Beyond Grading Accuracy: Exploring Alignment of TAs and LLMs
In this paper, we investigate the potential of open-source Large Language Models (LLMs) for grading Unified Modeling Language (UML) class diagrams. In contrast to existing work, which primarily evaluates proprietary LLMs, we focus on non-proprietary …
Authors: Matthijs Jansen op de Haar, Nacir Bouali, Faizan Ahmed
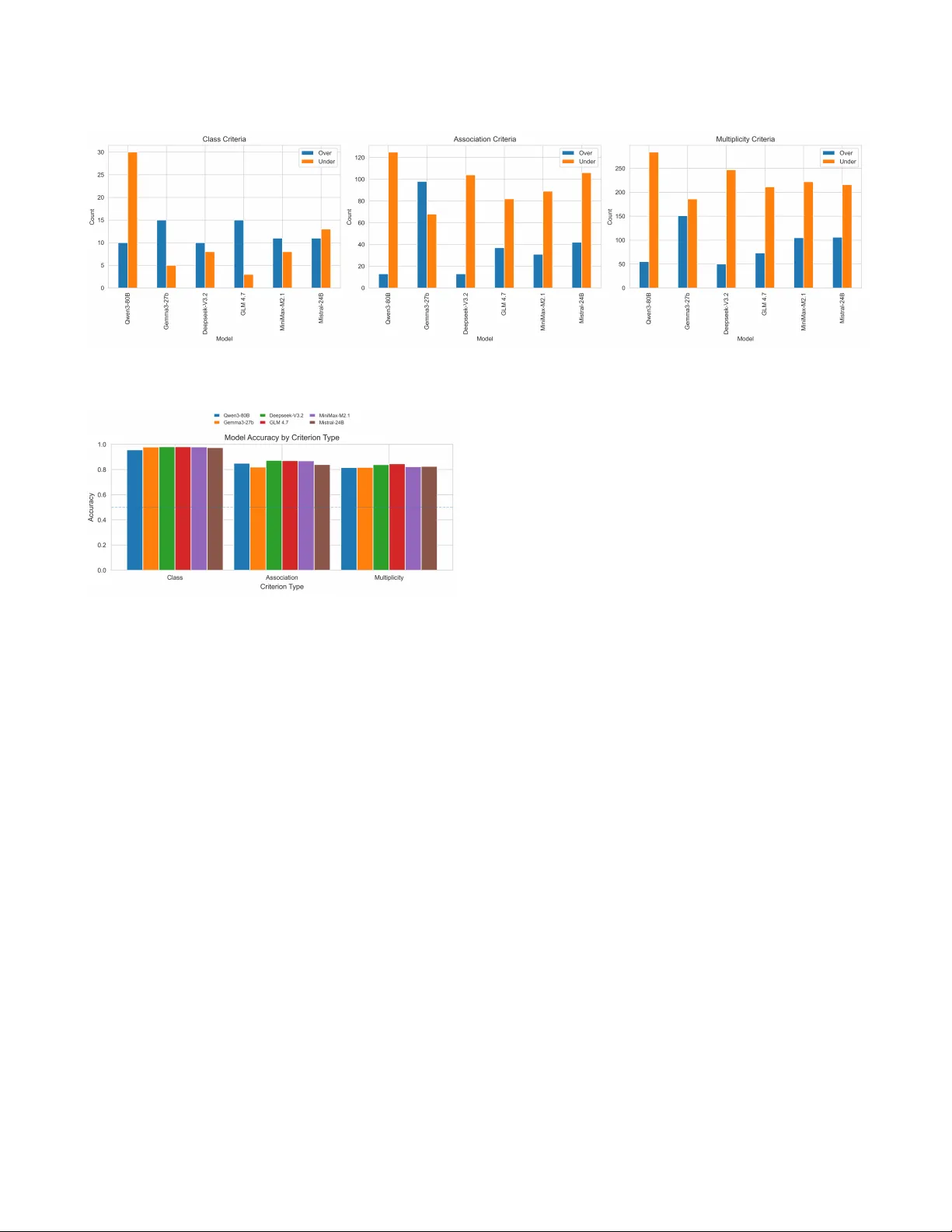
Bey ond Grading Accuracy: Exploring Alignment of T As and LLMs Matthijs Jansen op de Haar University of T wente The Netherlands Nacir Bouali University of T wente The Netherlands Faizan Ahmed University of T wente The Netherlands Figure 1: Overview of our parsing pipeline. The grading output of a class diagram ( JSON + PNG ) is produced by a student and evaluated thr ough two paths: (1) T eaching Assistants manually grade the class diagrams using a grading rubric and standardized output criteria and (2) Large Language Models get inputted a prompt that includes a natural language description of the student’s diagram that is parsed from a JSON le. Additionally , the prompt includes the grading rubric and desired output format. Finally , both of these outputs are compared and the dierence in the grades per criteria are then shown through several performance metrics. Abstract In this paper , we investigate the potential of open-source Large Language Models (LLMs) for grading Unied Modeling Language (UML) class diagrams. In contrast to existing work, which primarily evaluates proprietary LLMs, we focus on non-proprietary models, making our approach suitable for universities where transparency and cost are critical. Additionally , existing studies assess perfor- mance over complete diagrams rather than individual criteria, oer- ing limited insight into how automated grading aligns with human evaluation. T o address these gaps, we pr opose a grading pipeline in which student-generated UML class diagrams are independently evaluated by both teaching assistants (T As) and LLMs. Grades are then com- pared at the lev el of individual criteria. W e evaluate this pipeline through a quantitative study of 92 UML class diagrams from a software design course, comparing T A grades against assessments produced by six popular open-source LLMs. Performance is mea- sured across individual criterion, highlighting ar eas where LLMs diverge from human graders. Our results sho w per-criterion accu- racy of up to 88.56% and a Pearson correlation coecient of up to 0.78, representing a substantial impr ovement ov er previous w ork while using only open-source models. W e also explore the concept of an optimal model that combines the b est-performing LLM per criterion. This optimal model achieves performance close to that of a T A, suggesting a p ossible path toward a mixed-initiative grading system. Our ndings demonstrate that open-source LLMs can eec- tively support UML class diagram grading by explicitly identifying grading alignment. The proposed pipeline provides a practical ap- proach to manage increasing assessment workloads with growing student counts. CCS Concepts • Applied computing → Education ; Computer-assisted instruc- tion . Ke ywords AI- Assisted Grading, Autograding, T eaching Assistant, Large Lan- guage Mo dels, UML, Class Diagram, JSON, GPT , Llama, Claude, Gemini 1 Introduction Recent years hav e seen a steady increase in the number of Computer Science students within universities [ 20 ], resulting in logistical di- culties with assessments. Traditionally , univ ersities have addressed these challenges by employing T As. However , the drastic rise in student numbers has signicantly increased T A workloads. Addi- tionally , limitations related to cost and grading consistency can jeopardize the quality of education [1]. Existing research highlights clear b enets of automated grad- ing, including increased scalability , faster feedback, and reduced Mahijs Jansen op de Haar, Nacir Bouali, and Faizan Ahmed costs [ 2 , 5 , 6 , 16 ]. Nevertheless, pro viding high-quality automated grading for complex tasks such as UML class diagrams r emains non- trivial and requires substantial development eort [ 4 ]. At the same time, prior work emphasizes the importance of human-in-the-loop approaches, as fully automated systems may compromise fairness, reliability , and transparency [ 14 , 23 ]. In the context of assessment, this involves integrating a T A directly into the grading pip eline. One such approach is a mixed-initiative system [ 12 ], which enables interaction between a TA and a software agent such as an LLM. T o support these approaches, the capabilities of such agents must be carefully evaluated, and brought up to an adequate standard. In this work, we build up on prior research by Bouali et al. [ 6 ] which proposes an LLM-based grading pipeline for UML class dia- grams using JSON representations. While their results ar e promis- ing, the authors identify limitations related to parsing student out- put and the suitability for a proper human-in-the-loop approach. Moreover , the evaluation focuses purely on diagram-level accu- racy rather than individual grading criteria, which limits insight into the true performance of the pipeline as students may require per-criteria feedback. The analysis of LLMs additionally primarily focuses on proprietary models, which are not always feasible for universities, as data sensitivity and cost are a primary concern. W e address these limitations by improving the existing pipeline and advancing the performance and transparency of the LLM grad- ing agent. Furthermore, we conduct a per-criteria analysis across multiple open source LLMs over 92 diagrams to better assess their suitability for future human-in-the-loop usage. 2 Background Generative AI has recently emerged as an opportunity to enhance education, particularly by enabling the generation of detailed and personalized feedback. Such feedback has long been dicult to pro- vide at scale due to increasing student numbers and the substantial time required for manual assessment. With the emergence of large language models, several studies have explored leveraging their language capabilities to generate human-understandable feedback for students. However , these approaches introduce limitations and risks, which existing resear ch suggests can be mitigated through the inclusion of a human-in-the-loop [19]. A utomated feedback systems have a long history , dating back to early Intelligent T utoring Systems developed in the 1970 [ 8 ]. Within software engine ering e ducation, the majority of such systems focus on programming tasks. These traditional systems typically rely on hard-coded feedback patterns or rule-based architectures, which limits their adaptability and p edagogical expressiveness [ 13 , 15 ]. T opics that involve subjective judgment require considerable eort to assess and often necessitate the involvement of more experienced teaching sta ov er teaching assistants [ 1 , 11 ]. In software engine er- ing curricula, modeling and system design are a core topic, with UML serving as a widely adopted standard [ 3 ]. UML modeling is inherently subjective, and individual case studies frequently admit multiple equally valid solutions [ 6 ]. Prior work identies four main challenges in the automated assessment of UML class diagrams [ 5 , 6 ]. (1) Lexical and syntactic variation makes it dicult for tra- ditional systems to distinguish between semantic dierences and supercial deviations, such as naming or spelling. (2) The subjective nature of modeling leads to large solution spaces that cannot b e exhaustively encoded, as multiple design choices may be equally valid [ 10 ]. (3) A utomated systems often struggle to distinguish be- tween correctness and completeness, resulting in o ver penalization of partially correct solutions. (4) V ariation in diagram organization and notation complicates normalization and fair comparison across student submissions. Early approaches to automated UML grading primarily relied on rule-based or heuristic-driven systems [ 7 , 9 ]. These systems typically perform structured matching between a student solution and a reference mo del, [ 3 ] diering mainly in how they address semantic variation and partial correctness [ 21 ]. Rather than match- ing, machine learning approaches instead use historical grading data to predict scores, oering greater exibility in template cre- ation. However , due to the subjectivity of modeling tasks, such approaches often under perform compared to rule-based systems in practical grading scenarios [ 21 ]. Their eectiveness can be im- proved by incorporating structural similarity measur es [ 3 ]. Large language models present new opportunities to address these chal- lenges through their advanced language understanding capabilities. In addition, their ability to process multiple data modalities oers further potential to improve grading accuracy . As a result, their application to automated grading and feedback generation has re- ceived growing attention, both for programming tasks [ 17 ] and for modeling exercises such as UML class diagrams [6]. 3 Methodology This section describes the assumptions underlying the evaluation and grading pipeline shown in Figure 1. The goal of this study is to evaluate the alignment between per-criterion grades produced by dierent LLMs and those assigned by teaching assistants. While T A grades do not represent an absolute ground truth, as grading is subject to interpretation and error [ 1 ], they still provide valu- able insights. As noted, this work extends the system proposed by Bouali et al. (2025) [ 6 ]. As such, to ensure comparability , the same dataset, output format and grading rubric were used, with only minor adjustments to the prompt. 3.1 Student-generated Diagrams The pipeline starts with student generated UML class diagrams. In total, 92 diagrams were collected from rst-year bachelor students during an examination on a software design course. The exam covers dierent UML diagrams such as activity , use-case, state machine, sequence, and class diagrams and they are provided 90 minutes to complete the exam. The class diagram question is based on a written case describing a ctional company , in this case an electricity supplier , for which students are required to mo del a correct UML class diagram. Each diagram is made with an in-house tool, U TML 1 , which is capable of producing both JSON and PNG output. Students are required to submit both les. 3.2 T eaching Assistant Grading A grading rubric was dened base d on the exam, consisting of criteria that assess students’ understanding of UML class diagram elements such as classes, associations, and multiplicities. The 92 1 https://utml.apps.utwente.nl/ Beyond Grading Accuracy: Exploring Alignment of TA s and LLMs T able 1: Sample of grading criteria for teaching assistants Correction Criterion Points Class: Charging Station 0 to 1 pt Class: Charging Port 0 to 1 pt Association: Charging Station has Charging Ports 0 to 1 pt Multiplicity: Charging Port belongs to one Charging Station 0 to 1 pt [...] diagrams were divided among three teaching assistants, who coor- dinated before and during the grading process to ensure consistent interpretation of the criteria. In total, 40 criteria were dened, each scored with 0, 0.5, or 1 point. A subset of these criteria is shown in T able 1. During grading, T As relied on the submitted PNG les to visually inspect the diagrams and assign scores according to the rubric. Scores were recorded in a standardized format. All T As had previously completed the course and taken the exam themselves. The steps T As take are outlined in the lower half of gure 1. 3.3 Large Language Mo del Grading The upper half of Figure 1 illustrates the steps p erformed by the evaluated LLMs. The grading process consists of three stages: (1) parsing, (2) prompting, and (3) comparison. T o ensure reproducibil- ity , all LLMs were evaluated with a temperature setting of zero, resulting in deterministic outputs. The evaluated LLMs were chosen based on their popularity , viability in terms of cost and open source nature. 3.3.1 Parsing. The rst stage of the pipeline is a parser imple- mented in Python that converts the student-generated JSON le into a natural language representation suitable for inclusion in an LLM prompt. The JSON structure enco des classes as ClassNode objects, with class names stored in the text eld. Associations are represented using lab els, where startLabel and endLabel contain multiplicities and middleLabel contains the association name. Although parsing may appear straightforward, student inter- action with the modeling software introduces se veral challenges. Students are able to freely position labels, which often results in multiplicities and association names being placed in incorrect elds. In the system proposed by Bouali et al. (2025) [ 6 ], parsing assumes correct diagram construction, which does not consistently hold in practice. Additional issues arise fr om non-standard multiplicity representations, such as the use of te xtual descriptions instead of symbolic notation, as well as extraneous whitespace or text. The impro ved parser addresses these issues by independently in- specting all labels for valid multiplicities, including numeric values, the star symbol (i.e. * or ’many’), and written numbers. Detected multiplicities are then matched to the most likely associated class based on node identiers and the contents of dierent elds. For example, if a multiplicity is placed in the middle label rather than the start label, the parser corr ects this during conversion to natural language. One remaining limitation concerns manually added free text, which cannot be reliably associate d with a specic relationship using the available JSON information. T o mitigate this, a new ver- sion of the modeling software is required. This iteration has since been introduced, but was not considered in the evaluation. As the system proposed by Bouali et al. (2025) [ 6 ] does not account for this, making it dicult to attribute performance to the improvements in the parser . 3.3.2 Prompting. The natural language representation pr oduced by the parser is emb edded into a prompt provided to the LLM. The prompt is identical to that of Bouali et al. (2025) [ 6 ], with two key modications aimed at improving performance and transparency . Instructing the LLM to provide clarication. A key design con- straint when impr oving the pipeline was ensuring its suitability for a future human-in-the-loop system, and more specically a mixed- initiative system [ 12 ]. In such a setting, both the T A and the LLM participate in an iterative grading process. For this to be eective, the T A must be able to interpret and evaluate the grading decisions produced by the LLM. Instructing the LLM to provide clarication for each grading criterion therefore improves transparency and supports iterative renement. Interestingly , in our experiments, this addition also resulted in improved grading performance. Removal of total points in the answer format. As outlined by Bouali et al. (2025) [ 6 ], the previous pr ompt contained an instruction for the LLM to compute a total score. These scores would fr equently be incorrect, making them unreliable. Instead, scores are aggregated externally by summing the per criterion results. 3.3.3 Comparison. In the nal stage, grades produced by the LLM and the T As are compared using several metrics. These include per-criterion accuracy for each diagram, Pearson’s correlation co- ecient, and the mean absolute error . These metrics are use d to assess the suitability of LLM-based grading for UML class diagrams. Beyond evaluation, this comparison enables a human-in-the-loop setting, and more specically a mixed-initiative workow . Grading can be iteratively rened through two use cases: (1) a T A revie ws and adjusts their grading based on LLM feedback, and (2) a T A uses the LLM’s grading as an initial baseline. These congurations can also be chained across multiple iterations. 4 Findings W e evaluate the performance of the six LLMs against T As in grading 92 student-generated class diagrams. The evaluation was based on a 40-point rubric covering class identication, associations, and mul- tiplicity constraints. Our ndings indicate that while LLMs achieve high overall accuracy (85–89%), they exhibit systematic diculties with complex relationships and specic cardinality constraints. 4.1 Aggregate Accuracy and Correlation As shown in T able 2, GLM 4.7 demonstrated the strongest perfor- mance at the sum (total grade) level, achieving the highest correla- tion with T A scores ( 𝜌 = 0 . 798 ) and the lowest Mean Absolute Error (MAE = 3.22). These results indicate that current op en-source mod- els have reached performance parity with benchmarks established in previous research, where proprietary models such as GPT o1- mini and Claude Sonnet achie ved correlation coecients ab ove 0.76 and MAEs below 4 points on a similar 40-point scale [ 6 ]. Notably , four of the six open-source models evaluated in this study (GLM 4.7, Deepseek- V3.2, Mistral-24B, and MiniMax-M2.1) met or exceeded this 0.76 correlation threshold. W e also observe that most models performed better at the sum level than at the individual criterion Mahijs Jansen op de Haar, Nacir Bouali, and Faizan Ahmed T able 2: T otal Score Comparison (N=92 Diagrams) Model Pearson ( 𝑟 ) MAE (pts) GLM 4.7 0.798 3.22 Mistral-24B 0.775 3.32 Deepseek- V3.2 0.778 3.66 MiniMax-M2.1 0.761 3.55 Gemma3-27b 0.737 3.48 Qwen3-80B 0.719 4.37 level. This suggests that localized grading errors, which often man- ifest as a slight negative bias, tend to cancel each other out when aggregated, leading to a highly reliable nal score that matches the quality of both human assessors and high-tier proprietary mo dels. 4.2 Grading Bias When evaluating student work, the models tested generally tende d to assign lower grades than T As, showing a consistent harshness bias . Figure 2 sho ws that Q wen3-80B was most pr one to this, assign- ing grades signicantly lower than the T As with a mean dierence of − 0 . 087 . For every instance of a higher grade, there were 5.6 in- stances of a lower grade for this model. This negative bias was also evident in Deepseek- V3.2 ( − 0 . 067 ) and GLM 4.7 ( − 0 . 045 ), de- spite the latter achieving the highest overall accuracy of 88.56%. Gemma3-27b was the notable exception, showing a more balanced approach with a negligible bias of − 0 . 007 and similar rates of both higher and lower grades compared to T A evaluations. 4.3 Per-criterion Analysis The models were tested on 3,680 (i.e . 40 criterion over 92 diagrams) examples to see how well they could grade dierent concepts in UML diagrams. Overall, as shown in Figure 3, the mo dels were highly accurate , achieving results b etween 85% and 89%. They were most accurate at identifying classes, such as “User” or “Charging Station” (97.5% accuracy). A ccuracy decreased when assessing asso- ciations between classes (84.7%) and was lowest with multiplicities, specically , understanding complex relationships (82.7%). Grading accuracy also dropped when evaluating elements introduced later in the problem or those involving multiple connected relationships, falling as low as 55.1%. A detaile d examination of the ve most problematic criteria, specically those related to the “Maintenance Op erator” and com- plex relationship chains, reveals a signicant performance gap driven by divergent model biases. For the most dicult items, such as Criterion 39 (Multiplicity) and Criterion 38 (Association), the majority of models exhibited a severe under-grading bias. Notably , Qwen3-80B and Mistral-24B frequently failed to award points that T As de emed correct, with negative biases reaching as high as -0.250. In contrast, Gemma3-27b acted as a notable outlier by consis- tently over-grading these same items. For Criterion 19, Gemma’s tendency to be lenient resulted in a low accuracy of 46.7%, as it awarded points where T As did not. Acr oss these edge cases, GLM 4.7 proved to be the most robust mo del, maintaining the closest alignment with the T A average scores, such as a minimal bias of -0.011 on Criterion 39. These results indicate that while overall performance is strong, sp ecic architectural or attention-based lim- itations cause most models to default to harsh grading on complex criteria, whereas models like Gemma may fail through excessive leniency . 4.4 High-Error Criteria and Contextual W eaknesses Analyzing the most dicult criteria for the models, sp ecically the ten criteria with the lowest agreement scores, revealed three consistent problem areas that identify the current limits of LLM performance in UML grading: (1) Entities Introduced Later in the Problem (Contextual Neglect): Entities describe d at the end of the problem de- scription, such as the “Maintenance Operator” class, prov ed challenging for the models. Criteria 38–40, which focus on this entity , yielded the lowest accuracy across the dataset, ranging from 55% to 60%. This suggests a potential limita- tion in long-context attention or a “recency eect” where entities buried deep in narrative constraints are less likely to be correctly associated with the overall structure. (2) Deep Structural Dependencies (3-hop Relationships): Models struggled with criteria requiring them to follow logic through a chain of three or mor e connected entities (e.g., “Charging Port” to “Session” to “T ransaction”). Accu- racy for these multi-step logical paths (Criteria 19 and 21) hovered between 81% and 82%. While signicantly higher than the late-entity errors, this gap indicates that while LLMs excel at dir ect associations, their reliability decreases as the complexity of the relational path increases. (3) Multiplicity and Cardinality Constraints: Statistical analysis identied Multiplicity (Criteria 22–31) as the most dicult categor y overall. Criterion 31, in particular , saw agreement rates drop to 65.6%. Unlike class identication, which is binar y (presence vs. absence), multiplicities require parsing spe cic numerical constraints (e.g., 1.. * , 0..1) and mapping them to specic relationship ends. The models frequently applied a stricter or more literal interpr etation of the rubric than T As, leading to the “harshness bias” ob- served in the total scores. These weaknesses provide a clear roadmap for the proposed human-in-the-loop , and more specically mixe d-initiative , pipeline. Rather than requiring T As to review all 40 criteria, the system can automatically ag these high-error categories, specically late- appearing entities and multiplicity constraints, for human verica- tion, while condently automating the grading of basic structural elements. While at the same time providing feedback on grades assigned by T As. 5 Discussion The results of this study demonstrate that open source LLMs have reached a level of pr ociency that allows for high-accuracy auto- mated assessment of UML class diagrams. With overall accuracies ranging from 85% to 89%, these models show potential for sig- nicant workload reduction in large-scale software engineering courses. A dditionally , the study shows that open-source models are Beyond Grading Accuracy: Exploring Alignment of TA s and LLMs Figure 2: Error Distribution: O ver-grade vs Under-grade Figure 3: Model Accuracy per Criterion T ype already at such a level that they can be used in a human-in-the-loop and mixed-initiative system. 5.1 Model Comparisons and the “Compensation Eect” While the preliminary study fo cused on proprietary models like GPT o1-mini and Claude, our expanded analysis identies GLM 4.7 as the state-of-the-art performer for this task, achieving the highest total score correlation ( 𝑟 = 0 . 798 ). A key nding is the emergence of a “compensation eect” at the aggregate level. As detaile d in Section 4, most models (four out of six) performed better when evaluating the total score than when assessing individual criteria. This suggests that while LLMs may fail to parse spe cic, isolated structural tokens or logical points, they often maintain a correct holistic understanding of the student’s design. In these instances, errors tend to cancel out rather than comp ound. For educators, this implies that while LLM-generated total scores are reliable for broad performance tracking, individual criterion feedback still requires human oversight to ensure specic student misconceptions are not overlooked. 5.2 Structural vs. Logical Prociency A clear hierarchy of diculty emerged across all tested models. The near-perfect performance in Class Identication (97.5% accuracy ) conrms that LLMs are excellent at entity e xtraction. Howev er , the 15% performance drop-o for Multiplicity constraints (82.7%) highlights a fundamental gap between visual parsing and logical inference . Multiplicities require the model to not only identify ob- jects but to understand the mathematical constraints of the domain logic. This suggests that the boundar y for a mixe d-initiative system should be drawn here: LLMs can handle the "b ookkeeping" of entity existence, while T As should focus on the "logic" of relationships. 5.3 Positional and Complexity Bias The data suggests two primar y challenges to LLM grading accuracy: (1) Attention and Positional Bias: The “Maintenance Opera- tor” criteria (38–40) were consistently the lowest-performing items (55–60% accuracy). Since this entity was introduced at the end of the problem description, this may indicate a posi- tional bias where the model’s attention or context-window processing degrades for late-mentioned requirements. (2) Relationship Tracing: Accuracy was signicantly lo wer for items involving 3-hop relationship chains (e .g., Port → Session → Transaction). Models struggle to trace complex paths through the diagram’s logic, leading to a higher rate of false negatives. 5.4 Systematic Under-grading and Calibration The systematic under-grading bias obser ved in ve out of six mod- els (most notably Qwen3-80B with a 5.6:1 harshness ratio) has signicant implications for student trust . If students p erceive the LLM as "unfairly strict, " the perceived legitimacy of the automated system may decrease. While a +5% score adjustment could ser ve as a temporary calibration, the more robust solution is for our pro- posed mixed-initiative workow , where the LLM scores are treated as suggestions that must be veried by a T A b efore a nal grade is released. Alternatively , the opposite can hold, where an LLM can verify and make suggestions based on scores assigned by a T A. 5.5 Implications for Mixe d-Initiative Grading Although LLMs achieve high o verall accuracy , a fully automated grading system is not sucient for high-stakes assessment due to persistent logical and positional biases. Instead, the ndings sup- port the use of an integrated human-in-the-loop , and more spe ci- cally a mixed-initiative worko w in which automated grading is Mahijs Jansen op de Haar, Nacir Bouali, and Faizan Ahmed combined with targeted human super vison. In particular a mixed- initiative visual analytics system can provide such benets, as also outlined in a recent design space by Stähle et al. [22]. Within this workow , the LLM is primarily responsible for eval- uating rubric components that show high agreement and low am- biguity . In particular , for class identication , LLMs achieve an agreement rate of 97.5%, allowing approximately 40% of the rubric to b e grade d consistently without human inter vention. Delegat- ing these structurally straightfor ward, text-based criteria to the LLM substantially reduces grading eort. In contrast, multiplicity constraints and complex relationship chains require contin- ued human assessment. Agreement for these criteria is remarkably lower ( e.g., 65.6% for Criterion 31), r eecting the need for domain knowledge and logical interpretation to infer student intent b eyond what is explicitly expressed in diagram syntax. The mixed-initiative workow also mitigates the systematic harshness bias identied in Section 4. Models such as Qwen3-80B exhibit a pronounced tendency toward under-grading, with a skew of appr oximately 5.6:1. T o address this, the LLM produces a prelimi- nary rubric evaluation accompanie d by its reasoning. The teaching assistant then revie ws the de ductions, focusing on criteria involving indirect associations, ordering eects, or late-intr oduced entities, where model errors are most frequent. This division of labor reduces the risk of penalizing students for limitations in model interpreta- tion while preserving the eciency and consistency of automated feedback. Alternatively , T As could use the feedback generated by LLMs to verify their grades as dierences would be highlighted. As a result, grading shifts from a fully manual process to a focuse d verication task, impro ving scalability without compromising as- sessment fairness. This work establishes a clear roadmap towards designing such a mixed-initiative system in the future. 5.6 Model Size and Deployment Constraints In addition to accuracy dierences discusse d above, practical de- ployment for local grading systems is strongly inuenced by GP U memory and context scaling. Peak GP U memor y usage includes both quantized model weights and the Key– V alue (K V) cache re- quired for long-context auto regressive inference; K V cache memory grows approximately linearly with the maximum context length and key architectural parameters, and can be estimated as 𝑀 𝑒𝑚𝑜 𝑟 𝑦 𝐾𝑉 = 2 · 𝐵 · 𝑛 𝑙 · 𝑛 𝑘 𝑣 · 𝑑 ℎ · 𝐿 · 𝐵𝑦𝑡 𝑒 𝑠 𝑝 , (1) where 𝐵 is the number of parallel requests, 𝑛 𝑙 the number of trans- former layers, 𝑛 𝑘 𝑣 the number of key–value heads, 𝑑 ℎ the head dimension, 𝐿 the context window size, and 𝐵𝑦𝑡 𝑒 𝑠 𝑝 the storage pre- cision. This linear scaling b ehavior is well established in prior w ork on transformer inference and motivates recent eorts to reduce or ooad KV cache memor y for long-context models [ 18 ]. Architec- tural optimizations that reduce KV cache size, such as grouped or latent attention, can therefore realistically aect deployability . Open-weight dense models in the 24B–30B class (e .g., Mistral- 24B, Qwen3-27B) are generally feasible on a single high-end con- sumer GP U with 24–32,GB of VRAM when using 4-bit quantize d weights plus headroom for the KV cache. For privacy-preserving local grading workows with long con- texts, mid-scale open models balance resource requirements and performance: they t within commonly available VRAM budgets and support meaningful conte xt windows without complex ooad- ing. V ery large MoE models such as GLM-4.7, while potentially oering str ong raw capability , impose substantially higher memor y costs that are unlikely to be justied in typical academic envi- ronments and would complicate deplo yment relative to mid-scale alternatives. 6 Conclusion This study demonstrates that open-source LLMs are capable of accurate and scalable assessment of UML class diagrams. Overall accuracies range d from 85% to 89%, with GLM 4.7 achieving the highest correlation with TA grading. LLMs p erform reliably on structurally straightforward criteria, such as class identication, but show reduce d performance on multiplicity constraints and com- plex relationship chains. W e further identify systematic patterns in model performance, including positional biases, relationship- tracing diculties, and under-grading tendencies. These ndings suggest the ne ed for a human-in-the-lo op , and specically a mixed-initiative approach. In a mixed-initiative work- ow , LLMs can handle high-agreement, low-ambiguity criteria, reducing grading eort, while T As focus on complex or ambigu- ous elements requiring logical r easoning and domain knowledge. Iterative collaboration between LLM and T A ensures eciency , fairness, and mitigation of model biases. Furthermore, we consider a practical approach as open-source models can be feasibly hosted by universities given constraints regar ding cost and data privacy . Overall, this work provides an improv ed pipeline for automate d grading of UML class diagrams and establishes a roadmap for a future mixed-initiative system can deliver scalable, consistent, and interpretable assessment. T wo main iterative use cases would be supported: (1) LLMs provide fe edback to TA s, or (2) T As adopt grades generated by LLMs. Future work should explore iterative grading in a mixed-initiative system, application to other modeling tasks, and further improvements in response quality from LLMs. Which will prove to be a large step in tackling ever increasing student numbers. References [1] Faizan Ahmed, Nacir Bouali, and Marcus Gerhold. 2024. Teaching A ssistants as Assessors: An Experience Based Narrative. In Proceedings of the 16th International Conference on Computer Supported Education, CSEDU 2024 (International Confer- ence on Computer Supporte d Education, CSEDU - Proceedings) , Oleksandra Poquet, Alejandro Ortega- Arranz, Olga Viberg, Irene-Angelica Chounta, Bruce McLaren, and Jelena Jovanovic (Eds.). Science and T echnology Publications, Lda, Portugal, 115–123. doi:10.5220/0012624200003693 Publisher Copyright: Copyright © 2024 by SCI TEPRESS – Science and T echnology Publications, Lda.; 16th International Conference on Computer Supported Education, CSEDU 2024, CSEDU 2024 ; Conference date: 02-05-2024 Through 04-05-2024. [2] Rishabh Balse, Bharath V alaboju, Shreya Singhal, Jayakrishnan W arriem, and Prajish Prasad. 2023. Investigating the Potential of GPT -3 in Providing Feedback for Programming Assessments. 292–298. doi:10.1145/3587102.3588852 [3] W eiyi Bian, Omar Alam, and Jörg Kienzle. 2019. A utomated grading of class diagrams. In 2019 ACM/IEEE 22nd International Conference on Model Driven Engineering Languages and Systems Companion (MODELS-C) . IEEE, 700–709. [4] W eiyi Bian, Omar Alam, and Jörg Kienzle. 2020. Is automated grading of mo dels eective? assessing automated grading of class diagrams. In Proceedings of the 23rd A CM/IEEE International Conference on Model Driven Engineering Languages and Systems (Virtual Event, Canada) (MODELS ’20) . Association for Computing Machinery , New Y ork, NY, USA, 365–376. doi:10.1145/3365438.3410944 [5] W eiyi Bian, Omar Alam, and Jörg Kienzle. 2021. A utomated grading of class diagrams. In Proceedings of the 22nd International Conference on Model Driven Engineering Languages and Systems Companion (Munich, Germany) (MODELS ’19 Companion) . IEEE Press, 700–709. doi:10.1109/MODELS- C.2019.00106 Beyond Grading Accuracy: Exploring Alignment of TA s and LLMs [6] Nacir Bouali, Marcus Gerhold, T osif {Ul Rehman}, and Faizan Ahme d. 2025. T o- ward A utomated UML Diagram Assessment: Comparing LLM-Generated Scores with T eaching Assistants. In Proceedings of the 17th International Conference on Computer Supported Education, CSEDU 2025 (International Conference on Com- puter Supported Education, CSEDU - Proceedings, V ol. 1) , Benedict {du Boulay}, T ania {Di Mascio}, Edmundo T ovar , and Christoph Meinel (Eds.). Science and T echnology Publications, Lda, Portugal, 158–169. doi:10.5220/0013481900003932 Publisher Copyright: Copyright © 2025 by SCITEPRESS - Science and T echnol- ogy Publications, Lda.; 17th International Conference on Computer Supported Education, CSEDU 2025, CSEDU 2025 ; Conference date: 01-04-2025 Through 03-04-2025. [7] Y ounes Boubekeur , Gunter Mussbacher , and Shane McIntosh. 2020. Automatic assessment of students’ software models using a simple heuristic and machine learning. In Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems: Companion Proceedings . 1–10. [8] Albert T . Corbett, Kenneth R. Koedinger , and John R. Anderson. 1997. Intelligent T utoring Systems. In Handbook of Human-Computer Interaction . Elsevier , 849– 874. doi:10.1016/B978- 044481862- 1.50103- X [9] Sarah Foss, T atiana Urazova, and Ramon Lawrence. 2022. Automatic generation and marking of UML database design diagrams. In Proceedings of the 53rd ACM T echnical Symposium on Computer Science Education-V olume 1 . 626–632. [10] Sarah Foss, T atiana Urazova, and Ramon Lawrence. 2022. Learning UML data- base design and modeling with AutoER. In Pr oceedings of the 25th International Conference on Model Driven Engineering Languages and Systems: Companion Proceedings . 42–45. [11] Thomas P Hogan and John C Norcross. 2012. Undergraduates as T eaching Assistants. Eective college and university teaching: Strategies and tactics for the new professoriate (2012), 197. [12] Eric Horvitz. 1999. Principles of mixe d-initiative user interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Pittsburgh, Pennsylvania, USA) (CHI ’99) . Association for Computing Machiner y , New Y ork, NY, USA, 159–166. doi:10.1145/302979.303030 [13] Hieke Keuning, J. T . Jeuring, and Bastiaan Heeren. 2018. A systematic literature review of automated feedback generation for programming exercises. ACM Transactions on Computing Education 19, 1 (2018). doi:10.1145/3231711 [14] Sushant Kumar , Sumit Datta, Vishakha Singh, Deepanwita Datta, Sanjay Ku- mar Singh, and Ritesh Sharma. 2024. Applications, Challenges, and Future Directions of Human-in-the-Loop Learning. IEEE Access 12 (2024), 75735–75760. doi:10.1109/ACCESS.2024.3401547 [15] Nguyen- Thinh Le. 2016. A Classication of Adaptive Feedback in Educational Systems for Programming. Systems 4, 2 (2016), 22. doi:10.3390/systems4020022 [16] Gyeong-Geon Lee, Ehsan Latif, Xuansheng Wu, Ninghao Liu, and Xiaoming Zhai. 2024. Applying large language models and chain-of-thought for automatic scoring. Computers and Education: Articial Intelligence 6 (2024), 100213. doi:10. 1016/j.caeai.2024.100213 [17] Dominic Lohr , Hieke Keuning, and Natalie Kiesler . 2025. Y ou’re (Not) My Type- Can LLMs Generate Feedback of Specic Types for Introductory Programming T asks? Journal of Computer Assisted Learning 41, 1 (2025), e13107. [18] Cheng Luo, Zefan Cai, Hanshi Sun, Jinqi Xiao, Bo Y uan, W en Xiao, Junjie Hu, Jiawei Zhao, Beidi Chen, and Anima Anandkumar . 2025. HeadInfer: Memory- Ecient LLM Inference by Head-wise Ooading. arXiv:2502.12574 [cs.LG] https://arxiv .org/abs/2502.12574 [19] Alfredo Milani, V alentina Franzoni, Emanuele Florindi, Assel Omarbekova, Gulmira Bekmanova, and Banu Y ergesh. 2025. When AI Is Fooled: Hidden Risks in LLM-A ssisted Grading. Education Sciences 15, 11 (2025). doi:10.3390/ educsci15111419 [20] National Academies of Sciences, Medicine, Division on Engineering, Physical Sciences, Computer Science, T elecommunications Board, Global Aairs, Board on Higher Education, and Committee on the Growth of Computer Science Under- graduate Enrollments. 2018. Assessing and responding to the growth of computer science undergraduate enrollments . National Academies Press. [21] Dave R Stikkolorum, Peter van der Putten, Caroline Sp erandio, and Michel Chaudron. 2019. T owards Automated Grading of UML Class Diagrams with Machine Learning. BNAIC/BENELEARN 2491 (2019). [22] T obias Stähle, Matthijs Jansen op de Haar , Sophia Bo yer , Rita Sevastjanova, Arpit Narechania, and Mennatallah El- Assady . 2025. A Design Space for Intelligent Agents in Mixe d-Initiative Visual Analytics. arXiv:2512.23372 [cs.HC] https: //arxiv .org/abs/2512.23372 [23] Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, and Qingsong W en. 2024. Large Language Mo dels for Education: A Survey and Outlook. arXiv:2403.18105 [cs.CL]
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment