Who Benchmarks the Benchmarks? A Case Study of LLM Evaluation in Icelandic
This paper evaluates current Large Language Model (LLM) benchmarking for Icelandic, identifies problems, and calls for improved evaluation methods in low/medium-resource languages in particular. We show that benchmarks that include synthetic or machi…
Authors: Finnur Ágúst Ingimundarson, Steinunn Rut Friðriksdóttir, Bjarki Ármannsson
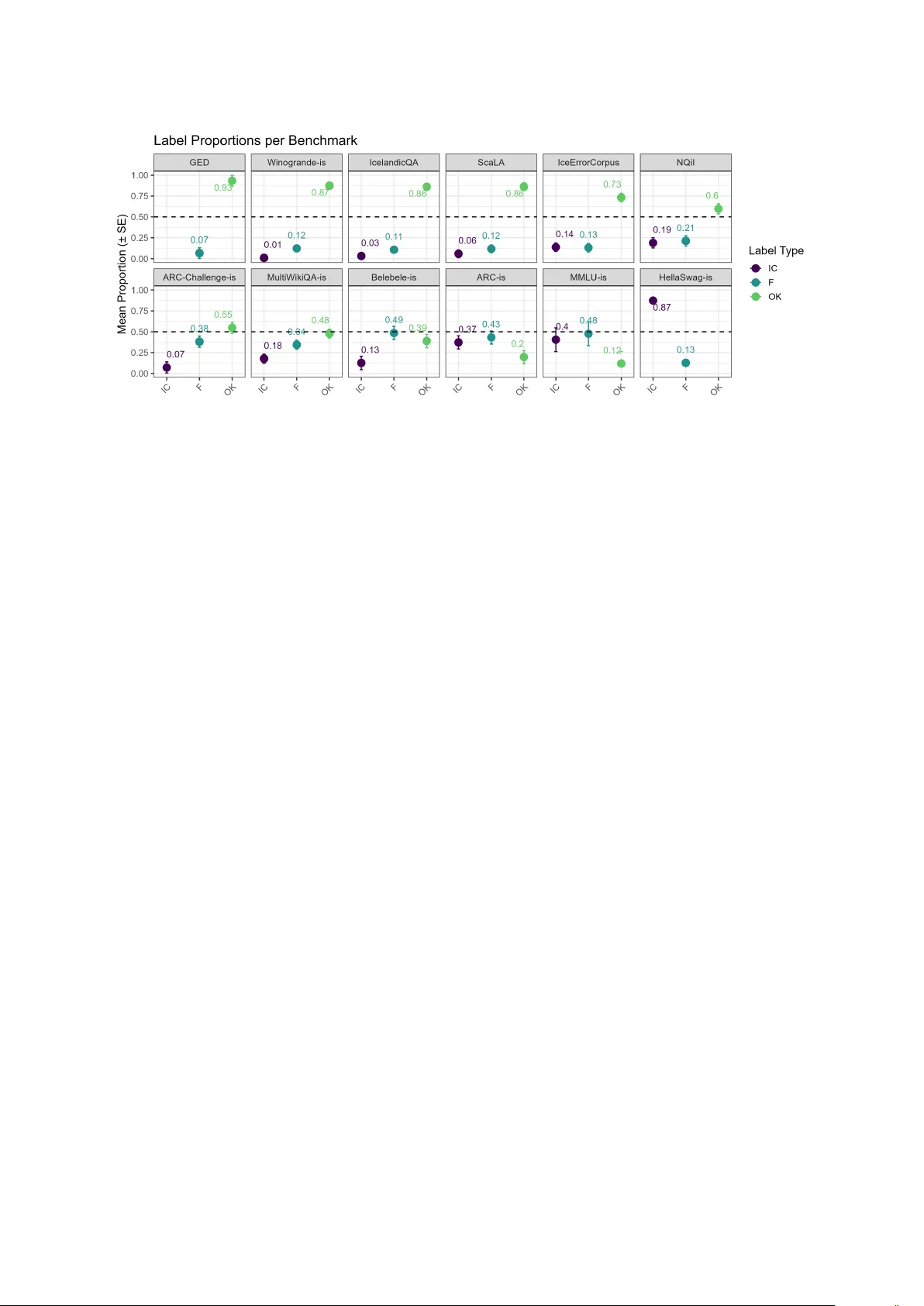
Who Benchmarks the Benchmark s? A Case Study of LLM Evaluation in Icelandic Finnur Ágúst Ingimundarson 1 , Steinunn Rut F riðriksdó ttir 2 , Bjarki Ármannsson 2 , 3 , Iris Edda Nowenstein 2 , Steinþór Steingrímsson 3 1 University of Zürich, 2 University of Iceland, 3 The Árni Magnússon Institute for Icelandic Studies finnuragust.ingimundarson@uzh.ch, {sr f, irisen}@hi.is, {bjarki.armannsson, steinthor .steingrimsson}@arnast ofnun.is Abstract This paper e valuat es curr ent Large Language Model (LLM) benchmarking for Icelandic, identifies problems, and calls for improv ed evaluation methods in low/medium-resource languages in particular . We show that benchmarks that include synthetic or machine-translated data that ha ve not been v erified in any wa y , commonly contain sev erely flawed test ex amples that are likely to ske w the results and undermine the tests’ validity . We warn against the use of such methods without verification in low/medium-resource settings as the translation quality can, at best, only be as good as MT q uality for a given language at any given time. Indeed, the results of our quantitative error analysis on existing benchmarks for Icelandic show clear differences between human-authored/-translated benchmarks vs. synthetic or machine-translated benchmarks. Ke ywords: benchmarking, machine translation, low-resource languages, Icelandic 1. Introduction Benchmarking has been an int egral part of dev elopment in NLP as a way of assessing perfor - mance on various tasks and traditionally on tasks with a single-label output, such as POS-tagging, NER, sentiment analysis, etc. With the advent of LLMs, that are not only capable of per forming all of these traditional tasks and yet more ( Brown et al. , 2020 ) but perhaps e ven of creating such data, the need for robust benchmarks is ev en greater than before. In their wak e also follow s a demand for creating new benchmarks that are better adapted to the capabilities of LLMs, i.e. bey ond ev aluating single-label output, and impor tantly , beyond tasks which purely target the scope of exper tise of NLP researchers ( Bowman and Dahl , 2021 ). This means that benchmar k set creators in- creasingly find themselves creating benchmarks for natural language production and understanding in languages they do not speak and within subjects of which they are not experts. For ex ample, there is a clear difference betw een constructing a NER ev al- uation metric in a language the researcher knows and generating a machine-translated benchmark - ing set for the evaluation of an LLMs ’ capabilities in medical t ext summarization ( Alaa et al. , 2025 ). F urthermore, the field – and therefore benchmark - ing – has largely been dominated by English (and a f ew other high-resour ce languages ( V ay ani et al. , 2024 ; Wang et al. , 2024b )), but giv en the multilin- gual capabilities of LLMs, it is impor tant to put them to the test in a valid manner . For one thing, it can be informative to see how different scripts or more morphologically rich languages compare. This is of par ticular impor tance for low-resour ce languages, as they run the risk of being submerged in the digital ocean of English data. For low- and medium-resource languages, it is often hard to keep up with the pace and establish what already exists for high-resource languages. Benchmarking is no e xcep tion. As benchmark pro- duction with human input can be time-consuming and costly , one common appr oach in such set- tings is to machine-translate existing benchmarks for other languages or use LLMs to create syn- thetic benchmarks, for instance by generating question-answer pairs from pre-existing data such as Wikipedia. But what are the drawbacks to this approach and do the y affect low-r esource languages dispropor tionally? In this paper w e look at the curr ent stat e of benchmarking for Icelandic as a case study of a low/medium-resour ce language, discuss the effects and results including machine-translated and syn- thetic data, and present the results of a q uanti- tative error analysis on exis ting benchmar ks for Icelandic. They show clear differences between human-authored or human-translat ed benchmarks vs. synthetic or machine-translated benchmarks, especially where the output has not been verified and/or corrected. 1 2. Related W ork Discussion on the pitfalls and problems of language model benchmarking, and the q uestion of how to best compare the capabilities of different models, 1 All code and data av ailable at https: //github.com/finaing/who_ benchmarks_ the_ benchmarks has been ongoing in the NLP community for y ears. At least as early as Bowman and Dahl ( 2021 ), it had become apparent that the best-performing NL U models of the day , though far from per fect in real- world applications, had almost completely satu- rated e xisting benchmarks, begging the question of how best to measure actual progress. Four years later , this is still an open and important question as evidenced by Eriksson et al. ( 2025 ) which identifies ‘ke y shor tcomings’ in benchmar king practices o v er the last decade, including ‘issues in the design and application’ , ‘misaligned incentives ’ , ‘construct v alid- ity issues, ’ and other shor tcomings directl y relat ed to the points made in this paper . As previously discussed, it has become common- place practice in recent years to automate the con- struction of benchmarks and evaluation sets either fully or par tially . Here, statistical power (which is cer tainly impor tant, see e.g. Card et al. ( 2020 )) is seemingly prioritized ov er precision and o verview , despite the fact that machine learning models are frequently ‘right for the wrong reasons’ ( McCoy et al. , 2019 ), capable of achieving high scores through learning unintended shallow heuristics. In- deed, there is considerable evidence that smaller , carefully curated test sets are of ten equally good or bett er indicators of per formance than larger , syn- thetic sets (see e.g. Gardner et al. ( 2020 ); Shaib et al. ( 2024 ); Y adav et al. ( 2024 )). This is in line with the im portance of validity in any kind of test- ing. Present already in e.g. Cronbach and Meehl ( 1955 ), validity is a ke y concept in psychome trics and addresses whether a test or ev aluation instru- ments truly measures what it intends to measure (the construct). In the conte xt of LLM testing and par ticularly in clinical applications, calls ha ve been made to prioritize construct validity and em plo y a Benchmark - V alidation-First Approach to (medical) LLM evaluation ( Alaa et al. , 2025 ). T o paraphrase, benchmarks need to be right for the right reasons. Even automatically constructing t est items using a structured template, now the norm for grammat- ical ev aluation sets ( W ar stadt et al. , 2020 ; Hueb- ner et al. , 2021 ; Song et al. , 2022 ; Jumelet et al. , 2025 ), can easily r esult in semantically bizarre ex am ples and items solvable through super ficial heuristics rather than genuine linguistic com pe- tence ( Vázquez Mar tínez et al. , 2023 ). Similarly , the widespread practice of evaluating syst ems for different languages by automatically translating e x- isting benchmarks (usually from English) has re- peatedly been shown to result in translation ar- tifacts which affect accuracy and omit language- and cultur e-specific cont ext ( Clark et al. , 2020 ; P ark et al. , 2024 ; Chen et al. , 2024 ; Liu et al. , 2025 ). For instance, Umutlu et al. ( 2025 ) e x- amine 17 T urkish datasets (a “mid-resource” lan- guage), many of which are translations/adaptations from English. They identify major shor tcomings related to coherence, fluency , cultural alignment, and increased risk of bias and error . Similarly , Y ao et al. ( 2024 ) note major shor tcomings in culturally specific machine translations where ex act transla- tion pairs might not exist. Furthermore, Semenov and Sennrich ( 2025 ) demonstrat e shortcomings of template-based translations in multilingual bench- marks, showing that sentence-lev el translations yield more reliable results. As noted by V ay ani et al. ( 2024 ), multilingual benchmarks remain limited in scope and dispropor - tionately represent high-resource languages, ne- glecting the cultural and linguistic diversity of lower - resource languages. Moreo v er , benchmar ks are often absorbed into training corpora, resulting in contamination and inflated ev aluation scores ( Y ang et al. , 2023 ). When evaluation datasets rely on translations of English benchmarks without cultural adaptation, models ma y optimize for unnatural constructions rather than authentic usage. This issue is amplified in small-language settings, where limited corpora increase the influence of benchmarks on model op- timization. Indigenous languages in particular face sev ere digital resource scarcity , bot h in corpus size and representativ eness. As Wiechetek et al. ( 2024 ) argue, when dev elopers lack proficiency or active engagement with the target language, systematic errors may go unnoticed. Scarcity increases re- liance on synthetic data, which can recursivel y dom- inate future training cy cles, amplifyin g distortions and reinforcing inaccuracies. In extr eme cases, synthetic outputs may even invert the meaning of source te xts, causing direct harm to the language community . Consequently , models may per form well on translated test sets while failing to capture cultur - ally grounded semantics or authentic discour se patterns, leading to syst ematic ov erestimation of model capabilities ( Sainz et al. , 2023 ). This con- cern is suppor ted by Wang et al. ( 2024a ), who show that LLM per formance is inconsistent across languages, with degradation in lower -resource set- tings and stronger results on English cultural rea- soning tasks. Similarly , W ang et al. ( 2024b ) demon- strate that LLMs tend to reproduce English-centric cultural assum ptions ev en when prompted in other languages. Direct translation of culturally specific English benchmarks may therefor e rew ard English- oriented reasoning rather than culturally situated understanding in the target language. 3. Leaderboards for Icelandic As of October 2025, there are two publicly available leaderboards for Icelandic. One is maintained b y the Icelandic L T com pan y , Miðeind, on Hugging F ace 2 and the other is a par t of the EuroEval project, previousl y ScandEval ( Nielsen , 2023 ). 3 3.1. Miðeind’s leaderboard At the time of writing, Miðeind’s leaderboard ev alu- ates 59 LLMs across 6 different benchmarks: • WinoGrande-IS : a human-translated and localized version of the WinoGrande test set ( Snæbjarnarson et al. , 2022 ; Sakaguchi et al. , 2021 ) • GED : binar y sentence-lev el GED with data from the Icelandic Error Corpus ( Arnardóttir et al. , 2021 ) • Inflection : inflection of 300 Icelandic adjective-noun pairs in all four cases and both numbers 4 • Belebele : Icelandic subset of Belebele (reading comprehension) ( Bandarkar et al. , 2024 ) 5 • ARC-Challeng e-IS : machine-translated version of the ARC-Challenge benchmark ( Clark et al. , 2018 ) 6 • WikiQA-IS : 1.9k QA pairs created by GPT -4o from Icelandic Wikipedia data, manually verified and cor - rected ( Arnardóttir et al. , 2025 ) 3.2. EuroEval’s leaderboard EuroEval’ s leaderboard contains benchmarks and ev aluation for 18 European languages, at the time of writing, and evaluat es all types of language mod- els, fine-tuning encoder models and either zero- or few-sho t prompting decoder models for different tasks. Like Miðeind, EuroEval uses WinoGrande-IS and Belebele, but a different machine-translat ed version of the ARC-Challenge. It additionally uses WikiQA- IS in a different format, where an LLM is used to generate three plausible answer alternativ es, turn- ing it into a multiple-choice answering task, but the benchmark has not been published in this format. Other datasets or benchmarks included are: • Hott er and Colder Sentiment : sentiment analysis dataset ( Friðriksdóttir et al. , 2025 ) • MIM-GOLD-NER : NER dataset ( Ingólfsdóttir et al. , 2020 , paper), ( Ingólfsdóttir et al. , 2020 , data) • ScaLA-IS ( Nielsen , 2023 ), IceEC (sam pled data from the Icelandic Error Corpus), subset of IceLin- guistic ( Ármannsson et al. , 2025 ): All used for a binary evaluation of grammaticality or GED 2 huggingface.co/spaces/mideind/ icelandic- llm- leaderboard 3 euroeval.com 4 huggingface.co/datasets/mideind/ icelandic- inflection- all- flat 5 huggingface.co/datasets/facebook/ belebele/viewer/isl_ Latn 6 huggingface.co/datasets/mideind/ icelandic- arc- challenge • NQiI : “Natural Questions in Icelandic”, dataset for open domain QA with retriev al ( Snæbjarnarson and Einarsson , 2022 ) 7 • MultiWikiQA-IS : created using LLM Gemini-1.5-pro on Wikipedia data (306 languages) ( Smar t , 2025 ) 8 • MML U-IS : machine-translated version of the US MML U benchmark ( Hendr ycks et al. , 2021 ) 9 • HellaSwag-IS : machine-translat ed version of the HellaSwag benchmark ( Zellers et al. , 2019 ) 10 • RRN : summarization dataset ( Sverrisson and Einarsson , 2023 ) 11 It is impor tant to not e two things. Fir st, in some cases datasets are being turned into benchmarks, despite not being intended as such originally . This goes for Hott er and Colder , MIM-GOLD-NER , IceEC , NQiI and RRN . Second, EuroEv al labels some benchmarks as “unofficial”. As far as we can see, there is no information to be found on the websit e on what fact ors are decisiv e in mak - ing this distinction between benchmarks, but the label apparently refers to benchmarks for which the results are not published on the leaderboard. “Offi- cial” benchmar ks are: Hott er and Colder Sentiment , MIM-GOLD-NER , SCaL A-IS , NQiI , IcelandicKnow l- edge , WinoGrande-IS and RRN . Howev er , the pub- lished code on Github and the EuroEval Python package include scripts to create all of the bench- marks (and splits), regardless of whether they are unofficial or not, and benchmar k models on them. 12 4. Quantitative Error Analysis A re view of benchmar ks that are currently being used for Icelandic rev ealed various problems in some of the datasets and, to some e xtent, in the wa y they are being used. T o k eep this paper from consisting of seemingly cherr y-pick ed examples, we conducted a quantitativ e error analysis of sub- sets of most of the benchmarks described in Sec- tion 3 . The review did not include RRN , MIM- GOLD-NER , IceLinguis tic and Hotter and Colder Sentiment . The fir st two for technical reasons and the other two to be impar tial in our judgments, as some of the authors par ticipated in their creation and we ac knowledge the drawback of that. The Inflection benchmark should hav e been included, 7 huggingface.co/datasets/vesteinn/ icelandic- qa- NQiI 8 huggingface.co/datasets/ alexandrainst/multi- wiki- qa 9 huggingface.co/datasets/ alexandrainst/m_ mmlu 10 huggingface.co/datasets/ alexandrainst/m_ hellaswag/viewer/is 11 huggingface.co/datasets/thors/RRN 12 github.com/EuroEval/EuroEval Benchmark Samples T otal size Synth IRR CI p-value ARC-IS (EuroEv al) 112 1,116 x 0.39 (0.28, 0.51) < . 001 ScaLA-IS 102 1,024 0.52 (0.36, 0.67) < . 001 IceEC 250 58,239 0.63 (0.55, 0.71) < . 001 IcelandicQA 200 2,000 0.54 (0.39, 0.68) < . 001 Belebele-IS 90 900 0.49 (0.36, 0.63) < . 001 MultiWikiQA-IS 250 5,004 x 0.71 (0.66, 0.77) < . 001 ARC-challenge-IS (Miðeind) 112 1,119 x 0.61 (0.50, 0.72) < . 001 GED 20 200 0.74 (0.14, 1) 0.018 NQiI 213 2,132 0.73 (0.66, 0.79) < . 001 MMLU-IS 28 277 x 0.31 (0.01, 0.62) 0.044 WinoGrande-IS 109 1,088 0.54 (0.36, 0.72) < . 001 HellaSwag-IS 250 9,368 x 0.22 (0.12, 0.32) < . 001 T able 1: Overview of benchmarks, sample size, total size, inter -rater reliability (IRR) scores along with their confidence intervals and p-v alues but simply w as not at this stage, which is unfortu- nate. Furthermore, we did not include Icelandic- Knowledg e , EuroEval’ s v ersion of the IcelandicQA dataset, that has been turned into a multiple-choice question-answering task and three new answer op- tions are creat ed by an LLM. As mentioned, the benchmark has not been published in this format and we did not make use of EuroEval’ s Python package to creat e our own version. T o keep the sample sizes of the datasets within feasible boundaries, we used the following ap- proach: If the dataset was longer than 250 ro ws, we took 250 randomly selected ex amples, else ran- domly selected 10%. Where different splits were av ailable, we used the train split, and for NQiI we only e xtracted rows that had an answer , like EuroEval, as rows with no answer are only meant to ser ve as negative examples in model training. The sam ples were annotated by three of the authors of this paper , all of whom have a back- ground in both Icelandic linguistics and NLP , and we used the following three labels and guidelines: • IC: one of the following: incorrect (e.g. wrong an- swer to a question), sever ely flawed, clearly/poorly machine-translated • F: flawed example, contains errors (spelling, gram- maticality , vocabular y) • OK: V alid example In the case of the question-answering benchmarks, IcelandicQA , NQiI and MultiWikiQA-IS , we focused on the QA pairs in our error annotation and only considered the context to verify validity , i.e. the con- te xt itself is not ev aluated. We admit that our labels could ha v e been more fine-grained with regards to error types to perhaps give some kind of estimate of their effect on the evaluation. Although the IC- label was intended to cov er all examples that would potentiall y affect the ev aluation v alidity there is a clear difference betw een factually wrong answers and v ery poor machine translations. The former will certainly affect the ev aluation whereas an LLM might still be able to “make sense” of the latt er and provide the correct answer . An overview of the sample size, original length and the inter -rater reliability (IRR) with confidence intervals is shown in T able 1 , where the x-label in the column ‘synth ’ indicates whe ther the benchmark was either machine-translated or created by an LLM. Not e that IcelandicQA does not ha ve such a label as the model output was manually verified and corrected where necessar y . For calculating the IRR, we use Krippendor ff’ s alpha and weighted agreement coefficients (ordinal) to account for the ordinal nature of the ratings, i.e. IC > F > OK. For each of the benchmarks we have three anno- tations and o verall the lev el of agreement is good (following Regier et al. ( 2013 )), questionable for ARC-IS (EE), MML U-IS and HellaSwag-is, and v ery good for MultiWikiQA-is, ARC-Challenge-is, GED and NQiI. We note that the low IRR score in HellaSwag-IS is only due to disagreement between the IC and F labels as the annotated sample has no v alid examples. This has, how ev er , not been analyzed any fur ther and the IRR values should be taken into account for our int erpretation of the results. 4.1. Results The results of our error annotation are shown in Figure 1 , where the mean proportion of each la- bel across all raters is shown for each benchmark with a 95% confidence interval. In Appendix A we show the label propor tions f or each rat er across the benchmarks. First, we obser v e a clear difference in bench- marks according to whether or no t humans hav e been involv ed in their creation, translation or verifi- cation. Based on our samples, we find Hellasw ag to be almost entirel y sev erely flaw ed and MML U very flawed, with less than 10% of the sample be- ing valid (admittedly , the sample size for MML U-IS could have been bigger and the inter -rat er agree- ment is questionable based on our int erpretation). F urthermore, we find that the machine-translated version of ARC that EuroEv al uses (ARC-is) has an OK propor tion of only 20%, whereas the localized version Miðeind uses (ARC-Challenge-is) is better , Figure 1: Mean proportion and 95% confidence interval for each of the labels across annotations and benchmarks, arranged by OK propor tion in descending order with a much lower IC-propor tion (7% compared to 37%) and a higher OK -propor tion (55%). For MultiWikiQA-IS , less than half of the ex am- ples in our sample receive the OK -label. Our error labels admittedly mak e no distinction between fac- tual and linguistic errors, but both types of flaws can affect the benchmark’s validity . In future ev al- uations, we aim to distinguish between these two types of flaws although the y can sometime appear in conjunction. The following ex ample illustrat es the type of problematic items in MultiWikiQA-IS : An ar ticle about the Icelandic philosopher Salvör Nordal is presented as context and the question is (in our translation): “Which married couple had the son Sigurjón Nordal?” The male name, Sig- urjón, does not appear in the ar ticle and the only Icelander to ev er hav e had that name is complet ely irrelev ant to the conte xt, but the answer to the ques- tion is Salvör’s parents. In contrast, IcelandicQA, where QA pairs generated by an LLM were manu- ally verified and corrected, is much better , although it contains validity errors as well. Surprisingly , the Icelandic v ersion of Belebele has a rather low propor tion of OK ex amples. In the paper by Bandar kar et al. ( 2024 ), the authors state that it “w as created end-to-end without the use of machine translation technology , relying solely on experts fluent in English and the target language. ” W e hav e, howev er , reasons to believe that the trans- lators involv ed in translating the data into Icelandic used MT ser vices, at least to some extent. One blatant ex ample is an item where one of the an- swer options, which only include geopolitical enti- ties, is the Icelandic word kalkúnn which translat es to the animal turke y , not the country , in English. Here, T yrkland would have been the correct trans- lation and this answer option also happens to be the correct one. No fluent expert in English and Ice- landic would make such a mistake. A good contrast to these machine-translated benchmarks is the Icelandic version of the WinoGrande benchmark ( Snæbjarnarson et al. , 2022 ), which was translated by humans and localized. Based on our sample, it contains no sev erely flaw ed examples. Regarding the results for NQiI ( Snæbjarnarson and Einarsson , 2022 ), it is impor tant to k eep in mind that this is a case of a dataset being turned into a benchmark despite this not being the intended use – it was originally creat ed for open domain QA retrie v al. As it is being used as a benchmark, how- ev er , we evaluat e it as such. Based on our sample, there unfor tunately seem to be some validity errors in the QA pairs. In one ex ample, conte xt about Kim Jong-Un is paired with a question about the capital of Bolivia, whereas the answer is related to the Kim Jong-Un (nqii_3570). In another ex ample, a badly- construed pair consists of a strange question about when tap wat er in Iceland was first boiled and the answer is that ‘it boils at 100 ° C’ (nqii_7841), where the context is an ar ticle about water in general (we refer to Section 5 for more discussion). 5. Discussion W e would like to begin by stressing that the goal is not to create flawless benchmar ks, but to improv e current practices, both b y revising and re-r eleasing e xisting benchmarks where possible and by design- ing stronger future ones. In light of our findings, we argue that it is impor tant to change the way bench- marking is approached in lower -resource settings and we will star t by addressing the use of MT . 5.1. Machine-translated benchmarks In general, we find it questionable to use machine- translated versions of for eign/non-localized bench- marks, especially in low/medium-r esource settings and even more so if the output is not verified or corrected. Such an approach immediat ely raises sev eral questions: 1) How was the MT model cho- sen? 2) Is the q uality of the output ev aluated in any wa y? 3) How suitable is the original benchmark for benchmarking another language? T o start with the first question, one point of ref- erence could be findings of WMT , the largest con- ference in the MT community , where Icelandic has been a part of the general shared MT task in the last two y ears. In 2024 ( Kocmi et al. ), human trans- lators achiev ed the highest score for for EN → IS with 93.1 on a 0–100 human evaluation scale (with 0 being ‘no meaning preserved’ and 100 being that the meaning and grammar is com plet ely consistent with the source). The best per forming ML syst em, Dubformer (a priv ate translation ser vice), scored 84.9, follow ed by Claude 3.5 Sonnet at 81.9. In- cidentally , two different translations by Claude 3.5 Sonnet of the ARC-Challenge are being used for Icelandic ev aluation by Miðeind and EuroEv al. This raises the question of whet her those translations can, out-of-the-bo x, be expect ed to be of better quality than 81.9%, and whether that level is suffi- cient for benchmark construction. As for the second question, the only MT quality assessment we identified for these benchmarks is the one conducted by Smart ( 2025 ) for MultiWikiQA . In that study , crowd workers rated the fluency of a small sample of translated items on a 1–3 scale, with Icelandic (n=150) scoring ∼ 2.68/3. Not e that the fluency was meant to be ev aluated reg ardless of whether the question was “unanswerable or re- quire[d] context to be answered”. W e refer to Sec- tion 4 for our ev aluation, but at this point we would like to not e that fluency ev aluation alone, without any measure of adequacy or accuracy , is unlikely to give a comprehensive assessment of the dataset. Regarding the third question, we use the ARC- Challenge as an e xample. The original benchmark consists of human-authored, grade-school science questions from the US. One might ask how per ti- nent it is to evaluat e LLM performance in Icelandic on it in the first place, regardless of whether it is human- or machine-translated, just as it would be questionable to make Icelandic grade-school pupils answer the same questions without accounting for cultural differences and some localization of con- tent. T o tak e a specific e xample from the original benchmark, in item Mercur y_7084648 the q uestion is about the causes of low precipitation in Nevada. It is unclear how culturally or educationally relev ant such a question is in Icelandic cont ext, highlight- ing the broader issue of conte xtual misalignment in translated benchmarks. As far as localization is concerned, in Miðeind’s version, the MT model seems to have translated most names that occur in the benchmark – presum- ably this was included in instructions to an LLM. At a q uick glance, this seems to be a valid localization method, but it has some unintended side-effects as ex am ple 1 in T able 2 show s, where the name Louis Past eur is erroneously changed to Louis Guð- mundsson , removing all relation to the real person, which is of relevance for the question. Another ex ample of the shortcomings of this ap- proach are items 2a and 2b in T able 2 . In Miðeind’s version, bi-flagellate is translat ed as tvíflag ella , which is not an Icelandic word ( tvísvipa is correct), and aut otr oph should be frumbjarg a lífver a , render - ing the translation incorrect. EuroEval’s version is only half-translated and the Icelandic translation of pro tist is wrong. These examples show how the MT can fail on scientific terminology , which is unfor tu- nate for a benchmark based on science q uestions. In light of this, can it be said that per formance on such data meaningfully reflects a model’s Icelandic reading comprehension abilities, if that is what the benchmark is intended to measure? F ur thermore, it is concerning that the output has seemingly not been filter ed prior to release. In EuroEval’ s v er - sion, one question ( ID Mercury_401011 ) includes the Icelandic word gös ‘gases’ repeated 399 times, nothing else. 13 Another e xample of a machine-translated bench- mark is HellaSwag-IS , e x cluded by Miðeind and marked “unofficial” by EuroEv al. Even a cursor y inspection reveals to any native speaker how poor the quality of translation is. Our quantitativ e error analysis (Section 4 ) confirms that the Icelandic v er - sion is sever ely flaw ed, and we argue that it should be discarded. The IRR score is admittedly low , but not a single item was labeled as valid by any of the annotators, which is telling for its quality . 5.2. N o nativ e speaker inv olvement Another concern arises when benchmarks are de- veloped without the inv olvement of native speakers of the target language. One such e xample is the ScaLA benchmark ( Nielsen , 2023 ), which cov ers the Nordic languages as well as German, Dutch and English. ScaLA measures linguistic acceptabil- ity through binary judgments of sentences that are either in their original form (“correct” sentences) or ar tificially corrupted, either by deleting a word or by swapping two adjacent words. The data is from 13 In the EuroEval code there are automatic checks in place to not include “ov erly repetitiv e samples” (and sam- ples with ov erly shor t or long te xts) but we are referring to the published data. Ref Original MT / Our translation 1 Louis P asteur created a process that reduced the amount of bacteria in milk. How does this process most likely benefit people? M: Louis Guðmundsson fann upp aðferð sem dró úr fjölda baktería í mjólk. Hv ernig nýtist þessi aðferð fólki líklega best? 2a Which protist is a bi-flagellate autotroph? M : Hvaða frumver a er tvíflagella sjálfnærandi lífvera? 2b - EE : Hvaða mótefni er bi-flagellate autotr oph? 3 Hvers vegna erum við ekki með lögin þannig að hver sem opinberlega hæðist að, rógber , smánar og ógnar manni og svo framvegis án tillits Forseti hringir . til nokkurs skapaðar hlutar sæti refsingu? Why are our laws not written such that any one who pub- licly mocks, defames, humiliates and threatens someone etc., with no regard to Speaker rings. an ything at all, is punished? 4 V arðandi smábátahlutfallið í þessu frumv arpi verð ég að segja ég hef ekki skoðað skiptinguna á því mjög „grundigt“. Regar ding the proportion of small fishing boats in this bill , I hav e to say that I hav e not looked into the distribution very thoroughly . T able 2: Examples of flaws in Icelandic benchmarks. For space reasons we use the same column for either machine-translated ex amples from the benchmarks or , in italics, our translation of Icelandic examples for the foreign reader . ( M : Miðeind, EE : EuroEval.) the Universal Dependencies framew ork 14 and the authors assume the original sentences are gram- matically correct. Although they describe steps taken to ensure that the corrupted sentences are indeed ungrammatical, this verification was con- ducted only on a random sample of Danish data. The problems with the Icelandic subset of this benchmark are twofold. The former is related to peculiarities in the data, of which the creators of ScaLA were probably unaw are. Most of the data consists of transcribed speeches from the Icelandic parliament. While the speeches are proofread and produced in a formal setting, it is still a word-for - word transcription of spoken language and not writ- ten te xt. While not necessarily ungrammatical, the y often include sentences that are perhaps not ideal for such a test. Moreo ver , the data includes procedural inser - tions such as a) Forse ti hringir . ‘Speaker rings’ and b) Gripið fram í: ‘Interruption’ , which mark, re- spectively , a) the moment when the speaker of the house rings a bell to indicate that the allocated time to an MP is up, and b) when someone interrupts a speech e x auditorio . An example of a) is shown in 3 in T able 2 . Although the sentence is labeled as cor - rect, such inser tions disrupt the syntactic structure of the surrounding speech. There are unfortunately also two instances in the benchmarks where these two phrases (a and b) ar e themselves subjected to ar tificial corruption through word-order re versal ( hringir F orseti. and fram Gripið í: ), which makes little sense as the phrases themselves are already corruptions of the sentence. The second problem is that in some cases the Icelandic sentence is still grammatically correct af- ter corruption. One such example is number 4 in T a- ble 2 . In the corrupted version, the noun in boldface is deleted, but the resulting sentence is just as cor - rect and grammatical as the original. Lastly , there are examples of original sentences being grammat- ically wrong, resulting in erroneous labels. A related issue concerns EuroEval’ s use of the 14 https://universaldependencies.org Icelandic Error Corpus ( Ingason et al. , 2021 ) for binary grammatical error de tection (GED). The corpus consists of proofread texts from various sources, with corrections made independently by different proofreaders, unfor tunatel y resulting in some inconsistencies. Errors were classified in five different categories: coherence , grammar , or - thogr aphy , sty le , v ocabulary . EuroEval, howev er , samples the data without regard to error type and treats the ‘has_error’ label as an indicator of the grammaticality of a sentence. This is problematic. A stylistic correction – of which there 39 ex amples in our sample – hardly changes an ungrammatical sentence to a grammatical one or vice versa. For GED pur poses, filtering the data by rele vant cate- gories such as grammar or or thograph y would be more appropriate, which Miðeind seems to ha ve done in their use of the same data. Similarly , ther e are instances where there is an error in a sentence that is supposed to be error -free, which again leads to erroneous labels, as well as errors in corrected sentences, but the latter are not used b y EuroEval so they have no bearing on the benchmarking. These deficiencies in bot h benchmarks do not mean that they are “bad”, but simply show how their creation or use as benchmarks could hav e been improv ed with native speaker involv ement and proper validation of the data for these purposes. W e would like to add that in both cases, the data that makes up these benchmarks was collected or created by native speakers but it is their use as benchmarks that is under scrutiny . 5.3. MT without nativ e speaker inv olvement Although it is not a par t of public leaderboards for benchmarking in Icelandic, a r ecent bench- mark illustrates similar concerns, namely GAM- BIT+: A Challenge Set for Evaluating Gender Bias in Machine T r anslation Quality Estimation Metrics by Filandrianos et al. ( 2025 ). Ther e, Icelandic is used as one ex ample of a grammatically gen- dered language (along with 10 others). For each English source t ext with gender -ambiguous occu- pation terms, two target language translations are created, intended to differ “only in the grammati- cal gender of the occupation and the dependent grammatical elements”. If, for instance, the English source sentence includes the word prof essor , the two target sentences should differ only in the gen- der of the translation of that word (and its dependent elements). The assumption is therefor e that this is possible in the languages involv ed, but that is simply not the case for Icelandic, as such minimal gender pair s in occupation terms are few (see e.g. F riðriksdóttir and Einarsson ( 2024 ) where 381 out of 394 occupation terms ex amined were masculine, eight feminine and five neuter). The word prof essor is used in the ex am ple taken in the paper to demon- strate the approach for all the languages included. In Italian the y use il professor e : la professor essa , in Serbian prof esor : prof esorica , etc. But in the Icelandic example, the sole difference lies in the use of the titles Sir (icel. Herra ) and Mrs. (icel. F rú ) with the noun (“Herra/F rú próf essorinn”), as no feminine version of the word exists. These titles are, howev er , very rarel y used in modern Icelandic and of course do not constitute a modification of the grammatical gender of the target noun. In Icelandic, masculine occupation nouns are generally used irrespective of the referent’ s gen- der , though some feminine counterpar ts exist in compounds, such as for st öðumaður : fors töðuk ona ‘director man/woman (of e.g. an institut e)’ . In the dataset, howe ver , man y minimal pairs rely on wrong or hallucinated feminine forms. Examples of this include rithöfundarins : rithöfundark onunnar , hallu- cinated feminine term for writer ; puntari : puntara , hallucinated translation of prom pt er (in a theater) regardless of gender; and kjarnorkuv erskjörinn : kjarnork uv erskjörinn (fem.) , where the translation of the occupation itself ( nuclear pow er plant oper - ator ) is hallucinated, the words are identical, and the feminine gender is added in parenthesis ( fem. ) to indicate a gender difference that does not e xist. Third, it is impor tant to note that masculine agree- ment in pronouns, adjectives etc. with masculine nouns is grammatically correct in Icelandic regard- less of the referent’ s gender . Feminine agreement may , howev er , be used to specifically e xpress the feminine gender of the person (and similarly , the neuter , for a non-binar y person). There are some Icelandic examples in the benchmark of this form, i.e. wher e the only difference lies in agreement with the noun but not the noun itself. Howev er , as the authors sa y , the target translations were “con- structed to be semantically and lexically identical, differing only in the gender marking of the occupa- tion and the dependent grammatical elements. ” It thus seems that ex amples with agreement only in dependent grammatical elements and not in the gender mar king of the occupation do not align with the authors’ intention, fur ther illustrating how ill- suited Icelandic is for this approach. The translations were generated with Claude Sonnet 3.5 and verified with Claude Sonnet 3.7 (same family as the translation model) to ensure that the gender of the occupation was the only dif- ference between the two target sentences and Ice- landic achiev ed the lowest accuracy among the included languages (86.75%) in this validation. On the face of the arguments presented here, we be- liev e that the quality of the Icelandic data is actually lower than this percentage indicates. A more rigor - ous and q uantitativ e ev aluation of the benchmark is needed to verify this, but it is already clear that the methodology can lead to serious flaws in the bench- mark. We would lastly like to not e that this dataset is intended to e valuat e gender bias in MT and the authors claim to rev eal “statistically significant score shifts driven solely by grammatical gender [...] with a clear ov erall tendency to fa vor masculine forms”. As far as Icelandic is concerned, we wonder to which extent these results are themselves biased by enforced and hallucinated feminine forms as in the examples abov e. 5.4. T ypos, errors and whether they matter LLMs are robust to linguistic errors, so why be finicky about that? The answer depends on the pur - pose and nature of the benchmar k. Consider the NQiI dataset, where natural ques tions are meant to indicate naturally occurring questions, such as a user might ask an LLM or search engines. In prac- tice, such questions can and do of ten contain errors that do not necessarily prev ent the system from cor- rectly interpreting or answering the question. This can also be useful as training data for models, to expose them to a wider v ariety of language than only the standard. Howev er , our focus is not on training utility but on the use of such datasets as benchmarks. In cases lik e this, with QA bench- marks, we are more concerned with v alidity errors, as in the ex amples in Section 4.1 , and not natural linguistic variation by humans. On the other hand, the machine-translated versions of ARC originate from carefully constructed US grade-school science questions, presumably well-f ormed and appropri- ate for the task in English. This raises a different concern, whether it is acceptable to ev aluate mod- els on translat ed versions that introduce linguistic distortions through “translationese” or outright er - rors which no native speaker would accept. A broader question, which we leav e for future work, is to what e xtent “translationese”, LLM hallu- cinations or fla ws in benchmar ks matter . Someone might contend that the most of the benchmarks inv olved in this paper , regardless of their flaws, are sufficient to show differences in model perfor - mance. But to what e xtent do the flaws affect the outcome? And does it matter if the y do? As an e x- ample, we can think of a benchmark that has 80% valid ex amples and 20% sev erely flawed. Given a large enough sample size for sufficient statis- tical pow er , are the 20% “acceptable” if the rest shows clear difference in model per formance? W e argue that, regardless of short-term per formance comparisons, flawed benchmarks can be harmful if incor porat ed into optimization pipelines, thereby influencing model dev elopment (see Section 2 ). In general, we believ e the goal should alwa ys be to design benchmarks which are right for the right reasons. With increased use of automat ed methods, ev er larger benchmarks can be built and with increas- ing size, it becomes increasingly unlik ely that any human will ever read through all of the ex amples for verification. The resulting loss of oversight makes systematic quality control even more essen- tial, even if it is only via stratified random sampling. 5.5. Beyond single-label output, tow ards more diverse benchmarks As mentioned in Section 1 , there is demand for creating new benchmarks that are better adapted to the capabilities of LLMs and go bey ond ev alu- ating single-label output. Most of the benchmarks inv olved in our ev aluation are indeed such bench- marks, where the answer is either T rue/F alse or an answer option in a multiple-choice task, with only the QA benchmarks as an ex ception. W e also not e that, ov erall, the benchmarks in- cluded in our ev aluation are quite similar . GED , ScaLA and IceErrorCorpus all measure v ery simi- lar phenomena with binar y outcomes, raising ques- tions about the added value of reporting them sep- arately . Similarly , the three QA benchmarks are all Wikipedia-based, although there is not necessarily ov erlap between them, and MultiWikiQA-IS was created despite the exis tence of IcelandicQA , that was created in a similar wa y but manually verified and corrected, which MultiWikiQA was not. There are two different versions of ARC, which are reading comprehension benchmar ks just lik e Belebele and MML U . WinoGrande-IS targets commonsense rea- soning, while HellaSw ag-IS , as we argued abov e, should likely be discarded. It would therefor e be of benefit to tr y and broaden the spectrum of bench- marks for Icelandic and include more diverse tes ts, for instance with respect to the te xt generation ca- pabilities of LLMs. This is to some e xtent done in three of the benchmarks that wer e not included in our ev aluation, Inflection , the Icelandic Linguistic Benchmark and RRN (see Section 3 ). 6. Conclusion In light of our findings, we would like to summarize a few key points to which attention should be paid in our opinion when benchmarking low/medium- resource languages: • A void use of machine-translated benchmarks, especially when MT quality is still not suffi- ciently fluent, and/or when the output (or at least a sample of it) has not been v erified and corrected • Using an LLM to generate data can be tanta- mount to machine-translating data in terms of te xt quality and the same cav eats apply • Inv olve native speakers and prioritize the use of native-authored data As already outlined, our results show clear differ- ences with reg ards to native speaker involv ement compared to machine-translated data where the output has not been v erified or corrected, and it is clear that the inv olvement of native speakers and native data makes a difference for the better . In the Icelandic context, fur ther oppor tunities exist to de- velop native benchmarks, for example by drawing on human-authored and validat ed materials from the school syst em ( à la the ARC Challenge and many more). As some of the authors of this paper hav e them- selves been involv ed in the creation of benchmarks for Icelandic, we acknowledge that building good benchmarks is a complicated task and that we are not ex empt from criticism of the problems outlined in the ov erall context of this paper . It is our hope that this can be a contribution to a health y debate on how to proceed and what to a void. We emphasize the need for native-author ed, community-v etted, and contamination-audited benchmarks, ideally de- veloped through par ticipatory design with native speakers. This approach ensures that e valua- tion metrics genuinely reflect linguistic and cultural specificities of the language, prev enting models from optimizing for superficial patterns introduced by translation ar tifacts or data leakage. Lastly , we return to the question posed in the title of this paper: who benchmarks the bench- marks? The responsibility must lie with their cre- ators. Benchmar k construction cannot be treated as a neutral or one-time contribution, it requires continuous scrutiny , documentation, and critical ev aluation. The work presented here originated from a simple re view of exis ting Icelandic datasets, where repeated irregularities and inconsistencies prompted the systematic analysis reported in this paper . Such ex amination should not be incidental, it should be standard practice. 7. Limitations W e first recognize that the annotation may ha v e been biased by the over all topic of this paper , i.e. flaws in benchmar king, as well as for benchmarks where the annotators knew that they were machine- translated or synthetic. Secondly , the sample size could hav e been bigger , especially for the 10% sam- ples of benchmarks. Third, in three cases, the level of agreement w as only questionable which must be taken into account. Fourth, the interpretation of the border betw een the error labels ‘IC’ (severel y flawed) and ‘F’ (flaw ed) may have varied from one annotator to the other . F ur thermore, the labels do not necessarily reflect whether the error is on the factual or linguistic lev el (although ‘IC’ was meant for ex amples that are flaw ed to such an extent that it pot entially affects the results validity). Moreov er , as mentioned in Section 4 , two benchmarks that are in- cluded in leaderboards for Icelandic were lef t out in the evaluation for impar tiality reasons. We concede that this is a dra wback and they should preferably be evaluat ed as well. Finally , our study e valuat es benchmark q uality rather than directly q uantifying the downstr eam impact of these flaws on model rankings or comparativ e conclusions. Futur e work should investig ate to what extent the identified is- sues materially alter evaluation outcomes. 8. Acknowledgements W e would like to thank our revie wers for useful com- ments and feedback as well as those who gav e their opinion on the paper in earlier versions. This project was in part funded by the Language T ech- nology Programme for Icelandic 2024—2026. The programme, which is managed and coordinated by Almannarómur , is funded by the Icelandic Ministr y of Education, Science and Culture. Steinunn Rut F riðriksdóttir was suppor ted by the Eimskip Fund of The University of Iceland no. HEI2025-96428 and the Ludvig Storr T rust no. LS TORR2023-93030. 9. Bibliographical References Ahmed Alaa, Thomas Har tvigsen, Niloufar Golchini, Shiladitya Dutta, Frances Dean, Inioluwa Debo- rah Raji, and T ravis Zack. 2025. Position: Medi- cal Large Language Model Benchmarks Should Prioritize Construct V alidity . In Pr oceedings of the 42nd Int ernational Conference on Machine Learning , volume 267 of Proceedings of Machine Learning Researc h , pages 80991–81004, V an- couver , Canada. PMLR. Bjarki Ármannsson, Finnur Ágúst Ingimundarson, and Einar F re yr Sigurðsson. 2025. An Icelandic Linguistic Benchmark for Large Language Mod- els . In Proceedings of the Joint 25th Nordic Con- fer ence on Computational Linguistics and 11th Baltic Conference on Human Language T ech- nologies (NoDaLiDa/Baltic-HL T 2025) , pages 37– 47, T allinn, Estonia. University of T ar tu Librar y . Þórunn Arnardó ttir , Elías Bjar tur Einarsson, Garðar Ingvarsson Juto, Þor valdur Páll Helga- son, and Hafsteinn Einarsson. 2025. WikiQA- IS: Assist ed Benchmark Generation and Aut o- mated Evaluation of Icelandic Cultural Knowl- edge in LLMs . In Pr oceedings of the Third W orkshop on Resources and Repr esentations for Under -Resourced Languages and Domains (RESOURCEFUL -2025) , pages 64–73, T allinn, Estonia. University of T ar tu Library . Þórunn Arnardóttir , Xindan Xu, Dagbjör t Guð- mundsdóttir , Lilja Björk Stef ánsdóttir , and Anton Karl Ingason. 2021. Creating an error corpus: Annotation and applicability . In Pr oceedings of CLARIN 2021 , pages 59–63, Vir tual Edition. Lucas Bandarkar , Davis Liang, Benjamin Muller , Mikel Artetx e, Satya Naray an Shukla, Donald Husa, Naman Goy al, A bhinandan Krishnan, Luke Zettlemo y er , and Madian Khabsa. 2024. The Belebel e Benchmark: a Parallel Reading Comprehension Dataset in 122 Language V ari- ants . In Proceedings of the 62nd Annual Meet- ing of the Association for Computational Linguis- tics (V olume 1: Long Paper s) , page 749–775, Bangkok, Thailand. Association for Computa- tional Linguistics. Samuel R. Bowman and George Dahl. 2021. What Will it T ak e to Fix Benchmarking in Natural Lan- guage Understanding? In Pr oceedings of the 2021 Confer ence of the North American Chapt er of the Association for Computational Linguistics: Human Language T echnologies , pages 4843– 4855, Online. Association for Computational Lin- guistics. T om B. Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, Ar vind Neelakantan, Prana v Shy am, Girish Sastry , Amanda Askell, Sandhini Agarwal, Ariel Herber t- V oss, Gretchen Krueger , T om Henighan, Rew on Child, Adity a Ramesh, Daniel M. Ziegler , Jeffre y Wu, Clemens Winter , Christ opher Hesse, Mark Chen, Eric Sigler , Mateusz Litwin, Scott Gra y , Benjamin Chess, Jack Clark, Christopher Berner , Sam McCandlish, Alec Radf ord, Ilya Sutske v er , and Dario Amodei. 2020. Language Models are F ew-Shot Learners. In Proceedings of t he 34th Inter national Conf erence on Neural Infor mation Processing Sy stems , NIPS ’20, Red Hook, NY , USA. Curran Associates Inc. Dallas Card, Pe ter Henderson, Ur v ashi Khandel- wal, Robin Jia, K yle Mahowald, and Dan Jurafsky . 2020. With Little P ower Comes Great Responsi- bility . In Proceedings of t he 2020 Conf erence on Empirical Met hods in Natural Language Process- ing (EMNLP) , pages 9263–9274, Online. Asso- ciation for Computational Linguistics. Pinzhen Chen, Simon Y u, Zhicheng Guo, and Barr y Haddow . 2024. Is It Good Data for Multilingual Instruction T uning or Just Bad Multilingual Ev al- uation for Large Language Models? In Pro- ceedings of the 2024 Conference on Empirical Met hods in Natural Language Processing , pages 9706–9726, Miami, Florida, USA. Association for Computational Linguistics. Jonathan H. Clark, Eunsol Choi, Michael Collins, Dan Garrette, T om Kwiatko wski, Vitaly Nikolae v , and Jennimaria Palomaki. 2020. T yDi QA: A Benchmark f or Information-Seeking Question Answering in T ypologically Div erse Languages . T ransactions of the Association f or Computa- tional Linguistics , 8:454–470. P et er Clark, Isaac Cowhe y , Oren Etzioni, T ushar Khot, Ashish Sabhar wal, Carissa Schoenick, and Oyvind T afjord. 2018. Think you hav e Solved Question Answering? T r y ARC, the AI2 Reason- ing Challenge . ArXiv , abs/1803.05457. Lee J. Cronbach and Paul E. Meehl. 1955. Con- struct validity in psychological tests. Psychologi- cal Bulletin , 52(4):281–302. Maria Eriksson, Erasmo Purificato, Arman Noroozian, João Vinagre, Guillaume Chaslot, Emilia Gomez, and David Fernández-Llorca. 2025. AI Benchmarks: Interdisciplinar y Issues and P olicy Considerations . In ICML W orkshop on T echnical AI Gov ernance (T AIG) . George Filandrianos, Orfeas Menis Mastromicha- lakis, Waf aa Mohammed, Giuseppe Attanasio, and Chr ysoula Zer va. 2025. GAMBIT : A Chal- lenge Set for Evaluating Gender Bias in Machine T ranslation Quality Estimation Metrics . In Pro- ceedings of the T enth Conf erence on Machine T ranslation , pages 314–326, Suzhou, China. As- sociation for Computational Linguistics. Steinunn Rut Friðriksdó ttir and Hafst einn Einarsson. 2024. Gendered Grammar or Ingrained Bias? Exploring Gender Bias in Icelandic Language Models . In Proceedings of the 2024 Joint Interna- tional Conference on Computational Linguistics, Language Resources and Ev aluation (LREC- COLIN G 2024) , pages 7596–7610, T orino, Italia. ELRA and ICCL. Steinunn Rut F riðriksdóttir , Dan Saattrup Nielsen, and Hafst einn Einarsson. 2025. Hotter and Colder: A New Approach to Annotating Sen- timent, Emo tions, and Bias in Icelandic Blog Comments . In Proceedings of the Joint 25th Nordic Conf erence on Computational Linguis- tics and 11th Baltic Conference on Human Language T echnologies (NoDaLiDa/Baltic-HL T 2025) , pages 181–191, T allinn, Estonia. Univ er - sity of T artu Library . Matt Gardner , Y oav Ar tzi, Victoria Basmov , Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Y anai Elazar , Ananth Gottumukkala, Nitish Gupta, Hannaneh Hajishirzi, Gabriel Ilharco, Daniel Khashabi, K evin Lin, Jiangming Liu, Nelson F . Liu, Phoebe Mulcaire, Qiang Ning, Sameer Singh, Noah A. Smith, Sanjay Subramanian, Reut T sar faty , Eric W allace, Ally Zhang, and Ben Zhou. 2020. Eval- uating Models’ Local Decision Boundaries via Contrast Sets . In Findings of the Association for Computational Linguistics: EMNLP 2020 , pages 1307–1323, Online. Association for Computa- tional Linguistics. Dan Hendr ycks, Collin Burns, Ste v en Basar t, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massiv e Multitask Language Understanding . In Proceedings of the Inter national Conference on Learning Represen- tations (ICLR) , Vienna, Austria. Philip A. Huebner , Elior Sulem, Fisher Cynthia, and Dan Ro th. 2021. BabyBER T a: Learning More Grammar With Small-Scale Child-Directed Lan- guage . In Proceedings of the 25th Conference on Comput ational N atural Language Learning , pages 624–646, Online. Association for Compu- tational Linguistics. Svanhvít Lilja Ingólfsdóttir , Ásmundur Guðjónsson, and Hrafn Lof tsson. 2020. Named Entity Recog- nition for Icelandic: Annotat ed Corpus and Mod- els . In Statistical Language and Speech Process- ing, 8th Int ernational Confer ence , pages 46–57, Cardiff, UK. Springer International Publishing. Jaap Jumelet, Leonie Weissweiler , Joakim Nivre, and Arianna Bisazza. 2025. MultiBLiMP 1.0: A Massively Multilingual Benchmark of Linguistic Minimal Pairs . arXiv: 2504.02768. T om Kocmi, Elef therios A vramidis, Rachel Bawden, Ondřej Bojar , Anton Dvorko vich, Christian F ed- ermann, Mark Fishel, Markus F reitag, Thamme Gowda, Roman Grundkiewicz, Barr y Haddow , Marzena Karpinska, Philipp Koehn, Benjamin Marie, Christ of Monz, Kenton Murra y , Masaaki Nagata, Mar tin Popel, Maja Popo vić, Mariy a Shmato va, Steinþór St eingrímsson, and Vilém Zouhar . 2024. Findings of the WMT24 General Machine T ranslation Shared T ask: The LLM Era Is Here but MT Is Not Solved Y et . In Proceedings of the Ninth Confer ence on Machine T ranslation , pages 1–46, Miami, Florida, USA. Association for Computational Linguistics. Chaoqun Liu, Wenxuan Zhang, Jiahao Ying, Ma- hani Aljunied, Anh T uan Luu, and Lidong Bing. 2025. SeaExam and SeaBench: Benchmark- ing LLMs with Local Multilingual Questions in Southeast Asia . In Findings of the Association for Computational Linguistics: N AA CL 2025 , pages 6119–6136, Albuquerque, New Mexico. Associ- ation for Computational Linguistics. R. Thomas McCoy , Ellie P a vlick, and T al Linzen. 2019. Right for the W rong Reasons: Diagnosing Syntactic Heuristics in Natural Language Infer - ence . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguis tics , pages 3428–3448, Florence, Italy . Association for Computational Linguistics. Dan Nielsen. 2023. ScandEval: A Benchmark for Scandinavian Natural Language Processing . In Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa) , pages 185–201, Tór sha vn, Faroe Islands. Univ ersity of T artu Library . ChaeHun P ar k, K oanho Lee, Hy esu Lim, Jae- seok Kim, Junmo Park, Y u-Jung Heo, Du-Seong Chang, and Jaegul Choo. 2024. T ranslation Deser v es Bett er: Analyzing T ranslation Ar ti- facts in Cross-lingual Visual Question Answer - ing . In Findings of the Association f or Computa- tional Linguistics: A CL 2024 , pages 5193–5221, Bangkok, Thailand. Association for Com puta- tional Linguistics. Darrel A. Regier , William E. Narrow , Diana E. Clarke, Helena C. Kraemer , S. Janet Kuramoto, Emily A. Kuhl, and David J. Kupfer . 2013. DSM-5 Field T rials in the United States and Canada, P ar t II: T est-Retest Reliability of Selected Categorical Diagnoses . The American Journal of Psy chiatry , 170(1):59–70. Oscar Sainz, Jon Campos, Iker García-Ferrer o, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. 2023. NLP e valuation in trouble: On the need to measure LLM data contamination for each benchmark. In Findings of the Associa- tion for Computational Linguistics: EMNLP 2023 , pages 10776–10787. K eisuke Sakaguchi, Ronan Le Bras, Chandra Bha- ga vatula, and Y ejin Choi. 2021. WinoGrande: an adversarial winograd schema challenge at scale . Communications of the A CM , 64(9):99–106. Kirill Semenov and Rico Sennrich. 2025. Measur - ing the Effect of Disfluency in Multilingual Knowl- edge Probing Benchmarks . In Pr oceedings of the 2025 Confer ence on Empirical Met hods in Natur al Language Pr ocessing . Chantal Shaib, Joe Barrow , Ale xa Siu, Byron W al- lace, and Ani Nenkov a. 2024. How Much An- notation is Needed to Compare Summarization Models? In Proceedings of the Third Work - shop on Bridging Human–Computer Inter action and Natural Language Processing , pages 51–59, Mexico City , Mexico. Association for Computa- tional Linguistics. Dan Saattrup Smart. 2025. MultiWikiQA: A Reading Comprehension Benchmar k in 300+ Languages . Vésteinn Snæbjarnarson and Hafsteinn Einarsson. 2022. Natural Questions in Icelandic . In Pro- ceedings of the Thirteent h Language Resources and Evaluation Conference (LREC) , pages 4488– 4496, Marseille, Fr ance. European Language Resources Association. Vésteinn Snæbjarnarson, Haukur Barri Símonar - son, Pétur Orri Ragnarsson, Svanhvít Lilja Ingólfsdóttir , Haukur Jónsson, Vilhjalmur Thorsteinsson, and Hafsteinn Einarsson. 2022. A Warm Star t and a Clean Crawled Cor pus - A Recipe for Good Language Models . In Proceed- ings of the Thir teent h Language Resources and Ev aluation Conference , pages 4356–4366, Mar - seille, France. European Language Resources Association. Yixiao Song, Kalpesh Krishna, Rajesh Bhatt, and Mohit Iyyer . 2022. SLING: Sino Linguistic Evalu- ation of Large Language Models . In Proceedings of the 2022 Confer ence on Empirical Methods in Natur al Language Processing , pages 4606– 4634, A bu Dhabi, Unit ed Arab Emirates. Associ- ation for Computational Linguistics. Þór Sverrisson and Hafsteinn Einarsson. 2023. Ab- stractiv e T ext Summarization for Icelandic . In Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa) , pages 17–31, T órshavn, Faroe Islands. Univ ersity of T artu Library . Elif Ecem Umutlu, A yse A ysu Cengiz, Ahmet Kaan Sev er , Se yma Erdem, Burak A ytan, Busra T ufan, Abdullah T oprakso y , Esra Darıcı, and Cagri T ora- man. 2025. Evaluating the Quality of Benchmark Datasets for Low-R esource Languages: A Case Study on T urkish . In Pr oceedings of the F ourth W orkshop on Generation, Ev aluation and Met- rics (GEM 2 ) , pages 471–487, Vienna, Austria and vir tual meeting. Association for Computa- tional Linguistics. Ashmal V a yani, Dinura Dissanay ake, Hasindri W atawana, Noor Ahsan, Nev asini Sasikumar , Omkar Thawakar , Henok Biadglign Ademt ew , Y ahy a Hmaiti, Amandeep Kumar , Kar tik Kuck - reja, Mykola Masly ch, W afa Al Ghallabi, Mi- hail Miha ylov , Chao Qin, Abdelrahman M. Shaker , Mike Zhang, Mahardika Krisna Ihsani, Amiel Esplana, Monil Gokani, Shachar Mirkin, Harsh Singh, Asha y Srivasta va, Endre Hamer - lik, Fat hinah Asma Izzati, F adillah Adamsyah Maani, Sebastian Cavada, Jenny Chim, Ro- hit Gupta, Sanja y Manjunath, Kamila Zhu- makhanov a, Feno Heriniaina Rabe vohitra, Azril Amirudin, Muhammad Ridzuan, Daniy a Kareem, K etan More, Kun y ang Li, Pramesh Shakya, Muhammad Saad, Amir pouy a Ghasemaghaei, Amirbek Djanibekov , Dilshod Azizov , Branisla v a Janko vic, Naman Bhatia, Alvaro Cabrera, Jo- han S. Obando-Ceron, Olympiah Otieno, F abian F arestam, Muztoba R abbani, Sanoojan Baliah, Santosh Sanjeev , Abduragim Shtanchae v , Ma- heen F atima, Thao Nguyen, Amrin Kareem, T oluwani Aremu, Nathan Xavier , Amit Bhatkal, Haw au T oyin, Aman Chadha, Hisham Cholakkal, Rao Muhammad Anwer , Michael Felsberg, Jorma Laaksonen, Thamar Solorio, Monojit Choudhury , Ivan Laptev , Mubarak Shah, Salman Khan, and Fahad Khan. 2024. All languages mat- ter : Evaluating lmms on culturally diverse 100 languages . CoRR , abs/2411.16508. Héctor Javier Vázquez Martínez, Annika Heuser , Charles Y ang, and Jordan Kodner . 2023. Evalu- ating Neural Language Models as Cognitiv e Mod- els of Language Acquisition . In Proceedings of the 1st GenBench Work shop on (Benchmarking) Generalisation in NLP , pages 48–64, Singapor e. Association for Computational Linguistics. Bin W ang, Zhengyuan Liu, Xin Huang, Fangkai Jiao, Y ang Ding, AiTi Aw , and Nancy Chen. 2024a. SeaEv al for Multilingual Foundation Mod- els: F rom Cross-Lingual Alignment to Cultural Reasoning. In Proceedings of the 2024 Con- fer ence of the North American Chapter of the Association for Computational Linguistics: Hu- man Language T echnologies (V olume 1: Long P apers) , pages 370–390. W enxuan Wang, W enxiang Jiao, Jingyuan Huang, Ruyi Dai, Jen-tse Huang, Zhaopeng T u, and Michael L yu. 2024b. Not All Countries Cele- brate Thanksgiving: On the Cultural Dominance in Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P a- pers) , pages 6349–6384. Alex W arstadt, Alicia Parrish, Haokun Liu, An- had Mohananey , Wei Peng, Sheng-Fu W ang, and Samuel R. Bowman. 2020. BLiMP: The Benchmark of Linguistic Minimal P airs for En- glish . T ransactions of the Association f or Com- putational Linguistics , 8:377–392. Linda Wiechetek, Flammie Pirinen, Maja Lisa Kappfjell, T rond T rost erud, Børre Gaup, and Sjur Nørstebø Moshagen. 2024. The Ethical Question – Use of Indigenous Cor pora for Large Language Models . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resour ces and Ev alua- tion (LREC-COLIN G 2024) , pages 15922–15931, T orino, Italia. ELRA and ICCL. Ankit Y adav , Himanshu Beniwal, and May ank Singh. 2024. PythonSaga: Redefining the benchmark to ev aluate code generating LLMs . In Findings of the Association for Computational Linguis- tics: EMNLP 2024 , pages 17113–17126, Miami, Florida, US A. Association for Computational Lin- guistics. Shuo Y ang, W ei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. 2023. Rethinking Benchmark and Contamination for Language Models with Rephrased Samples . Binwei Y ao, Ming Jiang, T ara Bobinac, Diyi Y ang, and Junjie Hu. 2024. Benchmar king Machine T ranslation with Cultural Awar eness . In Find- ings of the Association for Computational Lin- guistics: EMNLP 2024 , pages 13078–13096, Mi- ami, Florida, USA. Association for Computational Linguistics. Row an Zellers, Ari Holtzman, Y onatan Bisk, Ali F arhadi, and Y ejin Choi. 2019. HellaSwag: Can a machine reall y finish y our sentence? In Pro- ceedings of the 57th Annual Meeting of the As- sociation f or Computational Linguistics , pages 4791–4800, Florence, Italy . Association for Com- putational Linguistics. 10. Language Resource References Anton Karl Ingason, Lilja Björk St efánsdóttir , Þórunn Arnardóttir , and Xindan X u. 2021. Ice- landic error corpus (IceEC) version 1.1 . CL ARIN- IS. Svanhvít Lilja Ingólfsdóttir , Ásmundur Alma Guðjónsson, and Hrafn Lof tsson. 2020. MIM- GOLD-NER – named entity recognition corpus (21.09) . CL ARIN-IS. A. Appendix: Label Proportions per Rater In Figure 2 we show the distribution of labels per rater across the benchmarks. Figure 2: Label proportions per rater across the ev aluated benchmarks
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment