PashtoCorp: A 1.25-Billion-Word Corpus, Evaluation Suite, and Reproducible Pipeline for Low-Resource Language Development
We present PashtoCorp, a 1.25-billion-word corpus for Pashto, a language spoken by 60 million people that remains severely underrepresented in NLP. The corpus is assembled from 39 sources spanning seven HuggingFace datasets and 32 purpose-built web s…
Authors: Hanif Rahman
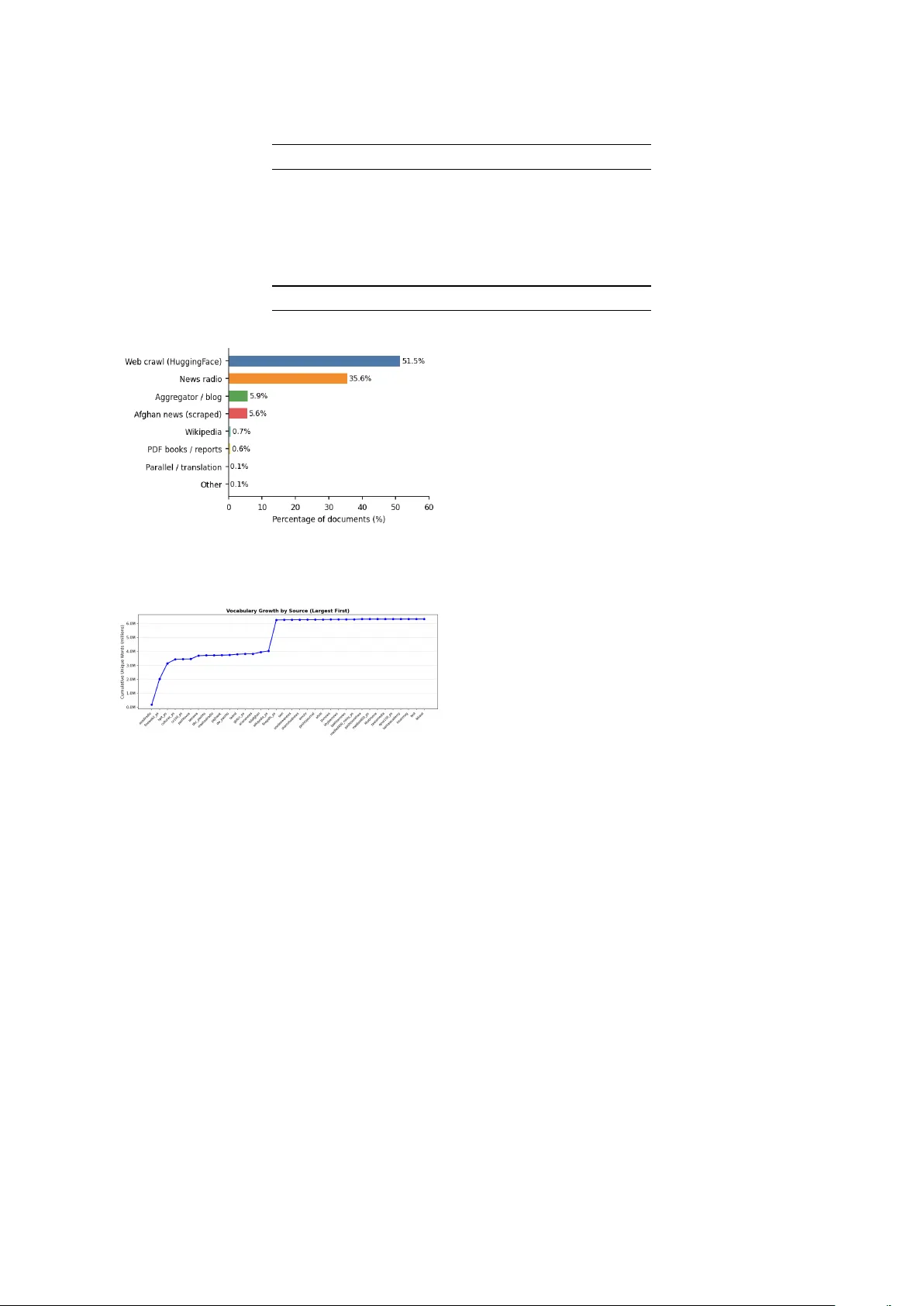
PashtoCor p: A 1.25-Billion-W ord Corpus, Ev aluation Suite, and Repr oducible Pipeline f or Low-Resour ce Language De velopment Hanif Rahman Independent Researcher hanif@hanifrahman.com Abstract W e present PashtoCorp , a 1.25-billion-word corpus for Pashto, a language spoken by 60 million people that remains sev erely underrepresented in NLP . The corpus is assembled from 39 sources spanning sev en HuggingFace datasets and 32 purpose-built web scrapers, processed through a reproducible pipeline with Arabic-script tokenization, SHA-256 deduplication, and quality filtering. At 1.25B words across 2.81 million documents, PashtoCorp is 40 × larger than the OSCAR Pashto subset and 83 × larger than the previously largest dedicated Pashto corpus. Continued MLM pretraining of XLM-R-base on PashtoCorp reduces held-out perplexity by 25.1% (8.08 → 6.06). On WikiANN Pashto NER, the pretrained model improv es entity F1 by 10% relati ve (19.0% → 21.0%) and reduces training variance nearly 7 × ; the largest gain appears at 50 training sentences (+27%), with PashtoCorp covering 97.9% of WikiANN entity vocab ulary . On Belebele P ashto reading comprehension, Gemma-3n achiev es 64.6% accuracy , the first published LLM baseline for Pashto on this benchmark. A leav e-one-out source ablation sho ws that W ikipedia (0.7% of documents) is the most critical source for NER: removing it alone reduces entity F1 by 47%. Corpus data, trained model, and code are av ailable at https://huggingface.co/ datasets/ihanif/pashto- corpus , https://huggingface.co/ihanif/ xlmr- pashto , and https://github. com/ihanif/pashto- corpus . 1 Introduction NLP has adv anced rapidly over the past decade, b ut progress has been une v en across languages. Pashto, an Indo-Iranian language spoken by 60 million peo- ple in Afghanistan, Pakistan, and diaspora commu- nities worldwide, remains poorly represented. The largest a v ailable P ashto resources are the OSCAR 2301 subset ( ∼ 31M words) and the NLPashto cor - pus ( ∼ 15M w ords) [ 1 ]. Both are too small for com- petiti ve language model training: e v en the P ashto W ikipedia has only ∼ 6M w ords. This paper makes three contrib utions: 1. PashtoCorp : a 1.25B-word corpus from 39 heterogeneous sources, built through a fully reproducible pipeline. 2. An e v aluation suite: MLM perplexity , vocab- ulary co verage, sample efficienc y , and base- lines on POLD, W ikiANN, and Belebele with fixed splits for reproducibility . 3. A source ablation: lea ve-one-out pretraining experiments quantifying each domain group’ s contribution to language-model quality and do wnstream NER. Our results sho w that domain-adapti ve pretrain- ing impro ves performance when corpus and task domains align (NER, news text) and does not when they di v erge (POLD, social media). W e report null findings alongside positiv e results, as both provide actionable guidance for practitioners working in lo w-resource settings. 2 Related W ork Prior Pashto NLP has been fragmented and small in scale. The NLPashto toolkit [ 1 ] introduced a 15M-word corpus and a Pashto BER T model, with a POS tagging model achie ving 96.24% ac- curacy on a 700K-word annotated corpus. The POLD dataset [ 2 ] provides 34,400 social media posts for of fensi ve language detection, with XLM- R (94.0% F1) and P ashto BER T (94.3% F1) base- lines. W ikiANN [ 3 , 4 ] includes a Pashto NER split with 300 sentences (100 each for train, val- idation, and test) and 7 BIO labels. Belebele [ 5 ] provides 900 P ashto reading comprehension ques- tions with no prior LLM baselines. The Uni v ersal T able 1: PashtoCorp sources by category . Category Sources Docs W ords (M) W eb crawl (HuggingFace) 4 1,447,599 773.1 News radio (scraped) 7 1,000,213 222.6 Afghan news (scraped) 12 158,644 77.9 Aggregator / blog 10 164,808 74.5 PDF books / reports 1 16,867 81.6 Encyclopedia 1 19,523 13.6 Parallel / translation 2 1,592 4.7 Other 2 1,667 1.7 T otal 39 2,810,913 1,249.8 Dependencies Pashto treebank [ 6 ] has 155 anno- tated sentences. Our HuggingFace sources include OSCAR [ 7 ], CulturaX [ 8 ], CC-100 [ 9 ], MADLAD-400 [ 10 ], GlotCC [ 11 ], FineW eb2 [ 12 ], and HPL T [ 13 ]. Domain-adapti ve pretraining has been shown to improv e do wnstream performance for multiple lan- guages [ 14 , 15 ]; gains depend on domain ov erlap between pretraining data and e v aluation tasks. 3 Data Collection PashtoCorp is assembled from 39 sources: 7 Hug- gingFace datasets and 32 websites scraped with purpose-built Scrap y spiders. T able 1 summarises the taxonomy . 3.1 HuggingF ace Datasets W e incorporate sev en datasets with Pashto or pbt_Arab subsets: FineW eb2, HPL T v2.0, Cul- turaX, CC-100, MADLAD-400 (clean and noisy), and GlotCC-V1. Each is streamed and filtered through our pipeline without storing intermediate files. 3.2 W eb Scraping W e built 32 Scrap y spiders tar geting Pashto ne ws outlets and radio services. Major sources in- clude Azadi Radio (720,871 documents), V O A Pashto (205,284), BBC P ashto (51,736), P ajhwok Afghan Ne ws (33,366), and Deutsche W elle P ashto (33,027). Each spider has three fields: a start URL, a link- follo wing rule (e.g., /archive/ , pagination pat- terns), and a CSS content selector (e.g., article p::text ). A url_must_contain path filter restricts crawling to the language-specific URL path (e.g., /pa/ for Pashto on RFE/RL and D W), removing the need for an external language-ID model at crawl time. Sites with hashed CSS class names (e.g., Next.js builds) use tag-based T able 2: Pipeline rejection statistics. Filter stage Docs remo ved % of raw Pashto ratio < 0.70 1,084,231 18.6% SHA-256 duplicate 356,943 6.1% Min tokens < 10 42,817 0.7% T otal rejected 1,483,991 25.5% Retained 2,810,913 74.5% selectors ( article p::text ) rather than class- based ones. For Jav aScript-rendered pages, a Playwright middle ware replaces the default HTTP do wnloader . A new spider typically requires 10–20 lines of configuration. T o adapt the pipeline to another Arabic-script language (e.g., Dari, Urdu, Sindhi), only the Uni- code range in the language identification filter changes; spider configurations, deduplication, and e v aluation scripts carry ov er unchanged. For other scripts, the character-range filter can be replaced with any tok en-le vel language detector . 4 Processing Pipeline 4.1 Language Identification Each document is scored by the fraction of to- kens in P ashto Unicode ranges (U+0600–U+06FF and extensions). Documents with fe wer than 70% Pashto-script tokens are discarded. This remov es code-switched and mislabelled text while retaining documents with numerals and Latin proper nouns. 4.2 Deduplication Documents are deduplicated via SHA-256 hashes of lowercased, whitespace-normalised content. This remov es 356,943 duplicates (11.1% of docu- ments passing language identification). 4.3 Quality Filtering Documents with fewer than 10 whitespace- separated tokens are remov ed. T able 2 shows rejec- tion rates per stage. 5 Corpus Analysis 5.1 Scale and Comparison PashtoCorp contains 1,249,765,401 words across 2,810,913 documents with 6,322,778 unique word types. T able 3 places it in context. T able 3: Comparison with prior Pashto corpora. Corpus W ords Docs vs. PashtoCorp NLPashto [ 1 ] ∼ 15M — 83 × smaller OSCAR 2301 ∼ 31M — 40 × smaller CC-100 (ps) ∼ 54M 257K 23 × smaller MADLAD-400 (ps) < 1M 4K > 1000 × smaller GlotCC (pbt-Arab) — 37K — HPL T v2.0 (pbt-Arab) — 466K — FineW eb2 (pbt_Arab) — 484K — PashtoCorp (ours) 1,250M 2,811K 1 × Figure 1: Document distribution by domain category ( N = 2 , 810 , 913 ). Figure 2: Cumulati v e unique vocab ulary (millions) as sources are incorporated in descending document-count order . Despite its small size (16.9K documents, position 17), FinePDFs contributes the largest mar ginal v ocabu- lary of any single source: 2.22M unique types. 5.2 Domain Distribution Figure 1 sho ws the domain distribution. W eb crawl sources account for 51.5% of documents; ne ws ra- dio for 35.6%. PDF books (0.6% of documents, a v- eraging 5,330 words each) are a register dispropor- tionately important for vocab ulary (Section 5.4 ). 5.3 V ocabulary Gr o wth Figure 2 sho ws cumulati ve vocab ulary as sources are added in descending document count. FinePDFs (16,867 documents, 0.6% of the cor- pus) adds 2,219,205 word types found in no other source: 35% of total vocabulary from less than 1% of documents. 5.4 Source Contrib ution Ablation W e conducted two lea ve-one-out ablations across six domain groups. The vocabulary ablation is a single-pass scan computing unique v ocab ulary and W ikiANN entity coverage when each group is excluded. The pr etraining ablation re-pretrains XLM-R-base on the filtered corpus (100M-w ord cap, 400 gradient steps) for each group. V ocabulary ablation. T able 4 shows the results. FinePDFs contributes more unique vocab ulary than any other group despite co vering only 0.6% of doc- uments: 2,219,205 w ord types from 16,867 digi- tized books and government reports. By contrast, Ne ws Radio accounts for 35.6% of documents but adds only 55,234 unique types (0.9% of vocab u- lary); broadcast speech is le xically homogeneous. Entity cov erage is robust across all ablations; e v en removing the entire web crawl loses only 4 W iki- ANN entity tokens. T able 5 shows per-source marginal v ocab ulary contrib utions. Pretraining ablation. T able 6 sho ws the results. W eb cra wl is most critical for language-model qual- ity: removing it raises perplexity from 6.06 to 6.58. W ikipedia is most critical for NER: its remov al drops entity F1 from roughly 20% to 10.3%, a 47% relati ve loss, despite W ikipedia being only 0.7% of documents. News Radio remov al slightly impr o ves MLM perplexity (6.20), because broadcast speech is repetiti ve and its remov al yields a more di v erse corpus per gradient step; ho we ver , news radio still matters for NER (removing it drops F1 to 13.0%). 5.5 Zipf ’ s Law Log-log re gression of frequency rank vs. frequency gi ves α = 1 . 624 ( R 2 = 0 . 985 ), higher than typ- ical English v alues ( α ≈ 1 . 0 – 1 . 2 ). This reflects Pashto’ s rich inflectional morphology , which pro- duces many lo w-frequenc y surface forms. T able 4: V ocabulary ablation (lea ve-one-out). Entity cov erage = W ikiANN tokens co vered. Group r emoved Docs V ocab V ocab lost Entity cov . — (Full corpus) — 6,322,778 — 99.5% PDF Books 16,867 4,103,573 − 35.1% 99.5% W eb Crawl 1,447,599 4,418,444 − 30.1% 98.5% Afghan News 126,867 6,132,742 − 3.0% 99.5% W ikipedia 19,523 6,239,562 − 1.3% 99.5% News Radio 1,060,498 6,267,544 − 0.9% 99.5% SWN 12,546 6,314,810 − 0.1% 99.5% T able 5: Per-source marginal vocabulary (top 10 sources). Source Docs Marginal vocab % corpus finepdfs_ps 16,867 2,219,205 35.1% hplt_ps 397,273 495,782 7.8% fineweb2_ps 483,890 345,935 5.5% culturax_ps 335,609 207,160 3.3% benawa 58,319 201,093 3.2% tolafghan 20,525 106,514 1.7% wikipedia_ps 19,523 83,216 1.3% taand 29,616 39,582 0.6% bbc_pashto 51,736 22,505 0.4% glotcc_ps 28,514 21,125 0.3% T able 6: Pretraining ablation (400 steps each, sorted by PPL). Full 750-step model shown as reference. Group r emov ed Docs PPL NER F1 Full (750 steps) 2,810,913 6.055 19.6% W eb Crawl 1,363,314 6.581 18.9% W ikipedia 2,791,390 6.412 10.3% SWN 2,798,367 6.399 13.6% PDF Books 2,794,046 6.384 12.9% Afghan Ne ws 2,684,046 6.314 21.5% Ne ws Radio 1,750,415 6.201 13.0% 6 Evaluation W e e v aluate PashtoCorp through intrinsic language- model quality metrics and extrinsic downstream task performance via continued pretraining of XLM-R-base. 6.1 Experimental Setup W e continue MLM pretraining of xlm- roberta- base [ 16 ] on 100M words from P ashtoCorp (283,569 training sequences of 512 tokens), using a 95/5 train/validation split. T raining runs for 750 gradient steps with batch size 32, learning rate 10 − 4 , 200 warmup steps, and MLM probability 0.15, on Apple M4 (MPS/Metal) for approximately 158 minutes. W e refer to this model as XLM-R+PashtoCorp . Figure 3: Log-log frequenc y vs. rank for the top 10 5 word types. The Zipf fit ( α = 1 . 624 , R 2 = 0 . 985 ) holds closely . T able 7: PashtoCorp coverage of W ikiANN tokens. T oken set Covered T otal Coverage All W ikiANN tokens 2,062 2,151 95.9% Entity tokens (all) 381 389 97.9% PER (persons) 164 164 100.0% LOC (locations) 101 102 99.0% ORG (organisations) 133 140 95.0% 6.2 Intrinsic: Perplexity and V ocabulary Coverage On 2,000 held-out PashtoCorp documents (3,204 sequences of 512 tokens), XLM-R-base scores PPL 8.08 and XLM-R+PashtoCorp scores PPL 6.06, a 25.1% reduction. T o understand the NER gains, we analyse o ver - lap between P ashtoCorp and W ikiANN entity vo- cabulary . PashtoCorp covers 97.9% of entity to- kens, higher than its 95.9% overall coverage (T a- ble 7 ). Person names hav e 100% co verage. Of en- tity tokens, 61.7% span multiple XLM-R subw ord units; in-domain pretraining directly improv es rep- resentations for these multi-token entities. 6.3 Extrinsic: POLD Offensive Language Detection POLD [ 2 ] contains 34,400 social media posts anno- tated for of fensi v e language. W e apply an 80/10/10 T able 8: POLD results (macro-F1). Model Acc. Macro-F1 CNN [ 2 ] 92.4% 91.8% XLM-R-base (published) 94.8% 94.0% Pashto BER T (published) 94.8% 94.3% XLM-R-base (our repro) 94.6% 94.1% XLM-R+PashtoCorp 94.5% 94.0% T able 9: W ikiANN Pashto NER (5 seeds, entity-level F1). Model F1 mean F1 std ∆ XLM-R-base 19.0% ± 4.7% — XLM-R+PashtoCorp 21.0% ± 0.7% +10.3% stratified split (seed=42). XLM-R+PashtoCorp sho ws no improv ement ov er the baseline ( − 0.07pp F1, T able 8 ). A vocabulary analysis confirms the domain gap: PashtoCorp cov ers 91.6% of POLD word types, 4.3pp below its 95.9% coverage of W ikiANN, with 3,651 OO V types that are colloqui- alisms and orthographic v ariants specific to social media text. 6.4 Extrinsic: WikiANN NER W ikiANN Pashto [ 3 , 4 ] provides 100/100/100 train/v al/test sentences with 7 BIO labels. W e fine- tune for token classification (10 epochs, batch 16, lr= 5 × 10 − 5 , max 128 tok ens) and e v aluate with seqe v al [ 17 ] entity-lev el F1 o ver 5 seeds. XLM-R+PashtoCorp reaches 21.0% F1 (+10.3% relati ve). T raining v ariance drops from ± 4.7% to ± 0.7%, a near 7 × reduction (T able 9 ). Per -entity-type br eakdown. A separate run o v er 3 seeds measures F1 per entity type (T able 10 ). PER benefits the most from pretraining (+11pp, +51% relati ve), consistent with P ashtoCorp co ver - ing 100% of W ikiANN person name vocab ulary . ORG and LOC see smaller improvements. The base model’ s high variance on PER (15.6%) re- flects the instability of learning person-name pat- terns from just 100 training sentences; pretraining more than halves this standard de viation (5.8%). 6.5 Sample Efficiency W e v ary training size n ∈ { 10 , 25 , 50 , 75 , 100 } across 5 seeds per condition (T able 11 , Figure 4 ). The pretrained model shows the lar gest relati ve adv antage at n = 50 (+27% F1). At n = 100 the base model’ s variance (12.9%) is 3 × higher than T able 10: NER per-entity-type F1 (3 seeds, mean ± std). Model Overall PER ORG LOC XLM-R-base 13.0% ± 8.5% 21.8% ± 15.6% 4.0% ± 5.7% 9.6% ± 9.1% XLM-R+PashtoCorp 20.6% ± 3.9% 33.1% ± 5.8% 8.8% ± 12.4% 10.9% ± 8.8% Figure 4: W ikiANN NER entity F1 vs. training set size (5 seeds, ± 1 std shaded). P ashtoCorp pretraining peaks at n = 50 (+27% relati ve F1). the pretrained model’ s (4.2%). 6.6 Belebele Reading Comprehension T able 12 reports zero-shot 4-option multiple-choice accuracy on Belebele Pashto ( pbt_Arab , 900 questions) [ 5 ]. Encoder-based similarity methods perform at random chance; cosine similarity is not suitable for multiple-choice comprehension. Ac- curacy rises consistently with model size within the Qwen3 family (27.7% → 33.4% → 37.9% for 0.6B → 1.7B → 4B parameters), and Llama-3.2-3B- Instruct reaches 40.3%. Gemma-3n-E4B achie ves 64.6%, the first published LLM result for Pashto on this benchmark; the remaining g ap abov e 40% likely stems from Gemma-3n’ s much wider multi- lingual pretraining data. 7 Discussion Domain alignment determines downstream gains. P ashtoCorp pretraining benefits NER be- cause corpus and task share overlapping te xt: news articles and W ikipedia. It does not benefit POLD because con v ersational social media is absent from the corpus. This is consistent with the domain- adapti ve pretraining literature [ 14 ] and suggests that corpus builders should characterize domain cov erage before expecting improvements on a gi ven do wnstream task. Small, diverse sources hav e outsized value. The ablation results make a clear case for regis- ter di versity o ver ra w volume. FinePDFs (0.6% of T able 11: Sample efficiency: entity-lev el F1 by training size (5 seeds, mean ± std). n XLM-R-base XLM-R+PashtoCorp ∆ 10 8.5% ± 5.6% 8.1% ± 5.1% − 0.4pp 25 10.9% ± 5.9% 9.3% ± 4.8% − 1.6pp 50 18.8% ± 4.7% 23.8% ± 7.6% +5.0pp (+27%) 75 36.1% ± 6.5% 28.2% ± 8.0% − 7.9pp 100 43.4% ± 12.9% 39.4% ± 4.2% − 4.0pp, 3 × lo wer σ T able 12: Belebele Pashto (zero-shot, 4-option MC). Method Accuracy Random baseline 25.0% MPNet embedding similarity 25.4% Pashto BER T embedding similarity 24.2% Qwen3-0.6B (Q8_0, llama-cpp) 27.7% Qwen3-1.7B (Q8_0, llama-cpp) 33.4% Qwen3-4B (Q4_K_M, llama-cpp) 37.9% Llama-3.2-3B-Instruct (Q4_K_M) 40.3% Gemma-3n-E4B (UD-Q4_K_XL) 64.6% documents) contrib utes 35% of total vocab ulary . W ikipedia (0.7% of documents) is the single most important source for NER; its remo v al alone causes a 47% relati ve F1 drop. For other lo w-resource corpus efforts, this is actionable: collecting ency- clopedic and book text early is disproportionately v aluable, e ven at small scale. Current pretraining uses a small fraction of PashtoCorp. Our experiments train on 100M words (400–750 gradient steps), approximately 8% of the full corpus. The 25.1% perplexity reduction and 10% NER improvement achie ved in this lim- ited compute budget suggest substantially larger gains are possible with full-corpus training. Reproducibility and transfer to other low- resour ce languages. Corpus assembly runs on a single machine in under 24 hours. Continued MLM pretraining (750 steps, 100M words) took 158 min- utes on an Apple M4 with no discrete GPU. The e valuation suite (perplexity , vocab ulary co verage, W ikiANN NER, POLD, and Belebele) runs end-to- end from publicly av ailable checkpoints. Adapting the pipeline to another Arabic-script language (e.g., Dari, Urdu, Sindhi) requires changing one Uni- code range; adapting to an y other script requires one language detector sw ap. W ikiANN and Bele- bele cov er 282 and 122 languages respecti v ely , so the benchmarking harness transfers to any covered language without code changes. T eams working on other under -resourced languages can apply the same data, model, and ev aluation stack with con- figuration changes only . Limitations Pretraining scale. All pretraining experiments use 100M words (400–750 gradient steps), approx- imately 8% of PashtoCorp. The reported NER and perplexity gains should therefore be treated as lo wer bounds on what the corpus can support with full training. NER ev aluation. W ikiANN Pashto has only 100 training sentences; absolute F1 values are there- fore inherently unstable. The main NER result (19.0% → 21.0%) is reported over 5 seeds; the source ablation NER v alues use a single seed and carry higher v ariance. W e recommend treating ab- lation NER values as relati v e indicators rather than precise estimates. Corpus biases. P ashtoCorp is 87.8% news and web crawl text, predominantly from Afghanistan- based outlets. Kandahari and Y ousafzai Pashto are o ver -represented; Pakistani Pashto (Pe- shaw ar/W aziri dialect) and diaspora register are under-represented. Models pretrained on Pashto- Corp may perform less well on text from these under-represented v arieties. POLD domain gap. PashtoCorp covers 91.6% of unique POLD v ocab ulary types, compared to 95.9% for W ikiANN (4.3pp lo wer). The 3,651 OO V POLD types include colloquialisms, informal verb forms, and orthographic v ariants typical of social media that are absent from formal news text. This cov erage gap quantitati v ely explains the null pretraining result on POLD and limits the scope of our extrinsic e v aluation to ne ws-adjacent tasks. 8 Ethical Considerations All scraped content is publicly av ailable text. No personally identifiable information be yond what ap- pears in published ne ws is collected. PashtoCorp is predominantly ne ws and web cra wl (87.8% of docu- ments), sk e wing to ward Afghanistan-based sources and formal registers; dialect cov erage fa vours Kan- dahari and Y ousafzai Pashto. PashtoCorp should not be used to b uild systems that identify or surv eil Pashto speak ers, giv en the vulnerability of Pashto- speaking communities in conflict-af fected regions. POLD contains offensi v e content; downstream moderation applications should include human ov ersight. Corpus data is released under the most permissi ve license compatible with each source’ s terms; code is MIT ; model checkpoints are Apache 2.0. 9 Conclusion W e have presented PashtoCorp, a 1.25B-word Pashto text corpus assembled from 39 sources through a reproducible pipeline. MLM pretrain- ing on PashtoCorp reduces held-out perplexity by 25.1% and improv es W ikiANN NER by 10% rela- ti ve, with a near 7 × reduction in training v ariance. The pretrained model co vers 97.9% of W ikiANN entity vocab ulary , and the sample efficienc y analy- sis shows the lar gest gains at 50 training sentences. On Belebele, Gemma-3n reaches 64.6% accurac y , the first published LLM result for Pashto on this benchmark. T wo findings from the source ablation hav e broader rele v ance. W ikipedia and PDF books, to- gether fe wer than 1.5% of documents, are dispro- portionately valuable: removing Wikipedia costs 47% of NER performance; removing PDF books costs 35% of v ocab ulary . For a ne w lo w-resource language, collecting a small set of encyclopedic and book documents early is more effecti ve per document than scaling up web crawl data alone. All data, code, checkpoints, and e v al- uation scripts are released: corpus at https://huggingface.co/datasets/ ihanif/pashto- corpus , model at https://huggingface.co/ihanif/ xlmr- pashto , and code at https: //github.com/ihanif/pashto- corpus . Future work includes training on the full 1.25B- word corpus, dev eloping Pashto-specific generati v e models, and extending cov erage to Pakistani Pashto and W aziri dialect. References [1] Inam Ullah Haq, W ei Zhang, Jing Guo, and Peng T ang. 2023. POS tagging of low-resource Pashto language: Annotated corpus and BER T-based model. Language Resour ces and Evaluation . [2] Hamza Ali, Rabia Mazhar , Irfan Ullah, Atiq Rehman, Asadullah Shah, and Muhammad Ahsan Choudhry . 2023. Pashto of fensi v e language detection: A bench- mark dataset and monolingual Pashto BER T. P eerJ Computer Science , 9:e1617. [3] Xiaoman Pan, Boliang Zhang, Jonathan May , Joel Nothman, K e vin Knight, and Heng Ji. 2017. Cross- lingual name tagging and linking for 282 languages. In Pr oceedings of the 55th Annual Meeting of the As- sociation for Computational Linguistics , pages 1946– 1958. [4] Afshin Rahimi, Y uan Li, and T re v or Cohn. 2019. Massi vely multilingual transfer for NER. In Pr oceed- ings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 151–164. [5] Lucas Bandarkar , Davis Liang, Benjamin Muller , Mikel Artetxe, Satya Narayan Shukla, Donald Husa, Naman Goyal, Abhinandan Krishnan, Luke Zettle- moyer , and Madian Kambadur . 2024. The Belebele benchmark: a parallel reading comprehension dataset in 122 language variants . In Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (A CL 2024) . [6] Joakim Nivre, Marie-Catherine de Marnef fe, Filip Ginter , Y oav Goldberg, Jan Haji ˇ c, Christopher D. Manning, Ryan McDonald, Slav Petrov , Sampo Pyysalo, Natalia Silveira, Reut Tsarf aty , and Daniel Zeman. 2016. Universal dependencies v1: A multi- lingual treebank collection. In Pr oceedings of the T enth International Conference on Language Re- sour ces and Evaluation (LREC 2016) . [7] Pedro Ja vier Ortiz Suárez, Benoît Sagot, and Lau- rent Romary . 2019. Asynchronous pipeline for pro- cessing huge corpora on medium to low resource infrastructures. In Pr oceedings of the W orkshop on Challenges in the Management of Larg e Corpor a (CMLC-7) at CLARIN 2019 . [8] Thuat Nguyen, Chien V an Nguyen, V iet Dac Lai, Hieu Man, Nghia Trung Ngo, Franck Dernoncourt, Ryan A. Rossi, and Thien Huu Nguyen. 2023. Cul- turaX: A cleaned, enormous, and di v erse multilingual dataset for large language models in 167 languages. arXiv pr eprint arXiv:2309.09400 . [9] Guillaume W enzek, Marie-Anne Lachaux, Alexis Conneau, V ishra v Chaudhary , Francisco Guzmán, Armand Joulin, and Edouard Gra ve. 2020. CCNet: Extracting high quality monolingual datasets from web crawl data. In Pr oceedings of the T welfth Lan- guage Resources and Evaluation Conference (LREC 2020) , pages 4003–4012. [10] Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Linting Xue, Ambrose Ferrara, Laila Huang, Naman Goyal, and Ankur Bapna. 2023. MADLAD-400: A multilingual and document-lev el lar ge audited dataset. arXiv preprint arXiv:2309.04662 . [11] Amir Hossein Kar garan, A yyoob Imani, Heshaam Faili, and Hinrich Schütze. 2024. GlotCC: An open broad-cov erage CommonCrawl corpus and pipeline for minority languages. In Advances in Neural Infor- mation Pr ocessing Systems (NeurIPS 2024) . [12] Guilherme Penedo, Hynek K ydlí ˇ cek, Alessandro Cappelli, Quentin Malartic, Daniel Castagné, Manuel Lagunas, and Loubna Ben Allal. 2024. The FineWeb datasets: Decanting the web for the finest text data at scale. arXiv preprint . [13] Ona de Gibert, Graeme Nail, Aitor Kumar , Niko- lay Arefyev , Jonne Väyrynen, Rob van der Goot, and Jörg T iedemann. 2024. A new massi v e multilin- gual dataset for high-performance language technolo- gies. In Pr oceedings of the 2024 Joint International Confer ence on Computational Linguistics, Language Resour ces and Evaluation (LREC-COLING 2024) , pages 16914–16928. [14] Suchin Gururangan, Ana Marasovi ´ c, Swabha Swayamditta, K yle Lo, Iz Beltagy , Doug Downey , and Noah A. Smith. 2020. Don’ t stop pretraining: Adapt language models to domains and tasks. In Pr oceedings of the 58th Annual Meeting of the Asso- ciation for Computational Linguistics , pages 8342– 8360. [15] Dat Quoc Nguyen and Anh T uan Nguyen. 2020. PhoBER T: Pre-trained language models for V iet- namese. In F indings of the Association for Computa- tional Linguistics: EMNLP 2020 , pages 1882–1890. [16] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, V ishrav Chaudhary , Guillaume W enzek, Fran- cisco Guzmán, Edouard Grav e, Myle Ott, Luke Zettlemoyer , and V eselin Stoyano v . 2020. Unsuper - vised cross-lingual representation learning at scale. In Pr oceedings of the 58th Annual Meeting of the As- sociation for Computational Linguistics , pages 8440– 8451. [17] Hiroki Nakayama. 2018. seqe v al: A Python frame- work for sequence labeling e v aluation .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment