$D^3$-RSMDE: 40$\times$ Faster and High-Fidelity Remote Sensing Monocular Depth Estimation
Real-time, high-fidelity monocular depth estimation from remote sensing imagery is crucial for numerous applications, yet existing methods face a stark trade-off between accuracy and efficiency. Although using Vision Transformer (ViT) backbones for d…
Authors: Ruizhi Wang, Weihan Li, Zunlei Feng
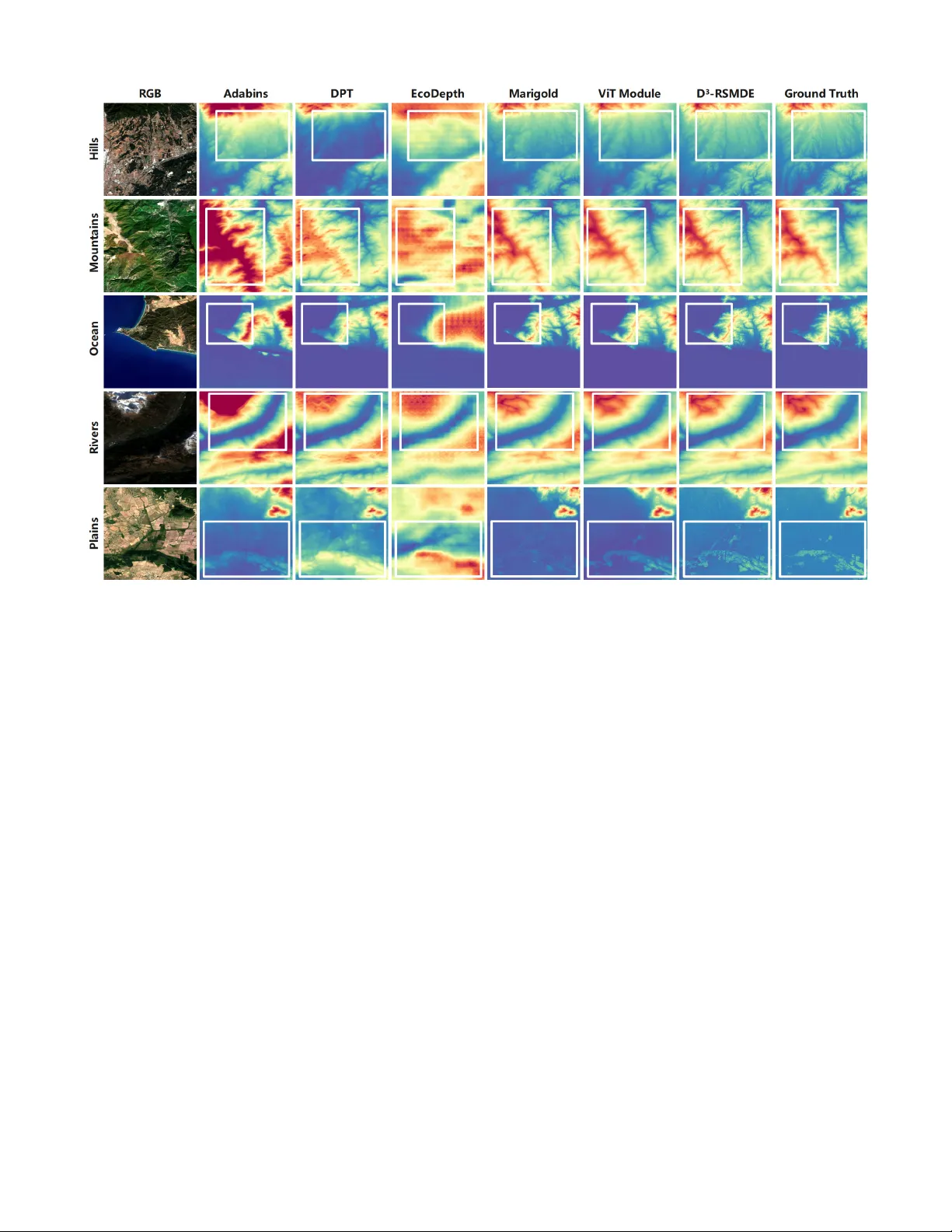
D 3 -RSMDE: 40 × F aster and High-Fidelity Remote Sensing Monocular Depth Estimation Ruizhi W ang 1 * , W eihan Li 1 * , Zunlei F eng 1,2 , Haofei Zhang 2,3 † , Mingli Song 1,2,3 , Jiayu W ang 4 , Jie Song 1 , Li Sun 5 1 School of Software T echnology , Zhejiang Univ ersity , 2 State Ke y Laboratory of Blockchain and Data Security , Zhejiang Univ ersity , 3 Hangzhou High-T ech Zone (Binjiang) Institute of Blockchain and Data Security , 4 College of Computer Science and T echnology , Zhejiang Univ ersity , 5 Ningbo Global Innov ation Center , Zhejiang Uni versity Abstract Real-time, high-fidelity monocular depth estimation from remote sensing imagery is crucial for numerous applica- tions, yet existing methods face a stark trade-off between accuracy and efficiency . Although using V ision T ransformer (V iT) backbones for dense prediction is fast, they often ex- hibit poor perceptual quality . Conv ersely , diffusion models offer high fidelity b ut at a prohibiti ve computational cost. T o ov ercome these limitations, we propose D epth D etail D iffusion for R emote S ensing M onocular D epth E stimation ( D 3 -RSMDE), an efficient frame work designed to achie ve an optimal balance between speed and quality . Our framework first le verages a V iT -based module to rapidly generate a high- quality preliminary depth map construction, which serves as a structural prior, effecti vely replacing the time-consuming initial structure generation stage of diffusion models. Based on this prior , we propose a P rogressiv e L inear B lending R efinement (PLBR) strategy , which uses a lightweight U- Net to refine the details in only a fe w iterations. The en- tire refinement step operates efficiently in a compact latent space supported by a V ariational Autoencoder (V AE). Ex- tensiv e experiments demonstrate that D 3 -RSMDE achie ves a notable 11.85% reduction in the Learned Perceptual Image Patch Similarity (LPIPS) perceptual metric over leading mod- els like Marigold, while also achieving over a 40 × speedup in inference and maintaining VRAM usage comparable to lightweight V iT models. Introduction Real-time, high-fidelity monocular depth estimation from remote sensing images is a fundamental and critical task in computer vision, with profound implications across nu- merous domains such as autonomous UA V navigation and 3D terrain modeling. One prominent technical approach to this task inv olves dense prediction architectures employ- ing V iT backbones (Dosovitskiy et al. 2021), such as DPT (Ranftl, Bochkovskiy , and K oltun 2021) and AdaBins (Bhat, Alhashim, and W onka 2021). Although offering rapid in- * These authors contributed equally . † Corresponding author Copyright © 2026, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserved. Figure 1: The dif ference between D 3 -RSMDE and Marigold. Compared to the multiple denoising reconstruc- tions of Marigold, our D 3 -RSMDE firstly adopts efficient V iT to regression coarse depth map and then obtain fine- grained high-fidelity depth map with fewer denoising steps. ference, these models hav e inherent limitations in captur- ing high-frequency details. Recent studies suggest that V iTs act as low-pass filters, showing a strong tendency to learn global, low-frequency signals while neglecting fine textures (Park and Kim 2022; Liu et al. 2022). This low-pass filter- ing characteristic of V iTs often leads to perceptually inferior depth maps with blurry details, a deficiency quantifiable by high LPIPS scores (Zhang et al. 2018). Con versely , an alternativ e paradigm is dif fusion-based generativ e framew orks, such as Marigold (K e et al. 2024) and EcoDepth (Patni, Agarwal, and Arora 2024). These methods demonstrate remarkable fidelity , generating depth maps with fine-grained te xtures. This capability is especially useful for remote sensing applications, which often in volv e intricate surface details. Howe v er , their iterativ e refinement process is computationally intensi ve and ill-suited for real- time requirements. While con ventional acceleration strate- gies exist, such as optimizing samplers (Zhao et al. 2023; Lu et al. 2025; Xue et al. 2024) or employing model distillation (Liu et al. 2023; Luo et al. 2023; W ang et al. 2024), they typically require the pre-training of a large and resource- intensiv e base model or sacrifice generative quality for speed (Lu et al. 2022; Song et al. 2023), and the limited av ailabil- ity of lar ge-scale training data in the remote sensing domain further constrains the applicability of such distillation-based methods. Furthermore, the iterati ve nature of dif fusion mod- els inherently dedicates the initial, computationally expen- siv e steps to establishing lo w-frequency macrostructures be- fore refining high-frequency details (Hertz et al. 2022; Kar- ras et al. 2024). Consequently , these traditional acceleration methods, which speed up the entire process uniformly , fail to radically alter this inefficient w orkflow . T o in vestigate this performance bottleneck, we analyzed the depth estimation pipeline of an advanced dif fusion model, Marigold, on remote sensing imagery (as illustrated in Fig. 1). W e observed a critical phenomenon: during the entire inference process, which took nearly 14 seconds on an NVIDIA 3090 GPU, a majority of the timesteps (the early stage) were dedicated to establishing the macro-structure and coarse outline of the depth map. In contrast, only a few final steps were used for detail refinement. This insight suggests that the time-consuming initial structure-building phase could be ef fectiv ely replaced by a more efficient, non- diffusion model, thereby dramatically improving efficienc y while preserving high-fidelity details. Motiv ated by this observ ation, we introduce D 3 -RSMDE, a novel frame work designed to achiev e a dual optimiza- tion of speed and accuracy . First, we lev erage a fast V iT - based module, optimized with the Hierarchical Depth Nor- mal (HDN) (Zhang et al. 2022) loss function, to efficiently predict a high-quality coarse depth map, thereby completely supplanting the time-consuming initial stage of the diffusion process. Second, we design a lightweight diffusion refine- ment module that performs coarse-to-fine detail enhance- ment over a significantly shorter trajectory . The core of this module is our innovati v e PLBR strategy , which ensures both accuracy and efficienc y . In PLBR, at each refinement step, the model is conditioned on both the original coarse map and the output from the previous step, with their influences dy- namically attenuated. This pro vides a stable global structure reference while preventing excessiv e interference with detail synthesis, enabling controllable and precise reconstruction. Finally , to further accelerate this process for lar ge-scale re- mote sensing images, we incorporate a V ariational Autoen- coder (V AE) (Kingma, W elling et al. 2013), mapping the entire refinement operation into a compact latent space to drastically reduce computational ov erhead. In summary , our main contributions are as follo ws: • W e propose D 3 -RSMDE, specifically designed for ef fi- cient and high-fidelity monocular depth estimation from remote sensing imagery , obtaining o ver 40 × speedups compared to Marigold. • W e introduce an innov ati ve PLBR and le verage a V AE to operate in the latent space, significantly enhancing accu- racy and computational ef ficiency . • Through extensi ve experiments on fiv e datasets, we demonstrate that our method achie ves SO T A or second- best performance, while its efficiency is comparable to that of lightweight V iT -based models, ef fectiv ely resolv- ing the bottlenecks of existing technologies. Related W orks V iT -based Monocular Depth Estimation V iTs (Dosovitskiy et al. 2021) ha ve been widely adopted for MDE, owing to their powerful global feature extraction capabilities. This line of research has produced a series of models prioritizing efficienc y and global consistency . One of the early explorations in this domain was AdaBins (2021). This work uses T ransformer (V aswani et al. 2017) to reformulate depth re gression as a classification problem and significantly improved accuracy . Subsequently , DPT (2021) pioneered the use of the V iT architecture as an encoder back- bone, demonstrating its superiority o ver traditional CNNs in capturing global image context and laying a solid foundation for subsequent research. T o enhance model generalization across di verse scenes, Eftekhar et al. introduced Omnidata (2021), an innov ativ e parametric pipeline for sampling and rendering multi-task vision datasets from real-world 3D scans. Subsequent stud- ies further proposed the HDN loss function (2022), which enhances geometric consistenc y by enforcing constraints on surface normals at multiple scales. These methods collec- tiv ely form the foundation for the first component of our work: the rapid generation of a structural depth map prior . More recently , Depth Anything (Y ang et al. 2024), demonstrates exceptional zero-shot capabilities on general- purpose scenes. Howe ver , its performance fails to general- ize to the domain of remote sensing imagery . The power - ful depth priors learned from near-vie w perspectiv es are ill- suited for the unique top-down viewpoints, distinct geomet- ric properties, and the absence of conv entional depth cues found in remote sensing data. This domain gap underscores the necessity of de veloping specialized algorithms tailored for the unique challenges of monocular depth estimation in the remote sensing context. Diffusion-based Monocular Depth Estimation Diffusion models (Anderson and Akram 2024) ha ve opened new frontiers in high-quality depth map synthesis, with their core strength lying in unparalleled detail reco very and re- alism. ECoDepth (2024) fuses pretrained V iT embeddings with a diffusion model for monocular depth estimation: global semantic features are first e xtracted via V iT , then con- ditioned alongside the input image in the diffusion denois- ing process to produce depth maps, achie ving outstanding results on near-vie w scenes. At the same time, Marigold (2024) ingeniously repur- poses a pre-trained text-to-image dif fusion model (like Sta- ble Dif fusion) for zero-shot monocular depth estimation. By incorporating depth information into Gaussian noise, it can generate depth maps with remarkable realism and fine de- tail. These works demonstrate the potent potential of diffu- sion models for detail generation, they also highlight their inherent drawback of high computational cost, a core prob- lem our work aims to solve. Lev eraging diffusion models for refinement is a nascent trend in computer vision. Howe ver , existing approaches are largely ill-suited for efficient, continuous depth map re- finement: DDRM (Kawar et al. 2022) in image restoration aims to rev erse physical degradation, not correct neural net- work prediction ambiguity; SegRefiner (W ang et al. 2023) in segmentation tackles discrete labels instead of contin- uous v alues; DifFlow3D (Liu et al. 2024) predicts scene flow through DDIM-based iterative diffusion and achie ves strong performance, yet it is designed for irre gular point clouds and cannot be directly applied to monocular depth estimation in remote sensing; and DCTPose (Chen et al. 2024) in pose estimation refines sparse coordinates rather than depth maps. These fundamental dif ferences in task def- inition and data structure highlight a critical gap in monoc- ular depth estimation for a framew ork designed specifically for efficient, high-fidelity refinement of fine-grained remote- sensing depth maps, our proposed D 3 -RSMDE is precisely intended to fill this gap. V AE for Diffusion Models T o mitigate the immense computational expense of operat- ing directly in the high-dimensional pix el space, researchers hav e shifted to performing the diffusion process within a compact latent space. The theoretical foundation for this paradigm was laid by Kingma & W elling (Kingma, W elling et al. 2013) with the introduction of the V AE, which pio- neered the use of variational Bayesian methods to learn a mapping from data to a probabilistic latent space. Y ears later , Rombach et al. (Rombach et al. 2022) ap- plied this concept to generati ve models, proposing Latent Diffusion Models and designing the crucial AutoencoderKL (AEKL). This V AE, widely adopted by models like Sta- ble Diffusion, efficiently compresses images into a lo w- dimensional latent space, drastically reducing the computa- tional cost of the diffusion process and establishing it as a mainstream approach. Howe v er , the standard AEKL faces an optimization dilemma between “reconstruction” and “generation”: it must both ensure high-fidelity image reconstruction and provide a smooth, regularized latent space for the dif fusion U-Net. T o address this, v arious improv ements have been proposed. For example, V A V AE (Y ao, Y ang, and W ang 2025) demon- strates that by introducing a lightweight auxiliary decoder to exclusi vely handle the reconstruction loss, the primary de- coder can be freed to focus on generati ve quality . This de- coupled design, while retaining the AEKL backbone, sig- nificantly accelerates training and enhances final generation quality . The de velopment of these V AE technologies is the key underpinning that enables our design of a computation- ally feasible, lightweight diffusion refinement module. Method Overview The D 3 -RSMDE frame work is a hybrid architecture that ef- ficiently combines different paradigms for accurate monocu- lar depth estimation from remote sensing images. It first em- ploys a V iT -based module to quickly generate a structurally consistent coarse depth map, avoiding the slo w contour con- struction of traditional dif fusion methods. A lightweight dif- fusion module then refines this depth scene in a fe w steps in a compact latent space, producing a detailed depth output. Preliminary Scene Structuring The preliminary depth scene estimation module is designed to produce a globally consistent and structurally coher- ent initial depth map scene for subsequent refinement. It refers to the DPT model and employs a hybrid architec- ture that combines a V iT encoder with a con volution-based decoder . The encoder divides the input image into non- ov erlapping patches of size p × p , yielding N p = H W p 2 flattened tokens. Each token is linearly projected into a D - dimensional embedding space, augmented with learnable positional encodings and a global readout token. These to- kens { t 0 , t 1 , . . . , t N p } are processed by L layers of multi- head self-attention, excelling at long-range dependenc y modeling to ensure global structural consistency . The N p tokens are then reassembled into a feature map of shape H p × W p × D based on their original patch positions. A Resample layer adjusts the resolution using a 1 × 1 con- volution to map channel dimension to ˆ D , follo wed by either a strided 3 × 3 con volution for downsampling (if s ≥ p ) or a transposed 3 × 3 conv olution with stride p/s for upsampling (if s < p ). This reassembly and resampling process is per - formed at transformer layers { 3 , 6 , 9 , 12 } to extract multi- scale representations. These are subsequently fused in a top- down manner using a RefineNet-style decoder , where each stage doubles the spatial resolution and merges features hi- erarchically . The final feature map, at half the original input resolution, is passed to a task-specific output head to gener - ate the coarse depth map. T o supervise the model, we employ the HDN loss, which balances global structural consistency with local de- tail preservation. The HDN loss is defined as: L HDN = 1 M M X i =1 1 |U i | X u ∈U i N u i ( d i ) − N u i ( ˜ d i ) , where the normalized representations is giv en by: N u i ( d i ) = d i − median u i ( d ) 1 | u i | P | u i | j =1 | d i − median u i ( d ) | , median u i computes the median depth of locations, M is the total number of effecti ve pixels, i represents each pix el, U i denotes the set of multi-scale conte xts to which pixel i be- longs, d is the ground truth and ˜ d is the predicted depth map. These contexts are constructed using three strategies: spa- tial grid partitioning, depth-range se gmentation, and depth- quantile grouping. For each conte xt, a shared SSI module Figure 2: The framework of our D 3 -RSMDE. During the training process, V iT first performs regression on the input original remote sensing images x to obtain the coarse depth map construction d c , and then together with Ground Truth d 0 and the x , obtains the samples for training Refiner Diffusion through PLBR . In the inference process, the d 0 is replaced by the output of each step of Refiner Diffusion to obtain a refined and high-fidelity remote sensing depth estimation map. (Zhang et al. 2022) computes the MAE, and the errors are aggregated across conte xts and scales. Progr essiv e Detail Refinement Although the coarse depth map generated by the initial prediction module exhibits a low MAE, it scores poorly on LPIPS, appearing visually blurry and lacking in high- frequency details. T o address this, we designed a Dynamic Guided Dif fusion Refiner . This design departs from the con- ventional paradigm of Marko vian based dif fusion models (Benton et al. 2024) that reconstruct data from pure noise. Inspired by SegRefiner (W ang et al. 2023), we instead for- mulate a non-Markovian based coarse-to-fine refinement process. This mechanism ensures that the globally consis- tent structural information from the coarse depth map con- tinuously guides the entire refinement process. This module greatly shortens the process of diffusion to reconstruct depth map details from pure noise, which can efficiently recov er clear and realistic depth details with only a few iterations. Efficient Diffusion backbone. The core is a conditional diffusion denoising model f , tasked with predicting the latent representation of the refined depth map at a given timestep t . T o strike a balance between computational ef- ficiency and expressi ve po wer , our model operates entirely within a compact latent space defined by a pre-trained V AE. Compared to a con ventional Stable Dif fusion U-Net, our model e xcises modules that are superfluous for our depth map refinement task, such as text cross-attention and multi- source conditioning framew orks. This results in a signifi- cantly more lightweight architecture specialized for refining depth details from image and timestep information. The de- tailed Unet architecture can be found in Appendix A.4. Progr essive Linear Blending Refinement. Unlike tradi- tional dif fusion models that gradually transform data into pure Gaussian noise, we introduces a refiner-specific strat- egy called PLBR. This process is different from the tradi- tional diffusion strategy based on Mark ov . PLBR is based on a non-Markovian process, linearly interpolates between the high-quality ground truth depth map and a coarse depth map during training. During inference, this process is reversed through a Progressiv e Refinement procedure. The goal of the forward process is to generate training samples of varying “lev els of noise” for the model f . W e define two key inputs: the ground truth depth map d 0 and a coarse depth map d c generated by a DPT module. These in- puts are first encoded by the V AE into their respecti ve latent representations, z 0 and z c . W e design a dif fusion schedule coefficient: ¯ α t = ϵ T − 1 ( T − t − 1) , where t ∈ [0 , ..., T − 1] , ϵ is a positi ve constant that close to 1 but not equal to 1, ensuring that the coarse depth map’ s contribution is always present (In our experiment, ϵ = 0 . 8 ). The blended latent representation z t at any timestep t is gen- erated via the following linear interpolation formula: z t = ¯ α t z 0 + (1 − ¯ α t ) z c , This process simulates a continuous transition from fine to coarse. When t is small, ¯ α t is close to 1, and the primary component of z t is the ground truth z 0 . As t increases, ¯ α t decreases, and z t progressiv ely approaches the coarse repre- sentation z c . At the same time, the original remote sensing image x will also be used as the input of additional infor- mation concat into the model to provide more basic infor- mation. This strategy enables the model to learn how to re- cov er fine depth structures from inputs of v arying coarseness across the entire refinement trajectory . The inference is an iterati ve refinement process that aims to progressiv ely recover a high-quality depth map d 0 , start- ing from the coarse map d c . The process begins at t = T − 1 and proceeds backward to t = 0 . Model MAE ↓ δ 3 ↑ PSNR ↑ LPIPS ↓ J&K SA Med Swi Ast J&K SA Med Swi Ast J&K SA Med Swi Ast J&K SA Med Swi Ast Adabins 16.7 28.4 29.0 19.6 44.3 79.9 68.9 86.3 93.1 73.2 22.3 17.4 17.7 21.2 14.7 0.181 0.405 0.367 0.127 0.528 DPT 17.3 34.2 29.7 30.9 43.5 77.3 62.5 81.6 84.6 72.7 22.2 16.7 17.8 17.6 14.9 0.313 0.604 0.520 0.204 0.579 Omnidata 20.1 30.7 28.0 19.2 42.6 61.9 67.8 80.9 90.8 72.1 21.2 18.5 18.2 21.6 15.0 0.354 0.482 0.479 0.135 0.553 Pix2pix 24.5 39.3 39.4 38.9 44.3 68.9 55.1 72.0 76.8 69.3 18.6 15.2 15.1 15.5 14.3 0.450 0.485 0.434 0.775 0.937 Marigold 14.2 23.7 24.7 21.3 40.0 83.1 71.7 85.8 89.6 72.8 24.3 19.6 19.3 21.4 15.7 0.162 0.326 0.329 0.144 0.488 EcoDepth 26.4 49.0 49.0 37.4 43.3 65.7 49.4 67.4 77.9 69.9 17.9 13.3 13.2 16.0 14.5 0.461 0.428 0.563 0.265 0.702 D 3 -RSMDE (V A V AE) 13.6 21.7 23.4 14.1 41.7 79.1 70.0 85.9 93.3 67.8 23.7 20.1 20.0 24.2 15.1 0.203 0.366 0.301 0.107 0.574 D 3 -RSMDE (AEKL) 12.7 20.5 22.1 13.4 36.1 83.3 73.9 88.1 94.3 76.1 24.5 20.6 20.4 24.8 16.2 0.180 0.318 0.290 0.104 0.511 T able 1: Quantitati v e analysis of SO T A methods. The best result is highlighted in bold and the second best result is underlined. • First, we encode the initial coarse depth map d c into its latent representation z c and set it as the input for the first timestep, i.e., z T − 1 = z c . • At each timestep t , the f model receiv es the current input z t , the remote sensing image latent z x , and the timestep embedding e t , and predicts the final refined latent repre- sentation ˜ z 0 | t : ˜ z 0 | t = f ([ z x , z t ] , e t ) , • Then, we employ a nov el progressive refinement strat- egy to generate the input for the ne xt step z t − 1 . Unlike con ventional DDPMs, which rely on the previous state z t and the current prediction ˜ z 0 | t to estimate z t − 1 , our method directly blends the new prediction with the orig- inal coarse representation z c . This ensures that each re- finement step is anchored to the initial coarse structure, prev enting error accumulation, follo ws the update rule: z t − 1 = ¯ α t − 1 ˜ z 0 | t + (1 − ¯ α t − 1 ) z c , This iterativ e process continues until t = 0 , yielding the final latent representation ˜ z 0 | 1 . Finally , the V AE decoder transforms ˜ z 0 | 1 back into the pixel space to produce the final, refined depth map ˜ d 0 . Experiment Experimental Settings Benchmark and Metrics. In order to comprehensively ev aluate the performance of the model in different terrain, resolution, and dataset sizes, we chose 5 datasets from RS3DBench(W ang et al. 2025): Japan + K orea (2,650 pairs, coastal mountainous terrain, 30 m resolution, J&K), South- east Asia (7,000 pairs, plains and hills, 30 m resolution, SA), Mediterranean (29,225 pairs, desert and plateau, 30 m resolution, Med), Australia (1,249 pairs, plain, 5m res- olution, Ast), Switzerland (4,827 pairs, mountain, 2m res- olution, Swi). In order to better reflect human perception of depth map quality , in addition to traditional MAE, δ 3 and PSNR, etc., we also introduce LPIPS metric. LPIPS is a trained perceptual loss metric that uses the pre-trained AlexNet netw ork to calculate the structural and texture sim- ilarity between images to ev aluate the perceptual effect of image reconstruction or generation quality . A detailed de- scription of the metrics can be found in Appendix A.1. Implementation Details. W e release two model versions using AEKL (2022) and V A V AE (2025), respectiv ely . For reproducibility , the random seed for all experiments was fixed to 42. The initial prediction module was trained using the HDN loss with an initial learning rate (LR) of 5 × 10 − 5 and a weight decay of 10 − 4 . W e employed a LR sched- uler that reduces the LR by a factor of 0 . 6 upon a valida- tion loss plateau of 5 epochs. T o generate unbiased training and testing sets for the diffusion refiner, we performed 5-fold cross-validation on the outputs of the initial prediction mod- ule. The refiner was subsequently trained on these outputs using an L1 loss. The initial LR was set to 1 × 10 − 4 with T = 6 , ϵ = 0 . 8 and a similar LR scheduler (patience= 5 , factor= 0 . 5 ). Additional hyperparameter details are provided in the Appendix A.2. Baselines for Comparison T o comprehensiv ely bench- mark our D 3 -RSMDE model against existing technologies, we selected a series of baseline models that ha ve achie ved SO T A performance and are based on different mainstream architectural paradigms. • V iT Models : W e include DPT , Omnidata and AdaBins. These three models are representativ e works that lev er- age V iT for efficient monocular depth estimation. • Diffusion Models : W e compare against Marigold and EcoDepth. The y represent the cutting edge in high- fidelity depth synthesis using diffusion processes. • GAN-based Model : W e also include Pix2pix (Pana- giotou et al. 2020), a GAN-based model specifically op- timized for remote sensing monocular depth estimation. Quantitative Analysis The quantitativ e ev aluation results for all models are sum- marized in T able 1, with visual comparisons against repre- sentativ e models shown in Fig. 4. The results comprehen- siv ely demonstrate that our proposed D 3 -RSMDE frame- work achiev es SO T A or second-best performance across Configuration MAE ↓ RMSE ↓ δ 3 ↑ PSNR ↑ LPIPS ↓ J&K SA Med J&K SA Med J&K SA Med J&K SA Med J&K SA Med DPT (Baseline) 17.3 34.2 29.7 22.1 42.3 36.4 77.3 62.5 81.6 22.2 16.7 17.8 0.313 0.604 0.520 V iT Module Only 12.8 23.3 23.2 17.2 30.4 28.5 79.2 70.3 84.8 24.4 19.8 20.2 0.305 0.503 0.439 Full Model (w/o V AE, T=3) 13.0 22.1 22.9 17.2 28.6 28.0 83.1 72.2 86.2 24.3 20.1 20.3 0.222 0.361 0.335 Full Model (w/o V AE, T=6) 12.4 21.6 22.6 16.7 27.9 27.5 84.9 72.4 86.6 24.5 20.3 20.4 0.218 0.343 0.344 Full Model (w/o V AE, T=10) 13.5 23.0 24.5 17.6 29.2 29.5 82.5 69.3 85.0 24.1 19.8 19.9 0.239 0.365 0.365 Full Model (AEKL, T=3) 13.3 21.8 24.3 17.4 28.3 29.8 82.3 71.5 83.0 24.2 20.1 19.7 0.199 0.350 0.323 Full Model (AEKL, T=6) 12.7 20.5 22.1 16.9 26.6 27.1 83.3 73.9 88.1 24.5 20.6 20.4 0.180 0.318 0.290 Full Model (AEKL, T=10) 13.3 21.9 24.1 17.3 28.3 29.7 80.8 72.0 84.5 24.1 20.0 19.6 0.187 0.349 0.334 Full Model (V A V AE, T=3) 14.4 21.9 24.3 19.3 28.3 29.8 78.2 69.0 83.0 23.2 20.1 19.7 0.260 0.388 0.323 Full Model (V A V AE, T=6) 13.6 21.7 23.4 18.2 28.1 28.8 79.1 70.0 85.9 23.7 20.1 20.0 0.203 0.366 0.301 Full Model (V A V AE, T=10) 14.9 21.9 24.1 20.1 28.6 29.7 77.8 70.4 84.5 22.7 20.0 19.6 0.324 0.374 0.334 T able 2: Ablation study of D 3 -RSMDE. The best result is highlighted in bold and the second best result is underlined. Figure 3: Comparison of model efficienc y . the majority of metrics on all test datasets. Our framework significantly outperforms the GAN-based Pix2pix and the V iT -based Adabins, DPT , and Omnidata. More remarkably , ev en when compared against retrained Marigold, a model renowned for its high-fidelity synthesis, our D 3 -RSMDE achiev es a substantial relati ve impro vement of up to 13.50% in MAE and 11.85% in LPIPS, sho wcasing its exceptional ov erall performance. The general observ ation is that all diffusion-based models, e xcept the retrained EcoDepth, out- perform the LPIPS perception metric. This highlights the distinct advantage of the diffusion architecture for generat- ing photorealistic RSMDE. A detailed diagnostic analysis for the underperformance of EcoDepth, which is also a dif- fusion model, is provided in Appendix A.3. Efficiency Analysis T o comprehensi vely e v aluate the computational ef ficiency of our D 3 -RSMDE framework, we conducted a system- atic analysis of the average inference time per image, train- ing time per epoch while training Japan + K orea Dataset, maximum inference VRAM usage, and maximum training VRAM usage (with a batch size of 2). All experiments were performed on a consistent hardware/software platform (Ubuntu 16.04, Intel CPU E5-2699 v4, NVIDIA 3090 GPU, 125G memory , python3.10.6), with the results presented in Fig. 3, where D 3 -RSMDE shows its dif fusion module. Experimental data rev eals that our framew ork demon- strates a decisiv e advantage across all efficienc y metrics when compared to SO T A dif fusion methods like Marigold and EcoDepth. Most notably , D 3 -RSMDE achieves an in- ference speed ov er 40 times f aster than Marigold while also significantly reducing training time. In terms of resource consumption, both the training and inference memory foot- prints of our model are substantially lower than other dif fu- sion models. Furthermore, it is noteworthy that the VRAM of our model is on par with that of lightweight V iT -based model such as DPT and Omnidata at inference and training time. This result provides strong e vidence that D 3 -RSMDE successfully reduces computational overhead to a le vel com- parable to non-generativ e models, all while retaining the high-quality synthesis capabilities of diffusion models. Ablation Study In this section, we conduct a series of detailed ablation stud- ies to individually validate the effecti veness and efficienc y of the key components within our D 3 -RSMDE framew ork. The comprehensiv e results are summarized in T able 2. Effectiveness of the V iT Module. First, we compared the performance of our V iT Module against a standard DPT . As sho wn in T able 2, although our module is based on the DPT architecture, its optimization with the HDN loss func- tion leads to a significant improvement in the quality of the initial depth map. This provides a superior structural prior for the subsequent diffusion refinement, thereby effecti vely enhancing the final output accuracy . Efficiency of using V AE. Next, we e v aluated the role of performing refinement in the latent space using a V AE. The results indicate that, with the same number of denoising steps, the model variant with a V AE achie ves comparable accuracy to a variant that performs refinement directly in the pixel space. Howe ver , considering the efficienc y data from Fig. 3, we found that incorporating a V AE improv es training speed by 54.91% and reduces training VRAM by 36.17%. This provides strong e vidence that latent space dif fusion can Figure 4: Comparison of our D 3 -RSMDE and some SO T A methods in different categories of remote sensing images. dramatically enhance training efficienc y and lo wer the re- source threshold without compromising model performance. Impact of Denoising Steps. W e in vestig ated the impact of varying the number of denoising steps (T) on the final result. As shown in T able 2, the vast majority of those achieving the SO T A metric are concentrated in the models with step=6 without V AE and with AEKL. The performance of the model improves markedly as the number of steps increases from 3 to 6, suggesting that T=3 allows for an insufficient refinement process that does not fully le verage the model’ s detail reco very capabilities. Howe ver , when the steps are further increased to 10, performance slightly degrades. W e hypothesize that this is due to an “over -refinement” phe- nomenon. After several iterations, the intermediate result is already quite detailed. Excessi ve additional steps may cause the model to amplify minor noise or artifacts from the ini- tial prediction, or ev en to hallucinate spurious textures that are plausible according to its generati v e prior but not faithful to the source image. Therefore, T=6 represents the optimal trade-off between performance and ef ficienc y . Effectiveness of Diffusion Refinement. Finally , to vali- date the effecti veness of the diffusion module in our frame- work, we compared the full model against the results from the initial prediction module alone (V iT Module Only). The data rev eals that after diffusion refinement, the LPIPS score significantly decreased by 40.98%, 36.78%, and 33.94% on the J&K, SA, and Med datasets, respectiv ely . Meanwhile, it can also be seen from the Fig. 4 that D 3 -RSMDE out- puts more texture information than V iT Module. These evi- dences strongly prov e that our lightweight dif fusion module dramatically enhances the perceptual quality and visual clar- ity of the generated depth maps. Conclusion In conclusion, e ven though inferring depth information from a single remote sensing image remains difficult for both models and human eyes, our comprehensive experiments strongly demonstrate the effecti v eness and exceptional ef- ficiency of the proposed D³-RSMDE frame work. Our model achiev es accuracy comparable to, and in some cases surpass- ing, the SO T A Marigold, a model renowned for its high- fidelity synthesis. More significantly , D³-RSMDE represents a breakthrough in computational efficienc y . It uses PLBR strategy that provides a substantially accelerated training process and achieves an inference speedup of up to 40 times, all while maintaining a VRAM footprint on par with lightweight V iT -based architectures. Therefore, our work successfully addresses the critical trade-off between accu- racy and efficienc y , resolving the prohibitive computational bottleneck that has hindered the practical deployment of high-fidelity dif fusion-based models in the field of RSMDE. Acknowledgments This work was sponsored by National Natural Science Foun- dation of China (62576305), and the Fundamental Research Funds for the Central Univ ersities (No. 226-2025-00057). References Anderson, J.; and Akram, N. 2024. Denoising Diffu- sion Probabilistic Models (DDPM) Dynamics: Unraveling Change Detection in Ev olving Environments. Innovative Computer Sciences Journal , 10(1): 1–10. Benton, J.; Shi, Y .; De Bortoli, V .; Deligiannidis, G.; and Doucet, A. 2024. From denoising diffusions to denoising markov models. Journal of the Royal Statistical Society Se- ries B: Statistical Methodology , 86(2): 286–301. Bhat, S. F .; Alhashim, I.; and W onka, P . 2021. Adabins: Depth estimation using adapti ve bins. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , 4009–4018. Chen, Z.; Dai, J.; Pan, J.; and Zhou, F . 2024. Diffusion model with temporal constraint for 3D human pose estima- tion. The V isual Computer , 1–17. Dosovitskiy , A.; Beyer , L.; Kolesnik ov , A.; W eissenborn, D.; Zhai, X.; Unterthiner , T .; Dehghani, M.; Minderer , M.; Heigold, G.; Gelly , S.; Uszkoreit, J.; and Houlsby , N. 2021. An Image is W orth 16x16 W ords: T ransformers for Image Recognition at Scale. ICLR . Eftekhar , A.; Sax, A.; Malik, J.; and Zamir , A. 2021. Om- nidata: A scalable pipeline for making multi-task mid-le vel vision datasets from 3d scans. In Proceedings of the IEEE/CVF International Confer ence on Computer V ision , 10786–10796. Hertz, A.; Mokady , R.; T enenbaum, J.; Aberman, K.; Pritch, Y .; and Cohen-Or , D. 2022. Prompt-to-prompt im- age editing with cross attention control. arXiv preprint arXiv:2208.01626 . Karras, T .; Aittala, M.; Lehtinen, J.; Hellsten, J.; Aila, T .; and Laine, S. 2024. Analyzing and Improving the Train- ing Dynamics of Dif fusion Models. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 24174–24184. Kawar , B.; Elad, M.; Ermon, S.; and Song, J. 2022. De- noising dif fusion restoration models. Advances in neur al information pr ocessing systems , 35: 23593–23606. Ke, B.; Obukho v , A.; Huang, S.; Metzger, N.; Daudt, R. C.; and Schindler , K. 2024. Repurposing dif fusion-based image generators for monocular depth estimation. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , 9492–9502. Kingma, D. P .; W elling, M.; et al. 2013. Auto-encoding vari- ational bayes. Liu, J.; W ang, G.; Y e, W .; Jiang, C.; Han, J.; Liu, Z.; Zhang, G.; Du, D.; and W ang, H. 2024. DifFlow3D: T o ward Ro- bust Uncertainty-A ware Scene Flow Estimation with Iter- ativ e Dif fusion-Based Refinement. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 15109–15119. Liu, X.; Zhang, X.; Ma, J.; Peng, J.; et al. 2023. Instaflow: One step is enough for high-quality diffusion-based text-to- image generation. In The T welfth International Conference on Learning Representations . Liu, Z.; Mao, H.; W u, C.-Y .; Feichtenhofer , C.; Darrell, T .; and Xie, S. 2022. A convnet for the 2020s. In Proceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , 11976–11986. Lu, C.; Zhou, Y .; Bao, F .; Chen, J.; Li, C.; and Zhu, J. 2022. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in neural in- formation pr ocessing systems , 35: 5775–5787. Lu, C.; Zhou, Y .; Bao, F .; Chen, J.; Li, C.; and Zhu, J. 2025. Dpm-solver++: F ast solver for guided sampling of dif fusion probabilistic models. Machine Intelligence Resear ch , 1–22. Luo, S.; T an, Y .; Huang, L.; Li, J.; and Zhao, H. 2023. Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference. Panagiotou, E.; Chochlakis, G.; Grammatikopoulos, L.; and Charou, E. 2020. Generating ele v ation surf ace from a single RGB remotely sensed image using deep learning. Remote Sensing , 12(12): 2002. Park, N.; and Kim, S. 2022. How Do V ision Transformers W ork? Patni, S.; Agarwal, A.; and Arora, C. 2024. Ecodepth: Effec- tiv e conditioning of diffusion models for monocular depth estimation. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 28285–28295. Ranftl, R.; Bochkovskiy , A.; and K oltun, V . 2021. V i- sion transformers for dense prediction. In Proceedings of the IEEE/CVF international confer ence on computer vision , 12179–12188. Rombach, R.; Blattmann, A.; Lorenz, D.; Esser , P .; and Om- mer , B. 2022. High-resolution image synthesis with latent diffusion models. In Pr oceedings of the IEEE/CVF confer- ence on computer vision and pattern reco gnition , 10684– 10695. Song, Y .; Dhariwal, P .; Chen, M.; and Sutske ver , I. 2023. Consistency models. V aswani, A.; Shazeer, N.; Parmar , N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser , L. u.; and Polosukhin, I. 2017. Attention is All you Need. In Guyon, I.; Luxburg, U. V .; Bengio, S.; W allach, H.; Fer gus, R.; V ishwanathan, S.; and Garnett, R., eds., Advances in Neural Information Pr ocess- ing Systems , v olume 30. Curran Associates, Inc. W ang, J.; W ang, R.; Song, J.; Zhang, H.; Song, M.; Feng, Z.; and Sun, L. 2025. RS3DBench: A Comprehensive Bench- mark for 3D Spatial Perception in Remote Sensing. arXiv pr eprint arXiv:2509.18897 . W ang, M.; Ding, H.; Liew , J. H.; Liu, J.; Zhao, Y .; and W ei, Y . 2023. Se gRefiner: T o wards Model-Agnostic Seg- mentation Refinement with Discrete Dif fusion Process. In NeurIPS . W ang, Y .; Cheng, L.; Duan, M.; W ang, Y .; Feng, Z.; and K ong, S. 2024. Improving knowledge distillation via regu- larizing feature direction and norm. In Eur opean Conference on Computer V ision , 20–37. Springer . Xue, S.; Liu, Z.; Chen, F .; Zhang, S.; Hu, T .; Xie, E.; and Li, Z. 2024. Accelerating diffusion sampling with optimized time steps. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 8292–8301. Y ang, L.; Kang, B.; Huang, Z.; Xu, X.; Feng, J.; and Zhao, H. 2024. Depth anything: Unleashing the power of large- scale unlabeled data. In Pr oceedings of the IEEE/CVF con- fer ence on computer vision and pattern reco gnition , 10371– 10381. Y ao, J.; Y ang, B.; and W ang, X. 2025. Reconstruction vs. generation: T aming optimization dilemma in latent diffusion models. In Pr oceedings of the Computer V ision and P attern Recognition Conference , 15703–15712. Zhang, C.; Y in, W .; W ang, Z.; Y u, G.; Fu, B.; and Shen, C. 2022. Hierarchical Normalization for Robust Monocular Depth Estimation. NeurIPS . Zhang, R.; Isola, P .; Efros, A. A.; Shechtman, E.; and W ang, O. 2018. The unreasonable effecti v eness of deep features as a perceptual metric. In Proceedings of the IEEE confer ence on computer vision and pattern r ecognition , 586–595. Zhao, W .; Bai, L.; Rao, Y .; Zhou, J.; and Lu, J. 2023. Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. Advances in Neural Information Pr ocess- ing Systems , 36: 49842–49869.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment