Rotated Robustness: A Training-Free Defense against Bit-Flip Attacks on Large Language Models
Hardware faults, specifically bit-flips in quantized weights, pose a severe reliability threat to Large Language Models (LLMs), often triggering catastrophic model collapses. We demonstrate that this vulnerability fundamentally stems from the spatial…
Authors: Deng Liu, Song Chen
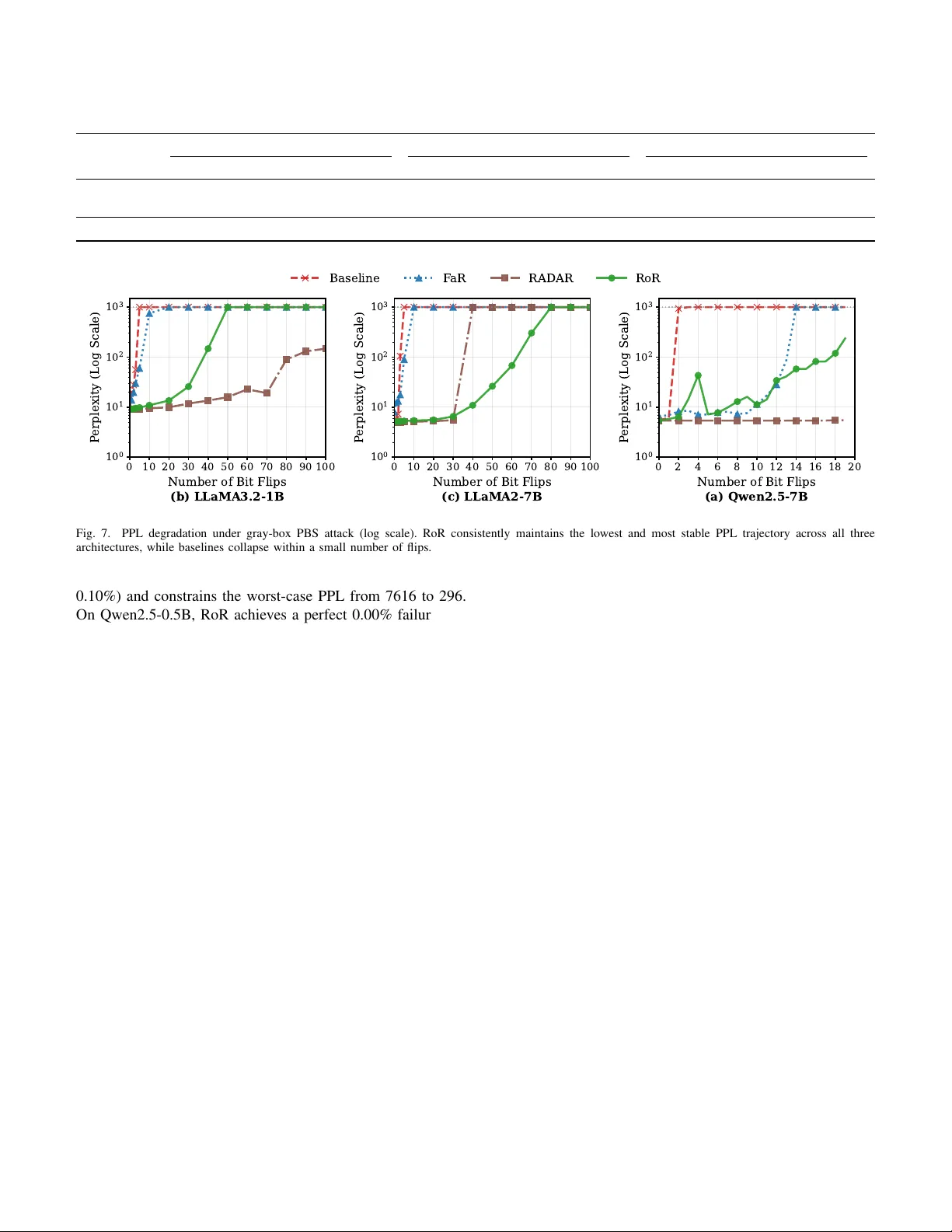
1 Rotated Rob ustness: A T raining-Free Defense against Bit-Flip Attacks on Lar ge Language Models Deng Liu, Student Member , IEEE , and Song Chen, Member , IEEE Abstract —Hardwar e faults, specifically bit-flips in quantized weights, pose a sever e reliability threat to Large Language Models (LLMs), often triggering catastrophic model collapses. W e demonstrate that this vulnerability fundamentally stems from the spatial alignment between sensitive weight bits and extreme activation outliers, which causes a single hardware fault to be massi vely amplified. T o address this, we propose Rotated Robustness (RoR), a training-free defense utilizing orthogonal Householder transf ormations. By applying an orthogonal r otation to the activation space, RoR geometrically smooths extreme outliers acr oss all feature dimensions. This mechanism effecti vely breaks the alignment between outliers and vulnerable weights, mathematically guaranteeing original model accuracy . Extensi ve empirical evaluations across Llama-2/3, OPT , and Qwen families demonstrate the superior reliability of our appr oach. Under random bit-flip attacks, RoR reduces the stochastic collapse rate from 3.15% to 0.00% on Qwen2.5-7B. Furthermore, under sever e targeted attacks with 50 Progressi ve Bit Search flips, RoR sustains robust reasoning on Llama-2-7B, maintaining a 43.9% MMLU accuracy that nearly matches its 45.2% unattacked accuracy , while competing defenses collapse to random guessing. Most notably , against the Single-Point Fault Attack (SPF A)— the most aggressive targeted threat—RoR exponentially inflates the attack complexity from a few bits to over 17,000 precise bit- flips. With a negligible storage overhead of 0.31% and a minimal inference latency increase of 9.1% on Llama-2-7B, RoR achieves true lossless robustness, pro viding a practical and highly reliable defense for LLM deployment. Index T erms —Large Language Models, Bit-Flip Attacks, Hard- ware Fault T olerance, Model Robustness, Orthogonal T ransfor - mation. I . I N T RO D U C T I O N Large Language Models (LLMs) ha ve significantly ad- vanced the field of artificial intelligence [1]. W ith billions of parameters, models like Llama 2/3 [2], [3], Qwen [4], and GPT -4 [5] now excel at comple x reasoning tasks [6]. As a result, their deployment is rapidly expanding from high- performance GPU clusters [7] to edge de vices [8], powering critical applications such as autonomous agents [9] and fi- nancial analysis [10]. Howe ver , deploying these models on physical hardware exposes them to memory-lev el reliability threats. The Rowhammer vulnerability [11], a hardware flaw in DRAM, allows attackers to flip memory bits by repeatedly activ ating specific rows, causing electrical char ge leakage This work was supported in part by the Strategic Priority Research Program of the CAS under Grant XDB0660000, and in part by the National Natural Science Foundation of China under Grant 92473114. (Corresponding author: Song Chen.) Deng Liu and Song Chen are with the School of Microelectronics, Uni- versity of Science and T echnology of China, Hefei 230026, China (e-mail: ld153@mail.ustc.edu.cn; songch@ustc.edu.cn). Preprint. Under revie w at IEEE Transactions on Information Forensics and Security . into adjacent cells. Recent systematic ev aluations, such as the end-to-end BitMine frame work [12], have demonstrated that software-induced DRAM faults can be efficiently and deterministically triggered across modern architectures by rev erse-engineering proprietary memory address mappings. This fundamental vulnerability has enabled precise Bit-Flip Attacks (BF As) [13], [14] that directly alter the stored weights of a neural network. Unlike input-lev el adversarial examples, BF As modify the model parameters directly , exposing a critical structural fragility within LLMs. While conv entional wisdom suggests that billion-parameter models possess inherent statistical re- dundancy , recent empirical e vidence in validates this assump- tion by exposing extreme parameter sensitivity . T ar geted bit- flips can completely bypass this presumed redundanc y to inflict dev astating consequences. For instance, ONEFLIP [15] demonstrates that a single bit-flip is sufficient to inject stealthy backdoors into deployed models. Similarly , Atten- tionBreaker [16] demonstrates that altering just three bits in an 8-bit quantized LLaMA3-8B model triggers a catastrophic functional collapse, plummeting its accuracy on the MMLU benchmark from 67 . 3% to exactly 0% . These findings confirm that hitting vulnerable bits causes the model’ s perplexity (PPL) to explode by orders of magnitude, highlighting the sev ere operational risks of hardware-induced weight bit-flips. Defending against BF As in billion-parameter LLMs remains profoundly challenging. Existing defenses mainly fall into two paradigms, both of which struggle with the strict efficienc y and utility demands of LLMs. Detection-based methods [17]–[21] employ runtime monitors or software-based ECC. Howe ver , verifying integrity at ev ery layer creates severe synchro- nization barriers and consumes critical memory bandwidth, exacerbating the memory-bound bottlenecks of token gen- eration. Conv ersely , weight-r obustness methods compromise either efficiency or model utility . Robust retraining or fine- tuning [22], [23] is computationally prohibitive at the LLM scale and risks catastrophic forgetting. Meanwhile, encoding schemes [24], [25] mandate e xtra decoding steps on the critical inference path, introducing unacceptable computational and memory traffic overheads. Our Insight: Outlier Alignment and Amplification. W e argue that the catastrophic fragility of LLMs under bit-flips is fundamentally driv en by the spatial alignment between cor- rupted weights and extreme activ ation outliers. In Transform- ers, specific feature channels frequently emerge as extreme outliers, reaching magnitudes up to 20 × the av erage [26], [27]. Consequently , when a stochastic memory fault corrupts a weight parameter that interacts directly with these outlier channels, the initial error undergoes se vere multiplicati ve 2 amplification. This massive perturbation cascades through and corrupts subsequent layers, triggering an irrev ersible network collapse and thus manifesting as the observed Single Point of Failure (SPoF) phenomenon. Our Appr oach: RoR. W e propose Rotated Robustness (RoR) , a training-free defense method based on orthogonal House- holder transforms [28]. RoR applies a targeted rotation to the activ ation space, geometrically smoothing the spike energy of outliers across all feature dimensions and breaking the fatal alignment between these outliers and vulnerable weights. This effecti vely reduces error amplification under both random and targeted bit-flips, while mathematically guaranteeing that the original accuracy of the model remains unaffected due to the orthogonality of the transformation. Our main contributions are summarized as follows: • V ulnerability Analysis & T raining-F r ee Defense: W e identify the multiplicative amplification caused by the spatial alignment of weight errors and activ ation outliers as the cause of SPoFs in LLMs. T o address this, we introduce RoR, a geometrically rigorous, training-free defense that le verages Householder transformations to smooth these outliers. This orthogonal rotation mathemat- ically guarantees the preservation of the model’ s original accuracy without requiring architectural modifications. • Superior Robustness & T ask Generalization: Extensiv e ev aluations across div erse LLM families demonstrate RoR’ s decisive superiority . It perfectly mitigates random hardware faults, reducing the stochastic collapse rate from 3 . 15% to 0 . 00 % on Qwen2.5-7B. Under sev ere targeted attacks (50 PBS flips), RoR sustains robust reasoning on Llama-2-7B with 43 . 9% MMLU accuracy , nearly matching its unattacked baseline ( 45 . 2% ). Most notably , against the dev astating Single-Point Fault Attack (SPF A), RoR exponentially inflates the attack cost: inducing a model collapse requires ov er 17 , 000 precise bit-flips, exposing the extreme fragility of unprotected baselines and recent defenses that collapse within a mere handful of flips ( ≤ 7 ). • Extreme Infer ence Efficiency: By strictly preserving hardware-friendly dense low-rank matrix multiplications and storing only compact WY representations, RoR in- curs negligible storage ov erhead ( < 0 . 4% ) and minimal latency impact ( +9 . 1% ∼ +19 . 2% ), providing a highly practical foundation for securing LLM deployments. I I . B A C K G RO U N D A N D T H R E A T M O D E L A. LLM Inference and Quantization Modern Large Language Models (LLMs) are fundamentally built upon the T ransformer architecture [29]. A standard T ransformer block comprises two primary sub-layers: Multi- Head Self-Attention (MHSA) and a Feed-Forward Network (FFN). The computational backbone of these blocks relies on dense linear transformations—General Matrix Multiplications (GEMMs). Formally , giv en an input token sequence (or acti- vation matrix) X ∈ R T × d , a linear layer computes: Y = XW (1) where W ∈ R d × d ′ is the weight matrix. As illustrated in Figure 1, the MHSA layer projects inputs into Queries, Keys, and V alues via learnable weight matrices ( W Q , W K , W V ). Similarly , the FFN consists of large linear transformations interleav ed with a non-linear activ ation function. T o alleviate memory and computational ov erhead during inference, Post-Training Quantization (PTQ) has emerged as a standard deployment paradigm [30]. In uniform quantization, high-precision weight elements w ∈ W are mapped to lo w-bit integers (e.g., INT8) using scaling factor s and zero-point z : w q = Clamp j w s m + z , − 2 b − 1 , 2 b − 1 − 1 (2) These quantized parameters w q permanently encode the se- mantic knowledge and reasoning capabilities acquired during the pre-training phase. B. Threat Model: Har dwar e F aults and Adversary Capabili- ties Since quantized parameters physically encode model intel- ligence, bit-level alterations directly corrupt an LLM’ s reason- ing capabilities. In real-world deployments, these memory- lev el corruptions manifest through two primary physical corruption mechanisms . First, adversaries can maliciously induce deterministic bit-flips via the Rowhammer vulnera- bility [11]. By exploiting electrical charge leakage between adjacent DRAM cells, attackers can precisely target neural network weights [12] to enable gradient-guided exploitation. Second, DRAM cells are susceptible to stochastic, unguided bit-flips triggered by transient physical disturbances, such as cosmic ray radiation [31] or aggressi ve undervolting in edge en vironments [32]. Based on these mechanisms and the adversary’ s access to model internals, we categorize the threat landscape into three hierarchical models: 1) Black-Box (Stochastic): The adversary has no knowledge of the model’ s architecture or parameters. Corruptions are unguided and stochastic, representing uninformed bit-flips at a specific Bit Error Rate (BER). This model realistically accounts for natural hardware soft errors, such as Single Event Upsets (SEUs) from cosmic radiation [31] or instability from extreme dynamic voltage scaling [32]. 2) Gray-Box (T ar geted): The attacker knows the model ar - chitecture and weight v alues but is blind to the internal defense configuration. This allo ws for gradient-guided or heuristic- based exploits, such as Progressive Bit Search (PBS) [13] and AttentionBreaker [16], to iteratively identify and flip the most vulnerable bits for maximal output degradation. 3) White-Box (Defense-A ware): Representing the most se- vere scenario, the attacker has unrestricted access to model weights, gradients, and the complete algorithmic logic of the defense. This aligns with K erckhoffs’ s principle [33] and the proliferation of open-weight models like Llama-2 [2]. As illustrated in Fig. 1, the adversary can execute defense-aware attacks explicitly tailored to bypass protection. By pinpointing and flipping a single critical bit in DRAM, the attack er exploits the Single Point of Failure (SPoF) phenomenon, where a localized physical error multiplicati vely amplifies across layers to corrupt the final output [34]. W e formally analyze the underlying mechanics of SPoF in Sec. III. 3 Q_Linear K_Linear RoPE MatMul SoftMax V_Linear MatMul O_Linear Input X LayerNorm MHSA LayerNorm FFN Output X ... ... Q_Linear : Q=XW Q W V W Q W K Input X Incorrect Output X V K Q × X X X X × X X X X X X BF A Input X Output Hardware Deployment Attention T ansformer Decoder DRAM Attacker X X Fig. 1. Bit-flip error propagation in T ransformers. A targeted physical attack (e.g., Rowhammer) corrupts a single bit in a weight matrix (e.g., W Q ) stored in DRAM. This localized error multiplicatively amplifies through subsequent Multi-Head Self-Attention (MHSA) and feed-forward layers, ultimately causing catastrophic output corruption. C. Defense Objectives Practical Bit-Flip Attacks are strictly constrained by the physical limits of hardware primitives. Rowhammer -class ex- ploits, for instance, can only induce a sparse and spatially uncontrolled set of flips within localized DRAM ro ws. Driv en by these constraints and the high-utility requirements of LLMs, an effecti ve defense must satisfy four core objectiv es: 1) Reliability (Black-Box): The defense must effecti vely mitigate catastrophic failures under stochastic, unguided bit- flip errors to ensure high operational reliability . 2) Complexity (Gray/White-Box): The defense must dras- tically increase the number of targeted flips required for model collapse. This ensures the necessary attack complexity fundamentally exceeds the localized physical limitations of practical Rowhammer-scale exploits. 3) Utility Pr eservation: The mechanism must maintain the LLM’ s original reasoning capabilities and generativ e accuracy , ensuring zero or near-zero degradation of the pre-trained baseline performance. 4) System Efficiency: T o support high-throughput deploy- ment, the defense must minimize both inference latency and storage ov erhead, av oiding the synchronization or memory- bound bottlenecks inherent in prior schemes. I I I . M OT I V ATI O N A. The Low-Probability SP oF Phenomenon Prior research has predominantly focused on gradient-based targeted Bit-Flip Attacks (BF A) [13], [35], while the threat of 0 20 40 60 80 100 Random Seed Index 20 50 100 500 2,000 10,000 P erplexity (Log Scale) Resilient (95/100) Collapse (5/100) Threshold (PPL=100) 1,808 Fig. 2. The SPoF Phenomenon. PPL fluctuations of OPT-125M under random bit-flips ( 100 seeds). Most trials survive (blue dots), while specific seeds trigger catastrophic PPL explosions (red star). stochastic bit-flips—stemming from hardware soft errors or voltage instability—is often trivialized. A pre vailing assump- tion is that the massive parameter redundancy of LLMs acts as a natural buf fer against random faults. Ho wev er , our empirical analysis fundamentally challenges this belief. W e conducted extensi ve simulations on OPT-125M by in- jecting random bit-flips (BER = 3 × 10 − 4 ) across 100 distinct seeds. As illustrated in Fig. 2, we observe a stark dichotomy in model behavior . While the model maintains silent resilience in most trials, approximately 5% of the cases exhibit a sudden, catastrophic system collapse . In these instances, the Perplexity (PPL) explodes by orders of magnitude (e.g., from ∼ 30 to 1808), leading to a complete loss of reasoning capability . W e define this low-probability catastrophic collapse as the Single Point of Failure (SPoF) phenomenon. This phenomenon proves that LLMs do not possess full sta- tistical redundancy; instead, critical SPoFs e xist within the v ast parameter space. For safety-critical deployments, even a non- zero probability of such collapse is unacceptable, necessitating a defense that neutralizes these latent vulnerabilities. B. Spatial Alignment of SP oFs with Outlier F eatur es T o inv estigate the cause of sporadic collapses, we employ a binary search strategy ( O (log N ) ) to pinpoint critical bits among billions of parameters. Tracing the most sev ere failures in OPT-125M (seeds 68 and 65) reveals that despite differing bit positions, both SPoFs conv erge on the same weight r ow (index 706), which interacts with activ ation channel 706. As visualized in Fig. 3, channel 706 is an extreme outlier whose magnitude ( ∼ 6) exceeds the typical range ( [ − 0 . 2 , 0 . 2] ) by over 30 × . In a standard linear layer ( Y = XW ), the output perturbation ∆ y i,k at token i caused by a weight bit- flip ∆ W j,k is: ∆ y i,k = x i,j · ∆ W j,k (3) where x i,j represents the activ ation at channel j . When a fault corrupts the Most Significant Bits (MSBs) of a weight row j that aligns with an outlier acti vation channel ( | x i,j | ≫ 0 ), the error undergoes severe multiplicativ e amplification across ev ery token. 4 Fig. 3. Spatial Alignment of SPoFs. V isualization of activ ations in OPT-125M layer2.fc1. Channel 706 (white vertical stripe) exhibits extreme magnitudes ( ∼ 6) compared to surrounding channels (dark background), creating a structural vulnerability for bit-flip in the corresponding weight row . Our findings empirically confirm that latent SPoFs are structurally anchored to these specific outlier dimensions, providing the key motiv ation for the geometric delocalization in our proposed RoR. I V . M E T H O D O L O G Y In this section, we analyze the outlier vulnerability and propose RoR, a highly efficient, precision-guided defense utilizing Compact WY Householder transformations [36]. A. V ulnerability Analysis: Bounding the W or st-Case Err or As established in Sec. III (Eq. 3), a hardware-induced bit- flip ∆ W j,k is multiplicativ ely amplified by the corresponding activ ation magnitude x i,j during the forward pass. Because LLMs autoregressiv ely condition future predictions on past outputs, corrupting the hidden state of even a single token can derail the entire generation process and trigger a cascading Single Point of Failure (SPoF). T o pre vent such catastrophic collapses, a robust defense must strictly bound the worst-case error injection across the sequence. The maximum perturbation introduced to any token i is directly governed by the Infinity Norm ( L ∞ ) of the corresponding activ ation channel j : max i | ∆ y i,k | = | ∆ W j,k | · || X : ,j || ∞ (4) where || X : ,j || ∞ = max i | x i,j | . Defining the vulnerability metric through L ∞ rigorously captures both continuous outlier stripes (Fig. 3) and isolated e xtreme spikes, ensuring no single- token failure goes undetected. Empirical Detection Strategy . Let m ∈ R d in be the vector of channel-wise L ∞ norms, with mean µ and standard deviation σ . T o precisely identify critical channels while av oiding false positiv es, we define a composite outlier threshold τ : τ = max( µ + α · σ | {z } Statistical , 2 µ |{z} Relativ e , 1 . 0 |{z} Absolute ) (5) where α is a sensitivity hyperparameter (default α = 6 ). The absolute floor of 1 . 0 explicitly filters out inactiv e channels. Any channel j satisfying m j > τ is flagged for targeted rotation. Dimensions k-th column X outlier X rotated H mirror plane (a) Householder T r ansformation Input X Rotated X Spike × H Spike Spread (b) Spik e Smoothing Fig. 4. Illustration of Householder Rotation and smoothing. (a) Geomet- rically , H reflects the outlier vector (red) into a smoothed vector (blue). (b) In the matrix view , this operation smooths the spike of the outlier column across all dimensions. B. RoR F rame work: Lossless Outlier Smoothing T o explicitly neutralize the identified structural vulnera- bilities, we propose Rotated Rob ustness (RoR). The core principle of RoR is to apply a targeted orthogonal rotation Q ∈ R d in × d in to the activ ation matrix. W e first guarantee that this defense is mathematically loss- less . By inserting an orthogonal identity term ( QQ ⊤ = I ) into the standard linear matrix multiplication, we deriv e: Y = XW = X ( QQ ⊤ ) W = ( XQ )( Q ⊤ W ) = ˜ X ˜ W (6) where ˜ X and ˜ W denote the rotated activ ations and pre- rotated weights, respectively . Because the final output Y remains strictly identical to the clean model, RoR induces zero degradation to the LLM’ s baseline generati ve capabilities. Our objectiv e is to construct a specific Q that strictly minimizes the L ∞ peak of the rotated activ ations: min Q || ˜ X || ∞ s.t. Q ⊤ Q = I (7) T o achiev e this tar geted smoothing ef ficiently , we employ the Householder transformation [28]. A Householder matrix H is defined by a unit vector v : H = I − 2 vv ⊤ (8) Suppose the k -th activ ation channel is an identified outlier , represented by the standard basis vector e k . W e aim to reflect this concentrated spatial energy into a uniformly smoothed vector u = [ d − 1 / 2 in , . . . , d − 1 / 2 in ] ⊤ . W e construct the exact normal vector v such that He k = u : v = e k − u , with v ← v || v || 2 (9) Applying this specific transformation perfectly redistributes the outlier spike. The resulting activ ation matrix becomes: X ′ = XH = X − 2( Xv ) v ⊤ (10) Specifically , for the outlier column k , the transformation strictly guarantees X ′ : ,k = Xu (as illustrated in Fig. 4). This redistributes the extreme magnitude into a uniform distribution, fundamentally eliminating the L ∞ vulnerability associated with that dimension. 5 C. Efficient Implementation via Compact WY Representation In practice, a layer may contain multiple identified out- liers ( m > 1 ). Suppressing all targets requires accumu- lating m sequential Householder transformations: Q = H 1 H 2 . . . H m . While this product rigorously maintains or- thogonality ( QQ ⊤ = I ), sequential ex ecution requires reading and writing the activ ation matrix m times, inducing se vere memory access overhead and underutilizing GPU tensor cores. T o resolve this bottleneck, we le verage the Compact WY Representation [36] to mathematically fuse m sequential ro- tations into a single low-rank block operation: Q = I − VTV ⊤ (11) where V ∈ R d in × m stacks the target Householder vectors, and T ∈ R m × m is an upper triangular factor matrix. End-to-End Deployment Pipeline. As summarized in Fig. 5 and Alg. 1, this compact formulation allows us to decouple the RoR framew ork into a highly efficient offline-online pipeline: 1) Offline Pr eparation & W eight Fusion: Using calibration data, we locate the m outlier channels (Phase 1) and construct the lo w-rank matrices V and T (Phase 2). Crucially , we absorb the in verse rotation into the original model weights ( W ∈ R d in × d out ) entirely offline (Phase 3): ˜ W = Q ⊤ W = W − VT ⊤ V ⊤ W (12) 2) Online Activation T ransform (Infer ence): During deploy- ment (Phase 4), the baseline matrix multiplication is dynami- cally protected by applying the low-rank WY transformation strictly to the incoming activ ations: ˜ X = X − ( XV ) TV ⊤ (13) This online correction is the only stage where RoR introduces computational overhead. Overhead Analysis. Because lethal outliers are highly sparse ( m ≪ d in , typically < 1% ), the correction term in Eq. (13) relies entirely on skinny low-rank matrix multiplications. This operation requires approximately O ( B · d in · m ) FLOPs, adding strictly < 1% latency compared to the heavy O ( B · d in · d out ) baseline matrix multiplication. Furthermore, the storage bur - den is restricted exclusi vely to the low-rank parameters V and T , making RoR exceptionally lightweight for memory- constrained edge deployments. V . E V A L U A T I O N In this section, we conduct a comprehensive empirical ev aluation of RoR, systematically e xamining its robustness against bit-flip attacks across black-box, gray-box, and white- box threat models, as well as its generalization to do wnstream tasks, computational efficienc y , and sensiti vity to hyperparam- eter configurations. W e organize our experiments to answer the following six research questions: • RQ1 (Black-Box Robustness): Can RoR maintain stable model performance under random bit-flip attacks, where the attacker has no knowledge of the model internals and inflicts unguided, stochastic memory faults? X X W X ror W ror × × outlier V 、 T V RoR ① ② T Offline W Fusion ③ ④ Online X rotation X X X X X X ... Incorrect Output ... Correct Output Fig. 5. The overall framework of RoR. The pipeline consists of four steps: Offline Outlier Identification, Compact WY Construction, Offline W eight Fusion, and Online Inference. The fusion process absorbs the majority of the computational cost offline, leaving only a negligible low-rank correction during inference. Algorithm 1 RoR: Outlier Suppression via Householder Require: Pre-trained LLM weights W , Calibration dataset D cal , Outlier threshold α Ensure: Rotated weights ˜ W , Rotation parameters { V , T } 1: Phase 1: Offline Outlier Identification 2: for each layer l in LLM do 3: Collect activ ation matrix X ( l ) using D cal 4: Compute channel-wise peaks: m k ← || X ( l ) : ,k || ∞ 5: Compute statistics: µ ← mean ( m ) , σ ← std ( m ) 6: Threshold: τ ← max( µ + α · σ , 2 µ, 1 . 0) 7: Identify outlier indices: I ← { k | m k > τ } 8: end for 9: Phase 2: Compact WY Construction 10: for each target layer do 11: Initialize V ← [ ] , T ← [ ] 12: for each outlier index k ∈ I do 13: Define target u (uniform smoothed vector) 14: Compute Householder vector: v ← e k − u 15: Update block representation V , T 16: end for 17: Phase 3: Offline W eight Fusion 18: Compute rotated weights: ˜ W ← W − VT ⊤ V ⊤ W 19: Store low-rank parameters V , T alongside ˜ W 20: end for 21: Phase 4: Online Inference 22: Given input activ ation X : 23: Apply low-rank rotation: ˜ X ← X − ( XV ) TV ⊤ 24: Compute output: Y ← ˜ X ˜ W • RQ2 (Gray-Box Robustness): Can RoR ef fectiv ely suppress catastrophic degradation under gradient-guided targeted attacks, where the attacker has partial knowledge of the model, specifically access to model weights and the ability to compute gradients? • RQ3 (White-Box Robustness): Under the strongest threat model where the attacker has full access to model 6 internals, including weights, defense configurations, and any encryption k eys, does RoR provide reliable protection against single point failure attacks? • RQ4 (T ask Generalization): Does the rob ustness con- ferred by RoR extend to diverse downstream tasks (e.g., HellaSwag, MMLU, PIQA), ensuring reliable perfor- mance beyond standard language modeling metrics? • RQ5 (Efficiency): What are the practical inference la- tency and storage ov erheads of deploying RoR? • RQ6 (Ablation Study): Ho w do hyperparameter con- figurations (e.g., outlier threshold α ) affect the trade-off between defensive performance and efficienc y? A. Experimental Setup Implementation Details. W e implement RoR using Python 3.10 and PyT orch 2.4.1 with CUD A 12.1. All experiments are conducted on a server equipped with an Intel Xeon Platinum 8558P CPU and a single NVIDIA H200 NVL GPU, ensuring precise measurement of inference latency and supporting the intensiv e computations required for gradient-based attacks. Models. W e e valuate RoR across a diverse set of LLMs spanning multiple scales and architectures, organized by threat scenario. For black-box ev aluation (RQ1), we use OPT - 125M [37], Qwen2.5-0.5B, and Qwen2.5-7B [38], where smaller models facilitate large-scale statistical testing un- der stochastic attacks and Qwen2.5-7B assesses scalability . For gray-box e valuation (RQ2), we adopt Llama-3.2-1B [3], Llama-2-7B [2], and Qwen2.5-7B [38], covering compact to mainstream-scale architectures under gradient-guided targeted attacks. For white-box ev aluation (RQ3), we use Llama-2- 7B [2] and Qwen2.5-7B [38] under the strongest threat model with full model knowledge. Datasets. For the primary robustness ev aluation, we use W ikiT ext-2 [39] as the canonical language modeling bench- mark, quantifying de gradation via Perplexity (PPL) under attack. PPL measures how confidently a model predicts held- out text, where a lower value indicates better performance and a higher value signals degraded capability . For task general- ization, we additionally employ HellaSwag [40], MMLU [41], and PIQA [42], with detailed descriptions deferred to Sec- tion V -E. Compared Defenses. W e compare RoR against the following representativ e methods. (i) Baseline : The vanilla quantized model with no defense applied, serving as the lower -bound reference. (ii) F aR [43] : A training-free structural defense for Trans- formers that rewires Linear layers by redistributing the func- tional importance of critical neurons to non-essential ones, reducing the attack surface for gradient-based adv ersaries without requiring full retraining. (iii) RADAR [17] : A run-time detection and recov ery scheme that or ganizes weights into interleav ed groups and computes a 2-bit checksum signature per group using masked summation. During inference, the li ve signature is compared against a securely stored golden signature to detect bit-flip attacks; upon detection, all weights in the compromised group are zeroed out to suppress accuracy degradation. Baseline F aR RoR 1 0 2 P ost-Flip P erplexity (Log Scale) Fig. 6. Distribution of post-flip perplexity over 2,000 random bit-flip attack trials on Qwen2.5-0.5B. B. Black-Box Robustness under Random Bit-Flip Attacks (RQ1) T o ev aluate RoR under the black-box threat model, we simulate stochastic bit-flip attacks via Monte Carlo experi- ments. Unlike gradient-guided attacks, random bit flips reflect the unpredictable nature of black-box adversaries who lack any kno wledge of model internals, resulting in unguided and stochastic perturbations to model weights. W e conduct 2,000 independent trials on OPT -125M, Qwen2.5-0.5B, and Qwen2.5-7B under a fixed bit error rate (BER) of 3 × 10 − 4 . In each trial, bits in the model weights are randomly flipped according to the specified BER, and the resulting perplexity (PPL) on W ikiT ext-2 is recorded. Results. T able I and Fig. 6 reports the statistical robustness metrics across all three models. The F ail Rate denotes the probability that a single random bit flip renders the model unusable (PPL > 100). The results rev eal three key findings. (i) Arc hitectural fra gility varies significantly . The leg acy OPT -125M is highly vulnerable under the undefended base- line, with a 5.35% failure rate — roughly 1 in e very 20 random flips triggers catastrophic collapse. The modern Qwen2.5-0.5B is comparati vely more resilient (0.20%), yet its w orst-case PPL still spikes to 237. Qwen2.5-7B presents a more severe result: despite a moderate 3.15% failure rate, a single unlucky flip can drive PPL to 2 . 8 × 10 5 , confirming that larger models are not immune to catastrophic fault ev ents. (ii) Existing defenses pr ovide inconsistent pr otection. FaR fails to reduce the failure rate on OPT -125M, where it marginally worsens from 5.35% to 5.40%, with the worst- case PPL remaining as high as 5920. On Qwen2.5-0.5B, FaR reduces the failure rate to 0.05% but still leav es a residual worst-case risk, as illustrated by the PPL distribution in Fig. 6 (Max PPL 168). On Qwen2.5-7B, FaR achie ves a 0.00% failure rate yet leav es the mean PPL elev ated at 8.10, indicating non-catastrophic but persistent de gradation. Overall, FaR e xhibits inconsistent ef fectiv eness across architectures and cannot reliably suppress failure risk. (iii) RoR pr ovides universal and tight pr otection. RoR deliv ers consistent robustness across all three architectures. On OPT -125M, it reduces the failure rate by 53 × (5.35% → 7 T ABLE I S TA T I ST IC A L RO BU ST N E S S UN D E R R A N D OM B I T - FL IP AT TAC K S ( 2 , 0 00 T R I A L S ). Method OPT -125M Qwen2.5-0.5B Qwen2.5-7B Mean PPL Max PPL Fail Rate (%) Mean PPL Max PPL F ail Rate (%) Mean PPL Max PPL Fail Rate (%) Baseline 97.93 7616.0 5.35 14.24 237.0 0.20 374.99 2 . 8 × 10 5 3.15 FaR [43] 113.18 5920.0 5.40 13.98 168.0 0.05 8.10 14.4 0.00 RoR (Ours) 35.32 296.0 0.10 13.39 20.4 0.00 5.60 6.8 0.00 0 10 20 30 40 50 60 70 80 90 100 Number of Bit Flips 1 0 0 1 0 1 1 0 2 1 0 3 P erplexity (Log Scale) (b) LLaMA3.2-1B 0 10 20 30 40 50 60 70 80 90 100 Number of Bit Flips 1 0 0 1 0 1 1 0 2 1 0 3 P erplexity (Log Scale) (c) LLaMA2-7B 0 2 4 6 8 10 12 14 16 18 20 Number of Bit Flips 1 0 0 1 0 1 1 0 2 1 0 3 P erplexity (Log Scale) (a) Qwen2.5-7B Baseline F aR RADAR RoR Fig. 7. PPL degradation under gray-box PBS attack (log scale). RoR consistently maintains the lowest and most stable PPL trajectory across all three architectures, while baselines collapse within a small number of flips. 0.10%) and constrains the worst-case PPL from 7616 to 296. On Qwen2.5-0.5B, RoR achiev es a perfect 0.00% failure rate and suppresses the maximum PPL to 20.4. On Qwen2.5-7B, RoR similarly achiev es 0.00% failure while reducing the mean PPL to 5.60 and the maximum to just 6.8 (nearly indistin- guishable from original baseline inference PPL). These results confirm that RoR’ s outlier smoothing mechanism effecti vely ensures that no single bit flip carries suf ficient magnitude to trigger catastrophic degradation, thereby providing reliable stability across diverse architectures and scales. C. Defense Efficacy under Gray-Box PBS Attack (RQ2) W e e valuate RoR under a gray-box threat model, where the adversary employs Progressive Bit Search (PBS) [13] with knowledge of the model architecture and quantization scheme, but without access to the defense mechanism internals. W e compare Baseline, FaR, RAD AR, and RoR across three model scales. For clarity , all PPL curves in Fig. 7 are displayed with a maximum PPL of 1000 to facilitate visual comparison; complete numerical results are provided in Appendix A. Results. Figure 7 rev eals distinct vulnerability profiles across architectures. (i) Baseline and F aR collapse rapidly . The unprotected Baseline is catastrophically fragile across all models. On Llama-2-7B, PPL explodes to 6720 after just 5 flips and reaches 1 . 69 × 10 9 by flip 100. FaR introduces an original- accuracy penalty (initial PPL 8.00 vs. 5.03 on Llama-2-7B, 10.12 vs. 9.06 on Llama-3.2-1B, 6.56 vs. 5.41 on Qwen2.5- 7B) and still collapses rapidly under attack — exceeding PPL 2000 within 10 flips on Llama-2-7B and PPL 10 5 within 16 flips on Qwen2.5-7B. (ii) RAD AR pr ovides str ong b ut unstable pr otection. RAD AR demonstrates remarkable resilience in the early attack phase, maintaining near-original PPL across all three models up to approximately 30–40 flips. Howe ver , it suffers a sudden and sev ere f ailure beyond this point: on Llama-2-7B, PPL jumps abruptly from 5.50 at flip 30 to 2624 at flip 40, and continues rising to 8640 by flip 100. This failure stems from an inherent limitation of group checksum detection: as PBS progressiv ely accumulates bit flips, the probability that two corrupted bits within the same group produce canceling check- sum grows monotonically , eventually causing the corruption to go undetected and the recovery mechanism to nev er trigger . (iii) RoR pr ovides smooth and sustained rob ustness. In contrast, RoR preserves original accuracy without any penalty (initial PPL matches Baseline on all models) and remains stable rather than collapsing abruptly . On Llama-2-7B, PPL remains at 5.56 after 20 flips and only reaches 26.25 after 50 flips — well within usable range. On Qwen2.5-7B, RoR holds PPL below 10 for the first 6 flips and below 120 through flip 18, where Baseline has already reached 1 . 95 × 10 11 . On the compact Llama-3.2-1B, RoR maintains PPL at 13.56 after 20 flips while Baseline has already collapsed beyond 10 5 . RoR is the only defense that simultaneously preserves original-model accuracy and maintains reliable protection under sustained PBS attacks across div erse architectures. RAD AR offers competitiv e early-phase protection but breaks down suddenly once attack accumulation exceeds its detection capacity , whereas FaR and Baseline of fer no meaningful resistance even under a small number of bit flips. 8 D. White-Box Robustness Against Single P oint F ailur e Attacks (RQ3) Under the white-box threat model, the adversary has com- plete knowledge of each defense’ s internal structure, enabling single point failure attacks (SPF A) that exploit defense-specific vulnerabilities to amplify a minimal fault into a catastrophic model failure. The critical vulnerable bit is identified via binary search ov er the model weights, as introduced in Sec- tion III: for instance, on Llama-2-7B, a single flip of bit 7 at layer1.self_attn.v_proj [1512 , 1100] suffices to collapse the model, while on Qwen2.5-7B the critical location is bit 7 at layer1.mlp.gate_proj [1923 , 17094] . Attack Construction. Each defense imposes a distinct ex- ploitation requirement for the adversary to successfully repli- cate the SPoF phenomenon. (i) Baseline requir es only 1 tar geted bit-flip at a weight pa- rameter structurally aligned with an extreme activ ation outlier . (ii) F aR r equir es 7 coor dinated flips: giv en white-box access to the neuron importance redistrib ution mapping, the adversary identifies the tar get critical neuron and simultaneously corrupts the target bit along with all 6 linked non-essential neuron, completely neutralizing the rewiring protection. (iii) RADAR requir es 2 coor dinated flips: giv en white-box access to the securely stored golden signature and the inter- leav ed group partition information ( G =512 ), the adversary simultaneously flips the target critical bit and a carefully chosen partner bit within the same checksum group. This mutual cancellation exactly preserv es the checksum, bypassing the integrity monitor while successfully inducing the original SPoF . (iv) RoR r equir es a massive sequence of coor dinated flips (e.g ., ∼ 17 , 000 flips on a single column): RoR stores the compact factors V and T as part of its defense configuration, which under the white-box threat model are assumed to be fully accessible to the adversary . Giv en these factors, the attacker can analytically reconstruct the orthogonal trans- formation Q = I − VTV ⊤ and exploit the mathematical equiv alence to translate a single-bit SPoF fault into a dense column attack on the rotated weights. Specifically , the baseline forward pass satisfies: Y = XW = ( X Q )( Q ⊤ W ) = ˜ X ˜ W , (14) where ˜ W = Q ⊤ W is the stored rotated weight and ˜ X = X Q is the rotated activ ation. A single-bit flip at the original weight W [ r, c ] with magnitude δ perturbs the original output by ∆ Y = δ · X : ,r e ⊤ c (i.e., solely affecting the c -th column of the output). T o reproduce this identical output perturbation via ˜ W , the adversary must apply a perturbation ∆ ˜ W such that ˜ X ∆ ˜ W = ∆ Y . This yields ∆ ˜ W = Q ⊤ ∆ W . Since ∆ W is non-zero only at [ r, c ] , the required perturbation becomes: ∆ ˜ W : ,c = δ · Q ⊤ : ,r , where Q ⊤ = I − VT ⊤ V ⊤ , (15) which corrupts the entir e c -th column of ˜ W rather than a single weight element. Results. T able II reports the original and post-attack PPL on W ikiT ext-2, with the required number of coordinated flips serving as the primary metric of defense strength. T ABLE II W H IT E - B OX S P FA R E S U L T S O N W IK I T E X T - 2 . Model Method Original PPL Attack Bits Post-Attack PPL Llama-2-7B Baseline 5.03 1 19,456 FaR 8.00 7 11,072 RAD AR 5.03 2 19,456 RoR (Ours) 5.03 17,877 18,304 1 Qwen2.5-7B Baseline 5.41 1 344,064 FaR 6.56 7 108,003,328 RAD AR 5.41 2 344,064 RoR (Ours) 5.41 17,494 284,672 (i) Existing defenses ar e bypassed with negligible effort. The unprotected Baseline collapses with just 1 targeted bit- flip, reaf firming the sev ere threat of latent SPoFs. RAD AR is neutralized by merely 2 coordinated flips, yielding an identical post-attack PPL to the Baseline (19,456 on Llama- 2-7B; 344,064 on Qwen2.5-7B). This demonstrates that its integrity monitor is trivially circumvented under white-box as- sumptions. FaR marginally raises the exploitation requirement to 7 coordinated flips, which still reliably precipitates complete model failure. (ii) RoR scales the exploitation cost to physical impossibil- ity . In contrast, successfully replicating the SPoF phenomenon against RoR necessitates corrupting an entire column of the orthogonalized weight matrix. Measured by the IEEE-format bitwise Hamming distance between the original and perturbed weight configurations, this optimal white-box ev asion trans- lates to 17,877 simultaneous physical bit-flips on Llama- 2-7B, and 17,494 on Qwen2.5-7B. State-of-the-art physical fault injection primitives, such as Rowhammer [11], can only induce sparse and spatially constrained bit-flips within a victim DRAM row . Consequently , it is physically impossible for any adversary to synchronously corrupt the thousands of precisely distributed bits required to bypass RoR. By geometrically delocalizing the vulnerability , RoR effecti vely shifts the SPoF exploitation cost far beyond the physical capabilities of exist- ing hardware threat models. E. T ask Generalization under Attack (RQ4) A defense that solely preserves tok en-lev el fluency (perple x- ity) may still conceal the silent degradation of higher-le vel reasoning capabilities. T o address this ev aluation limitation, we extend our analysis beyond W ikiT ext-2 to three div erse benchmarks, measuring whether RoR preserves semantic rea- soning and world knowledge under an increasing number of targeted bit-flips. Benchmarks. W e ev aluate on three benchmarks that probe distinct reasoning domains be yond basic language fluenc y . MMLU [41] is a 4-way multiple-choice benchmark; we report the macro-av erage accuracy over four representative domains (Elementary Mathematics, Computer Security , Phi- losophy , and Global Facts), where random guessing yields ≈ 25% . HellaSwag [40] is a 4-way commonsense completion 1 Theoretically expected to exactly match Baseline collapse; the minor gap is attributed to quantization rounding errors introduced by weight rotation, which are amplified at severely degraded PPL. 9 0 20 40 60 80 100 Number of Bit Flips 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Accuracy (a) MML U 0 20 40 60 80 100 Number of Bit Flips 0.0 0.2 0.4 0.6 0.8 Accuracy (b) HellaSwag 0 20 40 60 80 100 Number of Bit Flips 0.4 0.5 0.6 0.7 0.8 Accuracy (c) PIQA Baseline F aR RADAR RoR Fig. 8. T ask generalization under Progressive Bit-Search (PBS) attack on Llama-2-7B. Accuracy on three reasoning benchmarks (MMLU, HellaSwag, PIQA) as cumulative bit flips grow from 0 to 100. task (random baseline ≈ 25% ), reported as normalized accu- racy . PIQA [42] is a 2-way physical commonsense reasoning task (random baseline ≈ 50% ). T ogether, these tasks ev aluate STEM reasoning, specialized knowledge, abstract inference, and physical dynamics—dimensions that perplexity alone cannot comprehensi vely capture. Models are subjected to a Progressiv e Bit-Search (PBS) attack with up to 100 cumulativ e bit-flips on Llama-2-7B, e valuated in a 5-shot setting ( k =5 , N =200 instances per task). Results. Figure 8 reports the accuracy across all three bench- marks as a function of the number of flipped bits. The accuracy trajectories of all competing methods closely align with the W ikiT ext-2 PPL results in Section V -C: Baseline and F aR collapse within the first 5 flips, while RAD AR sustains near- original accuracy until an abrupt, simultaneous collapse across all three metrics between flip 30 and flip 40. This mirrors the sudden catastrophic degradation previously observ ed in the perplexity ev aluation. RoR is the sole method that r obustly preserves task per- formance acr oss all benchmarks. At flip 50, RoR retains 43.9% MMLU, 65.0% HellaSwag, and 75.0% PIQA. No- tably , e ven after enduring 50 targeted bit-flips, RoR’ s task performance remains highly competitiv e with the unprotected Baseline’ s original, unattacked state (Flip 0: 45.2% MMLU, 70.5% HellaSwag, 77.0% PIQA). It experiences only marginal degradation, whereas all competing defenses have completely collapsed to random guessing ( ≈ 25% for MMLU/HellaSwag, ≈ 50% for PIQA). At flip 100, RoR still holds 42.1% MMLU and 61.0% PIQA, long after e very competing method has degraded to near-chance performance. These results rigorously confirm that RoR’ s robustness generalizes beyond perplexity , ensuring the genuine preservation of semantic and reasoning capabilities across diverse downstream tasks. F . Infer ence Efficiency & Overhead (RQ5) W e benchmark inference latency on an NVIDIA H200 GPU (BFloat16, SeqLen=2048, Batch=16, PyT orch 2.4 with torch.compile ) across three models: OPT -125M, Qwen2.5-0.5B, and Llama-2-7B. Results are reported in T a- ble III. Defense Configurations and Storage Accounting. Each defense stores auxiliary data beyond the quantized model weights. FaR ( p =0 . 001 , K =6 rewiring rounds) records rewired weight indices and replacement values, incurring + 2.1–3.0% extra storage depending on model size. RADAR ( G =512 ) must materialize a full per-element ± 1 mask vector as a persistent GPU b uffer in software, causing its storage to scale linearly with model size and reach +50% of the BFloat16 weight footprint—far beyond the < 6 KB reported in the original paper , which assumes a dedicated hardware pipeline. RoR ( α =6 . 0 ) stores only the compact Householder factors V ∈ R d × m and T ∈ R m × m per protected layer, yield- ing merely + 0.17–0.31% extra storage across all models— one to three orders of magnitude smaller than the competing defenses. Empirical Latency . RoR incurs a modest latency overhead of +11.9% on OPT -125M, +19.2% on Qwen2.5-0.5B, and +9.1% on Llama-2-7B, consistently the lowest among all defenses. The gap between the theoretical < 1% FLOPs increase and the observed ∼ 10–20% latency on smaller models reflects that the WY update introduces memory-bandwidth pressure. In contrast, RADAR’ s run time checksum operations and FaR’ s unstructured sparse index accesses both trigger repeated graph breaks under torch.compile , yielding ov erheads of + 63– 84% and + 337–477% respectiv ely . Overall, RoR achiev es the lo west latency and smallest storage footprint across all models and configurations. On Llama-2-7B, RoR runs 1.7 × faster than RAD AR and 5.3 × faster than FaR, while incurring only +0.31% extra storage against +50% for RADAR and +3.04% for FaR. Combined with a theoretical FLOPs increase of < 1%, these results confirm that RoR imposes ne gligible o verhead in both compute and memory dimensions, with latency overhead ranging from +9.1% to +19.2% across all ev aluated models. G. Ablation Study: Effect of Outlier Threshold α (RQ6) The threshold parameter α dictates the aggressiv eness of RoR’ s outlier identification. Reducing α incorporates more feature dimensions into the orthogonal rotation, thereby ex- panding the defensiv e coverage at the cost of marginally 10 T ABLE III I N FE RE N C E L A T EN C Y A N D S T O R AG E OV E R H EA D . E X TR A S T O R AG E I S R E LAT I V E TO T HE B F L O AT 1 6 M O D E L W E I GH T F O O T P RI N T ; L AT E N CY OV E R H E AD I S R E L A T IV E TO T H E U N PR O T E CT ED B A S E L I NE . Model Method Extra Storage Latency (ms) ↓ Latency Overhead OPT -125M Baseline — 46.71 — FaR +2 . 10% 204.15 +336 . 9% RAD AR +50 . 0% 76.20 +63 . 1% RoR (Ours) + 0 . 23 % 52.28 + 11 . 9 % Qwen2.5-0.5B Baseline — 139.98 — FaR +2 . 20% 707.12 +405 . 2% RAD AR +50 . 0% 238.37 +70 . 3% RoR (Ours) + 0 . 17 % 166.87 + 19 . 2 % LLaMA2-7B Baseline — 1052.24 — FaR +3 . 04% 6075.90 +477 . 4% RAD AR +50 . 0% 1937.38 +84 . 1% RoR (Ours) + 0 . 31 % 1148.00 + 9 . 1 % T ABLE IV A B LAT I O N O N T H E O UT L I E R T H R E SH OL D α . Count D EN OT E S T H E N U MB E R O F R OTA T E D F E ATU R E D I ME N S I ON S ( E FFI CI E N C Y P RO X Y ); PPL@50 I N DI CAT E S T H E P E R P L EX IT Y A F T ER E N D U R I NG 5 0 T A R G E T ED P B S B I T - FLI P S . Config ( α ) Llama-3.2-1B Llama-2-7B Count PPL@50 Count PPL@50 Conservati ve ( α =9 . 0 ) 208 7,136 2,118 72,192 Standard ( α =6 . 0 ) 837 11,776 3,973 26.3 Aggressiv e ( α =3 . 0 ) 5,253 158.0 11,341 23.9 higher storage and computation for the auxiliary Compact WY factors. T able IV reports the number of rotated columns (serving as an efficiency overhead proxy) alongside the post- attack PPL after 50 PBS bit-flips across three α configurations on Llama-3.2-1B and Llama-2-7B, directly quantifying the robustness–ef ficiency trade-off. Robustness–Efficiency T rade-off. Reducing α from 9.0 to 3.0 drastically expands the rotational coverage, increasing the protected column count by 25 × on Llama-3.2-1B (208 → 5,253) and 5 × on Llama-2-7B (2,118 → 11,341). The resulting robustness improv ements, ho wev er , are substantial. On Llama-2-7B, transitioning to the standard setting ( α =6 . 0 ) abruptly drops the post-attack PPL from a catastrophic 72,192 to 26.3, successfully neutralizing the SPoFs with only ≈ 4 k rotated dimensions (a minimal footprint). Con versely , Llama- 3.2-1B requires the aggressive setting ( α =3 . 0 ) to stabilize the model to a PPL of 158.0, incurring a proportionally higher ov erhead of ≈ 5 k dimensions. Architectur e Sensitivity . The distinct sensitivities to α across ev aluated models reveal fundamental dif ferences in their in- ternal activ ation distrib utions and structural vulnerabilities. Llama-2-7B achiev es robust protection at α =6 . 0 , indicating that its activ ation outliers are extremely acute and heavily con- centrated within a tiny fraction of feature channels. In contrast, the necessity of α =3 . 0 for Llama-3.2-1B—a phenomenon consistently observed in other highly optimized architectures such as Qwen2.5-7B—demonstrates that certain models ex- hibit a less extreme, but more spatially dispersed distribution of critical activ ation magnitudes. This broader dimensional vulnerability inherently requires wider orthogonal rotation cov erage to sufficiently smooth these dispersed magnitudes and eliminate the latent SPoFs. Practical Recommendation. The threshold α serves as a principled, architecture-aware tunable parameter for practical deployments. Rather than strictly correlating with parame- ter scale, the optimal configuration is strictly gov erned by the intrinsic outlier distribution pattern of the target model. Architectures with highly concentrated outliers can operate at near -zero o verhead using a standard threshold ( α =6 . 0 ). Con versely , architectures characterized by a spatially dispersed vulnerability profile must adopt an aggressiv e setting ( α =3 . 0 ) to guarantee sufficient defensiv e cov erage against widespread latent faults. In all regimes, the number of dynamically rotated dimensions remains a minuscule fraction of the total hidden dimensions, confirming that RoR scales efficiently and adap- tiv ely across diverse LLM architectures. V I . D I S C U S S I O N A N D F U T U R E W O R K While RoR provides a structurally lossless defense against bit-flip attacks, we identify three primary av enues for future system-lev el optimization and cross-domain extension. A. Overcoming Memory-Bound Bottlenecks Although RoR introduces a mathematically negligible FLOP ov erhead ( < 1% ), empirical inference latency increases by 10% – 20% . This discrepancy stems from the memory-bound nature of modern GPUs. The low-rank WY updates exhibit ex- tremely low arithmetic intensity ; execution time is dominated by repetitive DRAM read/write latencies for the Householder factors ( V and T ) rather than actual computation. Future hardware-software co-design can eliminate this redundant memory traffic by developing custom, fused execution kernels (e.g., via T riton or CUD A) that persist these low-rank factors strictly within SRAM or registers. B. Scope Limitation: Normalization Layers RoR currently secures dense linear projections, which con- stitute the vast majority of LLM parameters. Ho wev er , the orthogonal rotation cannot be directly applied to normalization operations like RMSNorm. Mathematically , RMSNorm scales a normalized input x by a learned parameter γ via element- wise multiplication ( ⊙ ). Because an orthogonal matrix Q does not commute with this operation—i.e., Q ( x ⊙ γ ) = ( Qx ) ⊙ γ —applying Q would improperly mix feature dimensions and destroy channel independence. Securing this minuscule pa- rameter fraction without breaking its mathematical properties remains an open challenge. C. Limitations and Extension to Multimodal Ar chitectur es While the mathematical formulation of RoR is structurally modality-agnostic, its practical extension to Multimodal LLMs (MLLMs) presents unique challenges due to fundamental distributional shifts. RoR relies on identifying static, persis- tent channel-wise outliers via of fline calibration. Howe ver , recent empirical analyses rev eal that multimodal tokens and their intermediate layer activ ations exhibit significantly higher statistical variance and entropy compared to purely textual tokens [44]. Consequently , visual outliers are highly dynamic 11 and input-dependent rather than being strictly confined to fixed hidden channels. This high-entropy distribution implies that an offline-calibrated, static rotation matrix may fail to intercept image-specific outlier spikes during runtime, or it may require a substantially larger number of target channels that sev erely degrades the ef ficiency of the low-rank WY representation. Therefore, successfully extending this lossless defense to multimodal architectures necessitates a paradigm shift from static of fline rotation to dynamic, variance-a ware orthogonal transformations that can adaptively secure localized spatial features. V I I . R E L A T E D W O R K Existing defenses against hardware-induced Bit-Flip Attacks (BF As) were primarily tailored for conv entional Deep Neural Networks (e.g., CNNs) and smaller-scale T ransformers (e.g., V iTs). Howe ver , they face unique architectural and compu- tational challenges when scaling to billion-parameter, autore- gressiv e Large Language Models (LLMs). W e classify these prior methodologies into two dominant paradigms: detection- based monitors and weight-robustness mechanisms. 1) Detection-based Monitors. Detection-based methods aim to intercept hardware faults during inference by introducing runtime monitors and redundancy checks. Monitor-centric ap- proaches, such as NeuroPots [18], ModelShield [19], W eight- Sentry [45], Aegis [46], and anomaly detection schemes [47], rely on honey neurons, hash verification, range checks, or early-exit classifiers. Alternati vely , software-based Error Cor - rection Code (ECC) schemes [20], [21], [48], [49] integrate parity decoding directly into the computation path. T o address the se vere ov erhead of continuous verification, RADAR [17] serves as a pioneering baseline that embeds interleaved group checksums within the weight matrices. By comput- ing lightweight addition-based checksums of the quantized weights, RAD AR successfully detects parameter corruption with negligible latency on traditional CNNs architectures. Howe ver , translating such layer-by-layer runtime verifica- tion to autoregressiv e LLMs presents structural challenges. LLM inference is inherently memory-bandwidth bound. En- forcing integrity verification on weight matrices for every generated token introduces strict synchronization barriers that can impede high-throughput token generation. Furthermore, the detection efficac y of these group-based checksums heavily depends on the grouping granularity . Sophisticated adversaries can systematically craft targeted, multi-bit attacks designed to bypass group-lev el parity checks, silently corrupting the LLM’ s output. 2) W eight-Robustness and P arameter Hardening . Instead of monitoring for runtime errors, weight-robustness methods aim to inherently improve the fault tolerance of the model param- eters. While methods like robust retraining (e.g., SAR [22] and WRecon [50]) are computationally prohibitive at the LLM scale, encoding-based defenses (e.g., DeepNcode [24], CodeNet [51], and RREC [25]) demand complex codeword recov ery on the inference path. Consequently , post-training weight modification has emerged as a more practical alter- nativ e. Notably , FaR (For get-and-Rewire) [43] is a representative training-free hardening method. FaR structurally mitigates worst-case vulnerabilities by rewiring linear layers, redis- tributing the functional importance of critical neurons to less essential ones. While FaR reports minimal inference latency overheads on CNNs or V iTs, applying its sparse rewire operations to autoregressi ve LLMs incurs se vere latenc y bottlenecks (e.g., up to 500% overhead in our ev aluations) as unstructured memory accesses compound ov er sequential token generation steps. Furthermore, securing massive LLMs against aggressiv e targeted attacks requires applying higher hyperparameter configurations (e.g., larger rewiring ratios). This forced redistribution inherently distorts the pre-trained weight distribution, which inevitably de grades the model’ s baseline accuracy and generativ e capabilities. Unlike these prior paradigms, Rotated Robustness (RoR) achiev es true lossless robustness. By applying matched or- thogonal transformations to both the activation space and the weight matrices, RoR fundamentally neutralizes outlier-dri ven vulnerabilities while mathematically guaranteeing the perfect preservation of the model’ s original generativ e accuracy . Fur- thermore, by formulating these rotations as hardware-friendly , dense low-ra nk matrix multiplications, RoR minimizes both inference latency and storage ov erhead, completely avoiding the synchronization barriers and unstructured sparsity inherent in prior defense schemes. V I I I . C ON C L U S I O N This paper inv estigates the catastrophic vulnerability of Large Language Models (LLMs) to hardware-induced bit-flip attacks. W e demonstrate that these sudden model collapses stem fundamentally from the spatial alignment between sensi- tiv e weight bits and extreme activ ation outliers. T o neutralize this threat, we propose Rotated Robustness (RoR), a training- free defense utilizing orthogonal Householder transformations to geometrically smooth these outliers across all feature di- mensions. By breaking this dangerous alignment, RoR math- ematically guarantees true lossless robustness—preserving the model’ s original accuracy and perplexity . Extensiv e empirical ev aluations confirm RoR’ s superior reliability across diverse LLM families. Under black-box ran- dom fault injections, RoR effecti vely eliminates the risk of stochastic model collapse. Under gray-box scenarios in volv- ing targeted bit-search capabilities, RoR consistently sustains robust reasoning performance, maintaining near-lossless base- line accuracy where competing defenses suffer catastrophic failure. Against the most se vere white-box Single Point Failure Attacks (SPF A) with full system visibility , RoR drastically in- creases the required number of targeted bit-flips, thereby push- ing the attack complexity far beyond the physical limitations of Rowhammer . Furthermore, RoR achiev es this state-of-the- art robustness with a negligible storage footprint and minimal inference latency , delivering a highly efficient, scalable, and reliable defense for real-world LLM deployments. 12 T ABLE V C O MP LE T E P P L R E S ULT S U N D E R GR A Y - B OX P B S A T T AC K AC R O S S T H R EE M O D E L AR C H I TE C T U RE S . R E SU L T S E X C E ED I N G 10 15 A R E M A R K ED W I T H † . #Flips Llama-2-7B Llama-3.2-1B Qwen2.5-7B Baseline RoR FaR RADAR Baseline RoR FaR RADAR Baseline RoR FaR RADAR 0 5.03 5.03 8.00 5.03 9.06 9.19 10.12 9.06 5.41 5.41 6.56 5.41 1 5.66 5.19 12.38 5.03 20.12 9.19 13.81 9.06 — — — — 2 7.28 5.16 13.19 5.03 27.88 9.31 19.75 9.06 9 . 40 × 10 2 6.41 8.25 5.41 3 105.00 5.25 17.75 5.03 56.25 9.50 30.12 9.06 — — — — 4 — — — — — — — — 7 . 62 × 10 3 43.25 7.09 5.41 5 6 . 72 × 10 3 5.28 90.00 5.09 1 . 70 × 10 3 9.81 60.00 9.06 — — — — 6 — — — — — — — — 2 . 22 × 10 11 7.75 7.88 5.41 8 — — — — — — — — 5 . 42 × 10 13 12.94 7.28 5.41 10 4 . 38 × 10 4 5.41 2 . 90 × 10 3 5.12 1 . 18 × 10 4 10.94 752.00 9.50 3 . 54 × 10 14 11.25 11.44 5.41 12 — — — — — — — — 1 . 58 × 10 15 34.25 28.38 5.41 14 — — — — — — — — 9 . 15 × 10 15 † 58.00 8 . 10 × 10 3 5.41 16 — — — — — — — — 6 . 40 × 10 17 † 82.00 1 . 05 × 10 5 5.41 18 — — — — — — — — 1 . 95 × 10 11 119.50 1 . 20 × 10 6 5.50 19 — — — — — — — — 4 . 84 × 10 8 237.00 2 . 74 × 10 7 5.50 20 5 . 99 × 10 4 5.56 2 . 22 × 10 5 5.25 2 . 11 × 10 6 13.56 1 . 63 × 10 5 9.94 — — — — 30 4 . 35 × 10 3 6.53 9 . 54 × 10 7 5.50 3 . 70 × 10 6 25.75 7 . 83 × 10 6 11.81 — — — — 40 9 . 88 × 10 4 10.94 1 . 11 × 10 10 2 . 62 × 10 3 2 . 02 × 10 8 148.00 4 . 35 × 10 3 13.56 — — — — 50 3 . 01 × 10 4 26.25 8 . 16 × 10 10 5 . 92 × 10 3 7 . 44 × 10 7 1 . 18 × 10 4 5 . 73 × 10 6 15.88 — — — — 60 3 . 01 × 10 4 68.00 2 . 39 × 10 12 1 . 52 × 10 4 1 . 39 × 10 8 2 . 09 × 10 5 1 . 98 × 10 6 22.75 — — — — 70 5 . 02 × 10 5 304.00 1 . 64 × 10 12 1 . 61 × 10 4 2 . 79 × 10 9 6 . 49 × 10 6 3 . 11 × 10 7 19.12 — — — — 80 6 . 49 × 10 6 2 . 46 × 10 3 6 . 16 × 10 13 8 . 64 × 10 3 7 . 58 × 10 9 1 . 49 × 10 9 8 . 01 × 10 8 90.00 — — — — 90 1 . 39 × 10 8 1 . 72 × 10 4 7 . 48 × 10 14 8 . 64 × 10 3 2 . 64 × 10 10 8 . 16 × 10 10 8 . 59 × 10 9 131.00 — — — — 100 1 . 69 × 10 9 1 . 27 × 10 5 1 . 58 × 10 15 8 . 64 × 10 3 6 . 01 × 10 11 2 . 07 × 10 10 6 . 55 × 10 4 148.00 — — — — A P P E N D I X A F U L L P P L R E S U LT S U N D E R G R AY - B O X P B S A T T AC K T able V provides the complete numerical Perplexity (PPL) degradation results corresponding to the visualization in Sec- tion V -C (Fig. 7). The results demonstrate the progressive collapse of baseline defenses under the gray-box Progressiv e Bit Search (PBS) attack across Llama-2-7B, Llama-3.2-1B, and Qwen2.5-7B architectures. R EF E R E N C E S [1] T . Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P . Dhariwal, A. Neelakantan, P . Shyam, G. Sastry , A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T . Henighan, R. Child, A. Ramesh, D. Ziegler, J. W u, C. Winter , C. Hesse, M. Chen, E. Sigler , M. Litwin, S. Gray , B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskev er, and D. Amodei, “Language models are few-shot learners, ” in Advances in Neural Information Processing Systems , vol. 33. Curran Associates, Inc., 2020, pp. 1877–1901. [2] H. T ouvron, L. Martin, K. Stone, P . Albert, A. Almahairi, Y . Babaei, N. Bashlykov , S. Batra, P . Bharga va, S. Bhosale et al. , “Llama 2: Open foundation and fine-tuned chat models, ” 2023. [3] A. Grattafiori, A. Dubey , A. Jauhri, A. Pandey , A. Kadian, A. Al-Dahle, A. Letman, A. Mathur , A. Schelten, A. V aughan, A. Y ang, A. Fan et al. , “The llama 3 herd of models, ” 2024. [4] J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W . Ge, Y . Han, F . Huang et al. , “Qwen technical report, ” 2023. [5] OpenAI, J. Achiam, S. Adler , S. Agarwal, L. Ahmad, I. Akkaya, F . L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al. , “Gpt-4 technical report, ” 2024. [6] J. W ei, X. W ang, D. Schuurmans, M. Bosma, b. ichter , F . Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models, ” in Advances in Neural Information Pr ocessing Systems , vol. 35. Curran Associates, Inc., 2022, pp. 24 824–24 837. [7] D. Narayanan, M. Shoe ybi, J. Casper, P . LeGresley , M. Patwary , V . Korthikanti, D. V ainbrand, P . Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia, “Effic ient large-scale language model training on gpu clusters using megatron-lm, ” in Proceedings of the International Confer ence for High P erformance Computing, Networking, Storag e and Analysis (SC) , ser . SC ’21. New Y ork, NY , USA: Association for Computing Machinery , 2021. [8] Z. Liu, C. Zhao, F . Iandola, C. Lai, Y . T ian, I. Fedorov , Y . Xiong, E. Chang, Y . Shi, R. Krishnamoorthi, L. Lai, and V . Chandra, “Mo- bileLLM: Optimizing sub-billion parameter language models for on- device use cases, ” in F orty-first International Conference on Machine Learning , 2024. [9] J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P . Liang, and M. S. Bernstein, “Generativ e agents: Interactive simulacra of human beha vior , ” in Pr oceedings of the Annual ACM Symposium on User Interface Softwar e and T echnology (UIST) , ser . UIST ’23. New Y ork, NY , USA: Association for Computing Machinery , 2023. [10] S. W u, O. Irsoy , S. Lu, V . Dabrav olski, M. Dredze, S. Gehrmann, P . Kambadur, D. Rosenberg, and G. Mann, “Bloomberggpt: A large language model for finance, ” 2023. [11] Y . Kim, R. Daly , J. Kim, C. Fallin, J. H. Lee, D. Lee, C. W ilkerson, K. Lai, and O. Mutlu, “Flipping bits in memory without accessing them: an experimental study of dram disturbance errors, ” in Pr oceeding of the 41st Annual International Symposium on Computer Arc hitecutur e , ser . ISCA ’14. IEEE Press, 2014, p. 361–372. [12] Z. Zhang, W . He, Y . Cheng, W . W ang, Y . Gao, M. W ang, K. Li, S. Nepal, and Y . Xiang, “Bitmine: An end-to-end tool for detecting rowhammer vulnerability , ” IEEE T ransactions on Information F orensics and Security , vol. 16, pp. 5167–5181, 2021. [13] A. S. Rakin, Z. He, and D. Fan, “Bit-flip attack: Crushing neural network with progressiv e bit search, ” in Proceedings of the IEEE/CVF International Conference on Computer V ision (ICCV) , 2019. [14] S. Hong, P . Frigo, Y . Kaya, C. Giuf frida, and T . Dumitras, “T ermi- nal brain damage: Exposing the graceless degradation in deep neural networks under hardware fault attacks, ” in 28th USENIX Security Sym- posium (USENIX Security 19) . Santa Clara, CA: USENIX Association, Aug. 2019, pp. 497–514. [15] X. Li, Y . Meng, J. Chen, L. Luo, and Q. Zeng, “Rowhammer -based trojan injection: One bit flip is sufficient for backdooring dnns, ” in 34th USENIX Security Symposium (USENIX Security 25) . Seattle, W A, USA: USENIX Association, 2025, pp. 6319–6337. [16] S. Das, S. Bhattacharya, S. Kundu, S. Kundu, A. Menon, A. Raha, and K. Basu, “ Attentionbreaker: Adaptiv e ev olutionary optimization for un- masking vulnerabilities in LLMs through bit-flip attacks, ” T ransactions on Machine Learning Research , 2025. [17] J. Li, A. S. Rakin, Z. He, D. Fan, and C. Chakrabarti, “Radar: Run- time adversarial weight attack detection and accuracy recovery , ” in 2021 Design, Automation & T est in Eur ope Confer ence & Exhibition (DA TE) , 2021, pp. 790–795. [18] Q. Liu, J. Yin, W . W en, C. Y ang, and S. Sha, “NeuroPots: Realtime proactiv e defense against Bit-Flip attacks in neural networks, ” in 32nd USENIX Security Symposium (USENIX Security 23) . Anaheim, CA: USENIX Association, Aug. 2023, pp. 6347–6364. [19] Y . Guo, L. Liu, Y . Cheng, Y . Zhang, and J. Y ang, “Modelshield: A generic and portable framework extension for defending bit-flip based 13 adversarial weight attacks, ” in 2021 IEEE 39th International Confer ence on Computer Design (ICCD) , 2021, pp. 559–562. [20] H. Liu, V . Singh, M. Filipiuk, and S. K. S. Hari, “ Alberta: Algorithm- based error resilience in transformer architectures, ” IEEE Open Journal of the Computer Society , vol. 6, pp. 85–96, 2025. [21] S. T . Ahmed, S. Hemaram, and M. B. T ahoori, “Nn-ecc: Embedding error correction codes in neural network weight memories using multi- task learning, ” in 2024 IEEE 42nd VLSI T est Symposium (VTS) , 2024, pp. 1–7. [22] C. Zhou, J. Du, M. Y an, H. Y ue, X. W ei, and J. T . Zhou, “Sar: Sharpness-aware minimization for enhancing dnns’ robustness against bit-flip errors, ” J ournal of Systems Arc hitectur e , vol. 156, p. 103284, 2024. [23] J. Li, A. S. Rakin, Y . Xiong, L. Chang, Z. He, D. Fan, and C. Chakrabarti, “Defending bit-flip attack through dnn weight recon- struction, ” in 2020 57th ACM/IEEE Design Automation Conference (D AC) , 2020, pp. 1–6. [24] P . V el ˇ cick ´ y, J. Breier, M. K ov a ˇ cevi ´ c, and X. Hou, “Deepncode: Encoding-based protection against bit-flip attacks on neural networks, ” 2024. [25] L. Liu, Y . Guo, Y . Cheng, Y . Zhang, and J. Y ang, “Generating robust dnn with resistance to bit-flip based adversarial weight attack, ” IEEE T ransactions on Computers , vol. 72, no. 2, pp. 401–413, 2023. [26] T . Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “Gpt3.int8(): 8-bit matrix multiplication for transformers at scale, ” in Advances in Neural Information Processing Systems , vol. 35. Curran Associates, Inc., 2022, pp. 30 318–30 332. [27] G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “SmoothQuant: Accurate and efficient post-training quantization for large language models, ” in Pr oceedings of the 40th International Con- fer ence on Machine Learning , ser . Proceedings of Machine Learning Research, vol. 202. PMLR, 2023, pp. 38 087–38 099. [28] A. S. Householder, “Unitary triangularization of a nonsymmetric ma- trix, ” J. ACM , vol. 5, no. 4, p. 339–342, Oct. 1958. [29] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser , and I. Polosukhin, “ Attention is all you need, ” in Advances in Neural Information Processing Systems , vol. 30. Curran Associates, Inc., 2017. [30] E. Frantar, S. Ashkboos, T . Hoefler , and D. Alistarh, “OPTQ: Accurate quantization for generative pre-trained transformers, ” in The Eleventh International Conference on Learning Representations , 2023. [31] R. Baumann, “Radiation-induced soft errors in advanced semiconductor technologies, ” IEEE T ransactions on Device and Materials Reliability , vol. 5, no. 3, pp. 305–316, 2005. [32] K. K. Chang, A. G. Y a ˘ glıkc ¸ ı, S. Ghose, A. Agrawal, N. Chatter- jee, A. Kashyap, D. Lee, M. O’Connor , H. Hassan, and O. Mutlu, “Understanding reduced-voltage operation in modern dram devices: Experimental characterization, analysis, and mechanisms, ” Proc. ACM Meas. Anal. Comput. Syst. , vol. 1, no. 1, Jun. 2017. [33] N. Carlini, A. Athalye, N. Papernot, W . Brendel, J. Rauber, D. Tsipras, I. Goodfellow , A. Madry , and A. Kurakin, “On ev aluating adversarial robustness, ” 2019. [34] J. Guo, C. Chakrabarti, and D. Fan, “Sbfa: Single sneaky bit flip attack to break large language models, ” 2025. [35] F . Y ao, A. S. Rakin, and D. Fan, “DeepHammer: Depleting the intelli- gence of deep neural networks through targeted chain of bit flips, ” in 29th USENIX Security Symposium (USENIX Security 20) . USENIX Association, Aug. 2020, pp. 1463–1480. [36] R. Schreiber and C. V an Loan, “ A storage-efficient $wy$ representation for products of householder transformations, ” SIAM Journal on Scientific and Statistical Computing , vol. 10, no. 1, pp. 53–57, 1989. [Online]. A vailable: https://doi.org/10.1137/0910005 [37] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dew an, M. Diab, X. Li, X. V . Lin, T . Mihaylov , M. Ott, S. Shleifer, K. Shuster, D. Simig, P . S. Koura, A. Sridhar, T . W ang, and L. Zettlemoyer, “Opt: Open pre-trained transformer language models, ” 2022. [38] A. Y ang, B. Y ang, B. Hui, B. Zheng, B. Y u, C. Zhou, C. Li et al. , “Qwen2 technical report, ” 2024. [39] S. Merity , C. Xiong, J. Bradbury , and R. Socher, “Pointer sentinel mixture models, ” 2016. [40] R. Zellers, A. Holtzman, Y . Bisk, A. Farhadi, and Y . Choi, “HellaSwag: Can a machine really finish your sentence?” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics . Florence, Italy: Association for Computational Linguistics, Jul. 2019, pp. 4791–4800. [41] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding, ” in International Conference on Learning Representations , 2021. [42] Y . Bisk, R. Zellers, R. Le bras, J. Gao, and Y . Choi, “Piqa: Reasoning about physical commonsense in natural language, ” Proceedings of the AAAI Conference on Artificial Intelligence , vol. 34, no. 05, pp. 7432– 7439, 2020. [43] N. Nazari, H. M. Makrani, C. Fang, H. Sayadi, S. Rafatirad, K. N. Khasawneh, and H. Homayoun, “Forget and rewire: Enhancing the resilience of transformer-based models against Bit-Flip attacks, ” in 33r d USENIX Security Symposium (USENIX Security 24) . Philadelphia, P A: USENIX Association, Aug. 2024, pp. 1349–1366. [44] S. Bhatnagar , A. Xu, K.-H. T an, and N. Ahuja, “Luq: Layerwise ultra- low bit quantization for multimodal large language models, ” 2025. [45] M. Abumandour , S. Ramischetty , G. V enkataramani, and A. Alameldeen, “W eightsentry: Real-time bit-flip protection for deep neural networks on gpus, ” in Proceedings of the 14th International W orkshop on Hardwar e and Arc hitectural Support for Security and Privacy , ser . HASP ’25. New Y ork, NY , USA: Association for Computing Machinery , 2025, p. 91–99. [46] J. W ang, Z. Zhang, M. W ang, H. Qiu, T . Zhang, Q. Li, Z. Li, T . W ei, and C. Zhang, “ Aegis: Mitigating targeted bit-flip attacks against deep neural networks, ” in 32nd USENIX Security Symposium (USENIX Security 23) . Anaheim, CA: USENIX Association, Aug. 2023, pp. 2329–2346. [47] K. W en, X. W ang, J. Zhao, F . Xu, and Y . W ang, “ Anomaly-driven defense: Mitigating bit-flip attacks in deep neural networks via runtime parameter clipping, ” in Advanced Intelligent Computing T echnology and Applications . Singapore: Springer Nature Singapore, 2025, pp. 370– 382. [48] H. Guan, L. Ning, Z. Lin, X. Shen, H. Zhou, and S.-H. Lim, “In- place zero-space memory protection for cnn, ” in Advances in Neural Information Pr ocessing Systems , v ol. 32. Curran Associates, Inc., 2019. [49] S.-S. Lee and J.-S. Y ang, “V alue-aware parity insertion ecc for fault- tolerant deep neural network, ” in 2022 Design, Automation & T est in Eur ope Conference & Exhibition (DA TE) , 2022, pp. 724–729. [50] Z. He, A. S. Rakin, J. Li, C. Chakrabarti, and D. Fan, “Defending and harnessing the bit-flip based adv ersarial weight attack, ” in Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2020. [51] S. Dutta, Z. Bai, T . M. Low , and P . Grover , “Codenet: Training large scale neural networks in presence of soft-errors, ” 2019.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment