An Interpretable Machine Learning Framework for Non-Small Cell Lung Cancer Drug Response Analysis
Lung cancer is a condition where there is abnormal growth of malignant cells that spread in an uncontrollable fashion in the lungs. Some common treatment strategies are surgery, chemotherapy, and radiation which aren't the best options due to the het…
Authors: Ann Rachel, Pranav M Pawar, Mithun Mukharjee
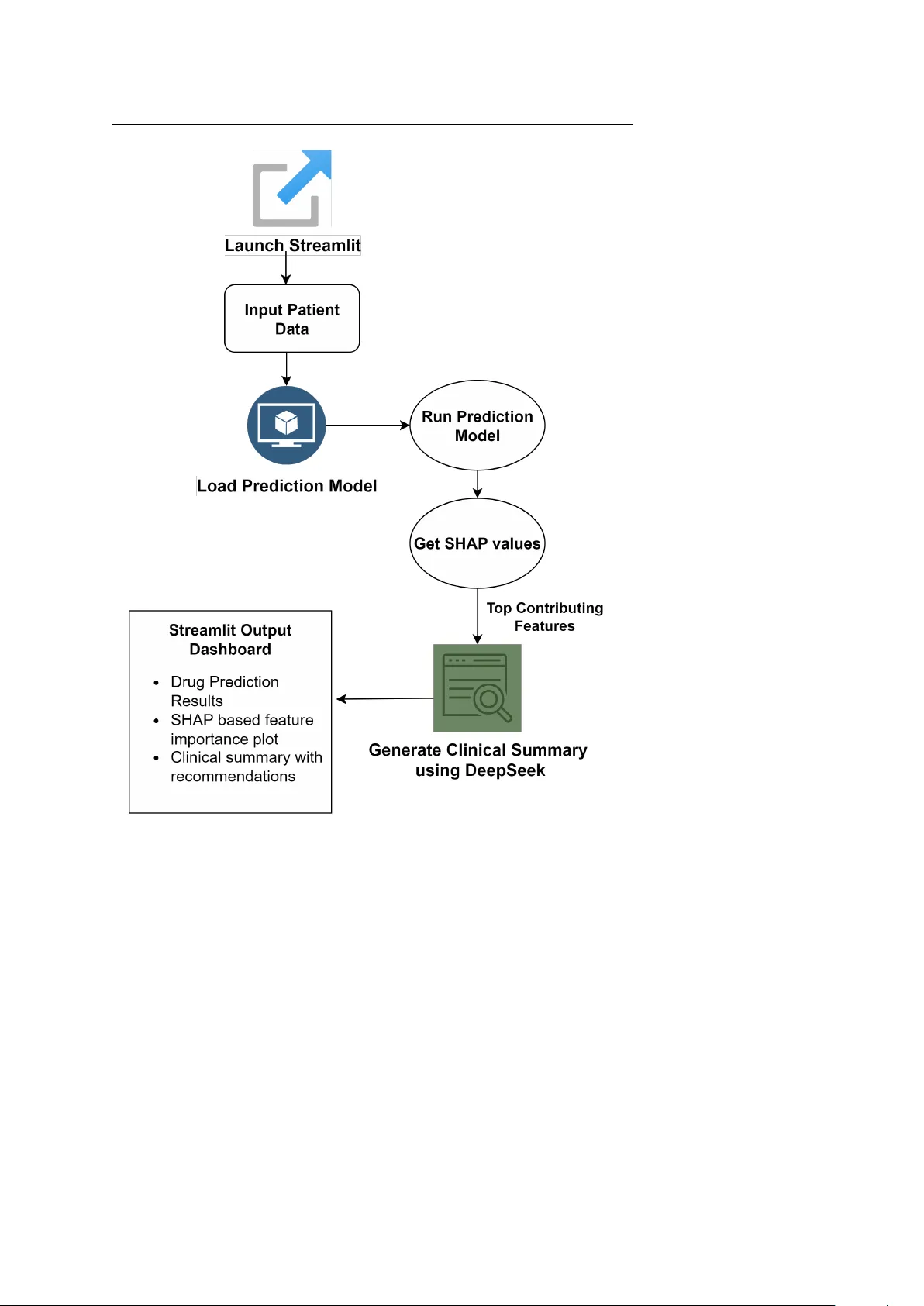
Noname man uscript No. (will b e inserted b y the editor) An In terpretable Mac hine Learning F ramew ork for Non-Small Cell Lung Cancer Drug Resp onse Analysis Ann Rachel · Prana v M P a w ar · Mith un Mukharjee · Ra ja M · T o jo Mathew Received: date / Accepted: date Abstract Lung cancer is a condition where there is abnormal gro wth of malig- nan t cells that spread in an uncontrollable fashion in the lungs. Some common treatmen t strategies are surgery , c hemotherap y , and radiation whic h aren’t the b est options due to the heterogeneous nature of cancer. In personalized medicine, treatmen ts are tailored according to the individual’s genetic in- for- mation along with lifest yle asp ects. In addition, AI-based deep learning meth- o ds can analyze large sets of data to find early signs of cancer, t yp es of tumor, and prosp ects of treatment. The pap er fo cuses on the developmen t of p erson- alized treatmen t plans using sp ecific patien t data focusing primarily on the genetic profile. Multi-Omics data from Genomics of Drug Sensitivit y in Can- cer hav e been used to build a predictiv e mo del along with mac hine learning tec hniques. The v alue of the target v ariable, LN-IC50, determines ho w sen- sitiv e or resistiv e a drug is. An X GBo ost regressor is utilized to predict the drug resp onse fo cusing on molecular and cellular features extracted from can- cer datasets. Cross-v alidation and Randomized Searc h are performed for h y- p erparameter tuning to further optimize the mo del’s predictive p erformance. F or explanation purposes, SHAP (SHapley Additiv e exPlanations) w as used. SHAP v alues measure eac h feature’s impact on an individual prediction. F ur- thermore, interpreting feature relationships was p erformed using DeepSeek, a large language model trained to v erify the biological v alidit y of the features. Con textual explanations regarding the most important genes or path w a ys were pro vided b y DeepSeek alongside the top SHAP v alue constituents, supp orting the predictabilit y of the mo del . Ann Rac hel, Pranav M Pa w ar, Mithun Mukherjee, Ra ja M, T o jo Mathew Department of Computer Science Birla Institute of T echnology and Science Pilani, Dubai Campus, Dubai, UAE E-mail: f0220078@dubai.bits-pilani.ac.in, pranav@dubai.bits-pilani.ac.in, mithun@dubai.bits-pilani.ac.in, ra ja.m@dubai.bits-pilani.ac.in, to jomathew@dubai.bits- pilani.ac.in 2 Ann Rachel et al. Keyw ords Lung Cancer · Multi-Omics Data · Personalized Medicine · SHAP · DeepSeek · Deep Learning 1 Introduction There has b een a revolutionary shift in mo dern on cology with the emergence of p ersonalized medicine, which provides therap eutic strategies based on phe- not ypic and genot ypic patient data. According the the W orld Health Orga- nization (WHO), one of the leading causes of cancer related deaths around the world is lung cancer [1]. Due to the significance of lung cancer, suc h an approac h, that is, using p ersonalized medicine along with artificial in telligence can make a significant difference in the field of oncology . Two of the pre- dominan t subtypes of Non-small cell lung cancer are: lung adeno carcinoma (LUAD), and lung squamous cell carcinoma (LUSC), whic h comprises of ap- pro ximately 85% of all lung cancer cases [2]. Both these t yp es exhibit different molecular profiles and response to therap y , ev en though they originate from the same lo cation, in the lung epithelium. Cancer’s heterogeneit y mak es it quite difficult to treat it and attain optimal outcomes, which is wh y there is a need to develop mo dels based on large data that can predict ho w a drug will resp ond for a specific patien t. Precision oncology can b e enabled using the p o werful tool, machine learning, which helps integrate and analyze biomedical data. This pap er fo cuses on LUAD and LUSC type of cancer, where AI mo dels can b e trained on m ulti omics datasets to predict the sensitivit y of cancer cells to v arious drugs. With the help of AI, hidden patterns in complex datasets can be identified whic h are generally difficult to detect using normal statistical approac hes 1.1 T raditional Metho ds Cancer or malignant neoplasm, a genetic condition, is brought on b y genetic or epigenetic changes in somatic cells. Radiotherapy , chemotherap y , and surgery are the three main treatments for cancer [3]. Eac h treatmen t approac h has dra wbacks and related issues, including my elosuppression, symptoms in the gastroin testinal tract, toxicit y to the liver and kidneys, and damage to the heart. Because of the heterogeneit y of tumors and the emergence of resistance, pharmaceutical treatmen ts are ineffectiv e. Surgery frequen tly lo w ers qualit y of life by increasing mortalit y and morbidity . Historically , generic, ”one size fits all” metho ds ha ve been used to treat cancer [4]. The effectiveness of these treatmen ts v aries greatly from p erson to p erson, and they frequently damage health y , noncancerous organs and tissues. T o increase patient surviv al and qualit y of life without sacrificing therap eutic efficacy , alternative therapies are required. Title Suppressed Due to Excessive Length 3 Fig. 1 AI/ML for Personalised Cancer T reatment 1.2 P ersonalized Medicine in Lung Cancer P ersonalized medicine helps facilitate the early diagnosis, treatment, and pre- v ention of a disease by taking into accoun t the patient’s genetic data, environ- men tal factors, and lifestyle decisions. By considering an individual’s genetic profile, it increases the p otential to predict which medical treatmen ts are safer and effective for them while at the same time minimizing adv erse reactions[5]. This paradigm has brough t ab out a more individualized approac h with regard to the patien t rather than the generic treatmen t approac h. The main ob jectiv e of the pap er is to prop ose an exhaustive mo del capable of efficiently analysing large-scale quan tities of healthcare data, unco v ering trends and insights for the enhancemen t of patient-orien ted individualized therap y . In addition to preci- sion medicine, the use of artificial intelligence in healthcare has the p otential to c hange asp ects such as patien t monitoring, clinical decision-making, and drug dev elopment and, therefore, accelerate medical progress. One field of application is oncology , as the heterogeneit y of cancer mak es it ineffectiv e to use standard approaches such as c hemotherapy and radiation, as these are effectiv e only in a fraction of patients. In the field of p erson- alised medicines with resp ect to cancer, AI can help in cancer detection and classification, drug discov ery and repurp osing, and patien t treatment outcome prediction [6]. With the help of deep learning tec hniques, molecular profiling and sp ecific m utations analysis, mo dels trained on genomic data can help pre- dict drug responses specific to that patient facilitating targeted cancer therap y . Additionally , AI based deep learning methods can analyse large sets of data to find out early signs of cancer, types of tumors, and prosp ects of treatment. 4 Ann Rachel et al. 1.3 AI Applications The in tegration of artificial intelligence with p ersonalized medicine can help to design b etter treatment plans for each individual. Suspicious lung no dules can b e iden tified as benign or malignan t using AI, as it can analyze CT, MRI or PET scans and help in earlier diagnosis and treatmen t. Also, based on imag- ing and clinical data, machine learning mo dels can predict the o verall surviv al rate. AI can also help iden tify mutations and determine how well a patient ma y react to a drug or certain treatmen t. Some common AI tec hniques used in this field are, mac hine learning and deep learning to predict disease risk, classify the cancer subtypes and understand medical images[7]. Natural Lan- guage Processing can b e used to extract information from Electronic Health Records (EHRs) and iden tify adverse drug reactions. Reinforcement Learning can help optimize dosing sc hedules and create p ersonalised treatment plan. This work mainly fo cuses on Drug Resp onse Prediction where genetic and clinical data are b eing analysed using AI techniques to iden tify the most ef- fectiv e drug for a lung cancer patien t while at the same time minimize an y adv erse effects. The model is further improv ed to predict drug sensitivit y based on clinical data lik e gene expression, mutations and other biomarkers[8]. The mo del also implemen ts explainable tec hniques like SHapley Additiv e exPla- nations (SHAP) to provide insights on ho w each feature affects the target v ariable(LN-IC50) and b y ho w m uc h. W e attain a more contextual understand- ing by passing SHAP v alues into DeepSeek whic h provides more information ab out the drug’s role, its metab olism, treatmen t adjustmen ts and actionable steps to be tak en by the clinician. By integration of AI with p ersonalized medicines, the pap er aims to impro ve precision oncology . 1.4 Key Comp onen ts of the Prop osed Metho d The pap er is fo cused on the developmen t of personalized treatmen t plans using sp ecific patien t data, including medical history and genetic profile. T o achiev e actionable and precise outcomes there are sev eral key steps are follow ed: 1. Data Pre-pro cessing: Missing and inconsistent v alues are handled such that the dataset is made ready for mo del training. One-hot encoding is p erformed to handle categorical v alues. The most relev ant v ariables for prediction are obtained through feature selection pro cess. 2. Mo del Selection and T raining: Personalized therapies are deliv ered us- ing the patient-specific profile and employing mac hine learning algorithms lik e XGBoost to predict sensitivit y of any drug to an individual based on their genetic profile. Hyp erparameter tuning is p erformed using Random- izedSearc hCV to identify the best parameters to use, enhancing the mo del’s p erformance. 3. V alidation and Optimization: Accuracy and reliability in predictions are improv ed using hyperparameter optimization. The mo dels are then tested with cross-v alidation. Title Suppressed Due to Excessive Length 5 4. Mo del Interpretabilit y: T o understand the mo del and its results, in- terpretabilit y is applied. Explainability techniques like SHAP and feature imp ortance analysis are emplo y ed to understand ho w sp ecific features in- fluence the prediction. SHAP v alues are also passed to DeepSeek, a large language mo del, to in terpret feature annotations and extract biological significance from literature, helping us understand why certain genomic or drug features are influen tial. Through our comprehensive analysis of drug sensitivit y fo cusing on lung cancer, we are able to pro vide insigh ts on the v arious factors that affect the sensitivit y of drugs to improv e decision making in the field on oncology . This article con tains a study about the researc h done in precision medicine fo cusing on drug sensitivity prediction and the problems addressed by v arious research pap ers. With the implemen tation of v arious machine learning tec hniques along with genetic data, w e made a significan t improv emen t for cancer patien ts b y fo cusing on their individualised genetic data. 2 Related W orks 2.1 ML/DL Applications for P ersonalised Medicine in Cancer The use of machine learning mo dels ha v e b een discussed in [9] to distinguish cancer and normal samples from genomic data with high accuracy based on classifiers trained on 19,627 genes from whole genome sequencing (WGS) data. Based on data from The Cancer Genome Atlas (TCGA) and Genotype-Tissue Expression (GTEx) pro jects, the mo dels are highly precise, sensitive, and sp e- cific and are promising for early cancer detection and diagnosis. How ev er, one of the ma jor limitations of this approach is sole reliance upon genomic data that cannot fully address the complexity of cancer biology . The study has not addressed combining other omics data—i.e., transcriptomics, proteomics, and metab olomics, which could possibly better guide the predictions and unra v el more holistic tumor biology . This lack of multi-omics integration can limit diagnostic precision, hinder the identification of new biomarkers essen tial to early diagnosis and treatment, and reduce the mo del’s effectiveness in person- alized medicine through the neglect of individual v ariabilit y in tumor biology . Bridging this researc h gap migh t greatly impro v e mo dels of cancer classifica- tion, offering a more complete and precise approac h to cancer diagnosis and treatmen t. The article [10] aims to improv e cancer patient stratification by leveraging b oth phenotypic and genetic features obtained from electronic health records and genetic test rep orts, appreciating the p otential of uniting these infor- mation sources for more precise treatment choice. The metho d relies on a three-step pro cess of feature pre-processing, classification of cancer patien ts, and clustering based on mac hine learning mo dels suc h as Logistic Regression (LR), Multi-Lay er Perceptron, Random F orest, and Supp ort V ector Machine. 6 Ann Rachel et al. No de2v ec em beddings are also used in the researc h to enhance asso ciation rep- resen tation b etw een phenotypic and genetic features. The database, compiled from May o Clinic’s electronic health records and genetic reports, facilitates full analysis since the results indicate joint phenot ypic and genetic features that impro ve the accuracy of classification m uch more than either dataset alone. Ho wev er, the study also indicates strong limitations in the shape of a small size for the dataset that affects the generalizabilit y of the mo del and v ariation in p erformance with classifiers. Interestingly , though conv olutional neural net- w orks were experimented with, they fared p o orly compared to other models with an F1 score of 0.74, suggesting the inabilit y to handle the complexity and high dimensionalit y of genomic information. This paper [11] fo cuses on the use of AI in cancer research and precision medicine and discusses ho w its potential can impro v e cancer care b y leveraging adv anced data analysis and machine learning mo deling. These include molecu- lar characterization deep learning mo dels that analyze multidimensional data to detect, classify , and predict the treatment outcomes of cancer. Three k ey genomic data sets are employ ed, i.e., TCGA, PCA WG, and MET ABRIC, but the study shows that these data sets hold attributes bias, esp ecially race and ethnicit y . The main strength of AI is ho w it handles intricate data sets in a quic k time, whic h results in b etter iden tification of cancer cases and formu- lation of personalized treatment plans considering genetic and en vironmen tal factors. The limitations are dataset biases that reduce mo del generalizability , and dep endence on loosely structured data, which adds illogical inconsisten- cies to the mo dels. The gaps that these biases lea v e are in regions of the lac k of rich datasets that co v er the en tire population and increased link age of information across disparate sources. F or the purpose of accuracy , the pri- mary supp ort pillars of concern p ertain to mo del verification based on several indep enden t datasets with different 0.8 strong A UC scores, which is clini- cally distinct. T o address the problem of ov erfitting, strategies in v olving cross- v alidation, increase in the size of the training set, and the use of ensemble metho ds are advised to increase the stabilit y of the mo del. While Electronic Health Records (EHRs) provide v aluable patien t data, they are yet to b e opti- mally used in AI mo dels as to its unstructured nature which requires massive curation. F urthermore real-time ev aluation to predict cancer risk can be en- abled by the in tegration of genetic susceptibility , EHRs, and lifestyle thereby pro viding p ersonalized interv en tion and risk management. The article [12] attempts to harmonize genetic and phenot ypic data to make primary cancer t yp e predictions and predict as-y et unknown primaries, p ermit- ting earlier diagnosis and optimal treatment selection. The study emplo yed ma- c hine learning and deep learning-based algorithms, including a stack ed sparse auto-enco der-based classifier and artificial neural netw ork tuned using genetic algorithm, that were trained using com bined electronic health record and ge- netic data. The information in tegrates genetic data from oncology rep orts and EHRs and pro vides a full analysis that impro ves the accuracy of predictions, Title Suppressed Due to Excessive Length 7 with high Area under the Receiver Op erating Characteristic Curve (AUR OC) scores (e.g., 99.5% for lung cancer) and clinical v alidit y guaranteed through real-patien t v alidation. Some of the limitations are the small dataset size, whic h affects robustness, and genetic data bias b ecause germline and somatic m utations cannot b e distinguished. The study’s research gaps are for larger, more diverse datasets for v alidation and the challenge of representing genetic data with relational databases, particularly anon ymization and aggregation. The method w as robust in predictiv e accuracy with a mean A UR OC of 96.56% in classifying primary cancers and 80.77% in predicting unknown primaries. This research ov ercomes previous ov erfitting and less-than-optimal utilization of EHRs through leveraging a net w ork-structured data representation using HL7 FHIR [13] standards and Node2vec embeddings for improv ed cancer pre- diction. An imp ortan t c hallenge remains: the genetic reports only considered somatic m utations, making it imp ossible to distinguish from germline muta- tions, thereb y introducing bias and weak ening the findings. This work by D’ Amico et al. [14] discusses the AI-generated synthetic data’s intended role in adv ancing research and precision medicine in hematol- ogy . This pap er will fo cus on the creation of syn thetic datasets for hematologi- cal neoplasms while ensuring fidelit y and priv acy using a Syn thetic V alidation F ramework (SVF). The article attempts to address the problem of improving the integrit y and priv acy of synthetic data so that the data might be used most efficiently in clinical trials and translational research. This is b ecause improp er synthetic data may compromise any researc h conclusions drawn and patien t priv acy . Syn thetic data aims to solv e data im balance, increases dataset, and k eeps priv acy in tact; ho w ever, c hallenges remain in fidelit y and possible misuse. Key knowledge gaps include clinical v alidation and longitudinal ap- plicabilit y . That supp orted accuracy was determined based up on the Clinical Syn thetic Fidelity (CSF) and Genetic Synthetic Fidelity (GSF) metrics. Clin- ical synthetic fidelit y w as found to b e 90%for acute my eloid leuk emia, while genomic syn thetic fidelit y reac hed 88%. F or a wider In ternational W orking Group for Prognosis in Myelodysplastic Syndromes (IWG-PM) My elodysplas- tic Syndromes (MDS) cohort, CSF and GSF rep orted mainly at 93%. Thus, the clinical v alidation ab ov e determines reliability across clinical con texts. T o mitigate dataset limitations, conditional Generative Adversarial Net work is used in generating syn thetic data and p erforming data augmentation, whic h enhances the robustness of the mo del. By v alidating synthetic cohorts in mul- tiple patient datasets, this researc h ensures their clinical relev ance, placing balanced fo cus and priority on fidelity and priv acy for an effectiv e role in clinical trials and translational researc h. With a fo cus on the integration of multi-omics data, including genomic, metab olomics, and imaging data, to improv e disease knowledge and patient- sp ecific treatment methods, this paper [15] describ es how mac hine learning tec hniques can b e utilized in p ersonalized medicine to handle complex data. Mac hine learning metho ds helps in seeing patterns that conv en tional statistical tec hniques might miss, enabling more precise classifications and predictions. 8 Ann Rachel et al. Citing earlier researc h that used genetic, imaging, and clinical data for im- pro ved illness prediction and categorization, the pap er also addresses practical uses of m ulti-omics integration. Researc h studies are also illustrated where the w ork is alwa ys b eing adv anced in integrating sev eral parameters from biology and the environmen t in machine learning environmen ts. Metho dologically , the pap er also discusses v arious machine learning frameworks, including con v olu- tional neural net w orks and Bay esian netw orks, applied to real data in order to derive useful insights. Ho wev er, one significant disadv antage of the research is that it do es not include external v alidation in the real w orld, as it do es not adequately test these machine learning mo dels using external clinical datasets. Also, although it includes man y differen t machine learning approac hes, it is dev oid of an exhaustiv e study of deep learning methods, whic h ha ve pro v ed to sho w excellent outcomes in dealing with multi-modal biomedical data. T o bridge these gaps w ould further enhance the contributions of the study by es- tablishing the real-world applicability of the suggested methodologies in clin- ical pro cedures. The pap er [16] discusses improv emen ts in pancreatic adeno carcinoma grad- ing via Bay esian Conv olutional Neural Net works for b etter prediction accuracy , incorp orating uncertaint y into the model’s action, which is imperative in the prev ention of clinical misdiagnosis. By exploiting transfer learning with archi- tecture lik e DenseNet-201, V GG-19, and ResNet-152V2, the mo del is tuned on a relativ ely small dataset con taining 3201 labeled high-resolution tissue sample patches across different cancer grades. Uncertain t y quan tification al- lo ws clinicians to rank cases for further review, whereas transfer learning helps out with generalizing where large datasets are not av ailable. This introduces learning difficulties when estimating the p osterior distribution b ecause of com- putational budgets, and although the impact of class imbalance is remov ed, it remains a quality challenge in some datasets. How ev er, a researc h gap w as iden tified concerning the relationship b etw een uncertaint y and accuracy; suc h w ould need to increase the acceptance threshold of clinical predictions. The main factor is th us accuracy , since malpractices in pan cancer misdiagnosis ha ve dire consequences, and the study found a great correlation ( ρ ¿ 0.95) b et ween uncertain t y and prediction errors, and therefore pitched the idea of uncertain ty-a w are metrics like AR Q that can balance classification accuracy and misclassification risk. The study also attempted to address issues regard- ing previous v ariant misclassification b y making use of uncertain t y estimation, allo wing for a reject option against uncertain predictions, and improving mo del resp onses to out of distribution samples. How ev er, a v ery key limitation re- mains, a small dataset size, which might inhibit generalizability despite trans- fer learning. The dataset construct, where training, v alidation, and testing accoun ted for 60%, 20%, and 20% resp ectively , means the mo del is restricted to little v ariability in cases, thus presenting a chance of o v erfitting, something that undermines its robustness for application in clinical settings. Title Suppressed Due to Excessive Length 9 2.2 AI Applications of P ersonalised Medicine in Lung Cancer The work demonstrated in this pap er[17] is aimed at developing a transparent and clinically in terpretable AI system for lung cancer detection in chest X- ra ys through an ante-hoc approac h that relies on concept bottleneck mo dels. Through this approach, everything from the AI’s decision-making process is transparen t for enhanced insight, solving the limitations of conv en tional p ost- ho c techniques, such as LIME or SHAP which t ypically establish unreliable explanations. T ested on 2,374 scans obtained from the MIMIC-CXR ((Medi- cal Information Mart for In tensiv e Care – Chest X-ra y) )dataset, the proposed mo del ac hieved an F1-score abov e 0.9 and a concept precision of 97.1%, signif- ican tly outperforming other existing XAI tools, such as CXR-LLaV A (Chest X-ra y Large Language and Vision Assistant ). While this study improv es clas- sification p erformance and generates clinically related explanations, such fac- tors’ reliability may v ary based on dataset qualit y and the threat of false negativ es. The study indicates a gap in the existing tec hniques of XAI and offers the developmen t of AI systems that embrace clinical concepts in to the real decision-making pro cess, for improv ed trust and applicabilit y in medical setups. Addressing the question of explanation reliability , this pap er puts for- w ard a promising pathw a y , w ould enhance the introduction of AI in to lung cancer diagnostics, improving b oth the fidelit y of mo dels and clinicians’ trust. This pap er b y Jiang et al. [18] prop oses a nov el approach that aims to pre- dict an ti-cancer drug sensitivit y using a new algorithm, WRE-X GBo ost, whic h in tegrates w eigh ted feature selection to increase accuracy . The WRE-X GBoost algorithm uses a mac hine learning approach to directly improv e feature rele- v ance for predictions p ertaining to drug sensitivity . This approach enables a b etter fo cus on data analytics which can significan tly improv e predicting the resp onse of cancer patien ts to v arious treatment options. The WRE-XGBoost algorithm is an extension of XGBoost and WRE-XGBoost, the latter tw o are w ell-known for their efficacy and effectiveness in dealing with v ast amounts of information and in tricate feature relationships. W eighted Relev ance Estima- tion (WRE) indicates a w eighting mec hanism that selects the most impactful features in the WRE-XGBoost dataset. The WRE-XGBoost algorithm’s ma- jor adv an tage is its focus on relev an t feature selection which impro ves accuracy to enhance personalized adaptive cancer treatmen t. One disadv antage of this design may be the detailed algorithm in design that requires extensiv e skill, cost, and computing p ow er to implemen t realistically making it less av ailable for widespread use in clinical setting. The fo cus of the article [19] was creating a mac hine learning mo del, which they named Personalized Drug Resp onse Prediction (PDRP), that would pre- dict drug resp onse levels in lung cancer patients b y in tegrating clinical, demo- graphic, energetic, and geometrical features. Performing Molecular Dynam- ics (MD) sim ulations to mo del the binding site of drug-target complexes. It inv olv es using machine learning classifiers and fo cusing on the X GBoost 10 Ann Rachel et al. T able 1 Summary of studies applying ML/DL to cancer classification and prediction using heterogeneous data sources. Reference Contribution ML/DL Metho d Cancer Type/F o cus Result [9] A. Hoosh- mand (2020) Proposed a mac hine learn- ing system to classify ge- nomic profiles for accurate cancer diagnosis. Na ¨ ıve Ba yes, SVM, De- cision T rees, Random F orest, Logistic Regres- sion, K-NN. 22 cancer types us- ing 19,627 genes from W GS data. Reported precision, sen- sitivity , and specificity of 1.0 for nearly all cancer types, indicat- ing excellent classifica- tion performance. [10] D. Oniani et al. (2021) Developed a classification framework combining phenotypic and genetic features from EHRs using multiple GNN models. Eight different Graph Neural Netw ork archi- tectures explored. Multiple cancer types, with focus on phenotypic- genotypic interac- tions. CNN achiev ed F1-score of 0.74; Logistic Regres- sion scored 0.90. [11] B. Bhinder et al. (2021) Demonstrated AI’s role in risk assessment and per- sonalized care by integrat- ing diverse omics and clin- ical datasets. Deep Neural Netw orks, Random F orest, Deep- V arian t. CNS and skin cancers; includes methylation and mutation analyses. No specific metrics re- ported; emphasized AI’s utility and lab-level val- idation. [12] N. Zong et al. (2021) Integrated genetic reports and EHRs to predict and classify b oth primary and unknown cancer types. Node2vec embeddings, CNNs, Autoencoders. Multiple cancers incl. prostate, breast, liver, pan- creas, and thyroid. Achiev ed 95% AUR OC for primary classifica- tion and 80% for un- known primaries. [14] S. D’Amico et al.(2022) Inv estigated AI-generated synthetic data as a priv acy-preserving so- lution for accelerating hematological cancer research. Conditional GANs (cGANs) for synthetic clinical-genomic data generation. Hematological malignancies: Myelodysplastic Syndromes, AML. Used NNDR (Nearest Neighbor Distance Ra- tio) b etween 0.60-0.85 to balance fidelity and priv acy . [15] S. J. MacEachern and N. D. F ork- ert (2021) Integrates different types of data, known as multi- modal or multi-omics data, to increase the level of precision medicine. Deep learning al- gorithm, such as DeepSEA and Deep- V arian t, that is applied in genomic data and in estimating the func- tional effects of genetic v ariants. The pap er men- tions the applica- tion of machine learning in various cancer types, not focusing on a cer- tain t ype. It highligh ts that ver- ification of the mod- els through independent test sets is an important factor to take care of, so the model does not do overfitting or under- fitting of the data. [16] B. Ghoshal and A. T uc ker (2022) This pap er utilizes uncer- taint y in the automated assessment of pancreatic adenocarcinoma through histopathology images. It uses an algorithm grounded in Bayesian Conv olutional Neural Netw orks capable of estimating uncertainty associated with pre- dictions made b y the model. The dataset inv es- tigated within this research comprises histopathology im- ages fo cusing on pancreatic adeno- carcinoma. The paper elaborates further on the merit of metrics that apply relative weights to classification accuracies against misclassifica- tion costs. [17] A. Rafferty et al. (2024) The pap er proposes an interpretable AI model for lung cancer detection using concept bottleneck models to enhance trans- parency . InceptionV3 for concept prediction; MLP , SVM, and DT for label predic- tion. Lung cancer detec- tion using chest X- ray images. Achiev ed F1-score ¿ 0.9 for lung cancer detection, showing strong classification performance. [18]Y. Jiang et al. (2024) Proposes WRE-X GBoost algorithm to enhance prediction of an ti-cancer drug sensitivit y and tailor treatment plans. WRE-XGBoost (an op- timized varian t of XG- Boost with weighted feature selection). Multiple cancer types; fo cus on genes mo dulating chemotherap y re- sponse. No specific metrics reported; emphasizes improv ed prediction through refined feature selection. [19]R. Qureshi et al. (2022) F ocuses on developing a p ersonalized drug re- sponse prediction model tailored to the needs of lung cancer patients. The b est performing model was constituted of an XGBoost classi- fier. It’s primary focus was lung can- cer, particularly patients with mutations in the epidermal growth factor receptor gene. The PDRP model demonstrated an un- precedented accuracy in predicting the levels of response to prescribed drugs. [20]J. R. Astley et al. (2024) Sharpens surviv al predic- tion in patients with non- small cell lung cancer (NSCLC) undergoing rad- ical radiotherap y . Utilizes Cox Prop or- tional Hazards model, random surviv al forests, and deep learning mo d- els to predict overall surviv al from pre- treatment cov ariables. Predicting overall surviv al in non- small cell lung cancer patien ts. The models’ p erfor- mance was primarily expressed in terms of C-index and integrated Brier score. The DL method promised a C-index of 0.670 and an IBS of 0.121. [21]L. Pant et al. (2024) Leverages genomic data to predict drug sensitivity in cancer and improve treat- ment outcomes b y pro vid- ing patients with tailored therapies. The authors use sev eral machine learning meth- ods to analyze complex genomic data and pre- dict drug resp onse. The study exam- ines cancer cell lines to assess how sensitive these cell lines are to a range of anti-cancer drugs. The findings show Ran- dom F orest was better than the other mo dels in predicting drug sen- sitivity . [22]Y. Shi et al. (2024) The paper provides a full, searchable database (D3EGFRdb) of patient cases with EGFR muta- tions and treatment re- sponses. The study utilizes a deep learning mo del to predict drug sensitiv- ity in patients with EGFR m utations, em- ploying underlying neu- ral network architec- tures . The study focuses on non-small-cell lung cancer and the association of EGFR mutations on drug sensitivity . The results sho w that the D3EGFRAI mo del was satisfactorily pre- dictive of drug sensi- tivity , sho wing potential utility for clinical deci- sion making. Title Suppressed Due to Excessive Length 11 classifier for data analysis concerning drug resp onses to b e predicted. The dataset incorporated demographic and clinical data for lung cancer patien ts, whic h included: age, gender, history of smoking, surviv al status, and lev el of resp onse to treatment. A total of 33 differen t Epidermal Growth F actor Re- ceptor (EGFR) point m utations w ere considered, with molecular dynamics (MD) sim ulations conducted for ev ery m utan t. The primary algorithm p er- formed w as the X GBo ost classifier, renowned for exemplary performance in classification problems. The model was conditioned on the features to ascer- tain the four stratified resp onses: complete response, partial response, stable disease, or progressiv e disease. An ov erarc hing b enefit of the PDRP mo del is the precision rate it has in accuracy kno wn to b e 97.5 p ercent when sp ot on classified. A noted dra wbac k was the male dataset from whic h misclassifica- tions were drawn.The efficiency of the PDRP model was assessed in terms of its precision, recall, F1-score, and balanced accuracy . The model exhibited a classification accuracy of 97.5 percent, which is an indicator of its pro ductivit y in predicting the resp onses to drugs. The ob jectiv e of the study [20] b y J. R. Astley et al.[] is to generate the OS of patien ts with NSCLC receiving radical radiotherap y b y applying different mo deling tec hniques to b o ost predictiv e accuracy . The Deep Learning model p erformed prominently among others, yielding a C-index of 0.670 and an IBS of 0.121. The authors also in tro duce Lo cal In terpretable Mo del-agnostic Ex- planations (LIME), whic h were v aguely addressed in past research, in order to enhance the in terpretabilit y of the model regarding feature contributions. While this adv ancement renders the mo del b etter suited for clinical applica- tions, the study ackno wledges limitations such as: • LIME reliabilit y regarding binary features: The p erturbation-based approach of LIME with binary v ari- ables may fail to accurately grasp the imp ortance of binary cov ariables. • Discrepancy betw een local vs. global interpretabilit y: LIME provides lo cal ex- planations whic h do not necessarily correlate with a global understanding of the model b eha vior. T o address these concerns, the authors propose ha ving SHAP v alues incorporated along with LIME for well-rounded explanations. F urthering, although the dataset consisting of 471 NSCLC patients receiving radical radiotherap y has a goo d basis for surviv al prediction, the small num ber of stage IV patien ts could sev erely limit generalizabilit y . The study raises a critical gap within researc h in in terpretable tools in machine learning-based surviv al prediction along with further needs for v alidation. The future will b e fo cused on em b edding local and global explainers to impro v e transparency and confidence in clinical decision-making based on LIME and SHAP v alues. The ob jectiv e of this researc h pap er [21] is to develop p ersonalized medicine for cancer treatment through the use of genomic data to determine drug sen- sitivit y . The ultimate goal is to improv e the patien t-specific therap eutic in- terv entions delivered to patien ts by wa y of the unique genetic and molecular profiles of individual tumors, rather than the existing standard of care that is deliv ered uniformly to all patients. In order to dev elop the patient-specific 12 Ann Rachel et al. therap eutic in terv entions, the data generation in v olved feature engineering and feature selection, which is the transformation of raw genomic data to b e input into machine learning mo dels. This inv olv ed pro cessing the genomic data, feature engineering, and finally feature extraction which allow ed for the complex genomic data to b e summarized into reasonable metrics. This last stage included dimension reduction metho dologies, for example using Prin- cipal Component Analysis (PCA) and auto enco ders to maintain informative patterns while reducing the n um ber of original v ariables. This study uses the Genomics of Drug Sensitivit y in Cancer (GDSC) dataset, whic h pro vides an extensiv e genomic profile for cancer cell lines along with sensitivity to a large range of anti-cancer drugs. The GDSC dataset is significant b ecause it pro vides the necessary details regarding the biological v ariabilit y in resp onse to drug sensitivit y regarding genomic alterations. The study utilizes many mac hine learning algorithms, for example using Logistic Regression as an initial mo del for binary classification of drug sensitivity (sensitiv e or resistan t), Random F orest as an ensemble option that fits man y decision trees to predict out- comes correctly and to impro v e accuracy , and finally using X G-Boost which is a h yp er-optimized v ersion of a gradien t bo osting mo dels and improv es in- terpretabilit y from phasing structural info together while decreasing training time and improving prediction p erformance.The positive asp ects of this ap- proac h included increased accuracy for predicting drug sensitivity with the use of genomic somatic data and the potential for individualized treatments leading to b etter treatment outcomes and decreased to xicit y to patien ts. How- ev er, the study included some negative asp ects as well, particularly related to utilizing highly dimensional genomic data whic h created complexit y for training models and mo del in terpretation, and also potentially causing logis- tic regression to struggle with high-dimensional datasets where the num ber of features exceeded the n um ber of samples. Overall, the random forest method sho wed better o v erall p erformance than the other modeling metho ds and in the v arious metrics of measuring prediction risk for drug sensitivity . The study expressed the ob jective of impro ving p ersonalized cancer treatment through genomic data and adv ancing data analysis on genomic molecular cancer data b y using mac hine learning algorithms to maximize predictiv e accuracy while ac knowledging the c hallenges asso ciated with using complex datasets. The main goal of the study [22] was to assess the effect of Epidermal Gro wth F actor Receptor (EGFR) mutations on drug sensitivity and how to b est pro vide treatmen t with a database of actual patien t cases and a drug sen- sitivit y prediction to ol. The study inv olv ed the integration of a clinical patien t database (D3EGFRdb) and a drug resp onse prediction mo del (D3EGFRAI). The database con tains patient cases with EGFR mutations, along with clini- copathological c haracteristics and instrumen tal therapies in terms of appro v ed drug responses. The mo del w as dev eloped by deep learning to ev aluate drug sensitivit y . The external clinical dataset included clinical records and outcomes for 102 patien ts treated with EGFR-Tyrosine Kinase Inhibitors (EGFR-TKIs) at the Shanghai Pulmonary Hospital from Marc h 2015 to October 2020. The Title Suppressed Due to Excessive Length 13 dataset included information pairs of v arious drugs and mutan ts, and w as com- plied according to Resp onse Ev aluation Criteria in Solid T umors v1.1. The study employ ed a deep learning mo del for prediction of drug detected and used drug and protein enco ders from DeepPurp ose. The mo del w as pretrained in a large scale bioactivity dataset, where a fraction of the dataset w as used as a test set and the remainder divided into the training and v alidation set. One adv antage of the D3EGFR platform is that it streamlines with real pa- tien t cases that feature sp ecific clinical information and medication outcomes, while also allowing patients to be reasonably correct on treatment.Moreo v er, the prediction model pro duced acceptable results in clinical patient cases, and therefore, increasing the p ossibility of precision medicine. A p otential disad- v antage argued in the study is ho w the study is reliant on retrosp ective data, as this could in troduce systematic biases and constrain the generalization of the findings. In addition, the prediction mo dels accuracy and reliability could b e improv ed with more reported and internal clinical trial results in the fu- ture. While certain p erformance measure v alues (like accuracy , sensitivity , or sp ecificit y) were not provided in the contextual descriptions, the study states the D3EGFRAI mo del has pro duced satisfactory prediction p erformance for clinical patien t cases, indicating a go o d ev aluation of its effectiveness. 3 Metho dology This section provides the metho dology adopted in this w ork for predicting drug sensitivity in lung cancer patients for tw o subt yp es of non-small cell lung cancer, i.e., lung adenoc arcinoma (LUAD), and lung squamous cell carcinoma (LUSC) with the help of explainable AI and mac hine learning. It inv olv es dataset preparation, mo del training, adding SHAP for in terpretabilit y , and streamlit implemen tation. 3.1 Mo del F ramework for Drug Sensitivity Prediction – Data Acquisition and Exploration: The dataset acquired from Genomics of Drug Sensitivity in Cancer is loaded into a Pandas DataF rame. The dataset is filtered to only con tain LUAD and LUSC cancer types. The target v ariable, LN-IC50, represents the drug sensitivity (a low er LN-IC50 v alue indicates higher sensitivit y). Using matplotlib, seab orn and plotly , exploratory data analysis is performed to understand the correlation within the dataset. – Data Prepro cessing: The missing v alues of v ariables greater than 5 p ercent are dropped and those under are filled in with the model v alues or mean v alues. One-hot encoding is performed to con v ert categorical v alues into n umerical v alues so that machine learning mo del can understand. 14 Ann Rachel et al. Fig. 2 Histogram Showing the Distribution of Log-T ransformed IC50 (LN-IC50) Across All Cancer Samples – Mo del T raining: A regressor X GBoost is trained on the selected features with LN-IC50 as target. Hyperparameter search is carried out using Ran- domized Search. The model is ev aluated using RMSE, MAE, and R ² on the test set. – Explainabilit y: SHAP is used to explain whic h features contribute most to the drug sensitivit y prediction for eac h sample. The SHAP v alues are then passed on to the DeepSeek API, which summarizes them into simple clinical insights, making the results more interpretable and easy to use in p ersonalized treatmen t planning. 3.2 Dataset The GDSC (Genomics of Drug Sensitivity in Cancer) dataset represen ts a complete pharmacogenomic resource aimed at examining the drug resp onse of n umerous cancer cell lines. The dataset provides 242,036 records spanning 19 columns of data, directly comprising biological data and molecular [electronic] data. Each cancer cell line is attached to unique identifiers like COSMIC- ID and CELL-LINE-NAME, as is each therap eutic comp ound like DRUG- ID and DRUG-NAME. The cell lines are denoted with TCGA identifiers (TCGA-DESC, Cancer Type, and Microsatellite instability Status (MSI)). Drug resp onse is quantitativ ely represented by LN-IC50 (the log-transformed inhibitory concentration),A UC, and Z-SCORE for comparative analyses across drugs and cell lines. The dataset provides ric h molecular profiling source data Title Suppressed Due to Excessive Length 15 Fig. 3 Boxplot representation of LN-IC50 Distribution in LUAD vs LUSC also including Gene Expression, Meth ylation, and CNA (Copy Number Alter- ations), facilitating research on sp ecific genetic and epigenetic effects on drug sensitivit y modeling. The columns T ARGET and T ARGET-P A THW A Y rep- resen t the drugs biological targets and affected path wa ys the drug expresses its action upon. Experimental conditions of screen medium and gro wth prop erties in the dataset pro vide additional con textual information regarding v ariances in lab oratory proto col. The GDSC dataset pro vides a multidimensional accoun t- ing of the biological and molecular prop erties of multiple cancer types, and a ven ues for predictiv e modeling for drug sensitivit y in a wide range of clin- ical circumstances, including identifying how v arious lung cancer cell types resp ond to some sp ecific drugs. 3.3 Data Prepro cessing T o obtain the lung cancer subtypes, the dataset w as filtered first to obtain lung cancer subt yp es, Lung Adeno carcinoma (LUAD) and Lung Squamous Cell Carcinoma (LUSC) b y filtering ro ws where TCGA-DESC column is either of LUAD or LUSC. Filtering the data in this wa y helped ensure that the analysis and mo deling predictions used the LUAD and LUSC lung cancer subtypes only . Missing data w as an important aspect of prepro cessing ensuring data qual- it y and accuracy of the mo del. An y rows with missing v alues in the T ARGET column were remov ed, as these data would not produce useful information for the mo del training. The other feature of in terest was the Microsatellite 16 Ann Rachel et al. instabilit y Status (MSI) feature. F or rows without v alues, the mo de (most common v alue normally) was imputed, as the random imputation w ould nor- mally in troduce bias. Imputing the mode and remo ving the cells that w ere n ull allo wed to keep as many v alues completion as p ossible in the dataset and not affect the integrit y of the MSI feature.Categorical v ariables were then enco ded with one-hot enco ding, which transforms categorical columns in to n umerous binary columns, each of whic h is categorically 0 or 1 for the sp ecified category . One-hot enco ding allows mac hine learning models to av oid defining ordinal relationships in categorical data while also av oiding assumptions inherent in lab eling. Additional features that were not useful for training a mo del (or w ere potentially leaking data) w ere remov ed from the feature set, including columns of unique identifiers (COSMIC-ID, CELL-LINE-NAME, DRUG-ID), the A UC column, and column v alues such as labels for cancer type, as the target v ariable w as LN-IC50 (the natural logarithm of the half-maximal in- hibitory concentration). In Figure 2, the histogram represents the distribution of log-transformed IC50 (LN-IC50) v alues across all cancer cell lines stud- ied. The data ha v e a right-sk ew ed distribution, with most v alues concentrated b et ween 2.5 and 6.0, whic h suggests v ariabilit y of drug sensitivity b etw een samples. Figure 3 show cases the distribution of LN-IC50 v alues for tw o lung cancer subt yp es, Lung Adeno carcinoma (LUAD) and Lung Squamous Cell Carci- noma (LUSC). Both subt yp es share similar median IC50 v alues but LUSC p oten tially slightly greater v ariabilit y and higher outliers in drug resp onse. After the dataset is preprocessed, the cleaned dataset was split for train- ing/testing with an 80-20 split to ev aluate the mo del’s performance on data it had not previously seen and in order to assess its generalization p erformance. 3.4 Dev elopment and Implemen tation of Mo del T o predict drug sensitivity (LN-IC50), an X GBoost regressor was employ ed giv en its go o d handling of tabular data, and theoretical ability to mo del com- plicated functions that hav e nonlinear non-remo v able terms. Before fitting the X GBo ost mo del to the training data, a h yp erparameter optimization proce- dure was p erformed via RandomizedSearchCV. This metho d searches o ver a defined parameter space where a random combination of h yp erparameters suc h as the n um ber of trees (n-estimators), learning rate, maxim um tree depth (max-depth), subsample ratio, and feature sampling ratio (colsample-bytree) are specified. Multiple combinations of parameter v alues are ev aluated using cross-v alidation to iden tify the combination of hyperparameters that yield the b est predictiv e p erformance based on the R ² metric. Once the optimal hyperparameters were selected, we then fit the XG- Bo ost model on the training data. The fitted mo del was then ev aluated on the hold-out test set to assess p erformance using regression error metrics, Mean Squared Error (MSE), Mean Absolute Error (MAE) and R ² score. This quantified the amoun t of prediction error, derived some insigh ts into Title Suppressed Due to Excessive Length 17 Fig. 4 Prop osed Predictiv e Model Architecture for Personalized Lung Cancer Drug Re- sponse T reatment T able 2 Regression Mo del P erformance Comparison Mo del MAE MSE R 2 X GBo ost 0.0851 0.0249 0.9971 Random F orest 0.8228 1.1032 0.8700 Linear Regression 0.2268 0.1298 0.9847 the mo del’s p erformance, and informed us ab out the amount of v ariability explained in drug sensitivit y . T o enhance the strength and reliability of the mo del, a pro cess of 10-fold cross-v alidation w as p erformed. In this pro cess, the entire dataset w as divided into 10 subsets (folds), and the mo del was trained on 9 out of the 10 folds while v alidation w as done on the remaining fold. This pro cess w as rep eated 10 times. This not only help ed ev aluate the reliabilit y of the mo del on certain subsets of data, but it also helped to con- trol ov erfitting and gav e a b etter generalized estimate of model p erformance. Algorithm 1 Drug Sensitivit y Prediction and Explainability for Lung Cancer T reatment Input: GDSC Dataset (filtered for LUAD and LUSC) Output: LN IC50 prediction model with SHAP-based clinical recommenda- tions 18 Ann Rachel et al. 1: Step 1: Load and Filter Data 2: Load the GDSC dataset in to a dataframe 3: Filter ro ws where TCGA DESC ∈ { LUAD, LUSC } 4: Step 2: Handle Missing V alues 5: for each column in the dataset do 6: if column is TARGET and v alue is missing then 7: Drop the ro w 8: else if column is MSI Status then 9: Fill missing v alues with most frequent v alue (mo de) 10: end if 11: end for 12: Step 3: F eature Selection and Enco ding 13: Drop iden tifier columns 14: Set target v ariable y ← LN IC50 15: One-hot enco de categorical features in X 16: Step 4: T rain-T est Split 17: Split dataset in to 80% training and 20% testing sets 18: Step 5: Hyp erparameter T uning 19: Define searc h space for XGBRegressor 20: P erform RandomizedSearchCV with 5-fold cross-v alidation 21: Step 6: Mo del T raining and Ev aluation 22: T rain final mo del using b est parameters 23: Predict LN IC50 on test data 24: Compute R 2 score and MAE 25: Ev aluate with 10-fold cross-v alidation 26: Step 7: Explainabilit y with SHAP 27: Initialize SHAP T reeExplainer with trained mo del 28: Compute SHAP v alues on test set 29: Plot SHAP summary and bar c harts 30: Rank features b y av erage SHAP imp ortance 31: Step 8: Instance-Lev el In terpretation 32: Select test instance i with index tr ue index . 33: Retriev e predicted LN IC50 and asso ciated DRUG NAME . 34: Determine resp onse t yp e: resistant if LN I C 50 > 4, sensitive otherwise 35: Extract top 5 con tributing SHAP features 36: Step 9: Clinical Summary Generation 37: Construct prompt using SHAP features and prediction 38: Send prompt to DeepSeek API for in terpretation 39: if API call is successful then 40: Prin t clinical explanation and actionable insigh ts 41: else 42: Log API error or retry 43: end if 44: Step 10: Streamlit App Deplo ymen t 45: Design in terface for input features and visualization 46: Displa y mo del prediction, SHAP plots, and DeepSeek output Title Suppressed Due to Excessive Length 19 Fig. 5 Mo del Flow chart for Drug Response Prediction System 3.5 Explainabilit y SHapley Additive exPlanations (SHAP) was used in this case to interpret the predictions generated by the X GBoost mo del to predict drug response. SHAP is a game-theoretic technique which allocates a con tribution v alue to 20 Ann Rachel et al. eac h feature and describ es the c hange in an y individual prediction. SHAP can provide detailed interpretabilit y globally or lo cally , and pro vides a ric her description of model behavior than merely lo oking at feature importance, as w e can describ e the impact of features on a given mo del output. F or the X GBoost mo del, T reeExplainer metho d was used specifically de- signed to calculate exact SHAP v alues for all the features for the entire test dataset using tree-based mo dels such as XGBoost. Summary plots of SHAP v alues-once w e assigned v alues using the scanner procedure-allow ed us to de- termine which features had the largest o v erall impact on the predicted drug sensitivit y . A mean absolute SHAP v alue bar plot provided further clarity ab out whic h features had the largest absolute effect on the mo del’s predicted drug resp onse. Lo cal in terpretabilit y w as illustrated by reviewing the SHAP v alues for eac h individual test sample. F or each patient, the features were rank ed based on the size of the SHAP v alues, and iden tified the top genomic or clinical fea- tures that most influenced the predicted drug resp onse (LN-IC50) as shown in Figure 6. This personalized in terpretation is extremely v aluable for precision medicine as it reveals patient sp ecific driv ers of drug sensitivity or resistance. T o increase clinical relev ance, the SHAP-based explanations were bundled into a clinical assistan t AI via the DeepSeek API. The clinical AI w as provided with information on the predicted drug response, drug name, and the top contribut- ing features. It then generated a rep ort con v eying a complete interpretation including the mec hanism of action of the drug, and considerations for drug metab olism along with p ersonalized treatment recommendations. This im- pro ved the transparency in the use of AI, easing the translation of complicated outputs from mac hine learning mo dels into applicable clinical b ehaviour. In summary , the SHAP framework provides a complete wa y for explaining predictions in this regard. It com bines b oth global information concerning whic h features were the most important predictors for the cohort, as well as individual explanations to aid personalized recommendations. This work con tributes tow ard an effective and safe implemen tation of AI in precision oncology . 4 Results and Discussion A relev an t study by Pan t et al. [13] introduced a machine learning framework to predict cancer drug sensitivity using genomic features. This study used the Genomics of Drug Sensitivity in Cancer (GDSC) dataset and performed sev eral prepro cessing steps suc h as feature engineering, dimensionalit y reduc- tion through Principal Comp onent Analysis (PCA) and auto enco ders, and emplo yed a v ariet y of mo deling strategies. The study explored logistic regres- sion, random forest and XGBoost; ho w ev er the random forest model w as the most robust for av erage v alidation metrics. The study reported a co efficient of determination (R ² ) of 0.99, a mean absolute error (MAE) of 0.16, mean squared error (MSE) of 0.08 and a ro ot mean squared error (RMSE) of 0.29. Title Suppressed Due to Excessive Length 21 Fig. 6 SHAP W aterfall Plot: Contribution of each F eature In contrast the current metho dology only analyzes LUAD and LUSC sub- t yp es in the GDSC and reframes the analysis from binary classification to re- gression problems predicting LN-IC50 v alues. This reframing allo ws the model to examine more nuanced levels of drug sensitivity . Each approach is trained on an optimized X GBo ost regressor with hyperparameter tuning from Random- izedSearc hCV. As a result of the new mo deling approach, the final mo del had impro ved predictive p erformance including R ² of 0.9971, MAE of 0.0851 and MSE of 0.0249 indicating impro v ed accuracy and generalization. In addition to predictive accuracy , the metho d fo cuses on explainability . This is not a new asp ect of machine learning in precision medicine, but the previously rep orted study did mention c hallenges with interpretabilit y of high-dimensional mo d- els relative to the future clinical application of models. The curren t metho d addresses this through the SHAP (SHapley Additive exPlanations) algorithm to offer global and lo cal feature attribution. This can be further enhanced through the DeepSeek API consumer natural language clinical interpretations based on the list of top con tributors features for each prediction. This provides a more clinically relev ant interpretation of the complex predictions. Also, the framew ork is deploy ed through a Streamlit based application to pro vide end users the ability to input data in teractiv ely , view predictions, visualize SHAP outputs, and view clinical summaries. The end-to-end pipeline from data prepro cessing and regression mo deling through explainability to real-time deploymen t create a holistic and in terpretable approach to adv ance p ersonalized treatmen ts of lung cancer based on genomic profiles. T o simulate the effect of shifting ep o chs of training, mo del p erformance is assessed by differen t v alues of n-estimators (XGBoost iterations). As shown in Figure 8, R ² score progressively increased with rising estimators from 0.77 (50 22 Ann Rachel et al. Fig. 7 W orkflow diagram of the end-user application dev elop ed to mak e use of the proposed model estimators) to 0.95 (250). Also, MAE decreased from 1.15 to 0.51, indicating greater accuracy of prediction. Title Suppressed Due to Excessive Length 23 T able 3 Comparison of Model Performance Metrics Metric Previous Study [13] Current W ork (XGBoost + SHAP) R 2 Score 0.9900 0.9971 MAE 0.1600 0.0851 MSE 0.0800 0.0249 RMSE 0.2900 0.1578 Fig. 8 Mo del Performance with V arying Boosting Rounds 5 Mo del Performance and Ov erfitting Assessmen t The mo del’s p erformance was ev aluated using 5-fold cross-v alidation to assess its generalization capabilit y . The results are summarized in T able 4. T able 4 Cross-V alidation P erformance Metrics Metric F old 1 F old 2 F old 3 F old 4 F old 5 Average R ² Score 0.9979 0.9967 0.9944 0.9974 0.9963 0.9965 MAE 0.0746 0.0755 0.0884 0.0786 0.0798 0.0794 5-fold Cross v alidation w as used to determine the performance of the model and test its abilit y to generalize. The R ² scores ac hiev ed on the folds were: 0.9979, 0.9967, 0.9944, 0.9974 and 0.9963, which gav e a mean of 0.9965. The corresp onding Mean Absolute Error (MAE) v alues were 0.0746, 0.0755, 0.0884, 0.0786 and 0.0798 with the av erage MAE of 0.0794. The high R ² v alues nearly equal to 1.0, and the low v alues of the MAE in all folds p oint to the fact that the mo del has high predictive accuracy . The low difference in cross-v alidation folds also sho ws consistency of p erformance across subsets of data. These findings are an indication that the model is not ov er-fitting the training set. Differences in p erformance b etw een folds would b e quite large or a large decline of accuracy on unseen data w ould be observ ed to character- 24 Ann Rachel et al. ize ov erfitting. This has b een observ ed to be consisten t and therefore implies that the mo del generalizes well to unseen new samples because of capture of patterns in data, not memorization of noise. 6 Conclusion In this pap er, a mac hine learning framework is presen ted to predict drug re- sp onsiv eness in lung cancer subt yp es LUAD and LUSC, using the Genomics of Drug Sensitivit y in Cancer (GDSC) dataset . By developing an X GBoost re- gression mo del and do wn-sampling the h yperparameter optimization via a ran- domized tuning process, the mo del ac hiev ed an R ² score of 0.9971 and v ery lo w error, which outp erformed the regression mo del Random F orest and Linear Re- gression. In addition, SHAP v alues w as utilized to interpret the mo del b ecause it allow ed to measure imp ortant genomic and clinical features that drov e drug sensitivit y and resistance. In terpretable mo dels are especially imp ortant for understanding complex biological interactions, and support decision-making in precision medicine. Additionally , DeepSeek API was used to summarize clinical observ ations and link it bac k to the w eb-based drug predictions, highlighting the practical implications of using explainable AI methods for precision on- cology applications. The significance of this w ork is that it can ultimately help impro v e therapeutic success rates b y tailoring drug regimens based on an individual’s molecular profile and eliminate the burden of trial and error, whic h is often the case in cancer drug decisions. P oten tial uses of this frame- w ork includes helping clinicians figure out which drugs to try first, identifying whic h resistance mec hanism might occur, and identifying w orth y candidate biomark ers for further exploration in the area of precision oncology . 7 Declarations – Av ailability of data and material: Not applicable – Comp eting in terests: Not applicable – F unding: Not applicable – Authors’ con tributions: Ann Rac hel directed the study’s conception and design, conducted a comprehensive literature review, structured the tax- onom y of c hallenges and strategies, and authored the initial draft of the man uscript. Prana v M. Pa w ar contributed to the drafting and enhancemen t of k ey sections of the man uscript, o v ersa w the researc h pro cess, and partic- ipated in the analysis of digital priv acy risks asso ciated with IoT, AI/ML, and federated learning solutions. Mithun Mukherjee engaged in man uscript revision, facilitated the critical assessmen t of existing methodologies, and con tributed to discussions regarding unresolved issues and prosp ective re- searc h directions. Ra ja M offered essential feedback, assessed and refined the manuscript for technical rigor and clarity , and guided the research tra- jectory . T o jo Mathew assessed and refined the manuscript for technical rigor and clarit y , and guided the researc h tra jectory Title Suppressed Due to Excessive Length 25 – Ac knowledgemen ts: Not applicable References 1. W orld Health Organization, ”Lung cancer,” WHO, F act Sheets, 2023. [Online]. Av ailable: https://www.who.in t/news-room/fact-sheets/detail/lung-cancer. 2. M. S. Abrazinski, ”Lung Cancer Overview,” Medscape, 2024. [Online]. Available: https://emedicine.medscape.com/article/279960-ov erview. 3. J. Smith et al., ”Adv anced Imaging in Lung Cancer Diagnosis,” The British Journal of Radiology , v ol. 96, no. 1152, p. 20230334, 2023. [Online]. Av ailable: https://academic.oup.com/bjr/article/96/1152/20230334/7499290. 4. A. P . Smith, B. Jones, and C. T aylor, ”Lung Cancer T reatmen t and Progress,” PMC, 2019. [Online]. Av ailable: https://pmc.ncbi.nlm.nih.go v/articles/PMC6352312/. 5. D. Stefanic k a-W o jtas and D. Kurpas, “P ersonalised Medicine—Implemen tation to the Healthcare System in Europ e (F o cus Group Discussions),” Journal of Personalized Medicine, vol. 13, no. 3, p. 380, F eb. 2023, doi: https://doi.org/10.3390/jpm13030380. 6. P . Krzyszczyk et al., “The growing role of precision and p ersonalized medicine for cancer treatment,” TECHNOLOGY, vol. 06, no. 03n04, pp. 79–100, Sep. 2018, doi: https://doi.org/10.1142/s2339547818300020. 7. Deshmukh SK. , ”Artificial Intelligence and Machine Learning in Cancer Care: Current Applications and F uture Perspectives,” Journal of Canc er Immunolo gy , v ol. 2, no. 2, Aug. 2020, doi: h ttps://doi.org/10.33696/cancerimmunol.2.011. 8. Chen et al. , “Integrativ e Machine Learning Approach for F orecasting Lung Can- cer Chemosensitivity: F rom Algorithm to Cell Line V alidation,” Computational and Structur al Biote chnolo gy Journal , vol. 27, pp. 3307–3318, Jan. 2025, doi: https://doi.org/10.1016/j.csbj.2025.07.043. 9. A. Hooshmand, “Machine Learn ing Against Cancer: Accurate Diagnosis of Cancer b y Machine Learning Classification of the Whole Genome Sequencing Data,” arXiv.org, Sep. 12, 10. D. Oniani et al., “Comparisons of Graph Neural Netw orks on Cancer Classifi- cation Lev eraging a Joint of Phenotypic and Genetic F eatures,” arXiv, Jan. 2021. https://doi.org/10.48550/arxiv.2101.05866 11. B. Bhinder et al., “Artificial Intelligence in Cancer Research and Preci sion Medicine,” Cancer Discov ery , vol. 11, no. 4,2021. https://doi.org/10.1158/2159-8290.cd-21-0090 12. N. Zong et al., “Leveraging Genetic Rep orts and Electronic Health Records for the Prediction of Primary Cancers,” JMIR Med. Inform., vol. 9, no. 5, 2021. https://doi.org/10.2196/23586 13. “Index - FHIR v4.0.1,” www.hl7.org . h ttps://www.hl7.org/fhir/ 14. S. D’Amico et al., “Synthetic Data Generation By Artificial Intelligence to Accelerate T ranslational Researc h and Precision Medicine in Hematological Malignancies,” Bloo d, vol. 140, no. Suppl. 1, pp. 9744–9746, No v. 2022. h ttps://doi.org/10.1182/bloo d-2022- 168646 15. S. J. MacEachern and N. D. F ork ert, “Machine learning for precision medicine,” Genome, vol. 64, no. 4, pp. 416–425, Apr. 2021, doi: h ttps://doi.org/10.1139/gen-2020- 0131. 16. B. Ghoshal and A. T uck er, “Lev eraging Uncertain ty in Deep Learning for Pancreatic Adenocarcinoma Grading,” arXiv (Cornell Universit y), 2022, doi: https://doi.org/10.48550/arxiv.2206.08787 17. A. Rafferty , R. Ramaesh, and A. Ra jan, “T ransparent and Clinically Interpretable AI for Lung Cancer Detection in Chest X-Ra ys,” arXiv (Cornell Univ ersity), Mar. 2024, https://doi.org/10.48550/arxiv.2403.19444 18. Y. Jiang, M. Chen, Z. Xiong, and Y. Qin, ”Predicting anti-cancer drug sensitivity through WRE-XGBoost algorithm with weigh ted feature selection,” Genes and Diseases, vol. 12, no. 2, p. 101275, Mar. 2024, doi:10.1016/j.gendis.2024.101275 19. R. Qureshi, S. A. Basit, J. A. Shamsi, X. F an, M. Naw az, H. Y an, and T. Alam, ”Mac hine learning based p ersonalized drug resp onse prediction for lung cancer patients,” Scientific Reports, vol. 12, no. 1, p. 18935, Nov.2022, doi: 10.1038/s41598-022-23649-0 26 Ann Rachel et al. 20. J. R. Astley , J. M. Reilly , S. Robinson, J. M. Wild, M. Q. Hatton, and B. A. T ahir, “Explainable deep learning-based surviv al prediction for non-small cell lung can- cer patients undergoing radical radiotherapy ,” Radiotherapy and Oncology , vol. 193, pp. 110084–110084, Jan. 2024, doi: https://doi.org/10.1016/j.radonc.2024.110084 21. ]L. Pan t, A. A. Muk addim, M. K. Rahman, A. A. Say eed, M. S. Hossain, M. T. Khan, and A. Ahmed, ”Genomic predictors of drug sensitivit y in cancer: Integrating genomic data for personalized medicine in the USA,” vol. 5, no. 12, Dec. 2024. 22. ]Y. Shi, C. Li, X. Zhang, C. Peng, P . Sun, Q. Zhang, L. W u, Y. Ding, D. Xie, Z. Xu, and W. Zhu, “D3EGFR: a webserver for deep learning-guided drug sensitivit y prediction and drug resp onse information retriev al for EGFR m utation-driven lung cancer,” Briefings in Bioinformatics, vol. 25, no. 3, Mar. 2024, Art. no. bbae121, doi:10.1093/bib/bbae121.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment