Sun, Jinyang Gao, Huawei Shen, and Bolin Ding. When to trust llms: Aligning confidence with response quality . In Findings of the Association for Computational Linguistics: ACL 2024 , pp. 5984–5996, 2024. W eiqin W ang, Y ile W ang, Kehao Chen, and Hui Huang. Beyond majority voting: T owards fine-grained and more r eliable rewar d signal for test-time reinfor cement learning. arXiv preprint arXiv:2512.15146 , 2025. Xuezhi W ang, Jason W ei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery , and Denny Zhou. Self-consistency improves chain of thought r easoning in language models. arXiv preprint , 2022. Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits r easoning in lar ge language models. Advances in neural information processing systems , 2022. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388 , 2025. Xizhong Y ang, Haotian Zhang, Huiming W ang, and Mofei Song. Believe your model: Distribution-guided confidence calibration. arXiv preprint , 2026. Y ang Y ue, Zhiqi Chen, Rui Lu, Andr ew Zhao, Zhaokai W ang, Shiji Song, and Gao Huang. Does reinfor cement learning r eally incentivize reasoning capacity in llms beyond the base model? arXiv pr eprint arXiv:2504.13837 , 2025. Qingyang Zhang, Haitao W u, Changqing Zhang, Peilin Zhao, and Y atao Bian. Right question is already half the answer: Fully unsupervised llm reasoning incentivization. arXiv preprint arXiv:2504.05812 , 2025. Y uxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Y uchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: T est-time reinfor cement learning. arXiv preprint arXiv:2504.16084 , 2025. 12 Preprint. Under review . A Pseudo Code Algorithm 1 DistriTTRL T raining Framework Require: T raining queries Q , initial policy π θ 0 , rewar d model R , total steps S Require: Batch size B , samples per query G , diversity threshold τ 1: Initialize confidence storage C ∈ R S × B × G 2: for step k = 1 to S do 3: Sample batch B k = { q 1 , . . . , q B } from Q 4: for each query q i ∈ B k do 5: Sample G rollouts: { o k , i , j } G j = 1 ∼ π θ k − 1 ( · | q i ) 6: Compute rewar ds: R k , i , j = R ( q i , o k , i , j ) for j = 1, . . . , G 7: Compute confidences: C k , i , j for j = 1, . . . , G 8: end for 9: C k agg ← C O N S T R U C T A G G R E G AT E D D I S T R I B U T I O N ( C , k ) ▷ Algorithm 2 10: for each query q i ∈ B k do 11: A k , i final ← E S T I M AT E P S E U D O L A B E L ( q i , C k agg , k ) ▷ Algorithm 3 12: D ( q i ) ← C O M P U T E D I V E R S I T Y W E I G H T ( { o k , i , j } G j = 1 , τ ) ▷ Algorithm 4 13: end for 14: Update policy: θ k ← G R P O U P D AT E ( θ k − 1 , B k , { A k , i final } , { D ( q i ) } ) 15: end for 16: return π θ S Algorithm 2 Construct Aggr egated Confidence Distribution 1: function C O N S T R U C T A G G R E G AT E D D I S T R I B U T I O N ( C , k ) 2: Fit GMM on C k , · , · via Equation 7 to obtain µ k pos , µ k neg 3: Initialize C k agg ← { C k , · , · } 4: for each previous step s = 1 to k − 1 do 5: Fit GMM on C s , · , · to obtain µ s pos , µ s neg 6: Compute shift offset ∆ s → k via Equation 8 7: Apply correction to get ˜ C s , · , · via Equation 9 8: C k agg ← C k agg ∪ { ˜ C s , · , · } 9: end for 10: return C k agg as defined in Equation 10 11: end function Algorithm 3 Estimate Pseudo-Label via Progr essive V oting 1: function E S T I M AT E P S E U D O L A B E L ( q i , C k agg , k ) 2: Fit GMM on C k agg to obtain global distributions via Equation 11 3: Initialize X k , i pos ← ∅ , X k , i neg ← ∅ 4: for each sample j = 1 to G do 5: Assign C k , i , j to X k , i pos or X k , i neg via Equation 12 6: end for 7: Obtain V k , i neg and vote for A k , i neg via Equation 13 8: Filter false positives to get ˆ X k , i pos via Equation 14 9: Obtain ˆ V k , i pos and vote for A k , i final via Equation 15 10: return A k , i final 11: end function 13 Preprint. Under review . Algorithm 4 Compute Diversity-T argeted W eight 1: function C O M P U T E D I V E R S I T Y W E I G H T ( { o i , j } G j = 1 , τ ) 2: Compute answer diversity: D ( q i ) ← | { o i , j } G j = 1 | unique 3: Compute batch-normalized weight: ˜ D ( q i ) ← exp ( D ( q i )) ∑ B k = 1 exp ( D ( q k )) 4: if D ( q i ) ≤ τ · G then 5: return ˜ D ( q i ) ▷ Apply penalty for low diversity 6: else 7: return 1 ▷ Neutral weight for sufficient diversity 8: end if 9: end function B Additional Results on V oting Accuracy-Budget Correlation In §6.2 of the main paper , we demonstrated the positive corr elation between voting accu- racy and sampling budget on AIME2024. T o further validate the generalizability of this observation, we conduct the same analysis across four additional benchmarks: HMMT2025, BRUMO2025 ( Balunovi ´ c et al. , 2025 ), AIME2025 ( AIME , 2025 ), and GPQA-D ( Rein et al. , 2023 ). All experiments follow the same setup as in the main paper , using DeepSeek-R1-8B (DeepSeek-R1-0528-Qwen3-8B) and averaging over 64 repetitions. 8 16 32 64 128 256 Budget 70 72 74 76 78 80 82 84 V oting Accuracy (%) DistriV oting DeepConf MoB BoN SC WSC (a) HMMT2025 8 16 32 64 128 256 Budget 79 80 81 82 83 84 85 86 87 V oting Accuracy (%) DistriV oting DeepConf MoB BoN SC WSC (b) AIME2025 8 16 32 64 128 256 Budget 66.5 67.0 67.5 68.0 68.5 69.0 69.5 70.0 70.5 V oting Accuracy (%) DistriV oting DeepConf MoB BoN SC WSC (c) GPQA-D 8 16 32 64 128 256 Budget 89 90 91 92 93 94 V oting Accuracy (%) DistriV oting DeepConf MoB BoN SC WSC (d) BRUMO2025 Figure 6: Impact of sampling budget on the accuracy of different test-time scaling strategies across four additional benchmarks (DeepSeek-R1-8B, averaged over 64 r uns). As illustrated in Figur e 6 , the positive corr elation between voting accuracy and sampling budget consistently holds across all four benchmarks, spanning mathematical reasoning (HMMT2025, AIME2025, BRUMO2025) and scientific reasoning (GPQA-D). This validates that DistriTTRL ’s design rationale generalizes well acr oss diverse reasoning domains. De- tailed experimental results ar e provided in T able 2 . 14 Preprint. Under review . T able 2: Complete voting accuracy comparison results of differ ent test-time scaling strategies under varying sampling budgets across 5 benchmarks using DeepSeek-R1-8B, averaged over 64 repetitions. Budget Method HMMT2025 GPQA-D AIME2024 AIME2025 BRUMO2025 8 MoB 69.48 67.22 88.39 80.83 89.27 BoN 69.69 66.26 87.60 78.75 88.33 SC 71.82 66.88 89.32 80.57 89.95 WSC 72.03 67.04 88.96 80.36 90.31 DeepConf 71.09 67.37 89.06 80.52 90.31 DistriV oting 72.71 66.94 89.27 81.20 90.05 16 MoB 72.29 68.16 89.69 81.73 91.72 BoN 69.95 67.44 88.65 80.16 90.73 SC 75.05 68.21 90.89 82.60 92.24 WSC 75.21 68.37 90.99 83.33 92.45 DeepConf 72.55 67.86 89.48 81.25 91.77 DistriV oting 74.58 68.35 91.09 82.97 92.40 32 MoB 72.29 68.25 90.77 82.50 92.92 BoN 71.56 67.76 89.17 80.84 90.78 SC 78.44 68.71 91.88 84.11 93.28 WSC 79.01 68.96 91.88 84.32 93.65 DeepConf 74.01 68.49 89.69 81.51 93.07 DistriV oting 79.43 68.69 92.34 83.80 93.59 64 MoB 77.60 69.07 91.51 83.14 93.18 BoN 71.82 67.83 90.16 81.23 92.40 SC 80.42 68.86 92.86 85.52 93.59 WSC 80.94 69.00 93.07 85.68 93.54 DeepConf 74.48 68.63 90.64 81.98 93.28 DistriV oting 80.94 69.14 92.97 85.21 93.75 128 MoB 76.98 69.70 91.95 84.53 93.33 BoN 72.05 67.91 90.52 81.34 92.44 SC 82.40 69.40 93.18 86.35 93.59 WSC 83.23 69.36 93.28 86.56 93.70 DeepConf 73.80 68.78 91.00 82.55 93.33 DistriV oting 82.55 69.82 93.13 85.52 93.70 256 MoB 80.00 70.35 93.28 84.92 93.33 BoN 72.24 68.21 90.68 82.28 92.71 SC 83.65 69.67 93.33 86.88 93.44 WSC 83.65 69.59 93.33 86.82 93.74 DeepConf 73.96 68.99 91.79 83.65 93.33 DistriV oting 83.91 70.21 93.33 86.77 94.43 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment