Agentic AI for SAGIN Resource Management_Semantic Awareness, Orchestration, and Optimization
Space-air-ground integrated networks (SAGIN) promise ubiquitous 6G connectivity but face significant resource management challenges due to heterogeneous infrastructure, dynamic topologies, and stringent quality-of-service (QoS) requirements. Conventi…
Authors: Linghao Zhang, Haitao Zhao, Bo Xu
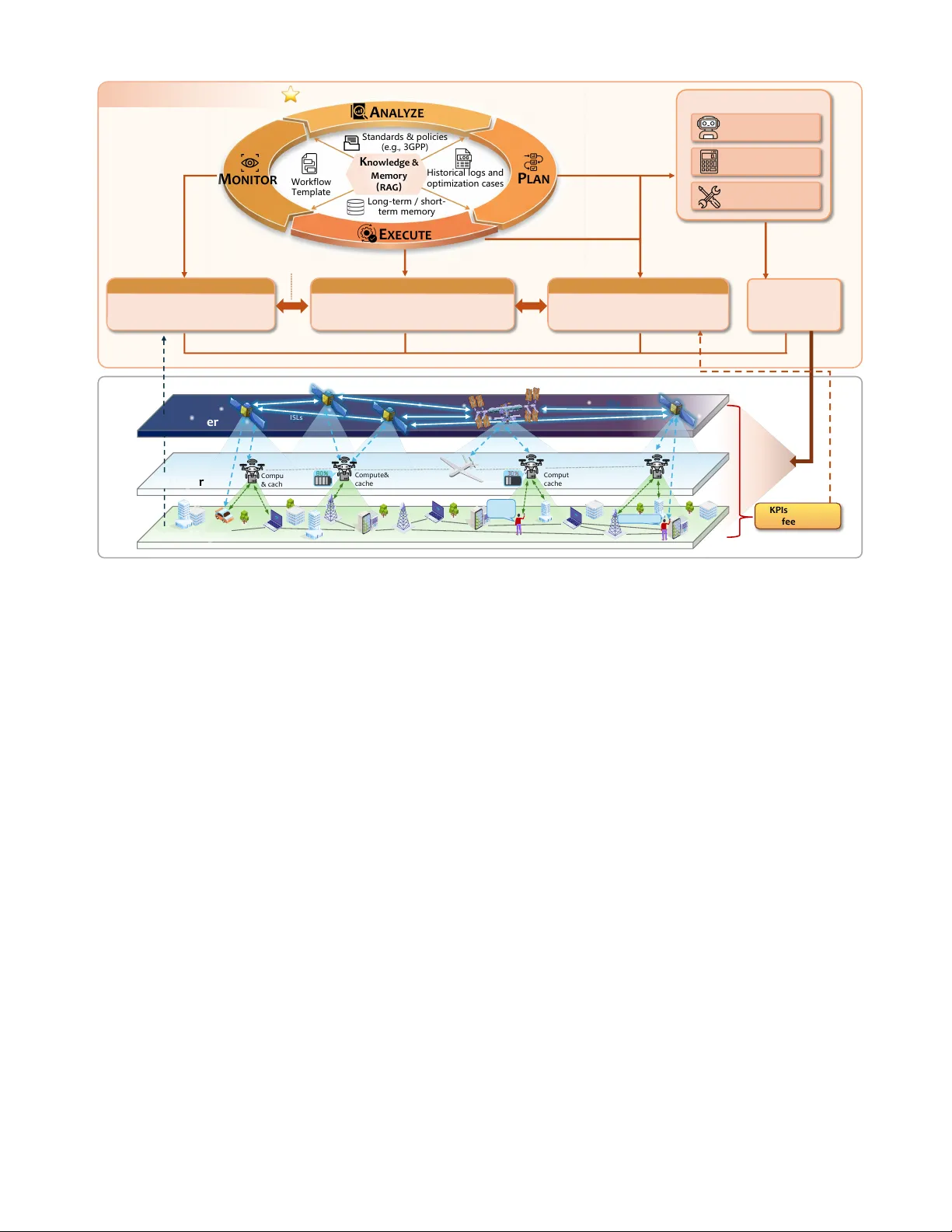
1 Space - air - ground integrated networks (SAGIN) promise ubiquitous 6G connectivity but face significant resource management challenges due to heterogeneous infrastructure, dynamic topologies, and stringent quality - of - service (QoS) requirements. Conventional model - driven approaches struggle with scalabil ity and adaptability in such complex environments . This paper presents an agentic artificial intelligence ( AI ) framework for autonomous SAGIN resource management by embedding large language model (LLM) - based agents into a Monitor - Analyze - Plan - Execute - Knowledge (MAPE - K) control plane. The framework incorporates three specialized agents, namely semantic resource perceivers, intent - driven orchestrators, and adaptive learners, that collaborate through natural language reasoning to bridge the gap between operator intents and net work execution. A k ey innovation is the hierarchical agent - reinforcement learning (RL) collaboration me chanism, wherein LLM - based orchestrators dynamically shape reward functions for RL agents based o n semantic network conditions. Validation through UAV - assisted AIGC service orchestration in energy - constrained scenarios demonstrates that LLM - driven reward s haping achieves 14% energy reduction and the lowest average service latency among all compared methods . This agentic paradigm offers a scalable pathway toward adaptive, AI - native 6G networks , capable of autonomously interpreting intents and adapting to dynamic environments . I ntroduction Space - air - ground integrated networks (SAGIN) are emerging as a critical infrastructure for 6G and beyond, promising seamless global connectivity and ubiquitous service delivery across terrestri al, aerial, and space users. By synergistic ally integrating sa t ell ites, aerial platforms, and ground infrastructure, SAGIN can support diverse applications such as emergency response, remote sensing, and intelligent transportation systems [1] . However, realizing this vi sion faces fundamental challenges arising from th e stark heterogeneity and strong coupling of network segments. SAGIN inherently integrates resource - constrained satellite networks, which are characterized by broad coverage despite limited onboard energy and computing capabiliti es, with resource - rich terrestrial networks. This integration creates a complex environment exhibiting drastic performance heterogeneity in terms of latency, data rates, and energy efficiency . Furthermore, these diverse resources must be orchestrated t o satisfy integrated yet divers e Quality - of - Service (QoS) requirements, which range from delay - sensitive control to bandwidth - hungry AIGC services. Conventional net work management appr oaches, including model - driven methods and Reinforcement Learning (RL), often struggle to navigate these complexities in large - scale, highly dynamic SAGIN. Model - driven approaches typically re ly on idealized assumptions and static models , which often struggle to characterize the complex coupling among communication links, buffer queues, and computing nodes , leading to suboptimal performance in r eal deployments [2] . Conversely , whil e RL methods off er adaptability, they enc ounter inherent di fficulties with scalability and sa mple efficiency when dealing with high - dimensional state - action spaces . More criti cally, these methods often operate as black boxes that lack the capability to interpret the semantic context of diverse QoS intents, such as distinguishing between emergency reliability and best - effort capacity needs. Given the increasing complexity of cross - layer interactions in SAGIN, there is an urgent need for more adaptive, knowledge - aware, and explainable intelligence i n resource management [3] . Recent advances in lar ge AI models (LAMs), particularly large language models (LLMs), have unlocked new paradigms for wireless resource optimization and network orchestration. Pre - trained LLMs exhibit strong capabili ties in reasoning, in - context learning, and decision - making, and have been widely ap plied to diverse network management tasks [4] . While Retrieval - Augment ed Generation ( RAG) further enhances decision quality by grounding LLM outputs in r eal - time domain knowledge [5 ], most existing approaches remain limited to open - loop operations. Specifically , they predominantly deploy LLMs as single - shot optimizers handling static network snapshots, generating one - off strategies without continuous adaptation. Consequently, these solutions lack real - time state monitoring and execution feedback Agentic AI for SAGIN Resource Manage ment: Semantic Awareness, Orchestration, and Optimizati on Linghao Zhang, Haitao Zha o, Bo Xu, Hongbo Zh u, and Xianbin Wang, Fell ow , IEEE 2 Figure 1 . Evolution of AI - driven network m anagement approaches for SAGIN, highlighting the progression from static m odel - driven optimization to autonomous agenti c AI systems . mechanisms, leaving them vulne rable to hallucina tions and limiting their efficacy in dynamic, closed - loop resource management [6]. Thi s p rogression , and the critical gap aiming toward closed - loop autonomy, is illustrated in the evolutionary timeline of Fig . 1. To achieve truly autonomous SAGIN resource management, we argu e that it is necessar y to elevate large models into agentic AI controllers. Agentic AI augments LLMs with capabilities such as tool invocation, memory manageme nt, and planning [7] . This enha ncement facili tates a paradigm s hift toward intelligent orchestration, where agents continuously perceive network condit ions with semantic awareness . Specifically , they can interpret the contextual value of constrained resources, such as prioritizing satellite energy preservation over latency reduction, and decompose high - level operator intents into actionable tasks. Furthermore, these agents coordinate heterogeneous modules, including traditional algorithms and RL - based units, to iteratively refine strategies based on execution feedback. By e ffectively bridging semantic understanding with network - level operations via software - defined networking (SDN) interfaces, this paradigm is particularly well - suited for handling the dynamic and heterogeneous nature of SAGIN resource management [8] . In this paper , we present an agentic AI - driven framework for autonomous SAGIN resource management an d make the fol lowing contr ibutions : • Agentic AI control plane archi tecture : We propos e a closed - loop control framework built upon the Monitor - Analyze - Plan - Execut e - Knowledge (MAPE - K) loop, incorporating three specialized AI agents for semantic resource perception, intent - driven orchestration, and adaptive learning. This architecture bridges the gap between operator intents and network - level execution through natural language reasoning and tool - augmented coordination, enabling autonomous adaptation to dynamic network conditions . • Hierarchic al age nt - RL collabo ration mecha nism : We design a c ollaborat ive scheme wh ere LLM - based orchestrators dynamically shape reward functions for RL agents based on s emantic networ k condition s, facilitating policy ada ptation to evolving environments. This hie rarchical ap proach lever ages LLMs for hig h- level semantic reasoning while delegating low - level real - time optimization to specialized RL algorithms, effectively combining interpretability with computational efficiency . • Valid ation through simulation : We condu ct a case study on task placement and resource allocation for AIGC services in energy - constrained SAGIN, benchmarking the proposed agent - enhanced RL against conventional baselines. Simulation results demonstrate a superior energy - latency balance and faster convergence, confirming the effectiveness of agentic AI for SAGIN res ource orchestration . Why Agentic AI for SAGIN Resource Management ? SAGIN integrates resource - constrained non - terrestrial nodes with heterogene ous terrestrial networks, creati ng a large - scale, time - varying infrastructure where cross - layer resource awareness and real - time optimization are tightly coupled. However, c onventional network management approaches struggle to deliver effective orchestration because of three inherent challenges . • Resource coupling and fragmented visibility : T he deep resource coupling between broad - coverage yet resource - limited non - terrestrial nodes and terrestrial networks fragments cross - layer visibility, hindering the acquisition of a unified global resource view . This necessitates semantic awareness to transform raw telemetry and network states into actionable cross - layer abstractions. 2015 2020 2023 2025 2026+ TIMELINE & TREND STAGE 1 STAGE 2 STAGE 3 STAGE 4 Model -Driven Optimization Rule - based State Action Reward Experience Replay Reward Learning Curve Environment Deep RL -Driven Prompt : Optimize network for low latency LLM : Allocate 60% ground, 40% satellite... Network configuration allocation No Feedback Loop LLM Prompt Interface One – Shot Optimization LLM - Enhanced Agentic AI (Our Framework) Key Features ü Convex optimization ü Heuristic algorithms ü Static resource allocation Limitations ✖ Simplified assumptions ✖ Poor adaptability Key Features ü DQN, DDPG, PPO ü Data -driven learning ü Online adaptation Limitations ✖ Sample inefficiency ✖ Black- box decisions Key Features ü Prompt - based reasoning ü In -context learning ü Semantic understanding Limitations ✖ No continuous feedback ✖ Isolated problem-solving Key Features ü Closed - loop MAPE -K ü Agent -RL collaboration ü Intent -driven orchestration ü Tool invocation & planning ü Continuous adaptation ü Real -time responsiveness S4 (Ours) S3 S2 S1 Capability ✅ ⚠ ⚠ ❌ Adaptability ✅ ✅ ❌ ❌ Semantic Reasoning ✅ ❌ ⚠ ❌ Continuous Feedback ✅ ❌ ⚠ ❌ Autonomy ✅ ❌ ❌ ❌ Tool Invocation Capability Comparison Ta b l e Monitor Plan Analyze Knowledge Autonomous ⭐ SDN controller Learner Too l Chain LLM - enhanced RL MAPE -K Control Loop Perceiver Adaptive Learning Orchestrator Execute 3 • Performance heterogeneity an d spa tiotemporal dynamics: D iverse nodes across space, air, and ground layers exhibit divergent physical attributes and transmission capabilities. These disparities are compounded by platform mobility, creating spatiotemporal dynamics that render static or segmented control mechanisms ineffectiv e. Addressing this requires intelligent o rchestration to dynamically coordinate cross - layer actions. • Conflicting QoS and decision complexit y : Divers e services ranging from latency - critical control to computation - intensive AIGC impose conflicting QoS requirements. This expands the decision space and amplifies uncertainty in joint offloading, caching, and routing, motivating adaptive optimization mechanisms that continuously refine policies based on execution feedback . Together, these complexities justify the deployment of an agentic AI control plane that unifies semantic awareness, intent - driven or chestration, and adaptive optimization for autonomous resource management in dynamic SAGIN environments [9] . A gentic AI Co ntrol Plane Architecture To address these challenges, we propose an agentic AI control plane that functionally decomposes autonomous resource management into three core capabilities, namely semantic cross - layer awareness, intent - driven orchestration, and continuous policy adaptation . As illustrated in Fig. 2 , these capabilities are realized through three specialized agent roles that collaborate to form a unified control plane for SAGIN resources . Rather than relying on a monolithic controller, this functional decomposition enables each agent to specialize in a distinct capability while maintaining coordinated operation through structured interactions [10] . Specifically, the control plane comprises the following three agent roles . • Semantic resource perceivers: These a gents br idge the gap between raw data and decision - making by fusing telemetry from satellites, aerial platforms, and ground nodes int o unified, high - level descriptions of the global network state. By combining raw metrics , such as link quality, buffer occupancy, and energy levels , with domain knowledge f rom st andards and historical logs, they create cross - layer views that highlight resource hotspots and bottl enecks in a format interpretable for both downstream algorithms and human operators. This directly addresses the issues of limited visibility and weak semantic a bstraction. • Intent - driven resource orchestrators: Acti ng as central planners, the orchestrators connect high - level objectives with concrete control actions . Given operator or service intents, such as minimizing delay under stri ngent energy budgets, they derive coordinated decisions on routing, spectrum allocation, and task offloading. Leveraging prior opt imization cases and external knowledge, these orchestrators handle trade - offs among l atency, reliability, and load balancing. They can also invoke specialized tools, including RL - based modules, classical optimization solvers, and SDN or orchestration APIs . • Adapt ive learners and policy refiners: By continuously monitoring key performance indicators (KPIs) and execution feedback, this agent role closes the loop between decisions and outcomes, enabling early detection of anomalies and performance drift s . Based on this feedback, they updat e internal memory and refine the prompts and reward functions used by other agents. This mechanism impr oves the robustness of policies under evolving condi tions and provides intrinsic support for explanation and auditing, as th e reasoning behind each update can be recorded and inspected . To inter act with the SAGIN infrastructur e, these agents leverage a model context protocol (MCP) that provides unified inter faces to heterogeneous data sources and control tools [1 0] . Through MCP, agents can access telemetry databases for network monitoring, retrieve domain knowledge from standards documents and historical logs, invoke optimization solvers and RL - based modules for decision - maki ng, and issue control commands to SDN con trollers and orchestration platforms for strategy execution. While the se a gent roles establish the functional foundation for autono mous resourc e management, their effecti ve operation requires a structured control workfl ow that coordinates monitoring, analysis, planning, and execution activities into a closed loop. C losed - loop C ontrol via MAPE - K Mechanis m A. MAPE - K Integr ation and Workf low Building o n the three specialized agents introduced above , we now describe their integration into a MAPE - K control loop to realize clos ed - loop resource management for SAGIN . The MAPE - K loop establishes a continuous cycle where network state drives decision - making and execution feedback enables adaptation. In this cycle, the Monitor phase collects multi - source telemetry and performance indicators from the SAGIN infrastructure. The Analyze phase then processes these observations into semantic resource views while evaluating their implications for resource management . Based on these insights, the Pl an phase generates candidate cr oss - layer manag ement strategies that reflect high - level intents and current network states. The Execute phase subsequently enforces select ed strategies through SDN and orchestration interfaces. Throughout this process, the shared Knowledge component provides domain expertise, historical logs, and operational m emory to all 4 Figure 2 . Agentic AI control plane architecture built upon the MAPE - K framework, incorporating semantic resource perceivers, intent - driven orchestrators, and adaptive learners to manage heterogeneous SAGIN resources . phases, supporting informed decision - maki ng. The three agent roles integrate naturally into this loop to enable autonomous, adaptive resource management . B. Monitor and Analy ze: Semantic Reso urce Awareness The Monitor phase continuously collects real - time, multi - dimensional network st ate data from the SAGIN infrastructure, encompassing traffic patterns, resource utilization, topol ogy dynamics, and system anomalies across space, air, and gr ound segments. Distributed sensors and network probe s ga ther operational data, which is then normalized for analysis . The An alyze phase employs semantic resource perceivers to perform comprehensive data fusion and state evaluation. Perceivers lever age advanced reasoning capabilities to process complex network patterns, integrating real - time observations with historical da ta and domain knowledge retrieved from the Knowledge base. This phase transforms raw telemetry into semantic cross - layer resource states that capture hi gh - level network conditions, such as identify ing relay link bottlenecks or energy constraints, thereby generati ng interpretable, decision - oriented views for the planning stage [11] . C. Plan and Execute: Intent - Driven Optimizatio n Based on semantic resource states from th e Analyze phase, the P lan phase formulates cross - layer management strategi es such a s spectrum allocation, routing adjustments, and task offloading. Intent - driven resource orchestrators generate action plans that balance competing metrics such as latency, reliability, and energy consumption [12] . Meanwhile, o rchestrators query the k nowledge base to sel ect appropriate optimization tools for each specific tas k. The Execute phase tr anslates pl anning strat egies into concrete network operations, distributing configurations to network segments through standardized control plane interfaces such as SDN controllers and orchestration APIs . Execution status and performance feedback are returned to adaptive learners, which refine internal memory and update reward functions for RL - based agents . This feedback mechanism enables continuous adaptatio n t o e volving network conditions . D. Knowledge Management and Continuous Learning The Knowledge component maint ains two categories of information to support agent decision - making. St atic domain knowledge includes wirel ess communication standards, network protocols, and resource management best practices that perceivers and orchestrators leverage to ensure compliance and informed reasoning. Dynamic operational knowledge comprises historical performance logs for few - shot learning , reusable workflow tem plates and skills for common management tasks, and interface documentation for tool invoc ation . Through RAG technology, agents query this knowledge base to retrieve contextually relevant information base d on M ON I T OR P LA N A NA L Y Z E E XE C UT E K no w le dg e & Me m o ry ( RA G ) St an d ar d s & p o l i c i e s (e . g . , 3 G P P ) Hi st o r i c a l l o g s a n d op tim iz a tion c a s e s Lo n g - t e rm / s h o rt - t e rm m e m o ry Wor k f low Te m p l a t e • Fuse multi -source telemetry • Semantic cross - layer reso urce view Semantic Re source Perc eiver • Tran slate intent s to routing / of floading … • Plan cross -layer resource decision s Intent - Driven R esource Orchestrato r • Use KPIs and feedback to update policies • Refi ne prompts, t ools, and RL rewards Adaptive L earner & Policy Refine r Semantic resource state Feedback & history semantic resource state & planning in puts Co m p u te & ca ch e Co m p u t e & ca ch e Co m p u t e& ca ch e IS L s ISLs Space Lay e r Air Laye r Ground L ayer Invoke tools Via MCP Optimization & Control Tools RL - based optimization agent Classical optimization solvers SDN / orchestration APIs control co mmands / configurati on SDN control lers & orchestration platforms Agentic AI control plane semantic resource state updated pro mpts / pol icies / rew ard shapin g 150ms latency backhaul, compute, cache AIGC Request LEO Space station Compute& cache Direct - to - Cell MEC server Self - driving car Ground BS HAPs SAGIN Architecture Agent Collaboration Relay links 20ms latency KP I s & Exec ute fe e dback resource configuration / control actions performance m etrics, anomalies, new patterns Monitoring & Te l e m e t r y 5 Figure 3 . Hierarchical agent - RL collaboration in the Plan phase. The LLM - based orchestrator interprets operator intents and semantic states, then configures R L agents through dynam ic reward shaping and diffusion - guided exploration. current network environment and optimization objectives. As the MAPE - K loop operates, execution feedback continuously enriches this knowledge ba se with new data and successful st rategies, enabling progressive improvement of resource management capabilities . A gent - RL collaborative Optimization While intent - driven orchestrators excel at semantic interpretation, tasks such as dynamic task offloading, real - time spectrum allocation, and adaptive routing in mobile SAGIN environments demand millisecond - level decisions over high - dimensional continuous action spaces . To address this challenge, the agentic AI framework adopts a hierarchical approach where orchestrators serve as high - level coordinators while invoki ng specialized RL agents f or low - level optimization. Within the Plan phase, orchestrators int erpret semantic resource states from percei vers, determine optimization objectives based on operator intents, and configure RL agents with appropriate parameters. RL agents then execute rapid decision - making, with execution feedb ack returned to adaptive learners for continuous policy refinemen t. To enhanc e this collaborati on, the framework incorporates two complementary mechanisms , as illustrated in Fig. 3 . Orchestrators employ LLM - driven reward shaping to align RL optimization with evolving network semantics [13] . When p erceivers report conditions such as satellite energy constraints or ground segment congestion , orchestrators generate modified reward functions. For example, under energy - constrained scenarios, the orchestrator adjusts rewards to penalize high - power transmissions while favoring energy - efficient routing paths. Meanwhile, the framework employs diffusion models to guide RL exploration. These generative models learn state - actio n d istributions from historical trajectories stored in the knowledge base and generate exploratory actions that remain within feasible regions, substantially reducing ineffective exploration in high - dimensional optimization tasks [14] . These mechanisms enable seamless integration of semantic awareness with reactive optimization while ensuring RL - based decisions remain aligned with high - level network intents . Case Study : UAV - assisted AIGC Service Orchestra tion A. Scenario Description We demonstr ate the prop osed framewo rk through a UAV - assisted AIGC service o rchestration scenario in SAGIN, as illustrated in Fig . 4. T he physical layer depicts a LEO satellite constellation providing global coverage, a heter ogeneous UAV cluster with varying energy states, and ground base stati ons with edge computing servers serving mobile users requesting real - time HD video generation se rvices [15] . At the captured time instant, UAV - 1 experiences critical energy depletion (25% remaining) while UAV - 2 maintains adequate energy (80%), creating a dynamic resource management cha llenge that requires intelli gent decision - making. The agentic AI control p lane demonstrates the complete MAPE - K operational workflow. Semantic resource perceivers continuously collect multi - dimensional telemetry and infer the semantic state “ UAV cluster energy - constrained with satelli te backup available but high latency. ” The inte nt - driven orchestrator receives this semantic state along with operator intent to minimize service latency while ensuring UAV ener gy sustainability. It then invokes a pre - trained Deep Diffusion Deterministic Policy Gradient (D3PG) agent to determine task placement across heterogeneous nodes, with communication routing and resource allocation . Crucially, the orchestrator shapes the reward functi on based on current network semantics to penalize energy - depleting UAV assignments while f avoring satellite - assisted or ground processing. As shown in t he embedded deep dive panel, this LLM - driven reward shaping mechanism enables the RL agent to rapid ly ada pt its policy. Finally, the orchestrator translates the resulting action into concrete S DN flow rules, resour ce allocations, and power control commands, with execution feedback returned to adaptive lear ners for continuous poli cy refinement. For instance, when the observed service latency exceeds the target threshold, the adaptive learner records this deviation and refines the orchestrator's reward configuration for subsequent decision cycles . B. Performance Evaluation To validate both the effectiveness of D3PG algorithm and LLM - driven reward shaping, we conduct simulation experiments focusing on the task placem ent Environment Reward Evaluation State Action Actor Network State Value Critic Network Experience Pool Shaped Reward Observation Mechanism 1: LLM -driven Reward Shaping Semantic Condition Analysis Translate to Reward Modifier LLM Mechanism 2: Diffusion-guided Exploration Historical Traj ec tor ie s Feasible Action Candidates Diffusion Model t = T D e n o i si n g t = T / 2 D e n o i si n g t = 0 t = T D e n o i si n g t = T/2 D e n o i si n g t = 0 t = T D e n o i si n g t = T / 2 D e n o i si n g t = 0 Modified Reward Plan Phase Intent -driven Orchestration Interpret Reason Configure Configure Reward Shaping Configure Exploration Knowledge Base Query domain Knowledge Semantic Resource State Operator Intents Performance target Resource constraints Execution Feedback 6 Figure 4 . UAV - assisted AIGC service orchestration scenario demonstrating the MAPE - K workflow. The control plane perceives UAV energy constraints, adapts D3PG reward functions through LLM shaping, and executes optimized task placement decisions . problem within the Plan phase. T he D3PG agent determines AIGC task allocation across heterogeneous processing nodes and transmission routing s elections to minimize serv ice latency whil e managing UAV ener gy consumption. The reward function combines latency and UAV energy consumption through a penalty coefficient, which is dynamically shaped by the LLM orchestrator based on semantic network conditions . Given task placement and ro uting de cisions, resources such as communica tion bandwidth, computation capacity, and transmit power are optimized through lightweight solvers to satisfy capacity and QoS constraints . We implement the scenar io using a simulator with 3 LEO satellites, 5 UAVs with varying energy s tates, 2 ground base stations, and 50 concurrent AIGC tasks under energy - constrained operational conditions. We compare five approaches to evaluate both algorithm effectiveness and reward shaping benefits : (1) LLM - shaped D3PG where the penalty coefficient is dynamically adjusted by the orchestrator based on UAV energy semantics, (2) Fi xed - reward D3PG with constant penalty coefficient, (3) DDPG with LLM - shaped rewa rd, (4) DQN with LLM - shaped reward, and (5) Greedy heu ristic that assigns tasks to lowest - latenc y nodes. The RL agents ar e implemented in Python using PyTorch and trained over 1000 epi sodes with experience replay . Fig. 5 presents the training convergence under energy - constrained conditions. The proposed LLM - shaped D3PG achieves the fastest convergence and highest episode reward, confi rming that semantically driven reward shaping provides more infor mative learning sig nals than fixed rewa rd functions. Fig. 6 further compares the converged service latency and UAV energy consumption. LLM - shaped D3PG attains the lowest average latency while reducing normalized ene rgy consumption by 14% relative to the fixed - reward variant. This improvement stems from the adaptive penalty coefficient, which guides the agent to b alance UAV utilizati on against energy depletion proactively. A mong the baselines, DDPG and DQN with LLM shaping exhibit intermediate performance, confirming the advantage of D3PG ’ s diffusion - based exploration in high - dimensional continuous action spaces, while the Greedy heuristic incurs substantially higher l atency and energy cost due to its inability to plan beyond the current time step. These results highlig ht a core des ign prin ciple whereby the LLM orchestrator shapes the rewa rd landscape on a slow timescale while the RL agent executes fast - timescale decisions, combining semantic reasoning with real - time responsiveness. This hierarchical agent - RL pattern is expected to generalize to other SAGIN tasks such as spectrum allocation and routing by replacing the semantic extraction rules and RL algorithm. D iscussion an d Future Directions While t his pape r demonst rates th e viabil ity of agentic AI for SAGIN resource management, sever al promising directions deserve further exploration. Integrating RAG could enable dynamic knowledge ISLs LEO Satellite Coverage: ✅ Latency: 1 80 ms LEO Satellite Coverage: ✅ Latency: 1 77 ms LEO Satellite Coverage: ✅ Latency: 1 83 ms Space segment Air segment Ground segment SAGIN environment - perceived by the Perception module UAV -1 UAV -2 AIGC Request: HD Video Generation AIGC Request: HD Video Generation Edge Server Edge Server Ground BS -1 Utilization: 55 % Latency: 5 ms Ground B S-2 Utilization: 70% Latency: 4 ms Latency: 25 ms Latency: 21 ms Latency: 20 ms Ne twor k Sta tus : • S a t e lli t e : ✅ • UA V - 1 : ⚠ 20% • UA V - 2: ✅ 80% • Gr ound BS: ✅ A c t iv e Ta s k s : 18 P e n d in g : 5 A g e n t ic A I C o n t r o l P l a n e (M A P E - K Lo o p ) Monitor Phase Semantic Resource Perceiver Input : Raw T elemetry - SNR: [18, 15, 20] dB - UAV Energy: [20%, 80%] - Ground CPU: [ 55 %, 70 %] - Queue: [12, 8, 15] Output: Structured State Vector state = {topology, resources, queue} Agent Action Collect and normalize telemetry via MCP interfaces. Analyze Phase Semantic Inference LLM Prompt to Perceiver Given network state: - UAV -1 energy at 20% (critical) - Satellite available with 180ms latency - Ground servers at 55% utilization Analyze bottlenecks and generate semantic resource state. LLM Response Network condition: UAV cluster energy- constrained. UAV -1 entering critical zone. Satellite relay available but high latency. Recommendation: Recommend minimizing UAV -intensive tasks. Plan Phase Intent - Driven Orchestrator LLM Prompt to Orchestrator Intent: Minimize latency while ensuring UAV energy sustainability. Current semantic state: UAV energy -constrained. Available tools: - D3PG agent ( task_placement) - Greedy heuristic Select optimization strategy and configure parameters. LLM Response Strategy: Invoke D3PG with reward shaping. Reward config : - Base: R = - latency - Penalty: λ = 5.0 - Shaped: R’ = R - λ * UAV_ener gy_cost Rationale : Penalize UAV usage to preserve energy while using satellite and ground. Execute Phase Action Executing LLM Prompt Translate action [0.6, 0.3, 0.1] into concrete network commands. Deep Dive: LLM – RL Collab LLM Orchestrator (High-level) D3PG Agent (Low-level) State à Action Shaped Reward Generated Commands SDN Flow Rule : Route 60% tasks to Ground - BS - 1 Bandwidth Allocation : Allocate 50Mbps to Satellite link Power Control : Reduce UAV- 1 transmit power to 20dBm Feedback Loop : Actual latency: 42ms à Learner Agent Execution Status: ✅ Success MCP Feedback: Latency, Energy, QoS Action Strategy T elemetry Data Semantic State Knowledge Base: Historical strategies, Network models, 3GPP standards Adaptive Learner : Update policy, Refine prompts, Store feedback Actions ↑ 7 acquisition from evolving technical standards and operational logs, reducing reliance on manually curated Figure 5 . Training convergence compari son across methods . Figure 6 . Performance comparison across methods : ( a) average service latency and (b) UAV energy consumption . prompt templates. Extending the framework to multi - objective optimization scenarios, such as spectrum efficiency, fairness, and network resilience, requires advanced preference elicitation mechanisms and multi - agent coordination protocols. Address ing partial observability and adversarial network conditions through diffusion - based state estimation represents another promising research direction. Finally, transitioning from simulation to real - world deployment requires rigorous safety assurances, including for mal verification of LLM - generated reward functions, explainability of RL - based decisions, and fail - safe mechanisms to handle ambiguous or c onflicting semantic guidance. Conclusion This paper presented an agentic AI framework for autonomous SAGIN resource management, establishing a control plane architecture built upon the MAPE - K loop with three collaborat ive AI agents , semantic resource perceivers, intent - driven orchestrators, and adaptive learners. The framework bridges high - level operator intents and low - level network optimization through hierarchical agent - RL collaboration, where LLM - based orchestrators provide seman tic reasoning and goal - oriented guidance while specialized RL age nts execute real - time decisions. Validation through UAV - assisted AIGC service scenarios confirm s the framewo rk ’ s effectiveness in balancing multiple objectives under dynamic constraints. This agentic paradigm offers a generalizable approach to a broad range of SAGIN resource management problems, including but not limited to spectrum allocation, task offloading, and routing optimization, paving the way toward adaptive, AI - native SAGIN systems that autonomously interpret operator intents and respond to dynami c environments. R eference s [1] R. Zhang et al., “Generative AI for Space - Air - Groun d Integrated Networks,” IEEE Wireless Commun., vol. 31, no. 6, pp. 10 - 20, 2024 . [2 ] P. Zhang et al. , “ AI - enabled space - air - ground integrated networks: Management and optimizati on, ” IEEE N etw., vol. 38, no. 2, pp. 186 - 192, Mar. 2024. [3 ] T. - H. Vu et al., “Appl ications of G enerative AI ( GAI ) for mobile and wi reless netwo rking: A survey, ” IEEE Internet Things J., vol. 12, no. 2, pp. 1266 - 1290, 2025. [4 ] H. Zhou et a l., “ Large l anguage model (LLM) for telecommun ications: A comprehensive survey on principles, key techniques, and opportunities, ” IEEE Commun. Surv. Tutorials, vol. 27, no. 3, pp. 1955 - 2005, 2025. [5] H. M. A. Ze eshan et al., “ LLM - based retrieval - augmented generation: A novel framework for resource optimization in 6G and beyond wireless networks, ” IEEE Commun. Mag., vol. 63, no. 10, pp. 60 - 67, Oct. 2025. [6 ] F. Jiang et al., “A comprehensive survey of large AI models for future communications: Foundations, applications and challenges,” IEEE Commun. Surv. Tutori als, early access, doi: 10.1109/COMST.2026.3660844. [7 ] R. Sapkota et al. , “ AI a gents vs. agentic AI: A con ceptual taxonomy, applications and ch allenges, ” In f. Fusion, vol. 126, p. 103599, Feb. 2026. [8] F. Jiang et al., “ F rom large AI models to agentic AI: A tutorial on future intelligent communications, ” arXiv preprint arXiv:2505.22311, May 2025. [9] C. Zhao et al., “ From agentification t o self - evolving agentic AI for wirel ess networ ks: Concepts , approache s, and futur e research directions, ” arXiv preprint arXiv:2510.05596, Oct. 2025. [10] R. Zhang et al., “ Toward edge general intellig ence with agentic AI and agentification: Concepts, technologies, and future directions, ” IEEE Commun. Surv. Tutorials, vol. 28, pp. 4285 - 4318, 2026. [11] C. Liang et al., “ Genera tive AI - driven se mantic communication networks: Archit ecture, technologies, and applications, ” IEEE Trans. Cogn. Commun. Netw., vol. 11, no. 1, pp. 27 - 47, Feb. 2025. [12] M. Shokrnezhad et al. , “ An autonomous networ k orchestration framework inte grating large language models with continual reinforcement l earning, ” IEEE Commun. Mag., vol. 63, no. 8, pp. 78 - 84, Aug. 2025. [13] G. Sun et al., “ Generative AI fo r de ep r einforceme nt learning: Framew ork, analysis, and use cases, ” IEEE Wireless Commun., vol . 32, no. 3, pp. 186 - 195, Jun. 2025. [14] H. Du et al., “ Enhancing deep reinforce ment lear ning: A tutorial on generative diffusion models in network optimization, ” IEEE Commun. Surv. Tutorials, vol. 26, no. 4, pp. 2611 - 2646, 2024. [15] H. Zhou et al., “ Gene rative AI as a s ervice in 6G edge - cloud: Generati on task o ffloadin g by in - context learning, ” IEEE Wirel ess Com mun. Let t., vo l. 14, no. 3, pp. 711 - 715, Mar. 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment